
VizNav: A Modular Off-Policy Deep Reinforcement Learning Framework for Vision-Based Autonomous UAV Navigation in 3D Dynamic Environments



Abstract
1. Introduction
- VizNav trains the agent to navigate complex environments using depth map images (DMIs) from a front-facing camera, providing a more accurate and comprehensive depth perspective. This approach enhances the realism of training environments and promotes genuine autonomous capabilities, overcoming the limitations of traditional models.
- VizNav utilizes TD3, an off-policy algorithm known for its stability and efficiency in handling continuous actions and reducing overestimations in value functions, making it a robust choice for the proposed navigation task.
- VizNav incorporates Prioritized Experience Replay (PER) to enhance TD3’s performance by focusing the agent’s learning process on key transitions, enabling improved training results and faster model convergence.
- VizNav is a modular and adaptable framework that can train different RL agents seamlessly, facilitate easy hyperparameter tuning, and that can integrate with various navigation environments.
2. Background
2.1. MDP and Deterministic Policy
2.2. Off-Policy vs. On-Policy RL
2.3. DDPG vs. TD3
3. Related Work
3.1. Navigation Using 1D/2D Environments or Restricted Actions
3.2. UAV Navigation Using Front-Facing Cameras
3.3. UAV Navigation Frameworks
3.4. RL Algorithm for UAV Navigation
4. Problem Formulation
4.1. VizNav Navigation
4.2. State and Action Space Specifications
- RGB Image is produced by the UAV front-facing camera capturing the UAV current scene.
- Depth Information is a 2D array that contains the estimated distance between all the points from the captured scene and the current UAV position. The 2D array is converted to a single-channel gray-scale image.
- Angular Velocity is the rate of rotation of a rigid body (here, UAV) relative to its center of rotation and independently of its origin, which is provided by the inertial measurement unit (IMU).
- Linear Acceleration , also measured by IMU, refers to the rate of change in velocity without a change in direction.
- Orientation measures the UAV’s orientation relative to the NED (North, East, Down) coordinate system using quaternion instead of Euler angles.
- Current Position measures the current UAV position using the NED coordinate system.
- Destination Position refers to the destination point using the NED coordinate system.
- Remaining Distance is the remaining distance from the current position to the destination point measured in meters.
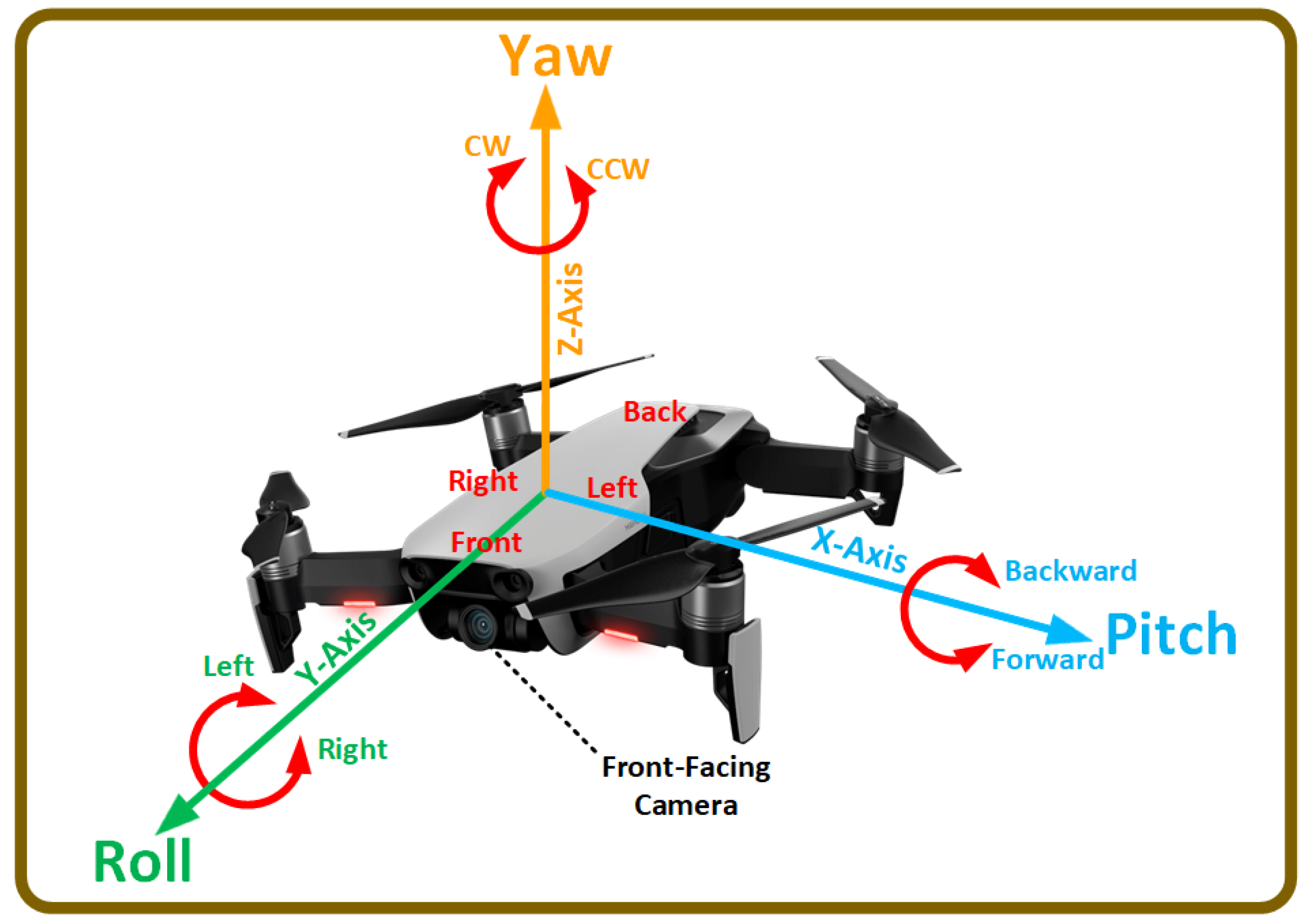
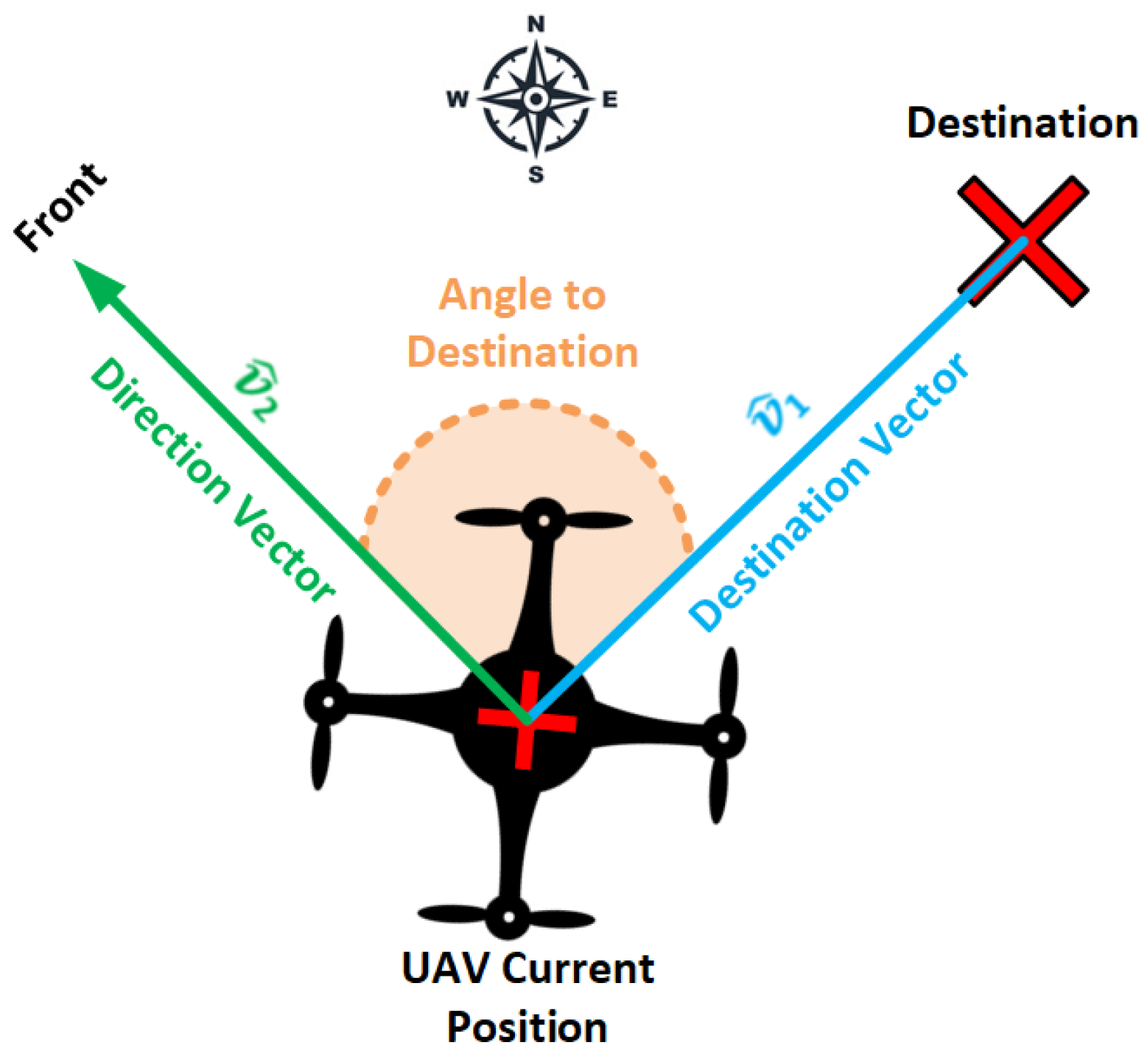
- Angle to Destination measures the angle between the UAV’s current orientation and the destination point . As shown in Figure 2, the angle is computed by defining two unit vectors, and . The first unit vector from the UAV’s current position to the destination point defines the destination direction, whereas defines the unit vector of the UAV’s facing direction with respect to the NED coordinate system. Equation (3) shows how the unit vector, also known as a normalized vector, is computed by dividing the direction vector () by its norm/magnitude (), whereas Equation (4) shows how the angle between the UAV’s current position and destination point is computed.Figure 1. The UAV control mechanism demonstrates regulating the UAV’s movement through the rotation angle around three axes—pitch, roll, and yaw—while the throttle adjusts the engines’ thrust. Rotation around the roll axis, highlighted in green, directs the UAV left or right. Rotation around the pitch axis, shown in blue, moves the UAV forward or backward. Rotation around the yaw axis, depicted in orange, enables clockwise (CW) or counterclockwise (CCW) rotation.Figure 1. The UAV control mechanism demonstrates regulating the UAV’s movement through the rotation angle around three axes—pitch, roll, and yaw—while the throttle adjusts the engines’ thrust. Rotation around the roll axis, highlighted in green, directs the UAV left or right. Rotation around the pitch axis, shown in blue, moves the UAV forward or backward. Rotation around the yaw axis, depicted in orange, enables clockwise (CW) or counterclockwise (CCW) rotation.
![Drones 08 00173 g001]()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4.3. Reward Engineering
5. VizNav Framework
5.1. Framework Modules
5.1.1. Training Manager
5.1.2. Replay Buffer Manager
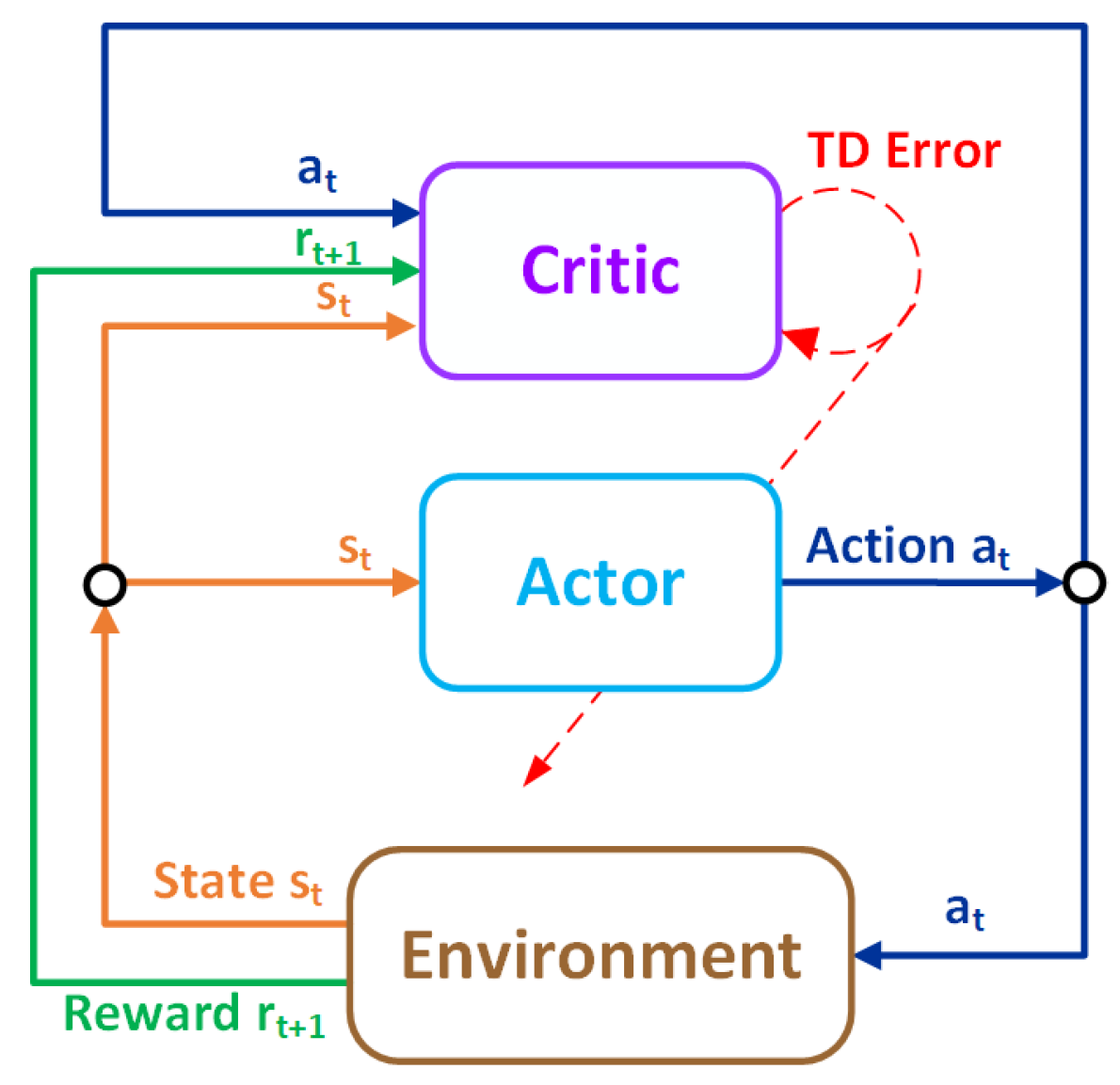
5.1.3. DRL Agent
5.1.4. UAV Controller
5.1.5. Reward Generator
5.2. Deep Agent Architecture
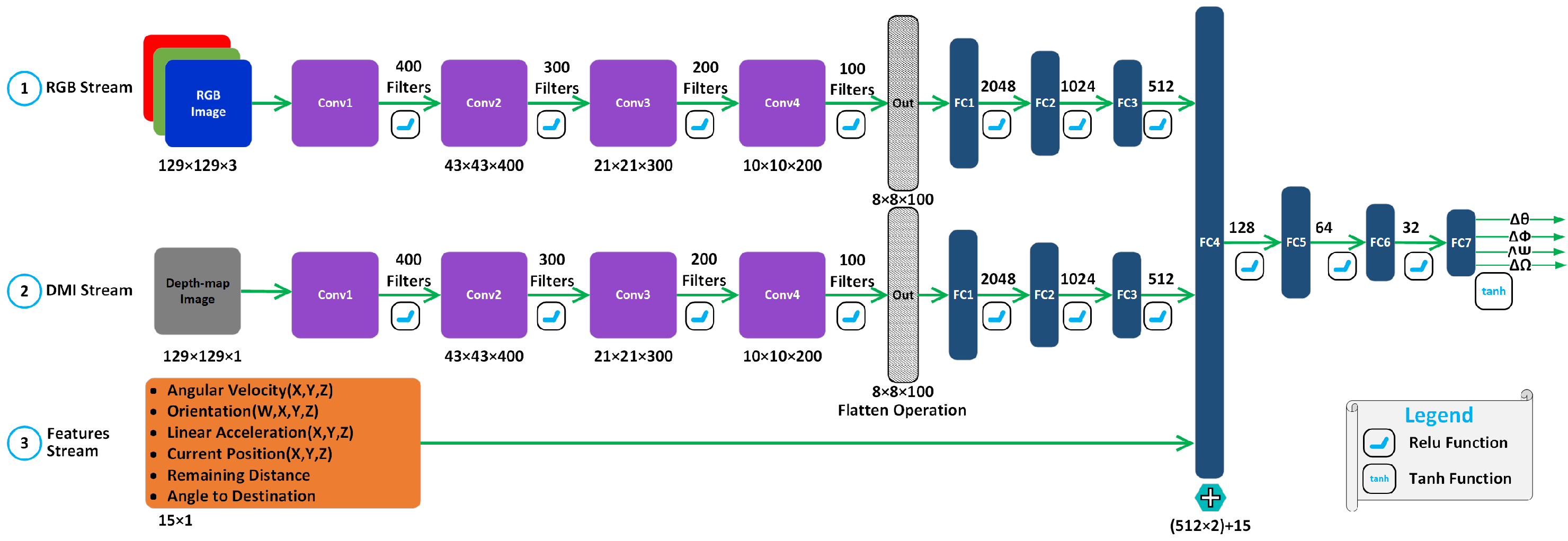
5.3. VizNav Navigation Training
- 1.
- Initialization (Lines 1–8):
- 1.1
- Experiment Configurations (Line 2): The algorithm starts by loading predefined settings that detail the UAV’s operating parameters and environmental setup.
- 1.2
- 3D Environment Launch (Line 3): A simulated 3D environment is initialized using Unreal Engine, creating a realistic navigation space.
- 1.3
- UAV Initialization (Line 4): The UAV’s starting position and control commands—pitch, roll, yaw, and throttle—are initialized according to the predefined settings in the configuration file to ensure a standardized baseline for each training session.
- 1.4
- DRL Agent Initialization (Lines 5–8): The replay buffer is initialized to store experiences of size M (Line 5), the reward generator is initialized to start calculating the reward (Line 6), and the DRL agent’s neural networks, i.e., policy and target networks, are initialized for both the actor and critic networks (Lines 7–8).
- 2.
- Main Training Loop (Lines 9–24):
- 2.1
- Episode Initialization (Lines 10–12):
- 2.1.1
- Reset UAV (Lines 10–11): At the start of each episode, the UAV is reset to its initial position and orientation. Following the reset, the UAV’s initial state is captured, including its position, orientation, and sensor data, to establish the starting point for the episode. This ensures that each episode begins under consistent conditions.
- 2.1.2
- Reset Collision Status (Line 12): The collision status is reset at the beginning of each episode. If a collision has occurred in a previous episode, the UAV status is reset to enable learning from mistakes without carrying over error states.
- 2.2
- Episode Processing (Lines 13–23): For each step in the episode, the following tasks are performed. The episode will end either by reaching the terminal state (i.e., target reached or collision occurred) or upon reaching a limit of number of steps:
- 2.2.1
- Exploration and Exploitation (Lines 14–16):
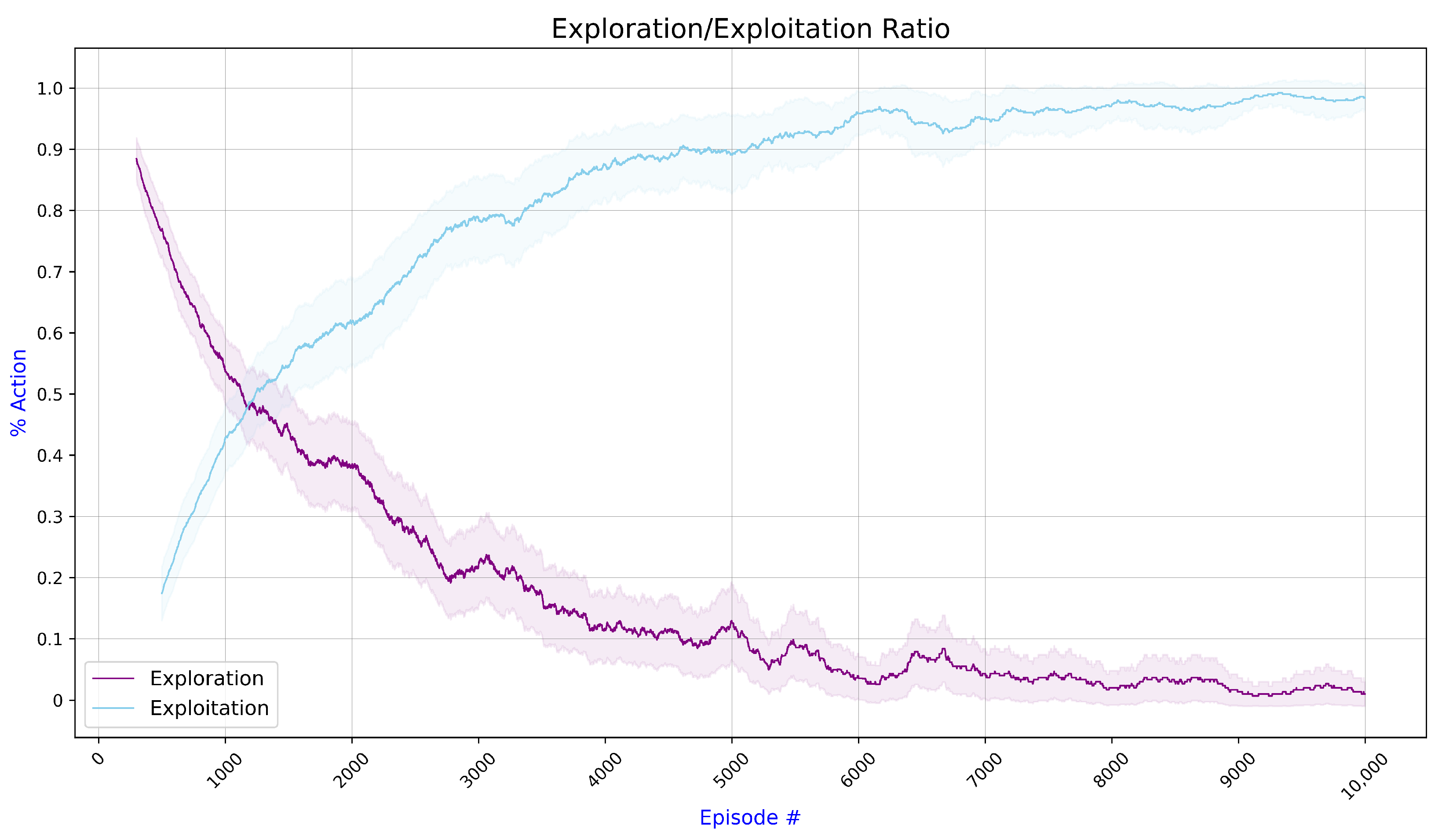
- Action Selection (Line 14): Actions are selected using a decaying -greedy strategy, which helps the UAV balance exploring new actions and exploiting known beneficial ones.
- Noise Addition and Clipping (Lines 15–16): To encourage exploration, random noise is added to the selected actions (Line 15), then the actions are clipped at Line 16 according to the configured threshold values to ensure they remain related and safe for execution.
- 2.2.2
- Action Execution and Feedback (Lines 17–19):
- Flight Command Execution and State Observation (Lines 17–18): The selected action is converted into UAV flight commands (i.e., adjustments in pitch, roll, yaw, and throttle) and executed, which moves the UAV in the simulated environment. After executing the action, the agent observes the new state, including the image captured using the front-facing camera, position, orientation, and environmental interactions.
- Reward Calculation (Line 19): A reward is generated based on the observed new state, influencing future actions.
- 2.2.3
- Learning from Experience (Lines 20–21):
- Experience Storage (Line 20): The experience (comprising the previous state, action taken, reward received, and new state) is stored in the replay buffer. These data are crucial for learning, as they provide a historical record of actions and outcomes.
- State Update (Line 21): After executing the action and observing the new state, the new state becomes the current state for the next step in the episode.
- 2.2.4
- Agent’s Learning (Line 22): At each training step, the DRL agent refines its decision-making model by learning from a batch of experiences sampled from the replay buffer, progressively improving its action selection (policy) based on accumulated knowledge.
| Algorithm 1 VizNav Training |
|
- 1.
- Check for Adequate Experiences (Line 2): The algorithm first checks if the replay buffer contains enough experiences to form a batch of size N. If it does, it proceeds to the sampling step; otherwise, it waits until there are enough experiences to form a batch of size N.
- 2.
- Sampling from Replay Buffer (Line 3): Extracts a mini-batch of N experiences from the replay buffer.
- 3.
- Importance Sampling for PER (Lines 4–6): If PER [30] is employed, the algorithm retrieves importance sampling weights (Line 5) to focus on significant experiences.
- 4.
- Target Action and Q-value Calculations (Lines 7–10): The algorithm computes the target actions using the policy network of the target model (Line 7), adds exploration noise (Line 8), and clips the actions to ensure they are within acceptable bounds (Line 9). It then calculates the target Q-values from the target critic network.
- 5.
- Policy and Critic Network Updates (Lines 11–20): The critic networks are updated based on the loss between computed Q-values and the target Q-values (Lines 11–15), adjusting the model to predict value estimates better. This includes updating priorities in the replay buffer if PER is used (Lines 14–15).
- 6.
- Policy Network Update (Lines 21–22): The policy network is periodically updated using a deterministic policy gradient approach.
- 7.
- Soft Update of Target Networks (Lines 23–26): This step applies a soft update rule to gradually merge the trained network weights into the target networks, ensuring the stability of learning updates.
| Algorithm 2 TD3 Agent Learning |
|
6. Evaluation
6.1. Experimental Setup
6.1.1. Simulation Environment
- 3D View Snapshot provides a sample view of the UAV in the environment, captured from a third-person perspective.
- Voxel Grid offers a simplified 3D view of the environment, where the environment is divided into a 3D grid of cubes (voxels), with each voxel representing whether the space is occupied. These grids provide a view of the complete environment, showcasing the complexity of the environment; nevertheless, the realistic 3D rendering (as in 3D view) is employed in simulations.
- Neighborhood Environment features a small neighborhood block including residential buildings, roads, and vegetation. This is a static environment used for basic UAV navigation.
- City Environment captures a complex urban setting with high-rise buildings, moving cars, and pedestrians. The dynamic nature of this environment poses advanced challenges for UAV navigation, requiring strategies that adapt to moving obstacles.
6.1.2. Data Collection Methodology

6.1.3. Experiment Configurations
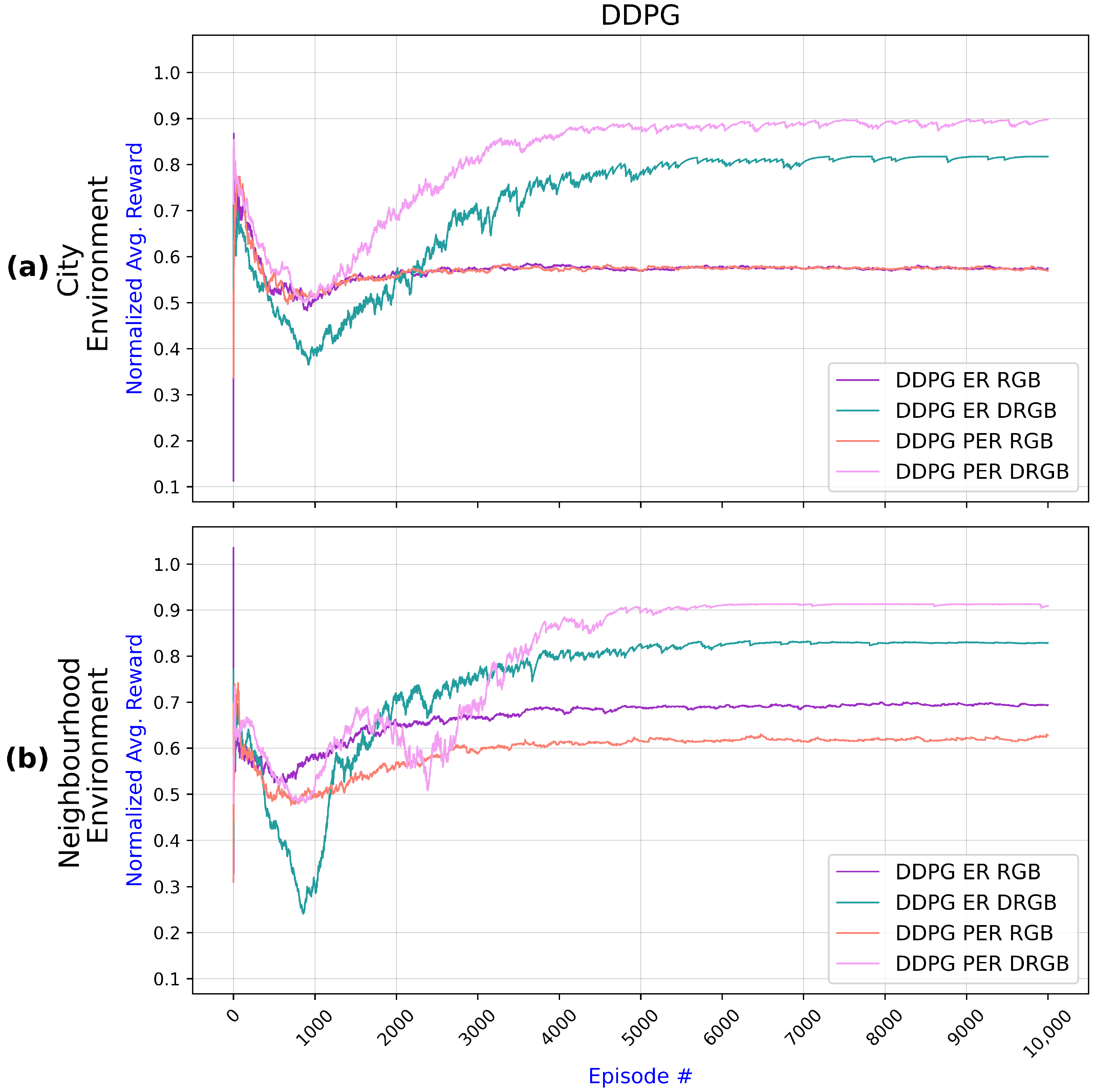
6.2. Performance Analysis
- Using ER and RGB images (ER RGB);
- Using PER and RGB images (PER RGB);
- Using ER with RGB and DMI (PER DRGB);
- Using PER with RGB and DMI (PER DRGB).
6.2.1. TD3 and DDPG Results
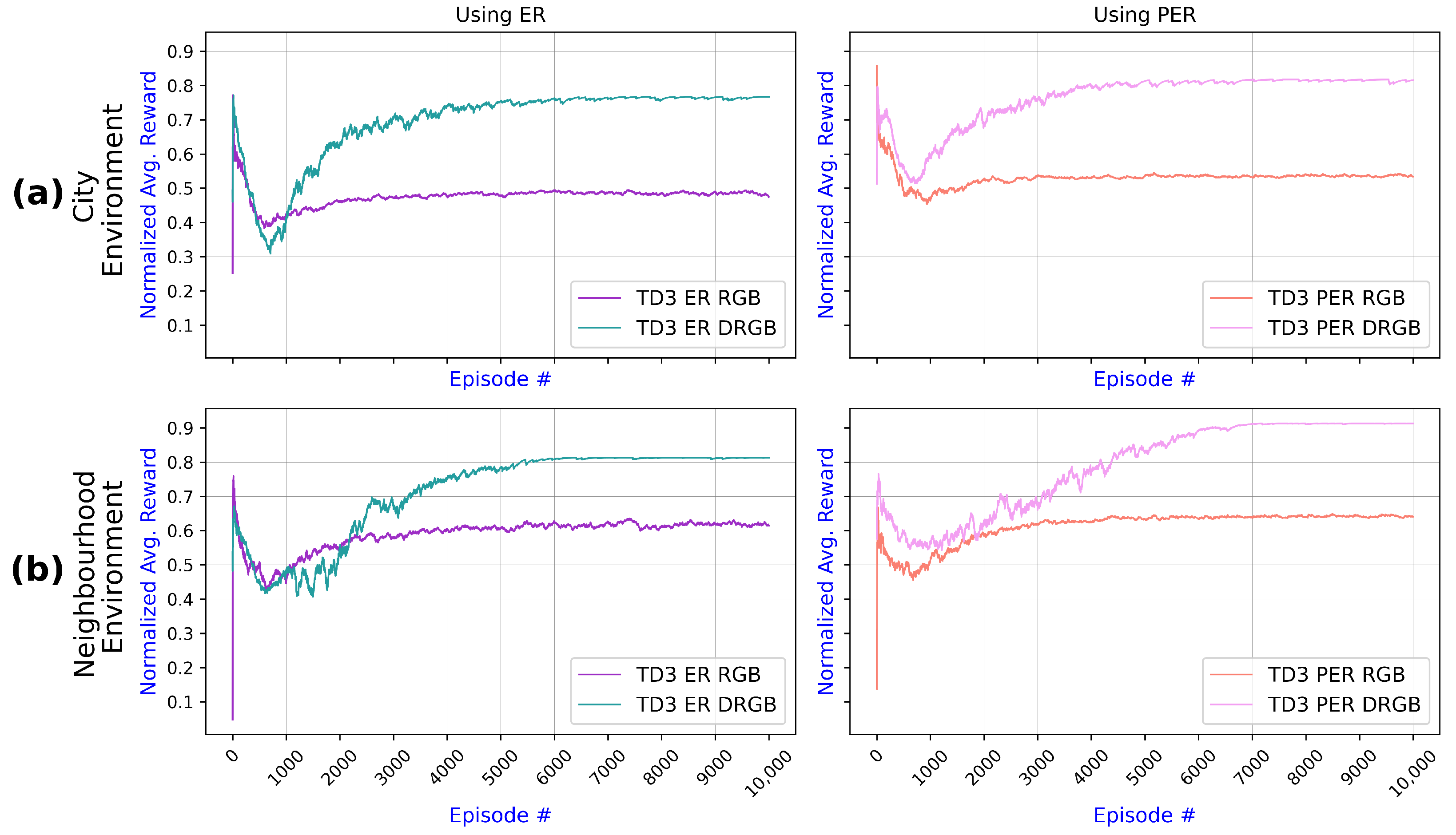
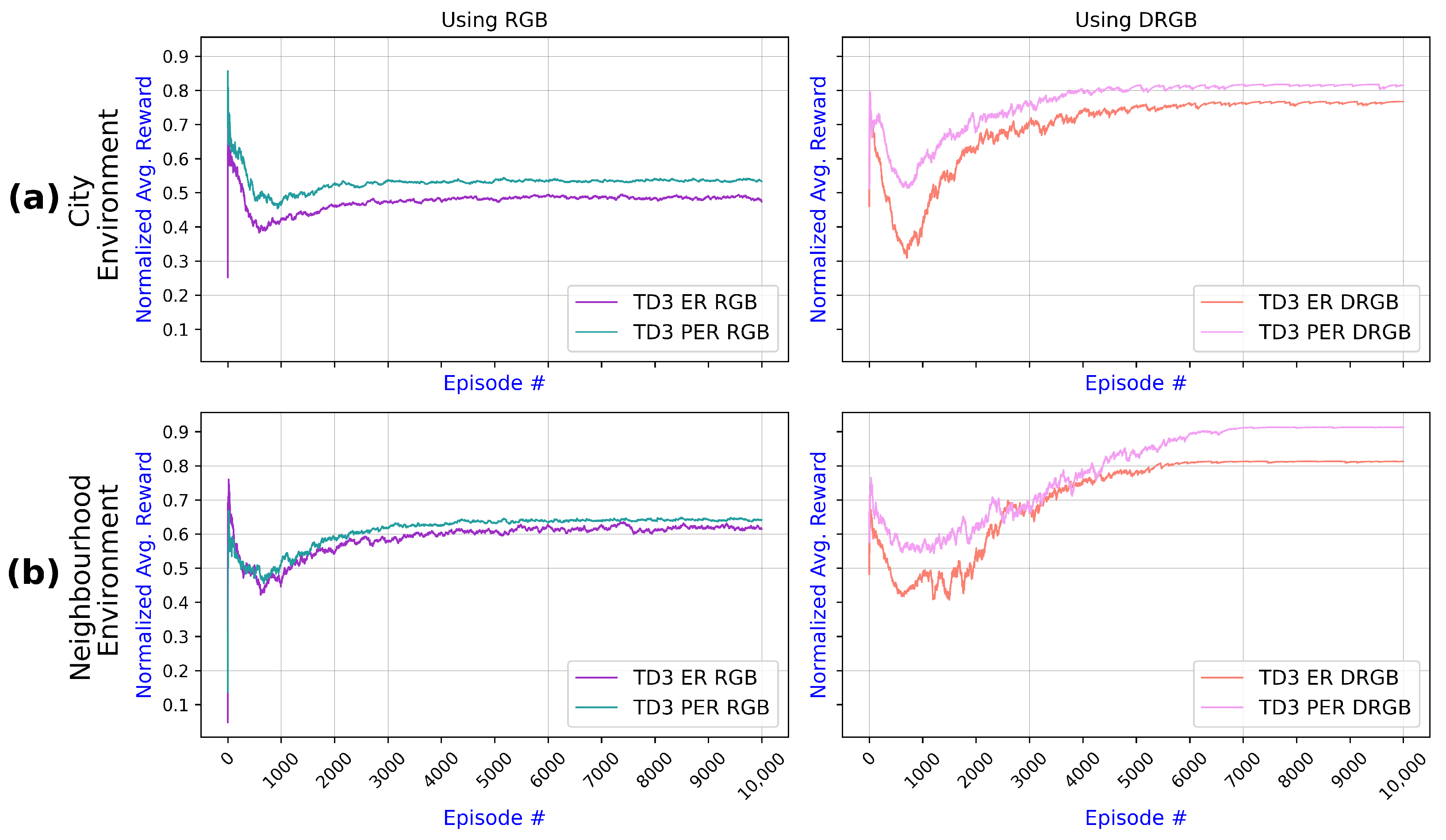
6.2.2. Examining Variants of TD3 and DDPG
6.2.3. Examining the Impact of DMI and PER
6.3. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- AlMahamid, F.; Grolinger, K. Autonomous Unmanned Aerial Vehicle Navigation using Reinforcement Learning: A Systematic Review. Eng. Appl. Artif. Intell. 2022, 115, 105321. [Google Scholar] [CrossRef]
- Arafat, M.; Alam, M.; Moh, S. Vision-Based Navigation Techniques for Unmanned Aerial Vehicles: Review and Challenges. Drones 2023, 7, 89. [Google Scholar] [CrossRef]
- Hauskrecht, M. Value-Function Approximations for Partially Observable Markov Decision Processes. J. Artif. Intell. Res. 2000, 13, 33–94. [Google Scholar] [CrossRef]
- Saghafian, S. Ambiguous partially observable Markov decision processes: Structural results and applications. J. Econ. Theory 2018, 178, 1–35. [Google Scholar] [CrossRef]
- Pyeatt, L.D.; Howe, A.E. A parallel Algorithm for POMDP Solution. In Proceedings of the Springer Recent Advances in AI Planning, Durham, UK, 8–10 September 1999; pp. 73–83. [Google Scholar]
- Paden, B.; Čáp, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A Survey of Motion Planning and Control Techniques for Self-Driving Urban Vehicles. IEEE Trans. Intell. Veh. 2016, 1, 33–55. [Google Scholar] [CrossRef]
- Huang, Y.; Du, J.; Yang, Z.; Zhou, Z.; Zhang, L.; Chen, H. A Survey on Trajectory-Prediction Methods for Autonomous Driving. IEEE Trans. Intell. Veh. 2022, 7, 652–674. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, K.; Liu, D.; Song, H. Autonomous UAV Navigation in Dynamic Environments with Double Deep Q-Networks. In Proceedings of the AIAA/IEEE Digital Avionics Systems Conference, San Antonio, TX, USA, 11–15 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Wang, C.; Wang, J.; Zhang, X.; Zhang, X. Autonomous navigation of UAV in large-scale unknown complex environment with deep reinforcement learning. In Proceedings of the IEEE Global Conference on Signal and Information Processing, Montreal, QC, Canada, 14–16 November 2017; pp. 858–862. [Google Scholar] [CrossRef]
- Bouhamed, O.; Ghazzai, H.; Besbes, H.; Massoud, Y. Autonomous UAV Navigation: A DDPG-Based Deep Reinforcement Learning Approach. In Proceedings of the IEEE International Symposium on Circuits and Systems, Virtual, 10–21 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Microsoft. Microsoft AirSim Home Page. 2021. Available online: https://microsoft.github.io/AirSim/ (accessed on 1 March 2024).
- Grando, R.B.; de Jesus, J.C.; Drews, P.L., Jr. Deep Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles. In Proceedings of the IEEE Latin American Robotics Symposium, Brazilian Symposium on Robotics and Workshop on Robotics in Education, Natal, Brazil, 9–12 November 2020; pp. 1–6. [Google Scholar]
- Wang, C.; Wang, J.; Wang, J.; Zhang, X. Deep-Reinforcement-Learning-Based Autonomous UAV Navigation with Sparse Rewards. IEEE Internet Things J. 2020, 7, 6180–6190. [Google Scholar] [CrossRef]
- Liu, C.H.; Ma, X.; Gao, X.; Tang, J. Distributed energy-efficient multi-UAV navigation for long-term communication coverage by deep reinforcement learning. IEEE Trans. Mob. Comput. 2019, 19, 1274–1285. [Google Scholar] [CrossRef]
- Yan, P.; Bai, C.; Zheng, H.; Guo, J. Flocking Control of UAV Swarms with Deep Reinforcement Learning Approach. In Proceedings of the IEEE International Conference on Unmanned Systems, Harbin, China, 27–28 November 2020; pp. 592–599. [Google Scholar]
- Wang, C.; Wang, J.; Shen, Y.; Zhang, X. Autonomous Navigation of UAVs in Large-Scale Complex Environments: A Deep Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2019, 68, 2124–2136. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Arola, S.; Bonnet, A. Drones Chasing Drones: Reinforcement Learning and Deep Search Area Proposal. Drones 2019, 3, 58. [Google Scholar] [CrossRef]
- Andrew, W.; Greatwood, C.; Burghardt, T. Deep Learning for Exploration and Recovery of Uncharted and Dynamic Targets from UAV-like Vision. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 1124–1131. [Google Scholar] [CrossRef]
- Imanberdiyev, N.; Fu, C.; Kayacan, E.; Chen, I.M. Autonomous navigation of UAV by using real-time model-based reinforcement learning. In Proceedings of the IEEE International Conference on Control, Automation, Robotics and Vision, Phuket, Thailand, 13–15 November 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, B.; Wang, W.; Liu, Z.; Wang, J. Vision-based Navigation of UAV with Continuous Action Space Using Deep Reinforcement Learning. In Proceedings of the IEEE Chinese Control and Decision Conference, Nanchang, China, 3–5 June 2019; pp. 5030–5035. [Google Scholar]
- Butt, M.Z.; Nasir, N.; Rashid, R.B.A. A review of perception sensors, techniques, and hardware architectures for autonomous low-altitude UAVs in non-cooperative local obstacle avoidance. Robot. Auton. Syst. 2024, 173, 104629. [Google Scholar] [CrossRef]
- Doukhi, O.; Lee, D.J. Deep Reinforcement Learning for End-to-End Local Motion Planning of Autonomous Aerial Robots in Unknown Outdoor Environments: Real-Time Flight Experiments. Sensors 2021, 21, 2534. [Google Scholar] [CrossRef]
- Kutila, M.; Pyykönen, P.; Ritter, W.; Sawade, O.; Schäufele, B. Automotive LIDAR Sensor Development Scenarios for Harsh Weather Conditions. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems, Rio de Janeiro, Brazil, 1–4 November 2016; pp. 265–270. [Google Scholar]
- Shin, S.Y.; Kang, Y.W.; Kim, Y.G. Automatic Drone Navigation in Realistic 3D Landscapes using Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Control, Decision and Information Technologies, Paris, France, 23–26 April 2019; pp. 1072–1077. [Google Scholar]
- Camci, E.; Campolo, D.; Kayacan, E. Deep Reinforcement Learning for Motion Planning of Quadrotors Using Raw Depth Images. In Proceedings of the IEEE International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Andrychowicz, M.; Raichuk, A.; Stańczyk, P.; Orsini, M.; Girgin, S.; Marinier, R.; Hussenot, L.; Geist, M.; Pietquin, O.; Michalski, M.; et al. What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2020. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Zhang, S.; Boehmer, W.; Whiteson, S. Generalized Off-Policy Actor-Critic. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Lin, L.J. Self-Improving Reactive Agents Based on Reinforcement Learning, Planning and Teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 1587–1596. [Google Scholar]
- AlMahamid, F.; Grolinger, K. Reinforcement Learning Algorithms: An Overview and Classification. In Proceedings of the IEEE Canadian Conference on Electrical and Computer Engineering, Virtual, 12–17 September 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21 June–26 June 2014; Volume 32, pp. 387–395. [Google Scholar]
- Konda, V.R.; Tsitsiklis, J.N. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 20 June 2000; pp. 1008–1014. [Google Scholar]
- Lapan, M. Deep Reinforcement Learning Hands-On: Apply Modern RL Methods to Practical Problems of Chatbots, Robotics, Discrete Optimization, Web Automation, and More; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Long Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Heess, N.; Hunt, J.J.; Lillicrap, T.P.; Silver, D. Memory-Based Control with Recurrent Neural Networks. arXiv 2015, arXiv:1512.04455. [Google Scholar]
- Anwar, A.; Raychowdhury, A. Autonomous Navigation via Deep Reinforcement Learning for Resource Constraint Edge Nodes Using Transfer Learning. IEEE Access 2020, 8, 26549–26560. [Google Scholar] [CrossRef]
- He, L.; Aouf, N.; Whidborne, J.F.; Song, B. Integrated moment-based LGMD and deep reinforcement learning for UAV obstacle avoidance. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 7491–7497. [Google Scholar] [CrossRef]
- Boiteau, S.; Vanegas, F.; Gonzalez, F. Framework for Autonomous UAV Navigation and Target Detection in Global-Navigation-Satellite-System-Denied and Visually Degraded Environments. Remote Sens. 2024, 16, 471. [Google Scholar] [CrossRef]
- Singla, A.; Padakandla, S.; Bhatnagar, S. Memory-Based Deep Reinforcement Learning for Obstacle Avoidance in UAV With Limited Environment Knowledge. IEEE Trans. Intell. Transp. Syst. 2021, 22, 107–118. [Google Scholar] [CrossRef]
- Hausknecht, M.; Stone, P. Deep Recurrent Q-learning for partially observable MDPS. In Proceedings of the Association for the Advancement of Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Walker, O.; Vanegas, F.; Gonzalez, F.; Koenig, S. A Deep Reinforcement Learning Framework for UAV Navigation in Indoor Environments. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 2–9 March 2019; pp. 1–14. [Google Scholar] [CrossRef]
- Bouhamed, O.; Ghazzai, H.; Besbes, H.; Massoud, Y. A Generic Spatiotemporal Scheduling for Autonomous UAVs: A Reinforcement Learning-Based Approach. IEEE Open J. Veh. Technol. 2020, 1, 93–106. [Google Scholar] [CrossRef]
- Camci, E.; Kayacan, E. Planning Swift Maneuvers of Quadcopter Using Motion Primitives Explored by Reinforcement Learning. In Proceedings of the American Control Conference, Philadelphia, PA, USA, 10–12 July 2019; pp. 279–285. [Google Scholar] [CrossRef]
- Lee, A.; Yong, S.P.; Pedrycz, W.; Watada, J. Testing a Vision-Based Autonomous Drone Navigation Model in a Forest Environment. Algorithms 2024, 17, 139. [Google Scholar] [CrossRef]
- Ye, Z.; Peng, Y.; Liu, W.; Yin, W.; Hao, H.; Han, B.; Zhu, Y.; Xiao, D. An Efficient Adjacent Frame Fusion Mechanism for Airborne Visual Object Detection. Drones 2024, 8, 144. [Google Scholar] [CrossRef]
- Fei, W.; Xiaoping, Z.; Zhou, Z.; Yang, T. Deep-reinforcement-learning-based UAV autonomous navigation and collision avoidance in unknown environments. Chin. J. Aeronaut. 2024, 37, 237–257. [Google Scholar]
- Zhang, N.; Nex, F.; Vosselman, G.; Kerle, N. End-to-End Nano-Drone Obstacle Avoidance for Indoor Exploration. Drones 2024, 8, 33. [Google Scholar] [CrossRef]
- Zhang, S.; Whiteson, S. DAC: The double actor-critic architecture for learning options. arXiv 2019, arXiv:1904.12691. [Google Scholar]
- Zhang, S.; Yao, H. ACE: An Actor Ensemble Algorithm for continuous control with tree search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5789–5796. [Google Scholar] [CrossRef]
- Zhou, S.; Li, B.; Ding, C.; Lu, L.; Ding, C. An Efficient Deep Reinforcement Learning Framework for UAVs. In Proceedings of the International Symposium on Quality Electronic Design, Santa Clara, CA, USA, 25–26 March 2020; pp. 323–328. [Google Scholar] [CrossRef]
- Shin, S.Y.; Kang, Y.W.; Kim, Y.G. Obstacle Avoidance Drone by Deep Reinforcement Learning and Its Racing with Human Pilot. Appl. Sci. 2019, 9, 5571. [Google Scholar] [CrossRef]
- Epic Games. Epic Games Unreal Engine Home Page. 2021. Available online: https://www.unrealengine.com (accessed on 11 March 2024).



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlMahamid, F.; Grolinger, K. VizNav: A Modular Off-Policy Deep Reinforcement Learning Framework for Vision-Based Autonomous UAV Navigation in 3D Dynamic Environments. Drones 2024, 8, 173. https://doi.org/10.3390/drones8050173
AlMahamid F, Grolinger K. VizNav: A Modular Off-Policy Deep Reinforcement Learning Framework for Vision-Based Autonomous UAV Navigation in 3D Dynamic Environments. Drones. 2024; 8(5):173. https://doi.org/10.3390/drones8050173
Chicago/Turabian StyleAlMahamid, Fadi, and Katarina Grolinger. 2024. "VizNav: A Modular Off-Policy Deep Reinforcement Learning Framework for Vision-Based Autonomous UAV Navigation in 3D Dynamic Environments" Drones 8, no. 5: 173. https://doi.org/10.3390/drones8050173
APA StyleAlMahamid, F., & Grolinger, K. (2024). VizNav: A Modular Off-Policy Deep Reinforcement Learning Framework for Vision-Based Autonomous UAV Navigation in 3D Dynamic Environments. Drones, 8(5), 173. https://doi.org/10.3390/drones8050173