1. Introduction
With the rise of the Sixth Generation (6G) of wireless communication networks, achieving ultra-high spectral and energy efficiency while meeting high-density user connectivity demands has become a crucial research topic in both academia and industry, particularly highlighted in complex urban scenarios. However, as these demands increase, so does the energy consumption of wireless devices, and energy-constrained devices become a bottleneck restricting the quality of service in urban networks [
1]. The question of how to sustainably and efficiently charge these energy-limited devices in densely populated urban environments has become a pressing issue. In order to solve this problem, Wireless Power Transfer (WPT) [
2] technology came into being, and wireless powered communication networks (WPCNs) [
3] were constructed. As a new framework for WPT, WPCN is considered a potential solution for 6G Green Internet of Things (IoTs) in the future [
4].
WPCNs transmit energy to energy-constrained devices on the downlink through a hybrid access point (HAP), while wireless devices utilize the collected energy to transmit information on the uplink. This new framework provides a new way to achieve high energy efficiency and long-lasting communication. Liu et al. [
5] investigated an unmanned aerial vehicle (UAV)-mounted intelligent reflecting surface -assisted simultaneous wireless information and power transfer system. By optimizing the UAV trajectory and employing a time-division multiple-access-based scheduling protocol, they maximized the minimum average achievable rate of multiple devices while meeting the energy-harvesting requirements of IoT devices. Zeng et al. [
6] proposed a resource allocation algorithm for maximizing the energy efficiency of the system by considering constraints such as energy collection, transmission time, and user quality of service. Considering imperfect channel state information, Sun et al. [
7] studied the robust resource allocation problem of sum-rate maximization. Although WPCNs have significant advantages in energy and information transmission, their network performance in urban environments is vulnerable to obstacle blocking in the above-mentioned network. This leads to a degradation in the quality of energy and information transmission between hybrid access points and nodes. Moreover, as the transmission distance increases, the transmission efficiency of a WPCN decreases due to signal attenuation. The efficiency of a WPCN can be improved by utilizing the high gain and transmit power resulting from deploying a large number of array antennas at transceiver nodes or relay nodes. However, multiple antennas and relays increase the processing complexity and hardware cost of transceiver nodes and relay nodes [
8,
9] while degrading the transmission performance of WPCNs. To overcome this problem, reconfigurable intelligent surfaces (RISs) have received extensive attention as an emerging technology with low power consumption and high energy efficiency.
RISs integrate large-scale passive reflection units that can independently adjust the phase shift and amplitude of the received signal, thus changing the transmission direction of the reflected signal [
10]. Hua et al. [
11] investigated the problem of a HAP propagating energy to the downlink in RIS-assisted WPCN systems with RISs optimizing the uplink transmission quality. The authors proposed three IRS beamforming configurations: full dynamic, partial dynamic, and static, utilizing a nonlinear energy-harvesting model aimed at reducing transmit energy consumption and meeting the minimum throughput requirements. Wang et al. [
12] investigated the resource allocation problem in RIS-assisted WPCNs. The authors achieved the challenge of achieving the desired performance gain by co-designing active transmit and receive beamforming for hybrid base stations (HBSs), passive beamforming for IRSs, and transmit power for each radio-powered device and jammer node. Xie et al. [
13] investigated time division multiple access protocols based on packet switching and user switching to evaluate the impact of energy recovery on system performance. Two different optimization problems were constructed by jointly optimizing the energy beamforming vectors, transmit power, and receive beamforming vectors, respectively, pointing out that protocols for IoT devices utilizing time division multiple access and energy recycling have a promising future for practical applications. Nevertheless, existing RIS technologies typically adopt fixed deployment modes, which have two significant limitations. First, static RIS deployment and reflection configurations fail to adapt dynamically to changes in urban user distributions. Second, RIS deployed at the ground level is prone to obstruction by buildings and obstacles, significantly increasing link interruption probabilities in complex urban environments.
To address these limitations, this paper proposes a model of a UAV equipped with a reconfigurable intelligent surface (UAV-RIS) and integrates it into an existing WPCN. This integration exploits the two-dimensional mobility of UAVs and the signal control capability of RISs, providing the possibility of dynamically optimizing the communication network. The UAV-RIS system can effectively improve the efficiency of information and energy transmission by changing its position in real time. Therefore, UAV-RIS-assisted power and information transmission has become a new research hotspot. Song et al. [
14] proposed using an aerial RIS as a mobile relay to mitigate the impact of obstacles on communication quality by optimizing the RIS phase and UAV trajectory. In order to achieve fair communication, Yu et al. [
15] took aerial RIS as a relay and maximized the minimum throughput among all MVs by jointly optimizing RIS passive beamforming, mobile vehicle (MV) scheduling, UAV trajectory, and power allocation. The subproblem was solved iteratively using Block Coodinate Descent (BCD) algorithm. Peng et al. [
16] investigated SWIPT assisted by UAV-RIS by optimizing node associations, UAV trajectories, and power allocation ratios to maximize the minimum average transmission rate. To improve the durability of UAV-RIS, Truong et al. [
17] developed a novel energy-harvesting scheme for SWIPT, utilizing resource allocation and the energy-harvesting of impacted radio frequency (RF) signals. A deep deterministic policy gradient (DDPG) scheme was designed to allocate the resources of the UAV-RIS successively in the time and spatial domains to maximize the total harvested energy. Zhou et al. [
18] proposed a new Quality of Experience (QoE)-driven UAV-IRS-assisted WPCN framework. The architecture realizes the accurate quantification of QoE through a nonlinear satisfaction function, and an adaptive reflection unit configuration strategy to reduce resource consumption while satisfying QoE was designed.
For multivariate optimization problems, existing research typically fixes one variable and optimizes the others. However, this strategy is prone to falling into local optima and lacks comprehensive global information. With increasing demands in wireless networks, there is an urgent need for technologies that exhibit flexibility, adaptability, and the capability to satisfy practical constraints. Deep reinforcement learning (DRL), as an adaptive intelligent decision-making framework, integrates the advantages of deep learning and reinforcement learning, enabling automatic learning of optimal policies to adapt to dynamically changing wireless environments. Yang et al. [
19] used RISs to help prevent secure communication from eavesdroppers. The DRL algorithm was used to optimize BS beamforming and RIS beamforming, which improved the secrecy rate and quality of service satisfaction. Nguyen et al. [
20] designed a wireless power information transmission scheme, jointly optimizing UAV trajectories, power allocation, fixed IRS phasing, and node scheduling to maximize the transmission rate. The problem was reconstructed as a Markov decision process, and DRL was used to solve the optimization problem.
Inspired by the above discussion, this paper considers a UAV equipped with a reconfigurable intelligent surface (UAV-RIS)-assisted wireless powered communication network. It employs a ‘harvest then transmit’ protocol, in which an energy-constrained device first harvests energy wirelessly and uses all the collected energy for transmission in the remaining time. In addition, DRL is introduced to further optimize the performance of the WPCN to reduce energy consumption while increasing the data transmission rate. We used DRL to optimize the position, the phase configuration of the UAV-RIS, and the energy-harvesting scheduling of the ground nodes, aiming to solve energy efficiency in the UAV-RIS-assisted wireless powered communication network, with the following main contributions:
- (1)
A UAV-RIS-assisted WPCN architecture is proposed to address the efficiency bottleneck of WPCNs under limited transmission distance and obstacle influence. To achieve the precise division of the time dimension, this paper adopts time division multiple access (TDMA) technology to achieve the parallel transmission of information and energy. On this basis, this article further introduces dynamic TDMA (DTDMA) technology to fully tap into the potential of time resources. It adopts a dual-layer time-division structure, which divides time at the macro level and allocates ground nodes at the micro level, achieving refined management and utilization of resources.
- (2)
This paper proposes a system energy efficiency optimization problem for a UAV-RIS-assisted WPCN architecture based on TDMA and DTDMA. By establishing a joint optimization problem, the RIS phase shift matrix, time slot allocation ratio for energy-harvesting stages, and UAV trajectory optimization are comprehensively considered. We transformed the optimization problem into a DRL model to overcome the problems of high computational complexity and the complexity of traditional methods and employed a DDPG algorithm to solve it. By monitoring the rewards of environmental feedback, the DRL algorithm can iteratively adjust parameters, gradually optimize energy efficiency, and achieve the acquisition of optimal strategies.
- (3)
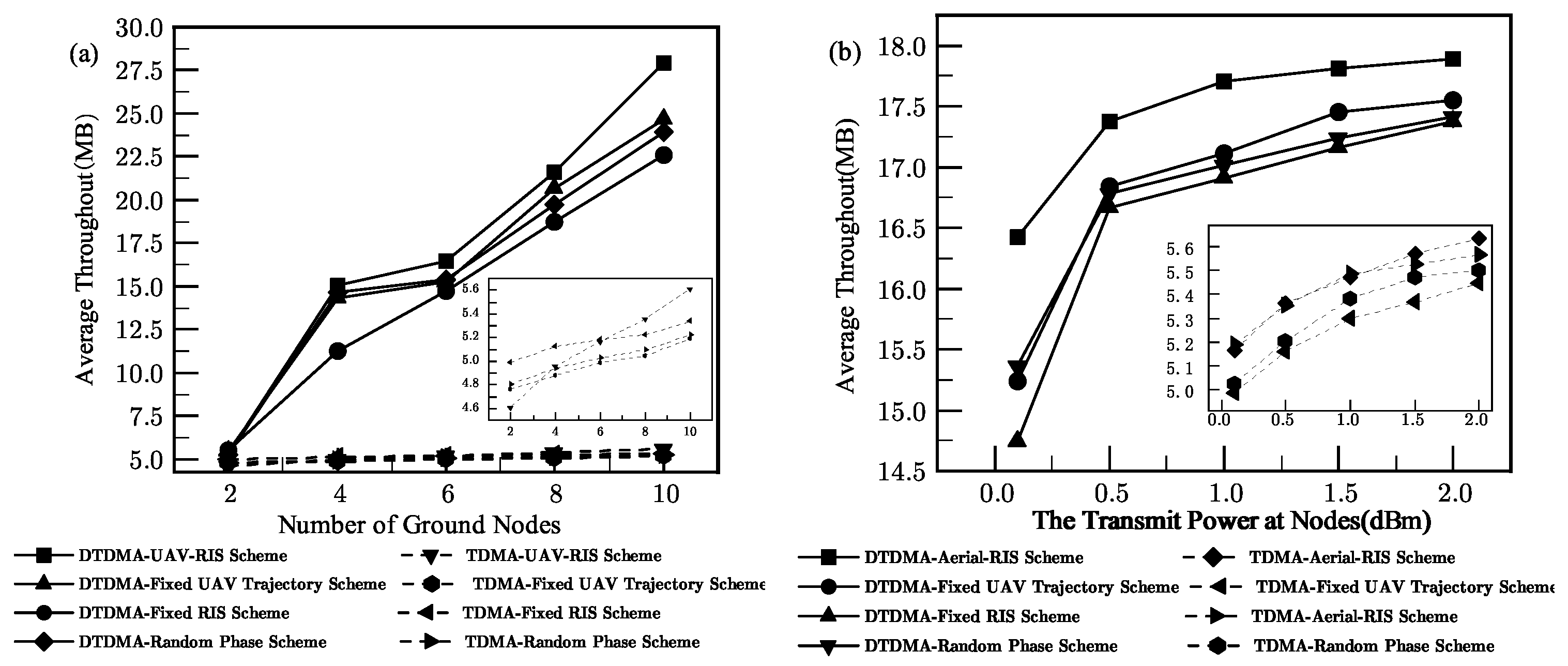
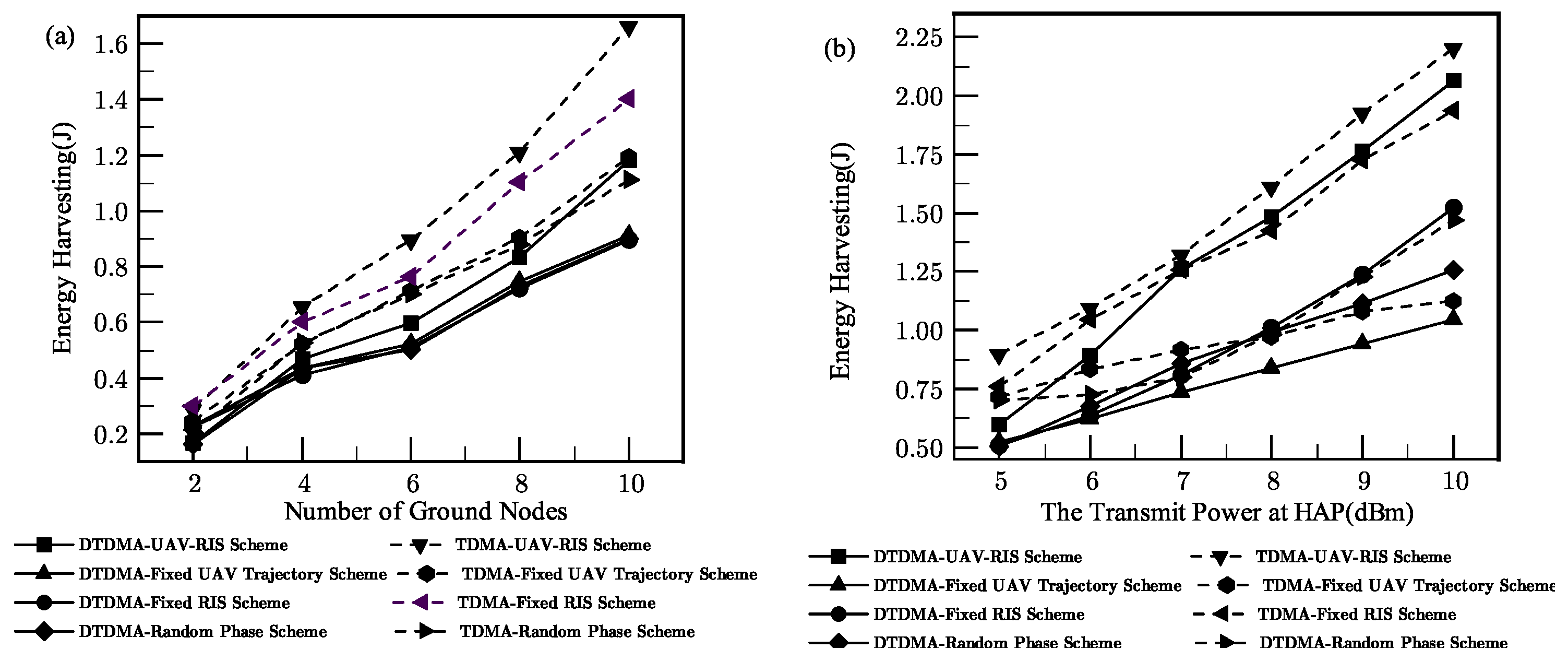
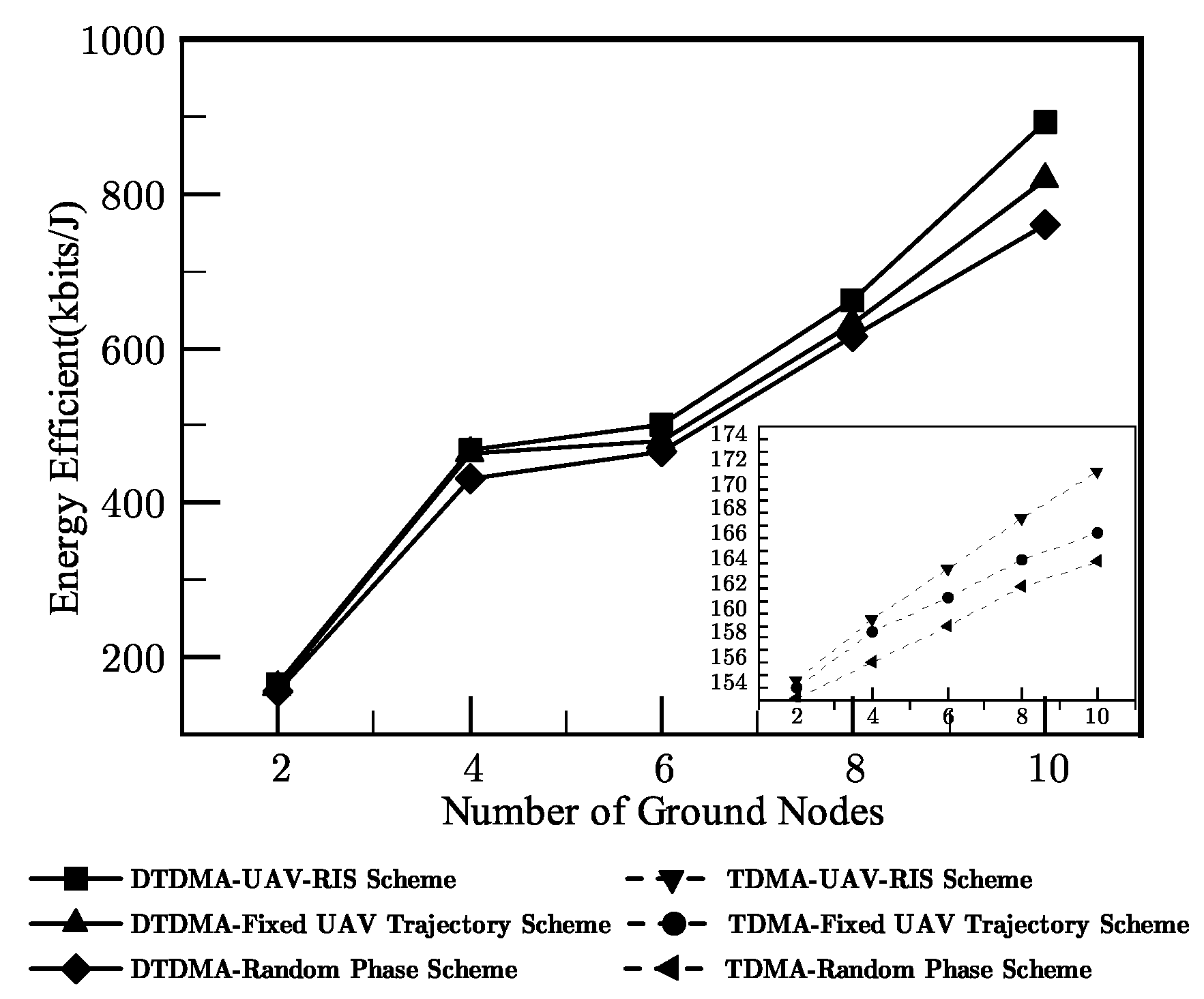
The simulation results have indicated that the proposed architecture significantly impacts WPCN performance, indicating a significant improvement in the effectiveness of this scheme compared to other methods, fully demonstrating its efficiency and superiority. In addition, this article reveals the advantages of different TDMA strategies, providing an important basis for selecting appropriate TDMA strategies in different application scenarios.
2. System Model and Problem Statement
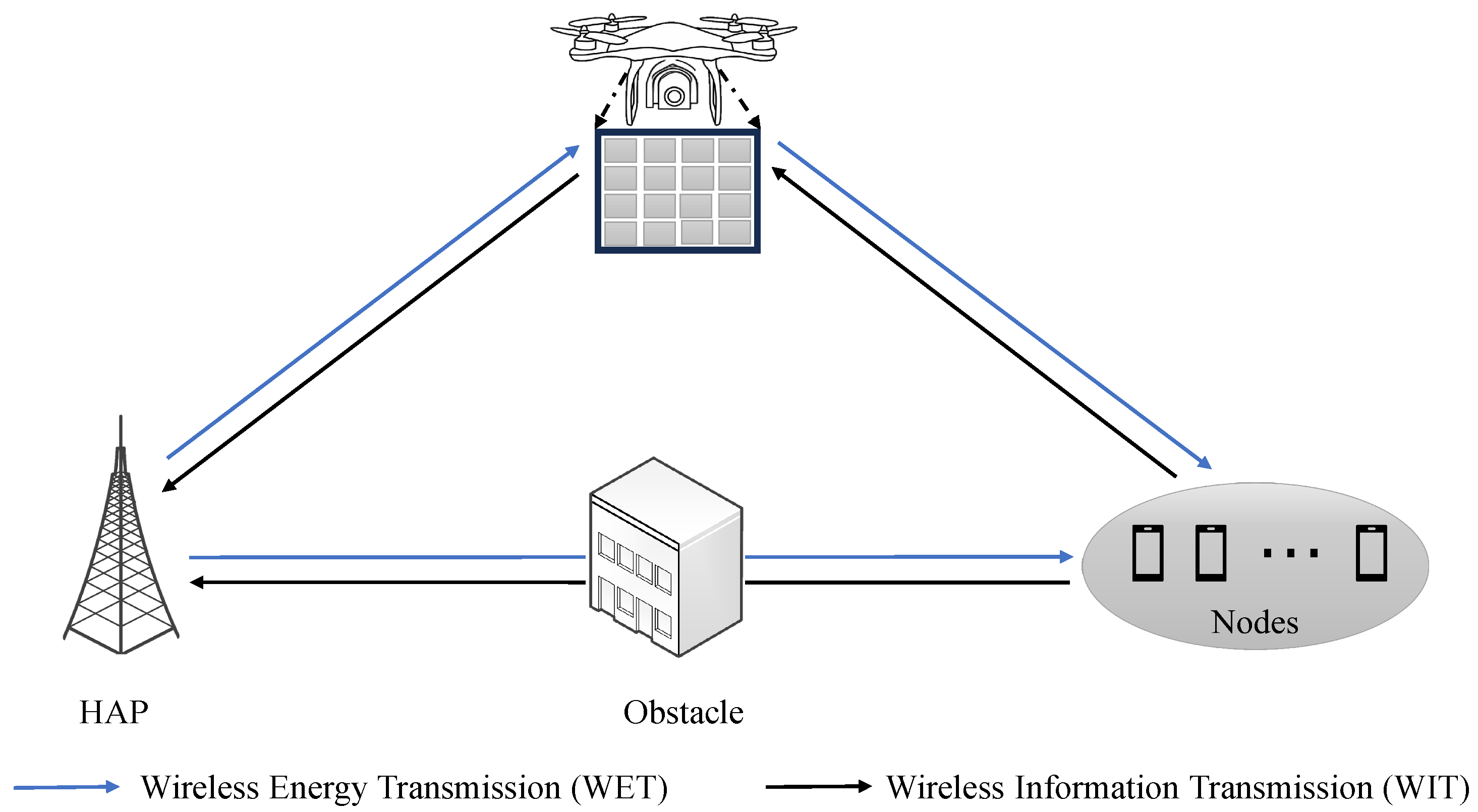
Given the challenges posed by obstacles in complex urban environments, which significantly impact channel quality between HAP and nodes, this paper introduces a framework leveraging UAV-RIS to bolster WPCN performance. As shown in
Figure 1, the framework exploits the mobility of UAV-RIS to improve channel quality between hybrid access points and nodes. An RIS with M reflection units was deployed on a dynamic UAV to reconfigure the wireless channel conditions between HAPs and
k single-antenna nodes by adjusting the phase shifts, and the set of nodes is defined as
k = {1, 2, …, K}.
For the sake of generality, a two-dimensional Cartesian coordinate system is considered in this article. To mitigate the intricacy of the system, an assumption is made here that the takeoff and landing phases of UAV are not considered, and only the time-varying time of flight time T is considered. In time slot n, the coordinates of the UAV can be expressed as . It maintains a constant altitude h with an initial position of .
2.1. Model of UAV-RIS-Assisted WPCN Based on TDMA
In order to provide services to different nodes at different times, this paper proposes a model based on TDMA for UAV-RIS-assisted WPCN.
In this model, UAV-RIS alters the state of a phase shifter in each time slot, enabling time-sharing services among nodes. Each time slot is segmented into two intervals, allocated according to the ratio
(
n), where
(
n) is used for energy transmission and 1−
(
n) for information transmission. A Uniform Linear Array (ULA) of M cells is used within the RIS. For convenience of implementation, it is assumed that the amplitude of all elements is 1, and the reflection coefficient matrix can be expressed as Equation (
1):
where
is the phase shift of the m
element in the RIS at time slot
n. Furthermore, channel state information can be obtained through existing methods (for example, minimum mean square error, maximum likelihood estimation, and deep learning prediction). Therefore, this chapter assumes that channel state information and node coordinates are perfectly known [
21].
Since the direct communication link between HAPs and ground nodes is obscured by obstacles, resulting in the lack of a direct signal transmission path, UAV-RIS is introduced to address this issue. It can dynamically adjust the wireless propagation environment to establish an effective signal transmission channel between HAPs and nodes by means of reflection, thus overcoming the problem of unreachable direct paths. Thus, the reflection path in the system encompasses two links: the communication link between UAV-RIS and HAP, as well as the communication link between UAV-RIS and nodes. A distance based on a path loss model is used between HAP and UAV-RIS at time slot
n, which takes into account distance and large-scale fading to ensure that the attenuation of the signal during transmission is accurately predicted and compensated. The signal during transmission is accurately predicted and compensated. The path loss
[
22] of the channel gain
of each reflective element from HAP to RIS is expressed as
where
denotes the path loss exponent,
denotes the additional attenuation factor caused by NLoS connection, and
denotes the distance separating HAP and the UAV-RIS.
is the position of the HAP, and
is the LoS probability between HAP and the RIS element, which can be calculated according to Equation (
2):
where constants
A and
B are determined by environmental factors [
23]. The equation for calculating the elevation angle between HAP and the hyper-surface elements is as follows [
16]:
The signal transmission between UAV-RIS and the nodes follows a small-scale Rician fading distribution, denoted as
where
is the path loss at the reference distance
,
is the path loss exponent,
denotes the distance separating the UAV-RIS and nodes,
denotes the location of the
kth node, and
denotes the Rician factor associated with small-scale fading. Additionally, the LoS path gain
consists of the array response of reflection units, while the NLoS path gain
follows an independent and identically distributed complex Gaussian distribution with zero mean and unit variance.
Therefore, the reflected channel gain between HAP and node
k is
where
is a binary variable denoting that node
k is connected to the HAP, and
denotes that HAP is connected to only one node in a time slot. Thus, Equation (
6) can be written as
2.2. Model of UAV-RIS-Assisted WPCN Based on DTDMA
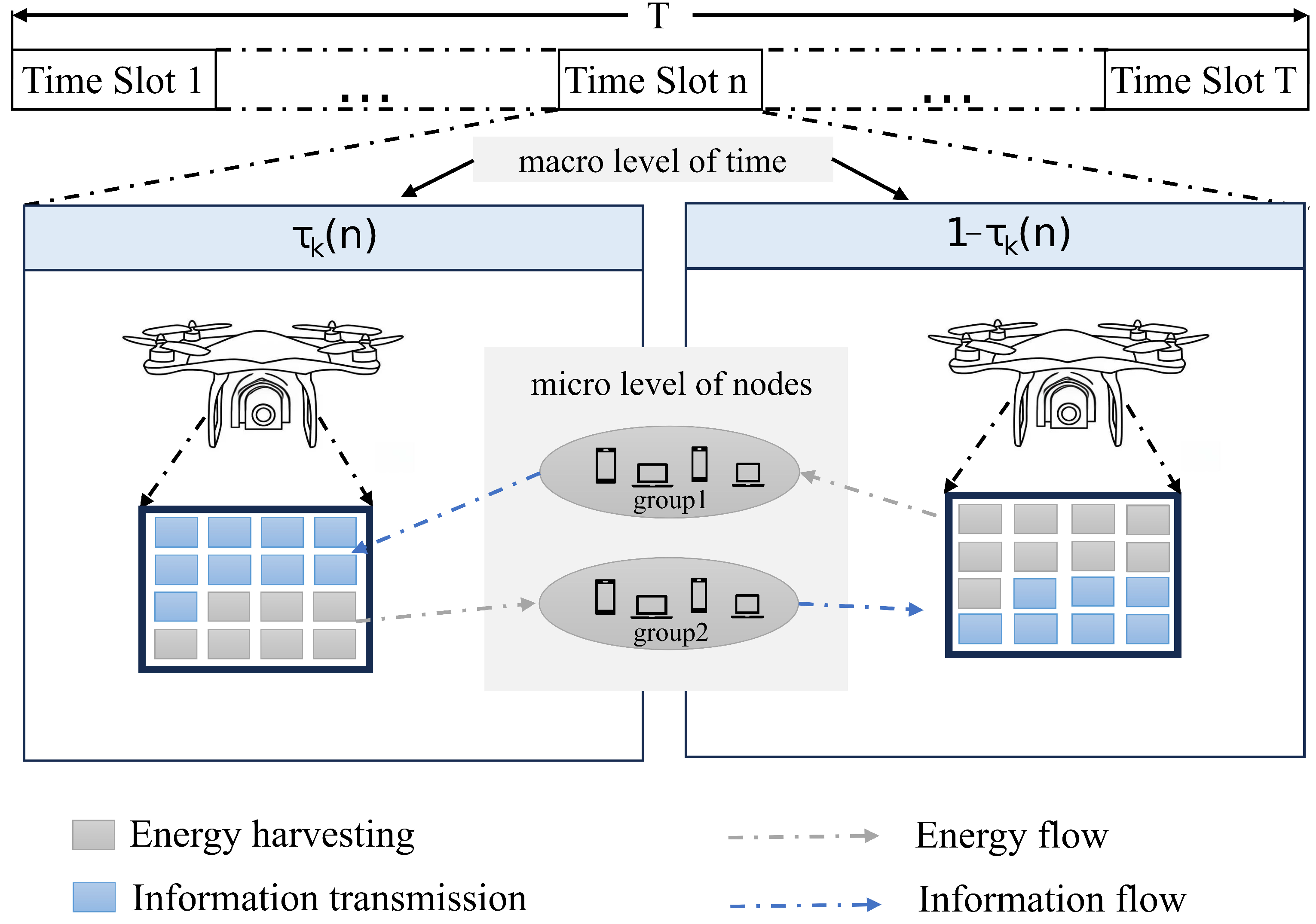
In order to maximize time resource utilization, this paper considers a DTDMA model, as per
Figure 2. The model introduces a two-layer time division structure, which realizes a fine-grained allocation of resources at the macro and micro levels:
Macro level: Each time slot is divided into two complementary time windows, forming an efficient closed-loop system for resource utilization.
Micro level: The system divides the ground nodes into two functionally complementary subgroups based on their locations and performs uplink wireless information transmission (WIT) and downlink wireless energy transmission (WET) tasks in each time window.
In this two-layer time division structure, the system interchanges the functional roles of the two subgroups in two time windows of the same time slot, interleaving the WIT and WET tasks. At the same time, the ratio of the two time windows is dynamically adjusted according to real-time channel conditions and communication requirements. This role-switching mechanism achieves more accurate resource matching while maximizing the overall average throughput of the network.
A. Wireless energy transfer phase
In the WET phase, UAV-RIS reflects the energy signal from the HAP to the ground node. The
kth ground node receives the signal as
where
is the noise signal following a Gaussian distribution, and
X and
represent the symbol signal and transmit power of the HAP, respectively. Therefore, the power received by ground node
k is
where
is the EH efficiency.
B. Wireless information transfer phase
In the WIT phase, UAV-RIS can reflect the signals sent by the nodes to the HAP. Assuming the ground nodes rely solely on harvesting energy for WIT phase operation, the signal transmitted from them and received by the HAP is
where
is the symbol signal coming from the ground node to the HAP, and
represents the transmit power of the
kth user. Thus, the throughput of node
k can be expressed by
2.3. Energy Consumption of the System
The propulsion energy consumption of the rotary-wing UAV [
24] per time interval
n is
where
and
represent the drag power and induced power of the UAV during hovering;
represents the tip speed of the rotor blade;
represents the induced velocity of the horizontal rotor within hover mode;
and
s denote the fuselage drag ratio and the stiffness of the wind turbine;
and
G represent the air density and the area swept by the rotation of the rotor, respectively.
The overall energy expenditure of this system can be formulated by
where
and
are the energy consumption of the
kth user, the HAP, and each reflection unit in time slot
n, respectively. In practice, communication-related energy consumption is small and negligible.
2.4. Problem Statement
This paper aims to achieve maximum system energy efficiency via the integrated optimization of the RIS phase-shift reflection coefficient, UAV position, and the time allocation ratio
of EH; it also aims to achieve synergistic management of communication quality and transmission energy consumption. Drawing from the foregoing analysis, the optimization problem is formulated as follows:
We aim to enhance the energy efficiency of this system to its peak in all time slots.
(
n) represents the proportion of transmission time during each slot;
Z represents the horizontal flight area, ensuring the UAV’s movement remains within the defined limits;
is the maximum speed of the rotary-wing UAV. It can be seen that Equation (
14) is a non-convex Mixed Integer Nonlinear Programming problem. Solving P1 with traditional optimization methods partially will be computationally expensive, and once the solution is obtained, it is hard to readjust the optimization strategy quickly enough to be deployed online. DRL has been proven to be highly effective in decision-making and achieving optimal results in dynamic environments. Due to these reasons, we propose solutions based on DRL to address problem P1 and use these together to maximize energy efficiency and average throughput.
3. DRL-Based Design for Energy Efficiency Optimization
We established a DRL-based resource optimization framework that maximizes the total harvested energy and average throughput of UAV-RIS while ensuring minimum energy consumption for its flight and communication.
3.1. MDP Definition
This framework consists of two components: environment and agent. The environment–agent interaction follows a Markov decision process (MDP). The agent then evaluates the previous operation using the reward provided by the environment. The agent takes an action in the environment based on its current state and then uses the reward feedback from the environment to assess the quality of the previous action.
The MDP is characterized by a four-tuple , where respectively denote state space and action space. P is the state transfer probability, indicating the likelihood of transitioning to the next state after taking an action at the current state . R quantifies the reward that the agent receives for such a transition. Then, we construct a game in the equation to solve this problem.
Agent: Activate the central processor to operate as an autonomous agent. It discovers an optimal strategy that maximizes energy efficiency. After training, the action formulation is implemented on the UAV for forecasting and choosing parameters.
State space: The channel consists of reflection channels. Therefore, the state space is defined here as
Action space: The action space is characterized as
. In state
, the UAV takes an action
and moves to the next state
, where the position of the UAV in time slot
n is denoted as
where
and
represent the environmental noise affecting the flight at time step
. The flight angle of the UAV is set by constraining a parameter
, and the speed of the UAV is set by constraining a parameter
v during the flight of the UAV.
Reward: We devised a reward function to optimize system energy efficiency by minimizing both UAV power usage and additional communication power during transmission. Specifically, the function quantifies the immediate reward, guiding the UAV towards actions that maximize energy efficiency.
3.2. Agent Design and Algorithm Implementation
Our goal was to identify the best strategy for maximizing the expected reward. In a partially observable environment, the agent operates with limited knowledge and interacts to earn rewards. It adjusts its policy based on received rewards and performs new actions in updated states. Through iterative interaction, agents can find better strategies and better rewards. After each action, the drone updates its position and receives environmental feedback. The agent can select the appropriate speed and flight direction for the drone according to channel state information (CSI). Additionally, optimization is performed on the parameters and phase shift matrix to maximize network performance. This study employs a DRL algorithm to find the optimal strategy.
DDPG is a model-free, policy-free, and actor-critic-based DRL algorithm that can handle the task of continuous action space well. In DDPG, the actor network determines the best action of an agent in the current state s with a function , while the critic network estimates the Q-value under the action pair in the current state with a function . DDPG consists of two actor-critic network pairs: the main network pair and the target network pair. The parameters of the critic network are updated based on the Temporal Difference (TD) error, and the parameters of the actor network are updated based on the output of the former. If a single network is used for both action selection and Q-value estimation, the update of the actor network’s parameter will directly affect the estimation results of the critic network, leading to instability during the training process. By introducing a target network, the interdependence between parameter updates can be reduced, and the stability of the algorithm can be improved.
In this paper, we build an experience replay pool
D with capacity
. The phase shifts of all RIS elements are set randomly within the range of 0 to
at the beginning of training. Prior to each training iteration, all involved channels are first computed. Following this, the policy network processes the state
as its input and then generates the corresponding action
to be executed.
where
is the random noise. The current reward
is calculated according to a corresponding action. Then,
is obtained using Equation (
15). Store
as a transition to
D; the value network then samples a small batch
(
) from it to calculate the target Q-value
.
The value network adjusts its parameters with the objective of reducing the loss function to an optimal level:
where
is the value network loss function,
is the target action value,
n represents the sample count, and
represents the sample weight. For each sample, the action
taken at a given state
is denoted by
, with the subsequent reward at the next time step represented by
. The discount factor
is also considered in this calculation.
Training employed the Adam optimizer for both the policy and value networks, with soft updates applied to the respective objective networks, as shown below:
where
is the learning rate of the soft updates on the actor network and critic network, respectively.
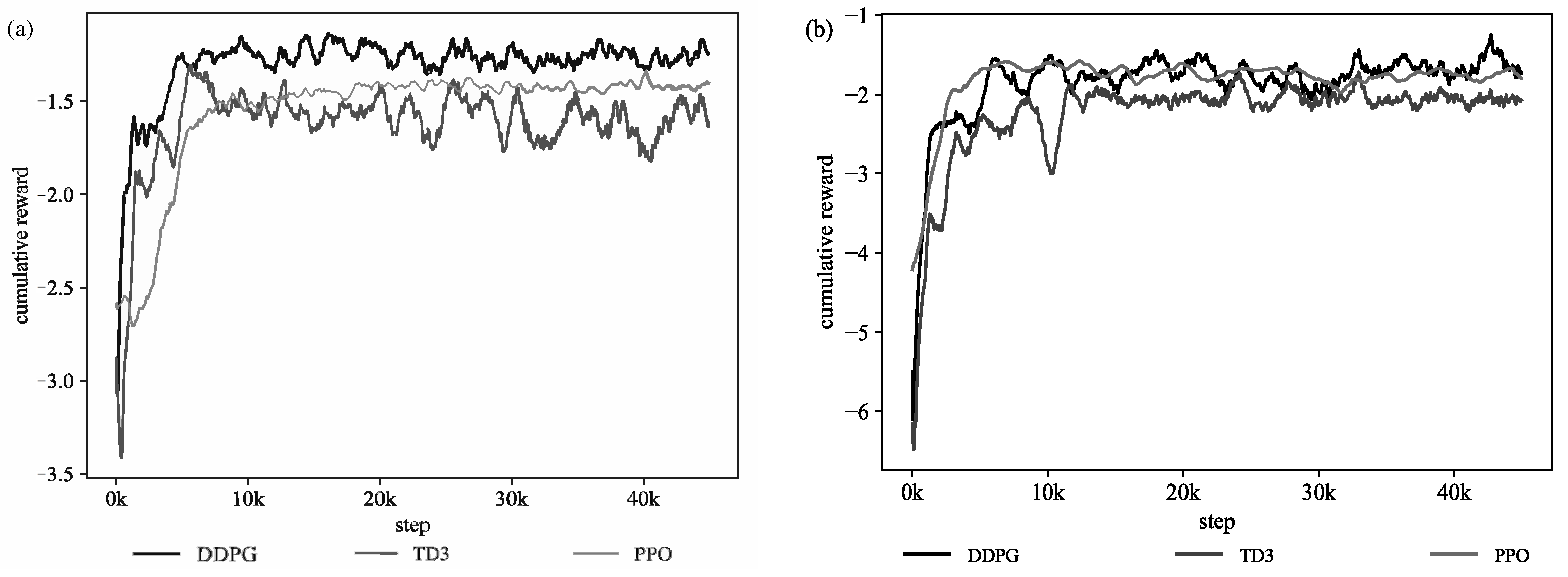
The pseudo-code of the UAV-RIS-assisted WPCN communication strategy process based on DDPG is shown in Algorithm 1. During training, the agent engages with the environment to perceive the current state of the system . At the start of each training round, a system state is initialized, and the initialized state is subsequently fed into the model. When the agent explores, the agent selects joint actions (time slot allocation, drone path, and phase shift design) guided by its current policy. Upon executing these actions, it observes a reward and a new system state, which is deposited into the cache pool. Then, the state is updated by randomly drawing samples in this buffer to compute the target Q-value, followed by updating both the policy and value networks. The correlation parameters are iteratively refined until convergence, resulting in a trained model that incorporates optimized UAV routes and reflected beam formation matrix strategies based on the chosen actions.
In order to promote better exploration during the training process, this paper employs the Adaptive Ornstein–Uhlenbeck Action Noise function. This noise function has configurable noise intensity and was gradually reduced during the training process to help the agent explore more at the early stage of learning and gradually converge to the optimal policy, enhancing the agent’s ability to explore the environment better during the training process and eventually learn a high-performance policy.
| Algorithm 1 UAV-RIS- assisted WPCN joint trajectory design; EH time and phase shift optimization design based on DDPG |
- Require:
Initial state of the system, discount factor , learning rate, experience replay size , small batch size - Ensure:
Best strategy
- 1:
Initialization: - 2:
Actor network and critic network , - 3:
target actor network and target critic network , - 4:
, , - 5:
experience replay buffer D, phase shift matrix . - 6:
for episode = 1 to N do - 7:
Accept the current environment and obtain the initial state ; - 8:
Initialize a random noise; - 9:
for to N do - 10:
Take state as input and get action from policy network; - 11:
Execute the action to get the reward and state ; - 12:
Store in experience replay pool D; - 13:
Draw a random batch of samples from D; - 14:
Calculate the target Q-value according to ( 18); - 15:
Minimize ( 19) to update the value network; - 16:
Update the gradient of the strategy network using SGD; - 17:
Update the policy network so that the actions of the policy network can better approximate the real actions; - 18:
Softly update the target network parameters according to ( 20); - 19:
Update the state . - 20:
end for - 21:
end for
|
3.3. Overall Algorithm Complexity Analysis
Traditional optimization algorithms often have high computational complexity, which limits their use in applications that require rapid response. Take the Successive Convex Approximation (SCA) algorithm as an example; its working principle is to iteratively approximate non-convex functions and solve the resulting convex subproblems at each step. Its complexity is
[
18], where the complexity of solving convex optimization problems using an interior-point method in CVX is
, with
being the number of SCA iterations [
25].
denotes the complexity of computing the optimal IRS phase, and
is the complexity of standard linear programming. As the problem size increases, this super-linear complexity growth makes solving large-scale problems extremely challenging. In contrast, DDPG optimizes the objective function through iterative updates of the policy network and Q network. The forward pass complexity of the policy network is
(where
is the action space size,
is the state space size, and
is the number of policy network parameters). The complexity of the Q network is
(where
is the number of Q network parameters). The total complexity is
, where
K is the total number of training iterations. Unlike the super-linear growth of traditional methods, the quadratic complexity growth of DDPG makes it more advantageous in high-dimensional state spaces and real-time scenarios. Additionally, its ability to obtain feasible solutions with fewer iterations makes it more suitable for scenarios requiring rapid response and online deployment.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}