

Collision-Free Path Planning for Multiple Drones Based on Safe Reinforcement Learning


Abstract
1. Introduction
2. Related Work
3. Problem Definition and Necessary Theory
3.1. Problem Description
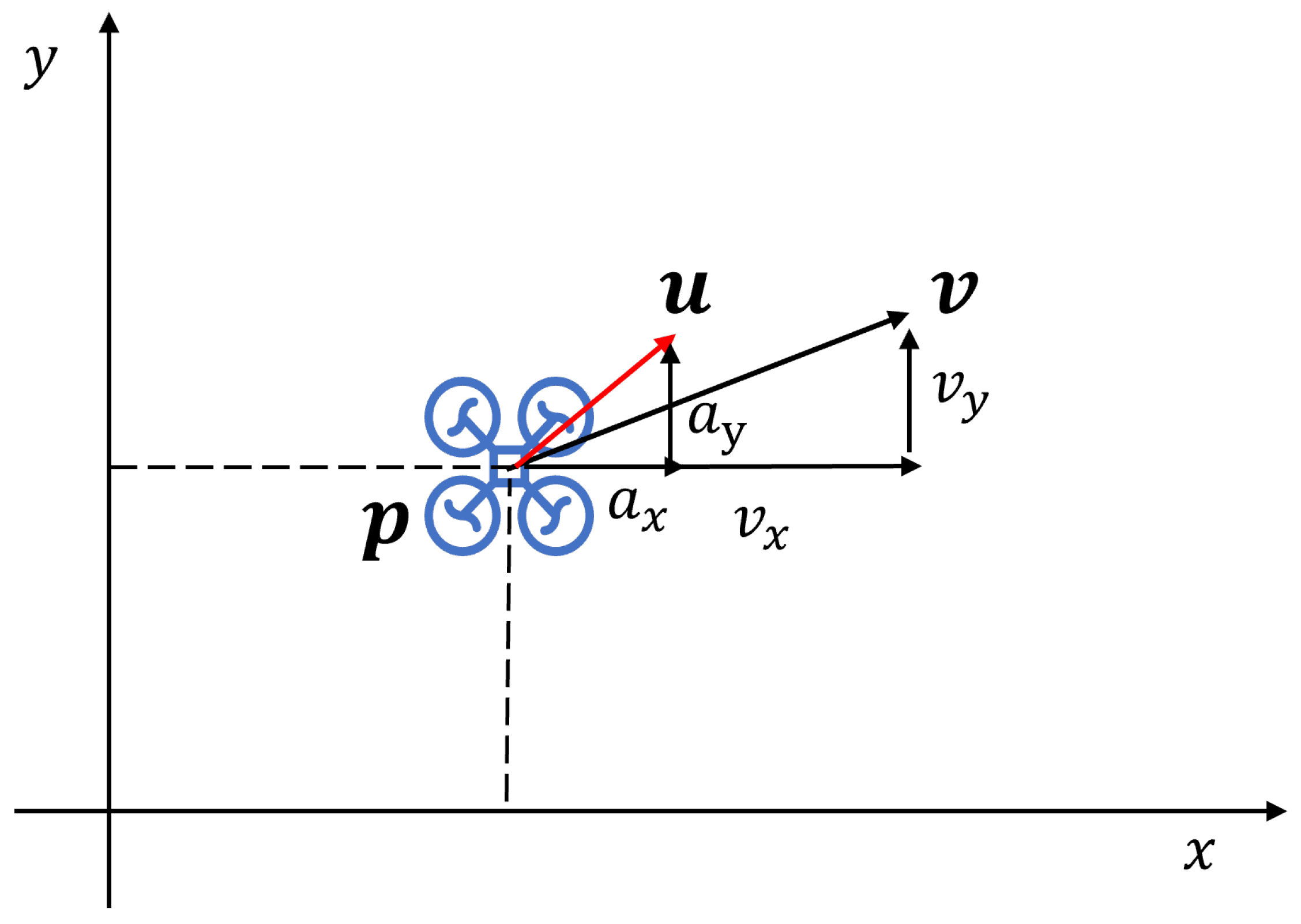
3.2. Drone Dynamics Model
3.3. Control Barrier Function
4. Proposed MADDPG-CBF Algorithm for Multi-Drone Path Planning
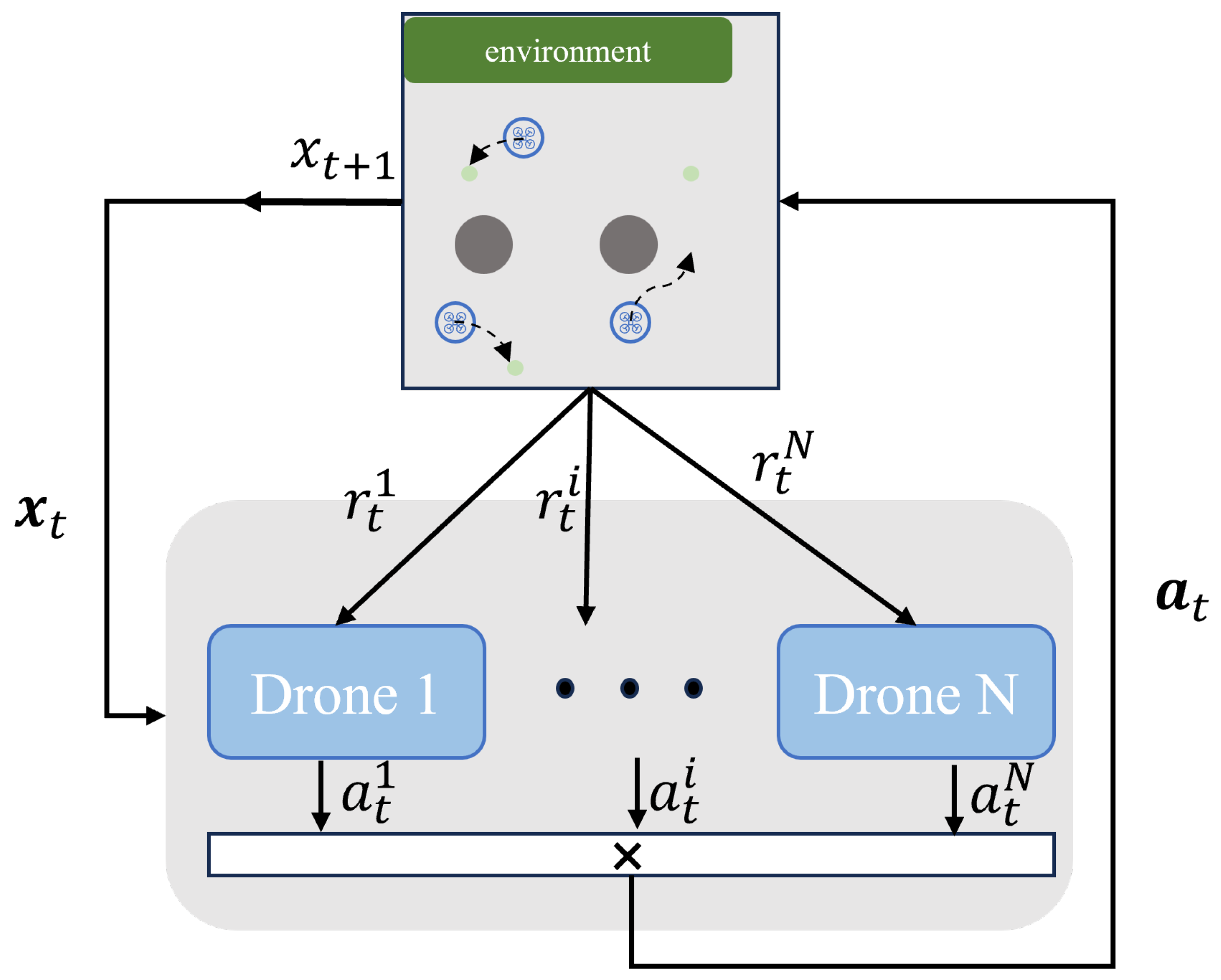
4.1. Multi-Agent Markov Decision Process
4.2. Multi-Agent Deep Deterministic Policy Gradient
4.2.1. Action Space
4.2.2. State Space
4.2.3. Reward Function
4.3. Proposed MADDPG-CBF Algorithm
5. Experiment and Result Analysis
5.1. Experimental Setup
| Algorithm 1 MADDPG-CBF |
|
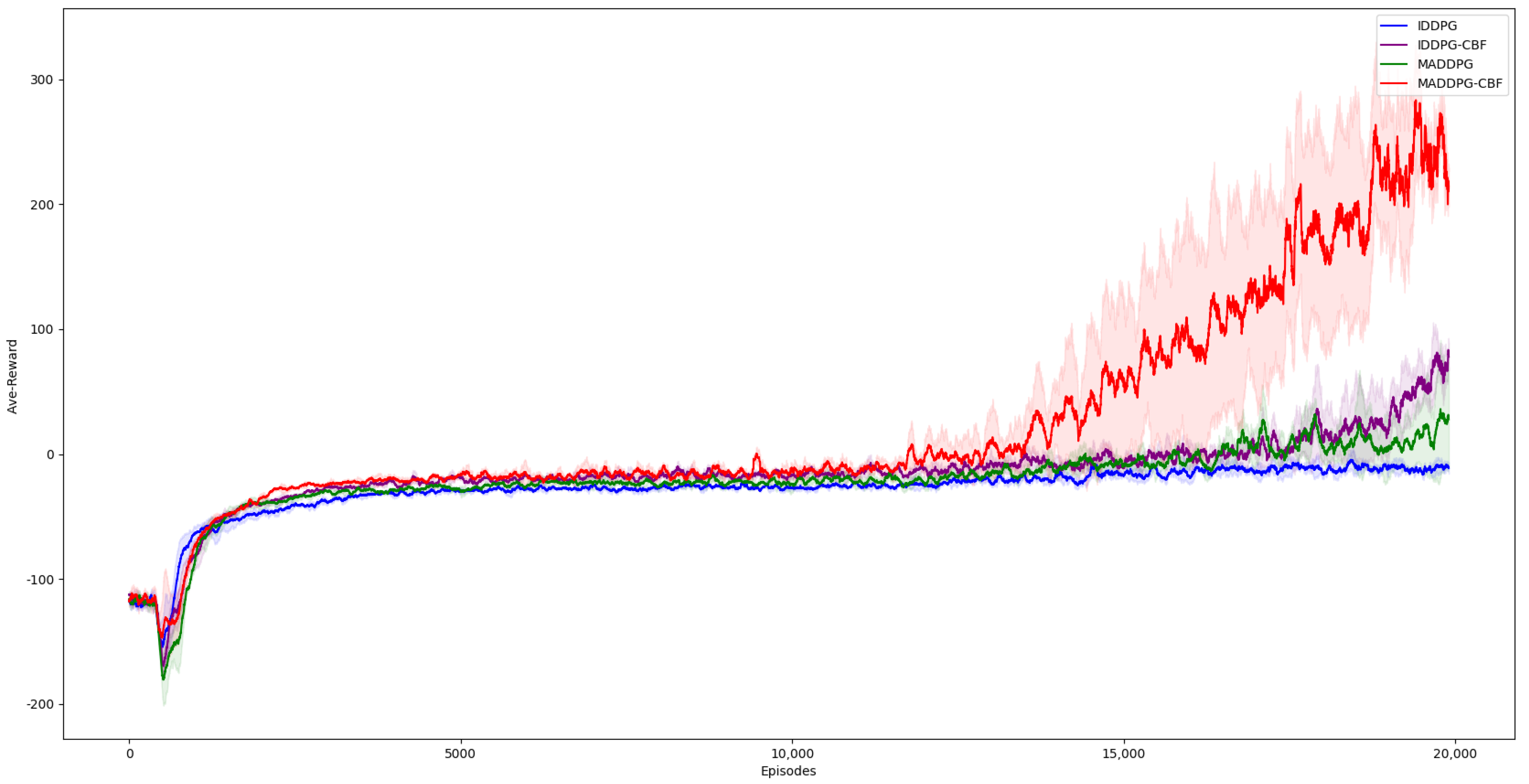
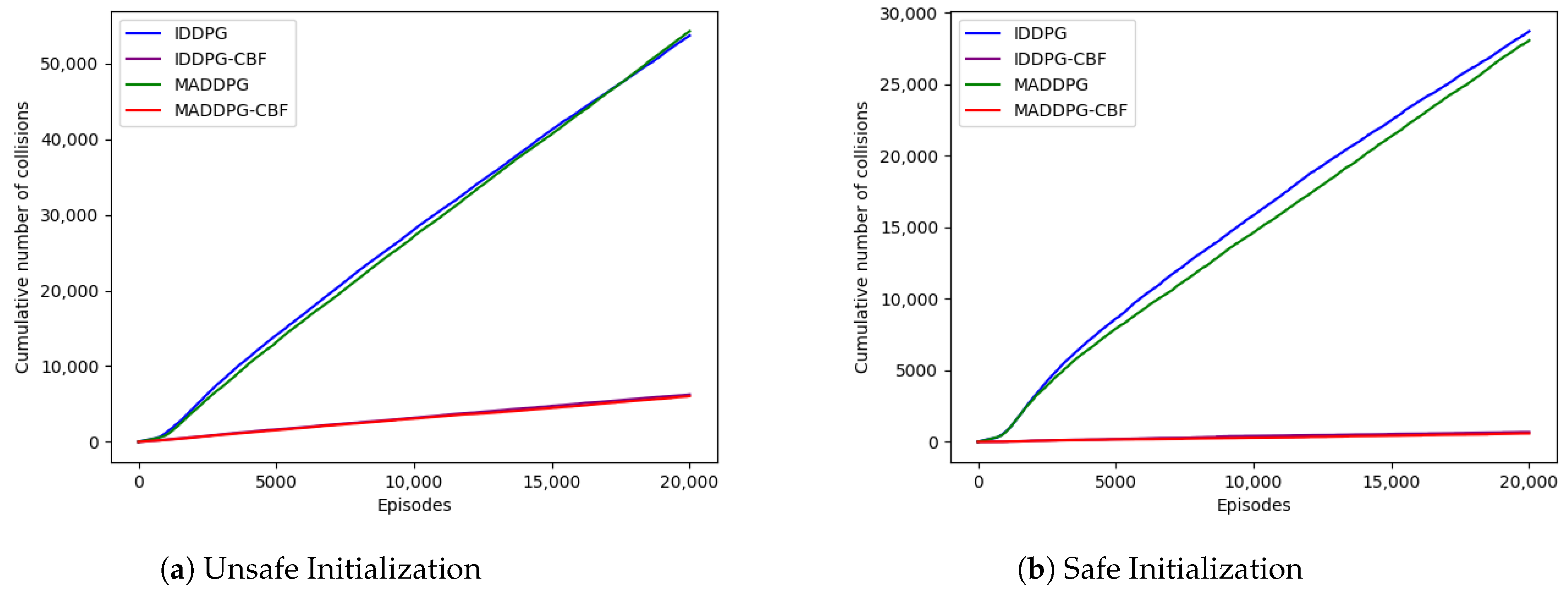
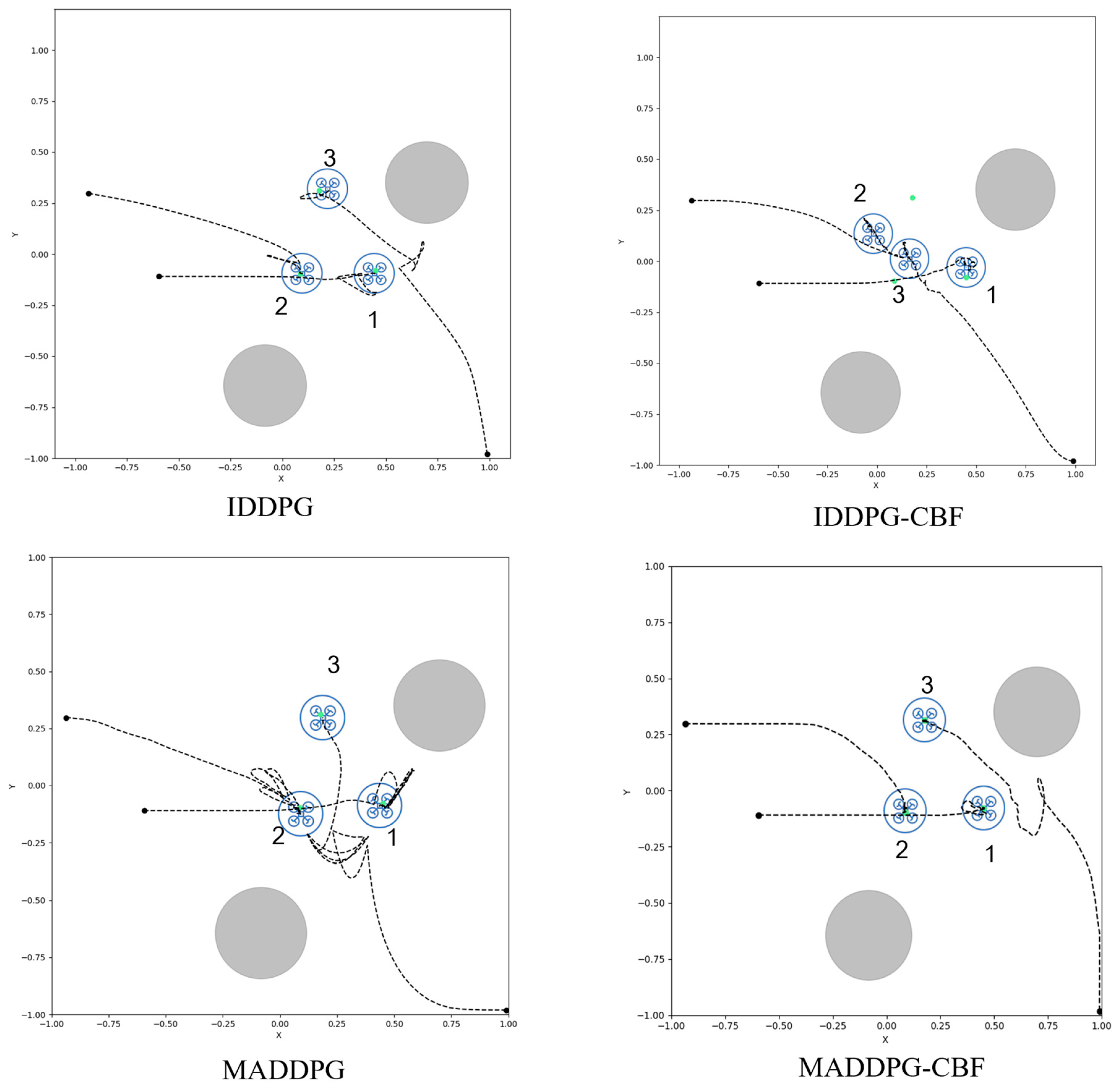
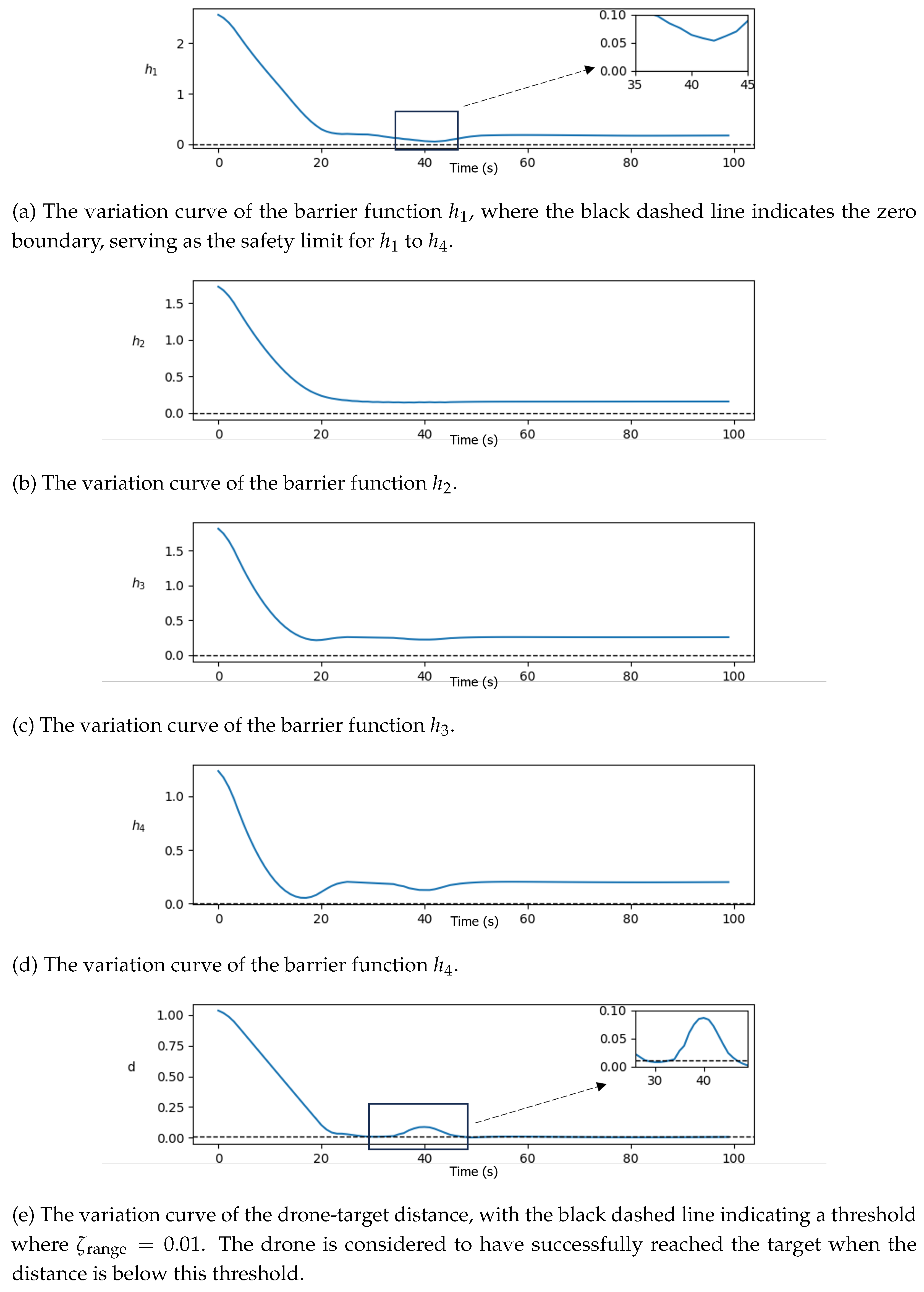
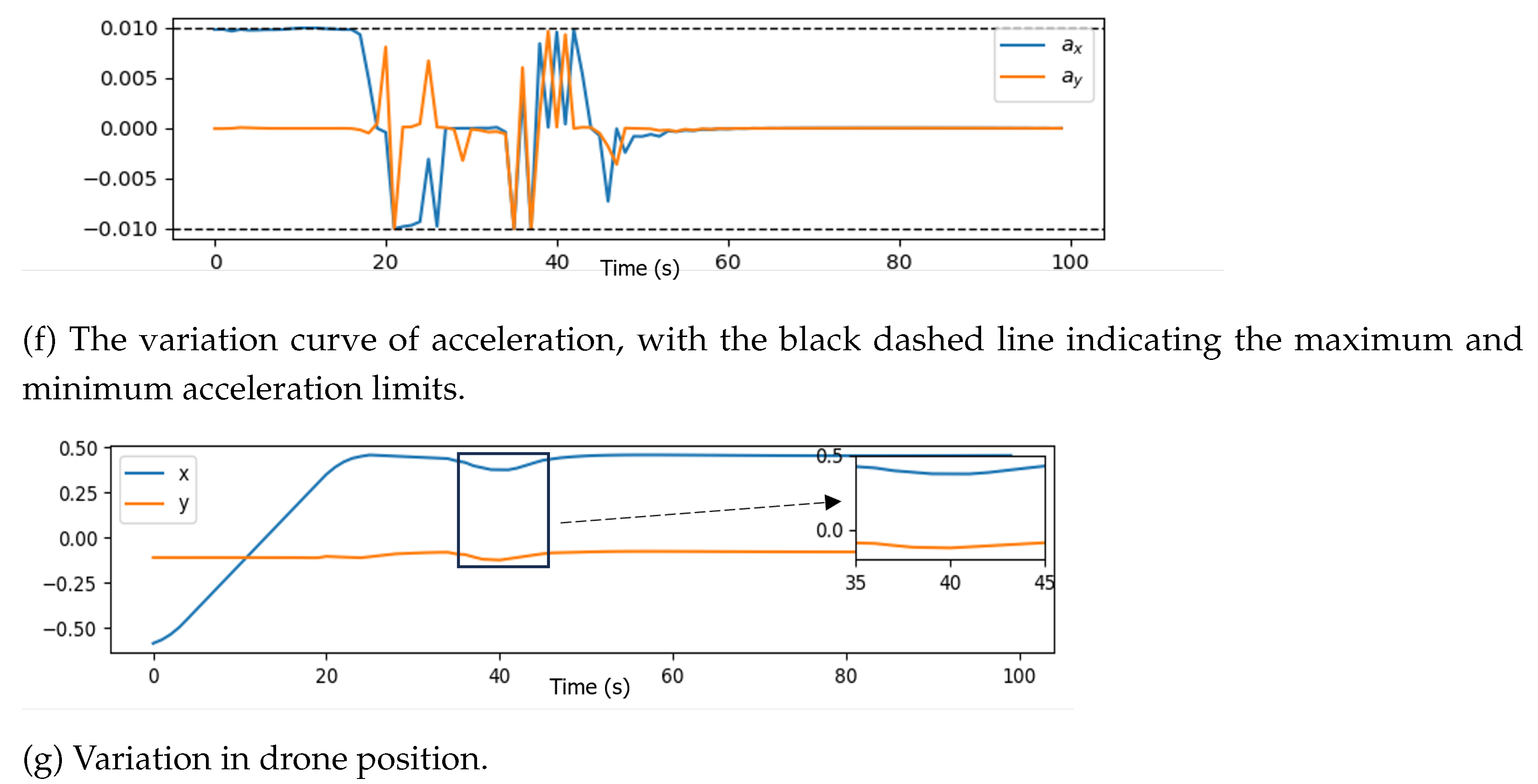
5.2. Results Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, Z.; Meng, D.; Chakraborty, C.; Fan, X.-R.; Bhardwaj, A.; Yu, K. Autonomous Behavioral Decision for Vehicular Agents Based on Cyber-Physical Social Intelligence. IEEE Trans. Comput. Soc. Syst. 2023, 10, 2111–2122. [Google Scholar] [CrossRef]
- Fu, G.; Gao, Y.; Liu, L.; Yang, M.; Zhu, X. UAV Mission Path Planning Based on Reinforcement Learning in Dynamic Environment. J. Funct. Spaces 2023, 2023, 9708143. [Google Scholar] [CrossRef]
- Khamidehi, B.; Sousa, E.S. Reinforcement-Learning-Aided Safe Planning for Aerial Robots to Collect Data in Dynamic Environments. IEEE Internet Things J. 2022, 9, 13901–13912. [Google Scholar] [CrossRef]
- Ding, Q.; Xu, X.; Gui, W. Path Planning Based on Reinforcement Learning with Improved APF Model for Synergistic Multi-UAVs. In Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023. [Google Scholar] [CrossRef]
- Hu, J.; Yang, X.; Wang, W.; Wei, P.; Ying, L.; Liu, Y. Obstacle avoidance for uas in continuous action space using deep reinforcement learning. IEEE Access 2022, 10, 90623–90634. [Google Scholar] [CrossRef]
- Razzaghi, P.; Tabrizian, A.; Guo, W.; Chen, S.; Taye, A.; Thompson, E.; Bregeon, A.; Baheri, A.; Wei, P. A survey on reinforcement learning in aviation applications. arXiv 2022, arXiv:2211.02147. [Google Scholar] [CrossRef]
- Lefevre, S.; Carvalho, A.; Borrelli, F. A Learning-Based Framework for Velocity Control in Autonomous Driving. IEEE Trans. Autom. Sci. Eng. 2016, 13, 32–42. [Google Scholar] [CrossRef]
- Tessler, C.; Mankowitz, D.J.; Mannor, S. Reward constrained policy optimization 2018. arXiv 2018, arXiv:1805.11074. [Google Scholar]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained Policy Optimization. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 22–31. [Google Scholar]
- Gu, S.; Kuba, J.G.; Chen, Y.; Du, Y.; Yang, L.; Knoll, A.; Yang, Y. Safe Multi-Agent Reinforcement Learning for Multi-Robot Control. Artif. Intell. 2023, 319, 103905. [Google Scholar] [CrossRef]
- Du, D.; Han, S.; Qi, N.; Ammar, H.B.; Wang, J.; Pan, W. Reinforcement Learning for Safe Robot Control Using Control Lyapunov Barrier Functions. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar] [CrossRef]
- Zeng, J.; Zhang, B.; Sreenath, K. Safety-Critical Model Predictive Control with Discrete-Time Control Barrier Function. In Proceedings of the 2021 American Control Conference (ACC), New Orleans, LA, USA, 25–28 May 2021. [Google Scholar] [CrossRef]
- Thirugnanam, A.; Zeng, J.; Sreenath, K. Safety-Critical Control and Planning for Obstacle Avoidance between Polytopes with Control Barrier Functions. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA) 2022, Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar] [CrossRef]
- Xue, H.; Lai, Y.H.; Sun, K. Human-like constraint-adaptive model predictive control with risk-tunable control barrier functions for autonomous ships. Ocean. Eng. 2024, 308, 118219. [Google Scholar] [CrossRef]
- Cohen, M.H.; Belta, C. Safe Exploration in Model-Based Reinforcement Learning Using Control Barrier Functions. Automatica 2023, 147, 110684. [Google Scholar] [CrossRef]
- Cheng, R.; Orosz, G.; Murray, R.M.; Burdick, J.W. End-to-End Safe Reinforcement Learning through Barrier Functions for Safety-Critical Continuous Control Tasks. Proc. Aaai Conf. Artif. Intell. 2019, 33, 3387–3395. [Google Scholar] [CrossRef]
- Emam, Y.; Notomista, G.; Glotfelter, P.; Kira, Z.; Egerstedt, M. Safe Reinforcement Learning Using Robust Control Barrier Functions. IEEE Robot. Autom. Lett. 2024, 1–8. [Google Scholar] [CrossRef]
- Borrmann, U.; Wang, L.; Ames, A.D.; Egerstedt, M. Control Barrier Certificates for Safe Swarm Behavior. IFAC-PapersOnLine 2015, 48, 68–73. [Google Scholar] [CrossRef]
- Sonny, A.; Yeduri, S.R.; Cenkeramaddi, L.R. Q-Learning-Based Unmanned Aerial Vehicle Path Planning with Dynamic Obstacle Avoidance. Appl. Soft Comput. 2023, 147, 110773. [Google Scholar] [CrossRef]
- Peng, L.; Donghui, C.; Yuchen, W.; Lanyong, Z.; Shiquan, Z. Path Planning of Mobile Robot Based on Improved TD3 Algorithm in Dynamic Environment. Heliyon 2024, 10, e32167. [Google Scholar] [CrossRef]
- Wang, Y.; He, Z.; Cao, D.; Ma, L.; Li, K.; Jia, L.; Cui, Y. Coverage Path Planning for Kiwifruit Picking Robots Based on Deep Reinforcement Learning. Comput. Electron. Agric. 2023, 205, 107593. [Google Scholar] [CrossRef]
- Westheider, J.; Rückin, J.; Popović, M. Multi-UAV Adaptive Path Planning Using Deep Reinforcement Learning. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023. [Google Scholar] [CrossRef]
- Yang, S.; Zhang, Y.; Lu, X.; Guo, W.; Miao, H. Multi-Agent Deep Reinforcement Learning Based Decision Support Model for Resilient Community Post-Hazard Recovery. Reliab. Eng. Syst. Saf. 2024, 242, 109754. [Google Scholar] [CrossRef]
- Ray, A.; Achiam, J.; Amodei, D. Benchmarking safe exploration in deep reinforcement learning. arXiv 2019, arXiv:1910.01708. [Google Scholar]
- Dalal, G.; Dvijotham, K.; Vecerik, M.; Hester, T.; Paduraru, C.; Tassa, Y. Safe exploration in continuous action spaces. arXiv 2018, arXiv:1801.08757. [Google Scholar]
- Sheebaelhamd, Z.; Zisis, K.; Nisioti, A.; Gkouletsos, D.; Pavllo, D.; Kohler, J. Safe deep reinforcement learning for multi-agent systems with continuous action spaces. arXiv 2021, arXiv:2108.03952. [Google Scholar]
- ElSayed-Aly, I.; Bharadwaj, S.; Amato, C.; Ehlers, R.; Topcu, U.; Feng, L. Safe Multi-Agent Reinforcement Learning via Shielding. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems 2021, Virtual, 3–7 May 2021; pp. 483–491. [Google Scholar]
- Khalil, H.K. Nonlinear System; Macmillan Publishing Company: New York, NY, USA, 1992; pp. 461–483. [Google Scholar]
- Cheng, R.; Khojasteh, M.J.; Ames, A.D.; Burdick, J.W. Safe Multi-Agent Interaction through Robust Control Barrier Functions with Learned Uncertainties. In Proceedings of the 2020 59th IEEE Conference on Decision and Control (CDC), Jeju, Republic of Korea, 14–18 December 2020. [Google Scholar] [CrossRef]
- Zhang, R.; Zong, Q.; Zhang, X.; Dou, L.; Tian, B. Game of Drones: Multi-UAV Pursuit-Evasion Game with Online Motion Planning by Deep Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 7900–7909. [Google Scholar] [CrossRef] [PubMed]
- Xiao, W.; Belta, C. High-Order Control Barrier Functions. IEEE Trans. Autom. Control. 2022, 67, 3655–3662. [Google Scholar] [CrossRef]
- Amos, B.; Kolter, J.Z. OptNet: Differentiable Optimization as a Layer in Neural Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 136–145. [Google Scholar]
- Jiang, Y.; Wang, C.; He, Z.; Song, L. A Differentiable QP-based Learning Framework for Safety-Critical Control of Fully Actuated AUVs. In Proceedings of the 2024 3rd Conference on Fully Actuated System Theory and Applications 2024, Shenzhen, China, 10–12 May 2024; pp. 259–264. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Drone Parameter | Symbol | Value |
|---|---|---|
| Initial velocity | 0 km/s | |
| Boundary length | 2 km | |
| Maximum velocity | 0.05 km/s | |
| Maximum acceleration | 0.01 km/s2 | |
| Safe distance for drone | 0.2 km | |
| Safe distance for obstacle | 0.3 km |
| Parameter | Symbol | Value |
|---|---|---|
| Replay buffer | 100,000 | |
| Max episode | 10,000 | |
| Max step | T | 100 |
| Learning rate | 0.005 | |
| Discount factor | 0.95 | |
| Soft update rate | 0.01 |
| Algorithm | Success Rate |
|---|---|
| IDDPG | |
| IDDPG-CBF | |
| MADDPG | |
| MADDPG-CBF |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Huang, D.; Wang, C.; Ding, L.; Song, L.; Liu, H. Collision-Free Path Planning for Multiple Drones Based on Safe Reinforcement Learning. Drones 2024, 8, 481. https://doi.org/10.3390/drones8090481
Chen H, Huang D, Wang C, Ding L, Song L, Liu H. Collision-Free Path Planning for Multiple Drones Based on Safe Reinforcement Learning. Drones. 2024; 8(9):481. https://doi.org/10.3390/drones8090481
Chicago/Turabian StyleChen, Hong, Dan Huang, Chenggang Wang, Lu Ding, Lei Song, and Hongtao Liu. 2024. "Collision-Free Path Planning for Multiple Drones Based on Safe Reinforcement Learning" Drones 8, no. 9: 481. https://doi.org/10.3390/drones8090481
APA StyleChen, H., Huang, D., Wang, C., Ding, L., Song, L., & Liu, H. (2024). Collision-Free Path Planning for Multiple Drones Based on Safe Reinforcement Learning. Drones, 8(9), 481. https://doi.org/10.3390/drones8090481