A Study on the Behavior of Clustering Techniques for Modeling Travel Time in Road-Based Mass Transit Systems †


Abstract
:1. Introduction
2. Related Works
3. Methodology
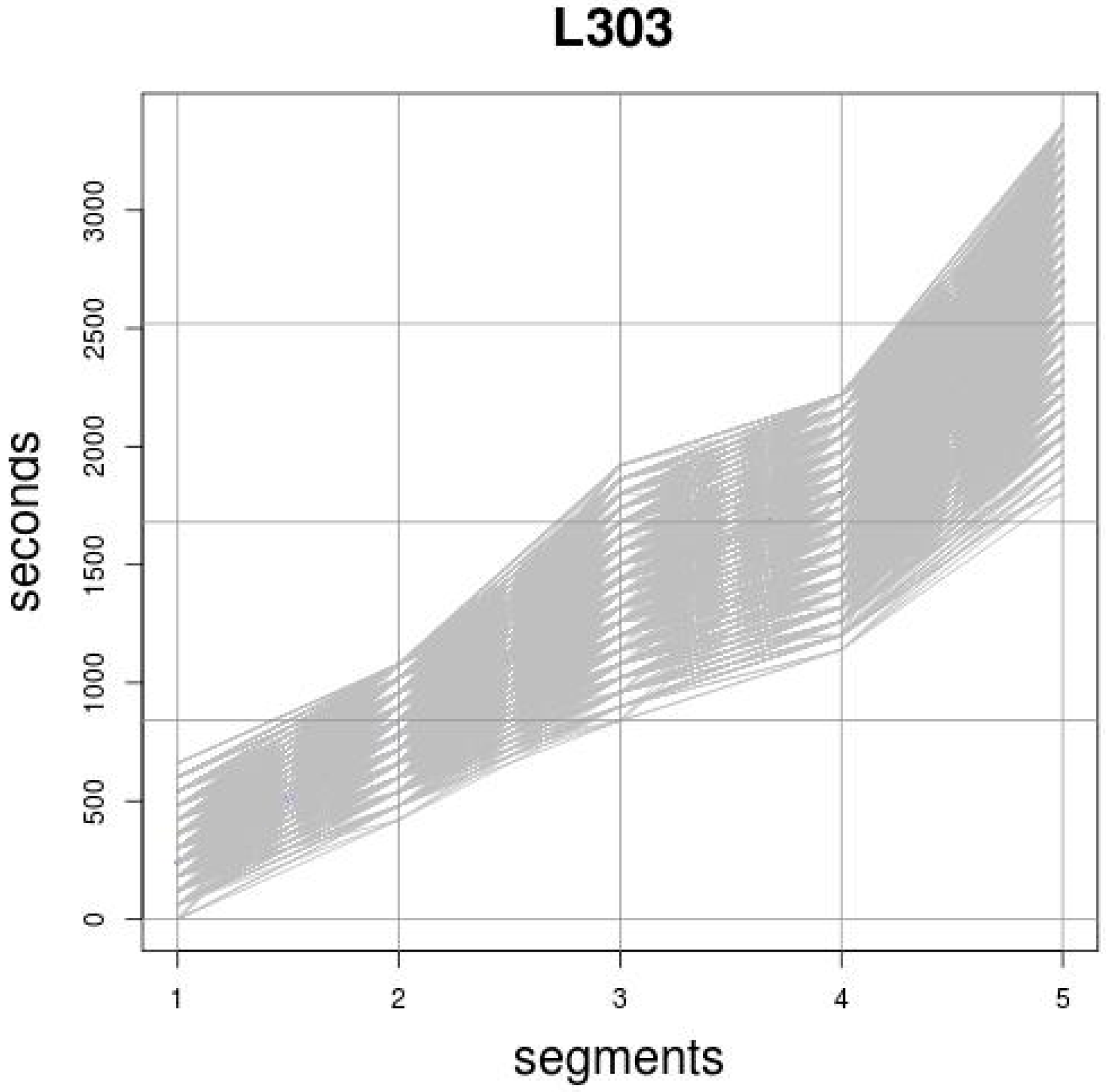
3.1. TT conceptualization
3.2. Representation of the TT
3.3. Clustering Techniques
- Techniques based on partitioning the set of observations into several clusters initially specified.
- Hierarchical techniques, in which it is not necessary to specify the number of clusters.
- Methods combining the above techniques.
3.4. Phases of the Methodology
- Phase 1. Given a route and a period, generate the whole EL,T from coherent and quality positioning records of the expeditions carried out in that period.
- Phase 2. Creation of the clusters, applying each of the clustering techniques indicated to the EL,T set, and selection of the optimum number of clusters.
- Phase 3. Representation of results to evaluate the new information obtained.
- Phase 4. Analysis of the results obtained.
4. Results and Discussion
4.1. Phase 1: Generation of the set EL,T
4.2. Phase 2: Creation of the Clusters and Determination of Their Optimum Number
4.3. Phase 3: Results Representation
4.4. Phase 4: Analysis of Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Wang, F.; Wang, K.; Lin, W.; Xu, X.; Chen, C. Data-driven intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2011, 4, 1624–1639. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Mendes-Moreira, J.; de Sousa, J.F.; Gama, J. Improving Mass Transit Operations by Using AVL-Based Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1636–1653. [Google Scholar] [CrossRef]
- Yu, B.; Yang, Z.; Yao, B. Bus Arrival Time Prediction Using Support Vector Machines. J. Intell. Transp. Syst. 2007, 10, 151–158. [Google Scholar] [CrossRef]
- Bai, C.; Peng, Z.-R.; Lu, Q.-C.; Sun, J. Dynamic Bus Travel Time Prediction Models on Road with Multiple Bus Routes. Comput. Intell. Neurosci. 2015, 2015, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Gurmu, Z.K.; Nall, T.; Fan, W. Artificial Neural Network Travel Time Prediction Model for Buses Using Only GPS Data. J. Public Transp. 2007, 17, 45–65. [Google Scholar] [CrossRef]
- Chang, H.; Park, D.; Lee, S.; Lee, H.; Baek, S. Dynamic multi-interval bus travel time prediction using bus transit data. Transportmetrica 2010, 6, 19–38. [Google Scholar] [CrossRef]
- Gal, A.; Mandelbaum, A.; Schnitzler, F.; Senderovich, A.; Weidlich, M. Traveling time prediction in scheduled transportation with journey segments. Inf. Syst. 2017, 64, 266–280. [Google Scholar] [CrossRef]
- Lee, W.-C.; Si, W.; Chen, L.-J.; Chen, M.C. http: A New Framework for Bus Travel Time Prediction Based on Historical Trajectories. In Proceedings of the International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL GIS 2012), California, CA, USA, 6–9 November 2012. [Google Scholar] [CrossRef]
- Mendes-Moreira, J.; Mario Jorge, A.; Freire de Sousa, J.; Soares, C. Comparing state-of-the-art regression methods for long term travel time prediction. Intell. Data Anal. 2012, 16, 427–449. [Google Scholar] [CrossRef]
- Comi, A.; Nuzzolo, A.; Brinchi, S.; Verghini, R. Bus travel time variability: Some experimental evidences. Transp. Res. Procedia 2017, 27, 101–108. [Google Scholar] [CrossRef]
- Yetiskul, E.; Senbil, M. Public bus transit travel-time variability in Ankara (Turkey). Transp. Policy 2012, 23, 50–59. [Google Scholar] [CrossRef]
- Bie, Y.; Gong, X.; Liu, Z. Time of day intervals partition for bus schedule using GPS data. Transp. Res. Part C 2015, 60, 443–456. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Partitioning around medoids (program PAM). In Finding Groups in Data Finding Groups in Data: An Introduction to Cluster Analysis; Kaufman, L., Rousseeuw, P.J., Eds.; Wiley: Hoboken, NJ, USA, 2009; pp. 68–125. [Google Scholar] [CrossRef]
- Kumar-Patnaik, A.; Kumar-Bhuyan, P.; Krishna-Raob, K.V. Divisive Analysis (DIANA) of hierarchical clustering and GPS data for level of service criteria of urban streets. Alex. Eng. J. 2016, 55, 407–418. [Google Scholar] [CrossRef]
- Murtagh, F.; Legendre, P. Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical Aid to the Interpretation and validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Cluster Analysis Basics and Extensions. R Package Version 2.0.6. Available online: https://CRAN.R-project.org/package=cluster (accessed on 28 June 2019).
- Factoextra: Extract and Visualize the Results of Multivariate Data Analyses. R Package Version 1.0.5. Available online: https://CRAN.R-project.org/package=factoextra (accessed on 28 June 2019).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TT0 | TT1 | TT2 | ... | TTn |
| NGPS | 615.813 |
| NEXP | 9.887 |
| NCEXP | 7.862 |
| Number of Clusters | |||||
|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | ||
| pam-manhattan | 8.35 | 4.07 | 15.8 | 10.39 | |
| pam-euclidea | 7.15 | 4.21 | 11.62 | 13.27 | |
| hclust-manhattan | 4.61 | 3.92 | 3.88 | 3.94 | |
| hclust-euclidea | 3.93 | 4 | 3.89 | 3.9 | |
| diana-manhattan | 1235.68 | 1238.88 | 1272.35 | 1279.8 | |
| diana-euclidea | 1317.6 | 1390.47 | 1387.73 | 1278.11 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cristóbal, T.; Padrón, G.; Quesada-Arencibia, A.; Alayón, F.; Blasio, G.d.; García, C.R. A Study on the Behavior of Clustering Techniques for Modeling Travel Time in Road-Based Mass Transit Systems. Proceedings 2019, 31, 18. https://doi.org/10.3390/proceedings2019031018
Cristóbal T, Padrón G, Quesada-Arencibia A, Alayón F, Blasio Gd, García CR. A Study on the Behavior of Clustering Techniques for Modeling Travel Time in Road-Based Mass Transit Systems. Proceedings. 2019; 31(1):18. https://doi.org/10.3390/proceedings2019031018
Chicago/Turabian StyleCristóbal, Teresa, Gabino Padrón, Alexis Quesada-Arencibia, Francisco Alayón, Gabriel de Blasio, and Carmelo R. García. 2019. "A Study on the Behavior of Clustering Techniques for Modeling Travel Time in Road-Based Mass Transit Systems" Proceedings 31, no. 1: 18. https://doi.org/10.3390/proceedings2019031018
APA StyleCristóbal, T., Padrón, G., Quesada-Arencibia, A., Alayón, F., Blasio, G. d., & García, C. R. (2019). A Study on the Behavior of Clustering Techniques for Modeling Travel Time in Road-Based Mass Transit Systems. Proceedings, 31(1), 18. https://doi.org/10.3390/proceedings2019031018