Depth-Based Lip Localization and Identification of Open or Closed Mouth, Using Kinect 2 †

Abstract
:1. Introduction
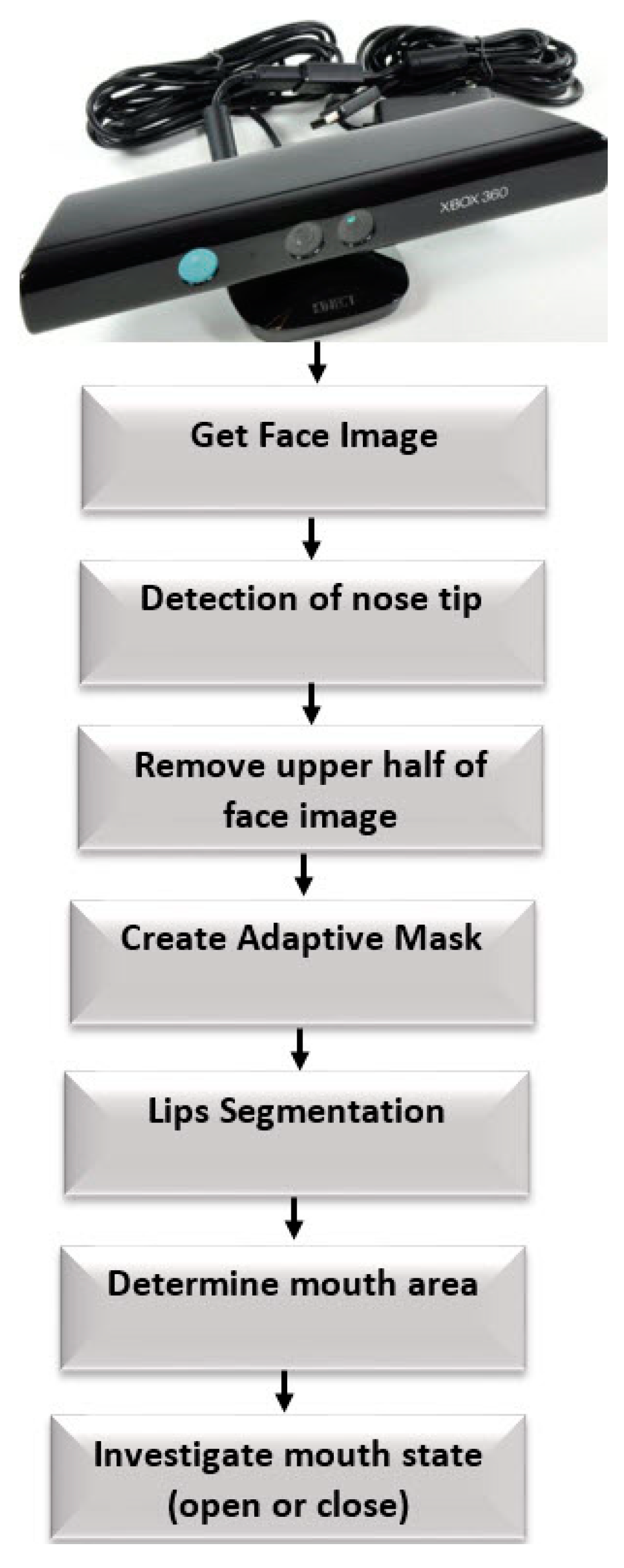
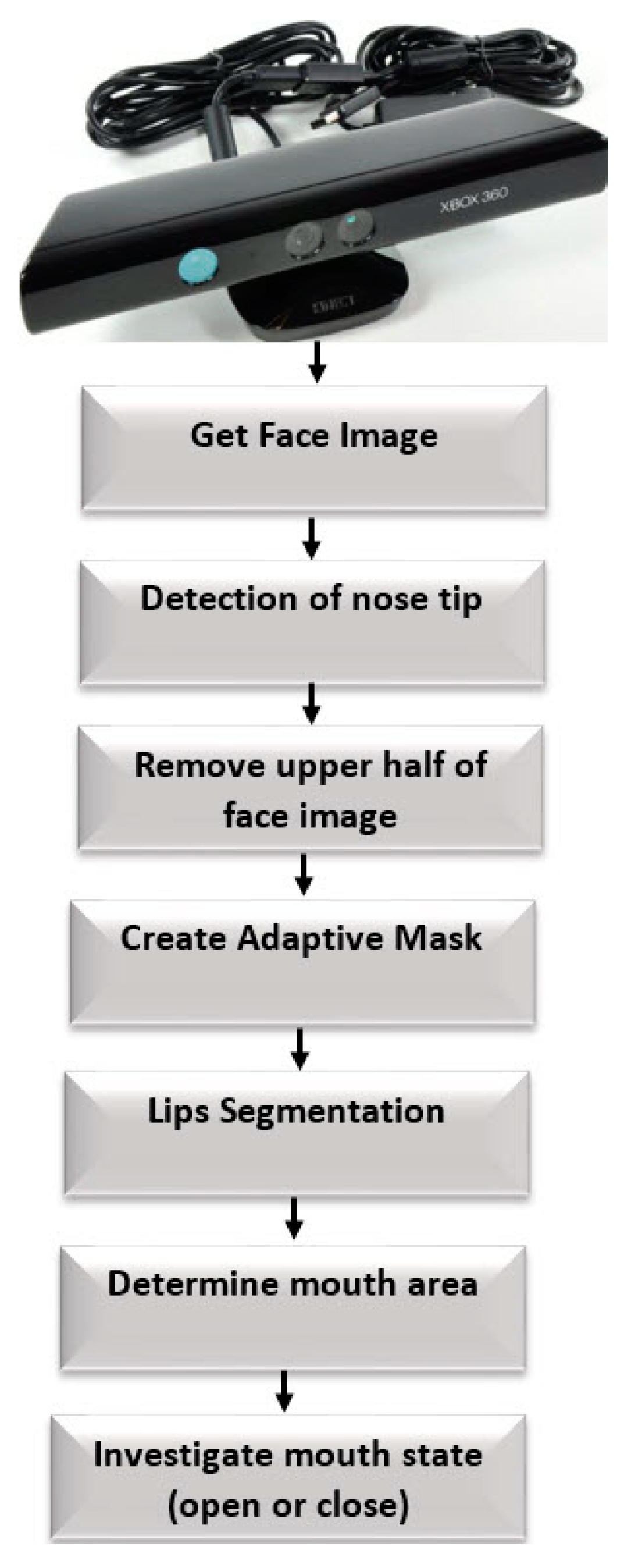
2. Proposed Approach
- Nose tip detection
- Lips segmentation and mouth area detection
- Open or closed mouth detection
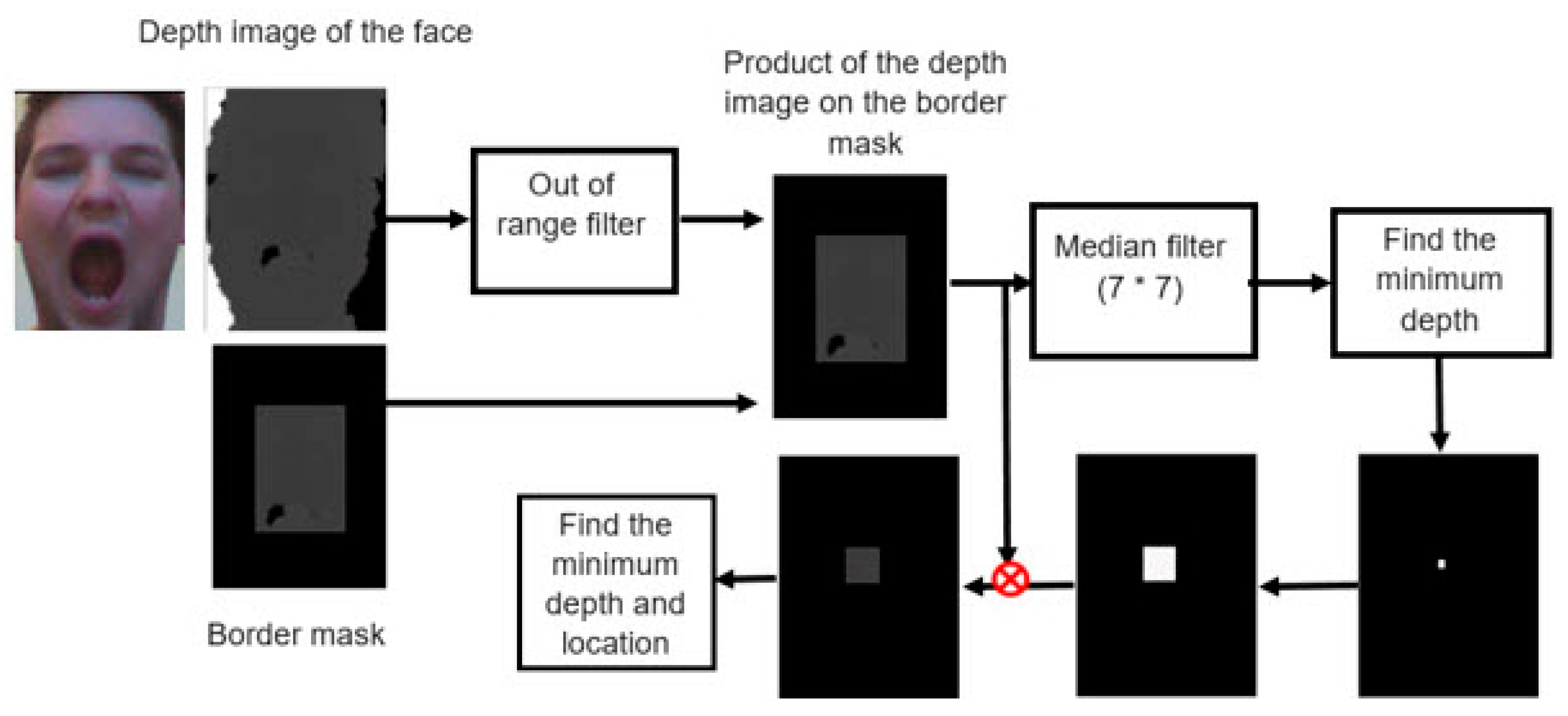
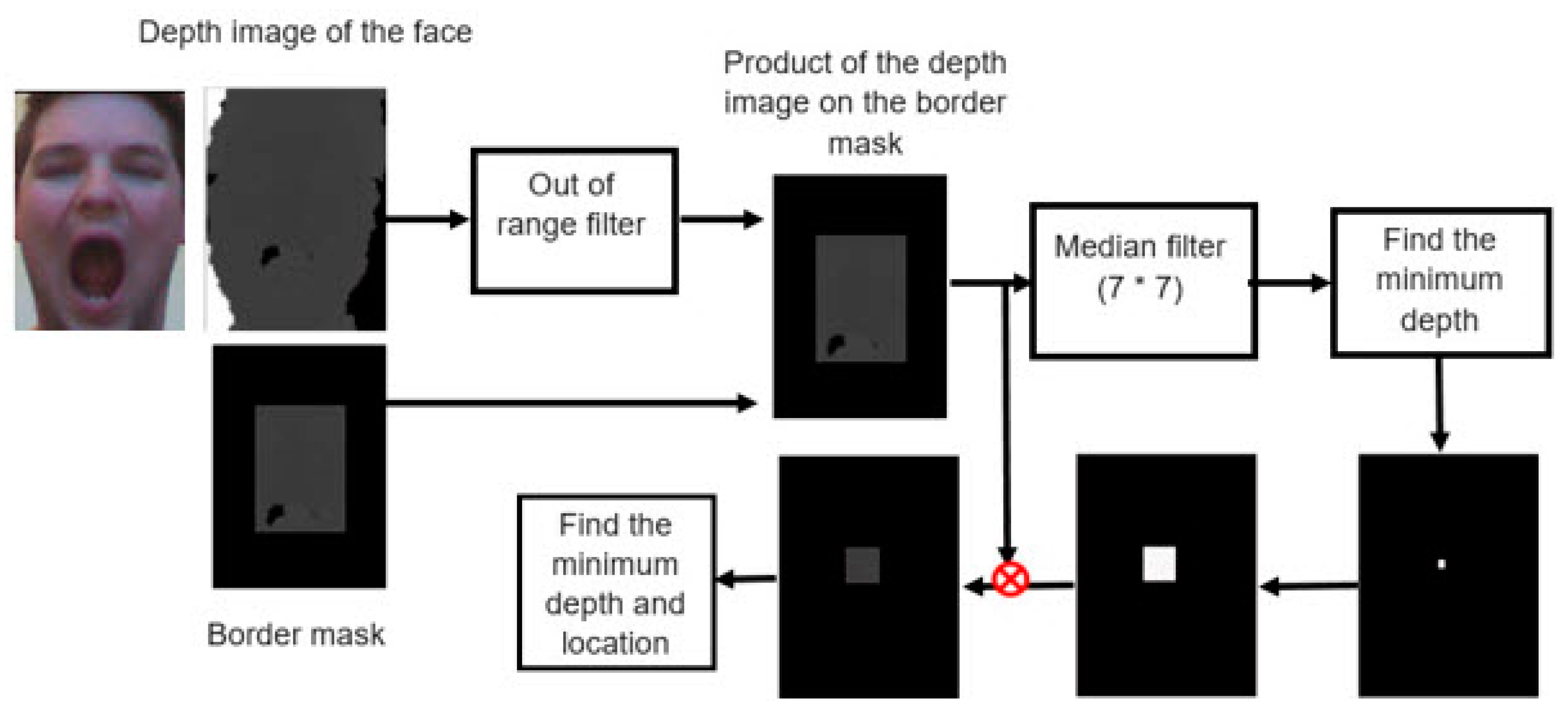
2.1. Nose Tip Detection
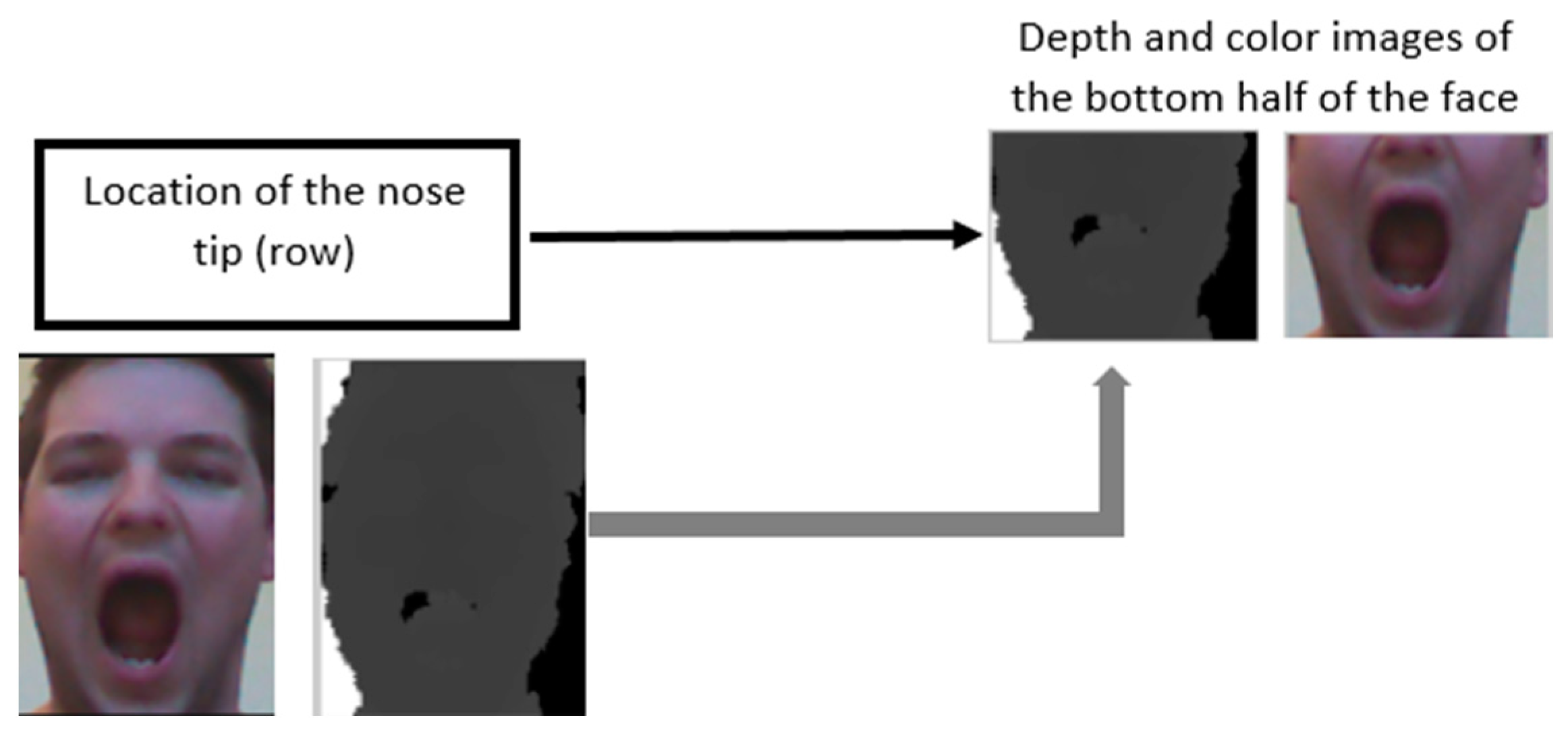
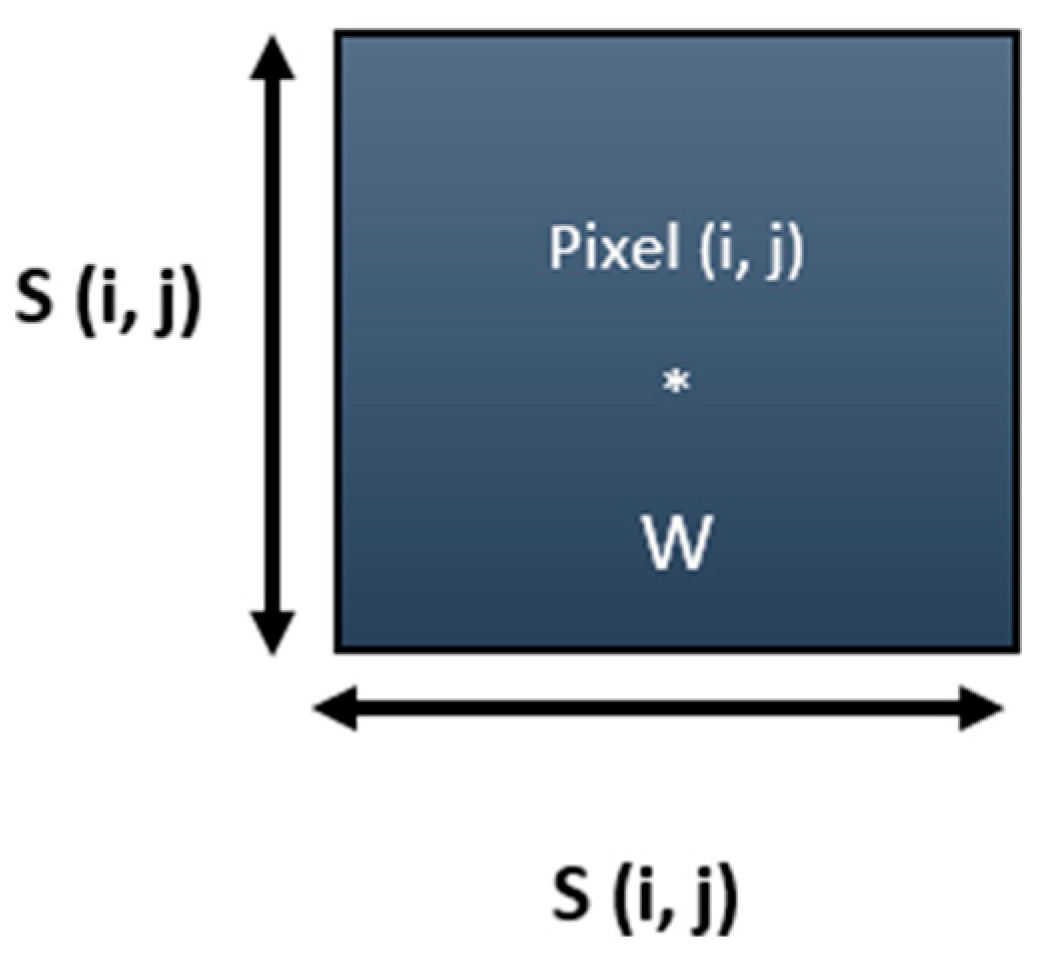
2.2. Lip Segmentation and Mouth Area Detection
2.3. Open or Closed Mouth Detection
3. Experimental Results
3.1. Nose Tip Detection
3.2. Lip Segmentation and Mouth Area Detection
3.3. Open or Closed Mouth Detection
4. Conclusions
References
- Wang, J.; Xiong, R.; Chu, J. Facial feature points detecting based on Gaussian Mixture Models. Pattern Recognit. Lett. 2015, 53, 62–68. [Google Scholar] [CrossRef]
- Agrawal, S.; Khatri, P. Facial expression detection techniques: Based on Viola and Jones algorithm and principal component analysis. In Proceedings of the 2015 Fifth International Conference on Advanced Computing & Communication Technologies, Rohtak, India, 21 February 2015; pp. 108–112. [Google Scholar]
- Galatas, G.; Potamianos, G.; Makedon, F. Audio-visual speech recognition incorporating facial depth information captured by the Kinect. In Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27 August 2012; pp. 2714–2717. [Google Scholar]
- Hassanat, A.B.; Alkasassbeh, M.; Al-awadi, M.; Esra’a, A.A. Color-based lips segmentation method using artificial neural networks. In Proceedings of the 6th International Conference on Information and Communication Systems (ICICS), Amman, Jordan, 7 April 2015; pp. 188–193. [Google Scholar]
- Lüsi, I.; Anbarjafari, G.; Meister, E. Real-time mimicking of estonian speaker’s mouth movements on a 3d avatar using kinect 2. In Proceedings of the 2015 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 28–30 October 2015; pp. 141–143. [Google Scholar]
- Kalbkhani, H.; Amirani, M.C. An efficient algorithm for lip segmentation in color face images based on local information. J. World’s Electr. Eng. Technol. 2012, 1, 12–6. [Google Scholar]
- Hsu, R.L.; Abdel-Mottaleb, M.; Jain, A.K. Face detection in color images. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 696–706. [Google Scholar]
- Ji, Y.; Wang, S.; Lu, Y.; Wei, J.; Zhao, Y. Eye and mouth state detection algorithm based on contour feature extraction. J. Electron. Imaging 2018, 27, 051205. [Google Scholar] [CrossRef]
- Fong, K.K. IR-Depth Face Detection and Lip Localization Using Kinect V2. Master’s Thesis, California Polytechnic State University, San Luis Obispo, CA, USA, 2015. [Google Scholar]
- Hg, R.I.; Jasek, P.; Rofidal, C.; Nasrollahi, K.; Moeslund, T.B.; Tranchet, G. An rgb-d database using microsoft’s kinect for windows for face detection. In Proceedings of the 2012 Eighth International Conference on Signal Image Technology and Internet Based Systems, Naples, Italy, 25–29 November 2012; pp. 42–46. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Samples = 180 | Viola Jones Algorithm | Proposed Algorithm | ||
|---|---|---|---|---|
| Closed Mouth | Open Mouth | Closed Mouth | Open Mouth | |
| Total No. of Closed mouth = 40 | 35 | 5 | 31 | 9 |
| Total No. of Open mouth = 140 | 69 | 71 | 4 | 136 |
| #Total Samples: 87 | Predicted Closed Mouth | Predicted Open Mouth |
|---|---|---|
| #Closed mouth: 37 | 32 | 5 |
| #Open mouth: 50 | 7 | 43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yazdi, M.Z. Depth-Based Lip Localization and Identification of Open or Closed Mouth, Using Kinect 2. Proceedings 2019, 27, 22. https://doi.org/10.3390/proceedings2019027022
Yazdi MZ. Depth-Based Lip Localization and Identification of Open or Closed Mouth, Using Kinect 2. Proceedings. 2019; 27(1):22. https://doi.org/10.3390/proceedings2019027022
Chicago/Turabian StyleYazdi, Mina Zohoorian. 2019. "Depth-Based Lip Localization and Identification of Open or Closed Mouth, Using Kinect 2" Proceedings 27, no. 1: 22. https://doi.org/10.3390/proceedings2019027022
APA StyleYazdi, M. Z. (2019). Depth-Based Lip Localization and Identification of Open or Closed Mouth, Using Kinect 2. Proceedings, 27(1), 22. https://doi.org/10.3390/proceedings2019027022