
An Effective Res-Progressive Growing Generative Adversarial Network-Based Cross-Platform Super-Resolution Reconstruction Method for Drone and Satellite Images

Abstract
1. Introduction
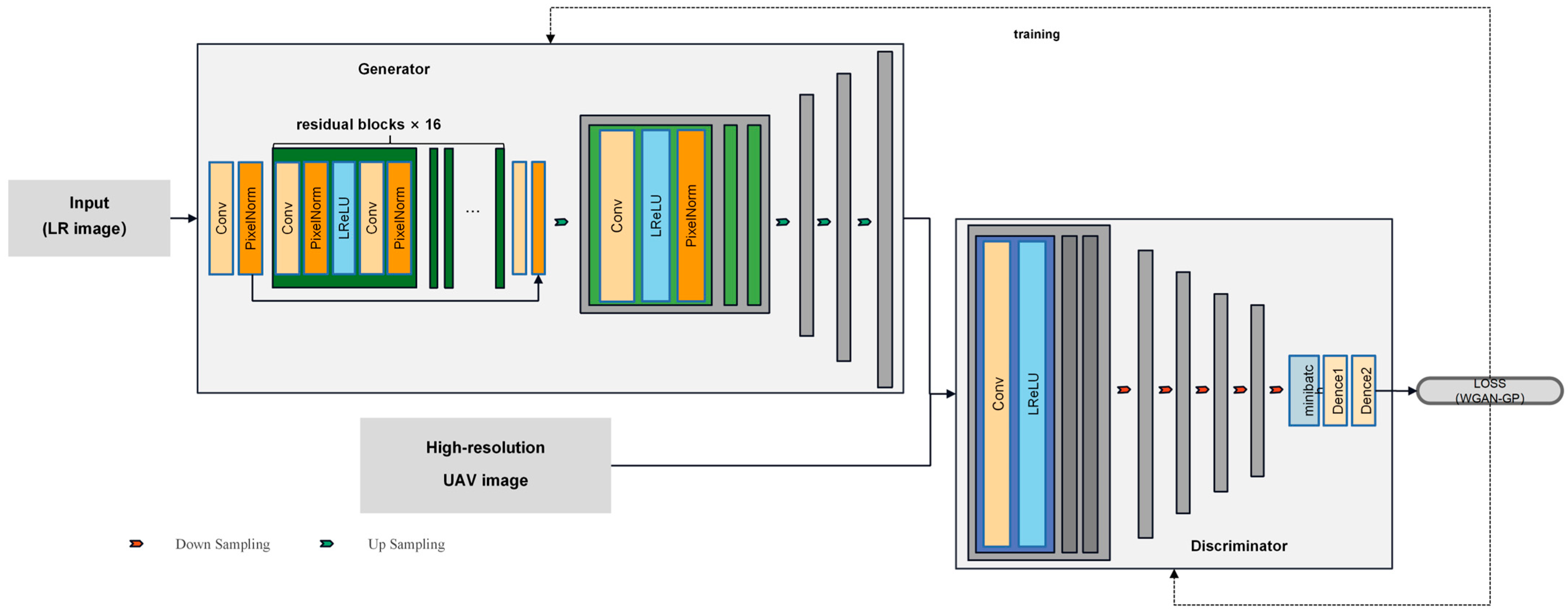
2. Methods
- (1)
- PGGAN
- (2)
- Res-PGGAN
3. Experiment Details
3.1. Datasets
3.1.1. Real Dataset
3.1.2. Pre-Training Dataset
3.2. Environments and Parameters
3.3. Evaluation Metrics
4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Weiss, M.; Jacob, F.; Duveiller, G. Remote Sensing for Agricultural Applications: A Meta-Review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Deng, L.; Mao, Z.; Li, X.; Hu, Z.; Duan, F.; Yan, Y. UAV-Based Multispectral Remote Sensing for Precision Agriculture: A Comparison between Different Cameras. ISPRS J. Photogramm. Remote Sens. 2018, 146, 124–136. [Google Scholar] [CrossRef]
- Chiu, M.S.; Wang, J. Evaluation of Machine Learning Regression Techniques for Estimating Winter Wheat Biomass Using Biophysical, Biochemical, and UAV Multispectral Data. Drones 2024, 8, 287. [Google Scholar] [CrossRef]
- Tanaka, T.S.T.; Wang, S.; Jørgensen, J.R.; Gentili, M.; Vidal, A.Z.; Mortensen, A.K.; Acharya, B.S.; Beck, B.D.; Gislum, R. Review of Crop Phenotyping in Field Plot Experiments Using UAV-Mounted Sensors and Algorithms. Drones 2024, 8, 212. [Google Scholar] [CrossRef]
- Segarra, J.; Buchaillot, M.L.; Araus, J.L.; Kefauver, S.C. Remote Sensing for Precision Agriculture: Sentinel-2 Improved Features and Applications. Agronomy 2020, 10, 641. [Google Scholar] [CrossRef]
- Nakalembe, C.; Becker-Reshef, I.; Bonifacio, R.; Hu, G.; Humber, M.L.; Justice, C.J.; Keniston, J.; Mwangi, K.; Rembold, F.; Shukla, S.; et al. A Review of Satellite-Based Global Agricultural Monitoring Systems Available for Africa. Glob. Food Secur. 2021, 29, 100543. [Google Scholar] [CrossRef]
- Pettorelli, N. Satellite Remote Sensing to Support Agriculture and Forestry. In Satellite Remote Sensing and the Management of Natural Resources; Pettorelli, N., Ed.; Oxford University Press: Oxford, UK, 2019; ISBN 978-0-19-871726-3. [Google Scholar]
- Blekanov, I.; Molin, A.; Zhang, D.; Mitrofanov, E.; Mitrofanova, O.; Li, Y. Monitoring of Grain Crops Nitrogen Status from Uav Multispectral Images Coupled with Deep Learning Approaches. Comput. Electron. Agric. 2023, 212, 108047. [Google Scholar] [CrossRef]
- Inoue, Y. Satellite- and Drone-Based Remote Sensing of Crops and Soils for Smart Farming—A Review. Soil Sci. Plant Nutr. 2020, 66, 798–810. [Google Scholar] [CrossRef]
- Benami, E.; Jin, Z.; Carter, M.R.; Ghosh, A.; Hijmans, R.J.; Hobbs, A.; Kenduiywo, B.; Lobell, D.B. Uniting Remote Sensing, Crop Modelling and Economics for Agricultural Risk Management. Nat. Rev. Earth Environ. 2021, 2, 140–159. [Google Scholar] [CrossRef]
- Ali, A.M.; Abouelghar, M.; Belal, A.A.; Saleh, N.; Yones, M.; Selim, A.I.; Amin, M.E.S.; Elwesemy, A.; Kucher, D.E.; Maginan, S.; et al. Crop Yield Prediction Using Multi Sensors Remote Sensing (Review Article). Egypt. J. Remote Sens. Space Sci. 2022, 25, 711–716. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, X.; Wang, Z.; Yang, L.; Xie, Y.; Huang, Y. UAVs as Remote Sensing Platforms in Plant Ecology: Review of Applications and Challenges. J. Plant Ecol. 2021, 14, 1003–1023. [Google Scholar] [CrossRef]
- Yue, L.; Shen, H.; Li, J.; Yuan, Q.; Zhang, H.; Zhang, L. Image Super-Resolution: The Techniques, Applications, and Future. Signal Process. 2016, 128, 389–408. [Google Scholar] [CrossRef]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-Resolution Image Reconstruction: A Technical Overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Jia, S.; Han, B.; Kutz, J.N. Example-Based Super-Resolution Fluorescence Microscopy. Sci. Rep. 2018, 8, 5700. [Google Scholar] [CrossRef] [PubMed]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-Based Super-Resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef]
- Chang, H.; Yeung, D.-Y.; Xiong, Y. Super-Resolution through Neighbor Embedding. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 1, p. I. [Google Scholar]
- Chan, T.-M.; Zhang, J.; Pu, J.; Huang, H. Neighbor Embedding Based Super-Resolution Algorithm through Edge Detection and Feature Selection. Pattern Recognit. Lett. 2009, 30, 494–502. [Google Scholar] [CrossRef]
- Pan, L.; Peng, G.; Yan, W.; Zheng, H. Single Image Super Resolution Based on Multiscale Local Similarity and Neighbor Embedding. Neurocomputing 2016, 207, 250–263. [Google Scholar] [CrossRef]
- Zhao, J.; Chen, C.; Zhou, Z.; Cao, F. Single Image Super-Resolution Based on Adaptive Convolutional Sparse Coding and Convolutional Neural Networks. J. Vis. Commun. Image Represent. 2019, 58, 651–661. [Google Scholar] [CrossRef]
- Ha, V.K.; Ren, J.-C.; Xu, X.-Y.; Zhao, S.; Xie, G.; Masero, V.; Hussain, A. Deep Learning Based Single Image Super-Resolution: A Survey. Int. J. Autom. Comput. 2019, 16, 413–426. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution Via Sparse Representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep Learning for Image Super-Resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3365–3387. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Computer Vision—ECCV 2018 Workshops; Leal-Taixé, L., Roth, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11133, pp. 63–79. ISBN 978-3-030-11020-8. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning Texture Transformer Network for Image Super-Resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5790–5799. [Google Scholar]
- Dahl, R.; Norouzi, M.; Shlens, J. Pixel Recursive Super Resolution. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Shang, T.; Dai, Q.; Zhu, S.; Yang, T.; Guo, Y. Perceptual Extreme Super Resolution Network with Receptive Field Block. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1778–1787. [Google Scholar]
- Chan, K.C.K.; Wang, X.; Xu, X.; Gu, J.; Loy, C.C. GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv 2018, arXiv:1710.10196v3. [Google Scholar]
- DJI M300 RTK. Available online: https://airborne.ed.ac.uk/airborne-research-and-innovation/unmanned-aircraft-systems-uas/unmanned-aircraft-systems-fleet/dji-m300-rtk (accessed on 28 February 2024).
- Matrice 300 RTK—Industrial Grade Mapping Inspection Drones—DJI Enterprise. Available online: https://enterprise.dji.com/matrice-300 (accessed on 4 March 2024).
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Hall, C.A. Natural Cubic and Bicubic Spline Interpolation. SIAM J. Numer. Anal. 1973, 10, 1055–1060. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Tanchenko, A. Visual-PSNR Measure of Image Quality. J. Vis. Commun. Image Represent. 2014, 25, 874–878. [Google Scholar] [CrossRef]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Bakurov, I.; Buzzelli, M.; Schettini, R.; Castelli, M.; Vanneschi, L. Structural Similarity Index (SSIM) Revisited: A Data-Driven Approach. Expert Syst. Appl. 2022, 189, 116087. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Drone Parameters | Indicators |
|---|---|
| Size | Dimensions (unfolded, excluding propellers): 810 × 670 × 430 mm (L × W × H) |
| Maximum take-off weight | 9 kg |
| RTK position accuracy | In RTK FIX: 1 cm + 1 ppm (horizontal) 1.5 cm + 1 ppm (vertical) |
| Maximum flight altitude | 5000 m |
| Maximum flight time | 55 min |
| GNSS | GPS + GLONASS + BeiDou + Galileo |
| Operating ambient temperature | −20°C–50°C |
| Maximum signal distance | NCC/FCC: 15 km CE/MIC: 8 km SRRC: 8 km |
| GSD/flight altitude (in this work) | 0.0163 cm/50.83 m |
| Satellite Parameters | Indicators |
|---|---|
| Date of launch | 23 June 2015 |
| Revisiting Period | 5 days (Sentinel-2A&B) |
| Image resolution | Bands 2,3,4,8: 10 m Bands 5,6,7,8a,11,12: 20 m Bands 1,9,10: 60 m |
| Swath/field of view | 290 km/20.6° |
| Altitude | sun-synchronous orbit (786 km) |
| OS | WSL2-Ubuntu20.04LST | CUDA | 12.0 |
| CPU | Intel Xeon Bronze 3204 | CuDNN | 8.2.4 |
| GPU | NVIDIA Quardo P5000 | Tensorflow | 2.8.0 |
| Python | 3.9.0 | OTB | 7.2 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| vgg type | vgg19 | batch size | 4 |
| vgg weight | 0.0003 | adam | 0.0002 |
| L1 weight | 200 | L2 weight | 0.0 |
| LR scale | 0.0001 | depth | 64 |
| HR scale | 0.0001 | epoc | 50 |
| SSIM | PSNR | UIQ | |
|---|---|---|---|
| Bicubic | 0.8990 | 41.1225 | −0.0086 |
| ESRGAN | 0.9664 | 43.8705 | 0.0266 |
| PGGAN | 0.9687 | 44.3229 | 0.0412 |
| Res-PGGAN-BN | 0.9710 | 44.7174 | 0.0375 |
| Res-PGGAN-PN | 0.9726 (±0.004) | 44.7971 (±0.003) | 0.0417 (±0.0003) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, H.; Du, W.; Feng, Z.; Guo, Z.; Xu, T. An Effective Res-Progressive Growing Generative Adversarial Network-Based Cross-Platform Super-Resolution Reconstruction Method for Drone and Satellite Images. Drones 2024, 8, 452. https://doi.org/10.3390/drones8090452
Han H, Du W, Feng Z, Guo Z, Xu T. An Effective Res-Progressive Growing Generative Adversarial Network-Based Cross-Platform Super-Resolution Reconstruction Method for Drone and Satellite Images. Drones. 2024; 8(9):452. https://doi.org/10.3390/drones8090452
Chicago/Turabian StyleHan, Hao, Wen Du, Ziyi Feng, Zhonghui Guo, and Tongyu Xu. 2024. "An Effective Res-Progressive Growing Generative Adversarial Network-Based Cross-Platform Super-Resolution Reconstruction Method for Drone and Satellite Images" Drones 8, no. 9: 452. https://doi.org/10.3390/drones8090452
APA StyleHan, H., Du, W., Feng, Z., Guo, Z., & Xu, T. (2024). An Effective Res-Progressive Growing Generative Adversarial Network-Based Cross-Platform Super-Resolution Reconstruction Method for Drone and Satellite Images. Drones, 8(9), 452. https://doi.org/10.3390/drones8090452