Identification of Annual Water Demand Patterns in the City of Naples †



 and
and 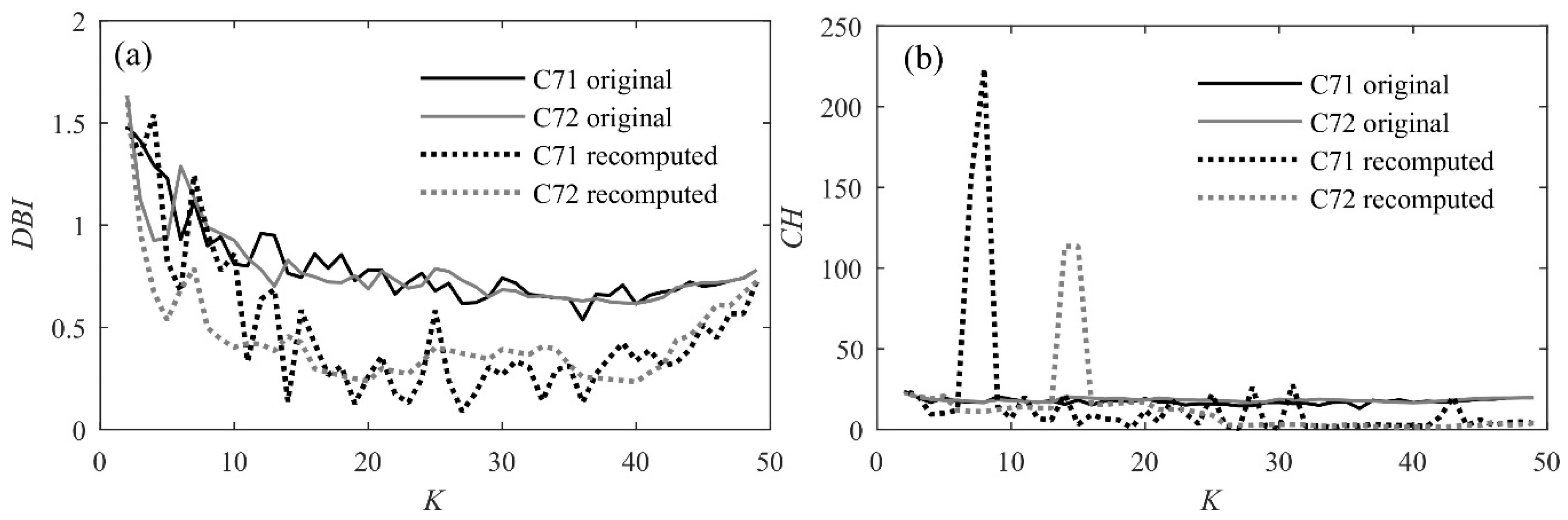{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Description
2.2. Clustering
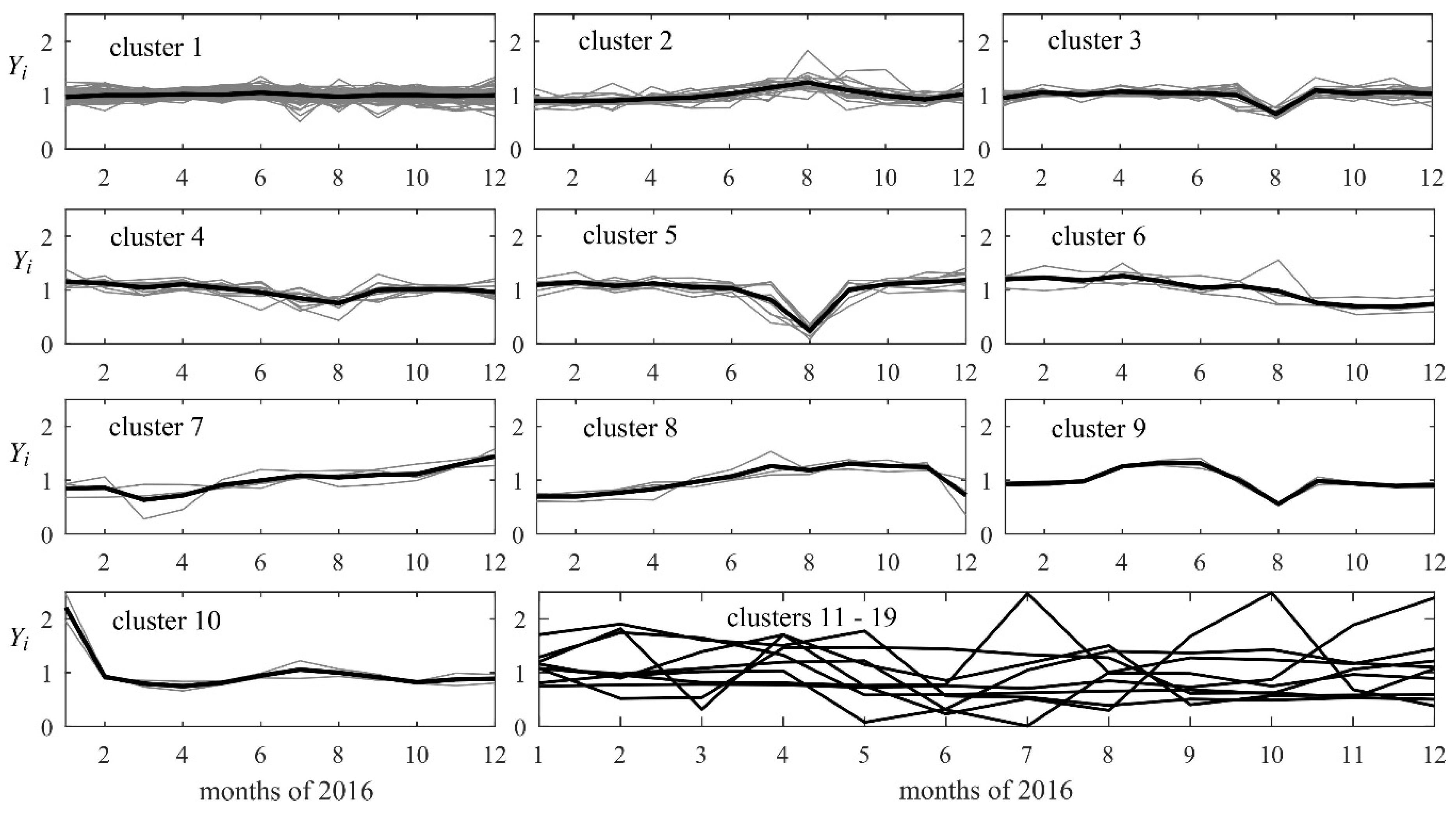
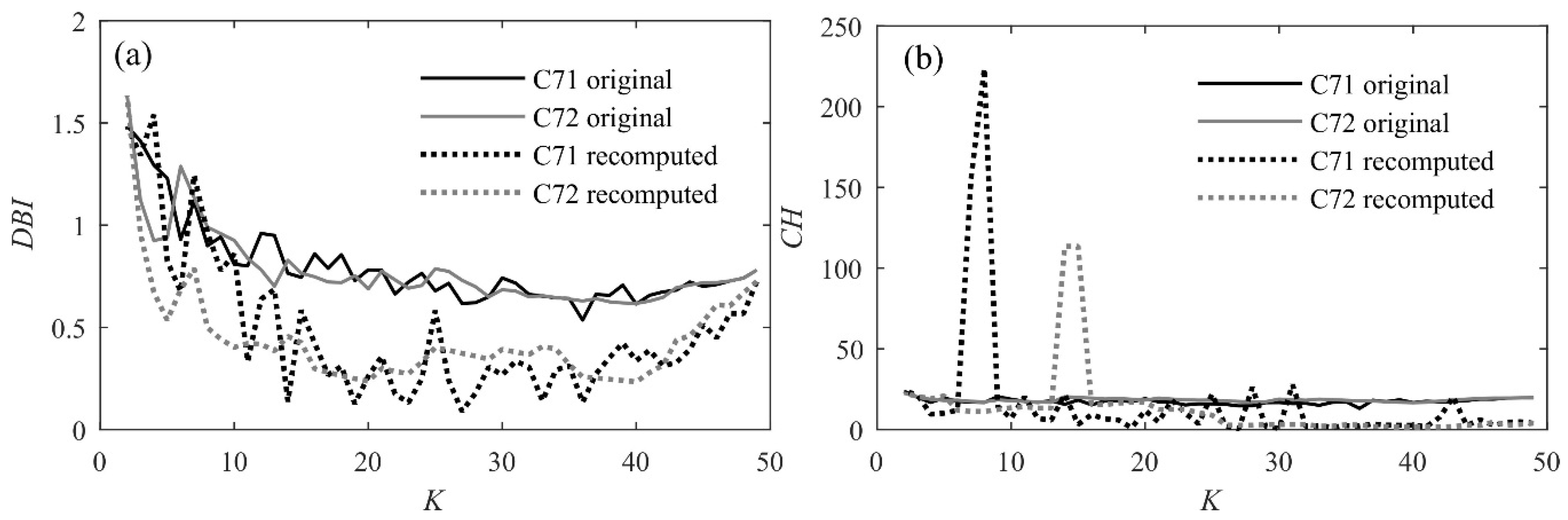
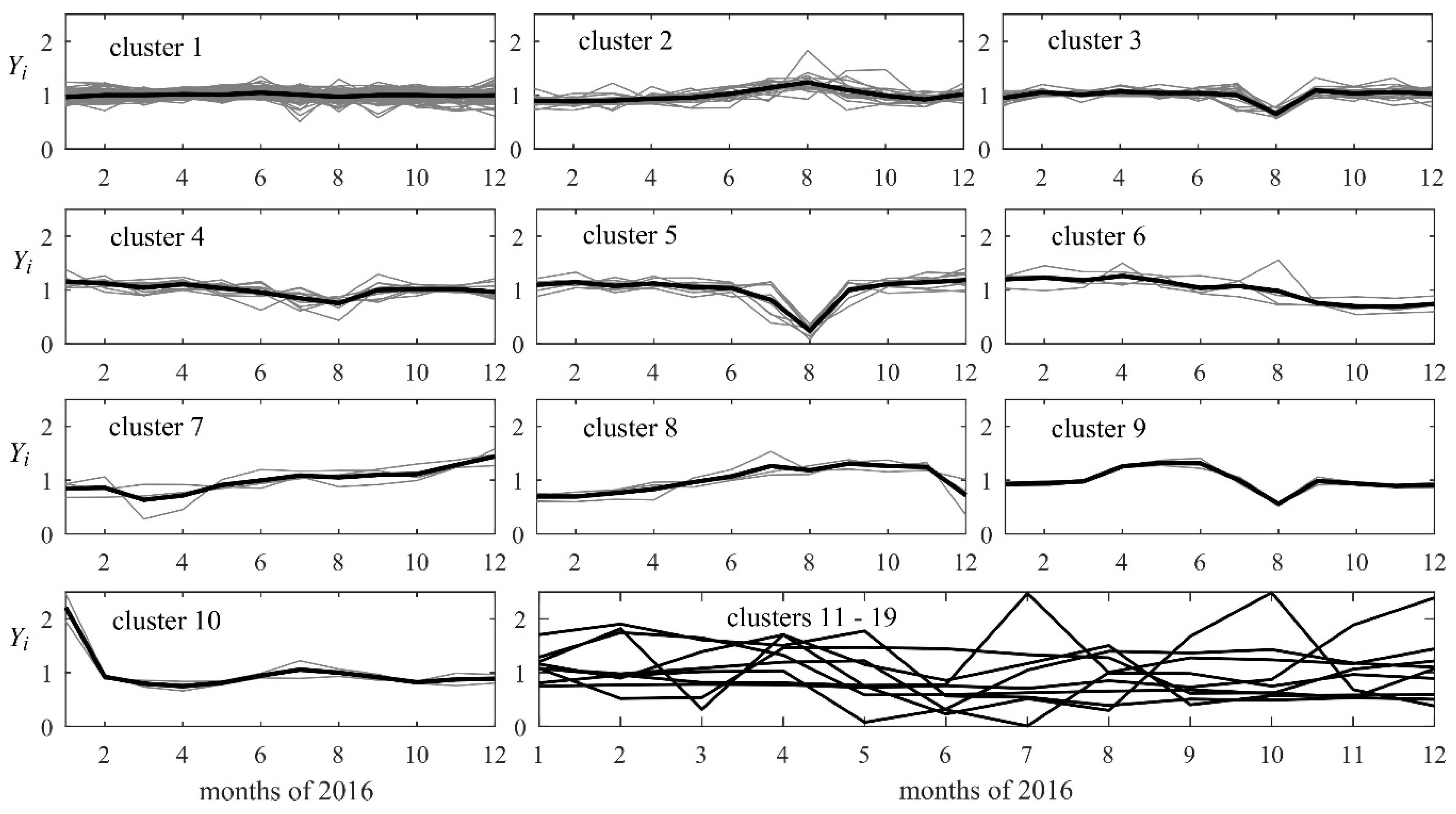
3. Discussion of Results
- As 1st-level clustering, a SOM is run with grid dimension set to a, so that the maximum allowed number of clusters is a2. To minimize random errors, SOM is run 10 times and the best result is chosen as the one that minimizes the sum of distances data/cluster centroid. For each cluster, the centroid is computed as the mean of all the patterns in the cluster.
- As 2nd-level clustering, another clustering method (K-means for d = 1, dendrogram if d = 2) is run where the a2 centroids are used as the input and K2 is set to a value b ranging between 2 and a2-1. K-means is run 10 times with K2 = b and for each run the algorithm replicates are set to 1000, in order to reach convergence and minimize the influence of initial points (same parameters were used for model A). Again, the best result is chosen as the one that minimizes the sum of distances data/cluster centroid. If the dendrogram is used, K2 is set to b and there is no need to iterate computations, since the method is only based on initial distances.
- Finally, the original 168 patterns that were used as the input for 1st-level clustering are reassigned to the b new clusters, and DBI and CH can be computed with reference to the final partition, called “cluster solution”.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gargano, R.; Tricarico, C.; Del Giudice, G.; Granata, F. A stochastic model for daily residential water demand. Water Sci. Technol. Water Supply 2016, 16, 1753–1767. [Google Scholar] [CrossRef]
- Rasanen, T.; Voukantsis, D.; Niska, H.; Karatzas, K.; Kolehmainen, M. Data-based method for creating electricity use load profiles using large amount of customer-specific hourly measured electricity use data. Appl. Energy 2010, 87, 3538–3545. [Google Scholar] [CrossRef]
- Lopez, J.J.; Aguado, J.A.; Martín, F.; Munoz, F.; Rodríguez, A.; Ruiz, J.E. Hopfield-K-Means clustering algorithm: A proposal for the segmentation of electricity customers. Electr. Power Syst. Res. 2011, 81, 716–724. [Google Scholar] [CrossRef]
- Ferreira, A.M.S.; Cavalcante, C.A.M.T.; Fontes, C.H.O.; Marambio, J.E.S. A new method for pattern recognition in load profiles to support decision-making in the management of the electric sector. Electr. Power Energy Syst. 2013, 53, 821–831. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, S.; Shen, C. A review of electric load classification in smart grid environment. Renew. Sustain. Energy Rev. 2013, 24, 103–110. [Google Scholar] [CrossRef]
- Macedo, M.N.Q.; de Almeida, G.J.J.M.; de Lima, A.C. Demand side management using artificial neural networks in a smart grid environment. Renew. Sustain. Energy Rev. 2015, 41, 128–133. [Google Scholar] [CrossRef]
- Avni, N.; Fishbain, B.; Shamir, U. Water consumption patterns as a basis for water demand modeling. Water Resour. Res. 2015, 51, 8165–8181. [Google Scholar] [CrossRef]
- McKenna, S.A.; Fusco, F.; Eck, B.J. Water demand pattern classification from smart meter data. Procedia Eng. 2014, 70, 1121–1130. [Google Scholar] [CrossRef]
- Sancho-Asensio, A.; Navarro, J.; Arrieta-Salinas, I.; Armendáriz-Íñigo, J.E.; Jiménez-Ruano, V.; Zaballos, A.; Golobardes, E. Improving data partition schemes in Smart Grids via clustering data streams. Expert Syst. Appl. 2014, 41, 5832–5842. [Google Scholar] [CrossRef]
- Keogh, E.; Chakrabarti, K.; Pazzani, M.J.; Mehrotra, S. Locally adaptive dimensionality reduction for indexing large time series databases. ACM Sigmod Rec. 2001, 30, 151–162. [Google Scholar] [CrossRef]
- Yiakopoulos, C.T.; Gryllias, K.C.; Antoniadis, I.A. Rolling element bearing fault detection in industrial environments based on a K-means clustering approach. Expert Syst. Appl. 2011, 38, 2888–2911. [Google Scholar] [CrossRef]
- Benaichouche, A.N.; Oulhadj, H.; Siarry, P. Improved spatial fuzzy c-means clustering for image segmentation using PSO initialization, Mahalanobis distance and post-segmentation correction. Digit. Signal Process. 2013, 23, 1390–1400. [Google Scholar] [CrossRef]
- Huhtala, Y.; Karkkainen, J.; Toivonen, H. Mining for similarities in aligned time series using wavelets. In Data Mining and Knowledge Discovery: Theory, Tools, and Technology; SPIE Proceedings Series; SPIE: Orlando, FL, USA, 1999; Volume 3695, pp. 150–160. [Google Scholar]
- Keogh, E.; Smyth, P. A probabilistic approach to fast pattern matching in time series databases. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data-Mining, Newport Beach, CA, USA, 14–17 August 1997; pp. 20–24. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965. [Google Scholar]
- Johnson, J.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef]
- Jota, P.R.S.; Silva, V.R.B.; Jota, F.G. Building load management using cluster and statistical analyses. Electr. Power Energy Syst. 2011, 33, 1498–1505. [Google Scholar] [CrossRef]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Kalteh, A.M.; Hjorth, P.; Berndtsson, R. Review of the self-organizing map (SOM) approach in water resources: Analysis, modelling and application. Environ. Model. Softw. 2008, 23, 835–845. [Google Scholar] [CrossRef]
- Verdú; SV; García, M. O.; Senabre, C.; Marín, A.G.; Garcìa Franco, F.J. Classification, filtering, and identification of electrical customer load patterns through the use of Self-Organizing Maps. IEEE Trans. Power Syst. 2006, 21, 1672–1682. [Google Scholar] [CrossRef]
- Laspidou, C.; Papageorgiou, E.; Kokkinos, K.; Sahu, S.; Gupta, A.; Tassiulas, L. Exploring patterns in water consumption by clustering. Procedia Eng. 2015, 119, 1439–1446. [Google Scholar] [CrossRef]
- Schikuta, E. Grid-clustering: An efficient hierarchical clustering method for very large data sets. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996; pp. 101–105. [Google Scholar]
- Dimitriadou, E.; Dolnicar, S.; Weingessel, A. An examination of indexes for determining the number of clusters in binary data sets. Psychometrika 2002, 67, 137–160. [Google Scholar] [CrossRef]
- Calinski, R.B.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Davies, D.; Bouldin, D. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 2, 224–227. [Google Scholar] [CrossRef]
- Lebart, L.; Morineau, A.; Piron, M. Statistique Exploratoire Multidimensionnelle; Dunod: Paris, France, 2004. [Google Scholar]
- Bocci, L.; Mingo, I. Clustering large data set: An applied comparative study. In Advanced Statistical Methods for the Analysis of Large Data-Sets; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–12. [Google Scholar]
- Padulano, R.; Del Giudice, G. A mixed strategy based on Self-Organizing Map for water demand pattern profiling of large-size smart water grid data. Water Resour. Manag. 2018, 32, 3671–3685. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Padulano, R.; Giudice, G.D.; Giugni, M.; Fontana, N.; Uberti, G.S.D. Identification of Annual Water Demand Patterns in the City of Naples. Proceedings 2018, 2, 587. https://doi.org/10.3390/proceedings2110587
Padulano R, Giudice GD, Giugni M, Fontana N, Uberti GSD. Identification of Annual Water Demand Patterns in the City of Naples. Proceedings. 2018; 2(11):587. https://doi.org/10.3390/proceedings2110587
Chicago/Turabian StylePadulano, Roberta, Giuseppe Del Giudice, Maurizio Giugni, Nicola Fontana, and Gianluca Sorgenti Degli Uberti. 2018. "Identification of Annual Water Demand Patterns in the City of Naples" Proceedings 2, no. 11: 587. https://doi.org/10.3390/proceedings2110587
APA StylePadulano, R., Giudice, G. D., Giugni, M., Fontana, N., & Uberti, G. S. D. (2018). Identification of Annual Water Demand Patterns in the City of Naples. Proceedings, 2(11), 587. https://doi.org/10.3390/proceedings2110587