EyeTrackUAV2: A Large-Scale Binocular Eye-Tracking Dataset for UAV Videos

 ,
,  ,
,  , , and
, , and 
Abstract
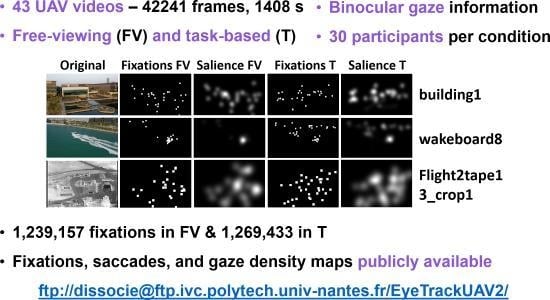
1. Introduction
2. Related Work
- The photographer bias often emphasizes objects in the content center through composition and artistic intent [29].
- Directly related to photographer bias, observers tend to learn the probability of finding salient objects at the content center. We refer to this behavior as a viewing strategy.
- With regards to the human visual system (HVS), the central orbital position, that is when looking straight ahead, is the most comfortable eye position [30], leading to a recentering bias.
- UAV may embed multi-modal sensors during the capture of scenes. Besides conventional RGB cameras, to name but a few thermal, multi-spectral, and infrared cameras consist of typical UAV sensors. Unfortunately, EyeTrackUAV1 lacks non-natural content, which is of great interest for the dynamic field of salience. As already mentioned, combining content from various imagery in datasets is advantageous for numerous reasons. It is necessary to continue efforts toward the inclusion of more non-natural content in databases.
- In general, the inclusion of more participants in the collection of human gaze is encouraged. Indeed, reducing variable errors by including more participants in the eye tracking experiment is beneficial. It is especially true in the case of videos as salience is sparse due to the short displaying duration of a single frame. With regards to evaluation analyses, some metrics measuring similarity between saliency maps consider fixation locations for saliency comparison (e.g., any variant of area under the curve (AUC), normalized scanpath saliency (NSS), and information gain (IG)). Having more fixation points is more convenient for the use of such metrics.
- EyeTrackUAV1 contains eye-tracking information recorded during free-viewing sessions. That is, no specific task was assigned to observers. Several applications for UAV and conventional imaging could benefit from the analysis and reproduction of more top-down attention, related to a task at hand. More specifically, for UAV content, there is a need for specialized computational models for person or anomaly detection.
- Even though there are about 26,599 frames in EyeTrackUAV, they come from only 19 videos. Consequently, this dataset just represents a snapshot of the reality. We aim to go further by introducing more UAV content.
3. EyeTrackUAV2 Dataset
3.1. Content Selection
- UAV123 included challenging UAV content annotated for object tracking. We restricted the content selection to the first set, which included 103 sequences (1280 × 720 and 30 fps) captured by an off-the-shelf professional-grade UAV (DJI S1000) tracking various objects in a range of altitudes comprised between 5–25 m. Sequences included a large variety of environments (e.g., urban landscapes, roads, and marina), objects (e.g., cars, boats, and persons) and activities (e.g., walking, biking, and swimming) as well as presenting many challenges for object tracking (e.g., long- and short-term occlusions, illumination variations, viewpoint change, background clutter, and camera motion).
- Aerial videos in the VIRAT dataset were manually selected (for smooth camera motion and good weather conditions) from rushes of a total amount of 4 h in outdoor areas with broad coverage of realistic scenarios for real-world surveillance. Content included “single person”, “person and vehicle”, and “person and facility” events, with changes in viewpoints, illumination, and visibility. The dataset came with annotations of moving object tracks and event examples in sequences. The main advantage of VIRAT videos was its perfect fit for military applications. It covered fundamental environment contexts (events), conditions (rather poor quality and weather condition impairments), and imagery (RGB and IR). We decided to keep the original resolution of videos (720 × 480) to prevent the introduction of unrelated artifacts.
- The 70 videos (RGB, 1280 × 720 and 30 fps) from DTB70 dataset were manually annotated with bounding boxes for tracked objects. Sequences were shot with a DJI Phantom 2 Vision+ drone or were collected from YouTube to add diversity in environments and target types (mostly humans, animals, and rigid objects). There was also a variety of camera movements (both translation and rotation), short- and long-term occlusions, and target deformability.
3.2. Content Diversity
3.3. Experimental Design
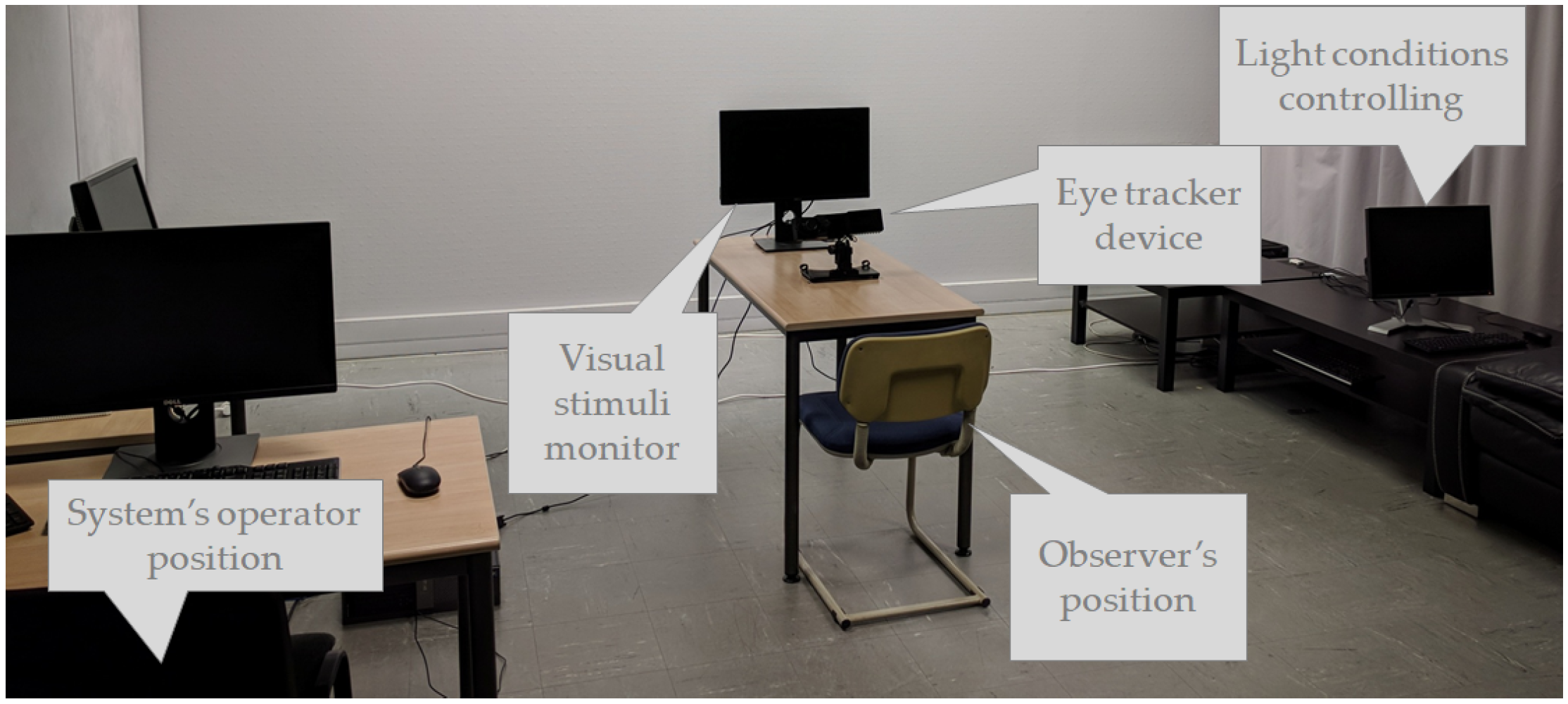
3.3.1. Eye-Tracking Apparatus
3.3.2. Stimuli Presentation
3.3.3. Visual Tasks to Perform
3.3.4. Population
3.4. Post-Processing of Eye-Tracking Data
3.4.1. Raw Data
3.4.2. Fixation and Saccade Event Detection
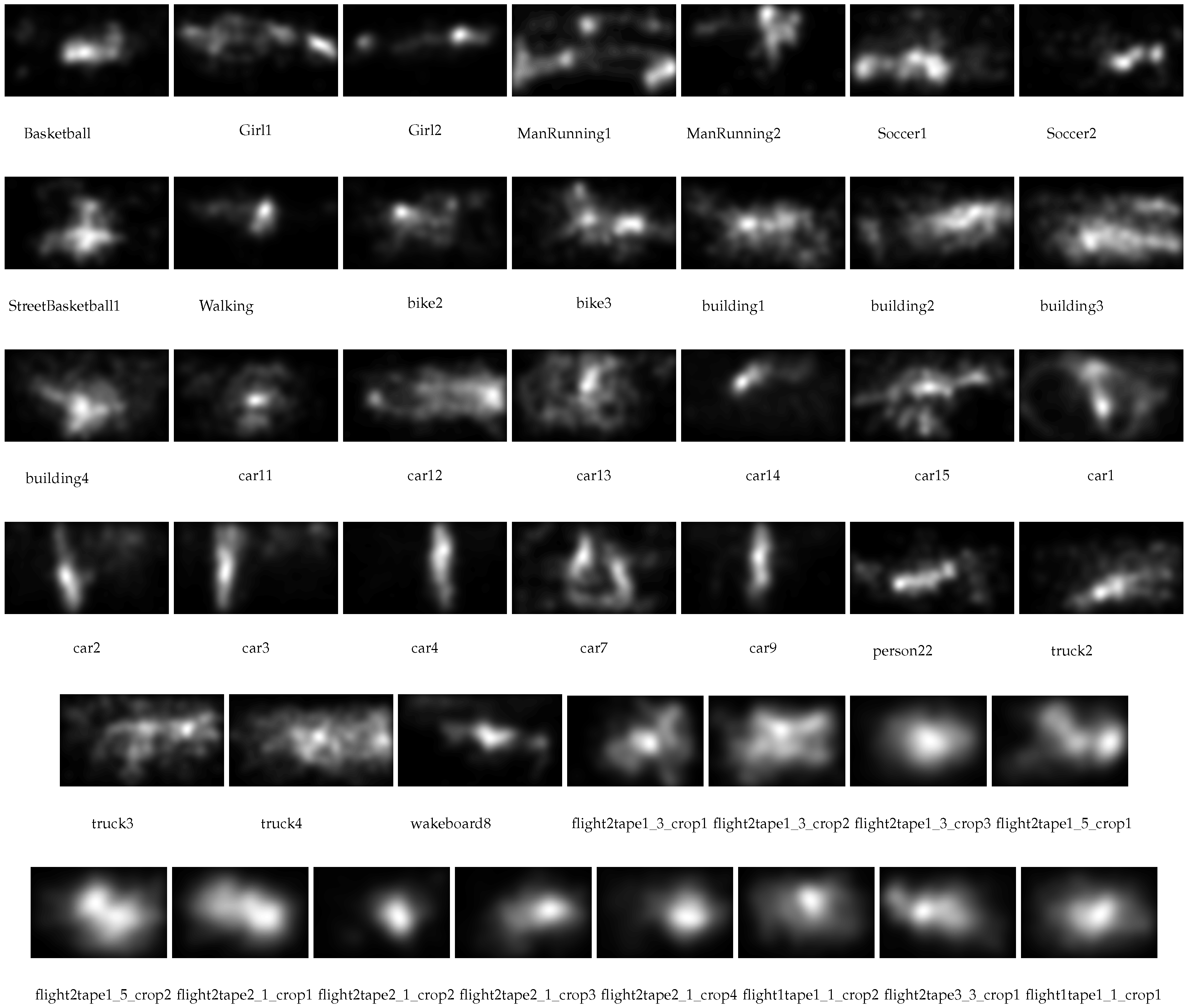
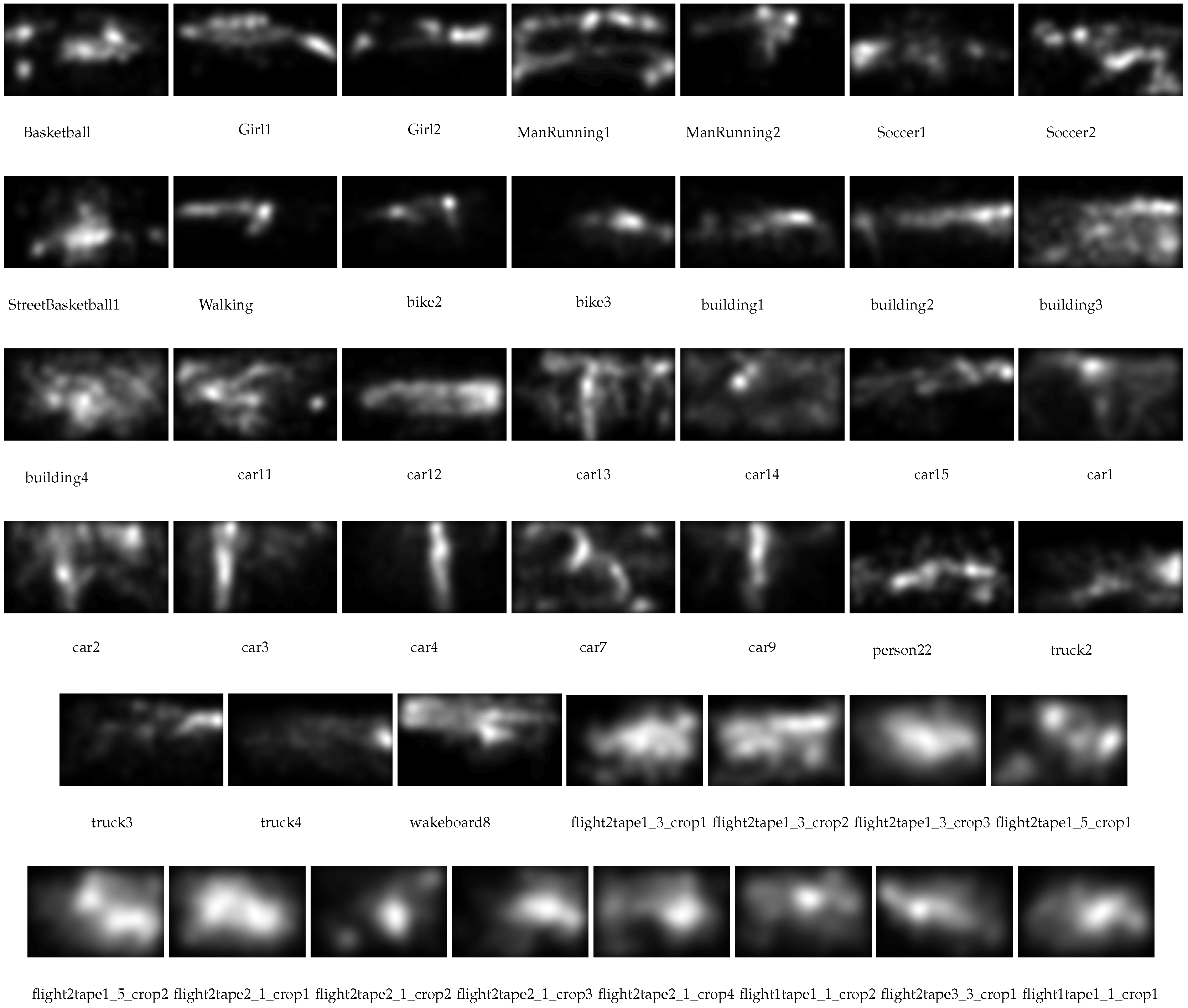
3.4.3. Human Saliency Maps
3.5. EyeTrackUAV2 in Brief
4. Analyses
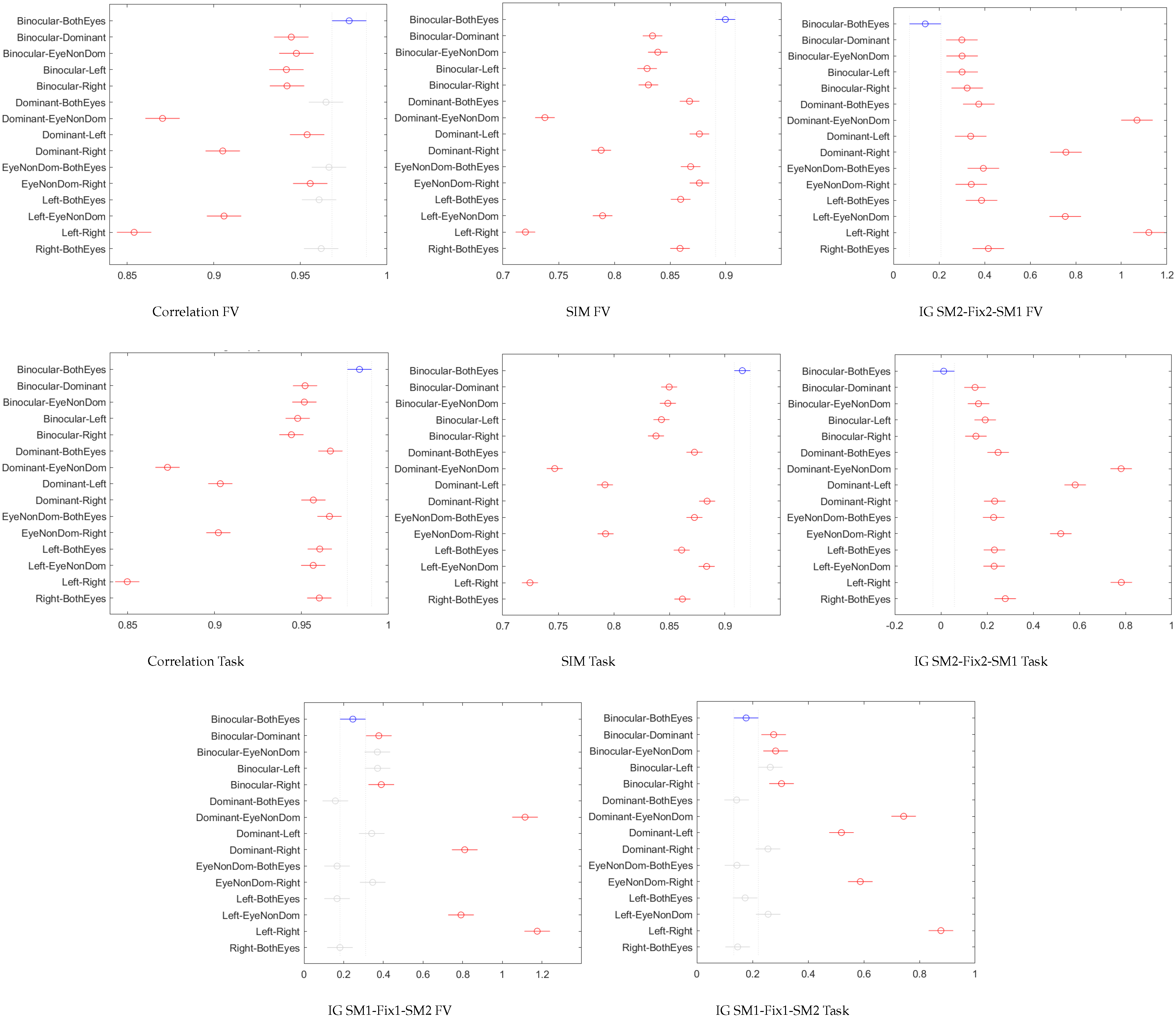
4.1. Six Different Ground Truths
- There was a high similarity between scenario gaze density maps. As expected, scores were pretty high (respectively low for IG), which indicates the high similarity between scenarios.
- All metrics showed the best results for comparisons including Binocular and BothEyes scenarios, the highest being the Binocular-BothEyes comparison.
- Left–Right and Dominant–NonDominant comparisons achieved worst results.
- It was possible to know the population main dominant eye through scenario comparisons (not including two eyes information). When describing the population, we saw that a majority of left-dominant-eye subjects participated in the FV test, while the reverse happened for the Task experiment. This fact is noticeable in metric scores.
- The first category showed the best similarities (i.e., highest for CC and SIM, and lowest for IGs) between scenarios, include all comparisons involving B and BE scenarios. There are also comparisons between single eye signals being the most and the least representative of the population’s eyedness (e.g., D vs L and nD vs R for FV, D vs R and nD vs L for Task).
- The second category included the comparison of single eye signals that do not represent the “same” population’s eyedness (i.e., D vs R and nD vs L for FV, D vs L and nD vs R for Task)
- Lastly, the third category presented the least similar scenario comparisons, in terms of the four evaluated metrics. Those comparisons are the single eye signals that come from different eyes (i.e., L vs R and D vs nD). Let us note that metrics gave reasonably good similarity scores, even for these two scenarios.
4.2. Biases in UAV Videos
4.2.1. Qualitative Evaluation of Biases in UAV Videos
4.2.2. Quantitative Evaluation of the Central Bias in UAV Videos
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in UAV imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef]
- Van Gemert, J.C.; Verschoor, C.R.; Mettes, P.; Epema, K.; Koh, L.P.; Wich, S. Nature conservation drones for automatic localization and counting of animals. In Workshop at the European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 255–270. [Google Scholar]
- Postema, S. News Drones: An Auxiliary Perspective; Edinburgh Napier University: Scotland, UK, 2015. [Google Scholar]
- Agbeyangi, A.O.; Odiete, J.O.; Olorunlomerue, A.B. Review on UAVs used for aerial surveillance. J. Multidiscip. Eng. Sci. Technol. 2016, 3, 5713–5719. [Google Scholar]
- Lee-Morrison, L. State of the Art Report on Drone-Based Warfare; Division of Art History and Visual Studies, Department of Arts and Cultural Sciences, Lund University: Lund, Sweden, 2014. [Google Scholar]
- Zhou, Y.; Tang, D.; Zhou, H.; Xiang, X.; Hu, T. Vision-based online localization and trajectory smoothing for fixed-wing UAV tracking a moving target. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, P.; Du, D.; Wen, L.; Bian, X.; Ling, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-VID2019: The vision meets drone object detection in video challenge results. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Aguilar, W.G.; Luna, M.A.; Moya, J.F.; Abad, V.; Ruiz, H.; Parra, H.; Angulo, C. Pedestrian detection for UAVs using cascade classifiers and saliency maps. In Proceedings of the International Work-Conference on Artificial Neural Networks, Càdiz, Spain, 14–16 June 2017; pp. 563–574. [Google Scholar]
- Dang, T.; Khattak, S.; Papachristos, C.; Alexis, K. Anomaly detection and cognizant path planning for surveillance operations using aerial robots. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 667–673. [Google Scholar]
- Edney-Browne, A. Vision, visuality, and agency in the US drone program. In Technology and Agency in International Relations; Routledge: Abingdon, UK, 2019; p. 88. [Google Scholar]
- Krassanakis, V.; Perreira Da Silva, M.; Ricordel, V. Monitoring human visual behavior during the observation of unmanned aerial vehicles (UAVs) videos. Drones 2018, 2, 36. [Google Scholar] [CrossRef]
- Howard, I.P.; Rogers, B. Depth perception. Stevens Handb. Exp. Psychol. 2002, 6, 77–120. [Google Scholar]
- Foulsham, T.; Kingstone, A.; Underwood, G. Turning the world around: Patterns in saccade direction vary with picture orientation. Vis. Res. 2008, 48, 1777–1790. [Google Scholar] [CrossRef] [PubMed]
- Papachristos, C.; Khattak, S.; Mascarich, F.; Dang, T.; Alexis, K. Autonomous aerial robotic exploration of subterranean environments relying on morphology–aware path planning. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 299–305. [Google Scholar]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194. [Google Scholar] [CrossRef]
- Katsuki, F.; Constantinidis, C. Bottom-up and top-down attention: Different processes and overlapping neural systems. Neuroscientist 2014, 20, 509–521. [Google Scholar] [CrossRef]
- Krasovskaya, S.; MacInnes, W.J. Salience models: A computational cognitive neuroscience review. Vision 2019, 3, 56. [Google Scholar] [CrossRef]
- Rai, Y.; Le Callet, P.; Cheung, G. Quantifying the relation between perceived interest and visual salience during free viewing using trellis based optimization. In Proceedings of the 2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Bordeaux, France, 11–12 July 2016; pp. 1–5. [Google Scholar]
- Kummerer, M.; Wallis, T.S.; Bethge, M. Saliency benchmarking made easy: Separating models, maps and metrics. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 770–787. [Google Scholar]
- Riche, N.; Duvinage, M.; Mancas, M.; Gosselin, B.; Dutoit, T. Saliency and human fixations: State-of-the-art and study of comparison metrics. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1153–1160. [Google Scholar]
- Guo, C.; Zhang, L. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE Trans. Image Process. 2009, 19, 185–198. [Google Scholar]
- Jain, S.D.; Xiong, B.; Grauman, K. Fusionseg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2126. [Google Scholar]
- Wang, W.; Shen, J.; Shao, L. Video salient object detection via fully convolutional networks. IEEE Trans. Image Process. 2017, 27, 38–49. [Google Scholar] [CrossRef]
- Li, G.; Xie, Y.; Wei, T.; Wang, K.; Lin, L. Flow guided recurrent neural encoder for video salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3243–3252. [Google Scholar]
- Le Meur, O.; Coutrot, A.; Liu, Z.; Rämä, P.; Le Roch, A.; Helo, A. Visual attention saccadic models learn to emulate gaze patterns from childhood to adulthood. IEEE Trans. Image Process. 2017, 26, 4777–4789. [Google Scholar] [CrossRef] [PubMed]
- Brunye, T.T.; Martis, S.B.; Horner, C.; Kirejczyk, J.A.; Rock, K. Visual salience and biological motion interact to determine camouflaged target detectability. Appl. Ergon. 2018, 73, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Perrin, A.F.; Zhang, L.; Le Meur, O. How well current saliency prediction models perform on UAVs videos? In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Salerno, Italy, 2–6 Spetember 2019; pp. 311–323. [Google Scholar]
- Bindemann, M. Scene and screen center bias early eye movements in scene viewing. Vis. Res. 2010, 50, 2577–2587. [Google Scholar] [CrossRef]
- Tseng, P.H.; Carmi, R.; Cameron, I.G.; Munoz, D.P.; Itti, L. Quantifying center bias of observers in free viewing of dynamic natural scenes. J. Vis. 2009, 9, 4. [Google Scholar] [CrossRef] [PubMed]
- Van Opstal, A.; Hepp, K.; Suzuki, Y.; Henn, V. Influence of eye position on activity in monkey superior colliculus. J. Neurophysiol. 1995, 74, 1593–1610. [Google Scholar] [CrossRef] [PubMed]
- Tatler, B.W. The central fixation bias in scene viewing: Selecting an optimal viewing position independently of motor biases and image feature distributions. J. Vis. 2007, 7, 4. [Google Scholar] [CrossRef] [PubMed]
- Le Meur, O.; Liu, Z. Saccadic model of eye movements for free-viewing condition. Vis. Res. 2015, 116, 152–164. [Google Scholar] [CrossRef]
- Vigier, T.; Da Silva, M.P.; Le Callet, P. Impact of visual angle on attention deployment and robustness of visual saliency models in videos: From SD to UHD. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 689–693. [Google Scholar]
- Zhang, K.; Chen, Z. Video saliency prediction based on spatial-temporal two-stream network. IEEE Trans. Circuits Syst. Video Technol. 2018. [Google Scholar] [CrossRef]
- Le Meur, O.; Le Callet, P.; Barba, D.; Thoreau, D. A coherent computational approach to model bottom-up visual attention. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 802–817. [Google Scholar] [CrossRef]
- Bylinskii, Z.; Judd, T.; Oliva, A.; Torralba, A.; Durand, F. What do different evaluation metrics tell us about saliency models? IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 740–757. [Google Scholar] [CrossRef]
- Paglin, M.; Rufolo, A.M. Heterogeneous human capital, occupational choice, and male-female earnings differences. J. Labor Econ. 1990, 8, 123–144. [Google Scholar] [CrossRef]
- Ehinger, K.A.; Hidalgo-Sotelo, B.; Torralba, A.; Oliva, A. Modelling search for people in 900 scenes: A combined source model of eye guidance. Vis. Cogn. 2009, 17, 945–978. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Heynderickx, I. Studying the added value of visual attention in objective image quality metrics based on eye movement data. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 3097–3100. [Google Scholar]
- Judd, T.; Durand, F.; Torralba, A. A Benchmark of Computational Models of Saliency to Predict Human Fixations; Computer Science and Artificial Intelligence Laboratory Technical Report; MIT Library: Cambridge, MA, USA, 2012. [Google Scholar]
- Ma, K.T.; Sim, T.; Kankanhalli, M. VIP: A unifying framework for computational eye-gaze research. In Proceedings of the International Workshop on Human Behavior Understanding, Barcelona, Spain, 22 October 2013; pp. 209–222. [Google Scholar]
- Koehler, K.; Guo, F.; Zhang, S.; Eckstein, M.P. What do saliency models predict? J. Vis. 2014, 14, 14. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; Itti, L. Cat2000: A large scale fixation dataset for boosting saliency research. arXiv 2015, arXiv:1505.03581. [Google Scholar]
- Bylinskii, Z.; Isola, P.; Bainbridge, C.; Torralba, A.; Oliva, A. Intrinsic and extrinsic effects on image memorability. Vis. Res. 2015, 116, 165–178. [Google Scholar] [CrossRef] [PubMed]
- Fan, S.; Shen, Z.; Jiang, M.; Koenig, B.L.; Xu, J.; Kankanhalli, M.S.; Zhao, Q. Emotional attention: A study of image sentiment and visual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7521–7531. [Google Scholar]
- McCamy, M.B.; Otero-Millan, J.; Di Stasi, L.L.; Macknik, S.L.; Martinez-Conde, S. Highly informative natural scene regions increase microsaccade production during visual scanning. J. Neurosci. 2014, 34, 2956–2966. [Google Scholar] [CrossRef]
- Gitman, Y.; Erofeev, M.; Vatolin, D.; Andrey, B.; Alexey, F. Semiautomatic visual-attention modeling and its application to video compression. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1105–1109. [Google Scholar]
- Coutrot, A.; Guyader, N. How saliency, faces, and sound influence gaze in dynamic social scenes. J. Vis. 2014, 14, 5. [Google Scholar] [CrossRef]
- Coutrot, A.; Guyader, N. An efficient audiovisual saliency model to predict eye positions when looking at conversations. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 1531–1535. [Google Scholar]
- Wang, W.; Shen, J.; Xie, J.; Cheng, M.M.; Ling, H.; Borji, A. Revisiting video saliency prediction in the deep learning era. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Oh, S.; Hoogs, A.; Perera, A.; Cuntoor, N.; Chen, C.C.; Lee, J.T.; Mukherjee, S.; Aggarwal, J.; Lee, H.; Davis, L.; et al. A large-scale benchmark dataset for event recognition in surveillance video. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3153–3160. [Google Scholar]
- Layne, R.; Hospedales, T.M.; Gong, S. Investigating open-world person re-identification using a drone. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 225–240. [Google Scholar]
- Bonetto, M.; Korshunov, P.; Ramponi, G.; Ebrahimi, T. Privacy in mini-drone based video surveillance. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–6. [Google Scholar]
- Shu, T.; Xie, D.; Rothrock, B.; Todorovic, S.; Chun Zhu, S. Joint inference of groups, events and human roles in aerial videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4576–4584. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 445–461. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning social etiquette: Human trajectory understanding in crowded scenes. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 549–565. [Google Scholar]
- Li, S.; Yeung, D.Y. Visual object tracking for unmanned aerial vehicles: A benchmark and new motion models. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Barekatain, M.; Martí, M.; Shih, H.F.; Murray, S.; Nakayama, K.; Matsuo, Y.; Prendinger, H. Okutama-action: An aerial view video dataset for concurrent human action detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 28–35. [Google Scholar]
- Hsieh, M.R.; Lin, Y.L.; Hsu, W.H. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4145–4153. [Google Scholar]
- Ribeiro, R.; Cruz, G.; Matos, J.; Bernardino, A. A dataset for airborne maritime surveillance environments. IEEE Trans. Circuits Syst. Video Technol. 2017. [Google Scholar] [CrossRef]
- Hsu, H.J.; Chen, K.T. DroneFace: An open dataset for drone research. In Proceedings of the 8th ACM on Multimedia Systems Conference, Taipei, Taiwan, 20–23 June 2017; pp. 187–192. [Google Scholar]
- Božić-Štulić, D.; Marušić, Ž.; Gotovac, S. Deep learning approach in aerial imagery for supporting land search and rescue missions. Int. J. Comput. Vis. 2019, 127, 1256–1278. [Google Scholar] [CrossRef]
- Fu, K.; Li, J.; Shen, H.; Tian, Y. How drones look: Crowdsourced knowledge transfer for aerial video saliency prediction. arXiv 2018, arXiv:1811.05625. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision meets drones: A challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Nyström, M.; Andersson, R.; Holmqvist, K.; Van De Weijer, J. The influence of calibration method and eye physiology on eyetracking data quality. Behav. Res. Methods 2013, 45, 272–288. [Google Scholar] [CrossRef] [PubMed]
- ITU-T Recommendations. Subjective Video Quality Assessment Methods for Multimedia Applications; Standardization (T), Telephone transmission quality, telephone installations, local line networks (P); International Telecommunication Union: Geneva, Switzerland, 2008. [Google Scholar]
- Rec, I. Subjective Assessment Methods for Image Quality in High-Definition Television; BT. 710-4, Recommendations (R), Broadcasting service TV (BT); International Telecommunication Union: Geneva, Switzerland, 1998. [Google Scholar]
- Cornelissen, F.W.; Peters, E.M.; Palmer, J. The Eyelink Toolbox: Eye tracking with MATLAB and the Psychophysics Toolbox. Behav. Res. Methods Instrum. Comput. 2002, 34, 613–617. [Google Scholar] [CrossRef] [PubMed]
- Rec, I. Methodology for the Subjective Assessment of the Quality of Television Pictures; BT. 500-13, Recommendations (R), Broadcasting service TV (BT); International Telecommunication Union: Geneva, Switzerland, 1998. [Google Scholar]
- Wandell, B.; Thomas, S. Foundations of vision. Psyccritiques 1997, 42, 649. [Google Scholar]
- Le Meur, O.; Baccino, T. Methods for comparing scanpaths and saliency maps: Strengths and weaknesses. Behav. Res. Methods 2013, 45, 251–266. [Google Scholar] [CrossRef]
- Guznov, S.; Matthews, G.; Warm, J.S.; Pfahler, M. Training techniques for visual search in complex task environments. Hum. Factors 2017, 59, 1139–1152. [Google Scholar] [CrossRef]
- Shah, M.; Javed, O.; Shafique, K. Automated visual surveillance in realistic scenarios. IEEE MultiMedia 2007, 14, 30–39. [Google Scholar] [CrossRef]
- Snellen, H. Test-Types for the Determination of the Acuteness of Vision; Williams and Norgate: Utrecht, The Netherlands, 1868. [Google Scholar]
- Ishihara, S. Test for Colour-Blindness; Kanehara: Tokyo, Japan, 1987. [Google Scholar]
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar]
- Krassanakis, V.; Filippakopoulou, V.; Nakos, B. EyeMMV toolbox: An eye movement post-analysis tool based on a two-step spatial dispersion threshold for fixation identification. J. Eye Mov. Res. 2014, 7. [Google Scholar] [CrossRef]
- Krassanakis, V.; Misthos, L.M.; Menegaki, M. LandRate toolbox: An adaptable tool for eye movement analysis and landscape rating Eye Tracking for Spatial Research. In Proceedings of the 3rd International Workshop, Zurich, Switzerland, 14 January 2018. [Google Scholar]
- Krassanakis, V.; Filippakopoulou, V.; Nakos, B. Detection of moving point symbols on cartographic backgrounds. J. Eye Mov. Res. 2016, 9. [Google Scholar] [CrossRef]
- Ooms, K.; Krassanakis, V. Measuring the spatial noise of a low-cost eye tracker to enhance fixation detection. J. Imaging 2018, 4, 96. [Google Scholar] [CrossRef]
- Cui, Y.; Hondzinski, J.M. Gaze tracking accuracy in humans: Two eyes are better than one. Neurosci. Lett. 2006, 396, 257–262. [Google Scholar] [CrossRef] [PubMed]
- Holmqvist, K.; Nyström, M.; Mulvey, F. Eye tracker data quality: What it is and how to measure it. In Proceedings of the Symposium on Eye Tracking Research and Applications, Santa Barbara, CA, USA, 28–30 March 2012; pp. 45–52. [Google Scholar]
- Hooge, I.T.; Holleman, G.A.; Haukes, N.C.; Hessels, R.S. Gaze tracking accuracy in humans: One eye is sometimes better than two. Behav. Res. Methods 2018. [Google Scholar] [CrossRef] [PubMed]
- Bylinskii, Z.; Judd, T.; Borji, A.; Itti, L.; Durand, F.; Oliva, A.; Torralba, A. MIT Saliency Benchmark; MIT Technical Report; MIT: Cambridge, MA, USA, 2015. [Google Scholar]
- Abdi, H.; Williams, L.J. Tukey’s honestly significant difference (HSD) test. In Encyclopedia of Research Design; Sage: Thousand Oaks, CA, USA, 2010; pp. 1–5. [Google Scholar]
- Le Meur, O.; Coutrot, A. Introducing context-dependent and spatially-variant viewing biases in saccadic models. Vis. Res. 2016, 121, 72–84. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Native Resolution | Proportion of Content Seen Per Degree of Visual Angle (%) | Videos Number | Frames Number (30 fps) | Duration (s) |
|---|---|---|---|---|---|
| VIRAT [51] | 720 × 480 | 1.19 | 12 | 17,851 | 595.03 |
| UAV123 [55] | 1280 × 720 | 0.44 | 22 | 20,758 | 691.93 |
| DTB70 [57] | 1280 × 720 | 0.44 | 9 | 3632 | 121.07 |
| Overall | 43 | 42,241 | 1408.03 (23:28 min) |
| Number of Frames | Duration (MM:SS) | |||||||
|---|---|---|---|---|---|---|---|---|
| VIRAT | UAV123 | DTB70 | Overall | VIRAT | UAV123 | DTB70 | Overall | |
| Total | 17,851 | 20,758 | 3632 | 42,241 | 09:55 | 11:32 | 02:01 | 23:28 |
| Average | 1488 | 944 | 404 | 982 | 00:50 | 00:31 | 00:13 | 00:33 |
| Standard Deviation | 847 | 615 | 177 | 727 | 00:28 | 00:21 | 00:06 | 00:24 |
| Minimum | 120 | 199 | 218 | 120 | 00:04 | 00:07 | 00:07 | 00:04 |
| Maximum | 3178 | 2629 | 626 | 3178 | 01:46 | 01:28 | 00:21 | 01:46 |
| ID | Video | Dataset | Number of Frames | Start Frame | End Frame | Duration (ms) | SI | TI | Altitude | Environment | Object Size | Horizontal Line (Sea, Sky) | Main Angle |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 09152008flight2tape1_3 (crop 1) | VIRAT | 120 | 1 | 120 | 4000 | 0.455 | 32 | High | Urban military - IR | Small | False | Oblique |
| 2 | 09152008flight2tape1_3 (crop 2) | 367 | 137 | 503 | 12,234 | 0.474 | 35 | High | Urban military - IR | Small | False | Oblique | |
| 3 | 09152008flight2tape1_3 (crop 3) | 3178 | 4735 | 7912 | 105,934 | 0.452 | 43 | Intermediate | Urban military | Medium, Small | False | Oblique | |
| 4 | 09152008flight2tape1_5 (crop 1) | 972 | 218 | 1189 | 32,400 | 0.467 | 37 | Intermediate | Urban military | Medium, Small | False | Oblique | |
| 5 | 09152008flight2tape1_5 (crop 2) | 1715 | 4555 | 6269 | 57,167 | 0.461 | 45 | Intermediate | Urban military | Medium, Small | False | Oblique | |
| 6 | 09152008flight2tape2_1 (crop 1) | 1321 | 1 | 1321 | 44,034 | 0.484 | 40 | Intermediate, Low | Urban military | Medium, Big | False | Oblique | |
| 7 | 09152008flight2tape2_1 (crop 2) | 1754 | 2587 | 4340 | 58,467 | 0.484 | 41 | High | Roads rural - IR | Small | False | Oblique | |
| 8 | 09152008flight2tape2_1 (crop 3) | 951 | 4366 | 5316 | 31,700 | 0.482 | 33 | Intermediate | Urban military | Medium, Big | False | Oblique | |
| 9 | 09152008flight2tape2_1 (crop 4) | 1671 | 6482 | 8152 | 55,700 | 0.452 | 32 | High | Roads rural | Medium | False | Oblique, Vertical | |
| 10 | 09152008flight2tape3_3 (crop 1) | 2492 | 3067 | 5558 | 83,067 | 0.474 | 42 | Intermediate | Urban military | Small | False | Oblique | |
| 11 | 09162008flight1tape1_1 (crop 1) | 1894 | 1097 | 2990 | 63,134 | 0.448 | 39 | Low | Urban military, Roads rural | Medium, Small | False | Oblique | |
| 12 | 09162008flight1tape1_1 (crop 2) | 1416 | 4306 | 5721 | 47,200 | 0.477 | 29 | Intermediate, High | Urban military | Small | False | Oblique | |
| Average | 1488 | 50,000 | 0.468 | 37.33 | |||||||||
| Standard deviation | 847 | 28,000 | 0.01 | 5.10 | |||||||||
| 13 | bike2 | UAV123 | 553 | 1 | 553 | 18,434 | 0.468 | 22 | Intermediate | Urban, building | Small, Very small | True | Horizontal |
| 14 | bike3 | 433 | 1 | 433 | 14,434 | 0.462 | 19 | Intermediate | Urban, building | Small | True | Horizontal | |
| 15 | building1 | 469 | 1 | 469 | 15,634 | 0.454 | 12 | Intermediate | Urban, building | Very Small | True | Horizontal | |
| 16 | building2 | 577 | 1 | 577 | 19,234 | 0.471 | 37 | Intermediate | Urban, building | Medium, Small | True | Horizontal | |
| 17 | building3 | 829 | 1 | 829 | 27,634 | 0.451 | 27 | High | Urban in desert | Small | True | Horizontal | |
| 18 | building4 | 787 | 1 | 787 | 26,234 | 0.464 | 29 | High, Intermediate | Urban in desert | None | True, False | Horizontal, Oblique | |
| 19 | car1 | 2629 | 1 | 2629 | 87,634 | 0.471 | 59 | Low, Intermediate | Road rural | Big, Medium | True | Oblique | |
| 20 | car11 | 337 | 1 | 337 | 11,234 | 0.467 | 31 | High | Suburban | Small | True, False | Horizontal, Oblique | |
| 21 | car12 | 499 | 1 | 499 | 16,634 | 0.467 | 39 | Low | Road urban, sea | Medium, Small | True | Horizontal | |
| 22 | car13 | 415 | 1 | 415 | 13,834 | 0.461 | 26 | High | Urban | Very very small | False | Oblique, Vertical | |
| 23 | car14 | 1327 | 1 | 1327 | 44,234 | 0.471 | 25 | Low | Road suburban | Medium | False | Oblique | |
| 24 | car15 | 469 | 1 | 469 | 15,634 | 0.471 | 18 | Intermediate | Road towards urban | Small, Very small | True | Oblique | |
| 25 | car2 | 1321 | 1 | 1321 | 44,034 | 0.464 | 24 | Intermediate | Road rural | Medium | False | Oblique, Vertical | |
| 26 | car3 | 1717 | 1 | 1717 | 57,234 | 0.467 | 27 | Intermediate | Road rural | Medium | False | Oblique, Vertical | |
| 27 | car4 | 1345 | 1 | 1345 | 44,834 | 0.462 | 23 | Intermediate, Low | Road rural | Big | False | Oblique, Vertical | |
| 28 | car7 | 1033 | 1 | 1033 | 34,434 | 0.464 | 18 | Intermediate | Road suburban | Medium | False | Oblique | |
| 29 | car9 | 1879 | 1 | 1879 | 62,634 | 0.470 | 23 | Intermediate, Low | Road suburban | Medium | False, True | Oblique, Horizontal | |
| 30 | person22 | 199 | 1 | 199 | 6634 | 0.456 | 31 | Low | Urban sea | Medium, Big | True | Horizontal | |
| 31 | truck2 | 601 | 1 | 601 | 20,034 | 0.453 | 24 | High | Urban road | Small | True | Horizontal | |
| 32 | truck3 | 535 | 1 | 535 | 17,834 | 0.472 | 18 | Intermediate | Road towards urban | Small, Very small | True | Oblique | |
| 33 | truck4 | 1261 | 1 | 1261 | 42,034 | 0.466 | 17 | Intermediate | Road towards urban | Small | True | Oblique, Horizontal | |
| 34 | wakeboard8 | 1543 | 1 | 1543 | 51,434 | 0.472 | 39 | Low | Sea urban | Medium, Big | True, False | Oblique, Vertical, Horizontal | |
| Average | 944 | 31,000 | 0.465 | 26.73 | |||||||||
| Standard deviation | 615 | 21,000 | 0.01 | 10.14 | |||||||||
| 35 | Basketball | DTB70 | 427 | 1 | 427 | 14,234 | 0.477 | 48 | Intermediate | Field suburban | Medium | True | Oblique |
| 36 | Girl1 | 218 | 1 | 218 | 7267 | 0.481 | 31 | Low | Field suburban | Big | True | Horizontal | |
| 37 | Girl2 | 626 | 1 | 626 | 20,867 | 0.482 | 30 | Low | Field suburban | Big | True | Horizontal | |
| 38 | ManRunning1 | 619 | 1 | 619 | 20,634 | 0.483 | 23 | Low | Field suburban | Big | True | Horizontal, Oblique | |
| 39 | ManRunning2 | 260 | 1 | 260 | 8667 | 0.484 | 27 | Low | Field suburban | Very big | False | Vertical, Oblique | |
| 40 | Soccer1 | 613 | 1 | 613 | 20,434 | 0.476 | 57 | Low, Intermediate | Field suburban | Very big, Big | True | Horizontal | |
| 41 | Soccer2 | 233 | 1 | 233 | 7767 | 0.475 | 24 | High | Field suburban | Small | True | Oblique | |
| 42 | StreetBasketball1 | 241 | 1 | 241 | 8034 | 0.379 | 37 | Low | Field urban | Big | True, False | Oblique, Vertical | |
| 43 | Walking | 395 | 1 | 395 | 13,167 | 0.476 | 31 | Low | Field suburban | Big, Very big | True | Oblique | |
| Average | 404 | 13,000 | 0.468 | 34.22 | |||||||||
| Standard deviation | 177 | 6000 | 0.03 | 11.39 | |||||||||
| Average | 982 | 33 s | 0.466 | 31.26 | |||||||||
| Standard deviation | 727 | 24 s | 0.02 | 10.30 | |||||||||
| Overall | 42,241 | 1408 s | |||||||||||
| Sample Statistics | FV | Task | Total |
|---|---|---|---|
| Participants | 30 | 30 | 60 |
| Female | 16 | 16 | 32 |
| Male | 14 | 14 | 28 |
| Average age | 31.7 | 27.9 | 29.8 |
| Std age | 11.0 | 8.5 | 10.0 |
| Min age | 20 | 19 | 19 |
| Max age | 59 | 55 | 59 |
| Left dominant eye | 19 | 9 | 28 |
| Right dominant eye | 11 | 21 | 32 |
| Participants with glasses | 0 | 4 | 4 |
| FV | Task | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| CC ↑ | SIM ↑ | IG ↓ | CC ↑ | SIM ↑ | IG ↓ | ||||
| SM1 | SM2 | SM1-Fix1-SM2 | SM2-Fix2-SM1 | SM1-Fix1-SM2 | SM2-Fix2-SM1 | ||||
| Binocular | Dominant | 0.94 | 0.83 | 0.377 | 0.300 | 0.952 | 0.850 | 0.276 | 0.148 |
| Binocular | EyeNonDom | 0.95 | 0.84 | 0.370 | 0.301 | 0.952 | 0.849 | 0.283 | 0.163 |
| Binocular | Left | 0.94 | 0.83 | 0.371 | 0.301 | 0.948 | 0.843 | 0.264 | 0.192 |
| Binocular | Right | 0.94 | 0.83 | 0.390 | 0.324 | 0.944 | 0.838 | 0.304 | 0.152 |
| Binocular | BothEyes | 0.98 | 0.90 | 0.246 | 0.139 | 0.983 | 0.916 | 0.177 | 0.012 |
| Dominant | BothEyes | 0.96 | 0.87 | 0.158 | 0.374 | 0.967 | 0.873 | 0.143 | 0.248 |
| EyeNonDom | BothEyes | 0.97 | 0.87 | 0.167 | 0.394 | 0.966 | 0.872 | 0.144 | 0.228 |
| Left | BothEyes | 0.96 | 0.86 | 0.166 | 0.387 | 0.960 | 0.861 | 0.174 | 0.232 |
| Right | BothEyes | 0.96 | 0.86 | 0.181 | 0.416 | 0.960 | 0.862 | 0.147 | 0.279 |
| Dominant | EyeNonDom | 0.87 | 0.74 | 1.115 | 1.069 | 0.873 | 0.747 | 0.743 | 0.781 |
| Dominant | Left | 0.95 | 0.88 | 0.341 | 0.339 | 0.903 | 0.792 | 0.520 | 0.582 |
| Dominant | Right | 0.91 | 0.79 | 0.810 | 0.757 | 0.957 | 0.884 | 0.256 | 0.233 |
| EyeNonDom | Right | 0.96 | 0.88 | 0.346 | 0.342 | 0.902 | 0.793 | 0.587 | 0.519 |
| Left | EyeNonDom | 0.91 | 0.79 | 0.792 | 0.754 | 0.957 | 0.884 | 0.256 | 0.231 |
| Left | Right | 0.85 | 0.72 | 1.176 | 1.121 | 0.850 | 0.725 | 0.877 | 0.782 |
| Mean | 0.937 | 0.832 | 0.467 | 0.488 | 0.938 | 0.839 | 0.343 | 0.319 | |
| Std | 0.037 | 0.052 | 0.340 | 0.295 | 0.038 | 0.053 | 0.230 | 0.234 | |
| FV | Task | ||||
|---|---|---|---|---|---|
| F-Value | p-Value | F-Value | p-Value | ||
| CC | F(14,630) = 77.72 | F(14,630) = 172.55 | |||
| SIM | F(14,630) = 200.07 | F(14,630) = 309.43 | |||
| IG | F(14,630) = 158.96 | F(14,630) = 156.16 | |||
| AUCJ | F(14,630) = 0.36 | 0.9857 | F(14,630) = 0.4 | 0.9742 | |
| AUCB | F(14,630) = 0.22 | 0.9989 | F(14,630) = 0.05 | 1 | |
| NSS | F(14,630) = 0.95 | 0.5036 | F(14,630) = 0.92 | 0.5344 | |
| FV | Task | |||||||
|---|---|---|---|---|---|---|---|---|
| CC ↑ | SIM ↑ | KL ↓ | IG ↓ | CC↑ | SIM ↑ | KL ↓ | IG ↓ | |
| VIRAT_09152008flight2tape1_3_crop1 | 0.50 | 0.48 | 7.17 | 1.53 | 0.46 | 0.48 | 6.85 | 1.62 |
| VIRAT_09152008flight2tape1_3_crop2 | 0.49 | 0.52 | 5.59 | 1.50 | 0.36 | 0.48 | 6.42 | 1.75 |
| VIRAT_09152008flight2tape1_3_crop3 | 0.46 | 0.43 | 8.46 | 1.91 | 0.37 | 0.43 | 7.98 | 1.99 |
| VIRAT_09152008flight2tape1_5_crop1 | 0.27 | 0.38 | 9.77 | 2.29 | 0.18 | 0.36 | 10.14 | 2.49 |
| VIRAT_09152008flight2tape1_5_crop2 | 0.42 | 0.44 | 8.05 | 1.90 | 0.30 | 0.45 | 7.41 | 1.87 |
| VIRAT_09152008flight2tape2_1_crop1 | 0.41 | 0.39 | 9.34 | 2.05 | 0.38 | 0.42 | 8.55 | 1.97 |
| VIRAT_09152008flight2tape2_1_crop2 | 0.40 | 0.35 | 10.90 | 2.50 | 0.32 | 0.42 | 8.01 | 2.01 |
| VIRAT_09152008flight2tape2_1_crop3 | 0.42 | 0.40 | 9.46 | 2.11 | 0.28 | 0.39 | 9.30 | 2.24 |
| VIRAT_09152008flight2tape2_1_crop4 | 0.36 | 0.36 | 10.35 | 2.34 | 0.28 | 0.38 | 9.79 | 2.30 |
| VIRAT_09152008flight2tape3_3_crop1 | 0.42 | 0.43 | 8.16 | 1.96 | 0.35 | 0.43 | 7.84 | 2.03 |
| VIRAT_09162008flight1tape1_1_crop1 | 0.47 | 0.45 | 7.76 | 1.80 | 0.37 | 0.42 | 8.40 | 2.00 |
| VIRAT_09162008flight1tape1_1_crop2 | 0.40 | 0.40 | 9.14 | 2.14 | 0.27 | 0.40 | 8.91 | 2.22 |
| UAV123_bike2 | 0.39 | 0.34 | 11.51 | 2.43 | 0.34 | 0.29 | 13.21 | 2.82 |
| UAV123_bike3 | 0.39 | 0.34 | 11.71 | 2.37 | 0.29 | 0.26 | 14.34 | 2.96 |
| UAV123_building1 | 0.40 | 0.37 | 10.64 | 2.18 | 0.32 | 0.31 | 12.74 | 2.69 |
| UAV123_building2 | 0.30 | 0.33 | 11.89 | 2.43 | 0.18 | 0.27 | 13.87 | 3.06 |
| UAV123_building3 | 0.27 | 0.34 | 11.50 | 2.42 | 0.17 | 0.32 | 11.82 | 2.56 |
| UAV123_building4 | 0.39 | 0.36 | 10.82 | 2.20 | 0.35 | 0.39 | 9.72 | 2.10 |
| UAV123_car11 | 0.37 | 0.32 | 12.37 | 2.58 | 0.21 | 0.30 | 12.68 | 2.67 |
| UAV123_car12 | 0.21 | 0.28 | 13.35 | 2.80 | 0.26 | 0.29 | 13.12 | 2.69 |
| UAV123_car13 | 0.30 | 0.34 | 11.48 | 2.39 | 0.20 | 0.33 | 11.50 | 2.44 |
| UAV123_car14 | 0.20 | 0.25 | 14.47 | 3.16 | 0.12 | 0.31 | 12.28 | 2.71 |
| UAV123_car15 | 0.31 | 0.34 | 11.52 | 2.47 | 0.10 | 0.30 | 12.70 | 2.81 |
| UAV123_car1 | 0.21 | 0.26 | 14.33 | 3.10 | 0.13 | 0.30 | 12.61 | 2.77 |
| UAV123_car2 | 0.22 | 0.27 | 13.91 | 3.02 | 0.13 | 0.30 | 12.68 | 2.80 |
| UAV123_car3 | 0.16 | 0.24 | 14.77 | 3.19 | 0.14 | 0.28 | 13.39 | 2.93 |
| UAV123_car4 | 0.22 | 0.20 | 16.27 | 3.55 | 0.20 | 0.24 | 14.76 | 3.23 |
| UAV123_car7 | 0.22 | 0.23 | 15.11 | 3.16 | 0.11 | 0.28 | 13.13 | 2.92 |
| UAV123_car9 | 0.26 | 0.23 | 15.41 | 3.27 | 0.21 | 0.28 | 13.69 | 2.86 |
| UAV123_person22 | 0.35 | 0.31 | 12.44 | 2.60 | 0.27 | 0.31 | 12.45 | 2.68 |
| UAV123_truck2 | 0.27 | 0.32 | 12.29 | 2.56 | 0.09 | 0.27 | 13.66 | 3.01 |
| UAV123_truck3 | 0.27 | 0.35 | 11.14 | 2.34 | 0.12 | 0.31 | 12.23 | 2.73 |
| UAV123_truck4 | 0.29 | 0.36 | 10.71 | 2.34 | 0.16 | 0.29 | 13.18 | 3.03 |
| UAV123_wakeboard8 | 0.23 | 0.21 | 15.91 | 3.45 | 0.11 | 0.24 | 14.93 | 3.29 |
| DTB70_Basketball | 0.38 | 0.27 | 14.13 | 2.89 | 0.30 | 0.31 | 12.30 | 2.59 |
| DTB70_Girl1 | 0.16 | 0.28 | 13.47 | 2.90 | 0.15 | 0.25 | 14.54 | 3.18 |
| DTB70_Girl2 | 0.20 | 0.20 | 16.04 | 3.60 | 0.19 | 0.23 | 15.04 | 3.34 |
| DTB70_ManRunning1 | 0.02 | 0.16 | 17.45 | 4.09 | 0.00 | 0.20 | 16.11 | 3.73 |
| DTB70_ManRunning2 | 0.12 | 0.13 | 18.40 | 4.31 | 0.10 | 0.15 | 17.99 | 4.24 |
| DTB70_Soccer1 | 0.21 | 0.26 | 14.23 | 3.04 | 0.17 | 0.26 | 14.03 | 3.18 |
| DTB70_Soccer2 | 0.21 | 0.22 | 15.56 | 3.33 | 0.22 | 0.32 | 11.86 | 2.69 |
| DTB70_StreetBasketball1 | 0.33 | 0.26 | 14.29 | 2.94 | 0.28 | 0.26 | 14.29 | 3.00 |
| DTB70_Walking | 0.29 | 0.20 | 16.14 | 3.51 | 0.27 | 0.22 | 15.81 | 3.51 |
| mean | 0.31 | 0.32 | 12.27 | 2.67 | 0.23 | 0.32 | 12.01 | 2.69 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perrin, A.-F.; Krassanakis, V.; Zhang, L.; Ricordel, V.; Perreira Da Silva, M.; Le Meur, O. EyeTrackUAV2: A Large-Scale Binocular Eye-Tracking Dataset for UAV Videos. Drones 2020, 4, 2. https://doi.org/10.3390/drones4010002
Perrin A-F, Krassanakis V, Zhang L, Ricordel V, Perreira Da Silva M, Le Meur O. EyeTrackUAV2: A Large-Scale Binocular Eye-Tracking Dataset for UAV Videos. Drones. 2020; 4(1):2. https://doi.org/10.3390/drones4010002
Chicago/Turabian StylePerrin, Anne-Flore, Vassilios Krassanakis, Lu Zhang, Vincent Ricordel, Matthieu Perreira Da Silva, and Olivier Le Meur. 2020. "EyeTrackUAV2: A Large-Scale Binocular Eye-Tracking Dataset for UAV Videos" Drones 4, no. 1: 2. https://doi.org/10.3390/drones4010002
APA StylePerrin, A.-F., Krassanakis, V., Zhang, L., Ricordel, V., Perreira Da Silva, M., & Le Meur, O. (2020). EyeTrackUAV2: A Large-Scale Binocular Eye-Tracking Dataset for UAV Videos. Drones, 4(1), 2. https://doi.org/10.3390/drones4010002