1. Introduction
Object tracking is one of the fundamental tasks of computer vision. The progress is that, given the initial information about any object, the tracker finds the given object in a series of tracking frames and returns the accurate position of each frame. Unmanned Aerial Vehicle (UAV) tracking refers specifically to the processing of videos captured from UAVs. UAV tracking is widely used in many fields as one of the important tasks of remote sensing observation [
1,
2], such as aerial inspection, aerial photography, visual localization [
3], etc.
Currently, the mainstream trackers for object tracking include the Discriminative Correlation Filters (DCFs) and the Siamese Networks (SNs). In DCFs, a filter
is trained by learning the object template online [
4]. Then, DCFs can find the object by similarity matching the search region through the filter
, while updating the filter
in tracking progress. SNs, including the template branch and the search branch, these two branches realize object tracking by minimizing the distance between the target template and the target in the search patch [
5]. The SNs first obtain the feature maps of both the template patch
and the search region
through the same feature extraction network, and then find the object by similarity matching between the
and
. Both DCFs and SNs have the common goal of matching the similarity information between the template patch and the search region to effectively distinguish the object from the background. In recent years, the SNs have outperformed DCFs in terms of accuracy and efficiency, so many trackers utilize Siamese networks for UAV tracking [
6]. The core of classical SNs is to establish an accurate appearance model of the given object as the template so that the correct object can be accurately found when using the template for matching. During this progress, the importance of the templates is evident.
However, there are two inherent limitations when SNs are used for UAV tracking. Firstly, the creation of the template only uses the ground truth box of the tracking sequences’ first frame, and the template is not modified during the whole tracking process [
5]. However, during the tracking process, especially for long-term tracking, the object will inevitably undergo appearance variations, and the fixed template information is not conducive to the accurate matching of similar information. For the tracking algorithm, the processed consecutive frames contain a lot of temporal context information, which can be used for template updates. However, most SNs ignore the temporal context information, which makes the tracker ineffective when it has an obvious appearance change. Secondly, the UAV platforms are accompanied by changes in flight altitude and horizontal movement, which cause scale variation and observation angle changes in the object. Additionally, aerial scenarios are more complex, often appearing with similar interference, also the presence of background interference, such challenges put more demands on the feature extraction capability of the trackers. However, UAVs are difficult to run weight-accurate feature extraction networks due to limited computing platforms, but shallow CNN feature extraction networks bring fixed sensory fields with single-scale and low-order features. The limited feature extraction capability does not allow the extraction of multiscale features, and it is difficult to achieve remote and high-order interactions between pixels, which loses much of the spatial information.
To make up for the first limitation, SNs try to use template replacement [
7] or linear template update [
8]. However, the direct and violent replacement of the template cannot guarantee the correctness of target information, and the linear template update is very limited due to the restriction of the linear model. To increase the spatial information and break the spatial limitation of CNN’s fixed receptive field, there are also many trackers using the transformer structure for feature extraction [
9,
10]. They do improve the tracking accuracy by increasing the spatial discrimination of the features, but along with the transformer structure is the increase in the computational quadratically with the increase in input size. Since the pixel points of the input image are at least
, if the transformer structure is used for feature extraction, it will require a computational amount that is difficult to run on UAV platforms. However, it does not mean that transformers cannot be run on UAV platforms, but we need to consider the input size of the transformer.
Inspired by the above research, we propose a lightweight spatial-temporal context Siamese tracker for UAV tracking. Specifically, a high-order multiscale spatial module is designed to extract multiscale remote high-order spatial information, and the temporal template transformer is used to update the template by introducing temporal context information. The proposed high-order multiscale spatial module first adopts adaptive channel splitting and convolution methods to extract multiscale features. Then, the high-order self-interaction of feature maps is realized by recursive multiplying, which not only realizes the parallel feature extraction of multiscale sensitivity fields but also the high-order interaction of features. The proposed temporal template transformer introduces the target context information of continuous frames to adjust the template. Instead of manually specifying the template update mechanism, we adaptively introduce temporal context information through the transformer encoder-decoder structure. Although we use the transformer structure here, due to the small template size, the increased computation amount of the temporal template transformer is acceptable compared to the high computation amount of feature extraction directly on pixels. Our main contributions are as follows:
- (1)
A spatial-temporal contextual aggregation Siamese network (SiamST) is proposed for UAV tracking to improve tracking performance by enhancing horizontal spatial information and introducing vertical temporal information.
- (2)
We propose a high-order multiscale spatial module to extract multiscale spatial information and increase the spatial information. Through the adaptive channel splitting convolution and recursive multiplying, the feature map achieves high-order self-interaction. Therefore, the new interaction architecture design effectively breaks through the deficiencies of the inherent linear sequential mapping of the traditional CNN-based model in terms of its ability to express shallow features without changing the depth of the features and introducing a huge amount of computation.
- (3)
The proposed temporal template transformer adaptively introduces temporal context information to realize adaptive template updates through the encoder and decoder structure, thereby enabling effective perception of dynamic feature information flows with a lightweight architectural design.
- (4)
Experimental results on three UAV tracking benchmarks, UAV20L, UAV123@10fps, and DTB70, demonstrate that the proposed SiamST has impressive performance compared with other cutting-edge methods and can reach 75.5 fps on NVIDIA 3060Ti.
The rest of this article is arranged as follows: In
Section 2, we briefly introduced the work related to SNs, UAV trackers, and spatial-temporal context information in UAV tracking. In
Section 3, we introduced the proposed SiamST in detail. In
Section 4, we described the details of the experiments, including test benchmarks, experimental setting, ablation experiments, and comparison results. In
Section 5, we discussed the results of the experiments and the limitations of the proposed method, and the direction of future development.
Section 6 provides the conclusion.
3. Method
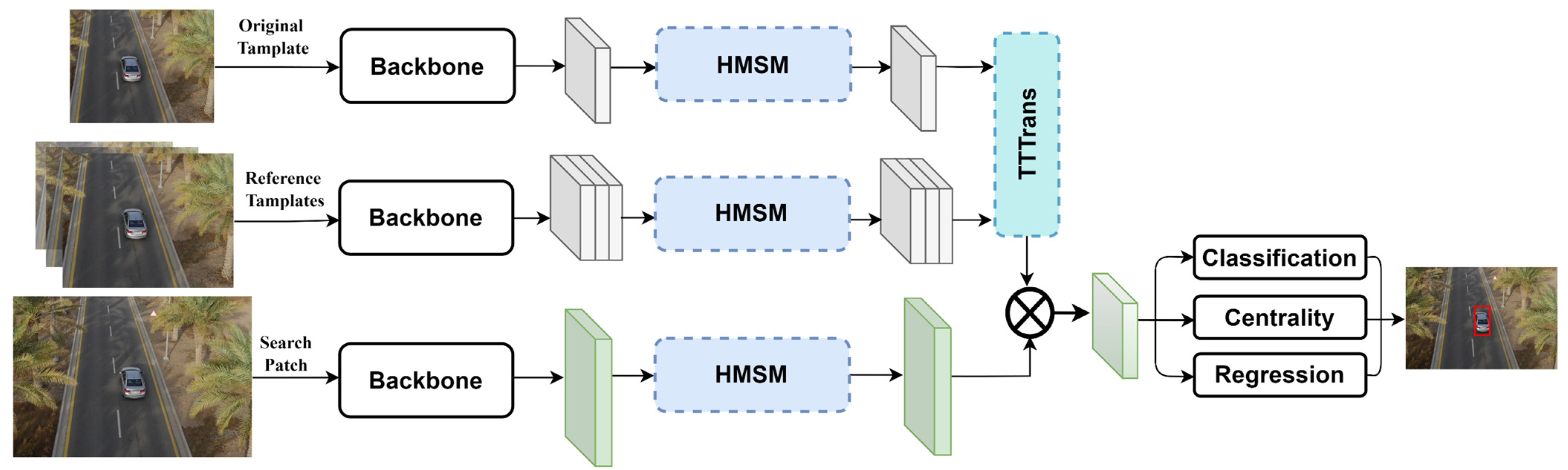
This section describes the proposed SiamST. As shown in
Figure 1, the proposed SiamST contains four main parts: a feature extraction network, a high-order multiscale spatial module and temporal template transformer, a cross-correlation fusion network, and a prediction head. We first briefly introduce the overall process of the proposed SiamST, as well as the input and output of each part. Then, we focus on the proposed high-order multiscale spatial module and temporal template transformer.
3.1. Overall Objective
Given the UAV tracking sequences, we select the ground truth of the first frame as the template patch
, and each subsequent frame of the sequence as the search patch
, where 127 and 255 are the sizes of the template patch and search patch, respectively, and each patch has three channels. The template and search patch are first sent into the backbone for feature extraction at the same time to obtain their respective feature maps
. In this work, we choose the CNN backbone, AlexNet, as the backbone. To further extract spatial information,
and
are secondly sent into the proposed high-order multiscale spatial module. We note the outputs as
and
. Thirdly, the temporal template transformer is used to update the template. The input of the temporal template transformer is the original template of the first frame
and the tracking result of consecutive frames as reference templates
. The updated template is outputted as
. Then, we use the cross-correlation fusion network to calculate the similarity information of
and
and generate the response map
The formula is as follows:
where the
is the cross-correlation fusion operation. Finally, by decoding the response map, the prediction head gets the accurate object estimate.
During the training process, the target patch and search patch input to the network in pairs.
In addition, there are many template patches as reference templates input to the network. The tracking network is trained using multiple templates and a single search patch. We take the template corresponding to the search area as the original template and the rest of the reference templates as the temporal context template patches as input. This input is used to train the proposed temporal template transformer.
During the testing process, we take the template information of the first frame as the original template . In the second frame of tracking sequences, the template information is only the original template, so we take the original template as the only input of the proposed temporal template transformer. When the tracking result of the second frame is obtained, we first determine the maximum position of the response map, that is, the location of the object center in the second frame. Then, select the corresponding position of the search feature map as the target template feature map of this frame. The advantage of using the response map to locate the object is to avoid the computation of the tracking head to judge the target position and the quadratic feature extraction.
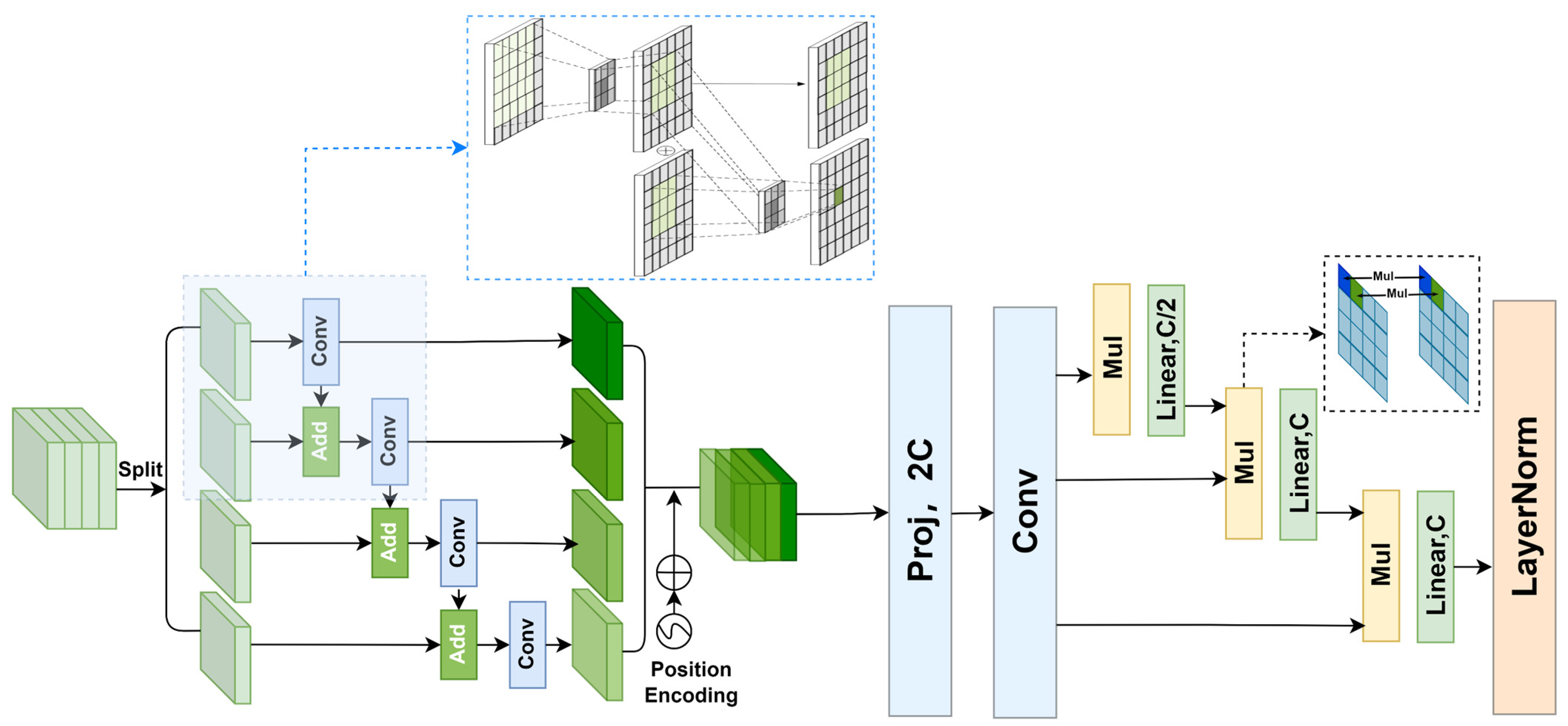
3.2. High-Order Multiscale Spatial Module
The specific structure of the proposed multiscale, high-order spatial module is shown in
Figure 2. We first implement multiscale feature extraction by channel splitting and multiple residual convolutions using a residual block hybrid structure. We know that in the process of feature extraction, the number of channels of feature maps represents the diversity of extracted features. In the designed high-order multiscale spatial module, we first carry out adaptive channel splitting, and the formula is as follows:
where
is the feature map obtained through the feature extraction network,
is the feature set obtained by splitting, and then the residual convolution of the obtained feature set is carried out. The formula is as follows:
where
is the
convolution operation and
is the output. Through adaptive splitting of channels, complex features can be extracted through multiple convolution residual structures to achieve deep features, while shallow features will adaptively undergo fewer convolution calculations. The feature sets will adaptively perform convolution operations once, twice, three, or four times. We compare the effects of different convolution times on the feature scale. As shown in
Figure 2, the input area covered by a
convolution kernel is
, which means each pixel in the calculated output feature map corresponds to
pixels of the original feature map. Multiple convolution operations enlarge the corresponding input feature size. The receptive fields corresponding to the once, twice, three, or four times convolution calculations are
,
,
,
respectively. Through the above structure, we can obtain different receptive fields, and then obtain multiscale features. In conclusion, this adaptive nonaverage convolution method enhances the multiscale property and feature extraction abilities of the model.
After that, we were inspired by HorNet to try to implement long-range and high-order feature interaction. We first encode the location of the features.
After the position encoding of the features, convolution is used to divide the features into multiple groups. It is worth noting that to realize the remote interaction of the feature map, large convolution
is used to realize the multihead mapping
. The calculation formula is as follows:
Next, we do group multiple multiplication convolution.
where
where
is convolution operation, and
realizes the alignment of channels. In the calculation process, we realize the high-order self-interaction of spatial information through the corresponding point calculation of feature maps. In this paper, we choose third-order computation to balance computational efficiency while realizing higher-order interaction of spatial information. After the process of splitting perception and multihead mapping channel alignment, the aggregation of spatial-dimensional long-range contextual information is achieved at shallower feature channels with lower computational effort. The multiscale and multidimensional feature rearrangement guided by the spatial contextual information successfully breaks the limitation of mechanical feature transfer caused by the linear mapping mechanism of the traditional CNN backbone.
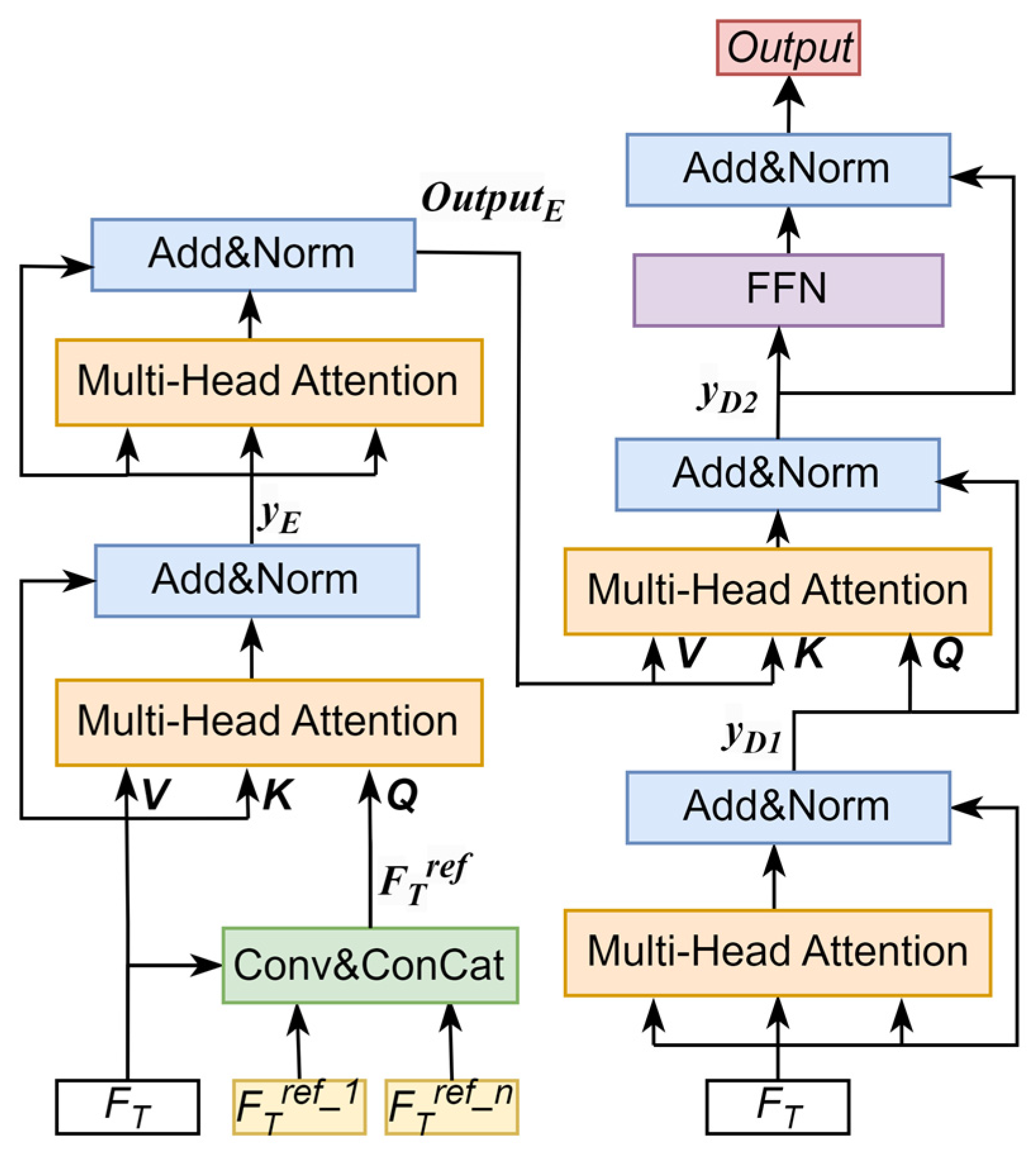
3.3. Temporal Template Transformer
The self-correlation operation of sequential feature blocks in multiple subspaces achieved by the self-attention mechanism in traditional transformer structures makes it difficult to achieve the mining of long-distance spatial-temporal contextual information, which is crucial for aerial tracking. Different from the traditional transformer architecture design, we introduce multistream reference temporal context information before feature interaction in the subspaces and introduce dynamic long-range relevance information in the current feature processing, which achieves lightweight and efficient exploration of the temporal context information that is used for feature information updating and saliency optimization. We introduce the proposed temporal template transformer in detail. As shown in
Figure 3, the proposed temporal template transformer contains an encoder and a decoder. The input of the encoder is the original template and the reference templates of consecutive frames, and the input of the decoder is the original template. The function of the encoder is to obtain the temporal context information for template enhancement by comparing and fusing the reference templates with the original template information, while the function of the decoder is to adaptively update the original template with the temporal context information obtained by the encoder. The complex template update mechanism and sensitive hyperparameter tuning are avoided in this process.
We chose the template as the carrier of temporal context information fusion for two reasons. First, template updates can be realized by introducing object information in continuous frames to alleviate the impact of object appearance changes on tracking. Secondly, although the transformer structure is used to realize the adaptive fusion of temporal context, the calculation amount is larger than that of the CNN network, but the size of the template patch after feature extraction is small, which is only a feature map in this work. Therefore, we believe that the increased calculation amount is acceptable.
Specifically, we fuse the reference templates, so the structure of the model does not need to change due to the number of reference frames. The calculation process is as follows:
where
is the set of reference templates, and
is the fusion result of the reference frames. In this work, to introduce the target information of adjacent frames, we use the tracking results of the first three frames near the search frame as the reference templates. Next, we employ the multihead attention to compute the original template
and the representative of the reference frames
. Multihead attention can better learn the multiple relationships and similarity information between each pixel, and effectively extract the global context information of the original template and reference templates. The specific formula is as follows:
where
where
means the input query, key, and value of the attention module.
is the scale scaling factor, and
are earnable parameters.
represents the number of heads of multihead attention. In this work, we set
N as 8. During the encoding process, we consider that the temporal templates of consecutive frames need to be queried with the original template information to obtain the difference and similarity information. Thus, we set the
as
and the
as
and
.
where the
is the output of the first multihead attention.
After passing the results through residual connection and layernorm, we realize further information fusion through multihead attention again.
where the
is the output of the encoder. We define the
as the adaptive update knowledge of the original template, which is input to the decoder to realize the enhancement of the template. During the decoding process, we first enhance the original template
through multihead attention.
The
and
are sent to multihead attention again to perform the decoding process. In the encoder, we take the temporal context information as a query, aiming to encode it with the template information to a greater extent. In the decoder, our purpose is to carry out an adaptive update of the template information. Therefore, we decode the template information as a query in the decoder. The formula is as follows:
Finally, through a feed-forward network and the last layernorm, we get the output of the proposed temporal template transformer.
where
In the proposed temporal template transformer, we keep the residual structure. Since not all reference templates are conducive to template updates, we choose to let the network update adaptively instead of specifying what template is useful. Thus, the residual structure helps to ensure that the model will not get worse.
3.4. Prediction Head
The prediction head is used to decode the response map and estimate the object. During training progress, the prediction head requires a lot of prior knowledge, which is crucial to achieving accurate target estimation. In this work, we use three branches of the network for object estimation, the classification branch, the regression branch, and the centrality branch. The input of these three branches is the response map, and the outputs are , , and , respectively.
The output of the classification branch is a classification map. We note it as
, where 25 is the size of the
and each pixel of
has two scores
and
for foreground and background. The scores are used to classify whether this pixel belongs to the foreground or the background. The cross-entropy loss function is used to calculate the classification loss. The formula is as follows:
where
is the label of each pixel and
,
N is the number of pixels within the ground truth. The output of the regression branch is
, each pixel
of
has a
vector
, which means the distances of the left, top, right, and bottom four edges
of the target estimation box from the center. We note the ground truth as
, where
and
are the left-top and right-bottom locations of ground truth. We only consider regression boxes within the ground truth to balance positive and negative samples when calculating regression losses. For each pixel
within the ground truth needs to calculate its label. The formula is as follows:
where
is the location of the figure patch corresponding to the pixel
of
. The regression can be calculated by IoU loss. The formula is as follows:
Considering that the prediction box will get lower quality and not be highly referable far from the target center, we add the centrality branch to improve the quality of the prediction box. The output of the centrality branch is
, each pixel of
has one score
of centerness. The label
of
is calculated by the distance between
and ground truth
. The formula is as follows:
With the label, we can calculate the centerness loss.
The overall loss can be calculated as follows:
4. Experiments
4.1. Implementation Detail
We train the proposed SiamST using an end-to-end training approach. Our training platform is RTX 3060Ti, CPU is AMD 3700X. Pytorch1.10 is used to build the training network. The Python version is 3.8, and the stochastic gradient descent (SGD) method is used to train a total of 20 epochs. Our learning rate is set to rise from 0.001 to 0.005 for the first five epochs and decrease from 0.005 to 0.0005 for the next 15 epochs. Our training benchmarks contain GOT-10K [
33], COCO [
34], VID [
35], and LaSOT [
36]. We evaluate the trained network on chosen testing benchmarks commonly used for UAV tracking evaluation, such as UAV123@10fps [
37], UAV20L, and DTB70 [
38]. We use the one-pass evaluation (OPE) method for evaluation and select precision rate and success rate as comparison metrics.
4.2. Comparision with the State-of-the-Arts
To show the tracking performance of the proposed SiamST, UAV evaluation benchmarks such as DTB70, UAV123@10fps, and UAV20L are selected as evaluation benchmarks. As one of the most used UAV evaluation benchmarks, DTB70 contains 70 tracking sequences from UAV perspectives and includes a variety of challenges that often occur under UAV tracking, such as occlusion, scale change, and low resolution, so it can well evaluate the robustness of the tracker. UAV123@10fps and UAV20L contain 123 and 20 common UAV scene sequences, respectively. They are used as short-term and long-term evaluation benchmarks for UAV tracking, which can comprehensively evaluate the tracking effect of the tracker for short and long time. To prove the superiority of the proposed tracker, we chose multiple state-of-the-art (SOTA) Siamese trackers for UAV tracking for comparison, such as TCTrack [
32], SGDViT [
25], SiamAPN [
21], SiamAPN++ [
22], SiamSA [
39], as well as HiFT [
23]. In addition, general trackers such as SiamRPN [
19], SiamCAR [
14], UpdateNet [
30], and so on [
40,
41,
42,
43] are also selected as comparison trackers.
4.2.1. UAV123@10fps Benchmark
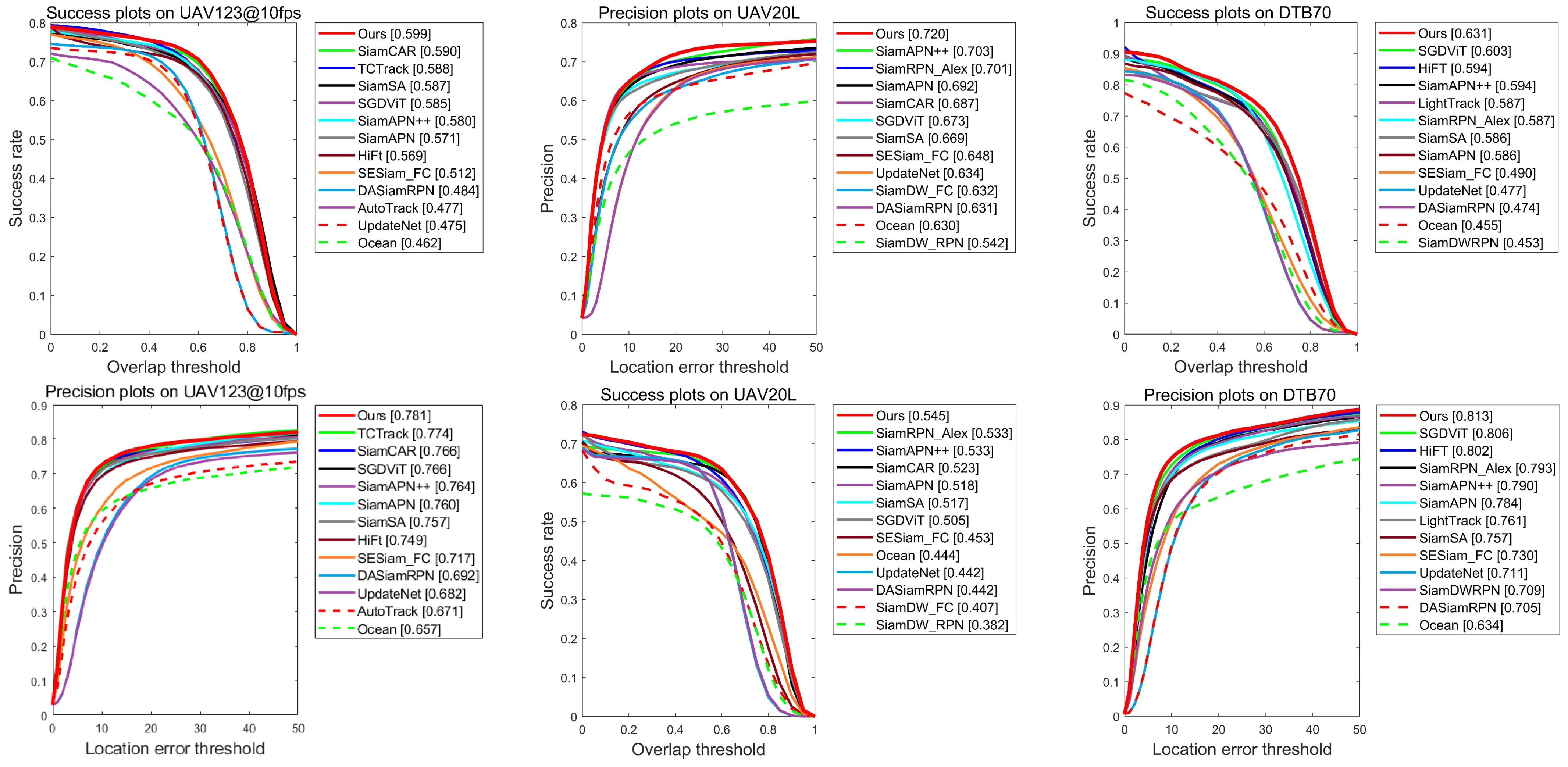
As shown in
Figure 4, we evaluate the tracking results of UAV123@10fps by success rate and precision rate. The precision rate and success rate of the proposed SiamST are 0.784 and 0.599, which rank first among the 12 compared trackers. Among the compared trackers, the precision rate and success rate of TCTrack are 0.774 and 0.588. Similar to SiamST, TCTrack also introduces temporal context information for UAV tracking. Different from the SiamST proposed in this paper to enhance template information, TCTrack designs a transformer structure to improve response maps by introducing temporal context information. The tracking results of SiamST and TCTrack prove that temporal context plays a very important role in UAV tracking. In addition, TCTrack also uses temporal adaptive convolution to enhance the spatial information of template features, and SiamST also proposes a high-order multiscale spatial module. Realize high-order interaction of information and long-distance interaction between target and background; thus, the organic complementarity of contextual information in the spatial and temporal dimensions is realized. Both SiamST and TCTrack improve the Siamese network at the spatial and temporal levels, so the tracking performance is higher than other trackers. The excellent results of the proposed SiamST at UAV123@10fps prove that the proposed tracking algorithm is accurate for UAV tracking.
4.2.2. UAV20L Benchmark
UAV20L is used as a long-term UAV tracking benchmark, with each tracking sequence exceeding 1000 frames. We use UAV20L to evaluate the long-term tracking performance of SiamST. As shown in
Figure 4, the precision rate and success rate of the proposed SiamST are 0.720 and 0.545, respectively, which are 1.7% and 1.2% higher than the Siamese-based UAV tracker SiamAPN++. SiamAPN++ introduces an attention mechanism into the Siamese framework for UAV tracking. Compared with SiamAPN++, the proposed SiamST in this paper has two advantages. Firstly, SiamST uses an atypical transformer structure that introduces long-distance temporal contextual information flow to achieve further lightweight and efficient exploration of the temporal context information, which is crucial for aerial tracking. However, SiamAPN++ ignores the temporal context information. Secondly, SiamAPN++ uses an anchor-based mechanism to perform scale estimation, while SiamST uses an anchor-free prediction head to avoid hyperparameter adjustment. Therefore, the results of the proposed SiamST are higher than SiamAPN++. The tracking performance of TCTrack accuracy ranks second, which also proves the important role of temporal context information in long-term tracking.
4.2.3. DTB70 Benchmark
As shown in
Figure 4, the proposed SiamST still performs well on the DTB70 benchmark. The precision rate and success rate are 0.813 and 0.631, respectively. Compared with SGDViT, the precision rate is higher than 0.7% and the accuracy is higher than 2.8%. SGDVit finds the problem that the background information will increase when there are changes in the object and focuses on the ratio change and scale variation, SGDViT proposes a saliency-guided dynamic vision transformer to distinguish foreground and background information and refine the cross-correlation work, which can meet many challenges under UAV tracking. With the help of the saliency-guided information, the performance of SGDViT is outstanding. SiamST also increases the guide information, which is temporal information from context frames. The multidimensional architecture design based on the organic complementarity of contextual information in the spatial and temporal dimensions makes its performance better than the SOTA aerial tracker SGDViT.
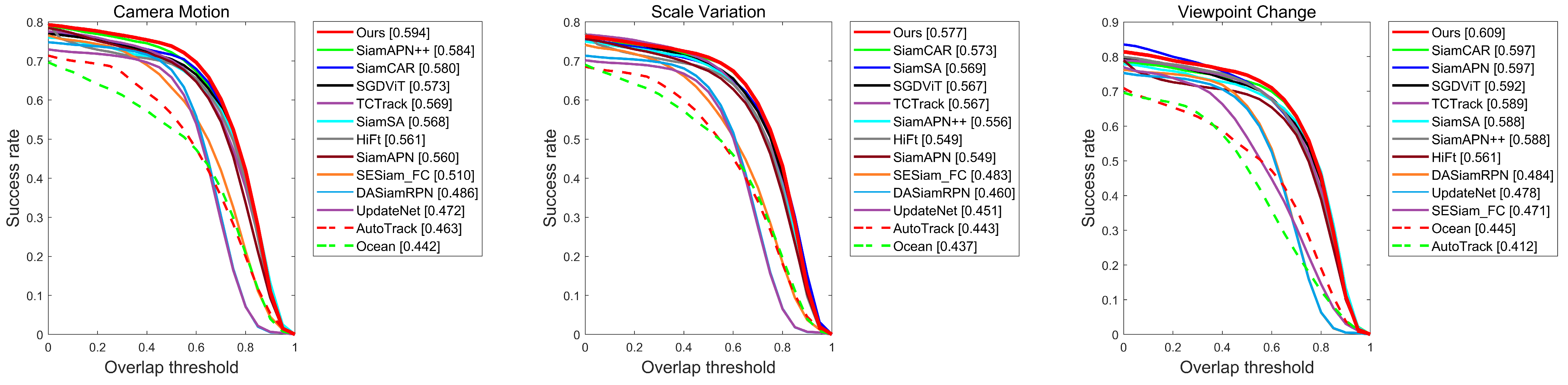
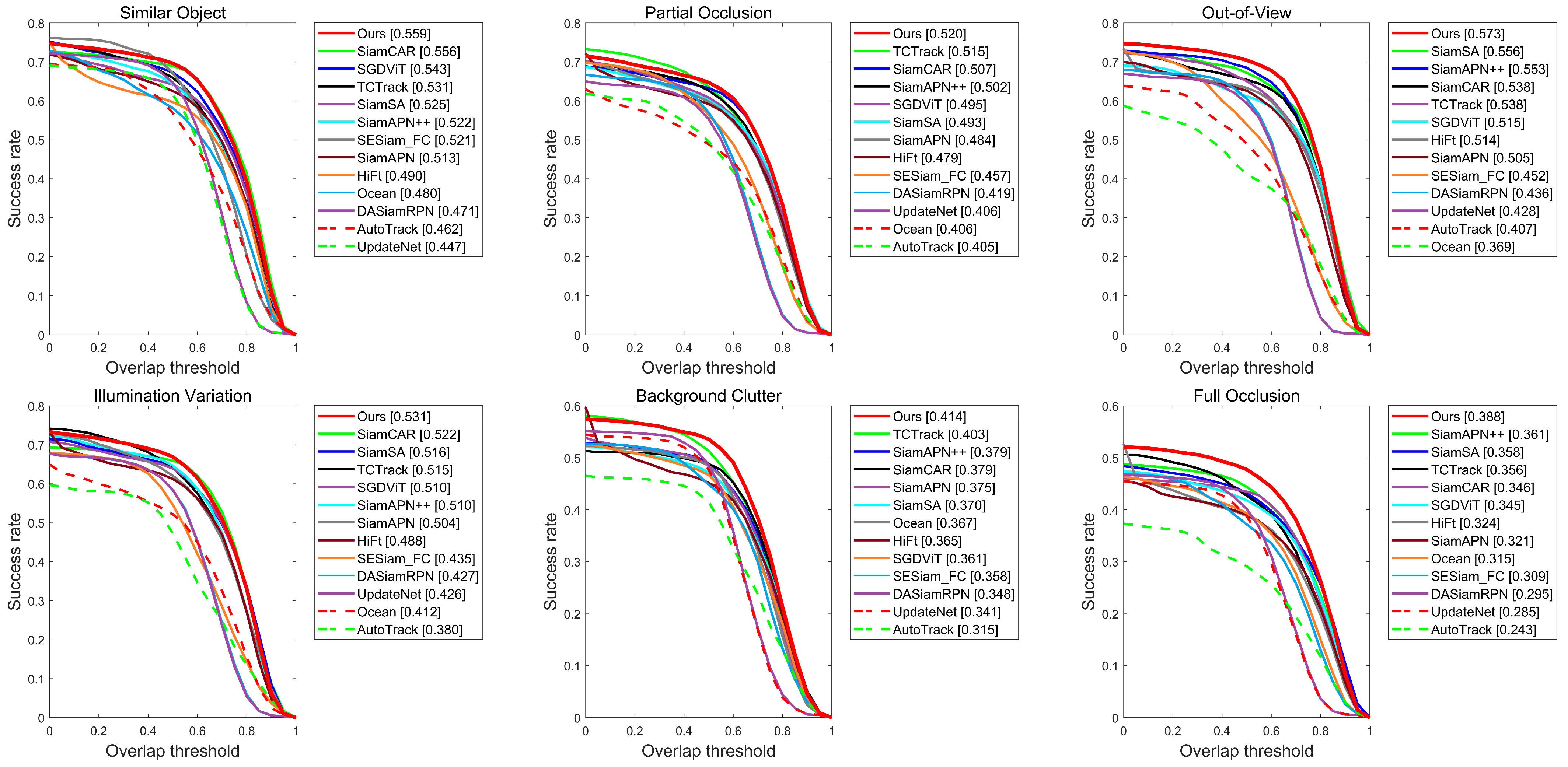
4.3. Results in Different Attributes
To further analyze the capability of the proposed SiamST to cope with UAV tracking of complex backgrounds, we evaluated its performance on UAV123@10fps under nine common UAV tracking challenges. The results are shown in
Figure 5. Firstly, using the UAV as a mobile platform, we tested the performance under camera motion, scale variation, and viewpoint change. The results show that, compared with the comparison trackers, the success rate of the proposed algorithm is 0.594, 0.577, and 0.609, respectively, which is higher than the comparison trackers. This proves that the spatial information enhancer proposed in this paper can improve the multiscale adaptability and spatial information extraction ability of the tracker. Additionally, the UAV tracking scene is complex, often facing the influence of background clutter, partial occlusion, full occlusion, and similar objects. The occlusion scene makes it easy to change the appearance of the object and difficult to extract the overall features of the target.
Additionally, background clutter and the appearance of similar targets make it easy to cause the tracking drift phenomenon. At this point, the introduction of temporal context information compensates for these shortcomings. Therefore, the tracker performs well in these scenarios. As can be seen from
Figure 5, in the face of the above challenges, the success rates of the proposed SiamST are 0.414, 0.520, 0.388, and 0.559, respectively, SiamST always ranks first. Additionally, with illumination variation and out-of-view as common challenges, the proposed SiamST performs well, which proves its generalization and strong adaptability to complex environments.
4.4. Ablation Experiments
We conducted ablation experiments to verify the effectiveness of the proposed high-order multiscale spatial module and temporal template transformer. As shown in the following table, we evaluated the short-term and long-term UAV tracking benchmarks UV123@10fps and UAV20L, respectively. To represent the fairness of the evaluation, the baseline is all the same with SiamST except for the multiscale, high-order multiscale spatial module and the temporal context template. The proposed high-order multiscale spatial module is noted as HMSM, and the temporal template transformer is noted as TTTrans in
Table 1.
As shown in
Table 1, the precision rate and success rate of the baseline with the proposed high-order multiscale spatial module on UAV123@10fps are 0.757 and 0.576, respectively, which achieved a precision rate increase of 0.9%, and an increase of 0.7% in the success rate compared to the baseline. Meanwhile, the tracking results on UAV20L are 0.685 and 0.525, which are 10.1% and 8.2% higher than the baseline.
As for the baseline, with the proposed temporal template transformer, there is better tracking performance than the baseline. The gains are 1.4% and 0.9%, respectively, on UAV123@10fps. On UAV20L, the precision rate and success rate are 0.702 and 0.527, and the gains are 11.8% and 8.4%, respectively.
Meanwhile, the gains of the tracker with both the proposed high-order multiscale spatial module and temporal template transformer are 3.3% and 3% on UAV123@10fps, achieving the best tracking results. At the same time, the comparison is more obvious on the UAV20L benchmark. The precision rate and success rate of the baseline are 0.72 and 0.545, respectively. Compared with the baseline, there are 13.6% and 10.2% gains in precision rate and success rate, respectively.
Ablation experiments demonstrate the effectiveness of the proposed high-order multiscale spatial module and temporal template transformer for improving UAV tracking, and the interaction between them can further improve the tracking performance. It further illustrates that the design of spatial-temporal context aggregation architecture in an aerial tracker using a lightweight backbone network is an efficient and necessary adaptive change, which is a novel and promising research idea in the field of UAV tracking.
Finally, we also compared the amount of calculation flops and the number of parameters. We have implemented the proposed SiamST on the mobile platform RK3588, achieving real-time speed. As shown in
Table 1, the proposed high-order multiscale spatial module and temporal template transformer both achieved a large accuracy improvement while increasing a small amount of calculation. To intuitively show the specific values of the amount of computation flops and the number of parameters, we chose the Siamese tracker SGDViT for UAV tracking for comparison, and it can be seen that our tracker achieved results with better performance and a lower computational amount than the SOTA aerial tracker SGDViT. This proves the superiority of the proposed SiamST.
4.5. Visual Comparisons and Case Discussion
To intuitively show the tracking effect of the proposed SiamST. We show the tracking results of SiamST and the TCTrack, SGDViT, SiamAPN, and SiamAPN++. All the comparison trackers are SNs and have the same backbone.
As shown in
Figure 6, we show three UAV tracking sequences. In the first tracking sequence, the object experienced partial occlusion and full occlusion of buildings in the tracking process. We can see that SGDViT, SiamAPN, and SiamAPN++ all had tracking drift to varying degrees. This is because SGDViT, SiamAPN, and SiamAPN++ only consider the original template and current tracking frame but do not consider the temporal context information, so the target features cannot be extracted when the target is occluded, making the tracker unable to track continuously. The proposed SiamST and TCTrack can cope with the challenge of occlusion because the introduction of temporal context information can guide the tracker to find the right location. After that, SGDViT tracked the target again, while SiamAPN and SiamAPN++ failed due to occlusion. In the second tracking sequence, part of the target is out of view with background clutter during tracking progress, which makes it hard to extract accurate features. As can be seen from
Figure 6, TCTrack, SGDViT, and SiamAPN all have tracking drift due to background interference in this process, while the proposed SiamST can continuously track the target. These tracking results demonstrate the robustness of the proposed SiamST.
In the third tracking sequence, both SGDViT and SiamAPN occurred tracking drift successively under the premise of no occlusion in dealing with complex background interference. SGDViT had tracking failure after the tracking drift, which indicates that the feature extraction ability of both of them needs to be improved. In the tracking process of the above three UAV tracking sequences, only the proposed SiamST tracks the target in the whole process, which proves that the proposed SiamST can cope with many challenges in UAV tracking, and intuitively shows the excellent tracking performance and robustness of the proposed SiamST with the introduction of multidimensional spatial-temporal context aggregation network architecture design.
5. Discussion
In the experimental part, we performed comparison experiments with the SOTA trackers on three common UAV benchmarks, and the results show that the proposed SiamST achieves the best tracking performance. We believe that there are two reasons for the best performance. First, the proposed high-order multiscale spatial module improves the feature extraction capability of the model, and second, the target template information from successive frames helps to alleviate the challenge brought by the change in the target appearance. In the attributes analysis in
Section 4.3, the proposed SiamST is superior to the comparison algorithm under the challenges of occlusion, scale variation, background interference, and out-of-view. It is worth mentioning that the proposed SiamST achieved 13.6% and 10.2% improvements over the baseline on the UAV20L benchmark. This proves the validity of the proposed high-order multiscale spatial module and temporal template transformer.
Although it is better than the comparison trackers, SiamST is not good enough to deal with all occlusions. We believe that adding trajectory prediction on the basis of the Siamese network will help to further improve tracking performance. Therefore, how to combine trajectory prediction with the Siamese network to achieve target tracking is the direction of our future research.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}