1. Introduction
Hypersonic UAVs mainly glide in near-space [
1]. In their early phase, a higher flight velocity is acquired, relying on the thin atmospheric environment, which is an advantage for effectively avoiding the interception of defense systems. At the end of a gliding flight, the velocity is mainly influenced by the aerodynamic force and suffers from the restrictions of heat flow, dynamic pressure, and overload [
2]. The velocity advantage leads to penetration becoming more difficult, so orbital maneuvering is applied by UAVs to achieve penetration. The main flight mission is split into avoiding defense system interception and satisfying multiple terminal constraints [
3]. The core of this manuscript is designing a penetration guidance strategy via orbital maneuvering capabilities, avoiding interception, and reducing the penetration’s impact on guidance accuracy.
The penetration strategy is summarized as a tactical penetration and a technical penetration strategy [
4]. The technical penetration strategy changes the flight path through maneuvering, aiming to increase the missed distance in order to successfully penetrate. Common maneuver manners include the sine maneuver, step maneuver, square wave maneuver, and spiral maneuver [
5]. There are some limitations and instability for technical penetration strategies, attributed to the UAV struggling to adopt an optimal penetration strategy according to the actual situation of the offensive and defensive confrontations. Compared with the traditional procedural maneuver strategy, the differential game guidance law has the characteristics of real-time operation and intelligence as a tactical penetration strategy [
6]. Penetration problems are essentially regarded as the continuous dynamic conflict problem of multi-party participants, and this strategy is an essential solution for solving multi-party optimal control problems. Applying it to the problem of attack–defense confrontation can not only fully consider the relative information between UAVs and interceptors but also obtain a Nash equation strategy to reduce energy consumption. Many scholars have proposed differential game models of various maneuvering control strategies based on control indexes and motion models. Garcia [
7] regarded the scenario of active target defense modeling as a zero-sum differential game, designed a complete differential game solution, and comprehensively considered the optimal strategy of closed-loop state feedback to obtain the value function. In Ref. [
8], the optimal guidance problem was studied between an interceptor and an active defense ballistic UAV, and an optimal guidance scheme was proposed based on the linear quadratic differential game method and the numerical solution of Riccati differential equations. Liang [
9] mainly analyzed the problem of pursuit and escape attacks of multiple players, inducted the three-body game confrontation into competition and cooperation problems, and solved the optimal solution of multiple players via differential game theory. The above methods are of great significance for analyzing and solving the confrontation process between UAVs and interceptors. Near-space UAVs have the characteristics of high velocity and short time in the phase of attack and defense confrontation terminal guidance [
10], and the differential game guidance law struggles to show advantages in this phase. Moreover, the differential game method requires a large amount of calculation, and the bilateral performance indicators are difficult to model [
11]; as a result, this theory is unable to be applied in practice.
DRL is a research hotspot in the field of artificial intelligence that has sprung up in recent years, and amazing results have been achieved in robot control, guidance, and control technologies [
12]. DRL specifically refers to agents learning in the process of interaction with the environment to find the best strategy to maximize cumulative rewards [
13]. With the advantages of dealing with high-dimensional abstract problems and making decisions quickly, DRL provides a new solution for the maneuvering penetration of high-velocity UAVs. In order to solve the problem of intercepting a high maneuvering target, an auxiliary DRL algorithm was proposed in Ref. [
14] to optimize the frontal interception guidance control strategy based on a neural network. Simulation results showed that DRL had a higher hit rate and larger terminal interception angle than traditional methods and proximal policy optimization algorithms. Gong [
15] proposed an Omni bearing attack guidance law for agile UAVs via DRL, which effectively dealt with aerodynamic uncertainty and strong nonlinearity at a high attack angle. DRL was used to generate a guidance law for the attack angle in an agile turning phase. Furfaro [
16] proposed an adaptive guidance algorithm based on classical zero-effort velocity, and the limitations of this algorithm were overcome via RL. A closed-loop guidance algorithm was created that is lightweight and flexible enough to adapt to a given constrained scene.
Compared with differential game theory, DRL is convenient for establishing the performance index function, and it is a feasible method to solve the dynamic programming problem by utilizing the powerful numerical calculation ability of computers to skillfully avoid solving the function analytical solution. However, the traditional DRL has some limitations, such as high sample complexity, low sample utilization, a long training time, and so on. Once the mission changes, the original DRL parameters are hard to adapt to the new mission and need to be learned from scratch. A change in mission or environment will lead to the failure of the trained model and poor generalization ability of the model. In order to solve the existing problems in DRL, researchers introduced meta-learning into DRL and proposed Meta DRL [
17]. Lu et al. [
18] mainly solved the issues of maximizing the total data collected and avoiding collisions during the guidance flight and improved the adaptability to different missions via meta RL. Hu et al. [
19] mainly studied a challenging trajectory design problem, optimized the DBS trajectory, and considered the uncertainty and dynamics of terrestrial users’ service requests. MAML was introduced for the purposes of solving raised POMDPS and enhancing adaptability to balance flight aggressiveness and safety [
20]. For suspended payload transportation tasks, the paper [
21] proposed a meta-learning approach to improve adaptability. The simulation demonstrated improvements in closed-loop performance compared to non-adaptive methods.
By learning useful meta knowledge from a group of related missions, agents acquire the ability to learn, and the learning efficiency on new missions is improved and the complexity of samples is reduced. When faced with new missions or environments, the network responds quickly based on the previously accumulated knowledge, so only a small number of samples are needed to quickly adapt to the new mission.
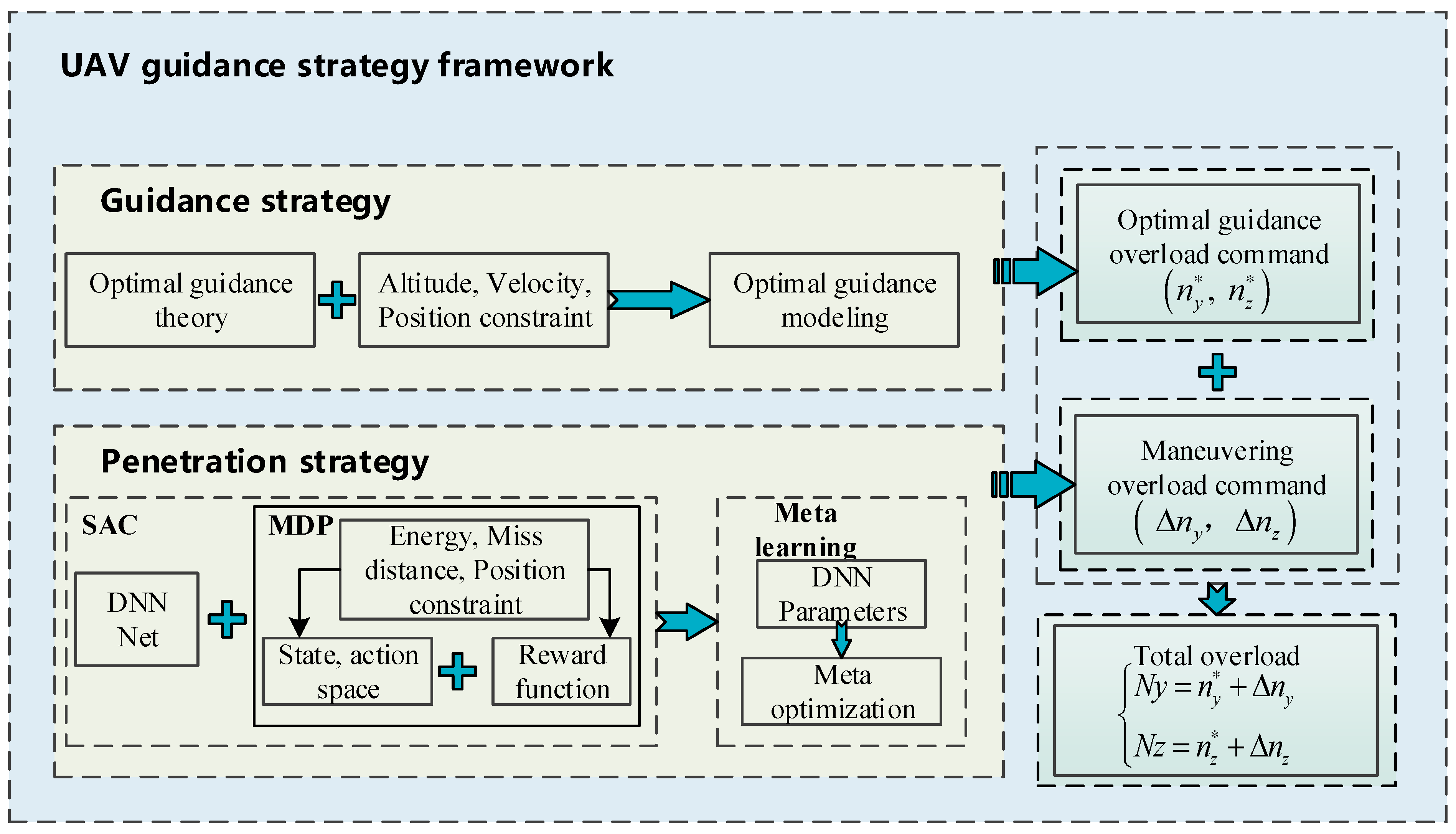
Based on the above analysis, this manuscript proposes Meta DRL to solve the UAV guidance penetration strategy, and the DRL is improved, resulting in enhancing the adaptability of UAVs in complex and changeable attack and defense confrontations. In addition, the idea of meta-learning is used to enable UAVs to learn and improve their ability for autonomous flight penetration. The core contributions of this manuscript are as follows:
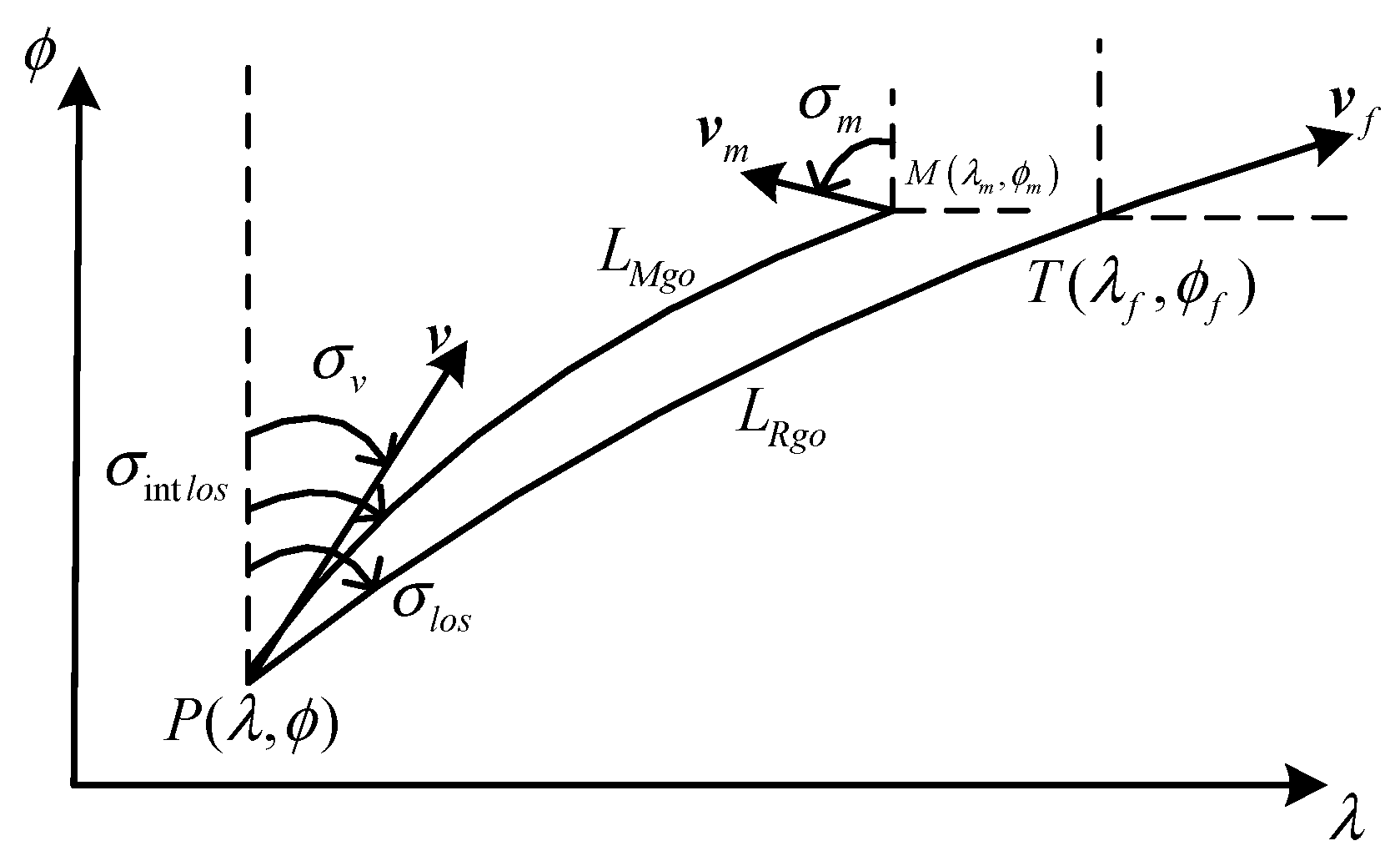
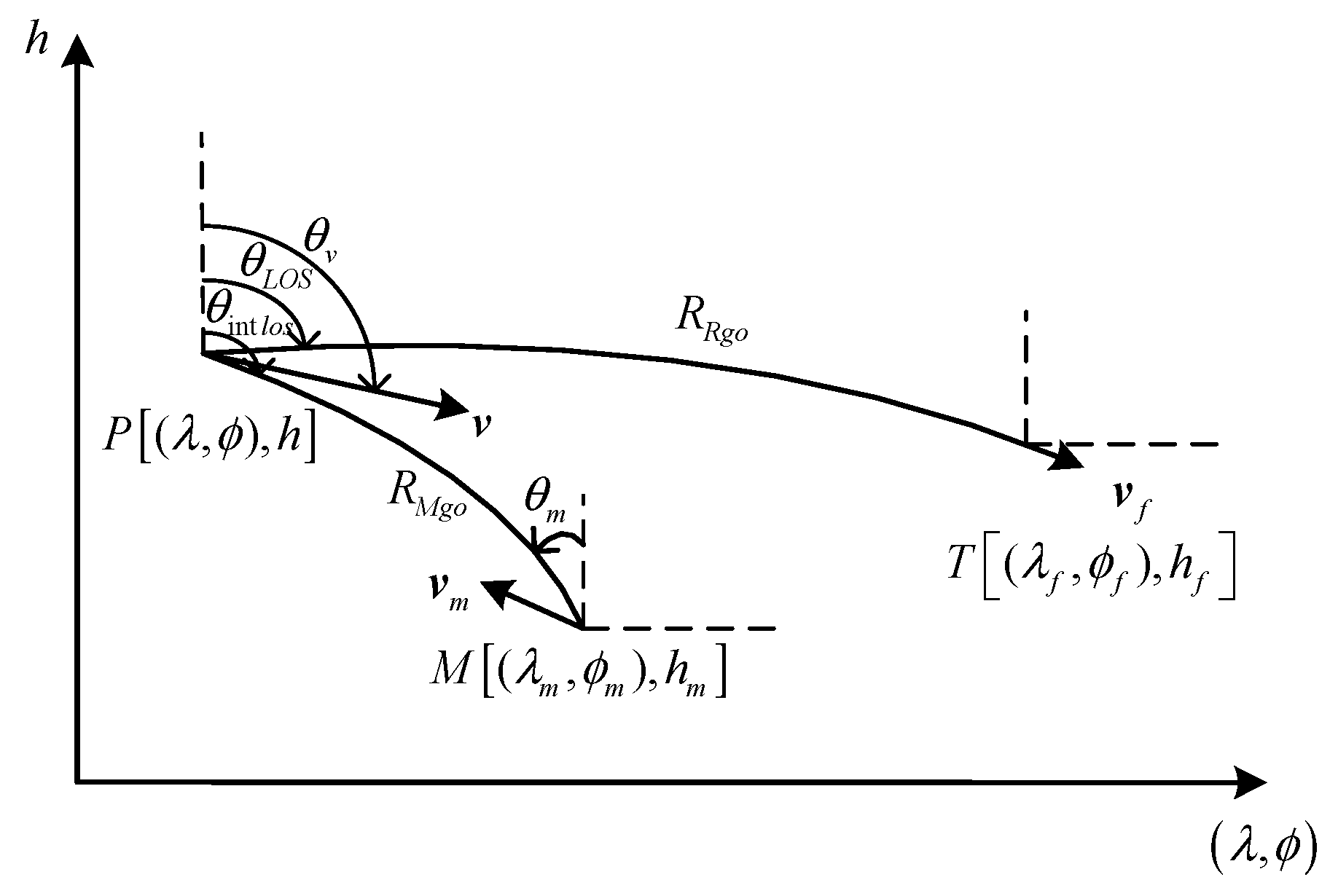
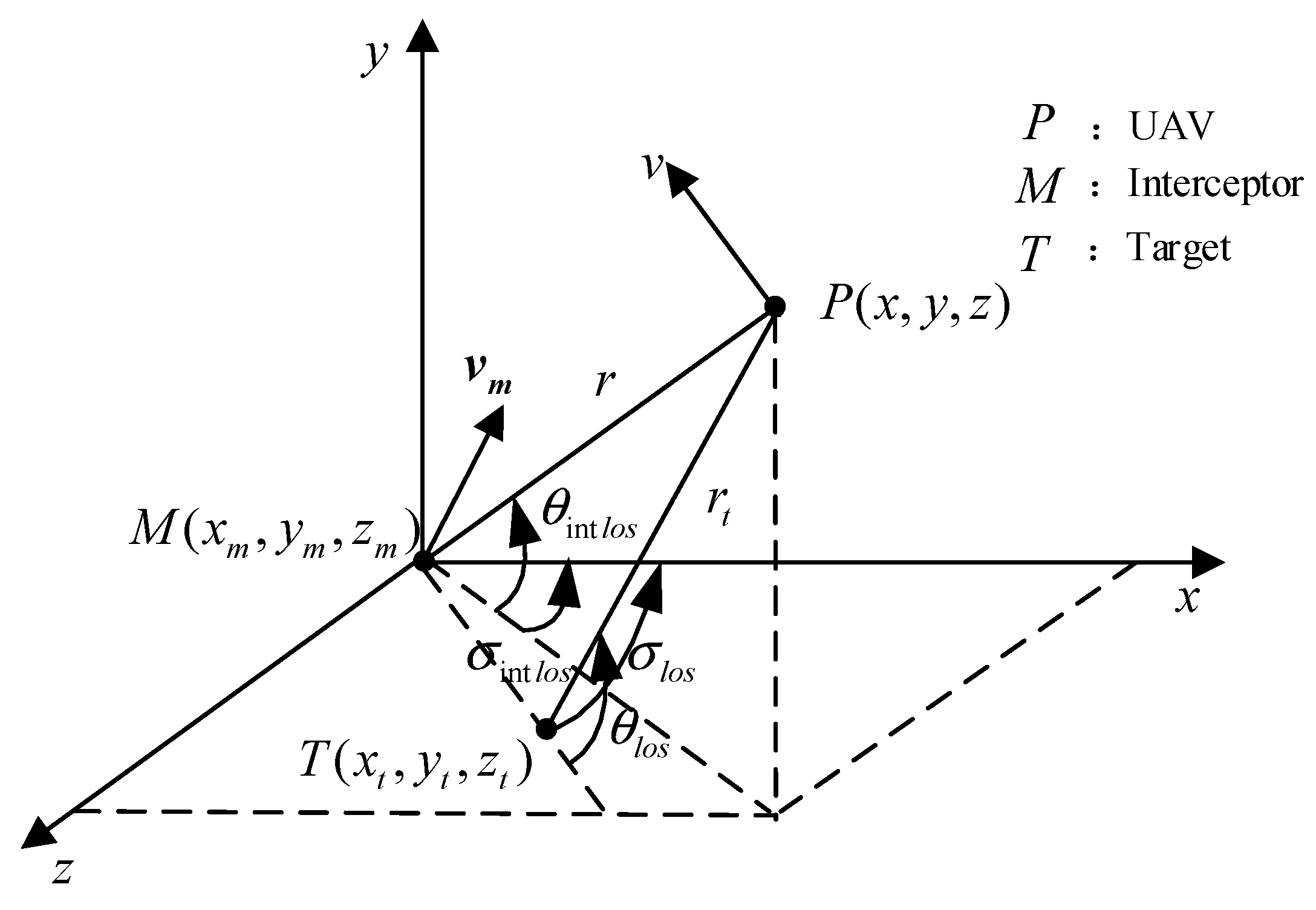
By modeling the three-dimensional attack and defense scene between UAVs and interceptors, we analyze the terminal and process constraints of UAVs. A guidance penetration strategy based on DRL is proposed, aiming to provide the optimal solution for maneuvering penetration under a constant environment or mission.
Meta-learning is used to improve the UAV guidance penetration strategy. The improvement enables the UAV to learn and enhances the autonomous penetration ability.
Through the simulation analysis, the manuscript analyzes the penetration strategy, explores penetration timing and maneuvering overload, and summarizes the penetration tactics.
5. DRL Penetration Guidance Law
5.1. SAC Training Model
Standard DRL maximizes the sum of expected rewards . For the problem of multi-dimensional continuous state inputs and a continuous action output, SAC networks are introduced to solve the MDP model.
Compared with other policy learning algorithms [
28], SAC augments the standard RL objective with expected policy entropy using Equation (47).
The entropy term
is shown in Equation (48), which represents the stochastic feature of the strategy, balancing the exploration and learning of networks. The entropy parameter
determines the relative importance of entropy against the immediate reward.
The optimal strategy of SAC is shown in the Equation (49), aiming at maximizing the cumulative reward and policy entropy.
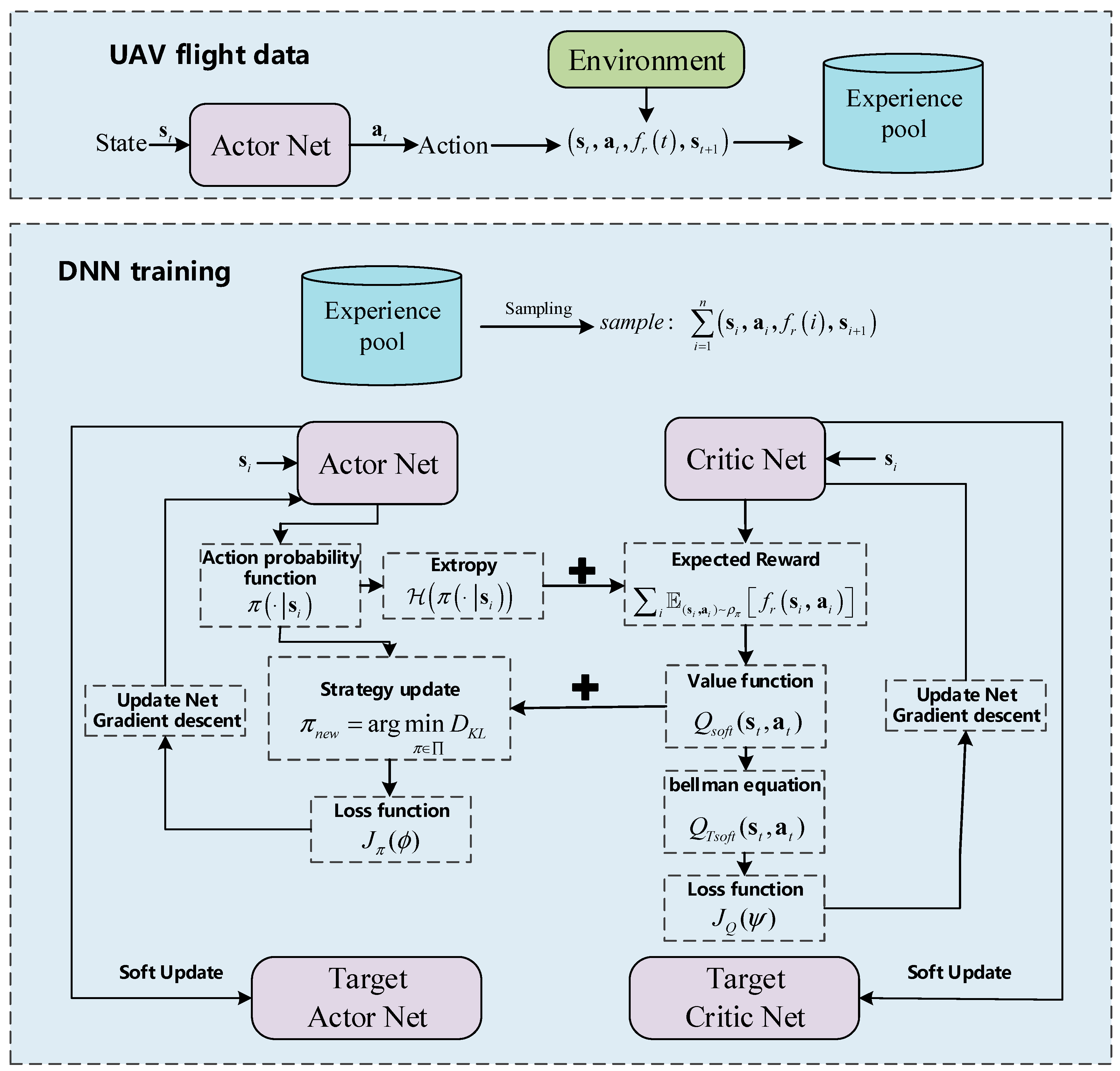
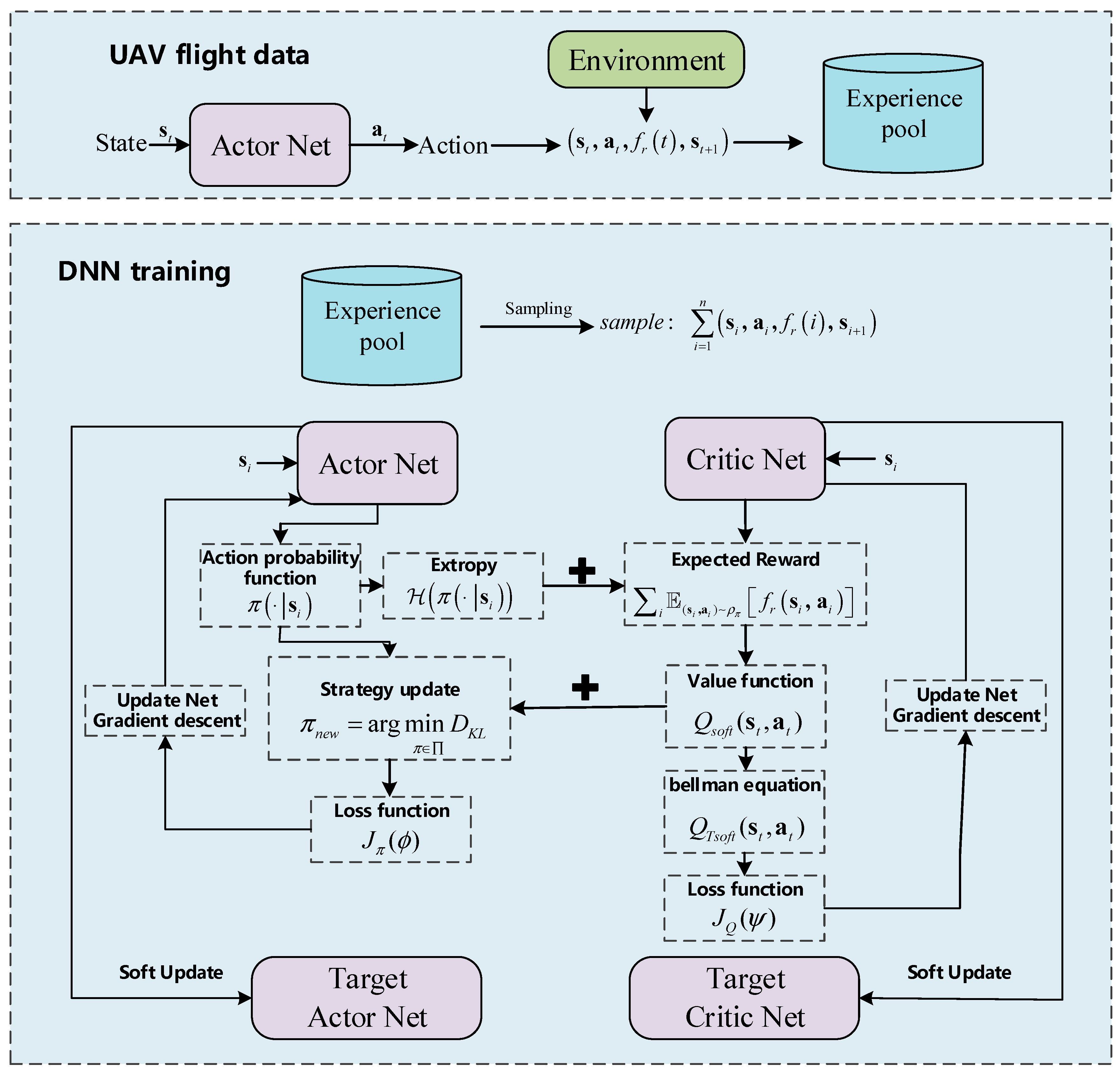
The framework of SAC networks is shown in
Figure 5, consisting of an Actor network and a Critic network. The Actor network generates the action, and the environment returns the reward and the next state. All of the ballistics data are stored in the experience pool, including the state, action, reward, and next state.
The Critic network is used to judge the found strategies, which impartially guides the strategy of the Actor network. At the beginning, the Actor network and Critic network are given random parameters. The Actor network struggles to generate the optimal strategy, and Critic network struggles to scientifically judge the strategy of the Actor network. The parameters of the networks need to be updated based on continuously generating data and sampling ballistics data.
For updating the Critic network, it outputs the expected reward
based on samples, and the Actor network outputs the action probability, which is depicted by the entropy term
. Combining
with
, the value function is conducted and shown in Equation (50)
We further obtain the Bellman equation, as shown in Equation (51):
Given by Equation (52), the loss function of the Critic network is acquired as follows:
For updating the Actor network, the updating strategy is shown in Equation (53)
where
represents the set of strategies, and
is the partition function, used to normalize the distribution.
is the Kullback–Leibler (KL) divergence [
29].
Combining the re-parameterization technique with Equation (54), the loss function of the Actor network is obtained as follows:
in which
, and
is the input noise, obeying the distribution
.
The method of stochastic gradient descent is introduced to minimize the loss function of networks. The optimal parameters of the Actor–Critic networks are obtained by repeating the updating process and passing the parameters to the target networks via soft updating.
5.2. Meta SAC Optimization Algorithm
The learning algorithm in DRL relies on a lot of interaction between the agent and the environment and high training costs. Once the environment changes, the original strategy is no longer applicable and needs to be learned from scratch. The penetration guidance problem under the stable flight environment can be solved using SAC networks. For a changeable flight environment, such as where the initial position of the interceptor changes greatly or the interceptor guidance law deviates greatly from the preset value, the strategy solved via traditional SAC struggles to adapt, which thus requires to restudy and redesign. This manuscript introduces meta-learning to optimize and improve SAC performance. The training goal of Meta SAC is to obtain initial SAC model parameters. When the UAV penetration mission is changed, through a few scenes of learning, the UAV can adapt to the new environment and complete the corresponding guidance penetration mission, without relearning model parameters. Meta SAC can achieve “learn while flying” for UAVs and strengthen the adaptability of UAVs.
The Meta SAC algorithm is shown in Algorithm 1, which is divided into a meta-training and meta-testing phase. The meta-training phase seeks to determine the optimal meta-learning parameters based on multi-experience missions. In the meta-testing phase, the trained meta parameters are interactively learned in the new mission environment to fine-tune the meta parameters.
| Algorithm 1 Meta SAC |
1: Initialize the experience pool , Storage space N
2: Meta training:
3: Inner loop
4: for iteration k do
5: sample mission(k) from
6: update actor policy to using SAC based on mission(k):
7: .
8: Outer loop
9:
10: Generate from and estimate the reward of .
11: Add a hidden layer feature as a random noise.
12:
13: The meta-learning process of different missions is carried out through SGD.
14: for iteration mission(k) do
15:
16:
17: Meta testing
18: Initialize the experience pool , Storage space N.
19: Load meta training network parameters .
20: Set training parameters.
21: for iteration i do
22: sample mission from
23:
End for |
The basic assumption of Meta SAC is that the experience mission for meta training and the new mission for meta testing obey the same mission distribution
. Therefore, there are some common characteristics between different missions. In the DRL scenario, our goal is to learn a function
with parameter
, which can minimize the loss function
of a specific mission
. In the meta DRL scenario, our goal is to learn a learning process
, which can quickly adapt to the new mission
with a very small dataset
. Meta SAC can be summarized as optimizing the parameters
and
in the learning process, and the optimization equation is shown in Equation (55).
where
and
, respectively, represent training and testing missions sampled from
, and
represents the testing loss function. In the meta-training phase, parameters are optimized via the inner loop and outer loop.
In the inner loop, Meta SAC updates the model parameters with a small amount of randomly selected data for the specific mission as the training data, reducing the loss of the model in mission . In this part, the updating of model parameters is the same as in the original SAC algorithm, and the agent learns several scenes from randomly selected missions.
The minimum mean square error of strategy parameters
corresponding to different missions in the inner loop phase is solved to obtain the initial strategy parameters
of the outer loop. In this manuscript, a hidden layer feature is added to the input part of strategy
as a random noise. The random noise is sampled again in each episode, in order to provide a more continuous random exploration in time, which is helpful for agent to adjust their overall strategy exploration according to the current mission MDP. The goal of meta-learning is to enable the agent to learn how to quickly adapt to new missions by simultaneously updating a small amount of gradient of strategy parameters and hidden layer features. Therefore, the
of
includes not only parameters of the neural network, but also the distribution parameters of hidden variables of each mission, namely the mean and variance of the Gaussian distribution, as shown in Equation (56).
The model is represented by a parameterized function
with parameter
, and when it is transferred to a new mission
, model parameter
is updated to
through gradient rise, as shown in Equation (57).
We update step
is a fixed super parameter. Model parameter
is updated to maximize the performance
of different missions, as shown in Equation (58).
The meta-learning process of different missions is carried out through SGD, and the principle of
is as follows:
where
is the meta update step.
In the meta-testing phase, a small amount of experience in new missions is used to quickly learn strategies for solving new missions. A new mission may involve completing a new mission goal or achieving the same mission goal in a new environment. The updating process of the model in this phase is the same as the cycle part in the meta-training phase, and by calculating the loss function with the data collected in the new mission and adjusting the model through back propagation, the new mission is adapted by the agent.
6. Simulation Analysis
In this section, the manuscript analyzes and verifies the escape guidance strategy based on Meta SAC. SAC is used to solve a specific escape guidance mission. We conduct comprehensive experiments to verify whether the UAV can complete the guidance escape mission under satisfying terminal and process constraints. Once the UAV guidance escape mission changes, the original strategy based on SAC cannot be easily adapted to the changed mission and thus needs to be relearned and retrained. The manuscript proposes an optimization method via meta-learning that improves the learning ability of UAVs during the training process. This section focuses on verifying the validation of Meta SAC and demonstrating its performance in various new missions. In addition, the maneuvering overload commands under different pursuit evading distances are analyzed in order to explore the influence of different maneuvering timings and distances on the escape results. We use CAV-H to verify the escape guidance performance. The initial conditions, terminal altitude, and Meta SAC training parameters are given in
Table 1.
6.1. Validity Verification on SAC
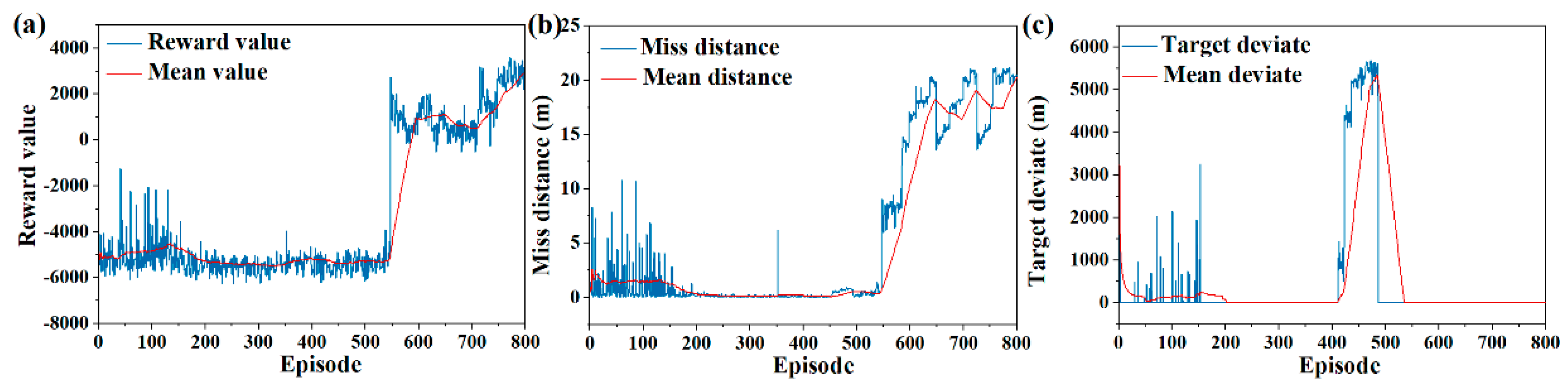
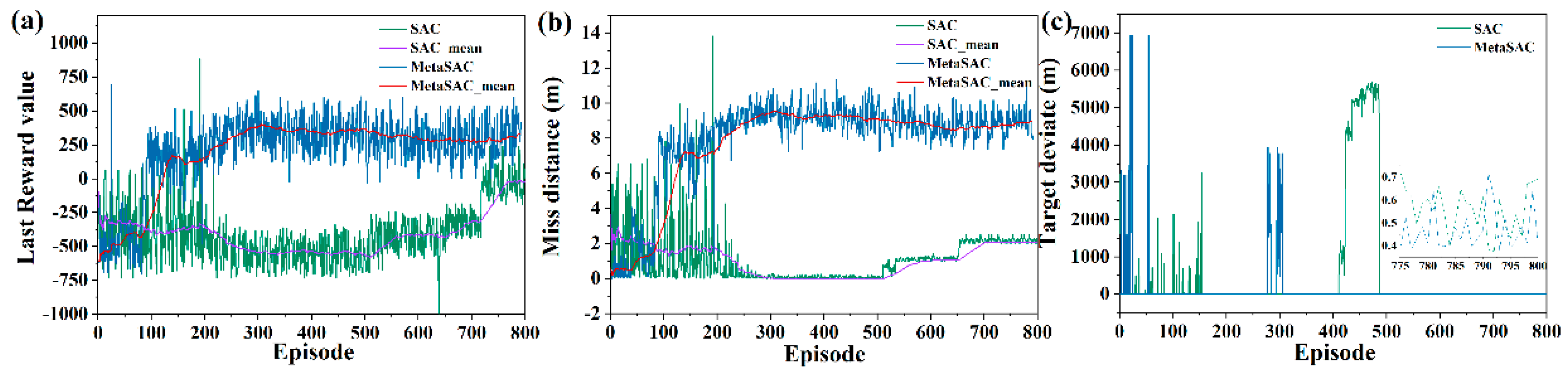
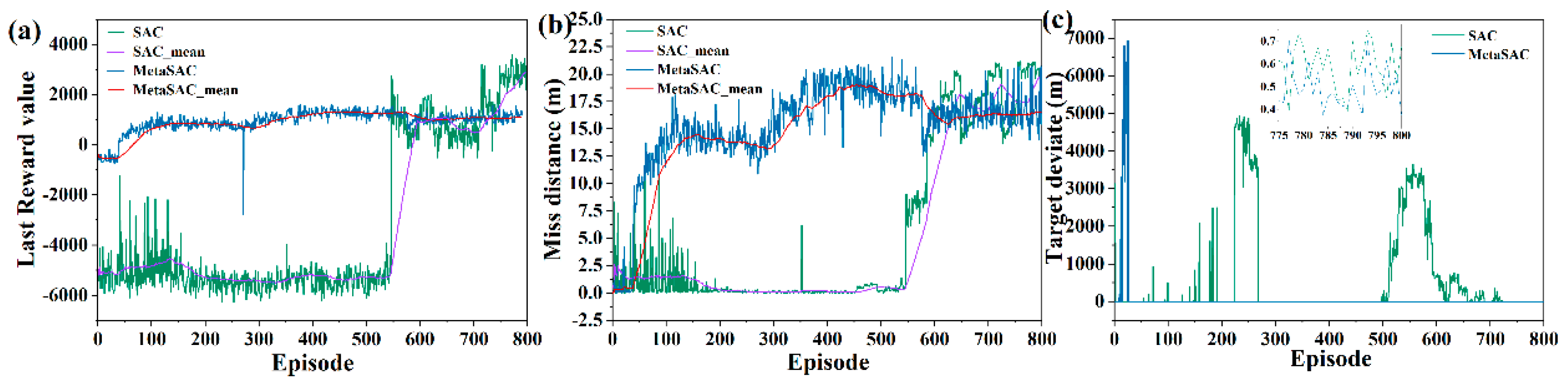
In order to verify the effectiveness of SAC, three different pursuit evading scenarios are constructed, and the terminal reward value, miss distance, and terminal position deviation are analyzed. As shown in
Figure 6a, the terminal reward value is poor in the initial phase of training, which demonstrates that the optimal strategy is not found. After 500 episodes, the terminal reward value increases gradually, indicating that a better strategy has been explored and converged. In the last 100 episodes, the optimal strategy is trained and learned, while the network parameters are adjusted to the optimal strategy. As can be seen from
Figure 6b, the miss distance is relatively divergent in the first 150 episodes of training, indicating that the Action network in SAC constantly explores new strategies, and the Critic network also learns scientific evaluation criteria. After 500 training episodes, the network gradually learns and trains in the direction of optimal solution. The miss distance at the encounter moment converges to about 20 m. As shown in
Figure 6c, the terminal position of the UAV has a large deviation in the early training phase, which is attributed to the exploration of the escape strategy by the network. In the later training phase, the position deviation is less affected by exploration. These pursuit evading scenarios tested in the manuscript can achieve convergence, and the final convergence values are all within 1 m.
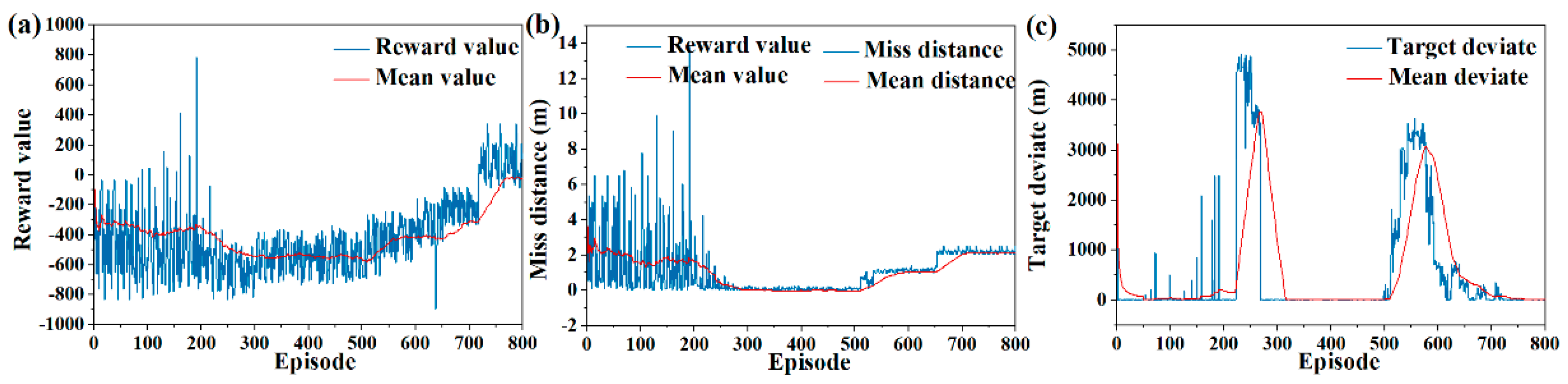
In order to verify whether the SAC algorithm can solve the escape guidance strategy that meets the mission requirements in different pursuit and evasion scenarios, the pursuing and evading distance is changed, and the training results are shown in
Figure 7. In the medium-range scenario, the miss distance converges to about 2 m, and the terminal deviation converges to about 1 m.
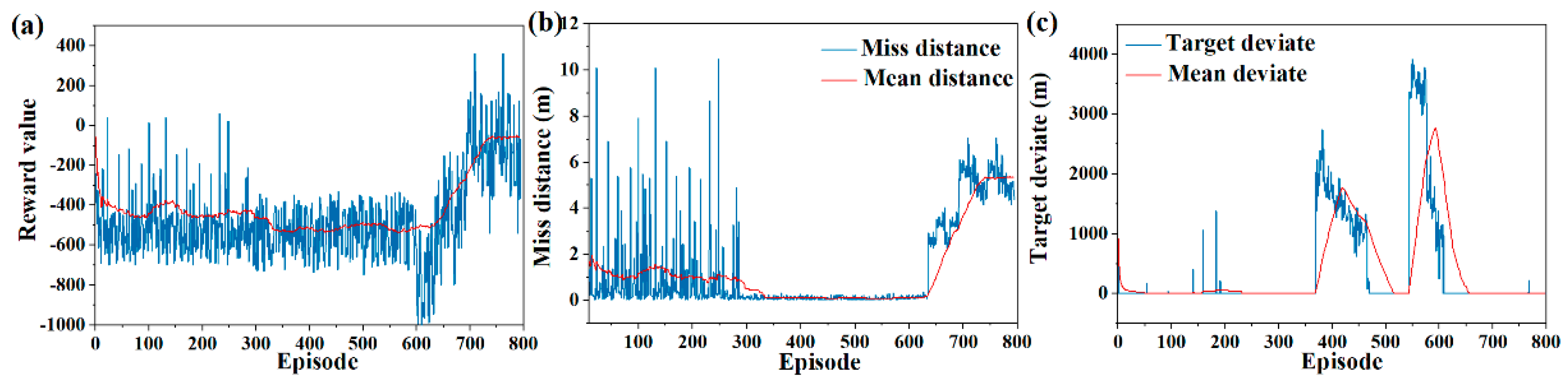
As shown in
Figure 8, in long-range attack and defense scenarios, the miss distance converges to about 5 m, and the terminal deviation converges to about 1 m.
Based on the above simulation analysis, SAC is a feasible method to solve the UAV guidance escape strategy. After limited episodes of learning and training, network parameters are converged, which is used to test the flight mission.
6.2. Validity Verification on Meta SAC
When the mission of the UAV changes, the original SAC parameters cannot meet the requirements of the new mission, and thus the parameters need to be retrained and relearned. The SAC proposed in the manuscript is improved via meta-learning. Strong adaptive network parameters are found using learning and training, and when the pursuit evading environment changes, the network parameters are fine-tuned to adapt to the new environment immediately.
Meta SAC is divided into a meta-training phase and a meta-testing phase, and initialization parameters for the SAC network are trained in the meta-training phase, which is fine-tuned by interacting with the new environment in the meta-testing phase. By changing the initial interceptor position, three different pursuit evading scenarios are constructed, which represent a short, medium, and long distance.
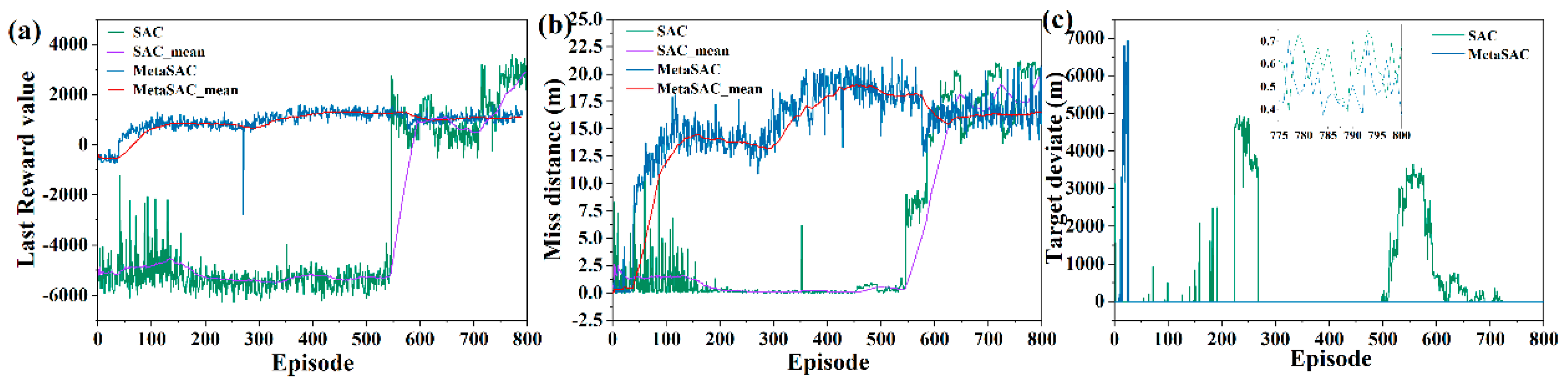
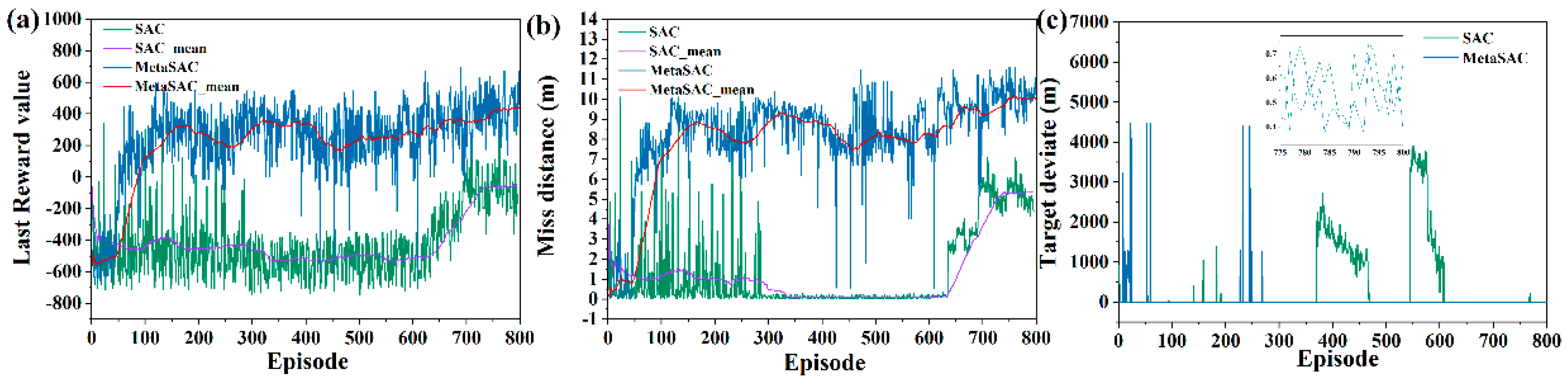
The training results of Meta SAC and SAC are compared, and terminal reward values are presented in
Figure 9a. Meta SAC is an effective method to speed up the training process, and after 100 episodes, a better strategy is learned by the network and converged gradually. In contrast, the SAC network needs 500 episodes to find the optimal solution. Miss distance is shown in
Figure 9b. The better strategy is quickly learned by Meta SAC, which is more effective than the SAC method.
Figure 9c shows the terminal deviation between the UAV and the target.
To explore the optimal solution as much as possible, some strategies with large terminal position deviations appear in the training process. As shown in
Figure 10b,c, in medium-range attack and defense scenarios, the miss distance converges to about 8 m based on Meta SAC, and the terminal deviation converges to about 1 m.
As shown in
Figure 11b,c, in long-range attack and defense scenarios, the miss distance converges to about 10 m based on Meta SAC, and the terminal deviation converges to about 1 m.
According to the theoretical analysis, in the training process, new missions corresponding to the same distribution are used to execute micro-testing using Meta SAC, resulting in more gradient-descending directions of the optimal solution being learned by the network. Combined with the theory analysis and training results, the manuscript demonstrates that meta-learning is a feasible method to accelerate convergence and improve the efficiency of training.
In the previous analysis, when the pursuit evading scenario is changed, network parameters obtained in the meta-training phase are fine-tuned through a few interactions. The manuscript verifies meta testing performance by changing the initial interceptor position, and results compared with the SAC method are shown in
Table 2. Based on the network parameters of the meta-training phase, the strategic solutions for the escape guidance missions are found through training within 10 episodes. On the contrary, network parameters based on SAC need more interaction to find solutions, and the episode of interactions comprises more than 50 episodes. According to the above simulation, the adaptability of Meta SAC is much greater than SAC, and once the escape mission changes, through very few episodes of learning, the new mission is completed by the UAV without re-learning and designing the strategy. The method provides the possibility of realizing UAV learning while flying.
6.3. Strategy Analysis Based on Meta SAC
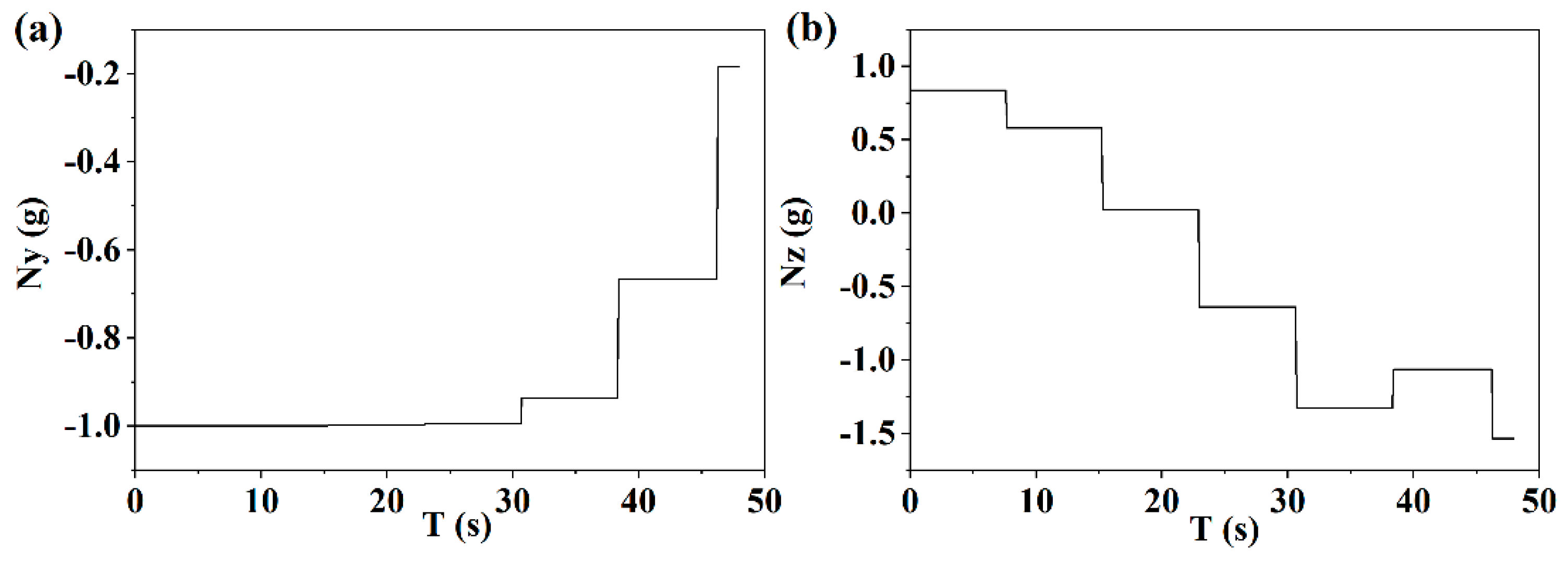
This section tests the network parameters based on Meta SAC, and analyzes the escape strategy and flight state under different pursuit evading distances. As shown in
Figure 12a, for the pursuit evading scene over a short distance, the longitudinal maneuvering overload is larger in the first half of the phase of escape, resulting in the velocity slope angle decreasing gradually. In the second half of the phase of escape, if the strategy is executed under the original maneuvering overload, the terminal altitude constraint cannot be satisfied, and therefore, the overload gradually decreases, and the velocity slope angle is slowly reduced. As shown in
Figure 12b, at the beginning of escape, the lateral maneuvering overload is positive, and the velocity azimuth angle constantly increases. With the distance between the UAV and the interceptor reducing, the overload increases gradually in the opposite direction, and the velocity azimuth angle decreases. On the one hand, this can confuse the strategy of the interceptor, while on the other hand, the guidance course is corrected.
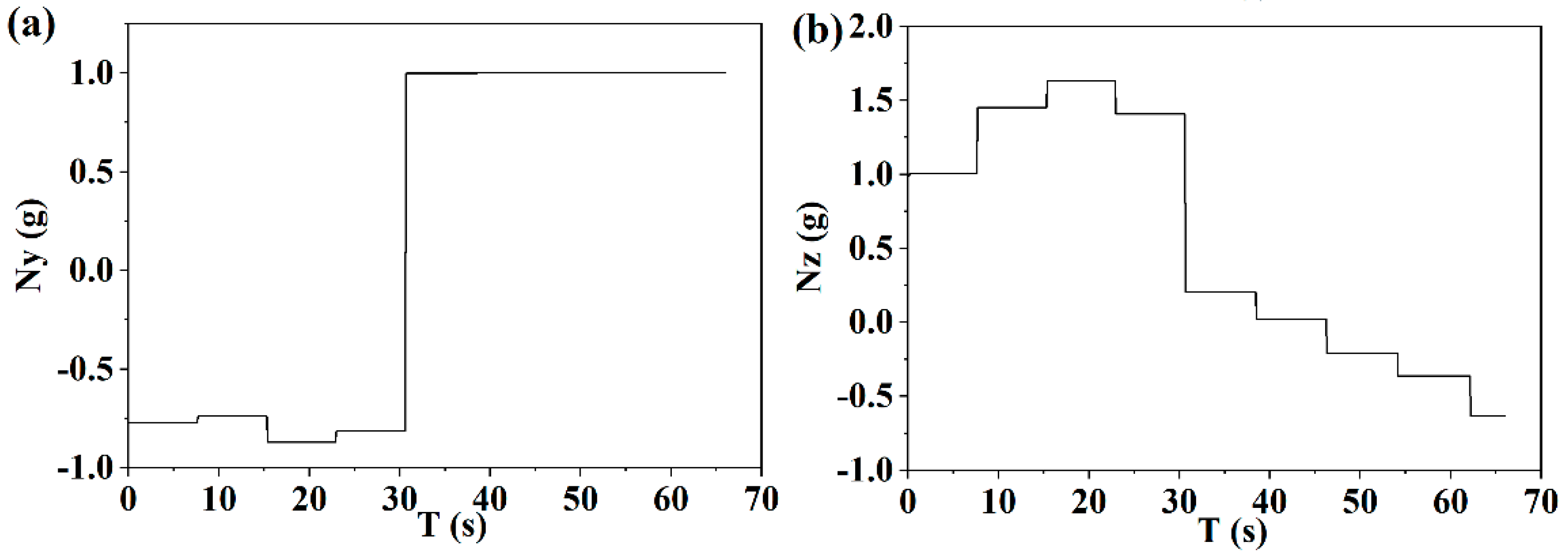
As shown in
Figure 13a, compared with the pursuit evading scene of a short distance, the medium-distance escape process takes longer, the pursuing time left to the interceptor is longer, and the UAV flies in the direction of increasing the velocity slope angle. The timing of the maximum escape overload corresponding to the medium distance is also different. As shown in
Figure 13b, in the first half of the phase of escape, lateral maneuvering overload corresponding to a medium distance is larger than that in a short distance, and in the second half of the phase of escape, the corresponding reverse maneuvering overload is smaller, resulting in the UAV being able to use the longer escape time to slowly correct the course.
As shown in
Figure 14, under a long pursuit distance, the overload change of the UAV maneuver is similar to that for a medium range, and the escape timing is basically the same as the escape strategy.
According to the above analysis, the escape guidance strategy via Meta SAC can be used as a tactical escape strategy, and the timing of escape and the maneuvering overload are adjusted in a timely manner under different pursuit evading distances. On the one hand, the overload corresponding to this strategy can confuse the interceptor and cause some interference, and on the other hand, it can take into account the guidance mission, correcting the course deviation caused by escape.
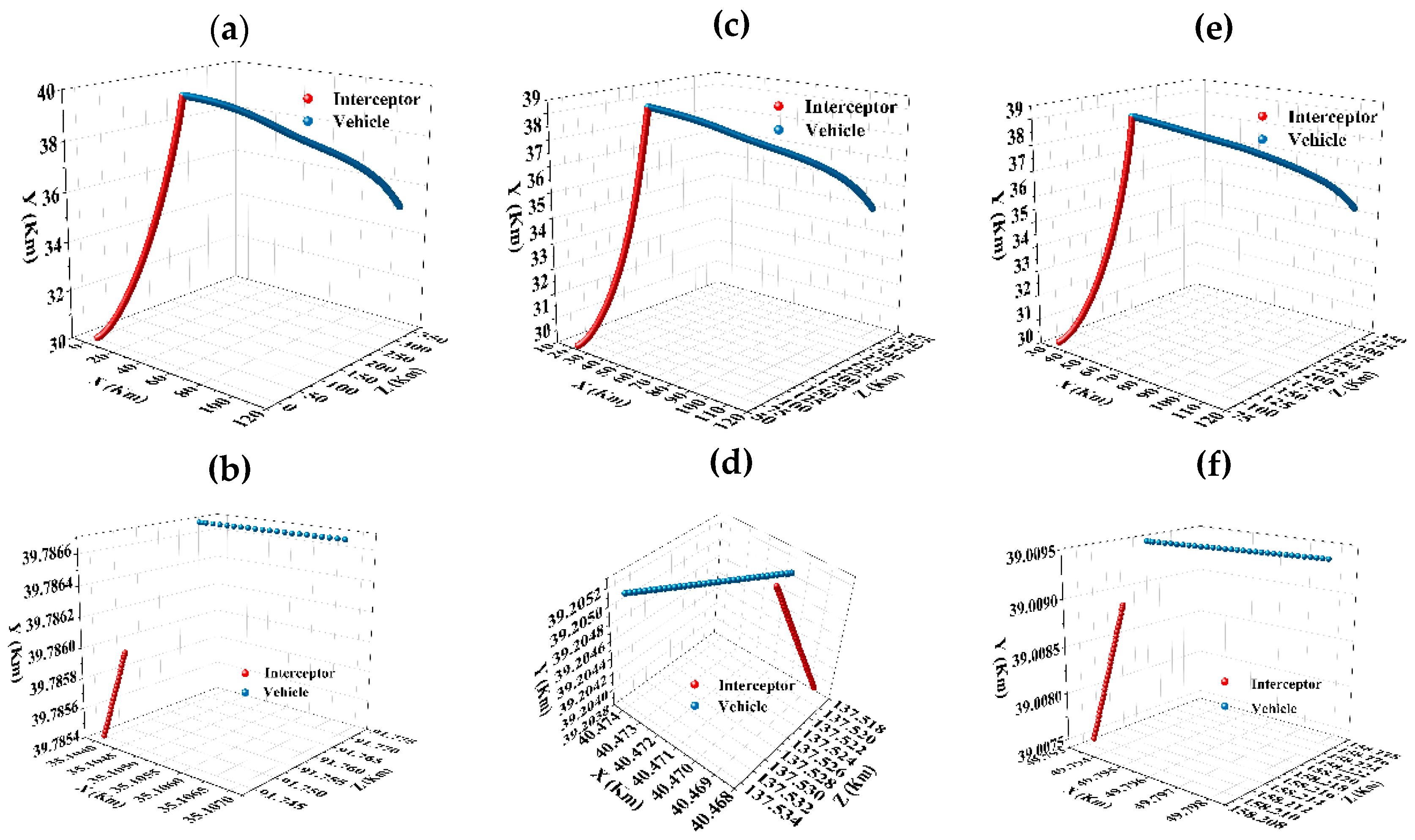
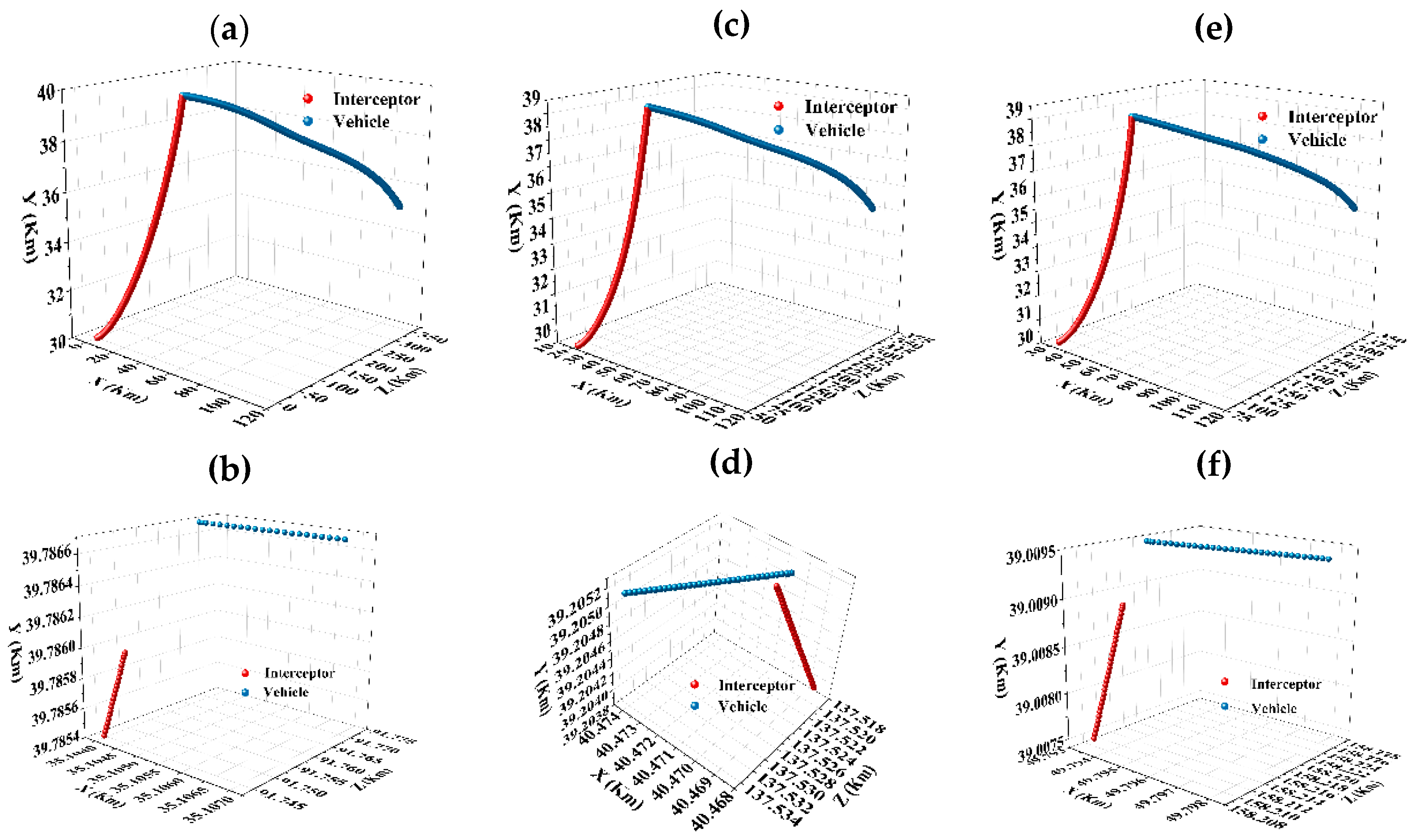
Figure 15a shows the flight trajectory of the interceptor against UAV at the North East Down (NED) coordinate (10 km, 30 km, 30 km), the trajectory point at the encountering moment is shown in
Figure 15b, and the miss distance is 19 m in this pursuit evading scene. To verify the scientific and applicability of Meta SAC, the initial position of interceptor is changed. Flight trajectories are shown in
Figure 15c,e, and trajectory points at the encountering moment are shown in
Figure 15d,f. The miss distances in these two pursuit evading scenarios are 3 m and 6 m, respectively. Based on the CAV-H structure, the miss distance between the UAV and the interceptor is greater than 2 m at the encountering moment, which means that the escape mission is achieved.
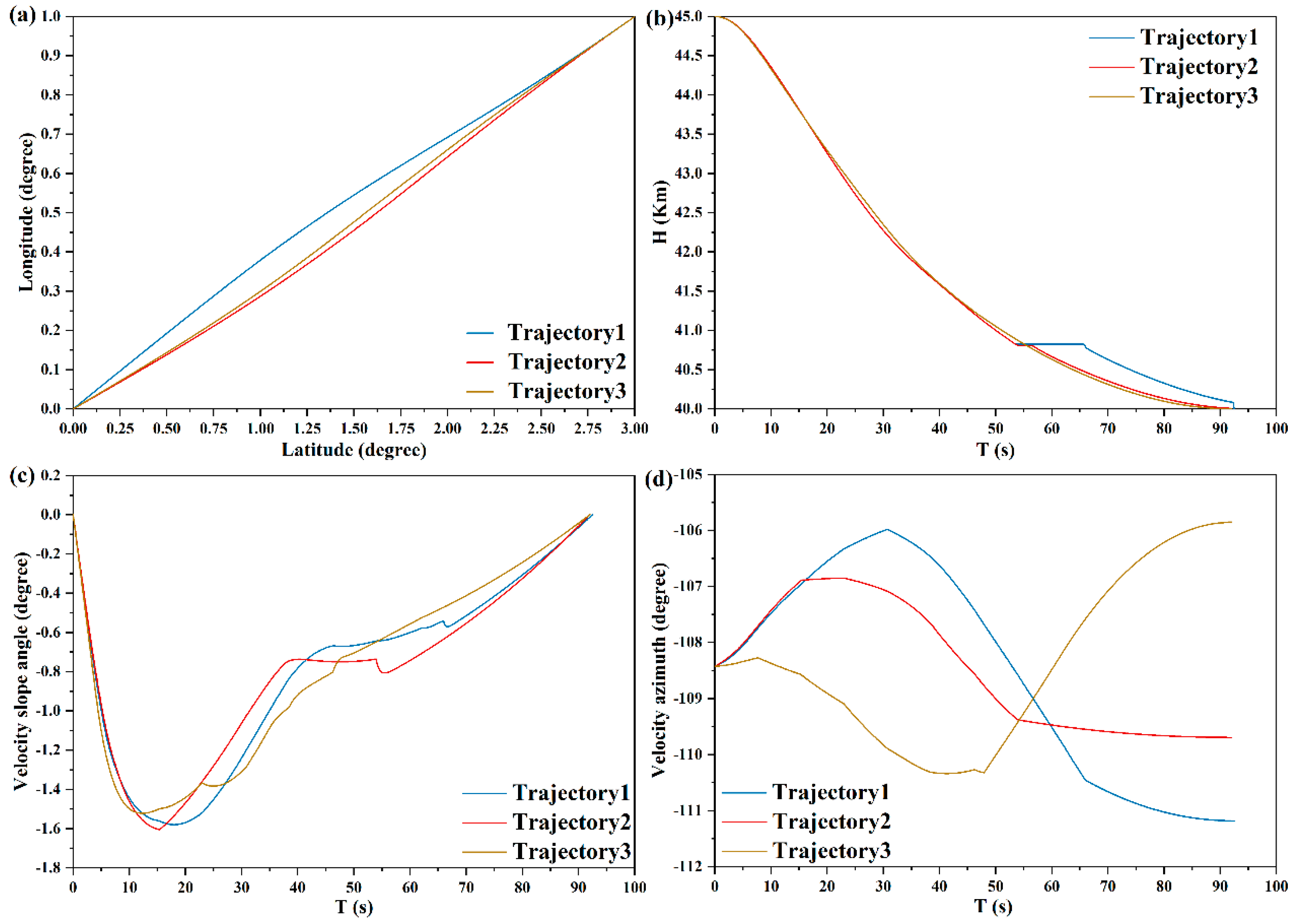
Based on the principles of Meta SAC and optimal guidance, flight states are shown in
Figure 16. Longitude, latitude, and altitude during the flight of the UAV are shown in
Figure 16a,b, under different pursuit evading scenarios, and the terminal position and altitude constraints are met. There is larger amplitude modification in the velocity slope and azimuth angle, which is attributed to the escape strategy via lateral and longitudinal maneuvering, as shown in
Figure 16c,d. The total change in velocity slope and azimuth angle is within two degrees, which meets the flight process constraints. Through the analysis of flight states, this escape strategy is an effective measure for guidance and escape with high accuracy.
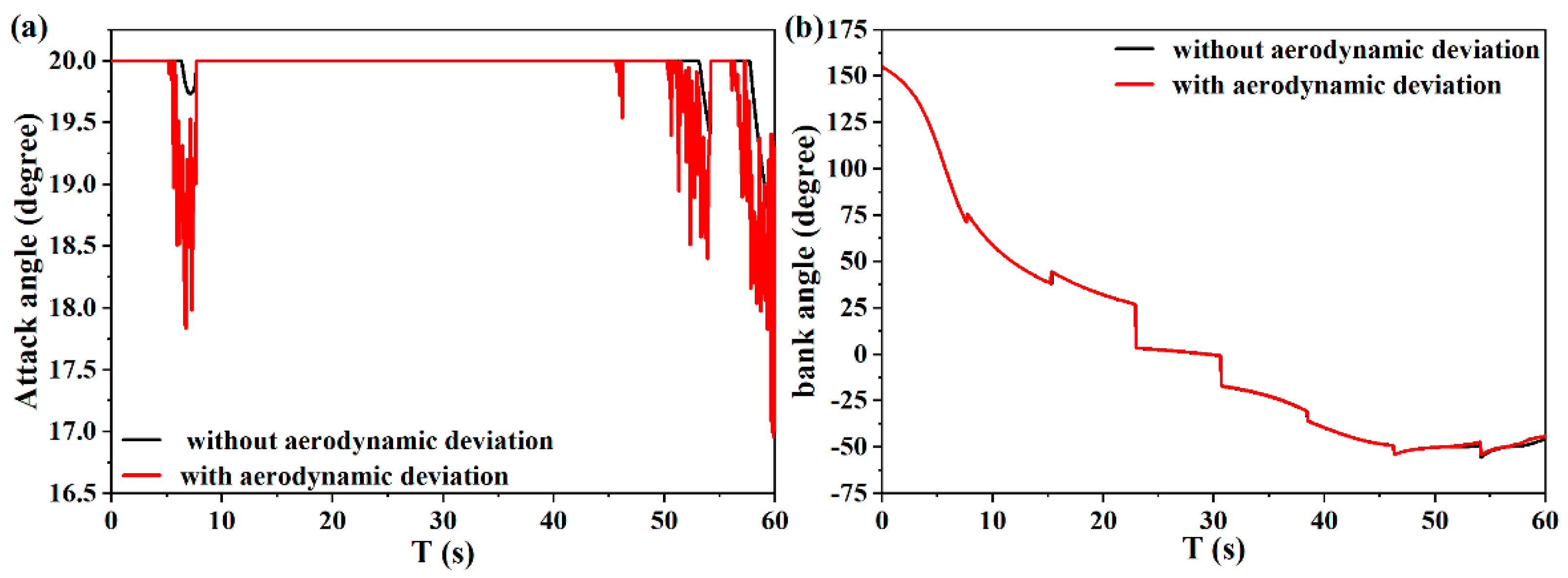
Flight process deviation mainly includes aerodynamic calculation deviation and output overload deviation. For the aerodynamic deviation, this manuscript uses the interpolation method to calculate it based on the flight Mach number and angle of attack, which may have some deviation. Therefore, when calculating the aerodynamic coefficient, random noise with an amplitude of 0.1 is added to verify whether the UAV can complete the guidance mission. As shown in
Figure 17a, aerodynamic deviation noise causes certain disturbances to the angle of attack during the flight. At the 10th second and end of the flight, the maximum deviation of the angle of attack is 2°. However, overall, the impact of aerodynamic deviation on the entire flight is relatively small, and the change in angle of attack is still within the safe range of the UAV. As shown in
Figure 17b, due to the constraints of UAV game confrontation and guidance missions, the bank angle during the entire flight process changes significantly, and aerodynamic deviation noise has a small impact on the bank angle. After increasing the aerodynamic deviation noise, the miss distance between the UAV and the interceptor at the time of encounter is 8.908 m, and the terminal position deviation is 0.52 m. Therefore, under the influence of aerodynamic deviation, the UAV can still complete the escape guidance mission.
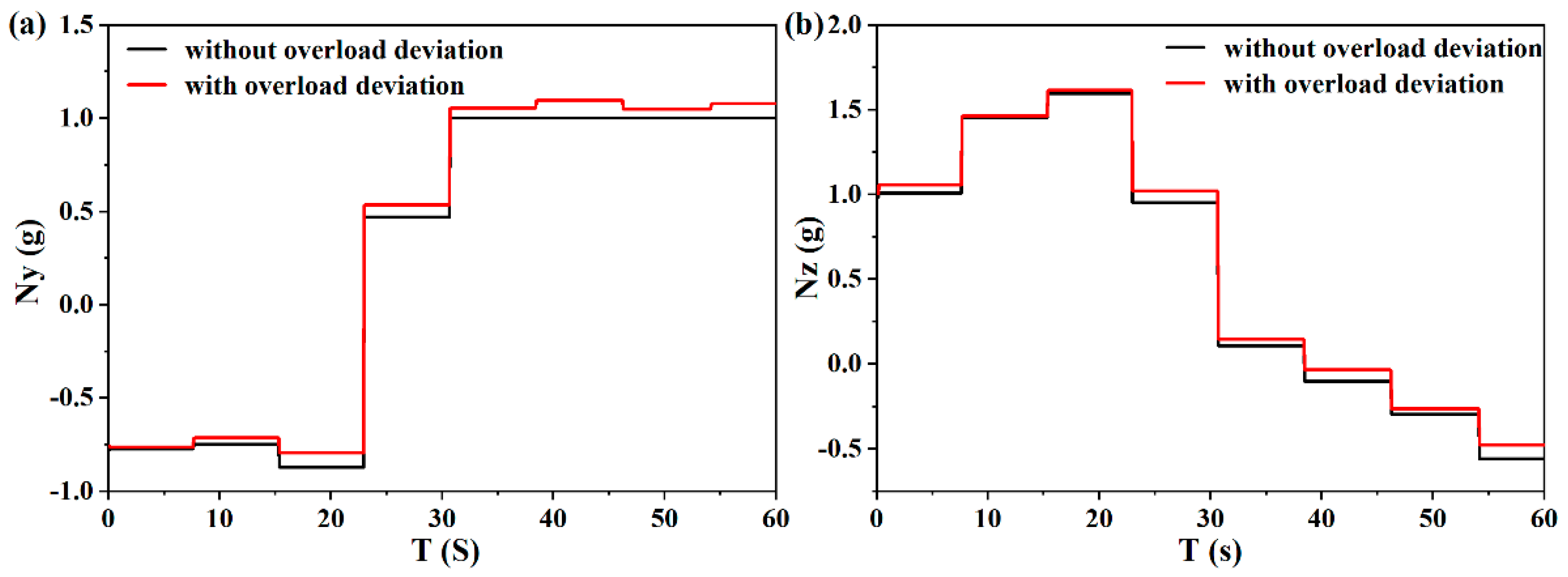
For the output overload deviation, the total overload is composed of the guiding overload derived from the optimal guidance law and the maneuvering overload output derived from the neural network. Random maneuvering overload with an amplitude of 0.1 is added to verify whether the UAV can complete the maneuver guidance mission. As shown in
Figure 18, random overloads are added in the longitudinal and lateral directions, respectively. Through simulation testing, the miss distance between the UAV and the interceptor at the encounter point is 10.51 m, and the terminal deviation of the UAV is 0.6 m. Under this deviation, the UAV can still achieve high-precision guidance and efficient penetration.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}