Joint Optic Disc and Cup Segmentation Using Self-Supervised Multimodal Reconstruction Pre-Training †




{kind=link}
Abstract
:1. Introduction
2. Methodology
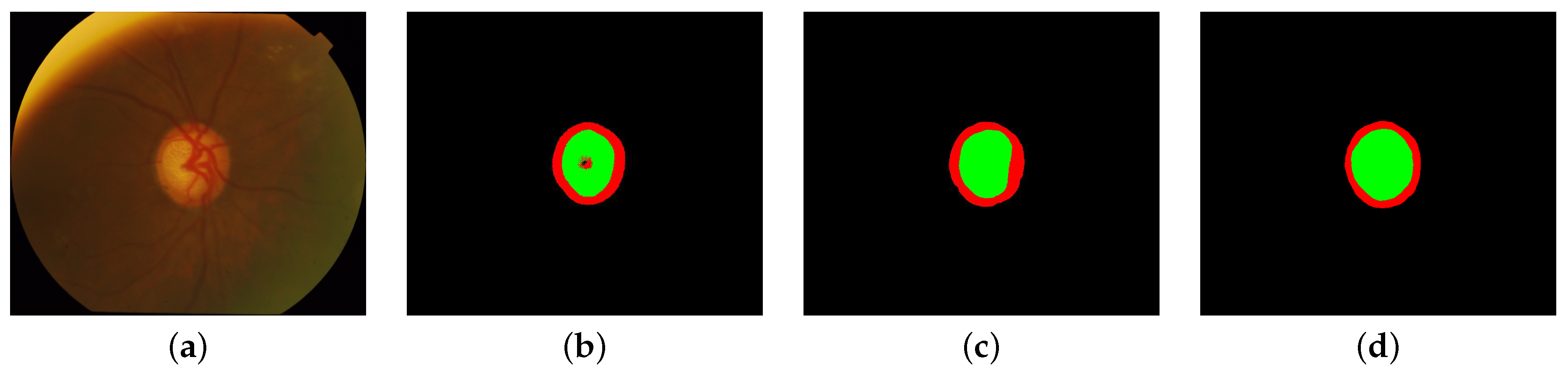
3. Results and Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Hervella, Á.S.; Ramos, L.; Rouco, J.; Novo, J.; Ortega, M. Multi-Modal Self-Supervised Pre-Training for Joint Optic Disc and Cup Segmentation in Eye Fundus Images. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 961–965. [Google Scholar] [CrossRef]
- Hervella, Á.S.; Rouco, J.; Novo, J.; Ortega, M. Learning the retinal anatomy from scarce annotated data using self-supervised multimodal reconstruction. Appl. Soft Comput. 2020, 91, 106210. [Google Scholar] [CrossRef]
- Hervella, Á.S.; Rouco, J.; Novo, J.; Ortega, M. Self-supervised multimodal reconstruction of retinal images over paired datasets. Expert Syst. Appl. 2020, 161, 113674. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hervella, Á.S.; Ramos, L.; Rouco, J.; Novo, J.; Ortega, M. Joint Optic Disc and Cup Segmentation Using Self-Supervised Multimodal Reconstruction Pre-Training. Proceedings 2020, 54, 25. https://doi.org/10.3390/proceedings2020054025
Hervella ÁS, Ramos L, Rouco J, Novo J, Ortega M. Joint Optic Disc and Cup Segmentation Using Self-Supervised Multimodal Reconstruction Pre-Training. Proceedings. 2020; 54(1):25. https://doi.org/10.3390/proceedings2020054025
Chicago/Turabian StyleHervella, Álvaro S., Lucía Ramos, José Rouco, Jorge Novo, and Marcos Ortega. 2020. "Joint Optic Disc and Cup Segmentation Using Self-Supervised Multimodal Reconstruction Pre-Training" Proceedings 54, no. 1: 25. https://doi.org/10.3390/proceedings2020054025
APA StyleHervella, Á. S., Ramos, L., Rouco, J., Novo, J., & Ortega, M. (2020). Joint Optic Disc and Cup Segmentation Using Self-Supervised Multimodal Reconstruction Pre-Training. Proceedings, 54(1), 25. https://doi.org/10.3390/proceedings2020054025