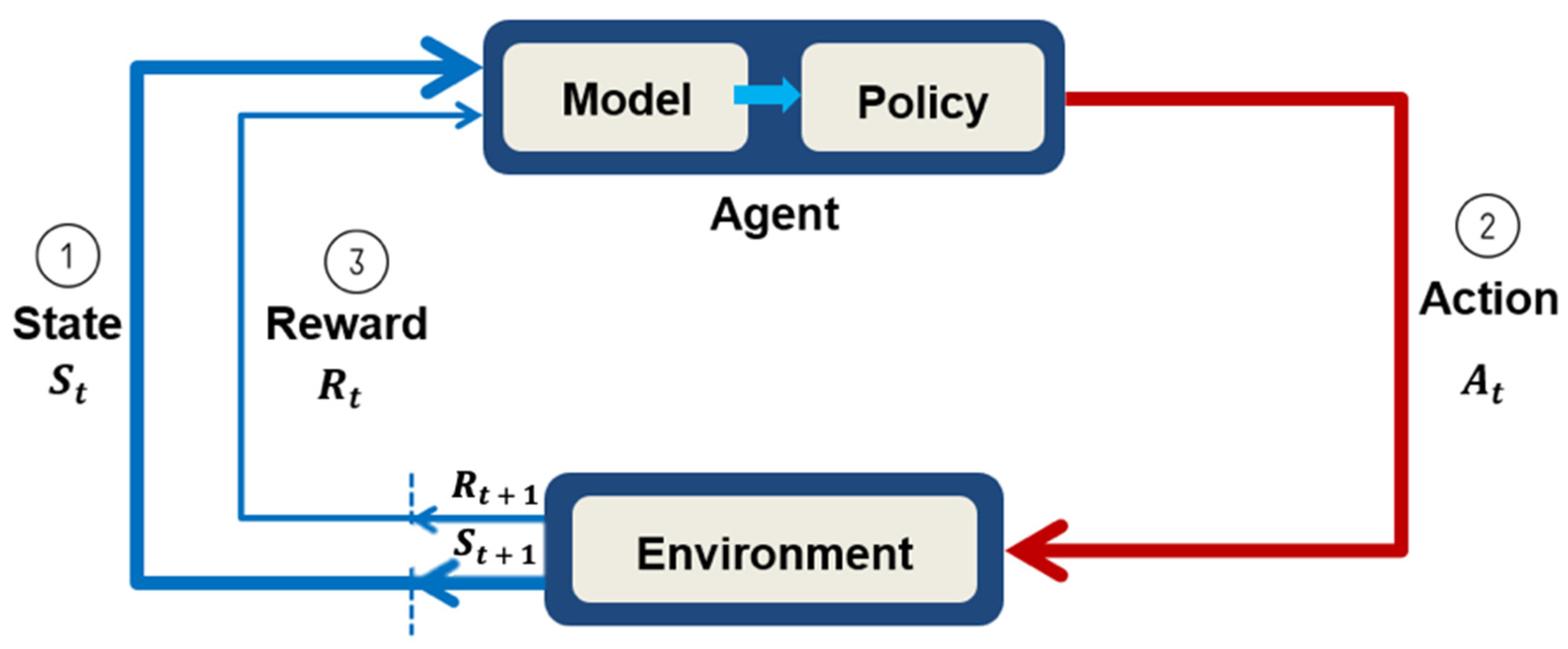
Figure 1.
Reinforcement learning architecture diagram.
Figure 1.
Reinforcement learning architecture diagram.
Figure 2.
Markov decision process model [
21].
Figure 2.
Markov decision process model [
21].
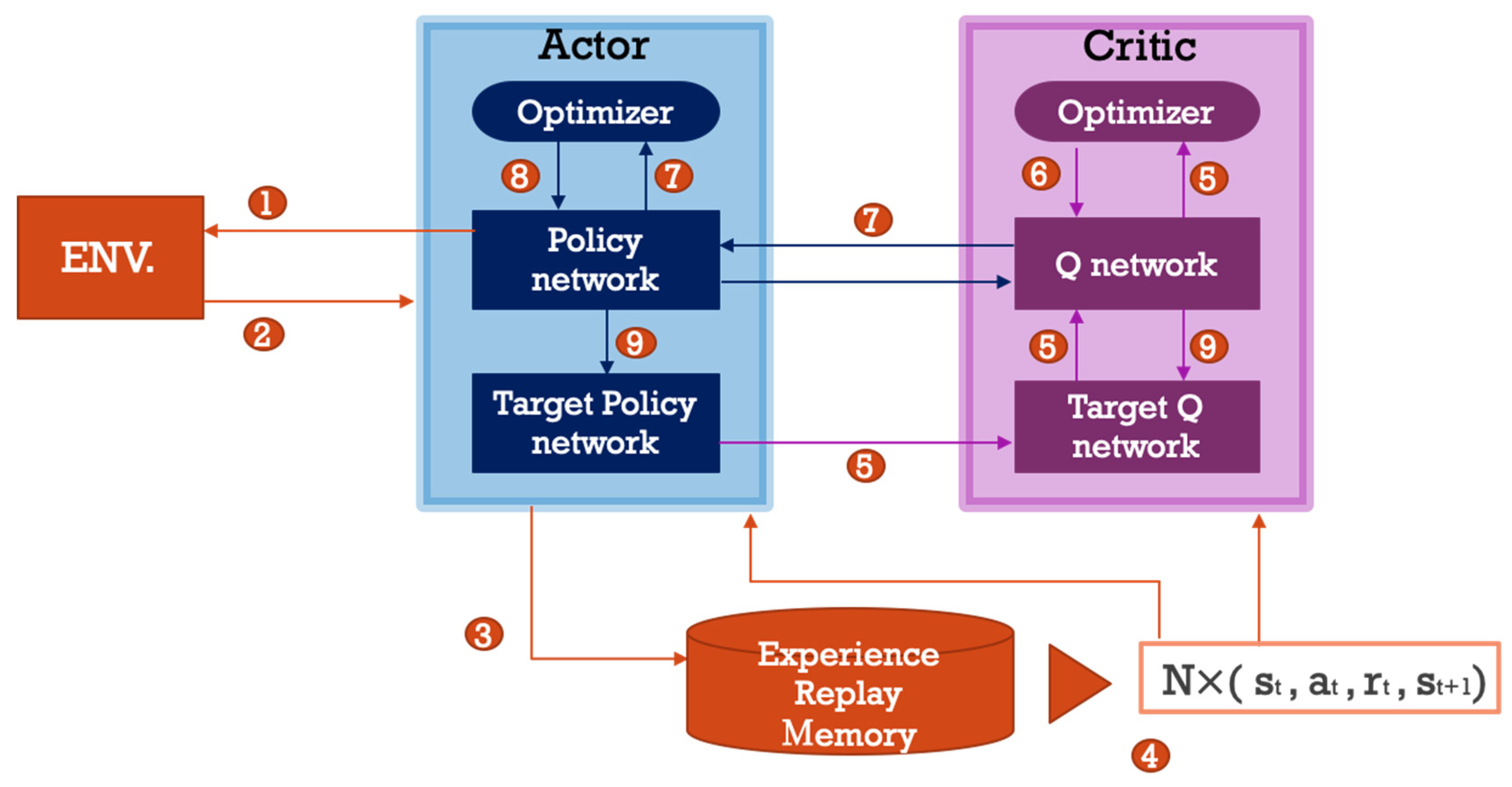
Figure 3.
Deep Deterministic Policy Gradient architecture diagram.
Figure 3.
Deep Deterministic Policy Gradient architecture diagram.
Figure 4.
Deep Deterministic Policy Gradient algorithm flow chart.
Figure 4.
Deep Deterministic Policy Gradient algorithm flow chart.
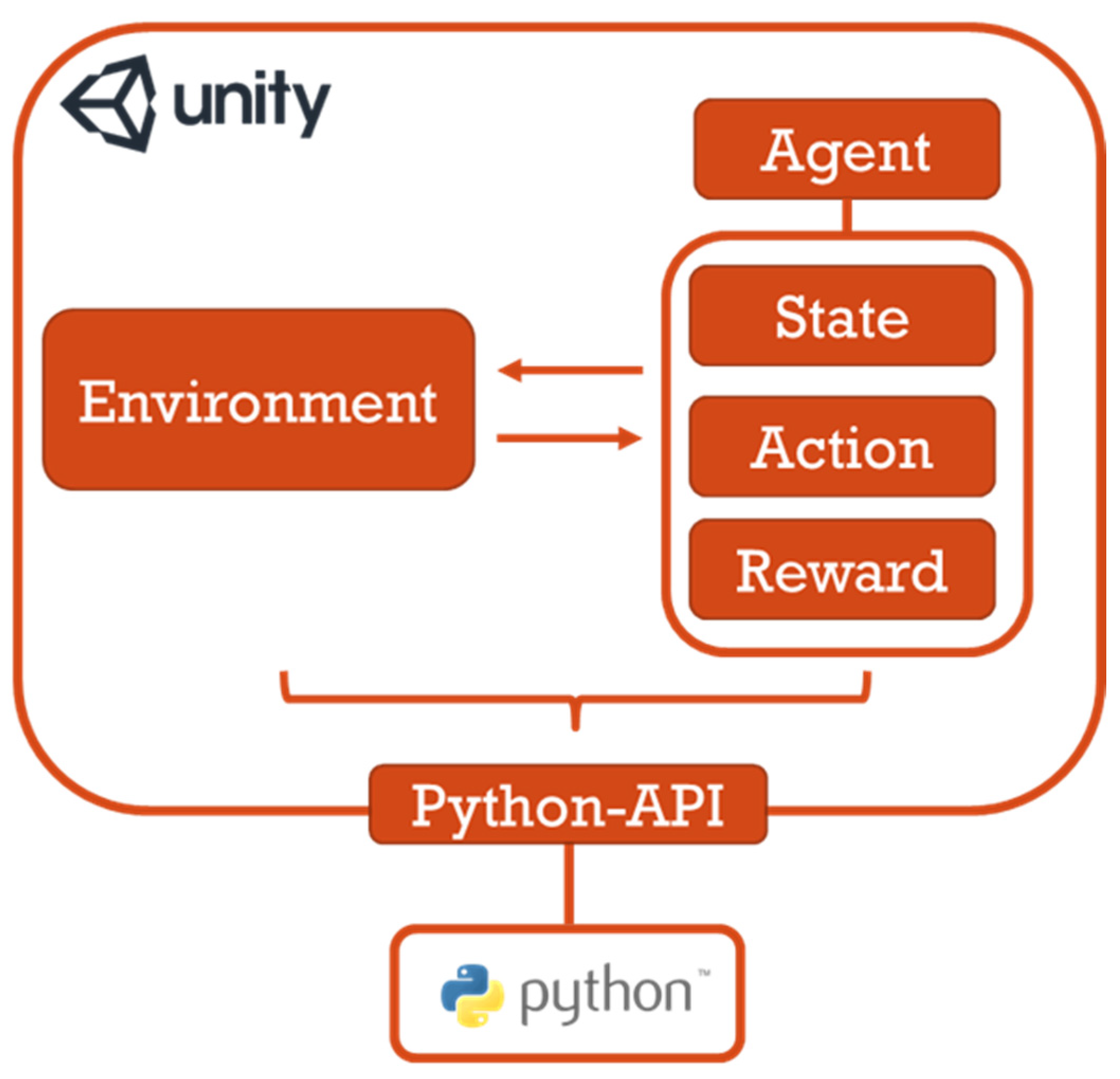
Figure 5.
Simulation system architecture.
Figure 5.
Simulation system architecture.
Figure 6.
Screen obtained during the actual flight. (a) 10 m above the ground (b) 5 m above the ground. The black dot in (a,b) indicates the center of the camera screen while the green box is the Yolo’s identified visual screen.
Figure 6.
Screen obtained during the actual flight. (a) 10 m above the ground (b) 5 m above the ground. The black dot in (a,b) indicates the center of the camera screen while the green box is the Yolo’s identified visual screen.
Figure 7.
Simulated PTZ screen.
Figure 7.
Simulated PTZ screen.
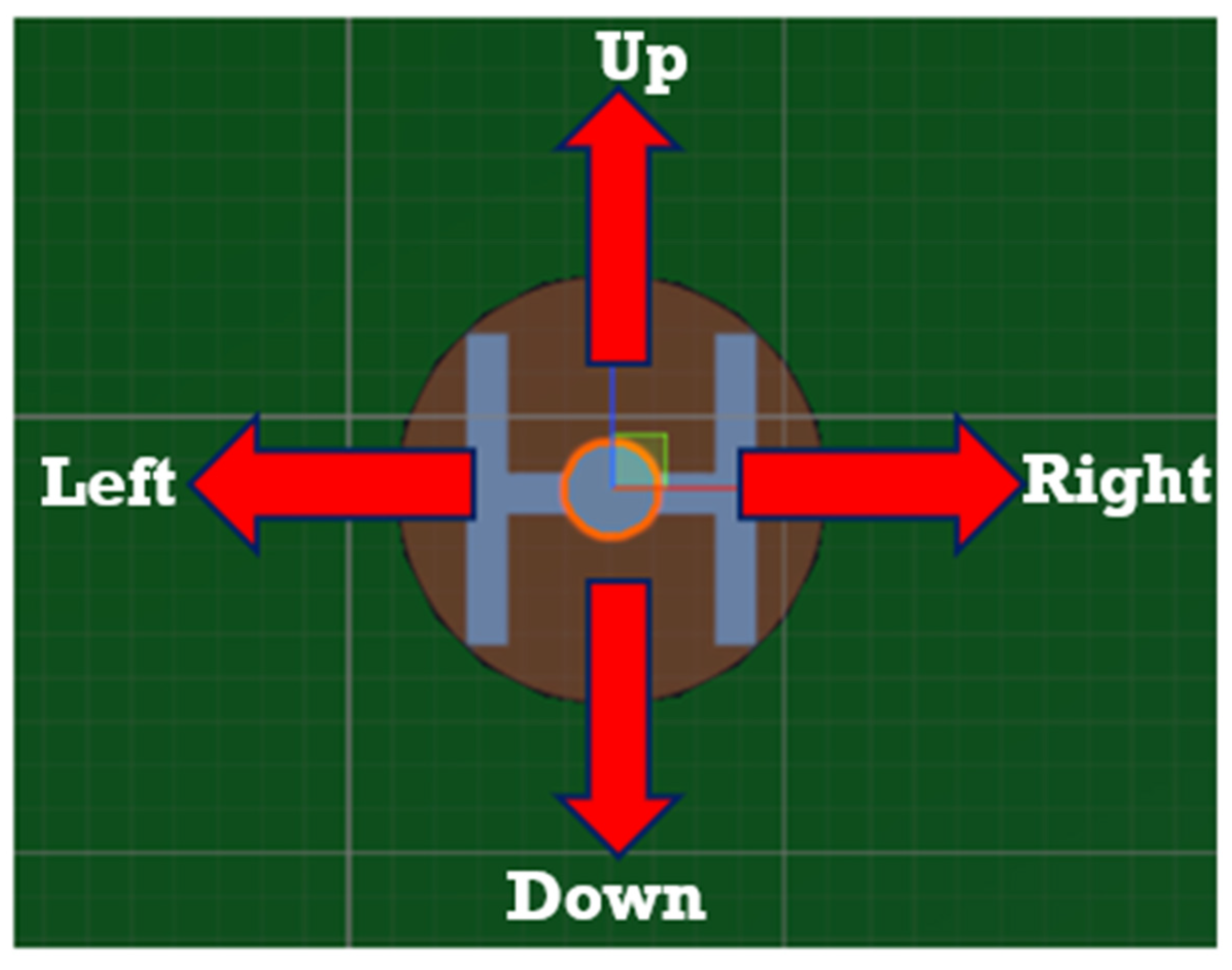
Figure 8.
Camera gimbal’s action diagram for object detection.
Figure 8.
Camera gimbal’s action diagram for object detection.
Figure 9.
The diagram of actual drone’s gimble movement (a) up (b) down (c) left (d) right.
Figure 9.
The diagram of actual drone’s gimble movement (a) up (b) down (c) left (d) right.
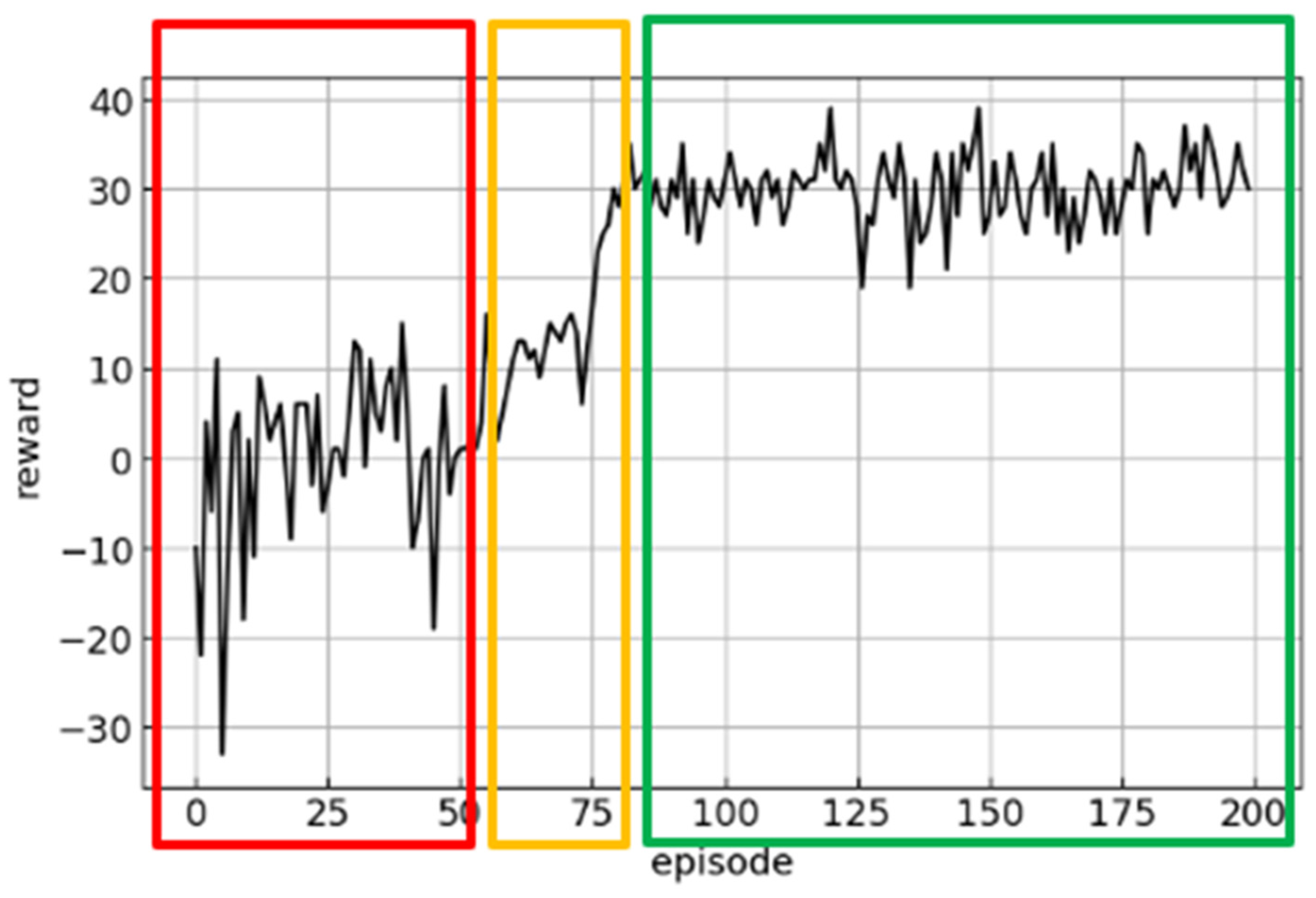
Figure 10.
Cumulative reward graph.
Figure 10.
Cumulative reward graph.
Figure 11.
Three learning stages.
Figure 11.
Three learning stages.
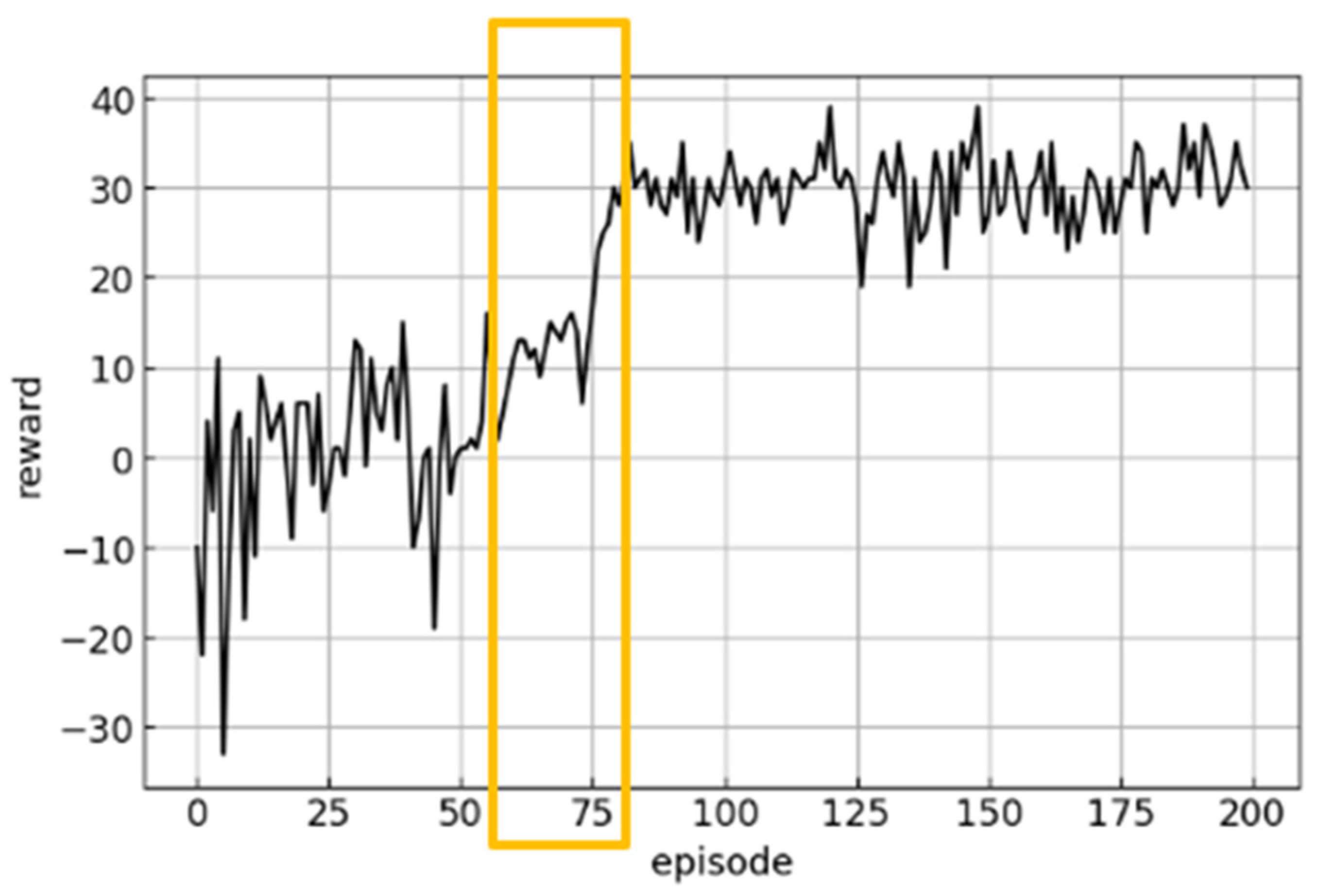
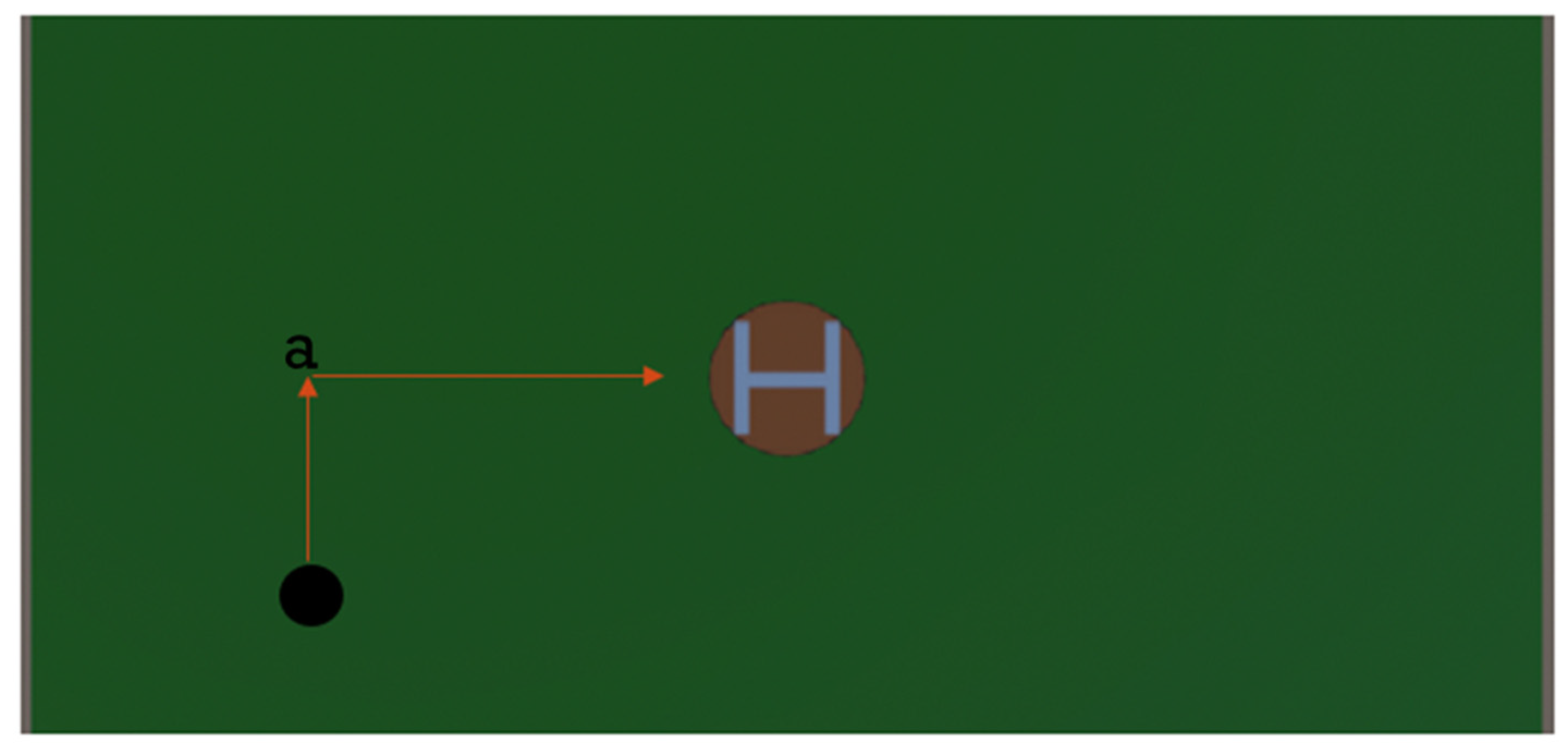
Figure 12.
Exploration phase (Red).
Figure 12.
Exploration phase (Red).
Figure 13.
Pretraining (action exploration).
Figure 13.
Pretraining (action exploration).
Figure 14.
Gradual stabilization phase (yellow).
Figure 14.
Gradual stabilization phase (yellow).
Figure 15.
Mid-training (closer to target to increase reward acquisition).
Figure 15.
Mid-training (closer to target to increase reward acquisition).
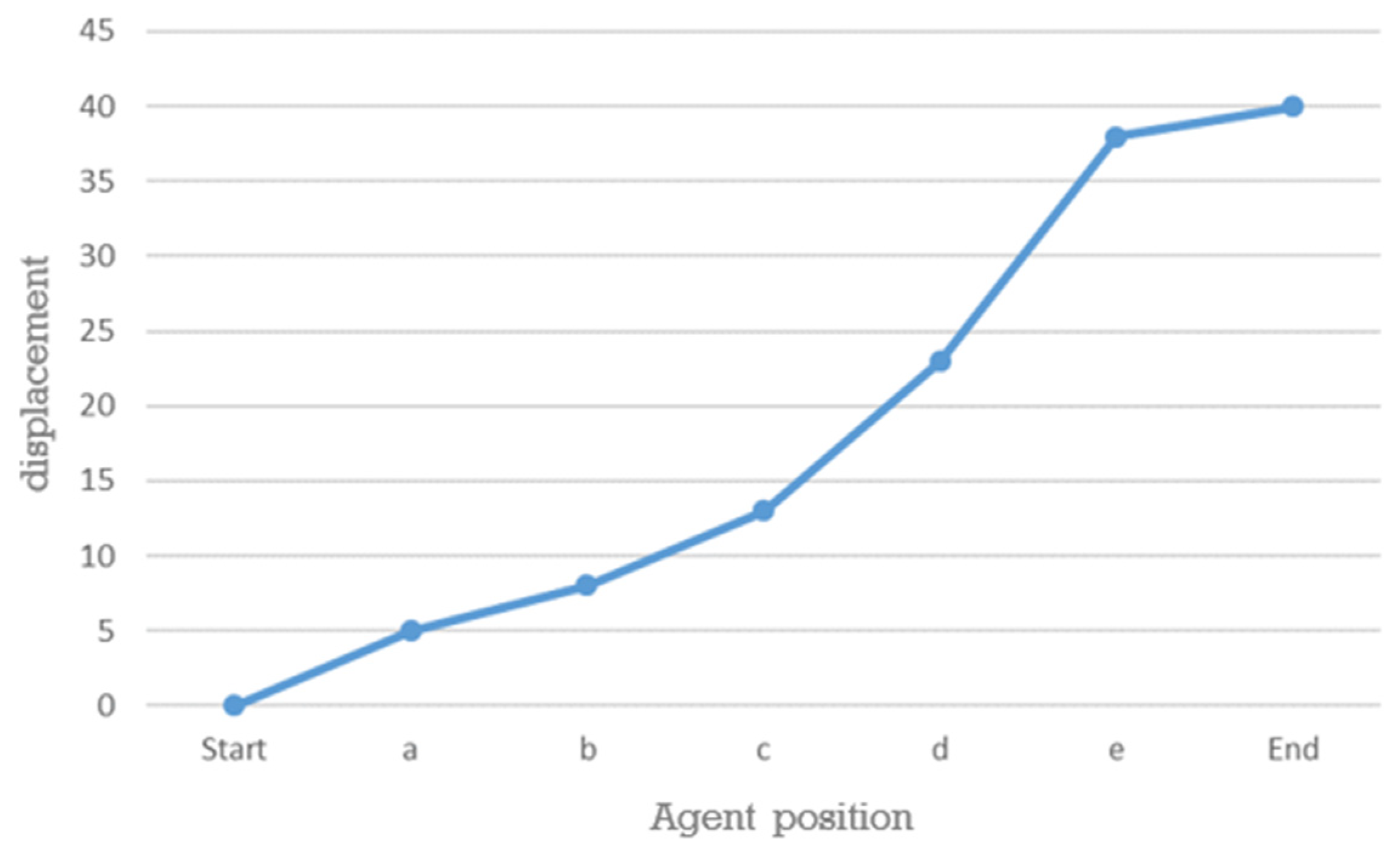
Figure 16.
Displacement curve 1.
Figure 16.
Displacement curve 1.
Figure 17.
Stable convergence phase (green).
Figure 17.
Stable convergence phase (green).
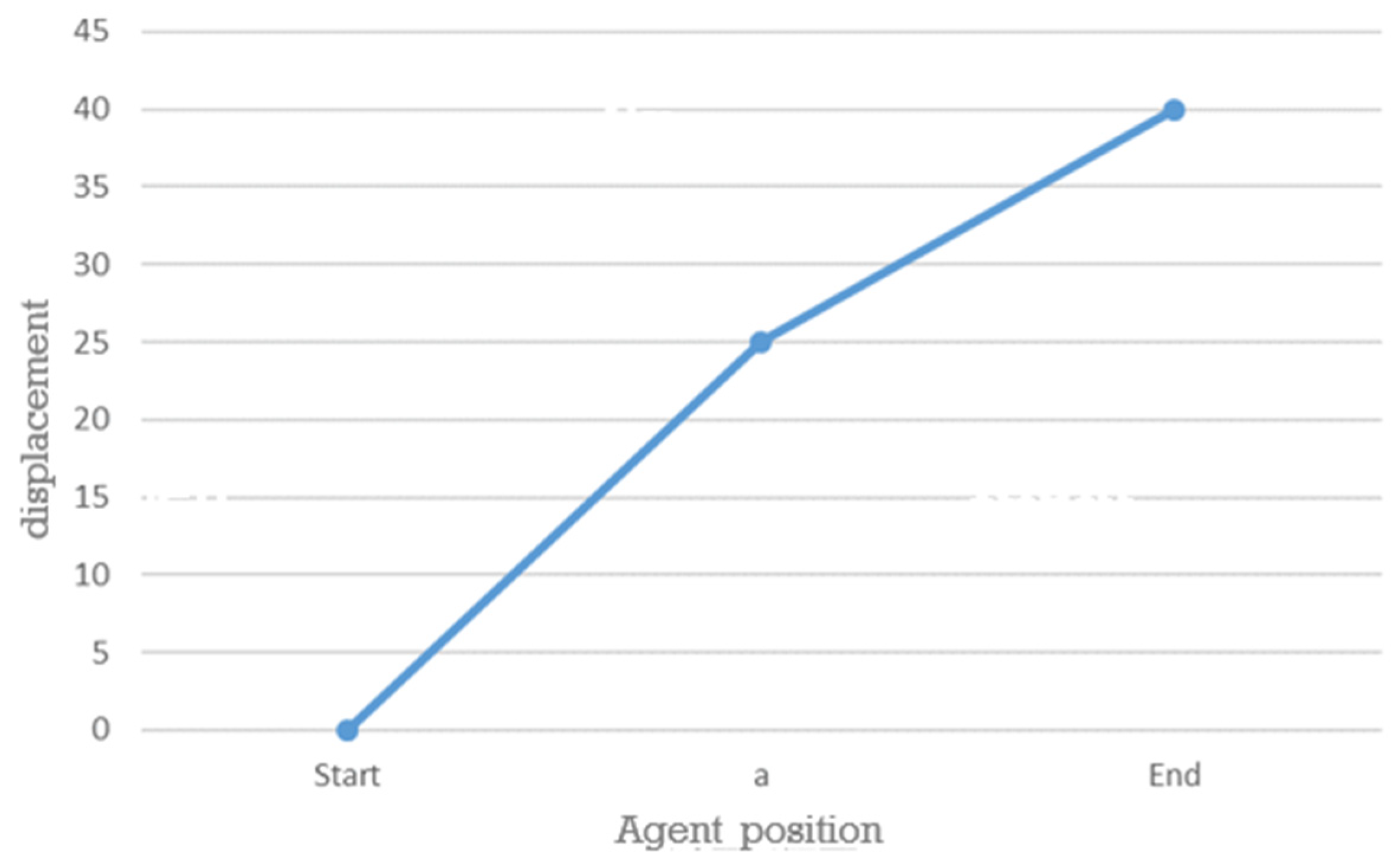
Figure 18.
Displacement Curve 2.
Figure 18.
Displacement Curve 2.
Figure 19.
Late phase of training (acting on the most efficient path).
Figure 19.
Late phase of training (acting on the most efficient path).
Figure 20.
Intended wind direction (the red arrow indicates wind direction).
Figure 20.
Intended wind direction (the red arrow indicates wind direction).
Figure 21.
Cumulative rewards after the introduction of external interference.
Figure 21.
Cumulative rewards after the introduction of external interference.
Figure 22.
Plot of the UAV’s camera gimbal rewards with episodes when different environments are simulated.
Figure 22.
Plot of the UAV’s camera gimbal rewards with episodes when different environments are simulated.
Figure 23.
The total number of training steps in each episode.
Figure 23.
The total number of training steps in each episode.
Figure 24.
The trajectory (blue) of the target moves along a square of 30 m2 and with a windy interference (red).
Figure 24.
The trajectory (blue) of the target moves along a square of 30 m2 and with a windy interference (red).
Figure 25.
X-axis dynamic tracking response due to single-interference environment.
Figure 25.
X-axis dynamic tracking response due to single-interference environment.
Figure 26.
Y-axis dynamic tracking response due to single-interference environment.
Figure 26.
Y-axis dynamic tracking response due to single-interference environment.
Figure 27.
X-axis dynamic tracking response in the continuous-interference environment.
Figure 27.
X-axis dynamic tracking response in the continuous-interference environment.
Figure 28.
Y-axis dynamic tracking response in the continuous-interference environment.
Figure 28.
Y-axis dynamic tracking response in the continuous-interference environment.
Figure 29.
X-axis dynamic tracking response in the mixed-interference environment.
Figure 29.
X-axis dynamic tracking response in the mixed-interference environment.
Figure 30.
Y-axis dynamic tracking response in the mixed-interference environment.
Figure 30.
Y-axis dynamic tracking response in the mixed-interference environment.
Figure 31.
Illustration for stabilized initial transfer-learning weight in
Figure 22 followed by four stabilized new transfer-learning RL controllers.
Figure 31.
Illustration for stabilized initial transfer-learning weight in
Figure 22 followed by four stabilized new transfer-learning RL controllers.
Figure 32.
X-axis dynamic response in the transfer-learning single-interference environment.
Figure 32.
X-axis dynamic response in the transfer-learning single-interference environment.
Figure 33.
Y-axis dynamic response in the transfer-learning single-interference environment.
Figure 33.
Y-axis dynamic response in the transfer-learning single-interference environment.
Figure 34.
X-axis dynamic response in the transfer-learning continuous-interference environment.
Figure 34.
X-axis dynamic response in the transfer-learning continuous-interference environment.
Figure 35.
Y-axis dynamic response in the transfer-learning continuous-interference environment.
Figure 35.
Y-axis dynamic response in the transfer-learning continuous-interference environment.
Figure 36.
X-axis dynamic response in the transfer-learning mixed-interference environment.
Figure 36.
X-axis dynamic response in the transfer-learning mixed-interference environment.
Figure 37.
Y-axis dynamic response in the transfer-learning mixed-interference environment.
Figure 37.
Y-axis dynamic response in the transfer-learning mixed-interference environment.
Table 1.
Agent action set.
Table 1.
Agent action set.
| Type | Simulation | Real World |
|---|
| Action 1 | Up | pitch (−110° to +70°) |
| Action 2 | Down | pitch (+70° to −110°) |
| Action 3 | Left | yaw (−360°) |
| Action 4 | Right | yaw (+360°) |
Table 2.
Reward and mechanism table.
Table 2.
Reward and mechanism table.
| Perform Actions | Reward Points |
|---|
| Successfully tracked target | +10 |
| Out of range | −5 |
| Each execution step | −1 |
| Reduced distance to target | +5 |
| Increased distance to target | −5 |
Table 3.
Reward accumulation.
Table 3.
Reward accumulation.
| Perform Actions | Reward |
|---|
| Epoch 1 | −10 |
| Epoch 2 | −22 |
| Epoch 3 | 4 |
| Epoch 4 | −6 |
| Epoch 5 | 11 |
| ⋮ | ⋮ |
| Epoch 80 | 30 |
| Epoch 81 | 28 |
| Epoch 82 | 31 |
| ⋮ | ⋮ |
| Epoch 199 | 32 |
| Epoch 200 | 30 |
Table 4.
Four modes of reward setting for tracking a target with a square motion.
Table 4.
Four modes of reward setting for tracking a target with a square motion.
| Type | Action | Reward |
|---|
| Mode 1 | Engaging | +10 |
| Moving out | −10 |
| Mode 2 | Engaging | +10 |
| Moving out | −10 |
| Each additional searching step | −0.1 |
| Mode 3 | Engaging | +10 |
| Moving out | −10 |
| Each additional searching step | −0.1 |
| Closer to the target | +0.2 |
| Mode 4 | Engaging | +10 |
| Moving out | −10 |
| Each additional searching step | −0.1 |
| Closer to the target | +0.2 |
| Farther away the target | −0.2 |
Table 5.
Reinforcement learning control models with different environments and reward types.
Table 5.
Reinforcement learning control models with different environments and reward types.
| RL Model Name | Environment | Reward Type |
|---|
| RLc 1 | no wind interference | Mode 1 |
| RLc 2 | Mode 2 |
| RLc 3 | Mode 3 |
| RLc 4 | Mode 4 |
| RLc 5 | continuous wind interference | Mode 1 |
| RLc 6 | Mode 2 |
| RLc 7 | Mode 3 |
| RLc 8 | Mode 4 |
Table 6.
Total error of the PID and RLc controllers disturbed by single-interference environment.
Table 6.
Total error of the PID and RLc controllers disturbed by single-interference environment.
| Type | X Total Error (m) | Y Total Error (m) | Total Error (m) |
|---|
| PID controller | 1376.527 | 1378.641 | 2755.168 |
| RLc 1s | 1639.447 | 1771.039 | 3410.486 |
| RLc 2s | 1515.326 | 1659.746 | 3175.072 |
| RLc 3s | 1757.004 | 1947.581 | 3704.585 |
| RLc 4s | 1863.846 | 1641.37 | 3505.216 |
| RLc 5s | 2436.504 | 2419.995 | 4856.499 |
| RLc 6s | 1817.888 | 2150.425 | 3968.313 |
| RLc 7s | 1987.844 | 2248.281 | 4236.125 |
| RLc 8s | 2473.454 | 2182.709 | 4656.163 |
Table 7.
The total error of the PID and RLc controllers disturbed by continuous-interference environment.
Table 7.
The total error of the PID and RLc controllers disturbed by continuous-interference environment.
| Type | X Total Error | Y Total Error | Total Error |
|---|
| PID controller | 2571.234 | 2689.52 | 5260.754 |
| RLc 1c | 2067.507 | 2531.231 | 4598.738 |
| RLc 2c | 1920.636 | 2314.86 | 4235.496 |
| RLc 3c | 2140.647 | 2583.775 | 4724.422 |
| RLc 4c | 2211.103 | 2148.11 | 4359.213 |
| RLc 5c | 1837.215 | 2730.256 | 4567.471 |
| RLc 6c | 1728.02 | 2375.396 | 4103.416 |
| RLc 7c | 1557.849 | 2447.863 | 4005.712 |
| RLc 8c | 2040.935 | 2232.779 | 4273.714 |
Table 8.
Total error in the mixed-interference environment.
Table 8.
Total error in the mixed-interference environment.
| Type | X Total Error | Y Total Error | Total Error |
|---|
| PID controller | 2824.23 | 3049.346 | 5873.576 |
| RLc 1m | 2182.383 | 2873.302 | 5055.685 |
| RLc 2m | 2027.009 | 2491.253 | 4518.262 |
| RLc 3m | 2248.814 | 2873.627 | 5122.441 |
| RLc 4m | 2419.873 | 2500.419 | 4920.292 |
| RLc 5m | 2098.563 | 3113.346 | 5211.909 |
| RLc 6m | 1705.526 | 2630.389 | 4335.915 |
| RLc 7m | 1636.336 | 2715.977 | 4352.313 |
| RLc 8m | 2148.323 | 2646.956 | 4795.279 |
Table 9.
The transfer-learning reward setting for tracking a target with a square motion.
Table 9.
The transfer-learning reward setting for tracking a target with a square motion.
| Type | Action | Reward |
|---|
| Mode 5 | Engaging continuously 500 times | +10 |
| Engaging | +2 |
| Moving out | −10 |
| Each additional searching step | −0.1 |
| Mode 6 | Engaging continuously 500 times | +10 |
| Engaging | +2 |
| Moving out | −10 |
| Each additional searching step | −0.1 |
| Closer to the target | +0.2 |
| Mode 7 | Engaging continuously 500 times | +10 |
| Engaging | +2 |
| Moving out | −10 |
| Each additional searching step | −0.1 |
| Closer to the target | +0.2 |
| Farther away the target | −0.2 |
Table 10.
The transfer-learning, reinforcement-learning models with a square motion.
Table 10.
The transfer-learning, reinforcement-learning models with a square motion.
| RL Model Name | Environment | Reward Type |
|---|
| RLc 9 | no wind interference | Mode 5 |
| RLc 10 | Mode 7 |
| RLc 11 | continuous wind interference | Mode 5 |
| RLc 12 | Mode 6 |
Table 11.
Total error in the transfer learning in single-interference environment.
Table 11.
Total error in the transfer learning in single-interference environment.
| Type | X Total Error (m) | Y Total Error (m) | Total Error (m) |
|---|
| PID controller | 1376.527 | 1378.641 | 2755.168 |
| RLc 9s | 1843.629 | 1628.196 | 3471.825 |
| RLc 10s | 1616.028 | 1943.649 | 3559.677 |
| RLc 11s | 1540.768 | 1919.177 | 3459.945 |
| RLc 12s | 2036.984 | 2400.906 | 4437.89 |
Table 12.
Total error in the transfer-learning continuous-interference environment.
Table 12.
Total error in the transfer-learning continuous-interference environment.
| Type | X Total Error (m) | Y Total Error (m) | Total Error (m) |
|---|
| PID controller | 2571.234 | 2689.52 | 5260.754 |
| RLc 9c | 2223.737 | 2221.629 | 4445.366 |
| RLc 10c | 1931.952 | 2583.501 | 4515.453 |
| RLc 11c | 1539.821 | 1795.958 | 3335.779 |
| RLc 12c | 1450.878 | 2479.654 | 3930.532 |
Table 13.
Total error in the transfer-learning mixed-interference environment.
Table 13.
Total error in the transfer-learning mixed-interference environment.
| Type | X Total Error (m) | Y Total Error (m) | Total Error (m) |
|---|
| PID controller | 2824.23 | 3049.346 | 5873.576 |
| RLc 9m | 2342 | 2494.434 | 4836.434 |
| RLc 10m | 2045.529 | 2774.131 | 4819.66 |
| RLc 11m | 1581.889 | 1969.969 | 3551.858 |
| RLc 12m | 1548.453 | 2758.587 | 4307.04 |






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}