1. Introduction
Visual target tracking is a critical research area within computer vision [
1], aiming to achieve continuous and stable tracking of a target across successive video frames based on the initial position and size of the target in the video sequence. Aerial remote sensing tracking, as a subset of visual tracking tasks, is fundamental to remote sensing image processing. It plays a pivotal role in numerous applications, including video surveillance [
2,
3], airborne detection [
4], intelligent transportation [
5], and various other domains.
Advances in UAV technology have significantly facilitated the acquisition of high-quality aerial remote sensing image data. Therefore, the study of UAV technology and its subtasks has garnered significant interest from researchers [
6,
7]. Aerial tracking tasks have emerged as a focal point of interest. However, unlike typical tracking tasks, aerial tracking faces unique challenges due to its distinctive imaging perspective [
8]. For example: 1. in actual application scenarios, drastic attitude changes in the UAV can lead to large-scale changes and rapid movements, requiring the algorithm to cope with target appearance changes; 2. a single aerial viewpoint can result in similar target interference, requiring the tracking algorithm to resist such interference; 3. complex and variable natural environments can produce problems like target occlusion, requiring the algorithm to handle occlusions as they occur; 4. aerial tracking tasks are often long and continuous, requiring the algorithm to have long-term tracking capabilities. Given these challenges, designing an accurate and robust real-time tracking algorithm for aerial tracking tasks remains challenging.
The emergence of deep learning has brought significant advancements in many fields [
9,
10,
11], and deep learning-based target trackers have demonstrated improved robustness [
12]. In recent years, various state-of-the-art deep learning-based tracking algorithms have been proposed [
13,
14]. Among these, the most representative is the Siamese tracker [
15], which has achieved satisfactory results in terms of both accuracy and efficiency. The Siamese-based tracker comprises three main stages [
16]. First, the deep features of the target template and the search area are extracted using the weight-sharing backbone network. Then, the similarity response of the features of the two branches is calculated. Finally, the best-matching search area is obtained through a classification regression network, and the corresponding tracking results are output. However, despite their impressive tracking performance, there are still some shortcomings. The features of the template and the search image are extracted independently, leading to a lack of interaction between their features before cross-correlation. The Siamese network cannot fully utilize the features of the two branches to suppress background clutter and enrich the template information in the search area. It performs poorly in challenging scenarios such as large appearance changes, rapid camera motion, or interference from similar objects. This inevitably limits the application scenarios of the tracker. Additionally, it is generally believed that shallow features contain more texture information, whereas deep features possess more semantic characteristics. The former is beneficial for locating the target position, while the latter is more suitable for distinguishing the target from the background. Therefore, the localization network differs in the attention it pays to shallow and deep features. However, many networks overlook this aspect. They fuse the cross-correlation response maps of different layers into a single similarity response and use it as the input for the localization subnetwork.
To address these issues, we propose a contextual enhancement–interaction and multi-scale weighted fusion network for aerial tracking. The overall structure is illustrated in
Figure 1. Specifically, it consists of three main parts: a feature extraction network, a feature interaction network guided by the contextual enhancement–interaction module (CEIM), and a target localization network driven by the multi-scale weighted fusion (MSWF) module. In the CEIM, the features from the two branches are first independently encoded by the Transformer-based enhancement module (TEM) to strengthen their representations. Then, a spatial cross-attention module (CAM) is used in parallel to aggregate the rich contextual interdependencies between the corresponding layers of the template and search features. Finally, the two features are fused using element-wise addition, obtaining three different levels of the similarity response. Combining the Transformer-enhanced template and cross-attention enhances the network’s ability to distinguish between similar distractors and complex backgrounds. This way, the tracker achieves more accurate and stable tracking. Additionally, we designed a selective fusion module that emphasizes the deep and shallow similarity responses to generate a better feature representation as input for target localization, enabling the network to achieve better tracking performance.
In summary, our work can be summarized as follows:
We introduce a novel tracker designed specifically for aerial tracking, capable of achieving accurate and stable tracking across diverse and complex aerial scenarios.
To mitigate insufficient information exchange between the template and search branches, we designed the contextual enhancement–interaction module (CEIM). This module facilitates interaction between the two branches at three different levels, thereby bolstering the algorithm’s ability to handle complex scenarios.
We introduce a new fusion module named multi-scale weighted fusion (MSWF), which dynamically learns and assigns weights to cross-correlation response maps across three different levels, enhancing the algorithm’s ability to generate robust responses.
We conducted experiments on four tracking benchmarks: DTB70, UAV123, UAV20L, and UAV123@10fps. Our results demonstrate that the proposed network exhibits high stability and effectiveness.
The rest of this paper is organized as follows: In
Section 2, we introduce Siamese-based trackers. In
Section 3, the details of our tracker are described in detail.
Section 4 presents the details of the experiments performed, including ablation experiments and a series of comparative experiments. Finally, the discussion and conclusion are given in
Section 5.
2. Related Work
The Siamese model was initially used for signature verification, and its simple yet efficient dual-branch structure later gained significant attention and gradually expanded into the field of object tracking. With the rapid evolution of deep learning, the precision of object tracking has been significantly enhanced. Consequently, the Siamese network is considered one of the most promising tracking technologies at present. It initially extracts the features of the search and template images separately through two weight-sharing backbone networks. Then, it utilizes a similarity function to calculate the resemblance between the template from the first frame and subsequent search images, enabling the realization of object tracking.
SINT [
17] was the first to apply the Siamese network to tracking tasks, pioneering its use and directly learning the matching function between two branches to address the tracking task through similarity. SiamFC [
18] determines the object’s position in each frame by comparing similarities across different locations in the search image and the template features, achieving an end-to-end deep learning-based tracking method. However, this approach requires strict translational invariance for correlation operations. SiamRPN [
19] introduces the RPN network, transforming the tracking task from a similarity matching problem between two branches into a classification problem of distinguishing the target foreground from the irrelevant background. By presetting different anchor boxes at the same location, it improves the accuracy and robustness of the task. DaSiamRPN [
20] improves tracking ability by solving the problem of imbalanced training data distribution. SiamRPN++ [
21] employs a deeper feature extraction network to achieve better tracking performance, but it overlooks the advantages of deep network feature fusion. However, anchor-based tracking networks are sensitive to predefined anchor box parameters and struggle to handle object deformations. Trackers like SiamCAR [
22], SiamBAN [
23], and SiamFC++ [
24] have been proposed to address this issue. They use an anchor-free mechanism to reduce the computational load and achieve faster and more stable tracking.
The attention mechanism emphasizes the importance of features that have been validated by many tracking algorithms for their effectiveness. RASNet [
25] introduced attention models into target tracking, proposing three models, namely, the general attention mechanism, the residual attention mechanism, and the channel attention mechanism, achieving good tracking results. SiameAttn [
26] integrates self-attention and cross-attention to form Deformable Siamese Attention Networks, enabling feature communication between the two branches. However, it overlooks spatial-level communication between the branches. SiamAPN++ [
27] utilizes the attention mechanism to form the Attention Aggregation Network, achieving real-time aerial tracking.
The Transformer was first proposed in the literature [
28] for natural language processing applications. The basic Transformer module is the attention module, which aggregates information from the entire input sequence. With the success of Transformers in other vision tasks, many approaches have emerged in recent years that use Transformers to improve tracking performance. HIFT [
29] directly employs a Transformer to fuse multi-scale feature information, but it is difficult to achieve real-time tracking. TMT [
14] considers it important to transfer information across multiple frames to reinforce each other. It obtains good tracking by introducing a Transformer structure to bridge multiple template frames for timing information. TCTrack [
30] uses the Transformer architecture to enhance feature extraction and improve the inter-correlation response maps using temporal information.
All of the above trackers achieve impressive results; however, they perform poorly in challenging scenarios like long-term tracking and the aerial tracking of similar targets. Most of them do not focus on information exchange between the two branches. Furthermore, the tracking network prediction head only pays attention to the fused feature context, ignoring the complementary role of deep and shallow features, potentially reducing the accuracy of aerial tracking. To address these issues, we propose a new aerial tracking tracker that fully considers branch feature correlations, implicitly updates template features, and suppresses background noise in search areas. Additionally, we introduce a learnable multi-scale adaptive fusion module for deep and shallow features with weighted integration, emphasizing the cross-correlation response map of the target localization network.
3. Methods
In this section, we first introduce the overall structure of our proposed network and then provide the specific details of how we designed the network. The specifics include the CEIM and MSWF. The overall structure of the proposed network is displayed in
Figure 1. We denote the template and search images by
and
, respectively, their feature mappings by
and
, and feature shapes by
and
, where
represents the number of channels,
and
denote the height and width of the template features, and
and
represent the height and width of the search features.
3.1. Overall Structure
As shown in
Figure 1, firstly, the template and search region images are separately input into a weight-sharing backbone network to extract their respective three layers of deep features. To guide the network in establishing mutual dependencies between template and search region features and to enhance the feature expression capabilities of these two branches, we meticulously designed a contextual enhancement–interaction module. The cross-attention module and Transformer-based enhancement module are used to guide the features to focus on the similar information between branches and strengthen the feature representation before the cross-correlation operation. Then, the strengthened features are fed into the deep cross-correlation module to generate the cross-correlation response. The application of deep correlation enables us to obtain multiple response maps rich in similar information, which play a crucial role in subsequent prediction subnets, aiding in more accurately determining the target’s position. To further exploit and utilize the complementary advantages of cross-correlation response maps at different scales, we developed a multi-scale weighted fusion module. This module can adaptively learn and allocate weights for each hierarchical feature, performing effective response fusion. Finally, we pass the fused response maps to the target localization subnet to achieve precise target localization. In the following sections, we will elaborate on the working principles and advantages of both the contextual enhancement–interaction module and the multi-scale weighted fusion module.
3.2. Contextual Enhancement–Interaction Module
In many previous Siamese tracking networks, the template and search branches were mostly independent. However, we believe that allowing them to complement each other is highly meaningful. On the one hand, learning the target information from the template branch can make the features of the search branch more discriminative when multiple similar objects or occlusions occur during tracking, enhancing the saliency of target features and aiding the network in accurately identifying the target. On the other hand, for the template branch, encoding more contextual information from the search images is beneficial for challenging tracking scenarios such as long-term tracking and target deformation. At the same time, this can also be regarded as using the information in the search image to update the template, providing an implicit way for the network to adaptively update the target template features. In many past Siamese networks, the template was fixed and could not be updated online, which could lead to the network being unable to adapt to scenarios where the target undergoes significant deformation, which is common in long-term tracking. Moreover, using explicit template updates in Siamese networks could result in excessive computation and failure to meet real-time requirements. Therefore, adopting methods for implicit template updates can effectively address these issues.
Inspired by [
26], we designed a contextual enhancement–interaction module that allows for feature interaction between the template and search branches before cross-correlation, thus aggregating rich contextual interdependencies between the template and search images. However, unlike [
26], which did not consider spatial-level interactions, our approach directly utilizes self-attention weights from one branch to weight the channels of the other branch. In this scenario, weight computation is independently performed at the spatial level, lacking sufficient spatial-level interaction between the two branches. We propose a CEIM that concurrently addresses feature enhancement within each branch and feature interaction between branches. It contains two parts: a Transformer-based feature enhancement module for individual branches and a cross-attention module for feature interaction between branches. Next, we will elaborate on their operations.
3.2.1. Cross-Attention Module
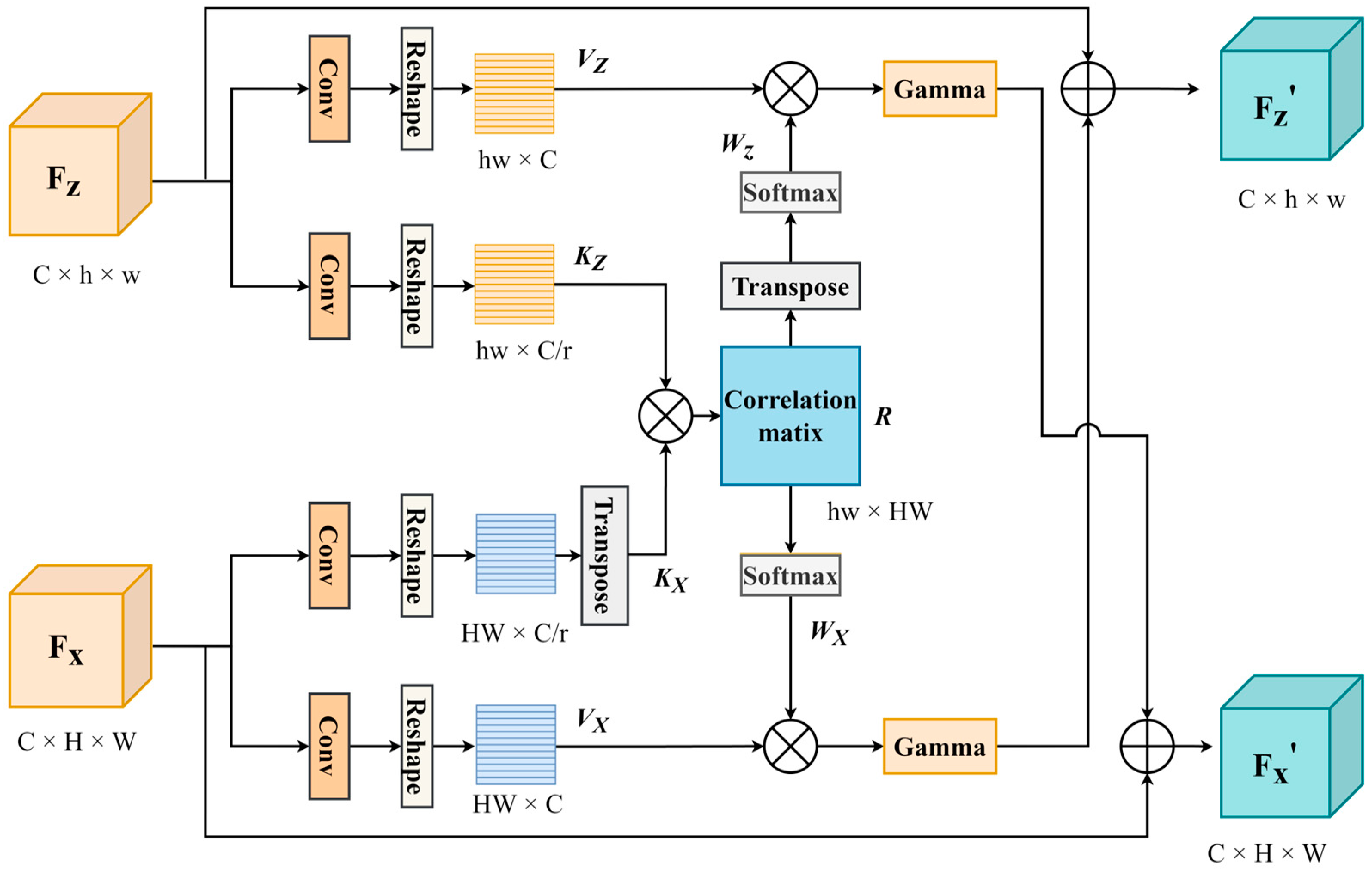
The cross-attention mechanism captures correlations between features. Therefore, we designed the CAM to capture correlations between the template and search features. The structure of the CAM is shown in
Figure 2.
The template and search features extracted by the backbone are input into the CAM, aiming to obtain their interaction features based on their content. To capture the similarity between feature maps, we employ dot-product computation to calculate the similarity.
For illustration purposes, we take one layer of features of the template branch as an example. Firstly, two 1 × 1 convolutional layers are used to adjust the number of channels to reduce the amount of calculation.
and
are obtained. Then, they are reshaped into 3D feature maps,
and
. Also, the same approach is used for the search features, obtaining
and
. The correlation matrix
is obtained by computing the dot product of each key in
with all keys in
. For computational convenience, we directly multiply
with the transpose of
to obtain the correlation matrix
, which has the shape of
. The formula is given by
Since each row in
represents the similarity between a specific spatial position in
and all positions in
, we apply the SoftMax function to the rows of
to obtain the weight matrix
. Then, we compute the weighted sum of all spatial positions in Vx with each row of
to obtain
. We employ the Gamma function to constrain the size of
and then perform element-wise addition with
to obtain
. The above process can be expressed as
Similarly, since each column in
represents the similarity between a particular spatial location in
and all locations in
, we apply the SoftMax function to the transpose in
to obtain the weight matrix
. We then perform a weighted sum of all spatial locations in
with each row of
to obtain
and similarly use the Gamma function to constrain the magnitude of
, and we perform an element-by-element summation to obtain
. The above process can be expressed as
3.2.2. Transformer-Based Enhancement Module
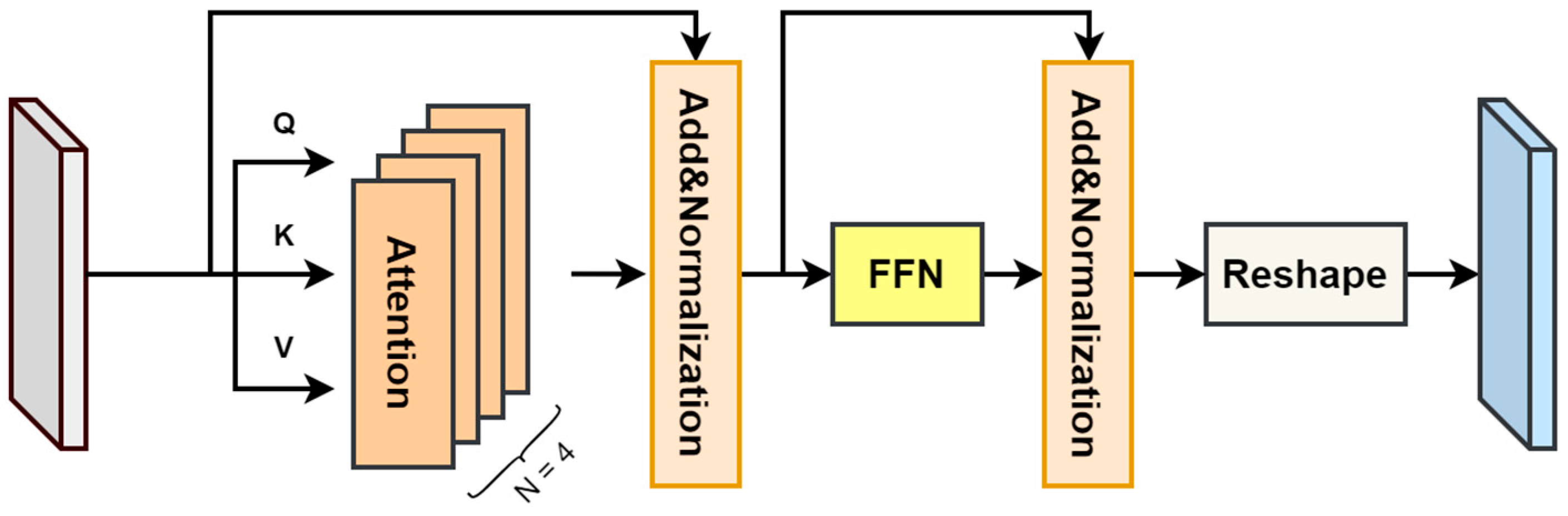
We not only realize the information interaction between the two branches through the CAM but also skillfully use the Transformer Encoder structure to independently encode the features. As shown in
Figure 3, the core components of this TEM structure include a multi-head attention module and a feedforward network. Taking the template branch as an example, we first define the features of each layer through three 1 × 1 convolutional layers for encoding and then reshape the encoded features into vector forms of queries
, keys
, and values
. Subsequently, we utilize dot-product operations to calculate the similarity between the queries
and the transposed keys
. To control the magnitude of the similarity scores, we scale them before applying the SoftMax operation, ensuring a more reasonable probability distribution as the output. Finally, the SoftMax function serves as the activation function to weight the values
, resulting in a weighted feature representation. The computational process of the single-head attention module can be precisely expressed through specific mathematical formulas. In addition, we use a head count of 4 for multi-head attention. The calculation process is as follows:
where
is the number of channels of the feature, and the value is 256.
The output enhanced by self-attention is added to the values
. Subsequently, layer normalization is applied. The result is then fed into a feedforward network consisting of two fully connected layers. The first layer utilizes the ReLU activation function, while the other layer does not apply any activation function. Additionally, residual connections and layer normalization are employed to ensure training stability and mitigate gradient disappearance. This process can be represented as
where
denotes layer normalization,
denotes the feedforward network, and
and
denote the weights and biases of the feedforward network.
Element-wise addition is utilized to fuse the output of the CAM with that of the TEM. Finally, a convolutional layer with a 3 × 3 kernel is applied to smooth the features, resulting in enhanced features for the template branch. These enhanced features, along with the corresponding enhanced features from the search branch, serve as the input to a deep cross-correlation operation to compute the cross-correlation response.
3.3. Multi-Scale Weighted Fusion Module
Based on Siamese trackers, after extracting deep features from the template and search branches, most commonly, cross-correlation operations are utilized to generate single-channel response maps. This approach is prone to overlooking crucial information since different feature channels contain distinct semantic details. Therefore, we aim to preserve as much useful information as possible in the generated response maps. Inspired by [
21], we introduce a depth correlation layer in our work to compute cross-correlations between feature maps channel-wise. Initially, the template and search features are divided into 256 two-dimensional matrices based on the number of feature channels, according to their depth. Subsequently, each pair of matrices from the template and search features is correlated to obtain the corresponding response results. Finally, the response results are concatenated depth-wise to produce multi-channel response maps. This allows the network to obtain multiple semantic similarity maps that retain rich information, which facilitates a more accurate determination of tracked target locations in subsequent prediction networks. The depth cross-correlation operation between the template features and search features, processed by the CEIM, can be represented as follows.
where
denotes the depth correlation operation.
Unlike predefined category tasks, such as classification or detection, visual object tracking deals with unknown target categories. The target category remains consistent throughout the tracking process. Depth and shallow convolutional features capture varying levels of image information. Shallow features typically contain information about textures and edges, aiding in target localization. Deep features, however, contain higher-level semantic information, helping to distinguish similar targets and improve tracking accuracy. A comprehensive consideration of both deep and shallow features is essential for effective object tracking. Treating all relevant response features equally may limit the tracking capability of the network. Combining deep and shallow features in a balanced manner can effectively utilize diverse image information for target tracking. Utilizing features from different levels holistically can enhance the robustness and performance of tracking algorithms, enabling effective tracking across diverse scenarios and target conditions.
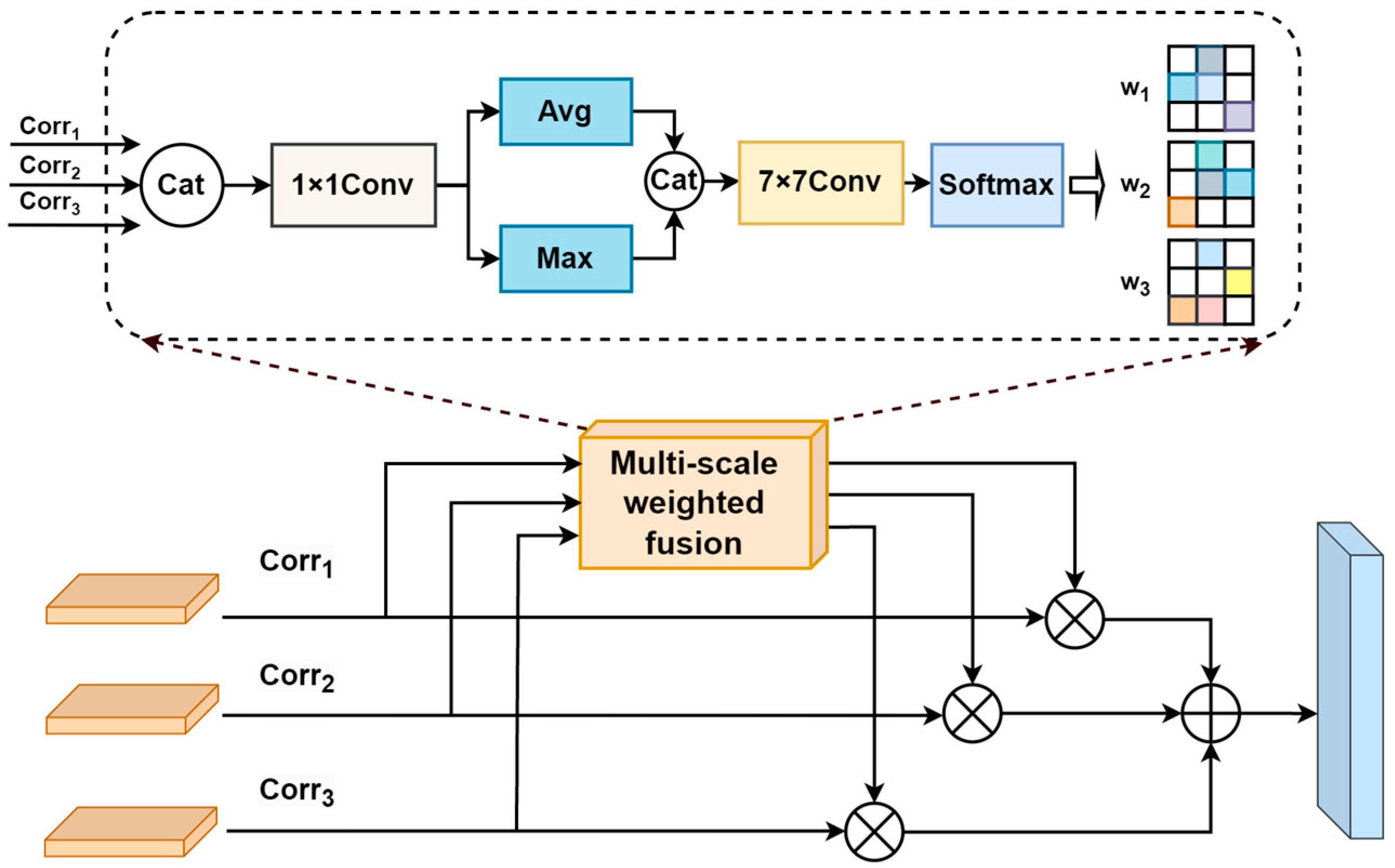
This paper proposes MSWF to guide the network to mine discriminative features, thus achieving more accurate tracking results. The structure of this module is shown in
Figure 4. First, response features from different convolutional depths are concatenated along the channel. Then, the channel count is downsampled to 256 using a 1 × 1 convolutional layer. Average pooling computes the average value of all elements, retaining background information, while max pooling focuses on the maximum element within the region, primarily preserving texture features. Therefore, we combine their advantages and employ both pooling methods, which enables the network to learn which information to pay more attention to. Next, after concatenating them along the channel dimension, a convolutional layer with a kernel size of 7 × 7 is applied to expand the number of channels to 3. Then, a SoftMax operation is applied across the channel dimension to obtain the weights for cross-correlation response features at three different scales. Finally, cross-correlation responses at different scales are weighted by these obtained weights and added element-wise to obtain the final fused features. The above operation can be expressed as
where
represents concatenation in the channel direction,
represents the cross-correlation response at three different levels, and
and
denote the average pooling and max pooling operations, respectively.
4. Results
In this section, first, the training and testing process is described in detail. Then, the test benchmarks and metrics are presented. The effectiveness of our proposed tracker in aerial remote sensing tracking is verified through ablation experiments. Finally, the performance of the proposed network is illustrated by comparing it with some SOTA trackers on the DTB70 [
31], UAV123 [
32], UAV20L, and UAV123@10fps benchmarks.
4.1. Implementation Details
Our platform utilizes the Windows 10 operating system, CUDA version 11.8, and the Python 3.7 programming framework with PyTorch 1.13 for training and validating algorithmic performance. The hardware platform consists of an AMD Ryzen 5 5600 CPU and an Nvidia GeForce RTX 3080 GPU. We leveraged datasets such as COCO [
33], GOT-10K [
34], VID, and LaSOT [
35] to train our proposed network. Subsequently, we fine-tuned the tracker using stochastic gradient descent with a batch size of 12. Employing a warm-up [
36] training strategy, we froze the ResNet50 backbone for the first 10 epochs and conducted a total of 20 epochs throughout the process. For the first five epochs, we used a warm-up learning rate ranging from 0.001 to 0.005. The learning rate was then reduced from 0.005 to 0.0005 for the subsequent 15 epochs.
4.2. Evaluation Index
We conducted a series of experiments with our tracker and compared it against state-of-the-art trackers on three UAV tracking dataset benchmarks, DTB70, UAV123, and UAV20L, as well as UAV123@10fps. We evaluated it using the One-Time Evaluation (OPE) procedure commonly used for target tracking. Specifically, the methodology uses the ground truth to initialize the first frame in the sequence. The tracker can then acquire subsequent target locations in the sequence based on the first frame’s information until the end of tracking, when no further information on the ground truth is acquired. Finally, the average precision and success rate are used as evaluation metrics to evaluate the performance of the tracker.
4.3. Ablation Study
To verify the effectiveness of the proposed structure,
Table 1 lists the success rate and accuracy metrics of different components and baselines. With the addition of the multi-scale weighted fusion module, the network’s perception of the cross-correlation response map with different depths is enhanced. The tracker achieves a 0.9% improvement in the success rate and a 1.2% improvement in accuracy. It integrates shallow texture features and deep semantic features well so that the network can deal with a variety of complex scenes. In addition, the CEIM was added to the model, which strengthens the feature representation of the branch itself and realizes the information exchange between branches. The tracking performance and robustness are further improved. Specifically, the tracker’s success rate increases by 2.3%, and the accuracy improves by 2.4%. When the two modules are used together, the tracker achieves a 65.5% success rate and an 83.9% accuracy. Notably, while the addition of both modules slightly reduces the running speed, our tracker still operates in real time.
4.4. Experiments on the DTB70 Benchmark
There are a total of 70 video sequences in the DTB70 benchmark. The videos were mostly captured at low altitudes, covering a variety of videos captured by UAV cameras. With the rapid movement of drones and quick changes in camera perspectives, targets undergo significant variations in their shape and aspect ratio, resulting in complex tracking scenarios. Additionally, the dataset defines 11 challenging attributes: scale variation (SV), aspect ratio variation (ARV), occlusion (OCC), deformation (DEF), fast camera motion (FCM), in-plane rotation (IPR), out-of-plane rotation (OPR), out-of-view (OV), background clutter (BC), surrounding similar objects (SOA), and motion blur (MB). These attributes cover various difficulties that may be faced during aerial tracking, making the evaluation of algorithm performance more comprehensive. We extensively compared algorithms with 15 state-of-the-art trackers, including SiamAttn [
26], TCTrack++, SiamCAR [
22], TCTrack [
30], SGDViT, HiFT [
29], SiamAPN++ [
27], LightTrack [
37], SiamSA [
38], SiamAPN [
39], SiamGAT [
40], SiamMask [
41], DASiamRPN [
20], and Ocean [
42], on the DTB70 benchmark to validate the tracking performance of the proposed tracker.
Overall Evaluation: The success rate and accuracy plots are shown in
Figure 5. Our tracker has a success rate of 0.655 and an accuracy of 0.838, which are 0.9% and 1.2% higher than those of SiamAttn with a similar structure, respectively. This is because SiamAttn only focuses on the interactions between branches and ignores similar response fusion; thus, our tracker exhibits better performance. The proposed network achieves the best results among all the trackers, which shows that our algorithm has superior accuracy and robustness.
Attribute-Based Evaluation: To analyze the capability of the tracker proposed in this paper in handling various complex scenes, we analyzed the six most common attributes in the DTB70 benchmark test: occlusion (OCC), fast camera motion (FCM), in-plane rotation (IPR), background clutter (BC), surrounding similar objects (SOA), and motion blur (MB). The success rate and accuracy plots are shown in
Figure 6.
As shown in
Figure 6, in the case of severe image motion (such as FCM, IPR), other types of information interference (such as BC, SOA, OCC), or motion blur (MB) of the target, our algorithm shows excellent performance by strengthening the information exchange between search and template branches and using the strategy of adaptive weighted fusion of multi-layer responses. Compared with other SOTA algorithms, our tracker achieves significant results. This indicates that the interaction between the two branches’ features and adaptive fusion features in our algorithm can effectively enhance the robustness of tracking in complex scenarios.
4.5. Experiments on the UAV123 Benchmark
The UAV123 benchmark consists of 123 video sequences, encompassing common remote sensing scenarios with objects such as bicycles, boats, cars, groups, pedestrians, trucks, UAVs, and wakeboards. It is one of the most commonly used aerial tracking datasets. In this test, our algorithm was compared to other SOTA algorithms, including Ocean, CGACD [
43], SiamCAR, SiamRPN++, SiamBAN, HiFT, SiamRPN, SiamDW [
44], and SiamFC.
The success rate and precision plots are shown in
Figure 7. Our algorithm ranks first with a success rate of 0.636 and an accuracy of 0.823. Compared with CGACD, the success rate and accuracy are 1.6% and 0.8% higher, respectively. This indicates the superior accuracy and robustness of our algorithm on the UAV123 dataset.
4.6. Experiments on the UAV20L Benchmark
The UAV20L benchmark is an aerial video dataset designed for long-term tracking, containing 20 long-time sequences. The average number of frames per test sequence in the UAV20L benchmark is about 3000 frames, and the maximum number of sequence frames reaches 5527 frames. As the number of video frames increases, the position prediction of the tracked target in subsequent frames becomes more difficult, and the shape becomes more irregular. The case of long-term tracking will lead to a variety of challenges in a video sequence, which requires the tracker to have good robustness. Therefore, in the actual UAV tracking application scenario for ground targets, only the trackers that overcome the challenge of long-term tracking can meet practical requirements.
We compared our algorithm with the following 10 SOTA algorithms with publicly available dataset results: SiamFC++, SiamBAN, SiamAPN++, SiamCAR, SiamAPN, SiamSA, SiamMask, TCTrack, and SGDViT [
45].
Overall Evaluation: As shown in
Figure 8, our tracker performs excellently in the long-term tracking scenario, with a success rate as high as 0.598 and an accuracy rate of 0.805, both among the top results. Compared with the baseline algorithm SiamCAR, our algorithm achieves a significant improvement of 7.5% and 11.8% in the success rate and accuracy, respectively. This significant advantage fully validates the effectiveness of our strategy in coping with long-term UAV ground-tracking scenarios. Unlike the baseline, our tracker enhances the interaction between the template and search branches to achieve better long-term tracking results. Our CEIM implements the implicit updating of templates and enhances the template representation itself. This prevents error accumulation due to over-updating.
Attribute-Based Evaluation: To further demonstrate the tracking performance of the proposed tracker in complex scenarios, a radar chart is used to compare the success rates of the nine challenging attributes in the UAV20L benchmark. As shown in
Figure 9, our algorithm significantly outperforms several other state-of-the-art algorithms in handling complex scenarios, such as fast motion, occlusion, viewpoint change, and low resolution. This proves that our algorithm can effectively tackle various complex scenarios encountered during the tracking process.
4.7. Experiments on the UAV123@10fps Benchmark
The UAV123@10fps benchmark was obtained by downsampling the UAV123 benchmark and contains 123 sequences with a frame rate of 10fps. This benchmark also contains 12 aerial tracking challenges, and thus, it is appropriate to use UAV123@10fps to evaluate our tracker.
Figure 10 shows the comparisons of our tracker with the other 12 state-of-the-art trackers on the UAV123@10fps dataset. The success and accuracy plots show that our tracker achieved the best performance, with 61.5% and 79.7%, respectively. Compared to the baseline SiamCAR, our method improved the success rate and accuracy by 1% and 2%, respectively. The reason for this is that SiamCAR neglects further enhancement of the branch’s features and does not effectively fuse the deep and shallow similarity responses. It also demonstrates the effectiveness of our strategy.
4.8. Qualitative Analysis
To intuitively showcase the tracking prowess of our algorithm and further emphasize its performance in handling challenging scenarios, we have visualized the tracking results using heatmaps, which vividly illustrate the tracker’s regions of interest. As depicted in
Figure 11, in the Bike1 sequence, where similar targets surrounding the target create interference, the baseline tracker diverts partial attention to the distracting objects, while our algorithm exhibits only a minor drift, maintaining a stable focus on the target. In the Boat8 sequence, the rapid movement of the target results in a significant amount of background noise, causing the baseline method to become distracted by the cluttered background. However, our algorithm remains accurate in capturing the target. In the Car1 sequence, despite the coexistence of partial occlusion and interference from similar targets, our algorithm’s attention remains unwavering, whereas the baseline method shifts its focus to the distracting objects. Lastly, in the Car13 sequence, the low resolution leads to a scarcity of usable features for the target itself, compounded by the added difficulty posed by similar surrounding objects. However, the attention of our method is still focused on the target and is not disturbed.
To further demonstrate the performance of our tracker in aerial tracking, we performed a tracking visualization comparison on four challenging video sequences on the DTB70 benchmark. The tracking results are visually compared between our tracker and three SOTA trackers, namely, siamAPN++, SiamCAR, and TCTrack++. The tracking results are shown in
Figure 12.
In the RcCar6 sequence, the four trackers suffered from drift due to aspect ratio variation (ARV), similar objects around (SOA), and motion blur (MB). However, our tracker quickly recovered the correct tracking of the target, while the baseline SiamCAR re-tracked the target only until the 220th frame with inferior accuracy compared to our tracker. The other two trackers failed to re-track, resulting in tracking failure. In the Sheep1 and SpeedCar4 sequences, facing challenges such as aspect ratio variation (ARV), deformation (DEF), fast camera motion (FCM), in-plane rotation (IPR), and similar objects around (SOA), only our tracker achieved successful tracking, proving the effectiveness of our strategy. For the Surfing3 sequence, including aspect ratio variation (ARV), fast camera motion (FCM), and background clutter (BC), our tracker stably tracked the target throughout the entire process.
5. Discussion and Conclusions
In this work, we propose a new Siamese tracker named contextual enhancement–interaction and multi-scale weighted fusion network to improve tracking performance in challenging UAV tracking scenarios, including similar targets, scale variations, and background clutter. The proposed tracker improves the tracking accuracy in two ways. Firstly, we introduce the contextual enhancement–interaction module (CEIM), which enhances the tracker’s feature representation capability. Using a cross-attention mechanism (CAM), this module effectively integrates contextual information across branches, suppressing background clutter in search features and enriching the features of the template branch. Additionally, a parallel Transformer-based enhancement module (TEM) reinforces feature representation. Secondly, we introduce the multi-scale weighted fusion (MSWF) module, which fuses similarity responses from different scales by learning weights for each level, thereby enhancing discriminative capabilities.
Ablation experiments on the DTB70 benchmark demonstrate the effectiveness of our CEIM and MSWF module in improving tracking accuracy. Comparative experiments on DTB70, UAV20L, UAV23, and UAV123@10fps benchmarks demonstrate that our tracker achieves efficient and accurate performance in aerial tracking tasks, comparable to state-of-the-art algorithms. Additionally, heatmap comparison experiments and qualitative analysis experiments further demonstrate the effectiveness of the algorithmic strategy in dealing with complex scenes. The proposed algorithm suppresses interference from similar targets by exchanging information between branches and enhancing feature representation, thereby improving target recognition. Employing MSWF to fuse deep and shallow texture and semantic features makes the algorithm more discriminative. Consequently, our tracker effectively manages diverse challenging attributes and accurately locates and sizes tracked targets.
We expect that the work presented in this paper will inspire more innovative research on UAV tracking algorithms. However, our algorithm still has some limitations, such as tracking speed. Although the algorithm can achieve real-time tracking, the tracking speed decreased with the addition of the CEIM and MSWF. And, as tracking speed is a critical issue in aerial tracking, looking to the future, we hope to balance the tracking speed and tracking accuracy to achieve faster and more accurate aerial tracking. We will work on further optimizing the network structure to make it more lightweight and meet the needs of more practical application scenarios, such as by using a more lightweight network backbone and adopting a lighter regression box acquisition method.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}