
OMCTrack: Integrating Occlusion Perception and Motion Compensation for UAV Multi-Object Tracking

Abstract
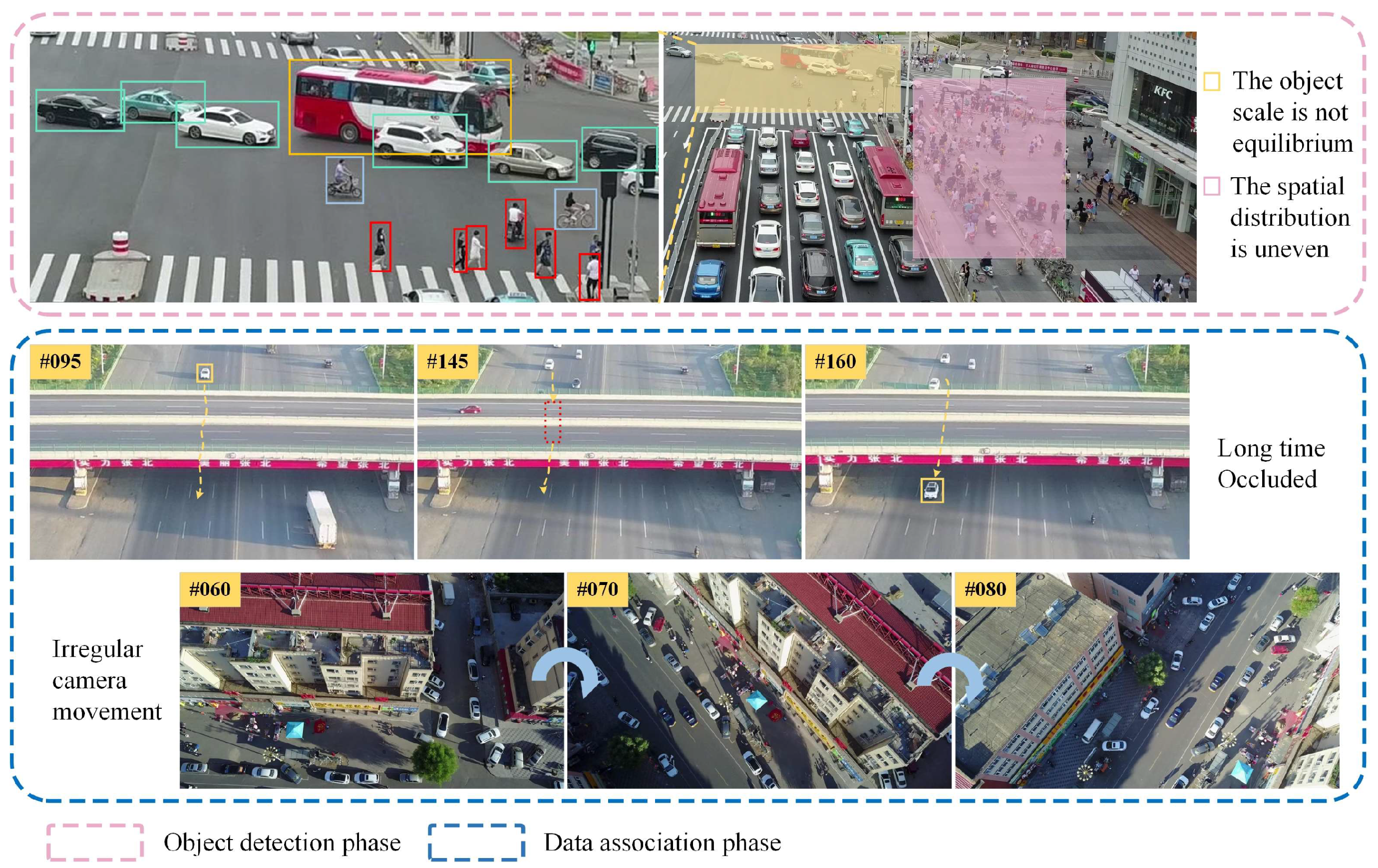
1. Introduction
- (1)
- We propose an occlusion perception module to solve the problem of short-term occlusion in MOT, which can re-identify lost objects and reduce the number of ID switching and trajectory fragments without increasing the amount of calculation.
- (2)
- In order to solve the problem of association confusion in dense scenes, we propose a simple and effective hierarchical association method to deal with ambiguity from a more fine-grained perspective, use the geometric properties of the object to supplement the motion cues, and reduce incorrect association matching.
- (3)
- For the platform motion interference in the UAV tracking scenario, we designed an adaptive motion compensation module that can autonomously perceive the image distortion, reduce the limitations of the camera motion compensation method in terms of real-time performance, and reduce the influence of platform motion in the process of UAV tracking.
2. Related Work
2.1. Tracking-by-Detection
2.2. Occlusion Handling
2.3. Motion Models
2.4. Datasets
3. Proposed Method
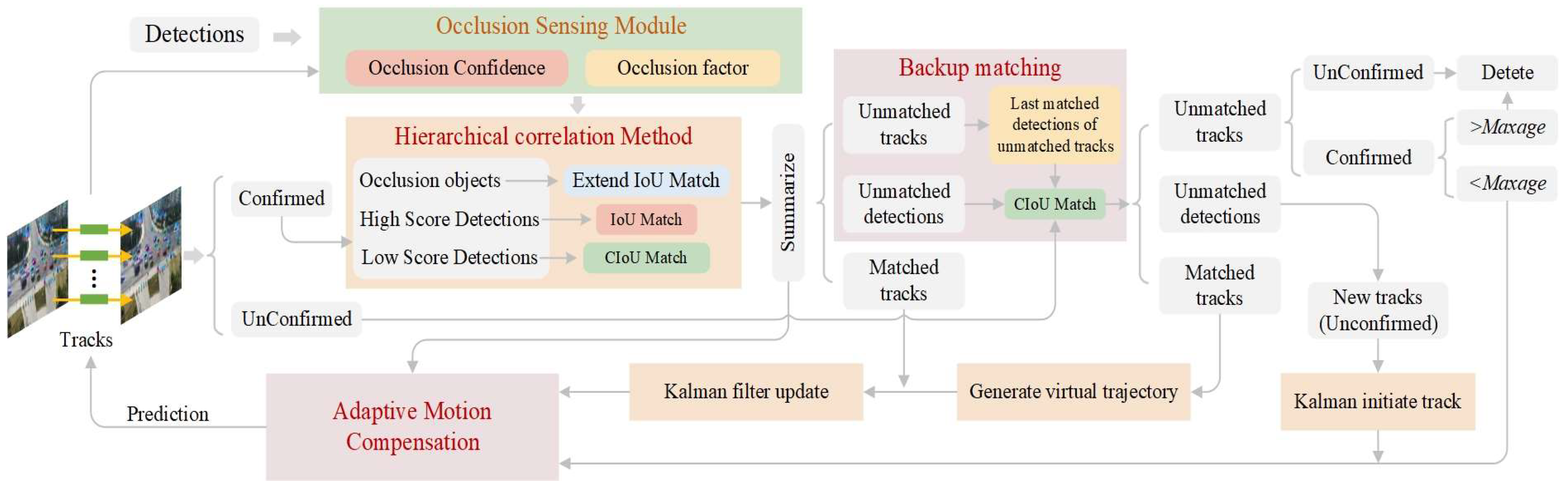
3.1. Overall Framework
3.2. Hierarchical Correlation of Fused Occlusion Perception
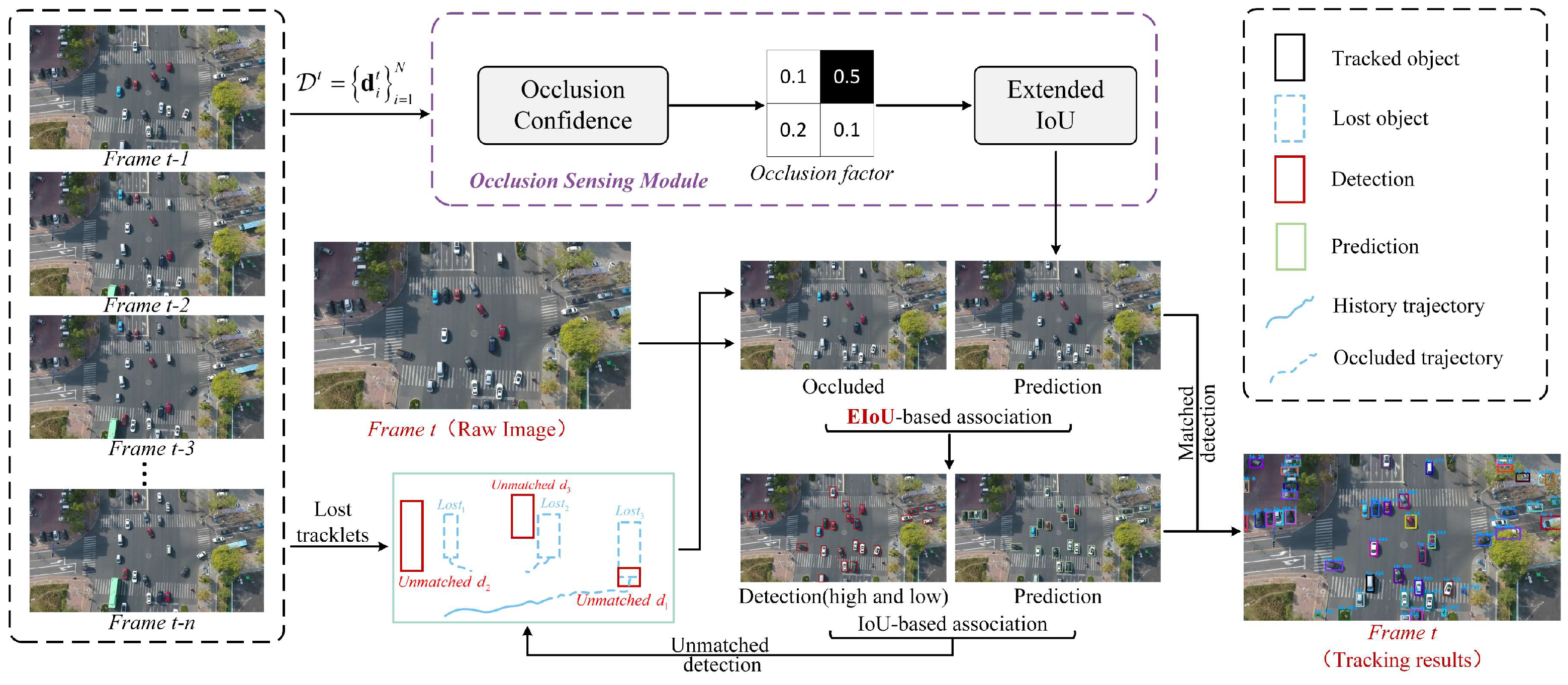
3.2.1. Occlusion Sensing Module
3.2.2. Extended IoU
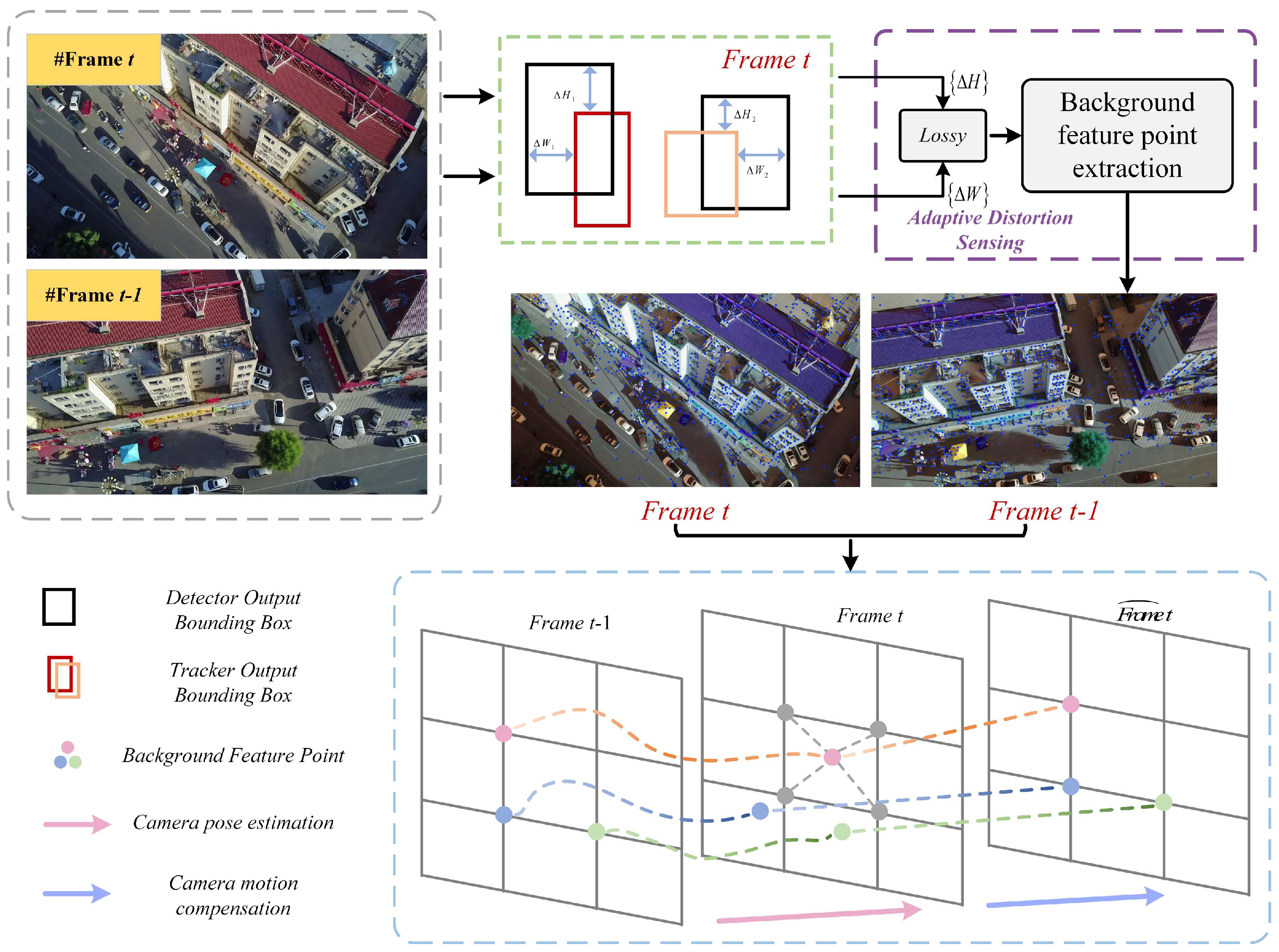
3.3. Adaptive Motion Compensation
3.3.1. Adaptive Distortion Sensing
3.3.2. Background Motion Estimation
4. Experiments
4.1. Dataset and Metrics
4.2. Implementation Details
4.3. Comparison with the State-of-the-Arts Methods
4.4. Ablation Studies
4.4.1. Module Effectiveness Analysis
4.4.2. Comparison of Occlusion Treatment Methods
4.4.3. Comparison of Camera Motion Compensation Methods
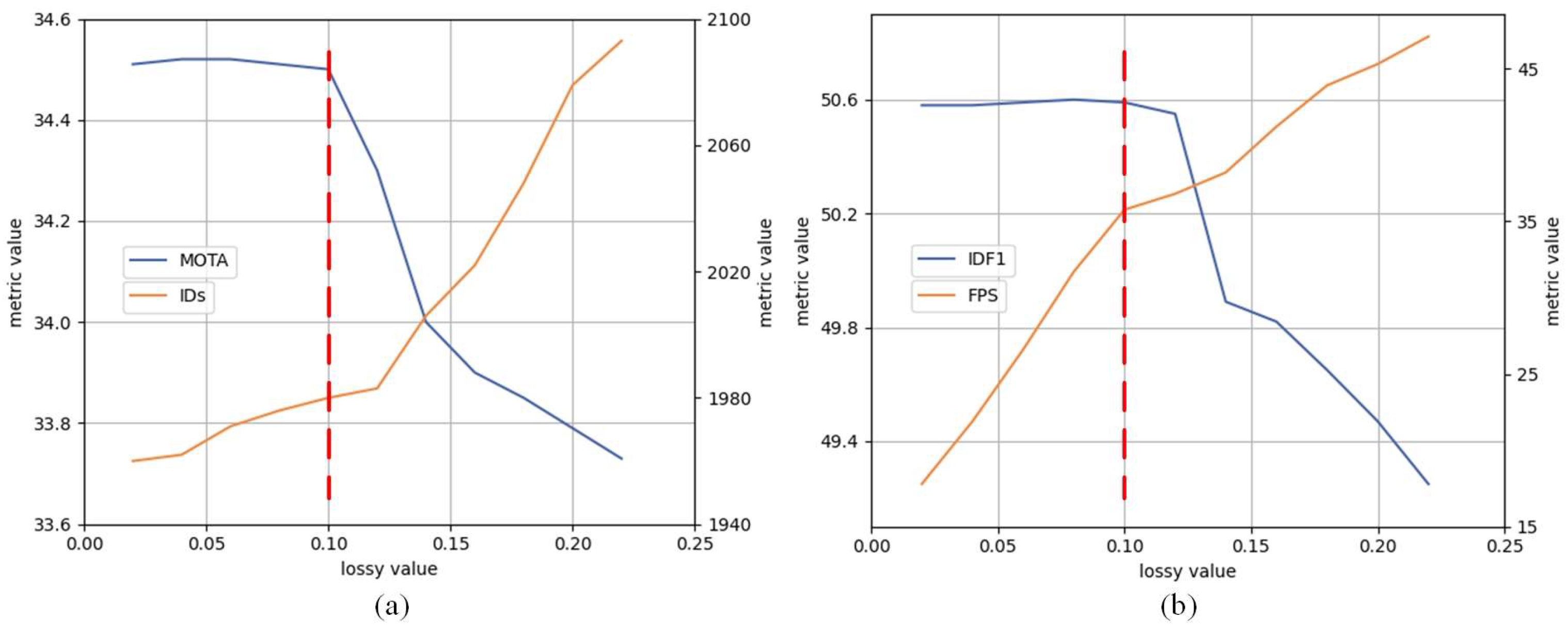
4.4.4. Related Parameter Settings
4.5. Case Study
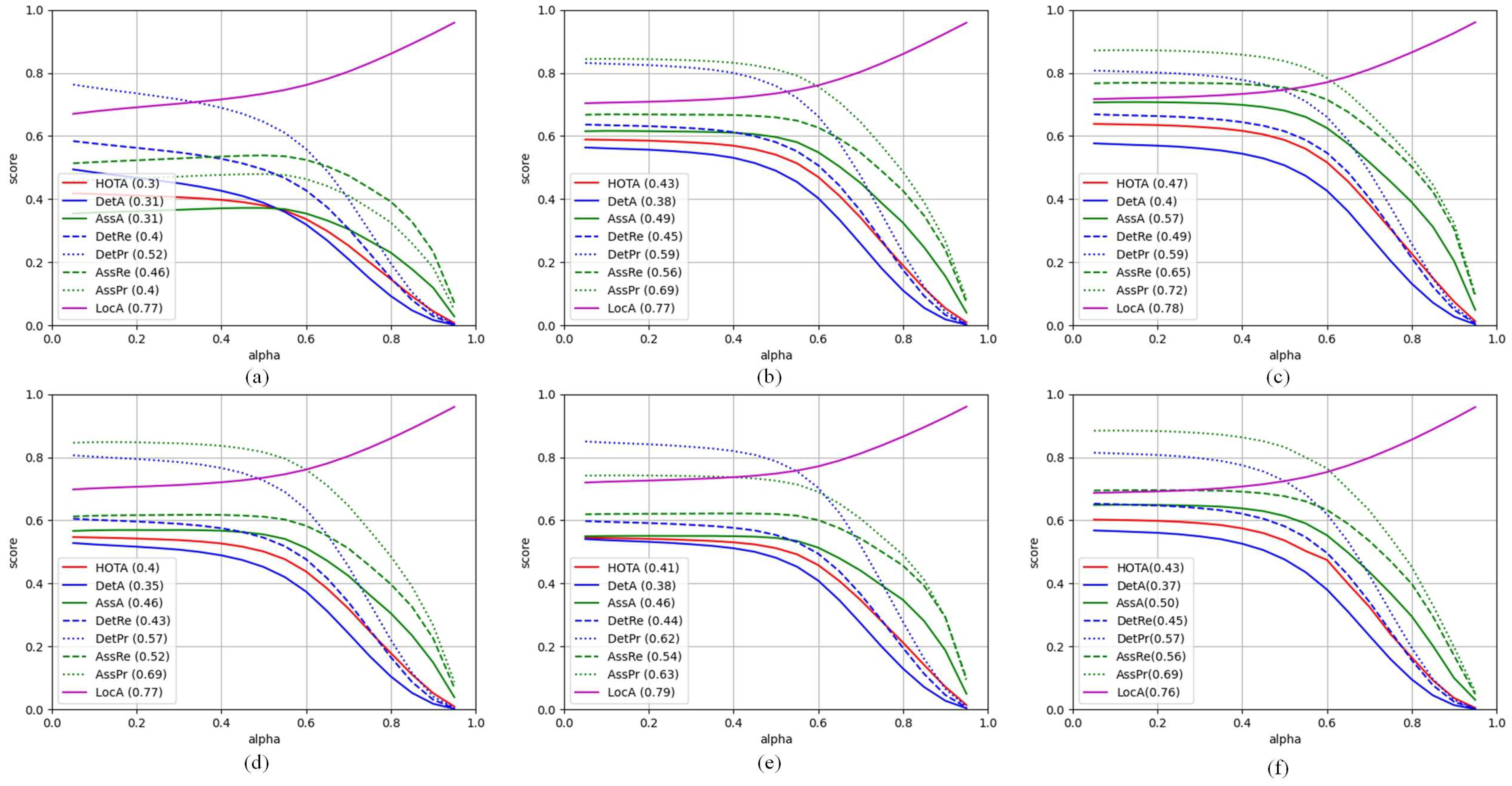
4.6. Visualization
4.7. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-Time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. StrongSORT: Make DeepSORT great again. arXiv 2022, arXiv:2202.13514. [Google Scholar] [CrossRef]
- Cao, J.; Weng, X.; Khirodkar, R.; Pang, J.; Kitani, K. Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 9686–9696. [Google Scholar]
- He, J.W.; Huang, Z.H.; Wang, N.Y. Learnable Graph Matching: Incorporating Graph Partitioning with Deep Feature Learning for Multiple Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5299–5309. [Google Scholar]
- Wang, Y.X.; Kitani, K.; Weng, X. Joint Object Detection and Multi-Object Tracking with Graph Neural Networks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13708–13715. [Google Scholar]
- Cai, J.R.; Xu, M.Z.; Li, W. MeMOT: Multi-Object Tracking with Memory. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, New Orleans, LA, USA, 18–24 June 2022; pp. 8080–8090. [Google Scholar]
- Wang, J.; Han, L.; Dong, X. Distributed sliding mode control for time-varying formation tracking of multi-UAV system with adynamic leader. Aerosp. Sci. Technol. 2021, 111, 106549. [Google Scholar] [CrossRef]
- Sheng, H.; Zhang, Y.; Chen, J.; Xiong, Z.; Zhang, J. Heterogeneous Association Graph Fusion for Target Association in Multiple Object Tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3269–3280. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, M.; Liu, X.; Wu, T. A group target tracking algorithm based on topology. J. Phys. Conf. Ser. 2020, 1544, 012025. [Google Scholar] [CrossRef]
- Zheng, Y.J.; Du, Y.C.; Ling, H.F.; Sheng, W.G.; Chen, S.Y. Evolutionary Collaborative Human-UAV Search for Escaped Criminals. IEEE Trans. Evol. Comput. 2019, 24, 217–231. [Google Scholar] [CrossRef]
- Lee, M.H.; Yeom, S. Multiple target detection and tracking on urban roads with a drone. J. Intell. Fuzzy Syst. 2018, 35, 6071–6078. [Google Scholar] [CrossRef]
- An, N.; Qi Yan, W. Multitarget Tracking Using Siamese Neural Networks. ACM Trans. Multimid. Comput. Commun. Appl. 2021, 17, 75. [Google Scholar] [CrossRef]
- Yoon, K.; Kim, D.; Yoon, Y.C. Data Association for Multi-Object Tracking via Deep Neural Networks. Sensors 2019, 19, 559. [Google Scholar] [CrossRef] [PubMed]
- Pang, H.; Xuan, Q.; Xie, M.; Liu, C.; Li, Z. Research on Target Tracking Algorithm Based on Siamese Neural Network. Mob. Inf. Syst. 2021, 2021, 6645629. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L. Simple Online and Real-Time Tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Real-Time Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Fu, H.; Wu, L.; Jian, M.; Yang, Y.; Wang, X. MF-SORT: Simple Online and Real-Time Tracking with Motion Features. In Proceedings of the 2019 International Conference on Image and Graphics (ICIG), Beijing, China, 23–25 August 2019; pp. 157–168. [Google Scholar]
- Aharon, N.; Orfaig, R.; Bobrovsky, B. BoT-SORT: Robust Associations Multi-Pedestrian Tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multi Object Tracking by Associating Every Detection Box. In Proceedings of the 2022 European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 1–21. [Google Scholar]
- Fang, L.; Yu, F.Q. Multi-object tracking based on adaptive online discriminative appearance learning and hierarchical association. J. Image Graph. 2020, 25, 708–720. [Google Scholar]
- Shu, G.; Dehghan, A.; Oreifej, O. Part-Based Multiple-Person Tracking with Partial Occlusion Handing. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1815–1821. [Google Scholar] [CrossRef]
- Chu, Q.; Ouyang, W.L.; Li, H.S. Online Multi-Object Tracking Using CNN-Based Single Object Tracker with Spatial-Temporal Attention Mechanism. In Proceeding of 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4846–4855. [Google Scholar] [CrossRef]
- Tokmakov, P.; Li, J.; Burgard, W. Learning to Track with Object Permanence. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10860–10869. [Google Scholar]
- Guo, S.; Wang, J.; Wang, X. Online Multiple Object Tracking with Cross-Task Synergy. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, IEEE Computer Society, Nashville, TN, USA, 19–25 June 2021; pp. 8132–8141. [Google Scholar]
- Han, R.Z.; Feng, W.; Zhang, Y.J. Multiple human aociation and tracking from egocentric and complementary top views. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5225–5242. [Google Scholar] [PubMed]
- Yeom, S.; Nam, D.H. Moving Vehicle Tracking with a Moving Drone Based on Track Association. Appl. Sci. 2021, 11, 4046. [Google Scholar] [CrossRef]
- Brown, R.G.; Hwang, P.Y.C. Introduction to Random Signals and Applied Kalman Filtering: With MATLAB Exercises and Solutions, 3rd ed.; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the ICCV International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 941–951. [Google Scholar]
- Khurana, T.; Dave, A.; Ramanan, D. Detecting invisible people. arXiv 2020, arXiv:2012.08419. [Google Scholar]
- Han, S.; Huang, P.; Wang, H.; Yu, E.; Liu, D. Mat: Motion-aware multi-object tracking. Neurocomputing 2022, 476, 75–86. [Google Scholar] [CrossRef]
- Stadler, D.; Beyerer, J. Modelling ambiguous assignments for multi-person tracking in crowds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 133–142. [Google Scholar]
- Du, Y.; Wan, J.; Zhao, Y.; Zhang, B.; Tong, Z.; Dong, I. Giaotracker: A comprehensive framework for mcmot with global information and optimizing strategies in visdrone2021. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2809–2819. [Google Scholar]
- Evangelidis, G.D.; Psarakis, E.Z. Parametric image alignment using enhanced correlation coefficient maximization. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1858–1865. [Google Scholar] [CrossRef] [PubMed]
- Rublee, E.; Rabaud, V.; Konolige, K. Orb: An Efficient Alternative to Sift or Surf. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Shah, A.P.; Lamare, J.B.; Tuan, N.A. CADP: A Novel Dataset for CCTV Traffic Camera based Accident Analysis. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Stepanyants, V.; Andzhusheva, M.; Romanov, A. A Pipeline for Traffic Accident Dataset Development. In Proceedings of the 2023 International Russian Smart Industry Conference, Sochi, Russia, 27–31 March 2023. [Google Scholar]
- Yu, F.; Chen, H.F.; Wang, X. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yu, F.; Yan, H.; Chen, R.; Zhang, G.; Liu, Y.; Chen, M.; Li, Y. City-scale Vehicle Trajectory Data from Traffic Camera Videos. Sci. Data 2023, 10, 711. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Su, S.; Zuo, Z.; Sun, B. RISTrack: Robust Infrared Ship Tracking with Modified Appearance Feature Extraction and Matching Strategy. In Proceedings of the IEEE Transactions on Geoscience and Remote Sensing, Changsha, China, 16–21 July 2023; Volume 61. [Google Scholar]
- Lindenberger, P.; Sarlin, P.; Pollefeys, M. LightGlue: Local Feature Matching at Light Speed. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023. [Google Scholar]
- Safaldin, M.; Zaghden, N.; Mejdoub, M. An Improved YOLOv8 to Detect Moving Objects. IEEE Access 2024, 12, 59782–59806. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Venue | IDF1 ↑ | MOTA ↑ | HOTA ↑ | AssA ↑ | DetA ↑ | FP ↓ | FN ↓ | IDs ↓ | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| VisDrone2019 | Sort | ICIP2016 | 41.1 | 29.9 | 37.5 | 37.7 | 39.7 | 38,129 | 175,539 | 5092 | 56.7 |
| Deepsort | ICIP2017 | 38.9 | 24.7 | 34.2 | 37.5 | 32.2 | 48,334 | 179,308 | 5937 | 21.3 | |
| Deepmot | CVPR2020 | 30.7 | 18.2 | 30.4 | 30.6 | 31.3 | 65,664 | 181,433 | 4788 | 13.7 | |
| Bytetrack | ECCV2022 | 49.1 | 33.7 | 42.7 | 49.1 | 38.0 | 45,679 | 156,223 | 2100 | 48.5 | |
| BoTSORT | CVPR2022 | 55.5 | 35.2 | 46.5 | 56.3 | 39.2 | 53,568 | 144,778 | 1070 | 14.3 | |
| UAVMOT | CVPR2022 | 46.3 | 29.4 | 39.7 | 45.7 | 35.3 | 50,198 | 164,931 | 2214 | 19.2 | |
| C_BIoUTracker | WACV2023 | 45.0 | 33.3 | 40.9 | 45.8 | 37.4 | 37,157 | 165,036 | 3255 | 52.6 | |
| Ours | --- | 50.6 | 34.5 | 43.3 | 49.7 | 37.2 | 47,892 | 151,623 | 1980 | 35.8 | |
| UAVDT | Sort | ICIP2016 | 84.2 | 79.1 | 69.9 | 71.6 | 69.7 | 20,629 | 51,154 | 745 | 81.2 |
| Deepsort | ICIP2017 | 83.5 | 78.7 | 69.3 | 71.1 | 67.9 | 22,461 | 49,539 | 763 | 45.5 | |
| Deepmot | CVPR2020 | 68.0 | 78.7 | 60.1 | 53.6 | 68.1 | 26,081 | 45,697 | 876 | 29.8 | |
| Bytetrack | ECCV2022 | 87.7 | 84.5 | 73.4 | 75.2 | 72.1 | 17,199 | 35,187 | 308 | 86.7 | |
| BoTSORT | CVPR2022 | 84.6 | 84.4 | 71.7 | 72.3 | 71.7 | 19,525 | 33,304 | 353 | 27.1 | |
| UAVMOT | CVPR2022 | 85.8 | 80.9 | 71.1 | 73.1 | 69.3 | 23,255 | 41,466 | 330 | 34.0 | |
| C_BIoUTracker | WACV2023 | 85.0 | 84.1 | 71.8 | 72.3 | 71.7 | 13,918 | 40,002 | 438 | 84.9 | |
| Ours | --- | 88.5 | 85.5 | 74.7 | 75.9 | 73.5 | 14,541 | 36,107 | 551 | 53.7 |
| Class | Instances | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|
| people | 5125 | 0.593 | 0.28 | 0.34 | 0.131 |
| bicycle | 1287 | 0.281 | 0.173 | 0.149 | 0.0653 |
| car | 14,064 | 0.716 | 0.778 | 0.799 | 0.567 |
| van | 1975 | 0.511 | 0.452 | 0.452 | 0.318 |
| bus | 251 | 0.729 | 0.534 | 0.569 | 0.411 |
| Dataset | Baseline | OAH | AMC | IDF1 ↑ | MOTA ↑ | HOTA ↑ | FPS |
|---|---|---|---|---|---|---|---|
| VisDrone2019 | ✓ | 49.1 | 33.7 | 42.7 | 48.5 | ||
| ✓ | ✓ | 49.8 | 33.8 | 42.9 | 47.7 | ||
| ✓ | ✓ | ✓ | 50.6 | 34.5 | 43.3 | 35.8 | |
| UAVDT | ✓ | 87.7 | 84.5 | 73.4 | 86.7 | ||
| ✓ | ✓ | 88.1 | 84.8 | 74.1 | 85.6 | ||
| ✓ | ✓ | ✓ | 88.5 | 85.5 | 74.7 | 53.7 |
| Dataset | Method | IDF1 ↑ | AssA | IDs | FPS |
|---|---|---|---|---|---|
| VisDrone2019 | Baseline + CBIoU | 49.3 | 49.2 | 2076 | 48.3 |
| Baseline + ReID | 49.8 | 49.5 | 2035 | 21.7 | |
| Baseline + OAH | 49.8 | 49.4 | 2047 | 47.7 | |
| UAVDT | Baseline + CBIoU | 87.8 | 75.2 | 398 | 86.6 |
| Baseline + ReID | 85.2 | 73.1 | 487 | 39.8 | |
| Baseline + OAH | 88.1 | 75.5 | 387 | 85.6 |
| Method | CMC | IDF1 ↑ | MOTA ↑ | HOTA ↑ | FPS |
|---|---|---|---|---|---|
| Baseline + OAH | NO | 49.8 | 33.8 | 42.9 | 47.7 |
| ORB | 50.3 (+0.5) | 34.1 (+0.3) | 43.1 (+0.2) | 13.7 | |
| ECC | 50.2 (+0.4) | 34.1 (+0.3) | 43.0 (+0.1) | 5.6 | |
| SIFT | 50.3 (+0.5) | 34.0 (+0.2) | 43.0 (+0.1) | 3.2 | |
| SparseOptFlow | 50.5 (+0.7) | 34.3 (+0.5) | 43.1 (+0.2) | 25.6 | |
| AMC | 50.6 (+0.8) | 34.5 (+0.7) | 43.3 (+0.4) | 35.8 |
| Method | IDF1 | HOTA | FP | FN | |
|---|---|---|---|---|---|
| Ours | 0.5 | 50.1 | 42.8 | 46,073 | 156,022 |
| 0.4 | 50.2 | 43.1 | 46,721 | 154,620 | |
| 0.3 | 50.6 | 43.3 | 47,892 | 151,623 | |
| 0.2 | 50.5 | 43.3 | 48,109 | 150,941 | |
| 0.1 | 50.1 | 42.9 | 50,367 | 148,256 | |
| 0.0 | 48.2 | 42.3 | 53,219 | 146,897 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, Z.; Sun, X.; Sun, B.; Guo, R.; Li, C. OMCTrack: Integrating Occlusion Perception and Motion Compensation for UAV Multi-Object Tracking. Drones 2024, 8, 480. https://doi.org/10.3390/drones8090480
Dang Z, Sun X, Sun B, Guo R, Li C. OMCTrack: Integrating Occlusion Perception and Motion Compensation for UAV Multi-Object Tracking. Drones. 2024; 8(9):480. https://doi.org/10.3390/drones8090480
Chicago/Turabian StyleDang, Zhaoyang, Xiaoyong Sun, Bei Sun, Runze Guo, and Can Li. 2024. "OMCTrack: Integrating Occlusion Perception and Motion Compensation for UAV Multi-Object Tracking" Drones 8, no. 9: 480. https://doi.org/10.3390/drones8090480
APA StyleDang, Z., Sun, X., Sun, B., Guo, R., & Li, C. (2024). OMCTrack: Integrating Occlusion Perception and Motion Compensation for UAV Multi-Object Tracking. Drones, 8(9), 480. https://doi.org/10.3390/drones8090480