

Observing Individuals and Behavior of Hainan Gibbons (Nomascus hainanus) Using Drone Infrared and Visible Image Fusion Technology


Abstract
:1. Introduction
- We propose an IR and visible image fusion method based on Hainan gibbon for the first time, termed Swin-UetFuse. The Swin-UetFuse has a powerful global and long-range semantic information extraction capability;
- We utilized 21 pairs of Hainan gibbon dataset to perform experiments, and the experimental results demonstrate that the proposed method achieves excellent fusion performance.
2. Materials and Methods
2.1. Study Area
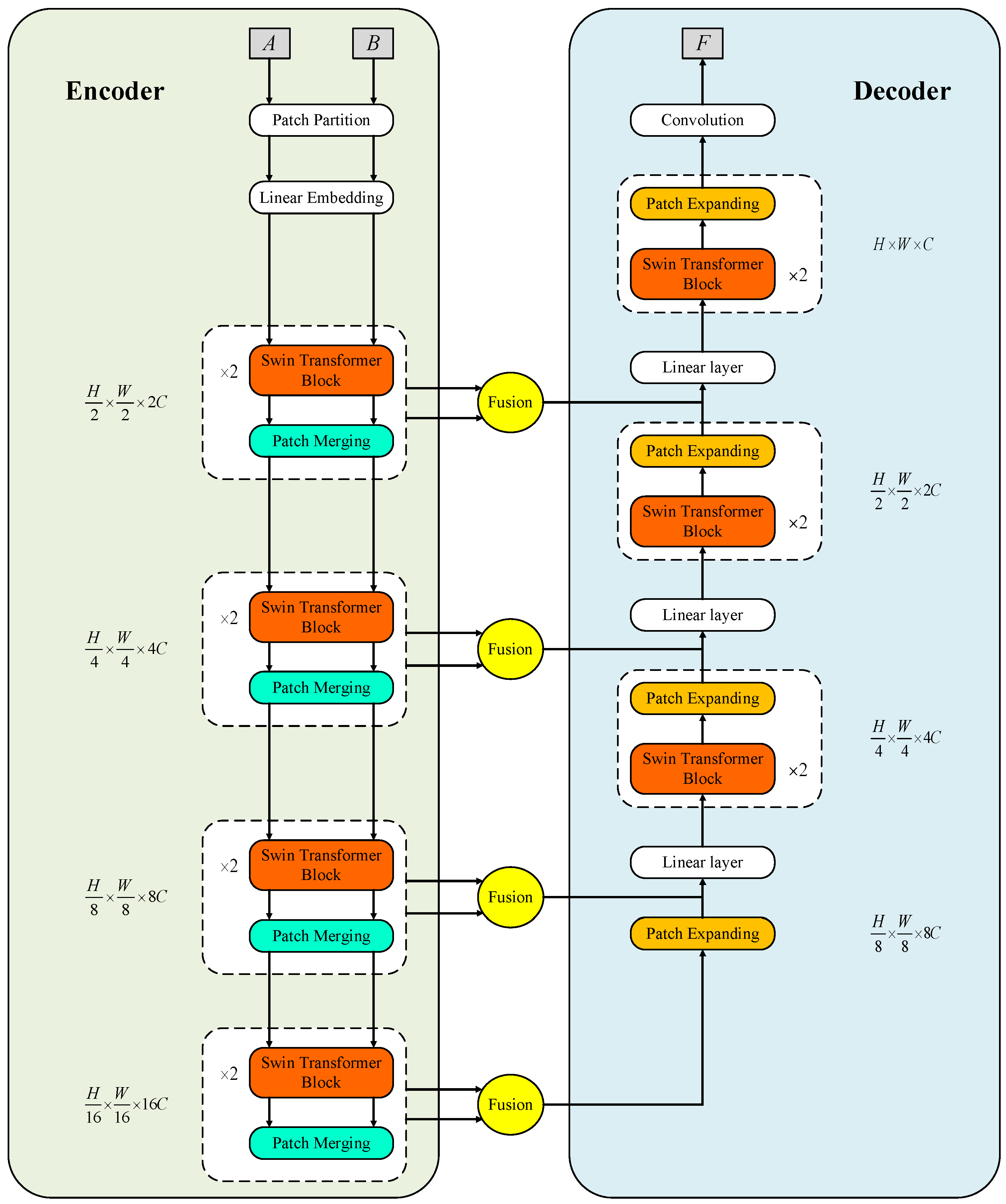
2.2. The Proposed Fusion Method Based on Hainan Gibbon
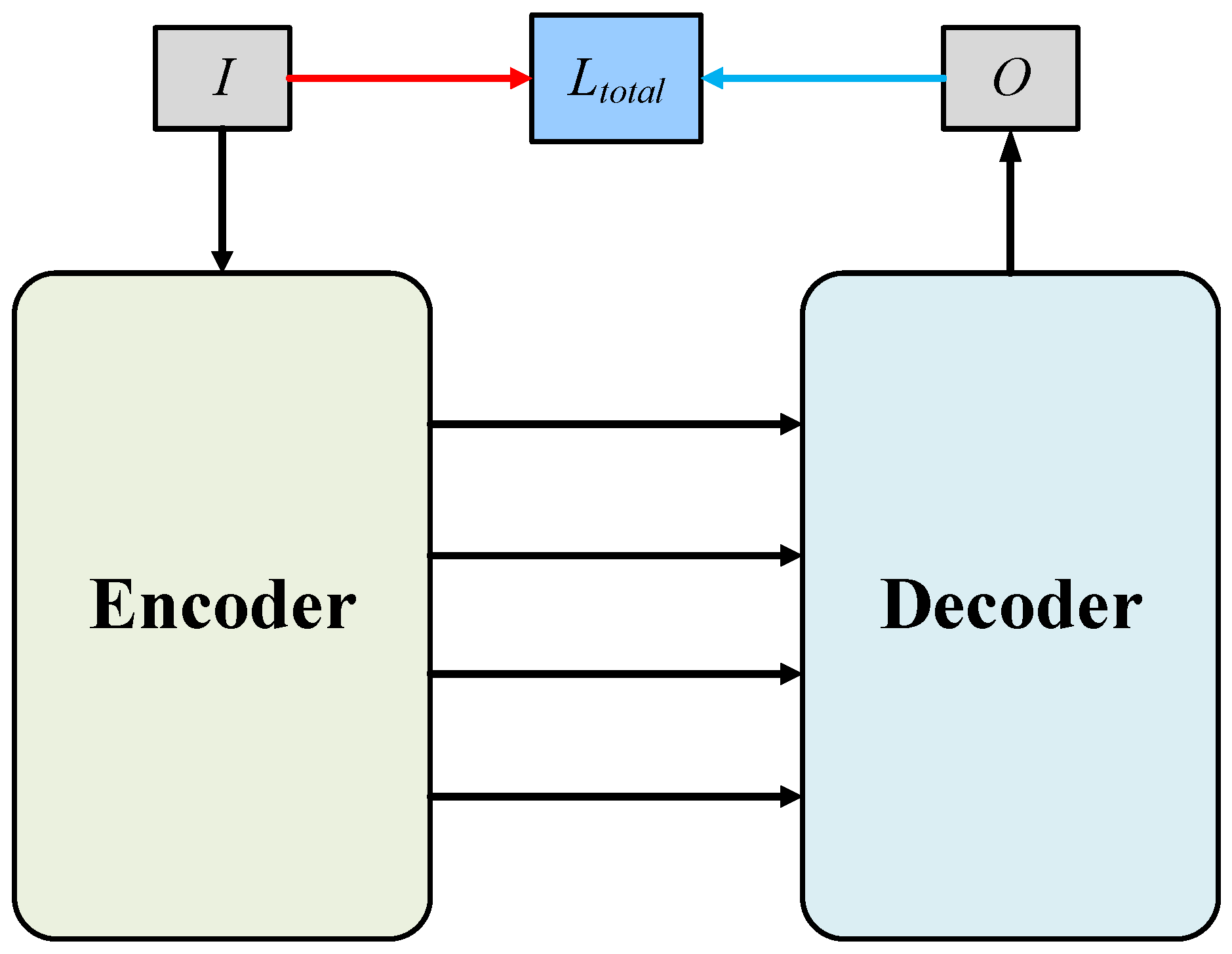
2.2.1. Encoder
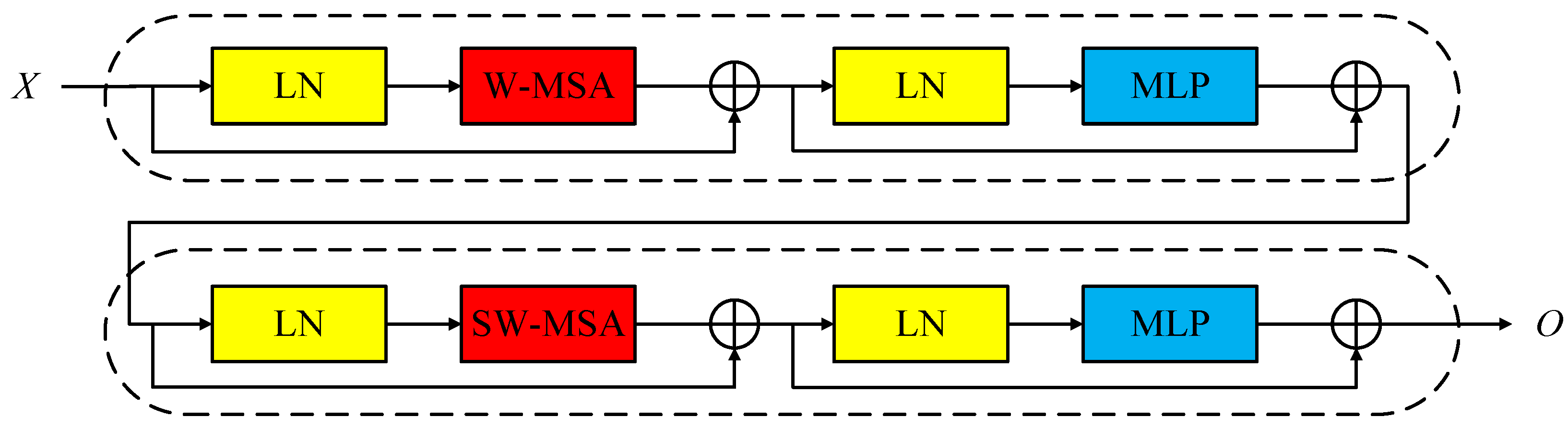
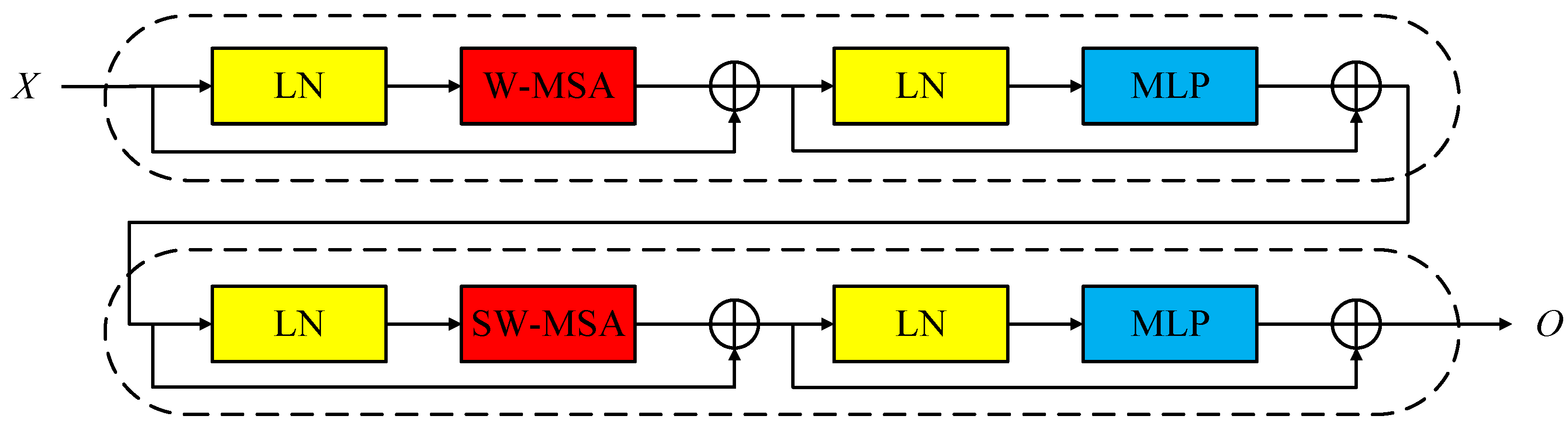
2.2.2. Swin Transformer Block
2.2.3. Fusion Strategy
2.2.4. Decoder
2.2.5. Loss Function
| Algorithm 1 The proposed infrared and visible image fusion algorithm |
| Training phase |
| 1. Initialize the networks of Swin-UnetFuse; |
| 2. Update the parameters of networks via minimizing according to Equations (21)–(23). |
| Testing (fusion) phase |
| Part 1: Encoder |
| 1. Feed infrared image A and visible image B into a series of Swin Transformer blocks and |
| patch merging layers to generate of different scales features |
| according to Equations (1)–(3); |
| Part 2: Fusion strategy |
| 2. Perform -norm based on row and column vector dimensions fusion strategy to and |
| to generate according to Equations (7)–(13); |
| Part 3: Decoder |
| 3. Perform up-sampling and concatenating operation to generate according to Equation (14); |
| 4. Perform a series of linear layers, Swin Transformer blocks, patch expanding layers and |
| concatenation layers to generate according to Equations (15)–(19); |
| 5. Feed the into the convolution operation to generate the result F according to Equation (20). |
3. Experiments and Discussion
3.1. Infrared and Visible Dataset of Hainan Gibbons
3.2. Experimental Setups
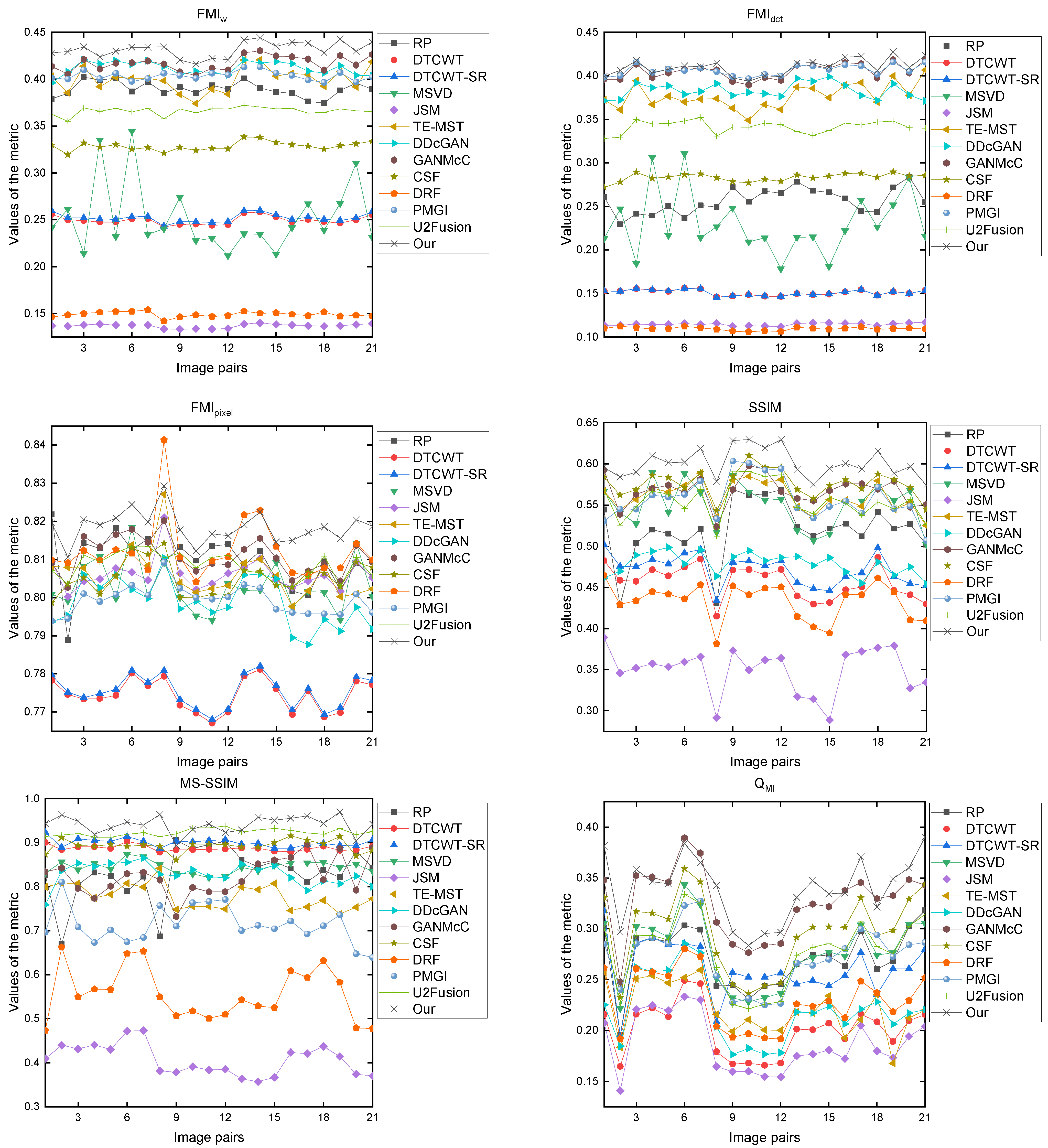
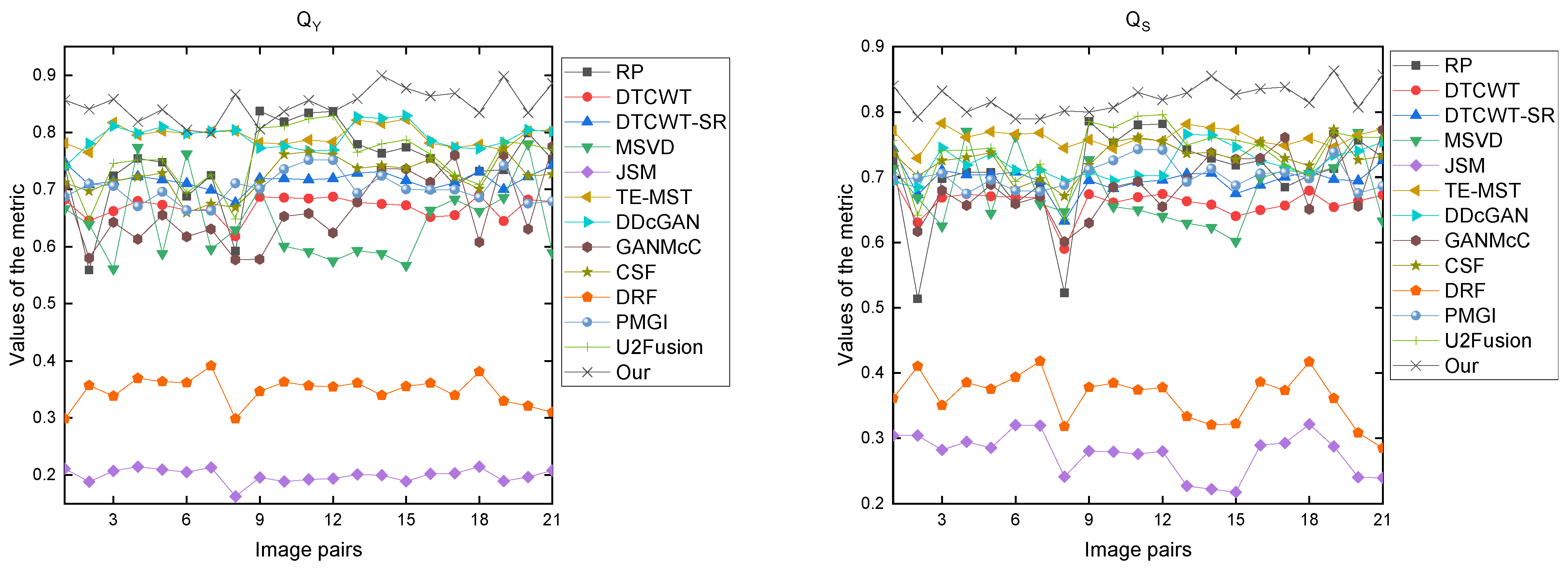
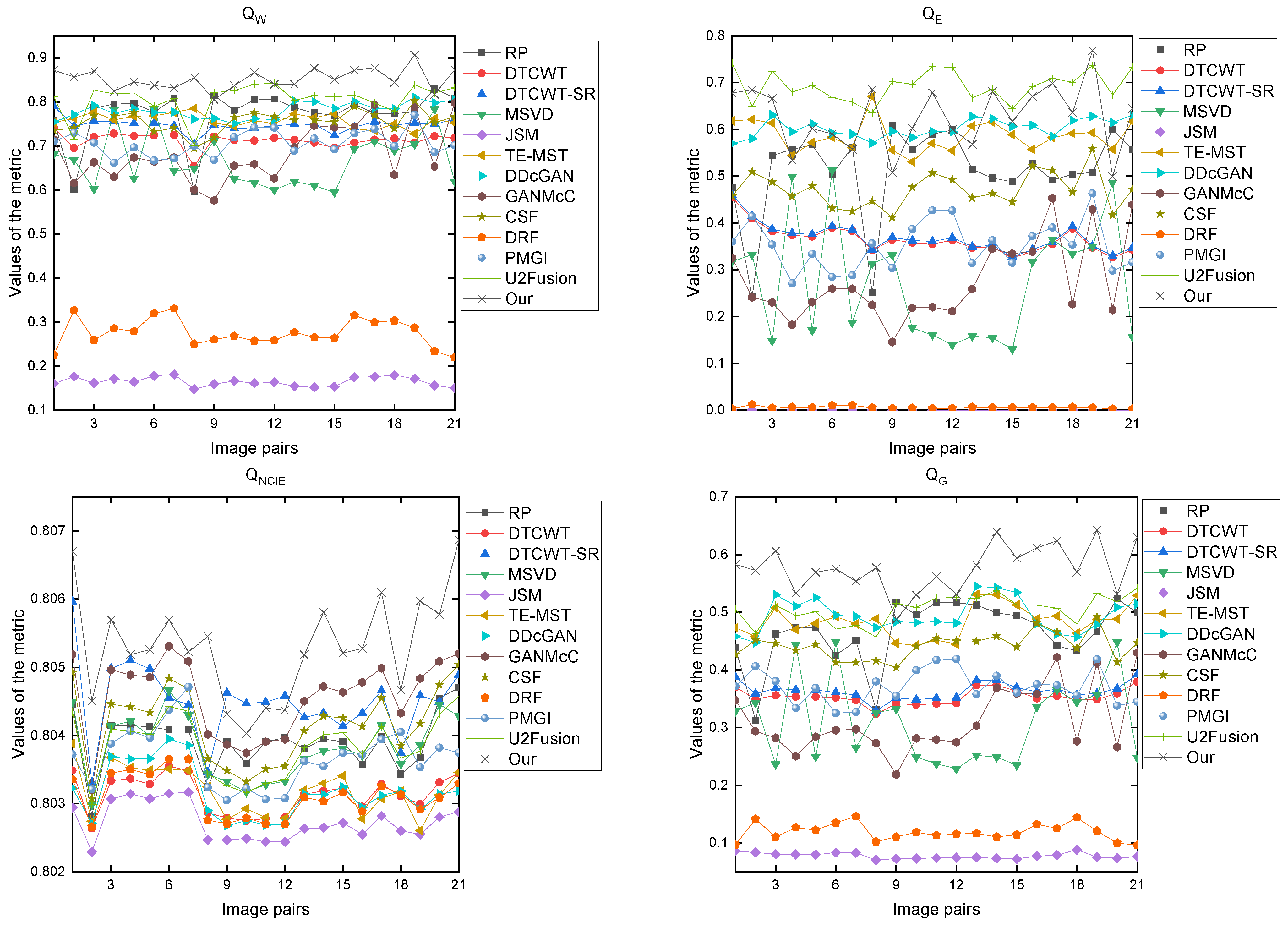
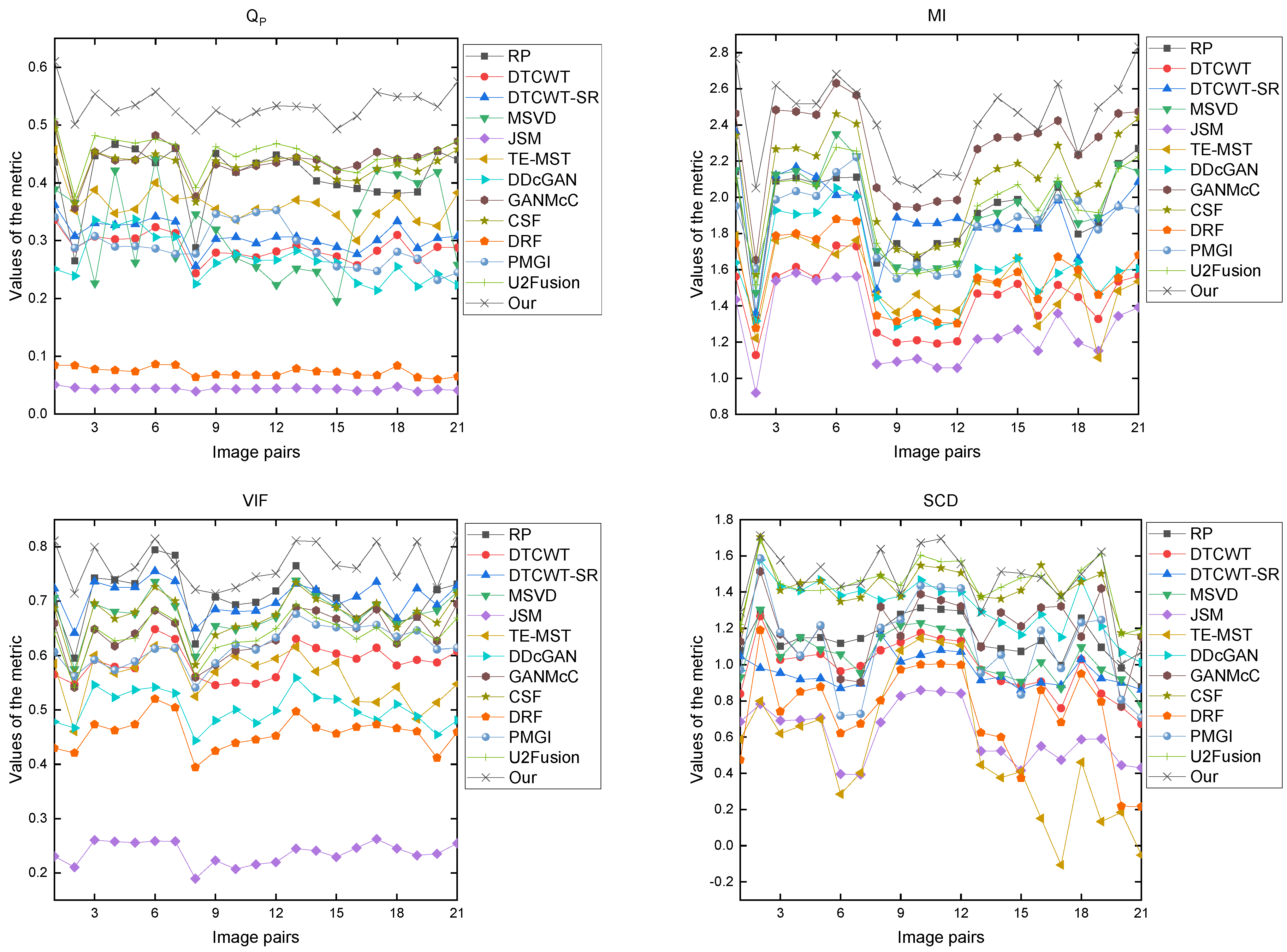
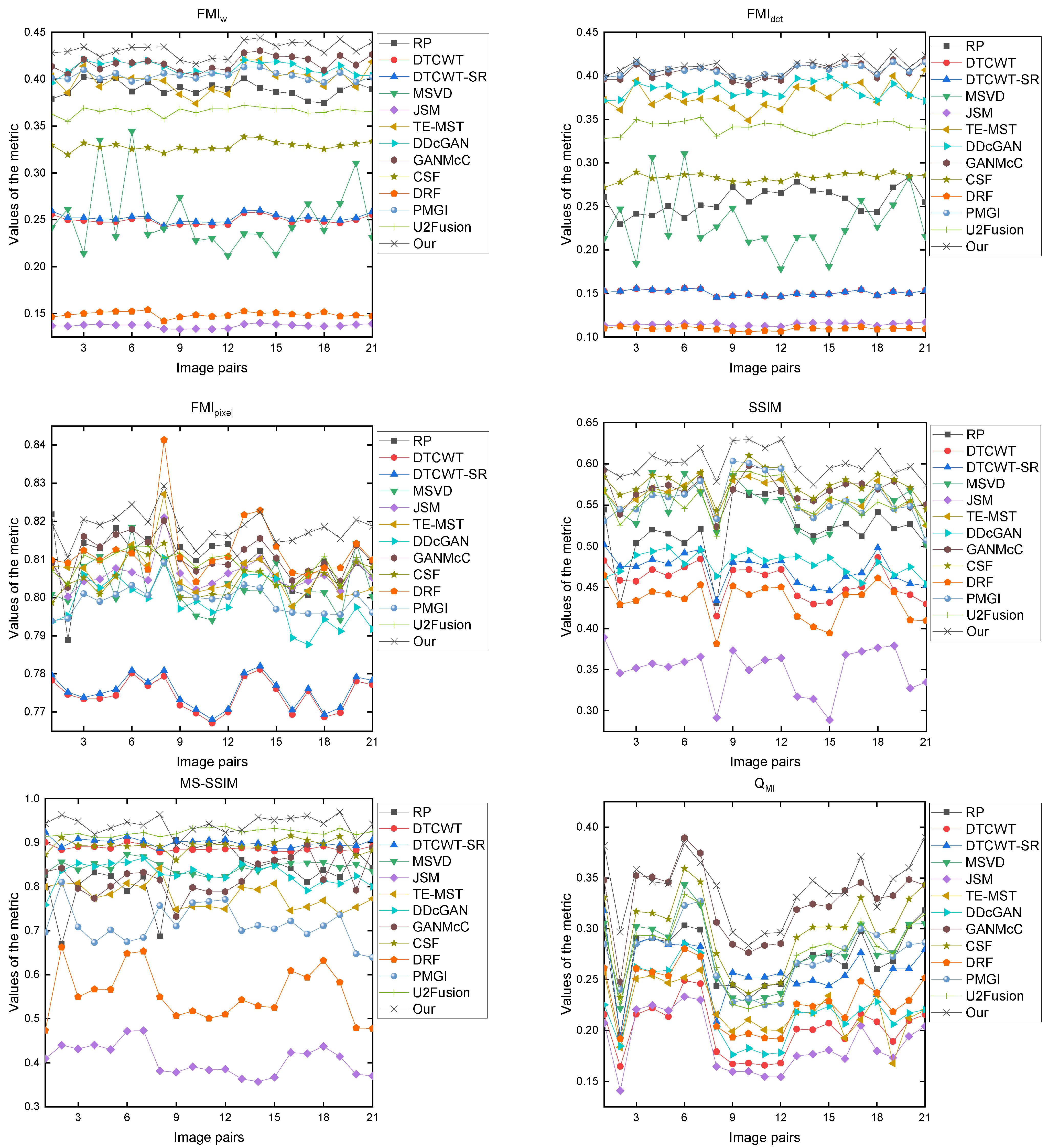
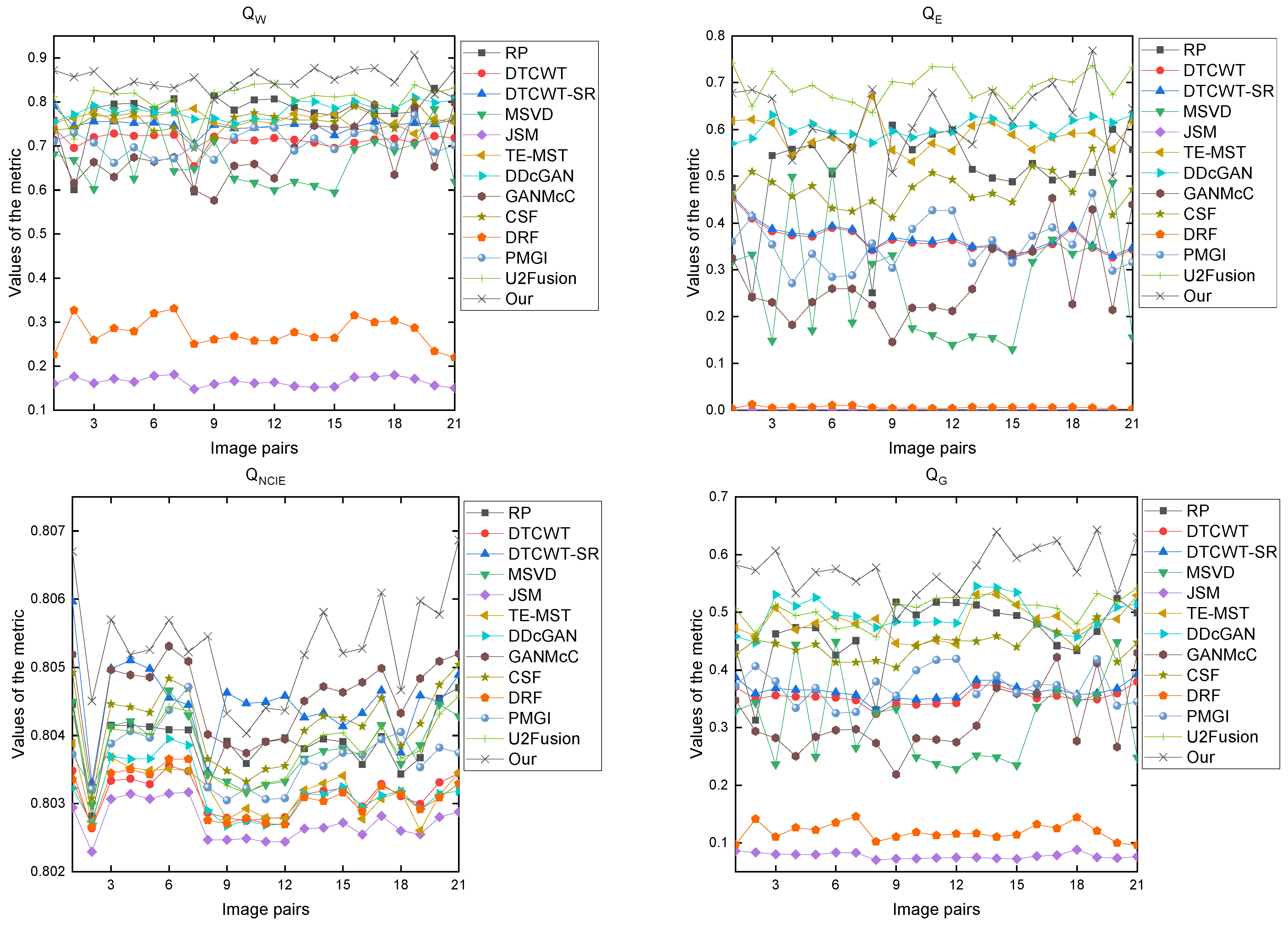
3.3. Image Fusion Evaluation
3.4. Ablation Studies
3.4.1. The Ablation Study of the Parameter in the Loss Function
3.4.2. The Skip Connection Ablation Study
3.4.3. The Multiple Scales Ablation Study
3.5. Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Estrada, A.; Garber, P.A.; Rylands, A.B.; Roos, C.; Fernandez-Duque, E.; Di Fiore, A.; Nekaris, K.A.I.; Nijman, V.; Heymann, E.W.; Lambert, J.E.; et al. Impending extinction crisis of the world’s primates: Why primates matter. Sci. Adv. 2017, 3, e1600946. [Google Scholar] [CrossRef] [PubMed]
- IUCN. The IUCN Red List of Threatened Species; Version 2019-2. 2019. Available online: http://www.iucnredlist.org (accessed on 10 July 2023).
- Zhang, Y.; Yu, J.; Lin, S.; He, J.; Xu, Y.; Tu, J.; Jiang, H. Spatiotemporal variation of anthropogenic drivers predicts the distribution dynamics of Hainan gibbon. Glob. Ecol. Conserv. 2023, 43, e02472. [Google Scholar] [CrossRef]
- Wang, X.; Wen, S.; Niu, N.; Wang, G.; Long, W.; Zou, Y.; Huang, M. Automatic detection for the world’s rarest primates based on a tropical rainforest environment. Glob. Ecol. Conserv. 2022, 38, e02250. [Google Scholar] [CrossRef]
- Turvey, S.T.; Bryant, J.V.; Duncan, C.; Wong, M.H.; Guan, Z.; Fei, H.; Ma, C.; Hong, X.; Nash, H.C.; Chan, B.P.; et al. How many remnant gibbon populations are left on Hainan? Testing the use of local ecological knowledge to detect cryptic threatened primates. Am. J. Primatol. 2017, 79, e22593. [Google Scholar] [CrossRef]
- Dufourq, E.; Durbach, I.; Hansford, J.P.; Hoepfner, A.; Ma, H.; Bryant, J.V.; Stender, C.S.; Li, W.; Liu, Z.; Chen, Q.; et al. Automated detection of Hainan gibbon calls for passive acoustic monitoring. Remote Sens. Ecol. Conserv. 2021, 7, 475–487. [Google Scholar] [CrossRef]
- Chan, B.P.L.; Lo, Y.F.P.; Hong, X.J.; Mak, C.F.; Ma, Z. First use of artificial canopy bridge by the world’s most critically endangered primate the Hainan gibbon Nomascus hainanus. Sci. Rep. 2020, 10, 15176. [Google Scholar] [CrossRef]
- Rahman, D.A.; Sitorus, A.B.Y.; Condro, A.A. From Coastal to Montane Forest Ecosystems, Using Drones for Multi-Species Research in the Tropics. Drones 2021, 6, 6. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, C.; Turvey, S.T.; Sun, Z.; Tan, Z.; Yang, Q.; Long, W.; Wu, X.; Yang, D. Thermal infrared imaging from drones can detect individuals and nocturnal behavior of the world’s rarest primate. Glob. Ecol. Conserv. 2020, 23, e01101. [Google Scholar] [CrossRef]
- Degollada, E.; Amigó, N.; O’Callaghan, S.A.; Varola, M.; Ruggero, K.; Tort, B. A Novel Technique for Photo-Identification of the Fin Whale, Balaenoptera physalus, as Determined by Drone Aerial Images. Drones 2023, 7, 220. [Google Scholar] [CrossRef]
- Jiménez-Torres, M.; Silva, C.P.; Riquelme, C.; Estay, S.A.; Soto-Gamboa, M. Automatic Recognition of Black-Necked Swan (Cygnus melancoryphus) from Drone Imagery. Drones 2023, 7, 71. [Google Scholar] [CrossRef]
- Povlsen, P.; Linder, A.C.; Larsen, H.L.; Durdevic, P.; Arroyo, D.O.; Bruhn, D.; Pertoldi, C.; Pagh, S. Using Drones with Thermal Imaging to Estimate Population Counts of European Hare (Lepus europaeus) in Denmark. Drones 2022, 7, 5. [Google Scholar] [CrossRef]
- Keshet, D.; Brook, A.; Malkinson, D.; Izhaki, I.; Charter, M. The Use of Drones to Determine Rodent Location and Damage in Agricultural Crops. Drones 2022, 6, 396. [Google Scholar] [CrossRef]
- Zhang, A.; Li, Z.; Zang, R.; Liu, S.; Long, W.; Chen, Y.; Liu, S.; Liu, H.; Qi, X.; Feng, Y.; et al. Food plant diversity in different-altitude habitats of Hainan gibbons (Nomascus hainanus): Implications for conservation. Glob. Ecol. Conserv. 2022, 38, e02204. [Google Scholar] [CrossRef]
- Du, Y.; Li, D.; Yang, X.; Peng, D.; Tang, X.; Liu, H.; Li, D.; Hong, X.; Song, X. Reproductive phenology and its drivers in a tropical rainforest national park in China: Implications for Hainan gibbon (Nomascus hainanus) conservation. Glob. Ecol. Conserv. 2020, 24, e01317. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2020, 70, 1–14. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12797–12804. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Ma, J. Classification saliency-based rule for visible and infrared image fusion. IEEE Trans. Comput. Imaging 2021, 7, 824–836. [Google Scholar] [CrossRef]
- Xu, H.; Wang, X.; Ma, J. DRF: Disentangled representation for visible and infrared image fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Li, S.; Zou, Y.; Wang, G.; Lin, C. Infrared and visible image fusion method based on principal component analysis network and multi-scale morphological gradient. Infrared Phys. Technol. 2023, 133, 104810. [Google Scholar] [CrossRef]
- Li, S.; Zou, Y.; Wang, G.; Lin, C. Infrared and Visible Image Fusion Method Based on a Principal Component Analysis Network and Image Pyramid. Remote Sens. 2023, 15, 685. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the Computer Vision—ECCV 2022 Workshops, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Long, W.; Zang, R.; Ding, Y. Air temperature and soil phosphorus availability correlate with trait differences between two types of tropical cloud forests. Flora-Morphol. Distrib. Funct. Ecol. Plants 2011, 206, 896–903. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Shao, W.; Li, H.; Zhang, L. SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images. arXiv 2022, arXiv:2204.11436. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference of the Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, H.; Turvey, S.T.; Pandey, S.P.; Song, X.; Sun, Z.; Wang, N. Commercial drones can provide accurate and effective monitoring of the world’s rarest primate. Remote Sens. Ecol. Conserv. 2023. early view. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. RIFT: Multi-modal image matching based on radiation-variation insensitive feature transform. IEEE Trans. Image Process. 2019, 29, 3296–3310. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Haghighat, M.; Razian, M.A. Fast-FMI: Non-reference image fusion metric. In Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), Astana, Kazakhstan, 15–17 October 2014; pp. 1–3. [Google Scholar]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 2015, 24, 3345–3356. [Google Scholar] [CrossRef]
- Hossny, M.; Nahavandi, S.; Creighton, D. Comments on ’Information measure for performance of image fusion’. Electron. Lett. 2008, 44, 1066–1067. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, J.Q.; Wang, X.R.; Liu, X. A novel similarity based quality metric for image fusion. Inf. Fusion 2008, 9, 156–160. [Google Scholar] [CrossRef]
- Piella, G.; Heijmans, H. A new quality metric for image fusion. In Proceedings of the 2003 International Conference on Image Processing (Cat. No. 03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 3, p. III–173. [Google Scholar]
- Wang, Q.; Shen, Y.; Jin, J. Performance evaluation of image fusion techniques. Image Fusion Algorithms Appl. 2008, 19, 469–492. [Google Scholar]
- Xydeas, C.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Zhao, J.; Laganiere, R.; Liu, Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. Int. J. Innov. Comput. Inf. Control 2007, 3, 1433–1447. [Google Scholar]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 1. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef]
- Aslantas, V.; Bendes, E. A new image quality metric for image fusion: The sum of the correlations of differences. Aeu-Int. J. Electron. Commun. 2015, 69, 1890–1896. [Google Scholar] [CrossRef]
- Toet, A. Image fusion by a ratio of low-pass pyramid. Pattern Recognit. Lett. 1989, 9, 245–253. [Google Scholar] [CrossRef]
- Lewis, J.J.; O’Callaghan, R.J.; Nikolov, S.G.; Bull, D.R.; Canagarajah, N. Pixel-and region-based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Naidu, V. Image fusion technique using multi-resolution singular value decomposition. Def. Sci. J. 2011, 61, 479. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, C. Texture clear multi-modal image fusion with joint sparsity model. Optik 2017, 130, 255–265. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 0.3626 | 0.3797 | 0.7980 | 0.5551 | 0.8501 | 0.2760 | 0.6625 | 0.6900 | 0.7161 | 0.3621 | 0.8038 | 0.3258 | 0.3807 | 1.9280 | 0.6557 | 1.2981 |
| 100 | 0.4239 | 0.4017 | 0.8107 | 0.5924 | 0.9073 | 0.3153 | 0.7989 | 0.7868 | 0.8005 | 0.5066 | 0.8047 | 0.5254 | 0.4934 | 2.2362 | 0.7199 | 1.2902 |
| 1000 | 0.4317 | 0.4100 | 0.8185 | 0.6010 | 0.9413 | 0.3396 | 0.8494 | 0.8210 | 0.8523 | 0.6272 | 0.8053 | 0.5765 | 0.5339 | 2.4336 | 0.7677 | 1.4630 |
| 10,000 | 0.4175 | 0.3932 | 0.8077 | 0.5927 | 0.9158 | 0.3200 | 0.8198 | 0.7990 | 0.8167 | 0.5386 | 0.8048 | 0.5416 | 0.4907 | 2.2820 | 0.7315 | 1.3487 |
| Method | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Without skip connection | 0.1850 | 0.1439 | 0.7845 | 0.4875 | 0.7958 | 0.2169 | 0.5471 | 0.5999 | 0.6010 | 0.1656 | 0.8031 | 0.2320 | 0.1535 | 1.4842 | 0.5467 | 0.6338 |
| Skip connection | 0.4317 | 0.4100 | 0.8185 | 0.6010 | 0.9413 | 0.3396 | 0.8494 | 0.8210 | 0.8523 | 0.6272 | 0.8053 | 0.5765 | 0.5339 | 2.4336 | 0.7677 | 1.4630 |
| Method | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Without multiple scales | 0.4362 | 0.4115 | 0.8143 | 0.6045 | 0.9156 | 0.3479 | 0.7997 | 0.7859 | 0.8006 | 0.5216 | 0.8052 | 0.5221 | 0.5066 | 2.4631 | 0.7185 | 1.3999 |
| Multiple scales | 0.4317 | 0.4100 | 0.8185 | 0.6010 | 0.9413 | 0.3396 | 0.8494 | 0.8210 | 0.8523 | 0.6272 | 0.8053 | 0.5765 | 0.5339 | 2.4336 | 0.7677 | 1.4630 |
| Method | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP | 0.3896 | 0.2567 | 0.8094 | 0.5200 | 0.8309 | 0.2714 | 0.7453 | 0.7059 | 0.7721 | 0.5118 | 0.8039 | 0.4649 | 0.4132 | 1.9215 | 0.7074 | 1.1432 |
| DTCWT | 0.2496 | 0.1511 | 0.7745 | 0.4567 | 0.8877 | 0.2007 | 0.6694 | 0.6612 | 0.7133 | 0.3651 | 0.8031 | 0.3536 | 0.2887 | 1.4343 | 0.5872 | 0.9799 |
| DTCWT-SR | 0.2522 | 0.1512 | 0.7755 | 0.4718 | 0.9005 | 0.2606 | 0.7169 | 0.6969 | 0.7480 | 0.3691 | 0.8045 | 0.3636 | 0.3095 | 1.9059 | 0.7066 | 0.9616 |
| MSVD | 0.2519 | 0.2303 | 0.8030 | 0.5500 | 0.8446 | 0.2772 | 0.6425 | 0.6784 | 0.6673 | 0.2734 | 0.8038 | 0.3107 | 0.3213 | 1.9276 | 0.6768 | 1.0470 |
| JSM | 0.1370 | 0.1147 | 0.8062 | 0.3496 | 0.4070 | 0.1872 | 0.1993 | 0.2764 | 0.1646 | 0.0002 | 0.8027 | 0.0774 | 0.0435 | 1.2778 | 0.2369 | 0.6169 |
| TE-MST | 0.3997 | 0.3767 | 0.8061 | 0.5605 | 0.7792 | 0.2208 | 0.7934 | 0.7611 | 0.7587 | 0.5860 | 0.8032 | 0.4837 | 0.3614 | 1.5199 | 0.5611 | 0.5390 |
| DDcGAN | 0.4116 | 0.3830 | 0.7988 | 0.4787 | 0.8285 | 0.2203 | 0.7916 | 0.7212 | 0.7808 | 0.6027 | 0.8032 | 0.4945 | 0.2660 | 1.6030 | 0.5017 | 1.3101 |
| GANMcC | 0.4170 | 0.4050 | 0.8110 | 0.5673 | 0.8240 | 0.3260 | 0.6634 | 0.6891 | 0.6833 | 0.2757 | 0.8046 | 0.3131 | 0.4395 | 2.2785 | 0.6397 | 1.1982 |
| CSF | 0.3286 | 0.2834 | 0.8051 | 0.5766 | 0.8934 | 0.2976 | 0.7233 | 0.7287 | 0.7559 | 0.4710 | 0.8042 | 0.4419 | 0.4305 | 2.0935 | 0.6726 | 1.4168 |
| DRF | 0.1492 | 0.1095 | 0.8123 | 0.4332 | 0.5559 | 0.2301 | 0.3474 | 0.3636 | 0.2756 | 0.0057 | 0.8031 | 0.1188 | 0.0729 | 1.5634 | 0.4572 | 0.7395 |
| PMGI | 0.4036 | 0.4065 | 0.7994 | 0.5574 | 0.7134 | 0.2724 | 0.7021 | 0.7022 | 0.7066 | 0.3521 | 0.8037 | 0.3715 | 0.2906 | 1.8591 | 0.6162 | 1.1040 |
| U2Fusion | 0.3662 | 0.3414 | 0.8085 | 0.5558 | 0.9234 | 0.2775 | 0.7544 | 0.7406 | 0.8064 | 0.6934 | 0.8039 | 0.5057 | 0.4512 | 1.9436 | 0.6375 | 1.4455 |
| Our | 0.4317 | 0.4100 | 0.8185 | 0.6010 | 0.9413 | 0.3396 | 0.8494 | 0.8210 | 0.8523 | 0.6272 | 0.8053 | 0.5765 | 0.5339 | 2.4336 | 0.7677 | 1.4630 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Wang, G.; Zhang, H.; Zou, Y. Observing Individuals and Behavior of Hainan Gibbons (Nomascus hainanus) Using Drone Infrared and Visible Image Fusion Technology. Drones 2023, 7, 543. https://doi.org/10.3390/drones7090543
Li S, Wang G, Zhang H, Zou Y. Observing Individuals and Behavior of Hainan Gibbons (Nomascus hainanus) Using Drone Infrared and Visible Image Fusion Technology. Drones. 2023; 7(9):543. https://doi.org/10.3390/drones7090543
Chicago/Turabian StyleLi, Shengshi, Guanjun Wang, Hui Zhang, and Yonghua Zou. 2023. "Observing Individuals and Behavior of Hainan Gibbons (Nomascus hainanus) Using Drone Infrared and Visible Image Fusion Technology" Drones 7, no. 9: 543. https://doi.org/10.3390/drones7090543
APA StyleLi, S., Wang, G., Zhang, H., & Zou, Y. (2023). Observing Individuals and Behavior of Hainan Gibbons (Nomascus hainanus) Using Drone Infrared and Visible Image Fusion Technology. Drones, 7(9), 543. https://doi.org/10.3390/drones7090543