

A Dynamic Visual SLAM System Incorporating Object Tracking for UAVs


Abstract
1. Introduction
- (a)
- Combining object-wise matching and point-wise matching to track dynamic objects. It solves the problem of tracking instability caused by small target pixel regions and is of great significance for airborne observation systems.
- (b)
- A new trained network model for UAV datasets. It should be noted that the application scenarios of UAVs are different from traditional vehicle scenarios, and simple combinations cannot fully solve such problems. So, we trained a network model suitable for UAV datasets and achieved success through experimental testing.
2. Related Work
2.1. Dynamic Visual SLAM
2.2. Object Tracking in Visual SLAM
2.3. Visual Navigation for UAVs
3. Proposed Method
3.1. Overview
3.2. Pre-Processing Module
- (1)
- Dynamic object detection. Object detection plays a crucial role in identifying dynamic objects within a scene. For instance, buildings and trees are typically static, whereas vehicles may be either stationary or moving. By utilizing object detection results, we can further partition the semantic foreground into distinct areas, thereby facilitating the tracking of individual objects. The dynamic objects in UAV-borne images usually have fewer pixels and are mainly observed from a top-down view.Compared to pixel-level segmentation, some first-stage object detection networks, such as the YOLO series [47], can offer notable advantages in terms of detection accuracy and speed [48]. Hence, we employ the YOLOv5 network to detect potential dynamic objects and generate object bounding boxes. Our network model used the trained weights from COCO dataset [49] and then fine-tuned them using the VisDrone dataset [50]. A trained deep network model can effectively process UAV-borne images and extract potential dynamic objects.
- (2)
- Monocular depth estimation. Depth estimation facilitates the retrieval of depth information for every pixel in a monocular image, which is crucial for maximizing tracked points on dynamic objects. However, dynamic objects typically occupy only a small portion of UAV-borne images. By employing estimated depth, we can densely sample the monocular images, thereby ensuring stable tracking of moving objects.We have employed two methods to acquire scene depth. For static regions, we construct sparse maps and calculate the depth map through a triangulation algorithm. For the potential dynamic regions, we derive the depth map from monocular depth estimation. Specifically, we employ a cutting-edge monocular depth estimation method, i.e., NeW CRFs [45], to calculate the depth map. This method utilizes a novel bottom-up-top-down network architecture and has a significant improvement in the monocular depth estimation. The model is trained on the KITTI Eigen split [51]. The visualization results are shown in Figure 2b.
- (3)
- Optical flow estimation. Dense optical flow provides an alternative approach to establishing feature correspondences by matching sampling points across image sequences, thereby facilitating scene flow estimation. It assists in the consistent tracking of multiple objects, as the optical flow can assign an object recognition marker to each point in the dynamic region and propagate it between frames. This capability becomes particularly valuable in cases where object tracking fails, as dense flow can recover the object area.We use PWC-Net [52] as the optical flow estimation method. The model is initially trained on the FlyingChairs dataset [53] and subsequently fine-tuned on the Sintel [54] and KITTI training datasets [55]. The visualization results are shown in Figure 2c. The deep network trained in our work can effectively extract the optical flow of targets from drone images. These optical flows form some independent rough contours of objects.
3.3. Map Scale Restoration
3.4. Object Tracking and Positioning
4. Experimental Results
4.1. Experiment Setup
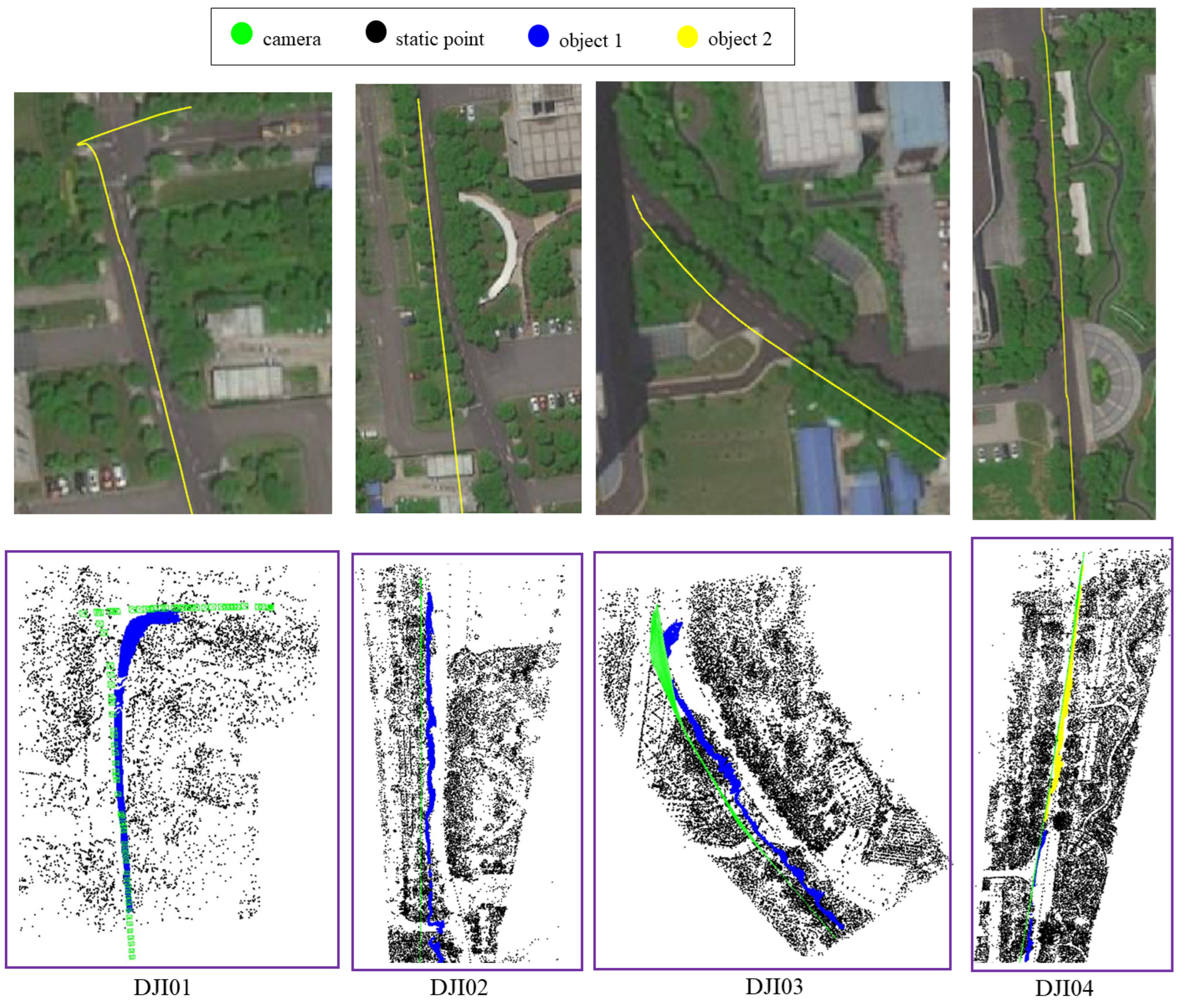
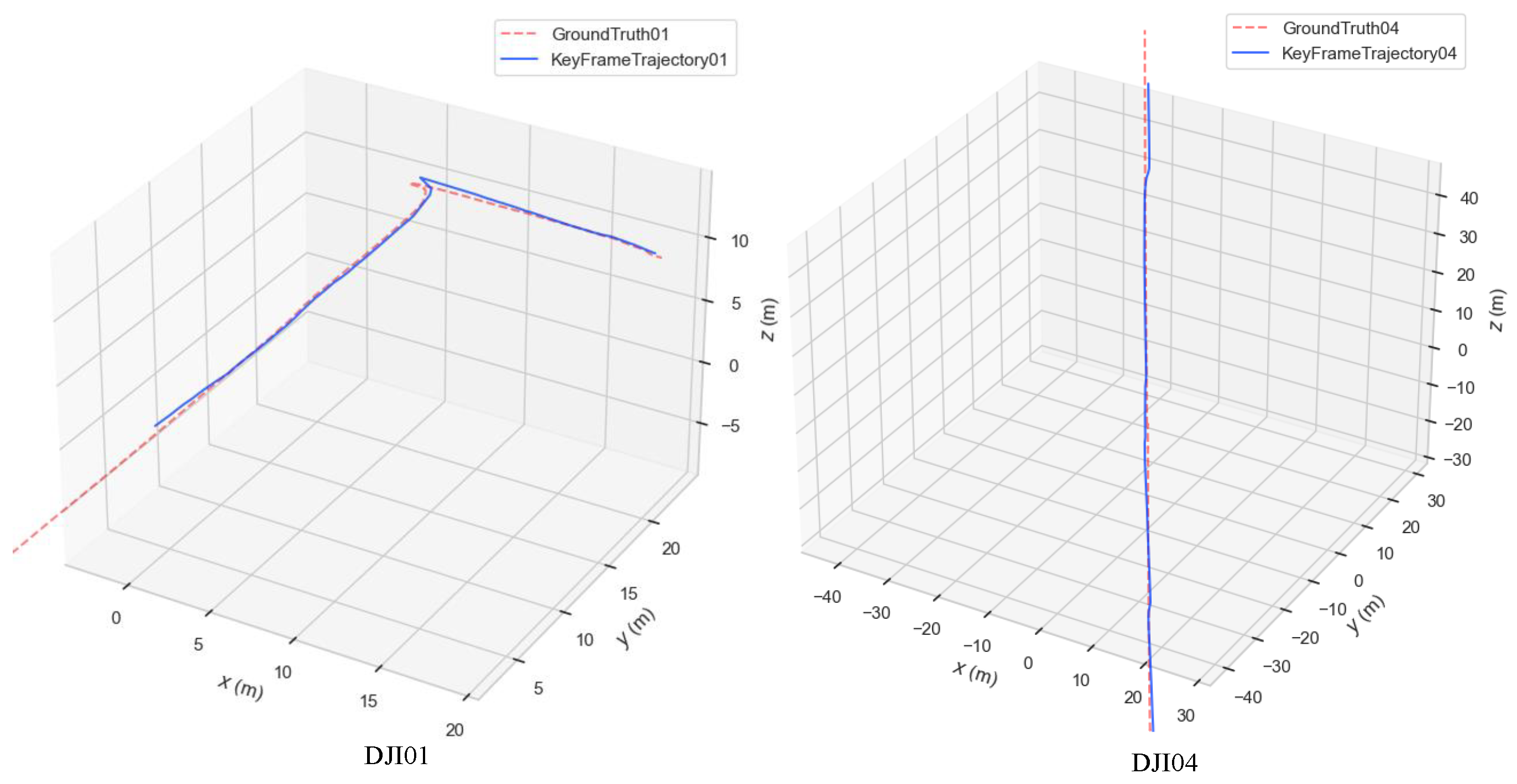
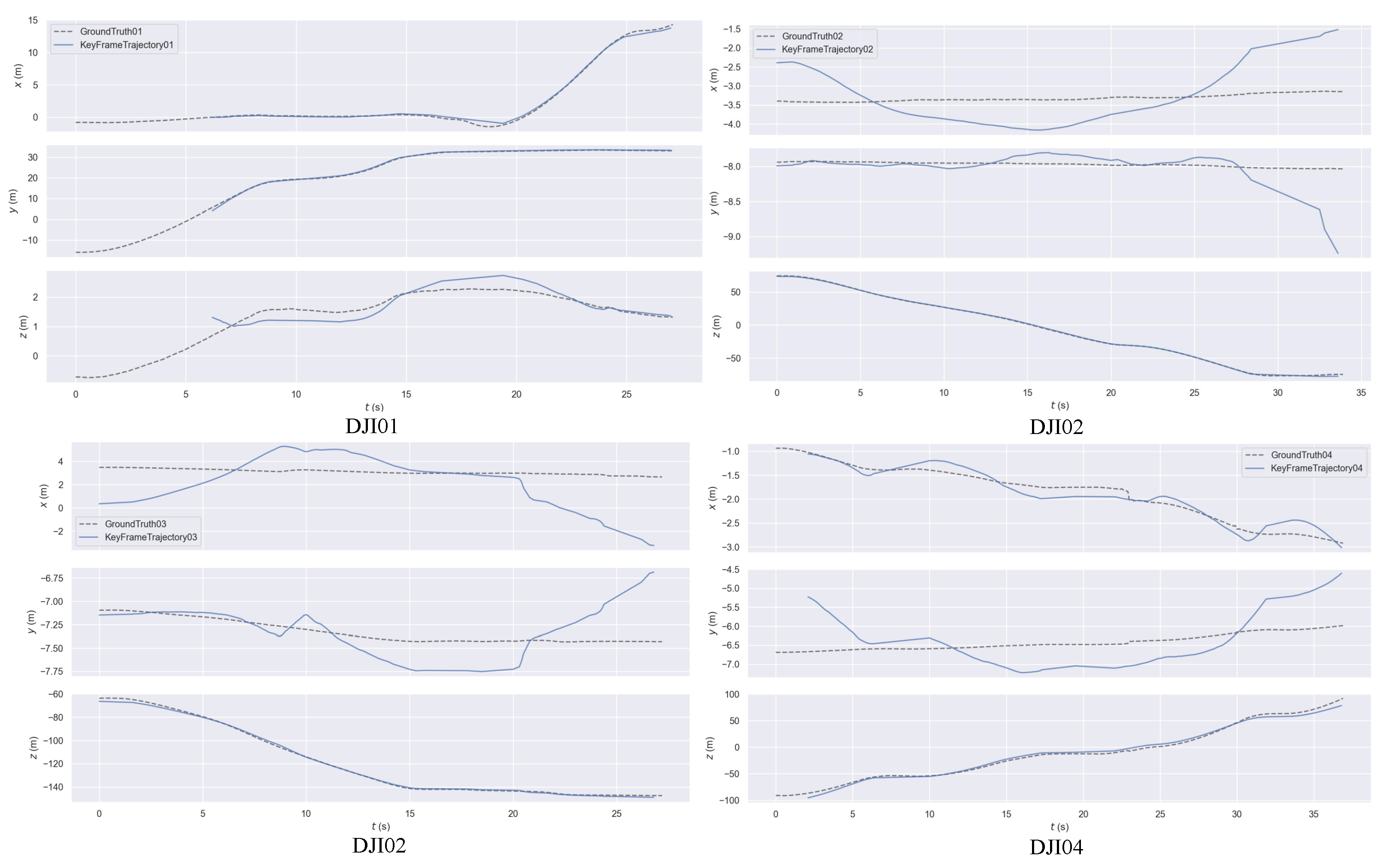
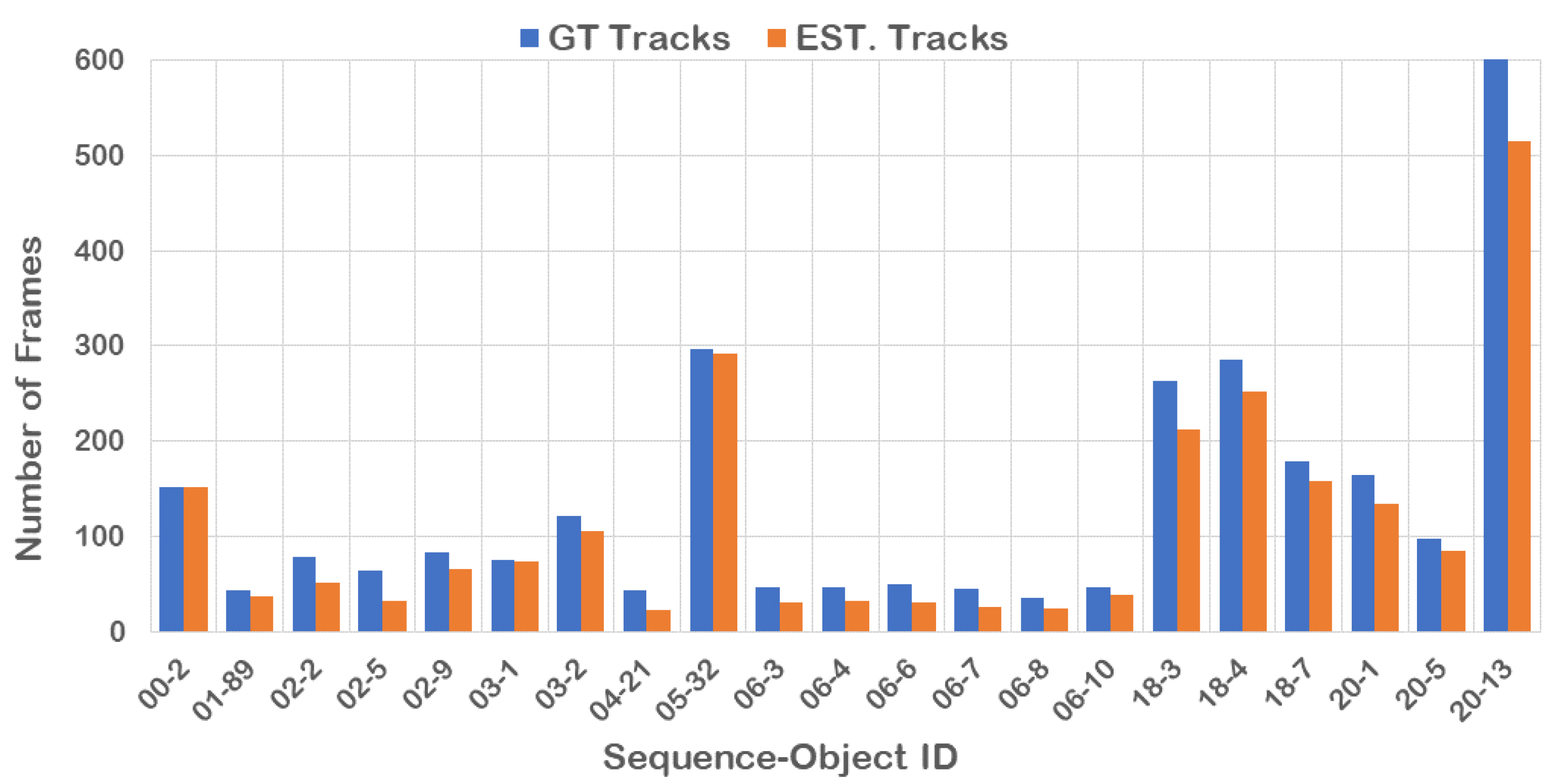
4.2. Test on Our UAV Dataset
4.3. Evaluation on the KITTI Dataset
4.4. Timing Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Balamurugan, G.; Valarmathi, J.; Naidu, V. Survey on UAV navigation in GPS denied environments. In Proceedings of the 2016 International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), Paralakhemundi, India, 3–5 October 2016; pp. 198–204. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. SD-SLAM:arge-scale direct monocular SLAM. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect visual odometry for monocular and multicamera systems. IEEE Trans. Robot. 2016, 33, 249–265. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 37. [Google Scholar] [CrossRef]
- Li, S.; Lee, D. RGB-D SLAM in dynamic environments using static point weighting. IEEE Robot. Autom. Lett. 2017, 2, 2263–2270. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Improving RGB-D SLAM in dynamic environments: A motion removal approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Xiao, L.; Wang, J.; Qiu, X.; Rong, Z.; Zou, X. Dynamic-SLAM: Semantic monocular visualocalization and mapping based on deepearning in dynamic environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Bescos, B.; Neira, J.; Siegwart, R.; Cadena, C. Empty cities: Image inpainting for a dynamic-object-invariant space. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5460–5466. [Google Scholar]
- Bešić, B.; Valada, A. Dynamic object removal and spatio-temporal RGB-D inpainting via geometry-aware adversarialearning. IEEE Trans. Intell. Veh. 2022, 7, 170–185. [Google Scholar] [CrossRef]
- Beghdadi, A.; Mallem, M. A comprehensive overview of dynamic visual SLAM and deepearning: Concepts, methods and challenges. Mach. Vis. Appl. 2022, 33, 54. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Zhong, F.; Wang, S.; Zhang, Z.; Wang, Y. Detect-SLAM: Making object detection and SLAM mutually beneficial. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1001–1010. [Google Scholar]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-coupled multi-object tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Li, A.; Wang, J.; Xu, M.; Chen, Z. DP-SLAM: A visual SLAM with moving probability towards dynamic environments. Inf. Sci. 2021, 556, 128–142. [Google Scholar] [CrossRef]
- Morelli, L.; Ioli, F.; Beber, R.; Menna, F.; Remondino, F.; Vitti, A. COLMAP-SLAM: A framework for visual odometry. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 48, 317–324. [Google Scholar]
- Azimi, A.; Ahmadabadian, A.H.; Remondino, F. PKS: A photogrammetric key-frame selection method for visual-inertial systems built on ORB-SLAM3. ISPRS J. Photogramm. Remote Sens. 2022, 191, 18–32. [Google Scholar] [CrossRef]
- Jian, R.; Su, W.; Li, R.; Zhang, S.; Wei, J.; Li, B.; Huang, R. A semantic segmentation basedidar SLAM system towards dynamic environments. In Proceedings of the Intelligent Robotics and Applications: 12th International Conference (ICIRA 2019), Shenyang, China, 8–11 August 2019; pp. 582–590. [Google Scholar]
- Zhou, B.; He, Y.; Qian, K.; Ma, X.; Li, X. S4-SLAM: A real-time 3DIDAR SLAM system for ground/watersurface multi-scene outdoor applications. Auton. Robot. 2021, 45, 77–98. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wang, C.C.; Thorpe, C.; Thrun, S. Online simultaneousocalization and mapping with detection and tracking of moving objects: Theory and results from a ground vehicle in crowded urban areas. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation (Cat. No.03CH37422), Taipei, Taiwan, 14–19 September 2003; pp. 842–849. [Google Scholar]
- Wangsiripitak, S.; Murray, D.W. Avoiding moving outliers in visual SLAM by tracking moving objects. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 375–380. [Google Scholar]
- Kundu, A.; Krishna, K.M.; Jawahar, C. Realtime multibody visual SLAM with a smoothly moving monocular camera. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2080–2087. [Google Scholar]
- Reddy, N.D.; Singhal, P.; Chari, V.; Krishna, K.M. Dynamic body VSLAM with semantic constraints. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1897–1904. [Google Scholar]
- Bârsan, I.A.; Liu, P.; Pollefeys, M.; Geiger, A. Robust dense mapping forarge-scale dynamic environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7510–7517. [Google Scholar]
- Huang, M.; Wu, J.; Zhiyong, P.; Zhao, X. High-precision calibration of wide-angle fisheyeens with radial distortion projection ellipse constraint (RDPEC). Mach. Vis. Appl. 2022, 33, 44. [Google Scholar] [CrossRef]
- Huang, J.; Yang, S.; Zhao, Z.; Lai, Y.K.; Hu, S.M. ClusterSLAM: A SLAM backend for simultaneous rigid body clustering and motion estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5875–5884. [Google Scholar]
- Henein, M.; Zhang, J.; Mahony, R.; Ila, V. Dynamic SLAM: The need for speed. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2123–2129. [Google Scholar]
- Zhang, J.; Henein, M.; Mahony, R.; Ila, V. VDO-SLAM: A visual dynamic object-aware SLAM system. arXiv 2020, arXiv:2005.11052. [Google Scholar] [CrossRef]
- Shan, M.; Wang, F.; Lin, F.; Gao, Z.; Tang, Y.Z.; Chen, B.M. Google map aided visual navigation for UAVs in GPS-denied environment. In Proceedings of the 2015 IEEE International Conference on Robotics and Biomimetics (ROBIO), Zhuhai, China, 6–9 December 2015; pp. 114–119. [Google Scholar]
- Zhuo, X.; Koch, T.; Kurz, F.; Fraundorfer, F.; Reinartz, P. Automatic UAV image geo-registration by matching UAV images to georeferenced image data. Remote Sens. 2017, 9, 376. [Google Scholar] [CrossRef]
- Volkova, A.; Gibbens, P.W. More robust features for adaptive visual navigation of UAVs in mixed environments: A novelocalisation framework. J. Intell. Robot. Syst. 2018, 90, 171–187. [Google Scholar] [CrossRef]
- Kim, Y. Aerial map-based navigation using semantic segmentation and pattern matching. arXiv 2021, arXiv:2107.00689. [Google Scholar] [CrossRef]
- Couturier, A.; Akhloufi, M.A. A review on absolute visualocalization for UAV. Robot. Auton. Syst. 2021, 135, 103666. [Google Scholar] [CrossRef]
- Qin, T.; Shen, S. Robust initialization of monocular visual-inertial estimation on aerial robots. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4225–4232. [Google Scholar]
- Qin, T.; Li, P.; Shen, S. VINS-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Fu, Q.; Wang, J.; Yu, H.; Ali, I.; Guo, F.; He, Y.; Zhang, H. PL-VINS: Real-time monocular visual-inertial SLAM with point andine features. arXiv 2020, arXiv:2009.07462. [Google Scholar] [CrossRef]
- Yuan, W.; Gu, X.; Dai, Z.; Zhu, S.; Tan, P. New CRFs: Neural window fully-connected CRFs for monocular depth estimation. arXiv 2022, arXiv:2203.01502. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach toinear filtering and prediction problems. J. Basic Eng. 1960, 82D, 35–45. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You onlyook once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deepearning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar] [CrossRef]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. PWC-net: CNNs for optical flow using pyramid, warping, and cost volume. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Saltake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. Aarge dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 611–625. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multi-object tracking by associating every detection box. In Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 1–21. [Google Scholar]
- Lv, Z.; Kim, K.; Troccoli, A.; Sun, D.; Rehg, J.M.; Kautz, J. earning rigidity in dynamic scenes with a moving camera for 3D motion field estimation. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 468–484. [Google Scholar]
- Huber, P.J. Robust estimation of aocation parameter. In Breakthroughs in Statistics: Methodology and Distribution; Springer: Berlin/Heidelberg, Germany, 1992; pp. 492–518. [Google Scholar]
- Agistoft, LLC. Agisoft Metashape. 2023. Available online: https://www.agisoft.com/zh-cn/downloads/installer (accessed on 1 May 2023).
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Yang, S.; Scherer, S. CubeSLAM: Monocular 3D object SLAM. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CubeSLAM [61] | VDO-SLAM [36] | Ours | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Camera Pose | Object Trace | Camera Pose | Object Trace | Camera Pose | Object Trace | |||||||
| Seq | (deg) | (m) | (deg) | (m) | (deg) | (m) | (deg) | (m) | (deg) | (m) | (deg) | (m) |
| 00 | - | - | - | - | 0.1830 | 0.1847 | 2.0021 | 0.3827 | 0.08240 | 0.08851 | 1.7187 | 0.5425 |
| 01 | - | - | - | - | 0.1772 | 0.4982 | 1.1833 | 0.3589 | 0.07378 | 0.1941 | 1.4167 | 0.8396 |
| 02 | - | - | - | - | 0.0496 | 0.0963 | 1.6833 | 0.4121 | 0.03120 | 0.06210 | 1.4527 | 0.6069 |
| 03 | 0.0498 | 0.0929 | 3.6085 | 4.5947 | 0.1065 | 0.1505 | 0.4570 | 0.2032 | 0.08360 | 0.1559 | 1.4565 | 0.5896 |
| 04 | 0.0708 | 0.1159 | 5.5803 | 32.5379 | 0.1741 | 0.4951 | 3.1156 | 0.5310 | 0.06888 | 0.1755 | 2.2280 | 0.8898 |
| 05 | 0.0342 | 0.0696 | 3.2610 | 6.4851 | 0.0506 | 0.1368 | 0.6464 | 0.2669 | 0.1371 | 0.0367 | 1.0198 | 1.0022 |
| 06 | - | - | - | - | 0.0671 | 0.0451 | 2.0977 | 0.2394 | 0.04546 | 0.02454 | 2.4642 | 0.9311 |
| 18 | 0.0433 | 0.0510 | 3.1876 | 3.7948 | 0.1236 | 0.3551 | 0.5559 | 0.2774 | 0.03618 | 0.09566 | 2.1584 | 0.9624 |
| 20 | 0.1348 | 0.1888 | 3.4206 | 5.6986 | 0.3029 | 1.3821 | 1.1081 | 0.3693 | 0.08530 | 0.5838 | 1.1869 | 1.2102 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Li, J.; Cao, Y.; Chen, G. A Dynamic Visual SLAM System Incorporating Object Tracking for UAVs. Drones 2024, 8, 222. https://doi.org/10.3390/drones8060222
Li M, Li J, Cao Y, Chen G. A Dynamic Visual SLAM System Incorporating Object Tracking for UAVs. Drones. 2024; 8(6):222. https://doi.org/10.3390/drones8060222
Chicago/Turabian StyleLi, Minglei, Jia Li, Yanan Cao, and Guangyong Chen. 2024. "A Dynamic Visual SLAM System Incorporating Object Tracking for UAVs" Drones 8, no. 6: 222. https://doi.org/10.3390/drones8060222
APA StyleLi, M., Li, J., Cao, Y., & Chen, G. (2024). A Dynamic Visual SLAM System Incorporating Object Tracking for UAVs. Drones, 8(6), 222. https://doi.org/10.3390/drones8060222