
DFLM-YOLO: A Lightweight YOLO Model with Multiscale Feature Fusion Capabilities for Open Water Aerial Imagery

Abstract
1. Introduction
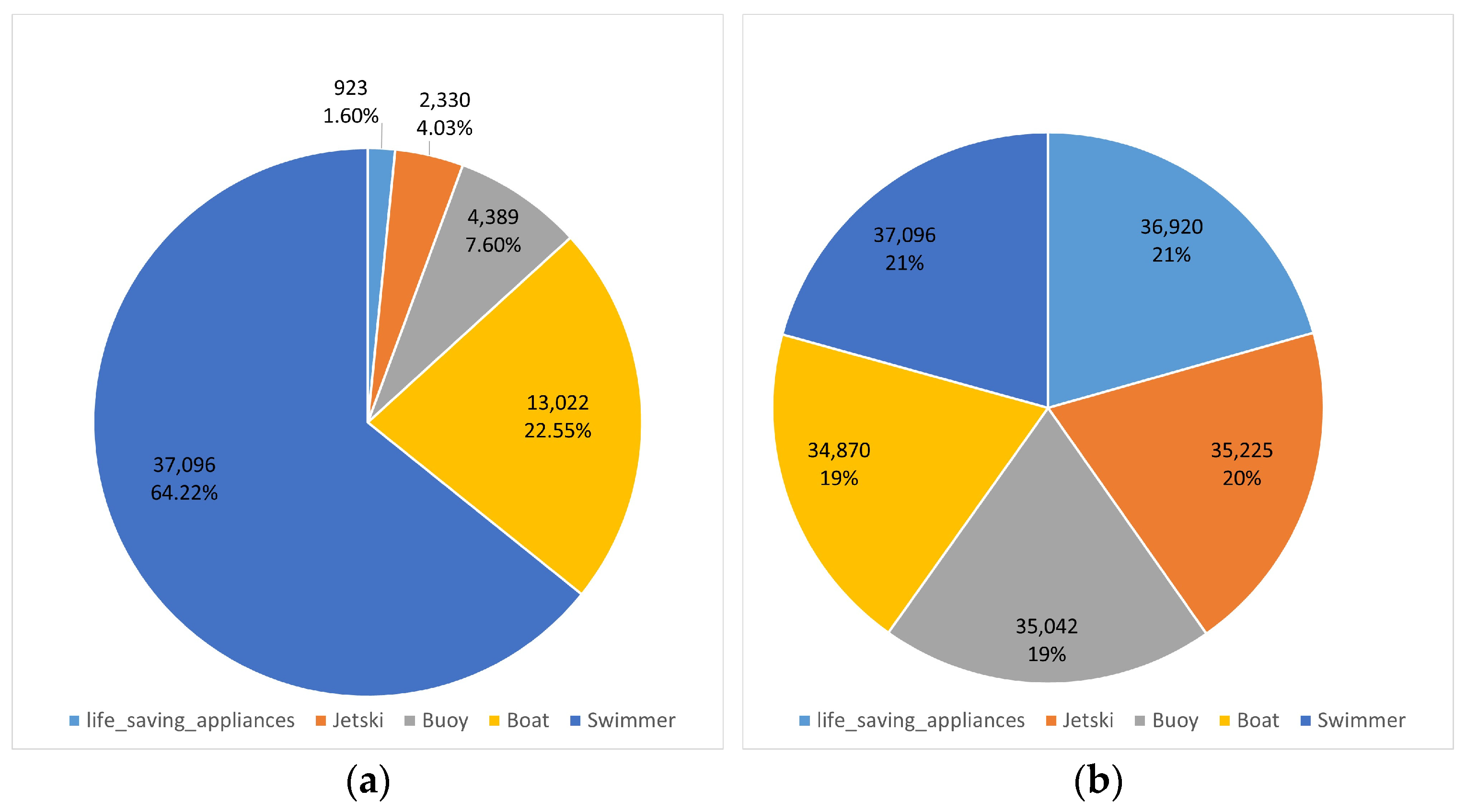
- The paper introduces a new data augmentation algorithm called SOM, which aims to expand the number of objects in specific categories without adding actual objects. This algorithm ensures that the characteristics of the added objects remain consistent with the original ones. The experiments demonstrate that this method enhances dataset balance and improves the model’s accuracy and generalization capabilities.
- A lightweight design of the backbone network:
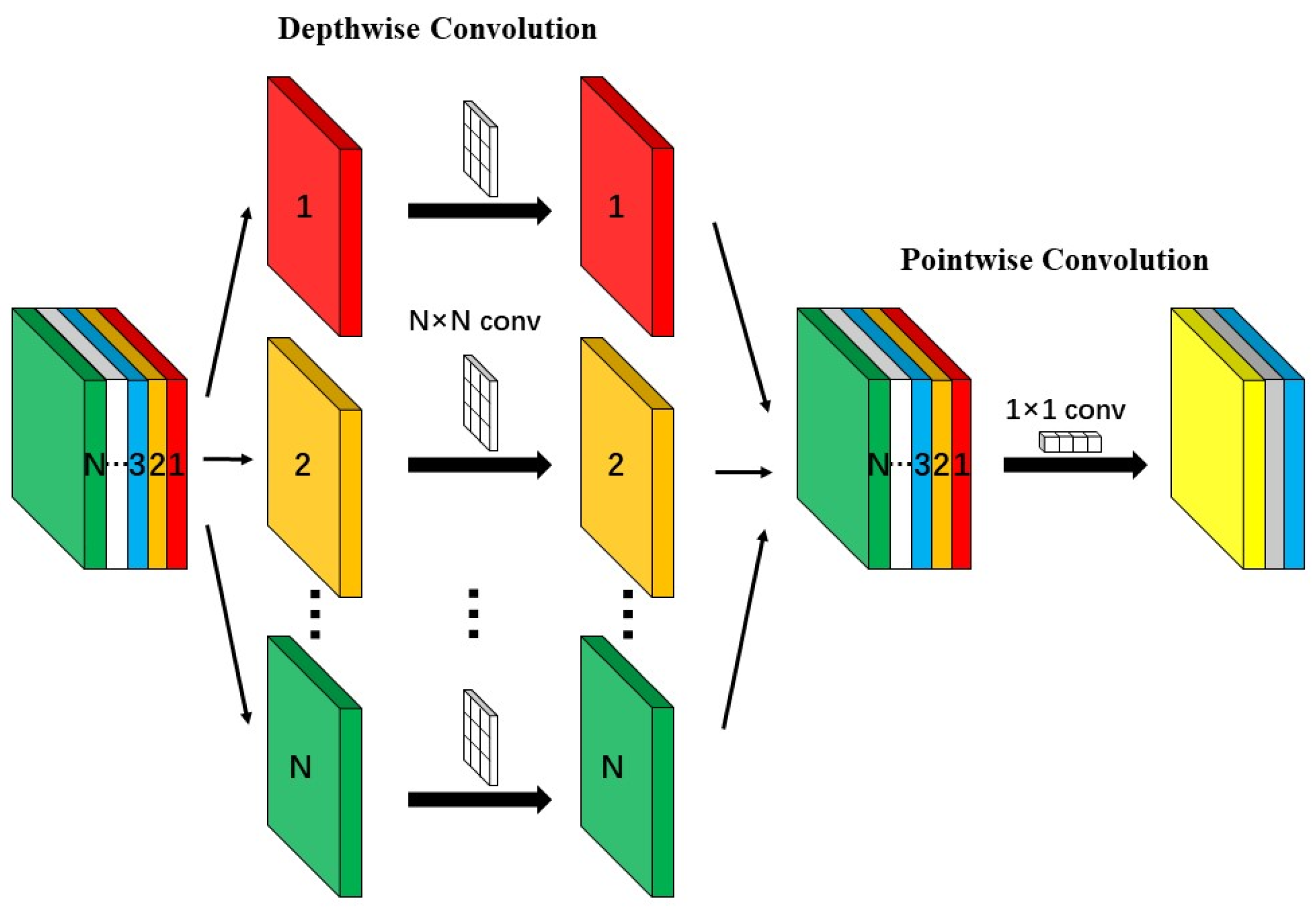
- Depthwise separable convolutions were utilized as the feature extraction module in the backbone network, reducing model parameters, the computation required for convolution operations, and network inference latency.
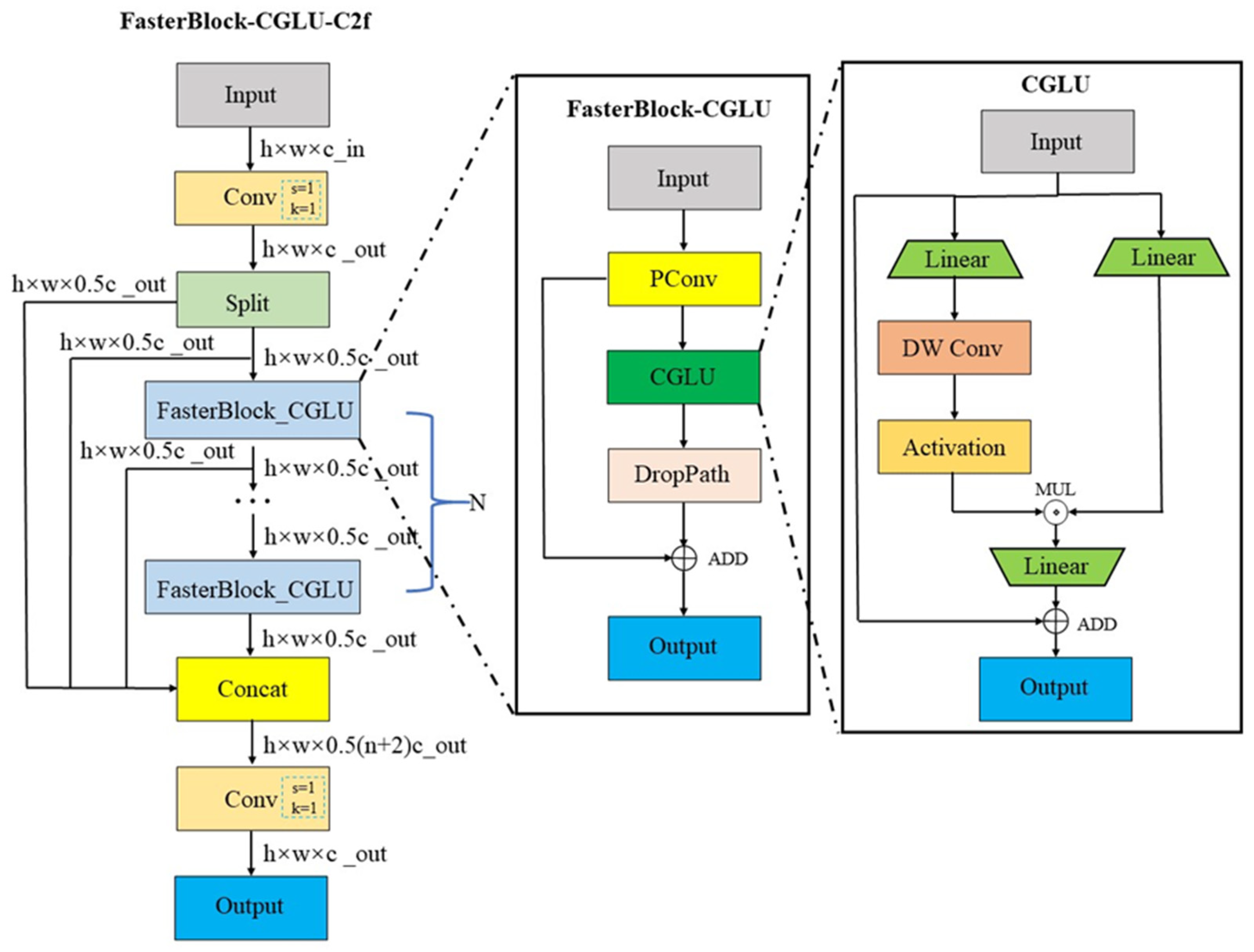
- A new plug-and-play module, FC-C2f, was designed to optimize the backbone network structure, reduce computational redundancy, and lower the model’s parameters and FLOPs.
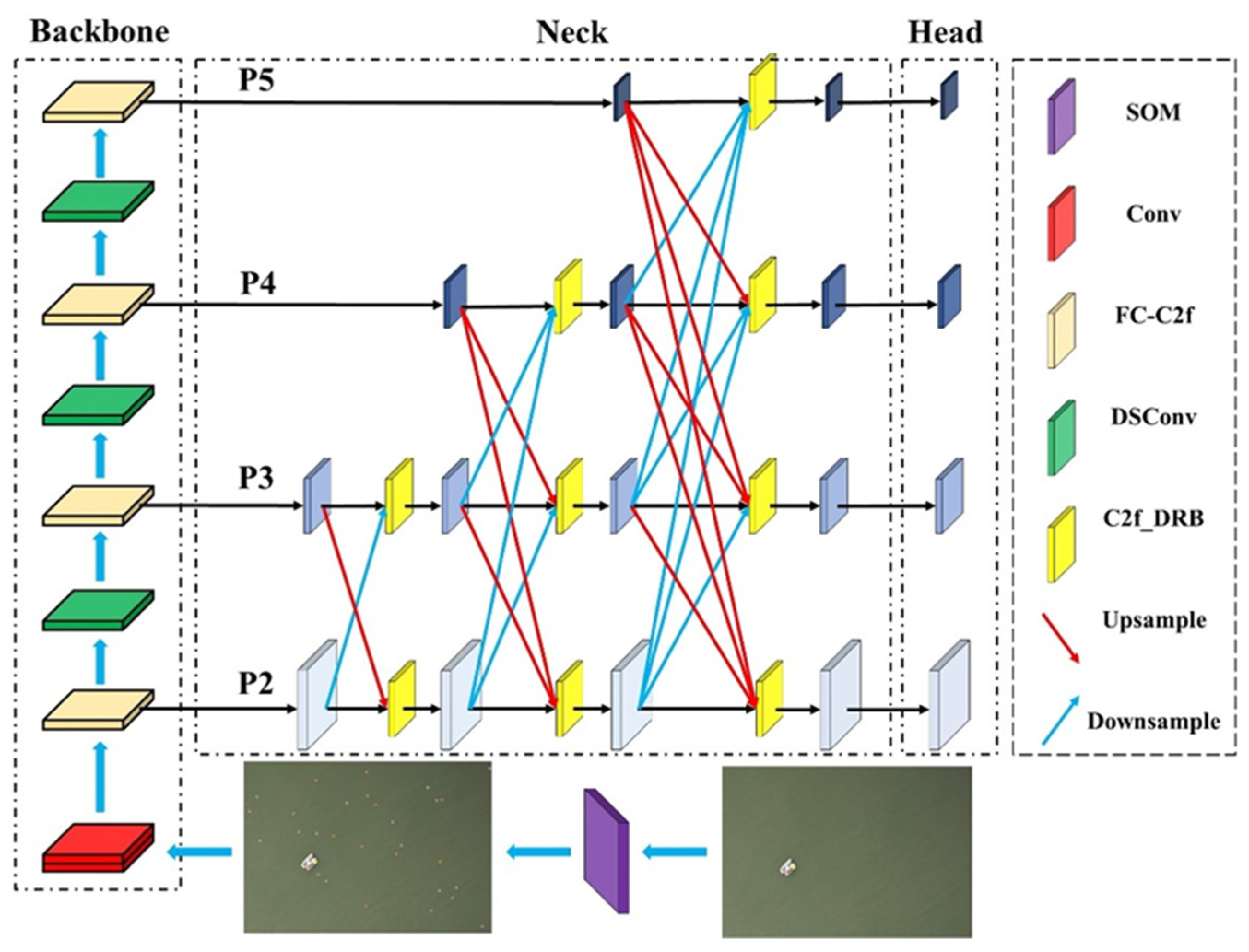
- A new multiscale fusion network, LMFN, was designed to address the accuracy issues in multiscale object recognition.
- By gradually integrating features from different levels, the connections between layers are effectively increased, and the model’s feature fusion process is optimized. This enhances the model’s capability to fuse multiscale features, improving detection accuracy for objects of various scales.
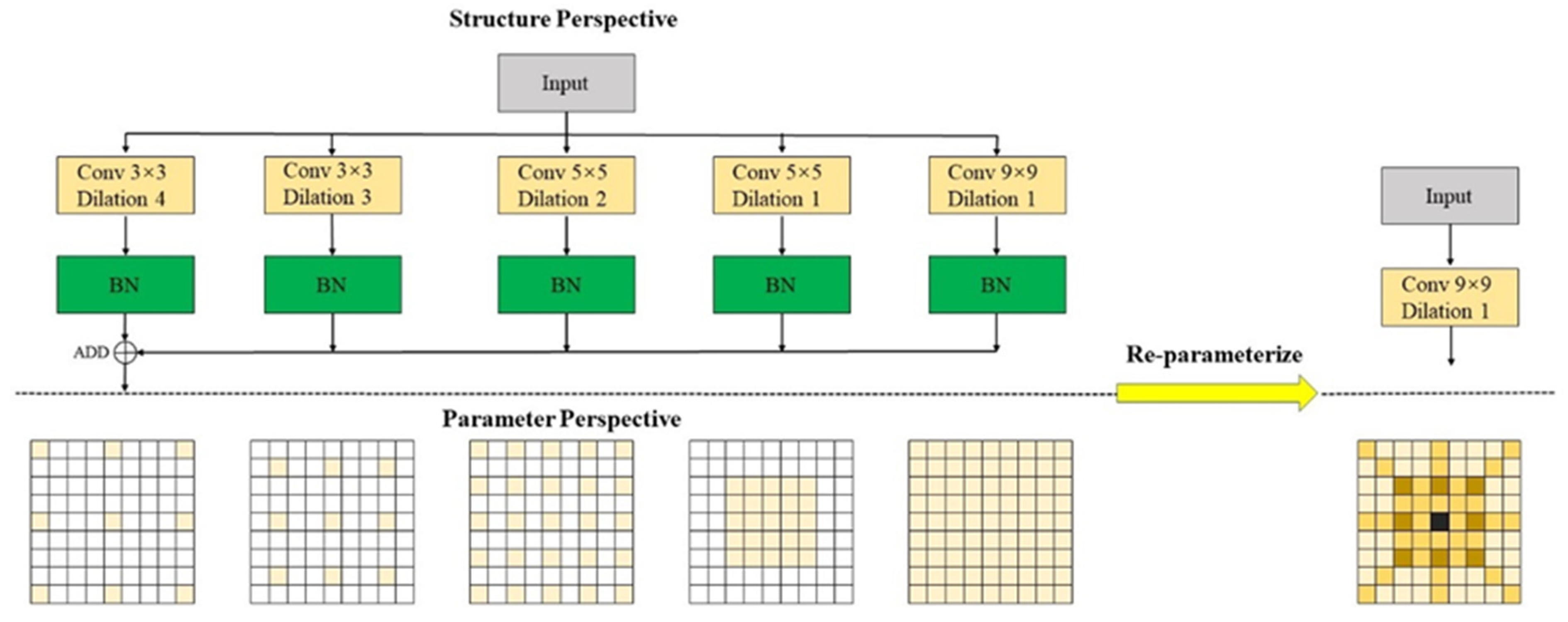
- Combined dilated convolutions with small kernels and cascaded convolutions into a re-parameterized large kernel convolution. This approach retains the benefits of small kernels, such as reduced computational load and fewer parameters, while achieving the large effective receptive field of large kernels. The experimental results demonstrate that this structure reduces model parameters and increases the receptive field.
2. Related Work
2.1. Data Augmentation
2.2. Lightweight Methods for Object Detection Networks Based on Deep Learning
2.3. MultiScale Feature Fusion
3. Materials and Methods
3.1. Small Object Multiplication Data Augmentation Algorithm
| Algorithm 1: The Working Steps of the SOM Data Augmentation Algorithm |
| Input: Image (IN), Annotation (AN), Object category index (L), Copy-Paste times (n).
Step 1: Iterate through the annotation information (AN) and check if there are any objects with the category index L and if their pixel size is smaller than 32 × 32. If these conditions are met, save the size and pixel information of these objects in List 1. for class_number in AN: if (class_number == L) and (object size < 32 × 32): List1.append(AN [class_number]) else: continue Step 2: The paste regions are randomly generated in the original image according to the number of duplications and their suitability is assessed. If unsuitable, new regions are generated. The qualifying object areas are pasted into these regions, and the annotation information for the newly generated objects is added to the annotation file. for object information in List1: for i in range(0, n): top-left coordinates = random(0, X), random(0, Y) bottom-right coordinates = top-left coordinates(x, y)—object size if bottom-right coordinates(x) > X or bottom-right coordinates(y) > Y: n = n – 1 continue SOM_Image = Paste(top-left coordinates, bottom-right coordinates, object information) SOM_Annotation = Add_New_Annotation(class number, object coordinates) Step 3: Use a Gaussian filter to smooth the edges of the pasted objects. The Blurred_image is the image after Gaussian smoothing, while GaussianBlur is the Gaussian filter applied to the entire image, particularly to the edges of the pasted regions. Blurred_image = GaussianBlur(SOM_Image, Gaussian kernel size, Gaussian kernel standard deviation) Output: The image after SOM data augmentation, Blurred_image, and the corresponding annotation file, SOM_ Annotation. |
3.2. Depthwise Separable Convolution
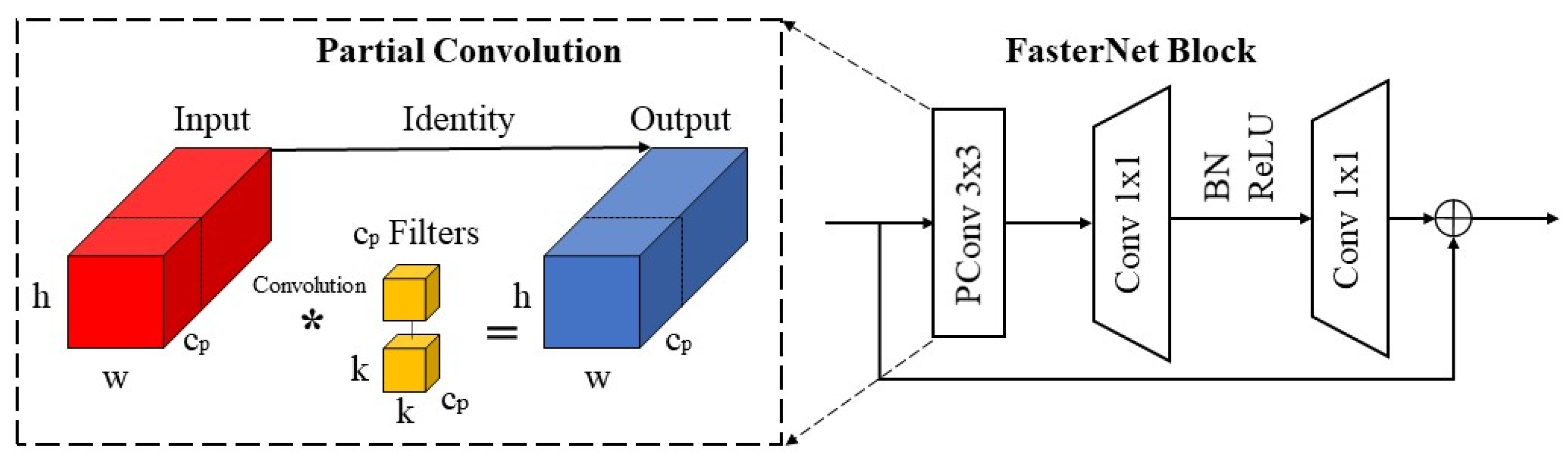
3.3. Improved C2f Module Based on Convolutional Gated Linear Unit and Faster Block
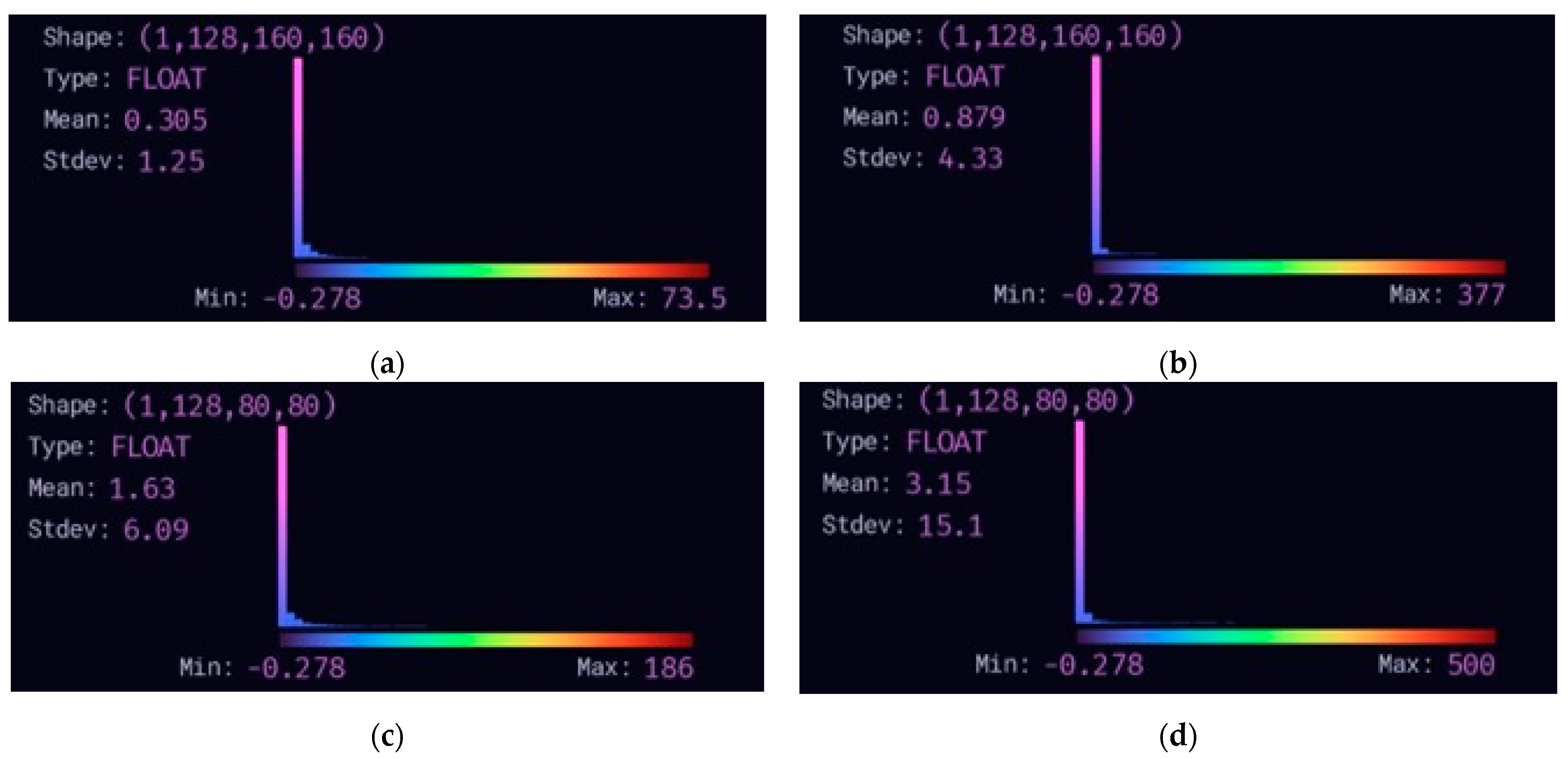
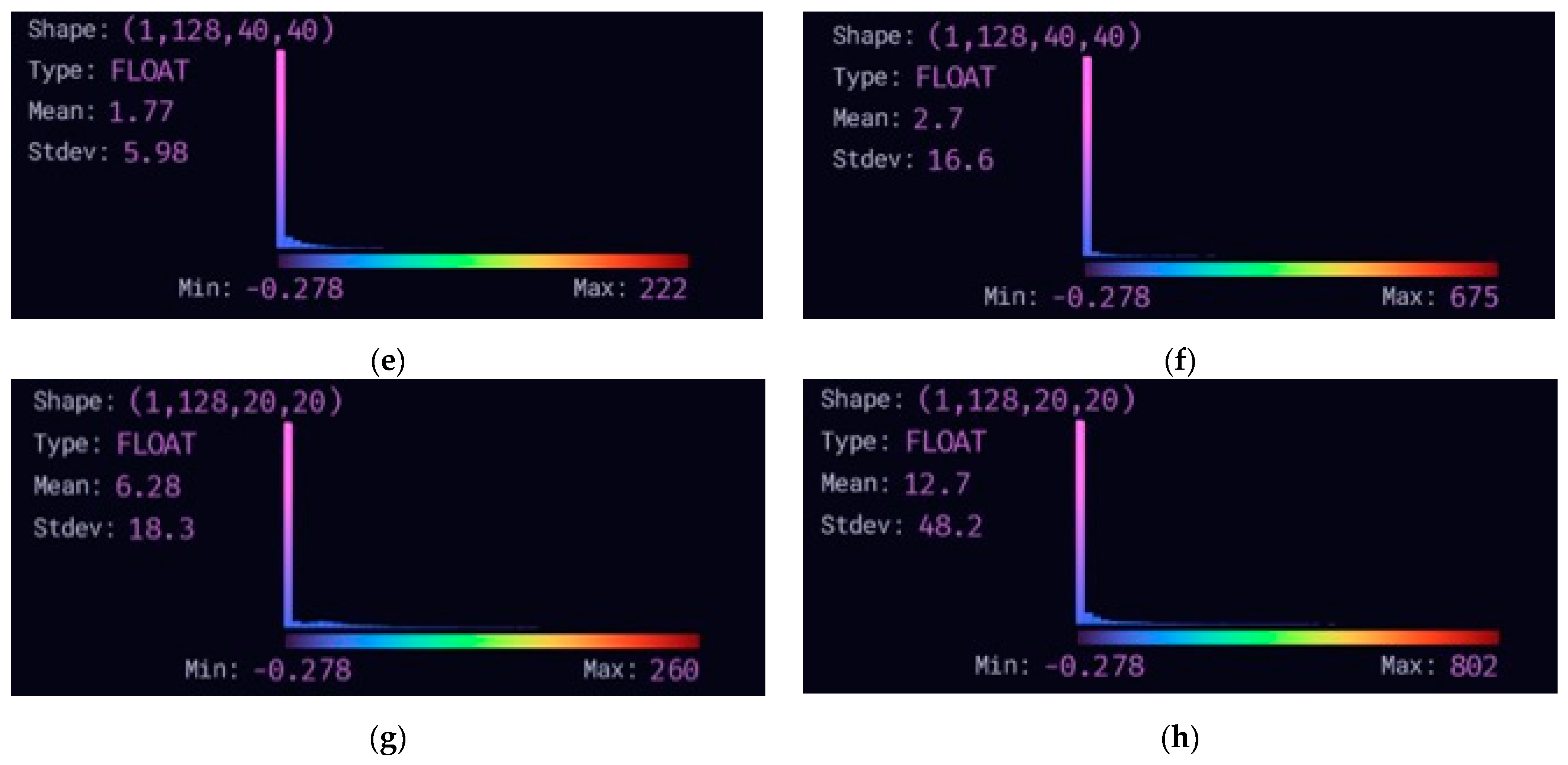
3.4. Lightweight Multiscale Feature Fusion Network
4. Experimental and Analysis
4.1. Experimental Environment and Parameter Settings
4.2. Experimental Metrics
4.3. Ablation Experiments
4.3.1. The Effect of SOM Data Augmentation on the Original Model
4.3.2. The Effect of DSConv on the Original Model
4.3.3. The Effect of FC-C2f on the Original Model
4.3.4. The Effect of LMFN on the Original Model
4.3.5. The Effect of Combining Multiple Improvement Modules on the Original Model
4.4. Comparative Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, T.; Jiang, Z.; Sun, R.; Cheng, N.; Feng, H. Maritime Search and Rescue Based on Group Mobile Computing for Unmanned Aerial Vehicles and Unmanned Surface Vehicles. IEEE Trans. Ind. Inform. 2020, 16, 7700–7708. [Google Scholar] [CrossRef]
- Tang, G.; Ni, J.; Zhao, Y.; Gu, Y.; Cao, W. A Survey of Object Detection for UAVs Based on Deep Learning. Remote Sens. 2024, 16, 149. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Deep Learning Techniques to Classify Agricultural Crops through UAV Imagery: A Review. Neural Comput. Appl. 2022, 34, 9511–9536. [Google Scholar] [CrossRef]
- Zhao, C.; Liu, R.W.; Qu, J.; Gao, R. Deep Learning-Based Object Detection in Maritime Unmanned Aerial Vehicle Imagery: Review and Experimental Comparisons. Eng. Appl. Artif. Intell. 2024, 128, 107513. [Google Scholar] [CrossRef]
- Guo, Y.; Xiao, Y.; Hao, F.; Zhang, X.; Chen, J.; de Beurs, K.; He, Y.; Fu, Y.H. Comparison of Different Machine Learning Algorithms for Predicting Maize Grain Yield Using UAV-Based Hyperspectral Images. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103528. [Google Scholar] [CrossRef]
- Yang, Z.; Yin, Y.; Jing, Q.; Shao, Z. A High-Precision Detection Model of Small Objects in Maritime UAV Perspective Based on Improved YOLOv5. J. Mar. Sci. Eng. 2023, 11, 1680. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 May 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022. [Google Scholar] [CrossRef]
- Varghese, R.; M., S. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Chen, G.; Pei, G.; Tang, Y.; Chen, T.; Tang, Z. A Novel Multi-Sample Data Augmentation Method for Oriented Object Detection in Remote Sensing Images. In Proceedings of the 2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP), Shanghai, China, 26–28 September 2022; pp. 1–7. [Google Scholar]
- Zhang, Q.; Meng, Z.; Zhao, Z.; Su, F. GSLD: A Global Scanner with Local Discriminator Network for Fast Detection of Sparse Plasma Cell in Immunohistochemistry. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 86–90. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.-Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste Is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50× Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Zhao, S.; Keutzer, K. SqueezeNext: Hardware-Aware Neural Network Design. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4—Universal Models for the Mobile Ecosystem. arXiv 2024, arXiv:2404.10518. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, J.; Chen, Z.; Yan, G.; Wang, Y.; Hu, B. Faster and Lightweight: An Improved YOLOv5 Object Detector for Remote Sensing Images. Remote Sens. 2023, 15, 4974. [Google Scholar] [CrossRef]
- Gong, W. Lightweight Object Detection: A Study Based on YOLOv7 Integrated with ShuffleNetv2 and Vision Transformer. arXiv 2024, arXiv:2403.01736. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware ReAssembly of FEatures. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. DAMO-YOLO: A Report on Real-Time Object Detection Design. arXiv 2023, arXiv:2211.15444. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, K.; Geng, Q.; Wan, M.; Cao, X.; Zhou, Z. Context and Spatial Feature Calibration for Real-Time Semantic Segmentation. IEEE Trans. Image Process. 2023, 32, 5465–5477. [Google Scholar] [CrossRef]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for Small Object Detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Guo, Y.; Li, Y.; Feris, R.; Wang, L.; Rosing, T. Depthwise Convolution Is All You Need for Learning Multiple Visual Domains. Available online: https://arxiv.org/abs/1902.00927v2 (accessed on 16 May 2024).
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. arXiv 2023, arXiv:2303.03667. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 122–138. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. arXiv 2024, arXiv:2304.08069v3. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. PMLR 2017, 70, 933–941. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. arXiv 2024, arXiv:2311.17132. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023. [Google Scholar]
- Ding, X.; Zhang, X.; Zhou, Y.; Han, J.; Ding, G.; Sun, J. Scaling Up Your Kernels to 31 × 31: Revisiting Large Kernel Design in CNNs. arXiv 2022, arXiv:2203.06717. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. arXiv 2017, arXiv:1701.04128. [Google Scholar]
- Ding, X.; Zhang, Y.; Ge, Y.; Zhao, S.; Song, L.; Yue, X.; Shan, Y. UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition. arXiv 2024, arXiv:2311.15599. [Google Scholar]
- Xu, J.; Fan, X.; Jian, H.; Xu, C.; Bei, W.; Ge, Q.; Zhao, T. YoloOW: A Spatial Scale Adaptive Real-Time Object Detection Neural Network for Open Water Search and Rescue From UAV Aerial Imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5623115. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | FLOPs (G) | Pre-Process (ms) | Inference (ms) | NMS (ms) |
|---|---|---|---|---|
| YOLOv8s | 28.8 | 0.2 | 1.6 | 0.8 |
| YOLOv8s + HGNetV2 | 23.3 | 0.2 | 1.6 | 0.7 |
| Experimental Environment | Parameter/Version |
|---|---|
| Operating System | Ubuntu20.04 |
| GPU | NVIDIA Geforce RTX 4090 |
| CPU | Intel(R) Xeon(R) Gold 6430 |
| CUDA | 11.3 |
| PyTorch | 1.10.0 |
| Python | 3.8 |
| Parameter | Setup |
|---|---|
| Image size | 640 × 640 |
| Momentum | 0.937 |
| BatchSize | 16 |
| Epoch | 200 |
| Initial learning rate | 0.01 |
| Final learning rate | 0.0001 |
| Weight decay | 0.0005 |
| Warmup epochs | 3 |
| IoU | 0.7 |
| Close Mosaic | 10 |
| Optimizer | SGD |
| Algorithms | YOLOv8s | YOLOv8s + SOM | ||||
|---|---|---|---|---|---|---|
| Classes | P(%) | R(%) | mAP(%) | P (%) | R(%) | mAP(%) |
| swimmer | 78.7 | 66.5 | 69.6 | 80.1 (+1.4) | 64.8 (−1.7) | 70.3 (+0.7) |
| boat | 89.8 | 86 | 91.6 | 89.9 (+0.1) | 87.4 (+1.4) | 91.2 (+0.4) |
| jetski | 76.8 | 82.2 | 83.7 | 86.3 (+9.5) | 82.5 (+0.3) | 84.6 (+0.9) |
| life_saving_appliances | 78.2 | 14.5 | 28.2 | 81 (+2.8) | 25.5 (+11) | 35.4 (+6.9) |
| buoy | 77.7 | 50.5 | 57.2 | 88.5 (+10.8) | 51.6 (+1.1) | 61.4 (+4.2) |
| All | 80.2 | 59.9 | 66.1 | 85.2 (+5) | 62.4 (+2.5) | 68.6 (+2.5) |
| Algorithms | P (%) | R (%) | mAP50val (%) | Params (M) | FLOPs (G) | Speed RTX4090 b16 (ms) |
|---|---|---|---|---|---|---|
| YOLOv8s | 80.2 | 59.9 | 66.1 | 11.14 | 28.7 | 2.6 |
| YOLOv8s + DSConv | 79.8 (−0.4) | 60.5 (+0.6) | 66.6 (+0.5) | 9.59 (−1.55) | 25.7 (−3) | 1.2 (−1.4) |
| Algorithms | P (%) | R (%) | mAP50val (%) | Params (M) | FLOPs (G) | Speed RTX4090 b16 (ms) |
|---|---|---|---|---|---|---|
| YOLOv8s | 80.2 | 59.9 | 66.1 | 11.14 | 28.7 | 2.6 |
| YOLOv8s + FB-C2f | 80.4 (+0.2) | 61.2 (+1.3) | 66.1 (+0) | 9.69 (−1.45) | 24.4 (−4.3) | 2.2 (−0.4) |
| YOLOv8s + FC-C2f | 82.8 (+2.6) | 59.5 (−0.4) | 66.5 (+0.4) | 9.48 (−1.66) | 23.8 (−4.9) | 1.4 (−1.2) |
| Algorithms | P (%) | R (%) | mAP50val (%) | Params (M) | FLOPs (G) | Speed RTX4090 b16 (ms) |
|---|---|---|---|---|---|---|
| YOLOv8s | 80.2 | 59.9 | 66.1 | 11.14 | 28.7 | 2.6 |
| AFPN | 83.2 (+3.0) | 71.4 (+11.5) | 76.3 (+10.2) | 8.76 (−2.38) | 38.9 (+10.2) | 3.1 (+0.5) |
| AFPN_C2f | 84.5 (+4.3) | 69.6 (+9.7) | 76.0 (+9.9) | 7.09 (−4.05) | 34.2 (+5.5) | 2.8 (+0.2) |
| LMFN | 86.8 (+6.6) | 70.5 (+10.6) | 76.7 (+10.6) | 6.86 (−4.28) | 31.1 (+2.4) | 2.3 (−0.3) |
| Class | Algorithms | P (%) | R (%) | mAP50val (%) | mAP50-95val (%) | Params (M) | FLOPs (G) | Speed RTX4090 b16 (ms) |
|---|---|---|---|---|---|---|---|---|
| 1 | YOLOv8s | 80.2 | 59.9 | 66.1 | 39.9 | 11.14 | 28.7 | 2.6 |
| 2 | a | 84.1 | 62.2 | 67.7 | 40.2 | 11.14 | 28.7 | 2.6 |
| 3 | b | 79.8 | 60.5 | 66.6 | 39.9 | 9.59 | 25.7 | 1.2 |
| 4 | c | 82.8 | 59.5 | 66.5 | 39.3 | 9.48 | 23.8 | 1.4 |
| 5 | d | 86.8 | 70.5 | 76.7 | 42.7 | 6.86 | 31.1 | 2.4 |
| 6 | b + c | 81 | 59.4 | 66.1 | 39.0 | 7.93 | 20.9 | 1.1 |
| 7 | b + c + d | 82.6 | 71.3 | 76.6 | 43.5 | 3.65 | 23.3 | 2.1 |
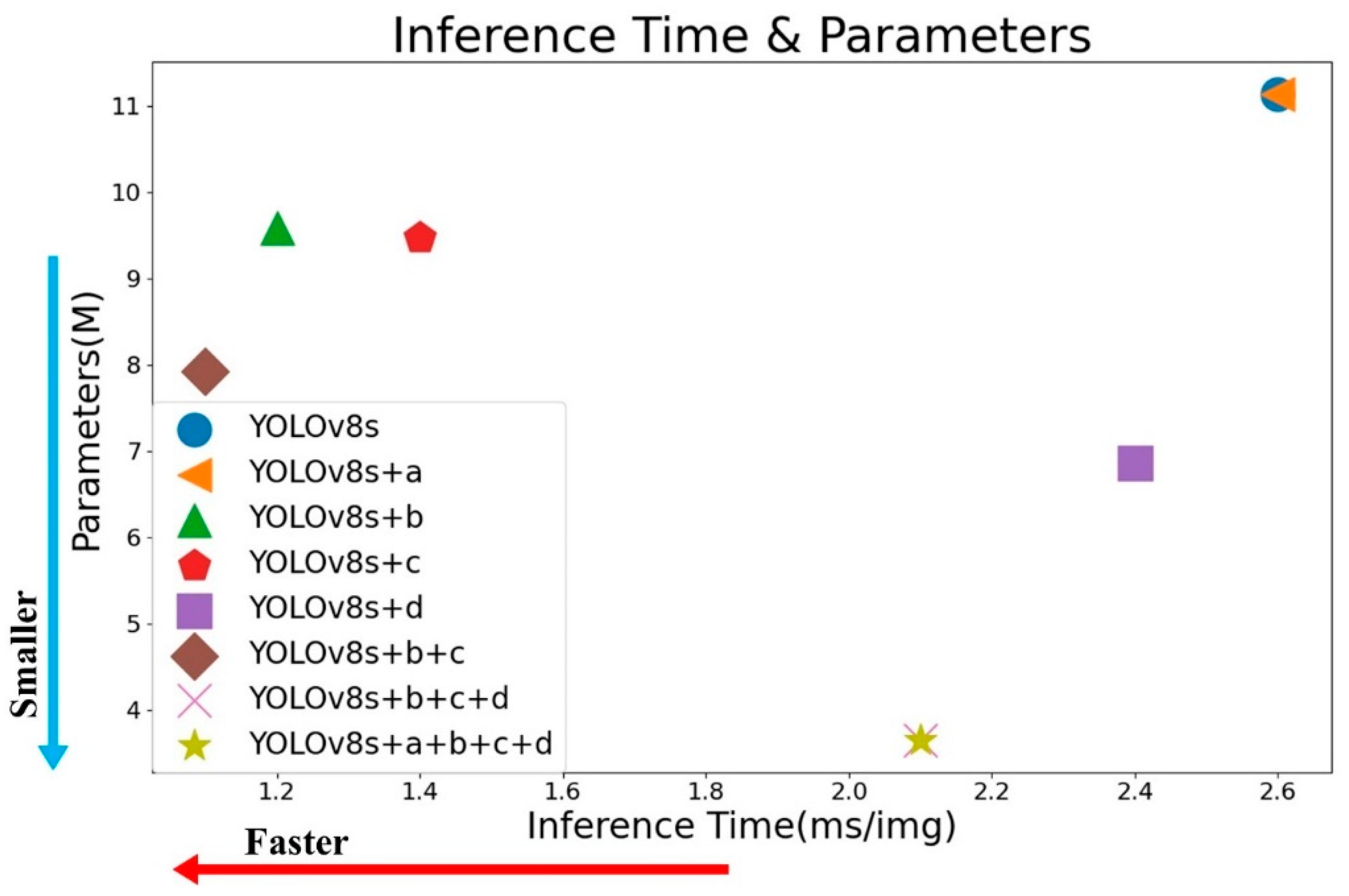
| 8 | a + b + c + d (our) | 85.5 | 71.6 | 78.3 | 43.7 | 3.64 | 22.9 | 2.1 |
| Class | Algorithms | Swimmer | Boat | Jetski | Life_Saving_Appliances | Buoy | mAP50val (%) |
|---|---|---|---|---|---|---|---|
| 1 | YOLOv8s | 69.6 | 91.6 | 83.7 | 28.2 | 57.2 | 66.1 |
| 2 | a | 66.0 | 91.2 | 84.6 | 35.4 | 61.4 | 67.7 |
| 3 | b | 69.4 | 91.1 | 85.6 | 30.7 | 56.1 | 66.6 |
| 4 | c | 70.4 | 91.7 | 81.4 | 28.7 | 60.2 | 66.5 |
| 5 | d | 77.6 | 95.6 | 87.4 | 45.5 | 77.2 | 76.7 |
| 6 | b + c | 69.8 | 90.5 | 82.4 | 27.6 | 60.1 | 66.1 |
| 7 | b + c + d | 78.3 | 95.5 | 86.3 | 45.8 | 77.3 | 76.6 |
| 8 | a + b+c + d (our) | 79.6 | 95.5 | 85.9 | 54.8 | 75.7 | 78.3 |
| Class | Algorithms | P (%) | R (%) | mAP50val (%) | mAP50-95val (%) | Params (M) | FLOPs (G) | Speed RTX4090 b16 (ms) |
|---|---|---|---|---|---|---|---|---|
| 1 | YOLOv5s | 82.7 | 57.9 | 65.4 | 38.6 | 9.11 | 23.8 | 2.1 |
| 2 | YOLOv6n | 79.5 | 57.7 | 60.6 | 35.9 | 4.23 | 11.8 | 1.7 |
| 3 | YOLOv8n | 79.0 | 58.8 | 63.6 | 37.1 | 3.0 | 8.1 | 1.6 |
| 4 | YOLOv9t | 74.1 | 58.5 | 62.3 | 37.8 | 2.62 | 10.7 | 4.5 |
| 5 | YOLOv10s | 82.3 | 59.3 | 63.8 | 37.7 | 8.04 | 24.5 | 1.0 |
| 6 | YOLO-OW | 83.1 | 75.5 | 75.5 | 39.9 | 42.1 | 94.8 | 4.6 |
| 7 | RT-DETR-R18 | 88.4 | 82.6 | 83.6 | 49.6 | 20.0 | 57.0 | 3.8 |
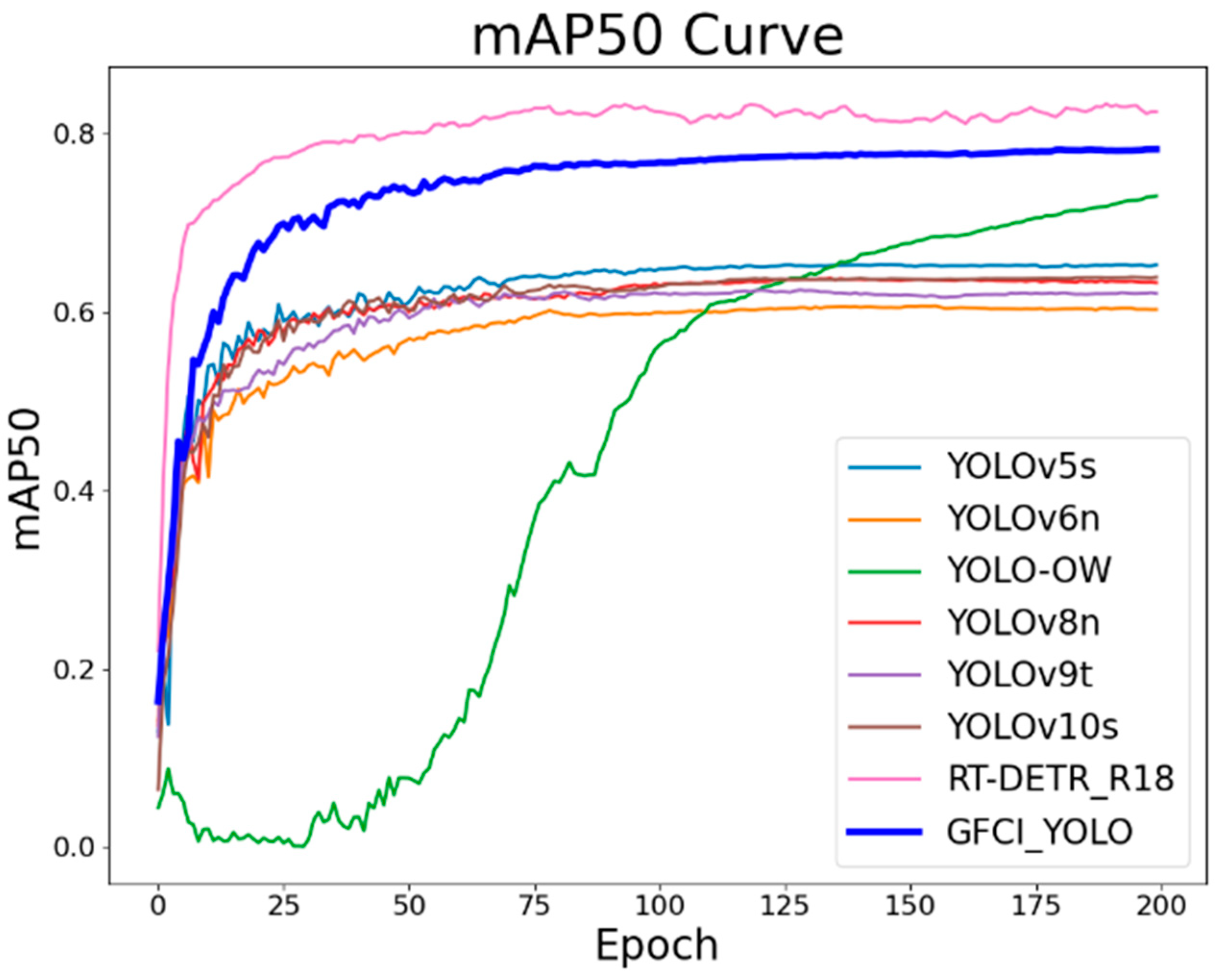
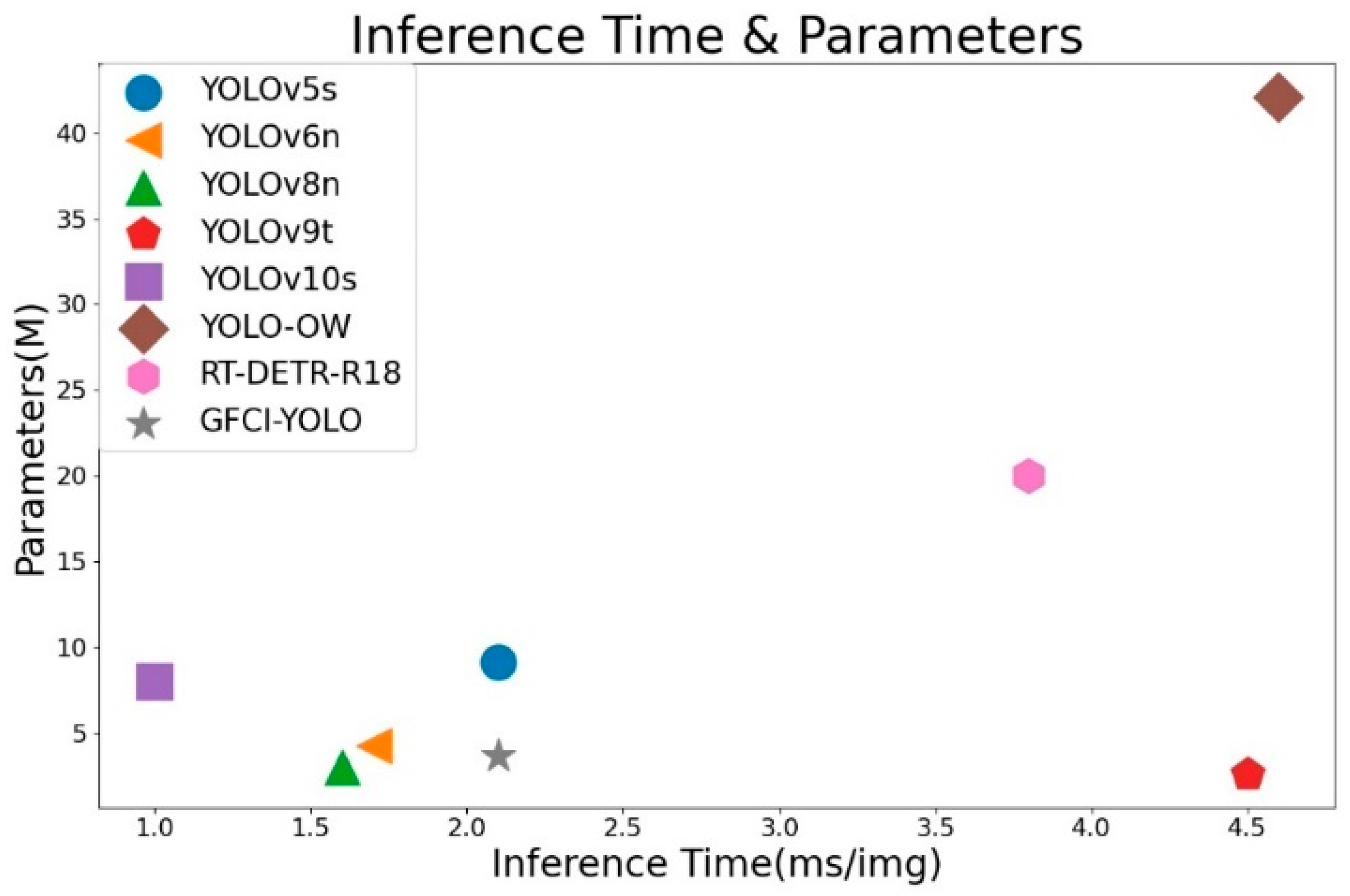
| 8 | DFLM-YOLO (our) | 85.5 | 71.6 | 78.3 | 43.7 | 3.64 | 22.9 | 2.1 |
| Class | Algorithms | Swimmer | Boat | Jetski | Life_Saving_Appliances | Buoy | mAP50val (%) |
|---|---|---|---|---|---|---|---|
| 1 | YOLOv5s | 69.9 | 91.6 | 81.1 | 26.0 | 58.5 | 65.4 |
| 2 | YOLOv6n | 65.4 | 90.7 | 78.6 | 14.2 | 54.1 | 60.6 |
| 3 | YOLOv8n | 66.7 | 92.0 | 83.9 | 19.8 | 55.6 | 63.6 |
| 4 | YOLOv9t | 68.5 | 91.5 | 84.5 | 14.3 | 52.7 | 62.3 |
| 5 | YOLOv10s | 67.5 | 90.1 | 86.0 | 23.6 | 51.9 | 63.8 |
| 6 | YOLO-OW | 67.9 | 92.0 | 93.0 | 49.8 | 74.8 | 75.5 |
| 7 | RT-DETR-R18 | 82.2 | 97.8 | 92.3 | 54.6 | 90.9 | 83.6 |
| 8 | DFLM-YOLO (our) | 79.6 | 95.5 | 85.9 | 54.8 | 75.7 | 78.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Zhang, Y.; Ma, S. DFLM-YOLO: A Lightweight YOLO Model with Multiscale Feature Fusion Capabilities for Open Water Aerial Imagery. Drones 2024, 8, 400. https://doi.org/10.3390/drones8080400
Sun C, Zhang Y, Ma S. DFLM-YOLO: A Lightweight YOLO Model with Multiscale Feature Fusion Capabilities for Open Water Aerial Imagery. Drones. 2024; 8(8):400. https://doi.org/10.3390/drones8080400
Chicago/Turabian StyleSun, Chen, Yihong Zhang, and Shuai Ma. 2024. "DFLM-YOLO: A Lightweight YOLO Model with Multiscale Feature Fusion Capabilities for Open Water Aerial Imagery" Drones 8, no. 8: 400. https://doi.org/10.3390/drones8080400
APA StyleSun, C., Zhang, Y., & Ma, S. (2024). DFLM-YOLO: A Lightweight YOLO Model with Multiscale Feature Fusion Capabilities for Open Water Aerial Imagery. Drones, 8(8), 400. https://doi.org/10.3390/drones8080400