1. Introduction
Unmanned aerial vehicles (UAVs), also known as drones, are ideally suited for road-traffic monitoring and management because of their mobility, increased altitude capability, low cost, and broad view range [
1]. Moreover, they avoid risks to pilots under difficult weather conditions and play a crucial role in managing transportation systems for next-generation intelligent cities [
2]. Significantly, vehicle detection is a fundamental problem faced by these applications. Considerable progress is being made to create fully autonomous vehicle detection with UAVs. However, technical obstacles remain.
Efficient object detectors, for instance, play a crucial role in UAV applications and pose severe challenges due to numerous constraints, such as limited energy, speed, and vulnerability to various conditions. Recent approaches can be grouped by the orientation of the bounding box, such as horizontal detectors (horizontal bounding boxes) and rotation detectors (arbitrary-oriented bounding boxes). Previous studies on generic horizontal detectors can be divided into two categories: two-stage and one-stage detectors [
3]. The two-stage detectors generate category-agnostic region proposals and then perform classification and regression on these candidate regions to classify and localize the targets, such as Faster R-CNN [
4] and R-FCN [
5]. Although two-stage detectors have high accuracy, they typically have slow speed and increased complexity. To achieve high efficiency, the developments of one-stage detectors perform bounding-box regression and classification simultaneously for improved inference speed and simplicity, such as SSD [
6], YOLO series [
7,
8,
9,
10], and RetinaNet [
11].
Although generic horizontal detectors have great success in natural scenes, a considerable performance drop is apparent when these detectors are directly used in UAV and aerial images. The poor performance is due to the specific nuisances of UAV images, such as complex backgrounds, significant differences in object sizes, and weather and illumination variations. Therefore, the improved generic horizontal detectors applied in UAV and aerial images have drawn increasing attention from researchers. Kim et al. [
12] proposed an efficient channel attention pyramid YOLO (ECAP-YOLO) to detect small objects precisely in aerial images. Walambe et al. [
13] combined different one-stage detector models and applied voting strategies to capture multi-scale objects in UAV images. Wu et al. [
14] proposed a deep nuisance disentanglement approach, the nuisance disentangled feature transform (NDFT), to learn domain-robust features and improve the vehicle detection performance of generic-object detectors in UAV images. Yang et al. [
15] proposed a clustered detection (ClusDet) network inspired by the often-clustered objects in some regions, which unifies object clustering and detection in an end-to-end framework. Vandersteegen et al. [
16] focused on real-time object detection and tracking on limited hardware through an improved YOLOv3 model and a multi-dataset learning strategy. Li et al. [
17] focused on the image-cropping strategy. They proposed a density map-guided object-detection network to address the challenge of the non-uniform distribution of objects in aerial images. The density map can judge whether there is an object in an area and help the network learn the scale information according to the pixel intensity, which can guide cropping images statistically. Koyun et al. [
18] proposed a crop-based two-stage model to address the small-object detection problem in aerial images, mainly consisting of two parts. The first part is to generate clusters of objects through Gaussian Mixture, and the second part proposes the incomplete box suppression (IBS) algorithm to solve the incomplete boxes caused by overlapping focal regions.
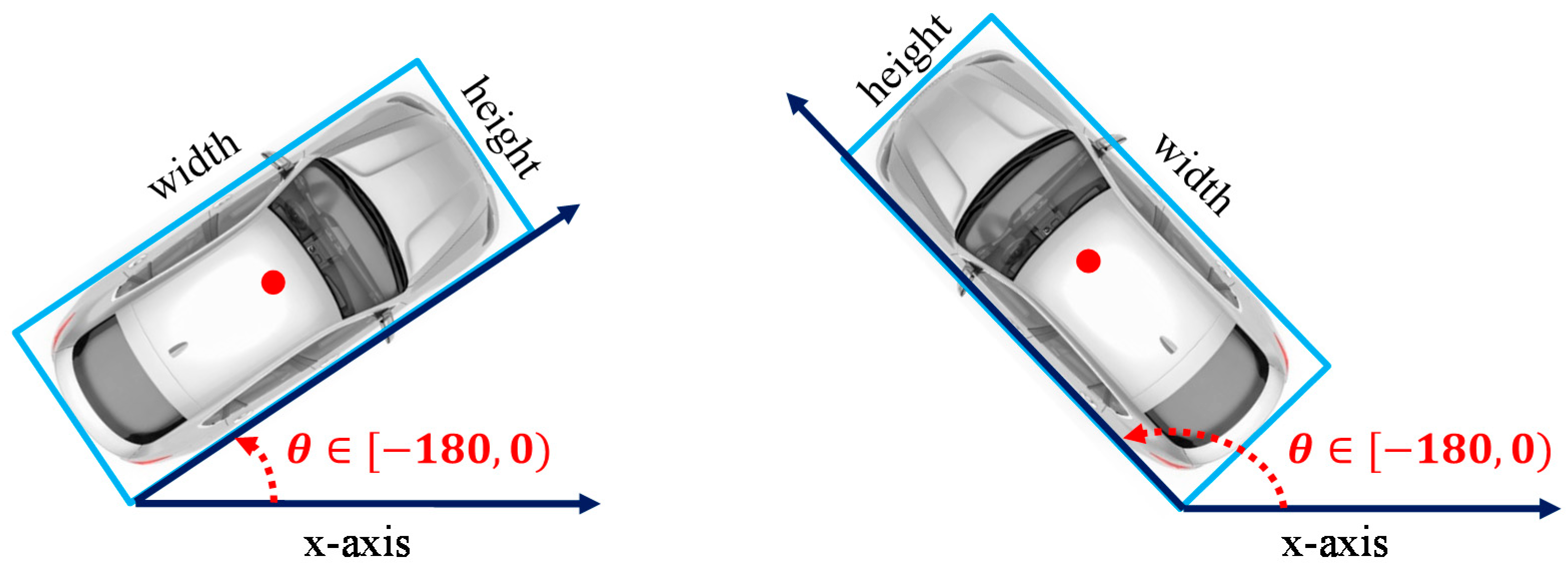
Most vehicles in UAV images have the characteristic of being arbitrary-oriented. The vehicle’s horizontal bounding box is less efficient when the vehicle orientation is not parallel to the coordinate axis from the drone’s perspective, as shown in
Figure 1. There is a large empty margin and a false intersection area when vehicles are bounded with horizontal boxes, and it does not provide accurate rotation and scale information. Therefore, these horizontal detectors cannot be used in UAV platforms for vehicle detection if the view angle is the bird’s view. The rotated bounding box used to process rotating objects from UAV and aerial images can provide more accurate regions for instances and introduce considerably less background noise. Ma et al. [
19] presented the extra orientation prediction and rotated anchor boxes into Faster RCNN to detect the oriented object. Yang et al. [
20] designed a sampling fusion network to obtain a more effective anchor sampling and an improved smooth L1 loss by adding the IoU constant factor to address the boundary problem of rotated bounding-box regression. Ding et al. [
21] applied a spatial transformation to transform the horizontal region of interest (ROI) into a rotated ROI. Yang et al. [
22] designed a circular smooth label (CSL) to convert angular prediction from a regression problem to a classification problem to avoid the discontinuous boundary problem. Based on this work, they further proposed a new angle-encoding mechanism, densely coded labels (DCL) [
23], to speed up the angle classification branch. Ming et al. [
24] proposed a critical feature capturing network (CFC-Net) to achieve superior detection performance through a polarized attention module and a dynamic anchor-selection strategy. Ming et al. [
25] proposed a dynamic anchor-learning (DAL) method to alleviate the imbalance between positive and negative samples and the problem of feature misalignment between classification and regression tasks. Yi et al. [
26] also regarded the angle prediction as a classification problem and captured the oriented bounding boxes through the box boundary-aware vectors (BBAVectors). Based on this work, Yu et al. [
27] designed an anchor-free arbitrary-oriented object detector and introduced a context enhancement module to improve multi-feature information interaction. Ming et al. [
28] constructed multiple representations of oriented targets and transformed the bounding-box regression task into an optimal matching process. In addition, Ming et al. [
29] selected high-quality anchors to alleviate the imbalance between classification and regression tasks. Feng et al. [
30] converted presented horizontal anchors into rotated anchors through anchor refinement in the RetinaNet algorithm. Despite the high-resolution UAV images, a lightweight model and real-time detection are required. These off-the-shelf arbitrary-oriented detection methods used in detecting vehicles still lack accurate, lightweight structure and real-time ability in the UAV platform.
Modeling the global units and their relations in an image is critical for arbitrary-oriented detection. The multi-head self-attention (MHSA) mechanism [
31] has been shown to learn the relationship among distant targets effectively [
32,
33]. Moreover, the MHSA can facilitate handling nuisances in natural images [
34], such as noise in the background and some occlusions. Therefore, several attention-based approaches have integrated the multi-head self-attention mechanism into their detector network [
35,
36,
37]. Yu et al. [
35] introduced a transformer module into the backbone network to enhance the detector performance in side-scan sonar images. Zhu et al. [
36] applied transformer encoder blocks in the YOLO head network and the end of the backbone. Sun et al. [
37] proposed an encoder-only DETR model to accelerate DETR training and improve the detector of FCOS and Faster RCNN based on it.
In addition to global relation capturing, computation-consuming and low storage capacity are essential for autonomous UAVs. Most rotation detectors build an intense and complex architecture of neural networks to achieve better accuracy. Thus, it brings up many more computations and storage burdens, making vehicle detection unaffordable for drones. The UAV platform’s key to accurate and real-time vehicle detection is finding a suitable base detection model that balances accuracy, model complexity, and inference speed. Furthermore, it should have a lightweight structure and be low-resource-intensive due to the UAV platform’s hardware computing power and storage-space limitation. Several efforts have been made to perform light-object detection. For instance, YOLOv5 [
38] is the SOTA, the most notable and convenient one-stage detector with fast detection speed and precision, including YOLOv5s, YOLOv5m, YOLOv5l, YOLOv5x. YOLOv5x can obtain 68.9% AP@0.5 for the COCO val2017 dataset, and the minimum model size of the YOLOv5s is only 14 megabytes. Considering the accuracy and model complexity, we selected YOLOv5s as our base model for the UAV dataset UAV-ROD [
30] and YOLOv5m for the remote-sensing dataset UCAS-AOD [
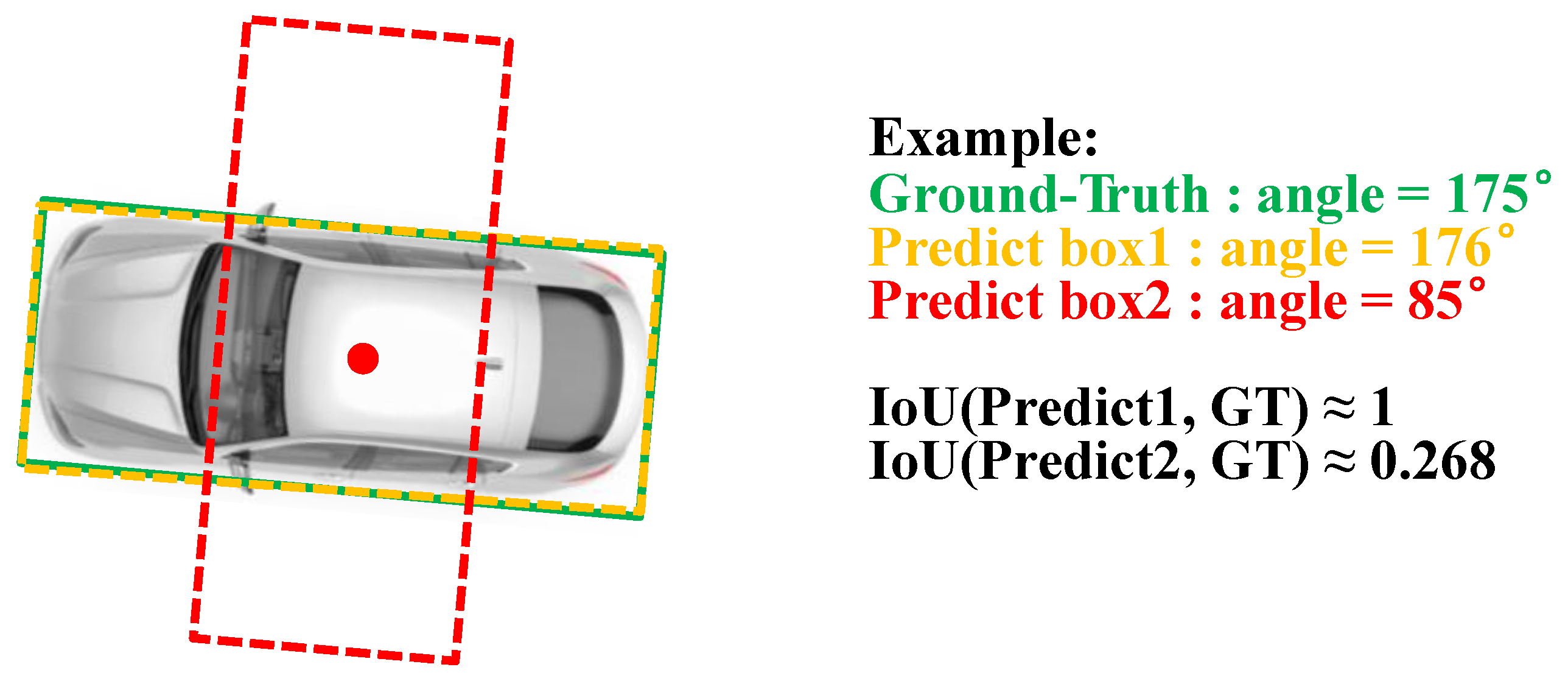
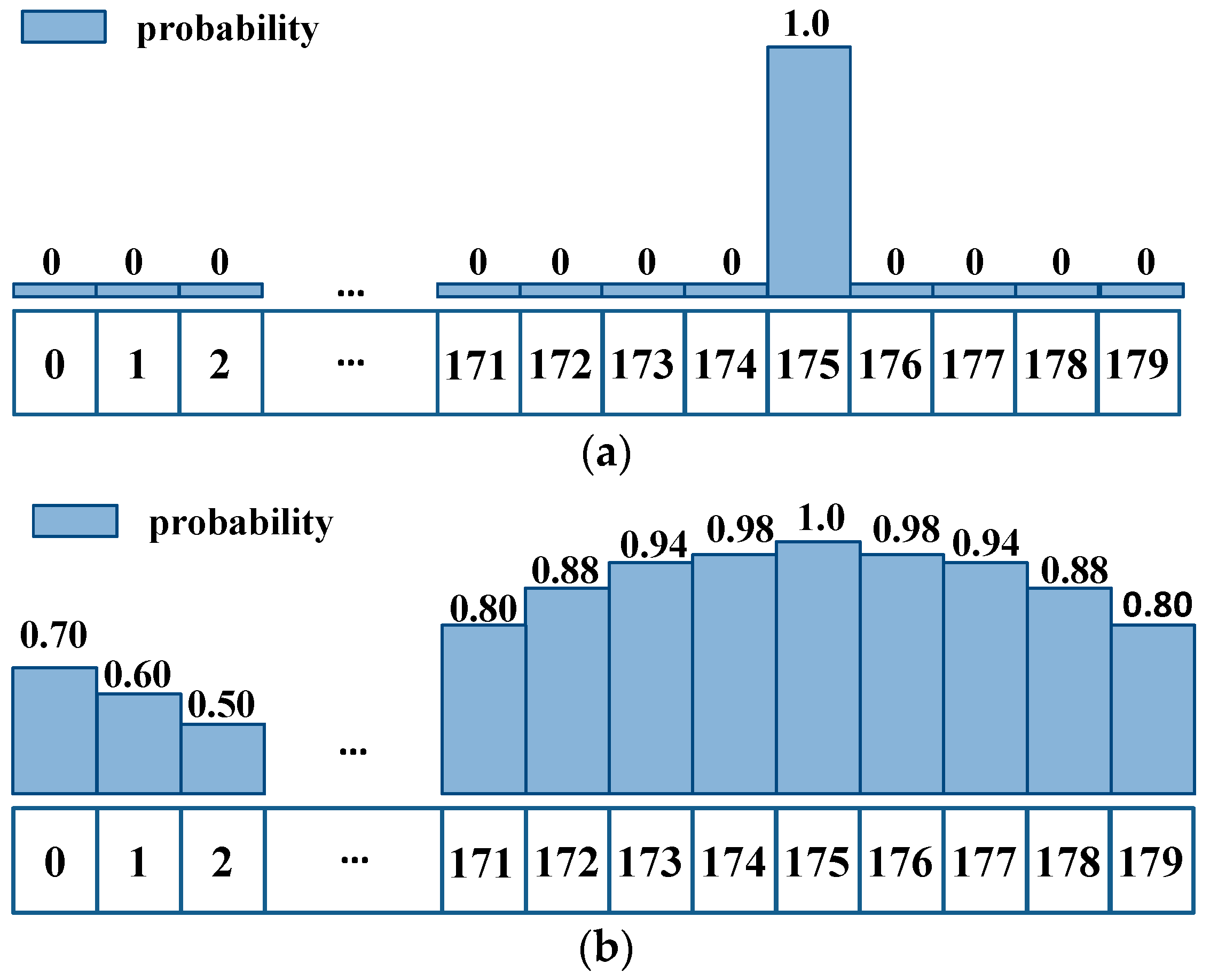
39]. However, YOLOv5 is a generic horizontal detector that is not fully applicable to UAV images. The horizontal bounding box for the vehicles is less efficient when the view angle of the UAV is bird-view. In contrast, we added an angle classification prediction branch in the YOLO head network and employed the circular smooth label to avoid the discontinuous boundary problem and reduce the classification loss.
While aiming for a cost-effective and scalable detection model for arbitrary-oriented vehicles in UAV Imagery, three serious challenges need to be addressed: (1) Efficiency. Current methods for arbitrary-oriented detection require a significant amount of computation and storage, making them impractical for time-critical applications. (2) Adaptivity. The UAV can fly at various altitudes while capturing images from different and complementary angles, which causes significant differences in target sizes and more different visual appearances of the same object. However, most works lack adaptivity, and they do not allow scale or angle differences that may require resampling to be considered. (3) Correlativity. Vehicles are distributed on the road randomly according to a Poisson distribution and tend to be highly clustered in certain regions, such as parking lots. However, most detectors do not consider the distribution characteristics of vehicles.
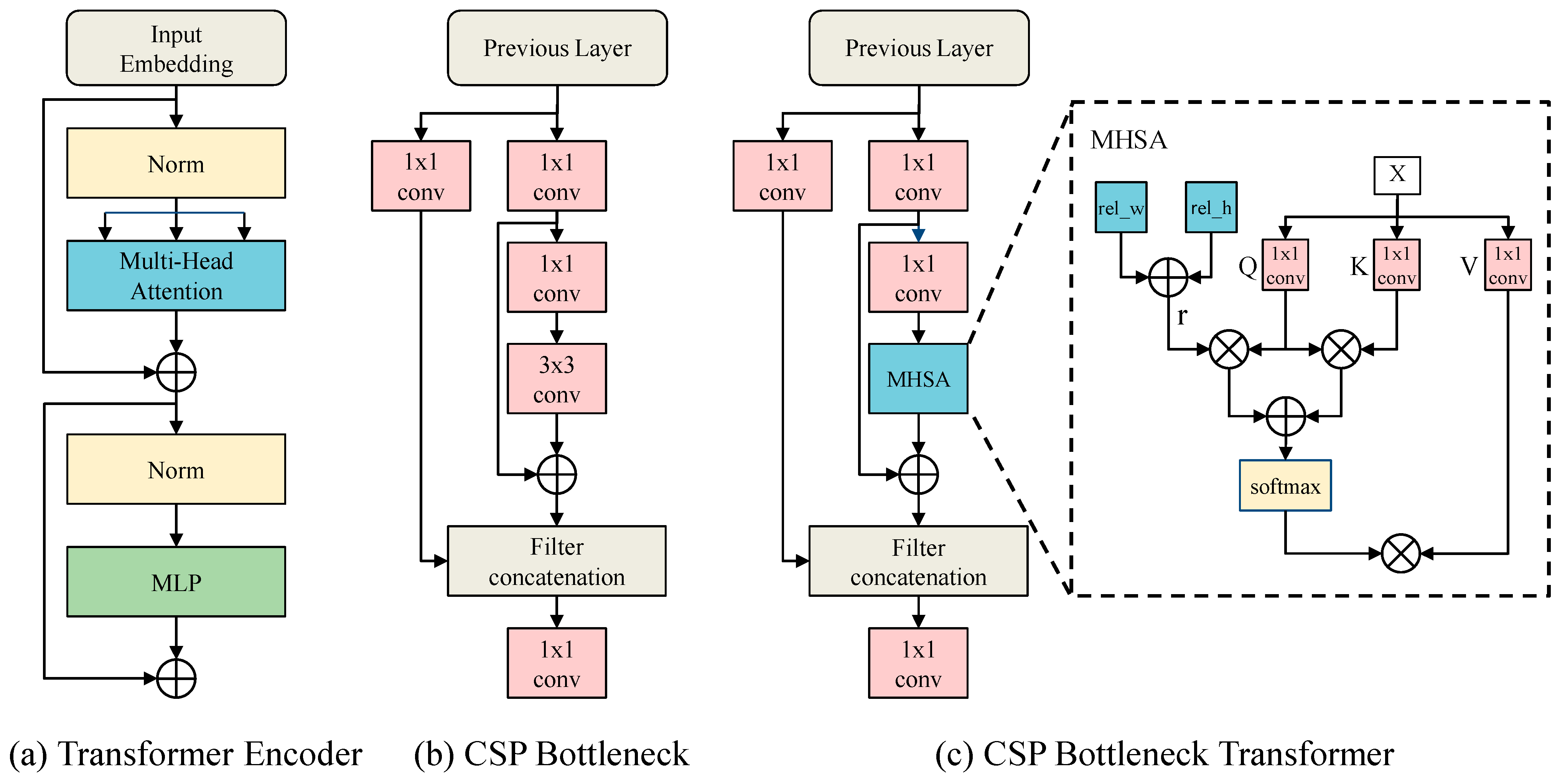
This paper addresses the above problems in a lightweight structure with global attentive relations and multi-path fusion. First, we developed a cross-stage partial bottleneck transformer (CSP BoT) module to capture vehicles’ potential global spatial relationships in UAV images and enhance the critical information. By replacing some blocks in YOLOv5 with the CSP BoT, it follows that detection tasks can capture vehicles’ potential global spatial relationships, thus enabling multi-scale insensitivity to uncertainties. Second, we proposed the multi-scale feature fusion by combining the prediction head network with the adaptive spatial feature fusion (ASFF) block [
40], which can autonomously learn the spatial weights of different feature maps and improve their interaction. Thus, it captures more detailed features, enabling global spatial correlation analysis. Furthermore, our approach, composed of simple but effective modules, balances model size and accuracy well. The experimental results validate its excellent performance in detecting arbitrary-oriented vehicles.
In summary, the main contributions of this article are summarized as follows:
We proposed a lightweight arbitrary-oriented vehicle detection network. We incorporated an angular classification prediction branch in the YOLO head network and employed a circular smooth label to reduce the classification loss. This significantly improves the detection performance for arbitrary-oriented vehicles in UAV images without incurring the extra model complexity and computation burden.
We presented a cross-stage partial bottleneck transformer (CSP BoT) module to our detection framework, a hybrid module using convolutions and the multi-head self-attention mechanism that can capture vehicles’ potential global spatial relationship in UAV images and enhance critical information.
Considering the specific characteristics of UAV images, such as complex backgrounds, different visual appearances of the same object, and significant variations in target sizes, we combined the adaptive spatial feature fusion (ASFF) block with the prediction head (ASFF-Head). This adaptively combines features of different resolutions before prediction to improve the multi-scale feature fusion and enhance information interaction.
Extensive experimental results on the UAV vehicle dataset UAV-ROD and remote sensing dataset UACS-AOD show the proposed method’s superiority, cost-effectiveness, and low model complexity.
4. Conclusions and Future Work
In this paper, we analyzed the characteristics of vehicles in UAV images and presented a lightweight detection network for arbitrary-oriented vehicles. First, since the horizontal bounding box is less efficient and does not provide accurate rotation and scale information for arbitrary-oriented vehicles, we proposed an angle classification prediction branch in the YOLO head network to generate angle information and employ the circular smooth label to reduce the angle classification loss. Second, to capture the potential global spatial relationship of vehicles in UAV images and enhance the vital information, we proposed a CSP bottleneck transformer (CSP BoT) module, a hybrid model using the multi-head self-attention mechanism convolutions. Finally, the ASFF-Head was presented to adaptively aggregate features at different resolutions by weighted cross-scale connections, adapting the spatial variation of prediction uncertainties.
Extensive experiments on the UAV dataset UAV-ROD and the remote-sensing dataset UCAS-AOD demonstrated that our approach could obtain encouraging accuracy, inference speed, and model-size results. Our method can reach a better accuracy while its model size, parameters, and inference speed are several times better than other methods. Overall, our method is superior to the existing arbitrary-oriented vehicle detection methods in UAV images in terms of accuracy, model size, and real-time ability, and it meets vehicle-detection needs better in drone platforms. In addition, the present study provides an approach using pre-collected datasets; however, actual experiments should be performed in future work to evaluate the application of the proposed framework further.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}