
A Deep Reinforcement Learning-Based Intelligent Maneuvering Strategy for the High-Speed UAV Pursuit-Evasion Game


Abstract
1. Introduction
- To ensure the rigor and challenge of the research scenarios in this paper, variables that significantly affect the difficulty of the PE game are considered from multiple perspectives. These variables include the pursuer tracking strategy, the PE game parties’ relative motion relationships, and the performance parameters of the vehicle.
- During the design of the reward function, evasion, energy consumption, and subsequent trajectory constraints are considered comprehensively. The intelligent maneuvering strategy minimizes energy consumption during evasion while reserving space for subsequent trajectory constraints, provided that successful evasion is achieved.
- In order to reduce the difficulty of the agent’s preliminary exploration and accelerate the convergence speed of the PE game network, we propose a combination of “terminal” and “process” rewards, as well as “strong” and “weak” incentive guidance forms of reward function.
- This paper presents a novel integration of an intelligent algorithm with LOS angle rate correction, aimed at enhancing the sensitivity of high-speed UAVs to changes in LOS angle rate and improving maneuver timing accuracy. This approach allows the intelligent algorithm to generate a decision online, simultaneously with the correction, thereby improving the effectiveness and generalization ability of the proposed algorithm.
2. Pursuit–Evasion Game Model and Problem Formulation
2.1. The Pursuit–Evasion Game Model
2.1.1. Three-Degrees of Freedom Model for Both Sides of the Game
2.1.2. Relative Motion Model
2.1.3. The Guidance Law of the Pursuer
2.1.4. Autopilot Model
2.2. The Pursuit–Evasion Game Problem
3. Intelligent Maneuvering Strategy
3.1. Markov Decision Model
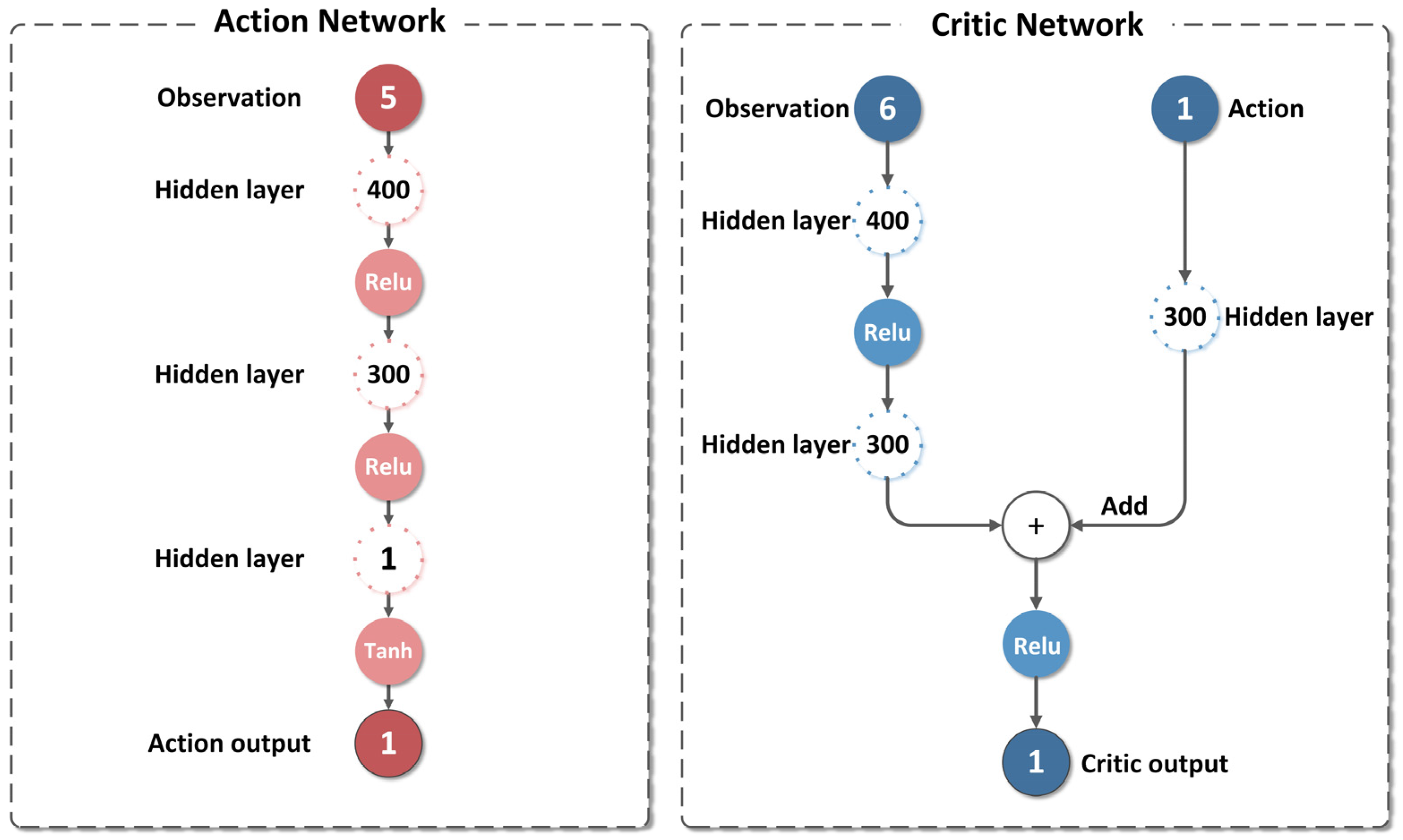
3.1.1. State Space
3.1.2. Action Space
3.1.3. Reward Function
- Miss distance-related reward function:where is the moment of rendezvous between the two sides of the game, is the miss distance, is the miss distance threshold for determining the success of evasion, and , , are the weighting coefficients. When the miss distance is less than , a larger punishment should be given, and the closer the miss distance threshold, the smaller the punishment; when the miss distance is larger than , a larger reward should be given, and on this basis, the larger the miss distance, the larger the reward.
- Energy consumption-related reward function:where is the actual overload of high-speed UAVs and is the weighting factor.
- Line-of-sight angle rate-dependent reward function:where is the rate of the LOS azimuth angle and is the weighting coefficient. When the LOS azimuth angle becomes larger, the lateral distance increases and a weak reward should be given, and vice versa, a weak punishment is given. The main role of this sub-reward function is to guide the agent to increase the LOS azimuth angle to enhance the probability of successful evasion. However, the LOS angle does not determine the success of evasion, so its reward and punishment are small.
- Reward function related to ballistic deflection angle for high-speed UAVs:where is the ballistic deviation angle of the high-speed UAV, is the ballistic deviation angle of the vehicle at the beginning of the game, and is the weighting coefficient. In order to deviate from the original trajectory as little as possible, it is necessary to ensure that the difference between the ballistic declination of the high-speed UAV and the ballistic declination at the initial moment is as small as possible.
3.1.4. The Termination Condition
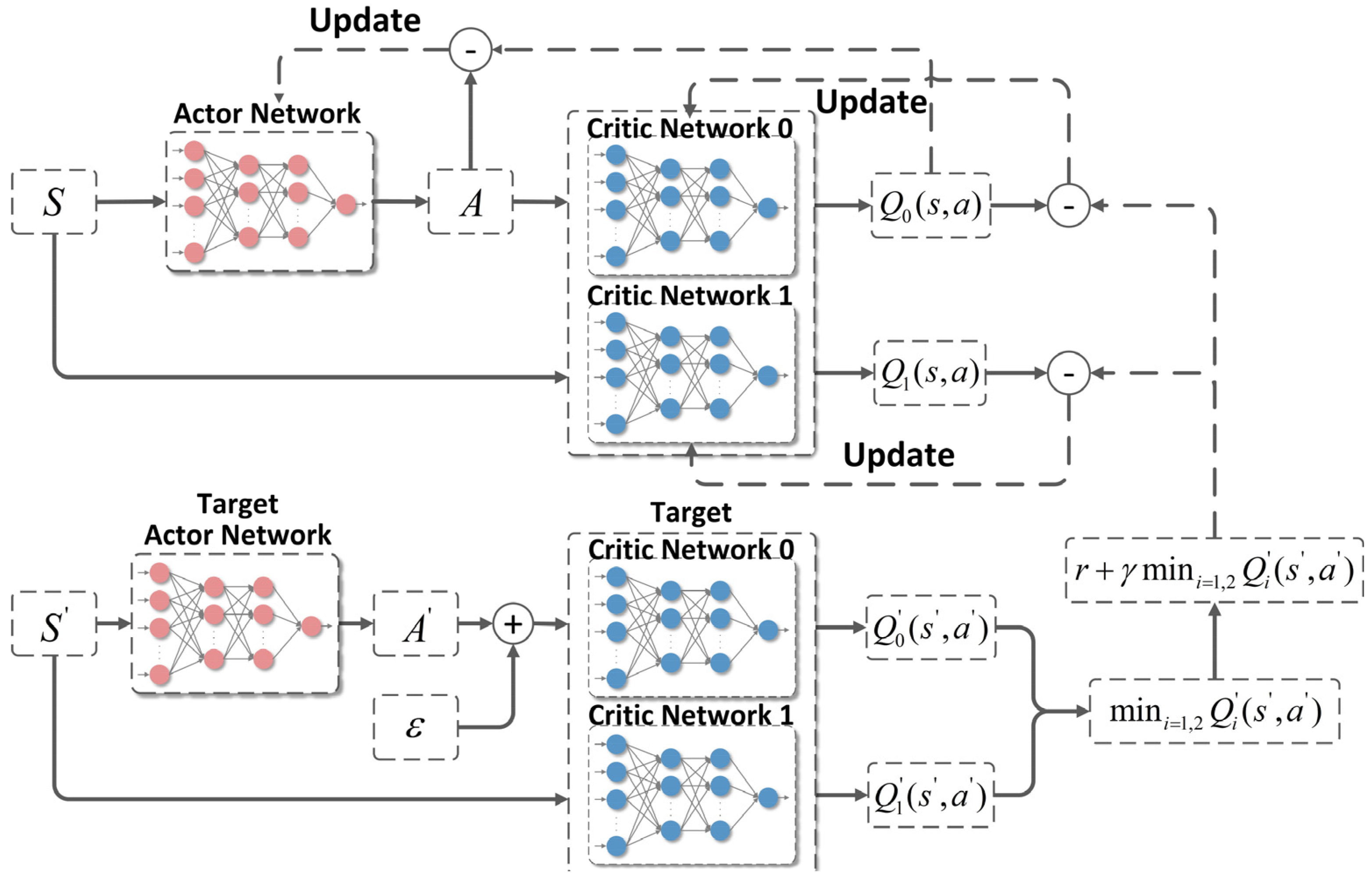
3.2. TD3 Algorithm
3.2.1. Double Network
3.2.2. Target Policy Smoothing Regularization
3.2.3. Delayed Policy Update
3.3. TD3 Algorithm Based on LOS Angle Rate Correction
- In the design of the reward function, evasion, energy consumption, and subsequent trajectory constraints are considered comprehensively, and the relevant sub-reward functions are designed. Evasion, energy consumption, and trajectory constraints are quantified as miss distance-related sub-reward function , overload-related sub-reward function , and trajectory deflection angle-related sub-reward function .
- In order to reduce the difficulty of the agent’s preliminary exploration and accelerate the convergence speed of the PE game network, we propose a combination of “terminal” and “process” rewards, as well as “strong” and “weak” incentive guidance forms of reward function. This is characterized by the fact that is the terminal reward; , , and are process rewards; and are strong rewards; and and are weak incentives.
- In enhancing the sensitivity of high-speed UAVs to changes in LOS angle rate and the accuracy of maneuver timing, this paper combines the intelligent algorithm with LOS angle rate correction for the first time. This integration of the intelligent algorithm with the correction enables the intelligent algorithm to generate the decision online, concurrently with the correction, which further improves the effectiveness and generalization ability of the proposed algorithm.
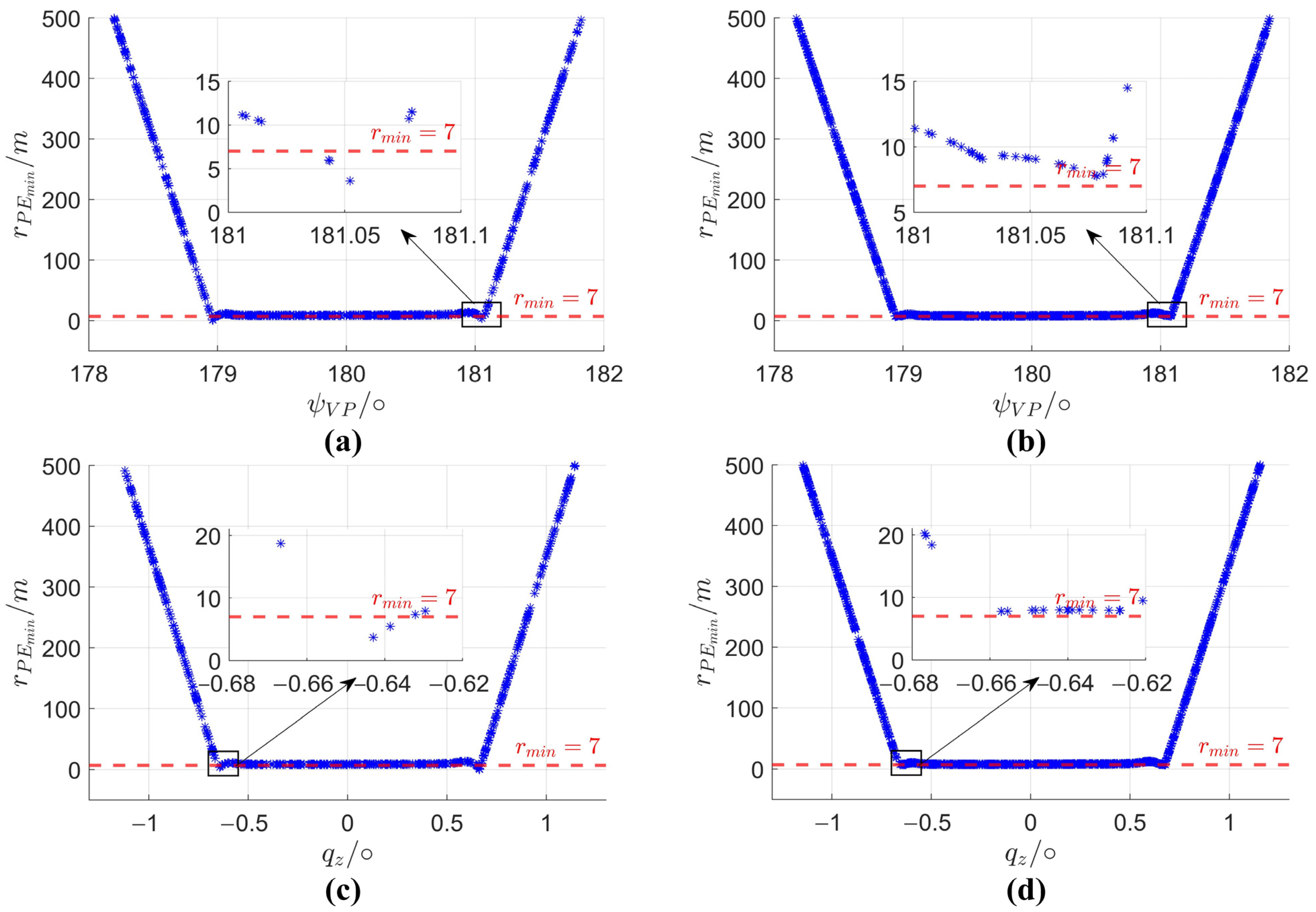
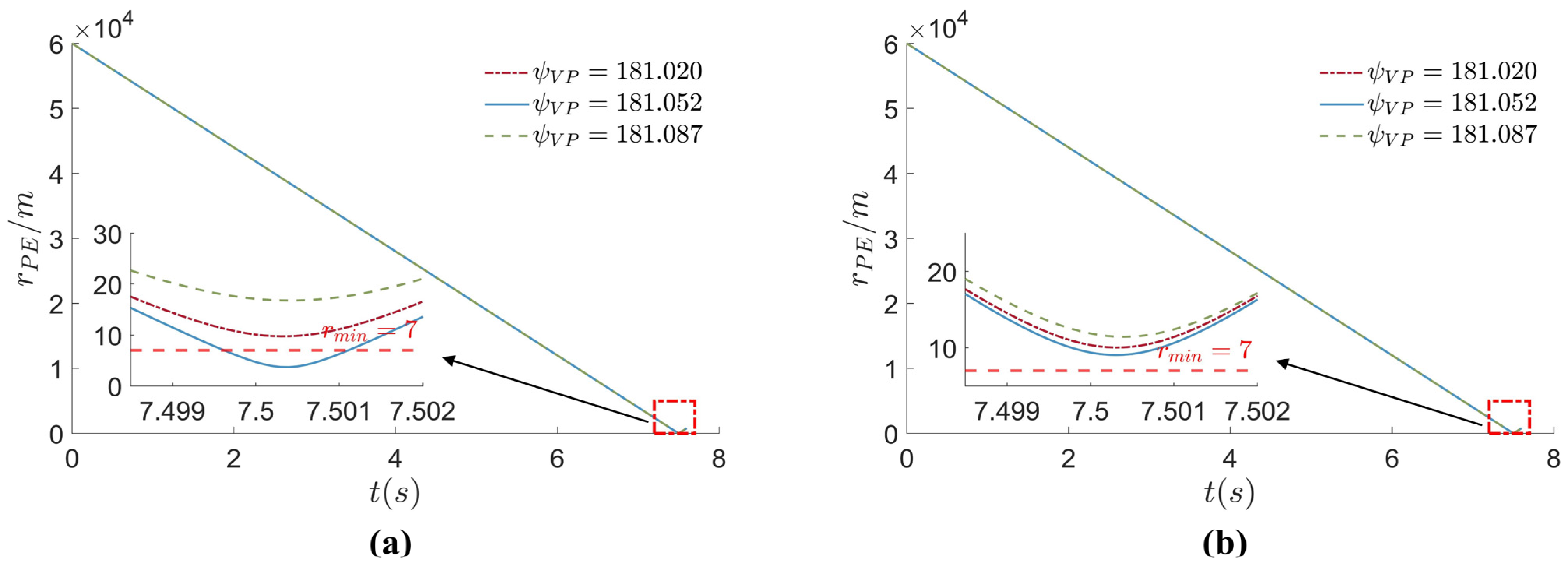
4. Simulation and Analysis
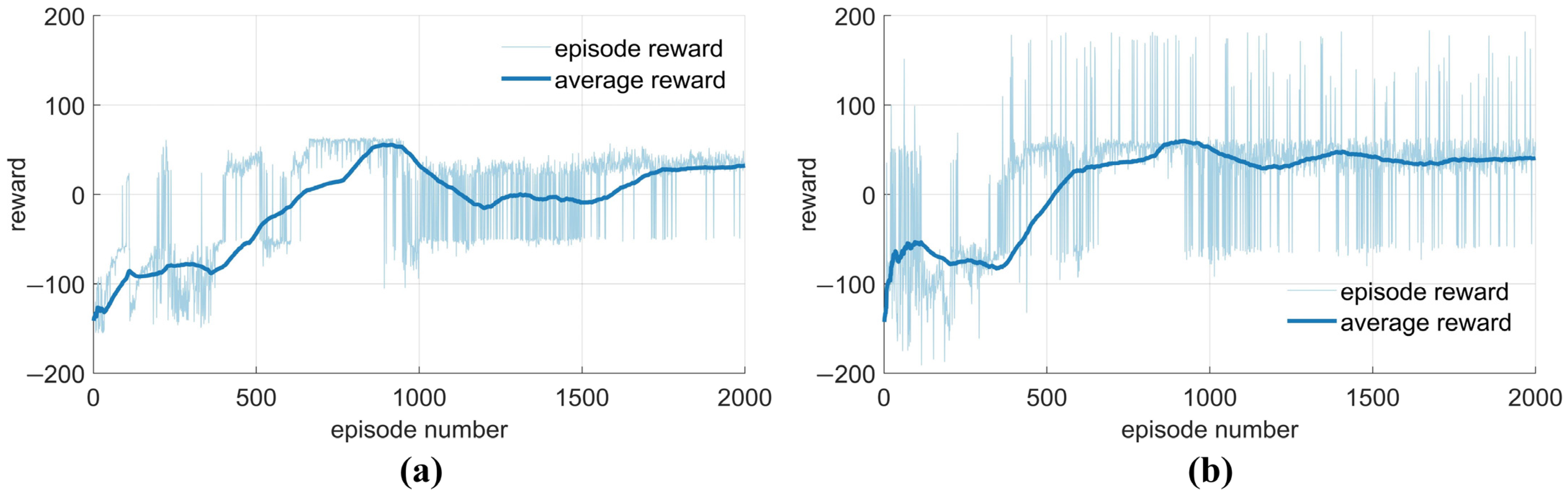
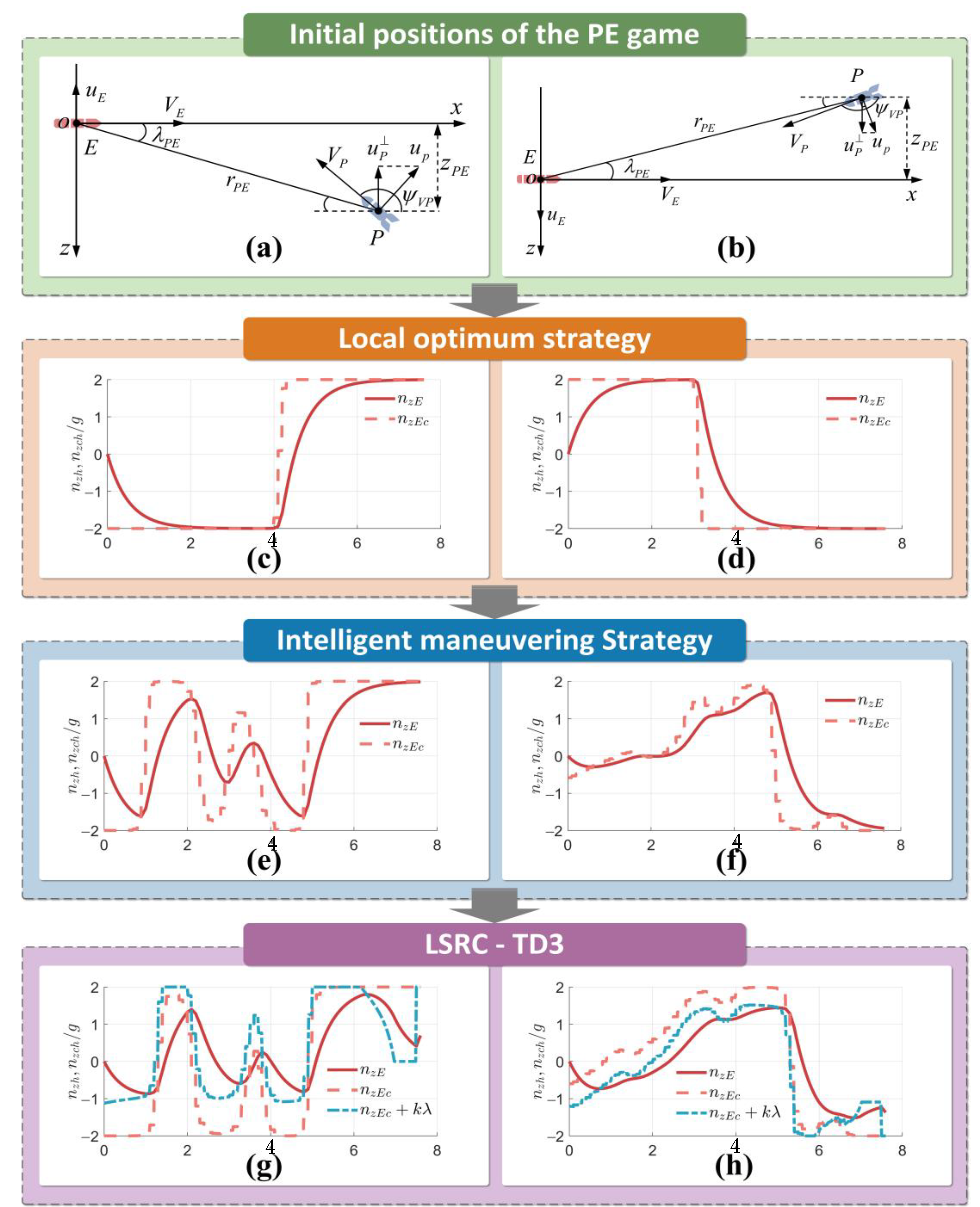
4.1. Initial Positions and Training Parameter Settings for PE Game
4.2. Simulation and Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, B.; Gan, Z.; Chen, D.; Sergey Aleksandrovich, D. UAV Maneuvering Target Tracking in Uncertain Environments Based on Deep Reinforcement Learning and Meta-Learning. Remote Sens. 2020, 12, 3789. [Google Scholar] [CrossRef]
- Zhuang, X.; Li, D.; Wang, Y.; Liu, X.; Li, H. Optimization of high-speed fixed-wing UAV penetration strategy based on deep reinforcement learning. Aerosp. Sci. Technol. 2024, 148, 189089. [Google Scholar] [CrossRef]
- Chen, Y.; Fang, Y.; Han, T.; Hu, Q. Incremental guidance method for kinetic kill vehicles with target maneuver compensation. Beijing Hangkong Hangtian Daxue Xuebao/J. Beijing Univ. Aeronaut. Astronaut. 2024, 50, 831–838. [Google Scholar]
- Li, Y.; Han, W.; Wang, Y. Deep Reinforcement Learning with Application to Air Confrontation Intelligent Decision-Making of Manned/Unmanned Aerial Vehicle Cooperative System. IEEE Access 2020, 8, 67887–67898. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, T.; Chen, W.; He, T. Optimal maneuver penetration strategy based on power series solution of miss distance. Beijing Hangkong Hangtian Daxue Xuebao/J. Beijing Univ. Aeronaut. Astronaut. 2020, 46, 159–169. [Google Scholar]
- Lu, H.; Luo, S.; Zha, X.; Sun, M. Guidance and control method for game maneuver penetration missile. Zhongguo Guanxing Jishu Xuebao/J. Chin. Inert. Technol. 2023, 31, 1262–1272. [Google Scholar]
- Zarchan, P. Proportional Navigation and Weaving Targets. J. Guid. Control Dyn. 1995, 18, 969–974. [Google Scholar] [CrossRef]
- Imado, F.; Uehara, S. High-g barrel roll maneuvers against proportional navigation from optimal control viewpoint. J. Guid. Control Dyn. 1998, 21, 876–881. [Google Scholar] [CrossRef]
- Zhu, G.C. Optimal Guidance Law for Ballistic Missile Midcourse Anti-Penetration. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2021. [Google Scholar]
- Shinar, J.; Steinberg, D. Analysis of Optimal Evasive Maneuvers Based on a Linearized Two-Dimensional Kinematic Model. J. Aircr. 1977, 14, 795–802. [Google Scholar] [CrossRef]
- Shinar, J.; Rotsztein, Y.; Bezner, E. Analysis of Three-Dimensional Optimal Evasion with Linearized Kinematics. J. Guid. Control Dyn. 1979, 2, 353–360. [Google Scholar] [CrossRef]
- Wang, Y.; Ning, G.; Wang, X.; Hao, M.; Wang, J. Maneuver penetration strategy of near space vehicle based on differential game. Hangkong Xuebao/Acta Aeronaut. Astronaut. Sin. 2020, 41, 724276. [Google Scholar]
- Guo, H.; Fu, W.X.; Fu, B.; Chen, K.; Yan, J. Penetration Trajectory Programming for Air-Breathing Hypersonic Vehicles During the Cruise Phase. Yuhang Xuebao/J. Astronaut. 2017, 38, 287–295. [Google Scholar]
- Yan, T.; Cai, Y.L. General Evasion Guidance for Air-Breathing Hypersonic Vehicles with Game Theory and Specified Miss Distance. In Proceedings of the 9th IEEE Annual International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (IEEE-CYBER), Suzhou, China, 29 July–2 August 2019; pp. 1125–1130. [Google Scholar]
- Yan, T.; Cai, Y.L.; Xu, B. Evasion guidance for air-breathing hypersonic vehicles against unknown pursuer dynamics. Neural Comput. Appl. 2022, 34, 5213–5224. [Google Scholar] [CrossRef]
- Liu, Q.; Zhai, J.W.; Zhang, Z.Z.; Zhong, S.; Zhou, Q.; Zhang, P.; Xu, J. A Survey on Reinforcement Learning. Chin. J. Comput. 2018, 41, 1–27. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: London, UK, 2018. [Google Scholar]
- Wang, X.F.; Gu, K.R. A penetration strategy combining deep reinforcement learning and imitation learning. J. Astronaut. 2023, 44, 914–925. [Google Scholar]
- Yan, P.; Guo, J.; Zheng, H.; Bai, C. Learning-Based Multi-missile Maneuver Penetration Approach. In Proceedings of the International Conference on Autonomous Unmanned Systems, ICAUS 2022, Xi’an, China, 23–25 September 2022; pp. 3772–3780. [Google Scholar]
- Zhao, S.B.; Zhu, J.W.; Bao, W.M.; Li, X.P.; Sun, H.F. A Multi-Constraint Guidance and Maneuvering Penetration Strategy via Meta Deep Reinforcement Learning. Drones 2023, 7, 626. [Google Scholar] [CrossRef]
- Gao, M.J.; Yan, T.; Li, Q.C.; Fu, W.X.; Zhang, J. Intelligent Pursuit-Evasion Game Based on Deep Reinforcement Learning for Hypersonic Vehicles. Aerospace 2023, 10, 86. [Google Scholar] [CrossRef]
- Zhou, M.P.; Meng, X.Y.; Liu, J.H. Design of optional sliding mode guidance law for head-on interception of maneuvering targets with large angle of fall. Syst. Eng. Electron. 2022, 44, 2886–2893. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Wang, J.; Bai, H.Y.; Chen, Z.X. LOS rate extraction method based on bearings-only tracking. Zhongguo Guanxing Jishu Xuebao/J. Chin. Inert. Technol. 2023, 31, 1254–1261+1272. [Google Scholar]
- Zhang, D.; Song, J.; Zhao, L.; Jiao, T. Line-of-sight Angular Rate Extraction Algorithm Considering Rocket Elastic Deformation. Yuhang Xuebao/J. Astronaut. 2023, 44, 1905–1915. [Google Scholar]
- Sun, C. Development status,challenges and trends of strength technology for hypersonic vehicles. Acta Aeronaut. et Astronaut. Sin. 2022, 43, 527590. [Google Scholar]
- Liu, S.X.; Liu, S.J.; Li, Y.; Yan, B.B.; Yan, J. Current Developments in Foreign Hypersonic Vehicles and Defense Systems. Air Space Def. 2023, 6, 39–51. [Google Scholar]
- Luo, S.; Zha, X.; Lu, H. Overview on penetration technology of high-speed strike weapon. Tactical Missile Technol. 2023, 5, 1–9. [Google Scholar] [CrossRef]
- Guo, H. Penetration Game Strategy for Hypersonic Vehicles. Ph.D. Thesis, Northwestern Polytechnical University, Xi’an, China, 2018. [Google Scholar]
- Li, K.X.; Wang, Y.; Zhuang, X.; Yin, H.; Liu, X.Y.; Li, H.Y. A Penetration Method for UAV Based on Distributed Reinforcement Learning and Demonstrations. Drones 2023, 7, 232. [Google Scholar] [CrossRef]
- Weiss, M.; Shima, T. Minimum Effort pursuit/evasion guidance with specified miss distance. J. Guid. Control Dyn. 2016, 39, 1069–1079. [Google Scholar] [CrossRef]
- Wang, Y.; Li, K.; Zhuang, X.; Liu, X.; Li, H. A Reinforcement Learning Method Based on an Improved Sampling Mechanism for Unmanned Aerial Vehicle Penetration. Aerospace 2023, 10, 642. [Google Scholar] [CrossRef]
- Wan, K.; Gao, X.; Hu, Z.; Wu, G. Robust motion control for UAV in dynamic uncertain environments using deep reinforcement learning. Remote Sens. 2020, 12, 640. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | High-Speed UAV | Pursuer |
|---|---|---|
| /km | (0,0) | (60,0) |
| Initial trajectory declination/deg | 0 | |
| Maximum available overload/g | 2 | 3 |
| Speed/m·s−1 | 3000 | 5000 |
| First-order time constant/s | 0.5 | 0.5 |
| 7 | / | |
| / | 4 |
| Hyperparameter | Value |
|---|---|
| Actor network learn rate | 1 × 10−3 |
| Critic network learn rate | 1 × 10−3 |
| Optimizer | adam |
| Gradient threshold | 1 |
| Experience buffer length | 1 × 106 |
| Discount factor | 0.99 |
| Target smooth factor | 5 × 10−3 |
| Mini batch size | 256 |
| Total number of rounds | 2000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, T.; Liu, C.; Gao, M.; Jiang, Z.; Li, T. A Deep Reinforcement Learning-Based Intelligent Maneuvering Strategy for the High-Speed UAV Pursuit-Evasion Game. Drones 2024, 8, 309. https://doi.org/10.3390/drones8070309
Yan T, Liu C, Gao M, Jiang Z, Li T. A Deep Reinforcement Learning-Based Intelligent Maneuvering Strategy for the High-Speed UAV Pursuit-Evasion Game. Drones. 2024; 8(7):309. https://doi.org/10.3390/drones8070309
Chicago/Turabian StyleYan, Tian, Can Liu, Mengjing Gao, Zijian Jiang, and Tong Li. 2024. "A Deep Reinforcement Learning-Based Intelligent Maneuvering Strategy for the High-Speed UAV Pursuit-Evasion Game" Drones 8, no. 7: 309. https://doi.org/10.3390/drones8070309
APA StyleYan, T., Liu, C., Gao, M., Jiang, Z., & Li, T. (2024). A Deep Reinforcement Learning-Based Intelligent Maneuvering Strategy for the High-Speed UAV Pursuit-Evasion Game. Drones, 8(7), 309. https://doi.org/10.3390/drones8070309