1. Introduction
Unlike the large number of sensors available and the various techniques for accurately interpreting visual and audio data, the sense of touch remains relatively less exploited for robotic applications in spite of the crucial role it can play in supporting sensing and environment understanding in many practical situations. In particular, human vision-touch interaction studies demonstrated the ability of visual information in assisting handling, grasping and dexterous manipulation tasks. In a similar manner, tactile sensing could support robot vision by compensating in situations where occlusions are present or when force estimates are required in various robotic manipulation tasks. Moreover, touching an object in order to recognize it can be inefficient, as probing requires direct contact which is lengthy and laborious to achieve in robot applications, where the sensor needs to be appropriately positioned and moved to collect quality data. This justifies the interest in guiding the tactile probing process such that the acquisition process becomes intelligent and efficient by collecting only relevant data. Drawing inspiration from the human vision-touch interaction, in this paper we evaluate the effect of human visual attention for detecting relevant areas over which tactile data can be collected in view of a subsequent recognition of the probed objects. In particular, the main contribution of this work is to demonstrate that a series of interest points computed based on object features that attract visual attention allows for the acquisition of only relevant tactile data using a force-resistive (piezo-resistive) tactile sensor array over the surface of 3D objects in order to enable their recognition.
2. Literature Review
Tactile force sensor arrays are one of the most known and well established tactile sensors. Data recuperated by such sensors has been successfully employed for various tasks, including object recognition. Symbols in form of embossed numbers and letters are recognized in [
1] using a feedforward neural network. A bag-of-feature technique is employed by [
2] to classify industrial objects. The same technique is used in [
3], on simulated data as returned by a tactile sensor array to estimate the probability of the object identity. Data from two tactile sensor array sensors mounted on a gripper performing a palpation procedure is classified as belonging to 10 objects by Drimus et al. [
4], using a combination of a k-neighbors classifier and dynamic time warping. Liu et al. [
5], classify empty and full bottles based on tactile data recuperated by tactile arrays placed on each of the three fingers of a robot hand making use of joint kernel sparse coding. To recognize a series of 18 objects in a fixed or movable position, Bhattacharjee et al. [
6], extract various features from tactile sensor array data (i.e., maximum force over time, contact area over time and contact motion) that are subsequently classified by a k-nearest neighbor classifier. The authors of [
7] exploit a different series of tactile features (i.e., positions and distances of the center of mass of the tactile image blob, pressure values, stochastic moments, the power spectrum and the raw, unprocessed windows centered at the points with the highest contact force) to identify objects using decision trees. The current paper aims at collecting tactile information using a force-resistive tactile sensor array only on relevant areas, represented by points of interest, over the surface of 3D objects in order to identify them.
3. Visual Attention Model for Guiding Tactile Data Acquisition for Object Recognition
The proposed solution for guiding data acquisition starts with a visual inspection of the object of interest. A 3D model of the object of interest can be obtained using an RGB-D sensor (Kinect), and a software that allows stitching data collected from multiple views in a unified 3D model (Skanect). Texture information, as recuperated by the color camera of the Kinect can then be added on the object surface to fully exploit the capabilities of the computational model of visual attention. The latter uses geometrical information (i.e., orientation of edges, curvature) and also color properties (i.e., color opponency, contrast) to identify the areas of interest that guide the deployment of attention. A novel, enhanced visual attention model and a method to extract interest points based on this model are proposed for this purpose. Taking inspiration from the human joint use of vision and tactile information for object manipulation tasks, we propose the use of these interest points for the acquisition of local tactile data (tactile imprints as collected by a force-resistive tactile sensor array). Because the acquisition of tactile data requires a direct contact with the object, the process to move and position the sensor can be extremely lengthy. We therefore use in an initial step a simulation that allows us to identify the best acquisition location and subsequently the best classifier to employ for recognizing the probed object based on the acquired tactile data. The method is then validated on real data collected using a force-sensitive tactile sensor array over a series of toy objects.
3.1. 3D Visual Attention Model for Interest Point Identification
In order to identify interest points over the surface of a 3D object, we have proposed an improved version of the classical visual attention system proposed by Itti [
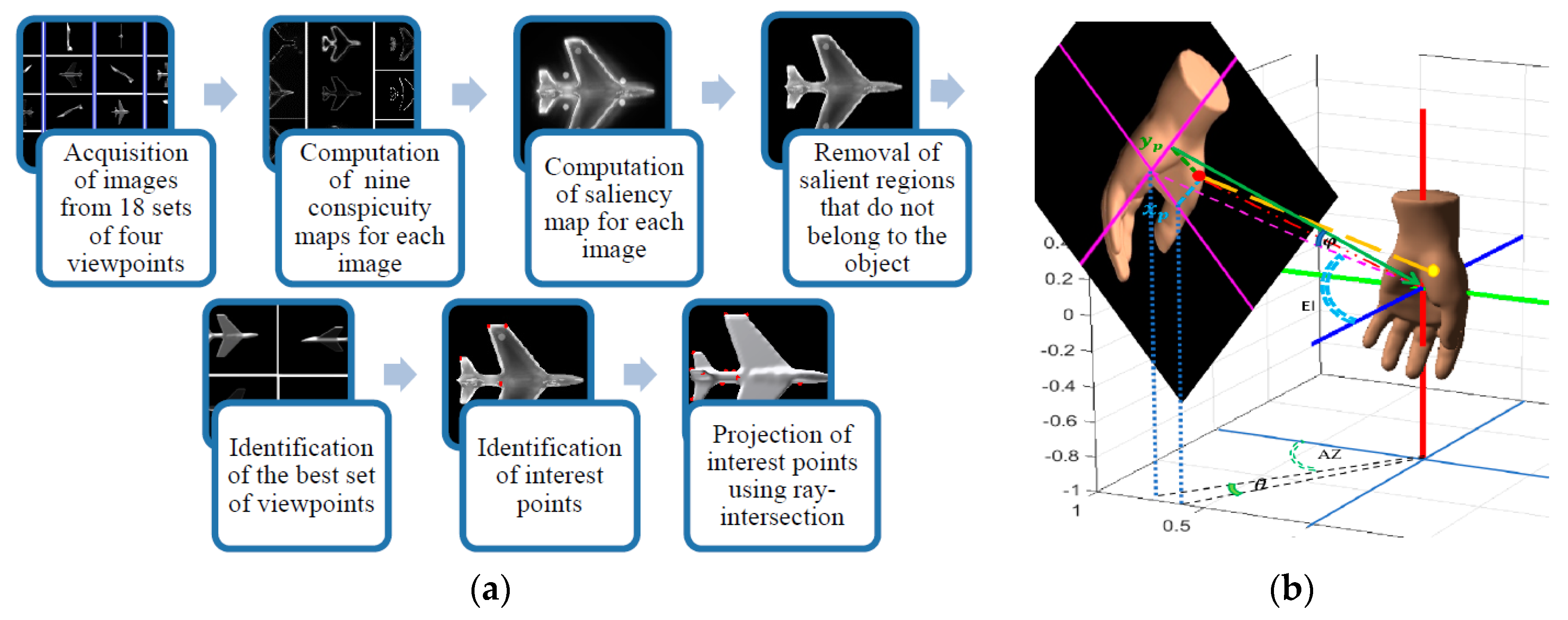
8]. The algorithm explores color, intensity, orientation, as the Itti model, but also capitalizes on the use of symmetry, curvature, DKL color space, contrast, and entropy to compute the level of saliency for different regions over the object model surface. All these features are known to guide the deployment of visual attention. As the visual attention model is only applicable on images, we used the virtual camera of Matlab to capture images from different viewpoints around the object. A saliency map is produced for each image based on the previously reported features, in which the interest regions are represented by bright areas on a black background (the brighter the area is, the more salient it is). Based on this map, the interest points are determined in 2D pixel coordinates and projected back as 3D vertices on the object surface.
Figure 1a summarizes the improved visual attention approach for interest point selection. In particular, 18 sets of viewpoints each containing 4 perpendicular viewpoints (to cover the whole surface of the object) are chosen to collect the images. For these, a series of conspicuity maps is created, eight for each image (one for each considered feature).
The classical visual attention model [
8] decomposes color, intensity and orientation modalities of captured images into a set of multiscale feature maps over which local spatial discontinuities are computed as center-surround differences. Further studies have proven that other features, including symmetry, curvature, DKL color space, contrast, entropy can also influence visual attention deployment. In this work, we have capitalized on all these features to compute an improved visual attention model. The bilateral and radial symmetric point detection algorithm introduced in [
9] is used to determine the symmetry conspicuity map. Subsequently the center-surround operations are applied on the resulting map. Curvature information is extracted using the saliency map proposed in [
10]. The color opposition model based on Derrington-Krauskopf-Lennie (DKL) color space [
11] is added to provide another color feature, closer to human visual capacities. The local entropy calculation is based on a
neighbourhood of the median filtered input image and yields the entropy conspicuity map [
12]. The luminance variance in a local neighborhood of
pixels as proposed in [
13] is adopted to create the contrast conspicuity map. Finally, the eight conspicuity maps contribute with equal weights to produce a comprehensive saliency map for each image.
Once the saliency map is obtained for all images, the salient regions detected outside of the surface of the object are removed. Such regions can sometimes occur around the outer surface of the object due to the local contrast, intensity and color changes between the object and its background. The most salient set of viewpoints is then chosen as the set with the highest average level of saliency. The level of saliency is computed as the normalized accumulation of pixel values for the saliency maps. Interest points are then identified as the brightest points on the saliency maps for the best set of viewpoints.
Figure 1b illustrates the projection geometry of an arbitrary interest point from image pixel coordinates (
and
) to the object surface. These values can be found in real world coordinate as
and
, where
PPWU is the number of pixels per world units, calculated as
. In this formula,
is the camera view angle and
d represents the distance from camera center to the origin. Knowing the spherical coordinate of the camera center
, where
El and
AZ are the elevation and azimuth angles of camera center position respectively, the spherical coordinate of the interest point (the red dot in
Figure 1b) can be calculated as
where,
,
and
. The positive or negative signs of
and
depend on the quadrant on the image plane to which the interest point belongs to. The ray starting from the real world coordinate of the interest point on image plane in perpendicular direction to the image plane (in parallel with the vector from camera center to the origin) [
14] intersects the corresponding point on object surface (yellow dot—
Figure 1b).
The interest points on object surface are then sorted in descending order according to their level of saliency. The level of saliency is first determined as the number of times the point or its neighbors are identified as salient from different viewpoints and then by their corresponding pixel values in the saliency map. A series of 15 interest points with highest saliency are then selected for each object to guide the tactile data acquisition process.
3.2. Tactile Data Acquisition Simulation
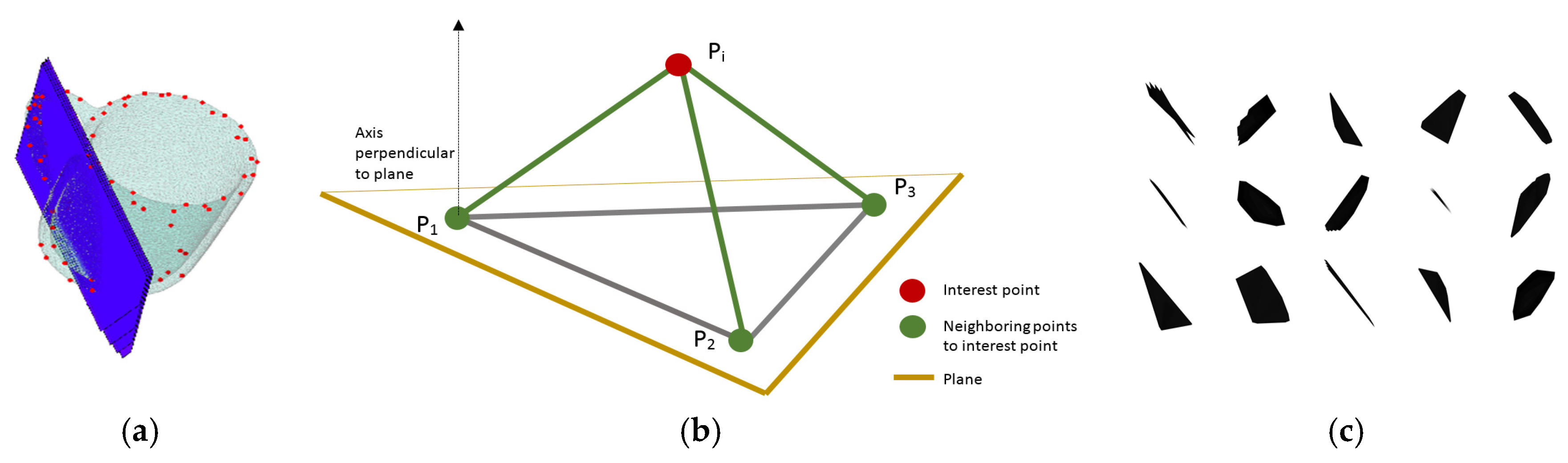
Once the interest points are identified over the surface of an object, the data acquisition process is simulated over the detected points. In particular, the sensor surface is estimated as a series of quasi-tangent planes to the surface of the object at the identified interest point.
A series of four such planes are used (
Figure 2a), situated close to each other in order to simulate the depth of the real sensor. The use of quasi-tangent planes is justified by the fact that research demonstrated that orienting the sensor along the local normal on the surface of the object maximizes the content and quality of acquired tactile data. To compute the first tangent plane (
Figure 2b), we first identify the three closest neighbors (P
1 to P
3) to the identified interest point (P
i) over the object mesh and build a plane passing through them. The local intersection contour is then estimated between this plane and the 3D object surface. Three other equidistant planes are built along the local normal on the surface. The normal is computed as being the orthogonal vector on the first plane and it becomes the translation axis along which other three equidistant planes are placed. For each of them, the local intersection contours are identified with the 3D object. The contour information is then projected onto a plane where the gray level encodes the depth information. The procedure is repeated for each of the 15 interest points detected in
Section 3.1. An example of tactile data acquired for the cup is shown in
Figure 2c. Because the resulting tactile images are simulated, they have a higher resolution than the ones obtained with the real sensor. They have therefore been down-sampled to 16-by-16, to better correspond with the capabilities of the real sensor. The corresponding 16-by-16 values are concatenated to create vectors that become inputs to a classifier.
3.3. Tactile Data Classification for Object Recognition
A series of classifiers, namely deep learning neural networks, Naïve Bayes, decision trees, evolutionary support vector machines (SVM) and k-nearest neighbors are then tested for the classification of objects based on the vectors encoding the tactile images. Because during experimentation we have realized that certain imprints are strongly resembling from one object to another (the ear of the dromedary and the ear of the cow), we proposed a selection of tactile imprints to be used for training the classifiers based on similarity. In particular, we have computed the similarity between the pairs of imprints of two objects at the time, as the normalized cross-correlation of the down-sampled 16-by-16 matrices. We have then eliminated all those imprints with a similarity larger than 0.85 (equivalent to similarities larger than 85%). The results obtained over simulated data are then validated using real data collected over the interest points using a force-resistive tactile sensor array [
15].
4. Experimental Results
We have performed experiments using the proposed framework for a series of four toy objects: cow, glasses, cup and hand; and then with a series of six object toys, namely cow, glasses, cup, hand, plane and dromedary, both for simulated and real data.
Table 1 displays the performance in the case in which simulated tactile imprints are used for the task of object recognition. The best recognition rates are achieved by the k-nearest neighbors classifier, followed by the evolutionary SVM classifier, with a maximum difference between them of 6.07%. The results are better when comparing the case when all the tactile imprints are used and when tactile imprints are selected for training based on similarity. An improvement of 15.95% is obtained using the selection process of imprints for the 4 objects and of 13.18% for the 6 objects. The best performance achieved is of 87.89% for 4 objects and of 75.82% for 6 objects.
The results for the real data collected over the same objects are displayed in
Table 2.
One can notice that the best performance in terms of recognition rates is obtained using the k-nearest-neighbors algorithm, again followed in the second position by the evolutionary SVM, similar to the observation made for the simulated data. As well, it can be observed that the performance is better when using the tactile imprints selection based on similarity, both for four objects (72.25% versus 67.23%) and six objects (70.47% versus 57.97%). Due to the low results obtained both for simulated and real data, the Naïve Bayes and decision tree techniques are not appropriate for the task of object recognition based on tactile data. By comparing the best performance obtained on real and simulated results, one can notice that the first is slightly lower (max. by 15.64%). This is expected, because the real data is noisier and of very lower resolution.
5. Conclusions
In this paper we have studied the problem of object recognition based on tactile data whose acquisition is guided by an improved computational model of visual attention. The latter takes into consideration, beyond the classical features such as orientation, color and intensity, information about symmetry, curvature, contrast, and entropy to identify over the surface of a 3D object a series of interest points. It was demonstrated that tactile data collected at these points using a force-resistive tactile sensor can be successfully employed to classify 3D objects using the k-nearest neighbors algorithm. When using the similarity measure to select the imprints for training the classifier, the recognition rate is of 87.89% for 4 objects and 75.82% for 6 objects for simulated data, while for real tactile sensor data is of 72.25% for 4 objects and 70.47% for 6 objects.





{kind=link}
{kind=link}