
TAN: A Transferable Adversarial Network for DNN-Based UAV SAR Automatic Target Recognition Models


Abstract
1. Introduction
- (1)
- For the first time, this paper systematically evaluates the transferability of adversarial examples among DNN-based SAR-ATR models. Meanwhile, our research reveals that there may be potential common vulnerabilities among DNN models performing the same task.
- (2)
- We propose a novel network to enable real-time transferable adversarial attacks. Once the proposed network is well-trained, it can craft adversarial examples with high transferability in real time, thus attacking black-box victim models without resorting to any prior knowledge. As such, our approach possesses promising applications in AI security.
- (3)
- The proposed method is evaluated on the most authoritative SAR-ATR dataset. Experimental results indicate that our approach achieves state-of-the-art transferability with acceptable adversarial perturbations and minimum time costs compared to existing attack methods, making real-time black-box attacks without any prior knowledge a reality.
2. Preliminaries
2.1. Adversarial Attacks for DNN-Based SAR-ATR Models
- For the non-targeted attack:
- For the targeted attack:
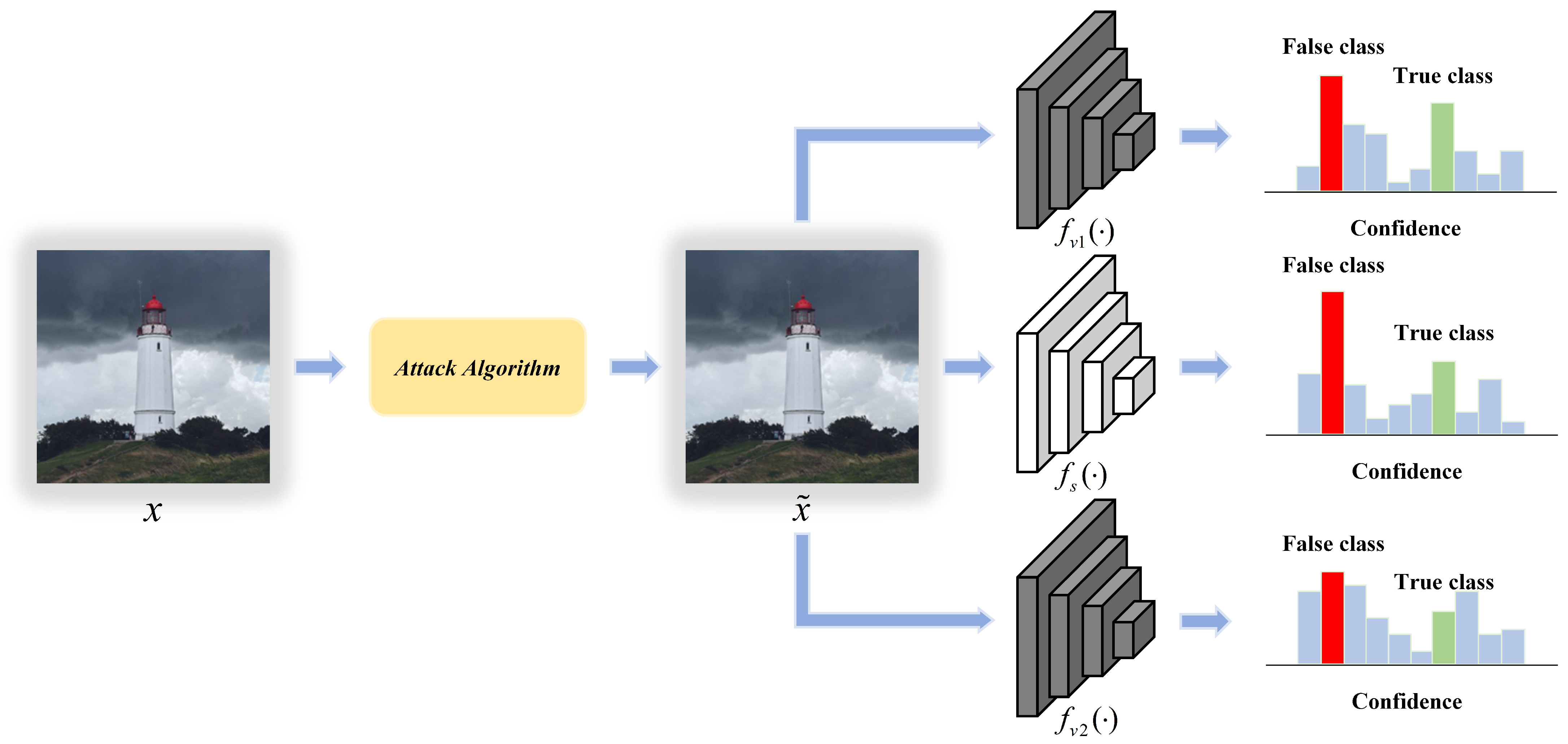
2.2. Transferability of Adversarial Examples
3. The Proposed Transferable Adversarial Network (TAN)
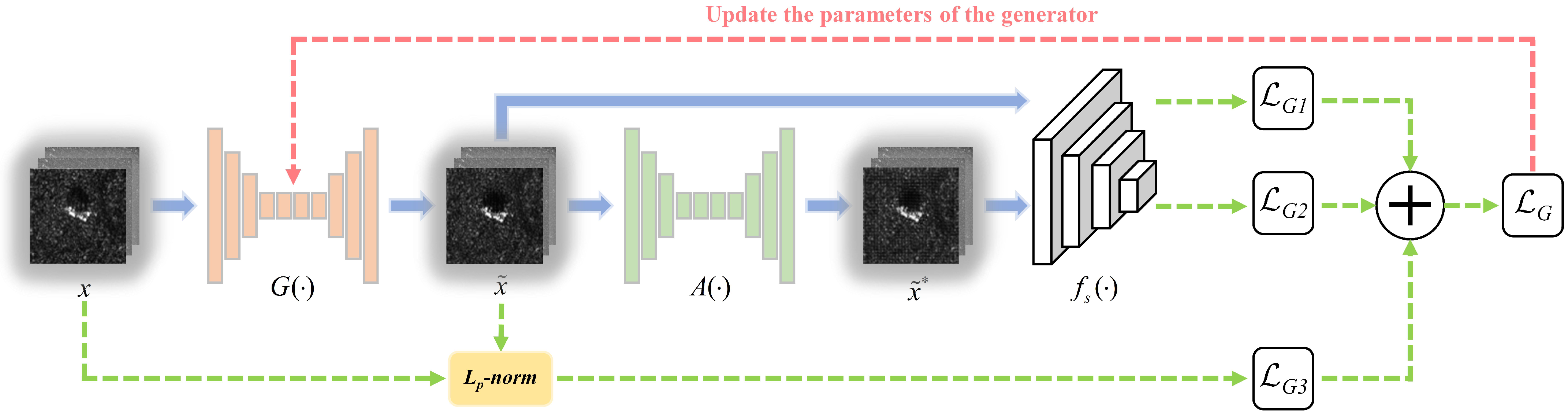
3.1. Training Process of the Generator
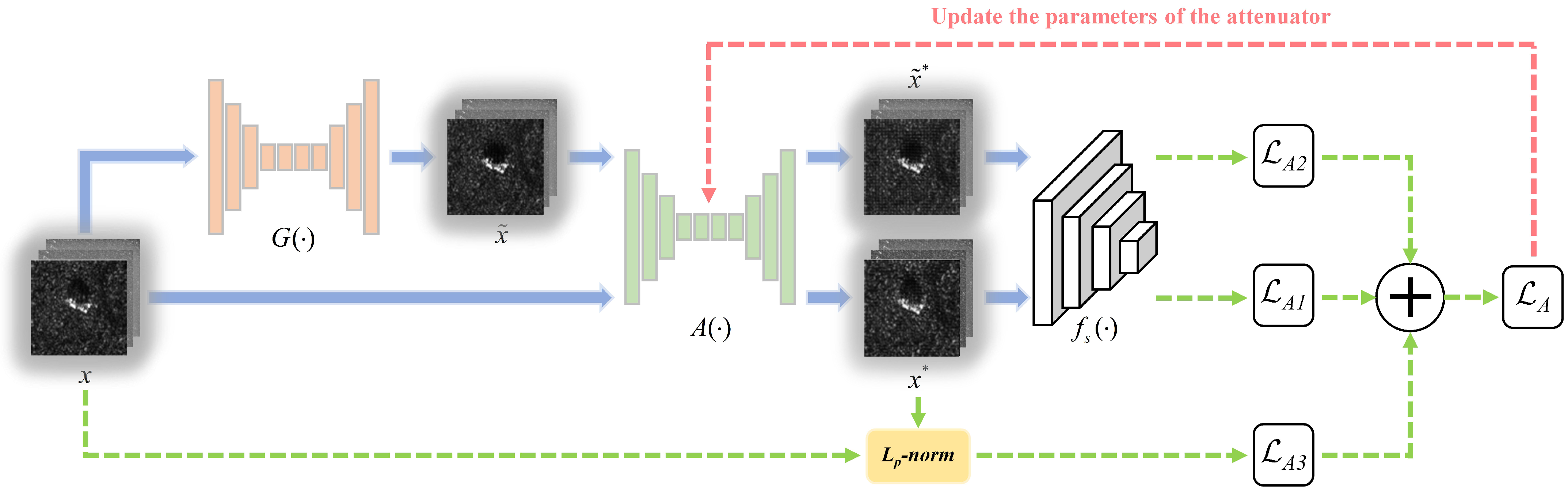
3.2. Training Process of the Attenuator
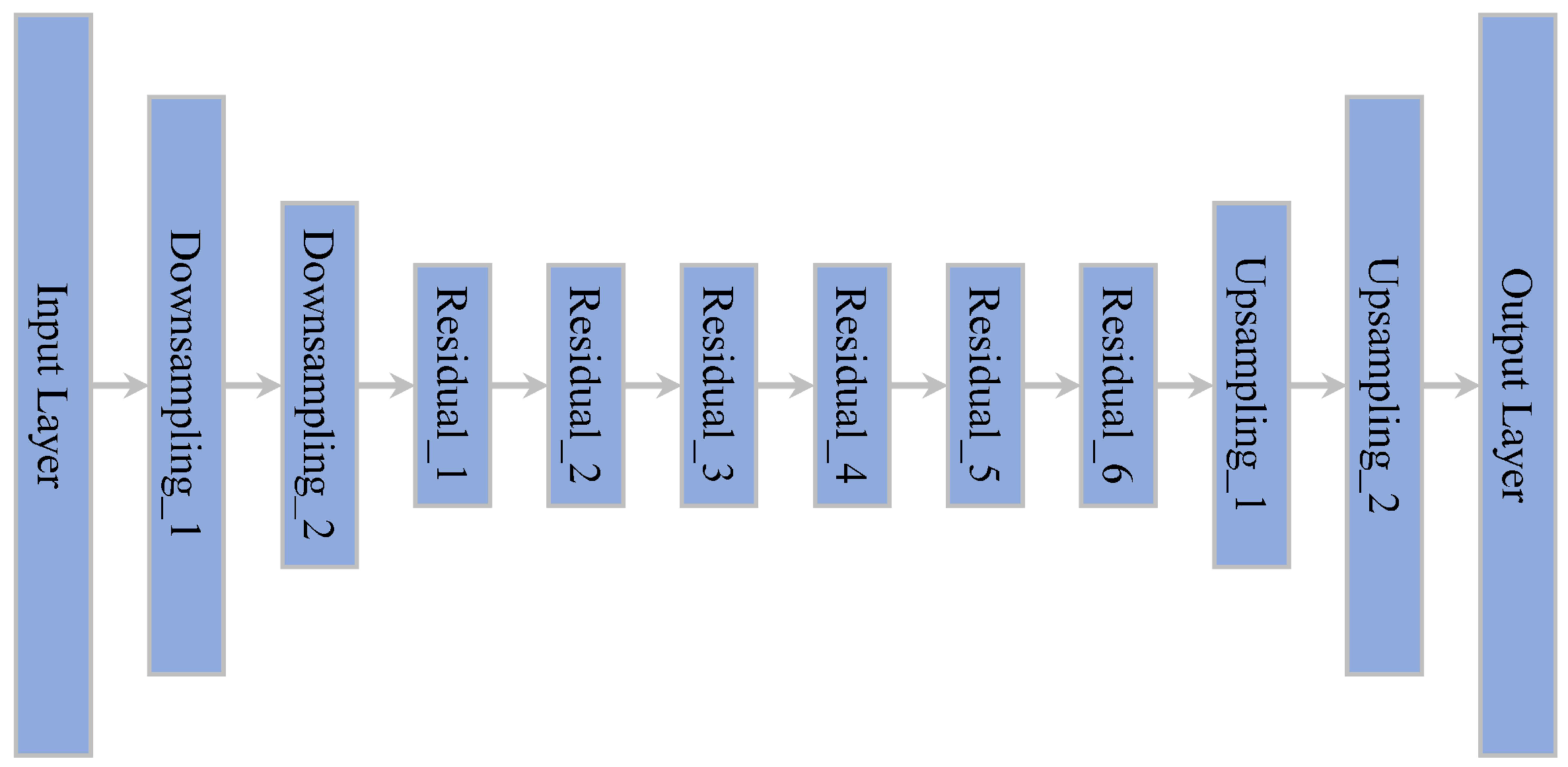
3.3. Network Structure of the Generator and Attenuator
3.4. Complete Training Process of TAN
| Algorithm 1:Transferable Adversarial Network Training |
|
4. Experiments
4.1. Data Descriptions
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. DNN-Based SAR-ATR Models
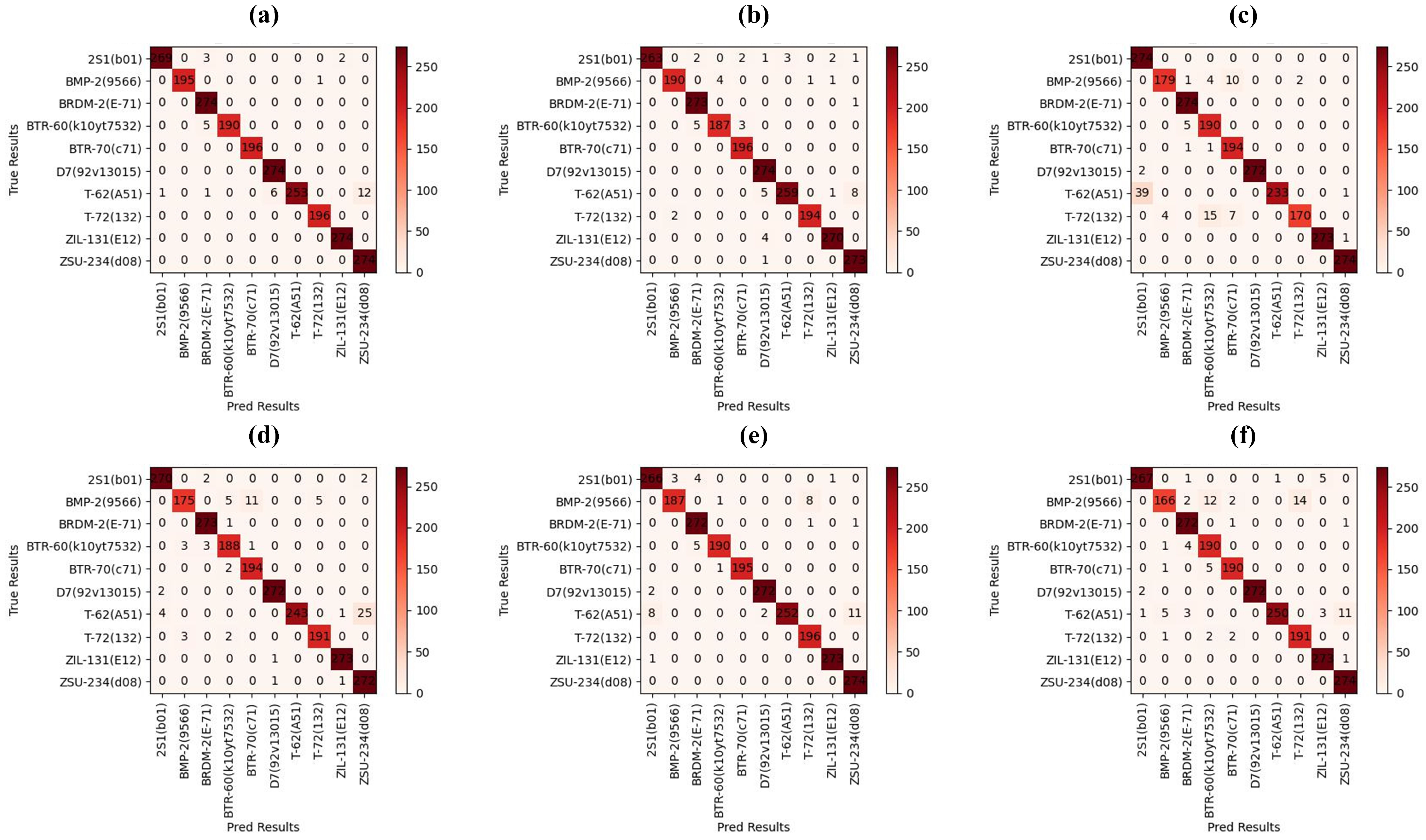
4.5. Comparison of Attack Performance
4.6. Comparison of Transferability
4.7. Comparison of Real-Time Performance
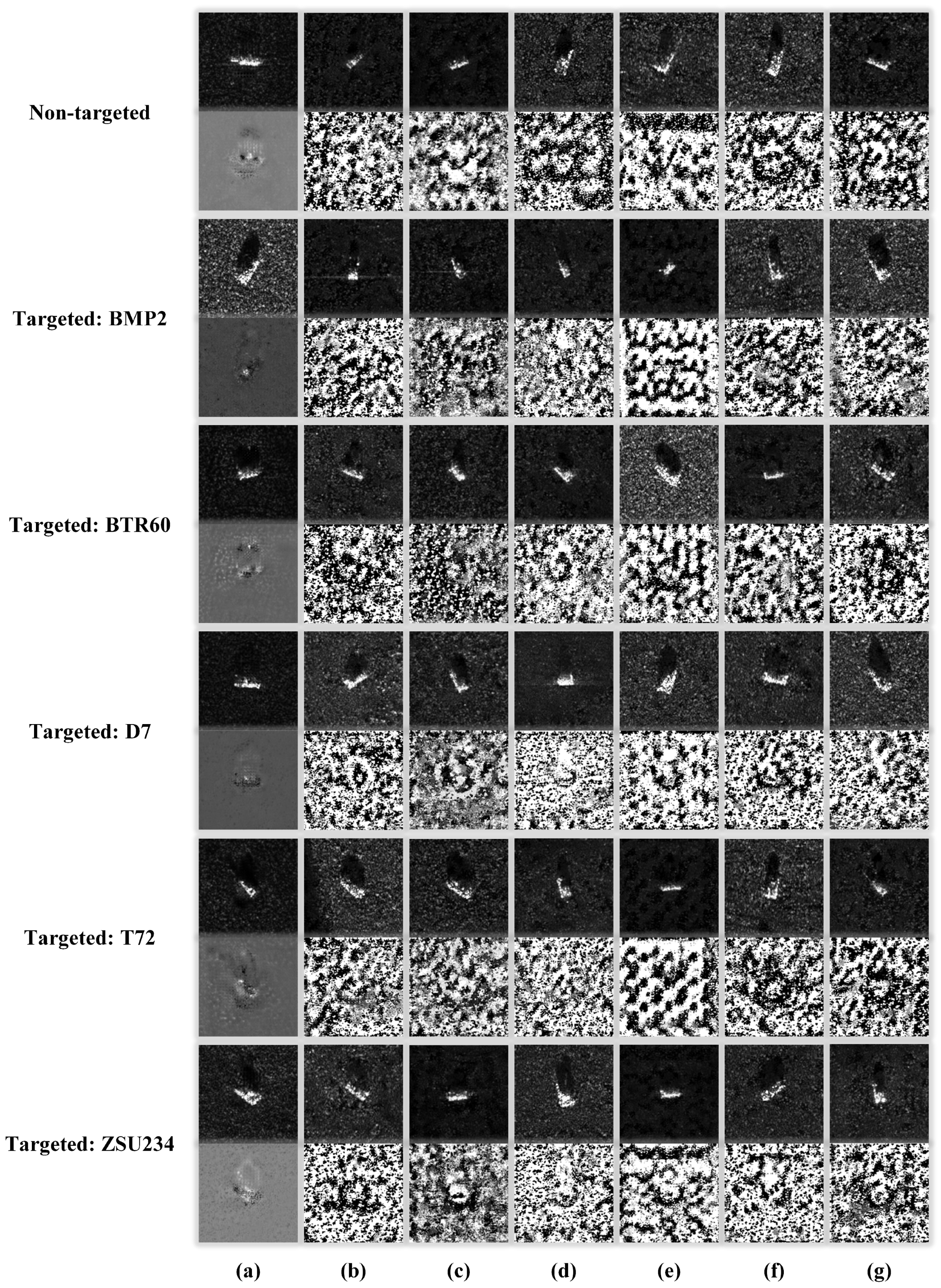
4.8. Visualization of Adversarial Examples
5. Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, D.; Kuai, Y.; Wen, G.; Liu, L. Robust Visual Tracking via Collaborative and Reinforced Convolutional Feature Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–19 June 2019. [Google Scholar] [CrossRef]
- Kuai, Y.; Wen, G.; Li, D. Masked and dynamic Siamese network for robust visual tracking. Inf. Sci. 2019, 503, 169–182. [Google Scholar] [CrossRef]
- Cong, R.; Yang, N.; Li, C.; Fu, H.; Zhao, Y.; Huang, Q.; Kwong, S. Global-and-local collaborative learning for co-salient object detection. IEEE Trans. Cybern. 2022, 53, 1920–1931. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Xiang, D.; Zhang, F.; Ma, F.; Zhou, Y.; Li, H. Incremental SAR Automatic Target Recognition With Error Correction and High Plasticity. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1327–1339. [Google Scholar] [CrossRef]
- Wang, L.; Yang, X.; Tan, H.; Bai, X.; Zhou, F. Few-Shot Class-Incremental SAR Target Recognition Based on Hierarchical Embedding and Incremental Evolutionary Network. IEEE Trans. Geosci. Remote Sens. 2023, 2023, 3248040. [Google Scholar] [CrossRef]
- Kwak, Y.; Song, W.J.; Kim, S.E. Speckle-Noise-Invariant Convolutional Neural Network for SAR Target Recognition. IEEE Geosci. Remote Sens. Lett. 2019, 16, 549–553. [Google Scholar] [CrossRef]
- Du, C.; Chen, B.; Xu, B.; Guo, D.; Liu, H. Factorized discriminative conditional variational auto-encoder for radar HRRP target recognition. Signal Process. 2019, 158, 176–189. [Google Scholar] [CrossRef]
- Vint, D.; Anderson, M.; Yang, Y.; Ilioudis, C.; Di Caterina, G.; Clemente, C. Automatic Target Recognition for Low Resolution Foliage Penetrating SAR Images Using CNNs and GANs. Remote Sens. 2021, 13, 596. [Google Scholar] [CrossRef]
- Huang, T.; Zhang, Q.; Liu, J.; Hou, R.; Wang, X.; Li, Y. Adversarial attacks on deep-learning-based SAR image target recognition. J. Netw. Comput. Appl. 2020, 162, 102632. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: London, UK, 2018; pp. 99–112. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2574–2582. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar] [CrossRef]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar] [CrossRef]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 1277–1294. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9185–9193. [Google Scholar] [CrossRef]
- Lin, J.; Song, C.; He, K.; Wang, L.; Hopcroft, J.E. Nesterov accelerated gradient and scale invariance for adversarial attacks. arXiv 2019, arXiv:1908.06281. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving transferability of adversarial examples with input diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2730–2739. [Google Scholar] [CrossRef]
- Wang, X.; He, K. Enhancing the transferability of adversarial attacks through variance tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1924–1933. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Assessing the threat of adversarial examples on deep neural networks for remote sensing scene classification: Attacks and defenses. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1604–1617. [Google Scholar] [CrossRef]
- Xu, Y.; Ghamisi, P. Universal Adversarial Examples in Remote Sensing: Methodology and Benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Li, H.; Huang, H.; Chen, L.; Peng, J.; Huang, H.; Cui, Z.; Mei, X.; Wu, G. Adversarial examples for CNN-based SAR image classification: An experience study. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1333–1347. [Google Scholar] [CrossRef]
- Du, C.; Huo, C.; Zhang, L.; Chen, B.; Yuan, Y. Fast C&W: A Fast Adversarial Attack Algorithm to Fool SAR Target Recognition with Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Du, M.; Bi, D.; Du, M.; Xu, X.; Wu, Z. ULAN: A Universal Local Adversarial Network for SAR Target Recognition Based on Layer-Wise Relevance Propagation. Remote Sens. 2022, 15, 21. [Google Scholar] [CrossRef]
- Xia, W.; Liu, Z.; Li, Y. SAR-PeGA: A Generation Method of Adversarial Examples for SAR Image Target Recognition Network. IEEE Trans. Aerosp. Electron. Syst. 2022, 2022, 3206261. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Keydel, E.R.; Lee, S.W.; Moore, J.T. MSTAR extended operating conditions: A tutorial. Algorithms Synth. Aperture Radar Imag. III 1996, 2757, 228–242. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kim, H. Torchattacks: A pytorch repository for adversarial attacks. arXiv 2020, arXiv:2010.01950. [Google Scholar]
- Kang, J.; Wang, Z.; Zhu, R.; Xia, J.; Sun, X.; Fernandez-Beltran, R.; Plaza, A. DisOptNet: Distilling Semantic Knowledge From Optical Images for Weather-Independent Building Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Liu, K.; Liang, Y. Underwater optical image enhancement based on super-resolution convolutional neural network and perceptual fusion. Opt. Express 2023, 31, 9688–9712. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Kiang, C.W.; Kiang, J.F. Imaging on Underwater Moving Targets With Multistatic Synthetic Aperture Sonar. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, H.; Sun, H.; Ying, W. Multireceiver SAS imagery based on monostatic conversion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10835–10853. [Google Scholar] [CrossRef]
- Choi, H.m.; Yang, H.s.; Seong, W.j. Compressive underwater sonar imaging with synthetic aperture processing. Remote Sens. 2021, 13, 1924. [Google Scholar] [CrossRef]
- Pate, D.J.; Cook, D.A.; O’Donnell, B.N. Estimation of Synthetic Aperture Resolution by Measuring Point Scatterer Responses. IEEE J. Ocean. Eng. 2021, 47, 457–471. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Input Size | Output Size |
|---|---|---|
| Input | ||
| Downsampling_1 | ||
| Downsampling_2 | ||
| Residual_1 ∼ 6 | ||
| Upsampling_1 | ||
| Upsampling_2 | ||
| Output |
| Target Class | Serial | Training Data | Testing Data | ||
|---|---|---|---|---|---|
| Depression Angle | Number | Depression Angle | Number | ||
| 2S1 | b01 | 299 | 274 | ||
| BMP2 | 9566 | 233 | 196 | ||
| BRDM2 | E-71 | 298 | 274 | ||
| BTR60 | k10yt7532 | 256 | 195 | ||
| BTR70 | c71 | 233 | 196 | ||
| D7 | 92v13015 | 299 | 274 | ||
| T62 | A51 | 299 | 273 | ||
| T72 | 132 | 232 | 196 | ||
| ZIL131 | E12 | 299 | 274 | ||
| ZSU234 | d08 | 299 | 274 | ||
| Surrogate | ||||||
|---|---|---|---|---|---|---|
| DenseNet121 | 98.72% | 1.90% | 81.53% | 24.03% | 3.595 | 4.959 |
| GoogLeNet | 98.06% | 3.83% | 89.78% | 36.11% | 2.884 | 3.305 |
| InceptionV3 | 96.17% | 0.82% | 89.41% | 19.62% | 3.552 | 4.181 |
| Mobilenet | 96.91% | 2.72% | 87.88% | 36.81% | 3.218 | 4.083 |
| ResNet50 | 97.98% | 3.34% | 83.80% | 28.65% | 3.684 | 4.568 |
| Shufflenet | 96.66% | 3.46% | 84.30% | 23.66% | 3.331 | 3.286 |
| Mean | 97.42% | 2.68% | 86.12% | 28.15% | 3.377 | 4.064 |
| Surrogate | ||||||
|---|---|---|---|---|---|---|
| DenseNet121 | 10.00% | 98.08% | 88.47% | 78.09% | 3.086 | 3.587 |
| GoogLeNet | 10.00% | 99.09% | 89.25% | 85.90% | 3.377 | 4.289 |
| InceptionV3 | 10.00% | 98.81% | 86.87% | 78.97% | 3.453 | 3.495 |
| Mobilenet | 10.00% | 97.40% | 88.38% | 81.37% | 3.257 | 3.553 |
| ResNet50 | 10.00% | 97.69% | 87.29% | 82.10% | 3.408 | 3.490 |
| Shufflenet | 10.00% | 98.36% | 86.85% | 83.11% | 3.345 | 3.874 |
| Mean | 10.00% | 98.24% | 87.85% | 81.59% | 3.321 | 3.714 |
| Surrogate | Method | Non-Targeted | Targeted | ||
|---|---|---|---|---|---|
| DenseNet121 | TAN | 1.90% | 3.595 | 98.08% | 3.086 |
| MIFGSM | 0.00% | 3.555 | 98.61% | 3.613 | |
| DIFGSM | 0.00% | 3.116 | 95.39% | 2.816 | |
| NIFGSM | 0.21% | 3.719 | 68.72% | 3.550 | |
| SINIFGSM | 1.15% | 3.676 | 82.32% | 3.648 | |
| VMIFGSM | 0.00% | 3.665 | 98.14% | 3.602 | |
| VNIFGSM | 0.08% | 3.691 | 96.89% | 3.635 | |
| GoogLeNet | TAN | 3.83% | 2.884 | 99.09% | 3.377 |
| MIFGSM | 0.04% | 3.615 | 98.36% | 3.601 | |
| DIFGSM | 0.04% | 3.090 | 94.47% | 2.830 | |
| NIFGSM | 0.41% | 3.674 | 64.32% | 3.520 | |
| SINIFGSM | 4.04% | 3.647 | 69.79% | 3.615 | |
| VMIFGSM | 0.04% | 3.587 | 97.84% | 3.601 | |
| VNIFGSM | 0.37% | 3.588 | 95.74% | 3.636 | |
| InceptionV3 | TAN | 0.82% | 3.552 | 98.81% | 3.453 |
| MIFGSM | 0.00% | 3.599 | 96.00% | 3.563 | |
| DIFGSM | 0.04% | 3.010 | 86.72% | 2.811 | |
| NIFGSM | 0.21% | 3.671 | 51.66% | 3.397 | |
| SINIFGSM | 2.93% | 3.689 | 62.46% | 3.593 | |
| VMIFGSM | 0.00% | 3.614 | 91.54% | 3.577 | |
| VNIFGSM | 0.00% | 3.632 | 84.02% | 3.605 | |
| Mobilenet | TAN | 2.72% | 3.218 | 97.40% | 3.257 |
| MIFGSM | 8.29% | 3.557 | 99.86% | 3.538 | |
| DIFGSM | 6.64% | 2.821 | 91.64% | 2.610 | |
| NIFGSM | 6.88% | 3.575 | 80.05% | 3.519 | |
| SINIFGSM | 1.77% | 3.664 | 85.14% | 3.662 | |
| VMIFGSM | 2.35% | 3.572 | 99.40% | 3.499 | |
| VNIFGSM | 1.32% | 3.635 | 95.58% | 3.582 | |
| ResNet50 | TAN | 3.34% | 3.684 | 97.69% | 3.408 |
| MIFGSM | 0.95% | 3.659 | 97.08% | 3.613 | |
| DIFGSM | 0.33% | 3.141 | 90.35% | 2.824 | |
| NIFGSM | 0.33% | 3.710 | 45.34% | 3.501 | |
| SINIFGSM | 3.96% | 3.720 | 71.64% | 3.652 | |
| VMIFGSM | 0.87% | 3.644 | 96.17% | 3.618 | |
| VNIFGSM | 0.25% | 3.692 | 94.17% | 3.632 | |
| Shufflenet | TAN | 3.46% | 3.331 | 98.36% | 3.345 |
| MIFGSM | 0.00% | 3.567 | 100.00% | 3.518 | |
| DIFGSM | 0.00% | 2.790 | 97.54% | 2.599 | |
| NIFGSM | 0.16% | 3.632 | 91.77% | 3.455 | |
| SINIFGSM | 0.00% | 3.660 | 95.79% | 3.568 | |
| VMIFGSM | 0.00% | 3.617 | 100.00% | 3.511 | |
| VNIFGSM | 0.04% | 3.654 | 99.73% | 3.568 | |
| Surrogate | Method | DenseNet121 | GoogLeNet | InceptionV3 | Mobilenet | ResNet50 | Shufflenet |
|---|---|---|---|---|---|---|---|
| DenseNet121 | TAN | 1.90% | 4.25% | 7.46% | 9.93% | 9.11% | 12.90% |
| MIFGSM | 0.00% | 10.10% | 12.82% | 26.46% | 16.32% | 28.65% | |
| DIFGSM | 0.00% | 8.16% | 11.46% | 26.01% | 19.17% | 30.83% | |
| NIFGSM | 0.21% | 14.67% | 14.67% | 26.75% | 20.07% | 30.67% | |
| SINIFGSM | 1.15% | 16.69% | 19.29% | 35.66% | 17.64% | 36.11% | |
| VMIFGSM | 0.00% | 8.86% | 11.62% | 24.40% | 15.13% | 25.89% | |
| VNIFGSM | 0.08% | 8.04% | 11.62% | 22.38% | 13.60% | 23.54% | |
| GoogLeNet | TAN | 6.88% | 3.83% | 8.16% | 23.62% | 10.51% | 26.88% |
| MIFGSM | 10.18% | 0.04% | 17.72% | 32.36% | 27.66% | 42.13% | |
| DIFGSM | 8.33% | 0.04% | 14.47% | 32.52% | 24.73% | 38.66% | |
| NIFGSM | 22.88% | 0.41% | 24.28% | 32.32% | 35.16% | 44.44% | |
| SINIFGSM | 7.96% | 4.04% | 13.15% | 33.22% | 15.09% | 28.07% | |
| VMIFGSM | 8.57% | 0.04% | 16.32% | 29.72% | 25.64% | 38.58% | |
| VNIFGSM | 10.02% | 0.37% | 15.50% | 27.99% | 26.30% | 36.93% | |
| InceptionV3 | TAN | 8.20% | 9.60% | 0.82% | 21.43% | 14.67% | 23.45% |
| MIFGSM | 19.25% | 35.00% | 0.00% | 39.45% | 33.14% | 42.54% | |
| DIFGSM | 16.86% | 33.22% | 0.04% | 43.69% | 33.76% | 47.07% | |
| NIFGSM | 32.11% | 34.46% | 0.21% | 42.09% | 43.08% | 44.89% | |
| SINIFGSM | 27.37% | 38.05% | 2.93% | 49.22% | 41.18% | 56.06% | |
| VMIFGSM | 18.51% | 26.92% | 0.00% | 34.46% | 31.04% | 37.18% | |
| VNIFGSM | 21.68% | 26.38% | 0.00% | 33.80% | 34.50% | 37.63% | |
| Mobilenet | TAN | 14.34% | 15.83% | 13.56% | 2.72% | 14.18% | 18.59% |
| MIFGSM | 65.99% | 59.32% | 53.59% | 8.29% | 55.56% | 59.77% | |
| DIFGSM | 51.28% | 53.34% | 49.34% | 6.64% | 49.34% | 52.18% | |
| NIFGSM | 65.75% | 58.66% | 51.85% | 6.88% | 52.31% | 55.56% | |
| SINIFGSM | 64.67% | 45.14% | 49.01% | 1.77% | 51.81% | 58.37% | |
| VMIFGSM | 62.49% | 52.10% | 50.45% | 2.35% | 49.63% | 52.84% | |
| VNIFGSM | 56.27% | 50.04% | 43.61% | 1.32% | 43.82% | 48.19% | |
| ResNet50 | TAN | 5.94% | 9.27% | 10.14% | 12.94% | 3.34% | 11.01% |
| MIFGSM | 14.59% | 24.15% | 17.72% | 16.90% | 0.95% | 26.42% | |
| DIFGSM | 11.13% | 17.07% | 15.09% | 20.45% | 0.33% | 26.59% | |
| NIFGSM | 21.72% | 28.19% | 20.28% | 19.74% | 0.33% | 29.43% | |
| SINIFGSM | 26.50% | 24.15% | 22.59% | 30.50% | 3.96% | 33.84% | |
| VMIFGSM | 13.31% | 22.42% | 16.36% | 15.95% | 0.87% | 23.33% | |
| VNIFGSM | 15.00% | 22.67% | 16.45% | 14.47% | 0.25% | 22.63% | |
| Shufflenet | TAN | 17.72% | 23.54% | 16.49% | 22.22% | 17.85% | 3.46% |
| MIFGSM | 66.69% | 70.03% | 65.00% | 55.81% | 65.00% | 0.00% | |
| DIFGSM | 53.46% | 57.58% | 55.32% | 51.44% | 55.44% | 0.00% | |
| NIFGSM | 67.23% | 61.58% | 58.62% | 48.35% | 61.62% | 0.16% | |
| SINIFGSM | 68.51% | 58.33% | 60.92% | 50.41% | 56.64% | 0.00% | |
| VMIFGSM | 57.25% | 55.32% | 54.29% | 40.23% | 53.34% | 0.00% | |
| VNIFGSM | 56.68% | 54.25% | 51.57% | 37.30% | 52.14% | 0.04% |
| Surrogate | Method | DenseNet121 | GoogLeNet | InceptionV3 | Mobilenet | ResNet50 | Shufflenet |
|---|---|---|---|---|---|---|---|
| DenseNet121 | TAN | 98.08% | 79.12% | 70.71% | 59.03% | 62.31% | 52.39% |
| MIFGSM | 98.61% | 52.47% | 49.05% | 39.47% | 43.78% | 37.62% | |
| DIFGSM | 95.39% | 51.08% | 46.62% | 35.02% | 39.51% | 32.29% | |
| NIFGSM | 68.72% | 33.06% | 27.61% | 22.18% | 25.78% | 22.92% | |
| SINIFGSM | 82.32% | 40.62% | 33.17% | 29.95% | 31.93% | 30.59% | |
| VMIFGSM | 98.14% | 48.94% | 44.10% | 33.56% | 39.29% | 34.06% | |
| VNIFGSM | 96.89% | 48.78% | 46.03% | 34.70% | 39.80% | 35.52% | |
| GoogLeNet | TAN | 81.04% | 99.09% | 66.59% | 56.72% | 63.86% | 55.02% |
| MIFGSM | 61.56% | 98.36% | 47.57% | 34.16% | 37.57% | 29.75% | |
| DIFGSM | 58.81% | 94.47% | 47.91% | 32.17% | 36.20% | 26.88% | |
| NIFGSM | 31.46% | 64.32% | 25.34% | 19.85% | 23.14% | 19.63% | |
| SINIFGSM | 41.97% | 69.79% | 34.39% | 28.21% | 29.77% | 25.48% | |
| VMIFGSM | 53.37% | 97.84% | 42.19% | 30.67% | 34.94% | 26.36% | |
| VNIFGSM | 56.26% | 95.74% | 43.96% | 32.31% | 36.11% | 29.49% | |
| InceptionV3 | TAN | 75.11% | 71.56% | 98.81% | 67.23% | 63.62% | 54.57% |
| MIFGSM | 42.64% | 35.92% | 96.00% | 32.49% | 35.00% | 29.51% | |
| DIFGSM | 42.99% | 33.70% | 86.72% | 31.16% | 34.13% | 28.20% | |
| NIFGSM | 27.12% | 24.67% | 51.66% | 19.49% | 23.76% | 22.45% | |
| SINIFGSM | 26.76% | 25.23% | 62.46% | 21.90% | 24.36% | 22.59% | |
| VMIFGSM | 36.38% | 34.05% | 91.54% | 30.15% | 31.43% | 28.52% | |
| VNIFGSM | 37.82% | 33.55% | 84.02% | 31.44% | 32.28% | 28.58% | |
| Mobilenet | TAN | 61.30% | 57.66% | 61.53% | 97.40% | 60.97% | 63.11% |
| MIFGSM | 19.98% | 18.66% | 22.87% | 99.86% | 23.55% | 20.31% | |
| DIFGSM | 23.96% | 21.92% | 23.79% | 91.64% | 24.51% | 22.65% | |
| NIFGSM | 15.76% | 15.58% | 16.85% | 80.05% | 18.06% | 15.91% | |
| SINIFGSM | 16.81% | 15.52% | 18.96% | 85.14% | 21.20% | 16.63% | |
| VMIFGSM | 18.46% | 17.84% | 18.70% | 99.40% | 21.49% | 19.61% | |
| VNIFGSM | 21.60% | 18.41% | 22.34% | 95.58% | 24.67% | 21.96% | |
| ResNet50 | TAN | 71.39% | 71.54% | 71.02% | 73.68% | 97.69% | 66.26% |
| MIFGSM | 43.23% | 30.51% | 41.57% | 42.41% | 97.08% | 36.29% | |
| DIFGSM | 45.18% | 34.25% | 42.37% | 39.40% | 90.35% | 34.36% | |
| NIFGSM | 22.07% | 20.45% | 20.33% | 19.36% | 45.34% | 19.75% | |
| SINIFGSM | 25.81% | 21.38% | 27.15% | 31.01% | 71.64% | 26.02% | |
| VMIFGSM | 36.44% | 26.33% | 35.75% | 38.61% | 96.17% | 32.79% | |
| VNIFGSM | 40.80% | 27.10% | 38.26% | 38.87% | 94.17% | 36.49% | |
| Shufflenet | TAN | 53.91% | 47.78% | 51.69% | 60.35% | 58.78% | 98.36% |
| MIFGSM | 18.29% | 16.43% | 17.06% | 19.46% | 17.20% | 100.00% | |
| DIFGSM | 23.55% | 20.36% | 20.80% | 22.55% | 21.35% | 97.54% | |
| NIFGSM | 13.96% | 13.06% | 13.14% | 14.47% | 13.66% | 91.77% | |
| SINIFGSM | 15.83% | 15.23% | 15.34% | 19.42% | 16.05% | 95.79% | |
| VMIFGSM | 17.58% | 16.34% | 17.09% | 21.65% | 18.46% | 99.94% | |
| VNIFGSM | 19.43% | 17.97% | 18.68% | 22.87% | 19.98% | 99.73% |
| Method | DenseNet121 | GoogLeNet | InceptionV3 | Mobilenet | ResNet50 | Shufflenet | Mean |
|---|---|---|---|---|---|---|---|
| TAN | 0.002029 s | 0.002201 s | 0.002039 s | 0.002218 s | 0.002031 s | 0.002045 s | 0.002094 s |
| MIFGSM | 0.018285 s | 0.006351 s | 0.012636 s | 0.005093 s | 0.013445 s | 0.004451 s | 0.010044 s |
| DIFGSM | 0.018276 s | 0.006363 s | 0.012653 s | 0.005103 s | 0.013468 s | 0.004488 s | 0.010059 s |
| NIFGSM | 0.018312 s | 0.006354 s | 0.012646 s | 0.005111 s | 0.013477 s | 0.004456 s | 0.010059 s |
| SINIFGSM | 0.091032 s | 0.031499 s | 0.063015 s | 0.024865 s | 0.067202 s | 0.021676 s | 0.049882 s |
| VMIFGSM | 0.109252 s | 0.037827 s | 0.075580 s | 0.029803 s | 0.080479 s | 0.025968 s | 0.059818 s |
| VNIFGSM | 0.109184 s | 0.037804 s | 0.075483 s | 0.029776 s | 0.080560 s | 0.025907 s | 0.059786 s |
| Method | DenseNet121 | GoogLeNet | InceptionV3 | Mobilenet | ResNet50 | Shufflenet | Mean |
|---|---|---|---|---|---|---|---|
| TAN | 0.002070 s | 0.002069 s | 0.002036 s | 0.002055 s | 0.002087 s | 0.002097 s | 0.002069 s |
| MIFGSM | 0.018281 s | 0.006353 s | 0.012634 s | 0.005088 s | 0.013451 s | 0.004446 s | 0.010042 s |
| DIFGSM | 0.018291 s | 0.006369 s | 0.012652 s | 0.005104 s | 0.013490 s | 0.004488 s | 0.010065 s |
| NIFGSM | 0.018306 s | 0.006358 s | 0.012661 s | 0.005105 s | 0.013486 s | 0.004460 s | 0.010063 s |
| SINIFGSM | 0.091064 s | 0.031539 s | 0.063066 s | 0.024871 s | 0.067216 s | 0.021664 s | 0.049903 s |
| VMIFGSM | 0.109262 s | 0.037860 s | 0.075579 s | 0.029776 s | 0.080481 s | 0.025984 s | 0.059823 s |
| VNIFGSM | 0.109176 s | 0.037819 s | 0.075502 s | 0.029798 s | 0.080546 s | 0.025923 s | 0.059794 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, M.; Sun, Y.; Sun, B.; Wu, Z.; Luo, L.; Bi, D.; Du, M. TAN: A Transferable Adversarial Network for DNN-Based UAV SAR Automatic Target Recognition Models. Drones 2023, 7, 205. https://doi.org/10.3390/drones7030205
Du M, Sun Y, Sun B, Wu Z, Luo L, Bi D, Du M. TAN: A Transferable Adversarial Network for DNN-Based UAV SAR Automatic Target Recognition Models. Drones. 2023; 7(3):205. https://doi.org/10.3390/drones7030205
Chicago/Turabian StyleDu, Meng, Yuxin Sun, Bing Sun, Zilong Wu, Lan Luo, Daping Bi, and Mingyang Du. 2023. "TAN: A Transferable Adversarial Network for DNN-Based UAV SAR Automatic Target Recognition Models" Drones 7, no. 3: 205. https://doi.org/10.3390/drones7030205
APA StyleDu, M., Sun, Y., Sun, B., Wu, Z., Luo, L., Bi, D., & Du, M. (2023). TAN: A Transferable Adversarial Network for DNN-Based UAV SAR Automatic Target Recognition Models. Drones, 7(3), 205. https://doi.org/10.3390/drones7030205