




Multi-UAV Roundup Inspired by Hierarchical Cognition Consistency Learning Based on an Interaction Mechanism


Abstract
1. Introduction
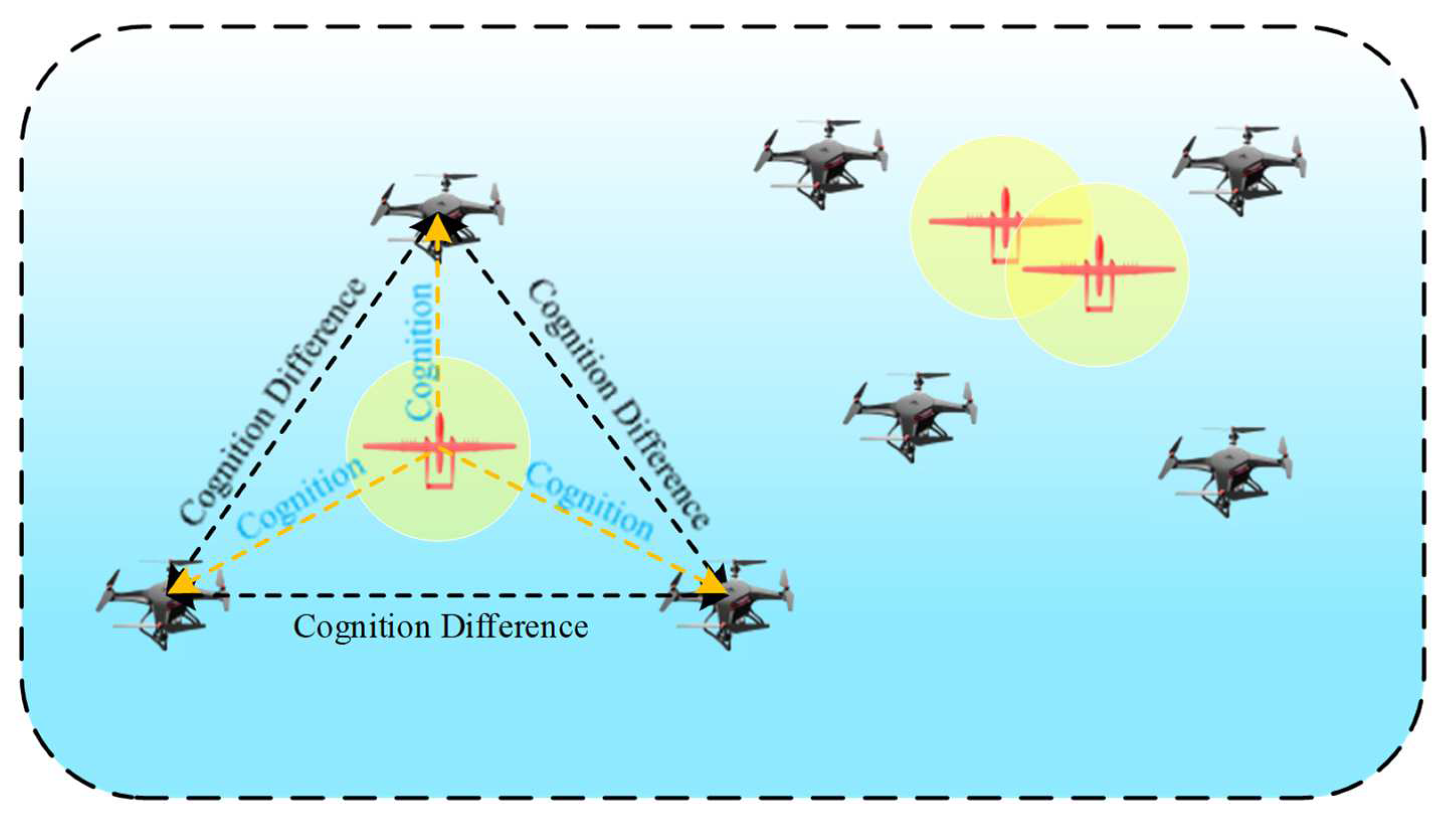
- We model the multi-target roundup problem based on neighborhood consistency theory to promote cognitive consistency during group tasks and realize coordinated behavior among predators.
- We propose a novel communication framework for MARL to explicitly quantify the information effectiveness among UAVs using graph attention neural networks; this is more in line with the information exchange that occurs in multi-agent systems. This is also the main innovation of this work, as previous methods of information interaction have been mainly based on a preset non-time-varying communication topology established at the beginning of the task.
- Unlike in previous studies, which have mostly focused on single-target roundup tasks, extensive experiments are conducted in the scenario of multitarget roundup to verify the superiority of our proposed method and the effectiveness of the components of the proposed model.
2. Related Work
2.1. Multi-Target Roundup
2.2. Multi-Agent Reinforcement Learning with Communication
2.3. Multi-Agent Communication with a Graph Attention Network Mechanism
3. Preliminaries
3.1. Partially Observable Markov Decision Process (POMDP)
3.2. Graph Attention Network (GAT)
4. Methodology
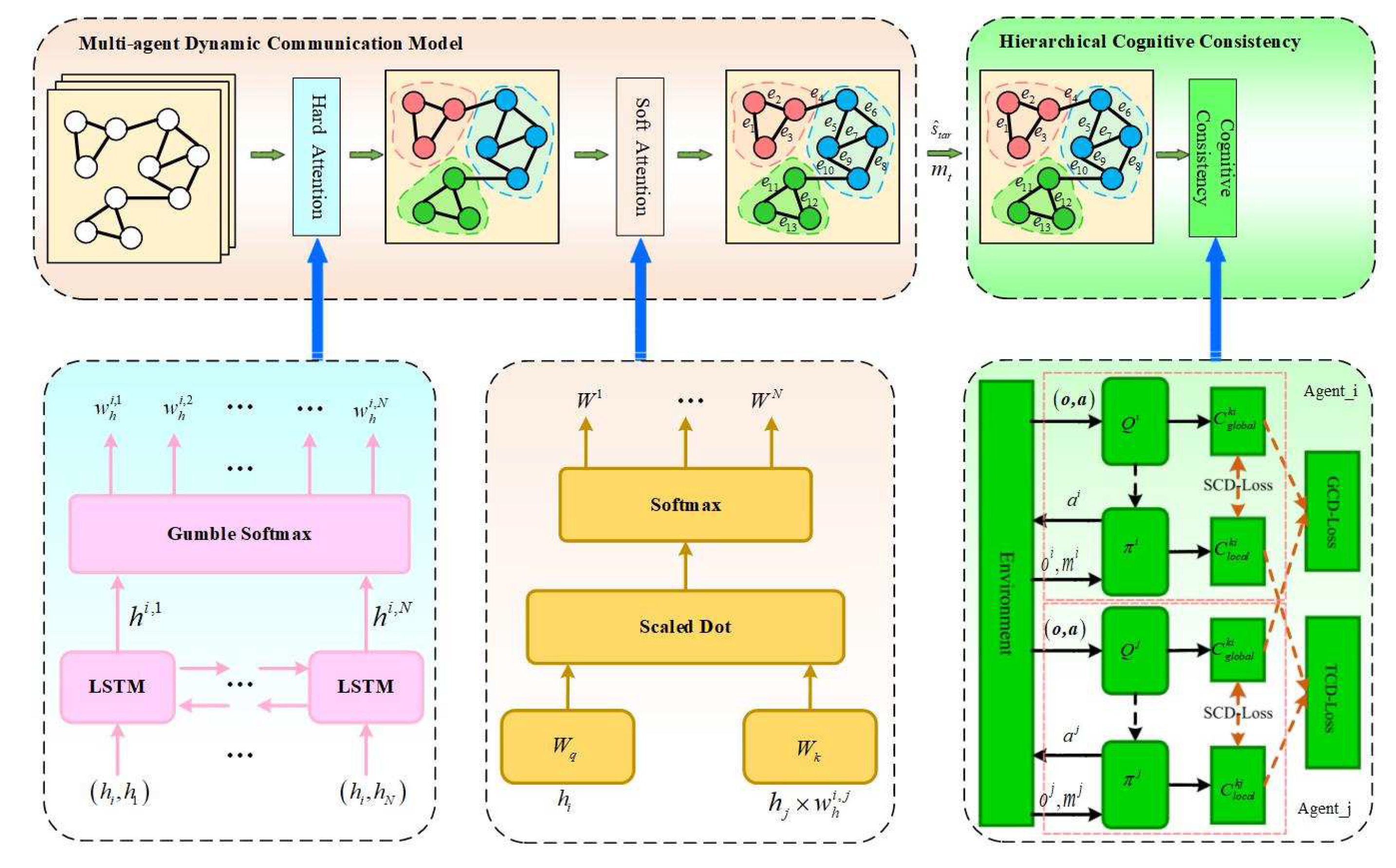
4.1. Overall Structure and Training Method
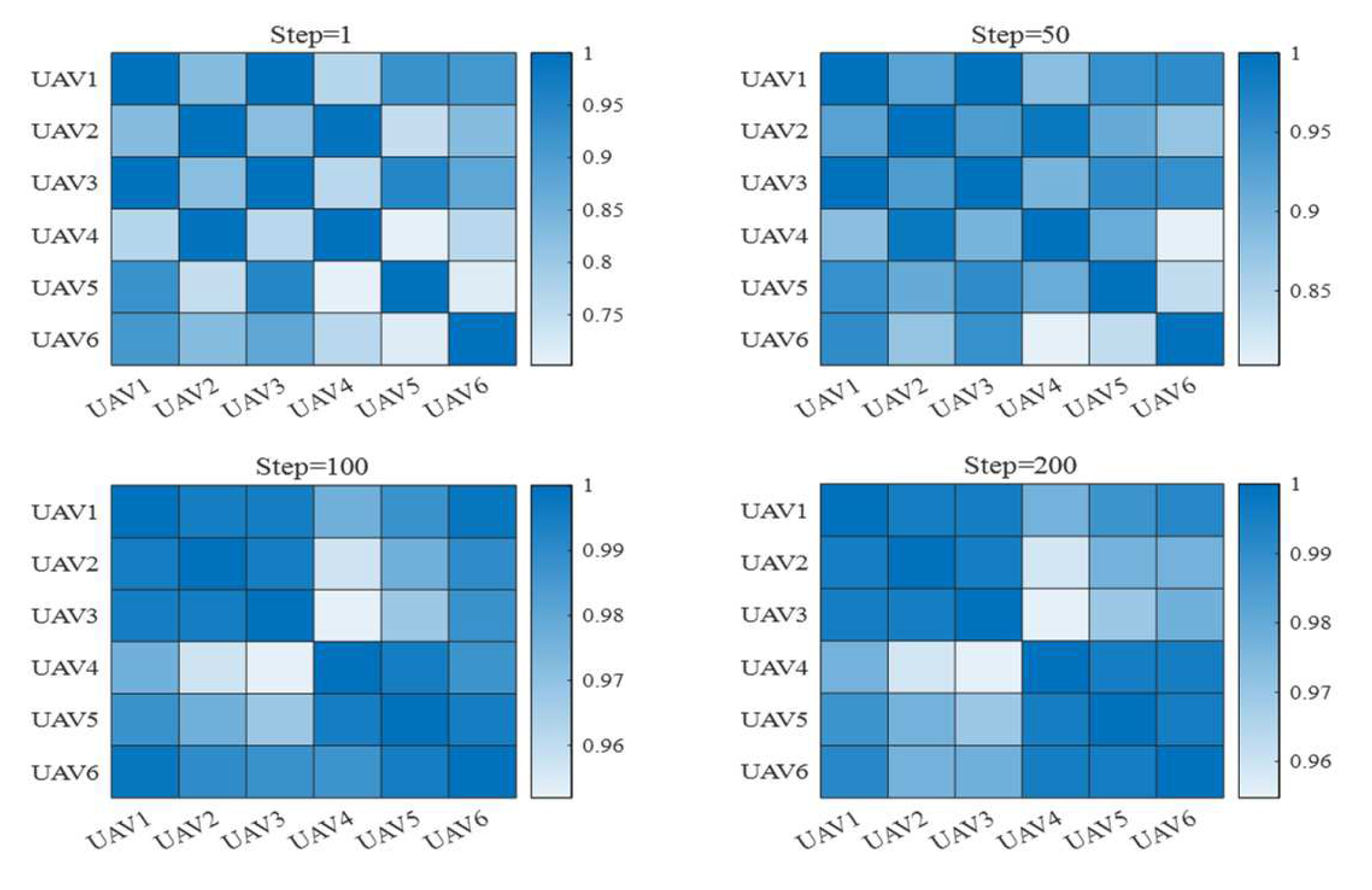
4.2. Multi-Agent Dynamic Communication Model
4.3. Hierarchical Cognitive Consistency Model
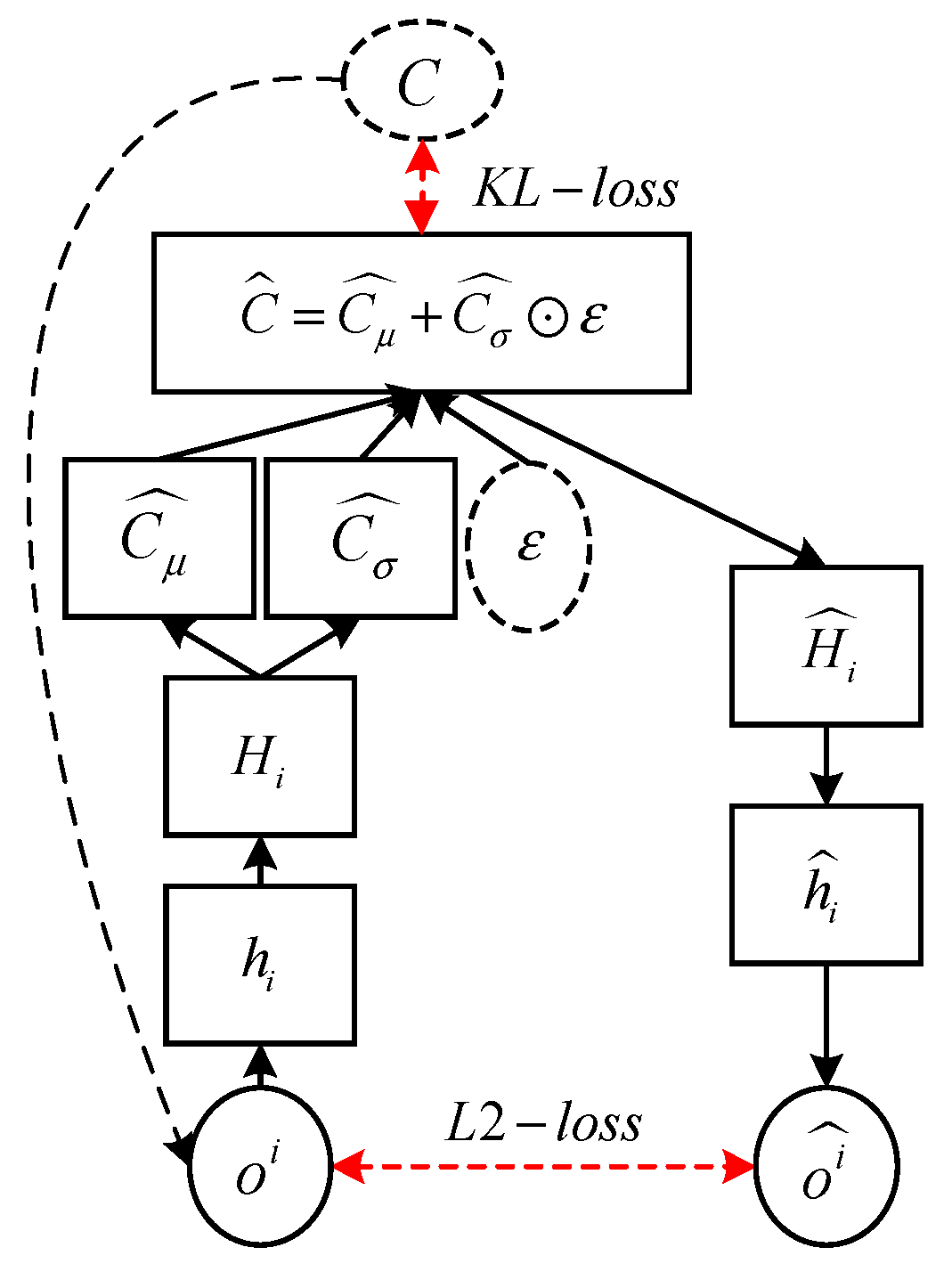
4.3.1. Consistency through Self-Supervised Learning
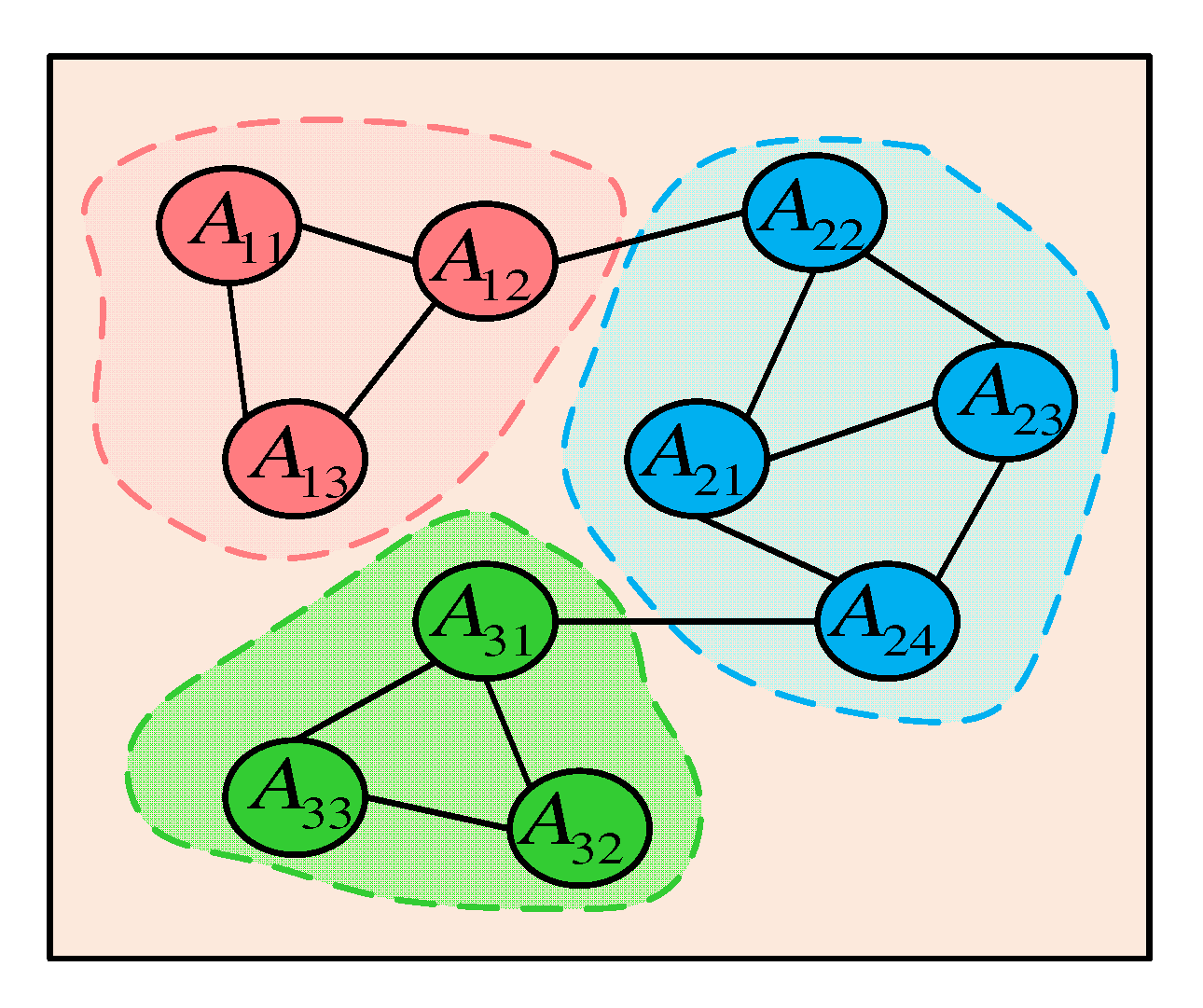
4.3.2. Consistency through Aligning Teammates in a Group
4.3.3. Consistency through Global Task Cognition
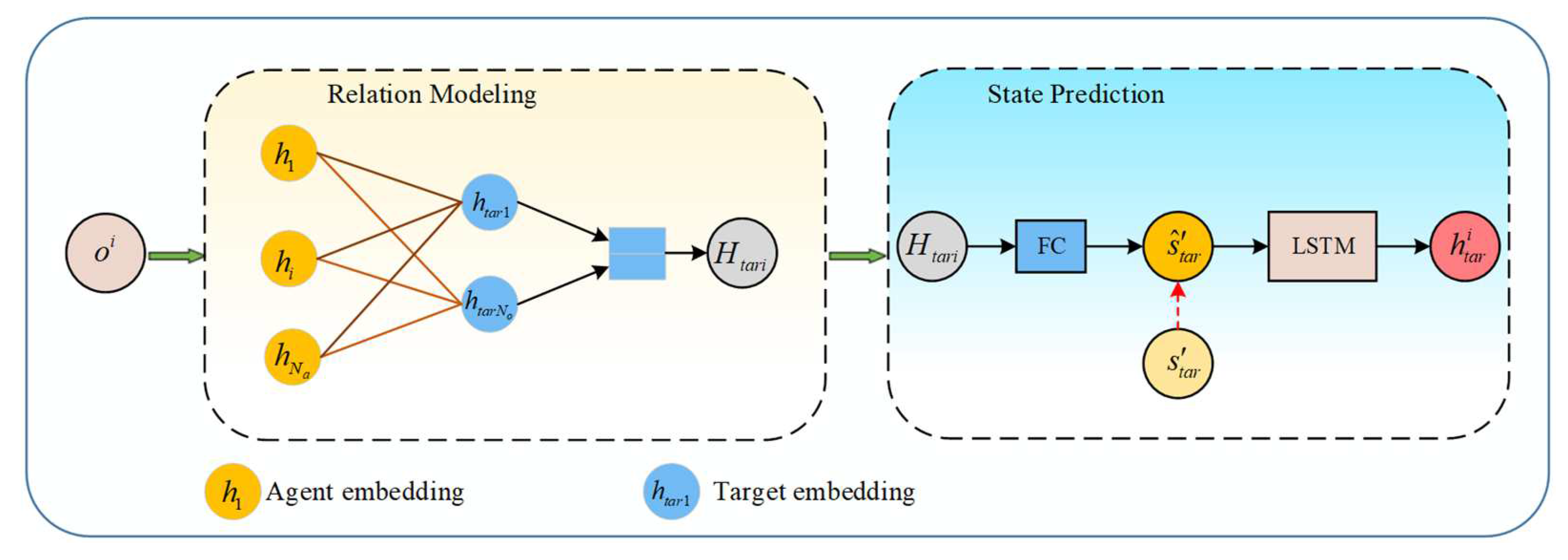
4.4. Opponent Graph Reasoning
5. Simulations
5.1. Experimental Setting and Baselines
5.1.1. Motion Model of a UAV
5.1.2. Extrinsic Reward Function
5.1.3. Baselines
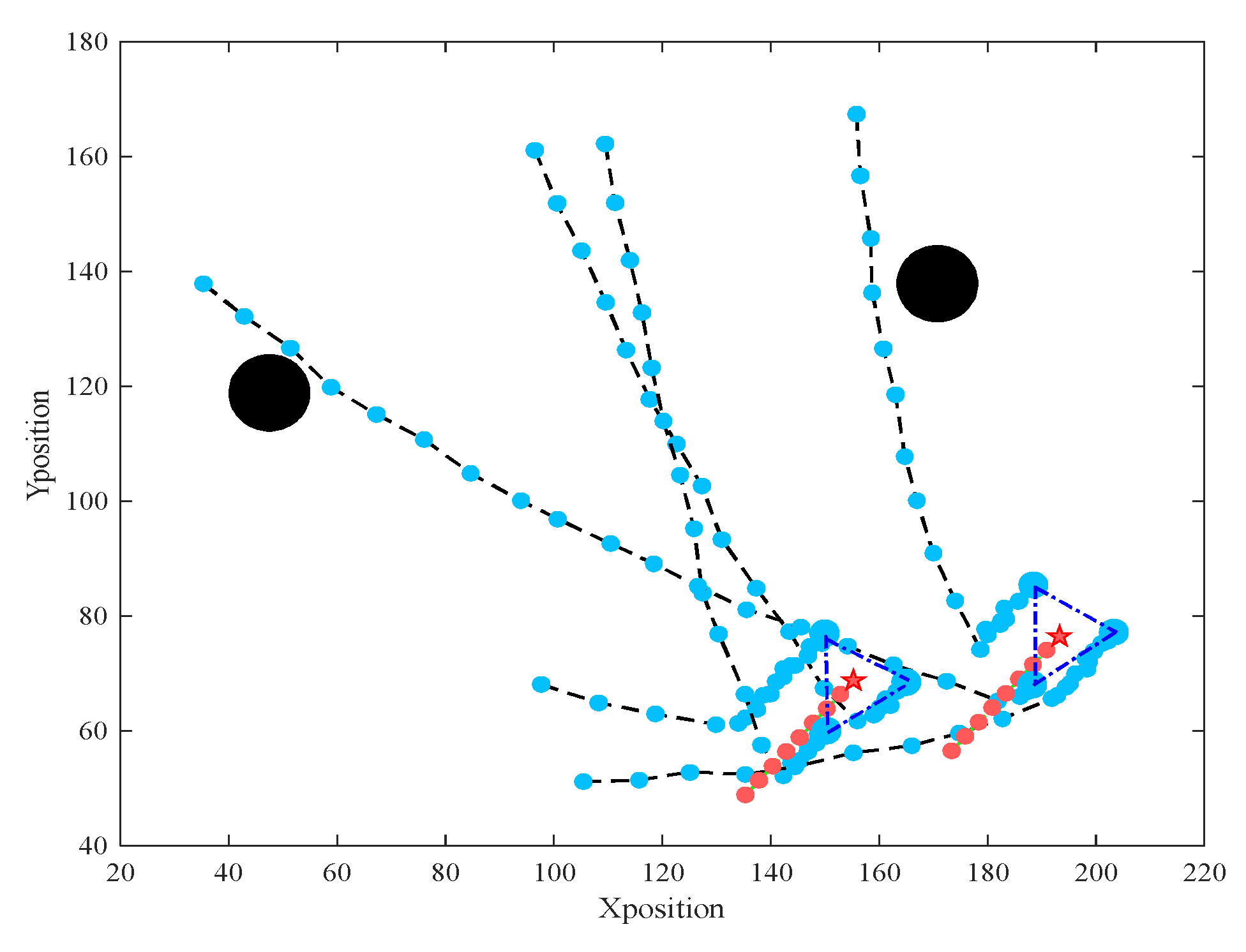
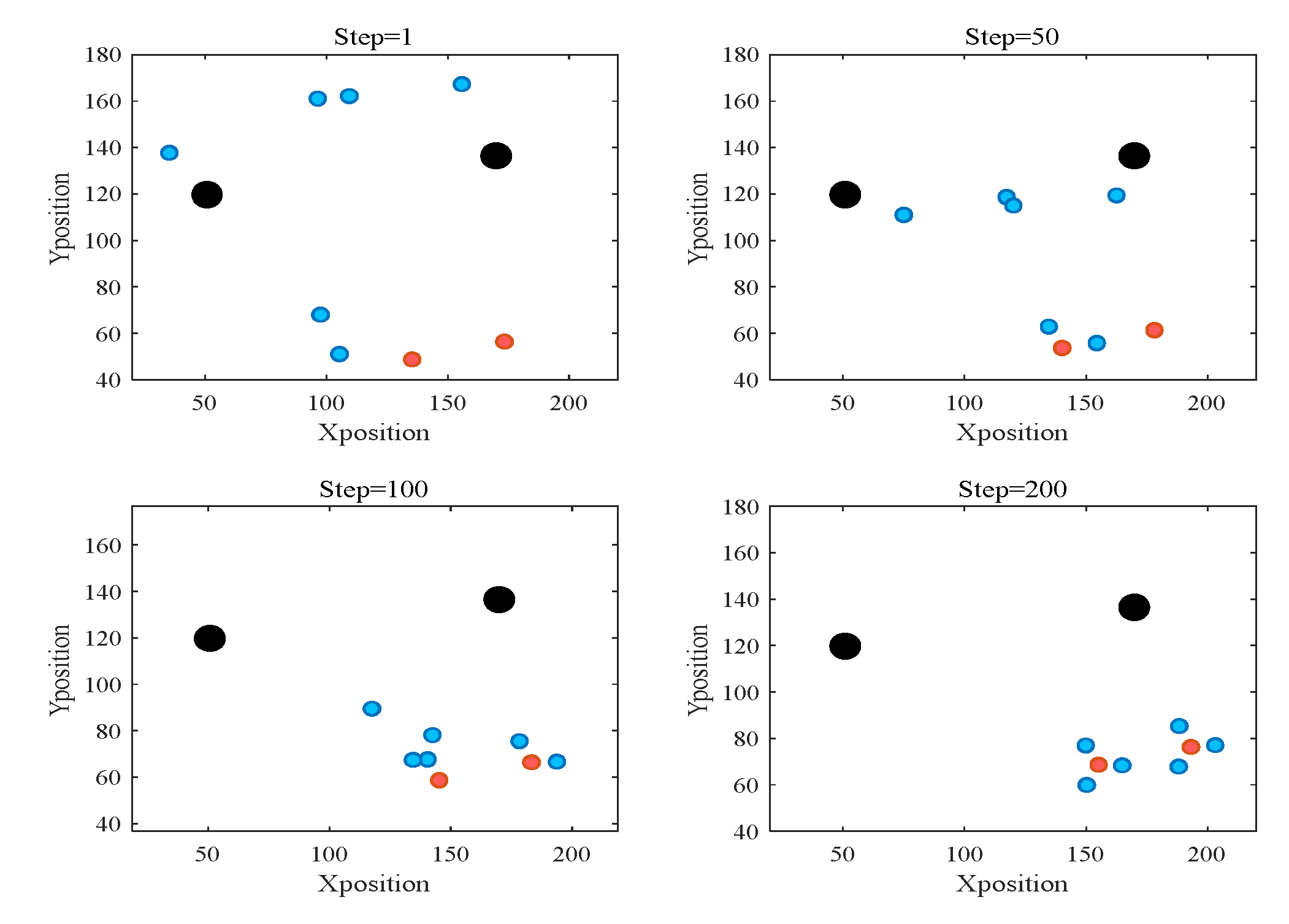
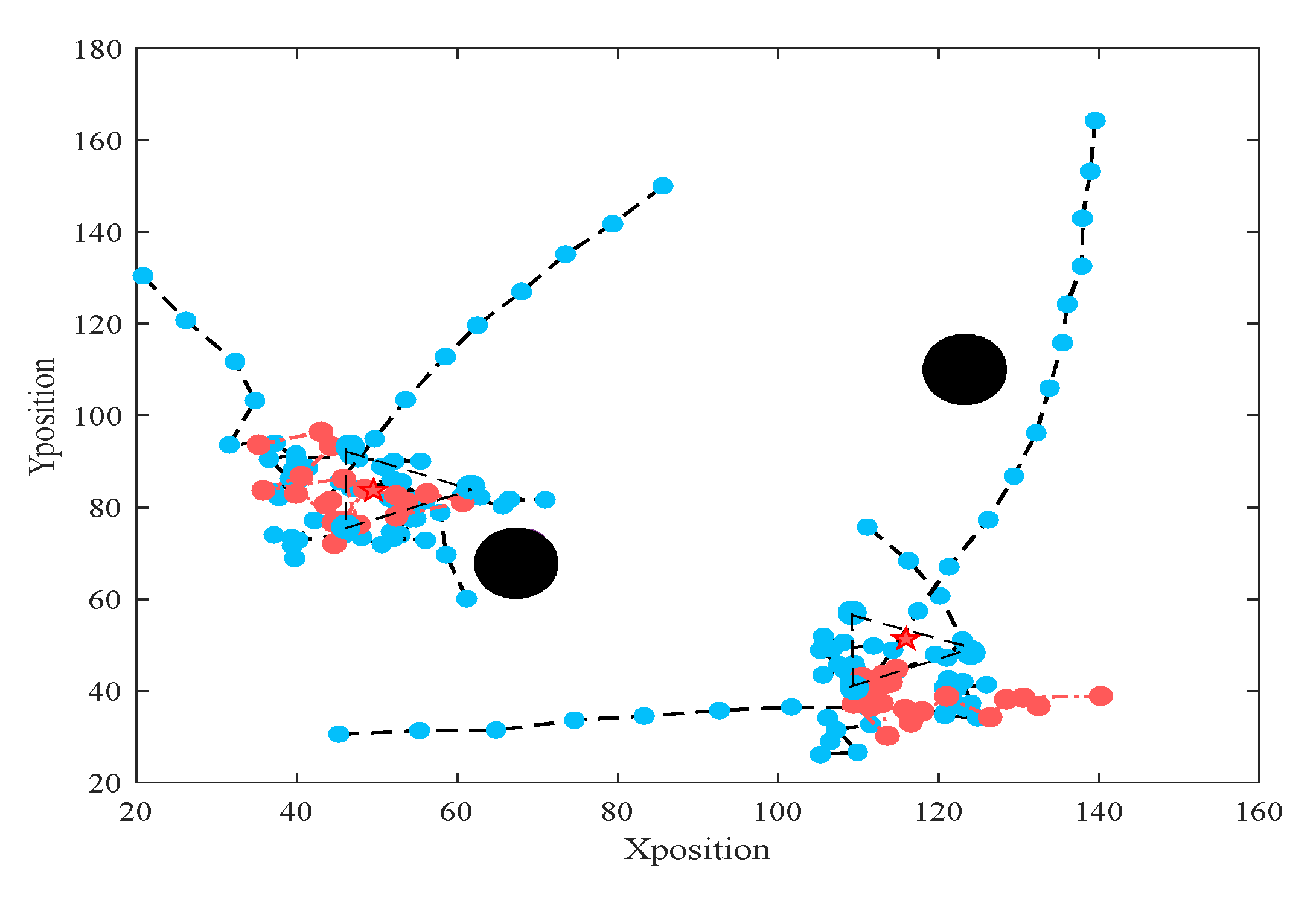
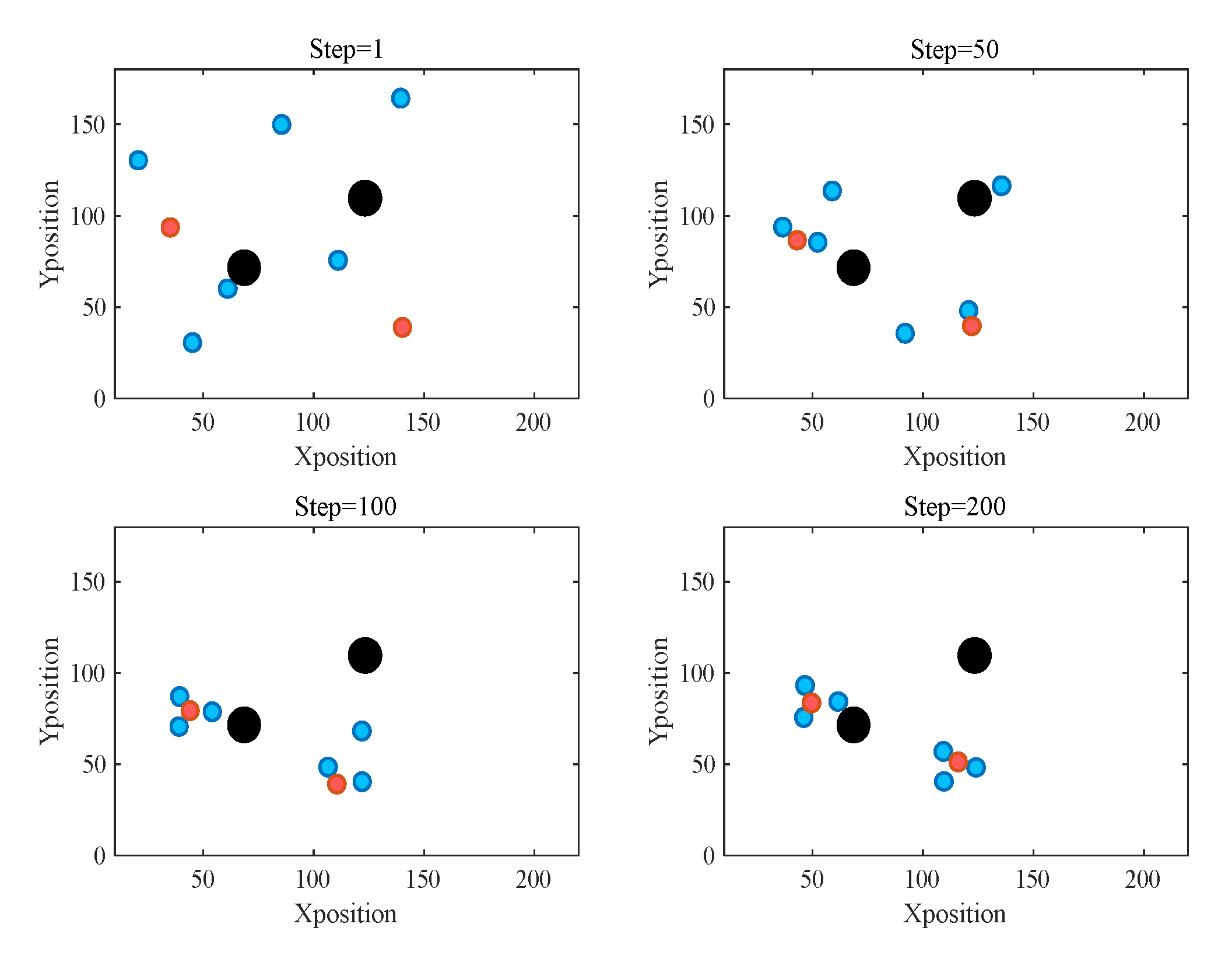
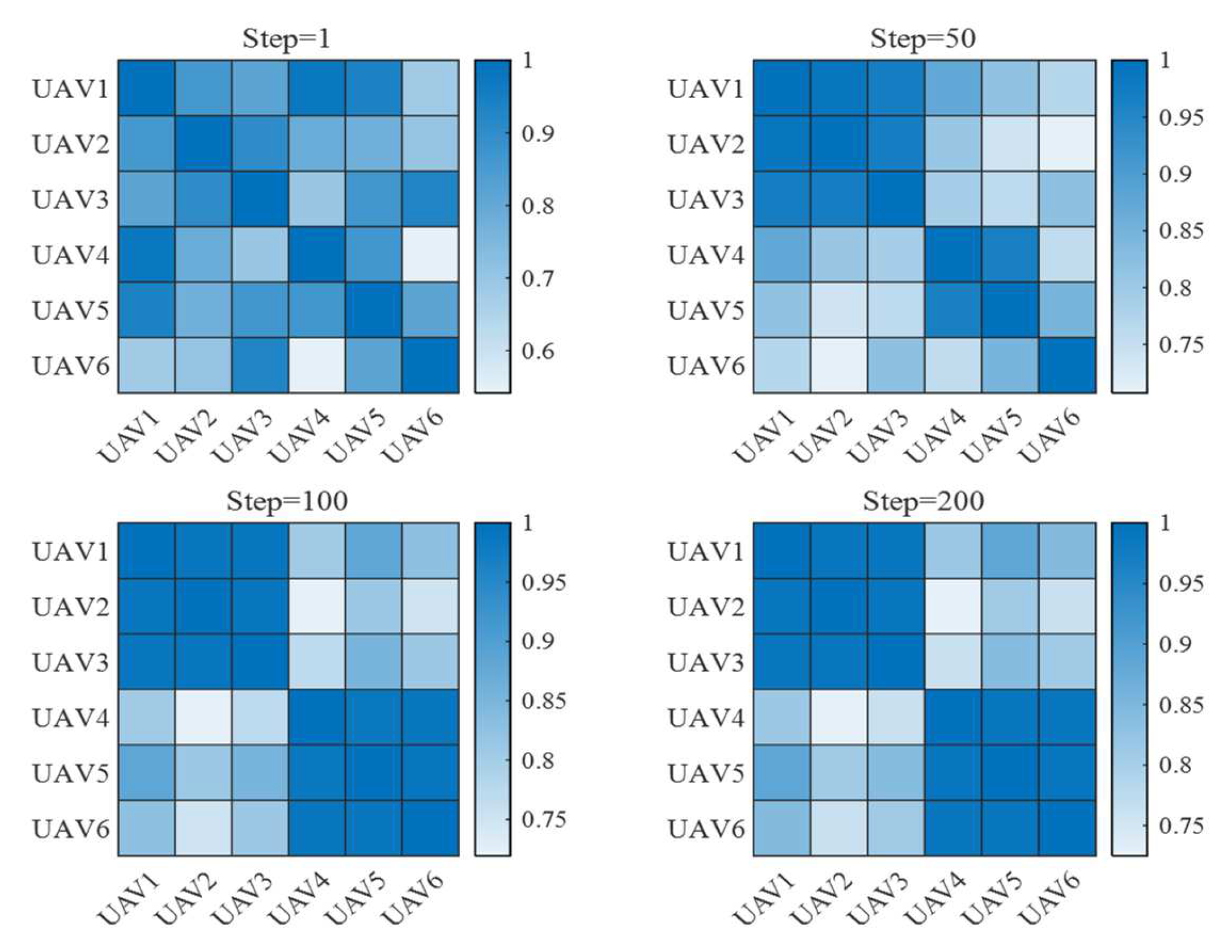
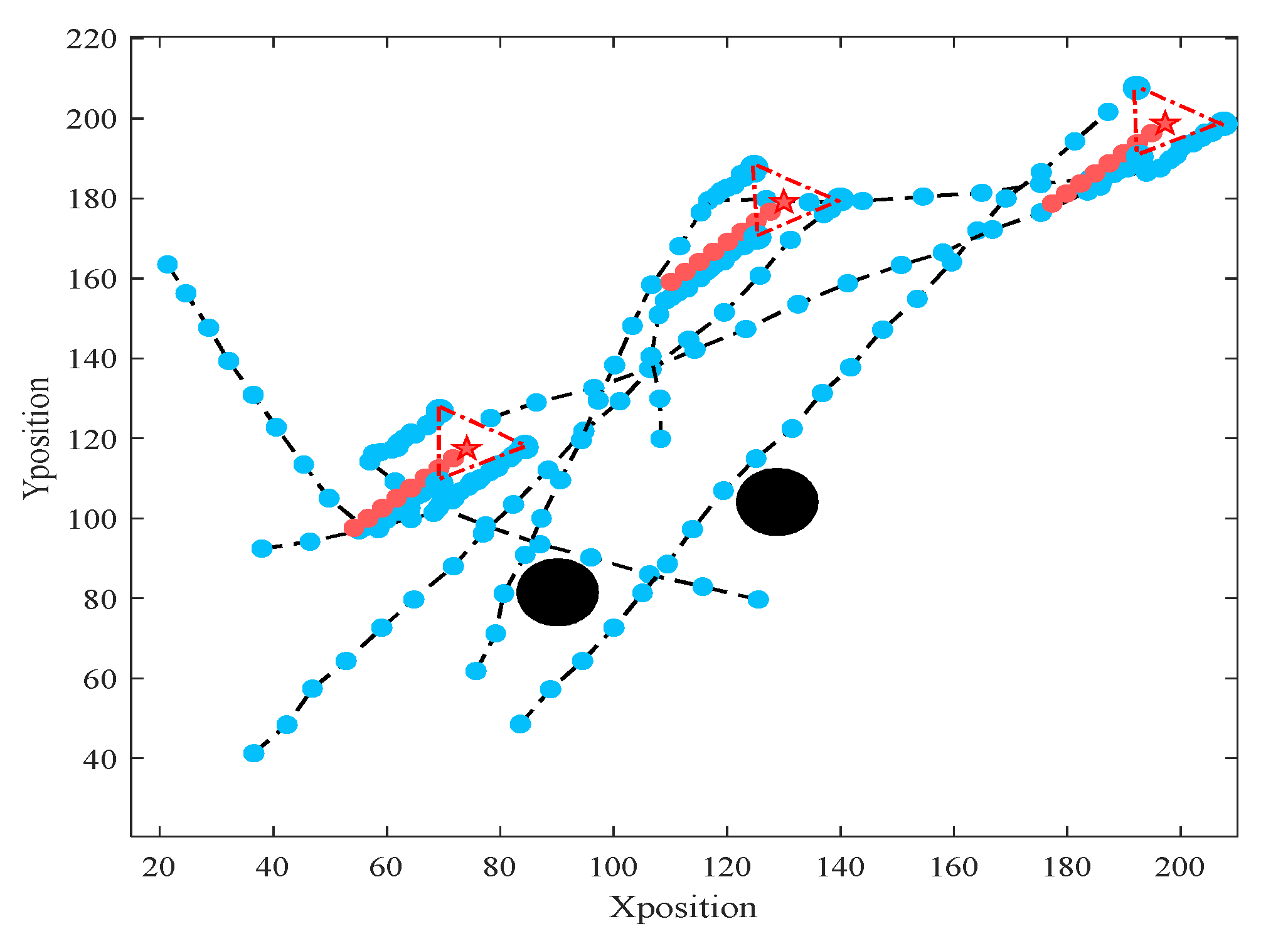
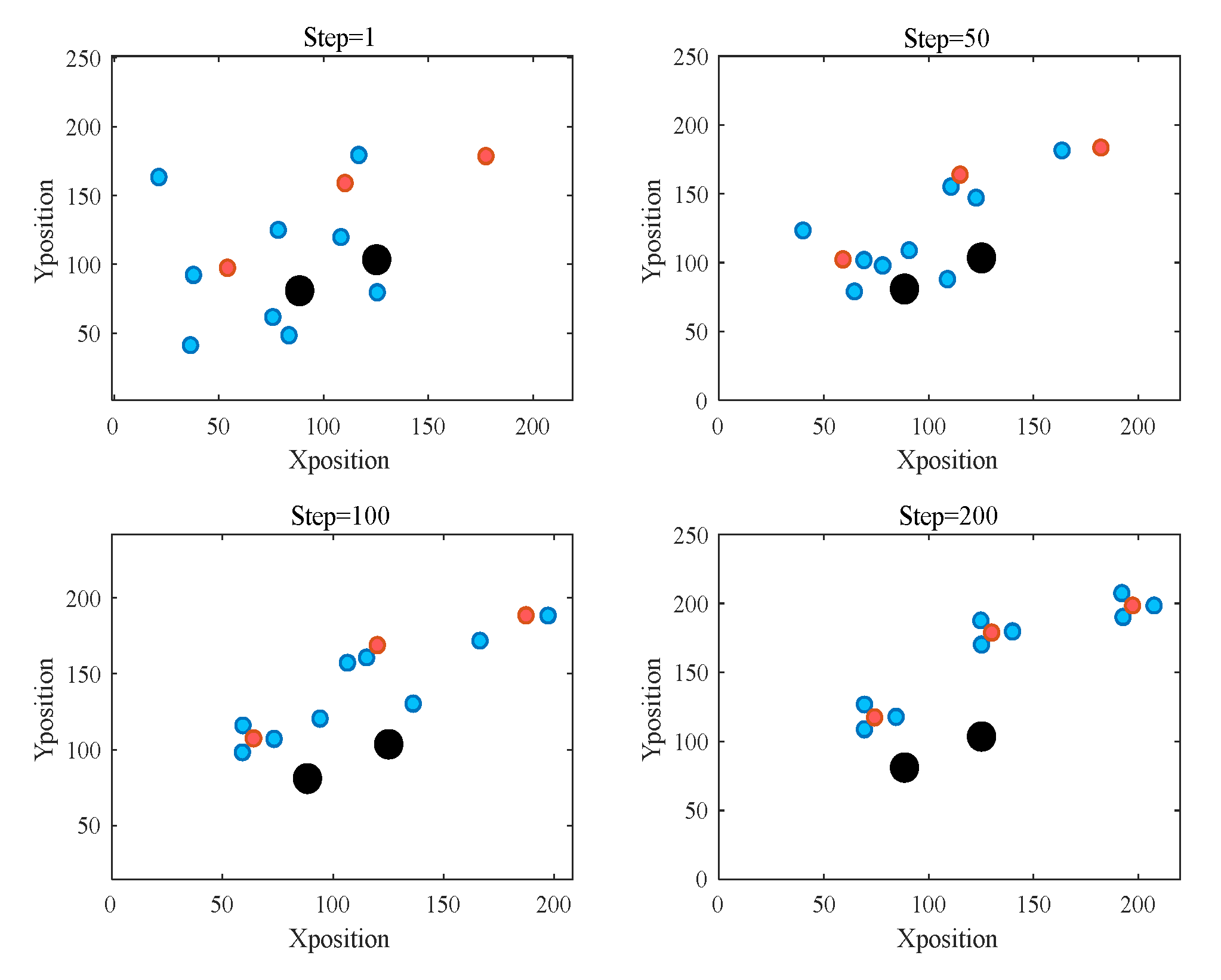
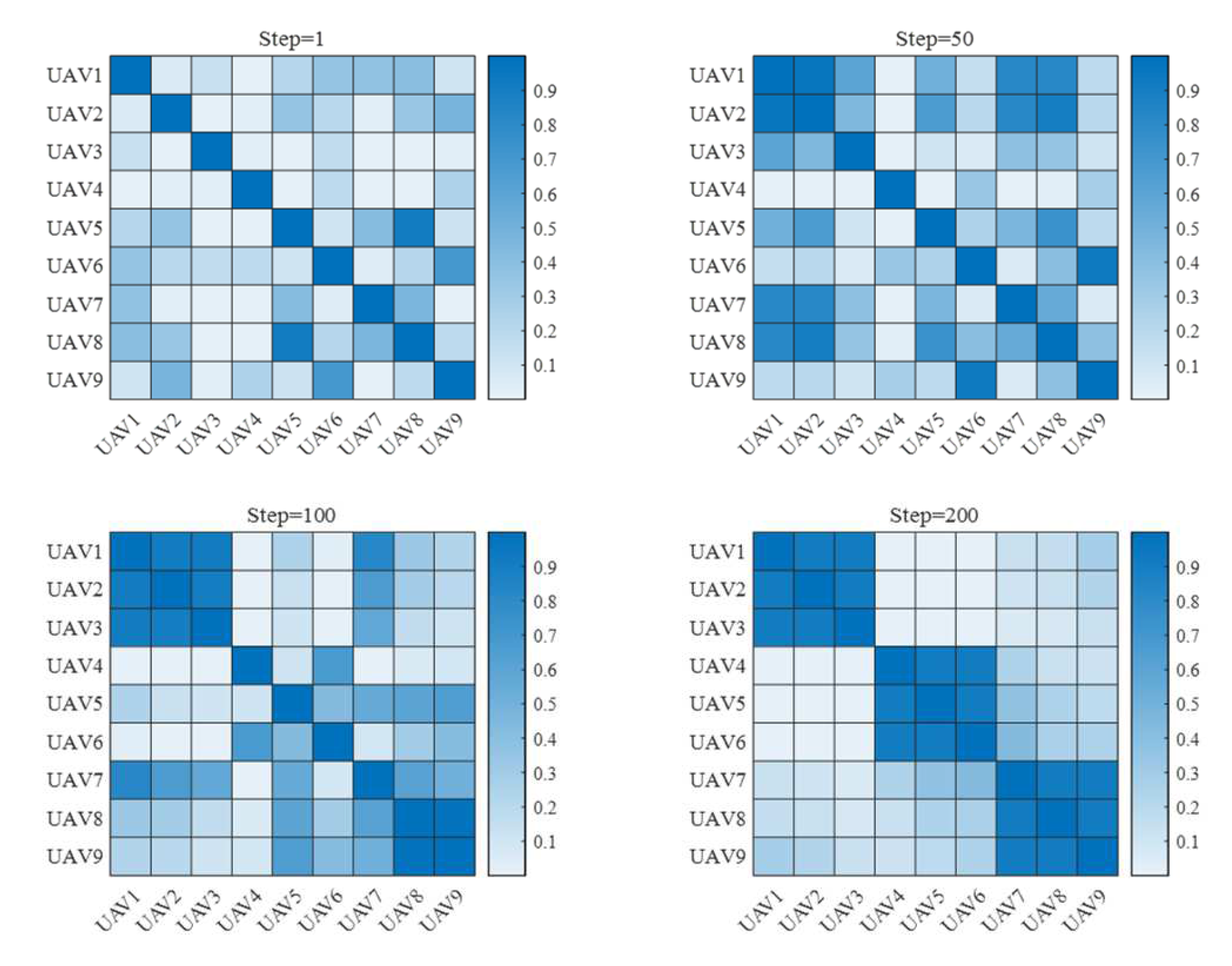
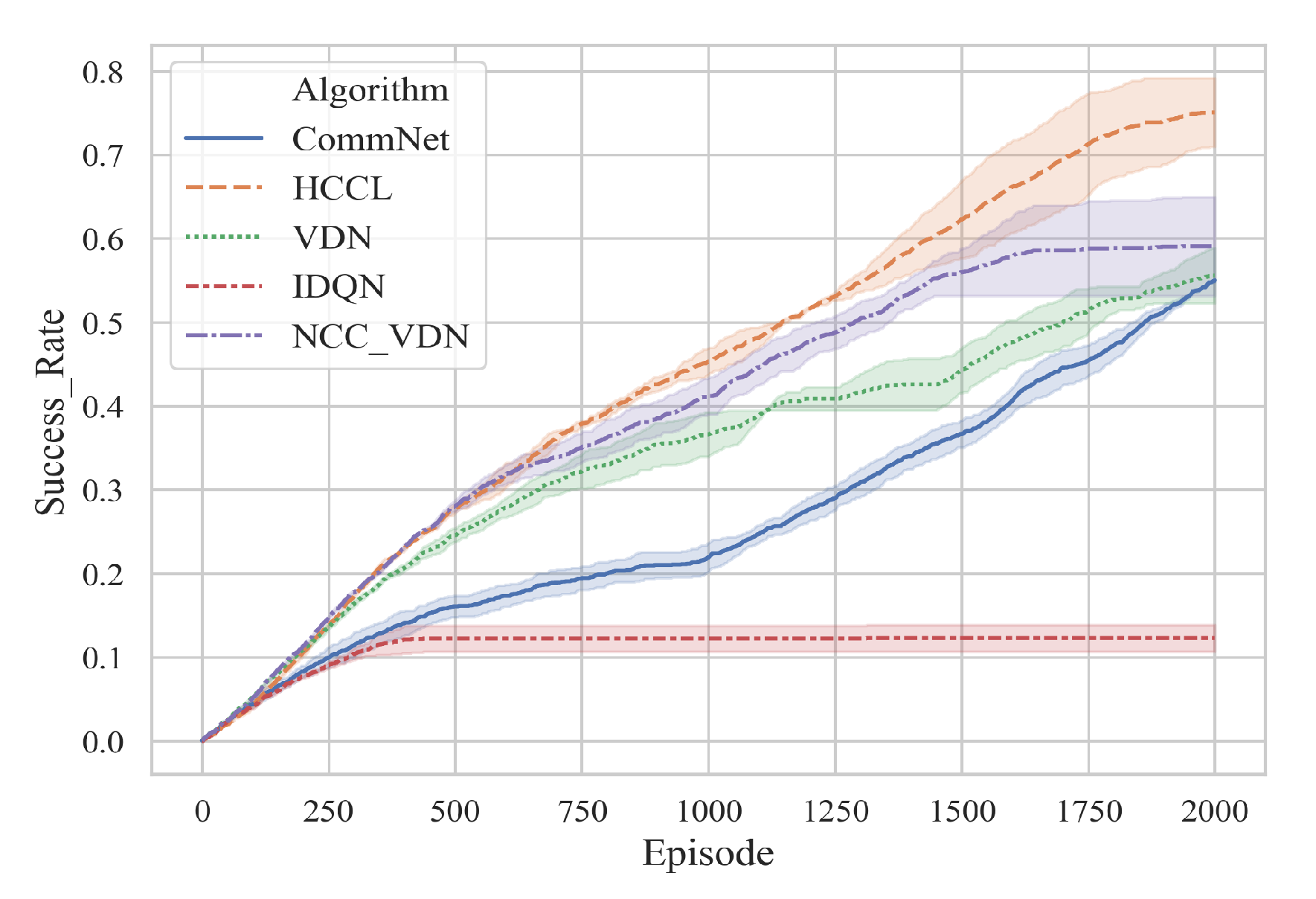
5.2. Validation Results
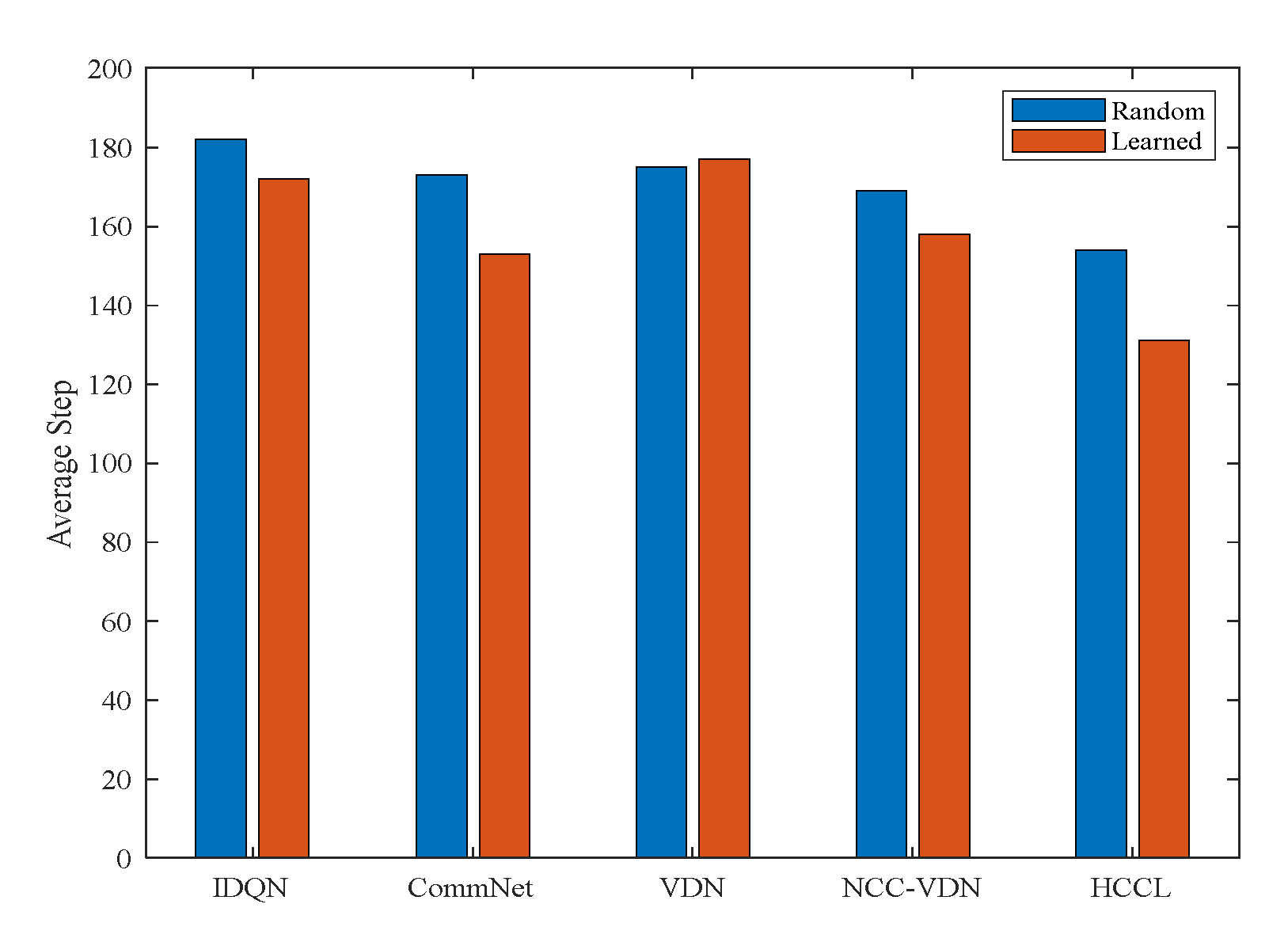
5.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tamakoshi, H.; Ishii, S. Multiagent reinforcement learning applied to a chase problem in a continuous world. Artif. Life Robot. 2001, 5, 202–206. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, L.; Zhou, Y.; Zhang, J.; Zhou, S.W.; Liu, Z.H. Self-organizing cooperative multi-target hunting by swarm robots in complex environments. Control Theory Appl. 2020, 37, 1054–1062. [Google Scholar]
- Yang, B.; Ding, Y.; Jin, Y.; Hao, K. Self-organized swarm robot for target search and trapping inspired by bacterial chemotaxis. Robot. Auton. Syst. 2015, 72, 83–92. [Google Scholar] [CrossRef]
- Gupta, S.; Hazra, R.; Dukkipati, A. Networked multi-agent reinforcement learning with emergent communication. arXiv 2020, arXiv:2004.02780. [Google Scholar]
- Deshpande, A.M.; Kumar, R.; Radmanesh, M.; Veerabhadrappa, N.; Kumar, M.; Minai, A.A. Self-organized circle formation around an unknown target by a multi-robot swarm using a local communication strategy. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4409–4413. [Google Scholar]
- Pakizeh, E.; Palhang, M.; Pedram, M.M. Multi-criteria expertness based cooperative Q-learning. Appl. Intell. 2013, 39, 28–40. [Google Scholar] [CrossRef]
- Wang, B.; Li, S.; Gao, X.; Xie, T. Weighted mean field reinforcement learning for large-scale UAV swarm confrontation. Appl. Intell. 2023, 53, 5274–5289. [Google Scholar] [CrossRef]
- Luo, G.; Zhang, H.; He, H.; Li, J.; Wang, F.Y. Multiagent Adversarial Collaborative Learning via Mean-Field Theory. IEEE Trans. Cybern. 2021, 51, 4994–5007. [Google Scholar] [CrossRef]
- Jiang, J.; Lu, Z. Learning attentional communication for multi-agent cooperation. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Singh, A.; Jain, T.; Sukhbaatar, S. Learning when to communicate at scale in multiagent cooperative and competitive tasks. arXiv 2018, arXiv:1812.09755. [Google Scholar]
- Mao, H.; Zhang, Z.; Xiao, Z.; Gong, Z. Modelling the Dynamic Joint Policy of Teammates with Attention Multi-agent DDPG. arXiv 2019, arXiv:1811.07029. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6382–6393. [Google Scholar]
- Geng, M.; Xu, K.; Zhou, X.; Ding, B.; Wang, H.; Zhang, L. Learning to cooperate via an attention-based communication neural network in decentralized multi-robot exploration. Entropy 2019, 21, 294. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Chen, X.; Mei, Y.; Xie, J.; Fang, H. A Cooperative Hunting Algorithm of Multi-robot Based on Dynamic Prediction of the Target via Consensus-based Kalman Filtering. J. Inf. Comput. Sci. 2015, 12, 1557–1568. [Google Scholar] [CrossRef]
- Chen, J.; Zha, W.; Peng, Z.; Gu, D. Multi-player pursuit–evasion games with one superior evader. Automatica 2016, 71, 24–32. [Google Scholar] [CrossRef]
- Wu, S.; Pu, Z.; Liu, Z.; Qiu, T.; Yi, J.; Zhang, T. Multi-target coverage with connectivity maintenance using knowledge-incorporated policy framework. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8772–8778. [Google Scholar] [CrossRef]
- Kim, T.H.; Hara, S.; Hori, Y. Cooperative control of multi-agent dynamical systems in target-enclosing operations using cyclic pursuit strategy. Int. J. Control 2010, 83, 2040–2052. [Google Scholar] [CrossRef]
- Awheda, M.D.; Schwartz, H.M. A decentralized fuzzy learning algorithm for pursuit-evasion differential games with superior evaders. J. Intell. Robot. Syst. 2016, 83, 35–53. [Google Scholar] [CrossRef]
- Wang, X.; Xuan, S.; Ke, L. Cooperatively pursuing a target unmanned aerial vehicle by multiple unmanned aerial vehicles based on multiagent reinforcement learning. Adv. Control Appl. Eng. Ind. Syst. 2020, 2, e27. [Google Scholar] [CrossRef]
- Yasuda, T.; Ohkura, K.; Nomura, T.; Matsumura, Y. Evolutionary swarm robotics approach to a pursuit problem. In Proceedings of the 2014 IEEE Symposium on Robotic Intelligence in Informationally Structured Space (RiiSS), Orlando, FL, USA, 9–12 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–6. [Google Scholar]
- Dutta, K. Hunting in groups. Resonance 2014, 19, 936–957. [Google Scholar] [CrossRef]
- Fan, H.; Sun, F.Z.; Ma, P.L.; Li, W.J.; Shi, Z.; Wang, Z.J.; Zhu, G.J.; Li, K.; Yin, B. Stigmergy-Based Swarm Robots for Target Search and Trapping. J. Beijing Inst. Technol. 2022, 42, 158–167. [Google Scholar] [CrossRef]
- Chu, T.; Chinchali, S.; Katti, S. Multi-agent reinforcement learning for networked system control. arXiv 2020, arXiv:2004.01339. [Google Scholar]
- Kim, D.; Moon, S.; Hostallero, D.; Kang, W.J.; Lee, T.; Son, K.; Yi, Y. Learning to schedule communication in multi-agent reinforcement learning. arXiv 2019, arXiv:1902.01554. [Google Scholar]
- Pu, Z.; Wang, H.; Liu, Z.; Yi, J.; Wu, S. Attention Enhanced Reinforcement Learning for Multi agent Cooperation. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Pu, Z.; Liu, Z.; Yi, J.; Qiu, T. A Soft Graph Attention Reinforcement Learning for Multi-Agent Cooperation. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1257–1262. [Google Scholar]
- Wang, H.; Liu, Z.; Pu, Z.; Yi, J. STGA-LSTM: A Spatial-Temporal Graph Attentional LSTM Scheme for Multi-agent Cooperation. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 23–27 November 2020; Springer: Cham, Switzerland, 2020; pp. 663–675. [Google Scholar]
- Iqbal, S.; Sha, F. Actor-Attention-Critic for Multi-Agent Reinforcement Learning. arXiv 2018, arXiv:181002912. [Google Scholar]
- Chen, H.; Liu, Y.; Zhou, Z.; Hu, D.; Zhang, M. Gama: Graph attention multi-agent reinforcement learning algorithm for cooperation. Appl. Intell. 2020, 50, 4195–4205. [Google Scholar] [CrossRef]
- Niu, Y.; Paleja, R.R.; Gombolay, M.C. Multi-Agent Graph-Attention Communication and Teaming. In Proceedings of the AAMAS, Online, 3–7 May 2021; pp. 964–973. [Google Scholar]
- Huang, L.; Fu, M.; Rao, A.; Irissappane, A.A.; Zhang, J.; Xu, C. A Distributional Perspective on Multiagent Cooperation with Deep Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Yan, L.; Zhu, L.; Song, K.; Yuan, Z.; Yan, Y.; Tang, Y.; Peng, C. Graph cooperation deep reinforcement learning for ecological urban traffic signal control. Appl. Intell. 2022, 53, 6248–6265. [Google Scholar] [CrossRef]
- Ruan, J.; Du, Y.; Xiong, X.; Xing, D.; Li, X.; Meng, L.; Zhang, H.; Wang, J.; Xu, B. GCS: Graph-Based Coordination Strategy for Multi-Agent Reinforcement Learning. arXiv 2022, arXiv:2201.06257. [Google Scholar]
- Jiang, J.; Dun, C.; Huang, T.; Lu, Z. Graph convolutional reinforcement learning. arXiv 2018, arXiv:1810.09202. [Google Scholar]
- Du, Y.; Liu, B.; Moens, V.; Liu, Z.; Ren, Z.; Wang, J.; Chen, X.; Zhang, H. Learning correlated communication topology in multi-agent reinforcement learning. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, Online, 3–7 May 2021; pp. 456–464. [Google Scholar]
- Wu, S.; Pu, Z.; Qiu, T.; Yi, J.; Zhang, T. Deep Reinforcement Learning based Multi-target Coverage with Connectivity Guaranteed. IEEE Trans. Ind. Inform. 2022, 19, 121–132. [Google Scholar] [CrossRef]
- Rădulescu, R.; Verstraeten, T.; Zhang, Y.; Mannion, P.; Roijers, D.M.; Nowé, A. Opponent learning awareness and modelling in multi-objective normal form games. Neural Comput. Appl. 2022, 34, 1759–1781. [Google Scholar] [CrossRef]
- Wu, S.; Qiu, T.; Pu, Z.; Yi, J. Multi-agent Collaborative Learning with Relational Graph Reasoning in Adversarial Environments. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 5596–5602. [Google Scholar] [CrossRef]
- Ge, H.; Ge, Z.; Sun, L.; Wang, Y. Enhancing cooperation by cognition differences and consistent representation in multi-agent reinforcement learning. Appl. Intell. 2022, 52, 9701–9716. [Google Scholar] [CrossRef]
- Wang, H.; Qiu, T.; Liu, Z.; Pu, Z.; Yi, J.; Yuan, W. Multi-Agent Cognition Difference Reinforcement Learning for Multi-Agent Cooperation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Mao, H.; Liu, W.; Hao, J.; Luo, J.; Li, D.; Zhang, Z.; Wang, J.; Xiao, Z. Neighborhood cognition consistent multi-agent reinforcement learning. Proc. AAAI Conf. Artif. Intell. 2020, 34, 7219–7226. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO. | Abbreviations | Algorithms |
|---|---|---|
| 1 | MARL | Multi-agent Reinforcement Learning |
| 2 | CTDE | Centralized Training with Decentralized Execution |
| 3 | MADDPG | Multi-agent Deep Deterministic Policy Gradient |
| 4 | CommNet | Communication neural network |
| 5 | NCC | Neighborhood Cognitive Consistency |
| 6 | HCCL | Hierarchical Cognitive Consistency Learning |
| 7 | SCD-Loss | Self-Cognitive Dissonance loss |
| 8 | TCD-Loss | Team Cognitive Dissonance loss |
| 9 | GCD-Loss | Global Cognitive Dissonance loss |
| 10 | LSTM | Long Short-Term Memory |
| 11 | IDQN | Independent Deep Q-learning Network |
| 12 | VDN | Value Decomposition Networks |
| 13 | QMIX | Q-mixing network |
| 14 | NCC-VDN | Neighborhood Cognitive Consistency based on Value Decomposition Networks |
| No. | Variable | Value |
|---|---|---|
| 1 | lr | 0.001 |
| 2 | 0.9 | |
| 3 | Episodes | 2000 |
| 4 | Batch_size | 64 |
| 5 | max_episode_length | 200 |
| 6 | 0.2 | |
| 7 | 0.8 |
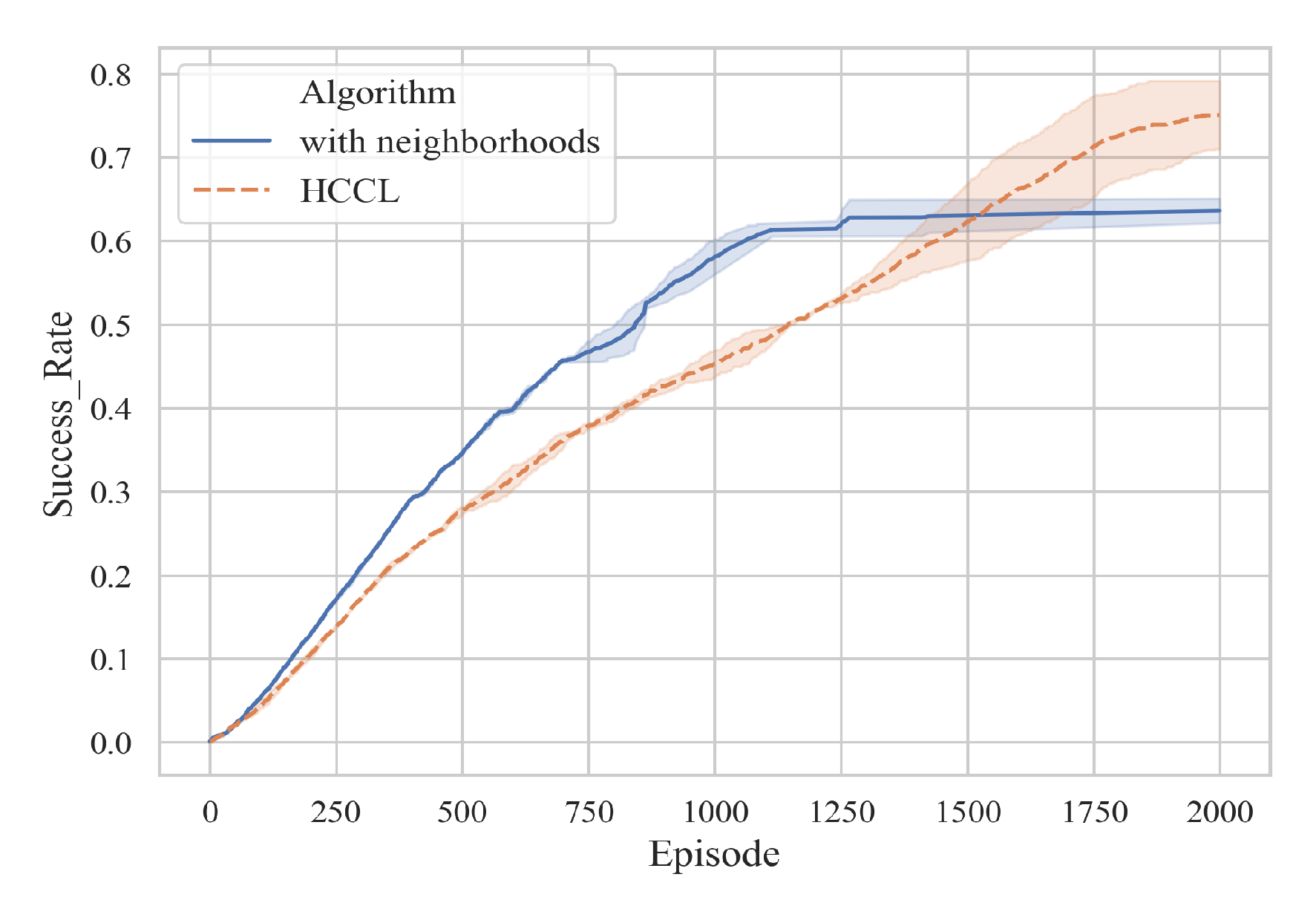
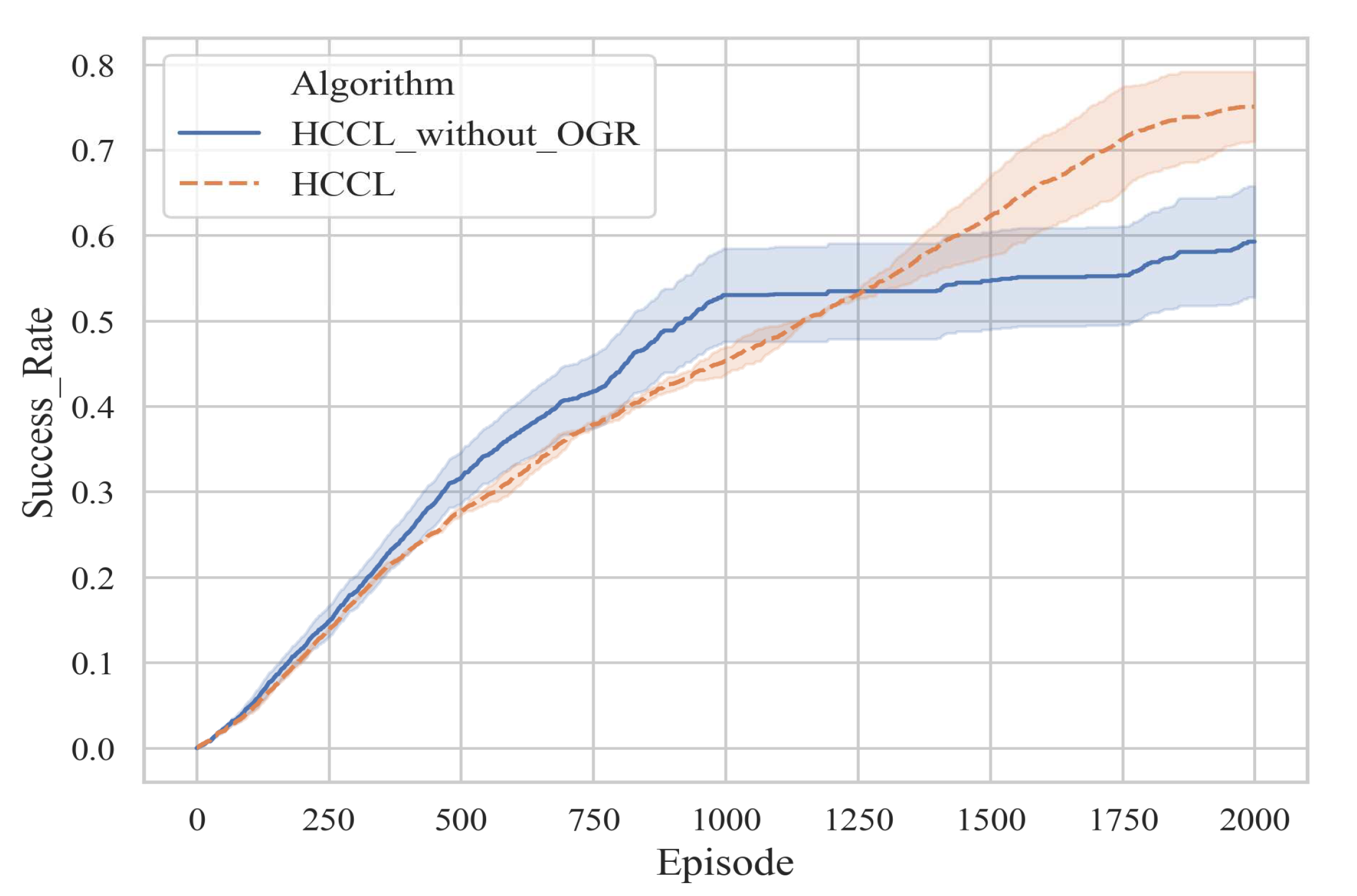
| Algorithms | IDQN | VDN | CommNet | NCC-VDN | HCCL |
|---|---|---|---|---|---|
| Success rate | 12.3% | 55.6% | 55.1% | 59.1% | 75.1% |
| Parameters | |||
|---|---|---|---|
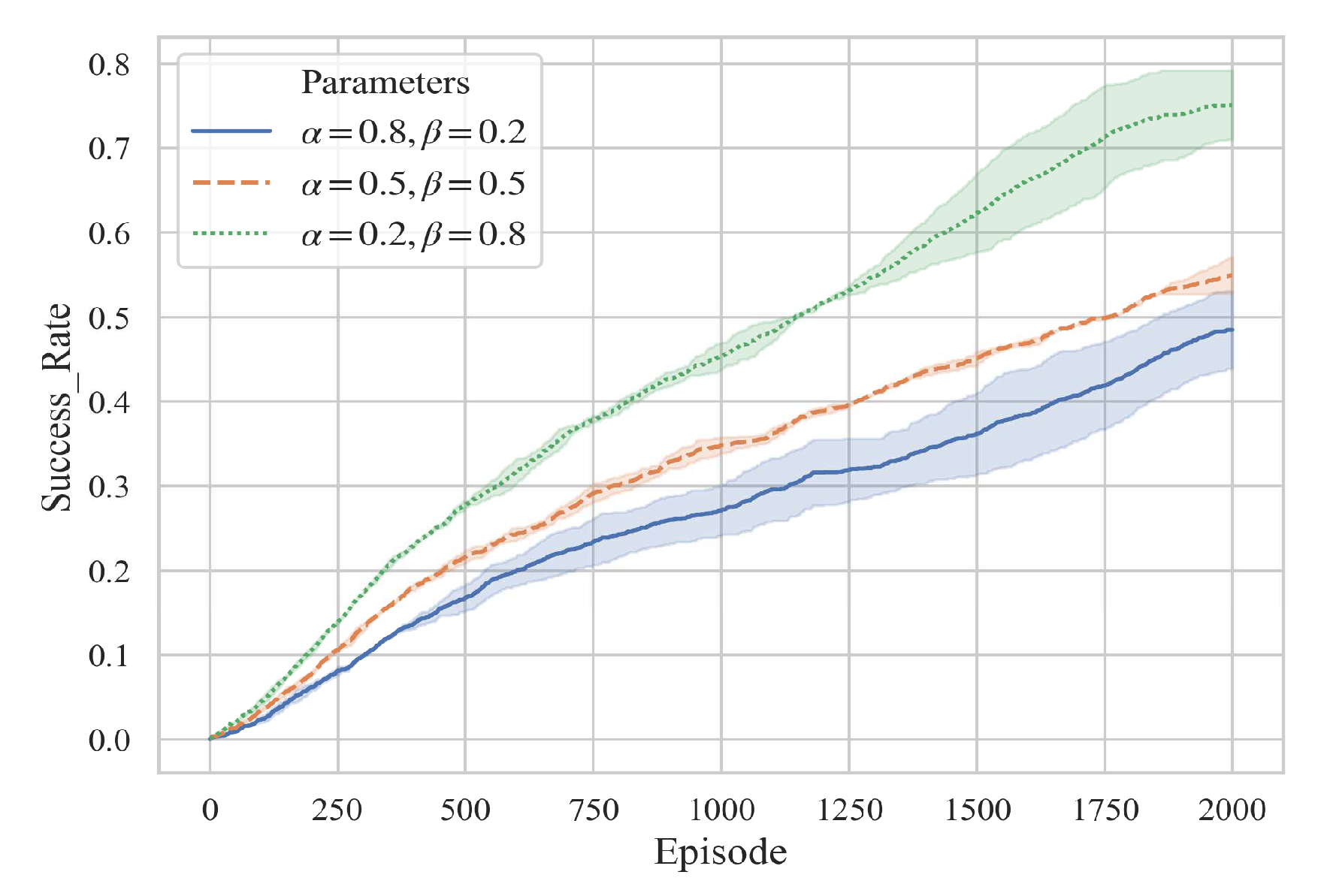
| Success rate | 48.5% | 54.9% | 75.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, L.; Wei, R.; Wang, D. Multi-UAV Roundup Inspired by Hierarchical Cognition Consistency Learning Based on an Interaction Mechanism. Drones 2023, 7, 462. https://doi.org/10.3390/drones7070462
Jiang L, Wei R, Wang D. Multi-UAV Roundup Inspired by Hierarchical Cognition Consistency Learning Based on an Interaction Mechanism. Drones. 2023; 7(7):462. https://doi.org/10.3390/drones7070462
Chicago/Turabian StyleJiang, Longting, Ruixuan Wei, and Dong Wang. 2023. "Multi-UAV Roundup Inspired by Hierarchical Cognition Consistency Learning Based on an Interaction Mechanism" Drones 7, no. 7: 462. https://doi.org/10.3390/drones7070462
APA StyleJiang, L., Wei, R., & Wang, D. (2023). Multi-UAV Roundup Inspired by Hierarchical Cognition Consistency Learning Based on an Interaction Mechanism. Drones, 7(7), 462. https://doi.org/10.3390/drones7070462