

DLSW-YOLOv8n: A Novel Small Maritime Search and Rescue Object Detection Framework for UAV Images with Deformable Large Kernel Net
Abstract
1. Introduction
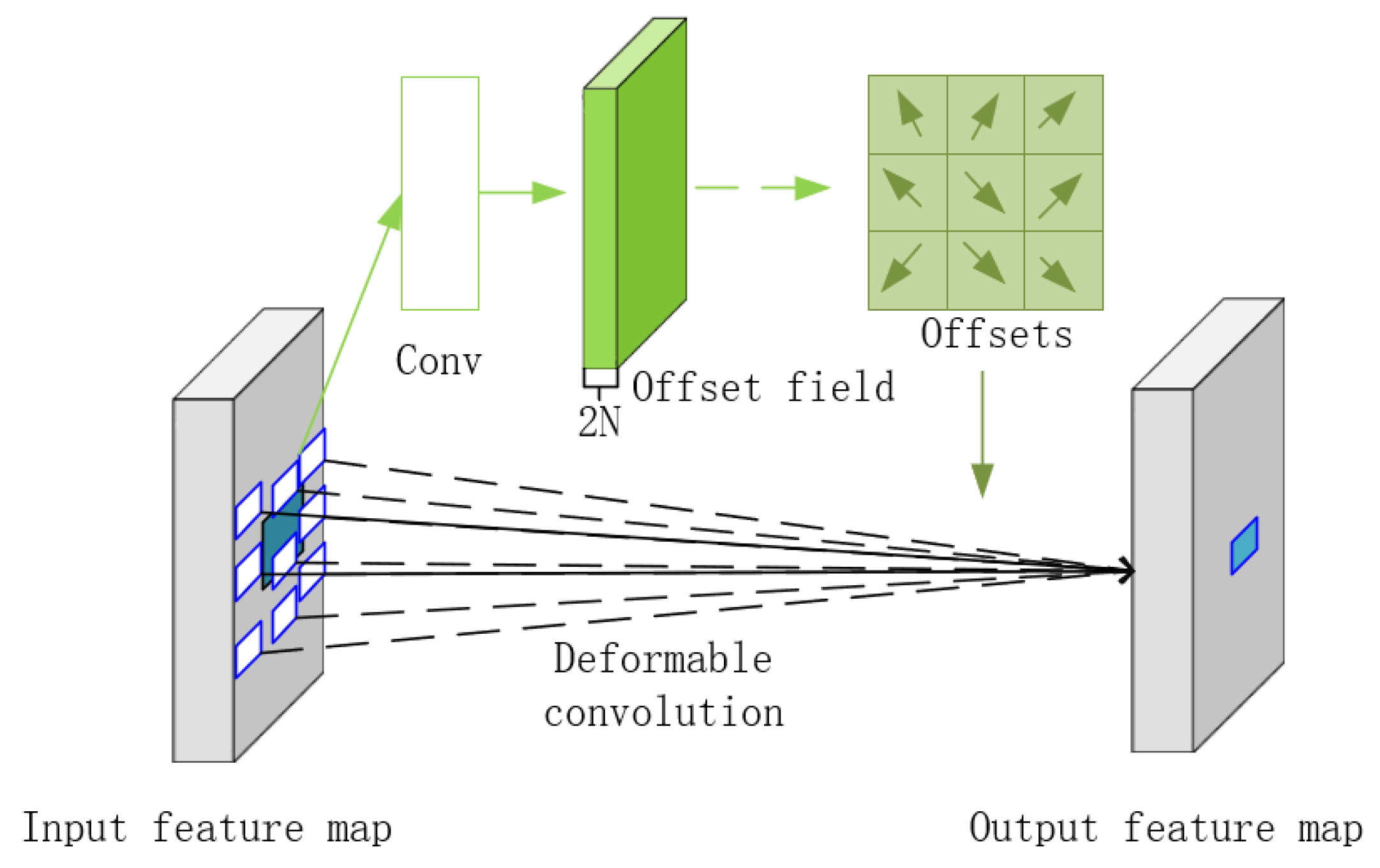
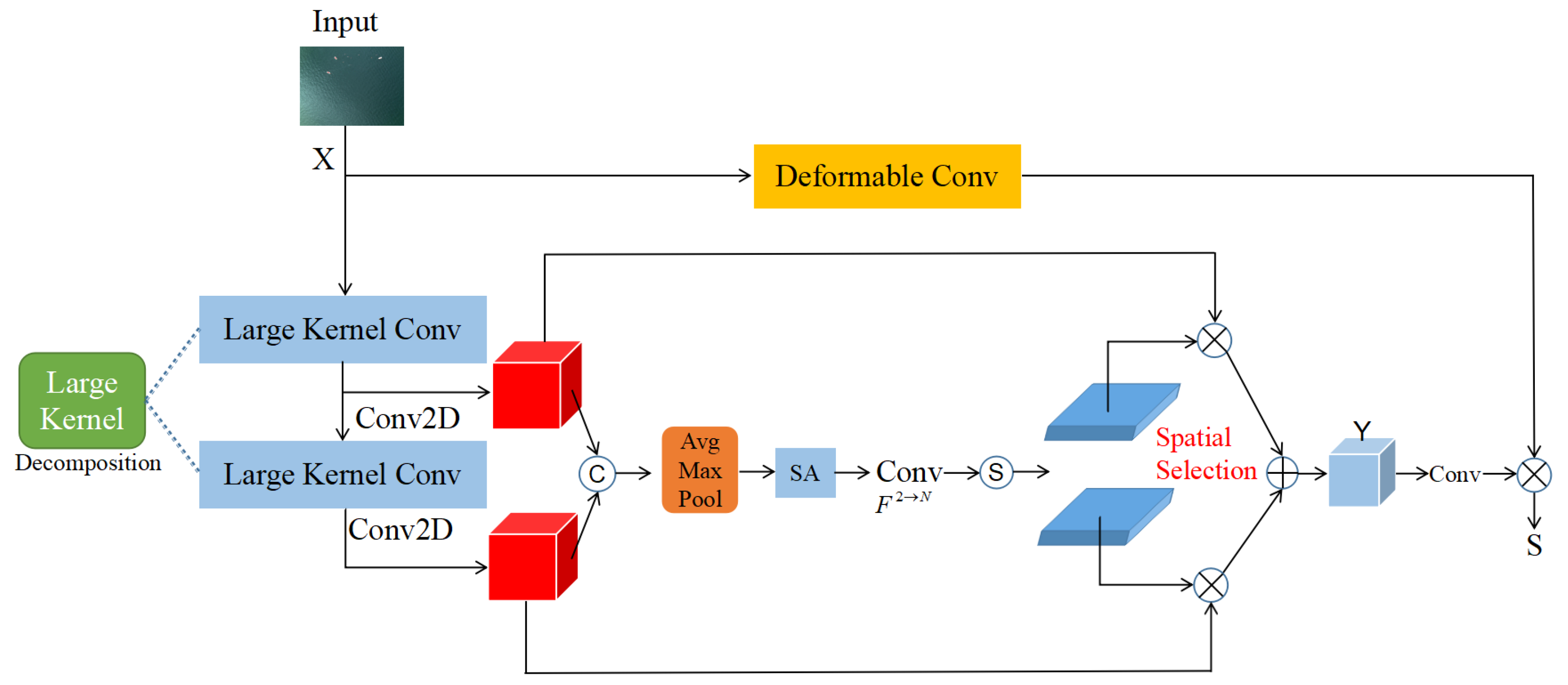
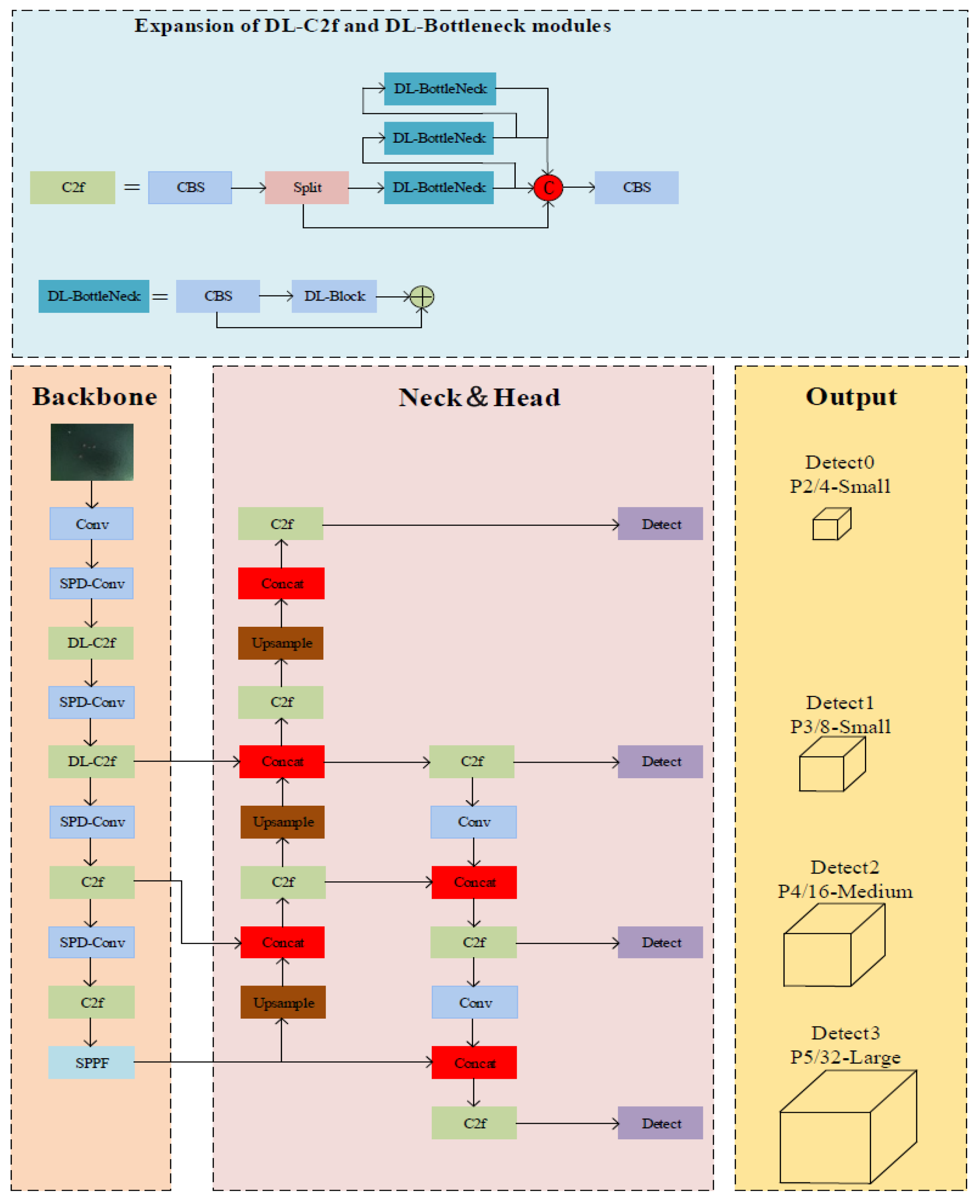
- Refining contextual understanding ability of the model. The Deformable Large Kernel Net(DL-Net) is integrated into the C2f module of the backbone network, which can enlarge the receptive field using a large kernel convolutional selection mechanism to effectively extract the small target’s spatial information. To prevent the loss of target boundary information caused by a fixed receptive field, deformable convolution is used to enhance the target’s boundary representation.
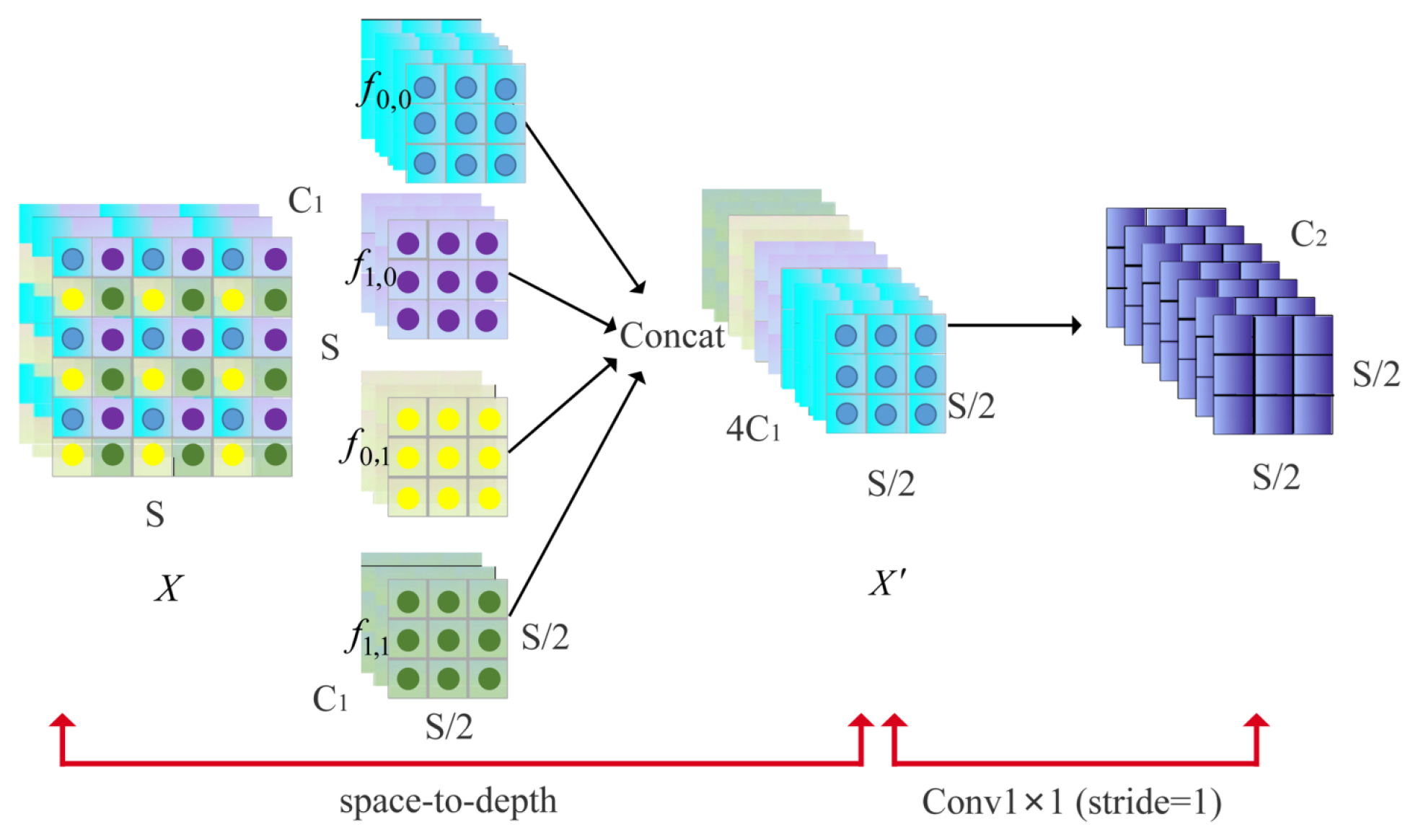
- Enhancing small target characterization representation. Small target detection heads are introduced into the shallow layers of the backbone network to handle insufficient small-target information in the high-level feature map. At the same time, the spatial depth layer is used instead of the convolutional and pooling layers to prevent the loss of fine-grained information.
- Improving small target localization performance. The loss function of Wise IoU v3 is considered to improve the accuracy of small target detection, and by dynamically adjusting the weight coefficients of the loss function, different pixel regions are balanced to improve small target localization performance.
2. Model and Proposed Method
2.1. Improvement Strategies
2.1.1. DL-Net
2.1.2. SPD-Conv
2.1.3. Loss Function
2.2. Introduction to the YOLOv8 Algorithm
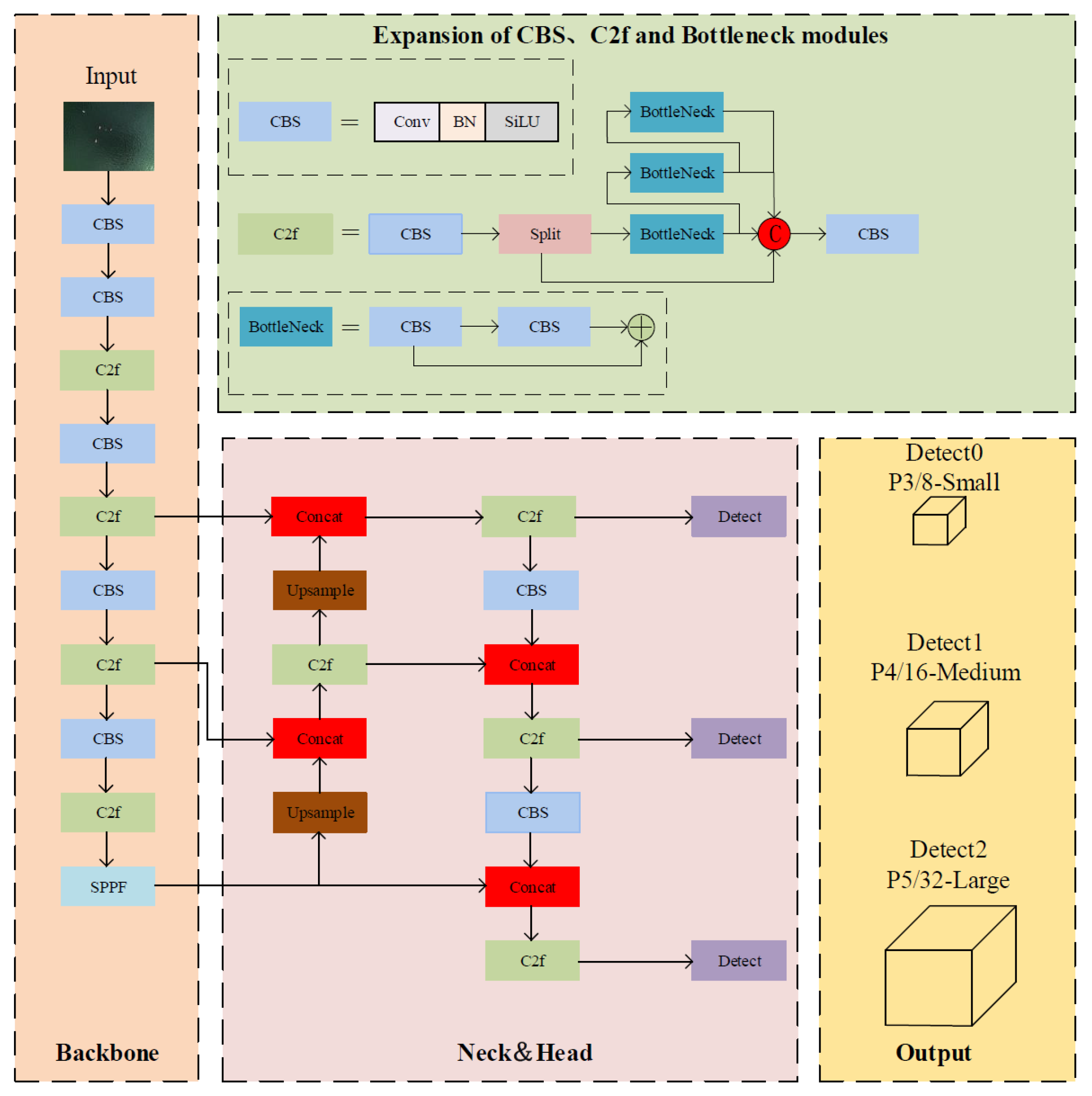
2.3. Improved Network Structure DLSW-YOLOv8n
3. Experiment
3.1. Dataset and Experimental Environment
3.2. Experimental Result
3.2.1. Detection Accuracy of DLSW-YOLOv8n
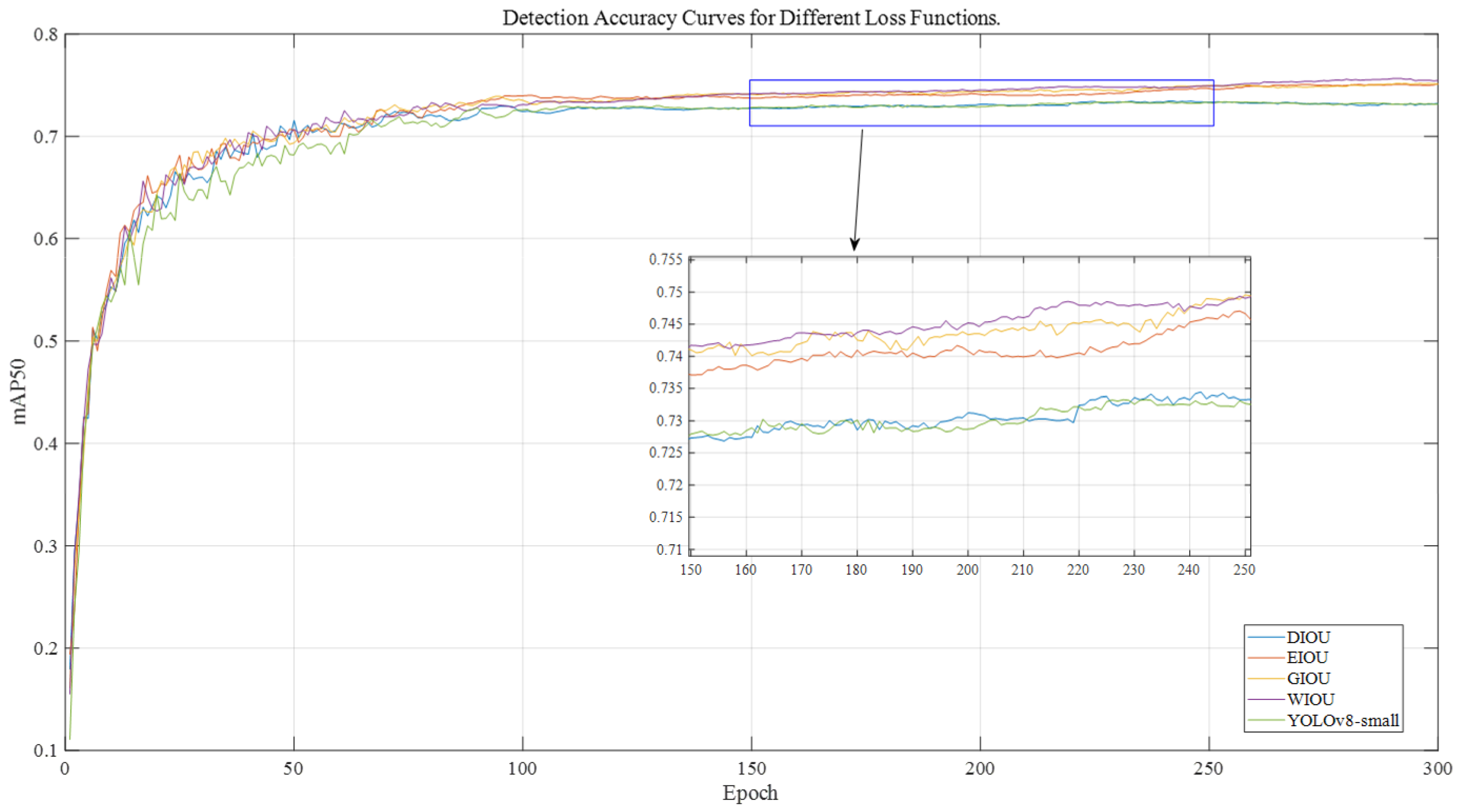
3.2.2. Comparative Analysis of Various Loss Functions in Experiments
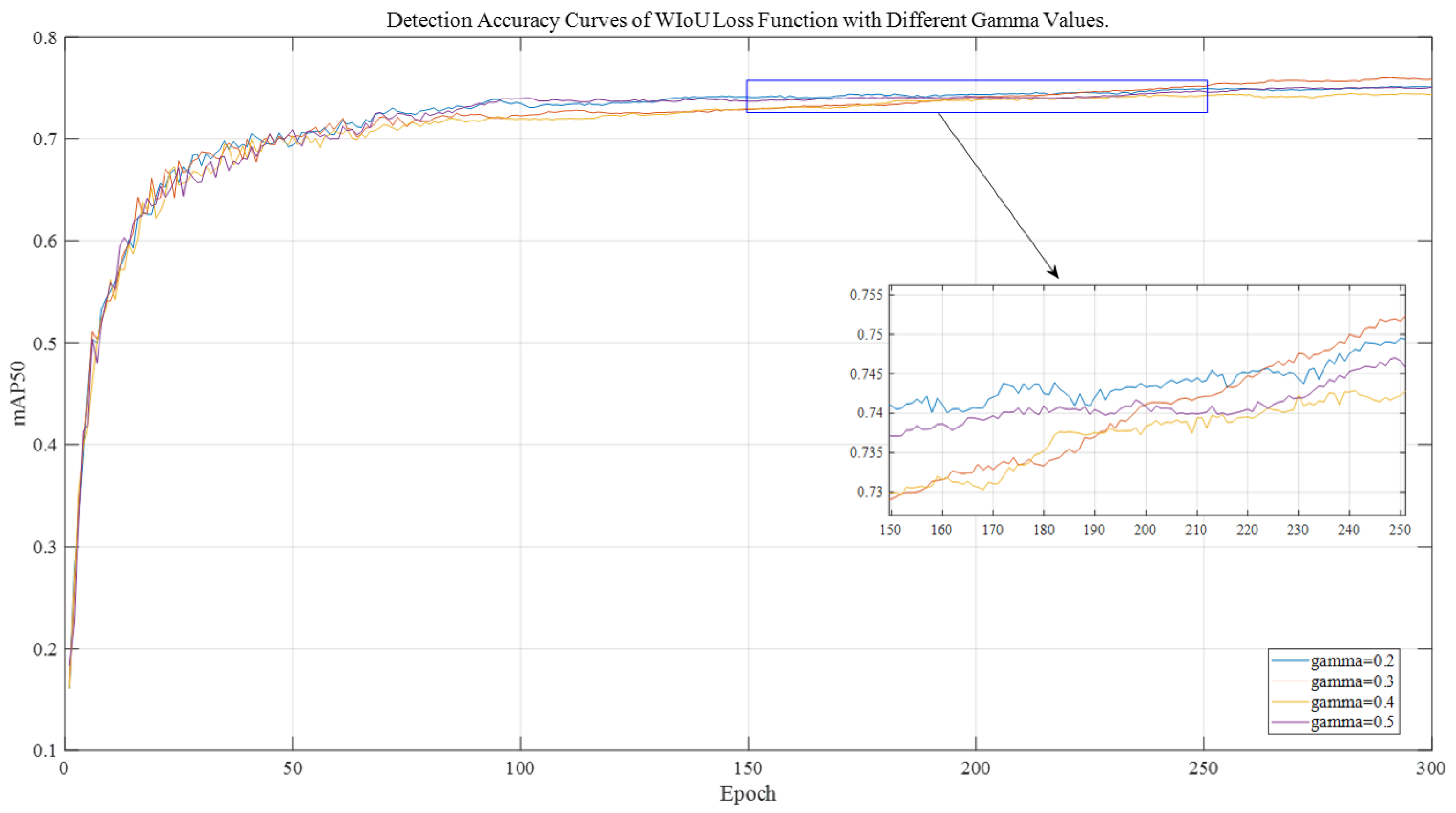
3.2.3. Comparing Different Gamma Values
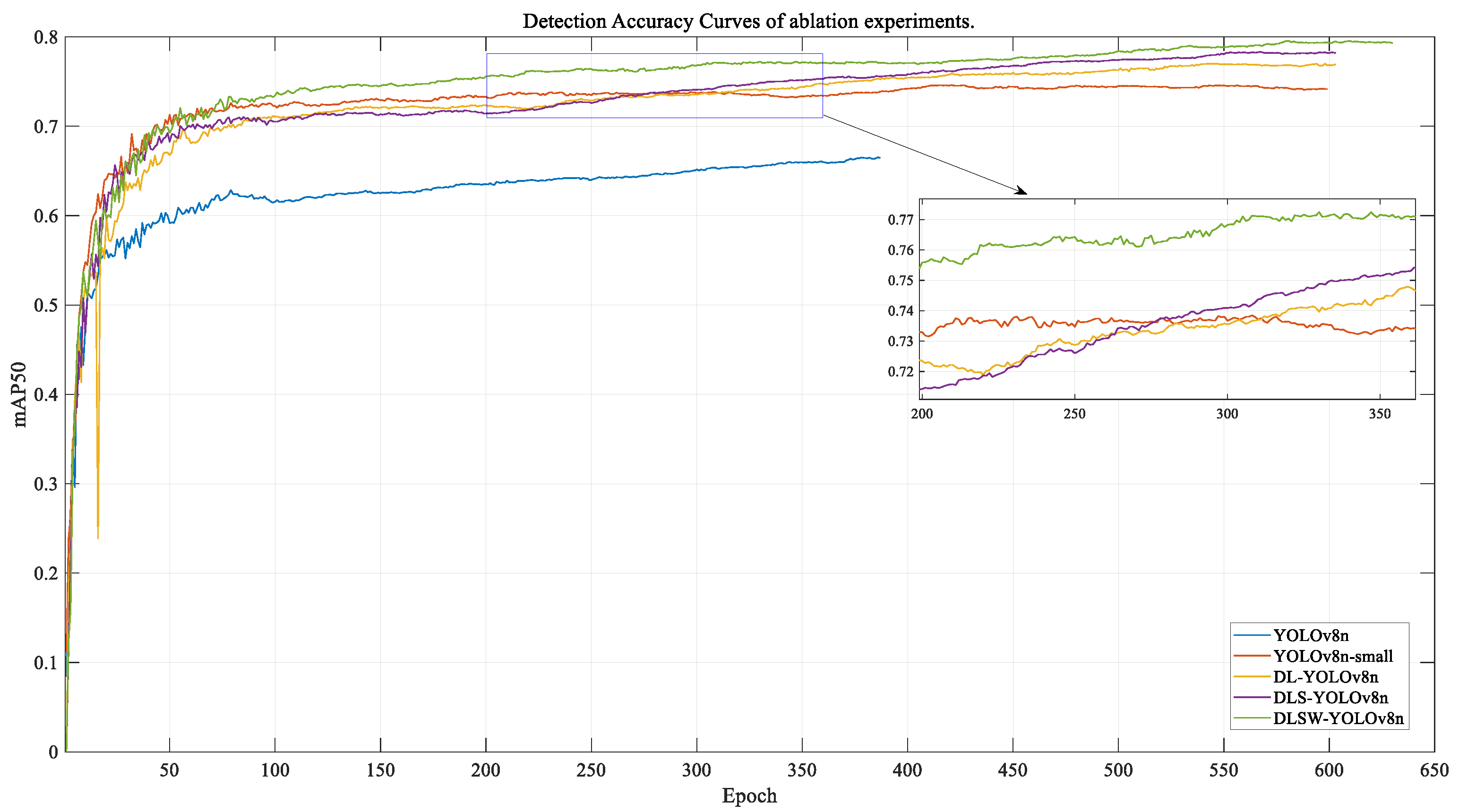
3.2.4. Ablation Experiments
3.2.5. Experimental Comparisons with Mainstream Algorithms
3.2.6. Algorithm Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Taylor, I.; Smith, K. United Nations Conference on Trade and Development (UNCTAD); Routledge: London, UK, 2007. [Google Scholar]
- Cho, S.W.; Park, H.J.; Lee, H.; Shim, D.H.; Kim, S.Y. Coverage path planning for multiple unmanned aerial vehicles in maritime search and rescue operations. Comput. Ind. Eng. 2021, 161, 107612. [Google Scholar] [CrossRef]
- Nunes, D.; Fortuna, J.; Damas, B.; Ventura, R. Real-time vision based obstacle detection in maritime environments. In Proceedings of the 2022 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Santa Maria da Feira, Portugal, 29–30 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 243–248. [Google Scholar]
- Nirgudkar, S.; Robinette, P. Beyond visible light: Usage of long wave infrared for object detection in maritime environment. In Proceedings of the 2021 20th International Conference on Advanced Robotics (ICAR), Ljubljana, Slovenia, 6–10 December 2021; pp. 1093–1100. [Google Scholar]
- Muhovič, J.; Mandeljc, R.; Bovcon, B.; Kristan, M.; Janez Perš, J. Obstacle tracking for unmanned surface vessels using 3-d point cloud. IEEE J. Ocean. Eng. 2020, 45, 786–798. [Google Scholar] [CrossRef]
- Bovcon, B.; Kristan, M. WaSR–AWater Segmentation and Refinement Maritime Obstacle Detection Network. IEEE Trans. Cybern. 2021, 52, 12661–12674. [Google Scholar] [CrossRef] [PubMed]
- Lin, L.; Goodrich, M.A. UAV intelligent path planning for wilderness search and rescue. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 709–714. [Google Scholar]
- Patel, J.; Bhusnoor, M.; Patel, D.; Mehta, A.; Sainkar, S.; Mehendale, N. Unmanned Aerial Vehicle-Based Forest Fire Detection Systems: A Comprehensive Review. SSRN 2023. [Google Scholar] [CrossRef]
- Cao, Z.; Kooistra, L.; Wang, W.; Guo, L.; Valente, J. Real-time object detection based on uav remote sensing: A systematic literature review. Drones 2023, 7, 620. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, S.; Chen, Y.; Huang, W. Application of UAV and computer vision in precision agriculture. Comput. Electron. Agric. 2020, 178, 105782. [Google Scholar]
- Ke, Y.; Im, J.; Son, Y.; Chun, J. Applications of unmanned aerial vehicle-based remote sensing for environmental monitoring. J. Environ. Manag. 2020, 255, 109878. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Ma, D.; Dong, L.; Xu, W. Detecting infrared maritime dark targets overwhelmed in sunlight interference by dissimilarity and saliency measure. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, T.; Pang, B.; Zhang, L.; Yang, W.; Sun, X. Sea surface object detection algorithm based on YOLO v4 fused with reverse depthwise separable convolution (RDSC) for USV. J. Mar. Sci. Eng. 2021, 9, 753. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, H.; Wang, Y. GGT-YOLO: A novel object detection algorithm for drone-based maritime cruising. Drones 2022, 6, 335. [Google Scholar] [CrossRef]
- Sambolek, S.; Ivasic-Kos, M. Automatic person detection in search and rescue operations using deep CNN detectors. IEEE Access 2021, 9, 37905–37922. [Google Scholar] [CrossRef]
- Zhang, Y.; Yin, Y.; Shao, Z. An Enhanced Target Detection Algorithm for Maritime Search and Rescue Based on Aerial Images. Remote Sens. 2023, 15, 4818. [Google Scholar] [CrossRef]
- Bai, J.; Dai, J.; Wang, Z.; Yang, S. A detection method of the rescue targets in the marine casualty based on improved YOLOv5s. Front. Neurorobot. 2022, 16, 1053124. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q.; Ma, K.; Wang, Z.; Shi, P. Yolov7-csaw for maritime target detection. Front. Neurorobot. 2023, 17, 1210470. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16794–16805. [Google Scholar]
- Dai, j.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Sunkara, R.; Luo, T. No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects. arXiv 2022, arXiv:2208.03641. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Kiefer, B.; Kristan, M.; Perš, J.; Žust, L.; Poiesi, F.; Andrade, F.; Yang, M.T. 1st workshop on maritime computer vision (macvi) 2023: Challenge results. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 265–302. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameters (M) | GFLOPs (B) | AP50 | FPS |
|---|---|---|---|---|
| YOLOv8n | 3.01 | 8.2 | 0.664 | 47 |
| YOLOv8n-small | 2.93 | 12.4 | 0.744 | 44 |
| DLSW-YOLOv8n | 2.76 | 14.6 | 0.795 | 42 |
| Model (Epoch = 300) | AP50 | Box Loss | Cls Loss |
|---|---|---|---|
| YOLOv8n-small | 0.732 | 1.12 | 0.53 |
| YOLOv8n-small + EIOU | 0.752 | 1.15 | 0.55 |
| YOLOV8n-small + DIOU | 0.733 | 1.17 | 0.57 |
| YOLOV8n-small + GIOU | 0.751 | 1.11 | 0.54 |
| YOLOV8n-small + WIOU | 0.752 | 1.0 | 0.59 |
| Model (Epoch = 300) | Alpha | Gamma | AP50 |
|---|---|---|---|
| YOLOV8n-small + WIOUV3 | 1 | 0.2 | 0.751 |
| YOLOV8n-small + WIOUV3 | 1 | 0.3 | 0.759 |
| YOLOV8n-small + WIOUV3 | 1 | 0.4 | 0.743 |
| YOLOV8n-small + WIOUV3 | 1 | 0.5 | 0.752 |
| Model | Parameters (M) | GFLOPs (B) | AP50 |
|---|---|---|---|
| YOLOv8n | 3.01 M | 8.2 | 0.664 |
| YOLOv8n-small | 2.93 M | 12.4 | 0.744 |
| DL-YOLOv8n | 2.94 M | 15.8 | 0.769 |
| DLS-YOLOv8n | 2.76 M | 14.6 | 0.783 |
| DLSW-YOLOv8n | - | - | 0.795 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Z.; Xiao, Y.; Tao, F.; Si, P.; Zhu, L. DLSW-YOLOv8n: A Novel Small Maritime Search and Rescue Object Detection Framework for UAV Images with Deformable Large Kernel Net. Drones 2024, 8, 310. https://doi.org/10.3390/drones8070310
Fu Z, Xiao Y, Tao F, Si P, Zhu L. DLSW-YOLOv8n: A Novel Small Maritime Search and Rescue Object Detection Framework for UAV Images with Deformable Large Kernel Net. Drones. 2024; 8(7):310. https://doi.org/10.3390/drones8070310
Chicago/Turabian StyleFu, Zhumu, Yuehao Xiao, Fazhan Tao, Pengju Si, and Longlong Zhu. 2024. "DLSW-YOLOv8n: A Novel Small Maritime Search and Rescue Object Detection Framework for UAV Images with Deformable Large Kernel Net" Drones 8, no. 7: 310. https://doi.org/10.3390/drones8070310
APA StyleFu, Z., Xiao, Y., Tao, F., Si, P., & Zhu, L. (2024). DLSW-YOLOv8n: A Novel Small Maritime Search and Rescue Object Detection Framework for UAV Images with Deformable Large Kernel Net. Drones, 8(7), 310. https://doi.org/10.3390/drones8070310