1. Introduction
Generally speaking, existing UAVs have high requirements for the terrain of the landing area. If the landing area is uneven, it may cause the UAV to overturn, which will not only seriously damage the UAV and destroy the ground facilities but can also cause harm to pedestrians on the ground. For existing autonomous UAV landing systems, it is usually necessary to set a fixed safe landing area and ensure that the landing area is relatively open and flat. Image or LiDAR sensors can be used to guide the UAV to achieve safe and autonomous landing. However, in most cases, the UAV does not have a priori information about the terrain of the landing area, such as disaster relief, geographic information survey and express delivery. In this kind of task, it is necessary for the people to monitor the landing situation or use manual remote control to land UAVs, which seriously affects the efficiency of the overall unmanned autonomous operation. In addition, in some emergencies, such as fuel shortage, signal loss and weather change, the UAV needs to land autonomously in unknown terrain areas. However, existing UAV systems do not have corresponding emergency response strategies.
Therefore, the autonomous recognition of a landing area is very important for UAVs. It can realize the comprehensive unmanned autonomous operation of UAVs, benefit the development of related applications, and avoid unnecessary risks and losses. The existing similar research is mainly divided into two streams: The first one pays attention to the mechanical structure design and control strategy of the UAV landing gear and does not actively acquire the terrain information of the landing area. For example, Sarkisov [
1] designed a landing gear that can automatically adapt to the terrain of the landing point and automatically adjust the length of the landing gear and the contact angle with the ground according to the feedback of sensors during landing. For the second one, the UAV is equipped with sensors to obtain the terrain information of the landing area in real-time and is guided to land autonomously and safely based on the acquired terrain information. There have been various recent research efforts for the successful landing of UAVs, and most of them have used vision sensors [
2,
3,
4,
5,
6,
7].
The goal of this paper is to propose an autonomous and safe landing solution. The existing methods for autonomous landing are mainly based on a single sensor to realize the recognition and tracking of the landing area and guide the UAV to achieve safe and autonomous landing. According to the different sensors used, these studies can be divided into three categories: landing area recognition based on a monocular camera [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18], landing area recognition based on a stereo camera [
19,
20,
21,
22,
23,
24], and landing area recognition based on 3D LiDAR [
25,
26,
27,
28,
29,
30]. Although these methods have good performance in some specific scenes, it is difficult to identify the landing area accurately and stably in some more complex scenes or with poor illumination.
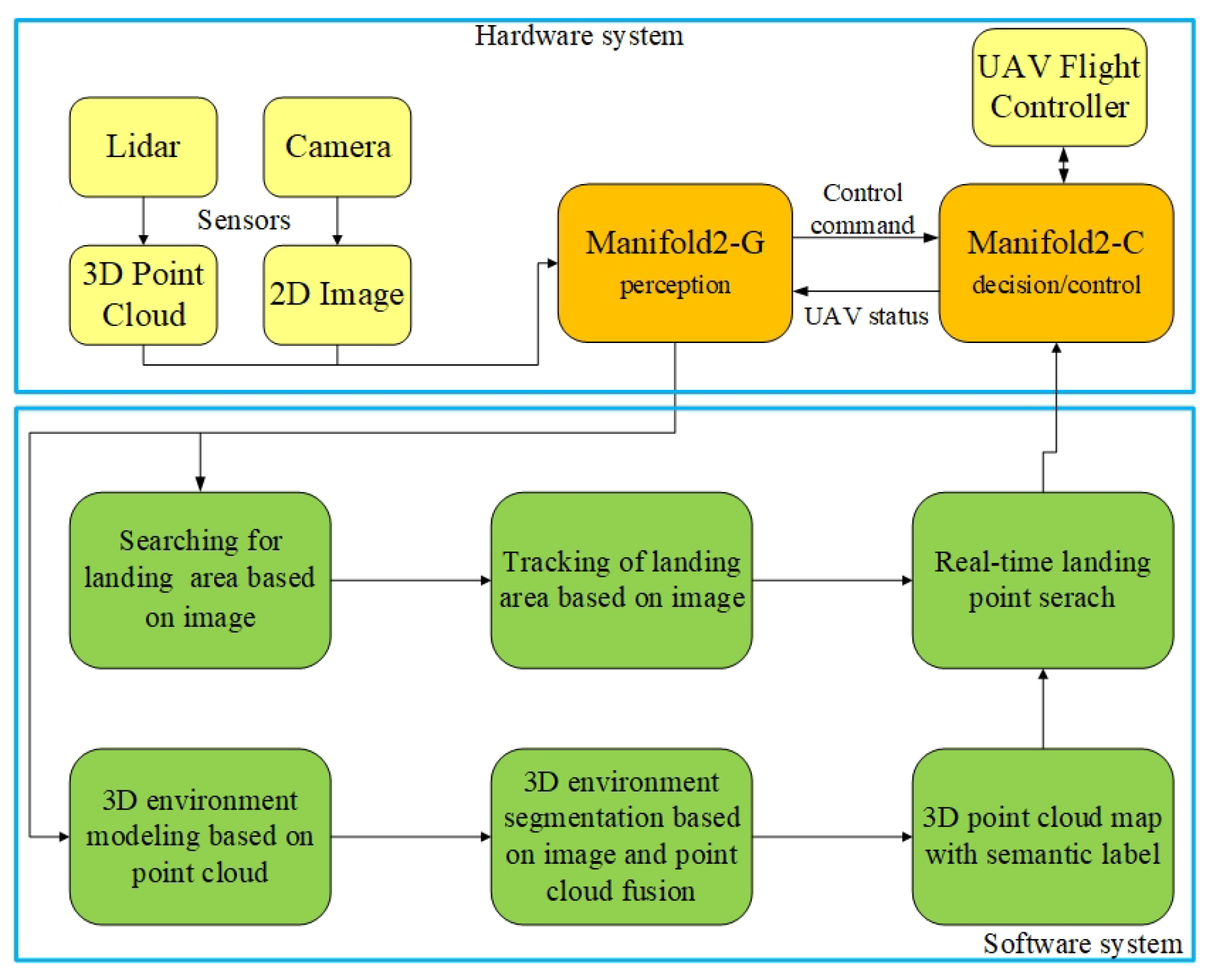
Therefore, in order to solve this problem, this paper proposes a UAV landing area recognition system based on multi-sensor fusion. This system firstly uses the method based on image semantic segmentation to identify the landing area below the UAV, uses image target tracking to guide the UAV to fly towards the landing area, and finally uses the fusion data of the image and point cloud to realize safe and autonomous landing. From simulation and real experimental tests, it is shown that the system can realize a robust recognition of the landing area and guide the UAV to land safely.
4. System Implementation
4.1. Searching for Landing Area Based on Image
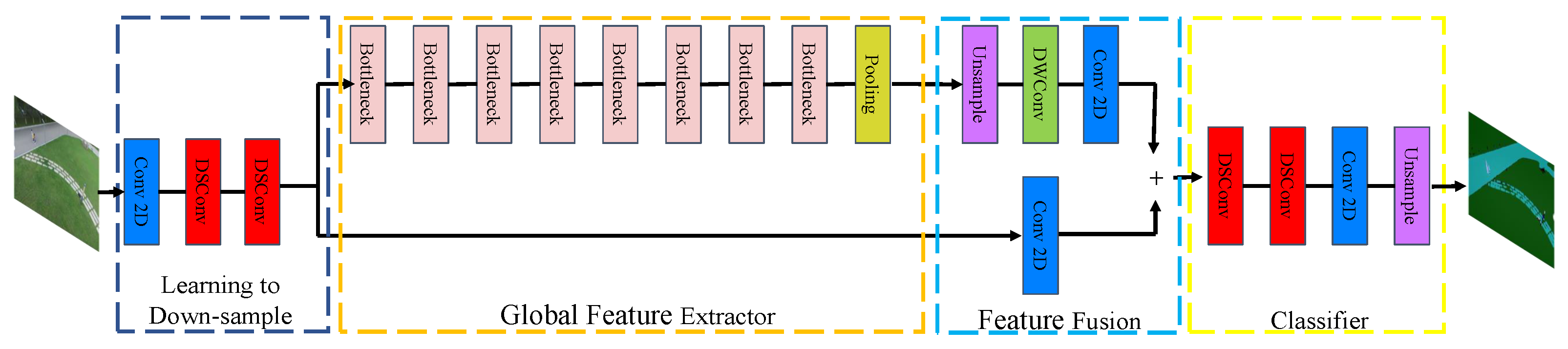
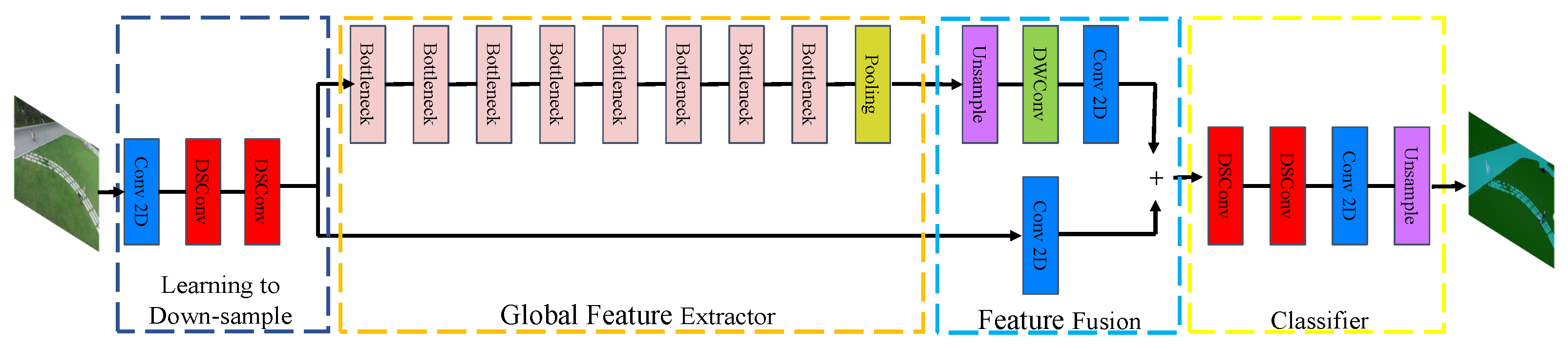
The purpose of image semantic segmentation is to assign every pixel of a picture or video stream taken by a camera with a corresponding category label. When the drone is at a high altitude, the point cloud captured by the LiDAR sensor is sparse, so it is impossible to identify the landing area. Fortunately, the camera can obtain high-resolution images to identify interesting areas. Therefore, through image feature extraction and semantic segmentation of the image data, the position of the landing area in the picture or video stream can be determined, which provides a preliminary recognition for the next step of tracking the landing target area. Since this system needs to process the input images in real-time on the UAV, the real-time performance of the semantic segmentation network should be considered firstly. In our system, we use a lightweight image extraction network to improve the running speed of the network. The model structure of the network is shown in
Figure 3, the network model parameters are shown in
Table 1, and the specific algorithm flow is as follows.
Firstly, the input image is downsampled by a convolution neural network, and three convolution layers are used to ensure that the low-level features can be effectively shared and used. The first layer is a standard convolution layer, and the other two layers are depthwise separable convolution (DSConv) layers. Different from the standard convolution, in the depth-separable convolution layer, one convolution kernel is only responsible for one channel, and one channel is convolved by only one convolution kernel, so the parameters required for its operation are greatly reduced compared with standard convolution. Although the DSConv has high computational efficiency, there are only three channels in the input image, which makes the advantage of DSConv’s computational speed not reflected at this stage. Therefore, a convolution layer is added before the DSConv layer to improve the input channel of the DSConv. These three layers of networks use a step size of 2 with a batch normalization layer and a Relu activation layer. The convolution kernel of the standard convolution layer and the kernel size of the DSConv layer are both 3 × 3.
Then, the down-sampled image features are input to the global feature extraction module, which aims to capture the global environment information needed for image segmentation. Different from the common semantic segmentation network, it takes a low-resolution tensor as input, that is, the output of the learning down-sampling module as input, and its resolution is one-eighth of the original input image. In order to further speed up the running of the network, we use an efficient bottleneck residual block to build a feature extraction network. This module uses an efficient deep separable convolution, which improves computational efficiency and reduces the number of network parameters and the memory burden. We use the residual connection layer in the bottleneck residual module to fuse the information of each layer. Finally, we add a pyramid pooling module (PPM) at the end of the global feature extraction module. This PPM module can fully aggregate the local information of different sizes obtained under different receptive fields and improve the accuracy and robustness of the network.
The high-level image features extracted by the global feature extraction module are input to the feature fusion module, which processes the features obtained by learning down-sampling through the convolution layer and adds them directly with the high-level features obtained by the global feature extraction module. This fusion method can reduce the computation as much as possible and improve the computation speed of the model without losing the original features and depth features.
The features fused by the feature fusion module are input into the classifier module. This classifier module uses two depth-separable convolution layers and a standard convolution layer. It can output the obtained tensor into a picture with the semantic category label so that the input picture information can be classified to find the preliminary landing area, which provides a basis for the UAV to identify the accurate landing area at low altitude.
We conduct experiments on the PyTorch platform using Python, and our experiments are executed on a workstation with Nvidia GPU with CUDA and CuDNN . We use stochastic gradient decent (SGD) with momentum , batchsize 16, and learning rate . Because the training data for semantic segmentation are limited, we apply various data augmentation techniques: random resizing between and 2, translation/crop, horizontal flip, color channels noise, and brightness. Our model is trained with cross-entropy loss. We train our model for 150 epochs using the Aeroscapes dataset. Our model can achieve mIoU.
4.2. Tracking of Landing Area Based on Image
After the UAV identifies the landing area, it needs to track the landing area in the subsequent image frames, so we design an image-based tracking algorithm for the landing area.
In this system, the output of the landing area search algorithm is used as the input of the landing area tracking algorithm. Four coordinates are used to represent a rectangular frame, where X, Y represent the center pixel coordinates of the rectangular frame, and W, H represent the width and length of the rectangular frame. The rectangular frame contains the area to be tracked. The output of this algorithm is the UAV flight control quantity, and the expression form is the UAV flight target control quantity mapped by coordinate difference (target pixel coordinate–actual pixel coordinate).
Considering the performance of the processor on the UAV and the demand of the whole system for deep learning computing power, the tracking algorithm should be as lightweight as possible. In order to ensure real-time and high accuracy, we build the Siamese network structure to track the image target. In addition, the algorithm also segments the foreground and background of the tracking target area, and the final output results are presented in the form of a mask. The matrix frame is also obtained by rotating rectangle fitting through the mask, which has a good performance for the situation that the geometric shape of the landing area might be irregular.
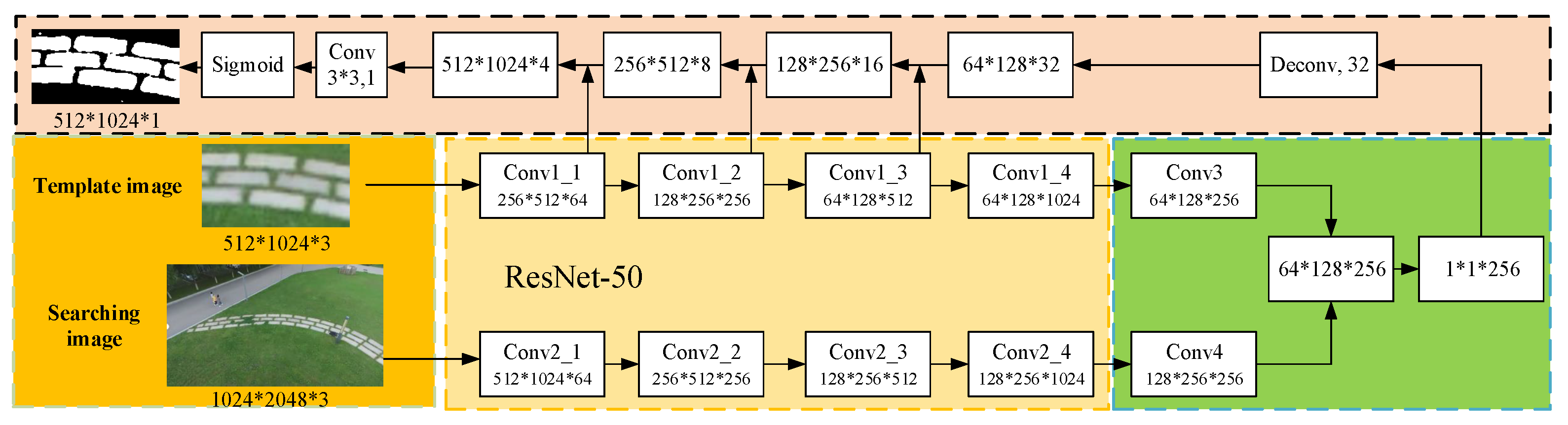
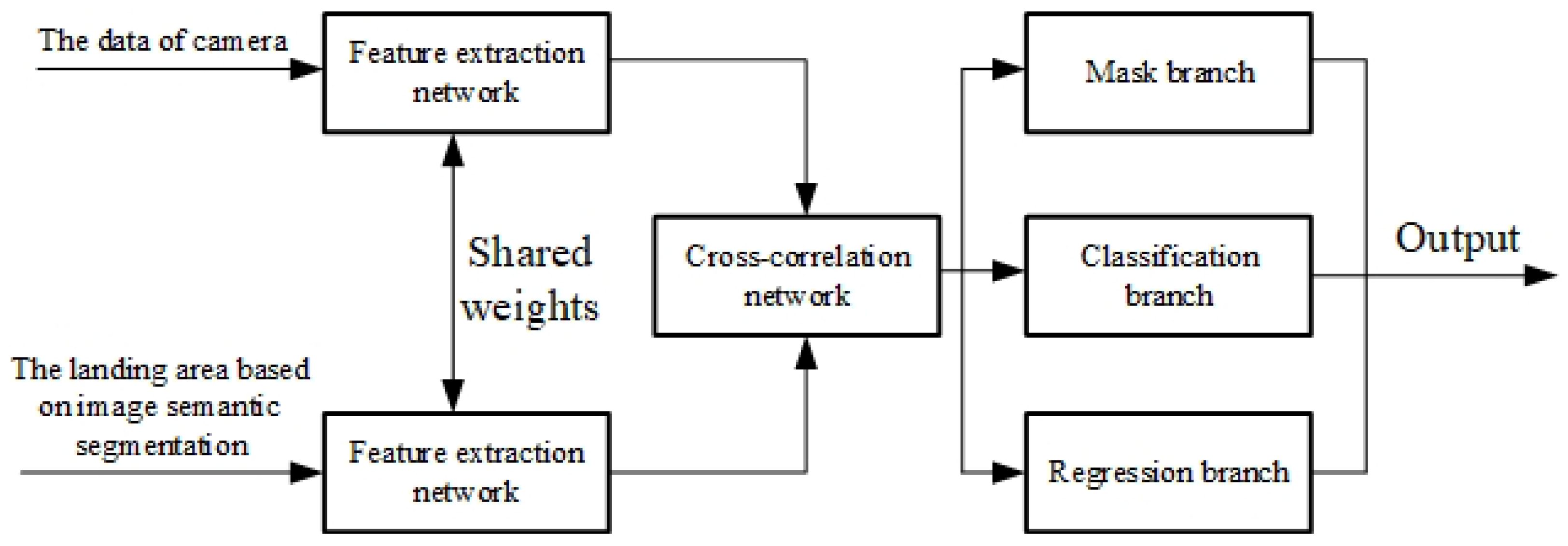
The image-based landing area tracking algorithm uses the Siamese network as the basic architecture of the whole network. The network structure of the Siamese network consists of two identical branches, as shown in the
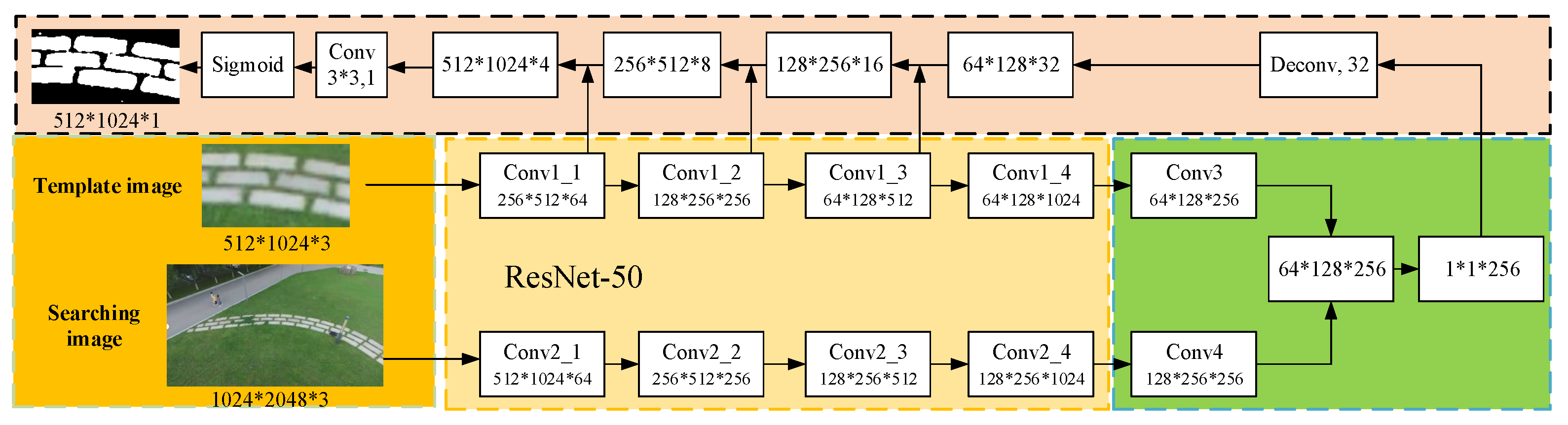
Figure 4. The two branches receive different inputs and then pass through the same feature extraction network to extract high-dimensional image features. In feature extraction, the two branch networks share weights. After that, the high-dimensional features obtained by the branches can be combined with the ground-truth data to construct a loss function. The network can be trained in the way of minimizing the loss so that the network can learn the most similar features of the two branches. The model structure of the network is shown in the
Figure 5, and the specific algorithm flow is as follows.
Firstly, the image information of the target region to be tracked is obtained by using the results of the image-based landing region search algorithm through the initial frame to define the target region to be tracked. This part of the image is then input to the ResNet50 backbone network for feature extraction, and the high-dimensional features of the target area to be tracked are generated as the tracking template area. The subsequent image frame input is clipped through the template area range of the first frame to obtain the initial search area. This part is input as a tracking search branch to the ResNet50 branch network with the same parameters as the backbone network for feature extraction, and high-dimensional search area features are obtained.
After obtaining the high-dimensional features of the template branch and the search branch, we carry out cross-correlation between them to obtain the feature map representing the similarity information.
Finally, we use the RPN network to map the similarity feature information map to the original map. There are two branches in the RPN network, namely, the classification branch and regression branch. In addition, a mask branch is added based on these two branches, and the mask of the segmentation field is introduced into the expression of tracking results so that the final result is expressed as the accuracy of the pixel sector, which greatly improves the accuracy of the tracking results. We judge which part of the area has the largest response from the response degree of the network output, which corresponds to the area that best matches the template, that is, the most likely position of the landing area in the next frame.
We conduct experiments on the PyTorch platform using Python, and our experiments are executed on a workstation with Nvidia
GPU with CUDA
and CuDNN
. We train our model for 120 epochs using the VOT-2018 dataset. The loss function is as follows:
where
is the ground-truth binary label,
is a pixel-wise ground-truth mask whose size is
, and
is the label corresponding to pixel
of the object mask in the
n-th candidate.
4.3. 3D Environment Modeling Based on Point Cloud
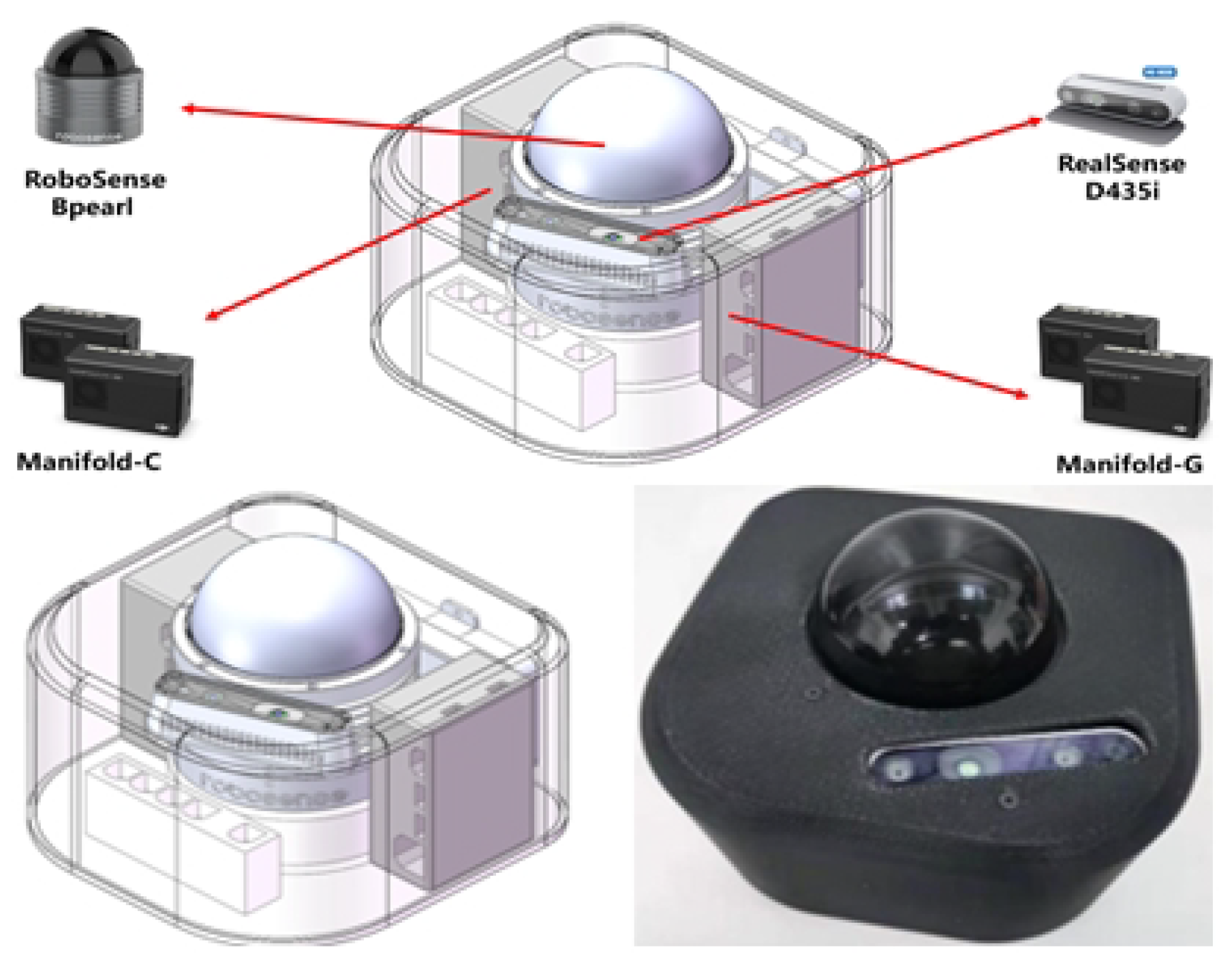
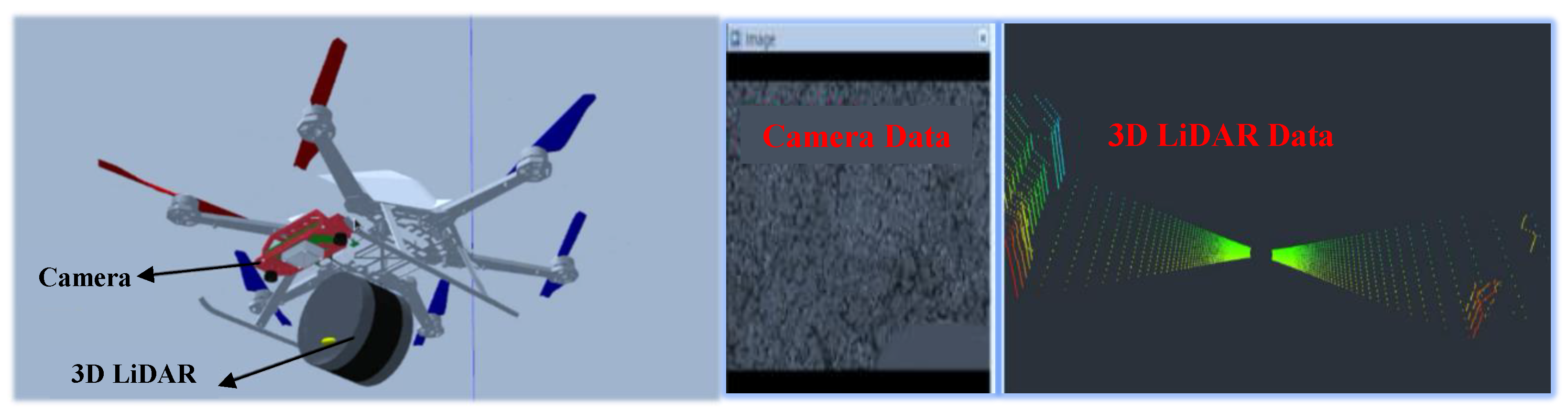
When the UAV identifies the approximate landing area, we guide the UAV towards the landing area, and then map the environment of the candidate landing area by 3D LiDAR carried by the UAV to obtain the terrain information of the landing area. Because the UAV needs accurate spatial information and needs to establish an accurate 3D map for landing point calculation, we use 3D LiDAR as the main sensor to create a 3D point cloud map of the environment. Considering that the landing environment of the UAV is an outdoor open area, there may be insufficient environmental features in the surrounding environment, which makes the motion estimation only by LiDAR fail. Therefore, the algorithm combines LiDAR odometer and IMU data to provide the spatial position information of the UAV motion, enhancing the robustness and accuracy of the UAV motion estimation. The algorithm framework of 3D environment modeling is shown in
Figure 6.
Because the LiDAR sensor scans the surrounding environment all the time, when the UAV moves, the laser point itself has a certain motion state, which makes the point cloud of one frame of LiDAR distort, caused by motion. In order to obtain the correct environmental point cloud information, it is necessary to dedistort the LiDAR point cloud. To remove the motion distortion of LiDAR point clouds, it is necessary to compensate for the motion change in LiDAR point clouds relative to the beginning of the laser frame. In this system, the motion change obtained by IMU is used to compensate for the motion of the LiDAR point clouds to obtain the point cloud data without motion distortion.
In order to calculate the motion pose of the UAV, we need to obtain the attitude transformation relationship between consecutive frames, so as to estimate the motion state. Considering the real-time requirement of the system, we use the feature points of the point cloud instead of the whole frame point cloud to solve the pose estimation. In order to improve the accuracy of pose estimation, for point cloud feature extraction, we extract the plane features of point clouds. The plane features in the point cloud are extracted, and the curvature of the local point cloud is calculated by using the surrounding points of the current point. The calculation method is as follows:
where
is the
i point in the laser coordinate system in the
k frame point cloud,
M is the surrounding point set corresponding to this point, and
is the
J point in the surrounding point set
M. The large curvature points are considered as edge points, and the small curvature points are considered as plane points, so the local point clouds with small curvature are selected as plane features.
After extracting the features of point clouds in each frame, we need to match the features of point clouds between different frames, so as to find the pose transformation between the two frames of point clouds. We transform the feature points of the previous frame point cloud into the current frame coordinate system and find the nearest three points in the previous frame point cloud:
,
, and
. The three points form a planar block, thus completing the feature matching between the current frame and the previous frame. Then, according to the matched surface blocks, we find the corresponding point–plane distance, and the calculation method is as follows:
According to the calculated point–plane distance d, the point–plane distance constraint is constructed. Based on this, the least square problem of point cloud feature point matching is established, which optimizes the relative pose change between laser frames and outputs the motion state of the UAV.
After the laser odometer is obtained, the point clouds can be spliced according to the position and orientation relationship of the point cloud frames. However, due to the interframe motion, the estimated odometer will have accumulated errors, which makes the error of point cloud mosaic increase only by using the odometer. Therefore, it is necessary to register the current frame point cloud with the global point cloud map, so as to eliminate the accumulated errors of the odometer and establish a globally consistent point cloud map. In order to reduce the amount of point cloud data, point cloud space is divided into voxels: only point clouds within a certain voxel space are considered, and unimportant point clouds in the environment are ignored. Then, a local voxel map is established according to odometer information by registering the plane features in the local voxel map with the global voxel map, accurate pose changes are obtained, and the accumulated errors existing in the front-end odometer are eliminated. According to the optimized pose, point clouds are spliced to obtain an accurate and globally consistent 3D environmental point cloud map.
4.4. 3D Environment Segmentation Based on Image and Point Cloud Fusion
Although the method based on semantic features of 2D images can estimate the position of the landing area roughly, the results of feature extraction may have some errors, and it is often difficult to accurately estimate the accurate 3D position of the landing area. If the UAV wants to complete the autonomous landing task more stably and safely, it needs to obtain accurate 3D position information of the landing area, so this system needs to realize 3D environment segmentation through point cloud information. The current 3D environment segmentation method based on point cloud needs high memory and computing power; however, our UAV has a limited onboard payload and cannot carry a GPU with stronger computing power. Therefore, this system does not use the deep learning method to directly extract semantic features of point clouds but indirectly obtains point cloud data with semantic tags through the image semantic segmentation method.
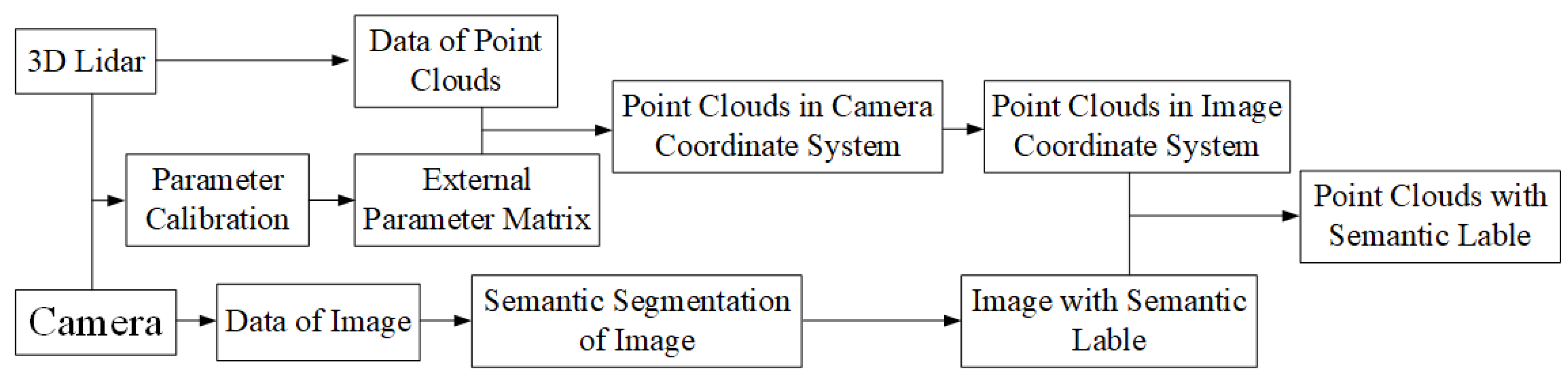
As shown in
Figure 7, firstly, the image semantic segmentation method proposed in the aforementioned section is used to segment the image semantically. Then, the point cloud data of LiDAR are projected into the camera coordinate system through the transformation matrix between the camera and LiDAR, and then they are projected into the image coordinate system of the camera through the internal reference coordinate system of the camera. Since we have obtained the camera image with pixel-by-pixel semantic category labels, the projected point cloud also has the semantic information from the image, and the semantic category label corresponding to the image pixel is the semantic label of the point. Finally, the point cloud data with semantic labels are obtained by transforming the point cloud back to the LiDAR coordinate system.
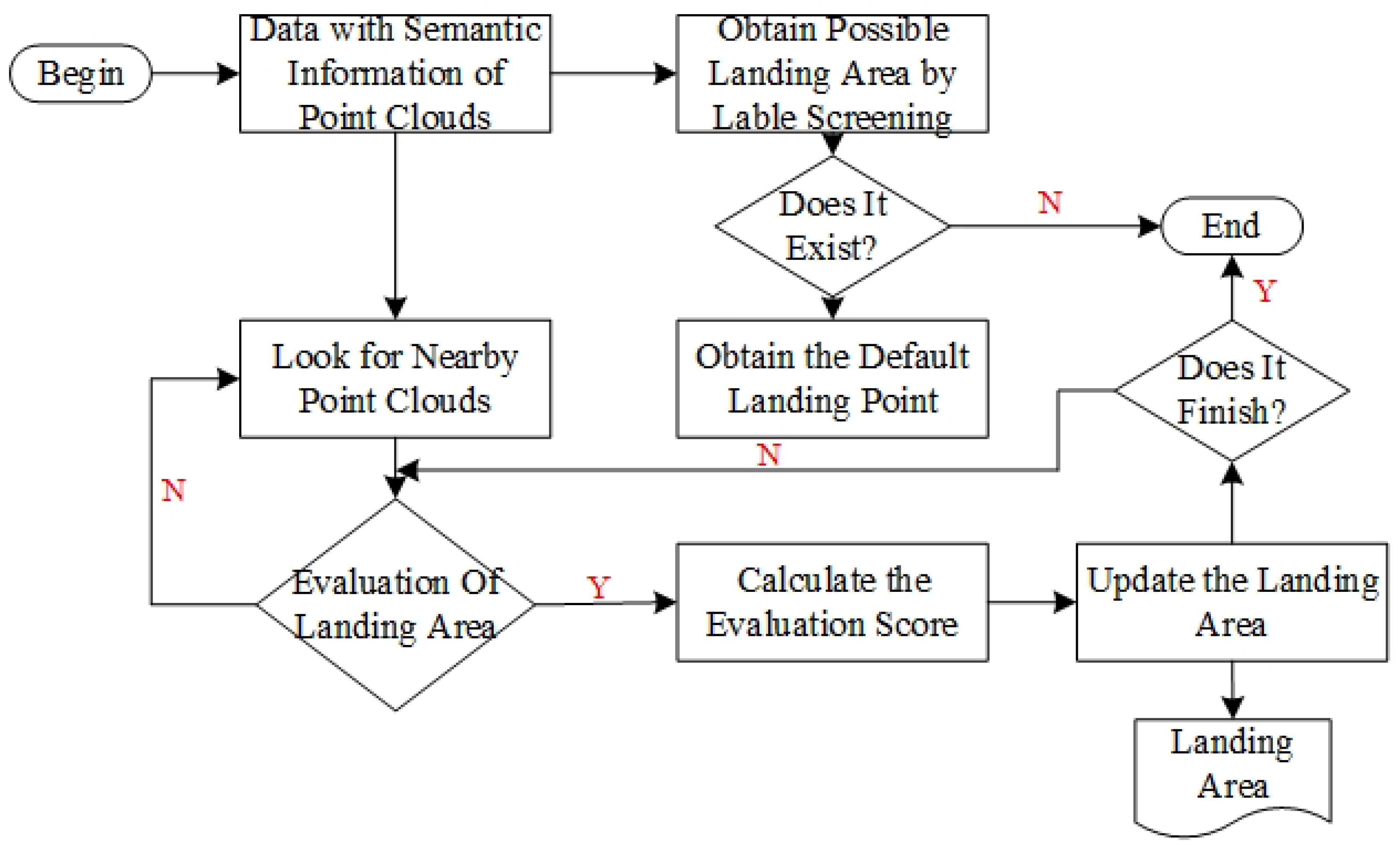
4.5. Real-Time Landing Point Search
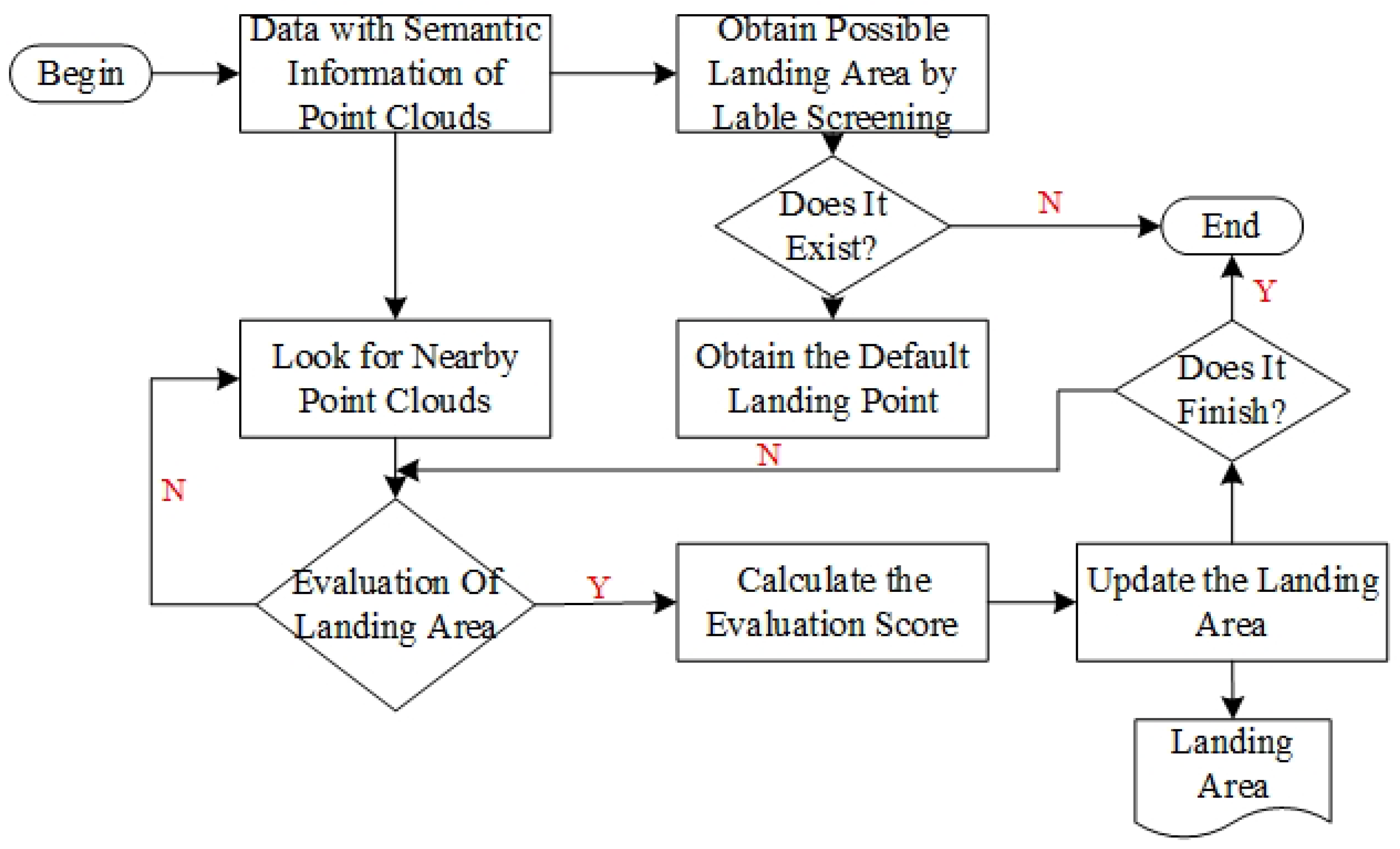
We can obtain the candidate landing area by screening the semantic tags of the point cloud. However, considering the robustness of semantic feature extraction and other factors, not all the candidate landing areas can be used as landing areas for the UAV. The area suitable for the UAV landing should also have the following characteristics: Firstly, the landing area should be flat enough without large bumps or depressions. Secondly, the landing area should be horizontal enough. If it lands on a slope, the drone may not stop smoothly. Thirdly, the re-landing area should be large enough for the UAV to land and far enough from the boundary of the area. Because our UAV is a vertical take-off and landing drone, there should be no obstacles above the landing area to avoid possible collision during landing. Finally, because the UAV makes contact with the ground through the landing gear, the terrain structure of the landing area should remain stable when the landing gear of the UAV makes contact with it. In order to ensure the correctness and stability of the algorithm, we add the geometric features of the point cloud as constraints based on semantic features to achieve accurate detection and recognition of the landing area.
The structure of the algorithm is shown in
Figure 8. First, we search the terrain on the ground in the point cloud map with semantic labels, select the area where the most suitable terrain is located as the possible landing area, and extract the corresponding point cloud in this area. According to the difficulty of the UAV landing in different terrain environments, the priority of the terrain is usually paved ground, hard land, grass land, and sand. However, even in suitable terrain, not every position is suitable for landing the UAV. There may also be slopes, bulges, depressions, etc., in the actual landable environment, such as paved ground, which are often not conducive to the UAV landing. However, the above-mentioned methods based on deep learning have difficulty identifying these conditions accurately and stably, so we use the geometric features of point clouds as constraints to select the most suitable landing site. Firstly, we down-sample the point cloud and obtain a sparse point cloud map of the possible landing areas. We assume that the final landing area of the UAV is circular, and each point in the point cloud is set as the center point of the possible candidate landing area of the UAV. For each possible center point, we extract the nearest point cloud corresponding to the point in the original point cloud. The point cloud can reflect the terrain of the candidate landing area. We use geometric methods to calculate the attributes of this part of the point cloud to estimate the terrain of the candidate landing area. First of all, we count the number of points in the point cloud of the candidate landing area. If the number of point clouds is not enough, it means that this part of the area has not been fully detected or there are terrains such as water surface that are not suitable for landing. Then, we calculate the standard deviation of the zcoordinate value of each point in the point cloud. If the standard deviation is too large, it means that the candidate landing area may be inclined or uneven, which is also unsuitable for the landing area. Finally, in order to further determine whether the candidate landing area is a horizontal plane, we try to use the RANSAC algorithm [
32] to fit the plane from the point cloud. If the plane cannot be fitted or the slope of the fitted plane is too large, it means that the candidate landing area is not suitable as the landing area. We use the angle between the plane normal and the
z coordinate axis to calculate the slope of the plane, namely:
where
is the vector of the
z axis,
n is the vector of the plane normal fitted by the RANSAC algorithm, and
is the slope of the plane.
Because the UAV makes contact with the ground through the landing gear during take-off and landing, the contact between the ground and the landing gear is an important factor for the UAV to maintain stability when landing. On the premise that the central landing site is determined, we assume that there are eight possible landing directions for the UAV. Therefore, there are four possible contact situations between the landing gear of the UAV and the ground. For each possible case, we can calculate the contact point between the landing gear of the UAV and the ground, and then calculate the torque of the UAV when landing. The smaller the
T, the more stable the UAV when landing. In order to calculate the best landing site for the UAV landing, we calculate a score for each candidate landing area by quantitative calculation. The score calculation formula is:
where
is the standard deviation of the
z coordinate value of each point in the landing area,
is the slope of the fitting plane of the landing area, and
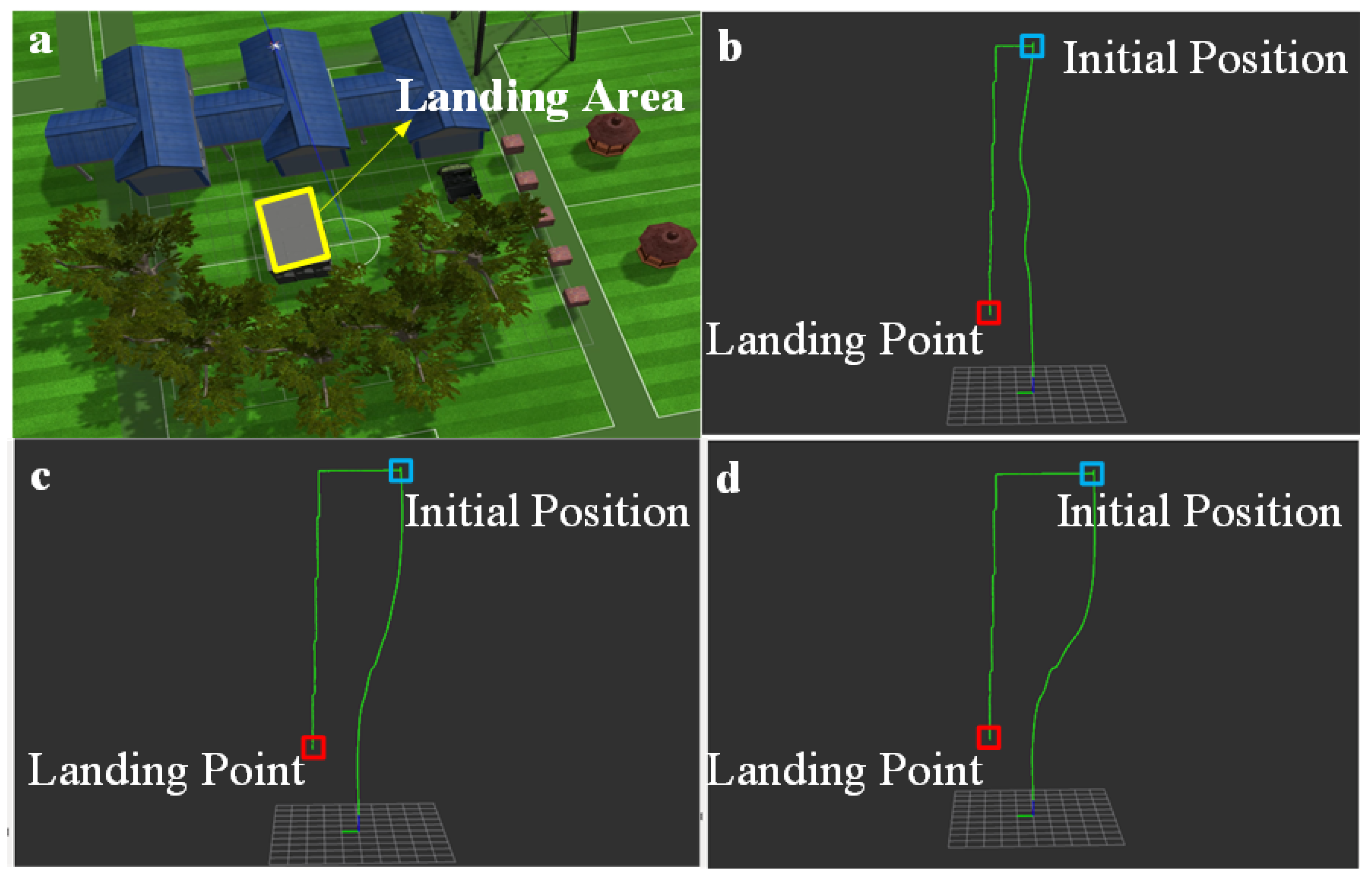
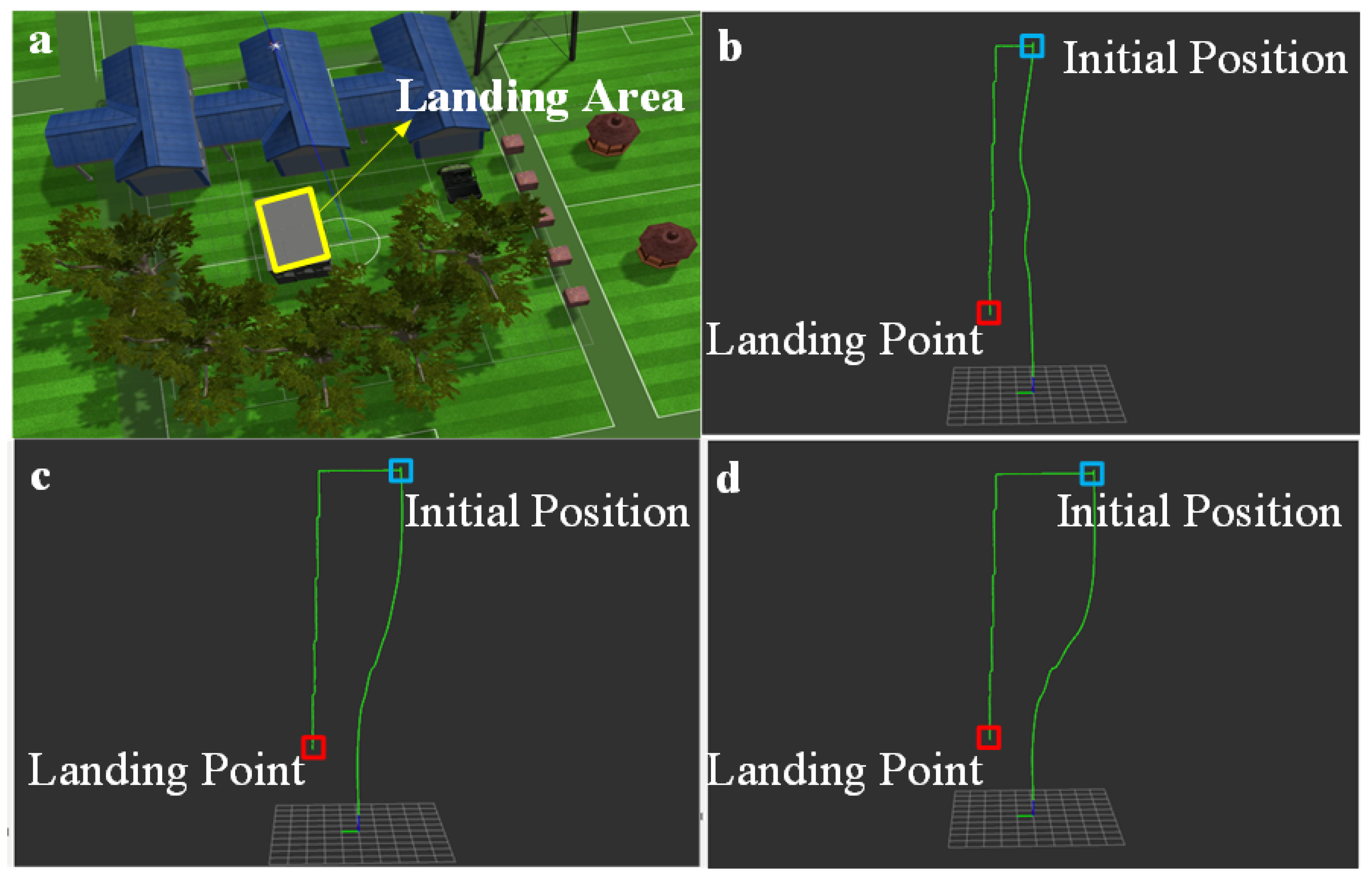
T is the stability of the UAV when landing. For all candidate landing sites, we choose the point with the largest score as the best landing area to provide landing area position information for autonomous landing of the UAV.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}