
Autonomous Maneuver Decision-Making of UCAV with Incomplete Information in Human-Computer Gaming



Abstract
1. Introduction
- (1)
- The maneuver decision-making process within the current time horizon is modeled as a game of UCAV and Human, which inherently reduces the computational complexity. In each established game decision-making model, a continuous maneuver library that contains all possible maneuvers is designed, where each maneuver corresponds to a mixed strategy of the game model, which not only enriches the maneuver library but also solves the problem of the executable of mixed strategies;
- (2)
- The partially observable state of Human is considered during the dynamic maneuver decision-making process of UCAV and Human, and a method to predict the unobservable state of Human is given via the Nash equilibrium strategy of the previous decision-making stage.
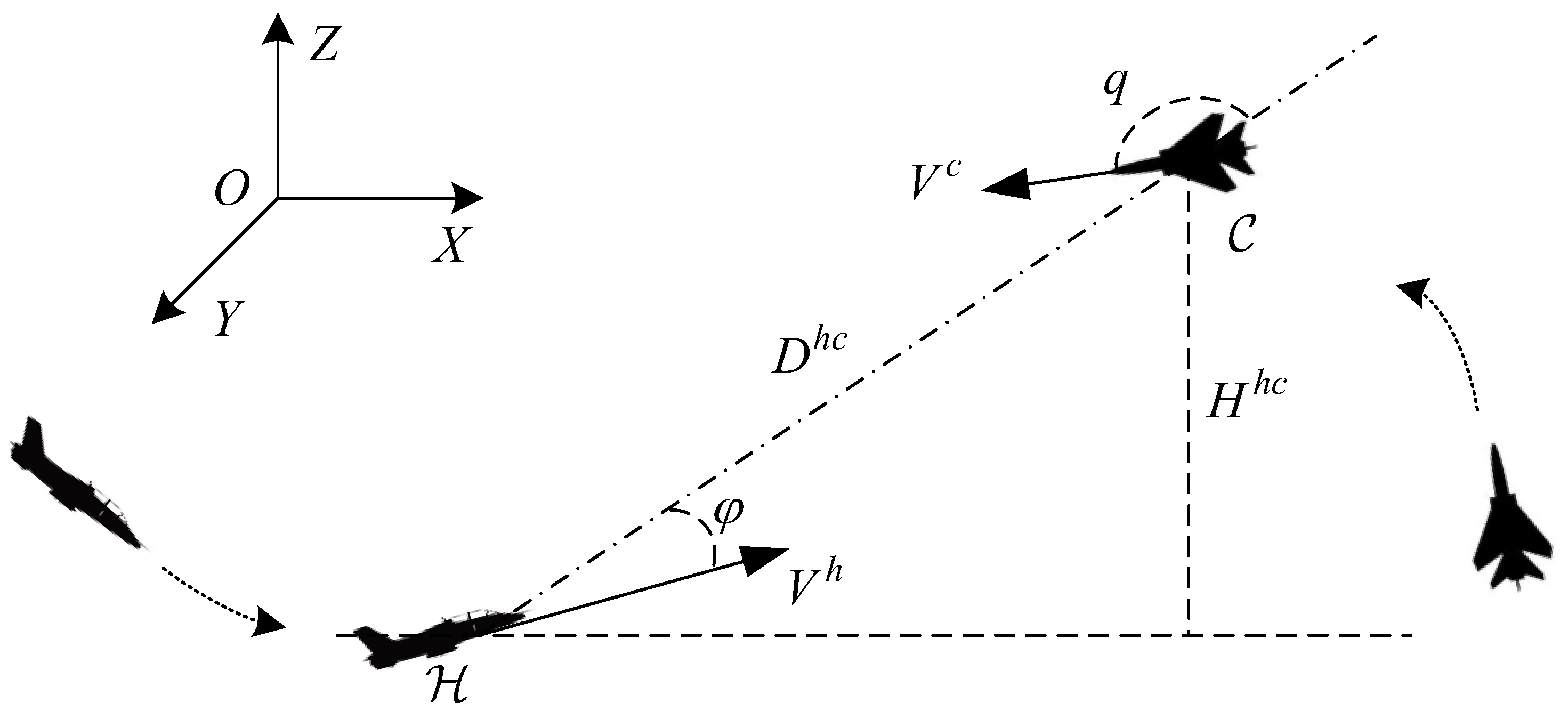
2. Problem Formulation and Preliminaries
3. Design of the Maneuver Decision-Making Method
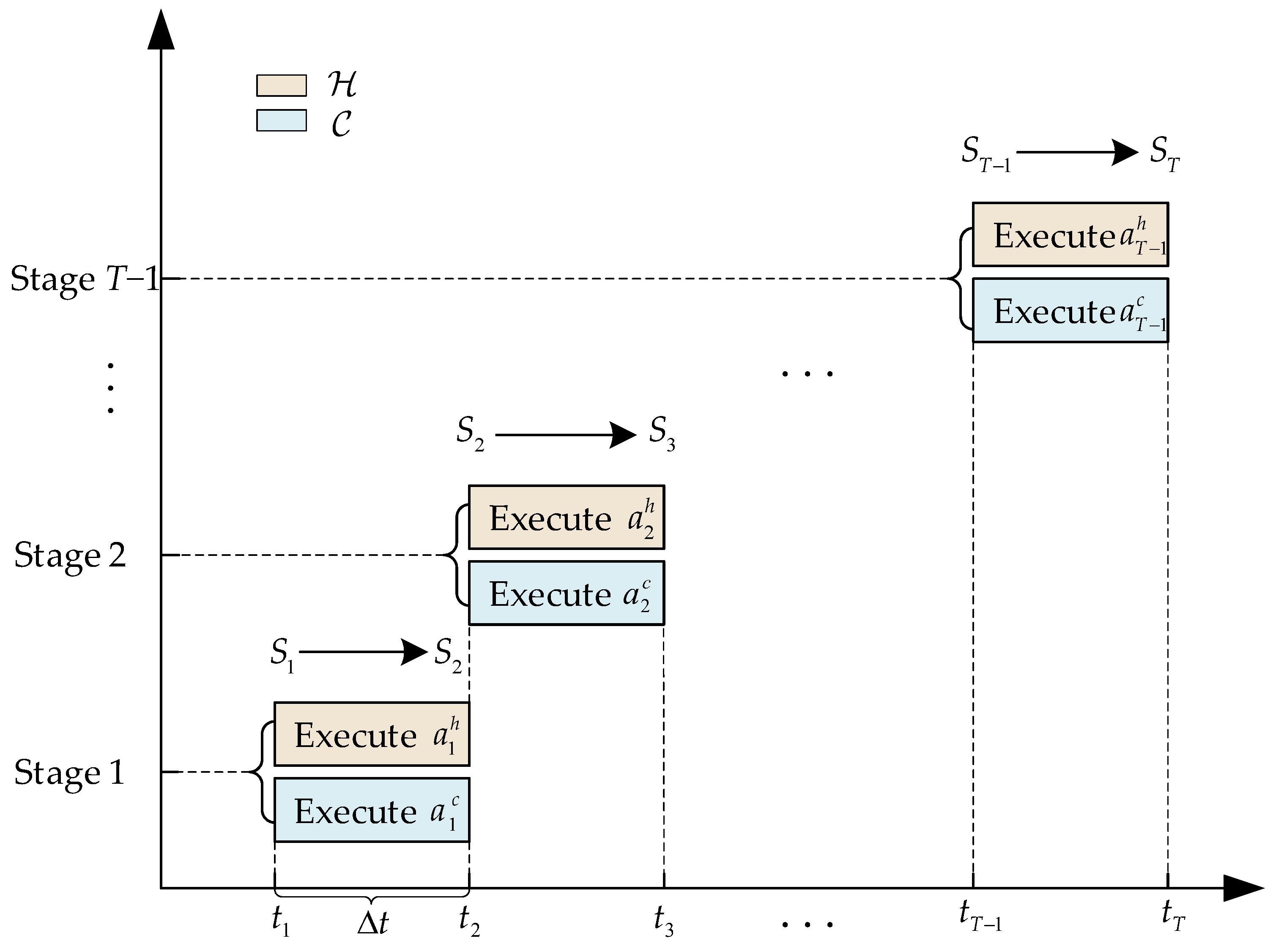
3.1. Game Decision-Making Model of the Current Time Horizon
- is the air combat situation of the i-th decision-making stage;
- and are the maneuver sets of and , respectively. Since both and have full maneuverability, we assume that they have the same maneuver set, i.e., ;
- is the payoff function of , which associates each with a real value . The payoff function of is defined as , due to the adversarial nature of and .
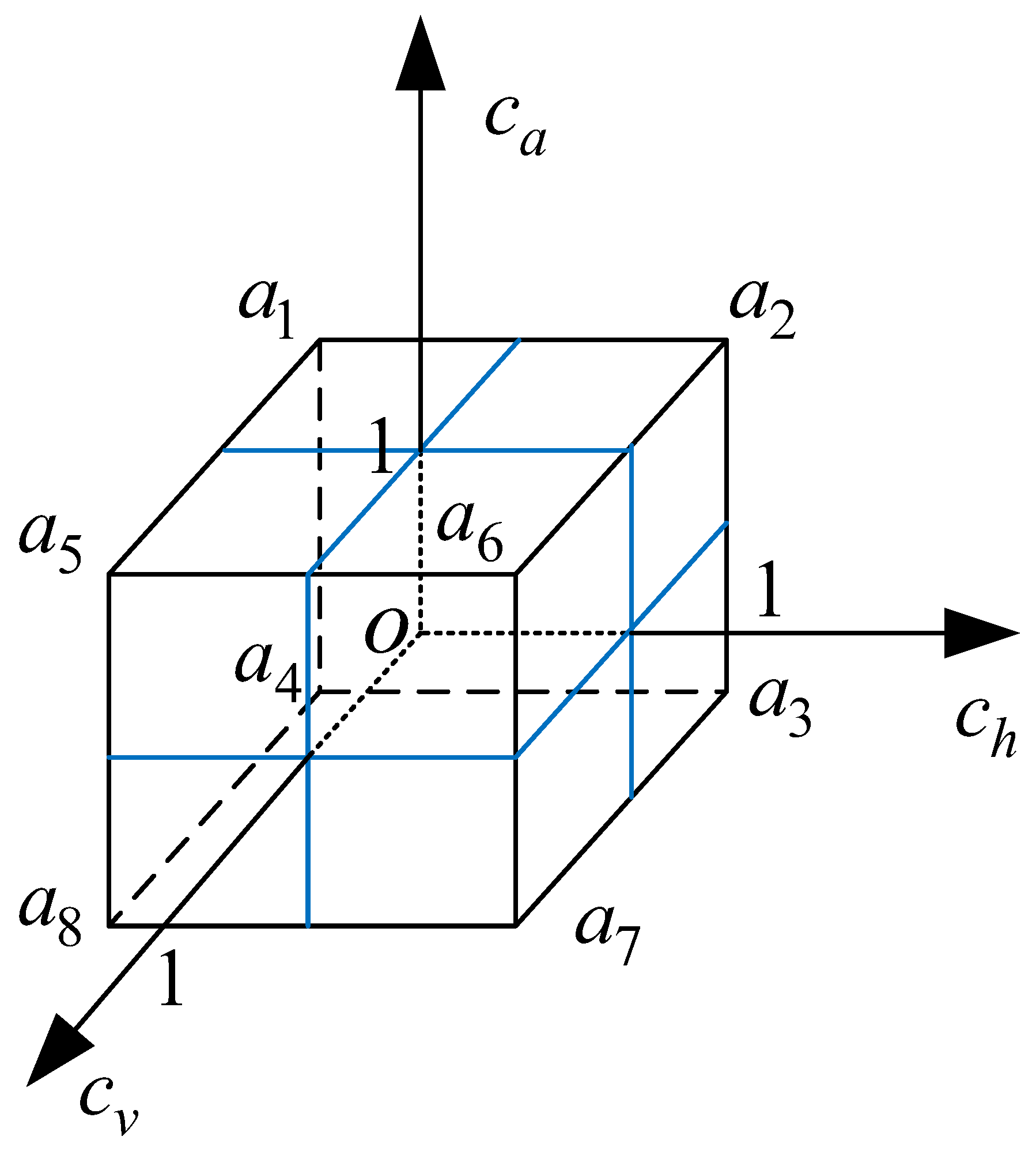
3.2. Continuous Maneuver Library
- The horizontal control variable belongs to the interval , where represents max load factor turn left, represents max load factor turn right, represents no horizontal turning maneuver, represents times max load factor turn left, and represents times max load factor turn right;
- The vertical control variable belongs to , where represents max load factor push over, represents max load factor pull up, represents no vertically turning maneuvers, represents times max load factor push over, and represents times max load factor pull up;
- The acceleration control variable belongs to , where represents the maximum thrust deceleration, represents the maximum thrust acceleration, represents that the thrust is 0, represents times maximum thrust deceleration, and represents times maximum thrust acceleration.
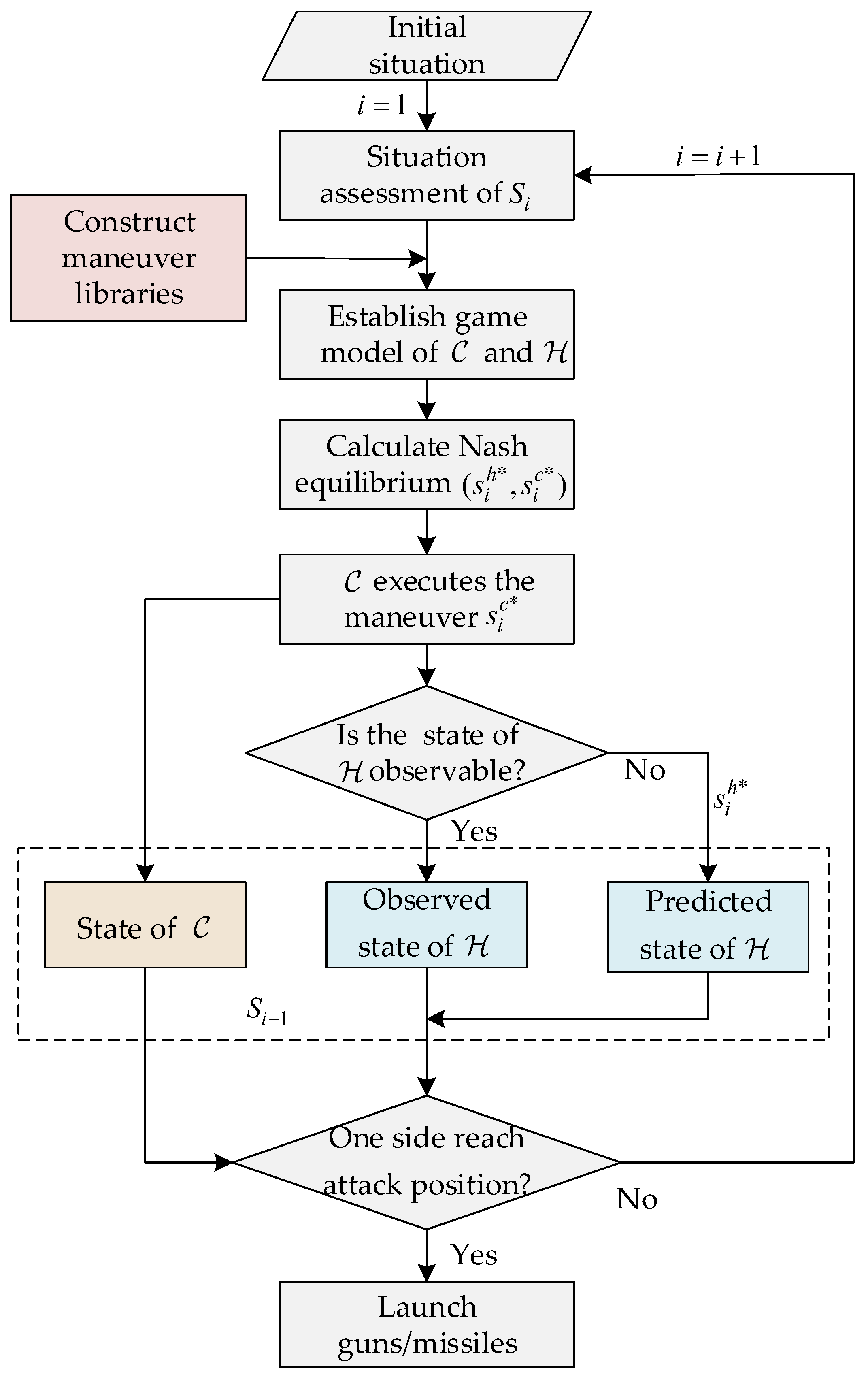
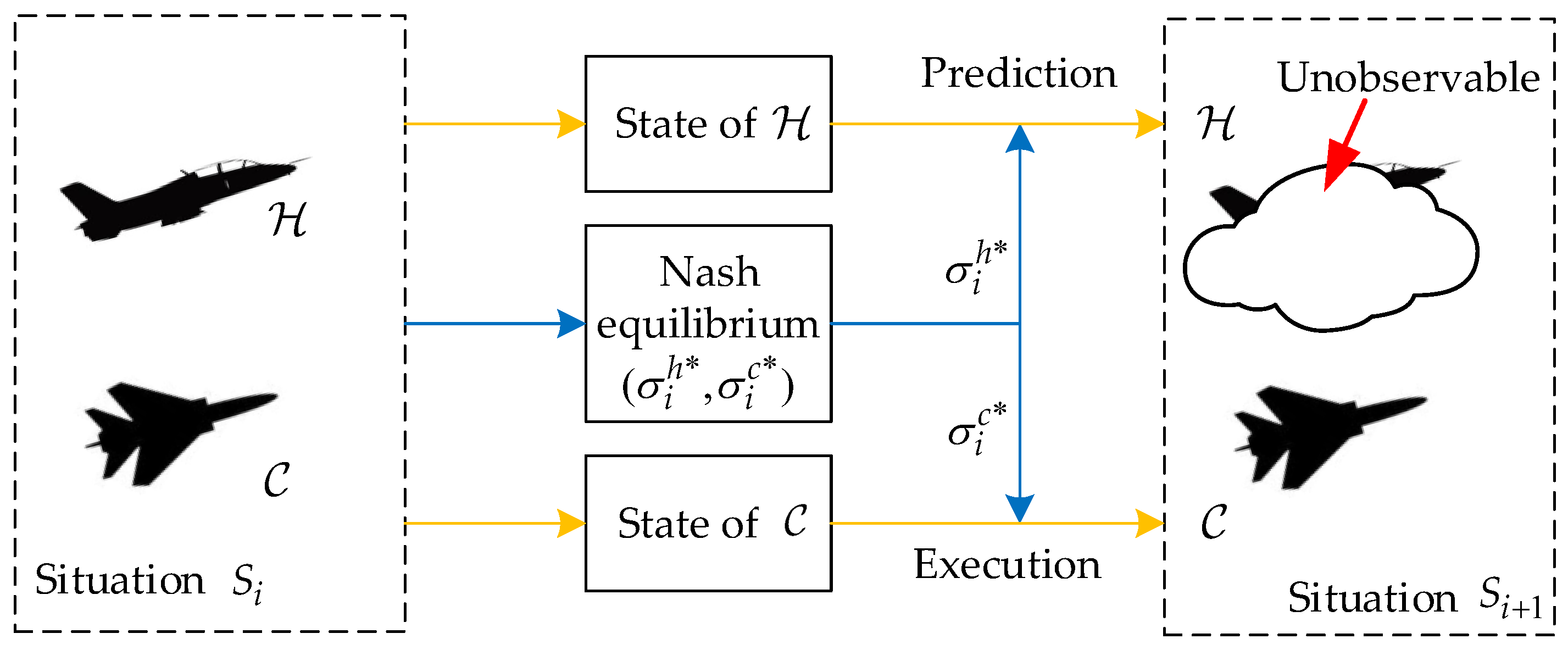
3.3. Prediction of the Unobservable State of Human
| Algorithm 1: Automatic maneuver decision-making algorithm (AMDM) |
Input: Initial air combat situation of and : ; |
Output: The maneuver decision sequence of : , , ⋯, |
|
 |
|
4. Simulations
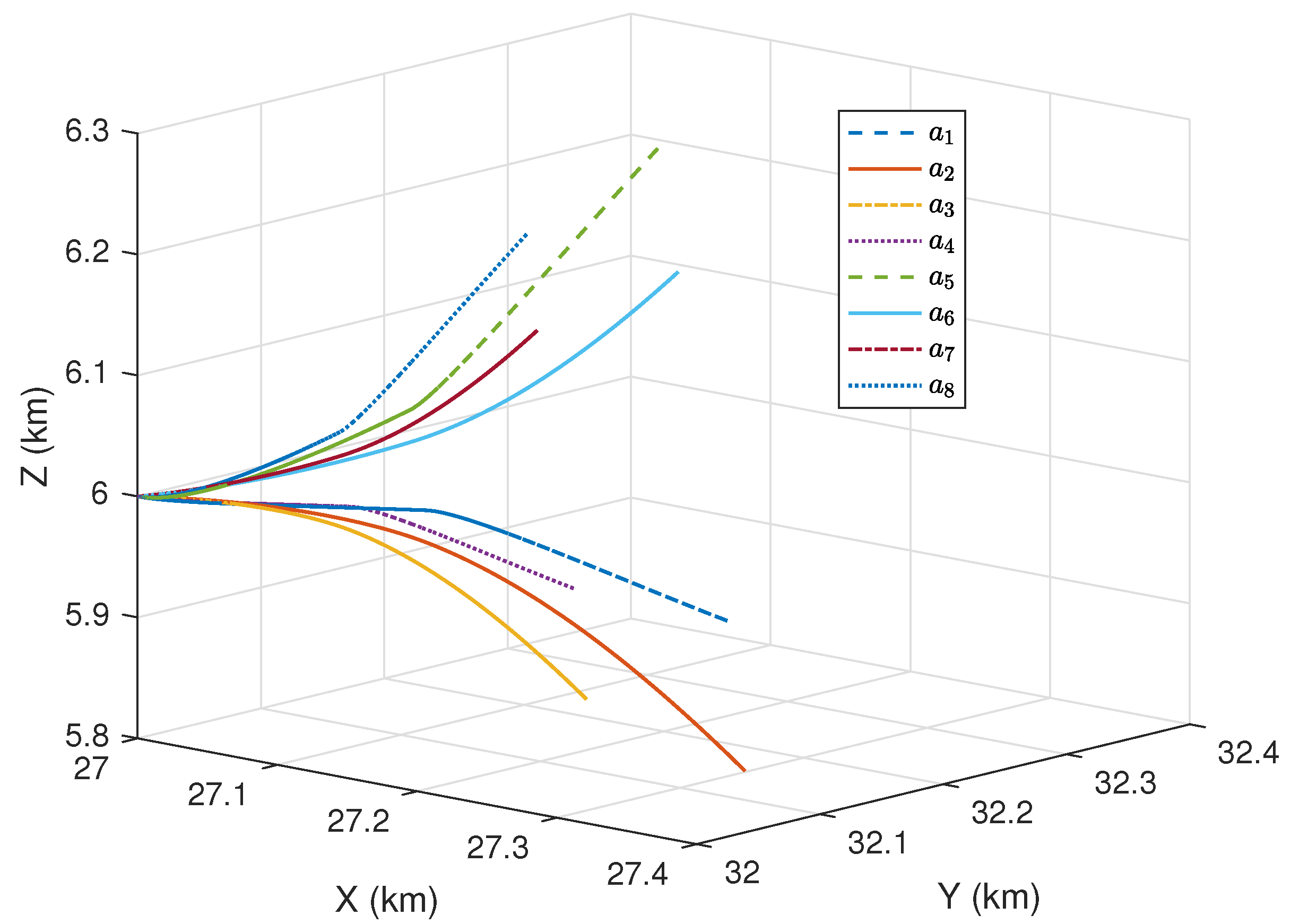
4.1. A Numerical Example of Maneuver Decision-Making in One Decision-Making Phase
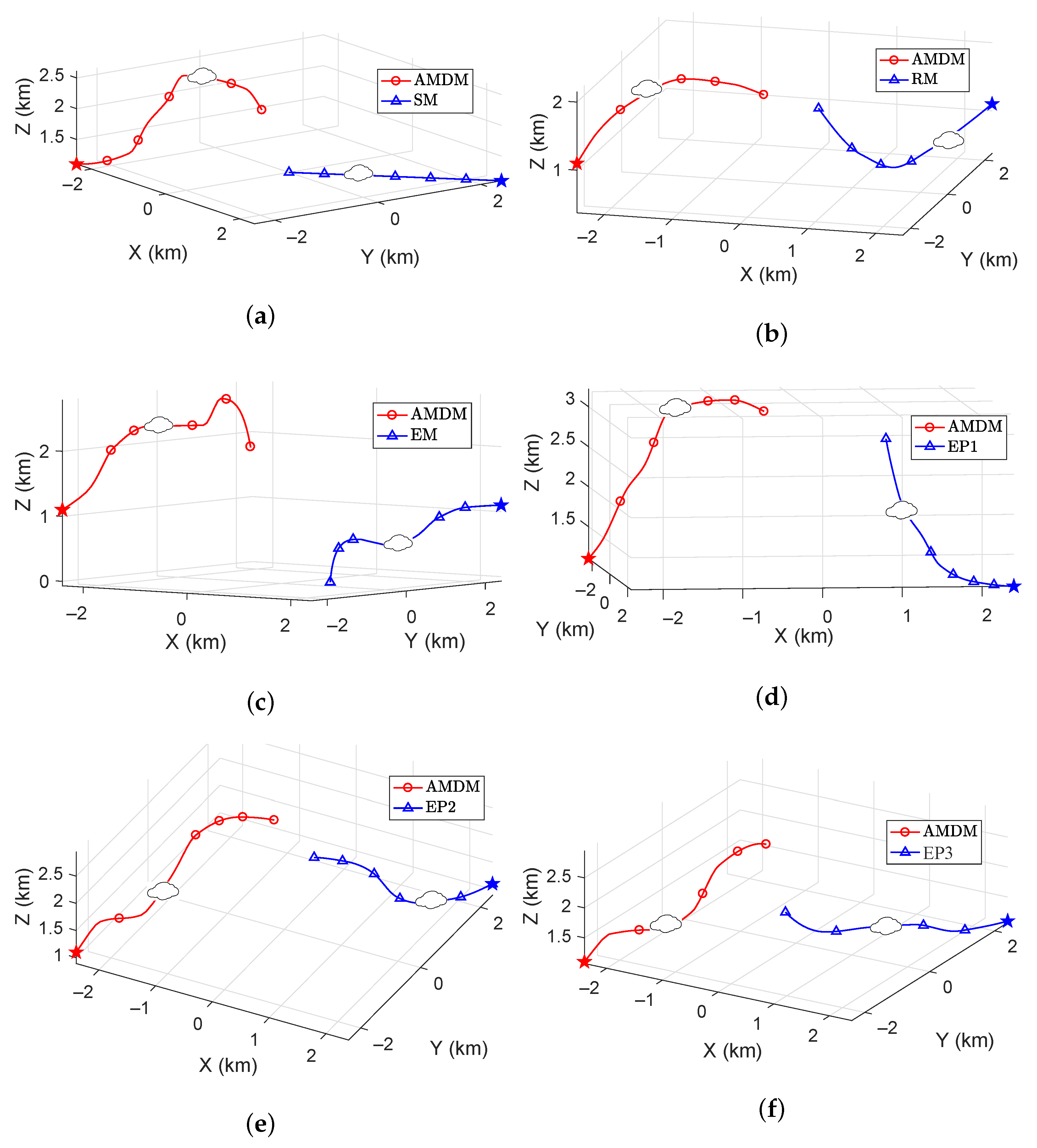
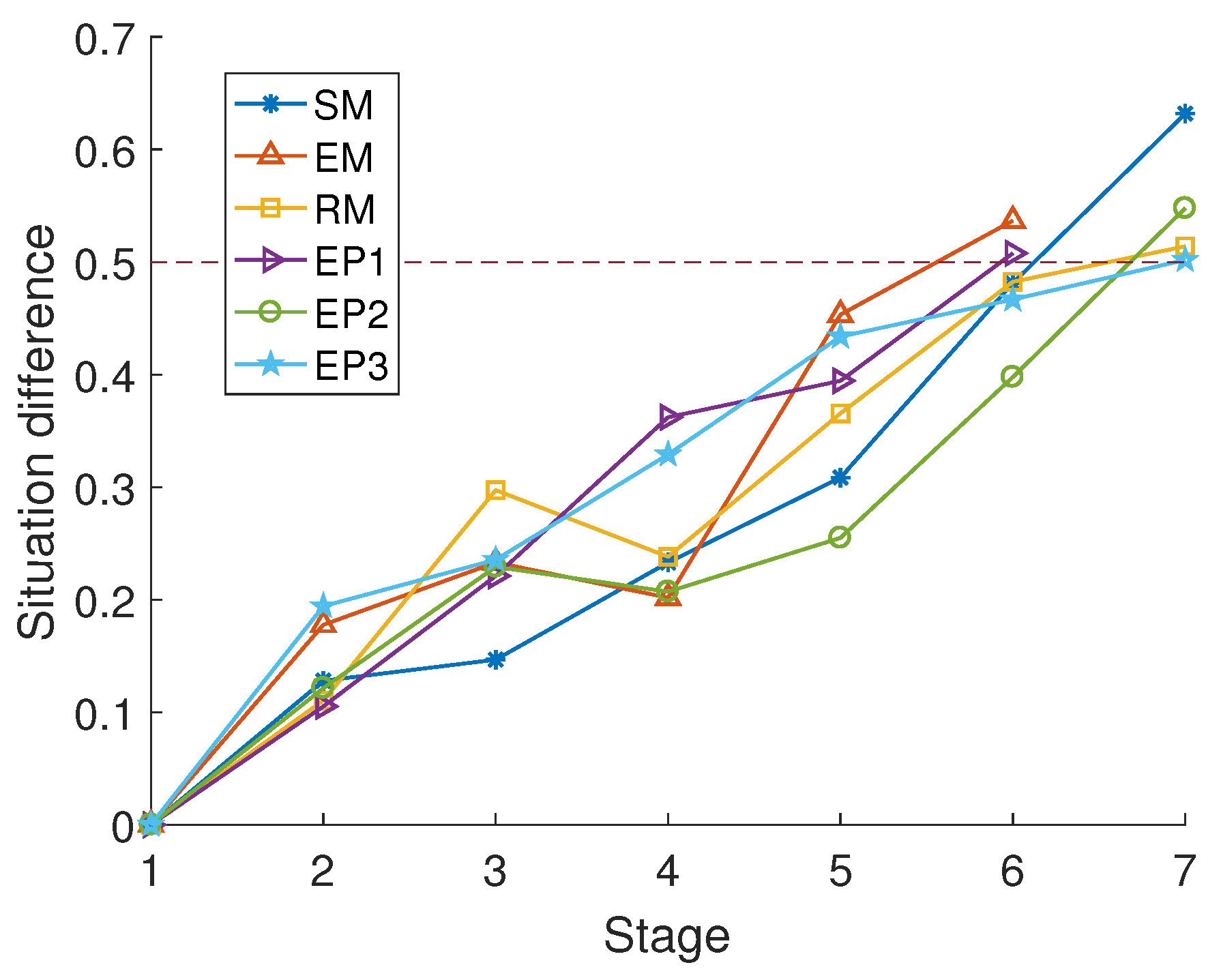
4.2. Some Comparative Experiments of Maneuver Decision-Making Process
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dalkıran, E.; Önel, T.; Topçu, O.; Demir, K.A. Automated integration of real-time and non-real-time defense systems. Def. Technol. 2021, 17, 657–670. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Z.X.; Piao, H.Y.; Huang, J.C.; Zhou, D.Y.; Ren, Z. Online hierarchical recognition method for target tactical intention in beyond-visual-range air combat. Def. Technol. 2022, 18, 1349–1361. [Google Scholar] [CrossRef]
- Li, S.; Wu, Q.; Chen, M.; Wang, Y. Air Combat Situation Assessment of Multiple UCAVs with Incomplete Information. In CISC 2020: Proceedings of 2020 Chinese Intelligent Systems Conference; Springer: Singapore, 2020; pp. 18–26. [Google Scholar]
- Guo, J.; Wang, L.; Wang, X. A Group Maintenance Method of Drone Swarm Considering System Mission Reliability. Drones 2022, 6, 269. [Google Scholar] [CrossRef]
- Shin, H.; Lee, J.; Kim, H.; Shim, D.H. An autonomous aerial combat framework for two-on-two engagements based on basic fighter maneuvers. Aerosp. Sci. Technol. 2018, 72, 305–315. [Google Scholar] [CrossRef]
- Li, J.; Chen, R.; Peng, T. A Distributed Task Rescheduling Method for UAV Swarms Using Local Task Reordering and Deadlock-Free Task Exchange. Drones 2022, 6, 322. [Google Scholar] [CrossRef]
- Zhou, X.; Qin, T.; Meng, L. Maneuvering Spacecraft Orbit Determination Using Polynomial Representation. Aerospace 2022, 9, 257. [Google Scholar] [CrossRef]
- Li, W.; Lyu, Y.; Dai, S.; Chen, H.; Shi, J.; Li, Y. A Multi-Target Consensus-Based Auction Algorithm for Distributed Target Assignment in Cooperative Beyond-Visual-Range Air Combat. Aerospace 2022, 9, 486. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, C.; Jiang, C.; Han, Z. Deep reinforcement learning assisted federated learning algorithm for data management of IIoT. IEEE Trans. Ind. Inform. 2021, 17, 8475–8484. [Google Scholar] [CrossRef]
- Du, B.; Mao, R.; Kong, N.; Sun, D. Distributed Data Fusion for On-Scene Signal Sensing With a Multi-UAV System. IEEE Trans. Control Netw. Syst. 2020, 7, 1330–1341. [Google Scholar] [CrossRef]
- Han, J.; Wu, J.; Zhang, L.; Wang, H.; Zhu, Q.; Zhang, C.; Zhao, H.; Zhang, S. A Classifying-Inversion Method of Offshore Atmospheric Duct Parameters Using AIS Data Based on Artificial Intelligence. Remote Sens. 2022, 14, 3197. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Brown, N.; Sandholm, T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science 2018, 359, 418–424. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Shi, J.; Wu, Y.; Wang, Y.; Lyu, Y. A Multi-UCAV cooperative occupation method based on weapon engagement zones for beyond-visual-range air combat. Def. Technol. 2022, 18, 1006–1022. [Google Scholar] [CrossRef]
- Kang, Y.; Pu, Z.; Liu, Z.; Li, G.; Niu, R.; Yi, J. Air-to-Air Combat Tactical Decision Method Based on SIRMs Fuzzy Logic and Improved Genetic Algorithm. In Advances in Guidance, Navigation and Control; Springer: Singapore, 2022; pp. 3699–3709. [Google Scholar]
- Li, B.; Liang, S.; Chen, D.; Li, X. A Decision-Making Method for Air Combat Maneuver Based on Hybrid Deep Learning Network. Chin. J. Electron. 2022, 31, 107–115. [Google Scholar]
- Li, S.; Chen, M.; Wang, Y.; Wu, Q. Air combat decision-making of multiple UCAVs based on constraint strategy games. Def. Technol. 2022, 18, 368–383. [Google Scholar] [CrossRef]
- Zhang, T.; Li, C.; Ma, D.; Wang, X.; Li, C. An optimal task management and control scheme for military operations with dynamic game strategy. Aerosp. Sci. Technol. 2021, 115, 106815. [Google Scholar] [CrossRef]
- Li, S.; Chen, M.; Wang, Y.; Wu, Q. A fast algorithm to solve large-scale matrix games based on dimensionality reduction and its application in multiple unmanned combat air vehicles attack-defense decision-making. Inf. Sci. 2022, 594, 305–321. [Google Scholar] [CrossRef]
- Ruan, W.; Duan, H.; Deng, Y. Autonomous Maneuver Decisions via Transfer Learning Pigeon-inspired Optimization for UCAVs in Dogfight Engagements. IEEE/CAA J. Autom. Sin. 2022, 9, 1–19. [Google Scholar] [CrossRef]
- Hu, J.; Wang, L.; Hu, T.; Guo, C.; Wang, Y. Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning. Electronics 2022, 11, 467. [Google Scholar] [CrossRef]
- Du, B.; Chen, J.; Sun, D.; Manyam, S.G.; Casbeer, D.W. UAV Trajectory Planning with Probabilistic Geo-Fence via Iterative Chance-Constrained Optimization. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5859–5870. [Google Scholar] [CrossRef]
- Austin, F.; Carbone, G.; Hinz, H.; Lewis, M.; Falco, M. Game theory for automated maneuvering during air-to-air combat. J. Guid. Control Dyn. 1990, 13, 1143–1149. [Google Scholar] [CrossRef]
- Yang, Q.; Zhang, J.; Shi, G.; Hu, J.; Wu, Y. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning. IEEE Access 2019, 8, 363–378. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, C.; Xuan, Y.; Tang, S. Maneuver Decision of Autonomous Air Combat of Unmanned Combat Aerial Vehicle Based on Deep Neural Network. Acta Armamentarii 2020, 41, 1613. [Google Scholar]
- Li, Y.; Shi, J.; Jiang, W.; Zhang, W.; Lyu, Y. Autonomous maneuver decision-making for a UCAV in short-range aerial combat based on an MS-DDQN algorithm. Def. Technol. 2022, 18, 1697–1714. [Google Scholar] [CrossRef]
- Hu, D.; Yang, R.; Zhang, Y.; Yue, L.; Yan, M.; Zuo, J.; Zhao, X. Aerial combat maneuvering policy learning based on confrontation demonstrations and dynamic quality replay. Eng. Appl. Artif. Intell. 2022, 111, 104767. [Google Scholar] [CrossRef]
- Du, B.; Sun, D.; Hwang, I. Distributed State Estimation for Stochastic Linear Hybrid Systems with Finite-Time Fusion. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 3084–3095. [Google Scholar] [CrossRef]
- Dong, Y.; Feng, J.; Zhang, H. Cooperative tactical decision methods for multi-aircraft air combat simulation. J. Syst. Simul. 2002, 14, 723–725. [Google Scholar]
- Jiang, C.; Ding, Q.; Wang, J.; Wang, J. Research on threat assessment and target distribution for multi-aircraft cooperative air combat. Fire Control Command Control 2008, 33, 8–12+21. [Google Scholar]
- Shen, Z.; Xie, W.; Zhao, X.; Yu, C. Modeling of UAV Battlefield Threats Based on Artificial Potential Field. Comput. Simul. 2014, 31, 60–64. [Google Scholar]
- Cruz, J.; Simaan, M.A.; Gacic, A.; Liu, Y. Moving horizon Nash strategies for a military air operation. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 989–999. [Google Scholar] [CrossRef]
- Maschler, M.; Solan, E.; Zamir, S. Game Theory; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Parthasarathy, T.; Raghavan, T.E.S. Some Topics in Two-Person Games; American Elsevier Publishing Company: New York, NY, USA, 1917. [Google Scholar]
- Huang, C.; Dong, K.; Huang, H.; Tang, S.; Zhang, Z. Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization. J. Syst. Eng. Electron. 2018, 29, 86–97. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | ||
|---|---|---|---|
| X coordinate of position | 81 | 27 | |
| Y coordinate of position | 70 | 32 | |
| Z coordinate of position | 7 | 6 | |
| X coordinate of speed | 234 | ||
| Y coordinate of speed | 215 | ||
| Z coordinate of speed | 32 | ||
| Maximum missile launch distance | 54 | 46 | |
| Maximum radar detection distance | 139 | 127 | |
| Maximum missile speed | |||
| Number of carried missiles | 2 | 3 |
| −0.0014 | −0.0045 | −0.0036 | −0.0006 | 0.0053 | 0.0020 | 0.0014 | 0.0047 | ||
| ine | −0.0073 | −0.0101 | −0.0093 | −0.0064 | −0.0004 | −0.0036 | −0.0043 | −0.0011 | |
| −0.0077 | −0.0106 | −0.0097 | −0.0068 | −0.0008 | −0.0040 | −0.0046 | −0.0015 | ||
| −0.0018 | −0.0049 | −0.0040 | −0.0010 | 0.0050 | 0.0016 | 0.0010 | 0.0043 | ||
| −0.0022 | −0.0052 | −0.0043 | −0.0014 | 0.0045 | 0.0012 | 0.0007 | 0.0039 | ||
| −0.0067 | −0.0096 | −0.0088 | −0.0059 | −0.0001 | −0.0033 | −0.0039 | −0.0006 | ||
| −0.0062 | −0.0091 | −0.0083 | −0.0054 | 0.0004 | −0.0028 | −0.0034 | −0.0002 | ||
| −0.0016 | −0.0047 | −0.0038 | −0.0009 | 0.0050 | 0.0017 | 0.0011 | 0.0044 | ||
| Symbol | Description | ||
|---|---|---|---|
| X coordinate of position | |||
| Y coordinate of position | |||
| Z coordinate of position | |||
| X coordinate of speed | 360 | ||
| Y coordinate of speed | 360 | ||
| Z coordinate of speed | 0 | 0 | |
| Maximum missile launch distance | 25 | 25 | |
| Maximum radar detection distance | 140 | 140 | |
| Maximum missile speed | 4 | 4 | |
| Number of carried missiles | 2 | 2 |
| Algorithm | SM | RM | EM | EP1 | EP2 | EP3 |
|---|---|---|---|---|---|---|
| BPNN | 0.1362 | 0.1459 | 0.1268 | 0.0842 | 0.0971 | 0.1327 |
| NESP | 0.1601 | 0.1452 | 0.1312 | 0.1105 | 0.1138 | 0.1492 |
| NESP-BPNN | +0.0239 | −0.0007 | +0.0026 | +0.0263 | +0.0167 | +0.0165 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Wu, Q.; Du, B.; Wang, Y.; Chen, M. Autonomous Maneuver Decision-Making of UCAV with Incomplete Information in Human-Computer Gaming. Drones 2023, 7, 157. https://doi.org/10.3390/drones7030157
Li S, Wu Q, Du B, Wang Y, Chen M. Autonomous Maneuver Decision-Making of UCAV with Incomplete Information in Human-Computer Gaming. Drones. 2023; 7(3):157. https://doi.org/10.3390/drones7030157
Chicago/Turabian StyleLi, Shouyi, Qingxian Wu, Bin Du, Yuhui Wang, and Mou Chen. 2023. "Autonomous Maneuver Decision-Making of UCAV with Incomplete Information in Human-Computer Gaming" Drones 7, no. 3: 157. https://doi.org/10.3390/drones7030157
APA StyleLi, S., Wu, Q., Du, B., Wang, Y., & Chen, M. (2023). Autonomous Maneuver Decision-Making of UCAV with Incomplete Information in Human-Computer Gaming. Drones, 7(3), 157. https://doi.org/10.3390/drones7030157