To evaluate the performance of the proposed method, this paper implements experiments using both synthetic and real image sequences. This section first describes the experimental settings. Subsequently, the robustness of the proposed method on the simulation data is analyzed. Further, the performance of the proposed method on the 3D model and 6D pose is evaluated on synthetic and real image sequences. Finally, the shortcomings of the proposed method and future improvements are demonstrated.
4.2. The Robustness Analysis of the Proposed Method
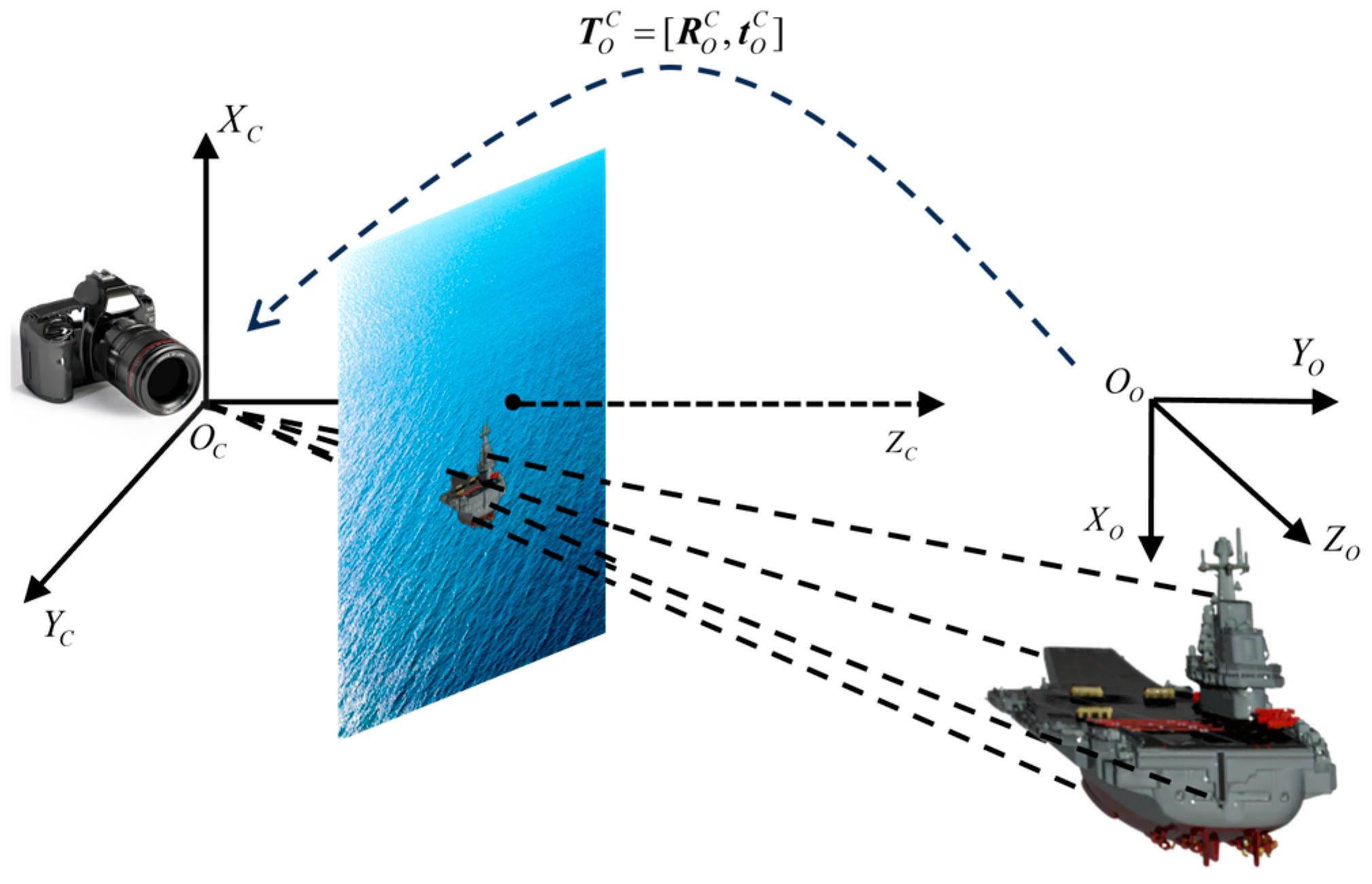
This paper adopts the geometry constraints within the monocular image sequence to handle the absence of an accurate 3D model. The accuracy of multi-view geometry constraints mainly depends on the following two critical factors: Firstly, the accuracy of 2D observations, which usually involves the precise extraction and positioning of feature points, line segments, or other geometric elements in the image, and, secondly, the magnitude of the rendezvous angle between viewpoints in the image sequence, which affects the stability and accuracy of reconstructing the 3D structure from different viewpoints. Thus, the accuracy of 2D landmark detection and the rendezvous angle of the image sequence are two crucial factors that influence the performance of the proposed method.
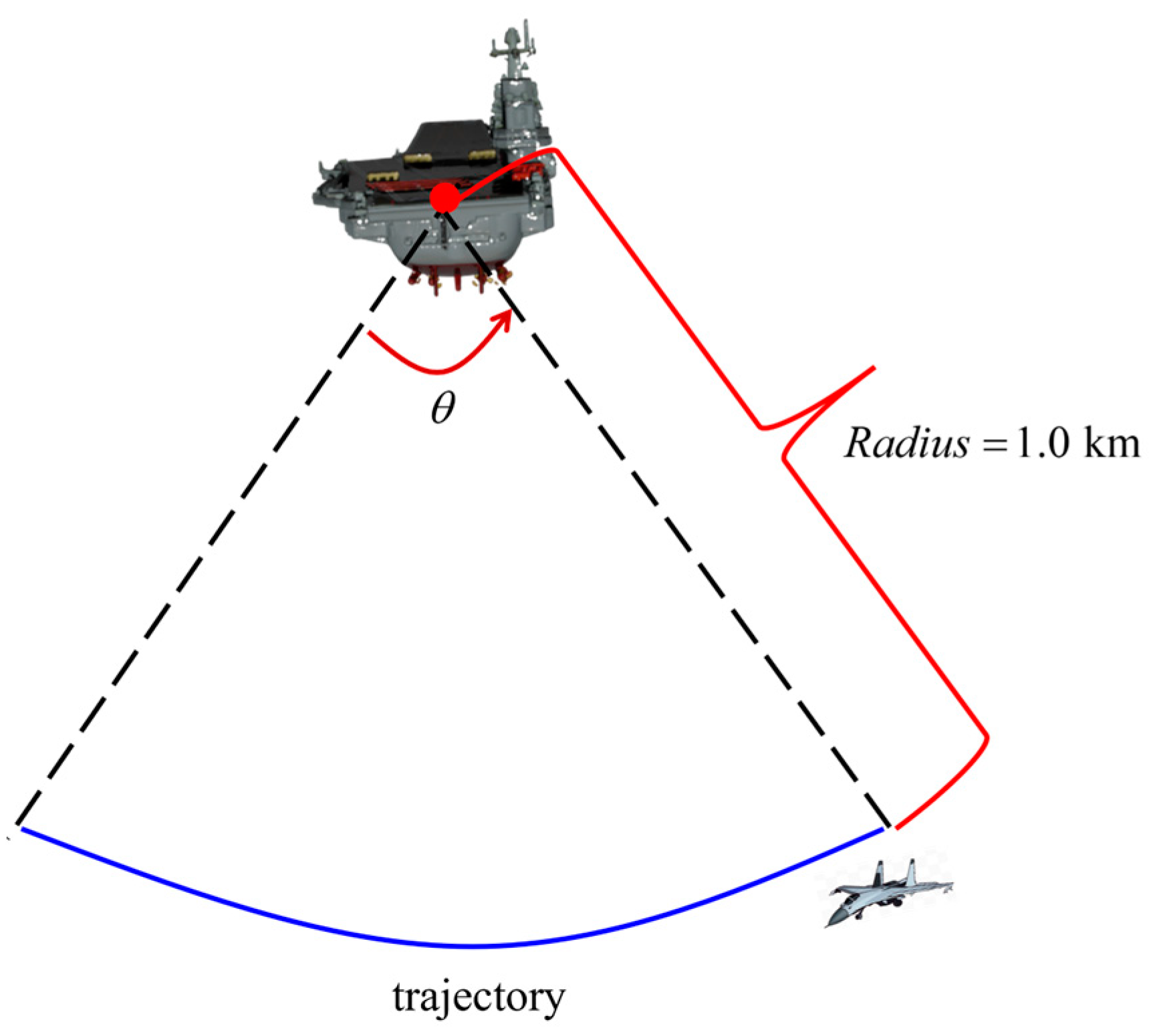
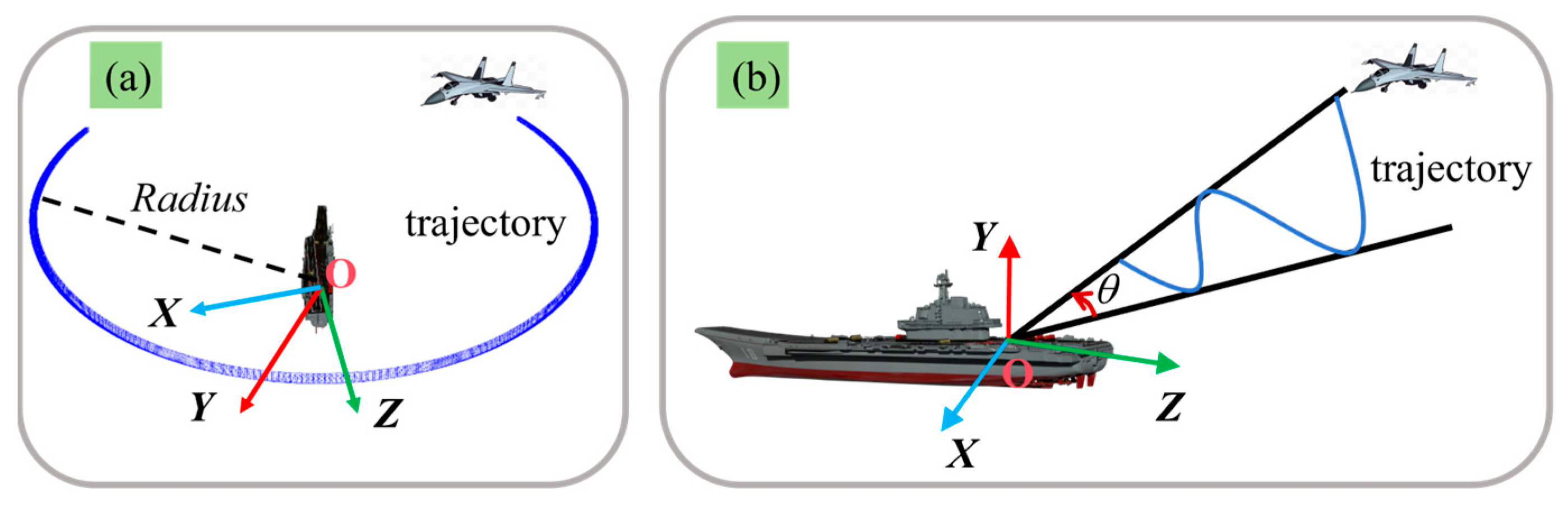
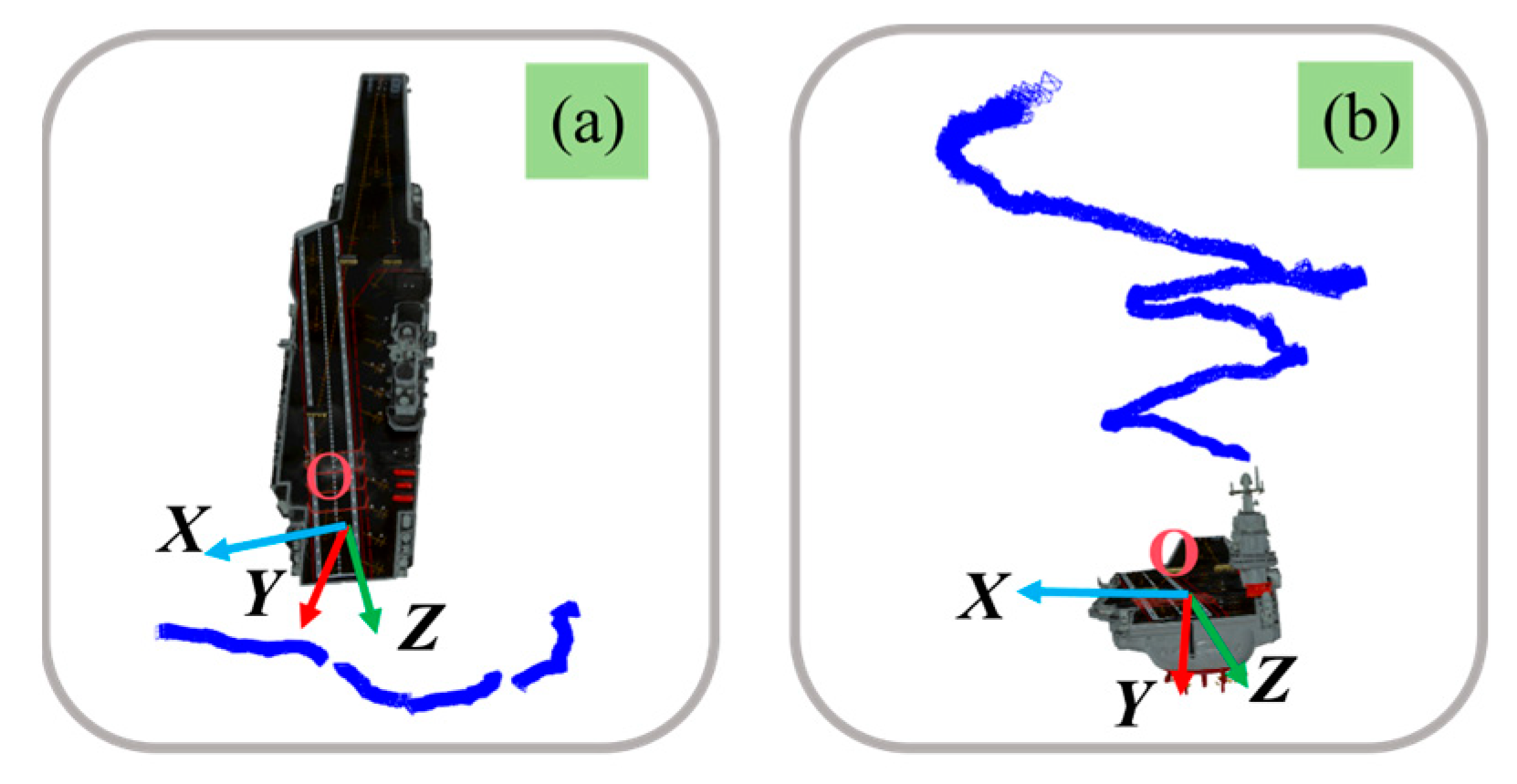
This paper takes the autonomous landing of UAVs as an example to verify the proposed method. Hence, as depicted in
Figure 6, this paper simulates the UAV flying around the central axis of the stern of the ship at a distance of 1.0 km. And the simulation experiment data are generated synchronously. In
Figure 6,
represents the setting rendezvous angle. Additionally, the projection of the 3D landmarks on the image is computed based on the true poses corresponding to the simulated trajectory.
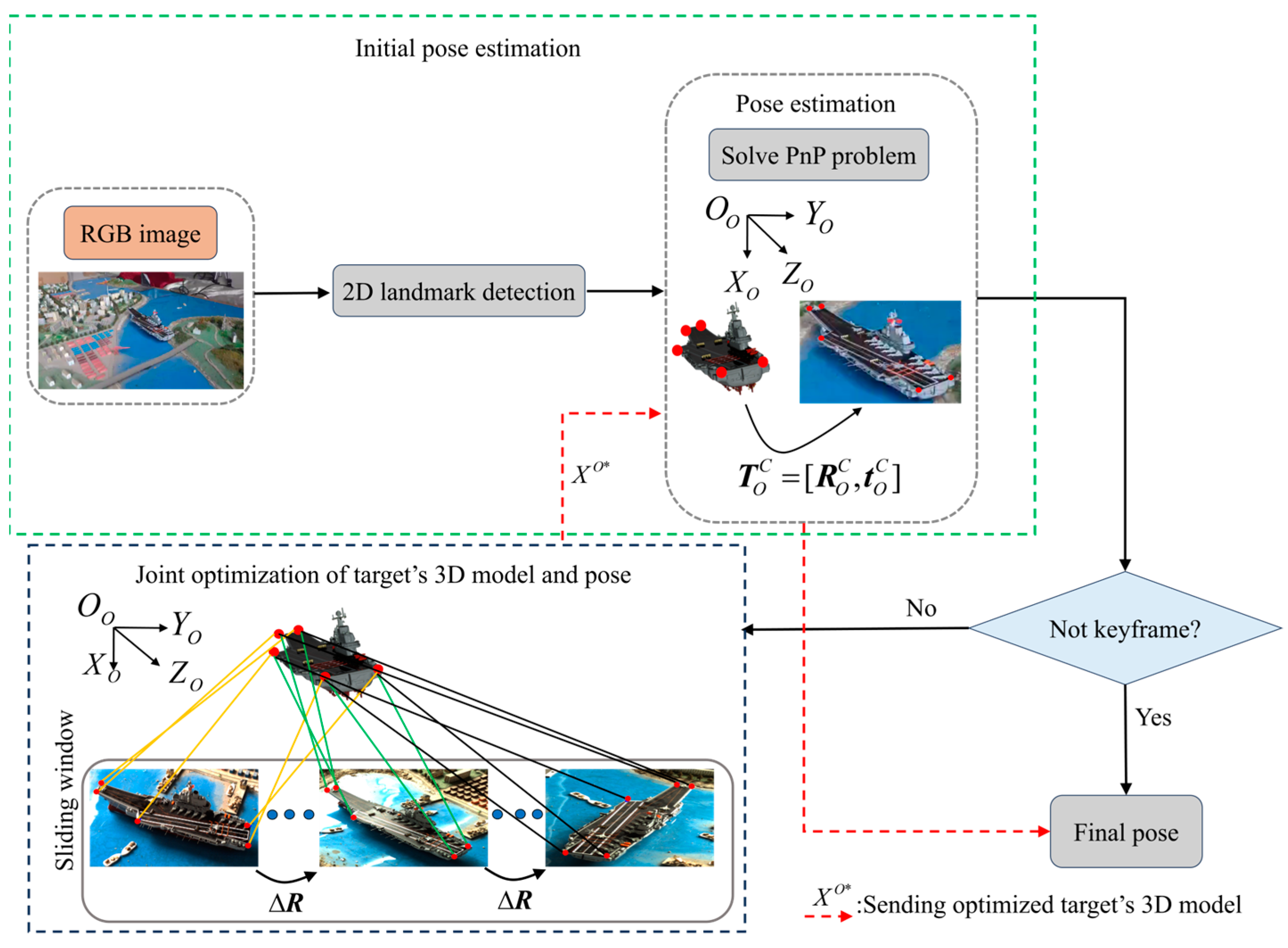
The optimization objective function presented in this paper jointly optimizes the 3D model and poses by minimizing the reprojection error. Hence, a significant 2D landmark detection error can result in the failure of the proposed method. To investigate the tolerance level of the proposed method towards landmark detection errors, this paper first selects the simulation data with
. Subsequently, this paper simulates 2D landmark detection errors by adding different levels of Gaussian noise
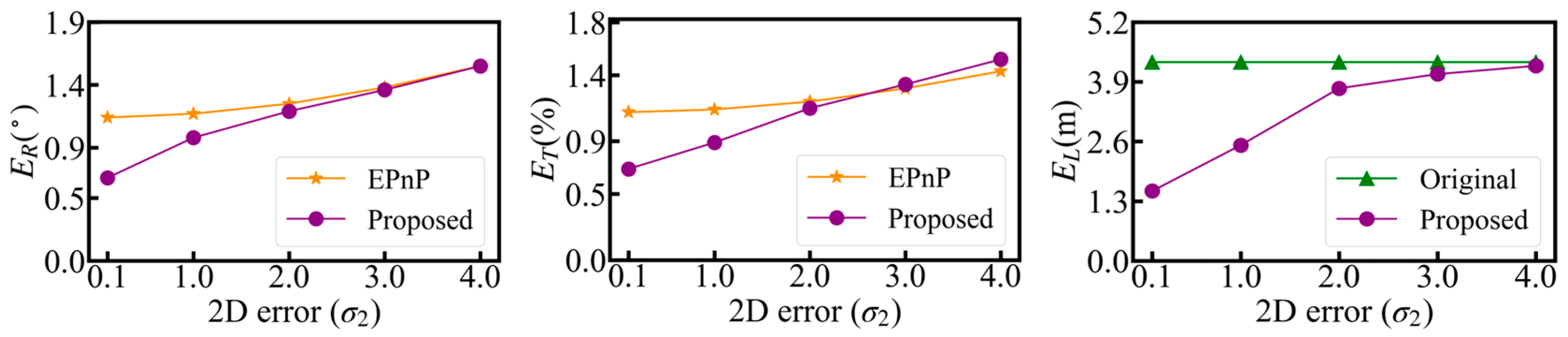
to 2D landmark ground truth. And different noise levels were simulated 1000 times, respectively. The average optimization outcomes of the pose and 3D model are depicted in
Figure 7. In
Figure 7 and the subsequent images, EPnP indicates the pose error acquired directly by resolving the PnP problem. The proposed represents the pose and 3D model error obtained through the further optimization of the proposed method. The original represents the initial 3D model error.
As depicted in
Figure 7, when
is less than 2.0, the proposed method effectively mitigates the pose and 3D model error by leveraging the multi-view geometry constraints information and attains high-precision monocular pose estimation. However, when
exceeds 2.0, the optimization ability of the proposed method for the 3D model attenuates, thereby further causing the pose error of the solution to be close to or even exceed that solved by EPnP. Thus, within the established simulation application scenario, the proposed method demands that the 2D noise standard deviation
be less than 2.0 for the effective optimization of the 3D model and poses. In fact, the above experiments indicate that the proposed method requires the reprojection error of the 3D model to be greater than the 2D landmark error to effectively optimize the 3D model and pose.
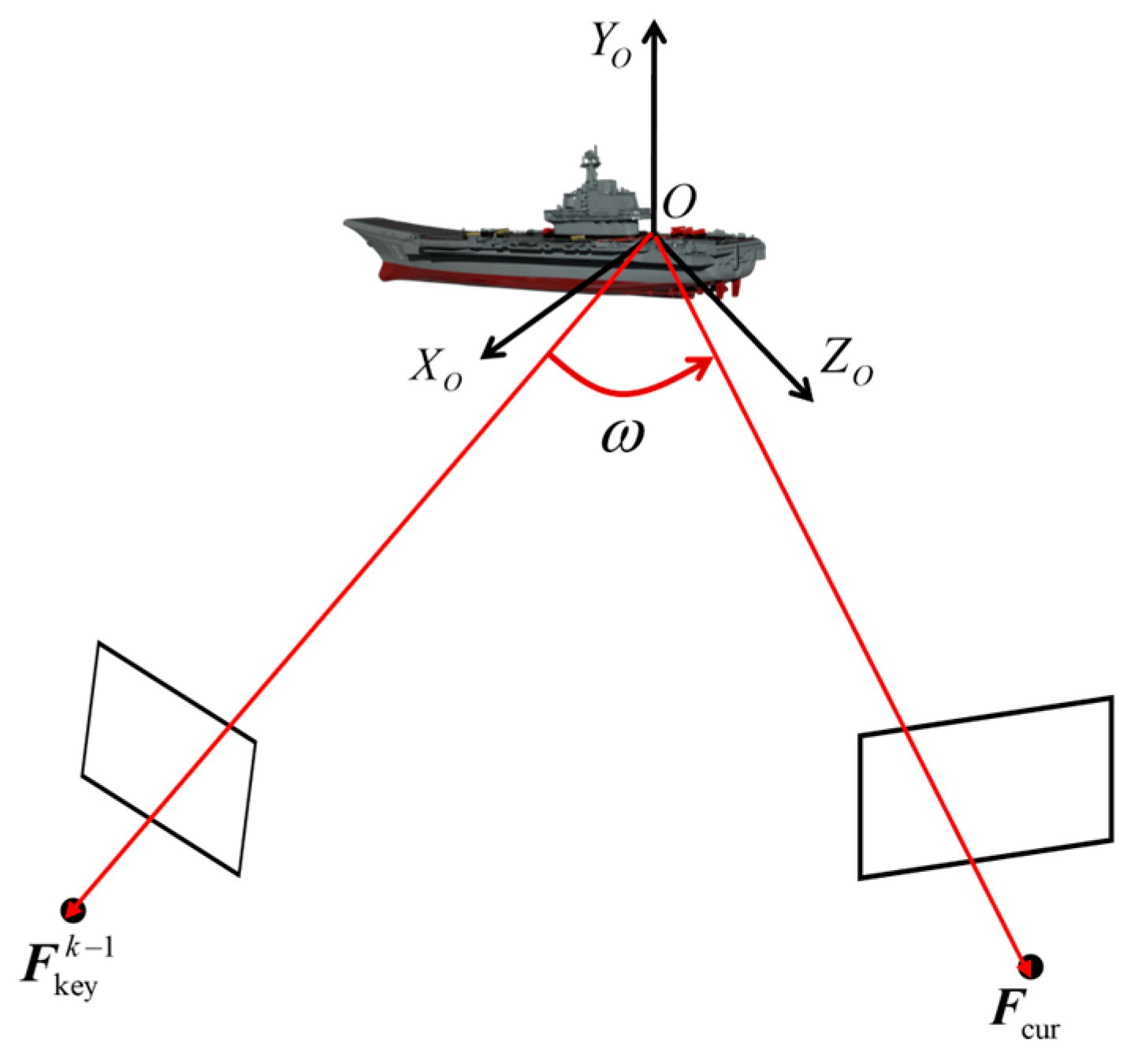
The proposed method jointly optimizes the 3D model and poses by leveraging the multi-view geometry constraints information. Hence, when the rendezvous angle is minor, it might cause insufficient geometry constraints of the observed data, thereby leading to a poorer optimization effect of the 3D model and pose. To investigate the impact of various rendezvous angles on the optimization effect of the proposed method, this paper first selects the simulation data with
and simulates it 1000 times. Subsequently, as depicted in
Figure 6, data segments with varying rendezvous angles
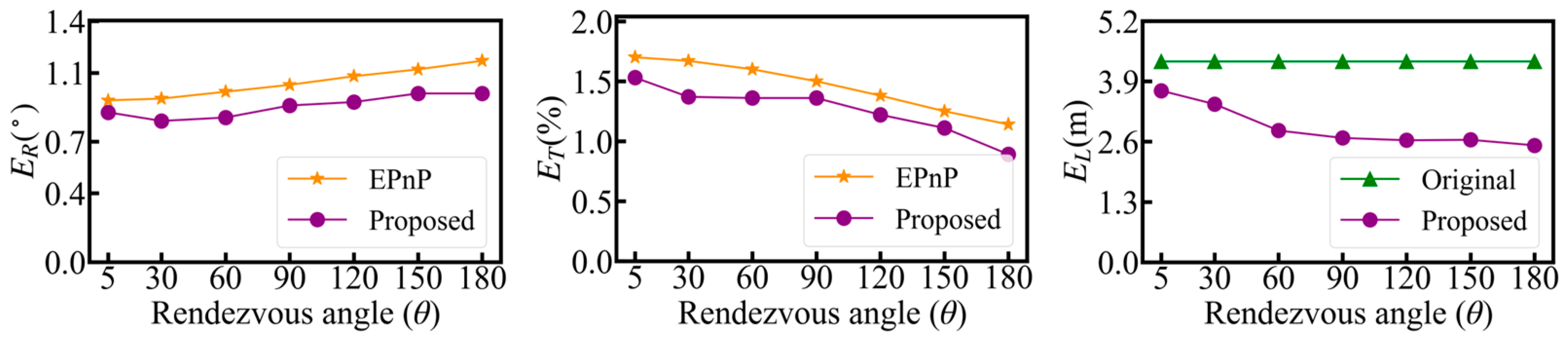
were selected from the simulation data for optimization. The average optimization outcomes of the pose and 3D model are depicted in
Figure 8.
As depicted in
Figure 8, when the rendezvous angle varies within the range of 5 degrees to 180 degrees, in all instances, the proposed method has mitigated the errors of the 3D model and the pose to a certain extent. However, when the rendezvous angle is 5 degrees, the optimization effect of the 3D model and the pose is insufficiently conspicuous. In actuality, the optimization outcome at this point merely holds statistical significance but lacks practical value for application. It can be observed from
Figure 8 that, within the established simulation application scenario, when the rendezvous angle exceeds 30 degrees, the proposed method can largely reduce the errors of the 3D model and pose. In fact, within the optimization approach presented in this paper, a larger rendezvous angle encompasses more geometry constraint information, which is more conducive to the optimization of 3D models and poses.
Through the above experiments, it was discovered that when the accuracy of the 2D landmarks was relatively high, that is, when its error was smaller than the reprojection error of the 3D model, the proposed method exhibited excellent performance. Additionally, when the rendezvous angle between the viewpoints in the image sequence was large, the proposed method was capable of further effectively jointly optimizing the 3D model and poses.
4.3. Experiments on Synthetic Image Sequences
In this section, this paper selects synthetic image sequences to conduct an experiment. The synthetic images are produced through the target’s 3D model combined with a computer graphics engine. Specifically, this paper employs the visual simulation tool BlenderProc [
51] to load the 3D CAD model of the ship. It sets the image resolution of the virtual camera to
pixels, the focal length to 1910 pixels, the acquisition frame rate to 25 fps, and the field of view angles to 30° (horizontal) and 30° (vertical). As depicted in
Figure 9, within the synthetic environments, corresponding image data are produced by establishing diverse camera trajectories. The generated synthetic image sequences are elaborated in detail below.
In
Figure 9a,
represents the flight radius parameter. The experiment detailed in
Section 4.2 demonstrates that in the circular flight scenario with a radius of 1 km, the proposed method can accommodate significant landmark noise. The detection of 2D landmarks in the synthetic images is comparatively precise. Consequently, in this section, the
in
Figure 9a is set to 2.0 km to investigate the optimization in a more distant circular flight scenario. And image sequence, namely Orbit-2.0 (
) is produced. In
Figure 9b, the rendezvous process of the UAV and the ships with different small rendezvous angles is simulated. And the image sequences Rendezvous-10 (
), Rendezvous-20 (
), and Rendezvous-30 (
) are generated, respectively.
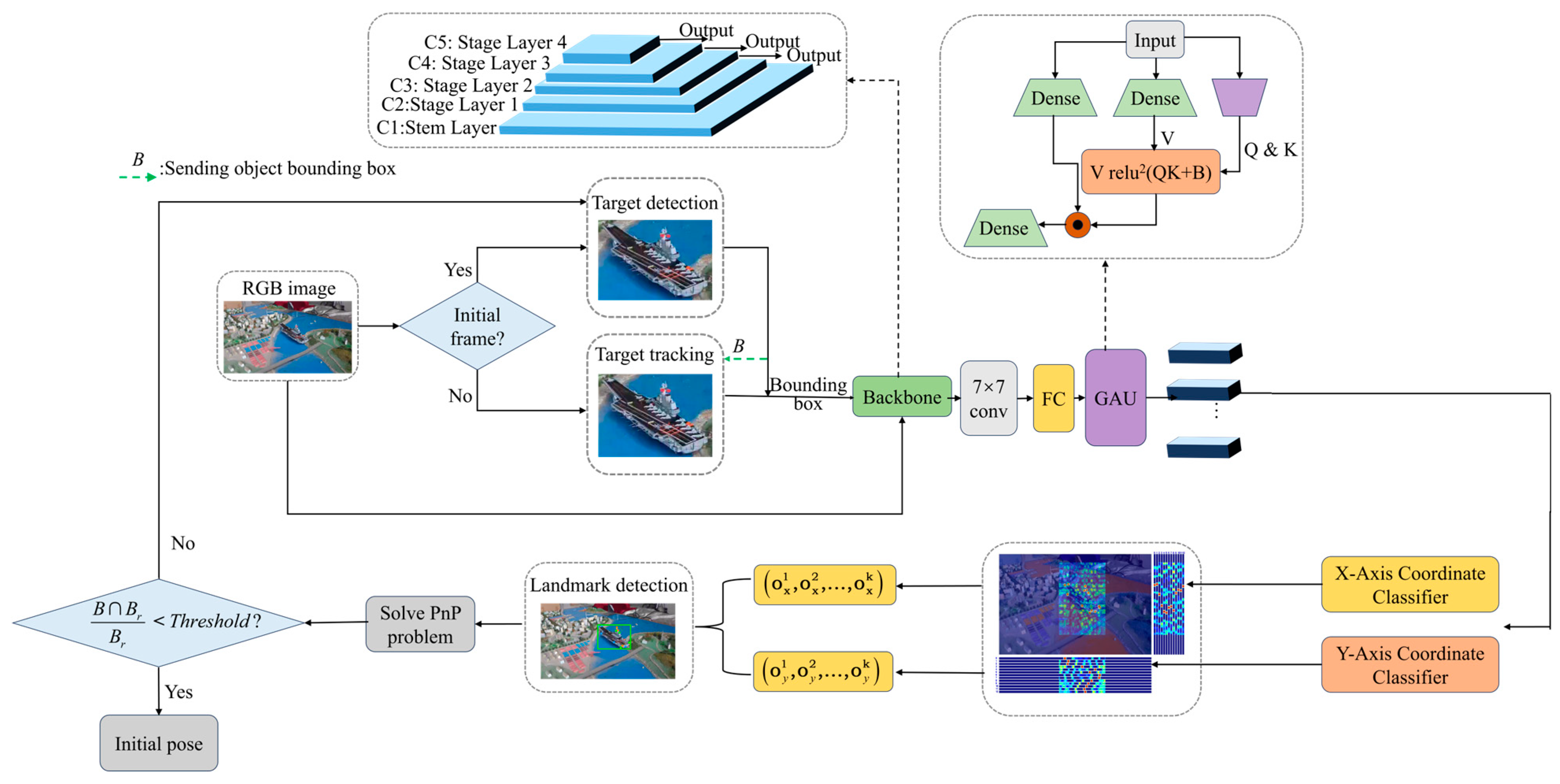
This paper selects Orbit-2.0, Rendezvous-10, Rendezvous-20, and Rendezvous-30 image sequences to conduct the experiment. Additionally, existing approaches typically adopt sparse or dense 2D–3D correspondence and directly resolve PnP problems to obtain pose estimation outcomes. Consequently, this paper separately employs the current cutting-edge RTMpose and PP-TinyPose [
52] approaches to detect 2D landmarks. Then, this paper contrasts the proposed method with the RTMPose-EPnP and PP-TinyPose-EPnP methods. Both the RTMPose-EPnP and PP-TinyPose-EPnP methods further solve PnP problems on the basis of landmark detection to obtain pose results.
The synthetic example results of reprojection using the poses of PP-TinyPose-EPnP, RTMPose-EPnP, and the proposed method are presented in
Figure 10, where the local zoomed-in results of the reprojection image are displayed in the red box at the upper left corner. And the yellow mask represents the ground truth, the green mask indicates the reprojection using the pose solved by PP-TinyPose-EPnP, the blue mask represents the reprojection using the pose solved by RTMPose-EPnP, and the purple mask corresponds to the proposed method.
As depicted in
Figure 10, owing to the inaccurate target’s 3D model, the PP-TinyPose-EPnP and RTMPose-EPnP methods fail to acquire precise poses. As demonstrated in the pose reprojection outcomes of the second and third rows, the pose reprojection results based on the two comparative methods do not fully align with the genuine target area. The proposed method takes advantage of the constraint information of multi-view geometry constraints to jointly optimize the target’s 3D model and pose parameters. The experimental results presented in the fourth row of
Figure 10 indicate that, by employing the proposed method, the reprojected target region conforms splendidly to the ground truth. The outcomes reveal that the proposed method can accomplish high-precision monocular pose estimation in the absence of an accurate target.
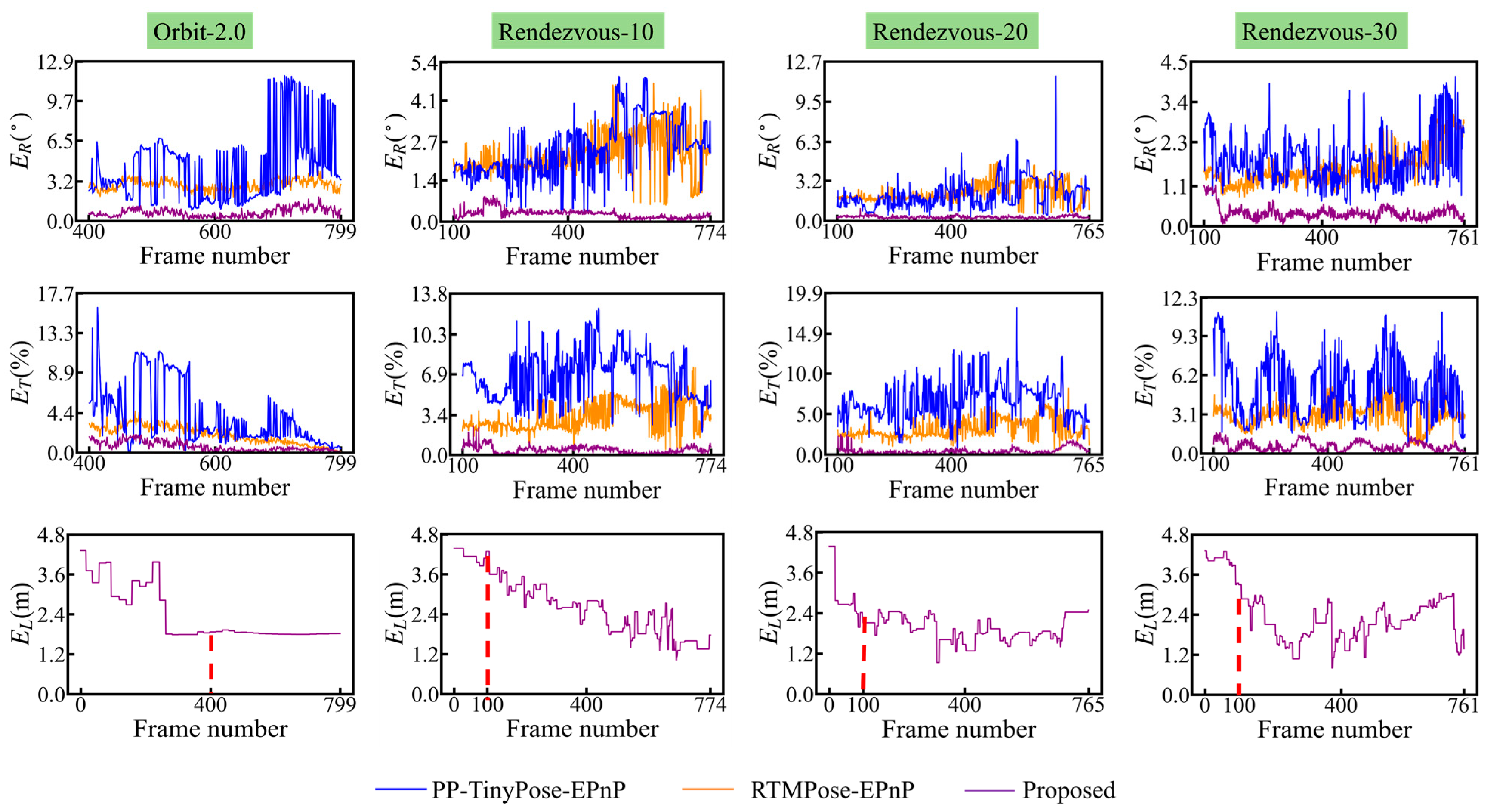
To quantitatively assess the performance of various methods in predicting pose, based on Equation (13), this paper selects a set of complete pose prediction samples from four synthetic image sequences, respectively. These samples are depicted in the first two rows of
Figure 11. Additionally, the proposed method is configured to output the pose optimization results of the current frame only when the number of optimized keyframes reaches the length of the sliding window. Thus,
Figure 11 presents only the optimized portion of the image sequence. In addition, the third row of
Figure 11 exhibits the variation in the average error of the target’s 3D model throughout the entire optimization within the four image sequence samples. Meanwhile,
Table 2 presents the average detection outcomes of 2D landmarks for PP-TinyPose and RTMPose in various synthetic image sequences.
As depicted in the first two rows of
Figure 11, within four image sequence samples, as a consequence of errors in the target’s 3D model and the detected 2D landmarks, the PP-TinyPose-EPnP and RTMPose-EPnP methods fail to obtain precise poses. Especially, as depicted in
Table 2, the 2D landmark error identified by PP-TinyPose is more substantial. Hence, the pose error addressed by PP-TinyPose-EPnP is conspicuously larger than that addressed by RTMPose-EPnP and the proposed method. In contrast, RTMPose has a relatively high accuracy in detecting 2D landmarks, and its detection error is less than the reprojection error of the 3D model. Hence, the proposed method utilizes multi-view geometry constraints to jointly optimize the target’s 3D model and pose, obtaining high-precision poses. As depicted in the third row of
Figure 11, throughout the entire joint optimization procedure, the error of the target’s 3D model generally manifests a downward trend. Hence, the pose error achieved by resolving the PnP problem based on the optimized 3D model is reduced accordingly.
In Orbit-2.0, the long imaging distance will magnify the influence of 2D errors on the optimization. Consequently, the successful pose optimization outcomes on Orbit-2.0 suggest that the approach presented in this paper is moderately robust against 2D landmark detection errors at extended distances. As analyzed in
Section 4.2, the rendezvous angles of Rendezvous-10, Rendezvous-20, and Rendezvous-30 are relatively small and unable to provide sufficient information for optimization. However, the continuous proximity between platforms serves to mitigate the influence of 2D detection errors on the proposed optimization algorithm. Hence, the proposed method still achieves favorable pose optimization results on these three sequence samples.
Figure 11 depicts the pose prediction outcomes of a solitary sample from each of the four synthetic image sequences. Subsequently,
Table 3 exhibits the statistical findings of the average pose errors of all samples within the four synthetic image sequences, with the minimum error highlighted in bold.
As demonstrated in
Table 3, in comparison with the PP-TinyPose-EPnP and RTMPose-EPnP approaches, the proposed method achieves the pose prediction outcomes that are closest to the ground truth in all four image sequences. Additionally, as can be observed from
Table 3, due to the magnified impact of a greater distance on the 2D landmark detection error, the optimization effect of the pose in Orbit-2.0 is marginally subpar.
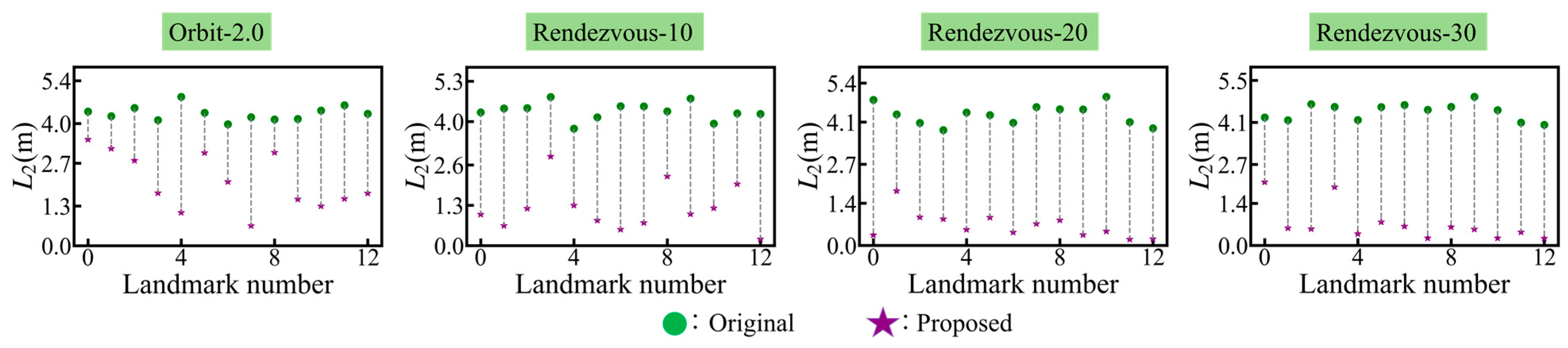
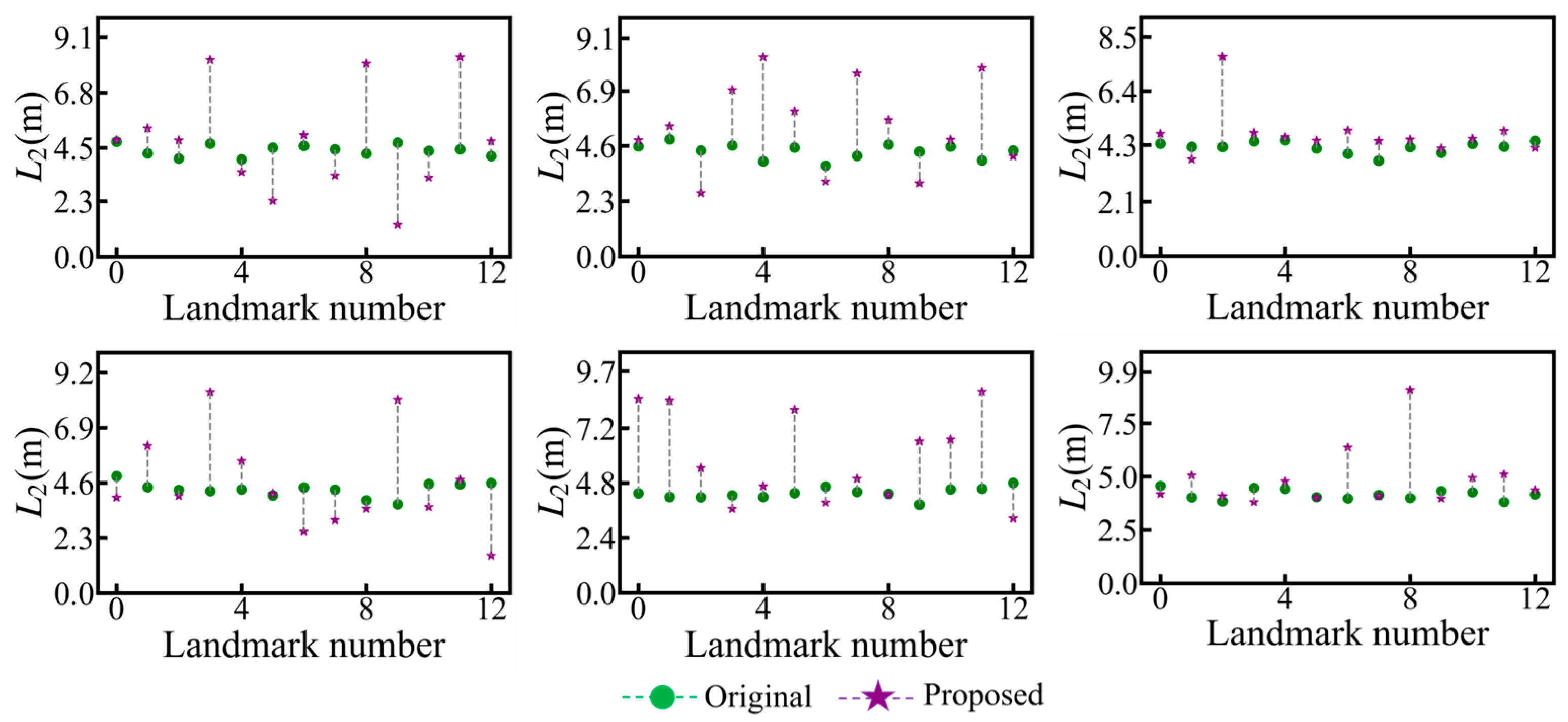
The proposed method employs multi-view geometry constraint information to jointly optimize the target’s 3D model and pose. Consequently, the optimization effect of the proposed method for the 3D model on a single sample from each of the four image sequences is presented in
Figure 12. In this figure, the green dot represents the original 3D model error and the purple five-pointed star represents the optimized 3D model error. As depicted in
Figure 12, the proposed method effectively decreases the overall error of the 3D model within four synthetic image sequence samples.
Figure 12 exhibits the influence of 3D model optimization in a solitary sample. Subsequently,
Table 4 presents the statistical outcomes of the average 3D model errors of all samples within four synthetic image sequences, where the minimum error is highlighted in bold.
As depicted in
Table 4, the proposed method reduces the 3D model error in all four image sequences. Furthermore, a longer imaging distance will increase the impact of 2D landmark detection errors on optimization. Therefore, the optimization effect for the 3D model in the Orbit-2.0 image sequence is relatively poor.
In addition, this paper compares the processing time of different algorithms on a single frame in
Table 5.
As shown in
Table 5, because of the benefit of the lightweight network design, PP-TinyPose-EPnP’s average processing time on the synthetic image sequence is only about 8.15 ms/frame. Due to the addition of the optimization module, the proposed method takes a longer time than RTMPose-EpnP at about 32.5 ms/frame. However, when the camera frame rate is greater than or equal to 20 Hz, the proposed method can still meet the requirements of real-time applications.
4.4. Experiments on Real Image Sequences
Similarly to synthetic experiments, in real experiments, this paper employs a handheld camera to simulate the scenarios where the UAV is circling around and rendezvousing with the ship. The simulation process of the UAV circling the ship at about 1 km in the real scene is presented in
Figure 13a, and its corresponding image sequence is named real orbit. The simulation process of the rendezvous between the UAV and the ship in the real scene is presented in
Figure 13b, and the corresponding image sequence is designated as real rendezvous. And the pose truth values for the real image sequences are obtained through manual annotation.
This paper selects real orbit and real rendezvous image sequences to conduct real experiments. Additionally, PP-TinyPose-EPnP and RTMPose-EPnP are also employed as comparative approaches. Similarly to
Figure 10, the example results of pose reprojection of PP-TinyPose-EPnP, RTMPose-EpnP, and the proposed method on real image sequences are presented in
Figure 14, where the local zoomed-in results of pose reprojection are depicted in the red box on the left. The meanings represented by the different color masks in the figure are consistent with those in
Figure 10. Moreover,
Table 5 presents the average detection outcomes of 2D landmarks for PP-TinyPose and RTMPose in various real image sequences.
In
Table 6, The 2D landmark detection error of PP-TinyPose on real image sequences is significantly greater than that of RTMPose. Therefore, in
Figure 14, even the pose reprojection of PP-TinyPose-EPnP exhibits severe deformation, indicating that the obtained pose results deviate significantly from the ground truth. In contrast, the accuracy of 2D landmarks detected by RTMPose generally meets the boundary conditions given in
Section 4.2. Therefore, the poses obtained by RTMPose-EPnP and the proposed method are more accurate. Furthermore, as shown in the first two examples in
Figure 14, due to the relatively large detection error of the 2D landmarks in the real image sequence, the subsequent optimization effect on the pose is poor.
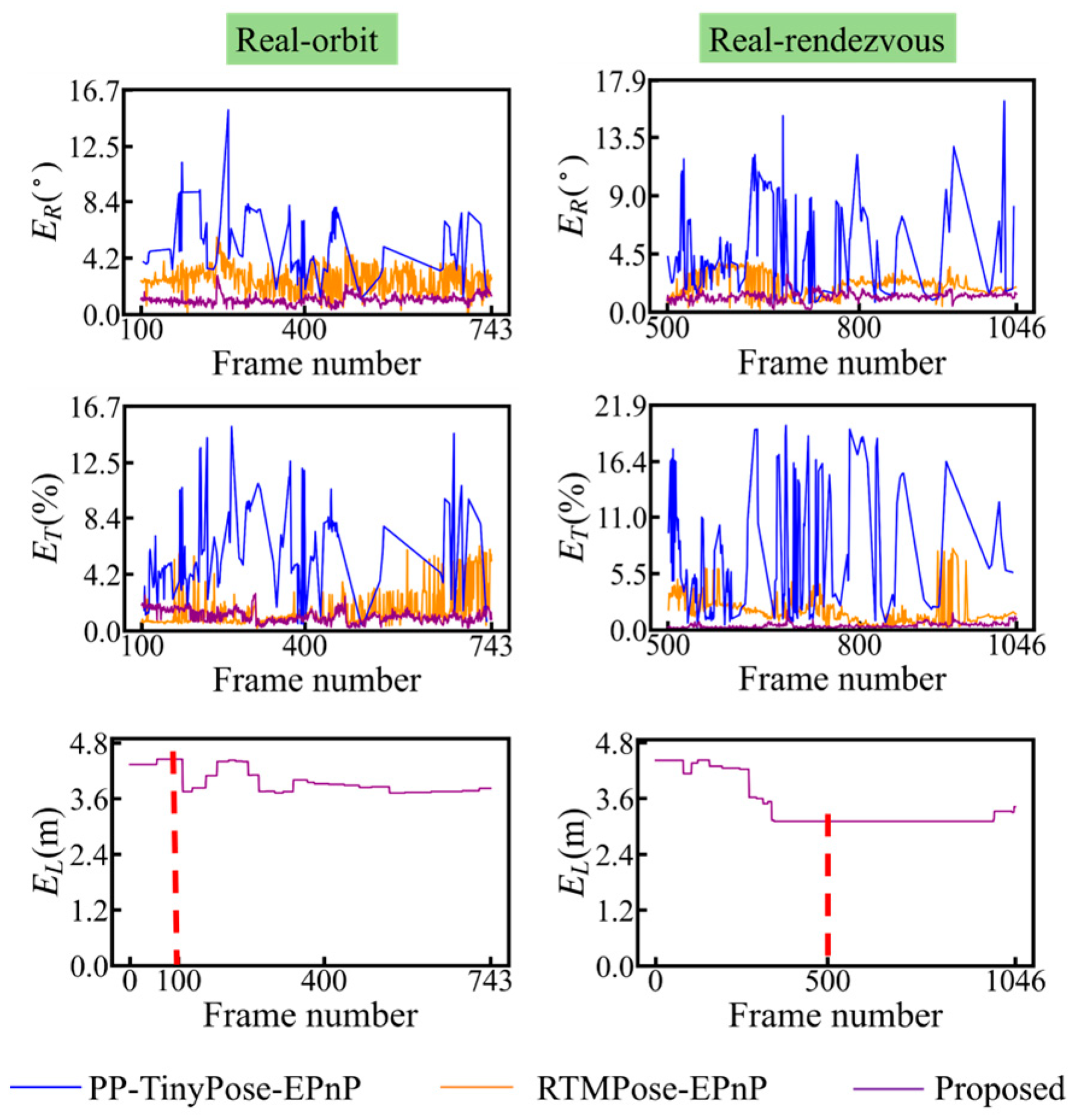
Similarly to the synthesis experiment, this paper selects a set of complete pose prediction samples from two real image sequences, respectively. These samples are depicted in the first two rows of
Figure 15. In addition, the third row of
Figure 15 exhibits the variation in the average error of the target’s 3D model throughout the entire optimization within the two image sequence samples.
As depicted in the initial two rows of
Figure 15, the pose errors achieved by the proposed method are consistently smaller than those obtained through the PP-TinyPose-EPnP and RTMPose-EPnP methods throughout the image sequence. This is predominantly due to the fact that, as exhibited in the third row of
Figure 15, the proposed method continuously diminishes the error of the 3D model during the optimization procedure, thereby reducing the pose error. However, owing to the significant 2D detection error in real images, the optimization effect of the 3D model presented in
Figure 15 is not as satisfactory as that of the synthetic experiment. As a result, in
Figure 15, the pose error curves of RTMPose-EPnP and the proposed method are not discriminated clearly enough. Additionally, in a few images, the pose error achieved by RTMPose-EPnP is smaller than that in the proposed method.
Figure 15 depicts the pose prediction outcomes of a solitary sample from each of the two real image sequences. Subsequently,
Table 7 exhibits the statistical findings of the average pose errors of all samples within the two real image sequences, with the minimum error highlighted in bold.
As demonstrated in
Table 7, in comparison with the PP-TinyPose-EPnP and RTMPose-EPnP approaches, the proposed method achieves the pose prediction outcomes that are closest to the ground truth in all two image sequences.
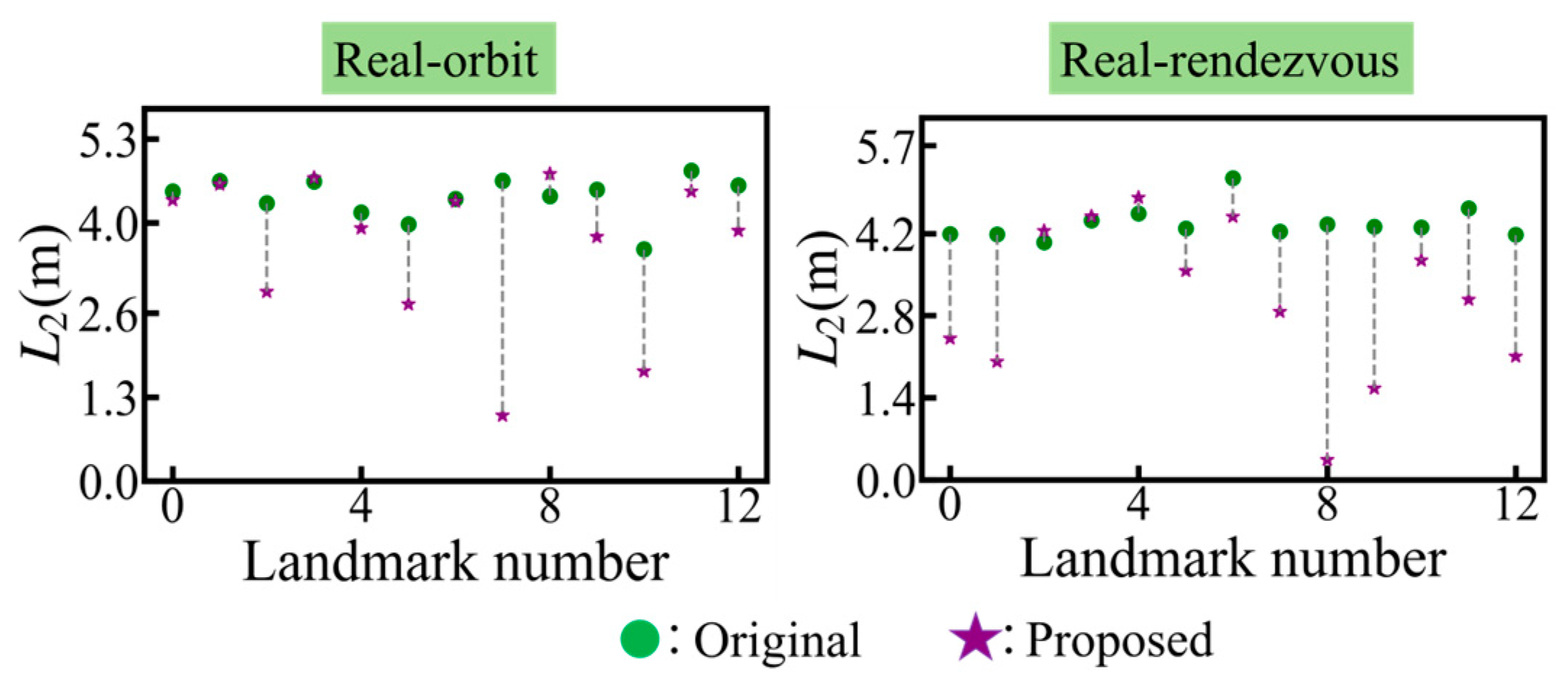
The proposed method employs multi-view geometry constraint information to jointly optimize the target’s 3D model and pose. Consequently, the optimization effect of the proposed method for the 3D model on a single sample from each of the two image sequences is presented in
Figure 16. In this figure, the green dot represents the original 3D model error and the purple five-pointed star represents the optimized 3D model error.
As depicted in
Figure 16, the proposed method effectively decreases the overall error of the 3D model within two real image sequence samples. However, in contrast to the synthesis experiments, in
Figure 16, the errors of a few 3D landmarks further escalate after optimization. This is mainly due to the large 2D landmark detection error on the real image sequence, which is not conducive to the subsequent optimization based on minimizing the reprojection error.
Figure 16 exhibits the influence of 3D model optimization in a solitary sample. Subsequently,
Table 8 presents the statistical outcomes of the average 3D model errors of all samples within two real image sequences, where the minimum error is highlighted in bold.
As depicted in
Table 8, the proposed method reduces the 3D model error in all two image sequences. Furthermore, in line with the aforementioned analysis, on account of the significant 2D detection error, the optimization effect of the 3D model in the real image sequence is restricted. For instance, in real orbit, the model error is reduced by merely approximately 4%, while in real rendezvous, the model error is decreased by approximately 10%. Therefore, high-precision 2D landmark detection is of crucial importance to the proposed method.
In addition, this paper compares the processing time of different algorithms on a single frame in
Table 9.
Similarly to the statistics in synthetic experiments, in real experiments, PP-TinyPose-EPnP consumes the least amount of time. RTMPose-EPnP takes slightly longer, approximately 29.15 ms. The proposed method has the longest duration of around 36.15 ms. It can be observed that, compared to synthetic experiments, the optimization module consumes more time in real experiments. This is primarily due to the larger landmark detection errors in real image sequences, which subsequently leads to an increase in the number of iterations required by the optimization module. Additionally, inaccurate landmark detection implies larger errors in the initial pose estimation, requiring the optimization algorithm to take longer to find the correct convergence direction.
4.5. Limitation Analysis
The joint optimization outcomes in synthetic and real image sequences demonstrate that the proposed method can effectively diminish the errors in both the pose and the target’s 3D model. Nevertheless, in some samples, as a result of significant 2D landmark detection errors, the proposed approach fails to effectively optimize the pose and 3D model.
Figure 17 shows the pose optimization failure results from a real sample. Since the pose error acquired by the PP-TinyPose-EPnP approach is considerably oversized, we merely compare RTMPose-EPnP and the proposed method. Further,
Figure 18 shows the multi-set failure optimization results of the target’s 3D model in real image sequences. In certain images within the real image sequence, the detection errors of 2D landmarks are significantly larger than the reprojection error of the 3D model. Consequently, as depicted in
Figure 17 and
Figure 18, it is challenging for the method presented in this paper to optimize the pose and 3D model by minimizing the reprojection error.
The current research of this paper primarily focuses on landmark detection under sufficient lighting and clear image conditions. And the in-depth discussions and experiments under adverse weather conditions have yet to be conducted. Consequently, the proposed method may exhibit lower robustness and accuracy in these challenging environments. This is primarily due to the fact that the algorithm learns feature representations under favorable conditions during the training process. Therefore, it lacks sufficient adaptability to the variations in image features under extreme weather conditions.
To enhance the robustness of the landmark detection algorithm under adverse weather conditions, this study will improve the proposed method in two aspects for future work. Firstly, this study introduced simulated adverse weather condition data (such as generating images with intense light, rain, snow, or fog through image processing techniques) during the training process to increase the model’s adaptability to such conditions. Secondly, this study explored the integration of other sensor data (such as infrared cameras, LiDAR, etc.) to assist in landmark detection, thereby improving detection accuracy and stability under adverse weather conditions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}