1. Introduction
The tailless unmanned aerial vehicle (UAV) has garnered immense attention due to its promising potential in both civil and military aviation. Its superior aerodynamic efficiency in comparison to traditional designs offers benefits such as improved voyage, carrying capacity, and stealth performance. This has led to the emergence of several tailless UAVs such as Boeing’s X-45 A, X-45B/C, Lockheed Martin’s RQ-170 Sentinel, BAE’s Taranis, and Dassault’s NEURON.
The Innovative Control Effector (ICE) aircraft [
1,
2], developed through research by Lockheed Martin, stands out among the latest tailless aerial vehicles. ICE is equipped with as many as 11 effectors relocated compactly on its main wing, which makes the system over-actuated. Such a unique layout was designed to investigate and measure the aerodynamics and performance of various low-observable tailless configurations using innovative control effectors. After decades of research, ICE has been found to have excellent maneuverability and stealth performance, making it a good choice for future UAV design.
The unique configuration of ICE allows its effectors to achieve goals beyond providing aerodynamic moments, such as minimizing drag or maximizing lift [
3]. However, this configuration also poses challenges for control. Like other tailless vehicles, ICE suffers from problems such as poor static stability and coupling between longitudinal and lateral dynamics. Additionally, the redundant effectors of ICE require dealing with the control allocation problem, which involves selecting appropriate effectors and providing deflection commands to generate the required moments. However, the compact layout of ICE’s effectors results in strong coupling effects between them, causing the control inputs to appear nonlinear in the system, which means that the system is nonaffine. As a result, the control allocation of ICE is an extremely challenging task.
Since the proposal of the concept of ICE, researchers in the flight control field have been paying constant attention to it [
4,
5,
6]. In 2017, Niestroy et al. [
7] published detailed aerodynamic data for ICE, which enabled the construction of a highly precise control-oriented nonlinear model and the development of advanced control algorithms. Many researchers have developed different control algorithms for the nonlinear ICE model. In a recent study, He et al. [
8] proposed an altitude tracker for ICE using the well-known decoupling conditions for nonaffine systems [
9,
10,
11,
12,
13,
14], while other researchers prefer incremental control methods.
The principle behind incremental control methods is timescale separation, which makes use of Taylor expansion. Incremental control methods can transform nonaffine systems into incremental affine forms. Therefore, the complexity of nonlinear optimization in CA can be avoided. This approach is highly effective for dealing with nonaffine systems [
15]. Recently, there have been several advancements in incremental control for ICE. Stolk et al. [
3] proposed a minimum drag CA method based on incremental nonlinear dynamic inversion. Matamoros [
16] implemented an incremental nonlinear CA in ICE, resulting in improved tracking and CA performance. Sun et al. [
17] improved the CA of ICE using hierarchical multi-objective optimization and adaptive incremental backstepping. Additionally, He et al. [
14] extended the incremental control to the outer-loop control of ICE trajectory tracking using the pseudo-control hedging technique and relaxing the need for a timescale separation principle.
The reason incremental control is effective for nonaffine systems is it makes good use of the partial derivative of control inputs, . This is obtained through the digital differentiation of aerodynamic data. It is worth noting that obtaining the partial derivative of control inputs may be challenging in some systems. However, with the advancements in wind-tunnel tests, we can obtain more accurate and economic aerodynamic data for flight control. When combined with model identification techniques, incremental control has great potential for the future.
Most of the aforementioned control methods separate the command tracking and control allocation (CA) tasks. The command tracker provides the aerodynamic coefficients command to ensure that the reference signal is accurately tracked, while the CA determines the specific effector deflection based on the aerodynamic coefficients command and its objective function. This framework is highly convenient for incorporating established flight control algorithms, and the CA can be viewed as an optimization problem that can leverage the well-established optimization theory. As a result, this framework is preferred by most researchers.
However, there are some aspects of the above framework that could be improved. The obvious drawback is that the CA is designed to minimize the objective function consisting of the moments tracking error and the effector deflection . From an input and output perspective, the moments tracking error is only an intermediate value, and what truly matters is the reference signal tracking error . Therefore, the ideal objective function should take both and the effector deflection into consideration, instead of just . Additionally, most existing flight control algorithms are based on Lyapunov theory and can only take into account the convergence of . To make these algorithms compatible with the over-actuated UAV, the above framework must be adopted, and the second goal is left to the CA.
Meanwhile, the above framework takes two steps to give effector deflection, increasing the computational time. Hou et al. [
18] introduced the recurrent neural network in CA and claimed that the recurrent neural network model could be solved in parallel to meet the real-time requirement. Still, this approach has only been validated in a linearized model, where the computational load is inherently small.
Hence, it is imperative to develop more reasonable and effective frameworks that abandon the meaningless intermediate values, therefore ensuring convergence of and achieving the second goal in one step. Optimal control is a promising option in this regard. Unlike the objective function of CA that only considers and the second goal, the performance function of optimal control can incorporate the tracking error and any other desired second goals. This means that the command tracking and CA can be described using a single equation. However, solving the nonlinear Hamilton–Jacobi–Bellman (HJB) equation remains a formidable challenge.
Adaptive dynamic programming(ADP) provides new ideas for solving the nonlinear HJB equation. ADP is a heuristic algorithm for solving optimal control. Compared with other heuristic algorithms, such as reinforcement learning, ADP is supported by optimal control theory, so it shows better convergence and stability and is more suitable for flight control. The first application of ADP in optimal control could be seen in a study by Werbos [
19]. ADP’s basic idea is to use sampling data to drive a neural network to approximate the optimal value function. In this way, APD turns the backward-in-time dynamic programming process into a forward-in-time manner and greatly expands the application of optimal control. For theoretical studies of ADP, Wei and Liu [
20] give the stability analysis of policy iterative APD, and the stability proof of value iterative ADP is given by Al-Tamimi and Lewis [
21]. Moreover, the researchers also proposed different frameworks of ADP, such as heuristic dynamic programming [
22], dual heuristic programming [
23], and globalized dual heuristic programming [
24]. These studies lay the foundation of ADP, and a more detailed review of recent studies on ADP can be found in the paper by Liu et al. [
25].
Model identification is a commonly adopted technique in recent applications of ADP in practical systems [
26,
27]. Model identification is an effective method for enhancing the robustness of ADP, but it requires introducing an identifier network. Compared to basic ADP, which uses only a critical network to approximate the value function, the incorporation of additional networks significantly increases the computational complexity. Therefore, approaches to alleviate the computational burden, such as the event-trigger technique [
28], are necessary for these methods.
However, it is often overlooked that the optimal control itself could be robust with an appropriate design of performance function. This idea is illustrated in a book by Lin [
29], and the author systematically discusses how to handle disturbance and model uncertainty in an optimal control way. This way, the ADP could enjoy robustness while avoiding heavy computational burdens. However, the author also points out that it is still an open question how to apply similar approaches to a nonaffine system. Most ADPs are developed to address the optimal regulation problem, but for flight control, the optimal tracking control has a more practical use. With the development of the aviation industry, modern flight control is no longer satisfied with just ensuring flight stability. Many researchers [
30,
31,
32,
33,
34] began to consider how to track the command signal optimally.
In the control field, optimal tracking control has attracted increased attention. One of the most common optimal tracking methods is the combination of feedforward control and feedbackward control [
35,
36,
37,
38,
39,
40]. The feedforward control is a traditional steady-state tracking controller to ensure the command reference signal is tracked. ADP is used in the feedbackward control to stabilize the transient error optimally. With the help of the traditional steady-state tracking controller, this optimal tracker shows good stability. Nevertheless, this optimal tracker is not suitable for ICE. Designing a traditional steady-state tracking controller for ICE has already been an arduous task, and the control allocation still needs to be considered in this process.
Some ADP-based optimal trackers do not rely on the feedforward control [
41,
42,
43]. These studies applied a discounted performance function to ensure the boundness of the optimal value function in the infinite-time process and constructed an augmented system using the error dynamic and reference signal dynamic to transform the tracking problem into the regulation problem. However, the dynamic of the reference signal is unavailable in these methods, limiting the use of these ADPs.
From the other view, nonlinear dynamic inversion [
44], as a tried-and-tested control method in the flight control area, constructs the dynamic of the desired signal using state value and command signal, which provides a new idea to overcome this drawback. Moreover, these ADPs also cannot address the nonaffine system, so they cannot be directly used for ICE.
To apply ADP in ICE, the nonaffine control input must be considered. Recent optimal trackers for nonaffine systems can be grouped into two types. One type is mainly for single-input systems, which decouple the nonaffine system into an affine system with model uncertainties [
45,
46,
47], but it is not easy to extend such a method to the multi-input system. Using decoupling conditions, these methods show robustness, but neglecting model details also makes their optimization performance poor. The other type uses the other neural network, known as the actor network, to handle nonlinearity in control input and update the policy through gradient-base algorithm [
48,
49,
50]. This method performs well but also needs more data and training, which undoubtedly increases the computational burden. Of course, some tricks commonly used in reinforcement learning [
34] could also help improve the convergence rate of the method, but this also causes the lack of stability proofs.
Motivated by the aforementioned studies, this article proposes a critic-only ADP technique for the attitude tracking of ICE featured by nonaffine control inputs and redundant effectors. Through ADP, our approach integrates control and control allocation so that the same performance can be achieved at a cost less than conventional methods. By the idea of nonlinear dynamic inversion, an augmented system is constructed. The optimal tracking problem is transformed into an optimal regulation problem with discounted performance function, and the command dynamic is avoided. Inspired by the successful use of in incremental control, we introduce into APD, letting our method handle the nonaffine system in a simple way. Moreover, this article proves that for the control of the nonaffine system, the robust tracking problem could be equivalent to the optimal tracking problem with an augmented cost. This provides another way to improve the robustness of ADP, and complex model identification methods can be avoided.
The rest of the paper is arranged as follows:
Section 2 introduces the aerodynamic model of the UAV.
Section 3 gives the problem formulation and shows at the theoretical level that the optimal control with a specially designed performance function is equivalent to robust control.
Section 4 presents the control scheme and stability analysis.
Section 5 presents two simulations that validate the superiority of our method over the conventional approach and demonstrate its robustness, respectively. Finally,
Section 6 gives the conclusion and the outlook for the next steps of research.
2. Model Description
This section introduces the ICE model. The basic parameters of ICE can be found in
Table 1 [
7], while more detailed information on the modeling of effectors can be found in Chapter 3 of [
3]. Due to space constraints, this information will not be repeated here.
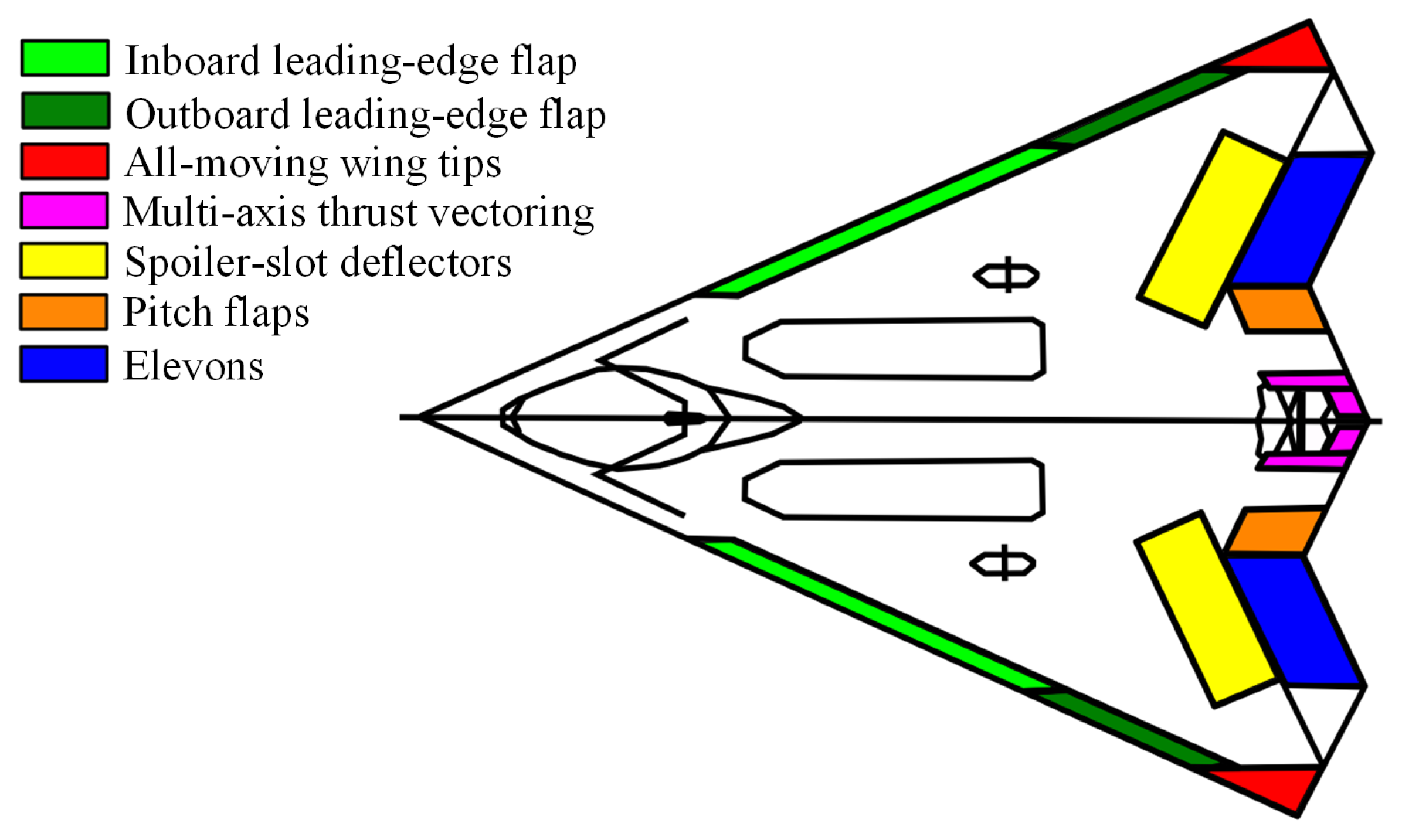
Figure 1 displays the layout of ICE, which features a high-sweep, tailless flying wing with a leading-edge sweep of 65 deg and 25 deg chevron shaping on the trailing edge. ICE is equipped with 13 independent effectors, including two pairs of leading-edge flaps (LEF), a pair of spoiler slot deflectors (SSD), a pair of all-moving tips (AMT), a pair of elevon (ELE), a pair of ganged pitch flaps (PF), and multi-axis thrust vectoring (MTV). Since this paper is focused on the cruising stage, MTV will not be taken into account.
The deflection ranges of the effectors are, inboard LEF: 0–40 deg, outboard LEF: ±40 deg, ELE: ±30 deg, PF: ±30 deg, AMT: ±60 deg, SSD: 0–60 deg. The rate limits on the leading-edge devices are 40 deg/s and on all the other surfaces 150 deg/s.
The modeling of the UAV is based on the following two assumptions: 1st, the UAV flies in the atmosphere, and the atmosphere is incompressible; 2nd, the UAV’s body is rigid. Please note that only the body of the UAV is considered a rigid body, but the effectors are deformable.
Remark 1. In previous studies [8,44,51], the MTV was used solely during the UAV’s vigorous maneuvers or when other effectors were saturated. However, this paper proposes a cruise-oriented approach where ADP enables a superior trade-off between effector deflection and tracking error. This effectively eliminates the need for MTV, ensuring that effector saturation is avoided. The motion equation of 6-DOF UAV model is given below [
14,
18,
52], the nomenclature of the variables in the following equation can be found in
Table 2.
where
V,
, and
are airspeed, flight path angle, and ground tracking angle, respectively.
and
represent
and
.
donate the sum of aerodynamic force and thrust, which could be approximated through accelerometers, and
represents gravitational forces. Define
,
, and
as the bank angle, angle of attack, and sideslip angle, then the dynamic of
is:
where
and
r are the body-axis roll, pitch, and yaw rates. The expression
is the transformation matrix from the body frame to the velocity frame, and
is the transformation matrix from the earth frame to the velocity frame. These matrices are given in [
53]:
The dynamic of
is:
where
is rotary inertia, defined as:
and
is the aerodynamic moment, defined by:
where the
is the dynamic pressure,
b is span,
is the mean aerodynamic chord,
represents the deflection of effectors,
is the deflection range of effectors [
3],
and
are the aerodynamic coefficients generated by the body and control surfaces.
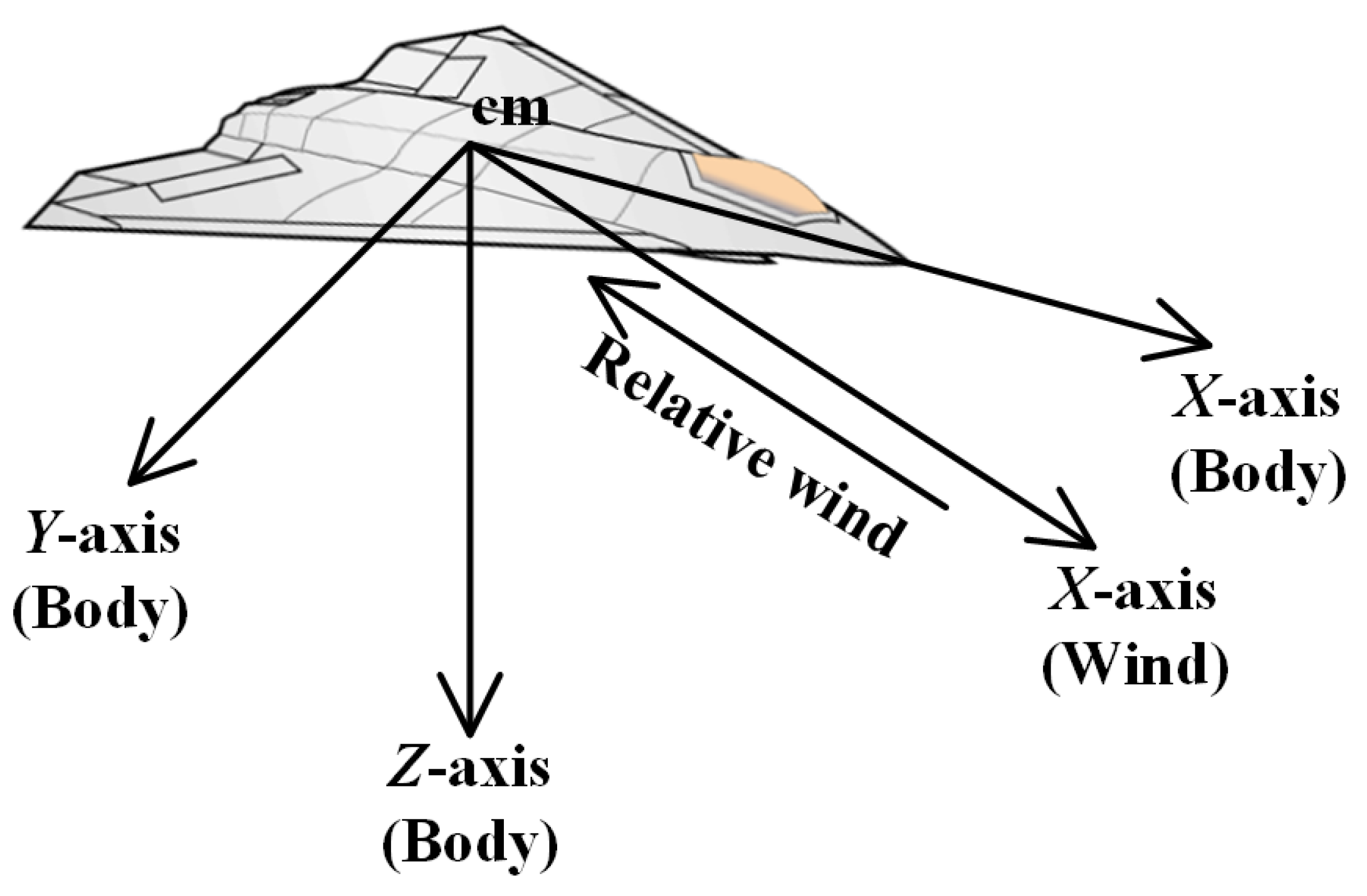
The coordinate system involved in the above kinetic equations is shown in
Figure 2. Equation (1) is defined in the tangent-plane coordinate system, which is aligned as a geographic system but has its origin fixed at a point of interest on the spheroid; Equation (2) is defined in the wind-axes system, and Equation (5) is defined in the body-fixed coordinate system. The relationship between the wind-axes system and the body-fixed coordinate system is shown in
Figure 1. The origin of both is at the UAV’s center of gravity, but the X-axis of the body-fixed coordinate system points in the direction of the nose, and the X-axis of the wind-axes system points in the direction of the relative wind [
53].
To facilitate the design of the attitude tracker, we first construct a control-oriented model that considers disturbances and model uncertainty caused by inaccurate aerodynamic parameters. Define
,
, then
where
where
stand for total uncertainty,
represents the control effectiveness that aerodynamic data fail to curve, and
d represents the external disturbances.
3. Problem Formulation
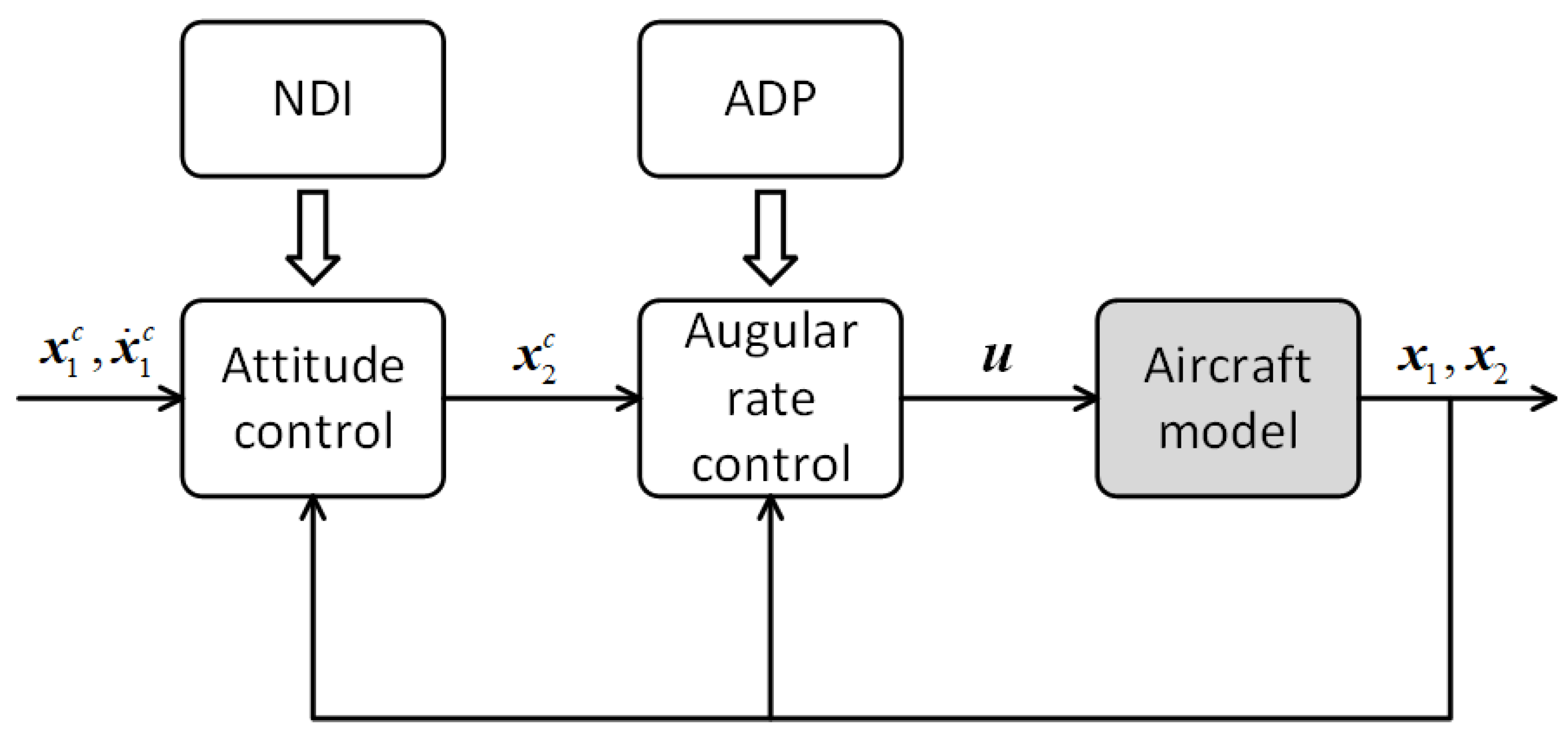
The control structure is shown in
Figure 3, donating
as the command signal. The control system consists of two parts, attitude control using NDI and angular rate control using ADP. The attitude control is to give the proper angular command so that the UAV can track the attitude command, assuming that the derivative of the attitude command is known, and gives the angular rate command as [
44]:
where
.
The goal of angular rate control is to give effectors’ deflection so that the angular rate command can be tracked optimally according to the performance function. First, we constructed an augmented system:
where
is positively defined, and
represents the desired angular rate.
Define
, and rewrite the augmented system in the compact form:
where
,
,
,
.
Remark 2. From Equation (14), it could be known that it is difficult to obtain the dynamic of because of its dependence on the second order derivative of . In many control methods, such as incremental control methods [14], is readily available, but is usually obtained through digital differentiation, which is not only sensitive to noise but also increases the computational complexity. Therefore, in ADP, the dynamic of is constructed using NDI, and the use of could be avoided in this way. To facilitate the following analysis, the following assumptions are given:
Assumption 1. The total model uncertainty is bounded, there exist , let .
Assumption 2. is line nonsingular, i.e., for , there exist , such that .
Remark 3. From Equation (8), it is obvious that the total model uncertainties can be equated to time-varying aerodynamic moment disturbances. To put it bluntly, Assumption 2 means that such disturbances are contained in the attainable moments set of ICE, and considering the redundant effectors that ICE is equipped with, its attainable moments set [54] has already been greatly expanded. From Equation (13), it also could be found that could only reflect the aerodynamic characteristic of ICE to a certain degree. Except for the accuracy loss in the wind-tunnel test, the raw aerodynamic data also must be well-tailored to make it more suitable for flight control design, and the aerodynamic that failed to reflect are seen as model uncertainties. Therefore, it is reasonable to say that has the properties stated in Assumption 2. Specifically, the angular rate control is to ensure the
tracks the
by minimizing the following performance function. Consider that when the command signal does not converge to 0, the control input also tends not to be 0. To ensure the boundness of the performance function, the following discounted performance function is introduced:
where
,
and
are positively defined matrices,
is the discounted factor. Compared to the conventional performance function, the upper bound of model uncertainties
is introduced into the performance function.
Remark 4. As a tried-and-tested control algorithm, NDI has been used in flight control for decades. In NDI, by feeding back the error between and , the tracking of could be achieved. Therefore, in the above performance function design, we also use the feedback of instead of .
Since the exact value of model uncertainties is unavailable, only the optimal tracker for the following nominal system that excludes the model uncertainties can be obtained:
However, the optimal tracker designed for the nominal system using the performance function in Equation (18) is capable of handling model uncertainties. This point will be elaborated on later, and the optimal tracker for the nominal system is derived as follows:
Define
, then the discounted performance function could be modified as:
Then define the optimal value function:
Remark 5. It is worth noting that the constraints imposed by the effector are not taken into account when solving the optimal control problem. However, it is possible to effectively prevent effector saturation by adjusting the weights in the performance function. This approach is widely adopted in the solution of optimization problems.
Differentiating Equation (20) and noting Equation (21) give the following Hamilton–Jacobi–Bellman (HJB) equation:
where
. Applying stationarity condition
, then we have the optimal tracker:
where
. If the HJB equation is solved, the optimal control can be obtained. Therefore, the main issue of this paper is to solve the HJB equation using ADP.
Remark 6. From Equation (23), it can be found that the only difference between the proposed optimal control for multi-input nonaffine systems and traditional optimal control lies in the use of , which is obtained through digital differentiation of aerodynamic data. In the theoretical study of the optimal control of nonaffine systems [49,50,55,56,57], the nonaffine part of the system is usually treated as completely unknown. Therefore, complex model identification methods are needed in these studies. However, for realistic control systems, even if the accurate analytical model is not available, the data-based model can be built by observing the input and output of the system. With the improvement of wind-tunnel tests for UAV modeling, the aerodynamic data we obtain is more accurate than ever. The aforementioned theoretical studies, however, have not made sufficient use of these data. This is undoubtedly a huge waste. In this paper, the wind-tunnel data are used to assist ADP. By introducing into the performance function, the ADP shows robustness against uncertainties in wind-tunnel data. Compared with online model identification, many more computational resources could be saved in this way. The following lemma shows that with the performance function Equation (20), the optimal tracker in Equation (23) shows robustness against model uncertainties.
Lemma 1. Assume that the optimal control of the nominal system (19) with performance function (20) exist, could also make the system with model uncertainties (17) asymptotically stable.
Proof. To facilitate the proof, an auxiliary system is proposed:
It is obvious that the subsystem
is asymptotically stable. Therefore, as long as the auxiliary system is proven to be asymptotically stable, Lemma 1 holds. Consider the optimal value function in Equation (21), for all
,
and
only when
. Therefore, choose the Lyapunov function as
, and the time derivation of
is:
according to the HJB equation and stationarity condition, we have:
where the
is the Moore-Penrose inverse of
. According to Assumption 2
, such that:
according to Assumption 2,
and
is positively definite,
. Therefore, it is clear that
is negative definite, the auxiliary system is asymptotically stable, and Lemma 1 is proven.
5. Simulation Verification
This section presents two representative simulations to illustrate the effectiveness of the ADP-based integrated-control-and-control-allocation scheme. The simulations are conducted using fixed-step ode4(Runge–Kutta) solver. The fixed-step size is 0.01 s. The block diagram of the 6-DOF UAV simulation model can be found in Figure 10 of the report given by Niestroy [
7]. Simulation 1 compares our control scheme with conventional incremental dynamic inversion and pseudo-inverse control allocation(INDIPI) to verify the optimality of our method. Simulation 2 aims to test the robustness of the proposed control scheme. It is assumed that the leading-edge actuators are represented by the transfer function
while all the other actuators, including thrust vectoring, as
.
The initial condition of the UAV is ft/s, , , deg, deg, deg, , , , and the initial height is 10,000 ft. The angle of attack command is generated by a band-limited white noise pass the second order filter , the bank angle signal command , and the sideslip angle command .
The control parameters are set as , , , , . Define , , , then the activation function vector are designed as , with initial weights .
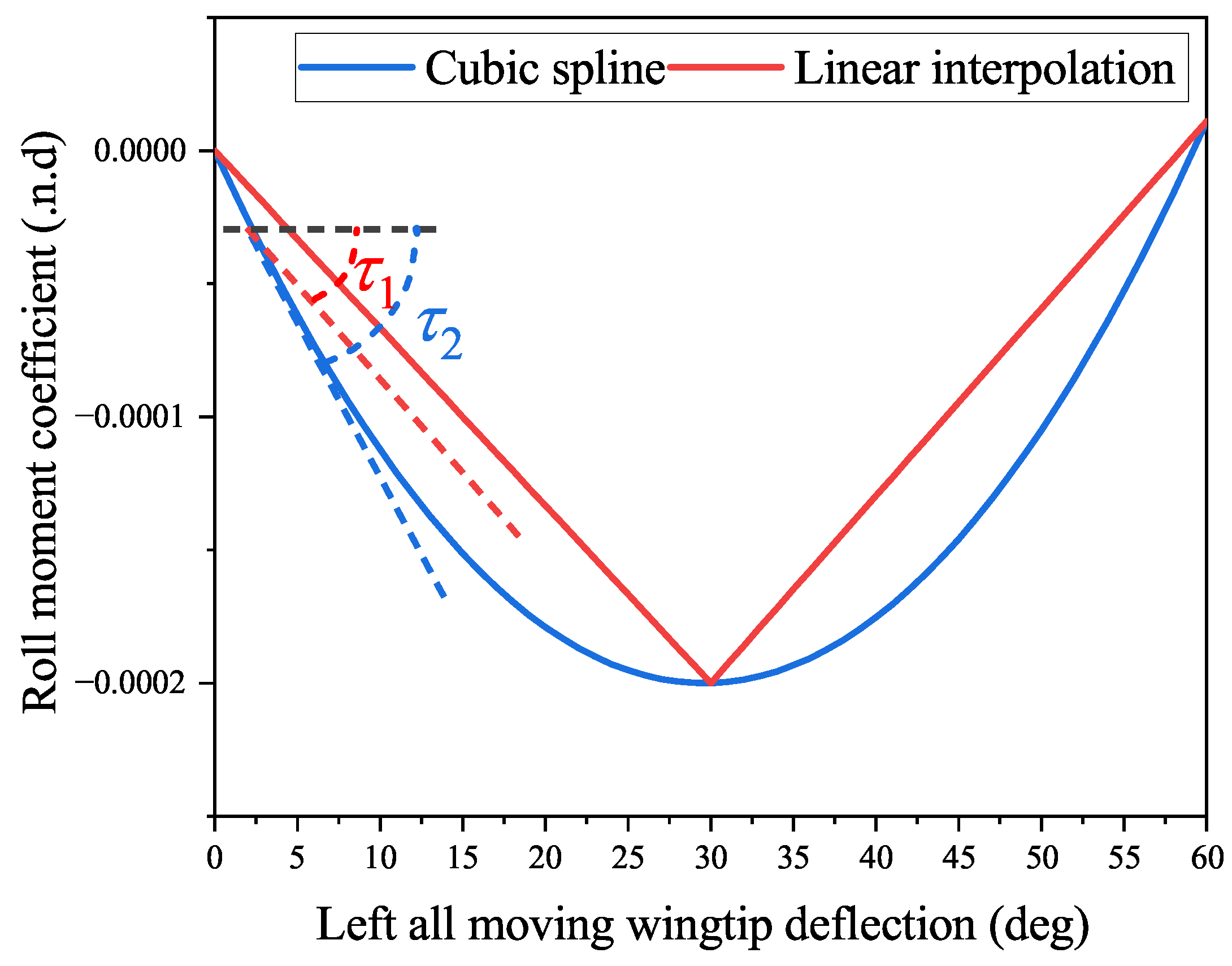
Remark 8. We designed the activation function vector as above because it would be easier to find the initial admissible control policy [59]. Clearly, there exists . In this sense, the initial control is equivalent to proportional control. Compared with dealing with complex nonlinear feedback, finding an admissible proportional control law is much easier. Model uncertainty exists in both simulations. As mentioned above, model uncertainty mainly comes from inaccurate aerodynamic data, which are used to obtain . Since the aerodynamic data provided by Niestroy is a series of discrete points, it takes interpolation so that these data are of practical use. In both simulations, different interpolation methods are used for controller design and model construction to simulate that controller cannot access accurate aerodynamic data. Specifically, the cubic spline is applied for model construction, and linear interpolation is used in controller design.
Remark 9. The cubic spline is applied for model construction because the actual aerodynamic data should be continuous and smooth. Meanwhile, using linear interpolation in control could save online computational load. As mentioned in [14], different interpolation methods can cause errors of up to 30%. Take the aerodynamic data of a set of all-moving wingtips as an example, as shown in Figure 5, from which it can be founded that the slopes of the tangents of linear interpolation and cubic spline, i.e., and , are different. 5.1. Simulation 1
In this simulation, the ADP-based control scheme is compared with INDIPI [
60]. Specifically, our approach and INDIPI are to track the same attitude command, and the performance of both is judged according to the tracking performance, flight quality, and control input. Considering that inaccurate control effectiveness could cause INDIPI to lose stability and this simulation is not to compare the robustness of INDIPI and ADP-based method, INDIPI could obtain accurate model information in this simulation, and model uncertainties only influence our method. Set
as 11-dimensional vector
. Please note that the same NDI scheme is applied in attitude control of the ADP-based method and INDIPI.
The result is shown in
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16 and
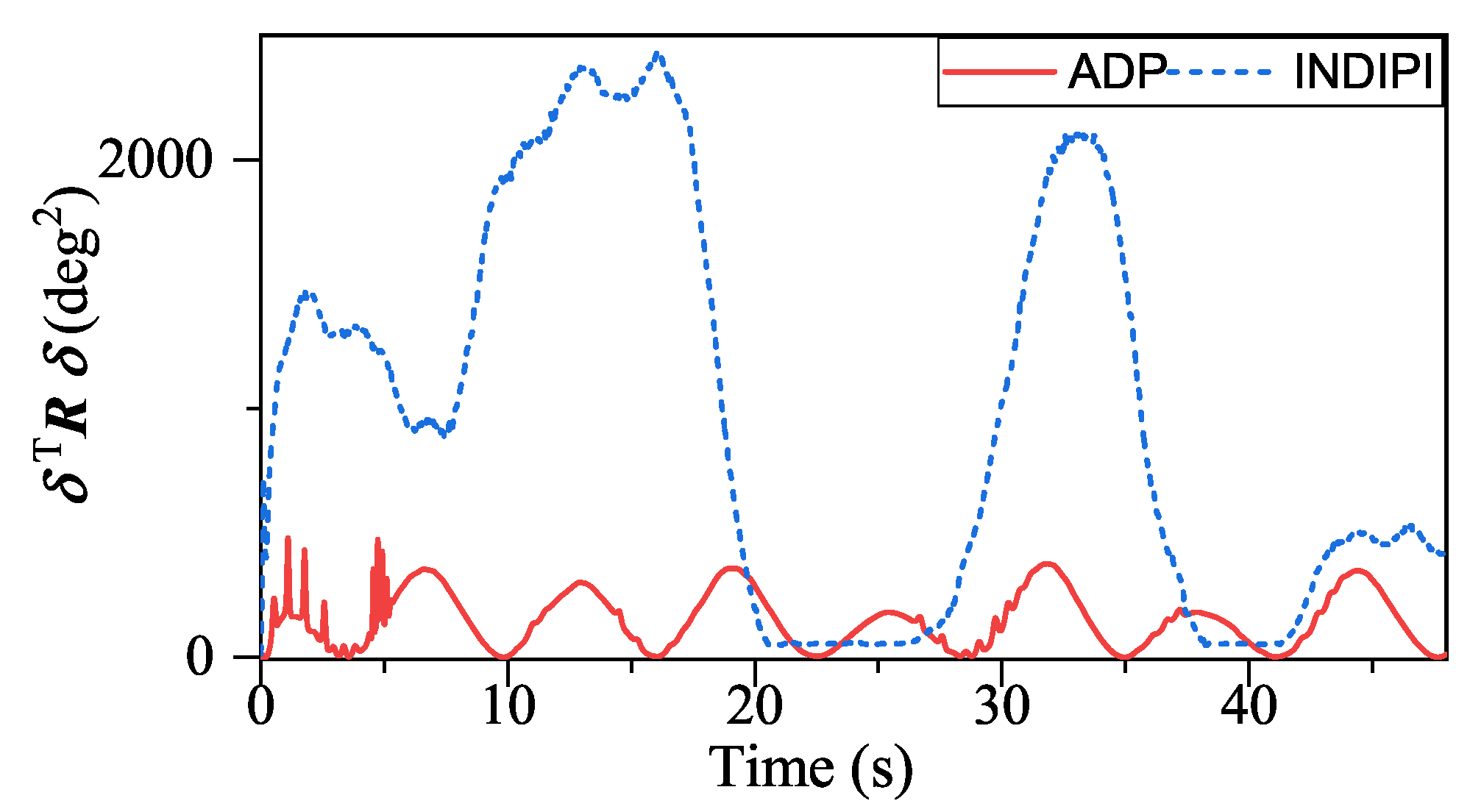
Figure 17. First, from
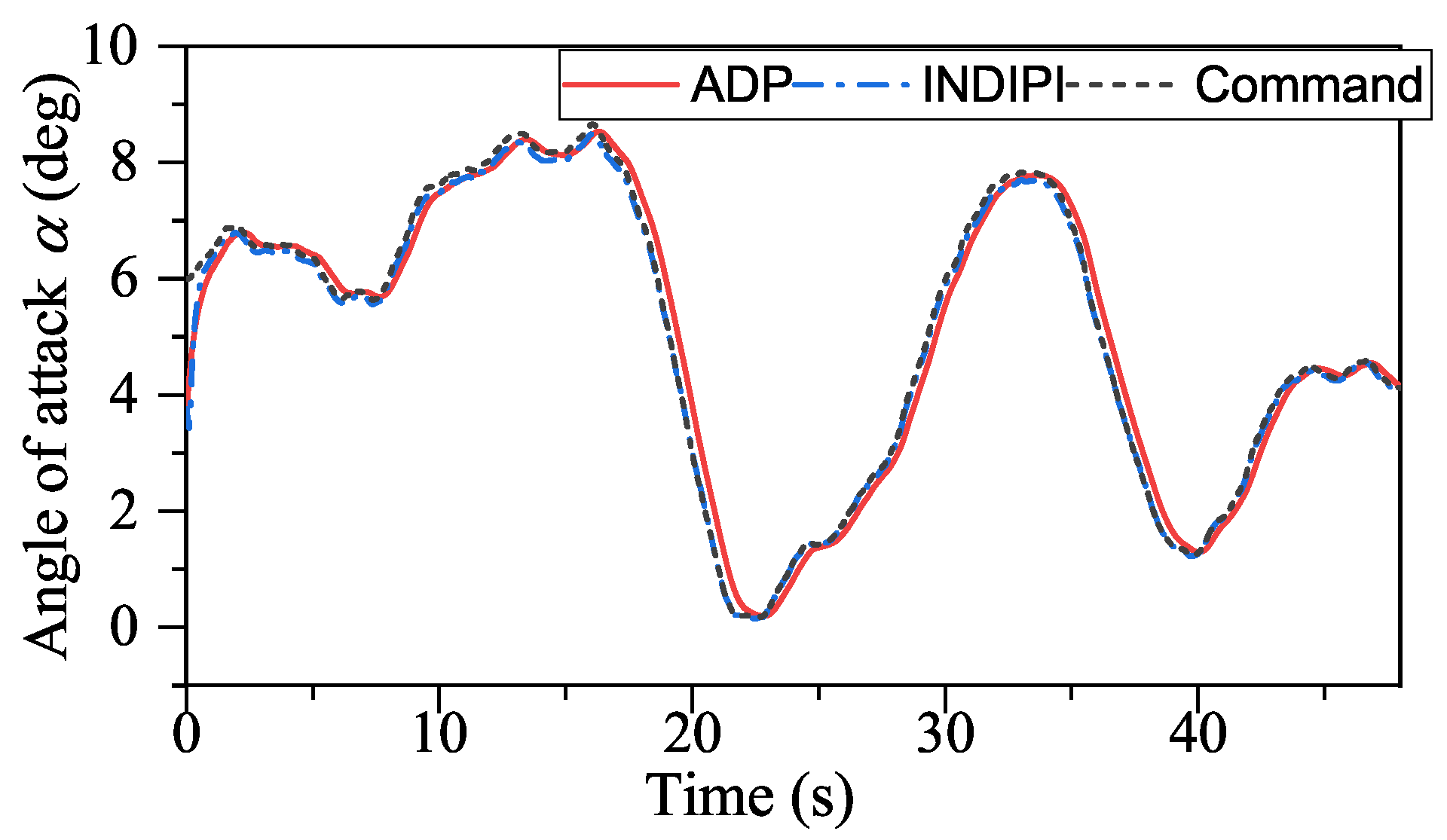
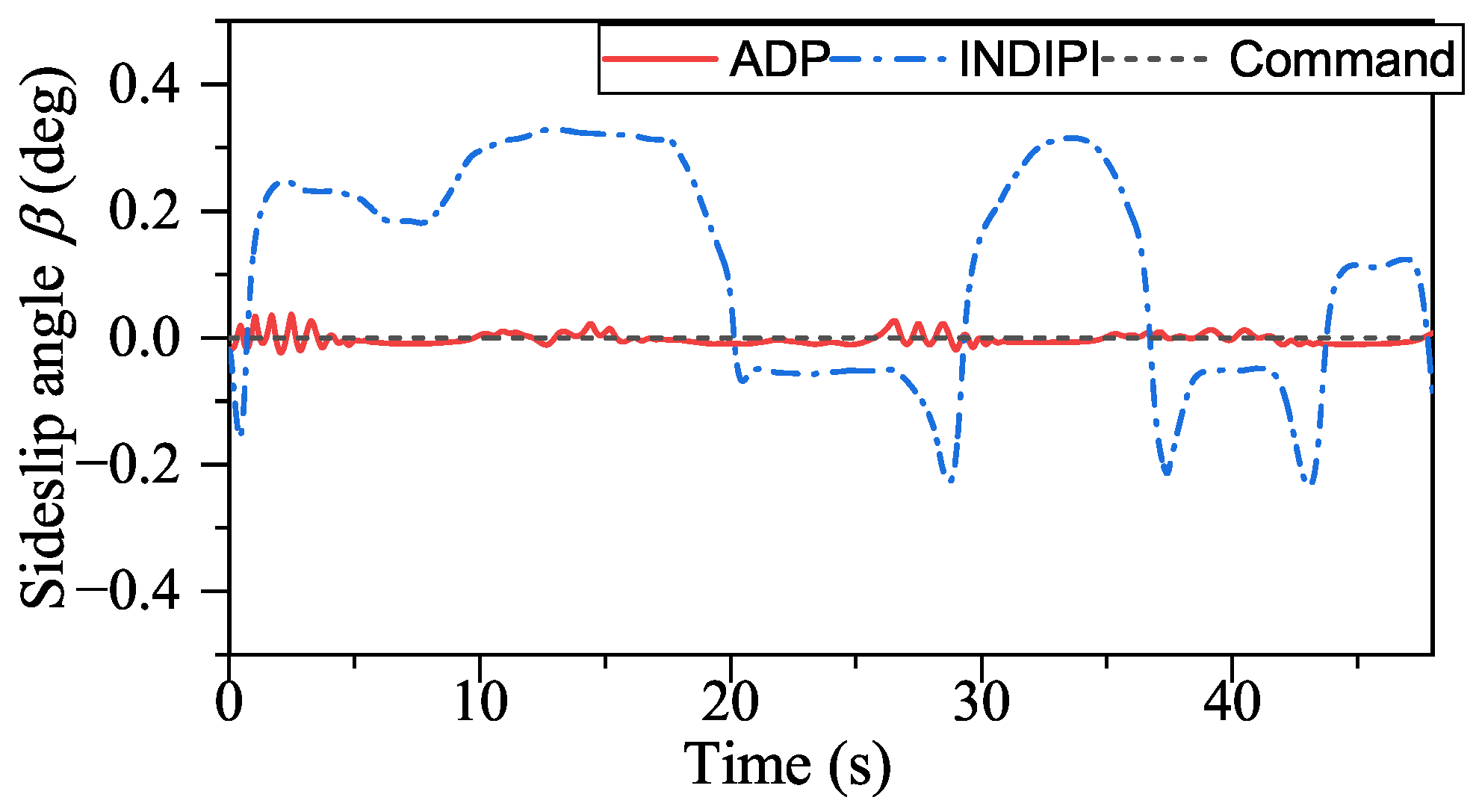
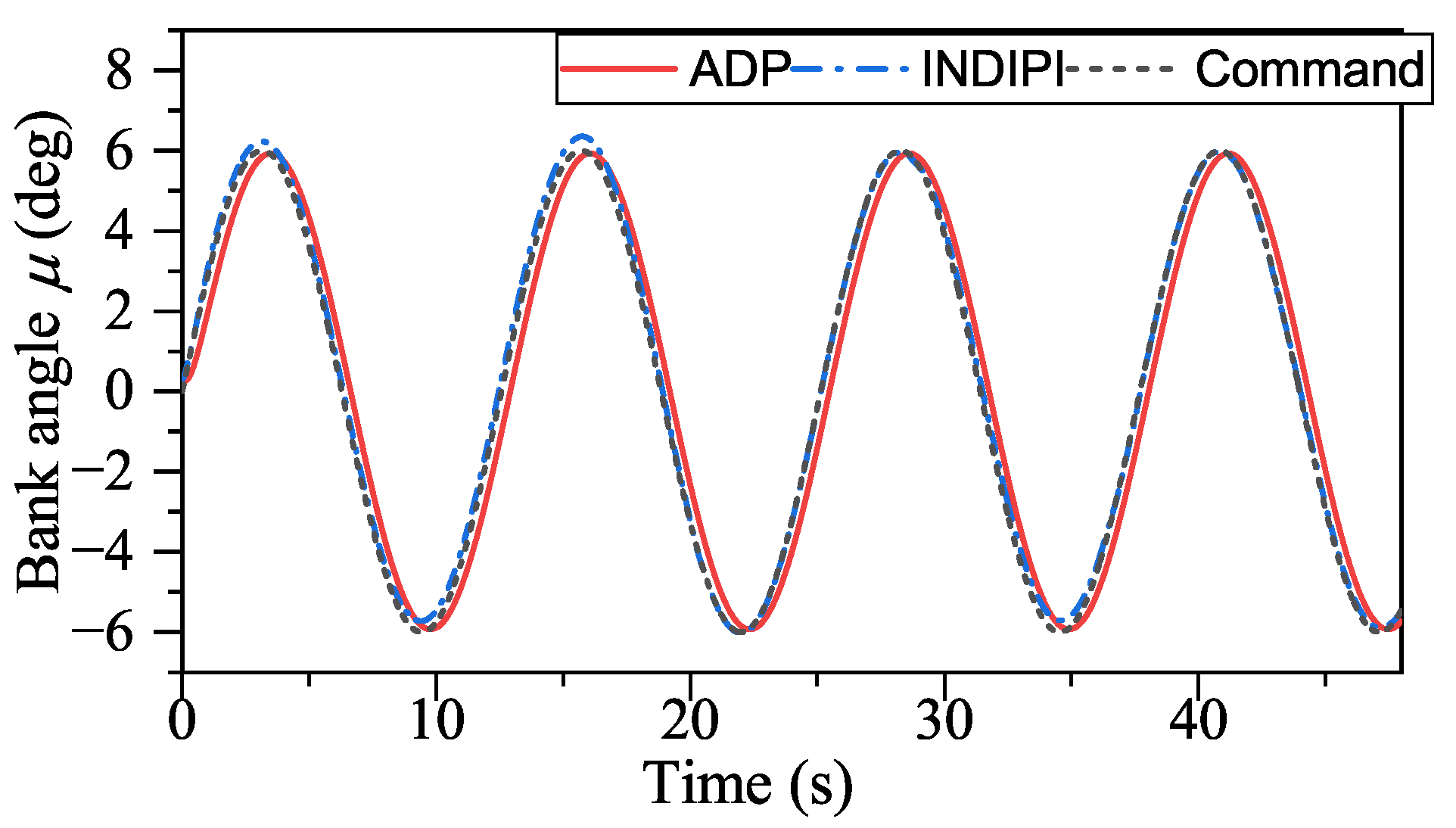
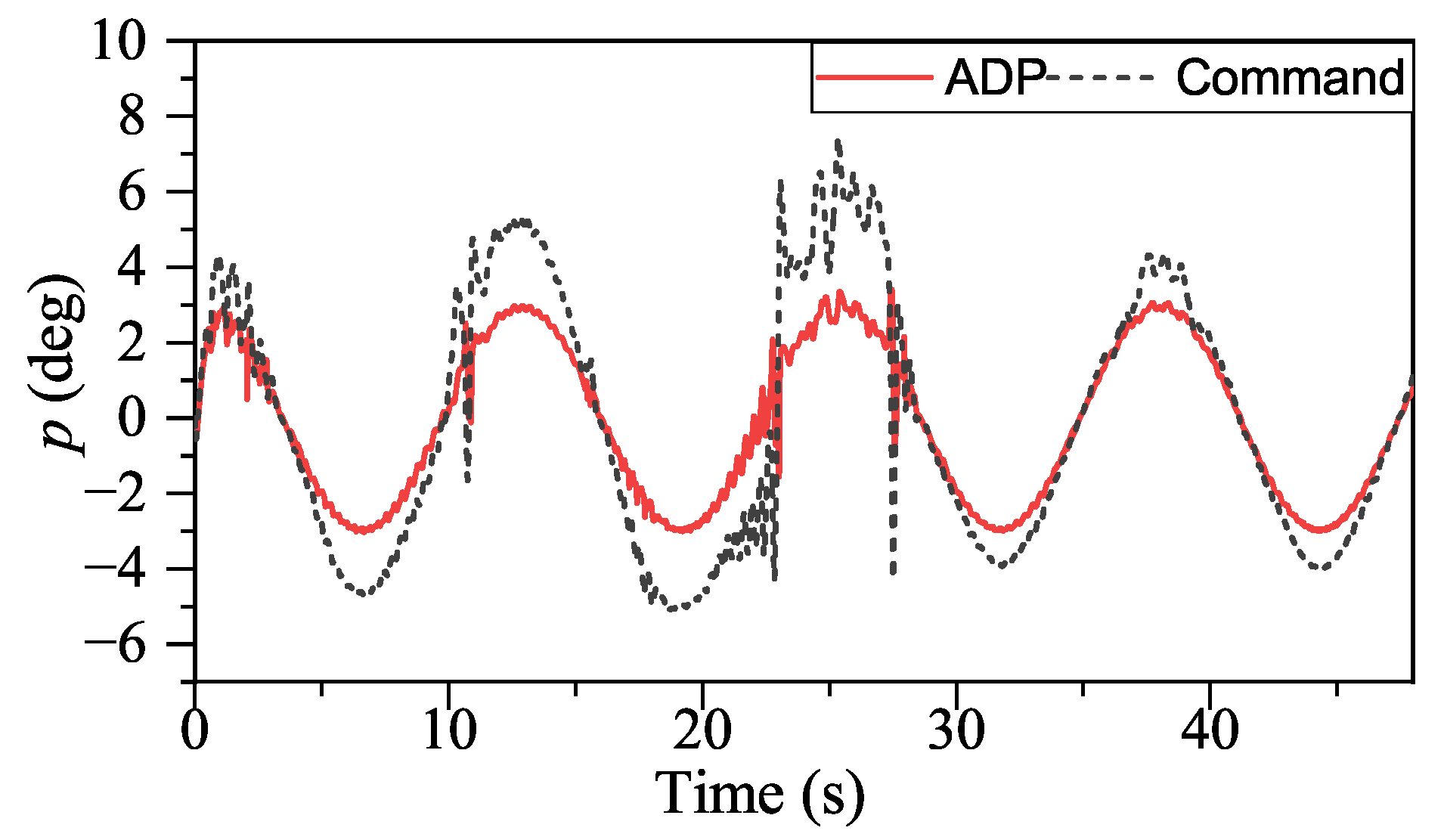
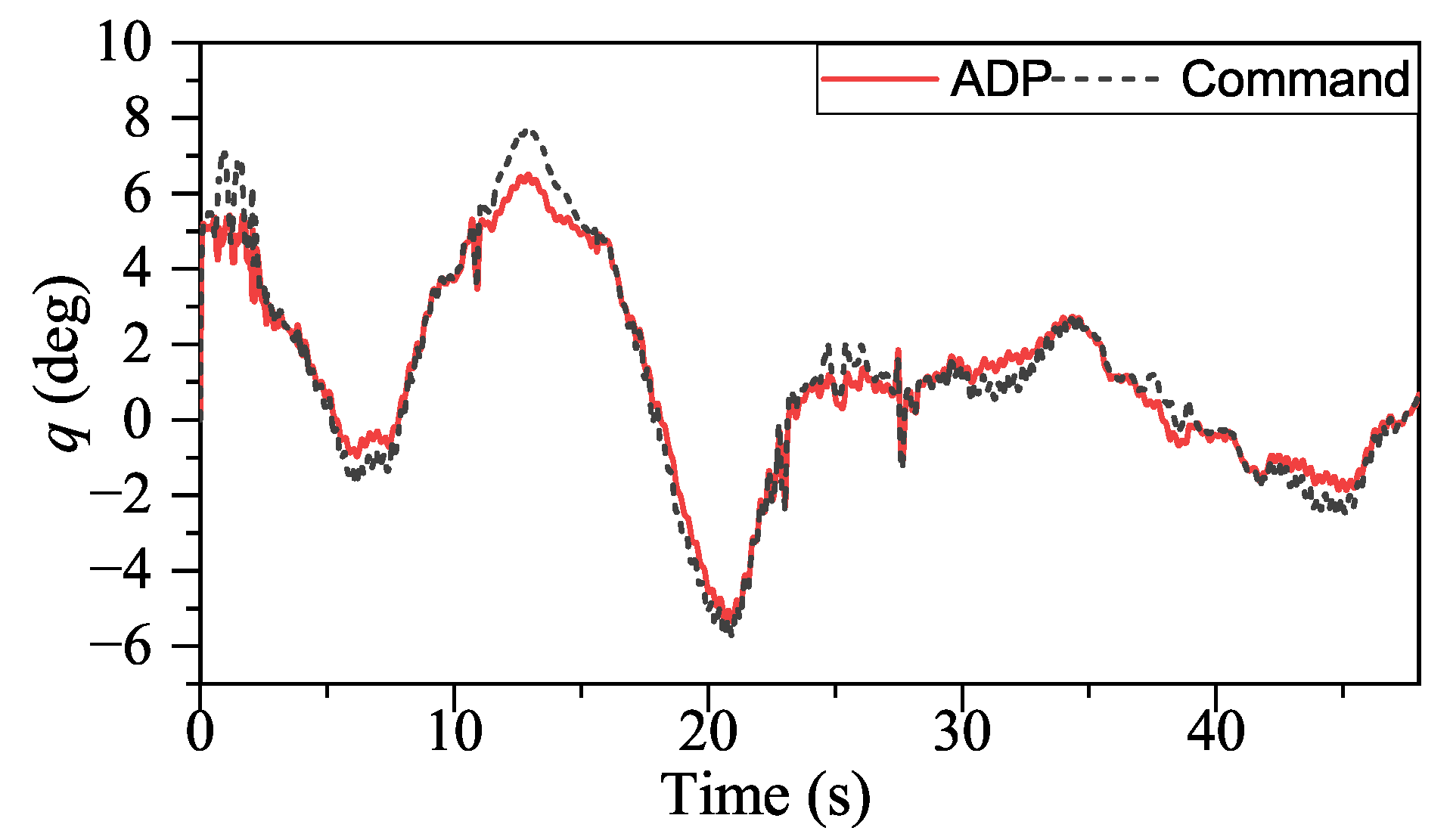
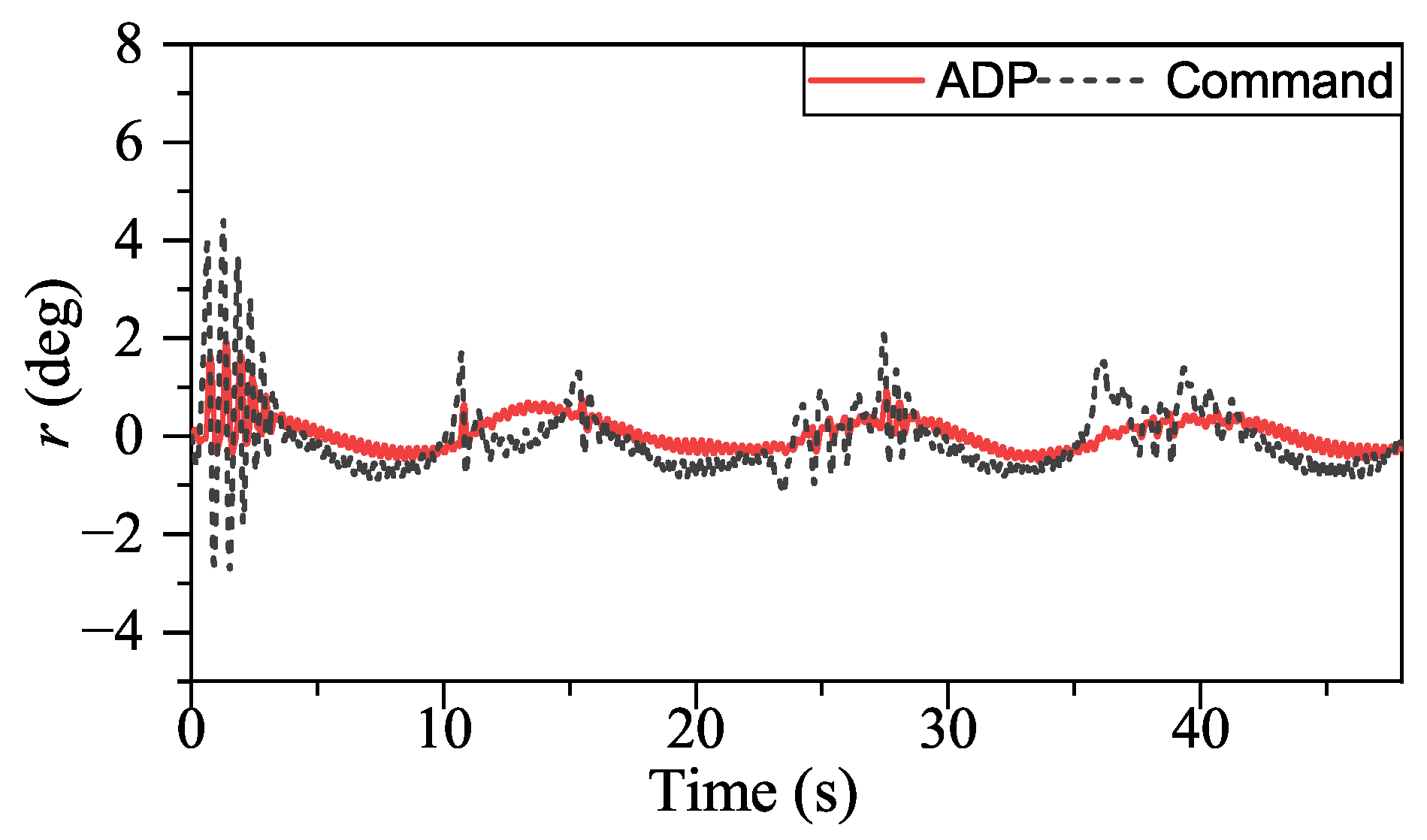
Figure 17, ADP-based method shows good convergence. Moreover, the proposed method outperforms INDIPI in three ways: superior flight quality, intelligence, and better effector deflection pattern.
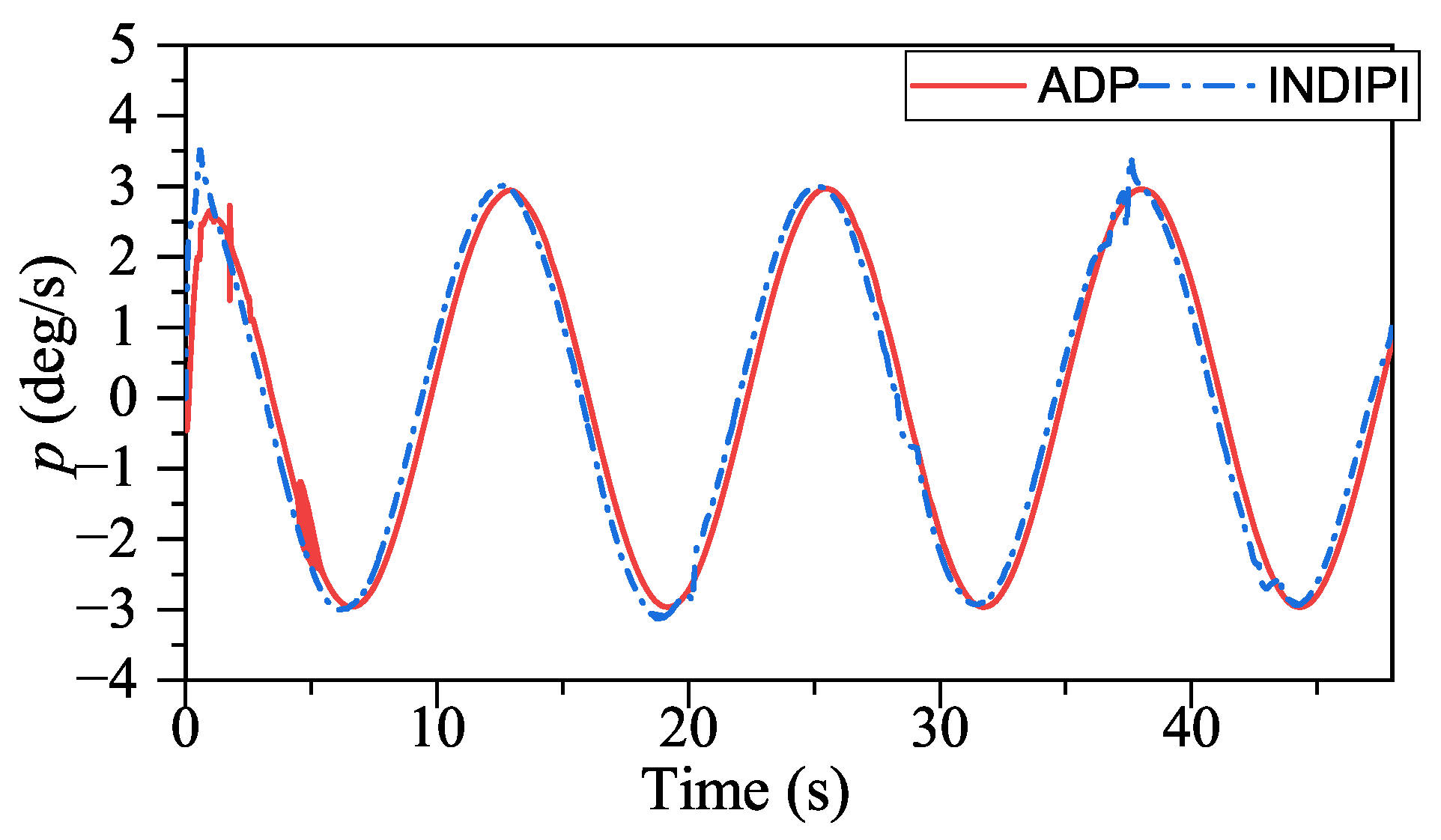
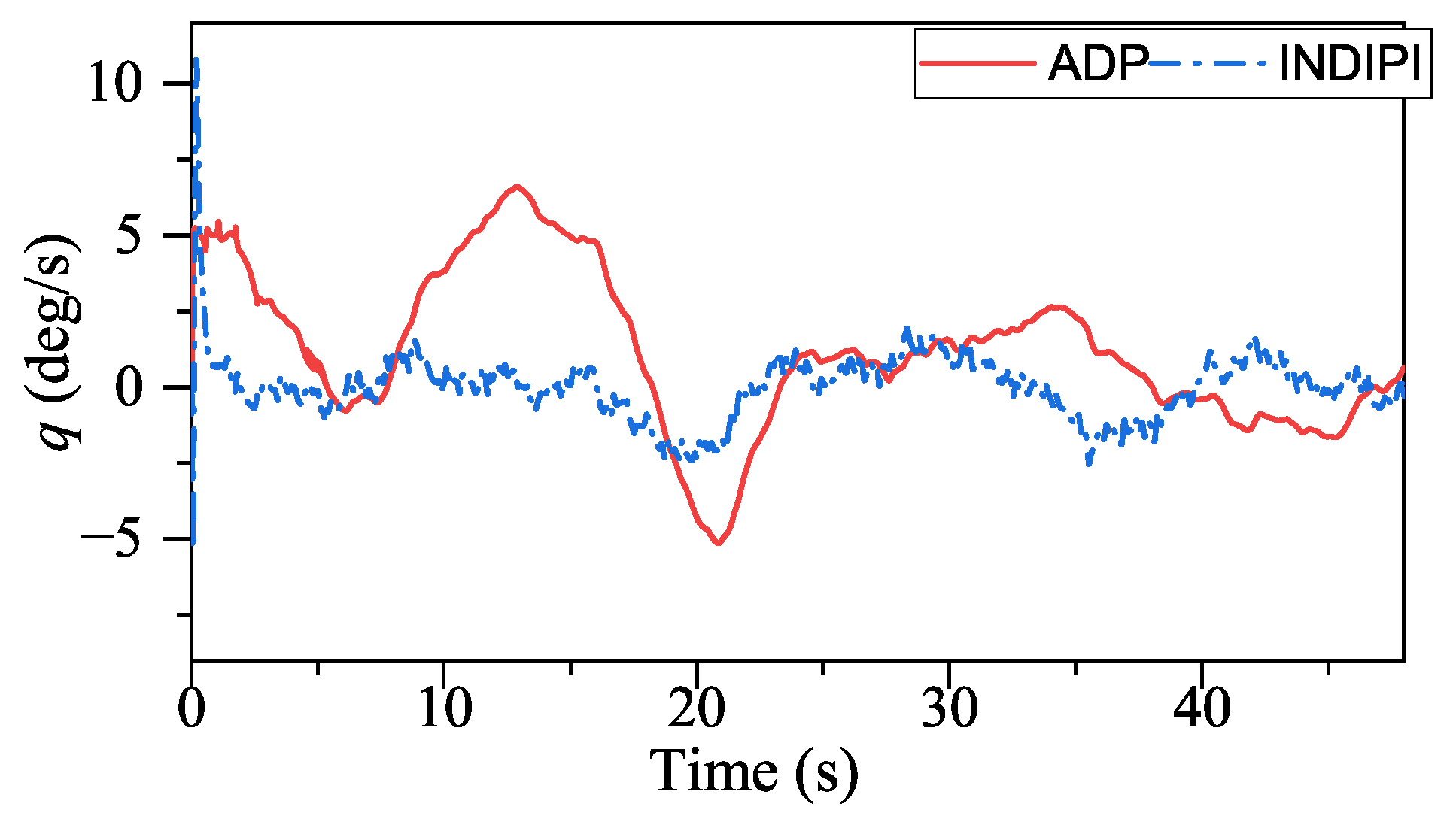
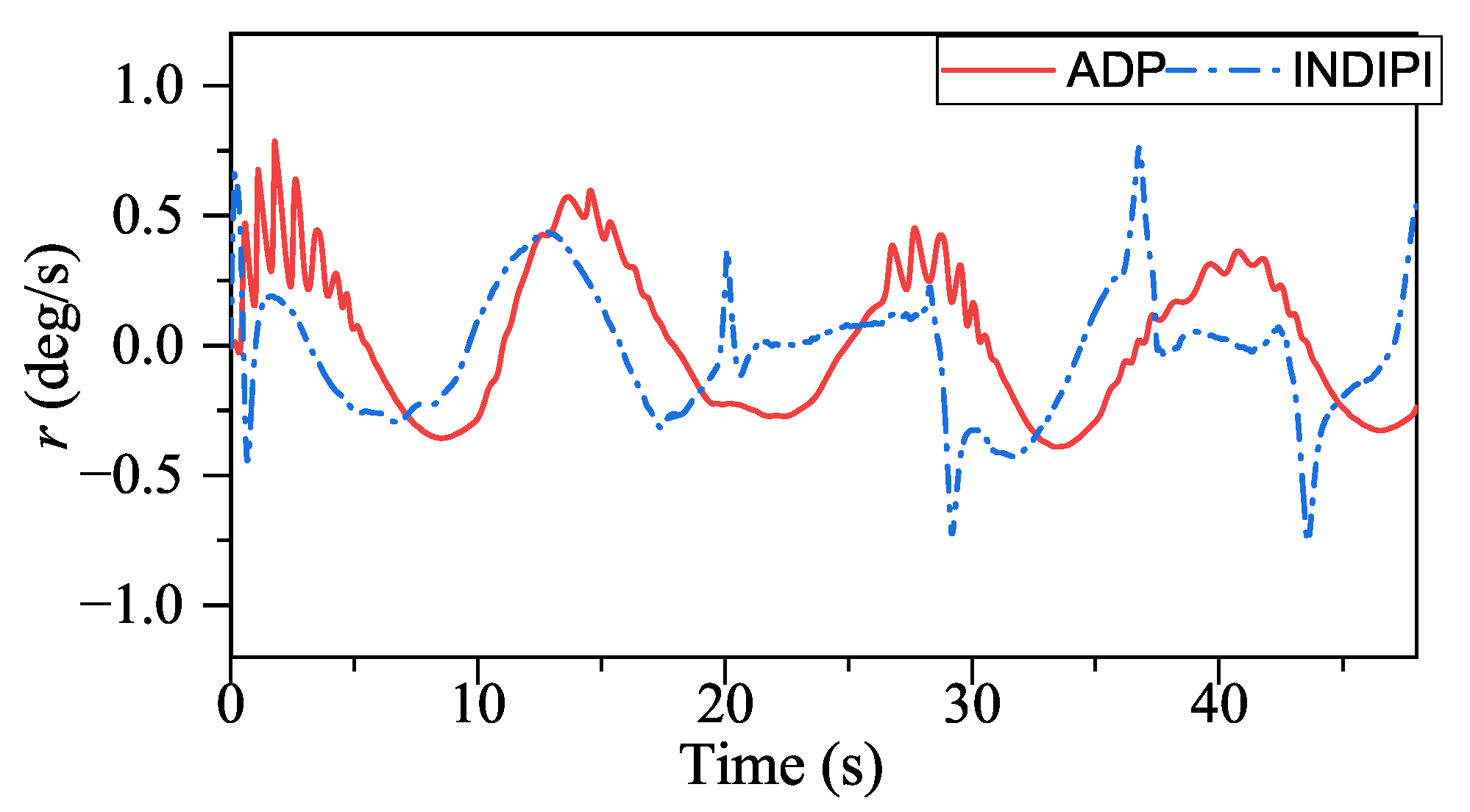
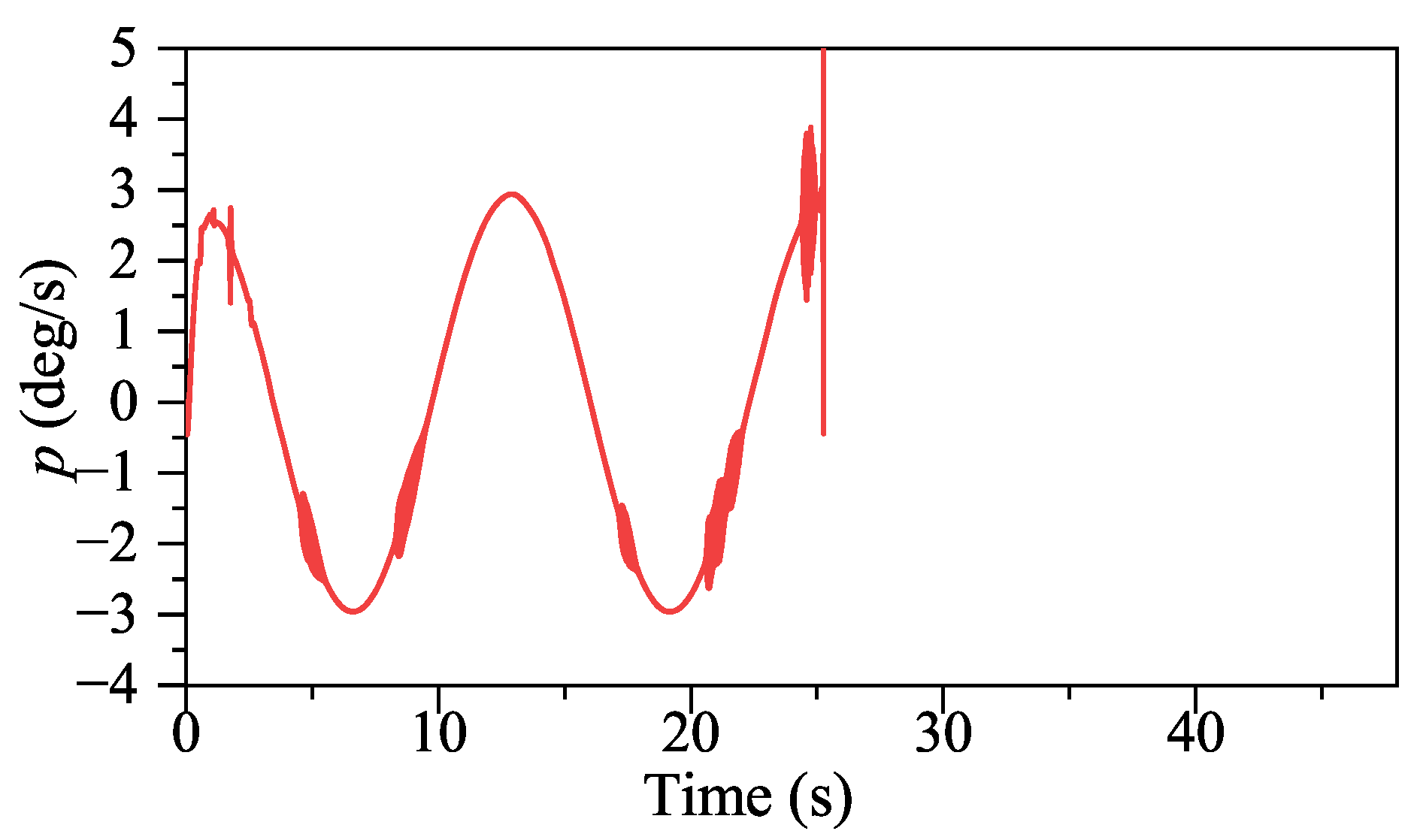
From
Figure 9,
Figure 10,
Figure 11 and
Figure 12, the flight quality under ADP control is better than that of INDIPI. From
Figure 9, the
p signal under ADP control is steadier. After the adjustment period before 5s, the
p signal under ADP control keeps steady, while the
p signal fluctuates under INDIPI control, such as around 38 s and 44 s. From
Figure 10,
q chattered all the time under the control of INDIPI, such chattering also can be found in effector deflection as shown in
Figure 16, and this can cause fatigue of the effector, which is very dangerous in reality, while the effector deflection under ADP control is more fluent. From
Figure 11, it can be found that there is a sudden change in
r signal under INDIPI control at 20 s, 29 s, 36 s, and 44 s. It also could be seen that the
r signal under ADP control also appears to fluctuate, but, differently from the sudden change under INDIPI control exhibited all the time, it can be found that the fluctuation under ADP control is becoming lighter.
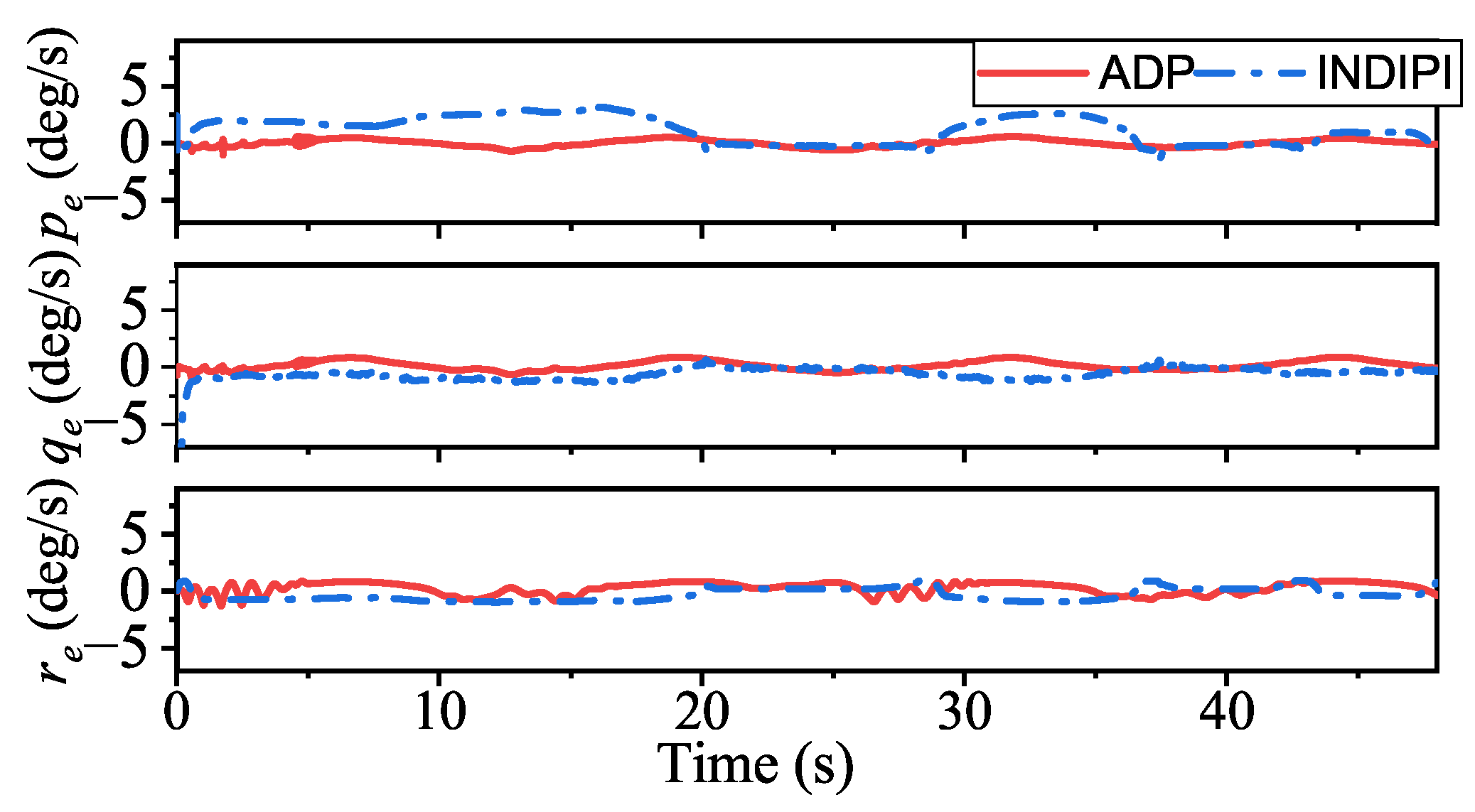
According to the above description, the control performance of our method is better compared to INDIPI. However, our method goes far beyond that. With the help of ADP, our method shows intelligence, i.e., it could improve its policy according to its experience.
The specific manifestations of the ADP-based method’s intelligence are p signal under ADP control only fluctuates once around 5 s. After that, it is always very smooth, and, compared with the sudden change in r under INDIPI control exhibited all the time, the fluctuation of r signal under ADP control becomes lighter as the control system runs.
A more extreme example is introduced to further illustrate the intelligence of ADP, as shown in
Figure 14, which shows the
p signal under the proportional control that adopts the initial weights of critical NN. Comparing
Figure 9 and
Figure 14 it can be found that no matter whether under ADP control or proportional control, fluctuation occurred around 5 s. However, such fluctuation only occurs once under ADP control; for proportional control, such fluctuation occurs repeatedly and eventually leads to losing control. From
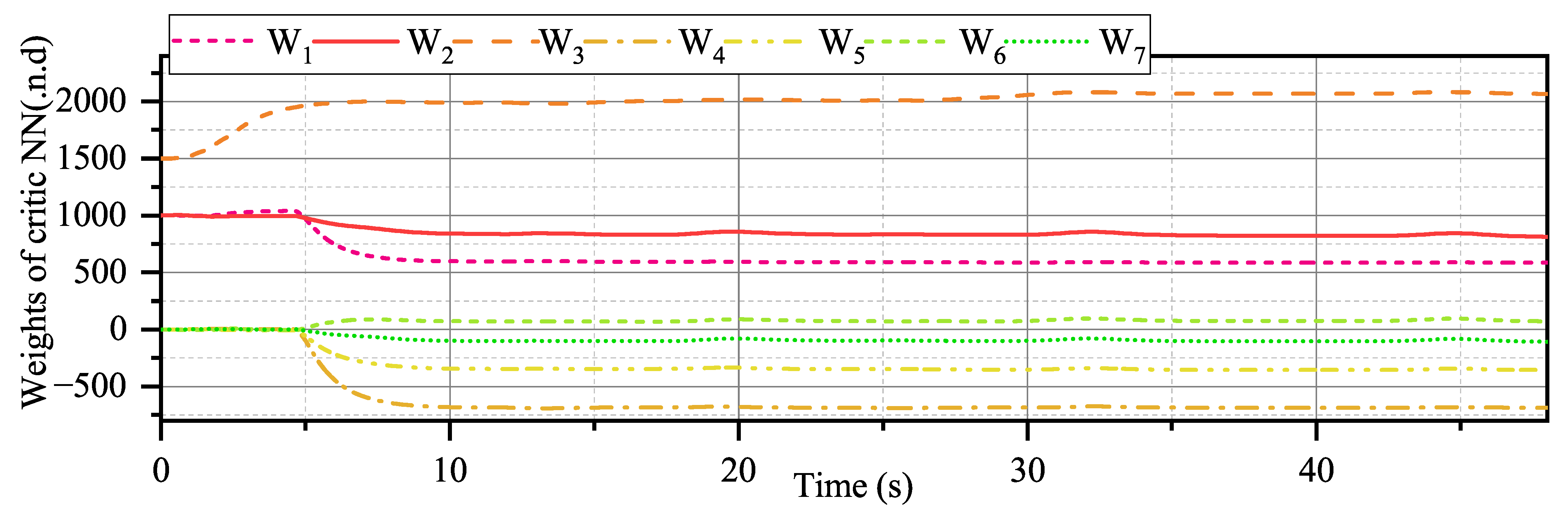
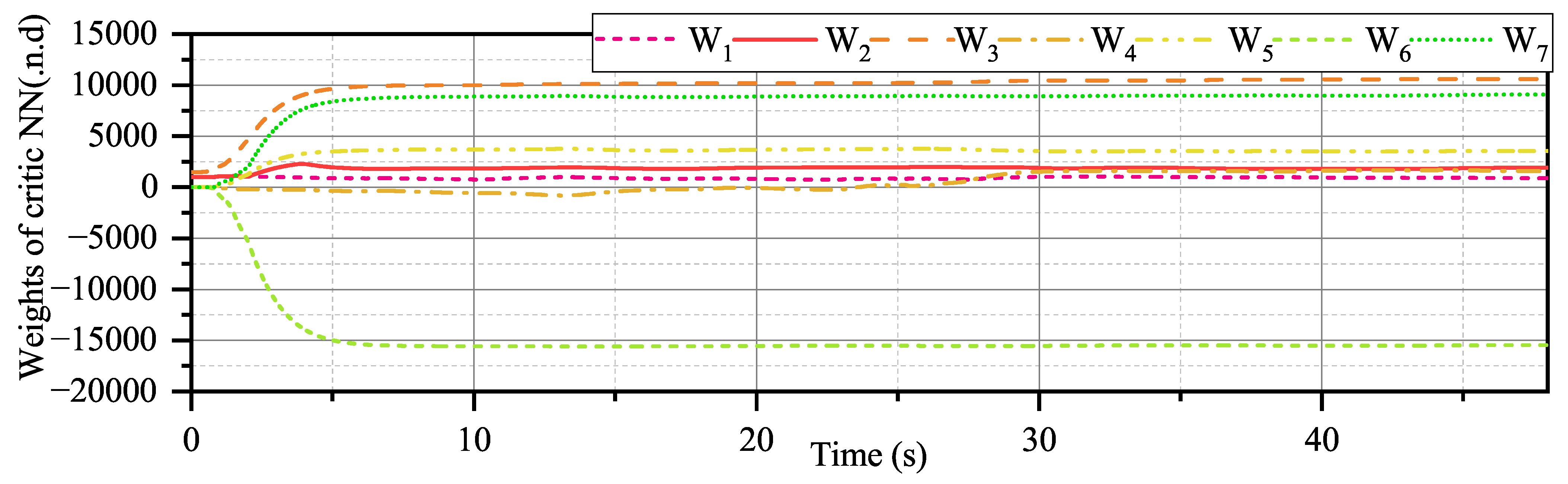
Figure 17, it can be seen that the critical NN weights undergo a large adjustment at 5 s, after which there is no more fluctuation similar to at 5 s. ADP could learn from such fluctuation; therefore, the subsequent policy is more suitable for flight control with a broader flight envelope.
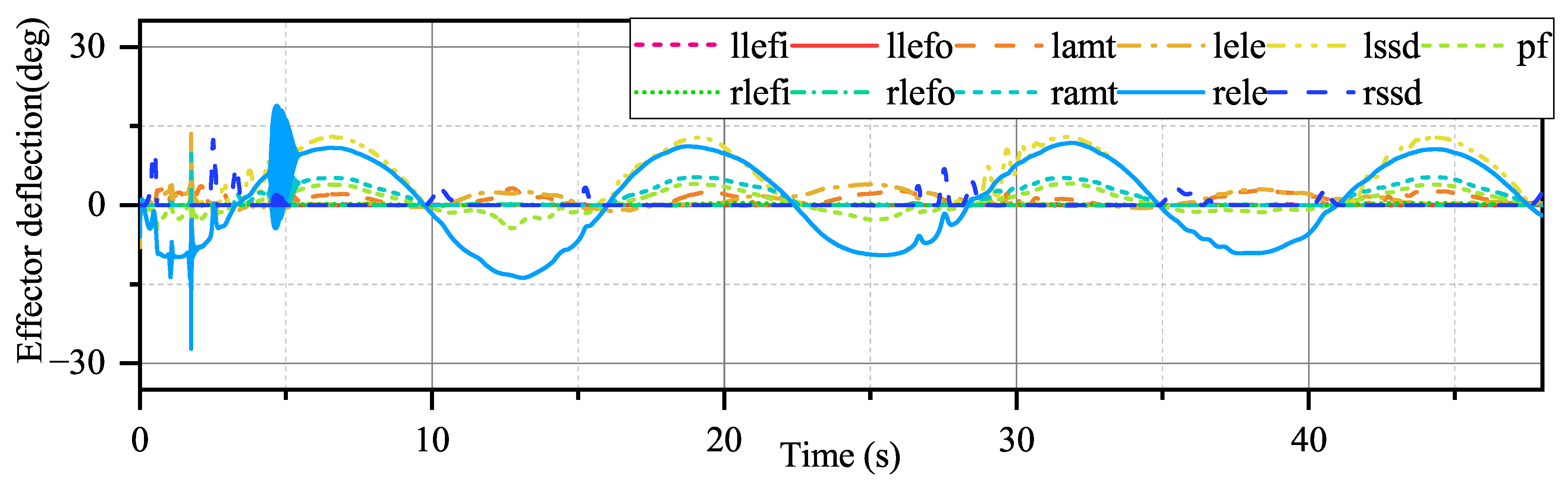
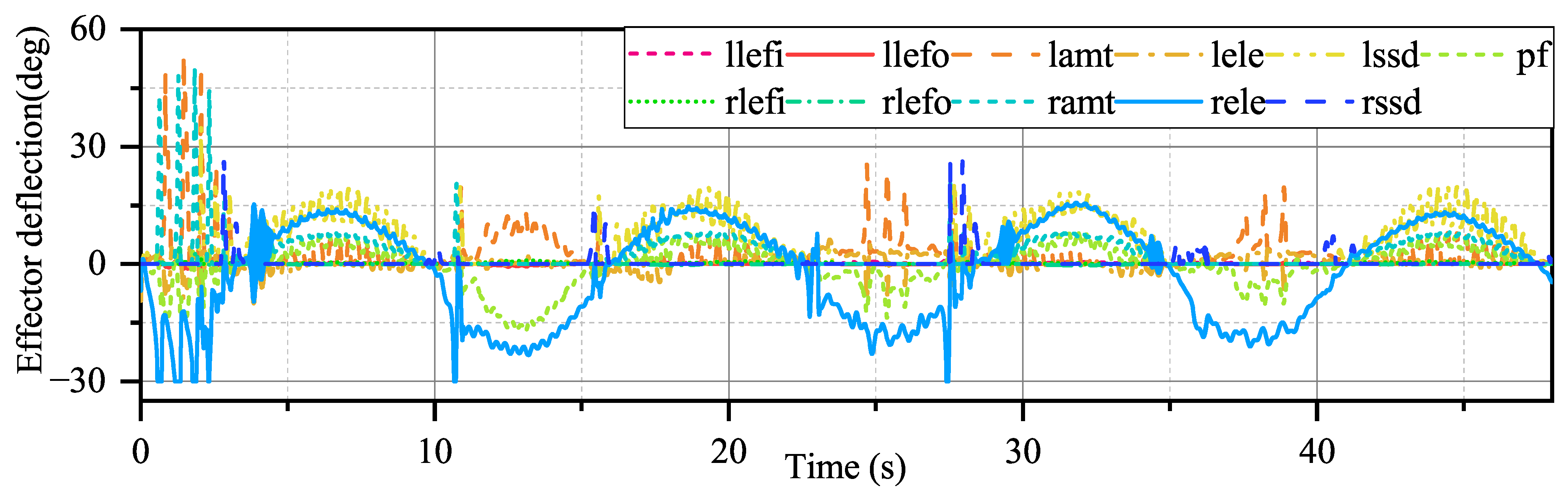
From
Figure 15 and
Figure 16, the effector deflection generated by INDIPI and ADP shows different patterns. In
Figure 16, it can be seen that only three effectors participate in the process under INDIPI control, even though some effectors appear to be saturated. However, for the ADP, under the modulation of the performance function, more effectors participate in the control process, and the effector deflection amplitude is significantly smaller than that of the INDIPI. From
Figure 13, it also can be seen that the weighted quadratic sum of effector deflection given by ADP is much smaller than INDIPI.
Overall, integrated-design ADP’s performance is better than conventional INDIPI’s. Compared with INDIPI, ADP allows for a trade-off between tracking performance and effector deflection. The performance function dominates such a trade-off, so ADP would not waste too many resources to pursue tiny improvements in tracking performance. Coupling with its learning mechanism, ADP can achieve the same tracking performance as INDIPI in an optimal manner.
5.2. Simulation 2
Simulation 2 discusses the robustness of the proposed method and the effect of
. The UAV suffers from aforementioned model uncertainties and external disturbances
. The UAV is to follow the same attitude command as Simulation 1 and set
as
, the result is shown in
Figure 18,
Figure 19,
Figure 20,
Figure 21,
Figure 22,
Figure 23,
Figure 24 and
Figure 25.
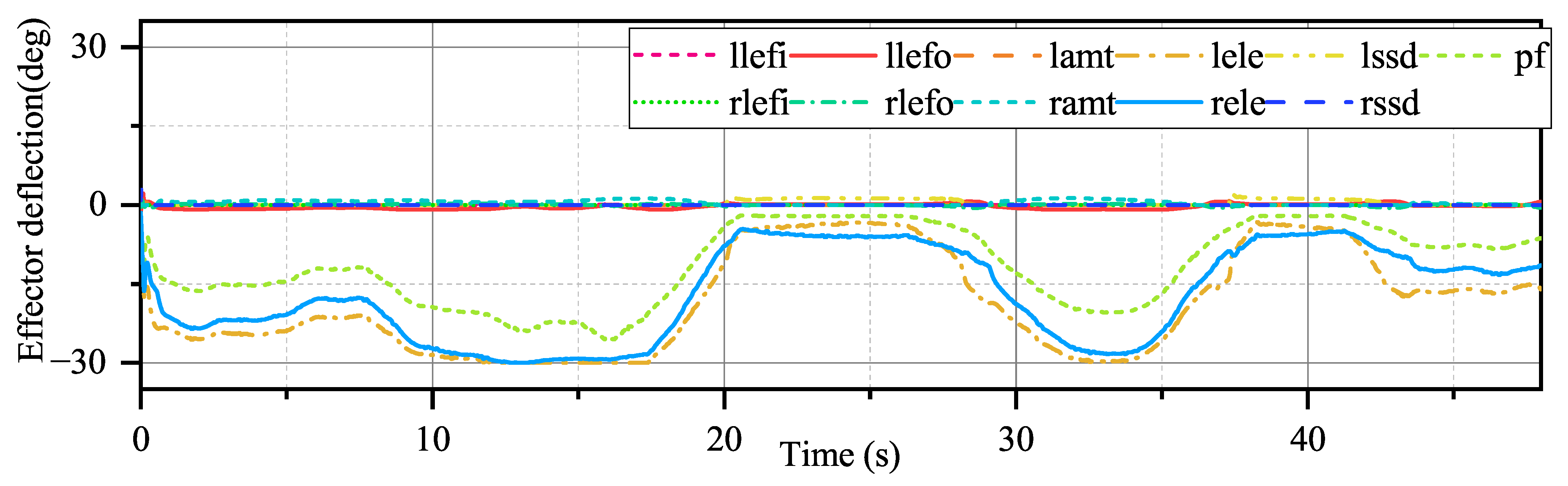
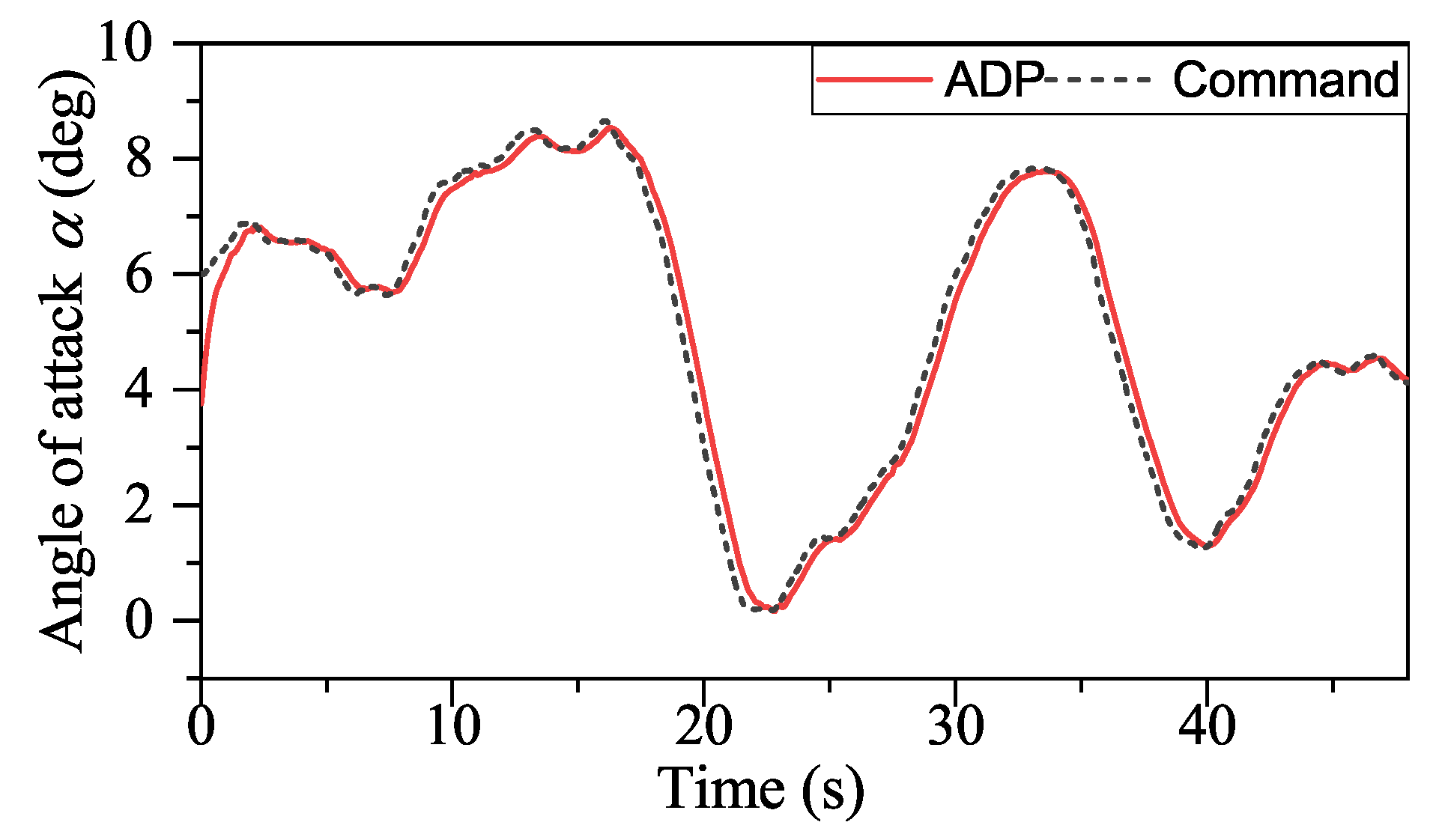
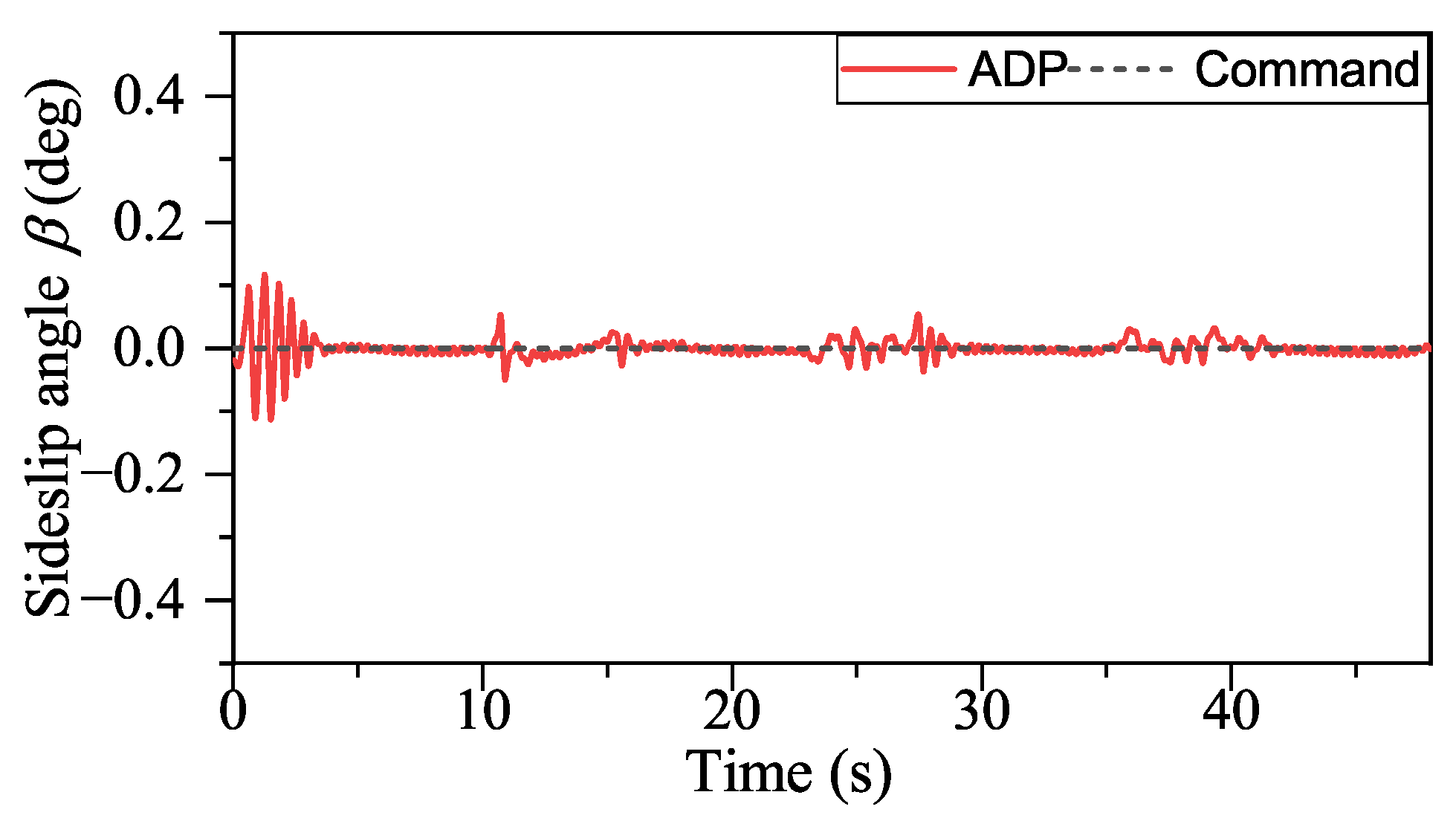
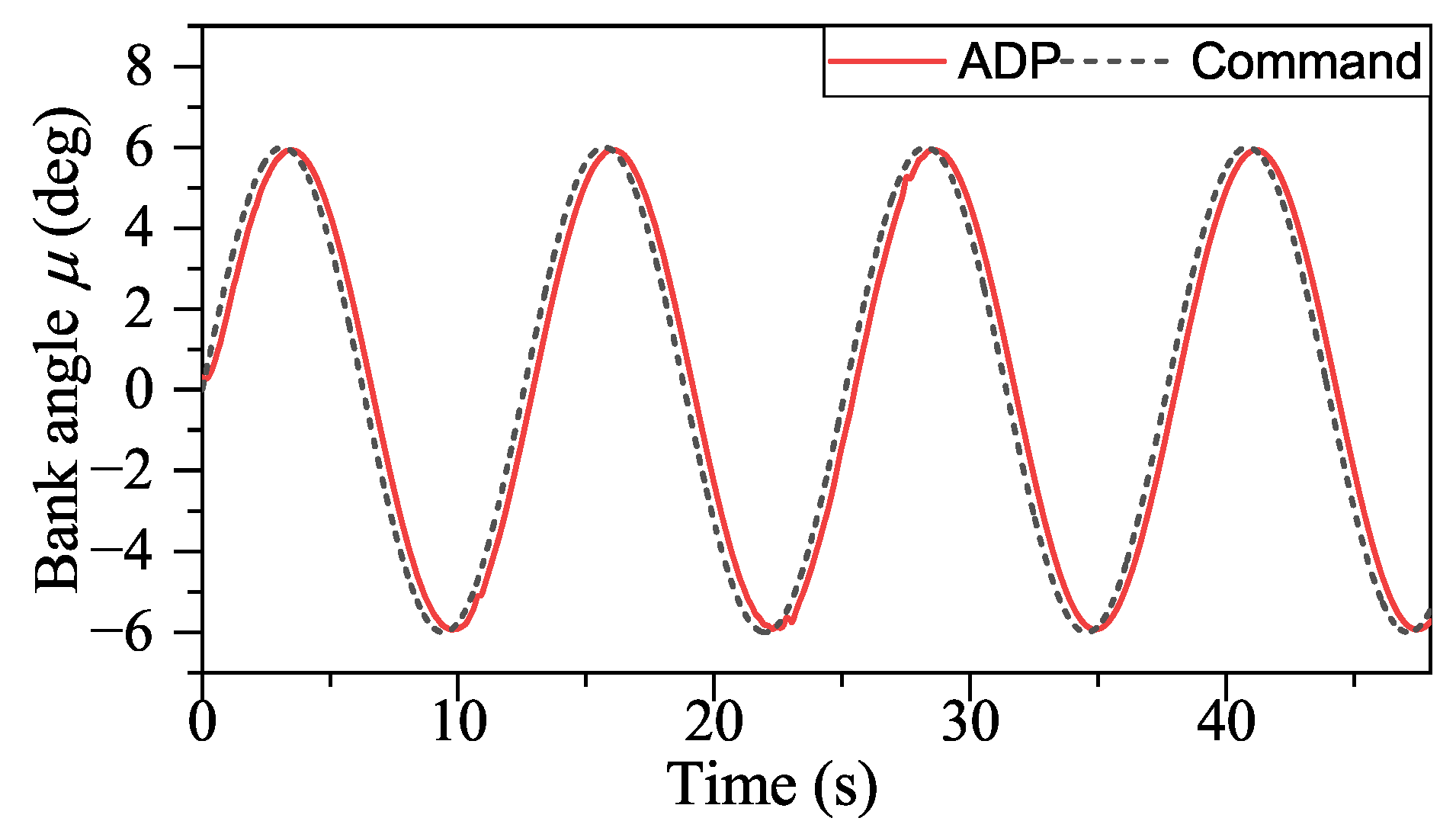
With the help of ADP, the tracking performance of our method in the presence of external disturbances is unaffected, as shown in
Figure 18,
Figure 19 and
Figure 20. However, some small chattering can be observed in the angular rate signal, as depicted in
Figure 21,
Figure 22 and
Figure 23, which is typical for a UAV subject to external disturbance. Nevertheless, this does not compromise the stability of the closed-loop system.
Figure 24 demonstrates that more effectors are involved in controlling external disturbances. Most importantly, the convergence of critical NN weights remains satisfactory, as demonstrated by
Figure 25.
From the stability analysis, it can be found that our method’s robustness comes from . In the following, the performance of different is tested.
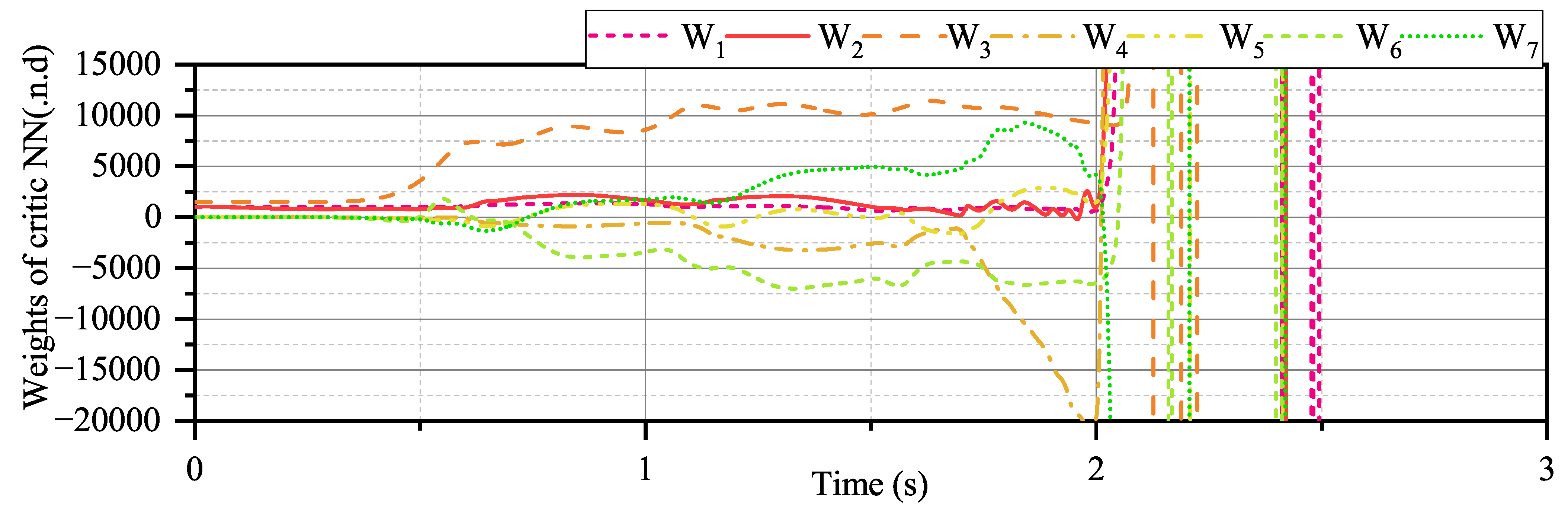
We begin by testing
. Due to space limitations, we only present the convergence of the critical NN weights in
Figure 26. As shown in
Figure 26, the convergence of the critical NN in this result is initially similar to Simulation 1. However, the critical NN weights do not ultimately converge due to external disturbances.
From a theoretical perspective, Lemma 1 can explain the non-convergence of the algorithm, as the closed-loop system’s stability can only be guaranteed when is of sufficient magnitude.
From the other point of view, if the UAV experiences intense external disturbances, the initial sampled data may not provide enough information for ADP to update critical NN weights. This is particularly true when the UAV is required to track random commands, as the old critical neural network weights may not be equipped to handle new, unforeseen scenarios. As a result, the NN weights may take longer to converge, making it difficult to maintain control of the UAV. In this sense, not only acts as a means of compensation for external disturbances that may initially affect performance but can also be seen as an estimation of the potential impact of such disturbances on performance function. This helps the ADP better understand the current situation, allowing the weights of the critical NN to converge more quickly to a stable value.
Unlike the affine systems, where the upper bound on the effect of external disturbances on the performance function is easily ascertained [
29], for the nonaffine system, the design of
is more rely on the experience. Still, considering that
has the actual physical definition, it would not be too hard to find a proper
.
The above result shows that must exceed the upper limit of external disturbance effects so that ADP can show robustness.
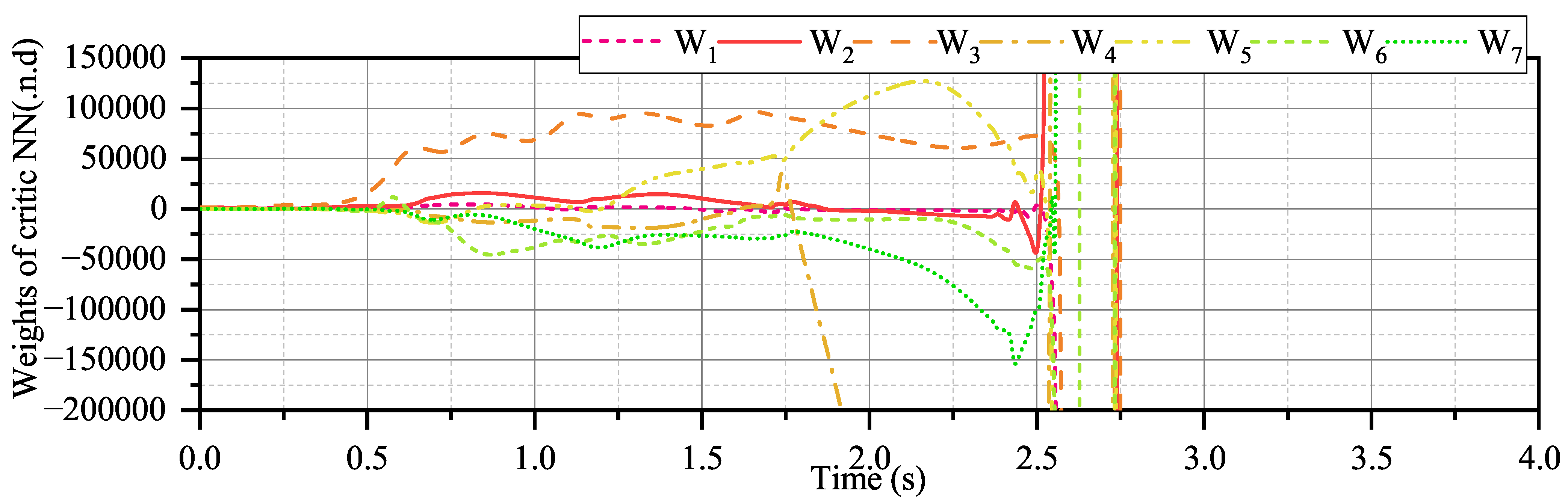
However,
should not exceed a reasonable value either. To illustrate this point, we conducted a convergence test of the critical neural network with
, which is very large. The result is depicted in
Figure 27. It can be observed that the system experiences a significant shift in critical NN weights, leading to a collapse within 3 s. From the analysis of Equation (34), having a too large
can result in
not being positively definite. More bluntly, too large
could dominate the dynamics of critical neural network weights, causing the ignored of sampled data that aid in policy improvement.
In conclusion, Simulation 2 demonstrates that our method can effectively withstand model uncertainties and external disturbances, given the appropriate selection of .
6. Conclusions and Outlook
The proposed method uses ADP to integrate control and control allocation, resulting in superior performance compared to conventional methods. Without using any model identification techniques, the ADP-based method exhibits strong convergence and robustness in the face of external disturbance and model uncertainty. Additionally, it presents a novel approach to flight control for over-actuated UAVs with nonaffine control inputs. From a control-theory perspective, the paper presents a straightforward yet efficient optimal tracking method for nonaffine systems, with theoretical evidence verifying its robustness. Specifically, this study has two key advantages in comparison to existing research. First, our method achieves better performance than traditional control architectures that separate control and control allocation by using a more optimized approach. Second, unlike many current optimal controllers for nonaffine systems, our method remains robust and does not depend on any model identifiers.
The proposed method has certain limitations that require attention. First, this method is only aimed at the cruise stage, as the nonlinear characteristics of the aircraft during this phase are not as prominent, and the optimal value function is relatively simple and can be well-fitted by a polynomial network. However, if large maneuvering flight is required, a more complex network structure needs to be introduced. This inevitably requires an improvement in the weight update rate to ensure system stability. Second, selecting the initial value for the critical network can be challenging when a complex network is used since the convergence of this method relies on the proper choice of the network’s initial value. Thirdly, the design of the is still heavily reliant on empirical knowledge. As demonstrated in the simulation section, a that is too small may weaken robustness, while too large may harm the closed-loop stability. Lastly, there is a dearth of real-world validation of this method. The external perturbations applied in the simulation offer only a limited exhibition of robustness and stability since the external interferences experienced by a UAV, in reality, are much more complex.
The next-step studies should focus on the following aspects: First, more complex neural networks can be introduced to further approximate the value function and handle more complex situations. Second, it would be very worthy work to introduce some intelligent algorithms to help design the performance function. Thirdly, only linear filters, as shown in Equation (34), are used in this paper, making our method better when facing high-frequency disturbances. In future studies, more advanced filters could be introduced to improve the performance of the ADP-based method when facing various disturbances. More importantly, it would be very expected that the performance of our method can be validated in real flight experiments.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}