
A Systematic Survey of Transformer-Based 3D Object Detection for Autonomous Driving: Methods, Challenges and Trends



Abstract
1. Introduction
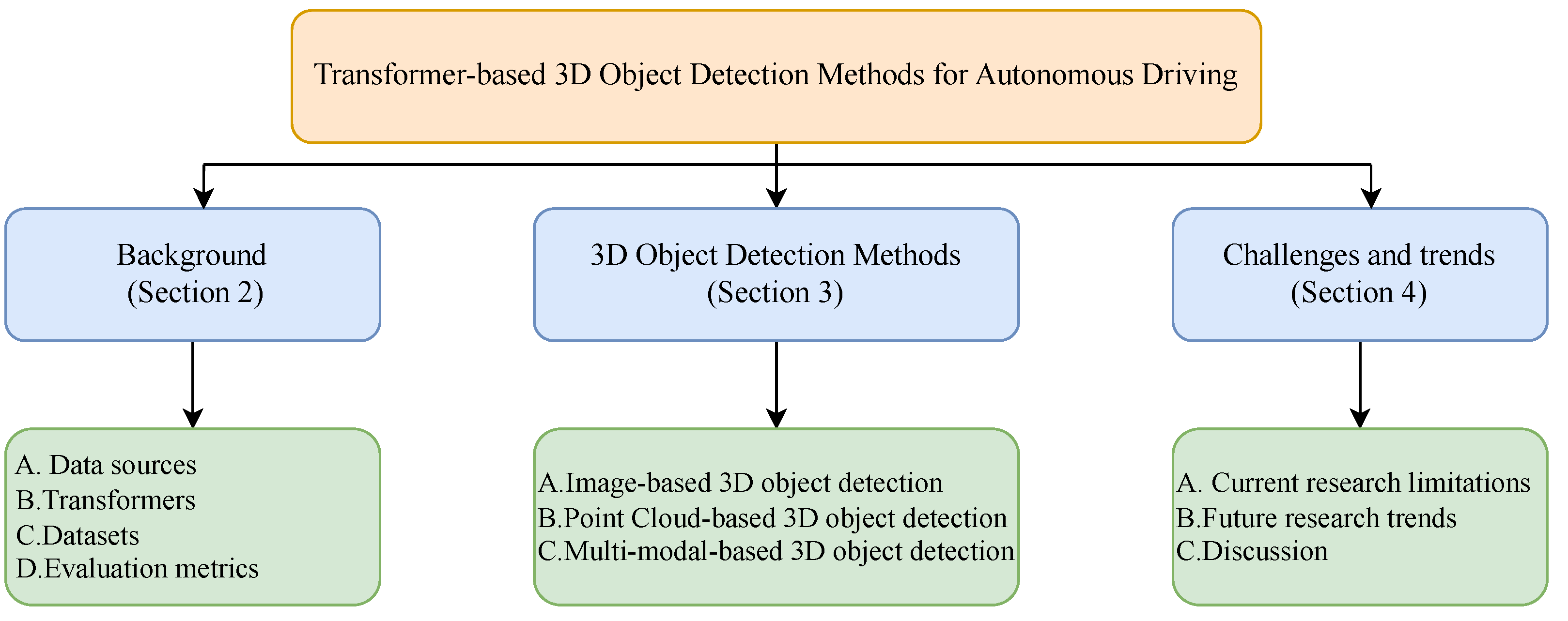
- Comprehensive Overview of Input Data and Methodologies: We present an in-depth analysis of input data characteristics, standard datasets, and commonly used evaluation metrics in Transformer-based 3D object detection. This includes a detailed outline of fundamental methodologies and the core mechanisms of current Transformer models, emphasizing how these models are uniquely suited for 3D object detection in autonomous driving. Our analysis delves into the intricate details of Transformer architectures, revealing their foundational principles and operational efficiencies.
- Novel Taxonomy for Transformer-based Approaches: We introduce an innovative classification method that categorizes Transformer-based 3D object detection methodologies according to their data source types. This approach allows for a nuanced understanding of each method’s motivations, technical intricacies, and advantages. We provide a critical assessment of selected methodologies, comparing their performance on standard datasets to offer a comprehensive evaluation. This classification offers a new perspective in the field, facilitating a clearer understanding of the characteristics and shortcomings of methods based on different data.
- Future Directions and Practical Implications: We identify and discuss the current challenges and limitations in Transformer-based 3D object detection. Building on this, we envision potential future research directions and highlight areas ripe for innovation. Furthermore, we explore practical applications of these technologies, considering their impact on the future development of autonomous driving systems. This foresight not only guides future research efforts but also bridges the gap between academic research and practical, real-world applications.
2. Background
2.1. Data Sources

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensors | Advantages | Disadvantages | Applications in Autonomous Vehicles | Output |
|---|---|---|---|---|
| Monocular Camera | Lower cost and lightweight, Easy Integration, Low-power consumption, Strong adaptability | Limited depth perception, Ambiguity in scene structure, Vulnerability to lighting conditions, Challenges in 3D scene understanding | Traffic sign and signal recognition, Lane detection, Environmental monitoring, Light condition analysis, Reading road conditions | RGB images |
| Stereo Camera | Lower cost, Depth perception, Better depth resolution, Reduced sensitivity to lighting conditions | Limited field of view, Calibration difficulty, Power consumption, Limited mobility | Depth perception and obstacle detection, Mapping and localization, Cross-traffic alert | RGB images Point clouds |
| LiDAR | High-resolution spatial information, Precise distance measurement, Independent of lighting conditions, Applicable in various environments | High cost, Limited perception range, Susceptible to harsh weather conditions | Essential for detailed environment mapping, and classification. Particularly useful for complex navigation tasks in urban environments | Point clouds |
| Radar | Adaptability, Long-range perception, Lower power consumption | Limited spatial resolution, Inability to provide high-precision maps | Primarily used for detecting vehicles and large objects at a distance, particularly useful for adaptive cruise control and collision avoidance | Point clouds |
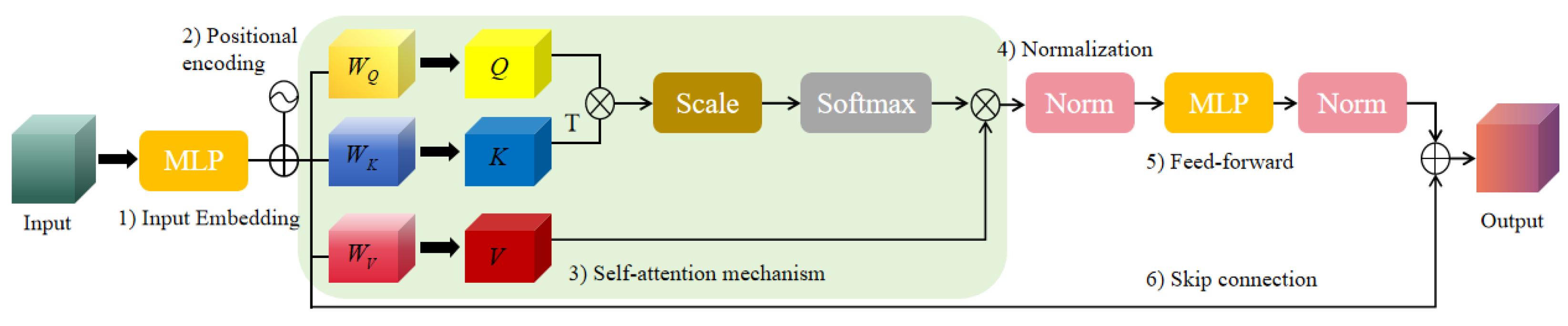
2.2. Transformers and Attention Mechanism
- Positional Encoding: Transformer introduces positional encoding to handle the position information of elements in a sequence, which is crucial for spatial relationships in 3D object detection. Positional encoding aids the model in better understanding the relative positions of target objects, thereby improving detection accuracy.
- Query-Value Association: In the Self-attention, computing the association between Query and Key enables Transformer to accurately capture the correlations between different elements in the input sequence. In the context of 3D object detection, this is crucial for determining the features and positions of target objects.
- Multi-Head Structure: Transformer’s multi-head structure enables the model to simultaneously focus on different aspects of the input sequence. This is beneficial for handling diverse information in 3D scenes, such as color, shape and size, contributing to improve overall detection performance.
- Global Relationship Modeling: Self-attention mechanism in Transformer allows the model to globally attend different parts of the input sequence rather than being limited to local regions. In 3D object detection, this mechanism helps the model better understand the entire scene, including the distribution and relative positions of objects.
2.2.1. Cross-Attention
2.2.2. Deformable-Attention
- Offset Learning: The model learns the attention shifts generated at each position. These offset vectors represent the direction and degree of attention adjustment at the current position.
- Offset-based sampling: Using the learned offset, samples are taken from the original feature map to obtain sample points at different positions.
- Attention weight calculation: Using sampled points, calculate attention weights. Usually, interpolation and other techniques are used to dynamically adjust the attention weights at the position.
- Weighted feature summary: Using the calculated attention weights, the original features are weighted and summarized to obtain the final representation of attention features.
2.3. Datasets
2.4. Evaluation Metrics
3. 3D Object Detection Methods
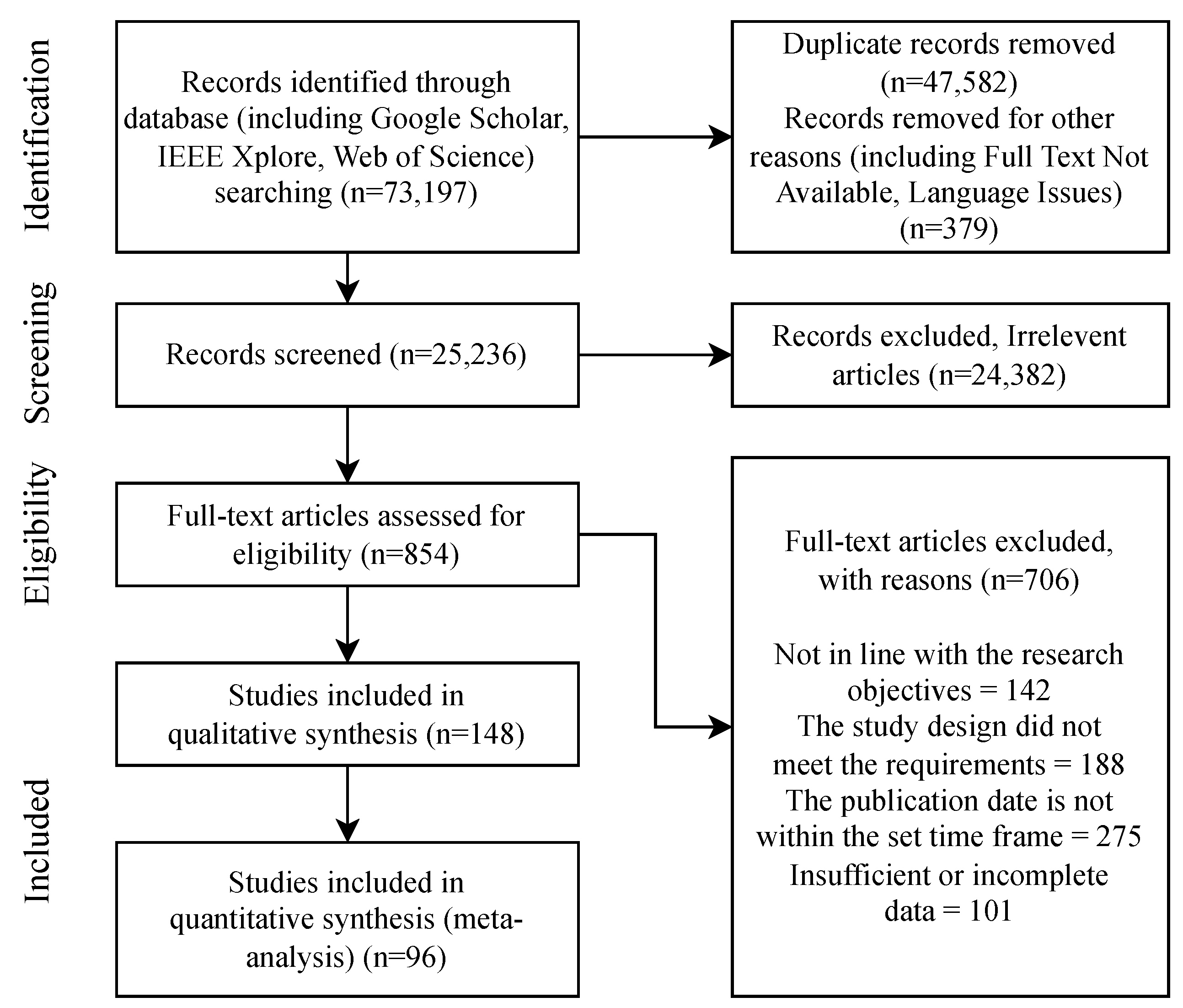
3.1. Search Strategy
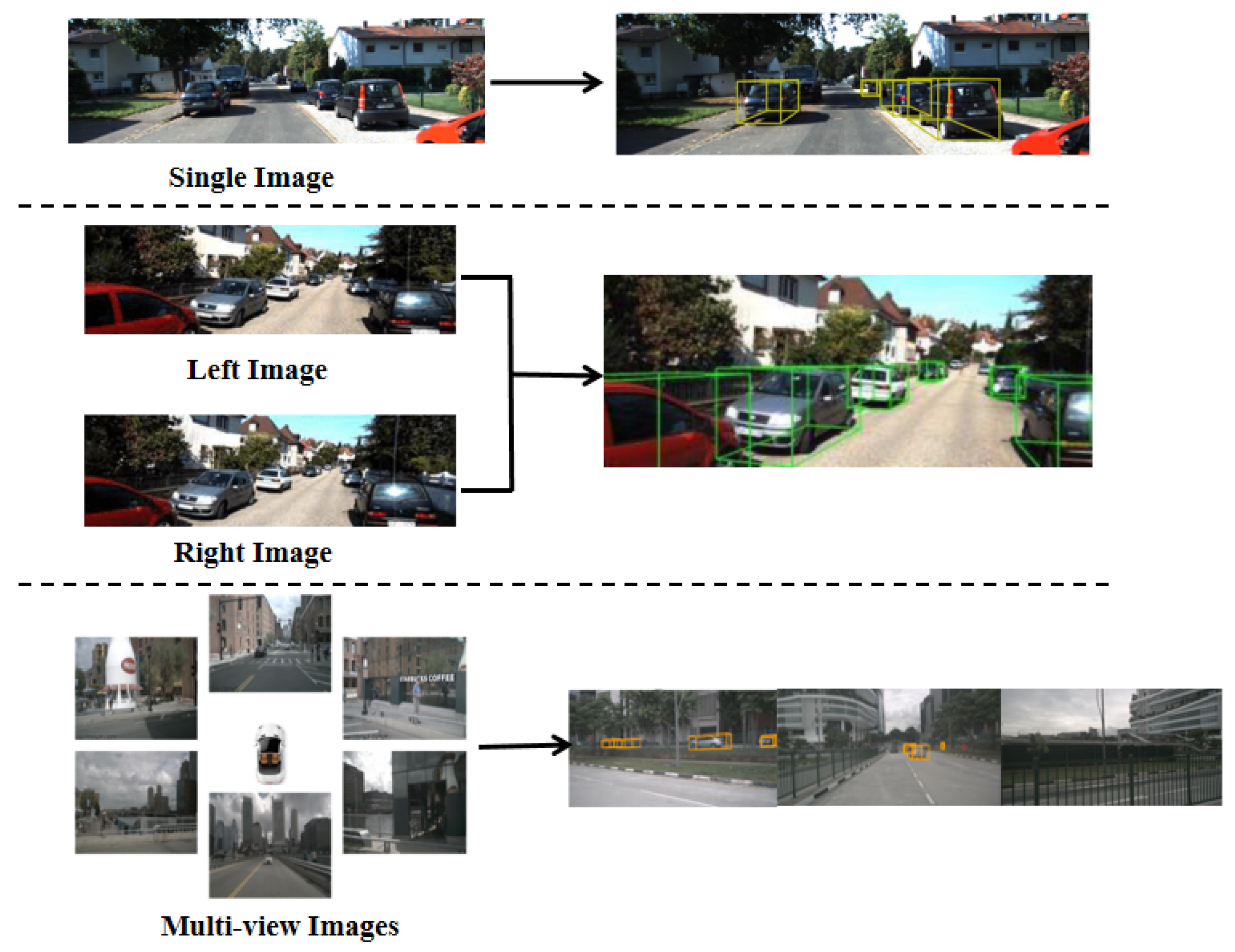
3.2. Image-Based 3D Object Detection
3.2.1. Monocular 3D Object Detection
3.2.2. Multi-View Based 3D Object Detection
3.3. Point Cloud-Based 3D Object Detection
3.3.1. Point-Based
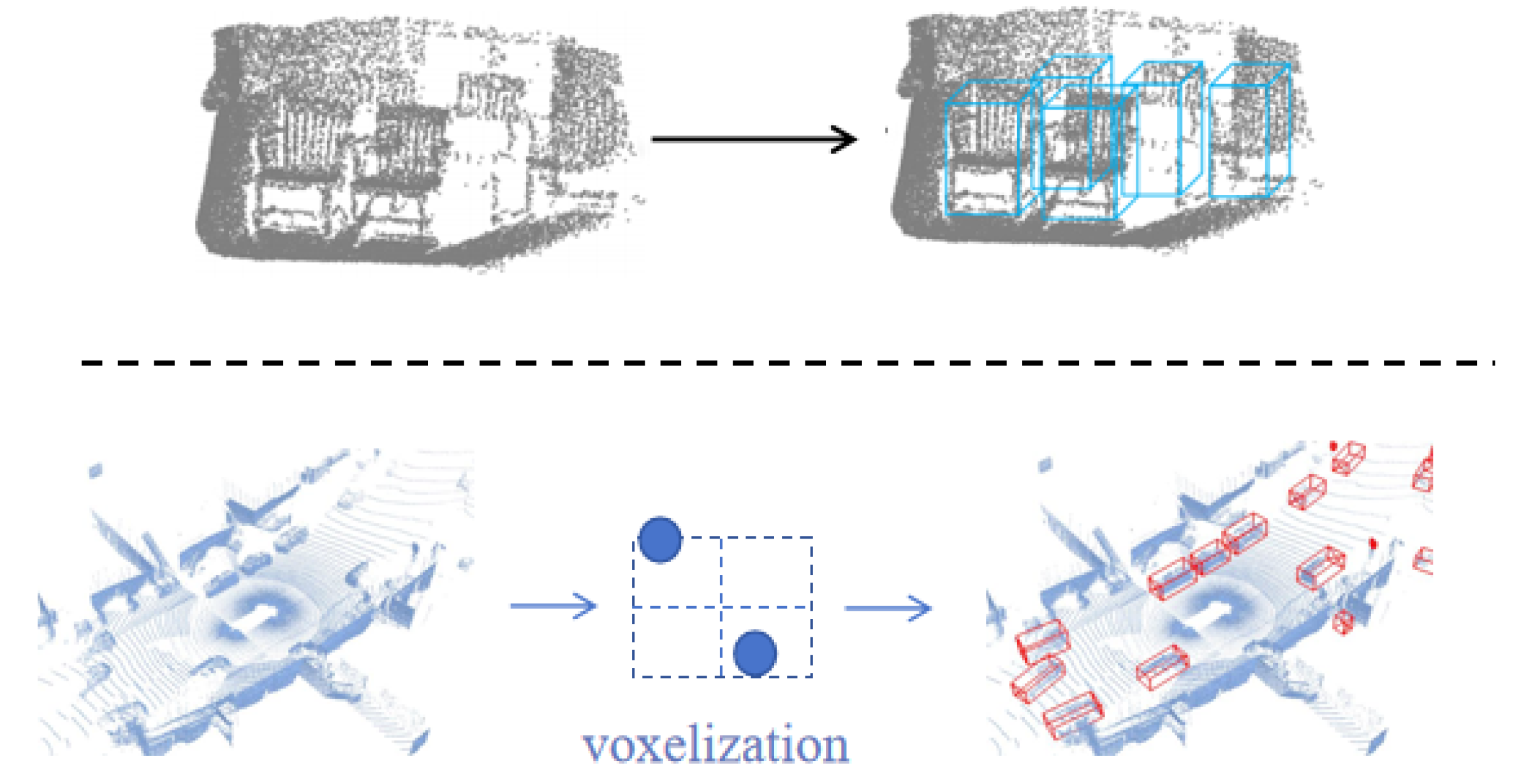
3.3.2. Voxel-Based
3.4. Multi-Modal-Based 3D Object Detection

4. Challenges and Trends
4.1. Current Research Limitations
4.1.1. Transformer Structure
4.1.2. Sensor Limitations
4.1.3. Inference Performance
4.2. Future Research Trends
4.2.1. Collaborative Perception
4.2.2. Occupancy Prediction
4.2.3. Large Model
4.3. Discussion
4.3.1. Feature Space
4.3.2. Feature Fusion
4.3.3. Feature Representation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shehzadi, T.; Hashmi, K.A.; Stricker, D.; Afzal, M.Z. 2D Object Detection with Transformers: A Review. arXiv 2023, arXiv:2306.04670. [Google Scholar]
- Zhong, J.; Liu, Z.; Chen, X. Transformer-based models and hardware acceleration analysis in autonomous driving: A survey. arXiv 2023, arXiv:2304.10891. [Google Scholar]
- Lu, D.; Xie, Q.; Wei, M.; Gao, K.; Xu, L.; Li, J. Transformers in 3d point clouds: A survey. arXiv 2022, arXiv:2205.07417. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Xie, Q.; Lai, Y.K.; Wu, J.; Wang, Z.; Zhang, Y.; Xu, K.; Wang, J. Mlcvnet: Multi-level context votenet for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Washington, USA, 14–19 June 2020; pp. 10447–10456. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3d object detection in point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9277–9286. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Qiao, Y.; Dai, J. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–18. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Wu, J.; Yin, D.; Chen, J.; Wu, Y.; Si, H.; Lin, K. A survey on monocular 3D object detection algorithms based on deep learning. J. Phys. Conf. Ser. 2020, 1518, 012049. [Google Scholar] [CrossRef]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D object detection for autonomous driving: A comprehensive survey. Int. J. Comput. Vis. 2023, 131, 1909–1963. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, T.; Bai, X.; Yang, H.; Hou, Y.; Wang, Y.; Qiao, Y.; Yang, R.; Manocha, D.; Zhu, X. Vision-centric bev perception: A survey. arXiv 2022, arXiv:2208.02797. [Google Scholar]
- Ma, X.; Ouyang, W.; Simonelli, A.; Ricci, E. 3D object detection from images for autonomous driving: A survey. arXiv 2022, arXiv:2202.02980. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.H.; Hwang, Y. A survey on deep learning based methods and datasets for monocular 3D object detection. Electronics 2021, 10, 517. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Barnes, D.; Gadd, M.; Murcutt, P.; Newman, P.; Posner, I. The Oxford Radar RobotCar Dataset: A Radar Extension to the Oxford RobotCar Dataset. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–21 August 2020. [Google Scholar]
- Alaba, S.Y.; Gurbuz, A.C.; Ball, J.E. Emerging Trends in Autonomous Vehicle Perception: Multimodal Fusion for 3D Object Detection. World Electr. Veh. J. 2024, 15, 20. [Google Scholar] [CrossRef]
- Oliveira, M.; Cerqueira, R.; Pinto, J.R.; Fonseca, J.; Teixeira, L.F. Multimodal PointPillars for Efficient Object Detection in Autonomous Vehicles. IEEE Trans. Intell. Veh. 2024, 1–11. [Google Scholar] [CrossRef]
- Chitta, K.; Prakash, A.; Jaeger, B.; Yu, Z.; Renz, K.; Geiger, A. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12878–12895. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Xiao, J.; Fu, X.; Liu, A.; Wu, F.; Zha, Z.J. Image de-raining transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12978–12995. [Google Scholar] [CrossRef]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–19 June 2019. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, K.; Tian, C.; Su, J.; Lin, J.C.W. Transformer-based cross reference network for video salient object detection. Pattern Recognit. Lett. 2022, 160, 122–127. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Jain, J.; Li, J.; Chiu, M.T.; Hassani, A.; Orlov, N.; Shi, H. Oneformer: One transformer to rule universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2989–2998. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- He, C.; Li, R.; Li, S.; Zhang, L. Voxel set transformer: A set-to-set approach to 3d object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8417–8427. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 954–960. [Google Scholar]
- Patil, A.; Malla, S.; Gang, H.; Chen, Y.T. The h3d dataset for full-surround 3d multi-object detection and tracking in crowded urban scenes. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9552–9557. [Google Scholar]
- Gählert, N.; Jourdan, N.; Cordts, M.; Franke, U.; Denzler, J. Cityscapes 3d: Dataset and benchmark for 9 dof vehicle detection. arXiv 2020, arXiv:2006.07864. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Mao, J.; Niu, M.; Jiang, C.; Liang, H.; Chen, J.; Liang, X.; Li, Y.; Ye, C.; Zhang, W.; Li, Z.; et al. One million scenes for autonomous driving: Once dataset. arXiv 2021, arXiv:2106.11037. [Google Scholar]
- Xiao, P.; Shao, Z.; Hao, S.; Zhang, Z.; Chai, X.; Jiao, J.; Li, Z.; Wu, J.; Sun, K.; Jiang, K.; et al. Pandaset: Advanced sensor suite dataset for autonomous driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3095–3101. [Google Scholar]
- Wang, L.; Zhang, X.; Song, Z.; Bi, J.; Zhang, G.; Wei, H.; Tang, L.; Yang, L.; Li, J.; Jia, C.; et al. Multi-modal 3D Object Detection in Autonomous Driving: A Survey and Taxonomy. IEEE Trans. Intell. Veh. 2023, 8, 3781–3798. [Google Scholar] [CrossRef]
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3d lidar using fully convolutional network. arXiv 2016, arXiv:1608.07916. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection. arXiv 2022, arXiv:2206.10092. [Google Scholar] [CrossRef]
- Huang, J.; Huang, G.; Zhu, Z.; Ye, Y.; Du, D. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv 2021, arXiv:2112.11790. [Google Scholar]
- Zhang, R.; Qiu, H.; Wang, T.; Guo, Z.; Xu, X.; Qiao, Y.; Gao, P.; Li, H. MonoDETR: Depth-guided transformer for monocular 3D object detection. arXiv 2022, arXiv:2203.13310. [Google Scholar]
- Wu, Y.; Li, R.; Qin, Z.; Zhao, X.; Li, X. HeightFormer: Explicit Height Modeling without Extra Data for Camera-only 3D Object Detection in Bird’s Eye View. arXiv 2023, arXiv:2307.13510. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 September 2022; pp. 180–191. [Google Scholar]
- Liu, Y.; Wang, T.; Zhang, X.; Sun, J. Petr: Position embedding transformation for multi-view 3d object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 531–548. [Google Scholar]
- Misra, I.; Girdhar, R.; Joulin, A. An end-to-end transformer model for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2906–2917. [Google Scholar]
- Zhou, Z.; Zhao, X.; Wang, Y.; Wang, P.; Foroosh, H. Centerformer: Center-based transformer for 3d object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 496–513. [Google Scholar]
- Chen, Z.; Li, Z.; Zhang, S.; Fang, L.; Jiang, Q.; Zhao, F.; Zhou, B.; Zhao, H. AutoAlign: Pixel-instance feature aggregation for multi-modal 3D object detection. arXiv 2022, arXiv:2201.06493. [Google Scholar]
- Yan, J.; Liu, Y.; Sun, J.; Jia, F.; Li, S.; Wang, T.; Zhang, X. Cross Modal Transformer via Coordinates Encoding for 3D Object Dectection. arXiv 2023, arXiv:2301.01283. [Google Scholar]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8445–8453. [Google Scholar]
- Reading, C.; Harakeh, A.; Chae, J.; Waslander, S.L. Categorical depth distribution network for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8555–8564. [Google Scholar]
- Ding, M.; Huo, Y.; Yi, H.; Wang, Z.; Shi, J.; Lu, Z.; Luo, P. Learning depth-guided convolutions for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1000–1001. [Google Scholar]
- Chen, H.; Huang, Y.; Tian, W.; Gao, Z.; Xiong, L. Monorun: Monocular 3d object detection by reconstruction and uncertainty propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10379–10388. [Google Scholar]
- Chen, Y.; Tai, L.; Sun, K.; Li, M. Monopair: Monocular 3d object detection using pairwise spatial relationships. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12093–12102. [Google Scholar]
- Zhang, Y.; Lu, J.; Zhou, J. Objects are different: Flexible monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3289–3298. [Google Scholar]
- Yang, W.; Li, Q.; Liu, W.; Yu, Y.; Ma, Y.; He, S.; Pan, J. Projecting your view attentively: Monocular road scene layout estimation via cross-view transformation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15536–15545. [Google Scholar]
- Chitta, K.; Prakash, A.; Geiger, A. Neat: Neural attention fields for end-to-end autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15793–15803. [Google Scholar]
- Can, Y.B.; Liniger, A.; Paudel, D.P.; Van Gool, L. Structured bird’s-eye-view traffic scene understanding from onboard images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15661–15670. [Google Scholar]
- Huang, K.C.; Wu, T.H.; Su, H.T.; Hsu, W.H. Monodtr: Monocular 3d object detection with depth-aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4012–4021. [Google Scholar]
- Philion, J.; Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 194–210. [Google Scholar]
- Yang, C.; Chen, Y.; Tian, H.; Tao, C.; Zhu, X.; Zhang, Z.; Huang, G.; Li, H.; Qiao, Y.; Lu, L.; et al. BEVFormer v2: Adapting Modern Image Backbones to Bird’s-Eye-View Recognition via Perspective Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17830–17839. [Google Scholar]
- Liu, Y.; Yan, J.; Jia, F.; Li, S.; Gao, A.; Wang, T.; Zhang, X.; Sun, J. Petrv2: A unified framework for 3d perception from multi-camera images. arXiv 2022, arXiv:2206.01256. [Google Scholar]
- Qin, Z.; Chen, J.; Chen, C.; Chen, X.; Li, X. UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird’s-Eye-View. arXiv 2022, arXiv:2207.08536. [Google Scholar]
- Qi, Z.; Wang, J.; Wu, X.; Zhao, H. OCBEV: Object-Centric BEV Transformer for Multi-View 3D Object Detection. arXiv 2023, arXiv:2306.01738. [Google Scholar]
- Wang, S.; Liu, Y.; Wang, T.; Li, Y.; Zhang, X. Exploring Object-Centric Temporal Modeling for Efficient Multi-View 3D Object Detection. arXiv 2023, arXiv:2303.11926. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Zhang, H.; Li, H.; Liao, X.; Li, F.; Liu, S.; Ni, L.M.; Zhang, L. DA-BEV: Depth Aware BEV Transformer for 3D Object Detection. arXiv 2023, arXiv:2302.13002. [Google Scholar]
- Chen, S.; Wang, X.; Cheng, T.; Zhang, Q.; Huang, C.; Liu, W. Polar parametrization for vision-based surround-view 3d detection. arXiv 2022, arXiv:2206.10965. [Google Scholar]
- Jiang, Y.; Zhang, L.; Miao, Z.; Zhu, X.; Gao, J.; Hu, W.; Jiang, Y.G. Polarformer: Multi-camera 3d object detection with polar transformer. Proc. AAAI Conf. Artif. Intell. 2023, 37, 1042–1050. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Chen, X.; Zhao, H.; Zhou, G.; Zhang, Y.Q. Pq-transformer: Jointly parsing 3d objects and layouts from point clouds. IEEE Robot. Autom. Lett. 2022, 7, 2519–2526. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Z.; Cao, Y.; Hu, H.; Tong, X. Group-free 3d object detection via transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 2949–2958. [Google Scholar]
- Lee, J.; Lee, Y.; Kim, J.; Kosiorek, A.; Choi, S.; Teh, Y.W. Set transformer: A framework for attention-based permutation-invariant neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 3744–3753. [Google Scholar]
- Sheng, H.; Cai, S.; Liu, Y.; Deng, B.; Huang, J.; Hua, X.S.; Zhao, M.J. Improving 3d object detection with channel-wise transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2743–2752. [Google Scholar]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3d object detection with pointformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7463–7472. [Google Scholar]
- Liu, Z.; Zhao, X.; Huang, T.; Hu, R.; Zhou, Y.; Bai, X. Tanet: Robust 3d object detection from point clouds with triple attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11677–11684. [Google Scholar]
- Fan, L.; Pang, Z.; Zhang, T.; Wang, Y.X.; Zhao, H.; Wang, F.; Wang, N.; Zhang, Z. Embracing single stride 3d object detector with sparse transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8458–8468. [Google Scholar]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3164–3173. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2020; pp. 10529–10538. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.L. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1090–1099. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V.; et al. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Zhang, Y.; Chen, J.; Huang, D. Cat-det: Contrastively augmented transformer for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 908–917. [Google Scholar]
- Chen, Z.; Li, Z.; Zhang, S.; Fang, L.; Jiang, Q.; Zhao, F. Autoalignv2: Deformable feature aggregation for dynamic multi-modal 3d object detection. arXiv 2022, arXiv:2207.10316. [Google Scholar]
- Chen, X.; Zhang, T.; Wang, Y.; Wang, Y.; Zhao, H. Futr3d: A unified sensor fusion framework for 3d detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 172–181. [Google Scholar]
- Ge, C.; Chen, J.; Xie, E.; Wang, Z.; Hong, L.; Lu, H.; Li, Z.; Luo, P. MetaBEV: Solving Sensor Failures for BEV Detection and Map Segmentation. arXiv 2023, arXiv:2304.09801. [Google Scholar]
- Wang, H.; Tang, H.; Shi, S.; Li, A.; Li, Z.; Schiele, B.; Wang, L. UniTR: A Unified and Efficient Multi-Modal Transformer for Bird’s-Eye-View Representation. arXiv 2023, arXiv:2308.07732. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2774–2781. [Google Scholar]
- Hu, C.; Zheng, H.; Li, K.; Xu, J.; Mao, W.; Luo, M.; Wang, L.; Chen, M.; Liu, K.; Zhao, Y.; et al. FusionFormer: A Multi-sensory Fusion in Bird’s-Eye-View and Temporal Consistent Transformer for 3D Objection. arXiv 2023, arXiv:2309.05257. [Google Scholar]
- Nabati, R.; Qi, H. CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection. arXiv 2020, arXiv:2011.04841. [Google Scholar]
- Lin, Z.; Liu, Z.; Xia, Z.; Wang, X.; Wang, Y.; Qi, S.; Dong, Y.; Dong, N.; Zhang, L.; Zhu, C. RCBEVDet: Radar-camera Fusion in Bird’s Eye View for 3D Object Detection. arXiv 2024, arXiv:2403.16440. [Google Scholar]
- Shen, Z.; Zhang, M.; Zhao, H.; Yi, S.; Li, H. Efficient attention: Attention with linear complexities. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3531–3539. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating long sequences with sparse transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Syu, J.H.; Lin, J.C.W.; Srivastava, G.; Yu, K. A comprehensive survey on artificial intelligence empowered edge computing on consumer electronics. IEEE Trans. Consum. Electron. 2023, 69, 1023–1034. [Google Scholar] [CrossRef]
- Liu, S.; Liu, L.; Tang, J.; Yu, B.; Wang, Y.; Shi, W. Edge computing for autonomous driving: Opportunities and challenges. Proc. IEEE 2019, 107, 1697–1716. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Lu, A.; Lee, J.; Kim, T.H.; Karim, M.A.U.; Park, R.S.; Simka, H.; Yu, S. High-speed emerging memories for AI hardware accelerators. Nat. Rev. Electr. Eng. 2024, 1, 24–34. [Google Scholar] [CrossRef]
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Han, Y.; Zhang, H.; Li, H.; Jin, Y.; Lang, C.; Li, Y. Collaborative perception in autonomous driving: Methods, datasets, and challenges. IEEE Intell. Transp. Syst. Mag. 2023, 15, 131–151. [Google Scholar] [CrossRef]
- Malik, S.; Khan, M.J.; Khan, M.A.; El-Sayed, H. Collaborative Perception—The Missing Piece in Realizing Fully Autonomous Driving. Sensors 2023, 23, 7854. [Google Scholar] [CrossRef]
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.H.; Ma, J. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 107–124. [Google Scholar]
- Zhang, H.; Luo, G.; Cao, Y.; Jin, Y.; Li, Y. Multi-modal virtual-real fusion based transformer for collaborative perception. In Proceedings of the 2022 IEEE 13th International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), Beijing, China, 4–6 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4460–4470. [Google Scholar]
- Li, Y.; Yu, Z.; Choy, C.; Xiao, C.; Alvarez, J.M.; Fidler, S.; Feng, C.; Anandkumar, A. Voxformer: Sparse voxel transformer for camera-based 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9087–9098. [Google Scholar]
- Huang, Y.; Zheng, W.; Zhang, Y.; Zhou, J.; Lu, J. Tri-perspective view for vision-based 3d semantic occupancy prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9223–9232. [Google Scholar]
- Zhang, Y.; Zhu, Z.; Du, D. OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction. arXiv 2023, arXiv:2304.05316. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Wang, X.; Zhu, Z.; Huang, G.; Chen, X.; Lu, J. DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving. arXiv 2023, arXiv:2309.09777. [Google Scholar]
- Hu, Y.; Yang, J.; Chen, L.; Li, K.; Sima, C.; Zhu, X.; Chai, S.; Du, S.; Lin, T.; Wang, W.; et al. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17853–17862. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. 2023, 42. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Xu, C.; Wu, B.; Hou, J.; Tsai, S.; Li, R.; Wang, J.; Zhan, W.; He, Z.; Vajda, P.; Keutzer, K.; et al. NeRF-Det: Learning Geometry-Aware Volumetric Representation for Multi-View 3D Object Detection. arXiv 2023, arXiv:2307.14620. [Google Scholar]
- Hu, B.; Huang, J.; Liu, Y.; Tai, Y.W.; Tang, C.K. NeRF-RPN: A general framework for object detection in NeRFs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23528–23538. [Google Scholar]


| Datasets | Sensors | LiDAR Scans | Images | 3D Boxes | Locations | Year |
|---|---|---|---|---|---|---|
| KITTI [15] | 1 LiDAR, 2 Cameras | 15 k | 15 k | 80 k | Germany | 2012 |
| ApolloScape [33] | 2 LiDARs, 2 Cameras | 20 k | 144 k | 475 k | China | 2019 |
| H3D [34] | 1 LiDAR, 2 Cameras | 27 k | 83 k | 1.1 M | USA | 2019 |
| Cityscapes [35] | 0 LiDAR, 2 Cameras | 0 | 5 k | - | Germany | 2020 |
| nuScenes [9] | 1 LiDAR, 6 Cameras | 400 k | 1.4 M | 1.4 M | SG, USA | 2020 |
| Waymo Open [36] | 5 LiDAR, 5 Cameras | 230 k | 1 M | 12 M | USA | 2020 |
| ONCE [37] | 1 LiDAR, 7 Cameras | 1 M | 7 M | 417 k | China | 2021 |
| PandaSet [38] | 2 LiDAR, 6 Cameras | 8.2 k | 49 k | 1.3 M | USA | 2021 |
| Methods | Category | Key Innovation Points | Strengths |
|---|---|---|---|
| MonoDETR [44] | Monocular | The pre-predicted foreground depth map serves as a guidance signal, and the Transformer is used to guide each object to adaptively extract its region of interest and help in subsequent 3D detection feature extraction. | Features in the global perceptual field are extracted. |
| HeightFormer [45] | Image-based | A Self-recursive method is used to learn height information layer by layer refinement, and query masks are used to avoid background misdirection. | The height truth can be obtained directly from the annotated 3D bounding box without additional depth data or sensors. |
| DETR3D [46] | Multi-view | Transformer is used for feature extraction in BEV feature space. Based on the idea of deformable DETR, points in 3D space are used to interact with features of 2D images. | The sparse BEV feature space is constructed while reducing the computational complexity. |
| PETR [47] | Multi-view | Based on DETR3D, the 3D position encoding is added to the encoder part and added to the 2D image features, which are then interacted with the 3D query features. | The network performance is enhanced while the inference speed is reduced. |
| BEVFormer [8] | Multi-view | Transformer is used to extract features from multi-view images to build BEV feature space from top to bottom. Optimizing BEV feature representation through temporal modeling. | The network performance is greatly improved by integrating temporal features. |
| 3DETR [48] | Point Cloud-based | Added non parametric queries and Fourier positional embeddings to the original Transformer. | The network is simple and easy to implement with excellent performance. |
| CenterFormer [49] | Point Cloud-based | Select the center candidate on top of the standard voxel point cloud encoder through the center heat map, and then use the features of the center candidate as a query to embed it in Transformer. | The design reduces the convergence difficulty and computational complexity of the Transformer structure. |
| AutoAlign [50] | Multi-modal-based | A learnable alignment map is used to model the mapping relationship between images and point clouds, enabling the model to automatically align non homomorphic features in a dynamic and data-driven manner. | The method fully utilizes the feature relationship between point clouds and images. |
| Cross Modal Transformer [51] | Multi-modal-based | Implicitly encoding 3D positions into multimodal features avoids bias in explicit cross view feature alignment | Strong robustness. In the absence of LiDAR, the performance of the model can reach a level comparable to that of vision based methods. |
| Category | Paradigm | Advantage | Disadvantaged | Representative Methods |
|---|---|---|---|---|
| LSS [62] | Bottom-up | Explicit depth estimation, First end-to-end training and solves the multi-sensor fusion problem | Relies heavily on the accuracy of depth information, and outer product operation is too time-consuming | BEVDet [43], BEVDepth [42]… |
| Transformer-based | Top-down | Modeling spatial features implicitly, Extensibility, Temporal fusion capability | Hard to train | BEVFormer [8], BEVFormer v2 [63]… |
| Model | Publisher | Modalities | mAP | NDS |
|---|---|---|---|---|
| FusionFormer [94] | arXiv | Camera, Lidar | 0.726 | 0.751 |
| UniTR [92] | arXiv | Camera, Lidar | 0.709 | 0.745 |
| CMT [51] | ICCV(2023) | Camera, Lidar | 0.704 | 0.730 |
| FUTR3D [90] | arXiv | Camera, Lidar | 0.694 | 0.721 |
| TransFusion [86] | CVPR(2022) | Camera, Lidar | 0.689 | 0.717 |
| AutoAlignV2 [89] | ECCV(2022) | Camera, Lidar | 0.684 | 0.724 |
| MetaBEV [91] | arXiv | Camera, Lidar | 0.680 | 0.715 |
| AutoAlign [50] | IJCAI(2022) | Camera, Lidar | 0.658 | 0.709 |
| StreamPETR [67] | ICCV(2023) | Camera | 0.620 | 0.676 |
| BEVFormerv2 [63] | CVPR(2023) | Camera | 0.556 | 0.634 |
| DA-BEV [69] | arXiv | Camera | 0.515 | 0.600 |
| PETRv2 [64] | ECCV(2022) | Camera | 0.490 | 0.582 |
| BEVFormer [8] | ECCV(2022) | Camera | 0.481 | 0.569 |
| MonoDETR [44] | arXiv | Camera | 0.435 | 0.524 |
| PETR [47] | ECCV(2022) | Camera | 0.434 | 0.481 |
| PolarDETR [70] | arXiv | Camera | 0.431 | 0.493 |
| HeightFormer [45] | arXiv | Camera | 0.429 | 0.532 |
| BEVDepth [42] | arXiv | Camera | 0.418 | 0.538 |
| OCBEV [66] | arXiv | Camera | 0.417 | 0.532 |
| PolarFormer [71] | arXiv | Camera | 0.415 | 0.470 |
| DETR3D [46] | PMLR(2022) | Camera | 0.412 | 0.479 |
| BEVDet [43] | arXiv | Camera | 0.397 | 0.477 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Gong, Y.; Tian, C.; Zhu, Z. A Systematic Survey of Transformer-Based 3D Object Detection for Autonomous Driving: Methods, Challenges and Trends. Drones 2024, 8, 412. https://doi.org/10.3390/drones8080412
Zhu M, Gong Y, Tian C, Zhu Z. A Systematic Survey of Transformer-Based 3D Object Detection for Autonomous Driving: Methods, Challenges and Trends. Drones. 2024; 8(8):412. https://doi.org/10.3390/drones8080412
Chicago/Turabian StyleZhu, Minling, Yadong Gong, Chunwei Tian, and Zuyuan Zhu. 2024. "A Systematic Survey of Transformer-Based 3D Object Detection for Autonomous Driving: Methods, Challenges and Trends" Drones 8, no. 8: 412. https://doi.org/10.3390/drones8080412
APA StyleZhu, M., Gong, Y., Tian, C., & Zhu, Z. (2024). A Systematic Survey of Transformer-Based 3D Object Detection for Autonomous Driving: Methods, Challenges and Trends. Drones, 8(8), 412. https://doi.org/10.3390/drones8080412