
Enhancing UAV Swarm Tactics with Edge AI: Adaptive Decision Making in Changing Environments



Abstract
1. Introduction
- Efficient and reliable network algorithms for UAV swarms. We propose a swarm drone operation system that leverages advanced network algorithms to build a dynamically efficient network called the ESUSN. This system limits the number of connections each drone maintains while optimizing overall cooperation to ensure robust and reliable drone operations.
- Optimal action selection through RL. We design a flexible MARL system that operates across various scenarios based on specific parameters. In this system, each drone within the swarm learns to select the optimal behavior using a limited set of inputs from surrounding drones and sensor values collected by the SBC. This adaptive framework reduces the need for complex networks and significantly enhances the efficiency of critical tasks such as reconnaissance and collision avoidance.
- Appropriate method of communication. Until now, when exchanging data between drones in a UAV swarm, various communication problems have occurred because the state of the drone was not taken into consideration and an inappropriate routing method was used. However, our system improved network performance by considering the drone’s environment and configuring an appropriate communication system to ensure that data are accurately delivered to the destination.
- Real-time adaptation. Each drone adapts in real time based on environmental changes and the status of neighboring drones. This dynamic adaptive ability maximizes mission performance efficiency and overcomes the limitations of traditional control methods.
2. Related Work
2.1. Communication Networks and Protocols for UAV Swarm
2.2. Reinforcement Learning Algorithms for UAV Decision Making
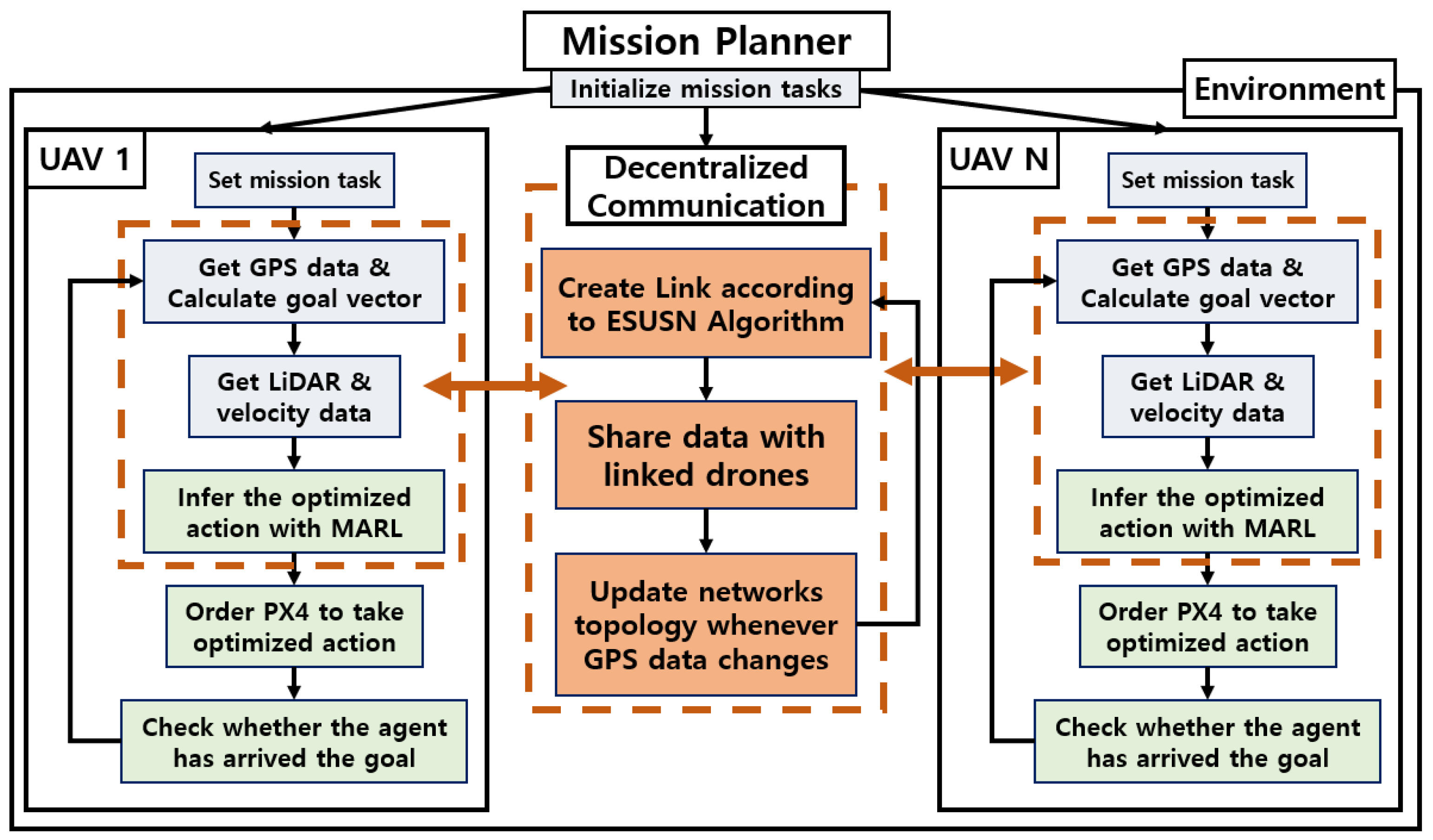
3. System Design and Algorithm
3.1. System Overview
3.2. Efficient Self UAV Swarm Network
- Euclidean Distance Calculation:where is the distance between drone i and drone j, and and are the coordinates of drones i and j, respectively.
- Minimum Spanning Tree (MST) Calculation using GHS Algorithm: The MST is considered to care for all drones in the swarm. In our system, MST is constructed using the GHS algorithm [39].where T is the MST, and G is the graph of drone distances.The algorithm involves the following steps:
- (a)
- Each drone starts as an individual fragment.
- (b)
- Each fragment identifies the smallest edge to another fragment and attempts to merge.
- (c)
- Repeat the merging process until all drones are connected into a single MST.
- Network Optimization: To ensure all drones are connected while maintaining the maximum number of links per drone:
- (a)
- For each drone i, identify the two closest drones and add links such that i has at most 2 links:
- (b)
- Remove excess links if a drone has more than two connections. Keep only the two shortest links:
- (c)
- Include the MST to ensure all drones are connected:
| Algorithm 1 Efficient Self UAV Swarm Network (ESUSN) using GHS Algorithm |
|
3.3. Collision Avoidance Using PPO
- Current UAV Information: The position and velocity of the current UAV, and the distance to the target.
- Sensor Value: Values output by the LiDAR sensor attached to the UAV.
- Colleague Information: Information of the UAVs connected through ESUSN, including their positions, velocities, and distances to their targets.
- Distance Reward: Each agent measures the distance reduction to the target point through the GPS value of the current point. Agents receive higher rewards as they move closer to their goal. This encourages agents to efficiently navigate toward their target points. This metric is shared among all agents, allowing for updates that might slightly increase the distance for a specific agent but enhance the overall reward for the group.
- Goal Reward: Check whether an agent has reached its destination. Agents receive a substantial reward upon reaching their target point, encouraging them to successfully complete their missions.
- Collision Reward: Determine if an agent has collided with another agent or an obstacle. If a collision occurs, the agent incurs a significant penalty. This discourages collisions and promotes safe navigation.
- Space Reward: Evaluate whether an agent maintains an appropriate distance from nearby agents. During environment initialization, the minimum and maximum recommended distances between agents are defined. Agents receive rewards for maintaining these defined distances and penalties for being too close or too far. By defining varied maximum and minimum distances, diverse scenarios and actions are encouraged, preventing agents from straying too far from the group.where the following holds:
- , , , are the weight for each reward score,
- is the positive reward for agent i being within a certain distance of its target, defined as:where is a very short distance to assume that the agent has arrived at the destination,
- is the negative reward for agent i being within a certain distance of other agents or obstacle, defined aswhere is a very short distance to assume that the agent has collided. And j is another agent or obstacle,
- is the negative reward that agents i receive when they are outside a certain range in the connected agent, defined aswhere a and b are the minimum and maximum distance parameters between agents declared for navigation and isolation prevention. And j are agents that are linked through ESUSN.
| Algorithm 2 MultiAgent PPO Algorithm with sharing ambient agent’s information through ESUSN |
|
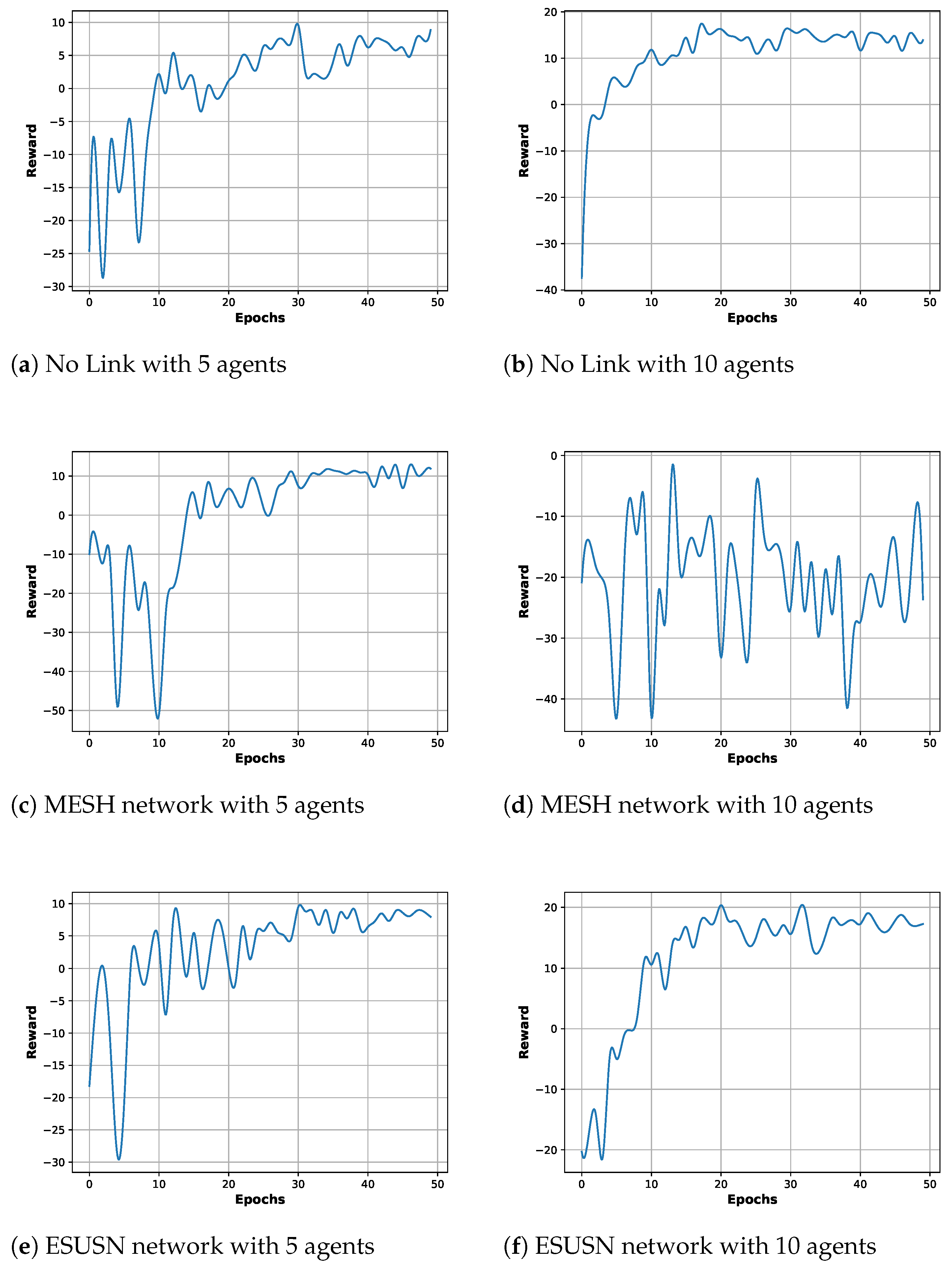
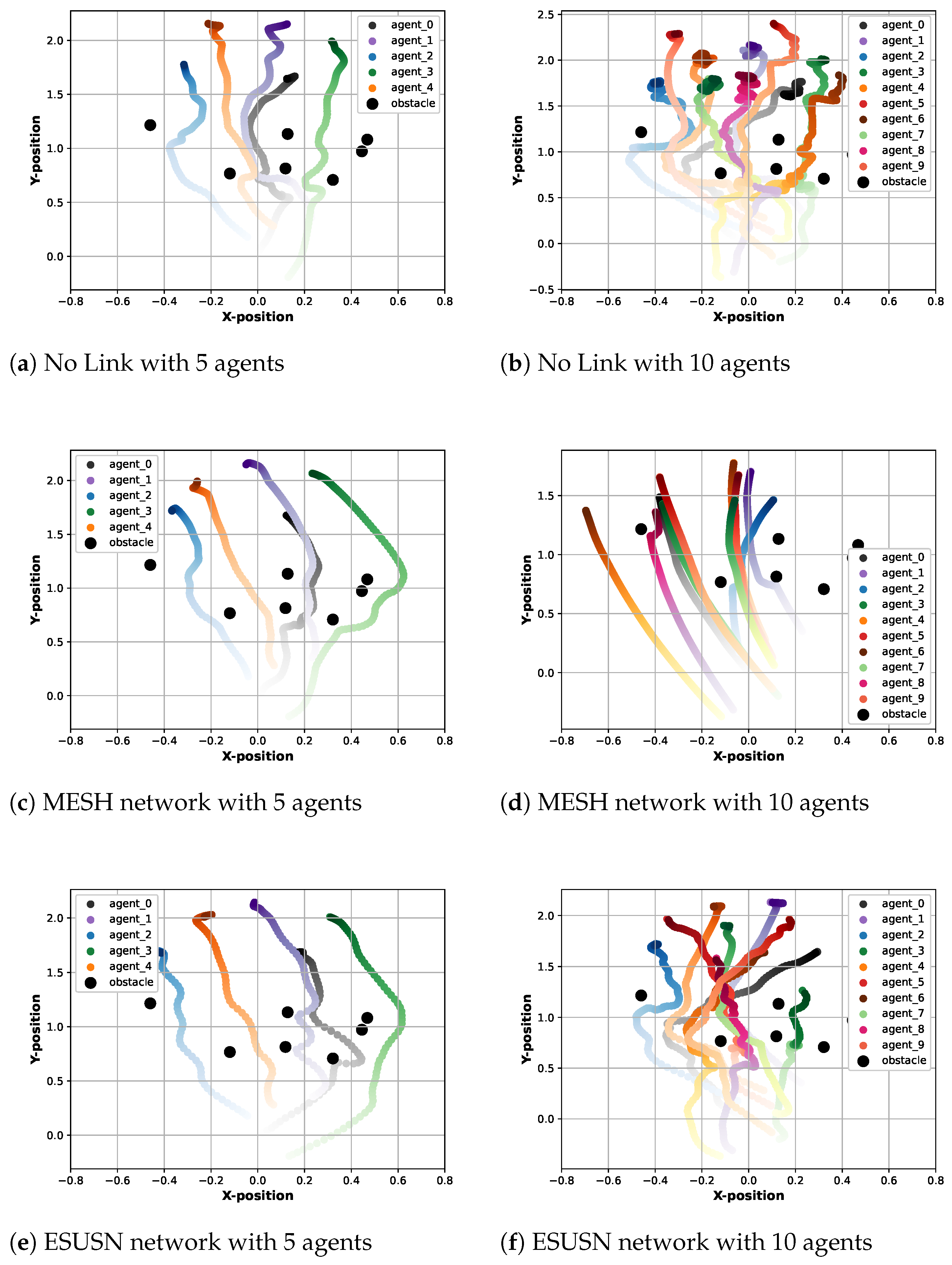
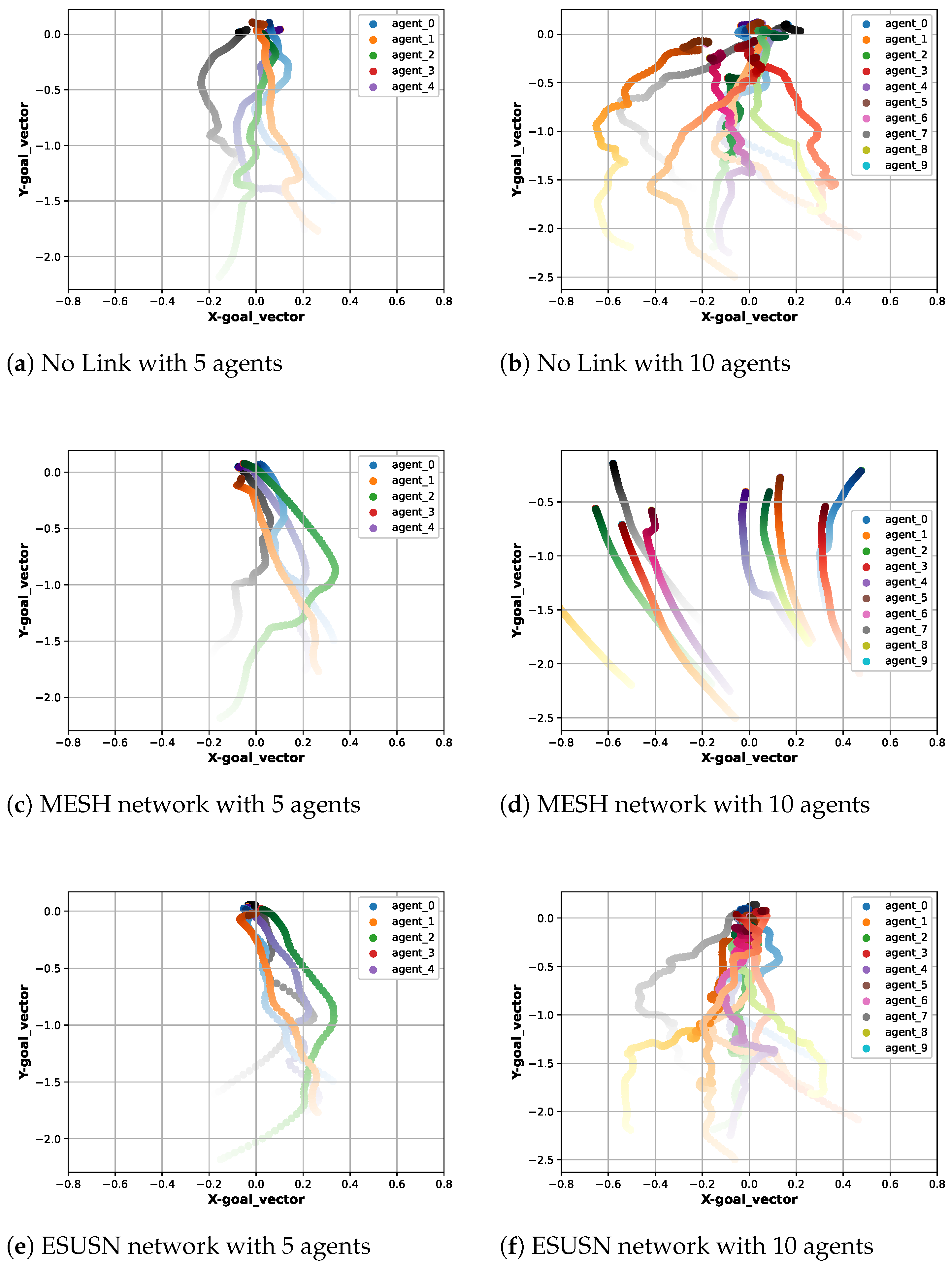
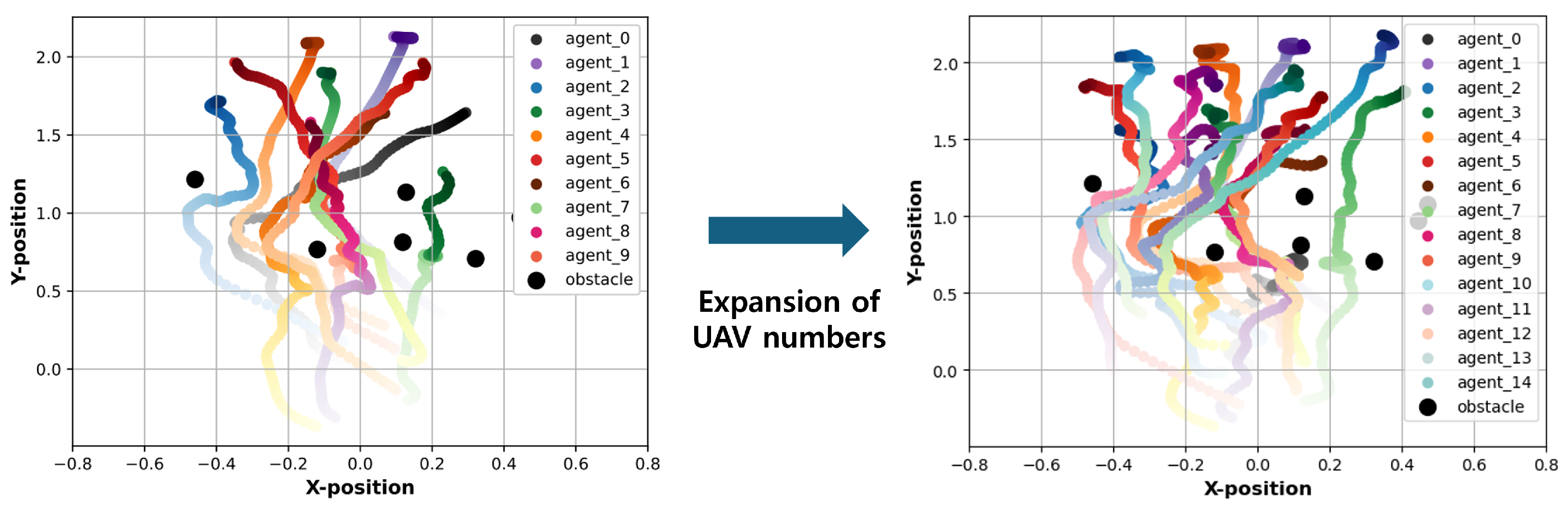
4. Performance Evaluation
4.1. Implementation
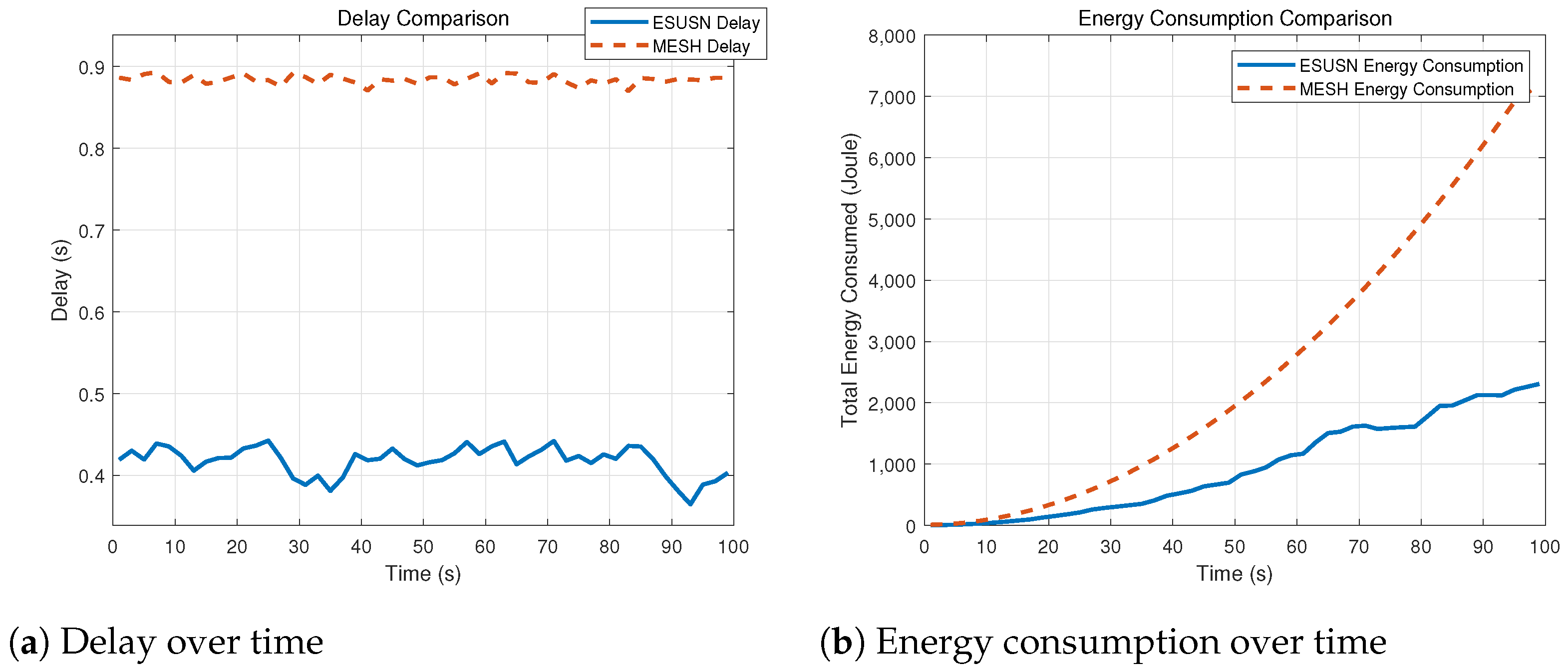
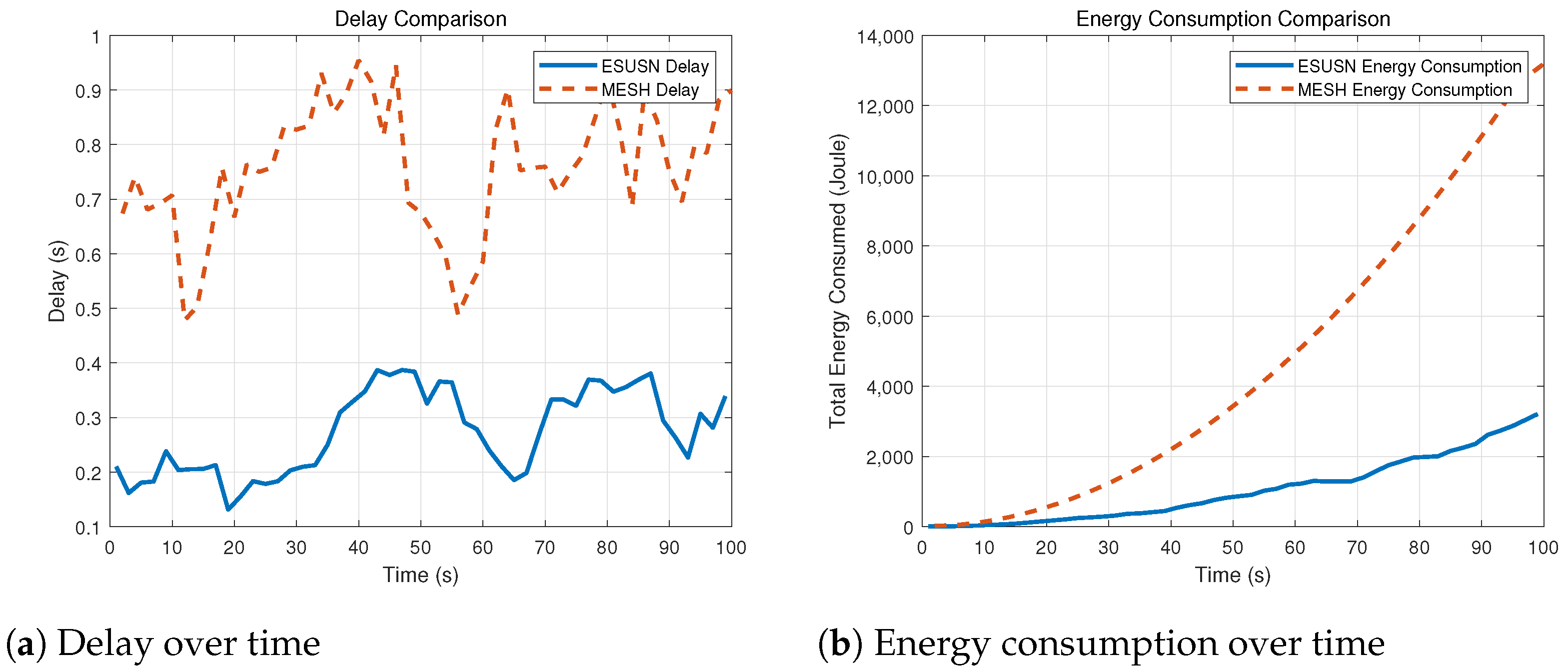
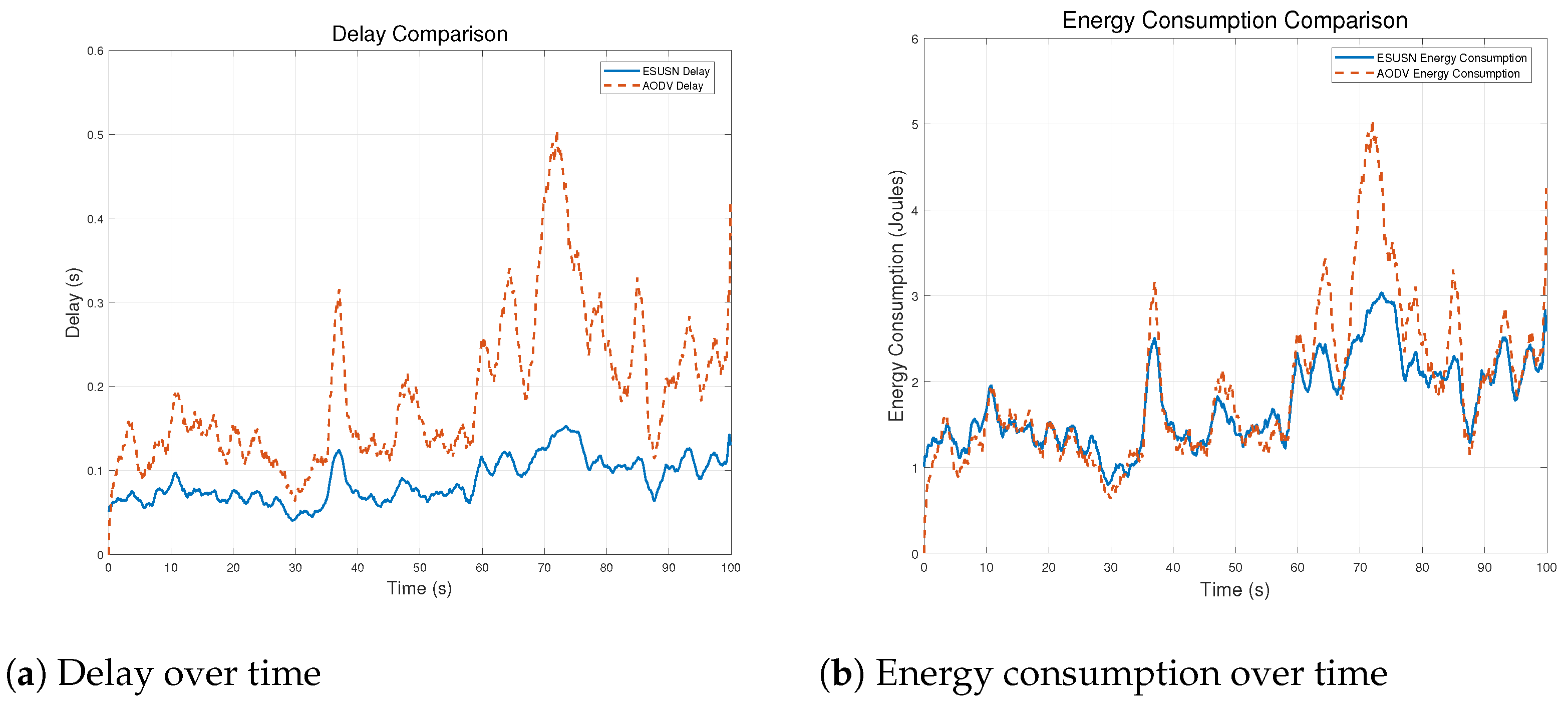
4.2. Network Efficiency Experiments
4.3. Experiments on Reinforcement Learning Performance
5. Future Research Directions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| RL | Reinforcement Learning |
| ESUSN | Efficient Self UAV Swarm Network |
| MARL | MultiAgent Reinforcement Learning |
| GCS | Ground Control Stations |
| SBC | Single-Board Computer |
| FANETs | Flying Ad Hoc Networks |
| MANETs | Mobile Ad Hoc Networks |
| SDN | Software-Defined Networking |
| DDPG | Deep Deterministic Policy Gradient |
| DQN | Deep Q-Networks |
| DDQN | Double Deep Q-Networks |
| PPO | Proximal Policy Optimization |
| LSTM | Long Short-Term Memory |
| MST | Minimum Spanning Tree |
| VMAS | Vectorized MultiAgent Simulator |
| LiDAR | Light Detection And Ranging |
References
- Hayat, S.; Yanmaz, E.; Muzaffar, R. Survey on Unmanned Aerial Vehicle Networks for Civil Applications: A Communications Viewpoint. IEEE Commun. Surv. Tutor. 2016, 18, 2624–2661. [Google Scholar] [CrossRef]
- Shakhatreh, H.; Sawalmeh, A.H.; Al-Fuqaha, A.; Dou, Z.; Almaita, E.; Khalil, I.; Othman, N.S.; Khreishah, A.; Guizani, M. Unmanned Aerial Vehicles (UAVs): A Survey on Civil Applications and Key Research Challenges. IEEE Access 2019, 7, 48572–48634. [Google Scholar] [CrossRef]
- Dutta, G.; Goswami, P. Application of drone in agriculture: A review. Int. J. Chem. Stud. 2020, 8, 181–187. [Google Scholar] [CrossRef]
- Veroustraete, F. The rise of the drones in agriculture. EC Agric. 2015, 2, 325–327. [Google Scholar]
- Yoo, T.; Lee, S.; Yoo, K.; Kim, H. Reinforcement learning based topology control for UAV networks. Sensors 2023, 23, 921. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Kim, H.T.; Kim, H. Vmcs: Elaborating apf-based swarm intelligence for mission-oriented multi-uv control. IEEE Access 2020, 8, 223101–223113. [Google Scholar] [CrossRef]
- Lee, W.; Lee, J.Y.; Lee, J.; Kim, K.; Yoo, S.; Park, S.; Kim, H. Ground control system based routing for reliable and efficient multi-drone control system. Appl. Sci. 2018, 8, 2027. [Google Scholar] [CrossRef]
- Fotouhi, A.; Ding, M.; Hassan, M. Service on Demand: Drone Base Stations Cruising in the Cellular Network. In Proceedings of the 2017 IEEE Globecom Workshops (GC Wkshps), Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Shahzad, M.M.; Saeed, Z.; Akhtar, A.; Munawar, H.; Yousaf, M.H.; Baloach, N.K.; Hussain, F. A review of swarm robotics in a nutshell. Drones 2023, 7, 269. [Google Scholar] [CrossRef]
- Yoon, N.; Lee, D.; Kim, K.; Yoo, T.; Joo, H.; Kim, H. STEAM: Spatial Trajectory Enhanced Attention Mechanism for Abnormal UAV Trajectory Detection. Appl. Sci. 2023, 14, 248. [Google Scholar] [CrossRef]
- Park, S.; Kim, H. Dagmap: Multi-drone slam via a dag-based distributed ledger. Drones 2022, 6, 34. [Google Scholar] [CrossRef]
- Bekmezci, I.; Sen, I.; Erkalkan, E. Flying ad hoc networks (FANET) test bed implementation. In Proceedings of the 2015 7th International Conference on Recent Advances in Space Technologies (RAST), Istanbul, Turkey, 16–19 June 2015; pp. 665–668. [Google Scholar]
- Corson, S.; Macker, J. Mobile ad Hoc Networking (MANET): Routing Protocol Performance Issues and Evaluation Considerations. RFC 2501 1999. Available online: https://www.rfc-editor.org/rfc/rfc2501 (accessed on 27 July 2024).
- Park, C.; Lee, S.; Joo, H.; Kim, H. Empowering adaptive geolocation-based routing for UAV networks with reinforcement learning. Drones 2023, 7, 387. [Google Scholar] [CrossRef]
- Park, S.; La, W.G.; Lee, W.; Kim, H. Devising a distributed co-simulator for a multi-UAV network. Sensors 2020, 20, 6196. [Google Scholar] [CrossRef] [PubMed]
- Nazib, R.A.; Moh, S. Routing protocols for unmanned aerial vehicle-aided vehicular ad hoc networks: A survey. IEEE Access 2020, 8, 77535–77560. [Google Scholar] [CrossRef]
- Saleem, Y.; Rehmani, M.H.; Zeadally, S. Integration of cognitive radio technology with unmanned aerial vehicles: Issues, opportunities, and future research challenges. J. Netw. Comput. Appl. 2015, 50, 15–31. [Google Scholar] [CrossRef]
- Gupta, L.; Jain, R.; Vaszkun, G. Survey of important issues in UAV communication networks. IEEE Commun. Surv. Tutor. 2015, 18, 1123–1152. [Google Scholar] [CrossRef]
- Khan, M.F.; Yau, K.L.A.; Noor, R.M.; Imran, M.A. Routing schemes in FANETs: A survey. Sensors 2019, 20, 38. [Google Scholar] [CrossRef]
- Srivastava, A.; Prakash, J. Future FANET with application and enabling techniques: Anatomization and sustainability issues. Comput. Sci. Rev. 2021, 39, 100359. [Google Scholar] [CrossRef]
- Nayyar, A. Flying adhoc network (FANETs): Simulation based performance comparison of routing protocols: AODV, DSDV, DSR, OLSR, AOMDV and HWMP. In Proceedings of the 2018 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 6–7 August 2018; pp. 1–9. [Google Scholar]
- Bekmezci, I.; Sahingoz, O.K.; Temel, Ş. Flying ad-hoc networks (FANETs): A survey. Ad Hoc Netw. 2013, 11, 1254–1270. [Google Scholar] [CrossRef]
- Zhu, L.; Karim, M.M.; Sharif, K.; Xu, C.; Li, F. Traffic flow optimization for UAVs in multi-layer information-centric software-defined FANET. IEEE Trans. Veh. Technol. 2022, 72, 2453–2467. [Google Scholar] [CrossRef]
- Ayub, M.S.; Adasme, P.; Melgarejo, D.C.; Rosa, R.L.; Rodríguez, D.Z. Intelligent hello dissemination model for FANET routing protocols. IEEE Access 2022, 10, 46513–46525. [Google Scholar] [CrossRef]
- Koch, W.; Mancuso, R.; West, R.; Bestavros, A. Reinforcement learning for UAV attitude control. ACM Trans.-Cyber-Phys. Syst. 2019, 3, 1–21. [Google Scholar] [CrossRef]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; et al. Drone deep reinforcement learning: A review. Electronics 2021, 10, 999. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Tsouros, D.C.; Bibi, S.; Sarigiannidis, P.G. A review on UAV-based applications for precision agriculture. Information 2019, 10, 349. [Google Scholar] [CrossRef]
- Yang, Q.; Zhu, Y.; Zhang, J.; Qiao, S.; Liu, J. UAV air combat autonomous maneuver decision based on DDPG algorithm. In Proceedings of the 2019 IEEE 15th International Conference on Control and Automation (ICCA), Edinburgh, UK, 16–19 July 2019; pp. 37–42. [Google Scholar]
- Cetin, E.; Barrado, C.; Muñoz, G.; Macias, M.; Pastor, E. Drone navigation and avoidance of obstacles through deep reinforcement learning. In Proceedings of the 2019 IEEE/AIAA 38th Digital Avionics Systems Conference (DASC), San Diego, CA, USA, 8–12 September 2019; pp. 1–7. [Google Scholar]
- Li, K.; Ni, W.; Emami, Y.; Dressler, F. Data-driven flight control of internet-of-drones for sensor data aggregation using multi-agent deep reinforcement learning. IEEE Wirel. Commun. 2022, 29, 18–23. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Hodge, V.J.; Hawkins, R.; Alexander, R. Deep reinforcement learning for drone navigation using sensor data. Neural Comput. Appl. 2021, 33, 2015–2033. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Tong, G.; Jiang, N.; Biyue, L.; Xi, Z.; Ya, W.; Wenbo, D. UAV navigation in high dynamic environments: A deep reinforcement learning approach. Chin. J. Aeronaut. 2021, 34, 479–489. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Drew, D.S. Multi-agent systems for search and rescue applications. Curr. Robot. Rep. 2021, 2, 189–200. [Google Scholar] [CrossRef]
- Gavin, T.; LacroiX, S.; Bronz, M. Multi-Agent Reinforcement Learning based Drone Guidance for N-View Triangulation. In Proceedings of the 2024 International Conference on Unmanned Aircraft Systems (ICUAS), Chania-Crete, Greece, 4–7 June 2024; pp. 578–585. [Google Scholar]
- Gallager, R.G.; Humblet, P.A.; Spira, P.M. A Distributed Algorithm for Minimum-Weight Spanning Trees. ACM Trans. Program. Lang. Syst. (TOPLAS) 1983, 5, 66–77. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Agents | 5 | 10 | ||||
|---|---|---|---|---|---|---|
| Network | No Link | Mesh | ESUSN | No Link | Mesh | ESUSN |
| Number of Steps | 140 | 110 | 70 | 199 | X | 105 |
| Collision | 1 | 0 | 0 | 2 | 5 | 0 |
| Epoch Time | 2 | 5 | 2 | 8 | 15 | 6 |
| Number of Agents | 5 | 10 | ||||
|---|---|---|---|---|---|---|
| Algorithm | Dijkstra | General RL | MARL with ESUSN | Dijkstra | General RL | MARL with ESUSN |
| Number of Steps | 73 | 90 | 70 | 96 | 150 | 105 |
| Collision | 1 | 2 | 0 | 2 | 3 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, W.; Park, C.; Lee, S.; Kim, H. Enhancing UAV Swarm Tactics with Edge AI: Adaptive Decision Making in Changing Environments. Drones 2024, 8, 582. https://doi.org/10.3390/drones8100582
Jung W, Park C, Lee S, Kim H. Enhancing UAV Swarm Tactics with Edge AI: Adaptive Decision Making in Changing Environments. Drones. 2024; 8(10):582. https://doi.org/10.3390/drones8100582
Chicago/Turabian StyleJung, Wooyong, Changmin Park, Seunghyeon Lee, and Hwangnam Kim. 2024. "Enhancing UAV Swarm Tactics with Edge AI: Adaptive Decision Making in Changing Environments" Drones 8, no. 10: 582. https://doi.org/10.3390/drones8100582
APA StyleJung, W., Park, C., Lee, S., & Kim, H. (2024). Enhancing UAV Swarm Tactics with Edge AI: Adaptive Decision Making in Changing Environments. Drones, 8(10), 582. https://doi.org/10.3390/drones8100582