
Segmentation Detection Method for Complex Road Cracks Collected by UAV Based on HC-Unet++




Abstract
1. Introduction
2. Materials and Methods
2.1. Data Acquisition
2.2. Methods
2.2.1. HC-Unet++
2.2.2. Deep Parallel Feature Fusion Module
2.2.3. SEnet
2.2.4. Blurpool
2.3. Experimental Environment and Settings
2.3.1. Data Preparation
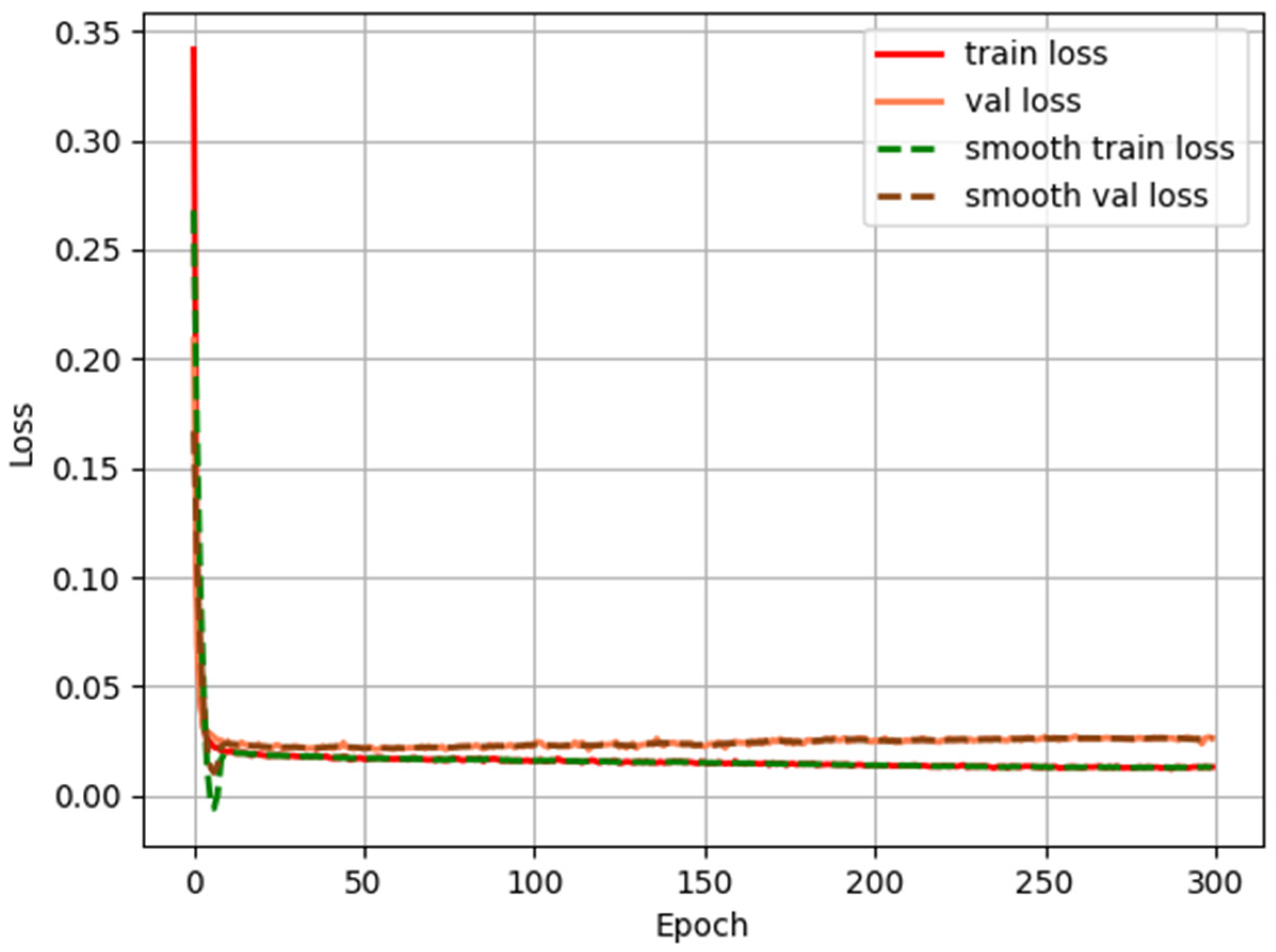
2.3.2. Training Methods
3. Experimental Results and Analysis
3.1. Experimental Evaluation Criteria
3.2. Module Performance Analysis
3.2.1. Effectiveness of Deep Parallel Feature Fusion Module
3.2.2. Effectiveness of SEnet
3.2.3. Effectiveness of Blurpool
3.3. Ablation Experiments
3.4. Comparsion of HC-Unet++ with Other Methods
3.5. Generalization Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, G.X.; Hu, B.L.; Yang, Z.; Huang, L.; Li, P. Pavement crack detection method based on deep learning models. Wirel. Commun. Mob. Comput. 2021, 2021, 5573590. [Google Scholar] [CrossRef]
- Ren, J.; Zhao, G.; Ma, Y.; Zhao, D.; Liu, T.; Yan, J. Automatic Pavement Crack Detection Fusing Attention Mechanism. Electronics 2022, 11, 3622. [Google Scholar] [CrossRef]
- Johnson, A.M. Best Practices Handbook on Asphalt Pavement Maintenance; Minnesota Technology Transfer/LTAP Program, Center for Transportation Studies: Minneapolis, MN, USA, 2000. [Google Scholar]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef]
- Xing, Z. An improved emperor penguin optimization based multilevel thresholding for color image segmentation. Knowl.-Based Syst. 2020, 194, 105570. [Google Scholar] [CrossRef]
- Tang, J.; Gu, Y. Automatic crack detection and segmentation using a hybrid algorithm for road distress analysis. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 3026–3030. [Google Scholar]
- Peng, L.; Chao, W.; Shuangmiao, L.; Baocai, F. Research on crack detection method of airport runway based on twice-threshold segmentation. In Proceedings of the 2015 Fifth International Conference on Instrumentation and Measurement, Computer, Communication and Control (IMCCC), Qinhuangdao, China, 18–20 September 2015; pp. 1716–1720. [Google Scholar]
- Li, H.; Song, D.; Liu, Y.; Li, B. Automatic pavement crack detection by multi-scale image fusion. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2025–2036. [Google Scholar] [CrossRef]
- Xu, D.; Zhao, Y.; Jiang, Y.; Zhang, C.; Sun, B.; He, X. Using improved edge detection method to detect mining-induced ground fissures identified by unmanned aerial vehicle remote sensing. Remote Sens. 2021, 13, 3652. [Google Scholar] [CrossRef]
- Zhao, H.; Qin, G.; Wang, X. Improvement of canny algorithm based on pavement edge detection. In Proceedings of the 2010 3rd international congress on image and signal processing, Yantai, China, 16–18 October 2010; pp. 964–967. [Google Scholar]
- Liang, S.; Sun, B. Using wavelet technology for pavement crack detection. In ICLEM 2010: Logistics for Sustained Economic Development: Infrastructure, Information, Integration, Proceedings of the International Conference of Logistics Engineering and Management (ICLEM) 2010, Chengdu, China, 8–10 October 2010; Zhang, J., Xu, L., Zhang, X., Yi, P., Jian, M., Eds.; American Society of Civil Engineers: Reston, VA, USA, 2010; pp. 2479–2484. [Google Scholar]
- Subirats, P.; Dumoulin, J.; Legeay, V.; Barba, D. Automation of pavement surface crack detection using the continuous wavelet transform. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 3037–3040. [Google Scholar]
- Cheng, Y.; Lin, M.; Wu, J.; Zhu, H.; Shao, X. Intelligent fault diagnosis of rotating machinery based on continuous wavelet transform-local binary convolutional neural network. Knowl.-Based Syst. 2021, 216, 106796. [Google Scholar] [CrossRef]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting tassels in RGB UAV imagery with improved YOLOv5 based on transfer learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Wang, B.; Yan, Z.; Lu, J.; Zhang, G.; Li, T. Explore uncertainty in residual networks for crowds flow prediction. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Hu, Y.; Zhan, J.; Zhou, G.; Chen, A.; Cai, W.; Guo, K.; Hu, Y.; Li, L. Fast forest fire smoke detection using MVMNet. Knowl.-Based Syst. 2022, 241, 108219. [Google Scholar] [CrossRef]
- Zhu, W.; Zhang, H.; Eastwood, J.; Qi, X.; Jia, J.; Cao, Y. Concrete crack detection using lightweight attention feature fusion single shot multibox detector. Knowl.-Based Syst. 2023, 261, 110216. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Fan, R.; Bocus, M.J.; Zhu, Y.; Jiao, J.; Wang, L.; Ma, F.; Cheng, S.; Liu, M. Road crack detection using deep convolutional neural network and adaptive thresholding. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 474–479. [Google Scholar]
- Sadrawi, M.; Yunus, J.; Abbod, M.F.; Shieh, J.-S. Higher Resolution Input Image of Convolutional Neural Network of Reinforced Concrete Earthquake-Generated Crack Classification and Localization. IOP Conf. Ser. Mater. Sci. Eng. 2020, 931, 012005. [Google Scholar] [CrossRef]
- Huang, H.-W.; Li, Q.-T.; Zhang, D.-M. Deep learning based image recognition for crack and leakage defects of metro shield tunnel. Tunn. Undergr. Space Technol. 2018, 77, 166–176. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. Deepcrack: Learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 2018, 28, 1498–1512. [Google Scholar] [CrossRef]
- Yuan, G.; Li, J.; Meng, X.; Li, Y. CurSeg: A pavement crack detector based on a deep hierarchical feature learning segmentation framework. IET Intell. Transp. Syst. 2022, 16, 782–799. [Google Scholar] [CrossRef]
- Billah, U.H.; Tavakkoli, A.; La, H.M. Concrete crack pixel classification using an encoder decoder based deep learning architecture. In Proceedings of the Advances in Visual Computing: 14th International Symposium on Visual Computing, ISVC 2019, Lake Tahoe, NV, USA, 7–9 October 2019; Proceedings, Part I 14. pp. 593–604. [Google Scholar]
- Li, C.; Wen, Y.; Shi, Q.; Yang, F.; Ma, H.; Tian, X. A pavement crack detection method based on multiscale Attention and HFS. Comput. Intell. Neurosci. 2022, 2022, 1822585. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Huo, B.; Li, E.; Liu, Y. A nondestructive automatic defect detection method with pixelwise segmentation. Knowl.-Based Syst. 2022, 242, 108338. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, J.; Cai, F. On bridge surface crack detection based on an improved YOLO v3 algorithm. IFAC-Pap. 2020, 53, 8205–8210. [Google Scholar] [CrossRef]
- Yang, J.; Li, H.; Zou, J.; Jiang, S.; Li, R.; Liu, X. Concrete crack segmentation based on UAV-enabled edge computing. Neurocomputing 2022, 485, 233–241. [Google Scholar] [CrossRef]
- Qiao, W.; Liu, Q.; Wu, X.; Ma, B.; Li, G. Automatic pixel-level pavement crack recognition using a deep feature aggregation segmentation network with a scse attention mechanism module. Sensors 2021, 21, 2902. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Xiang, X.; Zhang, Y.; El Saddik, A. Pavement crack detection network based on pyramid structure and attention mechanism. IET Image Process. 2020, 14, 1580–1586. [Google Scholar] [CrossRef]
- Han, C.; Ma, T.; Huyan, J.; Huang, X.; Zhang, Y. CrackW-Net: A novel pavement crack image segmentation convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2021, 23, 22135–22144. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Y.; Lang, H.; Ding, S.; Lu, J.J. The Improvement of Automated Crack Segmentation on Concrete Pavement with Graph Network. J. Adv. Transp. 2022, 2022, 2238095. [Google Scholar] [CrossRef]
- Liu, W.; Xia, X.; Xiong, L.; Lu, Y.; Gao, L.; Yu, Z. Automated vehicle sideslip angle estimation considering signal measurement characteristic. IEEE Sens. J. 2021, 21, 21675–21687. [Google Scholar] [CrossRef]
- Rehak, M.; Skaloud, J. Time synchronization of consumer cameras on Micro Aerial Vehicles. ISPRS J. Photogramm. Remote Sens. 2017, 123, 114–123. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. pp. 3–11. [Google Scholar]
- Zhang, R. Making convolutional networks shift-invariant again. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7324–7334. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, T.; Zhang, L.; Zhou, G.; Cai, W.; Cai, C.; Li, L. BC-DUnet-based segmentation of fine cracks in bridges under a complex background. PLoS ONE 2022, 17, e0265258. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Mou, L.; Zhao, Y.; Fu, H.; Liu, Y.; Cheng, J.; Zheng, Y.; Su, P.; Yang, J.; Chen, L.; Frangi, A.F. CS2-Net: Deep learning segmentation of curvilinear structures in medical imaging. Med. Image Anal. 2021, 67, 101874. [Google Scholar] [CrossRef]
- Park, H.; Sjösund, L.L.; Yoo, Y.; Bang, J.; Kwak, N. Extremec3net: Extreme lightweight portrait segmentation networks using advanced c3-modules. arXiv 2019, arXiv:1908.03093. [Google Scholar]
- Li, F.; Li, W.; Gao, X.; Liu, R.; Xiao, B. DCNet: Diversity convolutional network for ventricle segmentation on short-axis cardiac magnetic resonance images. Knowl.-Based Syst. 2022, 258, 110033. [Google Scholar] [CrossRef]
- Bianchi, E.; Hebdon, M. Concrete Crack Conglomerate Dataset; University Libraries, Virginia Tech: Blacksburg, VA, USA, 2021. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. pp. 234–241. [Google Scholar]






| Detection Result | |||
|---|---|---|---|
| Original |  |  |  |
| Ground truth |  |  |  |
| Unet++ |  |  |  |
| (a) | (b) | (c) | |
| Hardware environment | CPU | AMD EPYC 7543 32-Core Processor |
| ARM | 80GB | |
| Video memory | 48GB | |
| GPU | A40 | |
| Software Environment | OS | windows 11 |
| PyTorch | 1.11.0 | |
| Python | 3.8 | |
| Cuda | 11.3 |
| Size of Image | Batch_Size | Momentum | Initial lr | Optimizer | Iterations |
|---|---|---|---|---|---|
| 512 × 512 | 2 | 0.9 | Adam | 300 |
| Networks | Unet++ | SPP+Unet++ | ASPP+Unet++ | DPFFB+Unet++ |
|---|---|---|---|---|
| mIOU | 70.39% | 71.26% | 71.39% | 72.44% |
| Params | 47.19 M | 47.49 M | 47.71 M | 48.24 M |
| Hd95 | 12.62 | 10.16 | 10.03 | 8.16 |
| Networks | Unet++ | CBAM+Unet++ | CA+Unet++ | SE+Unet++ |
|---|---|---|---|---|
| mIOU | 70.39% | 72.98% | 72.84% | 73.14% |
| Params | 47.19 M | 47.85 M | 48.13 M | 47.35 M |
| Hd95 | 12.62 | 8.31 | 9.03 | 7.96 |
| Number | Method | mIOU (%) | mPA (%) | mPrecision (%) | Hd95 | Param |
|---|---|---|---|---|---|---|
| 1 | HC-Unet++ | 76.32 | 82.39 | 85.51 | 5.05 | 48.40 M |
| 2 | DPFFB+SE+Maxpool | 75.12 | 81.12 | 84.69 | 5.83 | 48.40 M |
| 3 | SE+Blur | 74.86 | 80.33 | 83.82 | 6.71 | 47.35 M |
| 4 | DPFFB+Blur | 73.69 | 78.69 | 82.47 | 7.23 | 48.24 M |
| 5 | DPFFB+Maxpool | 71.82 | 77.41 | 81.57 | 8.16 | 48.24 M |
| 6 | SE+Maxpool | 72.54 | 76.20 | 82.05 | 7.96 | 47.35 M |
| 7 | Blur | 71.16 | 75.21 | 81.94 | 11.26 | 47.19 M |
| 8 | Unet++ | 70.39 | 73.50 | 80.73 | 12.62 | 47.19 M |
| Detection Result | ||||
|---|---|---|---|---|
| original |  |  |  |  |
| Ground truth |  |  |  |  |
| Unet++ |  |  |  |  |
| DPFFB+SE+Maxpool |  |  |  |  |
| DPFFB+Blur |  |  |  |  |
| SE+Blur |  |  |  |  |
| HC-Unet++ |  |  |  |  |
| (a) | (b) | (c) | (d) | |
| Number | Method | mIOU (%) | mPA (%) | mPrecision (%) | Dice (%) | Hd95 |
|---|---|---|---|---|---|---|
| 1 | HC-Unet++ | 76.32 | 82.39 | 85.51 | 70.26 | 5.05 |
| 2 | BC-Dunet [42] | 72.41 | 78.59 | 79.38 | 61.19 | 9.82 |
| 3 | U2-Net [43] | 73.28 | 80.63 | 85.64 | 63.74 | 11.68 |
| 4 | CS2-Net [44] | 73.19 | 79.50 | 82.73 | 64.51 | 7.34 |
| 5 | Extremec3net [45] | 74.76 | 81.99 | 81.98 | 67.84 | 9.57 |
| 6 | DCNet [46] | 72.53 | 81.24 | 83.75 | 63.49 | 12.58 |
| Dataset | Method | mIOU (%) | mPA (%) | mPrecision (%) | Dice (%) | Hd95 |
|---|---|---|---|---|---|---|
| Concrete Crack Conglomerate | HC-Unet++ | 77.23 | 86.45 | 85.91 | 71.38 | 3.17 |
| FCN [48] | 69.38 | 80.13 | 79.19 | 60.64 | 14.89 | |
| Unet [49] | 71.06 | 82.54 | 83.64 | 62.52 | 11.68 | |
| Unet++ | 73.71 | 81.67 | 82.91 | 67.98 | 9.98 | |
| Crack 500 | HC-Unet++ | 76.91 | 84.04 | 87.49 | 69.54 | 4.68 |
| FCN [48] | 70.41 | 79.65 | 78.91 | 59.94 | 13.29 | |
| Unet [49] | 73.95 | 83.24 | 81.03 | 65.23 | 10.68 | |
| Unet++ | 73.83 | 82.94 | 84.57 | 64.26 | 9.35 |




































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, H.; Gao, Y.; Cai, W.; Xu, Z.; Li, L. Segmentation Detection Method for Complex Road Cracks Collected by UAV Based on HC-Unet++. Drones 2023, 7, 189. https://doi.org/10.3390/drones7030189
Cao H, Gao Y, Cai W, Xu Z, Li L. Segmentation Detection Method for Complex Road Cracks Collected by UAV Based on HC-Unet++. Drones. 2023; 7(3):189. https://doi.org/10.3390/drones7030189
Chicago/Turabian StyleCao, Hongbin, Yuxi Gao, Weiwei Cai, Zhuonong Xu, and Liujun Li. 2023. "Segmentation Detection Method for Complex Road Cracks Collected by UAV Based on HC-Unet++" Drones 7, no. 3: 189. https://doi.org/10.3390/drones7030189
APA StyleCao, H., Gao, Y., Cai, W., Xu, Z., & Li, L. (2023). Segmentation Detection Method for Complex Road Cracks Collected by UAV Based on HC-Unet++. Drones, 7(3), 189. https://doi.org/10.3390/drones7030189