
UAV-Enabled Diverse Data Collection via Integrated Sensing and Communication Functions Based on Deep Reinforcement Learning


Abstract
1. Introduction
1.1. Background
1.2. Related Works
1.3. Contributions of This Paper
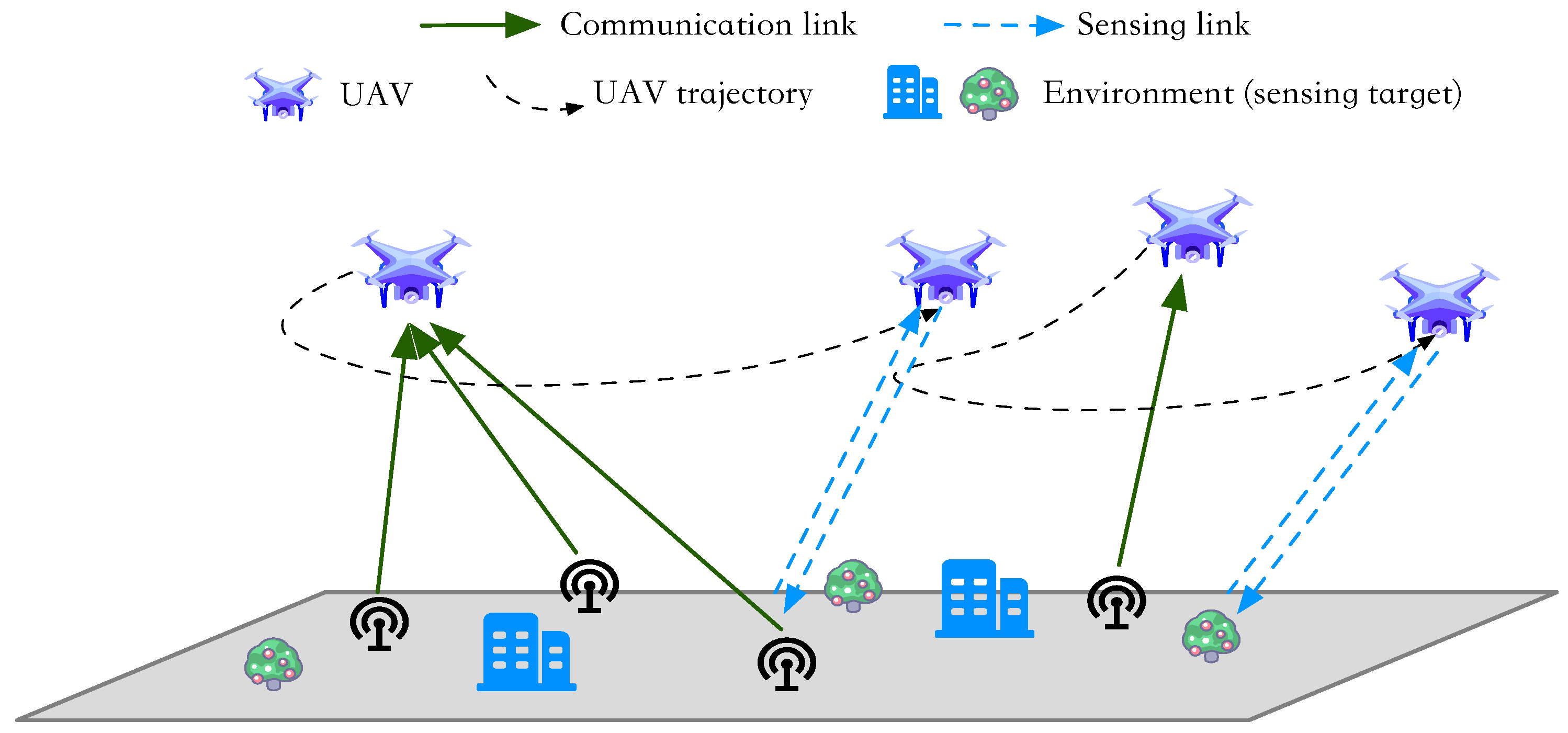
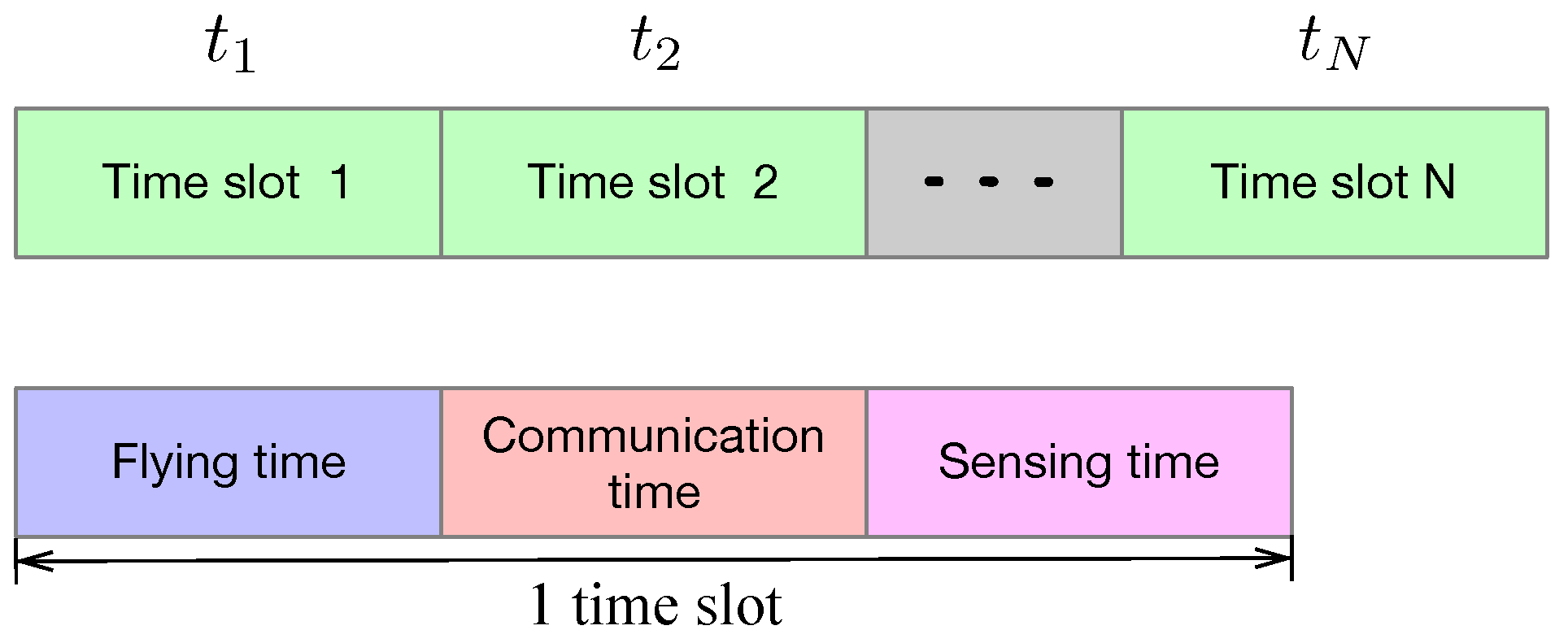
- We establish a diverse data collection scenario where the UAVs not only collect data from IoT devices (communication functionality) but also transmit radar pulses and receive echo signals (sensing functionality). To cancel the interference between communication and sensing, we adopt the time division scheme to perform communication and sensing functions sequentially. To cancel the mutual interference among IoT devices, we adopt the frequency division scheme to allocate different sub-carriers to different IoT devices.
- We define the successful transmission state to judge whether an IoT device successfully transmits its data to a UAV. Then, we define the data freshness indicator to characterize both the communication coverage and the fairness among IoT devices. Similarly, we define the successful sensing state and the detection freshness indicator, indicating the sensing coverage and the fairness among sensing targets, which further reflects the time-sensitivity and fairness of the system.
- We formulate an optimization for diverse data collection to minimize the summation of the data freshness indicator and detection freshness indicator by optimizing the UAV paths, the transmitted power of IoT devices and UAVs, and the transmission allocation indicators. Such an objective reflects the communication performance, the sensing performance, and their corresponding fairness. In addition, we reformulate the problem as a Markov decision process (MDP) to decide the movement distance of the UAVs, the power variations of the UAVs and IoT devices, and the allocation variations of tasks.
- To solve the formulated MDP, we propose three state-of-the-art DRL algorithms, namely twin delayed deep deterministic policy gradient (TD3), soft actor-critic (SAC), and proximal policy optimization (PPO). These are all mature algorithms designed to solve the problem with continuous action space and have been widely used in UAV trajectory planning. We provide the algorithm process to solve the established UAV-enabled diverse data collection optimization.
- Experiments are conducted in both single-UAV and multi-UAV scenarios, and the results verify the effectiveness of the algorithms. In addition, besides the joint mode, we also consider the other two data collection modes, i.e., data collection with only communication or sensing function. Moreover, we adopt the random strategy as the benchmark, and the results show that our methods outperform the benchmark. Furthermore, the numerical Pareto front between communication and sensing performance is obtained to reflect the inherent trade-offs.
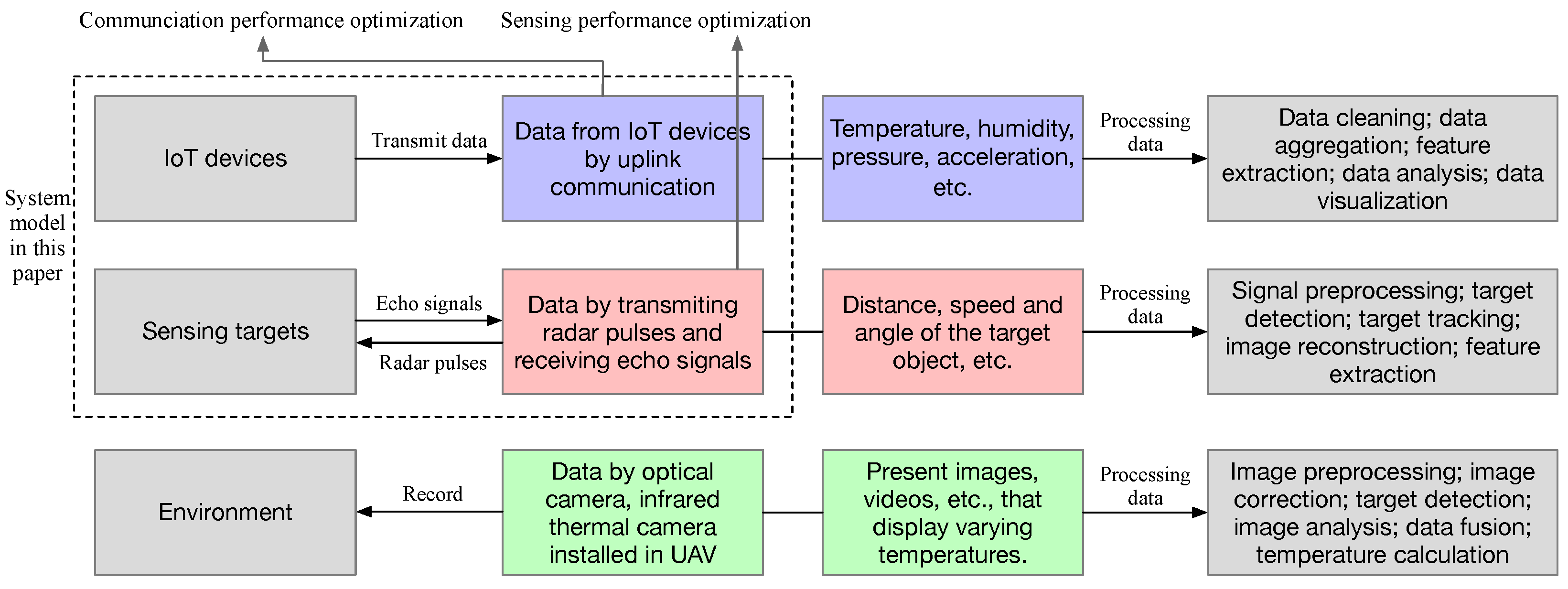
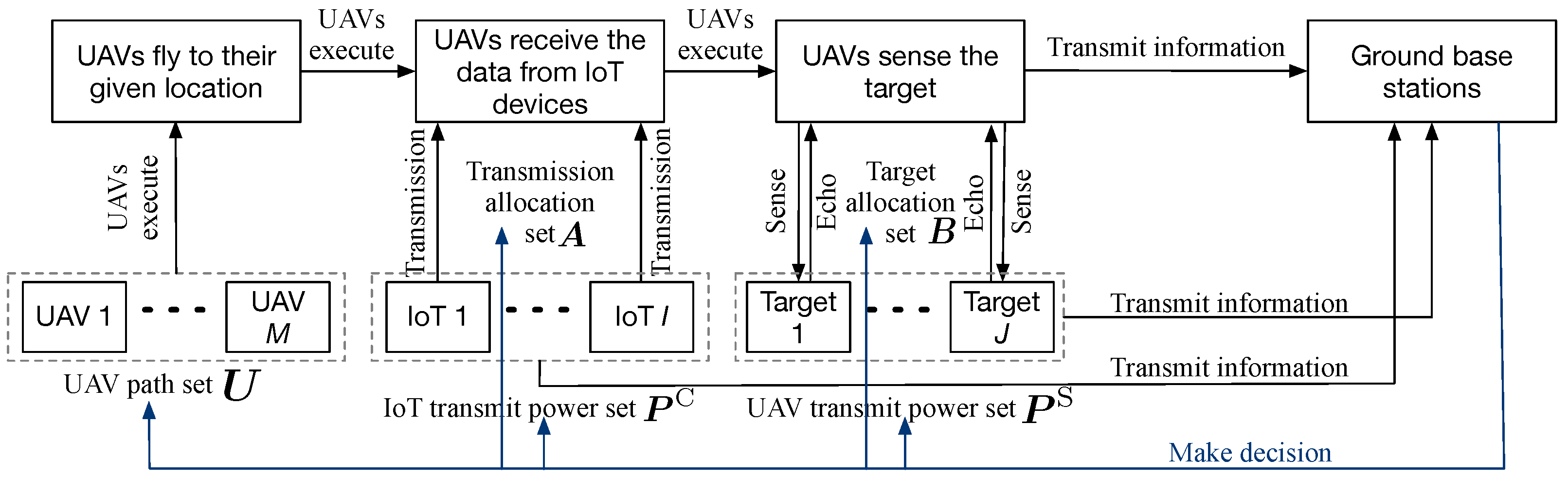
2. System Model and Problem Formulation
2.1. System Model
2.2. Communication Performance
2.3. Sensing Performance
2.4. Problem Formulation
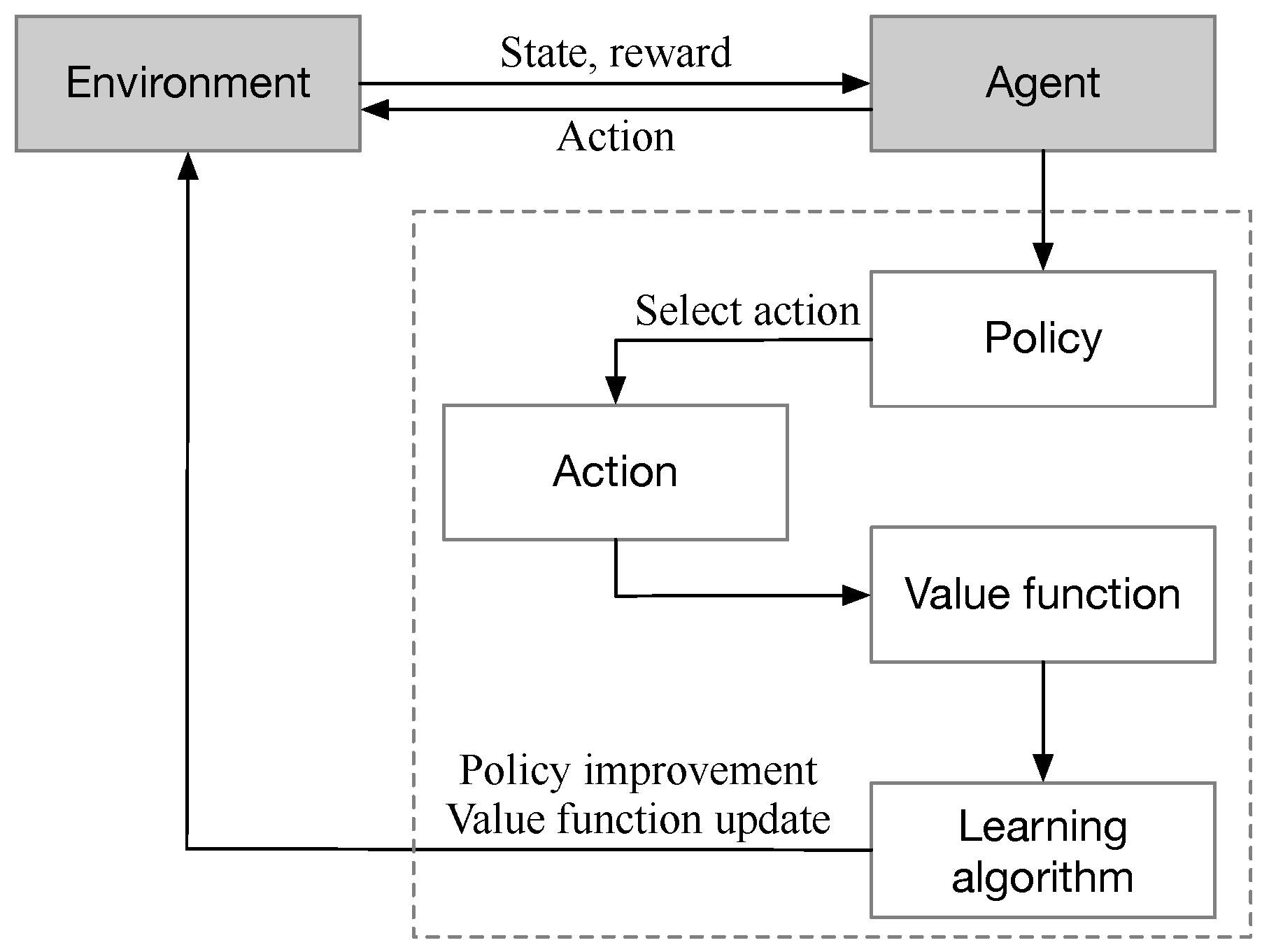
3. Deep Reinforcement Learning for UAV-Enabled Diverse Data Collection
3.1. Markov Decision Process
3.2. Twin Delayed Deep Deterministic Policy Gradient
- Initialization: Randomly initialize two value networks (critics, and with parameters and ) and a policy network (actor, with parameter ). Also, initialize the corresponding target networks (, , and with parameters , , and ) with the same parameters as the original networks.
- Data Collection: Execute the current policy , take actions in the environment, collect transitions (state , action , reward , next state ), and store them in D.
- Sample Extraction: Randomly sample a batch of experiences from D.
- Value Network Update: Calculate the target value using the minimum Q value and the action produced by the target policy network, and update both value networks using the mean squared error, expressed aswhere ; is the action sampled from state according to the current policy; is the discount factor; and is the noise added to the target policy action to ensure exploration and smooth out the value estimates.
- Policy Network Update: The policy network is updated using the policy gradient, which is computed using one of the value networks (typically ):
- Target Network Soft Update: The parameters of the target networks are slowly adjusted towards those of the main networks, with a small update magnitude, typically using a small learning rate, given bywhere is the soft update coefficient.
- Repeat steps 2–6 until the training conditions are satisfied.
| Algorithm 1 Twin delayed deep deterministic policy gradient for UAV-enabled diverse data collection optimization. |
|
3.3. Soft Actor-Critic
- Initialization: Initialize the policy network (actor, with parameter ), two value networks (critics, and with parameters and ), their target networks ( and with parameters and ), and the replay buffer D.
- Data Collection and Sample Extraction
- Value Network Update: Update the value networks using the sampled experiences, usually by minimizing the mean squared error between the predicted and target values, given bywhere d represents the termination flag and is the entropy regularization coefficient. Here, the entropy regularization coefficient is adaptively adjusted.
- Soft Value Update: Update the soft value function using the outputs of the value networks and the rewards.
- Policy Network Update: Update the policy network to maximize the soft value function while also increasing the entropy of the policy, given byHere, is the smaller of the two value networks, and .
- Target Network Soft Update: Periodically soft update the weights of the value networks to the target networks to stabilize the training process, given by
- Repeat steps 2–6 until the policy performance meets expectations or the training reaches a predefined number of iterations.
| Algorithm 2 Soft actor-critic for UAV-enabled diverse data collection optimization. |
|
3.4. Proximal Policy Optimization
- Initialization: Initialize the policy network (actor, with parameter ) and the value network (critic, with parameter ).
- Data Collection
- Advantage Estimation: Estimate the advantage function at each time step using the collected data, which typically involves calculating the discounted sum of rewards and a baseline to reduce variance. The temporal difference (TD) error is a method to evaluate the accuracy of the value function. At a given time step l, the TD error is given bywhere is the value function. Generalized advantage estimation (GAE) is a technique to reduce the variance of policy gradient estimates while maintaining a balance with bias, given bywhere is a parameter between 0 and 1 used to balance bias and variance. When , GAE reduces to the single-step TD error, and when , it approaches the Monte Carlo method.
- Policy Optimization: Optimize the policy by maximizing a specific objective function that includes a clipped ratio of probabilities and the estimated advantage function, along with an entropy bonus to encourage exploration, given bywhere is the clipping parameter.
- Probability Ratio Clipping: Clip the probability ratio if it goes beyond a predefined interval to limit the magnitude of policy updates.
- Value Function Update: Update the value function using the same trajectory data, usually by minimizing the mean squared error between the value predictions and the actual returns, given by
- Repeat steps 2–6 using the updated policy and value function until a termination condition is met, such as achieving a predetermined performance standard or completing a certain number of iterations.
| Algorithm 3 Proximal policy optimization for UAV-enabled diverse data collection optimization. |
|
4. Experimental Results and Discussions
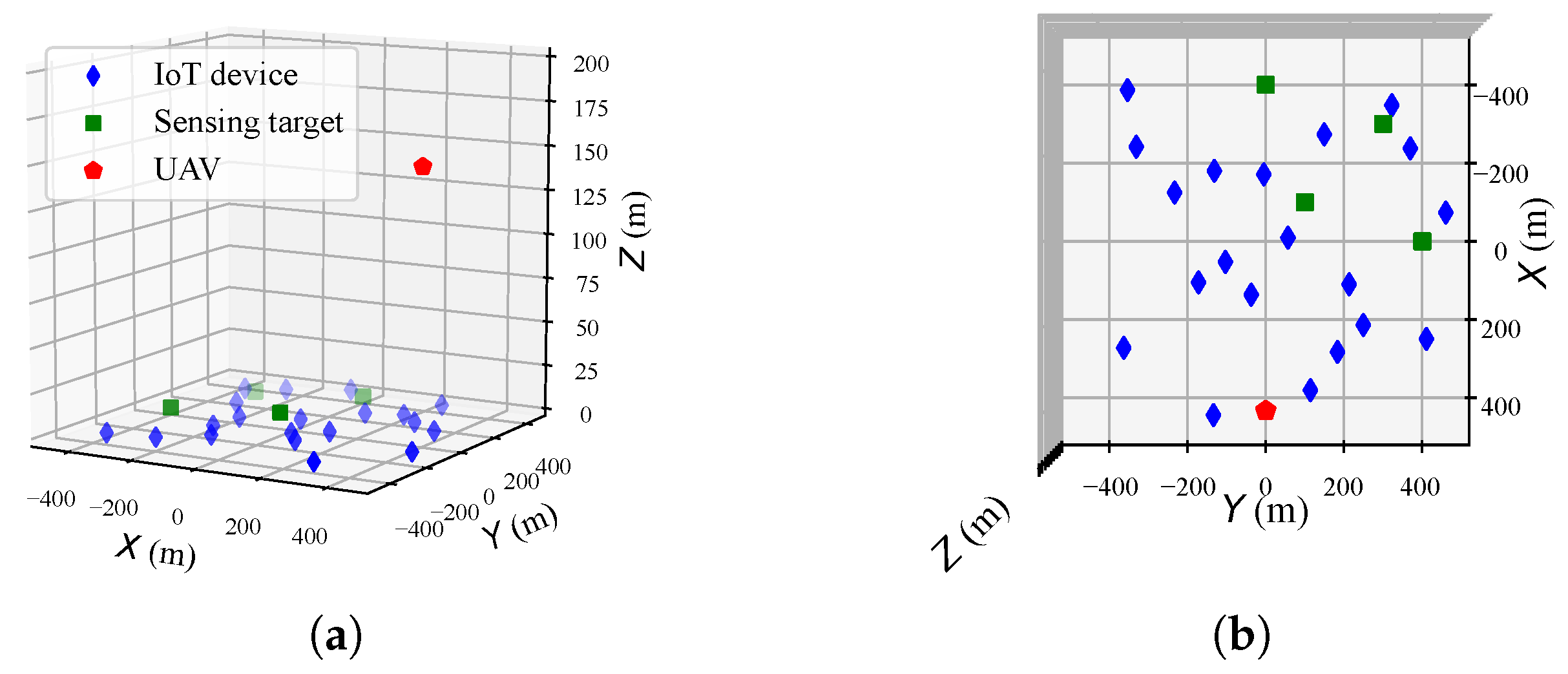
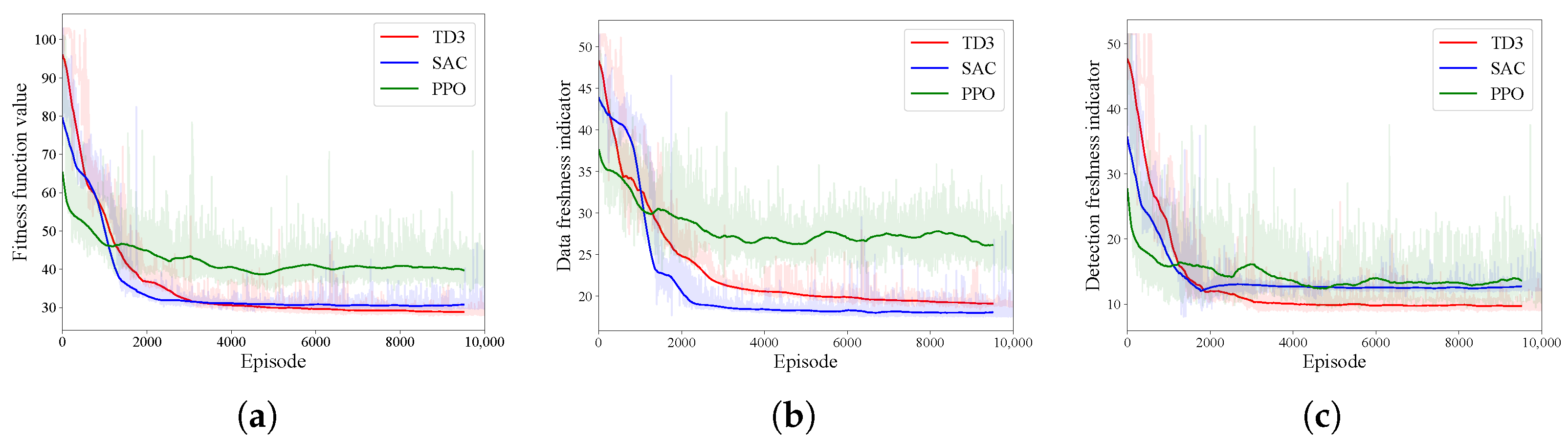
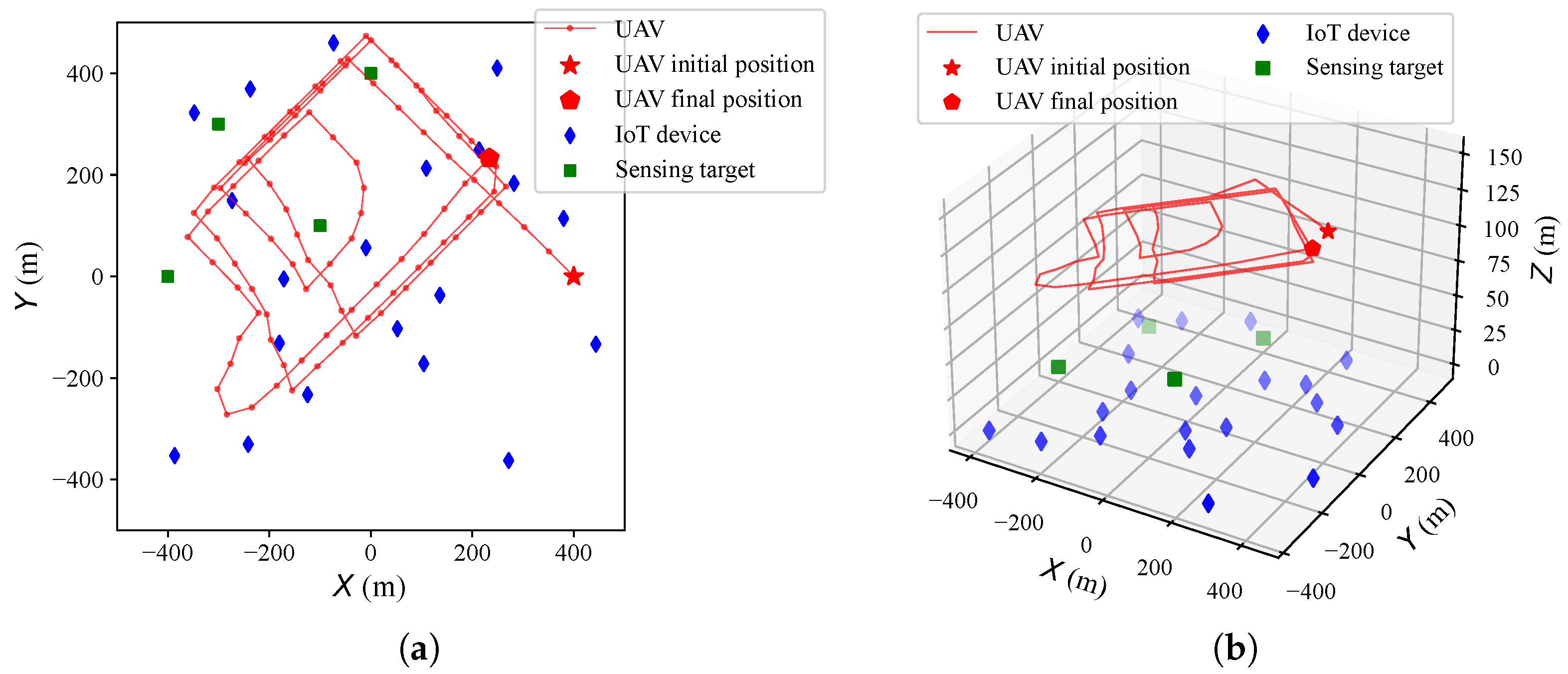
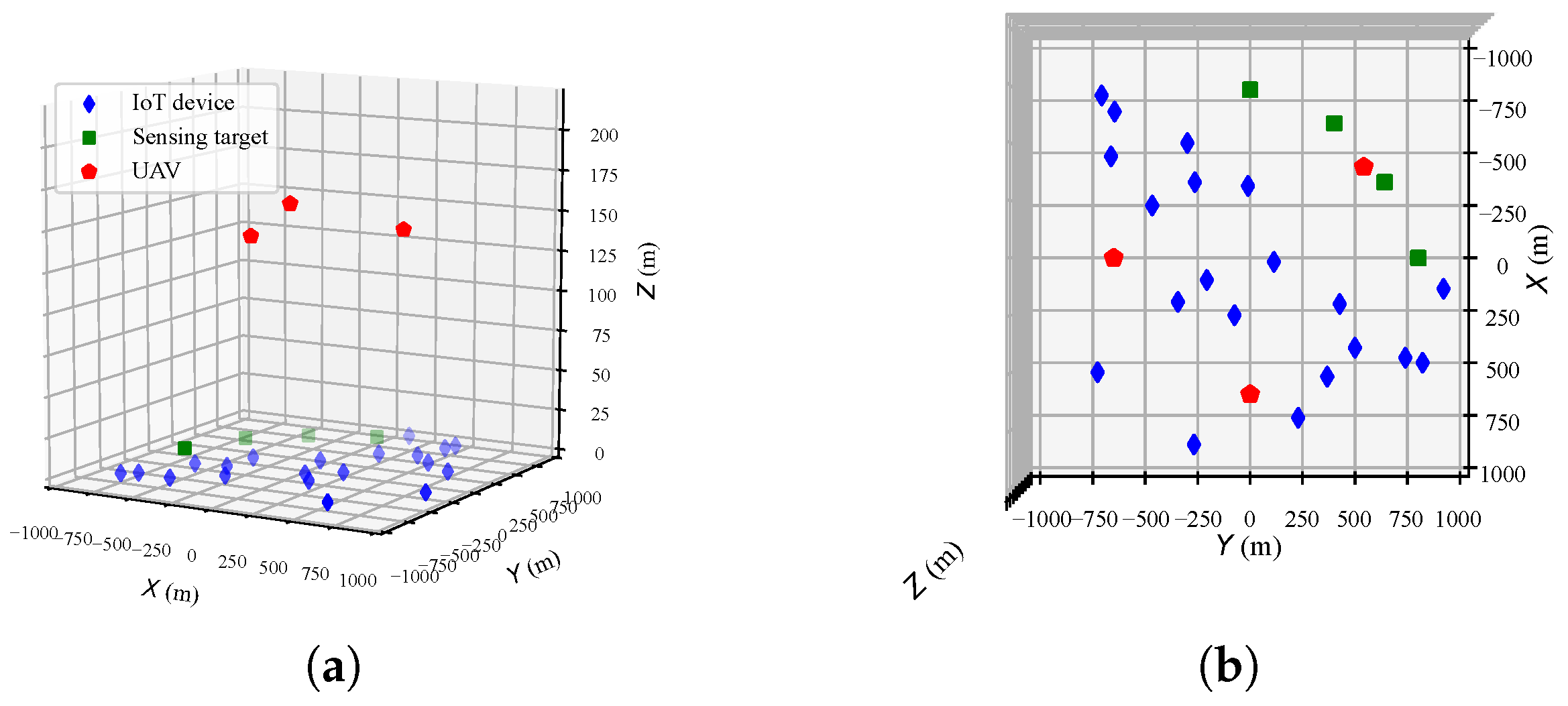
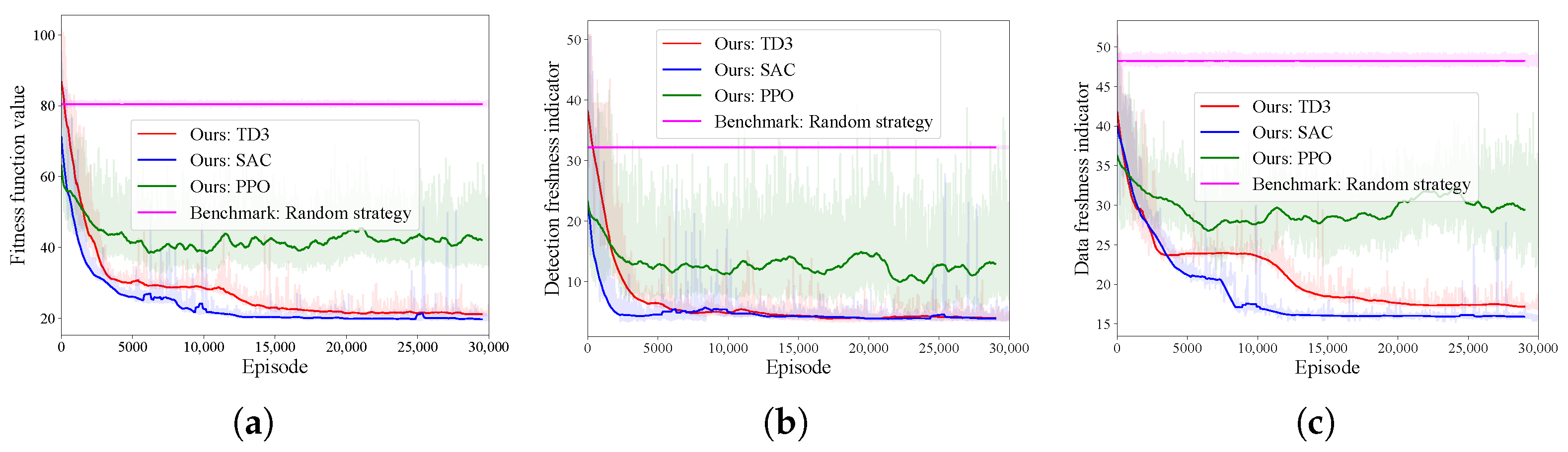
4.1. Algorithm Effectiveness in a Single-UAV Scenario
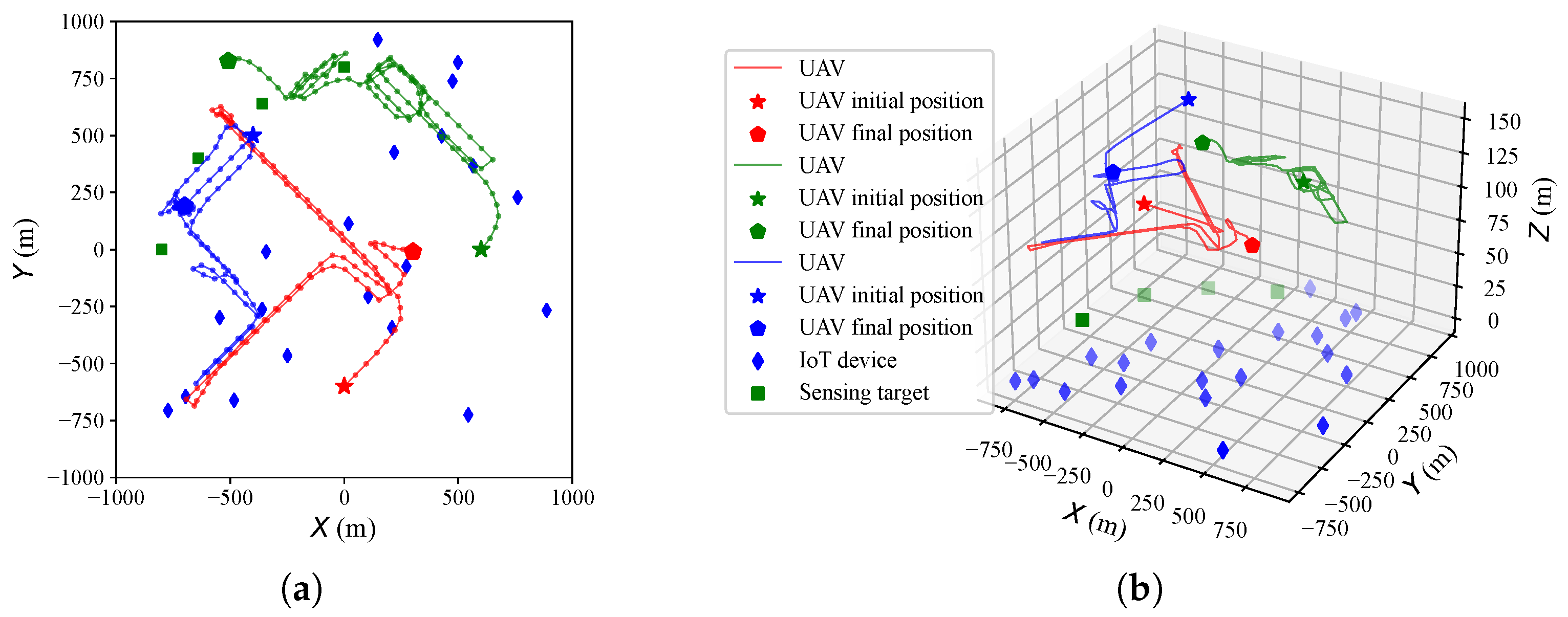
4.2. Algorithm Effectiveness in a Multi-UAV Scenario
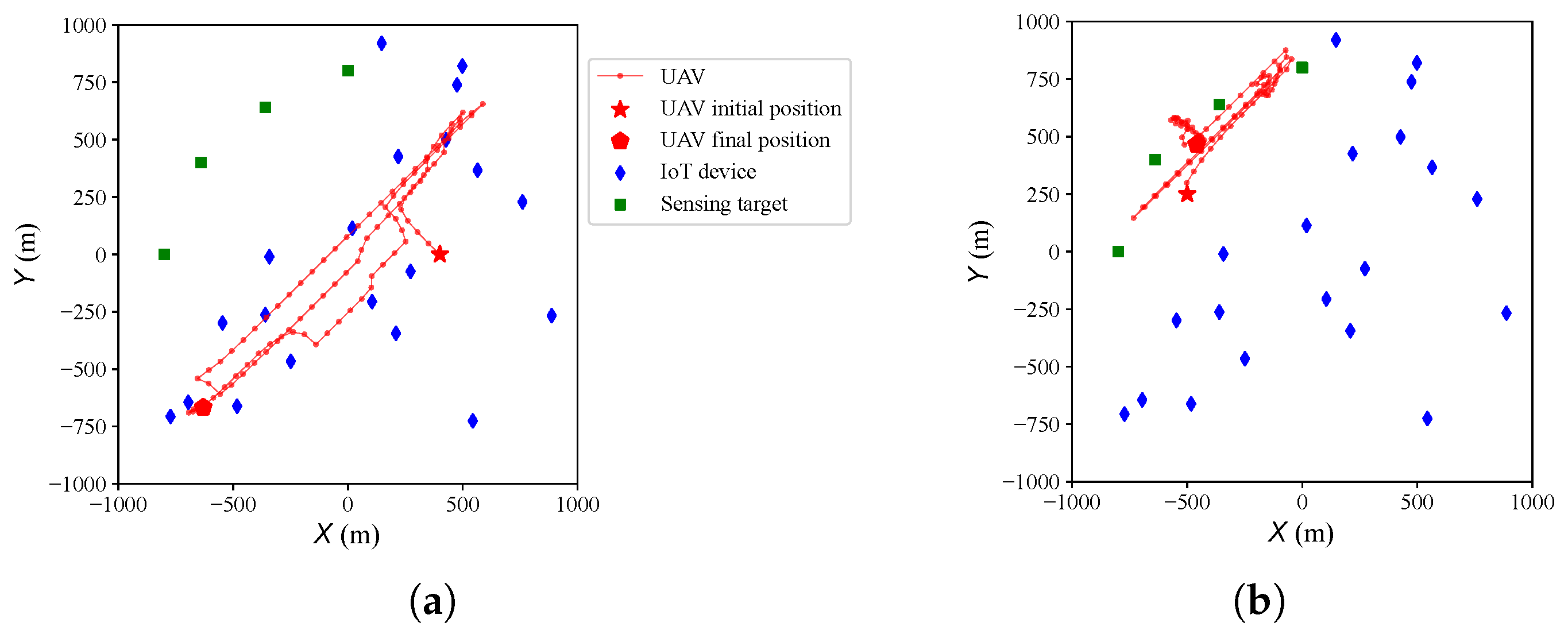
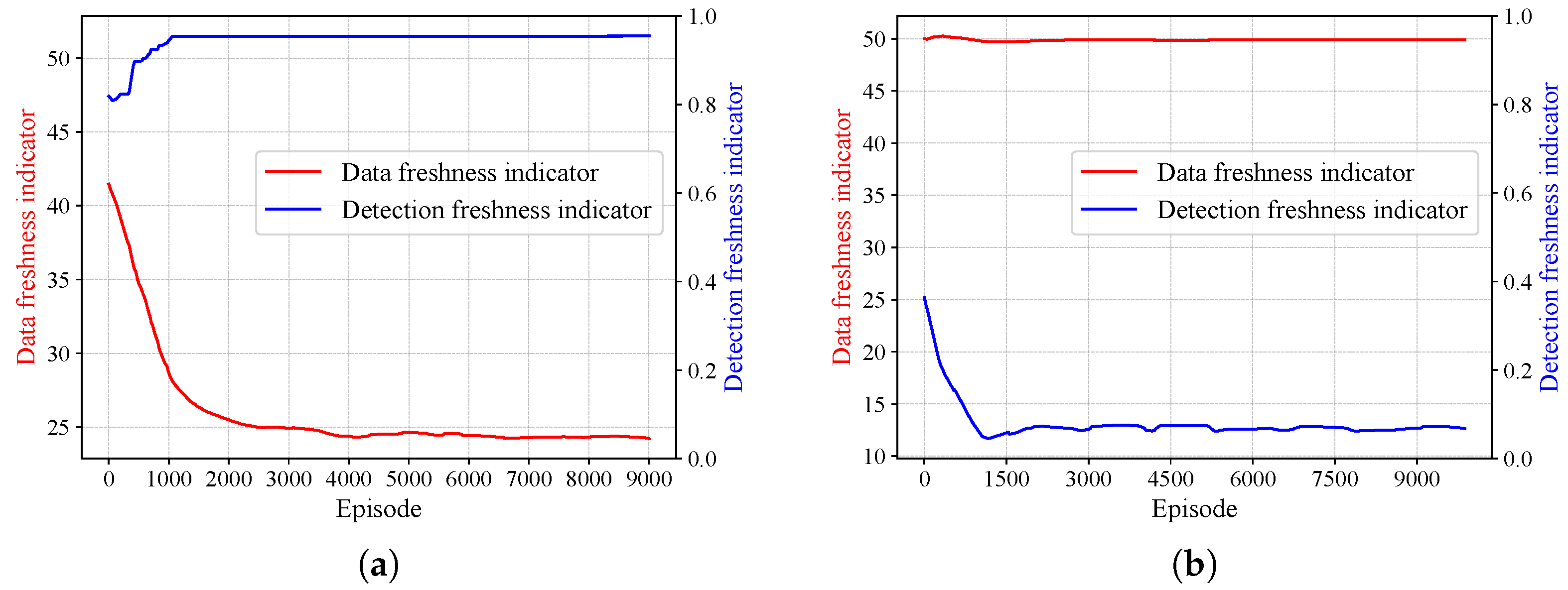
4.3. Individual Communication and Sensing Functions for Data Collection
- Data collection with joint communication and sensing functions: The objective function is defined aswhere represents the data freshness indicator, measuring communication performance, and represents the detection freshness indicator, measuring sensing performance.
- Data collection with only the communication function: The objective function is defined as
- Data collection with only the sensing function: The objective function is defined as
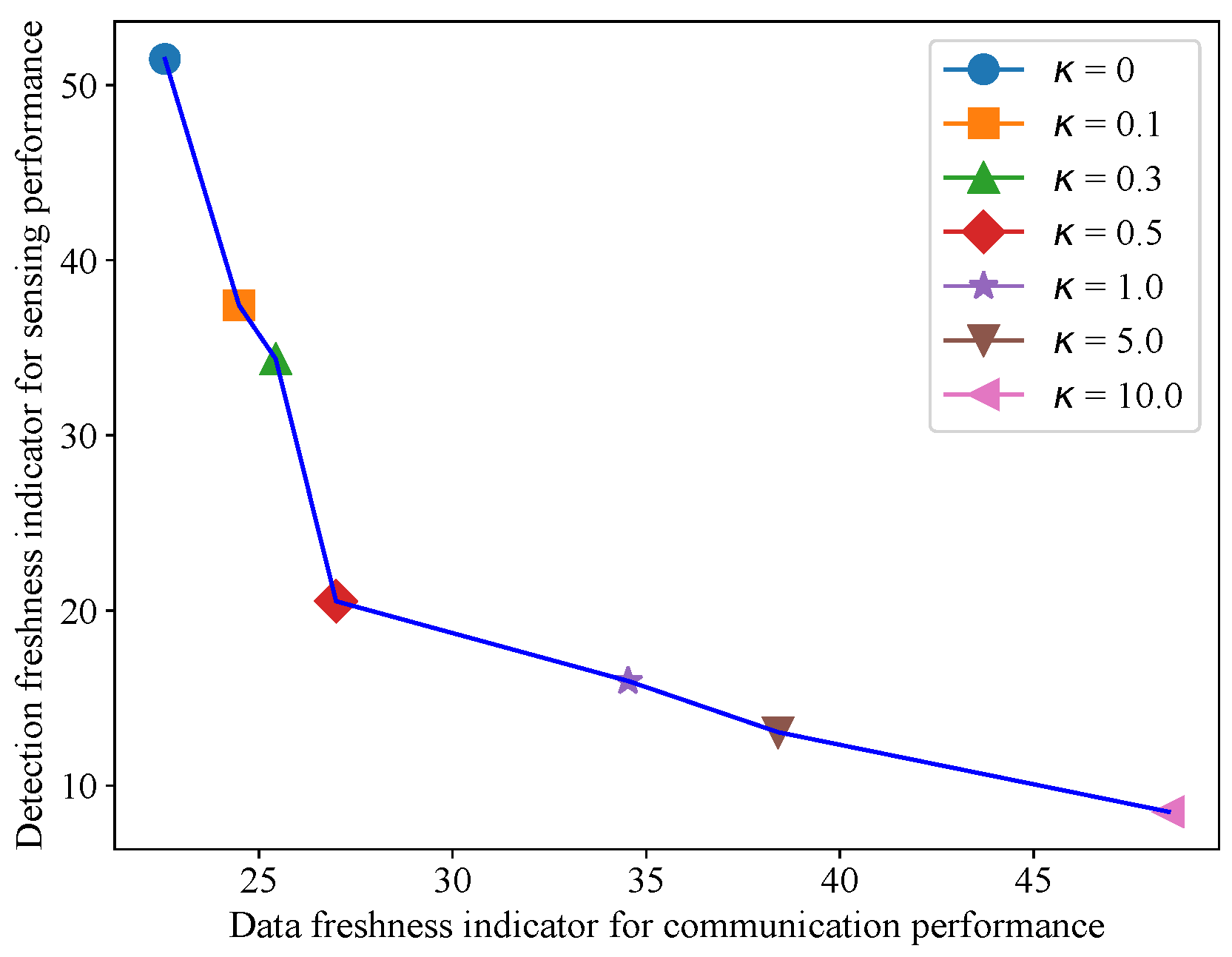
4.4. Trade-Off Between Communication and Sensing Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wei, X.; Guo, H.; Wang, X.; Wang, X.; Qiu, M. Reliable data collection techniques in underwater wireless sensor networks: A survey. IEEE Commun. Surv. Tutor. 2022, 24, 404–431. [Google Scholar] [CrossRef]
- Simonofski, A.; Handekyn, P.; Vandennieuwenborg, C.; Wautelet, Y.; Snoeck, M. Smart mobility projects: Towards the formalization of a policy-making lifecycle. Land Use Policy 2023, 125, 106474. [Google Scholar] [CrossRef]
- Cao, L. AI and data science for smart emergency, crisis and disaster resilience. Int. J. Data Sci. Anal. 2023, 15, 231–246. [Google Scholar] [CrossRef]
- Chen, X.; Zhao, N.; Chang, Z.; Hämäläinen, T.; Wang, X. UAV-aided secure short-packet data collection and transmission. IEEE Trans. Commun. 2023, 71, 2475–2486. [Google Scholar] [CrossRef]
- Ma, T.; Zhou, H.; Qian, B.; Cheng, N.; Shen, X.; Chen, X.; Bai, B. UAV-LEO integrated backbone: A ubiquitous data collection approach for B5G internet of remote things networks. IEEE J. Sel. Areas Commun. 2021, 39, 3491–3505. [Google Scholar] [CrossRef]
- Wei, Z.; Zhu, M.; Zhang, N.; Wang, L.; Zou, Y.; Meng, Z.; Wu, H.; Feng, Z. UAV-assisted data collection for Internet of Things: A survey. IEEE Internet Things J. 2022, 9, 15460–15483. [Google Scholar] [CrossRef]
- Liu, J.; Tong, P.; Wang, X.; Bai, B.; Dai, H. UAV-aided data collection for information freshness in wireless sensor networks. IEEE Trans. Wirel. Commun. 2021, 20, 2368–2382. [Google Scholar] [CrossRef]
- Liu, Y.; Huangfu, W.; Zhou, H.; Zhang, H.; Liu, J.; Long, K. Fair and energy-efficient coverage optimization for UAV placement problem in the cellular network. IEEE Trans. Commun. 2022, 70, 4222–4235. [Google Scholar] [CrossRef]
- Jia, Z.; Sheng, M.; Li, J.; Niyato, D.; Han, Z. LEO-satellite-assisted UAV: Joint trajectory and data collection for internet of remote things in 6G aerial access networks. IEEE Internet Things J. 2021, 8, 9814–9826. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Yeung, L.K.; James, J. Urban internet of electric vehicle parking system for vehicle-to-grid scheduling: Formulation and distributed algorithm. IEEE Trans. Veh. Technol. 2023, 73, 67–79. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Yuan, W.; Li, Y.; Hanzo, L. Efficient rate-splitting multiple access for the Internet of Vehicles: Federated edge learning and latency minimization. IEEE J. Sel. Areas Commun. 2023, 41, 1468–1483. [Google Scholar] [CrossRef]
- Abu-Baker, A.; Shakhatreh, H.; Sawalmeh, A.; Alenezi, A.H. Efficient Data Collection in UAV-Assisted Cluster-Based Wireless Sensor Networks for 3D Environment: Optimization Study. J. Sens. 2023, 2023, 9513868. [Google Scholar] [CrossRef]
- Alawad, W.; Halima, N.B.; Aziz, L. An unmanned aerial vehicle (UAV) system for disaster and crisis management in smart cities. Electronics 2023, 12, 1051. [Google Scholar] [CrossRef]
- Zhang, H.; Feng, L.; Liu, X.; Long, K.; Karagiannidis, G.K. User scheduling and task offloading in multi-tier computing 6G vehicular network. IEEE J. Sel. Areas Commun. 2022, 41, 446–456. [Google Scholar] [CrossRef]
- Ning, Z.; Hu, H.; Wang, X.; Guo, L.; Guo, S.; Wang, G.; Gao, X. Mobile edge computing and machine learning in the internet of unmanned aerial vehicles: A survey. ACM Comput. Surv. 2023, 56, 1–31. [Google Scholar] [CrossRef]
- Zhang, H.; Xi, S.; Jiang, H.; Shen, Q.; Shang, B.; Wang, J. Resource allocation and offloading strategy for UAV-assisted LEO satellite edge computing. Drones 2023, 7, 383. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, M.; Zhou, H.; Wang, X.; Wang, N.; Long, K. Capacity maximization in RIS-UAV networks: A DDQN-based trajectory and phase shift optimization approach. IEEE Trans. Wirel. Commun. 2022, 22, 2583–2591. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Q.; Dai, H.N.; Fu, Y.; Zhang, N.; Lee, C.C. UAV-assisted wireless backhaul networks: Connectivity analysis of uplink transmissions. IEEE Trans. Veh. Technol. 2023, 72, 12195–12207. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, X.; Liu, X.; Li, L.; Sun, K. GNN-Based Power Allocation and User Association in Digital Twin Network for the Terahertz Band. IEEE J. Sel. Areas Commun. 2023, 41, 3111–3121. [Google Scholar] [CrossRef]
- Hellaoui, H.; Bagaa, M.; Chelli, A.; Taleb, T.; Yang, B. On supporting multiservices in UAV-enabled aerial communication for Internet of Things. IEEE Internet Things J. 2023, 10, 13754–13768. [Google Scholar] [CrossRef]
- Nabil, Y.; ElSawy, H.; Al-Dharrab, S.; Attia, H.; Mostafa, H. Ultra-reliable device-centric uplink communications in airborne networks: A spatiotemporal analysis. IEEE Trans. Veh. Technol. 2023, 72, 9484–9499. [Google Scholar] [CrossRef]
- Feng, J.; Liu, X.; Liu, Z.; Durrani, T.S. Optimal Trajectory and Resource Allocation for RSMA-UAV Assisted IoT Communications. IEEE Trans. Veh. Technol. 2024, 73, 8693–8704. [Google Scholar] [CrossRef]
- Cai, X.; Kovács, I.Z.; Wigard, J.; Amorim, R.; Tufvesson, F.; Mogensen, P.E. Power Allocation for Uplink Communications of Massive Cellular-Connected UAVs. IEEE Trans. Veh. Technol. 2023, 72, 8797–8811. [Google Scholar] [CrossRef]
- Chen, R.; Cheng, W.; Ding, Y.; Wang, B. QoS-guaranteed multi-UAV coverage scheme for IoT communications with interference management. IEEE Internet Things J. 2023, 11, 4116–4126. [Google Scholar] [CrossRef]
- Duan, R.; Wang, J.; Jiang, C.; Yao, H.; Ren, Y.; Qian, Y. Resource allocation for multi-UAV aided IoT NOMA uplink transmission systems. IEEE Internet Things J. 2019, 6, 7025–7037. [Google Scholar] [CrossRef]
- Eldeeb, E.; Shehab, M.; Alves, H. Traffic Learning and Proactive UAV Trajectory Planning for Data Uplink in Markovian IoT Models. IEEE Internet Things J. 2023, 11, 13496–13508. [Google Scholar] [CrossRef]
- Yin, Z.; Cheng, N.; Song, Y.; Hui, Y.; Li, Y.; Luan, T.H.; Yu, S. UAV-assisted secure uplink communications in satellite-supported IoT: Secrecy fairness approach. IEEE Internet Things J. 2023, 11, 6904–6915. [Google Scholar] [CrossRef]
- Liu, F.; Cui, Y.; Masouros, C.; Xu, J.; Han, T.X.; Eldar, Y.C.; Buzzi, S. Integrated sensing and communications: Toward dual-functional wireless networks for 6G and beyond. IEEE J. Sel. Areas Commun. 2022, 40, 1728–1767. [Google Scholar] [CrossRef]
- Wang, D.; Wang, Z.; Yu, K.; Wei, Z.; Zhao, H.; Al-Dhahir, N.; Guizani, M.; Leung, V.C. Active aerial reconfigurable intelligent surface assisted secure communications: Integrating sensing and positioning. IEEE J. Sel. Areas Commun. 2024, 42, 2769–2785. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, T.; Liu, F.; Ma, D.; Huangfu, W.; Eldar, Y.C. Next-Generation Multiple Access for Integrated Sensing and Communications. Proc. IEEE 2024. early access. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, Y.; Liu, X.; Ren, C.; Li, H.; Sun, C. Time allocation approaches for a perceptive mobile network using integration of sensing and communication. IEEE Trans. Wirel. Commun. 2023, 23, 1158–1169. [Google Scholar] [CrossRef]
- Zhang, H.; Su, R.; Zhu, Y.; Long, K.; Karagiannidis, G.K. User-centric cell-free massive MIMO system for indoor industrial networks. IEEE Trans. Commun. 2022, 70, 7644–7655. [Google Scholar] [CrossRef]
- Liu, X.; Huang, T.; Shlezinger, N.; Liu, Y.; Zhou, J.; Eldar, Y.C. Joint transmit beamforming for multiuser MIMO communications and MIMO radar. IEEE Trans. Signal Process. 2020, 68, 3929–3944. [Google Scholar] [CrossRef]
- Wang, D.; Wu, M.; Chakraborty, C.; Min, L.; He, Y.; Guduri, M. Covert communications in air-ground integrated urban sensing networks enhanced by federated learning. IEEE Sens. J. 2023, 24, 5636–5643. [Google Scholar] [CrossRef]
- Liu, P.; Fei, Z.; Wang, X.; Zhang, J.A.; Zheng, Z.; Zhang, Q. Securing multi-user uplink communications against mobile aerial eavesdropper via sensing. IEEE Trans. Veh. Technol. 2023, 72, 9608–9613. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, X.; Zhai, X.; Zhu, Q.; Durrani, T.S. UAV-Enabled Integrated Sensing, Computing and Communication for Internet of Things: Joint Resource Allocation and Trajectory Design. IEEE Internet Things J. 2023, 11, 12717–12727. [Google Scholar] [CrossRef]
- Zhu, W.; Han, Y.; Wang, L.; Xu, L.; Zhang, Y.; Fei, A. Pilot optimization for OFDM-based ISAC signal in emergency IoT networks. IEEE Internet Things J. 2023, 11, 29600–29614. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, X.; Liu, Y.; Leung, V.C.; Durrani, T.S. UAV assisted integrated sensing and communications for Internet of Things: 3D trajectory optimization and resource allocation. IEEE Trans. Wirel. Commun. 2024, 23, 8654–8667. [Google Scholar] [CrossRef]
- Xu, J.; Zeng, Y.; Zhang, R. UAV-enabled multiuser wireless power transfer: Trajectory design and energy optimization. In Proceedings of the IEEE 23rd Asia-Pacific Conference on Communications (APCC), Perth, Australia, 11–13 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Chiriyath, A.R.; Paul, B.; Jacyna, G.M.; Bliss, D.W. Inner bounds on performance of radar and communications co-existence. IEEE Trans. Signal Process. 2015, 64, 464–474. [Google Scholar] [CrossRef]
- Liu, F.; Xiong, Y.; Wan, K.; Han, T.X.; Caire, G. Deterministic-random tradeoff of integrated sensing and communications in Gaussian channels: A rate-distortion perspective. In Proceedings of the 2023 IEEE International Symposium on Information Theory (ISIT), Taipei, Taiwan, 25–30 June 2023; pp. 2326–2331. [Google Scholar] [CrossRef]
- Xiong, Y.; Liu, F.; Lops, M. Generalized deterministic-random tradeoff in integrated sensing and communications: The sensing-optimal operating point. arXiv 2023, arXiv:2308.14336. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Value | Variable | Value |
|---|---|---|---|
| 5 dB | 15 dB | ||
| 0.1 m | 15 dB | ||
| 15 dB | 0.35 m | ||
| 1 | k | ||
| b | 1.3 | 0.98 | |
| 0.01 | 0.2 |
| Data Freshness Indicator | Detection Freshness Indicator | |
|---|---|---|
| 0 | 22.58 | 51.49 |
| 0.1 | 24.49 | 37.43 |
| 0.3 | 25.44 | 34.36 |
| 0.5 | 26.99 | 20.53 |
| 1.0 | 34.53 | 15.98 |
| 5.0 | 38.40 | 13.05 |
| 10.0 | 48.48 | 8.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Li, X.; He, B.; Gu, M.; Huangfu, W. UAV-Enabled Diverse Data Collection via Integrated Sensing and Communication Functions Based on Deep Reinforcement Learning. Drones 2024, 8, 647. https://doi.org/10.3390/drones8110647
Liu Y, Li X, He B, Gu M, Huangfu W. UAV-Enabled Diverse Data Collection via Integrated Sensing and Communication Functions Based on Deep Reinforcement Learning. Drones. 2024; 8(11):647. https://doi.org/10.3390/drones8110647
Chicago/Turabian StyleLiu, Yaxi, Xulong Li, Boxin He, Meng Gu, and Wei Huangfu. 2024. "UAV-Enabled Diverse Data Collection via Integrated Sensing and Communication Functions Based on Deep Reinforcement Learning" Drones 8, no. 11: 647. https://doi.org/10.3390/drones8110647
APA StyleLiu, Y., Li, X., He, B., Gu, M., & Huangfu, W. (2024). UAV-Enabled Diverse Data Collection via Integrated Sensing and Communication Functions Based on Deep Reinforcement Learning. Drones, 8(11), 647. https://doi.org/10.3390/drones8110647