
Scenario-Driven Evaluation of Autonomous Agents: Integrating Large Language Model for UAV Mission Reliability

Abstract
1. Introduction
- Limited Adaptability: conventional decision-making frameworks struggle in dynamic environments, failing to respond effectively to weather fluctuations, obstacles, and mission changes.
- Interoperability Issues: inconsistent data formats and communication protocols between drones and ground stations reduce efficiency.
- Scalability Constraints: as IoD networks grow, data processing delays and network congestion hinder their performance.
- Security Risks: IoD systems remain vulnerable to cyberattacks, GPS spoofing, and unauthorized access, threatening mission integrity [1].
- Inefficiency in Real-Time Processing: conventional models struggle to analyze telemetry data dynamically as conditions change.
- Fragmented Data Sources: IoD networks require multi-source data fusion, integrating telemetry logs, sensor feedback, and mission directives.
- Scalability Issues in Expanding Networks: as IoD systems grow, data bottlenecks and inefficiencies reduce their responsiveness.
- Real-Time Analysis: LLMs process telemetry data and mission logs dynamically.
- Contextual Data Retrieval: RAG enables drones to access mission-specific knowledge for informed decision-making.
- Optimized Multi-Drone Coordination: a cloud-powered intelligence unit ensures synchronized drone operations.
- Enhanced Situational Awareness: the model processes unstructured data (e.g., environmental reports and mission objectives) to improve adaptability.
2. Related Work
2.1. Foundational Integration of LLMs in Robotics
2.2. Enhancing Human–Robot Interaction and Task Execution
2.3. Dynamic Control and Adaptation in Robotic Systems
2.4. Security and Anomaly Detection in Autonomous Systems
2.5. UAV-Specific Applications and Optimization
2.6. Collaborative and Multi-Agent Systems
2.7. Synthetic Data Generation and Simulation
2.8. Code Generation and Software Development
2.9. Future Directions and Ethical Considerations
3. Methodology
3.1. Dataset Overview
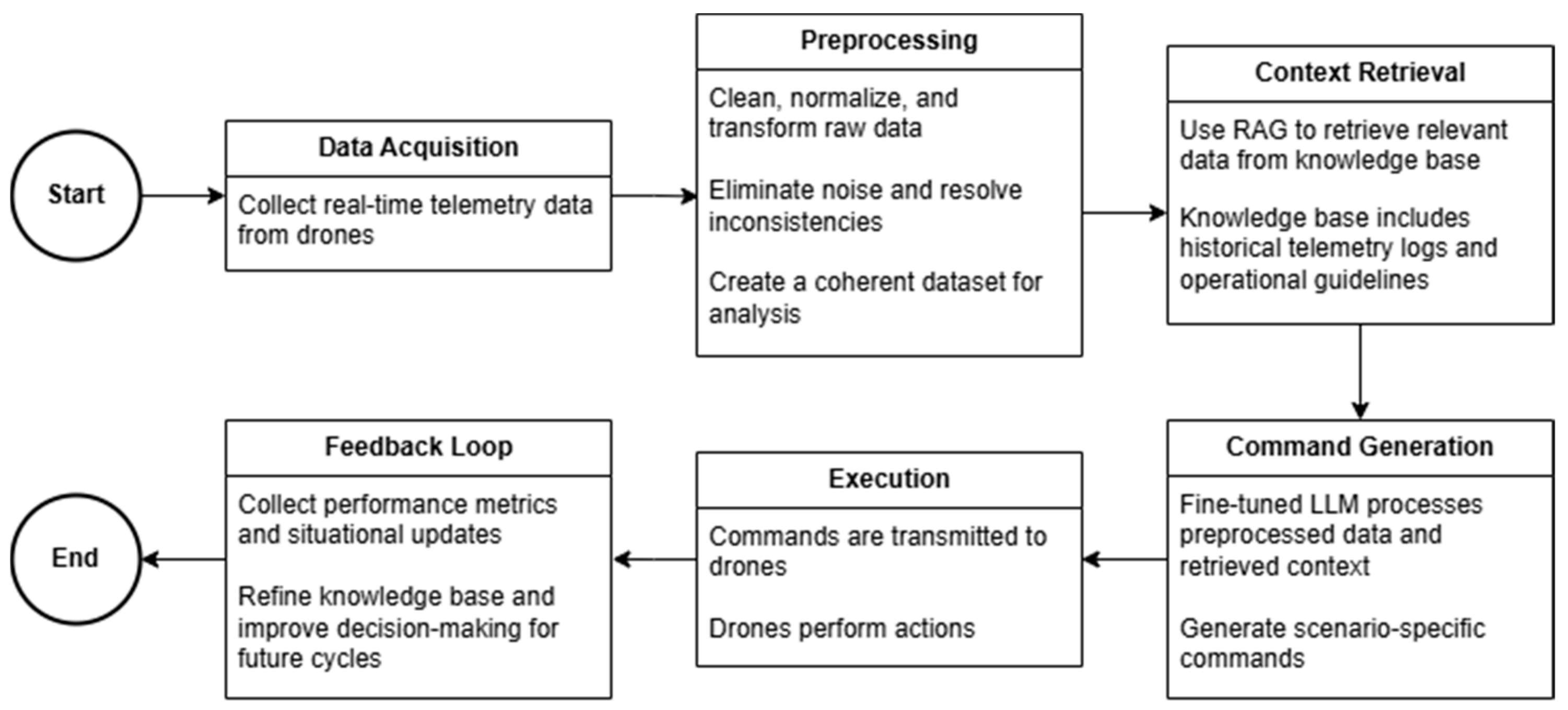
3.2. System Architecture
| Algorithm 1. IoD Decision-Making System |
| 1: Initialization: create a knowledge base with telemetry logs, mission records, and contextual inputs. Load the pre-trained LLM. 2: for each input_data perform 3: Extract telemetry, mission, and contextual data from input_data. 4: Retrieve relevant context from the knowledge base. 5: Compute the similarity score using cosine similarity. 6: Generate command using the LLM based on the retrieved context. 7: Compute the BLEU score for command accuracy. 8: Execute the generated command and log the process. 9: Monitor execution and collect performance metrics. 10: Update knowledge base with performance feedback. 11: end for 12: Return: the generated command, similarity score, BLEU score, and performance metrics. |
3.3. Decision Flow
4. Results and Experiments
4.1. Evaluation Metrics
4.2. Experimental Setup
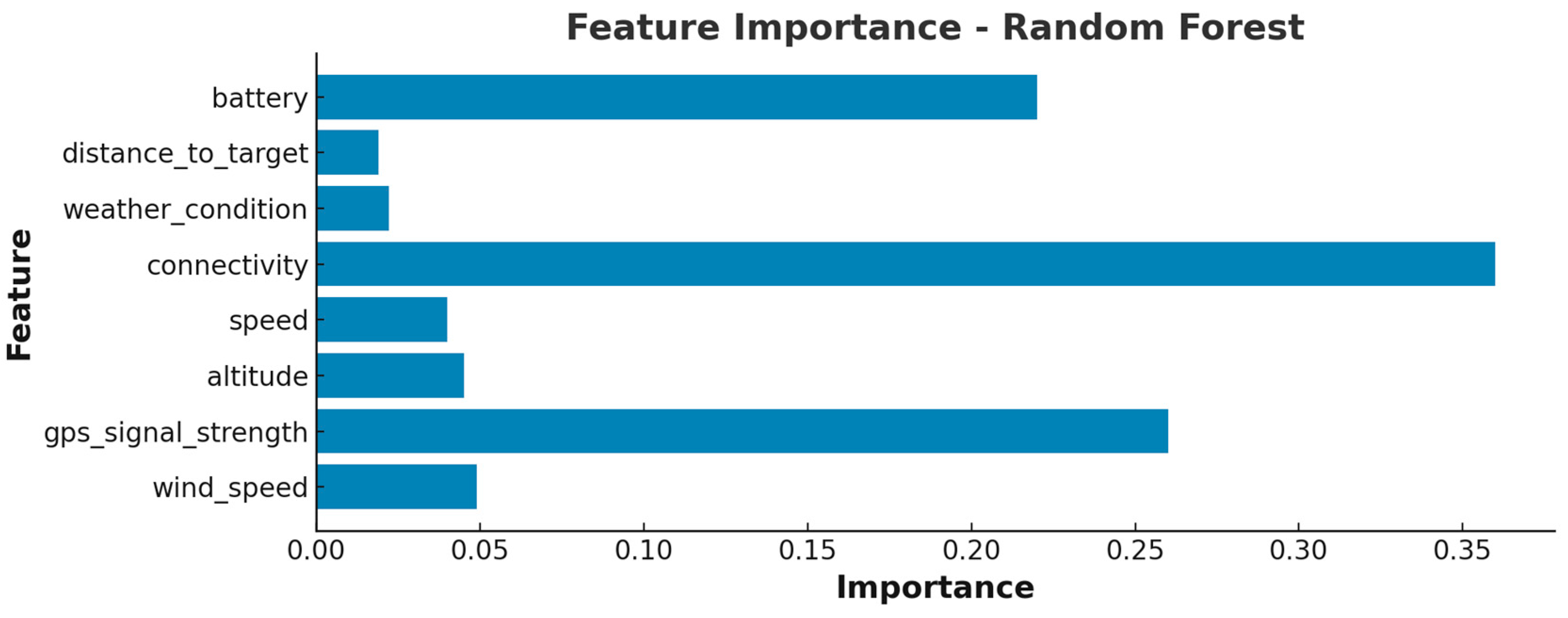
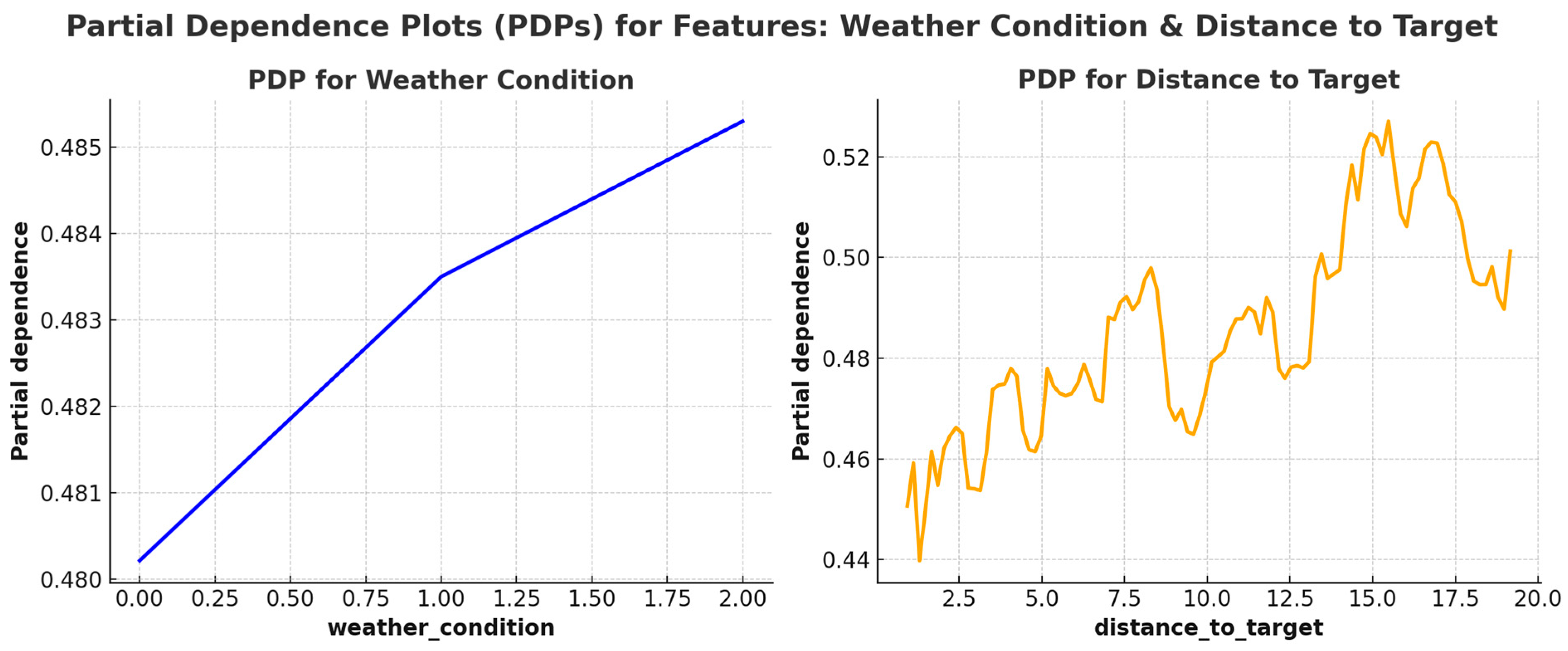
4.3. Results Analysis
5. Conclusions
6. Future Research
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LLM | Large Language Model |
| RAG | Retrieval-Augmented Generation |
| AI | Artificial Intelligence |
| ML | Machine Learning |
| UAV | Unmanned Aerial Vehicle |
| IoD | Internet of Drones |
| PDP | Partial Dependence Plot |
| GPS | Global Positioning System |
| BLEU | Bilingual Evaluation Understudy |
References
- Sezgin, A.; Boyacı, A. Rising Threats: Privacy and Security Considerations in the IoD Landscape. J. Aeronaut. Space Technol. 2024, 17, 219–235. [Google Scholar]
- Alharasees, O.; Adalı, O.H.; Kale, U. Human Factors in the Age of Autonomous UAVs: Impact of Artificial Intelligence on Operator Performance and Safety. In Proceedings of the 2023 International Conference on Unmanned Aircraft Systems (ICUAS), Warsaw, Poland, 6–9 June 2023. [Google Scholar]
- Alharasees, O.; Kale, U. Human Factors and AI in UAV Systems: Enhancing Operational Efficiency Through AHP and Real-Time Physiological Monitoring. J. Intell. Robot. Syst. 2025, 111, 5. [Google Scholar] [CrossRef]
- Sezgin, A.; Boyacı, A. Securing the Skies: Exploring Privacy and Security Challenges in Internet of Drones. In Proceedings of the 2023 10th International Conference on Recent Advances in Air and Space Technologies (RAST), Istanbul, Turkiye, 7–9 June 2023. [Google Scholar]
- Aldossary, M.; Alzamil, I.; Almutairi, J. Enhanced Intrusion Detection in Drone Networks: A Cross-Layer Convolutional Attention Approach for Drone-to-Drone and Drone-to-Base Station Communications. Drones 2025, 9, 46. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, D.; Choi, J.; Park, J.; Oh, N.; Park, D. A survey on integration of large language models with intelligent robots. Intell. Serv. Robot. 2024, 17, 1091–1107. [Google Scholar]
- Fan, H.; Liu, X.; Fuh, J.Y.H.; Lu, W.F.; Li, B. Embodied intelligence in manufacturing: Leveraging large language models for autonomous industrial robotics. J. Intell. Manuf. 2024, 36, 1141–1157. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, J.; Li, J.; Peng, Y.; Mao, Z. Large language models for human–robot interaction: A review. Biomim. Intell. Robot. 2023, 3, 100131. [Google Scholar]
- Jang, D.; Cho, D.; Lee, W.; Ryu, S.; Jeong, B.; Hong, M.; Jung, M.; Kim, M.; Lee, M.; Lee, S.; et al. Unlocking Robotic Autonomy: A Survey on the Applications of Foundation Models. Int. J. Control Autom. Syst. 2024, 22, 2341–2394. [Google Scholar]
- Asuzu, K.; Singh, H.; Idrissi, M. Human–robot interaction through joint robot planning with large language models. Intell. Serv. Robot. 2025, 1–17. [Google Scholar] [CrossRef]
- Choi, S.; Kim, D.; Ahn, M.; Choi, D. Large language model based collaborative robot system for daily task assistance. JMST Adv. 2024, 6, 315–327. [Google Scholar] [CrossRef]
- Lykov, A.; Karaf, S.; Martynov, M.; Serpiva, V.; Fedoseev, A.; Konenkov, M.; Tsetserukou, D. FlockGPT: Guiding UAV Flocking with Linguistic Orchestration. In Proceedings of the 2024 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Bellevue, WA, USA, 21–25 October 2024. [Google Scholar]
- Savenko, I. Command interpretation for UAV using language models. In Proceedings of the 2024 IEEE 7th International Conference on Actual Problems of Unmanned Aerial Vehicles Development (APUAVD), Kyiv, Ukraine, 22–24 October 2024. [Google Scholar]
- Zahedifar, R.; Baghshah, M.S.; Taheri, A. LLM-controller: Dynamic robot control adaptation using large language models. Robot. Auton. Syst. 2025, 186, 104913. [Google Scholar]
- Singh, I.; Blukis, V.; Mousavian, A.; Goyal, A.; Xu, D.; Tremblay, J.; Fox, D.; Thomason, J.; Garg, A. ProgPrompt: Program generation for situated robot task planning using large language models. Auton. Robot. 2023, 47, 999–1012. [Google Scholar] [CrossRef]
- Ishimizu, Y.; Li, J.; Yamauchi, T.; Chen, S.; Cai, J.; Hirano, T.; Tei, K. Towards Efficient Discrete Controller Synthesis: Semantics-Aware Stepwise Policy Design via LLM. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Danang, Vietnam, 3–6 November 2024. [Google Scholar]
- Sun, S.; Li, C.; Zhao, Z.; Huang, H.; Xu, W. Leveraging large language models for comprehensive locomotion control in humanoid robots design. Biomim. Intell. Robot. 2024, 4, 100187. [Google Scholar]
- Gerstmayr, J.; Manzl, P.; Pieber, M. Multibody Models Generated from Natural Language. Multibody Syst. Dyn. 2024, 62, 249–271. [Google Scholar]
- Abdelmaboud, A. The Internet of Drones: Requirements, Taxonomy, Recent Advances, and Challenges of Research Trends. Sensors 2021, 21, 5718. [Google Scholar] [CrossRef]
- Aharon, U.; Dubin, R.; Dvir, A.; Hajaj, C. A classification-by-retrieval framework for few-shot anomaly detection to detect API injection. Comput. Secur. 2025, 150, 104249. [Google Scholar]
- Arshad, U.; Halim, Z. BlockLLM: A futuristic LLM-based decentralized vehicular network architecture for secure communications. Comput. Electr. Eng. 2025, 123, 110027. [Google Scholar] [CrossRef]
- Tlili, F.; Ayed, S.; Fourati, L.C. Advancing UAV security with artificial intelligence: A comprehensive survey of techniques and future directions. Internet Things 2024, 27, 101281. [Google Scholar]
- Ibrahum, A.D.M.; Hussain, M.; Hong, J. Deep learning adversarial attacks and defenses in autonomous vehicles: A systematic literature review from a safety perspective. Artif. Intell. Rev. 2025, 58, 28. [Google Scholar]
- Abualigah, L.; Diabat, A.; Gandomi, A.H. Applications, Deployments, and Integration of Internet of Drones (IoD): A Review. IEEE Sens. J. 2021, 21, 25532–25546. [Google Scholar] [CrossRef]
- Zhou, L.; Yin, H.; Zhao, H.; Wei, J.; Hu, D.; Leung, V.C.M. A Comprehensive Survey of Artificial Intelligence Applications in UAV-Enabled Wireless Networks. Digit. Commun. Netw. 2024, in press. [Google Scholar] [CrossRef]
- Zhou, J.; Yi, J.; Yang, Z.; Pu, H.; Li, X.; Luo, J.; Gao, L. A survey on vehicle–drone cooperative delivery operations optimization: Models, methods, and future research directions. Swarm Evol. Comput. 2025, 92, 101780. [Google Scholar] [CrossRef]
- Sabet, M.; Palanisamy, P.; Mishra, S. Scalable modular synthetic data generation for advancing aerial autonomy. Robot. Auton. Syst. 2023, 166, 104464. [Google Scholar] [CrossRef]
- Maheriya, K.; Rahevar, M.; Mewada, H.; Parmar, M.; Patel, A. Insights into aerial intelligence: Assessing CNN-based algorithms for human action recognition and object detection in diverse environments. Multimed. Tools Appl. 2024, 1–43. [Google Scholar] [CrossRef]
- Li, X.; Wang, S.; Zeng, S.; Wu, Y.; Yang, Y. A survey on LLM-based multi-agent systems: Workflow, infrastructure, and challenges. Vicinagearth 2024, 1, 9. [Google Scholar] [CrossRef]
- Luo, H.; Luo, J.; Vasilakos, A.V. BC4LLM: A perspective of trusted artificial intelligence when blockchain meets large language models. Neurocomputing 2024, 599, 128089. [Google Scholar] [CrossRef]
- Oliveira, F.; Costa, D.G.; Assis, F.; Silva, I. Internet of Intelligent Things: A convergence of embedded systems, edge computing and machine learning. Internet Things 2024, 26, 101153. [Google Scholar] [CrossRef]
- Fang, H.; Zhang, D.; Tan, C.; Yu, P.; Wang, Y.; Li, W. Large Language Model Enhanced Autonomous Agents for Proactive Fault-Tolerant Edge Networks. In Proceedings of the IEEE INFOCOM 2024-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Vancouver, BC, Canada, 20–23 May 2024. [Google Scholar]
- Poth, A.; Rrjolli, O.; Arcuri, A. Technology adoption performance evaluation applied to testing industrial REST APIs. Autom. Softw. Eng. 2025, 32, 5. [Google Scholar] [CrossRef]
- Balasundaram, A.; Aziz, A.B.A.; Gupta, A.; Shaik, A.; Kavitha, M.S. A fusion approach using GIS, green area detection, weather API and GPT for satellite image based fertile land discovery and crop suitability. Sci. Rep. 2024, 14, 16241. [Google Scholar] [CrossRef]
- Hemberg, E.; Moskal, S.; O’Reilly, U. Evolving code with a large language model. Genet. Program. Evolvable Mach. 2024, 25, 21. [Google Scholar] [CrossRef]
- Hong, J.; Ryu, S. Type-migrating C-to-Rust translation using a large language model. Empir. Softw. Eng. 2025, 30, 3. [Google Scholar] [CrossRef]
- Ma, Z.; An, S.; Xie, B.; Lin, Z. Compositional API Recommendation for Library-Oriented Code Generation. In Proceedings of the 2024 IEEE/ACM 32nd International Conference on Program Comprehension (ICPC), Lisbon, Portugal, 15–16 April 2024. [Google Scholar]
- Kotstein, S.; Decker, C. RESTBERTa: A Transformer-based question answering approach for semantic search in Web API documentation. Clust. Comput. 2024, 27, 4035–4061. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, G.; Xu, G.; Yang, J.; Han, B.; Yu, J. A LLM-driven and motif-informed linearizing graph transformer for Web API recommendation. Appl. Soft Comput. 2025, 169, 112547. [Google Scholar] [CrossRef]
- Cao, C.; Wang, F.; Lindley, L.; Wang, Z. Managing Linux servers with LLM-based AI agents: An empirical evaluation with GPT4. Mach. Learn. Appl. 2024, 17, 100570. [Google Scholar] [CrossRef]
- Sauvola, J.; Tarkoma, S.; Klemettinen, M.; Riekki, J.; Doermann, D. Future of software development with generative AI. Autom. Softw. Eng. 2024, 31, 26. [Google Scholar] [CrossRef]
- Du, F.; Ma, X.; Yang, J.; Liu, Y.; Luo, C.; Wang, X.; Jiang, H.; Jing, X. A Survey of LLM Datasets: From Autoregressive Model to AI Chatbot. J. Comput. Sci. Technol. 2024, 39, 542–566. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Description |
|---|---|
| battery | Drone’s battery level (percentage) |
| distance_to_target | Distance of the drone to its target (in meters) |
| weather_condition | Weather condition (clear, rain, and fog) |
| connectivity | Connection status (strong, weak, and lost) |
| speed | Current speed of the drone (in m/s) |
| altitude | Altitude of the drone (in meters) |
| gps_signal_strength | GPS signal strength (range 0–1) |
| wind_speed | Wind speed (in m/s) |
| scenario | Operational scenario (e.g., “gps_signal_loss”, “battery_low”) |
| action | Action taken by the drone in response to the scenario (e.g., “switch_to_manual_navigation”) |
| Scenario | System-Generated Action | Cosine Similarity | BLEU Score |
|---|---|---|---|
| Battery failure detected | Return to base | 0.91 | 0.85 |
| Connectivity loss | Hover and reconnect | 0.88 | 0.80 |
| High wind conditions during flight | Adjust altitude and reduce speed | 0.86 | 0.83 |
| Obstacle detected mid-flight | Change flight path | 0.89 | 0.84 |
| Scenario | Total Actions | LLM Accuracy (%) | Decision Tree Accuracy (%) | Neural Network Accuracy (%) | Random Forests Accuracy (%) |
|---|---|---|---|---|---|
| Battery failure detected | 100 | 96.2 | 81.1 | 77.3 | 85.2 |
| Connectivity loss | 150 | 94.5 | 79.1 | 74.10 | 82.6 |
| High wind conditions during flight | 200 | 91.8 | 72.5 | 55.84 | 80.1 |
| Obstacle detected mid-flight | 120 | 95.0 | 82.8 | 76.3 | 82.80 |
| GPS signal loss | 135 | 92.3 | 78.6 | 70.9 | 83.4 |
| Wind induced connectivity issues | 185 | 93.6 | 80.2 | 72.4 | 81.7 |
| Maximum altitude exceeded | 140 | 90.4 | 74.6 | 69.5 | 79.8 |
| Low power and weak signal | 215 | 95.1 | 83.1 | 75.9 | 87.4 |
| Severe weather and GPS issues | 230 | 94.2 | 81.0 | 73.2 | 86.0 |
| Weak signal and GPS instability | 145 | 91.3 | 77.4 | 71.6 | 82.1 |
| Low altitude and weak GPS signal | 160 | 92.7 | 78.2 | 69.9 | 80.9 |
| Fog and connectivity loss | 200 | 94.8 | 82.0 | 74.1 | 85.7 |
| Normal operation | 180 | 96.0 | 84.5 | 78.0 | 88.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sezgin, A. Scenario-Driven Evaluation of Autonomous Agents: Integrating Large Language Model for UAV Mission Reliability. Drones 2025, 9, 213. https://doi.org/10.3390/drones9030213
Sezgin A. Scenario-Driven Evaluation of Autonomous Agents: Integrating Large Language Model for UAV Mission Reliability. Drones. 2025; 9(3):213. https://doi.org/10.3390/drones9030213
Chicago/Turabian StyleSezgin, Anıl. 2025. "Scenario-Driven Evaluation of Autonomous Agents: Integrating Large Language Model for UAV Mission Reliability" Drones 9, no. 3: 213. https://doi.org/10.3390/drones9030213
APA StyleSezgin, A. (2025). Scenario-Driven Evaluation of Autonomous Agents: Integrating Large Language Model for UAV Mission Reliability. Drones, 9(3), 213. https://doi.org/10.3390/drones9030213