
A Framework of Grasp Detection and Operation for Quadruped Robot with a Manipulator
 , ,
, ,
Abstract
1. Introduction
- (1)
- We propose a lightweight grasping convolutional neural network (CNN) based on DenseBlock (DES-LGCNN) to perform pixel-wise detection. Based on two self-made modules (UP and DOWN modules), this algorithm is capable of balancing accuracy and speed during grasp detection.
- (2)
- We develop a high-visibility motion planning algorithm for manipulators that can ensure the visibility of objects during motion in real time without adding other sensors.
- (3)
- We integrate the proposed grasping detection algorithm and trajectory optimization model into the control system of our independently developed quadruped robot with a manipulator, which can be used in various environments.
2. Preliminaries
3. Methodology
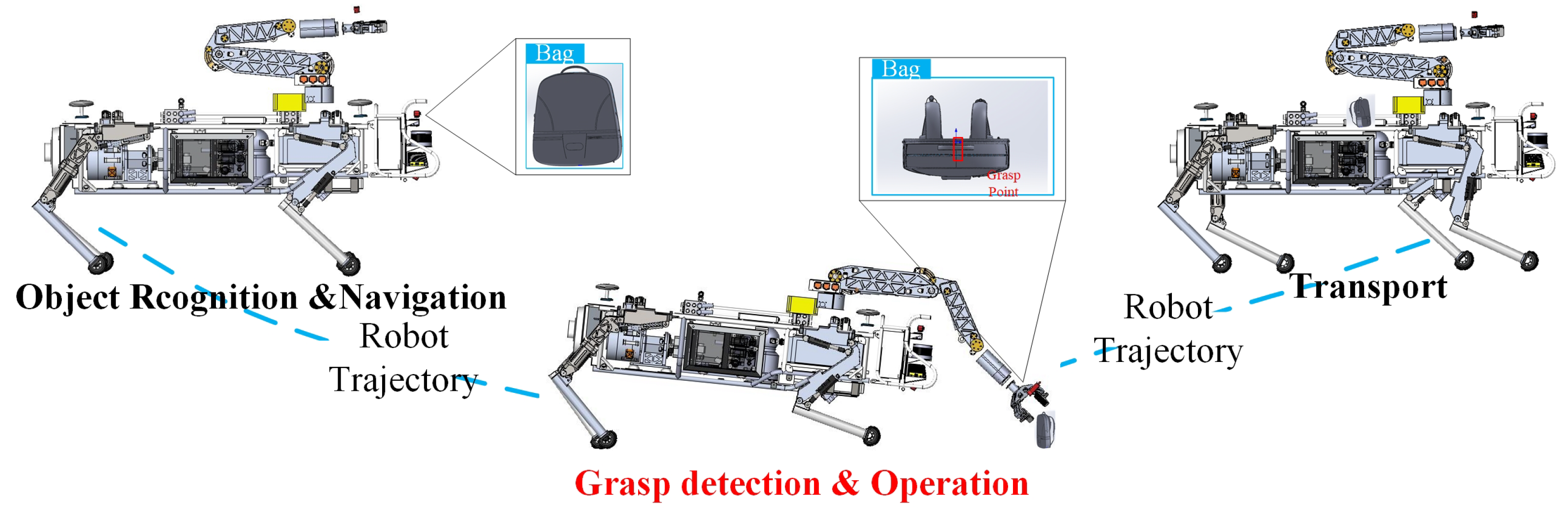
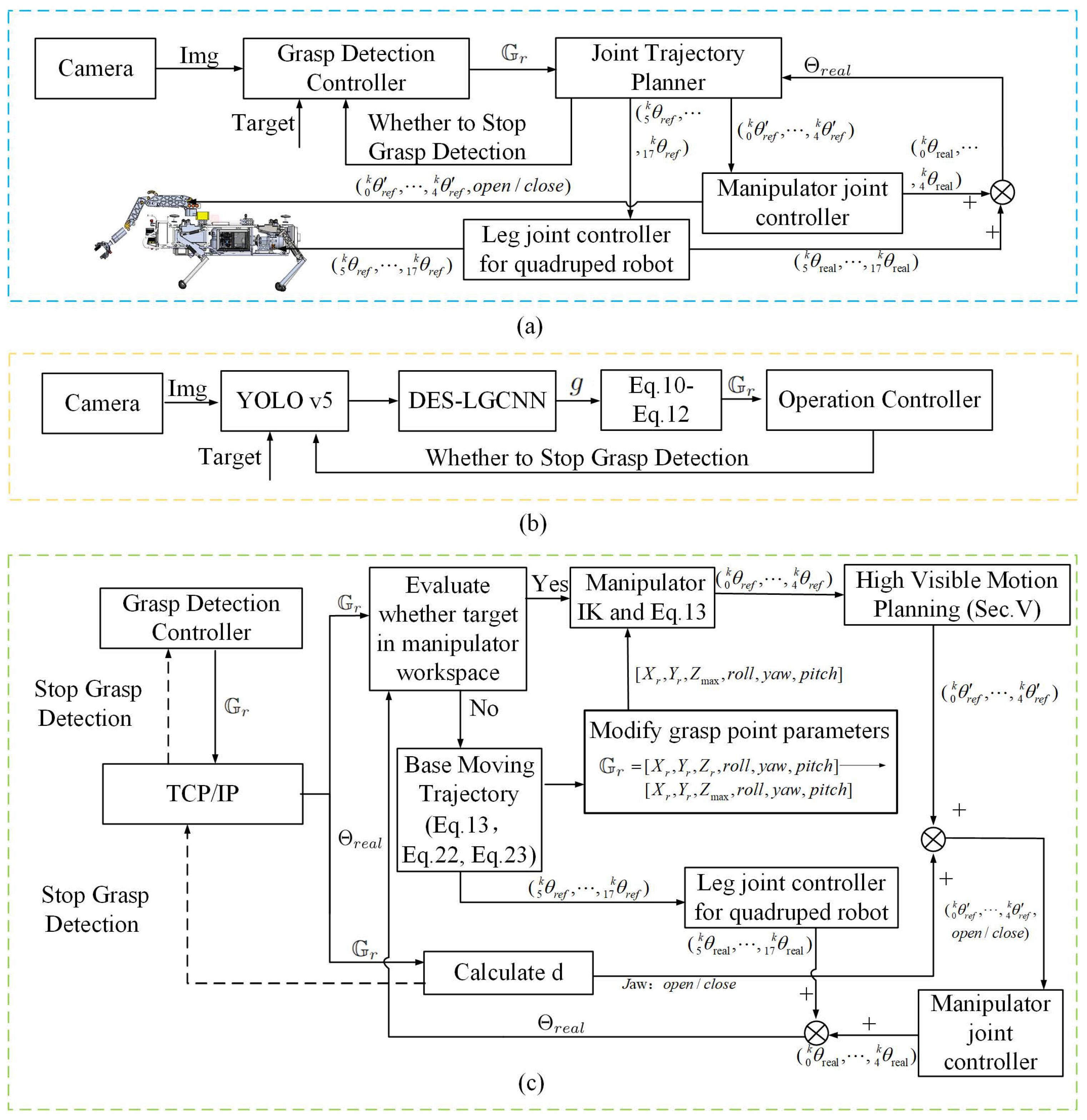
3.1. Architecture of the Framework
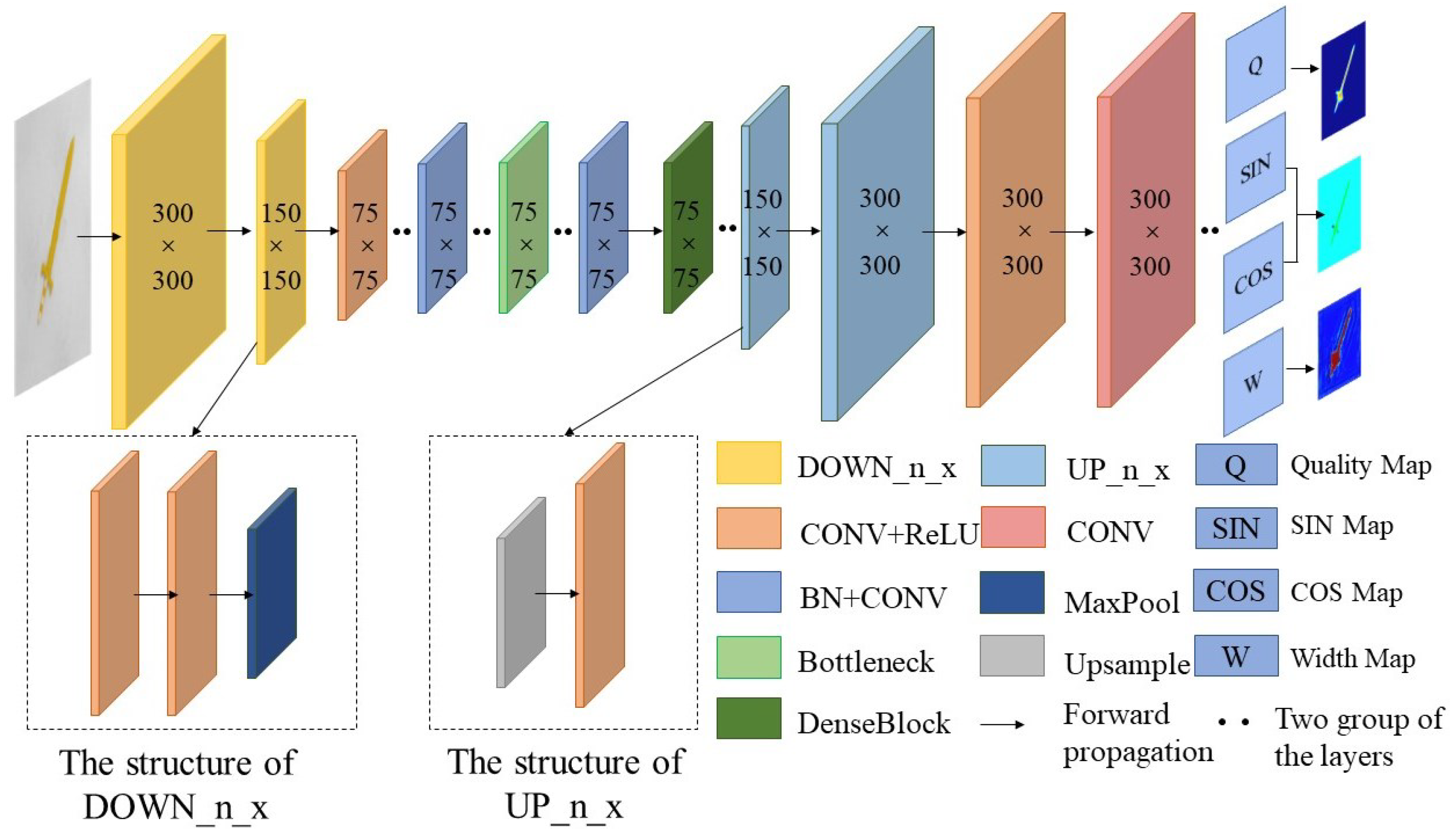
3.2. Lightweight Grasping Convolutional Neural Network Based on DenseBlock
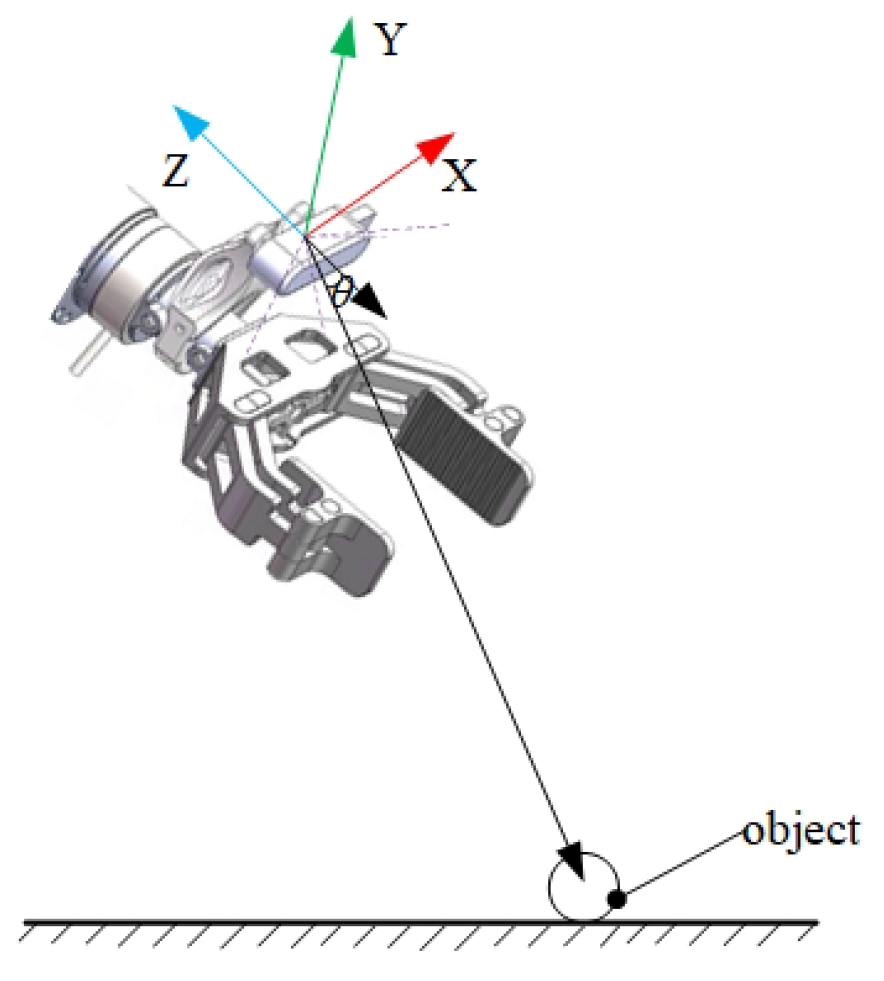
3.3. High-Visibility Motion Planning Module
| Algorithm 1 High-visibility motion planning algorithm |
|
4. Experiments
4.1. Experimental Environment
4.1.1. Network Training and Testing
4.1.2. Simulation Environment
4.1.3. Physical Prototype
4.2. Validation of DES-LGCNN
4.3. Simulation Experiment
4.4. Dynamic Grasping in Real-World Environments
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, G.; Hong, L. Research on Environment Perception System of Quadruped Robots Based on LiDAR and Vision. Drones 2023, 7, 329. [Google Scholar] [CrossRef]
- Chen, T.; Li, Y.; Rong, X.; Zhang, G.; Chai, H.; Bi, J.; Wang, Q. Design and Control of a Novel Leg-Arm Multiplexing Mobile Operational Hexapod Robot. IEEE Robot. Autom. Lett. 2021, 7, 382–389. [Google Scholar] [CrossRef]
- Zhang, G.; Ma, S.; Shen, Y.; Li, Y. A Motion Planning Approach for Nonprehensile Manipulation and Locomotion Tasks of a Legged Robot. IEEE Trans. Robot. 2020, 36, 855–874. [Google Scholar] [CrossRef]
- Chen, T.; Sun, X.; Xu, Z.; Li, Y.; Rong, X.; Zhou, L. A trot and flying trot control method for quadruped robot based on optimal foot force distribution. J. Bionic Eng. 2019, 16, 621–632. [Google Scholar] [CrossRef]
- Chai, H.; Li, Y.; Song, R.; Zhang, G.; Zhang, Q.; Liu, S.; Hou, J.; Xin, Y.; Yuan, M.; Zhang, G.; et al. A survey of the development of quadruped robots: Joint configuration, dynamic locomotion control method and mobile manipulation approach. Biomim. Intell. Robot. 2022, 2, 100029. [Google Scholar] [CrossRef]
- Pang, L.; Cao, Z.; Yu, J.; Guan, P.; Rong, X.; Chai, H. A visual leader-following approach with a TDR framework for quadruped robots. IEEE Trans. Syst. Man. Cybern. Syst. 2019, 51, 2342–2354. [Google Scholar] [CrossRef]
- Wang, P.; Zhou, X.; Zhao, Q.; Wu, J.; Zhu, Q. Search-based Kinodynamic Motion Planning for Omnidirectional Quadruped Robots. In Proceedings of the 2021 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Virtually, 12–16 July 2021; pp. 823–829. [Google Scholar]
- Zhang, Y.; Tian, G.; Shao, X.; Liu, S.; Zhang, M.; Duan, P. Building metric-topological map to efficient object search for mobile robot. IEEE Trans. Ind. Electron. 2021, 69, 7076–7087. [Google Scholar] [CrossRef]
- Fu, X.; Wei, G.; Yuan, X.; Liang, Y.; Bo, Y. Efficient YOLOv7-Drone: An Enhanced Object Detection Approach for Drone Aerial Imagery. Drones 2023, 7, 616. [Google Scholar] [CrossRef]
- Miller, A.T.; Allen, P.K. Graspit! A versatile simulator for robotic grasping. IEEE Robot. Autom. Mag. 2004, 11, 110–122. [Google Scholar] [CrossRef]
- Pelossof, R.; Miller, A.; Allen, P.; Jebara, T. An SVM learning approach to robotic grasping. In Proceedings of the 2004 IEEE International Conference on Robotics and Automation (ICRA), New Orleans, LA, USA, 26 April–1 May 2004; Volume 4, pp. 3512–3518. [Google Scholar]
- Saxena, A.; Driemeyer, J.; Ng, A.Y. Robotic grasping of novel objects using vision. Int. J. Robot. Res. 2008, 27, 157–173. [Google Scholar] [CrossRef]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3d recognition and pose using the viewpoint feature histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Guo, D.; Sun, F.; Liu, H.; Kong, T.; Fang, B.; Xi, N. A hybrid deep architecture for robotic grasp detection. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1609–1614. [Google Scholar]
- Zhang, H.; Zhou, X.; Lan, X.; Li, J.; Tian, Z.; Zheng, N. A real-time robotic grasping approach with oriented anchor box. IEEE Trans. Syst. Man. Cybern. Syst. 2019, 51, 3014–3025. [Google Scholar] [CrossRef]
- Zhou, X.; Lan, X.; Zhang, H.; Tian, Z.; Zhang, Y.; Zheng, N. Fully convolutional grasp detection network with oriented anchor box. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7223–7230. [Google Scholar]
- Chu, F.J.; Xu, R.; Vela, P.A. Real-world multiobject, multigrasp detection. IEEE Robot. Autom. Lett. 2018, 3, 3355–3362. [Google Scholar] [CrossRef]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. Int. J. Robot. Res. 2022, 41, 690–705. [Google Scholar] [CrossRef]
- Morrison, D.; Corke, P.; Leitner, J. Closing the loop for robotic grasping: A real-time, generative grasp synthesis approach. arXiv 2018, arXiv:1804.05172. [Google Scholar]
- Ma, J.; Chen, P.; Xiong, X.; Zhang, L.; Yu, S.; Zhang, D. Research on Vision-Based Servoing and Trajectory Prediction Strategy for Capturing Illegal Drones. Drones 2024, 8, 127. [Google Scholar] [CrossRef]
- Tranzatto, M.; Miki, T.; Dharmadhikari, M.; Bernreiter, L.; Kulkarni, M.; Mascarich, F.; Andersson, O.; Khattak, S.; Hutter, M.; Siegwart, R.; et al. CERBERUS in the DARPA Subterranean Challenge. Sci. Robot. 2022, 7, eabp9742. [Google Scholar] [CrossRef]
- Chen, H.; Chen, Y.; Wang, M. Trajectory tracking for underactuated surface vessels with time delays and unknown control directions. IET Control Theory Appl. 2022, 16, 587–599. [Google Scholar] [CrossRef]
- Chen, H.; Shen, C.; Huang, J.; Cao, Y. Event-triggered model-free adaptive control for a class of surface vessels with time-delay and external disturbance via state observer. J. Syst. Eng. Electron. 2023, 34, 783–797. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, H. Prescribed performance control of underactuated surface vessels’ trajectory using a neural network and integral time-delay sliding mode. Kybernetika 2023, 59, 273–293. [Google Scholar] [CrossRef]
- Park, D.H.; Kwon, J.H.; Ha, I.J. Novel position-based visual servoing approach to robust global stability under field-of-view constraint. IEEE Trans. Ind. Electron. 2011, 59, 4735–4752. [Google Scholar] [CrossRef]
- Shen, T.; Radmard, S.; Chan, A.; Croft, E.A.; Chesi, G. Optimized vision-based robot motion planning from multiple demonstrations. Auton. Robot. 2018, 42, 1117–1132. [Google Scholar] [CrossRef]
- Shi, H.; Sun, G.; Wang, Y.; Hwang, K.S. Adaptive image-based visual servoing with temporary loss of the visual signal. IEEE Trans. Ind. Inform. 2018, 15, 1956–1965. [Google Scholar] [CrossRef]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]
- Wang, Z.; Li, Z.; Wang, B.; Liu, H. Robot grasp detection using multimodal deep convolutional neural networks. Adv. Mech. Eng. 2016, 8, 1687814016668077. [Google Scholar] [CrossRef]
- Asif, U.; Tang, J.; Harrer, S. GraspNet: An Efficient Convolutional Neural Network for Real-time Grasp Detection for Low-powered Devices. In Proceedings of the 2018 International Joint Conference on Artificial Intelligence(IJCAI), Stockholm, Sweden, 13–19 July 2018; Volume 7, pp. 4875–4882. [Google Scholar]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 769–776. [Google Scholar]
- Depierre, A.; Dellandréa, E.; Chen, L. Scoring Graspability based on Grasp Regression for Better Grasp Prediction. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 4370–4376. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| length | 1420 |
| width | 693 |
| height | 700 |
| weight | 240 |
| climbing slope | 25° |
| obstacle crossing | 250 |
| max speed | 1.8 |
| manipulator load | 30 |
| Approach | IW (%) | OW (%) | Speed (ms) |
|---|---|---|---|
| SAE [14] | 73.9 | 75.66 | 1350 |
| Alxnet, MultiGrasp [29] | 88.0 | 87.1 | 76 |
| Two-stage closed-loop [30] | 85.3 | - | 140 |
| GG-CNN [20] | 73.0 | 69.0 | 19 |
| GraspNet [31] | 90.2 | 90.6 | 24 |
| ResNet-50x2 [32] | 89.2 | 88.9 | 103 |
| ours-RGB | 90.59 | 89.89 | 6 |
| ours-D | 80.48 | 81.26 | 5.5 |
| ours-RGBD | 92.49 | 92.39 | 6 |
| Approach | IW (%) | OW (%) | Speed (ms) |
|---|---|---|---|
| FCGN(ResNet-50) [17] | 89.83 | 89.26 | 28 |
| GG-CNN2 [20] | 84 | 83 | 19 |
| New DNN [33] | 85.74 | - | - |
| ours-RGB | 86 | 88.64 | 6 |
| ours-D | 91.39 | 91.08 | 5.5 |
| ours-RGBD | 92.22 | 92.35 | 6 |
| Algorithm | 150° | 120° | 90° | 60° |
|---|---|---|---|---|
| A* | 100% | 100% | 70.83% | 62.65% |
| RRT | 100% | 100% | 65.07% | 53.14% |
| RRT* | 100% | 100% | 59.61% | 51.71% |
| Ours | 100% | 100% | 97.15% | 83.33% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Chai, H.; Zhang, Q.; Zhao, H.; Chen, M.; Li, Y.; Li, Y. A Framework of Grasp Detection and Operation for Quadruped Robot with a Manipulator. Drones 2024, 8, 208. https://doi.org/10.3390/drones8050208
Guo J, Chai H, Zhang Q, Zhao H, Chen M, Li Y, Li Y. A Framework of Grasp Detection and Operation for Quadruped Robot with a Manipulator. Drones. 2024; 8(5):208. https://doi.org/10.3390/drones8050208
Chicago/Turabian StyleGuo, Jiamin, Hui Chai, Qin Zhang, Haoning Zhao, Meiyi Chen, Yueyang Li, and Yibin Li. 2024. "A Framework of Grasp Detection and Operation for Quadruped Robot with a Manipulator" Drones 8, no. 5: 208. https://doi.org/10.3390/drones8050208
APA StyleGuo, J., Chai, H., Zhang, Q., Zhao, H., Chen, M., Li, Y., & Li, Y. (2024). A Framework of Grasp Detection and Operation for Quadruped Robot with a Manipulator. Drones, 8(5), 208. https://doi.org/10.3390/drones8050208