4.1. Evolution of the Number of Links
In general, a complete characterization of
will be very cumbersome. Alternatively,we can partially characterize such process by considering
where
f is the function that computes the number of links in the network. We can partition the set
into equivalence classes
so that each class
gathers all graphs containing
k links:
. Then, we can define a stochastic process
with each
which characterizes the transition between classes, and whose state space represents such equivalence classes (hence, we identify
with state
k).
In general, for a given instant of time
i, based on Equation (5) we will have that the cross-sectional entropy of
and the entropy of
will satisfy
and this relationship will help to characterize
via the analysis of
. Therefore the following proposed models will be partially characterized by analyzing the associated stochastic process,
, for the evolution of the number of links.
4.2. A Simple Evolution Model
We define a simple network evolution process which may serve as a reference baseline for comparison purposes. Given (equivalently, or ), the next time step network is generated by randomly selecting a pair of nodes so that if there exists a link between them (i.e., ), such link is removed () and, if there is no link between the nodes (i.e., ), then it is created (). Note that if we consider the adjacency matrix representation , at each stage of time, an element of the matrix is randomly chosen so that its value is changed (from 0 to 1 or vice versa) to derive .
Note that the evolution law if determined by the number of links of
. Therefore, as mentioned above, we will start the analysis of this evolution model by characterizing the time evolution of the number of links. The corresponding
satisfies:
and for
:
This process is a Markov chain with the following matrix of transition probabilities:
which is known as the Ehrenfest model [
6], and which can be similarly interpreted as representing an urn with white and black balls, where we randomly select a ball and change it by another ball with different color, hence representing a sort of discrete-time birth-death Markov process [
7] but with finite number of states (two boundary conditions). Many discrete distributions have been obtained by studying urn models and Markov processes [
8,
9,
10]. Note that these models can be seen as a reference baseline since they do not exploit the network structure properties (i.e., the relative location of white balls and black balls).
The left stochastic, tri-diagonal, irreducible matrix
P of Equation (17) has period 2, but it has a unique eigenvector associated with eigenvalue
. This eigenvector defines the stationary distribution of the process, denoted by
, and it can be easily proved that such distribution is binomial:
so that taking a snapshot of the process for large
t is equivalent to generating a sample from the Gilbert model with
or, equivalently, the uniform model with maximum entropy (see [
5] for details). Note that given a number of links
, the distribution of
is uniform (following a Erdős-Rényi model [
5]), each link having probability
. Hence, considering Equation (18), the entropy expression provided in Equation (13) becomes
Concerning the entropy of
, it is known that Ehrenfest model cross-sectional (relative) entropy at time
t, defined in terms of the Kullback-Leibler divergence between the distribution and the steady state equilibrium distribution
is non-decreasing in time as approaches the maximum value zero, upon the so called
H-Theorem [
11].
4.3. Extensions of the Model for Asymmetric Evolution
One can extend the symmetric model provided in Equation (17) with the aim of considering cases in which the network may have an uneven tendency to increase or decrease in the number of edges.
Let us consider the following transition behavior from to : we start selecting a pairs of nodes in network ; if the selected pair already has an associated link, such link is removed with probability , whereas if such pair does not have an associated link, a link is added between such pair of nodes with probability . If no change (removal or addition) happens, the process is repeated until the network undergoes some modification, which is registered in .
Again, if we focus the analysis on the time evolution of the number of links,
, the corresponding transition matrix becomes:
The analysis of this system can be simplified if we denote
the
unbalance coefficient, since the matrix can be reformulated as
If the model has more tendency to add links than to remove them, and vice versa for . The analysis and interpretation of the network behavior can be performed either way due to such symmetry. For instance, if the model can be interpreted as characterizing the following behavior: if the selected pair in has an associated link, this link is removed with probability u; if the pair does not have and associated link, then a link is added. Again, the selection procedure is repeated until a link is either removed or added, defining .
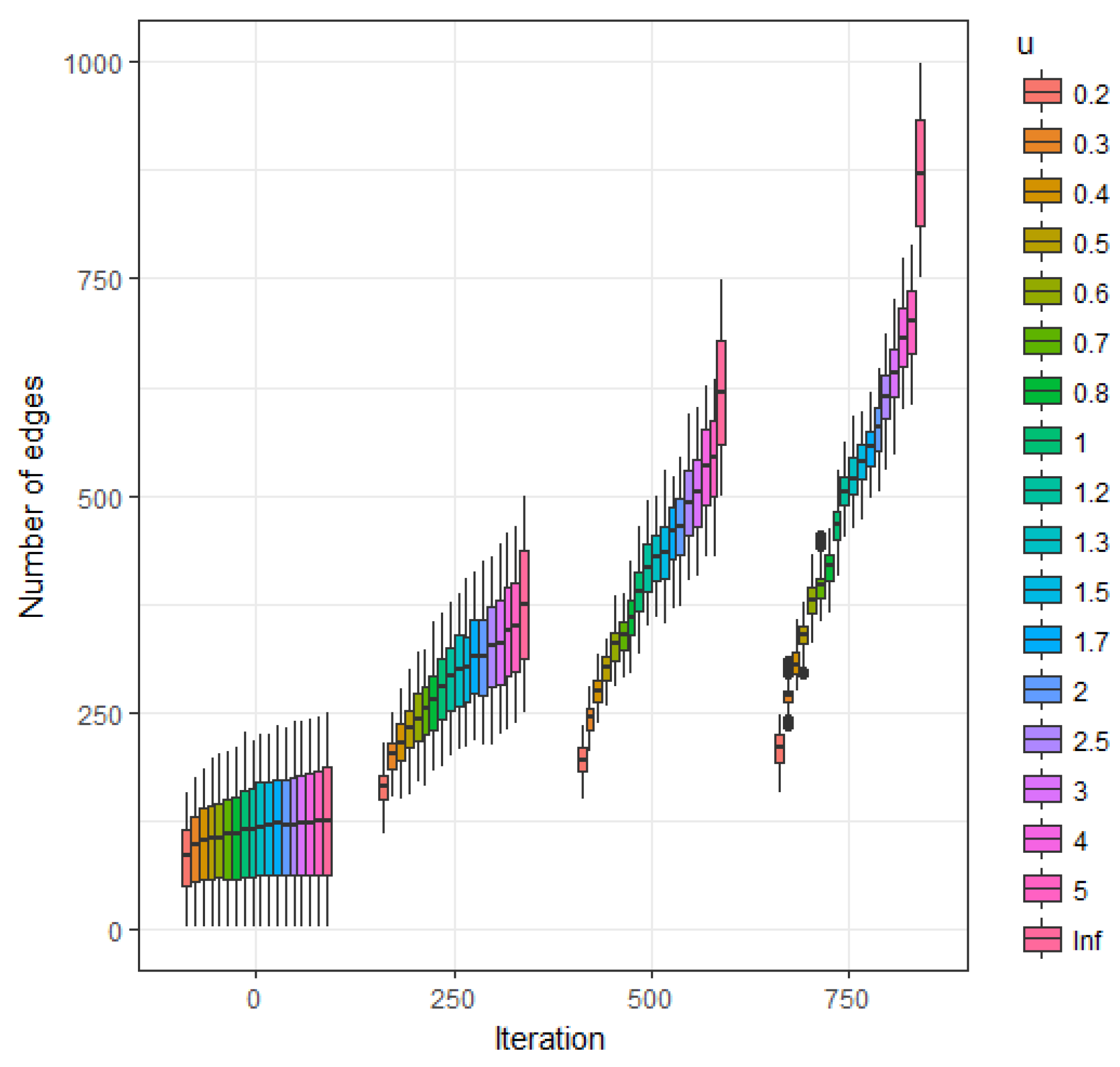
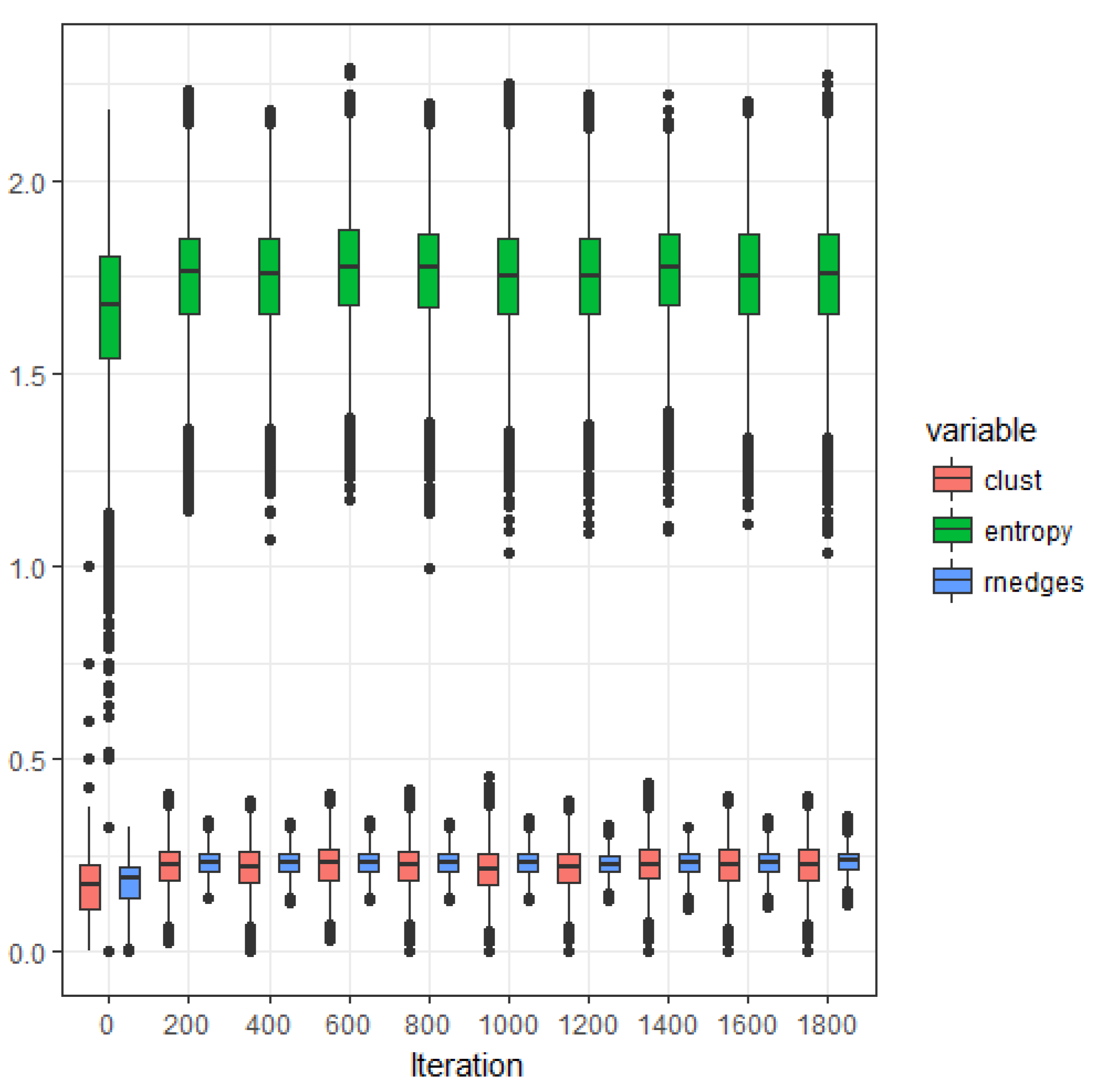
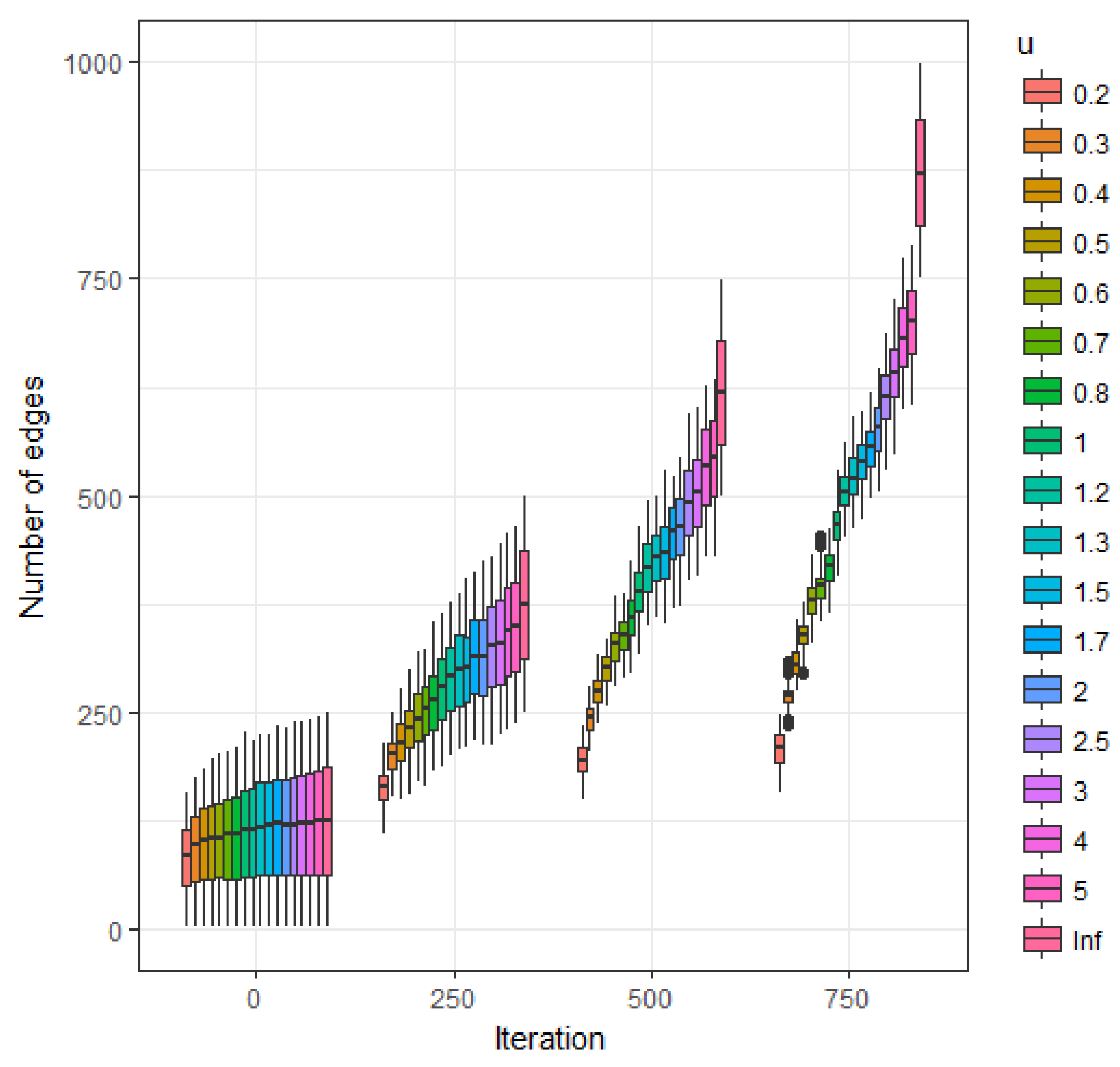
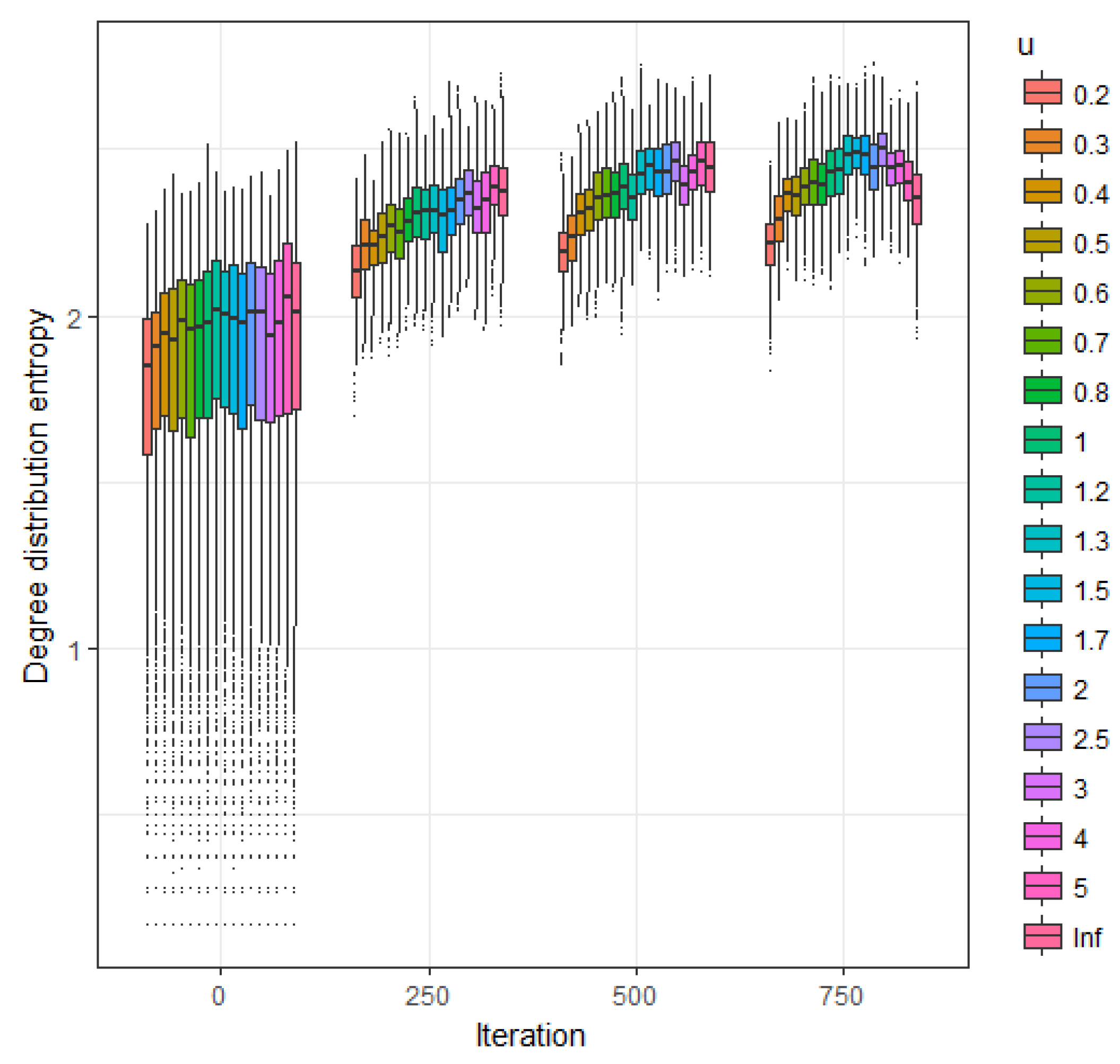
In
Section 5 the time evolution of the expected value for the number of links, the clustering coefficient, the connectivity and the sample degree distribution are estimated via simulations procedures.
It can be proved that the resulting stationary distribution has the form:
which can be seen as a generalization of the binomial distribution
via the new parameter
u.
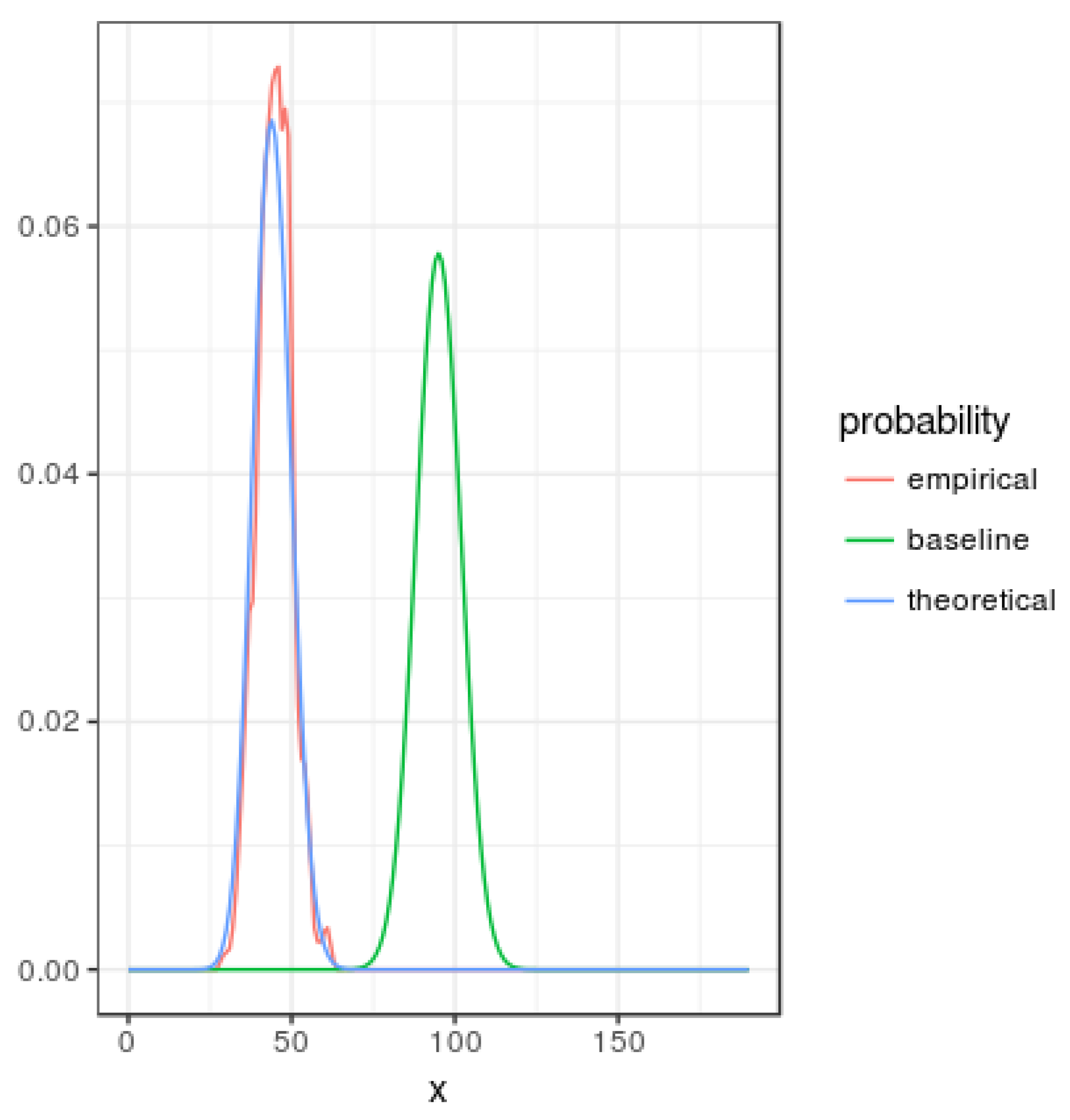
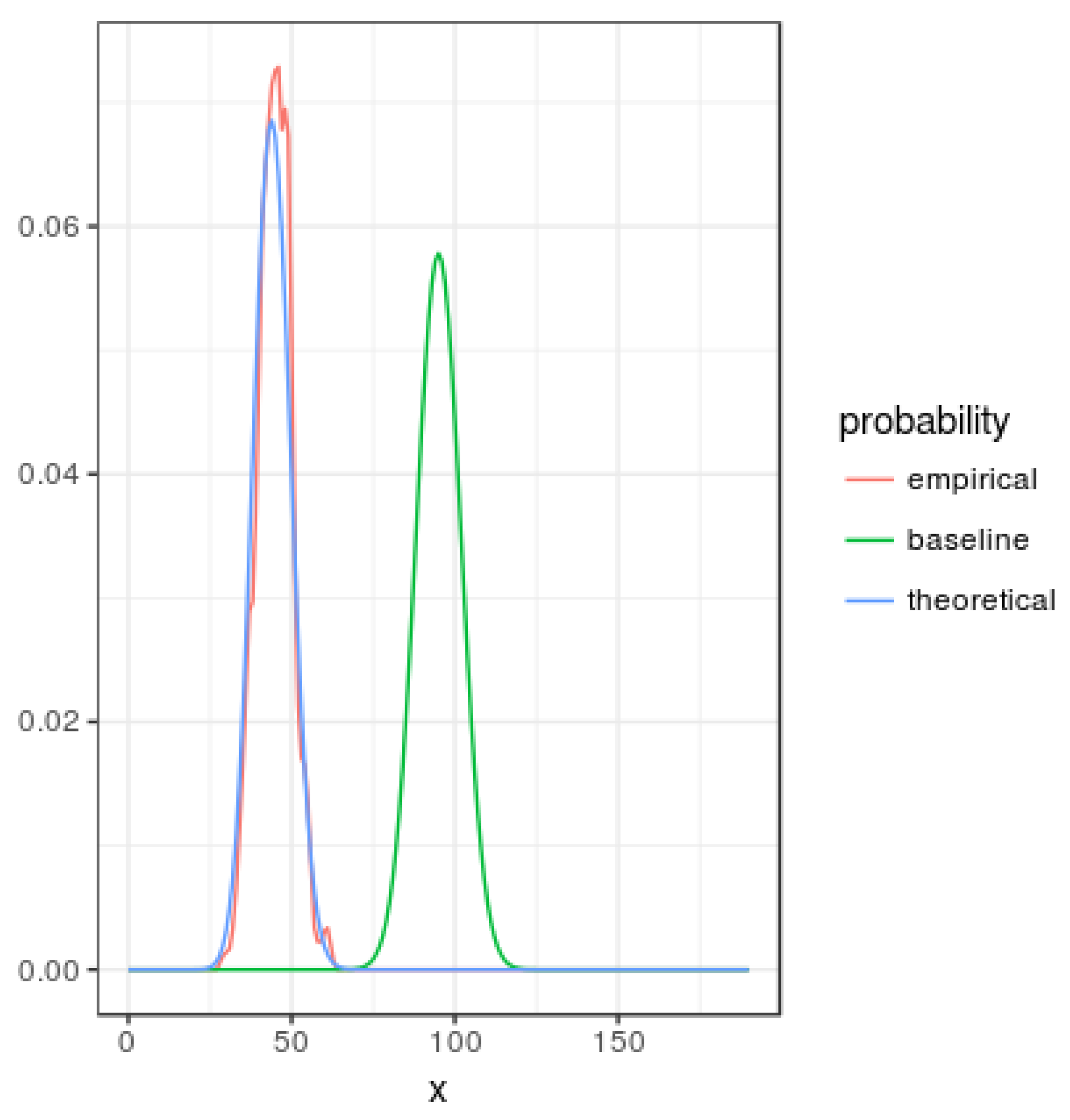
Figure 1 represents smoothed probability mass functions for the baseline, theoretical given by Equation (23) and empirical (based in simulations) with
and
. Note that asymmetry of the
u value generates a probability function with less entropy than the corresponding to the baseline mass function.
Repeating a similar procedure to Equations (19) and (20) the corresponding
entropy can be computed as
which for
becomes
.
4.3.1. Alternative Simple Model
Another simple model could assume that whenever an existing edge is selected to be removed, it is removed with probability
, whereas, alternatively, a new edge is randomly added. The transition matrix of the corresponding
for the number of links would be
Note that an equivalent symmetric model can be defined as follows. If the selected a pair of nodes does not have an associated link, we add such a link with probability , otherwise an existing link is removed.
It can be proved that the resulting stationary distribution has the form:
which can be seen as another generalization of the binomial distribution
via the new parameter
. Again the network cross-sectional entropy can be computed as
Both models Equations (22) and (24) provide respectively stationary distributions Equations (23) and (25) which, in general, are not binomial. Therefore, if we take a snapshot of these stationary distributions, the resulting network will follow a new static model, different from the standard known reference models for static networks.
Note that again these models can be interpreted as urn-derived finite state discrete-time birth-death models, in the sense that they do not incorporate network structural information, but only the total number of links. In other words, these models do not differentiate among networks that belong to the same equivalence class .


{kind=link}
{kind=link}
{kind=link}
{kind=link}