



Intelligent Mining Road Object Detection Based on Multiscale Feature Fusion in Multi-UAV Networks

 , , ,
, , ,
Abstract
1. Introduction
2. Related Work
2.1. Multisystem Collaboration Scenarios and Applications in Open-Pit Mines
2.2. 5G-Based Multi-UAV Collaboration Technology in Mining Areas
2.3. Obstacle Detection for Unmanned Mine Trucks
3. 5G-Multi-UAV-Based IMOD Autonomous Driving Model
- (1)
- To cope with the negative impact of adjacent scale feature fusion on models, we propose utilizing a feature fusion factor and improving the calculation method. By increasing effective samples post-fusion, this approach improves learning abilities toward small and medium-sized scale targets.
- (2)
- To enhance the detection accuracy of smaller targets in open-pit mining areas, reinforcing shallow feature layer information extraction via added shallow detection layers is crucial.
- (3)
- Adaptively selecting appropriate receptive field features during model training can help tackle insufficient feature information extraction in scenes containing vehicles and pedestrians with significant scaling changes. Therefore, an adaptive receptive field fusion module based on the concept of an RFB [21] network structure is proposed.
- (4)
- For efficiently detecting dense small-scale targets with high occlusion, we introduce StrongFocalLoss as a loss function while incorporating the CA attention mechanism to alter model focus toward relevant features, resulting in improved algorithmic accuracy.
3.1. Effective Fusion of Adjacent Scale Features
3.2. Multiscale Wide Field-of-View Adaptive Fusion Module
3.3. Attention Mechanism and Loss Function Optimization
3.4. Improved Multiscale Obstacle Object Detection Model
4. Experimental Analysis
4.1. Network Model Ablation Study
4.2. Robustness Experiment
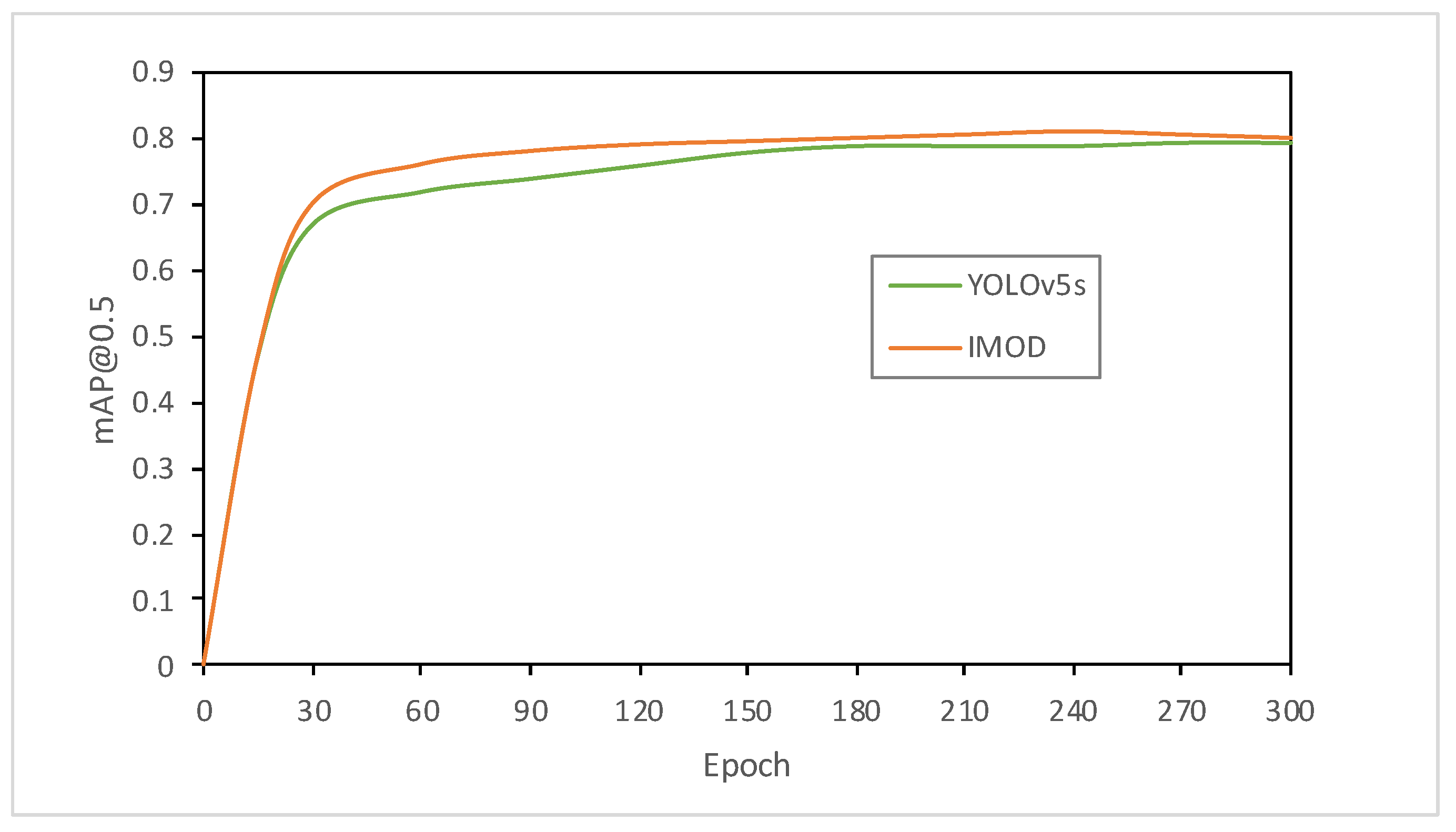
4.3. Comparative Experiment
4.3.1. Network Model Ablation Experiment
4.3.2. Robustness Experiment
4.3.3. Comparative Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gao, Y.; Ai, Y.; Tian, B.; Chen, L.; Wang, J.; Cao, D.; Wang, F.Y. Parallel end-to-end autonomous mining: An IoT-oriented approach. IEEE Internet Things J. 2019, 7, 1011–1023. [Google Scholar] [CrossRef]
- Ko, Y.; Kim, J.; Duguma, D.G.; Astillo, P.V.; You, I.; Pau, G. Drone Secure Communication Protocol for Future Sensitive Applications in Military Zone Number: 6. Sensors 2021, 21, 2057. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Wu, H.; Liu, H.; Gu, W.; Li, Y.; Cao, D. Blockchain-oriented privacy protection of sensitive data in the internet of vehicles. IEEE Trans. Intell. Veh. 2022, 8, 1057–1067. [Google Scholar] [CrossRef]
- Chen, S.; Hu, J.; Shi, Y.; Zhao, L.; Li, W. A vision of C-V2X: Technologies, field testing, and challenges with chinese development. IEEE Internet Things J. 2020, 7, 3872–3881. [Google Scholar] [CrossRef]
- Zhang, X.; Guo, A.; Ai, Y.; Tian, B.; Chen, L. Real-time scheduling of autonomous mining trucks via flow allocation-accelerated tabu search. IEEE Trans. Intell. Veh. 2022, 7, 466–479. [Google Scholar] [CrossRef]
- Ma, N.; Li, D.; He, W.; Deng, Y.; Li, J.; Gao, Y.; Bao, H.; Zhang, H.; Xu, X.; Liu, Y.; et al. Future vehicles: Interactive wheeled robots. Sci. China Inf. Sci. 2021, 64, 1–3. [Google Scholar] [CrossRef]
- Pan, Z.; Zhang, C.; Xia, Y.; Xiong, H.; Shao, X. An Improved Artificial Potential Field Method for Path Planning and Formation Control of the Multi-UAV Systems. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 1129–1133. [Google Scholar] [CrossRef]
- Krichen, M.; Adoni, W.Y.H.; Mihoub, A.; Alzahrani, M.Y.; Nahhal, T. Security Challenges for Drone Communications: Possible Threats, Attacks and Countermeasures. In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022; pp. 184–189. [Google Scholar]
- Girshick, R.; Donahue, J. Trevor DARRELL a Jitendra MALIK. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1497. [Google Scholar] [CrossRef] [PubMed]
- Xiang, X.; Lv, N.; Guo, X.; Wang, S.; El Saddik, A. Engineering vehicles detection based on modified faster R-CNN for power grid surveillance. Sensors 2018, 18, 2258. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, R. On-road vehicle detection in varying weather conditions using faster R-CNN with several region proposal networks. Multimed. Tools Appl. 2021, 80, 25985–25999. [Google Scholar] [CrossRef]
- Luo, J.Q.; Fang, H.S.; Shao, F.M.; Zhong, Y.; Hua, X. Multi-scale traffic vehicle detection based on faster R-CNN with NAS optimization and feature enrichment. Def. Technol. 2021, 17, 1542–1554. [Google Scholar] [CrossRef]
- Yin, G.; Yu, M.; Wang, M.; Hu, Y.; Zhang, Y. Research on highway vehicle detection based on faster R-CNN and domain adaptation. Appl. Intell. 2022, 52, 3483–3498. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Qiu, Z.; Bai, H.; Chen, T. Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network. Drones 2023, 7, 117. [Google Scholar] [CrossRef]
- Koay, H.V.; Chuah, J.H.; Chow, C.O.; Chang, Y.L.; Yong, K.K. YOLO-RTUAV: Towards real-time vehicle detection through aerial images with low-cost edge devices. Remote Sens. 2021, 13, 4196. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Z.; Wu, J.; Tian, Y.; Tang, H.; Guo, X. Real-Time Vehicle Detection Based on Improved YOLO v5. Sustainability 2022, 14, 12274. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 3 February 2023).
- Lu, X.; Ai, Y.; Tian, B. Real-time mine road boundary detection and tracking for autonomous truck. Sensors 2020, 20, 1121. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 404–419. [Google Scholar]
- Wu, H.; Xu, C.; Liu, H. S-MAT: Semantic-Driven Masked Attention Transformer for Multi-Label Aerial Image Classification. Sensors 2022, 22, 5433. [Google Scholar] [CrossRef]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Geirhos, R.; Jacobsen, J.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F. Shortcut Learning in Deep Neural Networks. Nat. Mach. Intell. 2020, 2, 665–673. [Google Scholar] [CrossRef]
- Cheng, X.; Yu, J. RetinaNet with difference channel attention and adaptively spatial feature fusion for steel surface defect detection. IEEE Trans. Instrum. Meas. 2020, 70, 1–11. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Yuan, J.; Wang, Z.; Xu, C.; Li, H.; Dai, S.; Liu, H. Multi-vehicle group-aware data protection model based on differential privacy for autonomous sensor networks. IET Circuits Devices Syst. 2023, 17, 1–13. [Google Scholar] [CrossRef]
- Li, M.; Zhang, H.; Xu, C.; Yan, C.; Liu, H.; Li, X. MFVC: Urban Traffic Scene Video Caption Based on Multimodal Fusion. Electronics 2022, 11, 2999. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CA | SRFB-s | AFHF | SFL | 4-Scale | mAP@0.5 | FPS |
|---|---|---|---|---|---|---|
| ✔ | 0.495 | 144 | ||||
| ✔ | 0.494 | 146 | ||||
| ✔ | 0.481 | 155 | ||||
| ✔ | 0.478 | 154 | ||||
| ✔ | 0.492 | 152 | ||||
| ✔ | ✔ | 0.514 | 123 | |||
| ✔ | ✔ | ✔ | 0.515 | 122 | ||
| ✔ | ✔ | ✔ | ✔ | 0.528 | 120 | |
| ✔ | ✔ | ✔ | ✔ | ✔ | 0.543 | 120 |
| Algorithm | Truck | Signboard | Excavator | Person | Car | Forklift |
|---|---|---|---|---|---|---|
| YOLOv5-s | 0.732 | 0.556 | 0.537 | 0.556 | 0.413 | 0.365 |
| v5s-SRFB-s | 0.754 | 0.582 | 0.563 | 0.587 | 0.406 | 0.398 |
| v5s-AFHF | 0.756 | 0.576 | 0.564 | 0.573 | 0.414 | 0.386 |
| v5s-CA | 0.726 | 0.562 | 0.541 | 0.555 | 0.417 | 0.373 |
| v5s-SFL | 0.744 | 0.546 | 0.542 | 0.546 | 0.414 | 0.313 |
| v5s-4-scale | 0.757 | 0.574 | 0.565 | 0.573 | 0.41 | 0.384 |
| IMOD | 0.815 | 0.592 | 0.612 | 0.596 | 0.489 | 0.396 |
| Algorithm | mAP@0.5 | FPS | Parameter/M | GFLOPs |
|---|---|---|---|---|
| YOLOv5-s | 0.466 | 155 | 7.08 | 16.2 |
| YOLOv5-m | 0.512 | 129 | 20.85 | 47 |
| IMOD | 0.535 | 120 | 11.19 | 20.4 |
| Algorithm | Backbone | mAP@0.5 | FPS (V100) |
|---|---|---|---|
| YOLOv4 | CSPDarknet53 | 0.452 | 65 |
| IMOD | Darknet53 | 0.318 | 12 |
| YOLOv5-s | CSPDarknet53 | 0.467 | 105 |
| YOLOv5-m | CSPDarknet53 | 0.511 | 89 |
| IMOD | CSPDarknet53 | 0.534 | 80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Zhao, S.; Xu, C.; Wang, Z.; Zheng, Y.; Qian, X.; Bao, H. Intelligent Mining Road Object Detection Based on Multiscale Feature Fusion in Multi-UAV Networks. Drones 2023, 7, 250. https://doi.org/10.3390/drones7040250
Xu X, Zhao S, Xu C, Wang Z, Zheng Y, Qian X, Bao H. Intelligent Mining Road Object Detection Based on Multiscale Feature Fusion in Multi-UAV Networks. Drones. 2023; 7(4):250. https://doi.org/10.3390/drones7040250
Chicago/Turabian StyleXu, Xinkai, Shuaihe Zhao, Cheng Xu, Zhuang Wang, Ying Zheng, Xu Qian, and Hong Bao. 2023. "Intelligent Mining Road Object Detection Based on Multiscale Feature Fusion in Multi-UAV Networks" Drones 7, no. 4: 250. https://doi.org/10.3390/drones7040250
APA StyleXu, X., Zhao, S., Xu, C., Wang, Z., Zheng, Y., Qian, X., & Bao, H. (2023). Intelligent Mining Road Object Detection Based on Multiscale Feature Fusion in Multi-UAV Networks. Drones, 7(4), 250. https://doi.org/10.3390/drones7040250