
Self-Adaptable Computation Offloading Strategy for UAV-Assisted Edge Computing


Highlights
- A deep neural network (DNN) is employed as an efficient approximate solver to produce real-time binary offloading decisions in UAV-assisted edge computing, effectively addressing the 0–1 mixed-integer programming problem.
- An online learning mechanism enables automatic adaptation to variations in key parameters (e.g., computing resources and task sizes), eliminating the need for time-consuming policy recomputation.
- The proposed QO2 method resolves the fundamental trade-off between computational complexity and decision timeliness in traditional optimization, supporting decision-making with high timeliness.
- It overcomes the limitations of conventional static optimization strategies, which fail under environmental changes, thereby reducing operational overhead and providing a theoretical foundation for deploy-and-adapt edge-computing systems.
Abstract
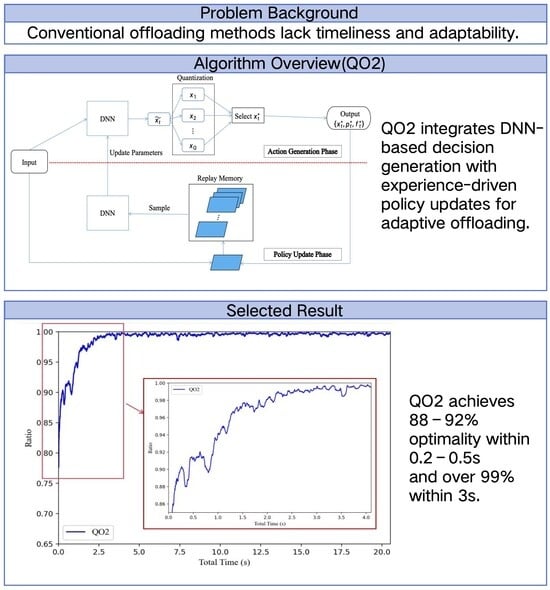
1. Introduction
- Computational Timeliness Deficiency: The solving time of these methods significantly impairs strategy timeliness, and thus even fails to harvest MEC. Specifically, time-varying wireless channel conditions largely impact offloading performance, which requires optimal adaptation of offloading decisions and resource allocations. This demands solving the combinatorial optimization problem within channel coherence time. However, the computation complexity is prohibitively high, particularly in large-scale networks. Methods like heuristic local search and convex relaxation often require numerous iterations to reach a satisfying local solution, making them unsuitable for real-time offloading decisions in fast-changing channels.
- Environment Adaptability Limitations: Existing algorithms are predominantly designed for fixed network parameter sets, while failing to exploit correlations between strategies under different environmental conditions. This limitation prevents effective utilization of historical computational data to rapidly adjust offloading and resource-allocation decisions. Consequently, when network environments change, strategy recalculation is necessary. For UAV-EC systems with rapidly changing environments, this constant recalculation would lead to substantial computational overhead.
- Joint Optimization Framework: We introduce a joint optimization framework for UAV-EC systems that simultaneously co-designs computation offloading decisions and resource allocation. This integrated approach is tailored for dynamic settings, explicitly accounting for time-varying wireless channels to deliver real-time solutions.
- Novel QO2 Algorithm with PPS Strategy: We design the QO2 algorithm, which leverages DNN-based learning to generate binary offloading decisions in real-time, eliminating the computational burden of traditional MINLP solvers. In addition, we design the PPS strategy, which leverages historical optimization patterns to enhance algorithmic robustness across varying environmental conditions.
- Comprehensive Performance Validation: Extensive simulations demonstrate that QO2 achieves superior solution quality compared to state-of-the-art baselines, consistently finding solutions closer to the global optimum. Our approach exhibits strong adaptability to dynamic network conditions and demonstrates rapid re-convergence capability under varying operational scenarios, with convergence time appropriately scaling with the magnitude of environmental changes.
2. Related Work
2.1. Computation Offloading
2.2. Learning-Based Offloading Decision Making
3. System Model and Problem Formulation
3.1. Network Model
3.1.1. Local Computation Model
3.1.2. Edge Computation Model
- Uplink Transmission: Each uplink channel is a block-fading Rayleigh channel with block length no less than the maximum execution time of offloaded tasks. The channel gain of UE k, denoted , accounts for the overall effects of path loss and small-scale fading. To emphasize again, we ignore subscripts t of to simplify labeling. Considering the white Guassian noise power is and user bandwidth is W, the data rate of UE k could be given by where is the transmitting power of UE k and could be configured flexibly.
- Edge Execution: We assume that ES could serve K UE concurrently by allocating computational resource to UE k.
3.2. Problem Formulation
3.2.1. QoE-Aware System Utitily
3.2.2. Utility Maximization Problem
3.2.3. Problem Analysis
- A tight coupled relationship among subproblems: More specifically, offloading decision would affect resource allocation and vice versa.
- Integer feature of offloading decision subproblem: Due to rgw integer feature of , it always needs to search among possible actions to find the optimal solution. Obviously, a violent search is not suitable for exponentially large search spaces.
- Non-convexity of resoure allocation subproblem: Even for a given offloading decision, it is still difficult to solve the resource-allocation problem due to its non-convexity.
4. Proposed Algorithm
4.1. Algorithm Overview
- Action Generation: First, a relaxed offloading decision is obtained firstly via utilizing a DNN with parameters . Then, a quantization operation is performed to guarantee its integer feature and uplink capacity constraint. Finally, the ES selects the optimal offloading action through solving RA and comparing utility for each quantized offloading decision; meanwhile, it determines the optimal resource-allocation strategy.
- Policy Update: To obtain more intelligent action, the ES would first add experience data to replay memory based on a given caching rule. Then, it would sample a batch of cached data to retrain DNN and accordingly update network parameters, which would be used to generate a new action in the next several blocks.

4.2. Action Generation: Offloading Decision
4.2.1. Relaxation Operation
4.2.2. Quantization and Select Operations
- First, we sort entries of in a descending order, e.g., where is the k-th order statistic of . DefineThen, the first binary offloading decision could be achieved byfor .
- To generate the remaining offloading actions, we first order entries of respective to their distances to 0.5, , where is the q-th order statistic of . Then, the binary offloading decision could be achieved byfor .
4.3. Action Generation: Resource Allocation
4.3.1. Uplink Power Control
| Algorithm 1 Bisection-based power control algorithm (BPC). |
|
4.3.2. Computation-Resources Allocation
4.4. Policy Update
- Sample Strategy: We sample a batch of data , marked by a set of time indices to train DNN (the reward signal is implicitly encoded in through the utility-maximization process. Specifically, is selected as the candidate achieving the maximum utility value among quantized alternatives, thus representing the optimal reward-maximizing action under the given channel state .). Intuitively, the latest data comes from a smarter DNN, and thus contributes more to policy update. However, relying solely on latest data to train DNN would lead to poor stability. To achieve a better balance, we propose a PPS strategy. Specifically, we record sample frequency of data i as , based on which we set its sample priority as . Here, is a coefficient to balance update efficiency and stability. Then, data i would be sampled with probability of . As shown in Section 5, PPS method outmatches Random Sampling (RS) method [50] and Priority-based Sampling (PS) method in terms of convergence rate and stability, respectively.
- Loss Function and Optimizer: Mathematically, training DNN with weights could be considered a logistic regression problem. Hence, we could choose cross-entropy as the loss function, defined aswith “·” denoting the dot product of two vectors. Additionally, Adam algorithm is utilized as our optimizer to reduce loss defined in (19). The details of the Adam algorithm are omitted for brevity.
| Algorithm 2 QoE-aware Online Offloading (QO2) Algorithm |
|
4.5. Computational Complexity Analysis and Deployment Issues
5. Numerical Results
5.1. Simulation Setup
- Communication parameters: We consider that UEs are randomly distributed within a area and a UAV is positioned at the center of the area at an altitude of . Here, the free-space path loss model, i.e., , is adopted to characterize path loss between UE k and ES, where , MHz, and denote antenna gain, carrier frequency, and path loss exponent, respectively. In addition, the small-scale channel fading follows Rayleigh fading, i.e., , and the power density of noise is —174 dBm [55]. Moreover, we consider that there are uplink subchannels with equal bandwidth MHz. Finally, we set the maximum transmit power W, static transmit power W, inverse of power amplifier efficiency , and uplink channel cost .
- Computation parameters: Computational speed of UE and power coefficient are set as cycles/s and . Moreover, we set computation capacity of ES as cycles/s [55].
- Application parameters: We set the input data size and its computation intensive degree as 10 Mb and 100 cycles/bit, respectively.
- Preference parameters: We set . Additionally, we set if k is an odd number and otherwise.
- Algorithm parameters: We choose a fully connected DNN consisting of one input layer and two hidden layers with 120 and 80 hidden neurons, respectively, and one output layer in our proposed QO2 algorithm (the 2-layer architecture with 120 and 80 neurons was selected through a systematic hyperparameter search, which explored configurations with 1–3 layers and various neuron combinations. This configuration demonstrated optimal convergence and robustness across different parameter settings.). Via experiments, we finally set the memory size, batch size, training interval , and learning rate of Adam optimizer as 1024, 128, 5, and 0.01, respectively. Additionally, we set sample parameter as 1 to balance policy efficiency and stability.
5.2. Convergence and Effectiveness Performance of QO2
5.3. Adaptability Performance of QO2
5.4. Performance of Sampling Method
- Priority Sampling (PS): Selects the most recent experiences equal to the batch size from memory.
- Random Sampling (RS): Randomly selects experiences equal to the batch size from all stored experiences.
- Probability-first Random Sampling (PRS): Sets the sampling probability for each experience based on its sampling frequency, then chooses a batch of experiences according to these probabilities.

5.5. Performance Comparison
- Edge computing (EC): All tasks are offloaded.
- Random scheduling (RS): All UE are randomly offloaded to the UAV.
- Branch-and-bound-aided offloading (BBAO) [39]: The branch-and-bound approach is utilized to obtain offloading decisions.Specifically, BBAO uses identical system parameters as other algorithms. For each time slot, it exhaustively enumerates all feasible resource allocations via depth-first search (DFS), computes the system rate for each allocation using the bisection method, and selects the allocation with maximum utility as the optimal solution. This process provides a near-optimal benchmark for performance comparison.
- Deep Reinforcement learning-based Online Offloading (DROO) [50]: DROO algorithm utilizes DRL technique to obtain offloading decision, where random sampling strategy is adopted in the policy update phase.
- Soft-actor–critic method (SAC) [46] scheme: Taking the wireless channel gain between the UE and the edge server as input, use SAC to output binary offloading decisions, and obtain the optimal system utility as a reward to train the SAC policy.
- Deep deterministic policy gradient (DDPG) [44] scheme: Similar to SAC scheme, use DDPG to take the wireless channel gain as input to output binary offloading decisions, and obtain the optimal system utility to train the DDPG policy (to ensure a relatively fair comparison, SAC and DDPG are integrated into QO2 framework via replacing the DNN component, rather than being standalone implementations of the original algorithm).
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| UAV-EC | Unmanned Aerial Vehicle-assisted Edge Computing |
| UE | User Equipment |
| MINLP | Mixed-Integer Nonlinear Programming |
| QoE | Quality of Experience |
| QO2 | QoE-aware Online Offloading |
| ISP | Internet Service Provider |
| DAG | Directed Acyclic Graph |
| TDMA | Time Division Multiple Access |
| FDMA | Frequency Division Multiple Access |
| NOMA | Non-Orthogonal Multiple Access |
| D2D | Device-to-Device |
| MEC | Mobile Edge Computing |
| RIS | Reconfigurable Intelligent Surface |
| MIP | Mixed-Integer Programming |
| DNN | Deep Neural Network |
| SCA | Successive Convex Approximation |
| DQN | Deep Q-Network |
| DDQN | Double Deep Q-Network |
| DDPG | Deep Deterministic Policy Gradient |
| SAC | Soft Actor–Critic |
| DROO | Deep Reinforcement learning-based Online Offloading |
| IOCO | Intelligent Online Computation Offloading |
| ES | Edge Server |
| BPC | Bisection-based Power Control |
| BBAO | Branch-and-Bound-Aided Offloading |
| PPS | Priority-Based Proportional Sampling |
| PRS | Probability-first Random Sampling |
| PS | Priority Sampling |
| RS | Random Sampling |
Appendix A
Appendix B
- Convexity of objective function: Consider the objective , where and . For each term , the second derivative is , which proves that is convex. For the multivariate function , the Hessian matrix is:Since all diagonal entries are non-negative, , which proves that is convex.
- Convexity of feasible region: The feasible region is defined by constraints C4 and C5. For C4: , each constraint defines a half-space, which is a convex set. The intersection of all such half-spaces, , is convex. For C5: , this is a linear inequality constraint of the form , where . Linear functions are both convex and concave, and the sublevel set is a half-space, which is convex. The feasible region is the intersection of convex sets (the non-negative orthant and a half-space). Since the intersection of convex sets is convex, is a convex set.
References
- Mu, J.; Zhang, R.; Cui, Y.; Li, J.; Wang, J.; Shi, Y. UAV Meets Integrated Sensing and Communication: Challenges and Future Directions. IEEE Commun. Mag. 2023, 61, 62–67. [Google Scholar] [CrossRef]
- Tang, J.; Nie, J.; Zhao, J.; Zhou, Y.; Xiong, Z.; Guizani, M. Slicing-Based Software-Defined Mobile Edge Computing in the Air. IEEE Wirel. Commun. 2022, 29, 119–125. [Google Scholar] [CrossRef]
- Alamouti, S.M.; Arjomandi, F.; Burger, M. Hybrid Edge Cloud: A Pragmatic Approach for Decentralized Cloud Computing. IEEE Commun. Mag. 2022, 60, 16–29. [Google Scholar] [CrossRef]
- Liu, B.; Wan, Y.; Zhou, F.; Wu, Q.; Hu, R.Q. Resource Allocation and Trajectory Design for MISO UAV-Assisted MEC Networks. IEEE Trans. Veh. Technol. 2022, 71, 4933–4948. [Google Scholar] [CrossRef]
- Sun, G.; Wang, Y.; Sun, Z.; Wu, Q.; Kang, J.; Niyato, D.; Leung, V.C.M. Multi-Objective Optimization for Multi-UAV-Assisted Mobile Edge Computing. IEEE Trans. Mob. Comput. 2024, 23, 14803–14820. [Google Scholar] [CrossRef]
- Bai, Z.; Lin, Y.; Cao, Y.; Wang, W. Delay-Aware Cooperative Task Offloading for Multi-UAV Enabled Edge-Cloud Computing. IEEE Trans. Mob. Comput. 2022, 23, 1034–1049. [Google Scholar] [CrossRef]
- Shen, L. User Experience Oriented Task Computation for UAV-Assisted MEC System. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 1549–1558. [Google Scholar]
- Sun, Z.; Sun, G.; He, L.; Mei, F.; Liang, S.; Liu, Y. A Two Time-Scale Joint Optimization Approach for UAV-Assisted MEC. In Proceedings of the IEEE INFOCOM 2024—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 20–23 May 2024; pp. 91–100. [Google Scholar]
- Sun, G.; He, L.; Sun, Z.; Wu, Q.; Liang, S.; Li, J.; Niyato, D.; Leung, V.C.M. Joint Task Offloading and Resource Allocation in Aerial-Terrestrial UAV Networks with Edge and Fog Computing for Post-Disaster Rescue. IEEE Trans. Mob. Comput. 2024, 23, 8582–8600. [Google Scholar] [CrossRef]
- Tian, J.; Wang, D.; Zhang, H.; Wu, D. Service Satisfaction-Oriented Task Offloading and UAV Scheduling in UAV-Enabled MEC Networks. IEEE Trans. Wirel. Commun. 2023, 22, 8949–8964. [Google Scholar] [CrossRef]
- Chai, F.; Zhang, Q.; Yao, H.; Xin, X.; Gao, R.; Guizani, M. Joint Multi-Task Offloading and Resource Allocation for Mobile Edge Computing Systems in Satellite IoT. IEEE Trans. Veh. Technol. 2023, 72, 7783–7795. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, M.; Ai, B.; Wang, Y.; Sun, S. Adaptive Bitrate Video Caching in UAV-Assisted MEC Networks Based on Distributionally Robust Optimization. IEEE Trans. Mob. Comput. 2023, 23, 5245–5259. [Google Scholar] [CrossRef]
- Wang, H.; Jiang, B.; Zhao, H.; Zhang, J.; Zhou, L.; Ma, D.; Wei, J.; Leung, V.C.M. Joint Resource Allocation on Slot, Space and Power Towards Concurrent Transmissions in UAV Ad Hoc Networks. IEEE Trans. Wirel. Commun. 2022, 21, 8698–8712. [Google Scholar] [CrossRef]
- Dai, M.; Wu, Y.; Qian, L.; Su, Z.; Lin, B.; Chen, N. UAV-Assisted Multi-Access Computation Offloading via Hybrid NOMA and FDMA in Marine Networks. IEEE Trans. Netw. Sci. Eng. 2022, 10, 113–127. [Google Scholar] [CrossRef]
- Lu, W.; Ding, Y.; Gao, Y.; Chen, Y.; Zhao, N.; Ding, Z.; Nallanathan, A. Secure NOMA-Based UAV-MEC Network Towards a Flying Eavesdropper. IEEE Trans. Commun. 2022, 70, 3364–3376. [Google Scholar] [CrossRef]
- Yang, D.; Zhan, C.; Yang, Y.; Yan, H.; Liu, W. Integrating UAVs and D2D Communication for MEC Network: A Collaborative Approach to Caching and Computation. IEEE Trans. Veh. Technol. 2025, 74, 10041–10046. [Google Scholar] [CrossRef]
- Yang, Z.; Xia, L.; Cui, J.; Dong, Z.; Ding, Z. Delay and Energy Minimization for Cooperative NOMA-MEC Networks with SWIPT Aided by RIS. IEEE Trans. Veh. Technol. 2023, 73, 5321–5334. [Google Scholar] [CrossRef]
- Wang, K.; Fang, F.; da Costa, D.B.; Ding, Z. Sub-Channel Scheduling, Task Assignment, and Power Allocation for OMA-Based and NOMA-Based MEC Systems. IEEE Trans. Commun. 2021, 69, 2692–2708. [Google Scholar] [CrossRef]
- Wang, K.; Ding, Z.; So, D.K.C.; Karagiannidis, G.K. Stackelberg Game of Energy Consumption and Latency in MEC Systems With NOMA. IEEE Trans. Commun. 2021, 69, 2191–2206. [Google Scholar] [CrossRef]
- Zhang, Y.; Di, B.; Zheng, Z.; Lin, J.; Song, L. Distributed Multi-Cloud Multi-Access Edge Computing by Multi-Agent Reinforcement Learning. IEEE Trans. Wirel. Commun. 2021, 20, 2565–2578. [Google Scholar] [CrossRef]
- Guo, K.; Gao, R.; Xia, W.; Quek, T.Q.S. Online Learning Based Computation Offloading in MEC Systems With Communication and Computation Dynamics. IEEE Trans. Commun. 2021, 69, 1147–1162. [Google Scholar] [CrossRef]
- Wang, C.; Zhai, D.; Zhang, R.; Li, H.; Yu, F.R. Latency Minimization for UAV-Assisted MEC Networks With Blockchain. IEEE Trans. Commun. 2024, 72, 6854–6866. [Google Scholar] [CrossRef]
- Sun, Y.; Xu, J.; Cui, S. User Association and Resource Allocation for MEC-Enabled IoT Networks. IEEE Trans. Wirel. Commun. 2022, 21, 8051–8062. [Google Scholar] [CrossRef]
- Maraqa, O.; Al-Ahmadi, S.; Rajasekaran, A.S.; Sokun, H.U.; Yanikomeroglu, H.; Sait, S.M. Energy-Efficient Optimization of Multi-User NOMA-Assisted Cooperative THz-SIMO MEC Systems. IEEE Trans. Commun. 2023, 71, 3763–3779. [Google Scholar] [CrossRef]
- Mao, W.; Xiong, K.; Lu, Y.; Fan, P.; Ding, Z. Energy Consumption Minimization in Secure Multi-Antenna UAV-Assisted MEC Networks With Channel Uncertainty. IEEE Trans. Wirel. Commun. 2023, 22, 7185–7200. [Google Scholar] [CrossRef]
- Ernest, T.Z.H.; Madhukumar, A.S. Computation Offloading in MEC-Enabled IoV Networks: Average Energy Efficiency Analysis and Learning-Based Maximization. IEEE Trans. Mobile Comput. 2024, 23, 6074–6087. [Google Scholar] [CrossRef]
- Wang, R.; Huang, Y.; Lu, Y.; Xie, P.; Wu, Q. Robust Task Offloading and Trajectory Optimization for UAV-Mounted Mobile Edge Computing. Drones 2024, 8, 757. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Y. Learning-Based Prediction, Rendering and Association Optimization for MEC-Enabled Wireless Virtual Reality (VR) Networks. IEEE Trans. Wirel. Commun. 2021, 20, 6356–6370. [Google Scholar] [CrossRef]
- Chu, W.; Jia, X.; Yu, Z.; Lui, J.C.S.; Lin, Y. Joint Service Caching, Resource Allocation and Task Offloading for MEC-Based Networks: A Multi-Layer Optimization Approach. IEEE Trans. Mobile Comput. 2024, 23, 2958–2975. [Google Scholar] [CrossRef]
- Michailidis, E.T.; Volakaki, M.G.; Miridakis, N.I.; Vouyioukas, D. Optimization of Secure Computation Efficiency in UAV-Enabled RIS-Assisted MEC-IoT Networks with Aerial and Ground Eavesdroppers. IEEE Trans. Commun. 2024, 72, 3994–4009. [Google Scholar] [CrossRef]
- Zhang, Y.; Kuang, Z.; Feng, Y.; Hou, F. Task Offloading and Trajectory Optimization for Secure Communications in Dynamic User Multi-UAV MEC Systems. IEEE Trans. Mobile Comput. 2024, 23, 14427–14440. [Google Scholar] [CrossRef]
- Lu, F.; Liu, G.; Lu, W.; Gao, Y.; Cao, J.; Zhao, N. Resource and Trajectory Optimization for UAV-Relay-Assisted Secure Maritime MEC. IEEE Trans. Commun. 2024, 72, 1641–1652. [Google Scholar] [CrossRef]
- Chen, Z.; Tang, J.; Wen, M.; Li, Z.; Yang, J.; Zhang, X. Reconfigurable Intelligent Surface Assisted MEC Offloading in NOMA-Enabled IoT Networks. IEEE Trans. Commun. 2023, 71, 4896–4908. [Google Scholar] [CrossRef]
- Fang, K.; Ouyang, Y.; Zheng, B.; Huang, L.; Wang, G.; Chen, Z. Security Enhancement for RIS-Aided MEC Systems with Deep Reinforcement Learning. IEEE Trans. Commun. 2025, 73, 2466–2479. [Google Scholar] [CrossRef]
- Wu, Z.; Zhang, H.; Liu, X.; Li, L.; Li, H. IRS Empowered MEC System With Computation Offloading, Reflecting Design, and Beamforming Optimization. IEEE Trans. Commun. 2024, 72, 3051–3063. [Google Scholar] [CrossRef]
- Hu, X.; Zhao, H.; Zhang, W.; He, D. Online Resource Allocation and Trajectory Optimization of STAR–RIS–Assisted UAV–MEC System. Drones 2025, 9, 207. [Google Scholar] [CrossRef]
- Hao, X.; Yeoh, P.L.; She, C.; Vucetic, B.; Li, Y. Secure Deep Reinforcement Learning for Dynamic Resource Allocation in Wireless MEC Networks. IEEE Trans. Commun. 2024, 72, 1414–1427. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, H.; Ji, H.; Yang, L.; Li, X.; Leung, V.C.M. Transaction Throughput Optimization for Integrated Blockchain and MEC System in IoT. IEEE Trans. Wirel. Commun. 2022, 21, 1022–1036. [Google Scholar] [CrossRef]
- Basharat, M.; Naeem, M.; Khattak, A.M.; Anpalagan, A. Digital Twin-Assisted Task Offloading in UAV-MEC Networks With Energy Harvesting for IoT Devices. IEEE Internet Things J. 2024, 11, 37550–37561. [Google Scholar] [CrossRef]
- Ding, Y.; Han, H.; Lu, W.; Wang, Y.; Zhao, N.; Wang, X.; Yang, X. DDQN-Based Trajectory and Resource Optimization for UAV-Aided MEC Secure Communications. IEEE Trans. Veh. Technol. 2023, 73, 6006–6011. [Google Scholar] [CrossRef]
- Liu, C.; Zhong, Y.; Wu, R.; Ren, S.; Du, S.; Guo, B. Deep Reinforcement Learning Based 3D-Trajectory Design and Task Offloading in UAV-Enabled MEC System. IEEE Trans. Veh. Technol. 2025, 74, 3185–3195. [Google Scholar] [CrossRef]
- Lin, N.; Tang, H.; Zhao, L.; Wan, S.; Hawbani, A.; Guizani, M. A PDDQNLP Algorithm for Energy Efficient Computation Offloading in UAV-Assisted MEC. IEEE Trans. Wirel. Commun. 2023, 22, 8876–8890. [Google Scholar] [CrossRef]
- Du, T.; Gui, X.; Teng, X.; Zhang, K.; Ren, D. Dynamic Trajectory Design and Bandwidth Adjustment for Energy-Efficient UAV-Assisted Relaying with Deep Reinforcement Learning in MEC IoT System. IEEE Internet Things J. 2024, 11, 37463–37479. [Google Scholar] [CrossRef]
- Ale, L.; King, S.A.; Zhang, N.; Sattar, A.R.; Skandaraniyam, J. D3PG: Dirichlet DDPG for Task Partitioning and Offloading with Constrained Hybrid Action Space in Mobile-Edge Computing. IEEE Internet Things J. 2022, 9, 19260–19272. [Google Scholar] [CrossRef]
- Wang, B.; Kang, H.; Li, J.; Sun, G.; Sun, Z.; Wang, J.; Niyato, D. UAV-Assisted Joint Mobile Edge Computing and Data Collection via Matching-Enabled Deep Reinforcement Learning. IEEE Internet Things J. 2025, 12, 19782–19800. [Google Scholar] [CrossRef]
- Goudarzi, S.; Soleymani, S.A.; Anisi, M.H.; Jindal, A.; Xiao, P. Optimizing UAV-Assisted Vehicular Edge Computing with Age of Information: A SAC-Based Solution. IEEE Internet Things J. 2025, 12, 4555–4569. [Google Scholar] [CrossRef]
- Li, D.; Du, B.; Bai, Z. Deep Reinforcement Learning-Enabled Trajectory and Bandwidth Allocation Optimization for UAV-Assisted Integrated Sensing and Covert Communication. Drones 2025, 9, 160. [Google Scholar] [CrossRef]
- Bai, Y.; Xie, B.; Liu, Y.; Chang, Z.; Jäntti, R. Dynamic UAV Deployment in Multi-UAV Wireless Networks: A Multi-Modal Feature-Based Deep Reinforcement Learning Approach. IEEE Internet Things J. 2025, 12, 18765–18778. [Google Scholar] [CrossRef]
- Wang, T.; Na, X.; Nie, Y.; Liu, J.; Wang, W.; Meng, Z. Parallel Task Offloading and Trajectory Optimization for UAV-Assisted Mobile Edge Computing via Hierarchical Reinforcement Learning. Drones 2025, 9, 358. [Google Scholar] [CrossRef]
- Huang, L.; Bi, S.; Zhang, Y.-J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mobile Comput. 2019, 19, 2581–2593. [Google Scholar] [CrossRef]
- Wang, Y.; Qian, Z.; He, L.; Yin, R.; Wu, C. Intelligent Online Computation Offloading for Wireless-Powered Mobile-Edge Computing. IEEE Internet Things J. 2024, 11, 28960–28974. [Google Scholar] [CrossRef]
- Wang, Y.; Sheng, M.; Wang, X.; Wang, L.; Li, J. Mobile-Edge Computing: Partial Computation Offloading Using Dynamic Voltage Scaling. IEEE Trans. Commun. 2016, 64, 4268–4282. [Google Scholar] [CrossRef]
- Sheng, M.; Wang, Y.; Wang, X.; Li, J. Energy-Efficient Multiuser Partial Computation Offloading with Collaboration of Terminals, Radio Access Network, and Edge Server. IEEE Trans. Commun. 2020, 68, 1524–1537. [Google Scholar] [CrossRef]
- Boyd, S.P.; Vandenberghe, L. Convex Optimization, 1st ed.; Cambridge University Press: Cambridge, UK, 2004; pp. 136–146. [Google Scholar]
- Liu, J.; Zhang, X.; Zhou, H.; Xia, L.; Li, H.; Wang, X. Lyapunov-Based Deep Deterministic Policy Gradient for Energy-Efficient Task Offloading in UAV-Assisted MEC. Drones 2025, 9, 653. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| K | Number of UE |
| Channel gain from UE k to ES | |
| N | Number of subchannels |
| Computational speed of UE k | |
| Input data bits of application k | |
| Allocated computational speed for UE k | |
| Computation intensive degree | |
| Total computational speed of MEC server | |
| Offloading indicator | |
| Uplink rate of UE k | |
| Coefficient of CPU energy consumption | |
| Time/energy consumption of local execution | |
| W | Subchannel bandwidth |
| Time/energy consumption of offloading | |
| Noise power | |
| Total time/energy consumption of UE k | |
| Static power consumption | |
| User preference time/energy consumption | |
| Transmit power of UE k | |
| Weighting factor of UE k | |
| Inverse of the power amplifier efficiency | |
| Sampling related coefficient | |
| Maximum transmit power of UE k | |
| Training interval |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Zhang, Y.; Qian, Z.; Zhao, Y.; Zhang, H. Self-Adaptable Computation Offloading Strategy for UAV-Assisted Edge Computing. Drones 2025, 9, 748. https://doi.org/10.3390/drones9110748
Wang Y, Zhang Y, Qian Z, Zhao Y, Zhang H. Self-Adaptable Computation Offloading Strategy for UAV-Assisted Edge Computing. Drones. 2025; 9(11):748. https://doi.org/10.3390/drones9110748
Chicago/Turabian StyleWang, Yanting, Yuhang Zhang, Zhuo Qian, Yubo Zhao, and Han Zhang. 2025. "Self-Adaptable Computation Offloading Strategy for UAV-Assisted Edge Computing" Drones 9, no. 11: 748. https://doi.org/10.3390/drones9110748
APA StyleWang, Y., Zhang, Y., Qian, Z., Zhao, Y., & Zhang, H. (2025). Self-Adaptable Computation Offloading Strategy for UAV-Assisted Edge Computing. Drones, 9(11), 748. https://doi.org/10.3390/drones9110748