3.1. Classification of the Satellite Image
Regarding the current image classification techniques, it is possible to obtain a high-resolution risk layer based on a pixel-level feature classification of a satellite image, which greatly enables a refined analysis and assessment of the needed risk factors.
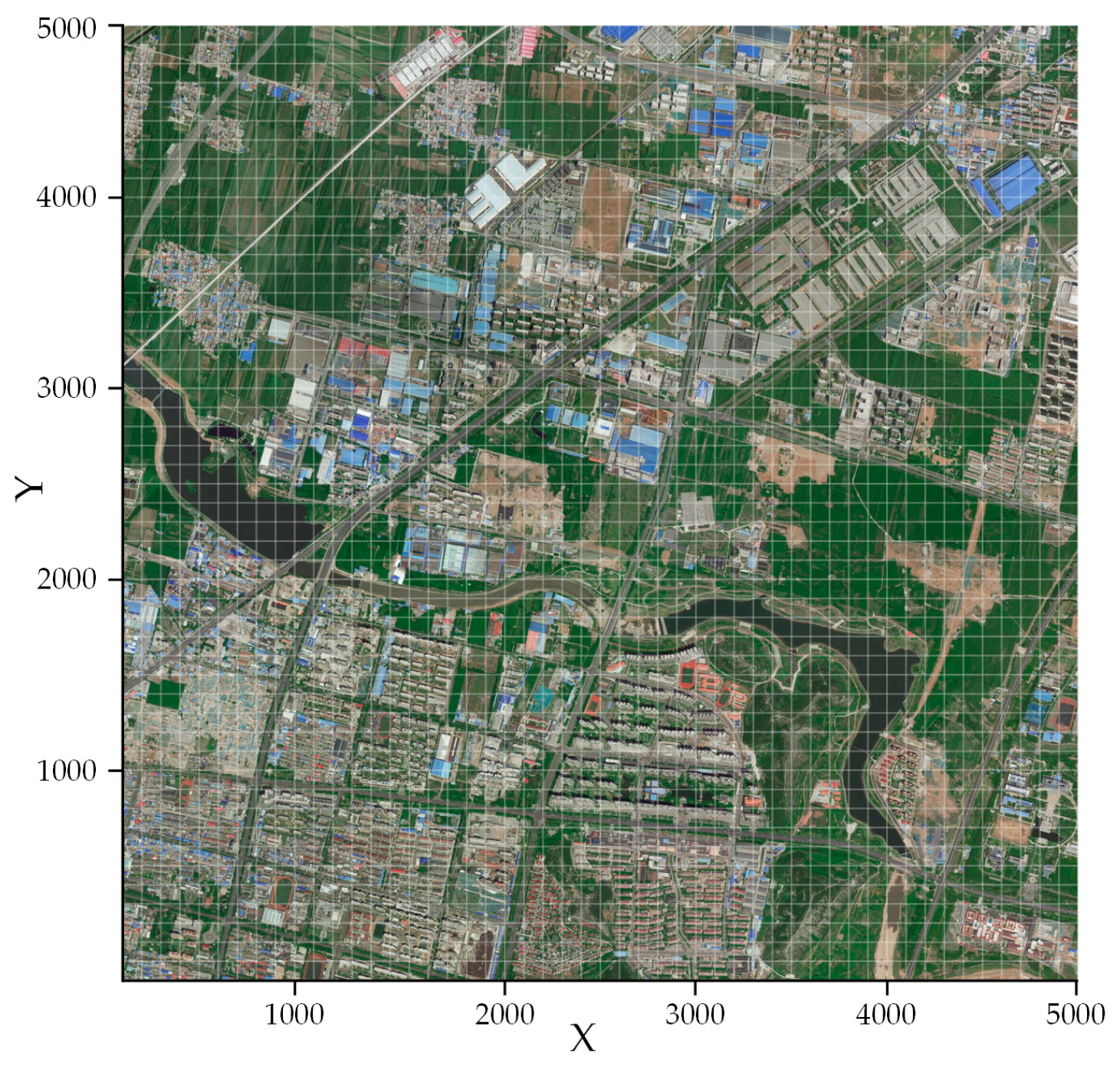
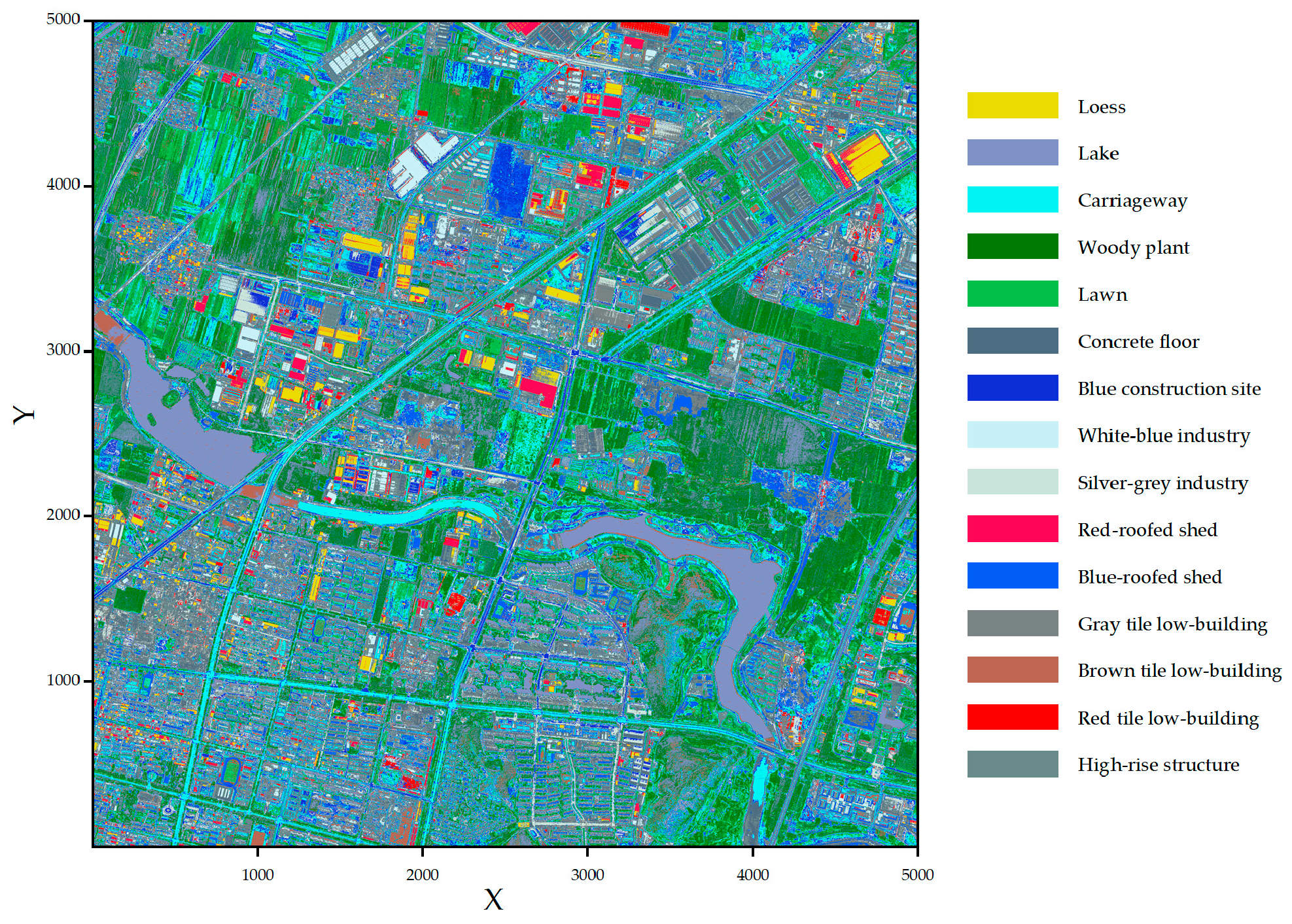
In this section, a satellite image of Changqing District in Jinan City is used, in which a sheltering factor layer is generated to further construct a risk-based airspace model. The satellite image was derived from Baidu Maps with a size of 5 km × 5 km. It means that all the UAVs would operate in this specified area. This selected area with a size of 5 km × 5 km is composed of many different ground features, such as high-rise buildings, industrial zones, and parks.
It is obvious that this obtained satellite image is composed of three channels of red, green, and blue (RGB), but with no label. In this situation, an unsupervised clustering method can be used to create a classification to extract the ground features. The K-Means clustering method [
23] is the most well-known and commonly used approach for clustering problems, and it is also a type of unsupervised learning method. This algorithm partitions a whole dataset into K clusters according to the similarities between different samples. Data points would exhibit a significant similarity within the same cluster, while they would be marked as quite dissimilar if they are in different clusters.
There are three channels in a satellite image denoted as RGB, which are red, green, and blue. RGB indicates that each pixel in a satellite image possesses three features. For each channel in RGB, there are 256 brightness levels with values ranging from 0 to 255. There is also no need for data normalization. The size of a pixel in an actual map is set as 1 m × 1 m. The Euclidean distance is employed for calculating the distance from each pixel point to a cluster center, and this objective function can be expressed in Equation (1).
In Equation (1), K is the number of clusters, Ci is the number of pixel points in the ith cluster, pij denotes the jth data point in the ith cluster, and ui signifies the center of mass of the ith cluster. In the K-Means clustering method, a cluster center ui would be updated iteratively by minimizing the objective function J in Equation (1). The aim is to assign the data points to the nearest cluster center and then to optimize the clustering effects by adjusting the location of a cluster center.
Using the K-Means clustering method, the ground features are extracted and divided into five main categories, each of which is composed of several types. The total number of ground features is 15 after the extraction, as given in
Table 1.
As shown in
Table 1, in Category 1 there are five types of ground features, which are Lawn, Lake, Concrete Floor, Loess, and Blue Construction Site. The Carriageway type belongs in Category 2. The Woody Plant, Blue-Roofed Shed, and Red-Roofed Shed are in the scope of Category 3. Tile Low Building (Brown, Gray, Red), and Industrial Area (Silver-Grey, White-Blue) are in Category 4. Category 5 is the High-Rise Structure.
Algorithm 1 shows the pseudocode of the K-Means clustering method. In this method, a pixel
P and an initial clustering center
U of all the pixels in a satellite image are defined as the input. Then the algorithm starts the iteration. Each data point is assigned to the nearest cluster center, and after that the position of the cluster center is updated according to all the data included in it. Each data point is assigned to the nearest cluster center. Following this assignment, the position of each cluster center is updated based on the mean of all data points assigned to that cluster. This iterative procedure continues until the cluster center remains unchanged. Finally, the clustering result
C and the set of cluster centers
U can be obtained.
| Algorithm 1 K-Means clustering method |
| 1: | Procedure K-Means (P, U) |
| 2: | Let m = len(P), K = len(U) |
| 3: | repeat |
| 4: | Let Ci = Ø (1 ≤ i ≤ K) |
| 5: | for j = 1, 2, …, m do |
| 6: | Calculate distance: dji = ||pj − ui||2 (ui in U) |
| 7: | Determine cluster label for pj: λj = argmini∈(1, 2, …, K) dji |
| 8: | Add pj to C: Cλj = Cλj ∪ {pj} |
| 9: | end for |
| 10: | for i = 1, 2, …, K do |
| 11: | Calculate new clustering center: u’i = ∑pij∈Ci pij/|Ci| |
| 12: | if u’i ≠ ui then |
| 13: | Update ui = u’i |
| 14: | end if |
| 15: | end for |
| 16: | until centroids remain unchanged |
| 17: | return (C, U) |
| 18: | end Procedure |
Furthermore, a similarity-matching process is required to identify the accurate types of ground features corresponding to the cluster center. In this paper, a total of 15 types of ground feature are considered and collected from a satellite image, and are represented as pixel points u’i (i = 1, 2, …., 15). All of them are denoted as a ground feature set U’ = {u’1, u’2, …, u’15}. The Euclidean distance is employed to calculate the distances between U and U’, which results in a similarity matrix D with a size of 15 × 15. U denotes the set of clustering centers obtained from applying the K-Means clustering algorithm to the satellite image. In this similarity matrix D, each element dij represents a Euclidean distance between the ith vector in U and the jth vector in U’. It is obvious that dij = ||ui − u’j||.
In order to determine the optimal clustering centers for different ground features, a similarity-matching problem is transformed into a task allocation problem by processing a similarity matrix
D. The objective function is defined as given in Equation (2).
In this equation, cij = 1 means the ith clustering center is matched to the jth ground feature. Otherwise, there would be no match and then n would be set as 15. In this way, each ground feature can find its optimal pixel center.
3.2. Modeling of a Population Density Layer
The population density layer defines ground population density and its distribution in specified urban areas, which is indispensable when the ground risk is assessed and estimated. Population density indicates the potential number of ground individuals that would be impacted by the crashed UAVs. Consequently, determining how to construct a population density layer with an accepted resolution based on the ground grid division becomes imperative.
3.2.1. Data Acquisition and Preprocessing
To generate a population density layer that is as accurate as possible, the population data were acquired from an open source of WorldPop (World Population) [
24] and the official government data of the Seventh National Census Bulletin of Jinan City. WorldPop is a project that aims to provide a global population distribution and population density data. The population data of WorldPop are usually based on various information sources such, as the satellite remote sensing images, geographic statistics, and ground surveys, which greatly improves its accuracy and reliability. The Seventh National Census is a comprehensive census conducted by the Chinese government every ten years and issued to the public. It collects data on the basic population information, economic status, education level, living conditions, and other aspects.
The Chinese population distribution estimation dataset of the year 2020 was obtained from WorldPop. For this dataset, the Geographic Coordinate System WGS84 is used and the ground is divided into many grids. The resolution of the ground grid is 100 m × 100 m, and its unit is the number of people located in a ground grid. A random forest-based asymmetric redistribution is used as a mapping approach. The data of the census bulletin are straightforward, and the total number of people in Changqing District of Jinan in the year 2020 was obtained to further correct and refine the population data from WorldPop.
3.2.2. Estimation of Ground Population Density
In this paper, Changqing District in Jinan City is selected as the UAV operation scenario and the population data of Changqing District from the Chinese population distribution dataset are cropped first. Because of the potential delay in the WorldPop dataset, and aiming for a more accurate population density, a correction coefficient is proposed by incorporating the census data.
The correction coefficient (
Cc) is defined in Equation (3), which represents a ratio of the census data of Changqing District (
Ncensus) to the total population (
NWorldPop) of Changqing District estimated by WorldPop. Subsequently, to derive a more accurate population distribution of Changqing District, the population density in each ground grid is corrected by multiplying the proposed correction coefficient (
Cc).
Equation (4) shows the accurate calculation of the population density using the WorldPop population density in each ground grid and the proposed correction coefficient (
Cc).
ρcorrection is the corrected population density in a ground grid and
ρpeople is the corresponding population density of a ground grid. Upon obtaining the corrected population density of Changqing District with Equation (4), it should be adjusted according to the dimension of the UAV operation areas. In this paper, all the UAVs are restricted within an area of 5 km × 5 km with a resolution of 100 m × 100 m. This means that the distribution of the corrected population density should follow this setting at the same time.
To obtain higher-resolution population density estimates, the classified ground features listed in
Table 1 are considered. It is known that different ground features in a satellite image possess different population densities. However, the population density of the same ground feature in different locations would also be quite different. For example, a population density of a sidewalk near a shopping mall is definitely different from that of a sidewalk in a residential area. According to the analysis above, the total number of people on the ground in a specified urban area should be calculated first using Equation (5) based on different ground features.
In Equation (5),
Np is the total number of people on the ground in a specified urban area.
ρi is the population density of the
i-th ground feature.
Ai is the area of this corresponding
i-th ground feature. In this paper, the resolution of the ground feature classification is defined as 1 m × 1 m, and the area of each ground feature can then be calculated easily. The initial grid size for a population density layer is 50 × 50. In this way, a total of 2500 linear equations can be established to calculate the number of people in a specified ground grid, as shown in Equation (6).
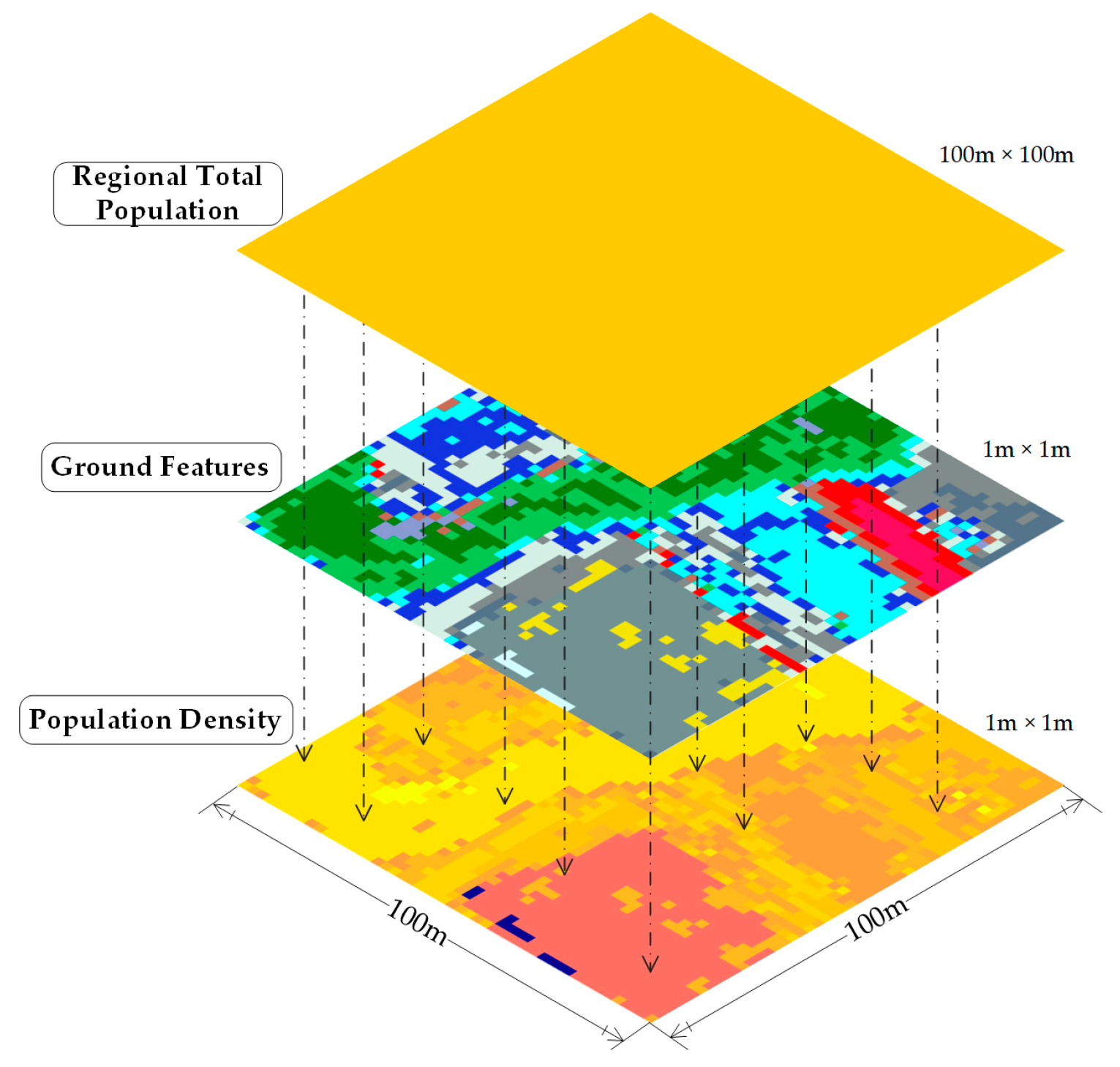
Figure 5 illustrates how each equation calculates population density using ground feature classification and regional total population. Specifically, the top layer of the diagram represents the WorldPop data adjusted by a correction coefficient, yielding
ρcorrection with a resolution of 100 m × 100 m. By calculating the area of each ground feature in the middle layer (with a resolution of 1 m × 1 m), the population density of each ground feature in the bottom layer can be determined. In the bottom layer of the figure, the color spectrum ranges from pale yellow to deep brown, where pale yellow indicates the lowest population density, and deep brown signifies the highest population density. This gradient provides a clear visual representation that different ground features have their corresponding population densities.
In Equation (6),
An’k denotes the area of the
kth ground feature given in
Table 1 in the
nth ground region and
ρk is the population density of the
kth ground feature.
Nn is the total number of people in the
nth ground region.
Because Equation (6) is a multiple linear regression model, it can be solved by a multiple linear regression method. However, it is also essential to emphasize that the key intercept term in this mentioned regression model should be 0.
Considering the fact that the population densities of the same type of ground feature may vary in different locations, the WorldPop data are used to correct the population densities of the same ground feature in different urban places. This step makes the obtained population density more accurate and reliable. To evaluate the contributions by incorporating these two kinds of data to a population density, a weight factor
αk is defined, and the final population density can be obtained with Equation (7).
In Equation (7), ρP is the final obtained population density. αk denotes the kth weight factor and ρk is the kth population density. It should be noted that ρ1 and ρ2 correspond to the population densities of the ground features and WorldPop at a location, respectively. Here {α1, α2} ∈ (0, 1] and α1 + α2 = 1.
3.3. Modeling of a Sheltering Factor Layer
The sheltering factor is the level of protection that could be provided by buildings, structures, or trees to pedestrians in the event of a UAV crashing to the ground [
25]. A sheltering factor is a positive number that reflects the degree of shielding effects, with higher values indicating a greater level of the provided protection. The sheltering factor is crucial as it mitigates the kinetic energy impact in the event of a UAV crash, thereby decreasing the fatality risk. Neglecting the sheltering factor leads to an assessment that fails to accurately represent the actual conditions, overlooking the protective shading effects of buildings, vehicles, and trees offered to ground people.
The precise concept of a sheltering factor has been defined differently across multiple studies, yet it can be generally classified into two categories. The first is that a sheltering factor is defined as a real number ranging from 0 to positive infinity, where 0 signifies the absence of any shelter with no protections and infinity denotes powerful protection. However, an excessively high value of the sheltering factor suffers from a lack of an evaluative significance. This is because substantial kinetic energy would be required to cause a fatality once it is beyond a certain threshold. Another approach is to confine the sheltering factor within a fixed range, ensuring that the assessment of the sheltering effect is more scientific and accurate.
In this section, a sheltering factor is defined based on the previous results of ground feature classifications. This means that the sheltering factors are assigned to the classified ground features with limited values. According to the classifications of ground features given in
Table 1, the fifteen classified types of ground features are allocated with a fixed sheltering factor with a value between 0 and 1.
Table 2 gives the sheltering factors of different ground features. As shown in
Table 2, the sheltering factors are set as 0, 0.25, 0.50, 0.75, and 1 for the five classified categories of ground features, respectively.
The sheltering factor of Lawn, Lake, Concrete Floor, Loess, and Blue Construction Site is 0, which means no protection can be provided when the UAVs crash into these areas. The Carriageway could provide protection with a sheltering factor 0.25. Woody Plant, Blue-Roofed Shed, and Red-Roofed Shed belong to the third category, whose sheltering factor is set as 0.5. Tile Low Building (Brown, Gray, Red), and Industrial Area (Silver-Grey, White-Blue) are in the scope of Category 4. Its sheltering factor is 0.75. Category 5 is High-Rise Structure, whose sheltering factor is the greatest, at 1.
Based on the above settings, for the ground feature classification results generated from the satellite image in
Section 3.1, we assign the corresponding sheltering factor to obtain the sheltering factor layer. Similar to the ground feature classification, the resolution of this layer is also defined as 1 m × 1 m. This ensures that each 1 m × 1 m grid cell is assigned an appropriate sheltering factor, reflecting the level of protection provided by the ground feature in that grid.
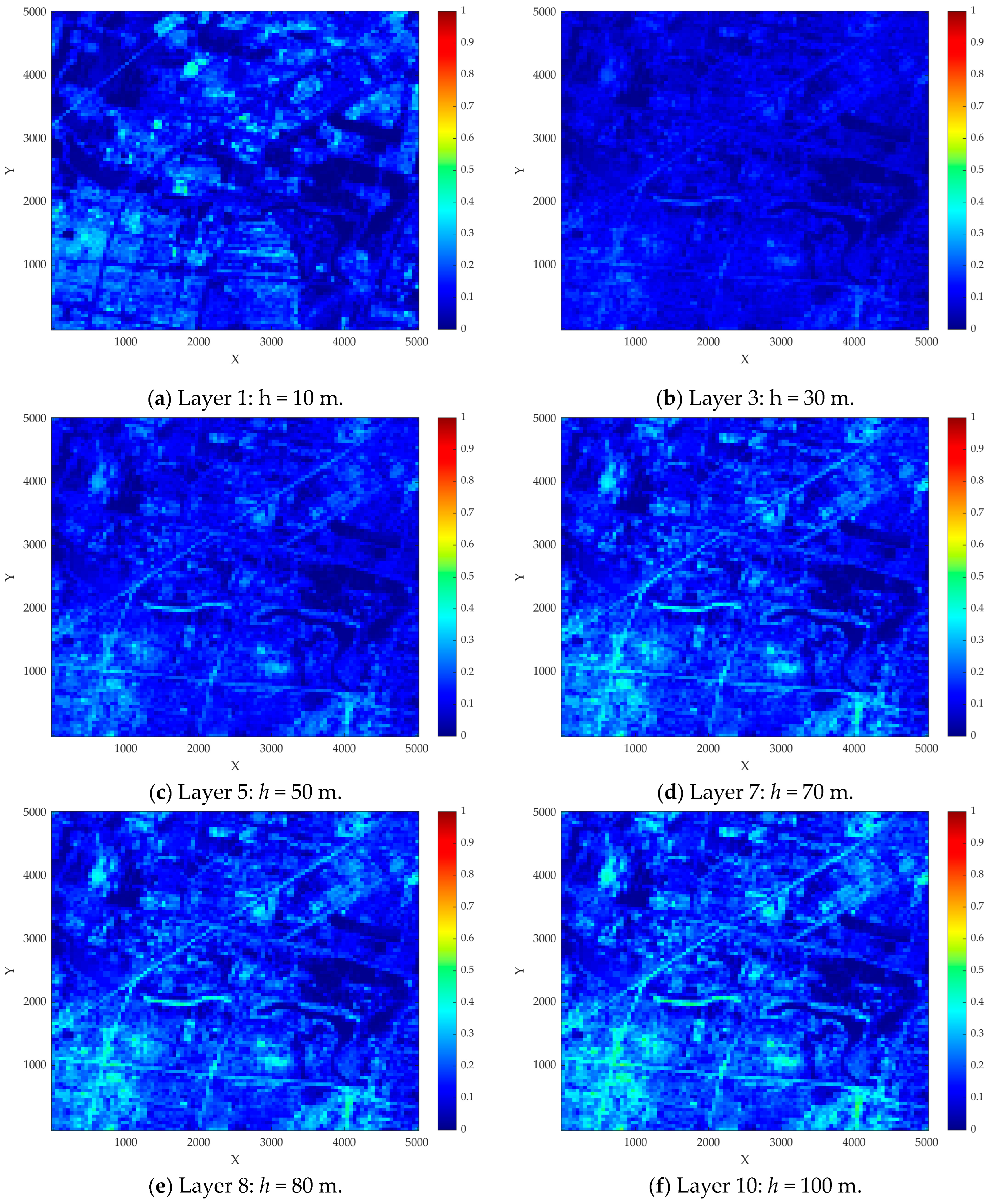
3.4. Modeling of a Ground Obstacle Layer
In this section, the classified ground features given in
Table 1 are taken into account to generated a ground obstacle layer. It is known that each type of ground feature has a specific height and can be treated as an obstacle in the urban airspace. In this way, all the UAVs are not permitted to fly within these occupied spaces or collide with them. Generally speaking, the denser the obstacles, the more risk for UAV operations in that area.
To generate a more accurate obstacle layer, all the ground obstacles are categorized into three main types by considering all the ground features given in
Table 1 The first type consists of ground areas without high structures, such as grasslands or lakes, whose sheltering factor is generally zero. The second type includes trees, which are typically not as high in urban environments. The third type comprises urban buildings, which usually have a height of 4 m or more, and would significantly influence the UAV operation’s efficiency and safety.
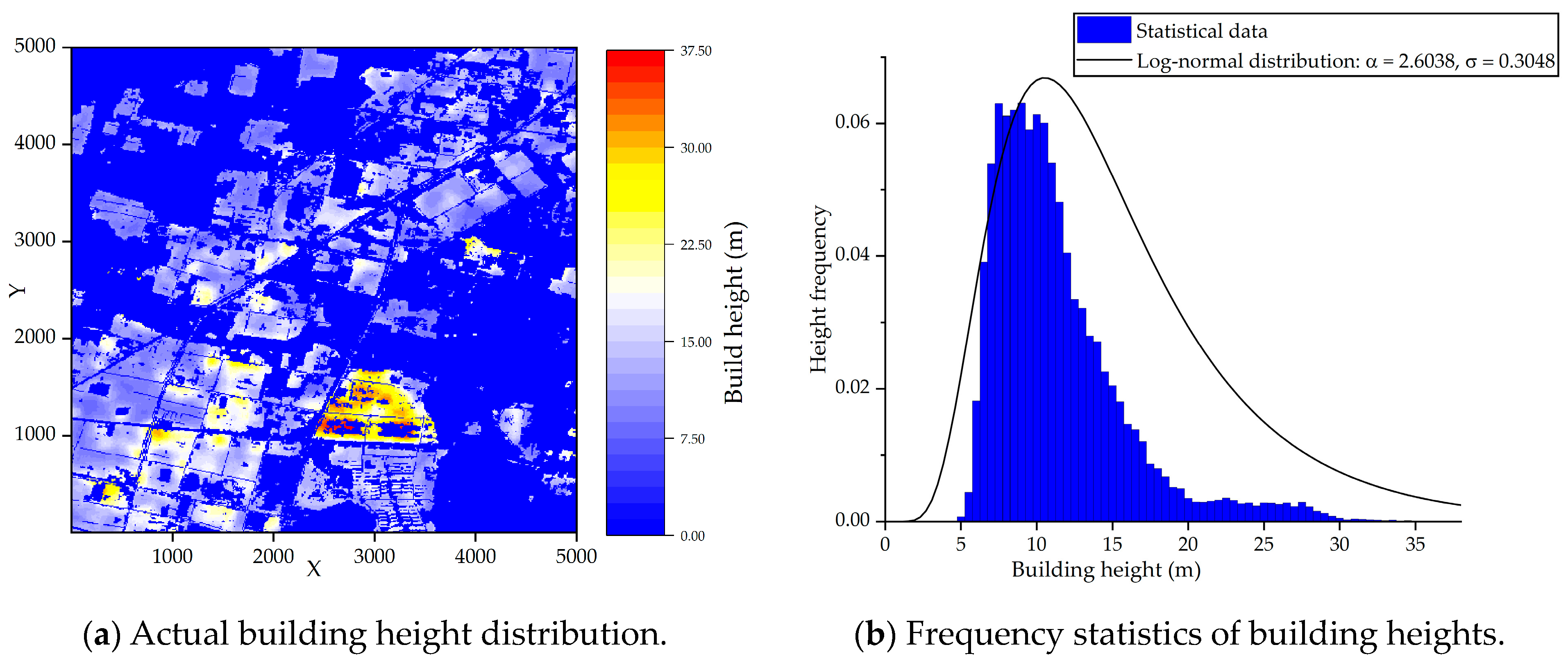
The accurate densities and heights of all the obstacles on the ground are fundamental when a ground obstacle layer is constructed. In this paper, the Chinese building height at 10 m resolution (CNBH-10 m) is the data source for the building densities [
26], in which the resolution of a building height map is ten meters. However, due to the lack of specific data, the heights of the trees are defined as a normal distribution, and range from 3 m to 8 m to simulate the actual conditions in the urban environments. Meanwhile, this normal distribution is assumed to have a mean value (
μtree) of 5.5 and a standard deviation (
σtree) of 1.25. In this way, based on this assumption, as shown in Equation (8), the tree heights are randomly generated from the normal distribution N(
μtree,
σtree) to obtain
hrandom. Then, the tree heights
htree are constrained within the range of 3 to 8 m.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}