1. Introduction
Object detection, a central challenge in computer vision, necessitates algorithms that possess robust classification capabilities and precise spatial localization for the identification and location of various targets, such as humans, animals, and vehicles, in images and videos. The performance of detection has been markedly improved by the rapid advancement of deep learning, particularly Convolutional Neural Networks (CNNs) [
1], fueling progress in the field and spurring interest in downstream tasks [
2,
3,
4]. The rise of unmanned aerial vehicles (UAVs), with their agility and efficient data collection capabilities, has given birth to the task of drone-based object detection [
5]. However, the significant scale variations and variable angles in UAV imagery pose challenges to object detection. Existing algorithms for rotated object detection [
6,
7,
8,
9,
10], often designed for remote sensing images, struggle to meet these demands.
In the field of drone-based object detection, current algorithms primarily depend on visible light imagery, which inherently limits their effectiveness in complex environments such as nighttime, rainy conditions, dense fog, and instances of occlusion (See
Figure 1). With the advancement of sensor technology, modern drones are equipped with a variety of sensors, including infrared payloads, vastly expanding their range of applications and making dual-modal object detection a hot topic of research in the drone sector. The distinct imaging mechanism of infrared, which captures thermal energy, complements visible light imagery, markedly improving the precision and robustness of object detection. However, existing dual-modal detection algorithms often employ dual-stream backbone networks to process each modality separately, neglecting the issue of information imbalance between the two modalities. This leads to a substantial amount of parameter redundancy, highlighting the need for research into more efficient fusion strategies.
The Transformer architecture has achieved great success in the field of natural language processing [
11,
12] and has since been adopted by researchers in the realm of computer vision [
13,
14,
15]. Its efficiency in processing long-range dependencies and parallelization capabilities have established it as a new paradigm. Dealing with issues such as lighting variations and target occlusions in dual-modal object detection poses challenges for CNNs. CNNs excel at local feature extraction via convolutions but struggle with lighting changes that alter pixel values and occlusion that disrupts these local patterns. Their limited global context understanding and multi-modal interaction hinder performance. Transformers, on the other hand, leverage global context capture capabilities, enabling better generalization across different lighting conditions. For occlusions, Transformers utilize pre-trained masking mechanisms to handle obscured regions, and their self-attention mechanism tracks information changes before and after occlusion, facilitating robust multi-modal global information interaction. However, in the domain of dual-modal object detection, the application of Transformers is limited, with their attention mechanisms often confined to the fusion module [
16], not fully harnessing their potential for understanding global context. Additionally, with the emergence of efficient self-supervised learning methods like Masked Autoencoders (MAEs) [
17], the Vision Transformer (VIT) [
13] architecture can leverage a wealth of pre-trained weights, offering superior feature extraction and generalization for downstream tasks. Therefore, employing a VIT for dual-modal object detection is a promising and innovative approach.
Considering the fine-tuning of models pre-trained on extensive datasets, visual prompt tuning has emerged as a dominant approach. It significantly lightens the computational load and storage requirements of model fine-tuning by introducing only a few parameters. The VPT [
18] integrates prompts into pre-trained networks through embeddings, yielding favorable results across 24 downstream tasks in fine-grained classification. The ViPT [
19] creatively employs prompts as a dual-modal fusion tool, expanding visible light object tracking to include infrared, depth, and event-based image tracking. Drawing from this insight, we can conceptualize dual-modal object detection as a fine-tuning task. By refining single-modal benchmark models with prompts, we can transition them to dual-modal detection, thereby improving their versatility and robustness for complex scenarios.
In conclusion, we develop a Transformer-based algorithm for visible–infrared object detection, named Visual Prompt multi-modal Detection (VIP-Det). To fully exploit the capabilities of Transformer-based dual-modal algorithms, the Vision Transformer is utilized as the backbone for feature extraction, leveraging its strength in capturing long-range dependencies and global context. To simplify the complex architecture of dual-modal object detection, a prompt-based fusion module is devised that introduces prompts for fusion within a single-stream network, significantly reducing the number of parameters. To optimize pre-trained models and balance modal information, a stage-wise optimization strategy is introduced that commences with training single-modal benchmark models and subsequently refines features with additional modalities, fostering more effective modal integration and refined feature extraction. Our algorithm is tested on the DroneVehicle dataset, and the results demonstrate that it achieves high precision and adeptly accommodates the demands of object detection in intricate settings.
In summary, the contributions of this paper are as follows:
We propose a novel Transformer-based framework for dual-modal object detection, which incorporates the Vision Transformer (VIT) as a backbone, capable of efficiently extracting features and enhancing the precision of object detection;
We introduce a prompt-based fusion module and a stage-wise optimization strategy, utilizing prompts to guide feature fusion and enhance the aggregation capabilities of dual-modal information. Additionally, we employ a phased fine-tuning approach to guide parameter optimization, thereby better transferring the feature representation capabilities of the original model;
We assess the performance of our proposed framework on the DroneVehicle dataset and showcase its superior accuracy when compared to other comparable Transformer-based methods.
3. Models and Methods
In this section, we introduce VIP-Det (Visual Prompt dual-modal Detection), an innovative algorithm for drone-based visible–thermal object detection that leverages the Vision Transformer architecture. This section commences with an exposition of the motivations that drove the development of the algorithm and an elucidation of its overarching framework. Subsequently, it delves into the technical nuances of the implementation of the prompt-based fusion module. This section concludes with an elucidation of the algorithm’s stage-wise training optimization strategy.
3.1. Overview
Traditional drone-based object detection algorithms are often limited to visible light imagery and may fail under complex environmental conditions such as nighttime, rainy weather, fog, and occlusions. Existing visible–thermal object detection algorithms typically rely on dual-stream backbone networks for feature extraction, which significantly increases the number of parameters and is hindered by the imbalance between the two modalities, thereby limiting the efficiency of their fusion. Vision Transformers (ViTs) have demonstrated impressive performance across a wide range of visual tasks; however, in the domain of visible–thermal object detection, their attention mechanisms are often confined to the fusion module, and the potential of their feature modeling has not been fully exploited.
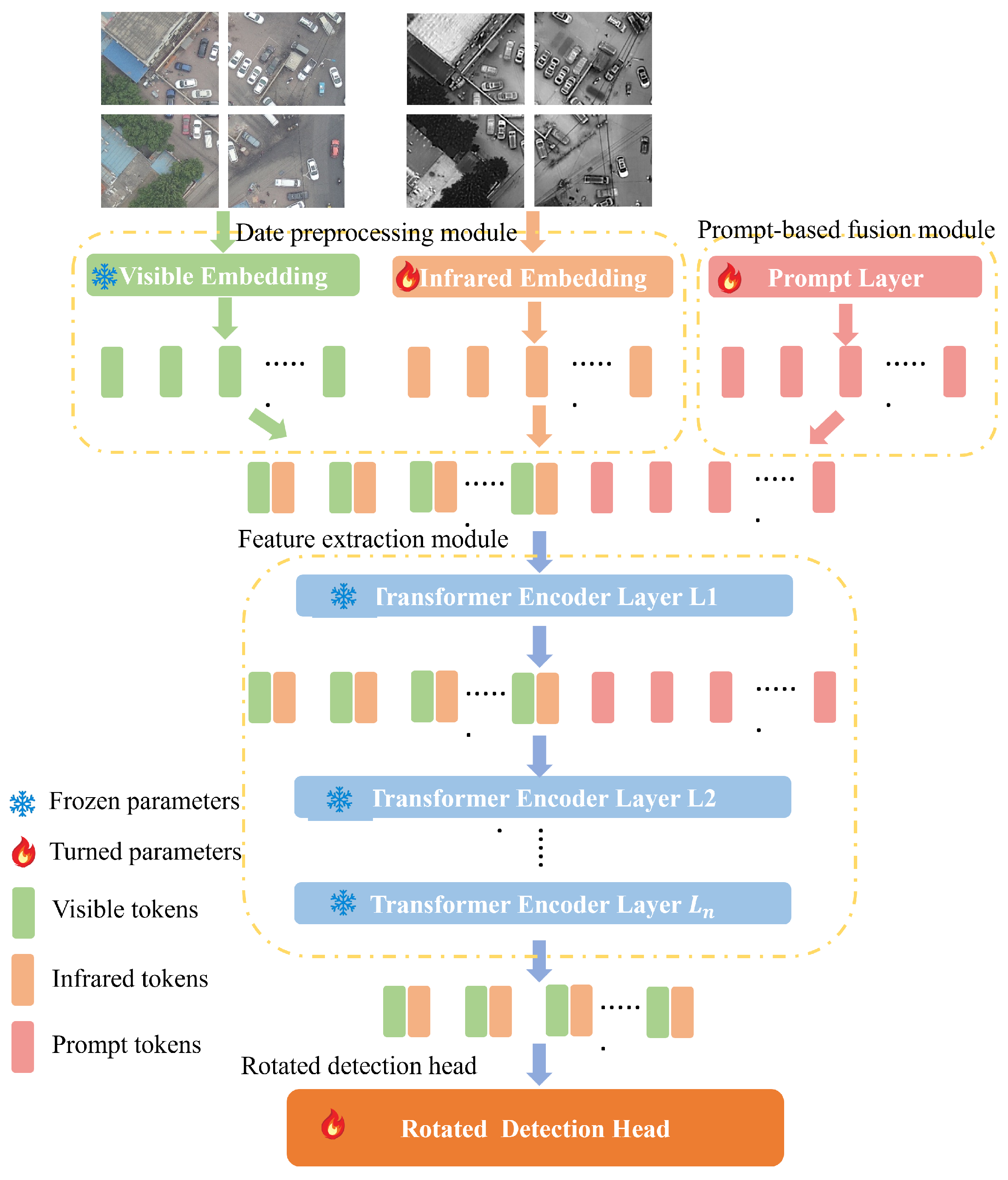
To address these limitations, our VIP-Det, designed for visible–thermal object detection, introduces the Vision Transformer as its backbone. The algorithm adopts a single-stream network architecture to concurrently extract features from visible and infrared images. A novel prompt mechanism is employed to introduce a small set of learnable parameters for feature-level integration. During training, the algorithm first establishes a baseline model on single-modal data and then refines the model parameters using dual-modal data. The overall network architecture is designed to efficiently integrate the information from both modalities, aiming to enhance the algorithm’s capability in object detection. The overall architecture is illustrated in the accompanying
Figure 2.
Our VIP-Det algorithm is composed of four main components: a data preprocessing module, a prompt-based fusion module, a feature extraction module, and a rotated detection head. The data preprocessing module processes both visible light and infrared imagery by patching them into tokenized form and stacking them. The prompt-based fusion module introduces prompts as learnable parameters, guiding feature fusion through training iterations. These prompt-embedded tokens are then inputted into the feature extraction module. This module employs an MAE pre-trained Vision Transformer model, which features 12 layers of Transformer blocks, as its backbone network instead of ResNet-50. The extracted features are then fed into the rotated detection head for classification and regression. In our experiments, we utilized the rotated detection head of STD [
33] to achieve the most precise detection results. During the training process, we initially selected one modality as the baseline model and trained it to establish a foundation. Subsequently, we integrated the other modality to facilitate fusion, achieving dual-modal object detection with minimal parameter adjustments for efficient fine-tuning.
3.2. Vision Transformer Architecture
The Vision Transformer (ViT) represents a significant advancement in computer vision, reshaping the traditional approach of Convolutional Neural Networks (CNNs). Instead of sliding convolutional kernels across an image to extract features, the ViT divides the input image into a grid of nonoverlapping patches. Each of these patches is then flattened and converted into a vector, effectively transforming the two-dimensional image data into a sequence of one-dimensional vectors. To encode the spatial relationships between these patches, positional encodings are added to the vector representations, ensuring that the model can distinguish and utilize the positional information. These enriched embeddings serve as the input to a stack of Transformer encoder layers, which form the core of ViT’s architecture. Each encoder layer leverages self-attention mechanisms to allow each patch to attend to and interact with every other patch in the sequence, capturing long-range dependencies and contextual information. This is complemented by feedforward neural networks, which introduce non-linearities and enable the model to learn complex feature representations. As the embeddings traverse through the stacked encoder layers, they are progressively transformed and enriched, ultimately encoding a rich semantic understanding of the input image. In the context of this specific task, the output of the final encoder layer, now enriched with features extracted from both visible and infrared modalities, serves as the foundation for subsequent dual-modal target detection. These features, reflecting the unique properties of both spectra, empower the model to detect and identify objects with unprecedented accuracy and robustness, demonstrating the versatility and power of the Vision Transformer framework in addressing complex computer vision challenges.
3.3. Prompt-Based Fusion
3.3.1. Overview
To fine-tune a single-modal object detection model based on prompts, we first need a pre-trained baseline model for the specific modality, where the embedding layer and Vision Transformer layers are already equipped with relevant parameters. During subsequent fine-tuning, these layers are frozen to preserve their feature extraction capabilities. When pre-training the baseline model, the embedding layer and Transformer layers for feature extraction of that modality, along with the detection head, are trained, while the prompt layer remains untrained.
For simplicity, let us assume there is a pre-trained baseline model for the visible light modality; hence, the visible embedding layer is frozen, and a certain number of Vision Transformer layers are also frozen as per the requirement. Since the infrared modality has not been trained, the infrared embedding layer requires fine-tuning.
For input images, visible light and infrared images are separately fed into their corresponding embedding layers, where they undergo patch partitioning and encoding to obtain visible tokens and infrared tokens. This step is performed in the data preprocessing module. Subsequently, the prompt layer is initialized to generate a certain number of prompt tokens, which are then combined with the previously extracted visible and infrared tokens to form fused tokens. As training progresses, the parameters of the prompt layer are iteratively fine-tuned to produce prompt tokens with lower losses.
These fused tokens are then fed into the Transformer layers of the feature extraction module, where the output from the previous layer, including the prompt tokens, serves as input for the next layer. This process continues through all Transformer layers, from which the visible and infrared tokens are extracted to obtain feature maps. These feature maps are then input into the rotated detection head. For the specific code process, refer to
Appendix A.
3.3.2. Introduction
Given a pair of prealigned and coregistered visible and thermal images, denoted (where v stands for visible) and (where t stands for thermal), respectively, with H and W being the height and width of the images, and assuming a batch size of 1 for simplicity, we explore the integration of these modalities within a Vision Transformer framework for object detection.
3.3.3. Image Patch Embedding
A typical ViT with
N layers divides the input images into
m fixed-size patches
and
for
, where
h and
w are the height and width of each patch. These patches are then embedded into a
d-dimensional latent space and position encodings are added:
The sets of patch tokens at layer
i are represented as:
3.3.4. Prompt-Based Feature Fusion
To facilitate dual-modal feature fusion, we introduce a set of continuous prompt tokens
initialized randomly and inserted before the first encoder layer
of the pre-trained Transformer. During fine-tuning, only the task-relevant prompts are updated, while the main Transformer parameters are frozen. This leads to:
where
Z represents the prompt parameters after iteration within the network. The forward pass through the Transformer layers can be expressed as:
Each layer consists of multihead self-attention (MSA) and a feedforward network (FFN), accompanied by Layer Normalization (LayerNorm) and residual connections.
3.3.5. Detection Head
Finally, a rotated object detection head denoted as Head processes the fused features from the last layer to predict rotated bounding boxes and categories:
3.4. Stage-Wise Training Optimization
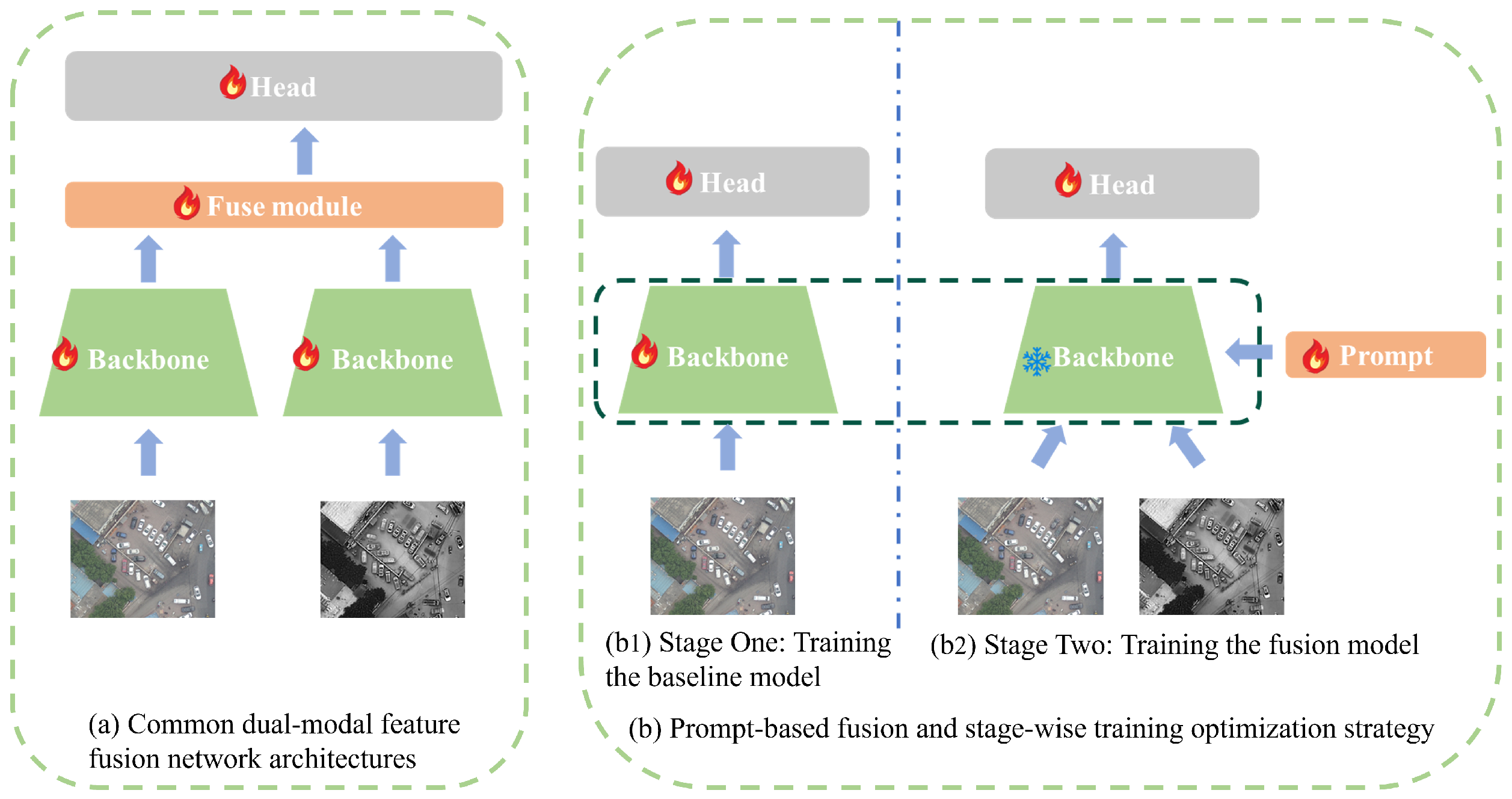
The typical approach to dual-modal object detection adheres to a standardized process: Initially, two separate backbone networks are employed to extract features from paired visible and infrared images independently. Subsequently, these dual-modal features are fed into a feature fusion module, integrating information from the two distinct modalities. Ultimately, an object detection head is leveraged for regression prediction, enabling the localization and classification of objects within the images.
However, a notable issue arises from this methodology: During a single training cycle, all network architecture parameters must be learned, resulting in a substantial parameter count and sluggish training speed. To address this challenge, we propose a stage-wise training optimization strategy. See
Figure 3.
First, we individually train the mono-modal visible and infrared images using a Vision Transformer backbone network, aiming to develop the capacity to extract fundamental and generic features. This phase targets the establishment of benchmark mono-modal models. Next, we proceed with dual-modal image inputs for modal fine-tuning, freezing partial weights within the backbone networks and introducing prompt parameters for fine-tuning. This promotes efficient dual-modal feature fusion.
By adopting this training paradigm, we not only drastically reduce the parameter count but also simplify the overall model architecture. As there is no need for a separate feature fusion module, our approach relies solely on a minimal set of prompt parameters to achieve dual-modal feature fusion. This not only decreases model complexity but also renders the model more concise and interpretable.
Furthermore, our method harnesses the power of pre-trained models, facilitating seamless migration to dual-modal object detection tasks. By maintaining the invariance of selected weights from the pre-trained models during the fine-tuning phase, our approach effectively leverages the rich feature representations already learned, further enhancing the performance of dual-modal object detection.
4. Results
In this section, we commence by detailing the datasets and evaluation metrics employed in our experiments. Subsequently, we provide the pertinent setup and configuration details. We proceed with a series of ablation studies to validate the efficacy of our algorithm. Finally, we conduct comparative experiments against related algorithms.
4.1. Datasets and Evaluation Metric
The DroneVehicle [
22] dataset is a comprehensive and diverse collection of RGB–infrared (RGB-IR) images captured by drones. This dataset encompasses a wide range of scenarios, including urban roads, residential areas, parking lots, and other environments, spanning various times of the day and night. The dataset consists of 28,439 image pairs, each pair containing corresponding RGB and infrared images that have been precisely aligned to ensure accurate representation of the scene. The annotations provided by the dataset authors are extensive and include oriented bounding boxes for five distinct vehicle categories: cars, buses, trucks, vans, and freight cars. The dataset is organized into a training set and a test set, with the training set comprising 17,990 image pairs and the test set consisting of 1469 image pairs. Our experiments were conducted on this DroneVehicle dataset, leveraging its richness and variability to test and refine our vehicle detection algorithm.
We utilized the mean average precision (mAP) as the primary evaluation metric for our detection algorithm, applied to the validation set. To ensure accurate detections, we employed an Intersection over Union (IoU) threshold of 0.5, which helped filter out false positives and contributed to a reliable assessment of the algorithm’s performance.
4.2. Implementation Details
Utilizing pre-trained weights initialized from the MAE, we embarked on training our network specifically for the DroneVehicle dataset, leveraging the computational prowess of an NVIDIA RTX 4090 GPU. Our training strategy commenced with initializing a single-modal base model through 12 epochs, subsequently transitioning into a 12-epoch fusion model training phase, where prompts were integrated to enhance performance. The optimization process employed stochastic gradient descent (SGD) equipped with a momentum factor of 0.9 and a weight decay rate of 0.0001.
During each training iteration, we processed batches containing two images apiece, initiating with a learning rate of 0.001. This learning rate underwent a strategic halving at epochs 8 and 11 to facilitate a smoother convergence. To augment the training data and bolster the model’s generalization capabilities, we applied various image transformations such as flipping, cropping, and splicing.
Post-training, during the inference phase, we utilized non-maximum suppression (NMS) with an Intersection over Union (IoU) threshold set at 0.3 to effectively eliminate redundant bounding boxes, ensuring the precision of our detections. Throughout these endeavors, we leveraged customized versions of the MMRotate and MMDetection frameworks.
4.3. Ablation Experiment
4.3.1. Ablation on Prompt-Based Fusion
To validate the efficacy of our prompt-based fusion module in enhancing the quality of fusion outcomes, we conducted a rigorous ablation study. This investigation entailed a comparative analysis between two experimental setups: the baseline approach, which directly stacked modalities without utilizing the fusion module, and our algorithm augmented with the integrated prompt-based fusion module.
The outcomes of this study, tabulated in
Table 1, reveal a notable improvement. Specifically, the inclusion of the prompt-based fusion module resulted in a marked 1.3% increase in mean average precision (mAP). This substantial gain underscores the pivotal role played by our fusion module in bolstering the overall performance of the algorithm, highlighting its effectiveness in fostering seamless and effective modality integration.
4.3.2. Ablation on the Number of Frozen Layers
In the two-stage optimization training strategy, we strategically froze the Transformer encoder layers to safeguard the model’s foundational representation and generalization capabilities. The experiment compared freezing the first 6 layers, fine-tuning the last 6 layers, and fine-tuning all 12 layers, assessing the trade-off between accuracy and efficiency.
The results in
Table 2, tabulated, reveal that freezing the first six layers results in a minimal 0.4% decrease in mAP compared to fine-tuning of the full layer, showcasing the effectiveness of partial freezing in reducing training parameters without compromising accuracy. This approach accelerates training and reduces computational demands, facilitating large-scale deployments and iterations.
In conclusion, partial freezing of the backbone network layers in two-stage optimization training is an efficient and practical method, allowing us to balance speed and accuracy by adjusting the number of frozen layers. This discovery offers an innovative approach to optimizing deep learning model training workflows.
4.3.3. Ablation on Stage-Wise Optimization
We conducted experiments to train both a single-stage mono-modal baseline model and a two-stage dual-modal model to validate the effectiveness of the staged training optimization for the detection of dual-modal objects. In our setup, we initially trained mono-modal models for visible light and infrared data, and then we introduced the data of the other modality to fine-tune the corresponding models. The results, as tabulated in
Table 3, show that the fine-tuned models exhibited impressive improvements in mAP: the visible light model saw a remarkable 15.6% increase, and the infrared model experienced a 3% increase. The dual-modal object detection algorithms outperformed their mono-modal counterparts on the dataset, which contains challenging environments such as nighttime. The introduction of infrared data mitigates the limitations of using only visible light for object detection, enhancing performance in complex scenarios.
4.4. Performance Comparison
For the purpose of comparison, our experiment involved the implementation of a dual-modal object detection algorithm that underwent fine-tuning on the visible light base model, referred to as VIP-Det. This was set against a range of baseline mono-modal object detection algorithms, including the single-stage R3Det [
8], the two-stage Oriented R-CNN [
9], and the anchor-free SASM [
10]. To ensure a fair comparison, these baseline algorithms were trained separately on either the visible light or infrared datasets. Furthermore, we conducted a meticulous re-implementation of four established RGB + T multispectral methodologies—Halfway Fusion [
23], UA-CMDet [
22], TSFADet [
24], and C2Former [
16]—with the objective of rigorously assessing their efficacy in the realm of RGB-IR object detection.
4.4.1. Comparison with Single-Modal Algorithm
The experimental results, as presented in
Table 4, offer profound insights upon analysis. Specifically, in the comparison of single-modality algorithms for visible light, Oriented R-CNN emerges as the top performer, surpassing the single-modality benchmark VIP-Det algorithm in terms of precision. This underscores the advanced detection framework and optimization strategies employed by Oriented R-CNN in handling complex scenes and recognizing intricate features.
However, when shifting our focus to infrared data, the narrative shifts. VIP-Det, when trained solely on infrared datasets, demonstrates a remarkable superiority over other single-modality object detection algorithms, including the formidable Oriented R-CNN in visible light. Its precision advantage over Oriented R-CNN reaches a significant 6.84%, highlighting VIP-Det’s unique strengths in processing infrared imagery, possibly attributed to its sensitivity and adaptability to spectral characteristics.
Moreover, in the head-to-head comparison between single-modality and dual-modality algorithms, VIP-Det claims the highest precision level. This achievement not only validates the inherent superiority of the VIP-Det algorithm but also underscores the profound impact of multi-modality information fusion on enhancing object detection performance. By integrating information from both visible and infrared spectra, VIP-Det is able to comprehensively capture target features, mitigating information loss and interference inherent in single-modality approaches. Consequently, it achieves more precise and robust target detection in complex environments.
4.4.2. Comparison with Dual-Modal Algorithm
As shown in
Table 5, when compared with the current state-of-the-art dual-modal object detection algorithms, our algorithm has demonstrated remarkable performance, achieving a significant mAP of 75.5%. This achievement not only surpasses other relevant dual-modal algorithms but also validates the effectiveness of our algorithmic innovations in multi-source information fusion and efficient feature extraction.
4.4.3. Comparison of Visual Detection Results
In this experiment, we aimed to validate the robustness of our algorithm and explore the efficacy of multi-modal object detection in complex environments. To this end, we selected Oriented R-CNN, the top-performing algorithm under single-modality conditions, as a benchmark for comparison. Our objective was to demonstrate the advantages of dual-modal object detection in the same environments where Oriented R-CNN is typically applied.
To comprehensively assess performance, we chose four distinct scenarios: daylight, nighttime, rainy/foggy conditions, and scenes with occlusion. Each of these scenarios poses unique challenges to object detection systems, requiring robust algorithms that can overcome factors such as illumination variations, poor visibility, and partial visibility of targets. The results are shown in
Figure 4.
In daylight conditions, visible light predominates. Regarding the section highlighted in the red frame, the single-modality Oriented R-CNN misclassifies it in infrared imagery, whereas VIP-Det accurately determines the target category, effectively addressing the issues of low resolution and lack of clarity in infrared images.
Under nighttime conditions, the Oriented R-CNN fails to detect the red-framed area entirely in the single visible light modality due to insufficient information. Conversely, VIP-Det supplements visible light information with infrared imagery, mitigating the inability of visible light-based target detection at night.
In rainy or foggy environments, visible light images tend to blur due to light reflection by raindrops or fog particles, whereas infrared imaging, relying on thermal conduction, is less affected. For the red-framed section, Oriented R-CNN, operating solely on visible light, misses the detection, while VIP-Det, leveraging infrared imagery as an aid, adeptly resolves the issue of unclear textures and blurred contours in visible light images under adverse weather conditions.
In cases of occlusion, such as by trees or other objects, visible light imaging suffers from information loss due to reflection. However, thermal radiation from targets can penetrate certain obstructions. For the red-framed region, Oriented R-CNN, using only visible light, experiences missed detections, whereas VIP-Det, by successfully fusing infrared and visible light information, is capable of detecting occluded targets. For a more extensive showcase of visual results, please refer to
Appendix B.
5. Discussion
Our research is primarily focused on the dual-modal object detection task within the UAV field. We have conducted a comprehensive set of ablation studies to validate the reliability of our proposed modules, and we have compared our algorithm with relevant state-of-the-art methods, showcasing its superior detection accuracy and impressive visual results. In contrast to single-modal object detection algorithms, our approach ingeniously fuses features through the use of prompts, endowing it with the capability of dual-modal complementarity and heightened robustness. Compared to existing dual-modal detection algorithms, our method fully exploits the representation and modeling power of Vision Transformers, achieving even better dual-modal feature extraction.
Looking ahead, we envision numerous avenues for further exploration to enhance the performance and practicality of our algorithm in real-world applications. Beyond developing more effective fusion modules and simplifying network architectures, we aim to optimize our model for seamless integration with UAV edge devices, enabling real-time, accurate detections under diverse environmental conditions. Additionally, we will investigate the potential of leveraging both visual and thermal data for battlefield reconnaissance and target identification, paving the way for safer and more efficient drone operations in the field.
6. Conclusions
In this work, our main contribution lies in the introduction of a Transformer-based algorithm for visible–thermal object detection tailored for applications of unmanned aerial vehicles (UAVs), named VIP-Det (Visual Prompt dual-modal Detection). VIP-Det employs a Vision Transformer as its backbone network, innovatively incorporates a prompt-based fusion module for refined feature integration, and adopts a stage-wise optimization strategy for efficient fine-tuning. Through a series of quantitative and qualitative experiments conducted on the DroneVehicle dataset, we demonstrate that VIP-Det surpasses existing dual-modal object detection algorithms, effectively tackling complex UAV-to-ground target detection scenarios, including rainy conditions, nighttime environments, and occlusion, with remarkable performance. This underscores the significant advancement of our proposed methodology in the realm of UAV-based object detection, which has immense potential to improve autonomous surveillance and monitoring capabilities in diverse and challenging environments.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}