
Machine Learning Methods for Inferring the Number of UAV Emitters via Massive MIMO Receive Array

 ,
, 
Abstract
1. Introduction
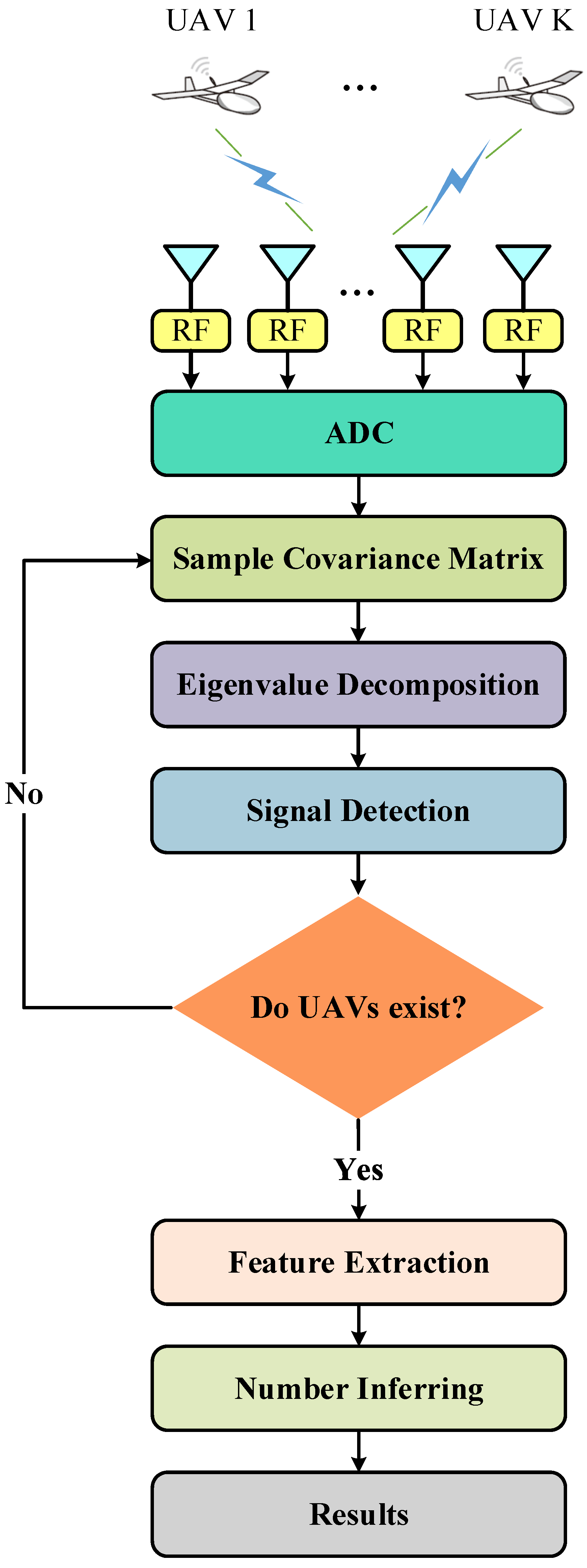
- A DOA preprocessing system is proposed for obtaining the number of UAV emitters via a massive MIMO array. The main steps of this system include signal detection and inferring the number of emitters. The received signals are first inputted into signal detectors. If the detection result shows the presence of emitters, this signal is further transmitted to signal classifiers to determine the number of emitters.
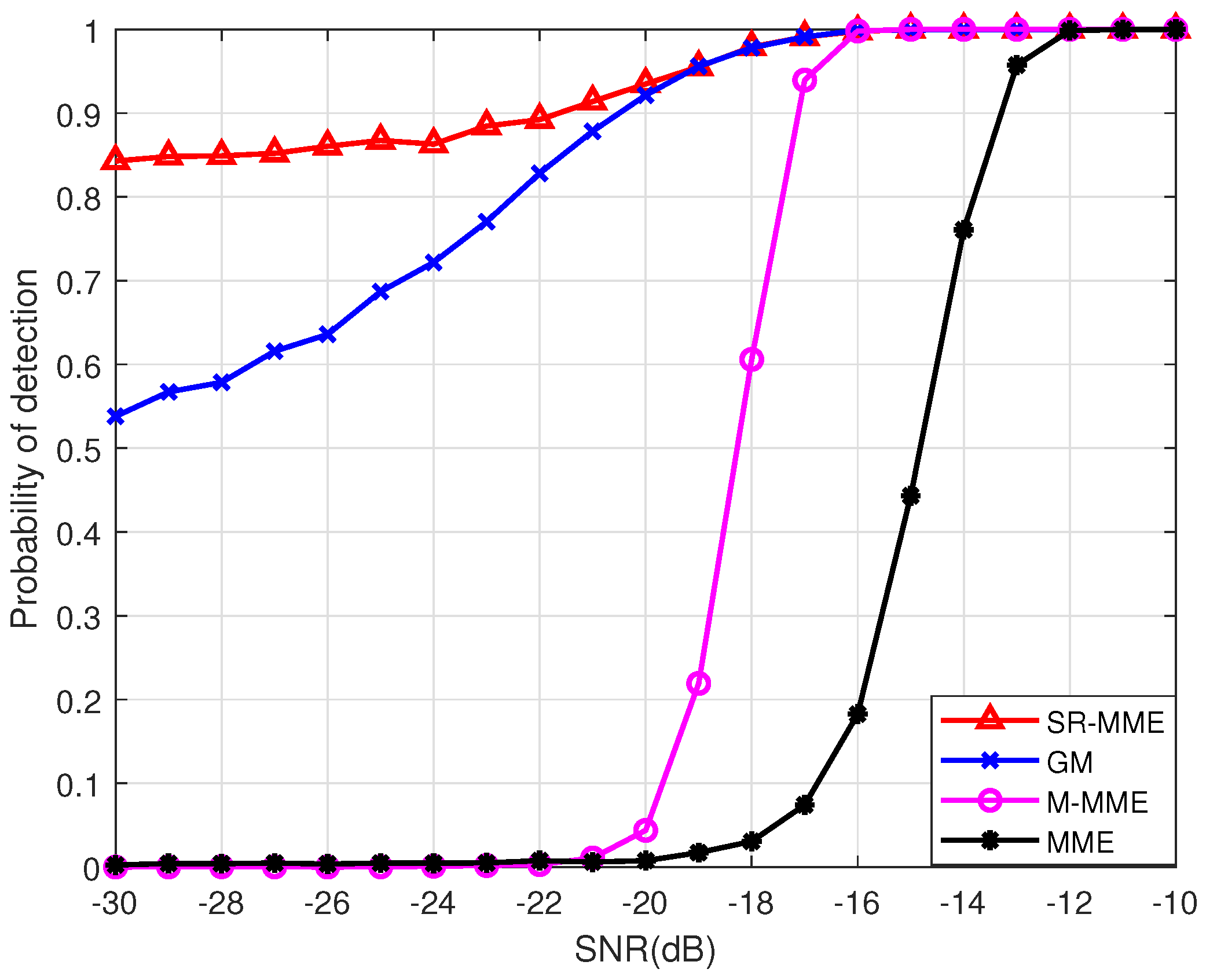
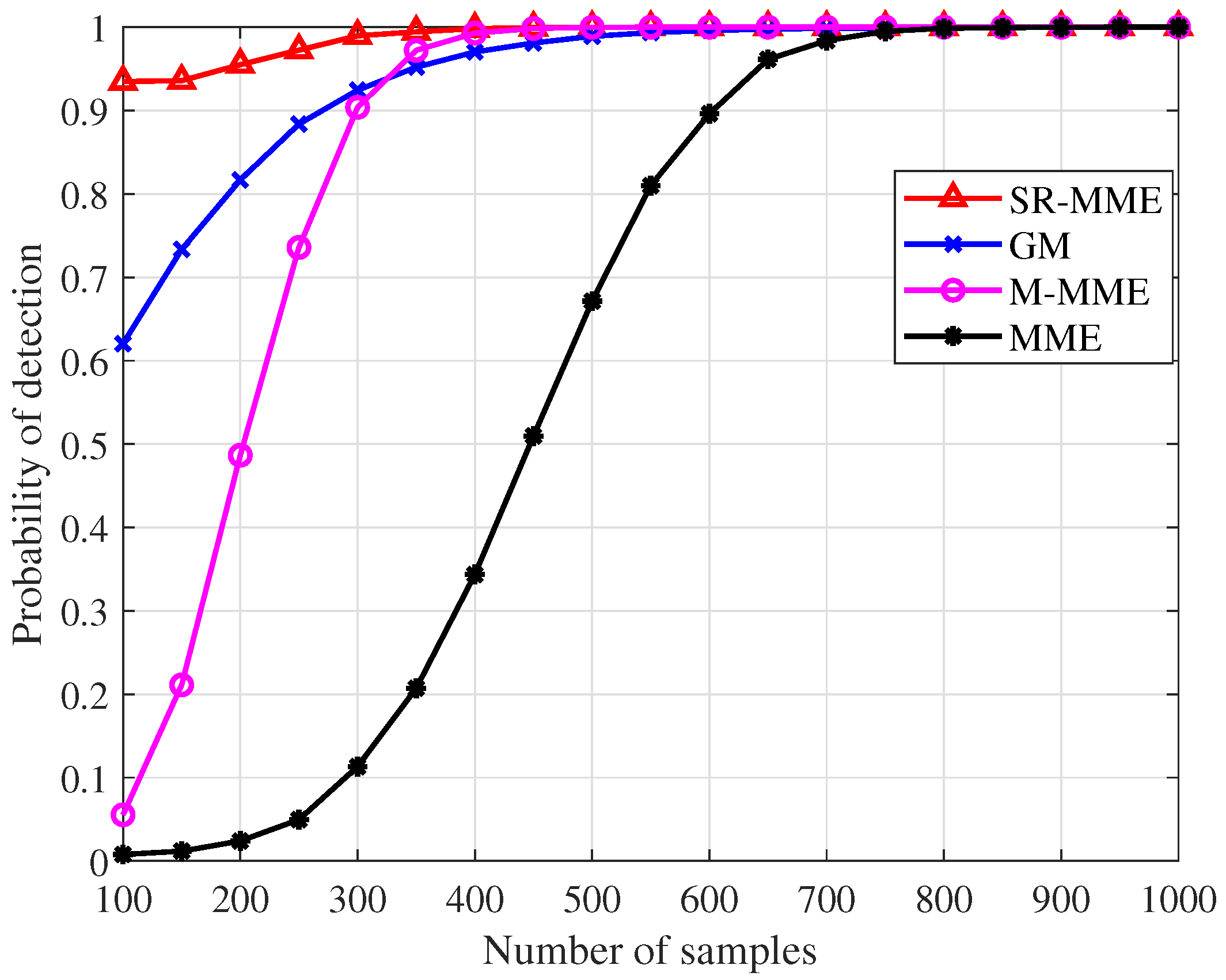
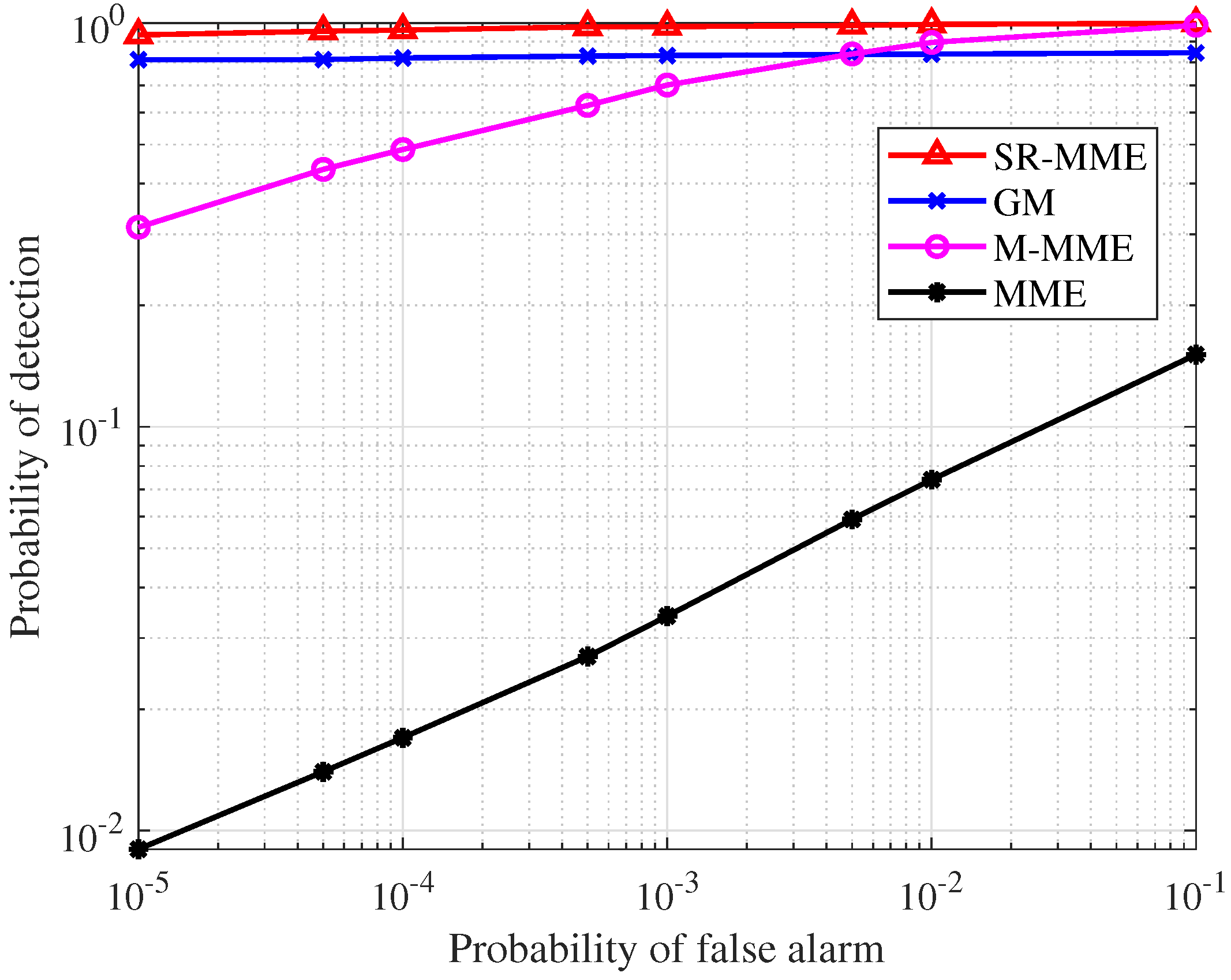
- Two high-precision signal detectors, the square root of the maximum eigenvalue times the minimum eigenvalue (SR-MME) and the geometric mean (GM), are proposed in Section 3. Their thresholds and probability of detection are also derived with the aid of random matrix theories. The simulation results show that SR-MME and GM have significant improvement in detection performance compared with the MME detector proposed in [27] and the M-MME detector proposed in [36], even though the SNR is very low and the number of samples is small. The simulation results also show that SR-MME and GM can maintain a low false alarm probability while achieving a high detection probability.
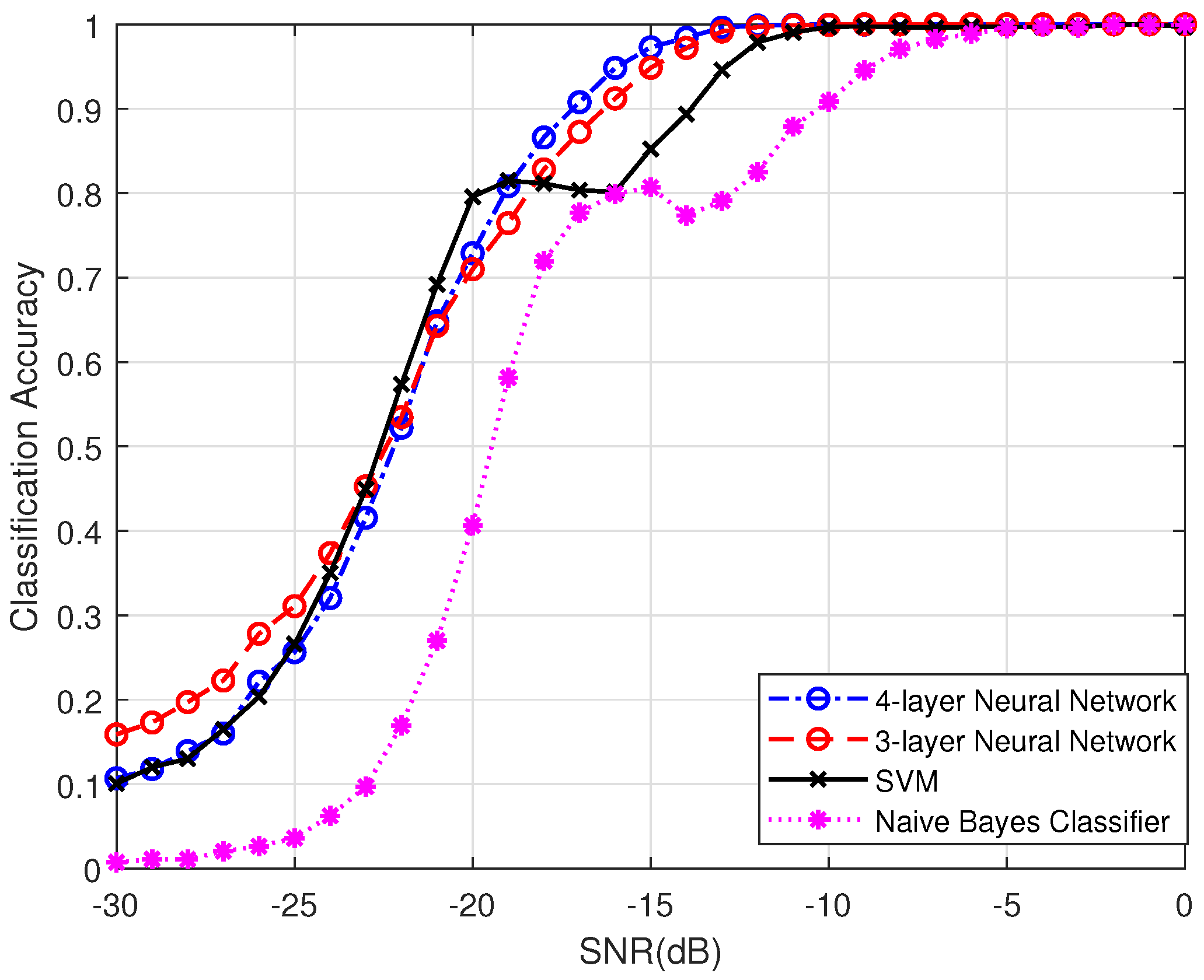
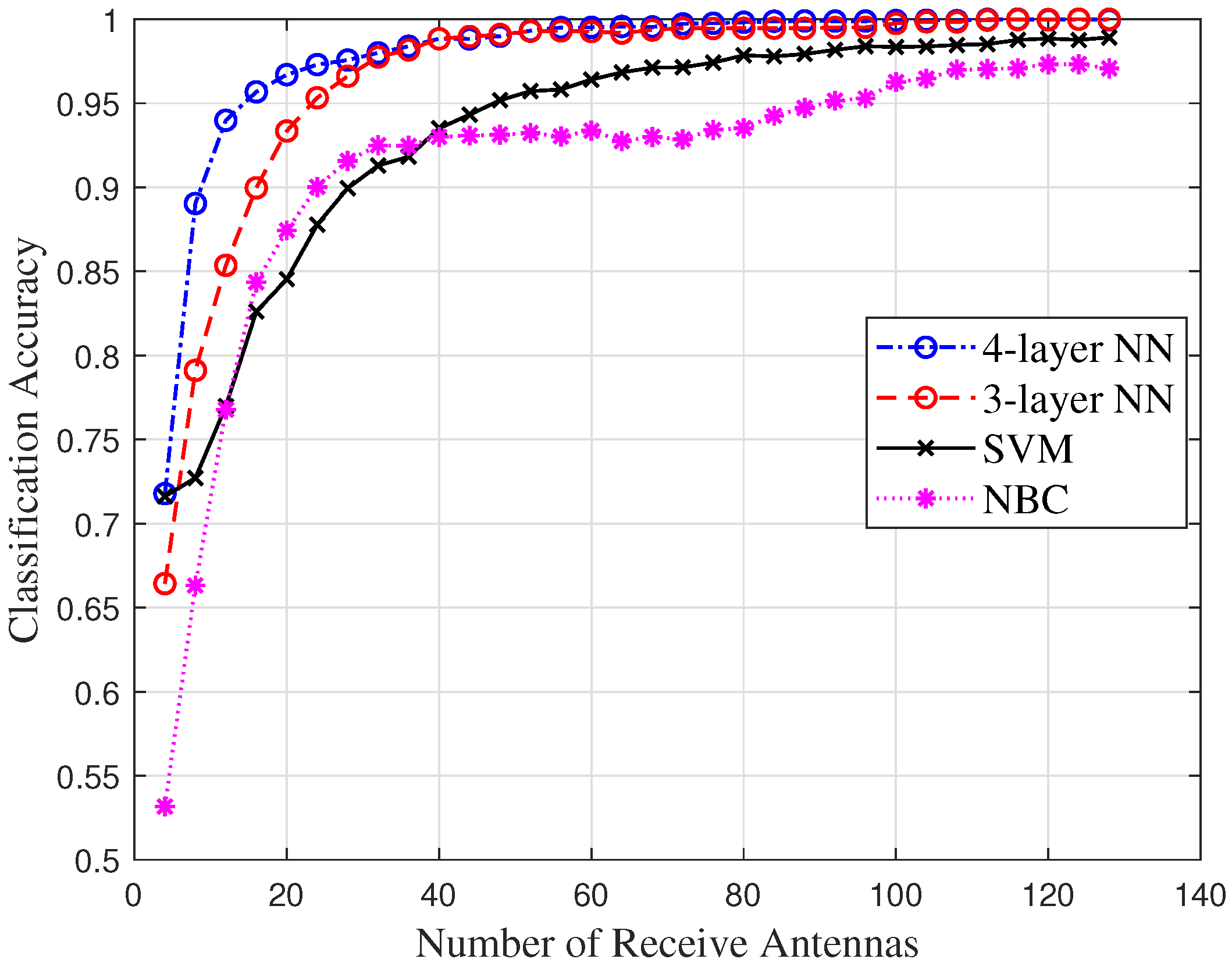
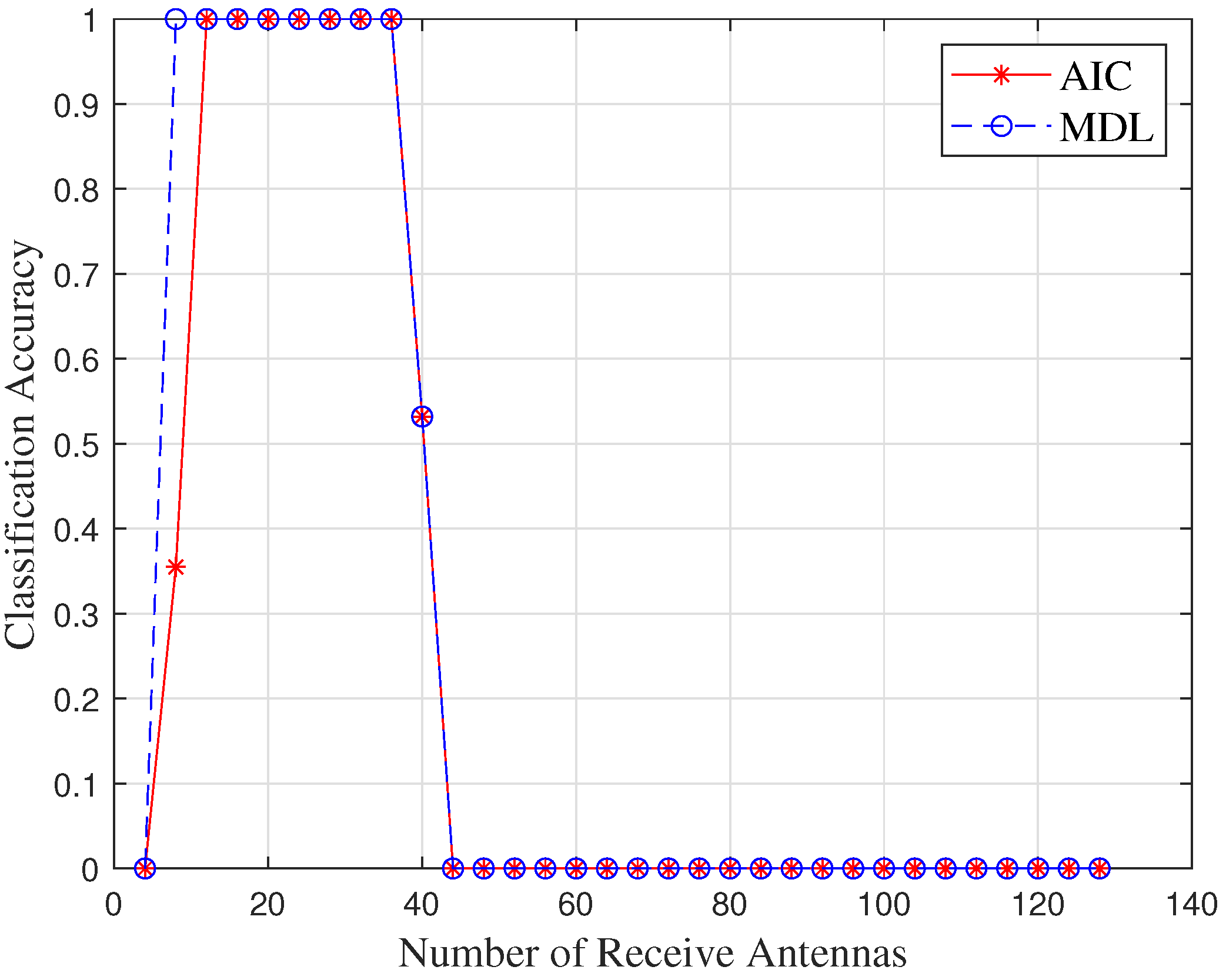
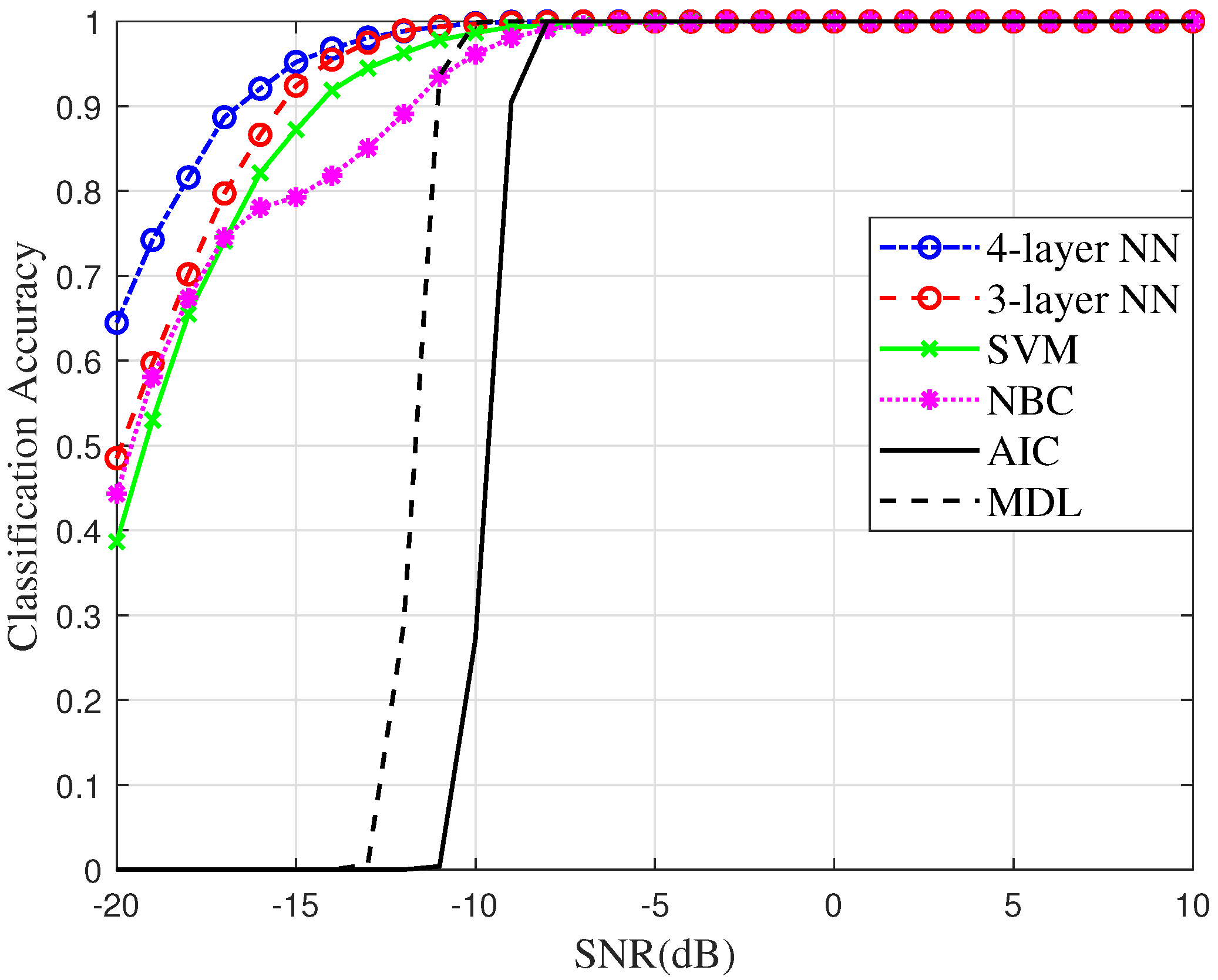
- Since the existence of emitters is known, we innovatively introduce machine learning-based classifiers to infer their number, including multi-layer neural networks (ML-NNs), support vector machine (SVM), and naive Bayesian classifier (NBC). Important features which make up feature vectors are also extracted from eigenvalue sequences of signals’ sample covariance matrices. The results show that machine learning methods are very suitable for performing signal classification, especially neural networks, because they can achieve a classification accuracy of 70%, even under extreme conditions. Finally, we validate the classification performance of AIC and MDL under different SNR and number of receive antennas. We show that they are unapplicable to scenarios with low SNR and massive MIMO receive arrays compared to machine learning-based methods.
2. System Model

3. Signal Detectors
3.1. Proposed SR-MME Detector
3.2. Proposed GM Detector
4. Proposed Classifiers for Inferring the Number of UAV Emitters
4.1. Feature Selection and Extraction
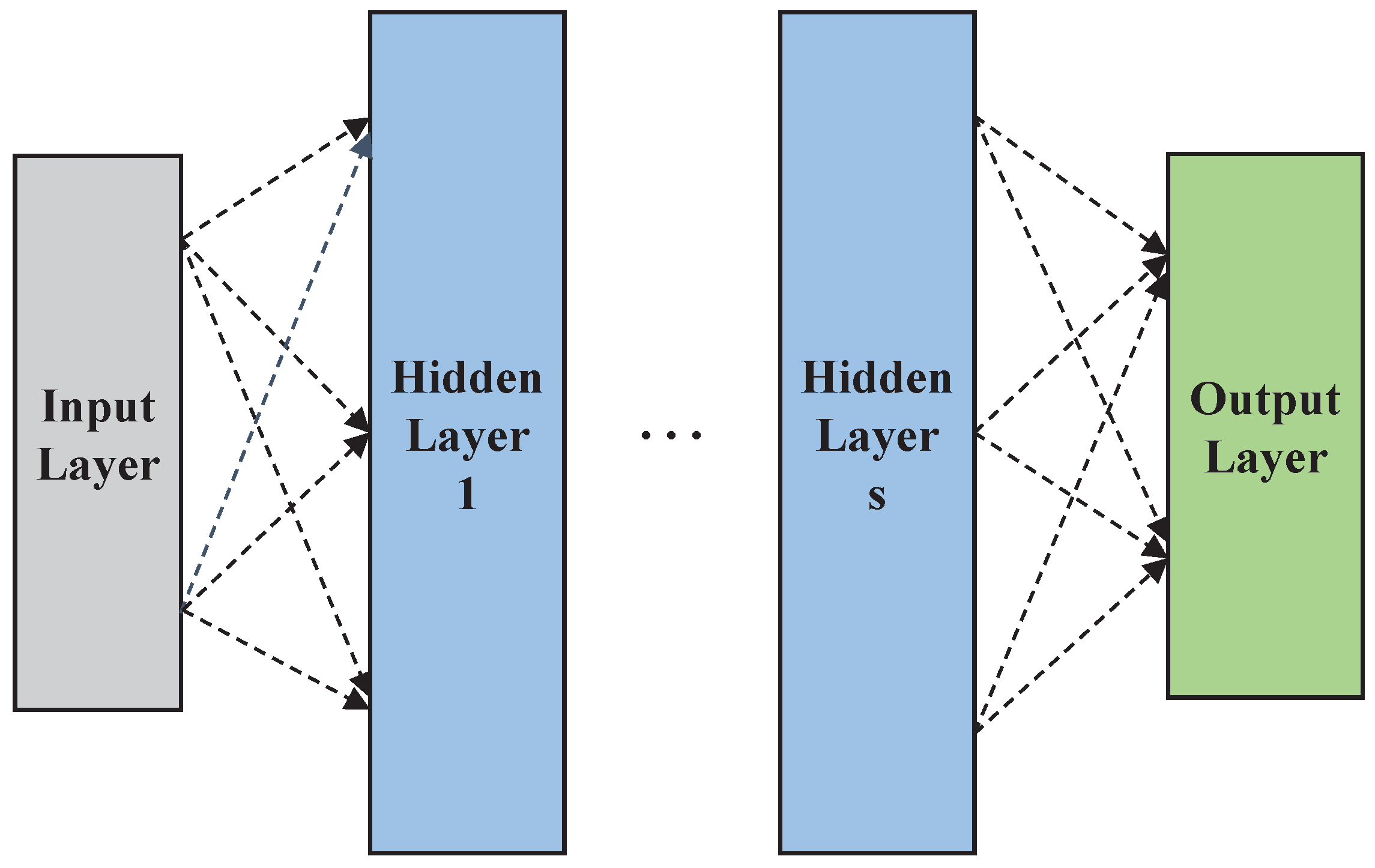
4.2. Proposed Multi-Layer Neural Network Classifier

4.3. Support Vector Machine Classifier
4.4. Naive Bayesian Classifier
5. Simulation Results
5.1. Signal Detectors
5.2. Signal Classifiers
5.3. Analysis of Classic Classifiers
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zeng, Y.; Zhang, R.; Lim, T.J. Wireless communications with unmanned aerial vehicles: Opportunities and challenges. IEEE Commun. Mag. 2016, 54, 36–42. [Google Scholar] [CrossRef]
- Huang, Y.; Wu, Q.; Lu, R.; Peng, X.; Zhang, R. Massive MIMO for cellular-connected UAV: Challenges and promising solutions. IEEE Commun. Mag. 2021, 59, 84–90. [Google Scholar] [CrossRef]
- Wang, C.X.; Haider, F.; Gao, X.; You, X.H.; Yang, Y.; Yuan, D.; Aggoune, H.M.; Haas, H.; Fletcher, S.; Hepsaydir, E. Cellular architecture and key technologies for 5G wireless communication networks. IEEE Commun. Mag. 2014, 52, 122–130. [Google Scholar] [CrossRef]
- Saad, W.; Bennis, M.; Chen, M. A vision of 6G wireless systems: Applications, trends, technologies, and open research problems. IEEE Netw. 2019, 34, 134–142. [Google Scholar] [CrossRef]
- Zhang, Z.; Xiao, Y.; Ma, Z.; Xiao, M.; Ding, Z.; Lei, X.; Karagiannidis, G.K.; Fan, P. 6G wireless networks: Vision, requirements, architecture, and key technologies. IEEE Veh. Technol. Mag. 2019, 14, 28–41. [Google Scholar] [CrossRef]
- Chandhar, P.; Larsson, E.G. Massive MIMO for connectivity with drones: Case studies and future directions. IEEE Access 2019, 7, 94676–94691. [Google Scholar] [CrossRef]
- Harris, P.; Malkowsky, S.; Vieira, J.; Bengtsson, E.; Tufvesson, F.; Hasan, W.B.; Liu, L.; Beach, M.; Armour, S.; Edfors, O. Performance characterization of a real-time massive MIMO system with LOS mobile channels. IEEE J. Sel. Areas Commun. 2017, 35, 1244–1253. [Google Scholar] [CrossRef]
- Geraci, G.; Garcia-Rodriguez, A.; Azari, M.M.; Lozano, A.; Mezzavilla, M.; Chatzinotas, S.; Chen, Y.; Rangan, S.; Di Renzo, M. What will the future of UAV cellular communications be? A flight from 5G to 6G. IEEE Commun. Surv. Tuts. 2022, 24, 1304–1335. [Google Scholar] [CrossRef]
- Bai, L.; Huang, Z.; Cheng, X. A Non-Stationary Model with Time-Space Consistency for 6G Massive MIMO mmWave UAV Channels. IEEE Trans. Wireless Commun. 2022, 22, 2048–2064. [Google Scholar] [CrossRef]
- Chandhar, P.; Danev, D.; Larsson, E.G. Massive MIMO for communications with drone swarms. IEEE Trans. Wireless Commun. 2017, 17, 1604–1629. [Google Scholar] [CrossRef]
- Huang, L.; Qian, C.; So, H.C.; Fang, J. Source enumeration for large array using shrinkage-based detectors with small samples. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 344–357. [Google Scholar] [CrossRef]
- Krim, H.; Viberg, M. Two decades of array signal processing research: The parametric approach. IEEE Signal Process. Mag. 1996, 13, 67–94. [Google Scholar] [CrossRef]
- Aquino, S.; Vairavel, G. A Review of Direction of Arrival Estimation Techniques in Massive MIMO 5G Wireless Communication Systems. In Proceedings of the Fourth International Conference on Communication, Computing and Electronics Systems: ICCCES 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 15–34. [Google Scholar]
- Björnson, E.; Sanguinetti, L.; Wymeersch, H.; Hoydis, J.; Marzetta, T.L. Massive MIMO is a reality—What is next? Five promising research directions for antenna arrays. Digit. Signal Process. 2019, 94, 3–20. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Rissanen, J. Modeling by shortest data description. Automatica 1978, 14, 465–471. [Google Scholar] [CrossRef]
- Stoica, P.; Selen, Y. Model-order selection: A review of information criterion rules. IEEE Signal Process. Mag. 2004, 21, 36–47. [Google Scholar] [CrossRef]
- Lu, Z.; Zoubir, A.M. Generalized Bayesian information criterion for source enumeration in array processing. IEEE Trans. Signal Process. 2012, 61, 1470–1480. [Google Scholar] [CrossRef]
- Lu, Z.; Zoubir, A.M. Flexible detection criterion for source enumeration in array processing. IEEE Trans. Signal Process. 2012, 61, 1303–1314. [Google Scholar] [CrossRef]
- Williams, D.B.; Johnson, D.H. Using the sphericity test for source detection with narrow-band passive arrays. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 2008–2014. [Google Scholar] [CrossRef]
- Brcich, R.F.; Zoubir, A.M.; Pelin, P. Detection of sources using bootstrap techniques. IEEE Trans. Signal Process. 2002, 50, 206–215. [Google Scholar] [CrossRef]
- Wax, M.; Adler, A. Detection of the Number of Signals by Signal Subspace Matching. IEEE Trans. Signal Process. 2021, 69, 973–985. [Google Scholar] [CrossRef]
- Cabric, D.; Mishra, S.M.; Brodersen, R.W. Implementation issues in spectrum sensing for cognitive radios. In Proceedings of the Conference Record of the Thirty-Eighth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 7–10 November 2004; Volume 1, pp. 772–776. [Google Scholar]
- Cabric, D.; Tkachenko, A.; Brodersen, R.W. Spectrum sensing measurements of pilot, energy, and collaborative detection. In Proceedings of the Milcom 2006-2006 IEEE Military Communications Conference, Washington, DC, USA, 23–25 October 2006; pp. 1–7. [Google Scholar]
- Gardner, W.A. Exploitation of spectral redundancy in cyclostationary signals. IEEE Signal Process. Mag. 1991, 8, 14–36. [Google Scholar] [CrossRef]
- Zeng, Y.; Liang, Y.C. Eigenvalue-based spectrum sensing algorithms for cognitive radio. IEEE Trans. Commun. 2009, 57, 1784–1793. [Google Scholar] [CrossRef]
- Zhang, R.; Lim, T.J.; Liang, Y.C.; Zeng, Y. Multi-antenna based spectrum sensing for cognitive radios: A GLRT approach. IEEE Trans. Commun. 2010, 58, 84–88. [Google Scholar] [CrossRef]
- Liu, C.; Li, H.; Wang, J.; Jin, M. Optimal eigenvalue weighting detection for multi-antenna cognitive radio networks. IEEE Trans. Wirel. Commun. 2016, 16, 2083–2096. [Google Scholar] [CrossRef]
- Yang, M.; Ai, B.; He, R.; Huang, C.; Ma, Z.; Zhong, Z.; Wang, J.; Pei, L.; Li, Y.; Li, J. Machine-learning-based fast angle-of-arrival recognition for vehicular communications. IEEE Trans. Veh. Technol. 2021, 70, 1592–1605. [Google Scholar] [CrossRef]
- Bithas, P.S.; Michailidis, E.T.; Nomikos, N.; Vouyioukas, D.; Kanatas, A.G. A survey on machine-learning techniques for UAV-based communications. Sensors 2019, 19, 5170. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.C.; Hanzo, L. Machine learning paradigms for next-generation wireless networks. IEEE Wirel. Commun. 2016, 24, 98–105. [Google Scholar] [CrossRef]
- Thilina, K.M.; Choi, K.W.; Saquib, N.; Hossain, E. Machine learning techniques for cooperative spectrum sensing in cognitive radio networks. IEEE J. Sel. Areas Commun. 2013, 31, 2209–2221. [Google Scholar] [CrossRef]
- Zhuang, Z.; Xu, L.; Li, J.; Hu, J.; Sun, L.; Shu, F.; Wang, J. Machine-learning-based high-resolution DOA measurement and robust directional modulation for hybrid analog-digital massive MIMO transceiver. Sci. China Inf. Sci. 2020, 63, 1–18. [Google Scholar] [CrossRef]
- Shu, F.; Liu, L.; Yang, L.; Jiang, X.; Xia, G.; Wu, Y.; Wang, X.; Jin, S.; Wang, J.; You, X. Spatial Modulation: An Attractive Secure Solution to Future Wireless Network. arXiv 2021, arXiv:2103.04051. [Google Scholar] [CrossRef]
- Jie, Q.; Zhan, X.; Shu, F.; Ding, Y.; Shi, B.; Li, Y.; Wang, J. High-performance Passive Eigen-model-based Detectors of Single Emitter Using Massive MIMO Receivers. arXiv 2021, arXiv:2108.02011. [Google Scholar] [CrossRef]
- Zhang, R.; Shim, B.; Wu, W. Direction-of-Arrival Estimation for Large Antenna Arrays With Hybrid Analog and Digital Architectures. IEEE Trans. Signal Process. 2021, 70, 72–88. [Google Scholar] [CrossRef]
- Chen, C.E.; Lorenzelli, F.; Hudson, R.E.; Yao, K. Stochastic maximum-likelihood DOA estimation in the presence of unknown nonuniform noise. IEEE Trans. Signal Process. 2008, 56, 3038–3044. [Google Scholar] [CrossRef]
- Chiani, M. Distribution of the largest eigenvalue for real Wishart and Gaussian random matrices and a simple approximation for the Tracy–Widom distribution. J. Multivar. Anal. 2014, 129, 69–81. [Google Scholar] [CrossRef]
- Wei, L.; Tirkkonen, O. Analysis of scaled largest eigenvalue based detection for spectrum sensing. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 1–5. [Google Scholar]
- Tracy, C.A.; Widom, H. The distributions of random matrix theory and their applications. In Proceedings of the New Trends in Mathematical Physics: Selected Contributions of the XVth International Congress on Mathematical Physics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 753–765. [Google Scholar]
- Fokas, A.S.; Its, A.R.; Novokshenov, V.Y.; Kapaev, A.A.; Kapaev, A.I.; Novokshenov, V.I. Painlevé Transcendents: The Riemann-Hilbert Approach; Number 128; American Mathematical Society: Providence, RI, USA, 2006. [Google Scholar]
- Perry, P.; Johnstone, I.; Ma, Z.; Shahram, M. Rmtstat: Distributions and Statistics from Random Matrix Theory. R Software Package Version. 2009. Available online: https://cran.rstudio.com/web/packages/RMTstat/index.html (accessed on 6 April 2023).
- Hagan, M.T.; Demuth, H.B.; Beale, M. Neural Network Design; PWS Publishing Co.: Boston, MA, USA, 1997. [Google Scholar]
- Prähofer, M.; Spohn, H. Exact scaling functions for one-dimensional stationary KPZ growth. J. Stat. Phys. 2004, 115, 255–279. [Google Scholar] [CrossRef]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Selected Papers of Hirotugu Akaike; Springer: Berlin/Heidelberg, Germany, 1998; pp. 199–213. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| t | −3.70 | −2.90 | −1.80 | −0.60 | −0.23 | 0.49 | 1.32 | 2.06 | 2.68 |
| 0.01 | 0.1 | 0.5 | 0.9 | 0.95 | 0.99 | 0.999 | 0.9999 | 0.99999 |
| Classifiers | Number of Training Samples | |||||
|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 40 | 50 | 100 | |
| 4-layer Neural Network | 0.734149 | 0.809213 | 0.936686 | 1.038361 | 1.133686 | 1.660306 |
| 3-layer Neural Network | 0.629034 | 0.705787 | 0.799842 | 0.875255 | 0.949917 | 1.356083 |
| SVM | 0.221015 | 0.333413 | 0.520857 | 0.753500 | 1.007692 | 3.077889 |
| NBC | 0.090488 | 0.092070 | 0.093222 | 0.094849 | 0.095326 | 0.113129 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Shu, F.; Hu, J.; Yan, S.; Song, H.; Zhu, W.; Tian, D.; Song, Y.; Wang, J. Machine Learning Methods for Inferring the Number of UAV Emitters via Massive MIMO Receive Array. Drones 2023, 7, 256. https://doi.org/10.3390/drones7040256
Li Y, Shu F, Hu J, Yan S, Song H, Zhu W, Tian D, Song Y, Wang J. Machine Learning Methods for Inferring the Number of UAV Emitters via Massive MIMO Receive Array. Drones. 2023; 7(4):256. https://doi.org/10.3390/drones7040256
Chicago/Turabian StyleLi, Yifan, Feng Shu, Jinsong Hu, Shihao Yan, Haiwei Song, Weiqiang Zhu, Da Tian, Yaoliang Song, and Jiangzhou Wang. 2023. "Machine Learning Methods for Inferring the Number of UAV Emitters via Massive MIMO Receive Array" Drones 7, no. 4: 256. https://doi.org/10.3390/drones7040256
APA StyleLi, Y., Shu, F., Hu, J., Yan, S., Song, H., Zhu, W., Tian, D., Song, Y., & Wang, J. (2023). Machine Learning Methods for Inferring the Number of UAV Emitters via Massive MIMO Receive Array. Drones, 7(4), 256. https://doi.org/10.3390/drones7040256