1. Introduction
Nowadays, knowledge is the driver for development in any context. It has become the most important strategic factor in corporate operations [
1] because it is associated with the capabilities of companies to achieve a competitive advantage [
2,
3]. Within an organization, knowledge is not only electronic or printed documents; the employees’ own knowledge and the implicit knowledge within the organization’s processes are part of the assets related to knowledge [
4].
Knowledge management is one of the key priorities of institutions and companies; they invest significant resources in developing their capacity to share, create, and apply new knowledge to improve both their internal and external business processes [
5]. On the other hand, according to Davenport et al. [
6], the implementation of knowledge management processes within an organization could be expensive, meaning that not all organizations have the capability and the resources to profit from their knowledge.
These aims and problems are present in any organization, but gain importance when the organization is part of the healthcare system. In this context, knowledge management processes affect not only patients and their relatives directly or indirectly, but also healthcare professionals. In particular, there is a need to improve knowledge management processes related to dependent persons owing to the aging of the population, with a special emphasis in developed countries. The number of persons over 60 years is growing faster than all younger age groups [
7], and these numbers have an impact on the cost of care and the resources needed for this population.
From a technological point of view, technological ecosystems have emerged as a solution focused on improving knowledge management in a heterogeneous context. They provide a general framework that allows defining and developing any type of technological solution in which data and information are the backbone of the problem [
8,
9,
10]. In particular, they can be employed to manage knowledge related to patients with cognitive and physical impairments, in addition to the people involved in their care, with a particular focus on their caregivers, both formal (professionals that provide care to patients) and informal (persons that provide care to patients).
Technological ecosystems can combine different software components with a set of human elements, such as methodologies or management workflows. In previous works, a technological ecosystem for supporting informal caregivers has been proposed [
11,
12]. Among the software components, a dashboard is proposed. Dashboards are one of the most useful tools for generating knowledge about certain domains. Information dashboards allow the identification of patterns, outliers, relationships, and so on, fostering insight delivery through visual analysis [
13,
14].
However, dashboards need to be adapted to their audience [
15], to specific data domains, and to the tasks that will be performed to analyze these data, among other factors. The main reason is that there is not a “one-size-fits-all” when referring to dashboards; users have different mental models [
16], goals, experience, literacy, domain knowledge, and so on [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26], making the design process of a dashboard a complex task, where the elicitation of requirements can be seen as the backbone process, as it will drive the subsequent phases and design decisions.
Although a complex process, the development of a tailored dashboard has huge benefits; if the dashboard is developed for a specific user and a specific dataset, it will match the identified necessities, making the dashboard more effective, comfortable, and usable for the user, thus fostering the generation of knowledge and properly supporting the user’s decision-making processes.
However, in order to deliver tailored dashboards without consuming significant amounts of resources and time, this process must be automatized. By automatizing and creating a pipeline for generating dashboards, the complexity of matching particular requirements can be reduced, delivering effective dashboards adapted to a specific context (data, users, goals, and so on) in less time.
There are different methods to ease the adaptation of these tools to concrete contexts: configuration wizards (where the users can customize or build their dashboards through explicit interactions) [
27], agents that retrieve user behaviour data and reconfigure the display accordingly [
28], configuration files that hold the specific requirements and are rendered into a properly configured dashboard [
29,
30], and so on. However, one of the most powerful methods to enable the generation of concrete products given a set of requirements is model-driven engineering [
31]. Model-driven paradigms leverage high-level models for instantiating concrete models. Therefore, abstracting the features of dashboards into a set of common characteristics can support a generative process through model mappings and instantiations of concrete dashboard products.
One of the main benefits of using a dashboard meta-model is the possibility of instantiating dashboards adapted to different contexts through a single artifact, not only fostering reuse at development phases, but also allowing knowledge reuse. This characteristic is very useful in the healthcare context; the technological ecosystem mentioned above should adapt to different healthcare scenarios, such as hospitals, nursing homes, or health centers.
The present work aims to define a dashboard based on the meta-model to support caregivers in order to be included in the eHealth technological ecosystem for caregivers.
The rest of the paper is organized as follows.
Section 2 describes the methodology used to instantiate the dashboard from the meta-model.
Section 3 presents the meta-model to define information dashboards.
Section 4 describes the architecture of the technological ecosystem in which the dashboard will be included.
Section 5 presents the dashboard for supporting caregivers. Finally,
Section 6 summarizes the main conclusions of this work.
2. Methodology
Model-driven development (MDD) allows separating the data and the operations specification of the system from the technical details related to a specific program language or platform. The object management group (OMG) provides the model-driven architecture (MMA) as a proposal to implement MDD. It provides a framework for software development that uses models to describe the system to be built [
32]. The main difference between MDD and MDA is that the OMG proposal uses a set of standards such as meta-object facility (MOF), unified modeling language (UML), XML (Extensible Markup Language) metadata interchange (XMI), and query/view/transformation (QVT).
The dashboard meta-model and the healthcare dashboard model are part of the four-layer meta-model architecture provided by the OMG, in which a model at one layer is used to specify models in the layer below [
33]. In particular, the dashboard meta-model is an instance of MOF (i.e., an M2-model), and the healthcare dashboard is a model instantiated from this meta-model (i.e., an M1-model). The M0-model is not used because the implementation is not the object of study of the present work.
The healthcare dashboard is part of the technological ecosystem for caregivers, which is based on a meta-model defined and validated in previous works. The first version of the ecosystem meta-model is based on MOF, and the last validated version is an instance of Ecore [
34]. Both versions are M2-models, and the model of the technological ecosystem for caregivers is an M1-model [
12]. The model has served as a map to develop and deploy the ecosystem in a real context. The C4 model was used to represent the architecture of the final system. The C4 model was inspired by the UML and the 4+1 model for software architecture. It is a simplified version of the underlying concepts, designed to make it easier for software developers to describe and understand how a software system works and to minimize the gap between the software architecture description and the source code [
35].
3. Dashboard Meta-Model
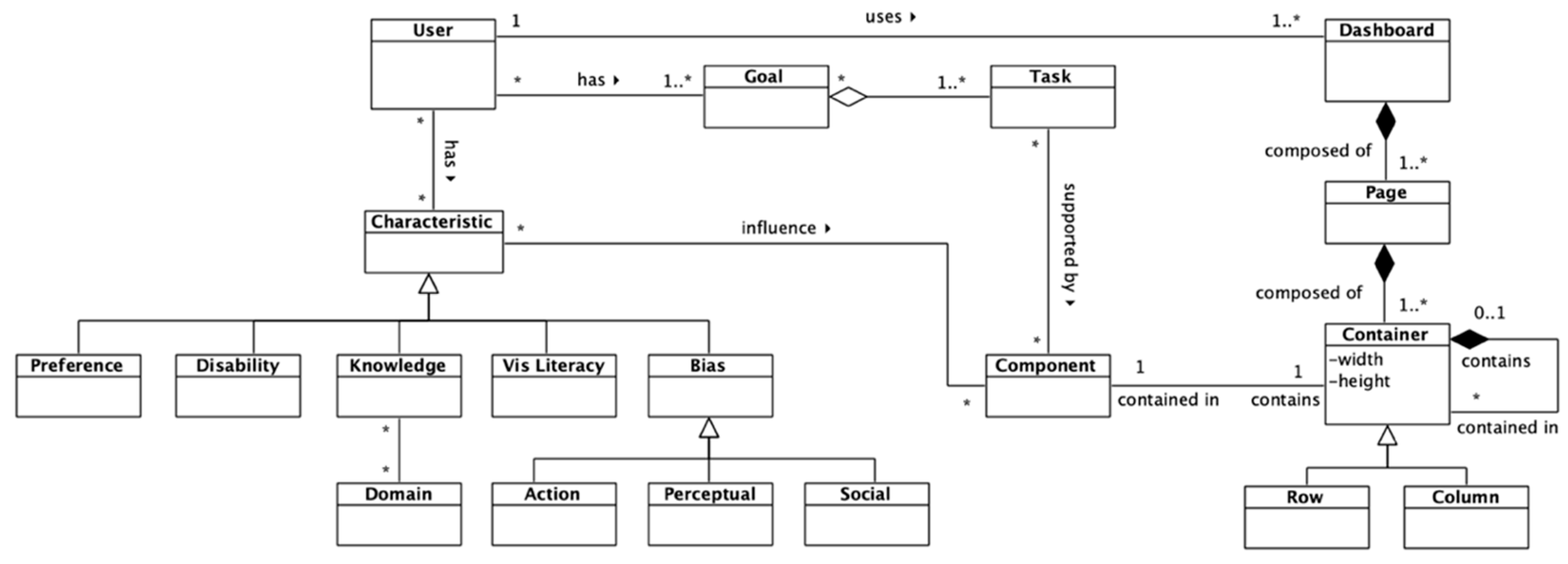
The dashboard meta-model was elaborated on, taking into account three main dimensions or elements: the user, the layout, and the components. The whole personalization process must be driven by end-users; this is why this entity is included in the meta-model. The characteristics that a user has (preferences, disabilities, knowledge about the displayed data’s domain, visualization literacy, and bias) influence the dashboard components to match specific necessities.
On the other hand, users have a series of goals that they will try to accomplish through the information displayed on the dashboards. Goals can be decomposed into different low-level tasks, and the selected dashboard components must support the identified tasks to help users reach their goals (
Figure 1). For more detail regarding this section of the meta-model, please refer to the work of [
36].
The purpose of the layout section of the dashboard is to model the generic structure of a dashboard. Dashboards can be composed of different pages, with different containers (rows or columns) that hold different components. This can be seen in the right section of
Figure 1.
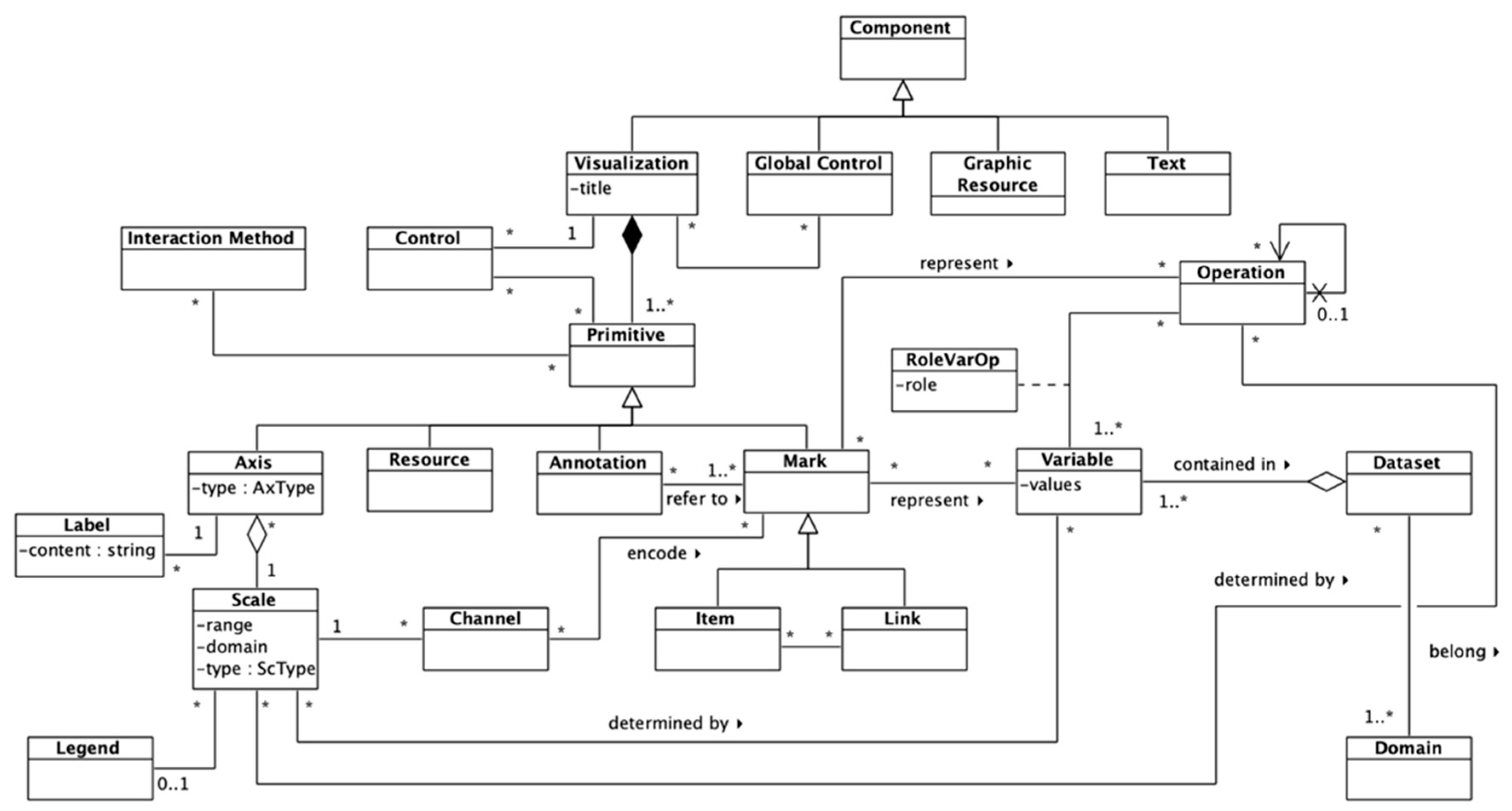
Regarding the components of the dashboard, several elements were identified. The main components of dashboards are the information visualizations that present the data, although dashboards can also contain controls (handlers, filters, and so on), graphic resources, or text. A visualization can be affected by global controls, as well as by “local” controls, that is, controls that only affect a single visualization.
The Primitive class is a high-level class that encompasses basic elements for composing visualizations. These elements can be axes, annotations, marks, and resources (images, text, and so on). Interaction methods and local controls can modify these primitives to enable drill-down. Axes contain information about the scales, and thus about some channels that can influence a visual mark. An axis is always associated to a scale, and a single axis cannot represent more than one scale at once; however, a scale can be represented in several axes, if providing redundant information is necessary, for example.
On the other hand, there are popular terms to refer to data elements, but the most used among the literature are “marks” and “visual channels” or “visual encodings” [
27,
37,
38,
39]. Marks can be of two types: items or links. While items represent nodes, points, and so on, links represent connections, containments, and so on, among items [
39]. Marks can hold not only raw information about data variables, but also about the results of operations, following the PTAH meta-model presented in the work of [
40]. Different channels can be used to encode data values visually.
Channels are associated with a scale, which maps a variable’s or operation’s values to specific channel values, modifying the properties of visual marks (position, color, opacity, size, and so on). The RoleVarOp association class models the role of a variable within an operation. Also, a recursive relationship in the Operation class was included to support potential chained operations.
Finally, datasets can be related to different domains. This
Domain class is connected to the previously described
Knowledge meta-class shown in
Figure 1 (user section of the meta-model). This association captures the familiarity or understanding that a user can have regarding the data being displayed on the dashboard.
The dashboard meta-model presented in
Figure 1 and
Figure 2 is connected to the ecosystem meta-model (available
https://doi.org/10.5281/zenodo.1066369). The ecosystem meta-model does not represent each software component in detail; it only provides a high-level abstraction of the ecosystem, in which software components are represented as black boxes. The dashboard, although it is one of the most important elements of a knowledge management ecosystem, is one of these black boxes because of its complexity. The dashboard meta-model provides the required details to model that part of the ecosystem. These details, however, are still at a M2-level following the OMG’s four-layer architecture, because the dashboard meta-model is an instance of MOF (although the dashboard meta-model and the learning ecosystem meta-model are at different abstraction levels).
Moreover, some elements in the dashboard meta-model connect this proposal with the ecosystem meta-model. First, the users are an important part of both meta-models, the human factor has an important role, and the technology is defined and evolved to support their needs. On the other hand, the Goals in the dashboard meta-model are represented as Objectives in the ecosystem meta-model. These elements are translated into Information Flows as a way to model the interactions among components in the ecosystem meta-model, and into Tasks in the dashboard meta-model, as a way to define which components will be available in the dashboard and which interactions they will provide.
4. Healthcare Ecosystem for Caregivers
The aim of the technological ecosystem for caregivers is to support the learning and knowledge management processes to develop and enhance the caregiving competences both at home and in care environments of formal and informal caregivers [
12]. In particular, the ecosystem allows providing psychoeducation [
41] to dependent persons and informal caregivers in order to alleviate the physical and mental health problems that they suffer, such as work overload, depression, or anxiety.
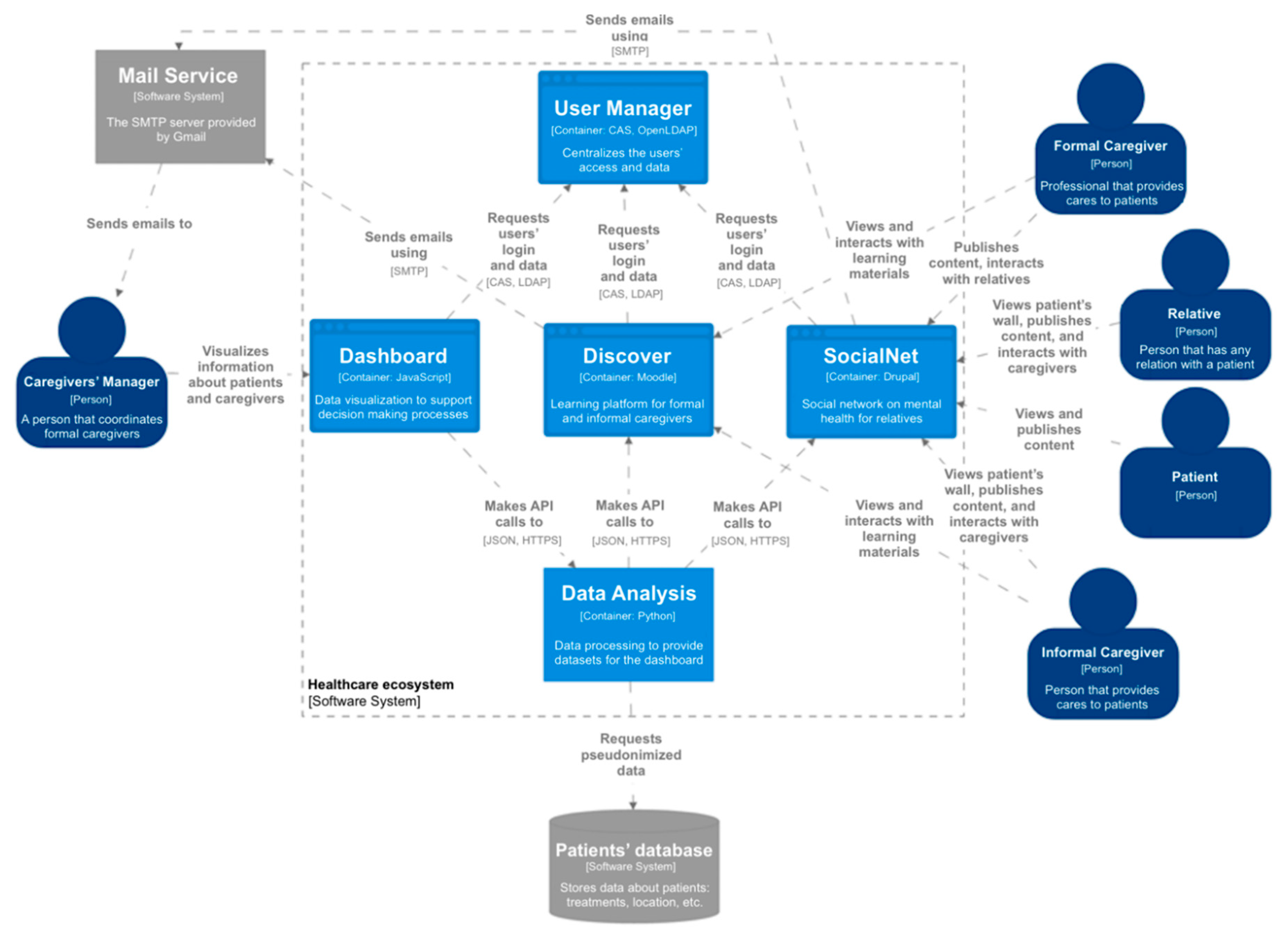
The ecosystem makes it possible to provide remote access to different services. It is composed of a set of software components (
Figure 3) and is based on a set of management and methodological input streams—a business plan, a training plan, and a medical protocol. First, it provides remote teaching–learning environments to support both informal and formal caregivers. Through
Discover, psychoeducation is accessible to these profiles, so they can obtain answers to the questions that arise daily during their care duties and psychological support, as well as information, advice, and guidance.
Second,
SocialNet is an online tool that provides a private social network composed of a set of private and safe areas, called walls, for each patient [
42]. The main users are the relatives of the patients and their caregivers. In some cases, patients can also access
SocialNet to publish their activities and view the contents published by their caregivers and relatives. Finally, the caregivers’ managers can access the social network, but only to manage which caregivers control a patient’s wall (this relationship is not represented in
Figure 3 to avoid lines crossing the whole system).
Third, the dashboard is a tool to support decision-making processes. In particular, it is focused on supporting caregivers’ managers to make decisions about the workload of the caregivers, as well as the activity of the patients based on the insights from the different components of the ecosystem.
Moreover, two software components provide support to other components, the User Manager that centralizes the users’ data management and the access, and a tool to support the analysis of the data from Discover, SocialNet, and an external database with medical and personal information about the patients. The Data Analysis Support provides the datasets for the dashboard component.
5. Dashboard for Supporting Caregivers
Technological ecosystems support decision-making processes based on the knowledge created or transformed into the different components of the ecosystem. In the healthcare ecosystem, these processes should be supported in order to improve the physical and mental health problems of the caregivers, both formal and informal, and the patients with cognitive and physical impairments.
One of the main goals of information dashboards is to facilitate decision-making processes. In particular, it is important to facilitate these processes to caregivers’ managers. Moreover, the data generated from the different software components and the patients’ database should be processed in a way that it is understandable by the managers. Visualizations adapted to the skills of the caregivers’ managers can provide useful information to support the decisions related to patients and caregivers. The visual analysis allows the identification of patterns, outliers, relationships, and so on.
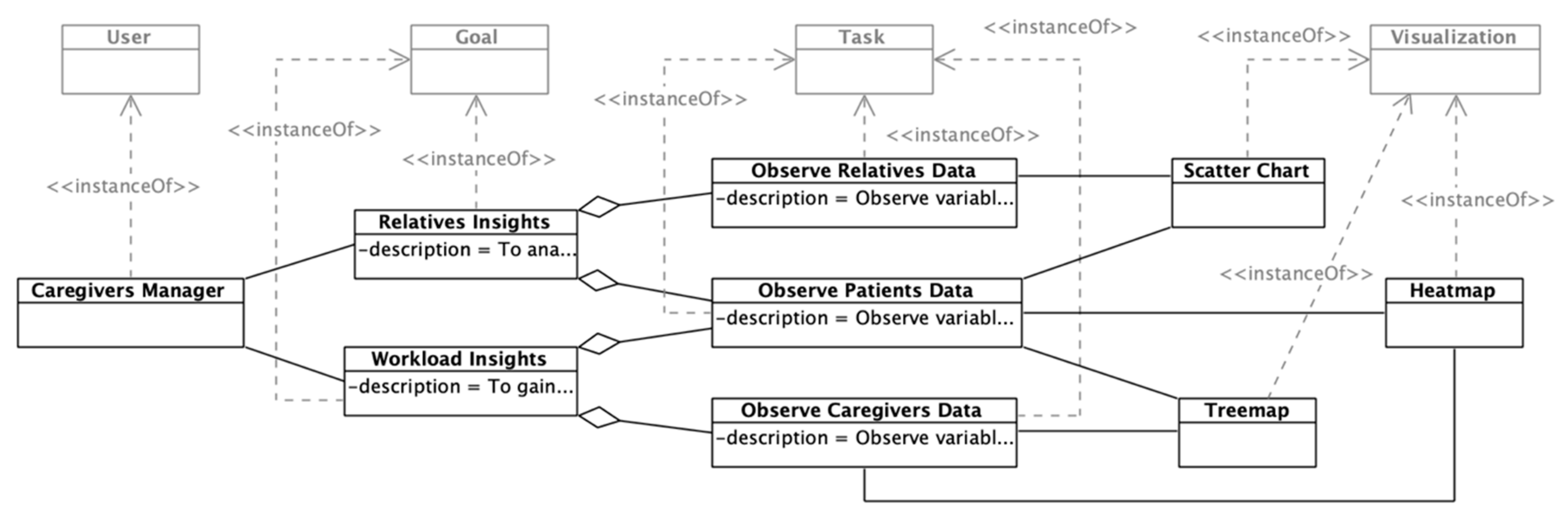
A series of goals have been extracted from the caregivers’ manager profile that will be addressed in this case study. Caregivers’ managers have a series of objectives regarding the analysis of the collected data. These requirements can be classified into two main goals: insights about the patients’ relatives and insights about the workload of the caregivers. The generated knowledge from the obtained insights can support decision-making regarding the distribution of caregivers to reduce workload and the impact of the patients’ relatives on their healthcare.
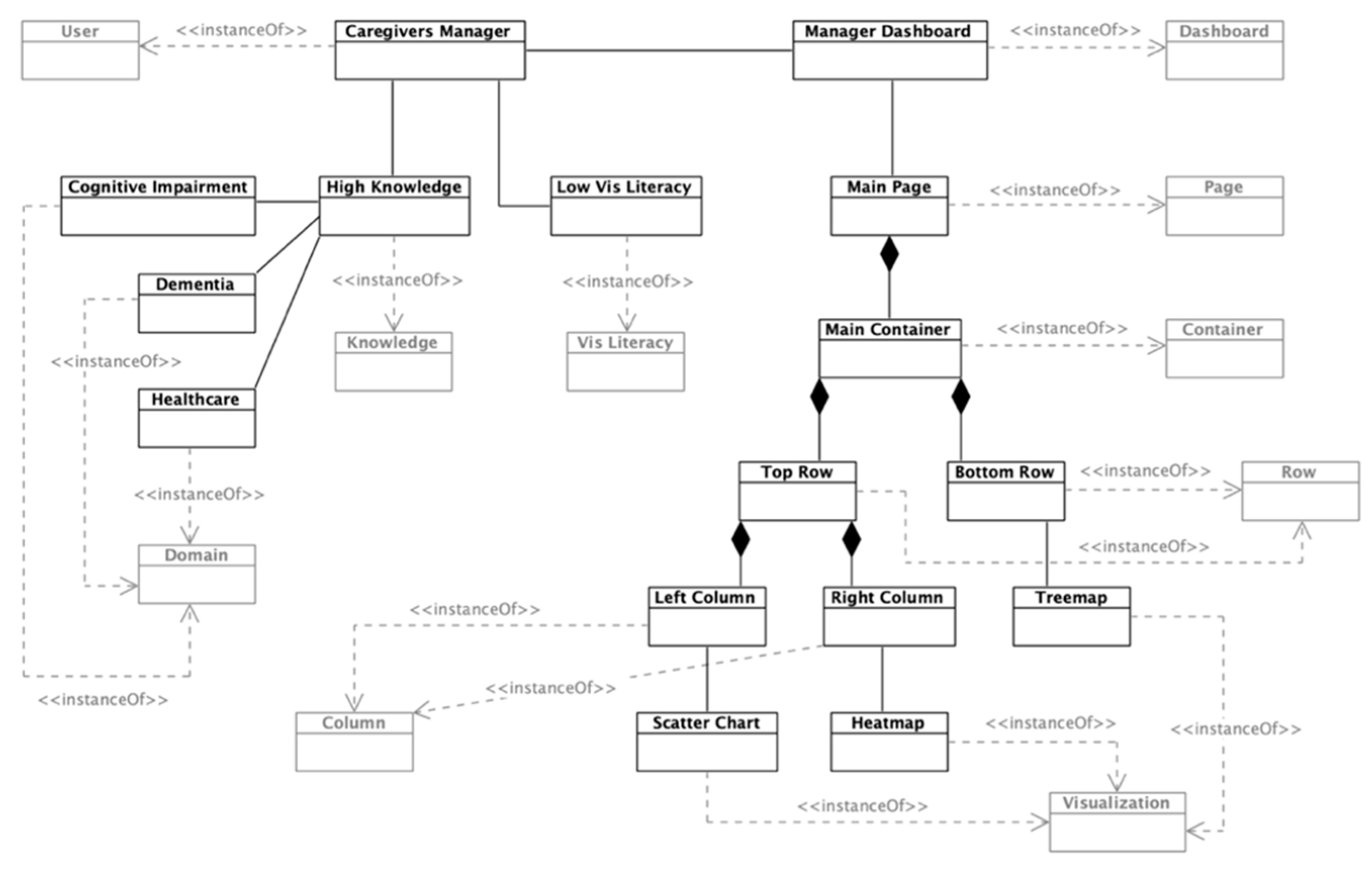
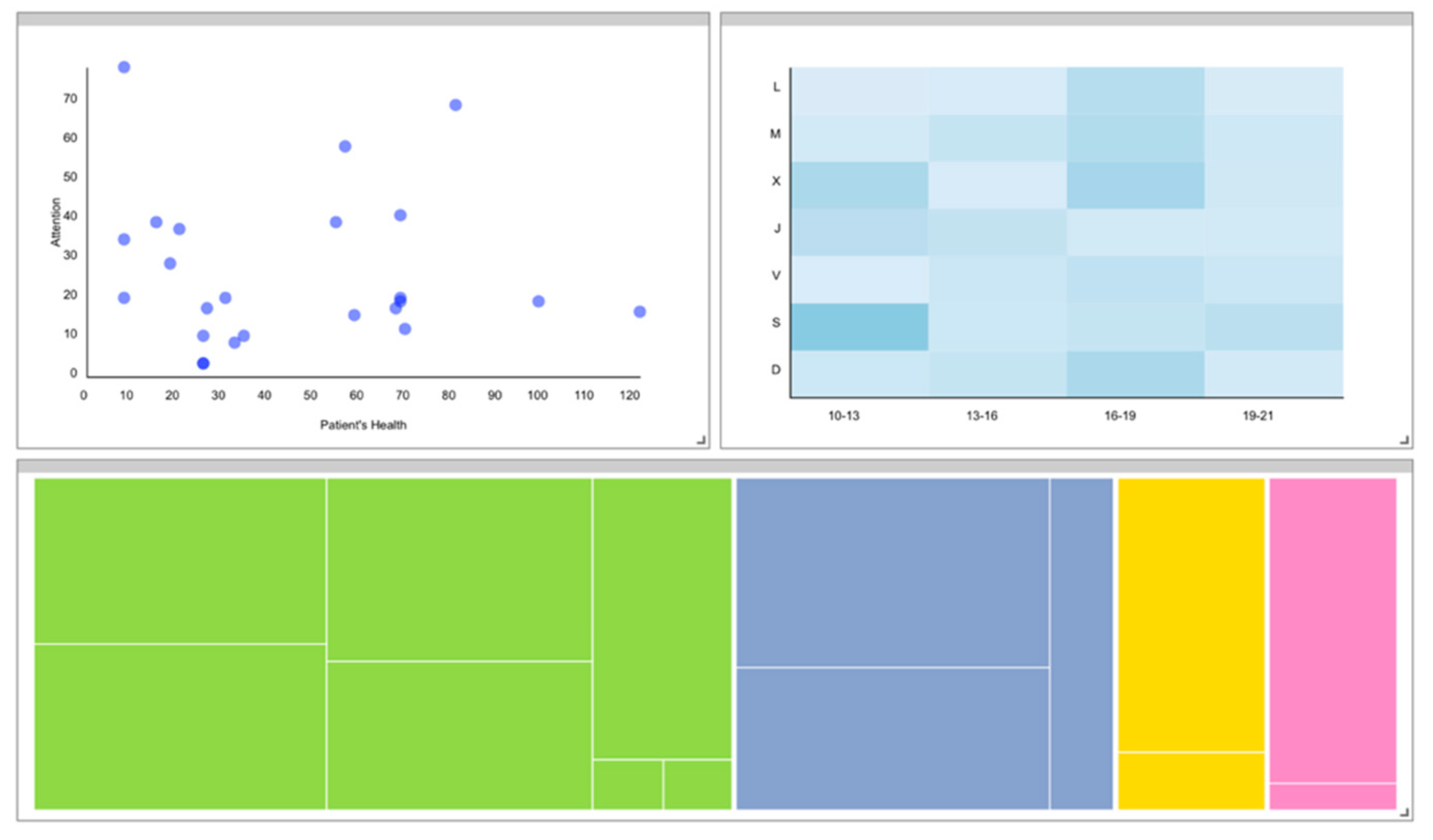
Figure 4 shows the instantiation of the meta-model’s section that addresses the users’ goals. On the one hand, the first goal regarding relatives has the following description: “To analyze the relationship between the attention given by relatives and the patient’s health”. In this case, relatives (i.e., persons that have any kind of relationship with the patient) are the targets of the analysis. Two lower-level tasks arise to achieve that goal; that is, observe the relatives’ data and observe the patients’ data. Given the fact that the goal asks for “analyzing a relationship”, a dashboard component must support the mentioned tasks to enable managers to obtain insights. The selected component is a scatter chart that will be detailed later.
On the other hand, it is necessary to provide support to the second goal: “To gain insights about the workload of the caregivers”. The workload can be visualized in different ways and can involve different variables. In this case, two components were selected to support the second goal: a heat map and a treemap, to let managers identify patterns or relevant data points regarding the caregivers’ distribution along time and among patients.
Moreover, the caregiver manager profile has the following characteristics: high domain knowledge about the context (i.e., healthcare, dementia, and cognitive impairment). This profile also has low visualization literacy, which, along with the domain knowledge, will influence the selection of proper components and features for the dashboard, as reflected in the meta-model.
As this case study is focused on a user profile (and not on an individual user), preferences, bias, and disabilities are not considered, because they are very personal data that cannot be generalized into a unique profile. However, these characteristics would have the same influencing role on the dashboard as the domain knowledge and visualization literacy. The user profile instance can be seen in
Figure 5.
Using the identified characteristics and goals, a “Manager Dashboard” was instantiated. This dashboard consists of a page with two rows, with the top one containing two columns. These specific containers hold the components, in this case, the three aforementioned visualizations: a scatter chart, a heat map, and a treemap. The dashboard layout and the location of the visualizations are given by the structure and space available for the components. Finally, each visualization can be decomposed on primitives that support the introduced requirements.
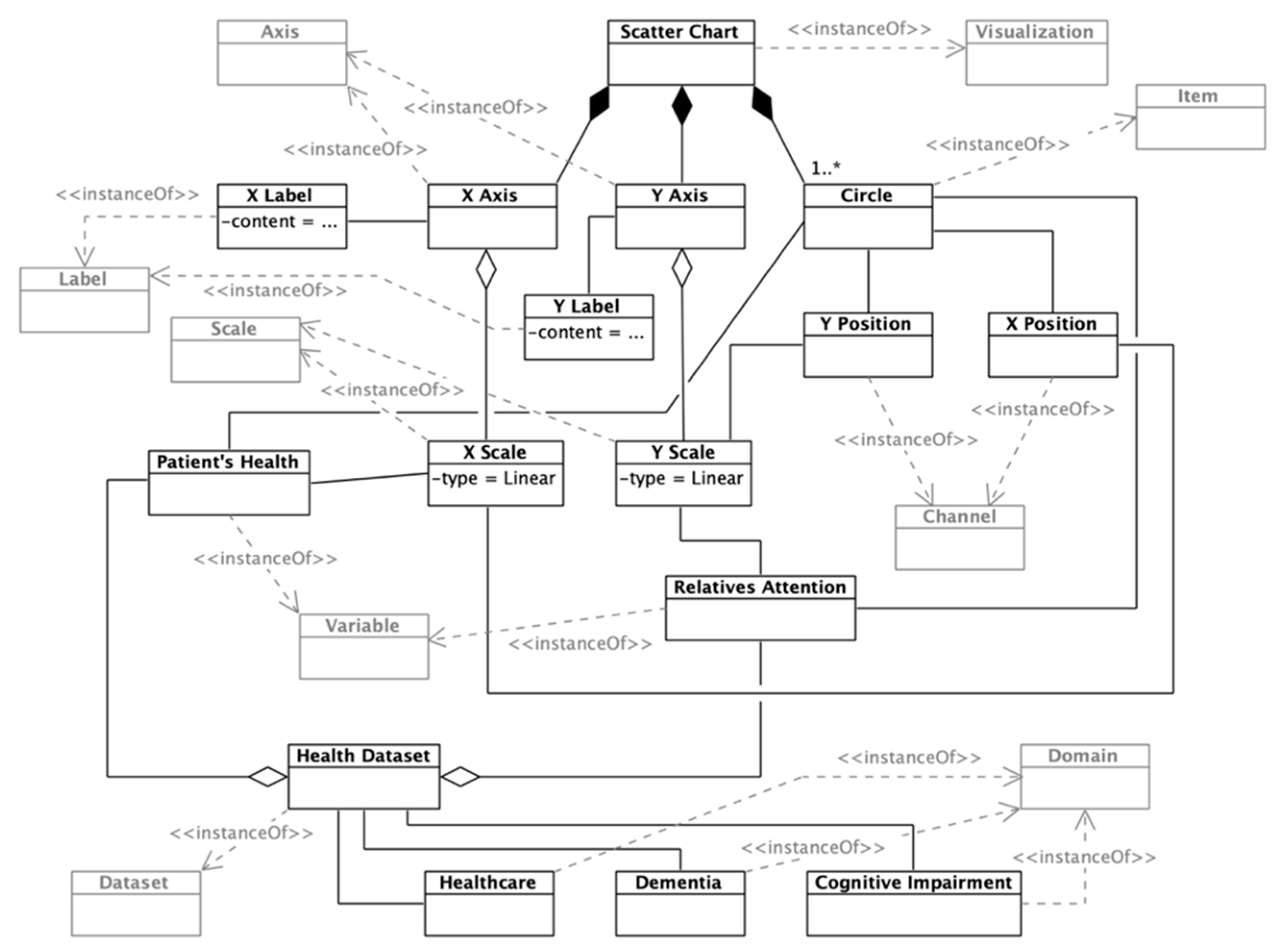
First, a scatter chart can be composed of different primitives that will hold different data dimensions encoded through different channels (
Figure 6). In this case, two data variables will be encoded through the scatter chart: the patient’s health and the patient’s given attention (by his/her relatives). These two variables are encoded through two linear scales that will position each data point (circles) within the visualization container. The scales are visible through two axes: the
X-Axis and
Y-Axis. Each axis has a label to ease the readability of the visualization.
The two represented variables are part of a health dataset, which belongs to three main domains: Healthcare, Dementia, and Cognitive Impairment. This visualization enables caregivers’ managers to obtain insights about the relationship between the patients’ health and their attention levels given.
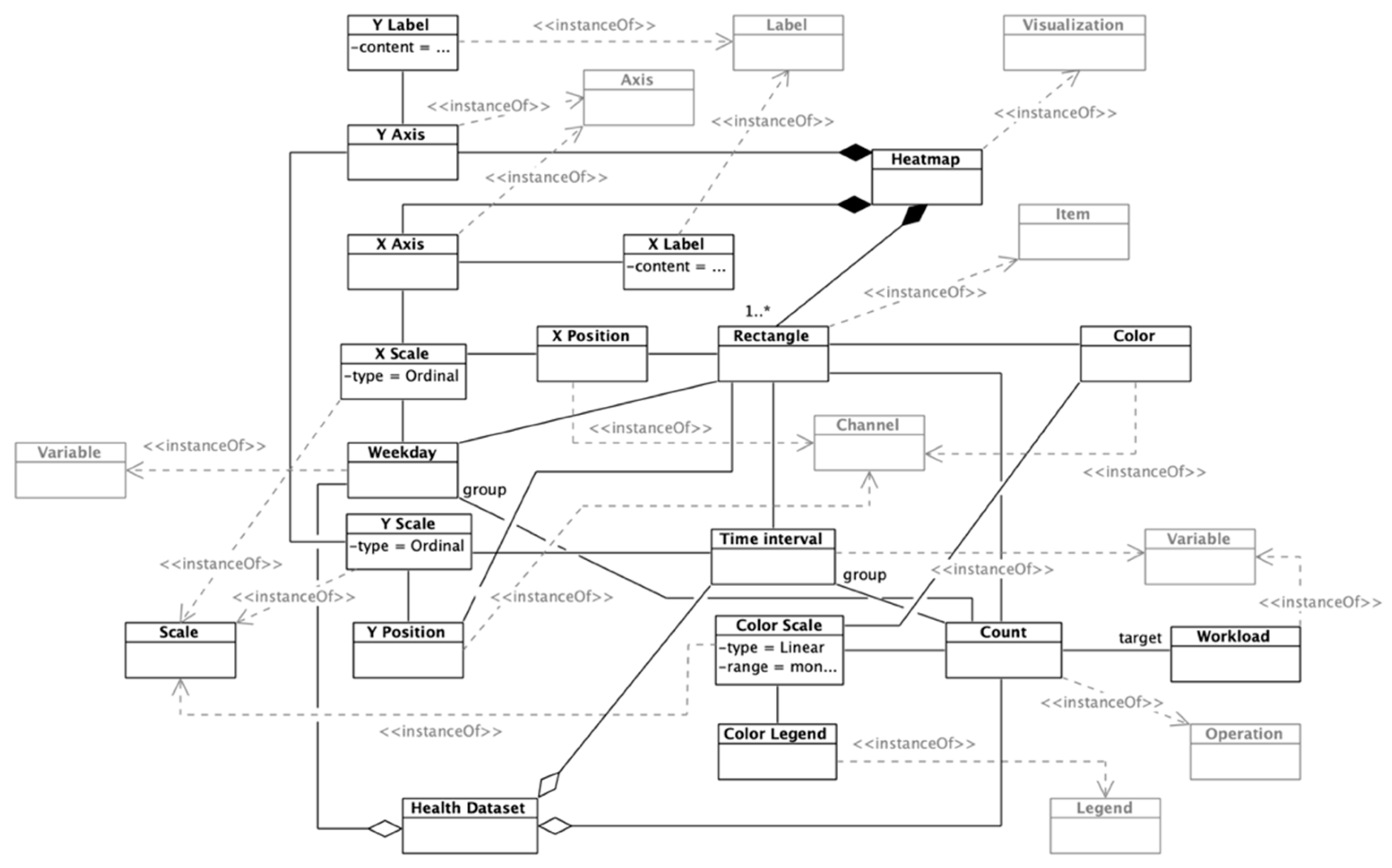
The next visualization is a heat map (
Figure 7). The instantiated heat map is composed of a series of cells (rectangles, in this case) positioned by two categorical scales (weekday and time interval). The actual workload is encoded by a monochromatic color scale that would be more intense if the workload is high, and less intense if the workload is low, so each rectangle has three channels: X and Y positions and color. The color scale is associated with a legend to increase the readability of the visualization. The color encoding values are the outcome of an operation, more specifically, an aggregation (count) of the workload variable by weekday and time interval, obtaining the total workload for each individual cell of the heat map. This visualization allows the recognition at first sight of the days and time intervals in which the workload is higher, and enables the manager to make decisions about the distribution of caregivers to improve efficiency.
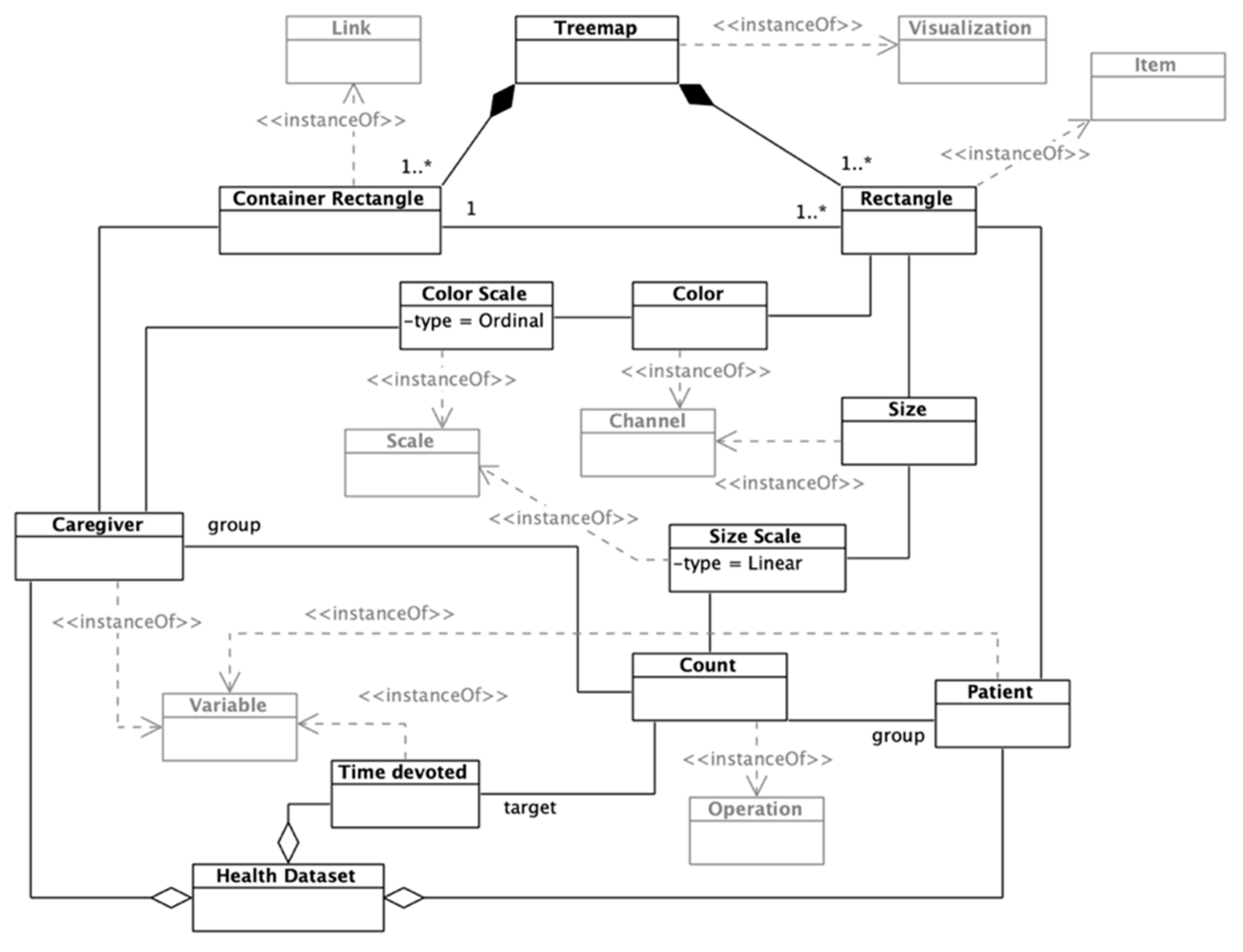
Finally, the treemap component would hold information about the patients assigned to each caregiver (
Figure 8). The caregivers’ workload regarding patients is encoded through rectangles, the size of which varies depending on the quantity of time devoted to each patient. These data are obtained by grouping the time devoted variable by caregiver and patient, performing a
Count operation. Each rectangle’s color also encodes the caregiver in charge of the patient.
The mentioned rectangles are enclosed within a container rectangle that represents each caregivers’ patients. The container rectangle is an instance of a
Link mark, which allows encoding containment and connection relationships among visual items [
39]. The instantiated treemap encodes the workload-by-patient of each caregiver, supporting managers in analyzing how to balance each caregiver’s workload without reducing patient care.
To provide a visual example of how the instantiated dashboard would look, a simple dashboard following the described structure and features was implemented (
Figure 9).
6. Conclusions
Technological solutions are used in the medical area not only to support the daily activities in health organizations, but also to improve treatments. In particular, there is a need to improve the support received by informal and formal caregivers and dependent persons at their homes. The proposed ecosystem aims to provide a set of services to prevent the institutionalization of the dependent persons, enabling them to stay at home and thus reducing care costs. The ecosystem offers psychoeducation tools to caregivers and provides tools to involve relatives in the patients’ daily life.
The dashboard for supporting caregivers is part of the healthcare ecosystem. It aims to provide tools based on visual analysis to support decision-making processes related to the workload of caregivers and the situation of the patients. The dashboard should be adapted to the different needs of its users. Furthermore, the medical contexts in which the ecosystem could be implemented are very different, so the ecosystem should be adapted to these different contexts.
The dashboard meta-model provides a “template” for generating concrete dashboard solutions. This meta-model was instantiated to obtain a concrete model for the presented context; that is, healthcare. Three visualizations were selected and instantiated to support the caregivers’ managers’ goals and decisions with data.
The meta-model supports the instantiation of fine-grained features regarding visualizations by distinguishing basic primitives that can be combined to build any type of chart. The meta-model structure makes possible any combination of marks, axes, annotations, resources, and so on, avoiding the necessity of relying on pre-defined charts, thus allowing more freedom when building custom visualizations for certain dashboards.
Introducing the user in the meta-model is essential, as their information goals are the backbone of the design processes. Characteristics including biases, literacy, preferences, disabilities, and so on, however, should also be considered to ensure that the dashboard is developed, taking into account different users’ dimensions that could influence their user experience. As has been shown, the users’ characteristics and goals were crucial to select appropriate visualizations and encodings. Future research lines will involve the refinement of the meta-model through the addition of constraints, rules, and design guidelines, seeking the support of the automatic generation of concrete dashboards.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








