Recent advancements in deep learning algorithms have catalyzed the proliferation of algorithms in the domain of point cloud processing. Notable among these algorithms are PointNet++ and RandLA-Net, distinguished for their computational efficiency and high accuracy, as evidenced by various studies [
4,
5]. The selection of PointNet++ and RandLA-Net as the focal point of this study stems from these promising outcomes. Within the realm of point cloud processing, in addition to PointNet++ and RandLA-Net, various other artificial intelligence algorithms have found utility. Lei et al. [
6] introduced a framework founded on fuzzy kernel separation for 3D point cloud segmentation. This framework incorporates the SegGCN (Segmentation Graph Convolutional Network) structure for segmenting point clouds, integrating fuzzy logic into discrete convolutional kernels tailored for 3D point cloud data. Challenges were encountered during segmentation, particularly in delineating areas characterized by small geometries. In a study by Liu et al. [
7], the under-utilization of semantic information in 3D data was addressed. They proposed the Point Context Encoding (PointCE) structure, aimed at integrating semantic information into 3D point clouds. Additionally, they introduced the Semantic Context Encoding Loss (SCE Loss) controller to guide the learning of semantic context features, obviating extensive hyperparameter tuning while ensuring high accuracy. Fan et al. [
8] focused on learning spatial features, introducing the Spatial Contextual Features (SCF) structure, distinct from that proposed by Liu et al. [
7]. SCF is designed to work harmoniously with different algorithms, facilitating evaluations with diverse algorithm integrations and datasets. Cheng et al. [
9] recognized the high costs associated with labeling in 3D point cloud segmentation and the sensitivity of current algorithms to label information. They proposed SSPC-Net, a semi-supervised, semantic point cloud segmentation network. SSPC-Net predicts points based on their semantic significance, employing 3D superpoints and superpoint graphs for partially predicting unlabeled data. Atik and Duran [
10] proposed an approach for enhancing deep learning-based 3D semantic segmentation results, leveraging 3D geometric features and filter-based feature selection with algorithms like RandLA-Net and superpoint graph. Hedge and Gangisetty [
11] introduced PIG-Net, an inception-based architecture for characterizing local and global features of 3D point clouds, demonstrated on the ShapeNet and PartNet datasets. Jiang et al. [
12] proposed the 3D PointSIFT algorithm, inspired by 2D SIFT, and verified its performance against prominent 3D segmentation algorithms using the S3DIS and ScanNet datasets. In a separate work by Duran et al. [
13], machine learning algorithms were applied to photogrammetric and LiDAR data, integrating color information into segmentation processes, with the MLP algorithm yielding the highest accuracy. Wu et al. [
14] proposed a novel network architecture for indoor point cloud semantic segmentation, addressing the limitations of existing methods that focus primarily on complex local feature extraction, neglecting global features. Their method, based on anisotropic separable set abstraction (ASSA), includes an improved ASSA module for enhanced local feature extraction, an inverse residual module to improve global feature extraction, and a mixed pooling method to fuse coarse- and fine-grained features. Lin et al. [
15] tackled the common issue of over- and under-segmentation arising from nonhomogeneous objects of interest and uneven sampling densities. Their approach combines conditional and voxel filtering to reduce the spatial range and amount of point cloud data. They further segmented the spatial range into a concentric circular grid to simplify data processing and employed a dynamic threshold model for accurate ground point identification, particularly on uneven, broken, and sloped roads. Additionally, they utilized a point cloud homogeneity model to enhance ground point identification in vegetated areas. Ozturk et al. [
16] proposed a feature-wise fusion strategy of optical images and LiDAR point clouds to enhance road segmentation performance. Using high-resolution satellite images and LiDAR data, they trained a deep residual U-Net architecture, improving prediction statistics across different ResNet backbones. The integration of optical images and LiDAR point clouds enhances road segmentation performance, particularly in woodland and shadowed areas.
Despite the numerous studies conducted, there remains a limited number of research efforts that address operational problems while incorporating UAV systems and making substantial algorithmic contributions. Particularly notable is the scarcity of studies that effectively bridge the gap between academic research and industrial applications. This study addresses these gaps by introducing several key contributions. First, it presents a novel enhancement of the PointNet++ algorithm by integrating color attributes, which significantly improves segmentation accuracy. Second, it demonstrates the application of advanced deep learning techniques to automate 3D object segmentation and detection in aerial defense operations, a critical area of interest. Lastly, the study provides a comprehensive evaluation using both photogrammetric and LiDAR-derived point cloud data, offering practical insights into the use of UAV systems for data acquisition and processing. These contributions not only advance the field of 3D point cloud segmentation but also offer valuable solutions for real-world applications involving UAV technology.












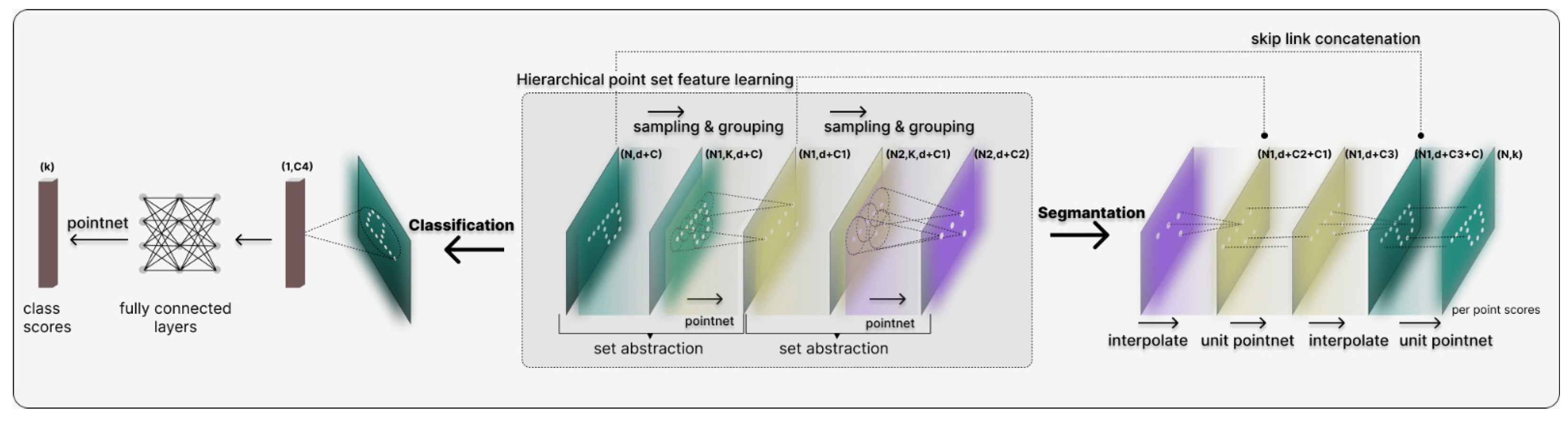










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}