Bivariate Flood Frequency Analysis Using Copulas †




Abstract
:1. Introduction
2. Data and Methodology
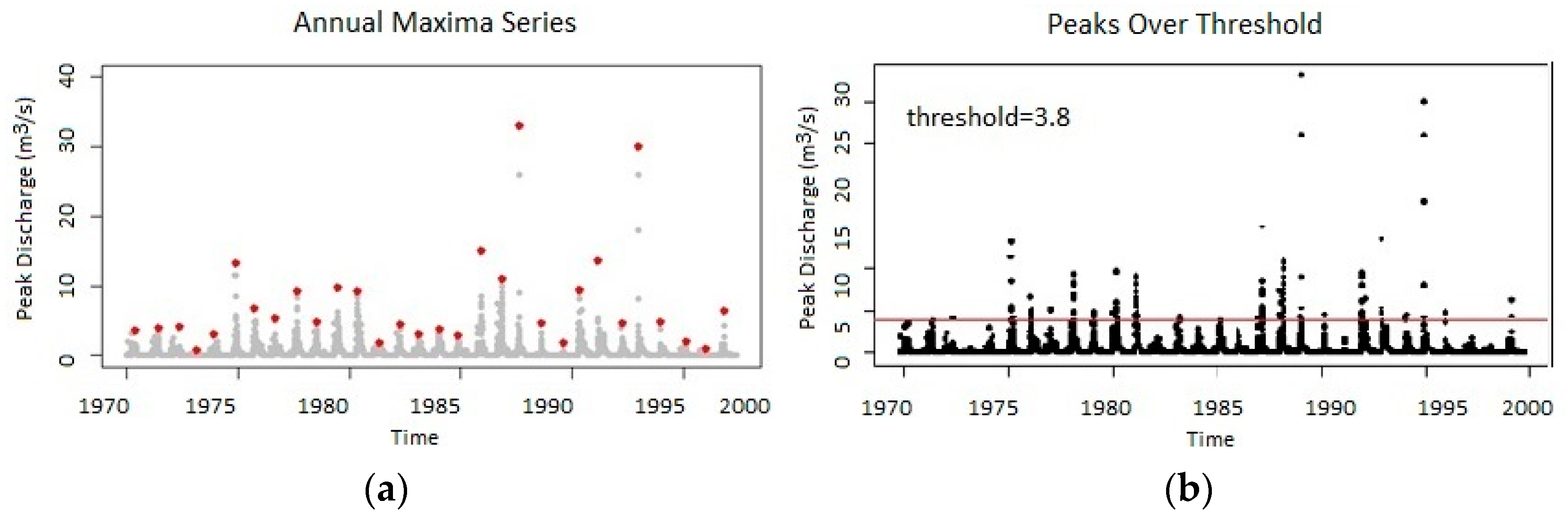
2.1. Data
2.2. Methodology
3. Results
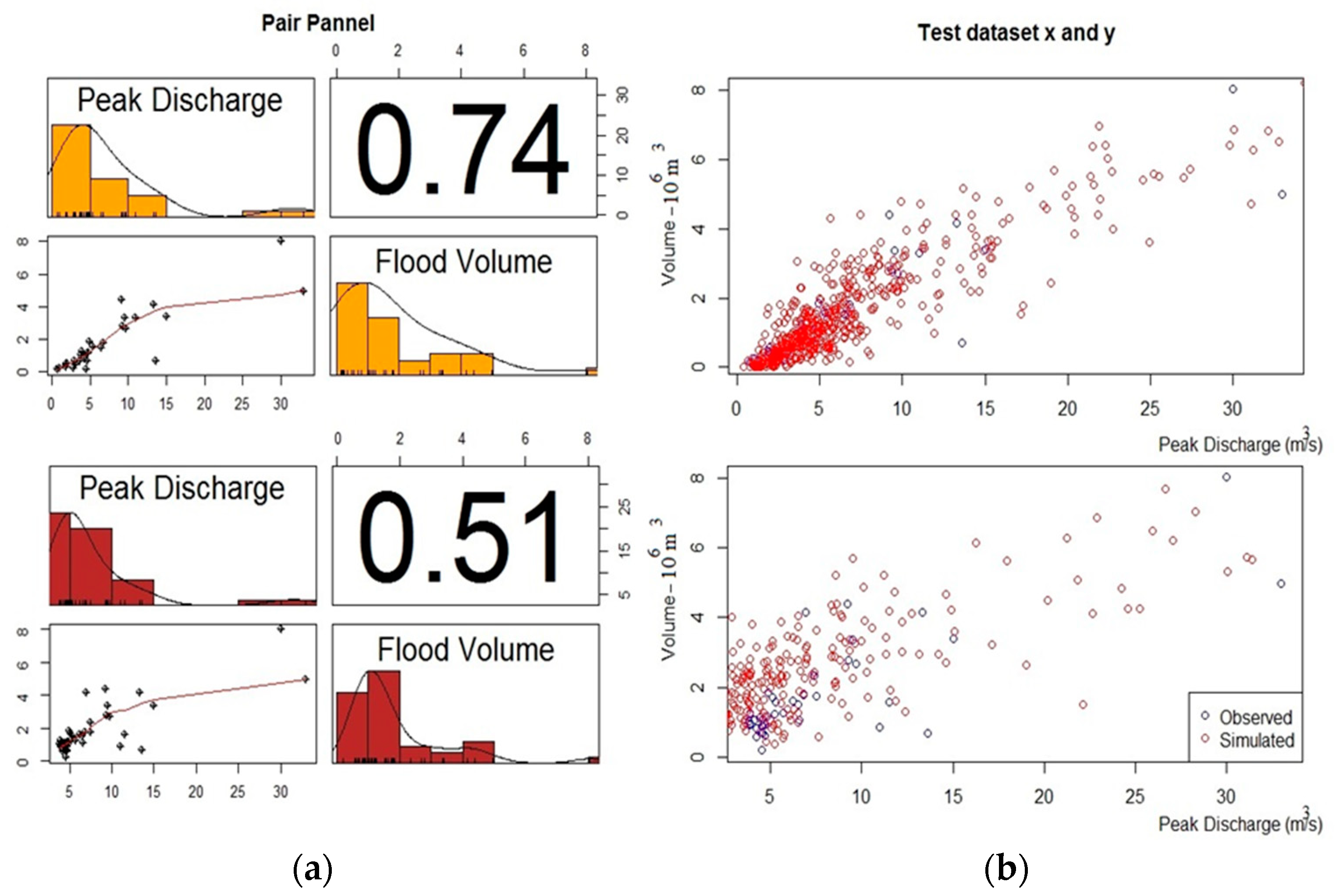
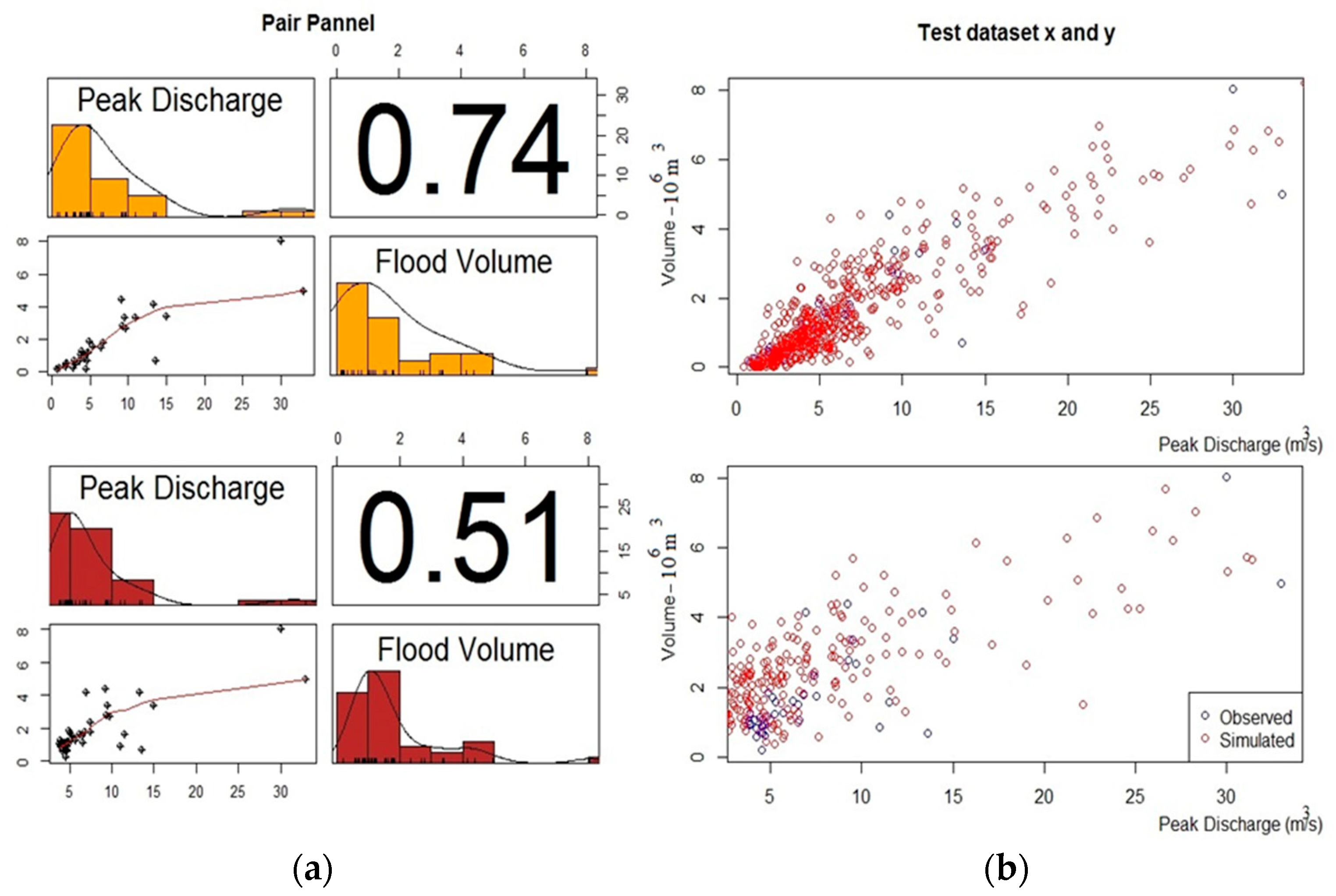
3.1. Univariate Analysis
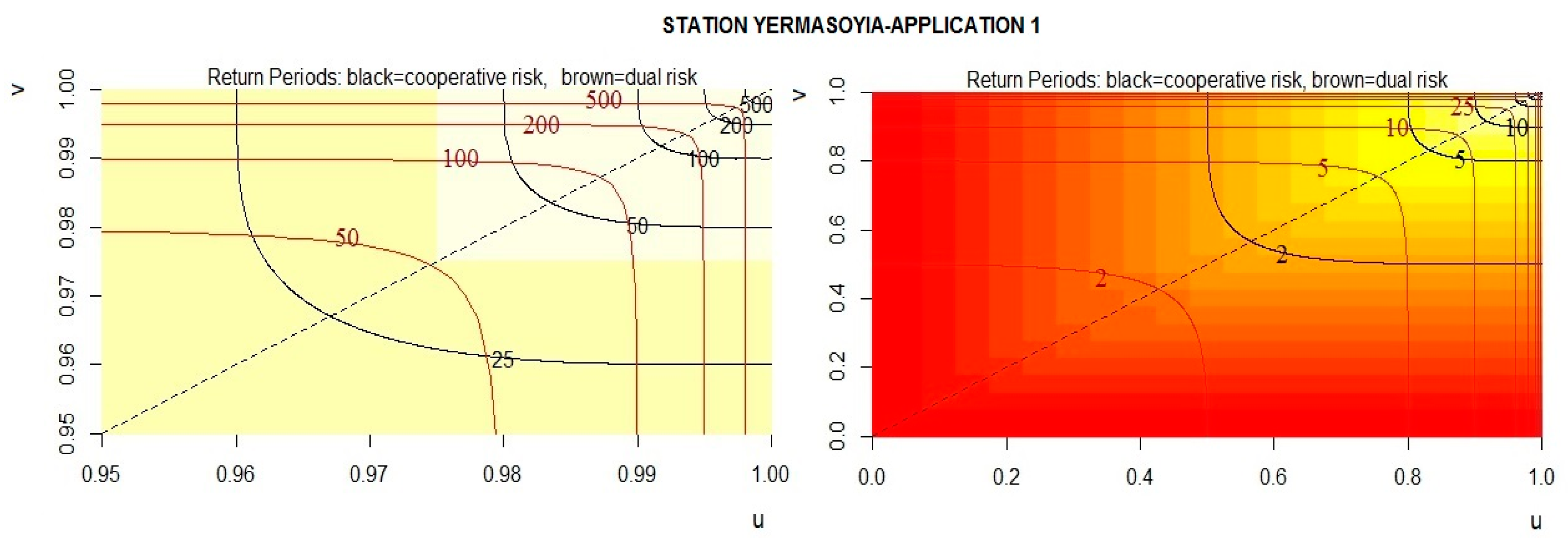
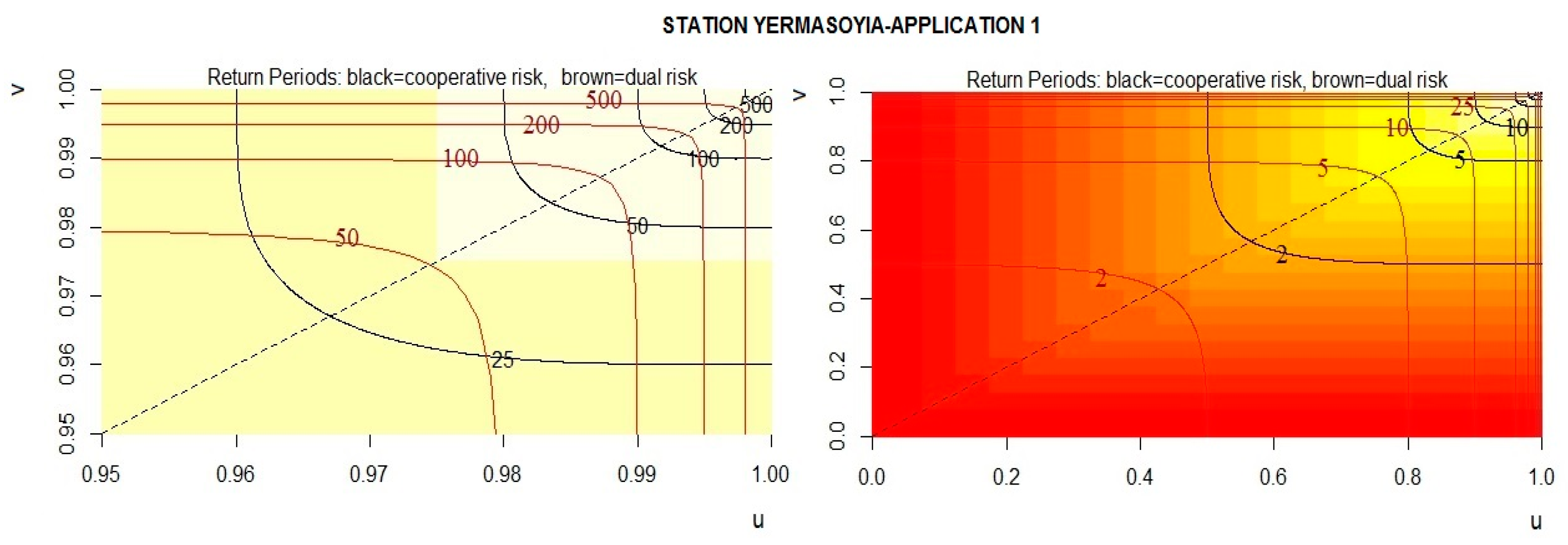
3.2. Bivariate Analysis
4. Concluding Remarks
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Zhang, L.; Singh, V.P. Bivariate rainfall frequency distributions using Archimedean copulas. J. Hydrol. 2007, 332, 93–109. [Google Scholar] [CrossRef]
- De Michele, C.; Salvadori, G. A Generalized Pareto intensity-duration model of storm rainfall exploiting 2-Copulas. J. Geophys. Res. Atmos. 2003, 108. [Google Scholar] [CrossRef]
- Favre, A.C.; El Adlouni, S.; Perreault, L.; Thiémonge, N.; Bobée, B. Multivariate hydrological frequency analysis using copulas. Water Resour. Res. 2004, 40, W01101. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Frequency analysis via copulas: Theoretical aspects and applications to hydrological events. Water Resour. Res. 2004, 40. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C.; Kottegoda, N.T.; Rosso, R. Extremes in Nature. An Approach Using Copulas; Springer: Dordrecht, The Netherlands, 2007; Volume 56, p. 292. [Google Scholar]
- Genest, C.; Favre, A.C. Everything You Always Wanted to Know about Copula Modeling but Were Afraid to Ask. J. Hydrol. Eng. 2007, 12, 347–368. [Google Scholar] [CrossRef]
- Juri, A.; Wüthrich, M.V. Copula convergence theorems for tail events. Insur. Math. Econ. 2002, 30, 405–420. [Google Scholar] [CrossRef]
- Papaioannou, G.S.; Kohnová, T.; Bacigal, J.; Szolgay, K.; Hlavčová, A.; Loukas, A. Joint Modelling of Flood Peaks and Volumes: A Copula Application for the Danube River. J. Hydrol. Hydromech. 2016, 64, 382–392. [Google Scholar] [CrossRef]
- Sklar, A. Fonctions de répartition à n dimensions et leurs marges. Publ. Inst. Stat. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Gräler, B.; Vandenberghe, S.; Petroselli, A.; Grimaldi, S.; Baets, B.D.; Verhoest, N.E.C. Multivariate return periods in hydrology: A critical and practical review focusing on synthetic design hydrograph estimation. Hydrol. Earth Syst. Sci. 2013, 17, 1281–1296. [Google Scholar] [CrossRef]
- Salvadori, G. Bivariate return periods via 2-copulas. Stat. Methodol. 2004, 1, 129–144. [Google Scholar] [CrossRef]
- Hrissanthou, V. Comparative application of two mathematical models to predict sedimentation in Yermasoyia Reservoir, Cyprus. Hydrol. Process. 2006, 20, 3939–3952. [Google Scholar] [CrossRef]
- Lyne, V.; Hollick, M. Stochastic time-variable rainfall-runoff modeling. In Proceedings of the Hydrology and Water Resources Symposium, Perth, Australia, 10–12 September 1979; pp. 89–92. [Google Scholar]
- Genest, C.; Rémillard, B.; Beaudoin, D. Goodness-of-fit tests for copulas: A review and a power study. Insur. Math. Econ. 2009, 44, 199–213. [Google Scholar] [CrossRef]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Second International Symposium on Information Theory; Petrov, B.N., Csaki, F., Eds.; Academiai Kiado: Budapest, Hungary, 1973; pp. 267–281. [Google Scholar]
- Brunner, M.I.; Favre, A.C.; Seibert, J. Bivariate return periods and their importance for flood peak and volume estimation. Wiley Interdiscip. Rev. Water 2016, 3, 819–833. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C.; Durante, F. On the return period and design in a multivariate framework. Hydrol. Earth Syst. Sci. 2011, 15, 3293–3305. [Google Scholar] [CrossRef]
- Salvadori, G.; Durante, F.; Tomasicchio, G.R.; D’Alessandro, F. Practical guidelines for the multivariate assessment of the structural risk in coastal and offshore engineering. Coast. Eng. 2014, 95, 77–83. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Return Level (Years): | 2 | 5 | 10 | 25 | 50 | 100 | 200 | 500 |
| AMS Sampling | ||||||||
| Peak Discharge (m3/s) | 5.14 | 10.34 | 15.53 | 25.09 | 35.28 | 49.05 | 67.73 | 103.01 |
| Flood Volume (106 m3) | 1.26 | 2.93 | 4.20 | 5.87 | 7.13 | 8.39 | 9.66 | 11.33 |
| POT Sampling | ||||||||
| Peak Discharge (m3/s) | 1.77 | 5.37 | 9.53 | 18.01 | 27.81 | 41.97 | 62.44 | 104.12 |
| Flood Volume (106 m3) | 1.43 | 2.58 | 3.52 | 4.89 | 6.05 | 7.32 | 8.72 | 10.79 |
| Return Level (Years): | 2 | 5 | 10 | 25 | 50 | 100 | 200 | 500 |
| AMS Sampling | ||||||||
| Peak Discharge/dual (m3/s) | 4.46 | 8.98 | 13.53 | 21.87 | 31.14 | 43.41 | 58.01 | 93.07 |
| Peak Discharge/cooperative (m3/s) | 5.86 | 11.47 | 17.07 | 27.39 | 38.42 | 53.35 | 75.06 | 108.06 |
| Flood Volume/dual (106 m3) | 1.01 | 2.59 | 3.82 | 5.49 | 6.72 | 7.98 | 9.34 | 10.84 |
| Flood Volume/cooperative (106 m3) | 1.53 | 3.28 | 4.57 | 6.26 | 7.52 | 8.78 | 9.99 | 11.93 |
| Return Level (Years): | 2 | 5 | 10 | 25 | 50 | 100 | 200 | 500 |
| POT Sampling | ||||||||
| Peak Discharge/dual (m3/s) | 1.77 | 5.18 | 8.82 | 15.25 | 22.21 | 31.89 | 44.69 | 70.86 |
| Peak Discharge/cooperative (m3/s) | 5.31 | 8.80 | 12.69 | 20.92 | 30.85 | 45.56 | 66.26 | 110.35 |
| Flood Volume/dual (106 m3) | 0.28 | 1.16 | 2.43 | 4.22 | 5.53 | 6.88 | 8.36 | 10.47 |
| Flood Volume/cooperative (106 m3) | 1.46 | 2.68 | 3.72 | 5.32 | 6.67 | 8.12 | 9.79 | 12.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stamatatou, N.; Vasiliades, L.; Loukas, A. Bivariate Flood Frequency Analysis Using Copulas. Proceedings 2018, 2, 635. https://doi.org/10.3390/proceedings2110635
Stamatatou N, Vasiliades L, Loukas A. Bivariate Flood Frequency Analysis Using Copulas. Proceedings. 2018; 2(11):635. https://doi.org/10.3390/proceedings2110635
Chicago/Turabian StyleStamatatou, Nikoletta, Lampros Vasiliades, and Athanasios Loukas. 2018. "Bivariate Flood Frequency Analysis Using Copulas" Proceedings 2, no. 11: 635. https://doi.org/10.3390/proceedings2110635
APA StyleStamatatou, N., Vasiliades, L., & Loukas, A. (2018). Bivariate Flood Frequency Analysis Using Copulas. Proceedings, 2(11), 635. https://doi.org/10.3390/proceedings2110635