



FGFNet: Fourier Gated Feature-Fusion Network with Fractal Dimension Estimation for Robust Palm-Vein Spoof Detection


Abstract
1. Introduction
- -
- This is the first study in the field of palm-vein recognition to generate fake palm-vein images that retain both visual and class identity information of real palm-vein images and propose a spoof detection method for them. To achieve this, we introduce a novel Fourier-gated feature-fusion network (FGFNet) for spoof detection.
- -
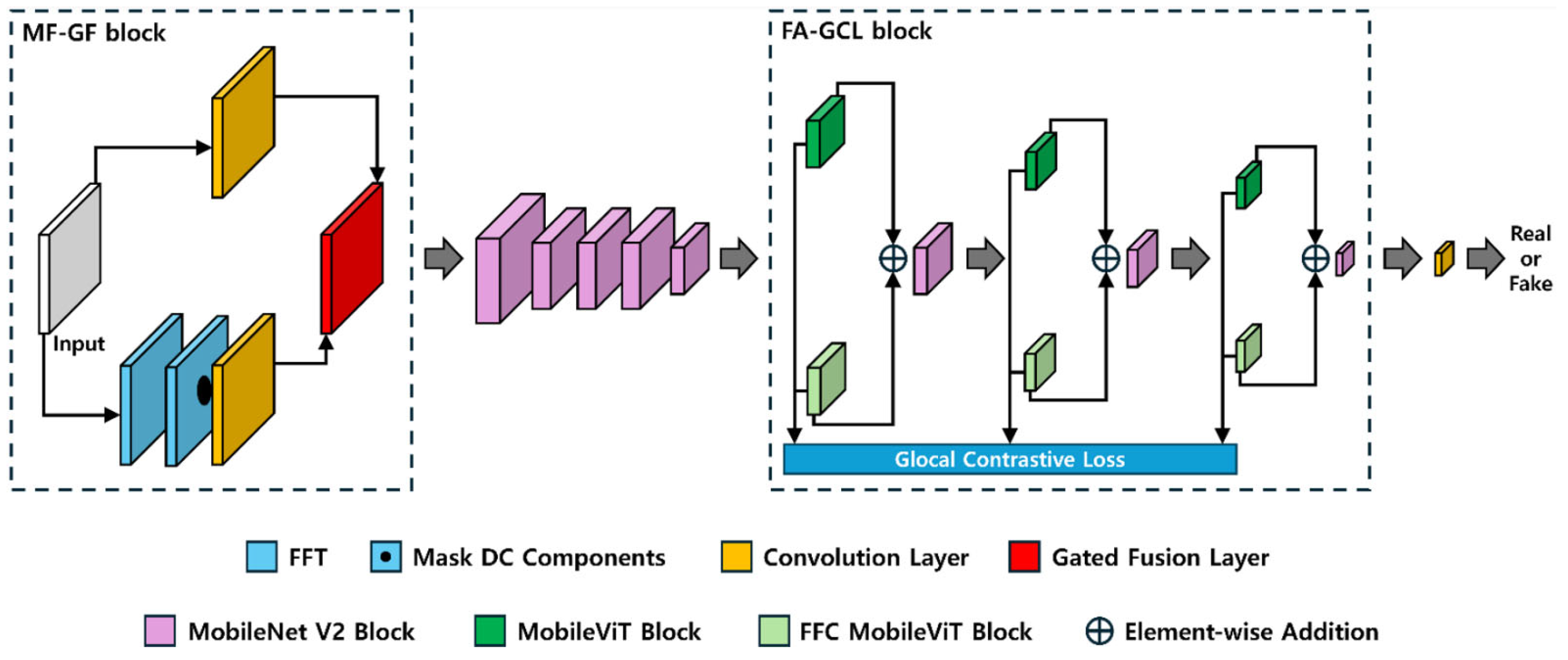
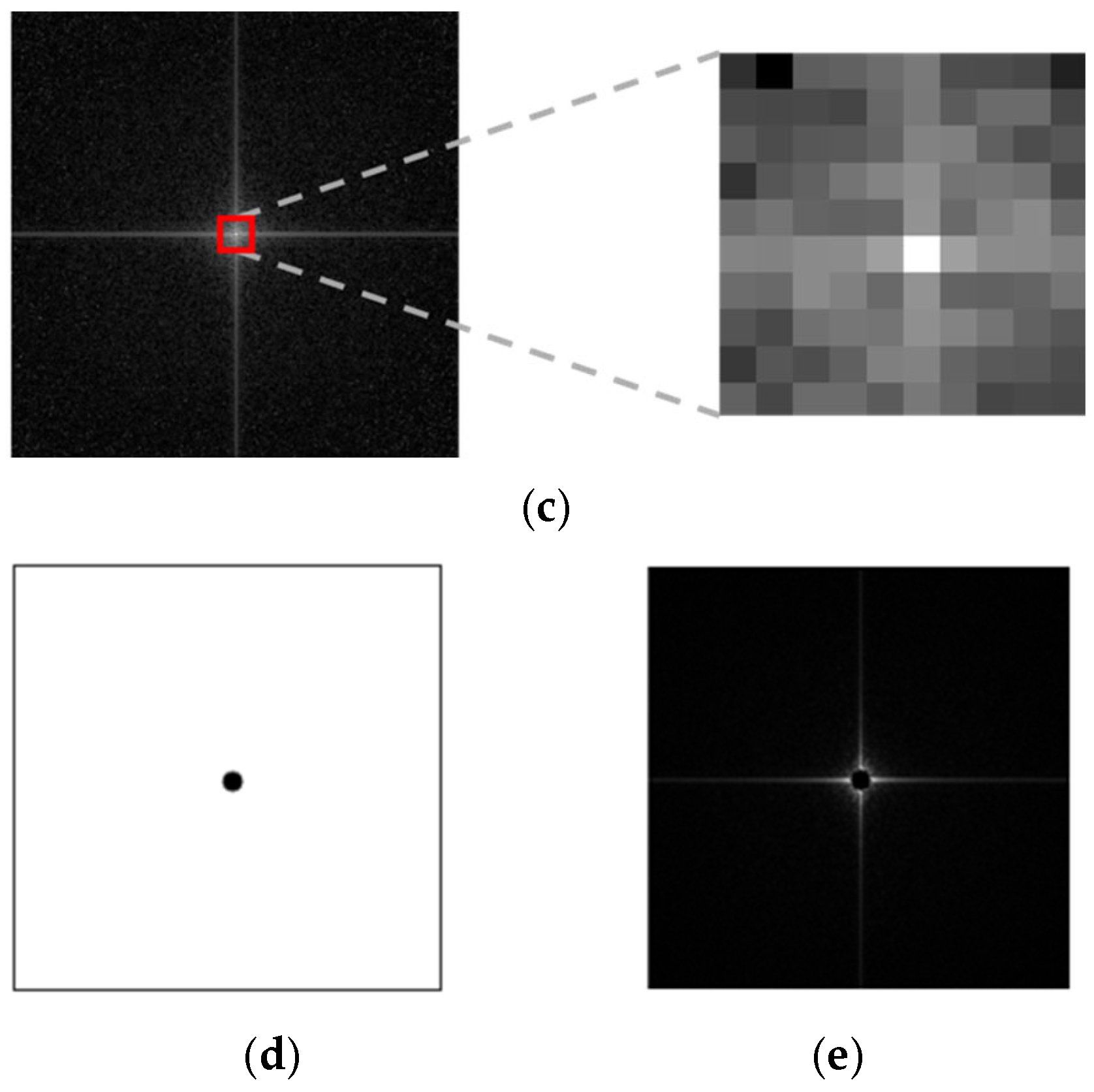
- Generated fake palm-vein images typically contain traces of GAN fingerprints in high-frequency components. To extract these feature maps, the proposed FGFNet incorporates a masked fast Fourier transform (FFT) map-based gated feature fusion (MF-GF) block. In this block, feature maps are obtained by applying convolution separately to a masked FFT image with direct current (DC) components removed and an RGB image in the palm-vein region of interest (ROI). Gated fusion is then used to emphasize the high-frequency components of fake images in the final feature map.
- -
- As mentioned earlier, to simultaneously extract global information from the blurry and low-quality real palm-vein images and local information from fake images, we propose the fast Fourier convolution (FFC) attention with global contrastive loss (FA-GCL) block. In FA-GCL, both global features obtained through FFC and local features obtained through conventional convolution are extracted using contrastive loss-based correlation between the two feature types.
- -
- Fractal dimension estimation (FDE) is employed both to assess the structural realism of the generated fake palm-vein images and to quantitatively validate the spoof detection performance of FGFNet, thereby reinforcing the effectiveness of both the generation and detection processes. In addition, the fake palm-vein images generated in this study, along with the proposed model and algorithm codes, are shared via a GitHub repository [7] to facilitate fair performance evaluation by other researchers.
2. Related Work
2.1. Spoof Detection Robust to Fake Fabricated Artifacts
2.1.1. Using Handcrafted Features and Machine Learning Algorithms
2.1.2. Using Deep Learning Algorithms
2.2. Spoof Detection Robust to Fake Generated Images
3. Proposed Method
3.1. Overall Procedure of Proposed Method
3.2. Pre-Processing of Palm-Vein Image
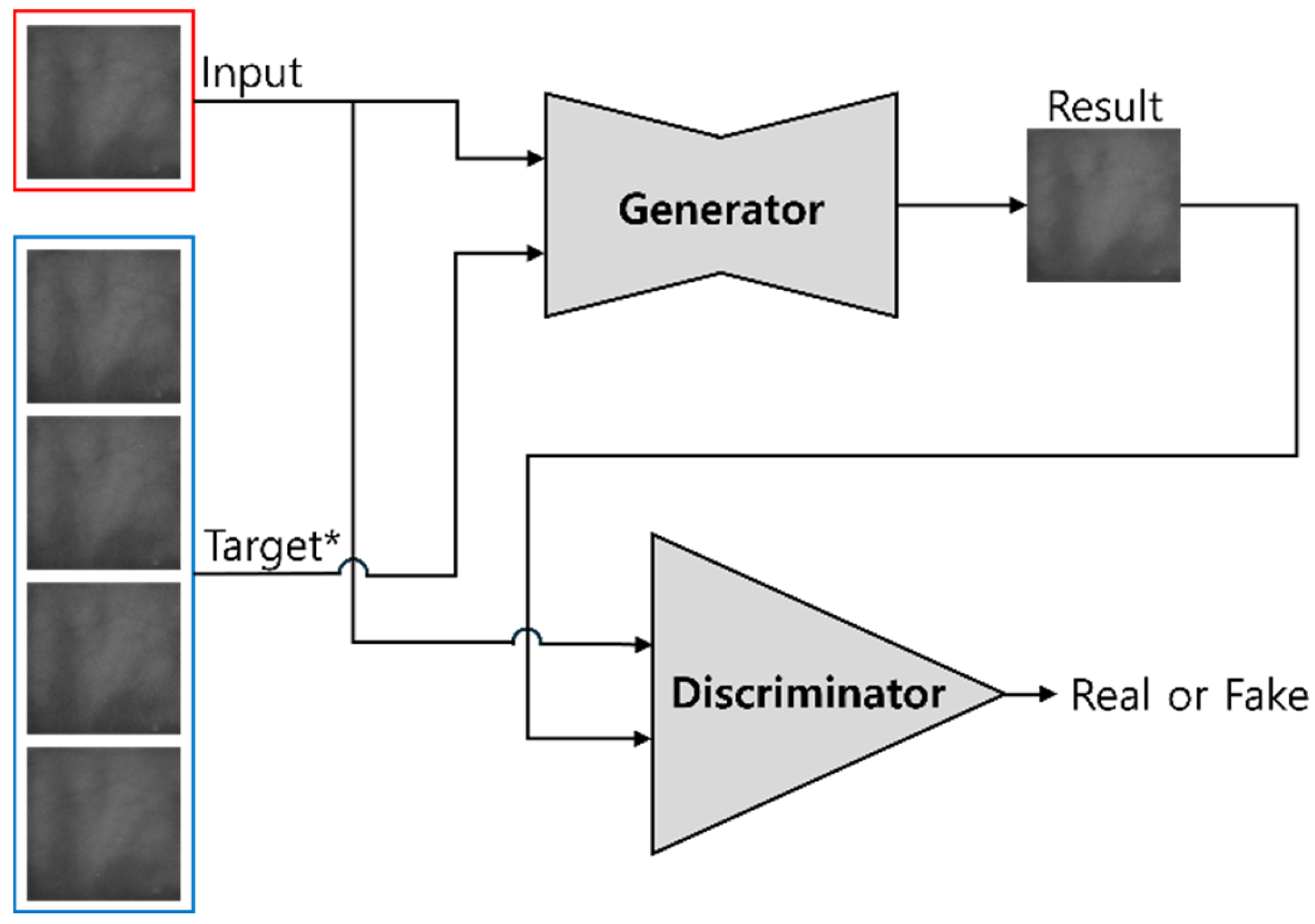
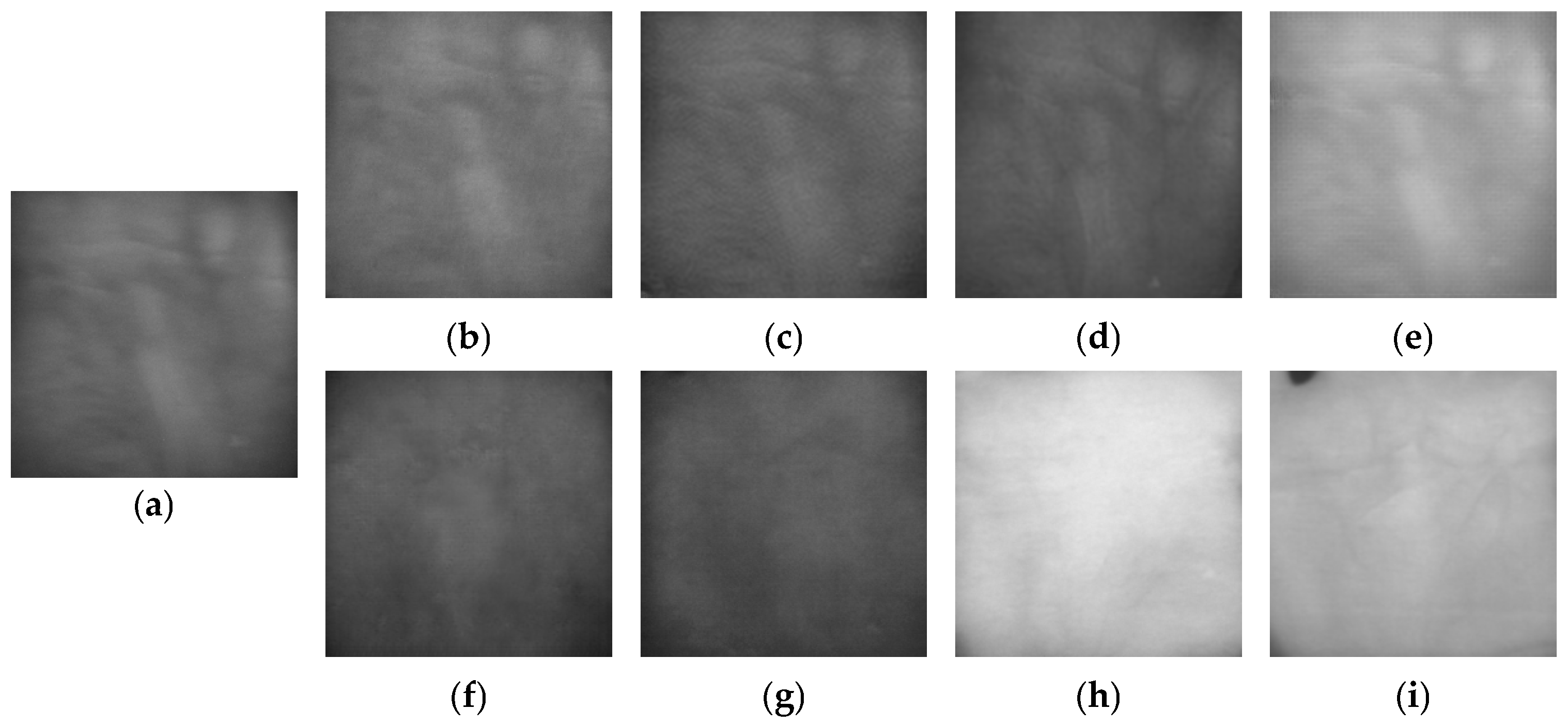
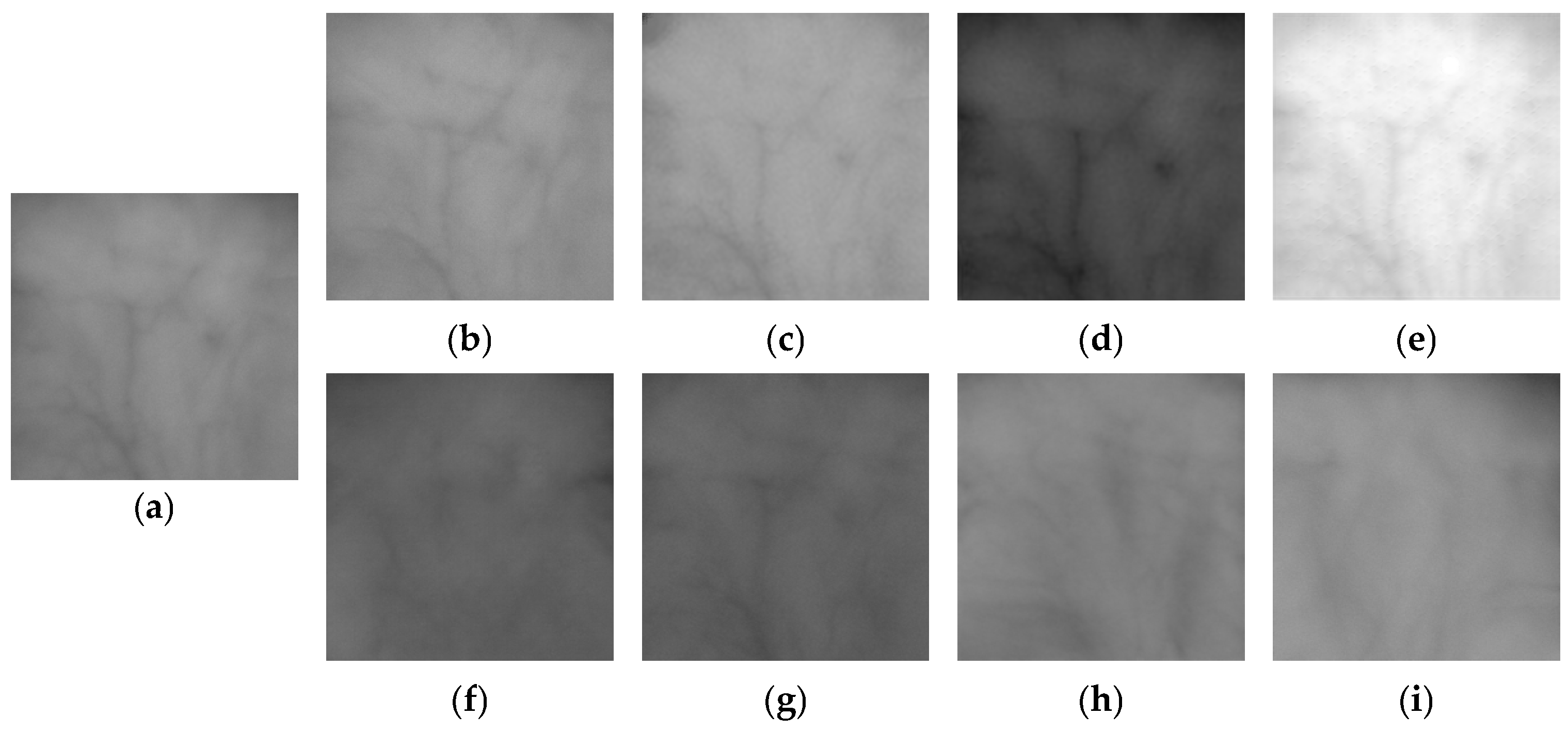
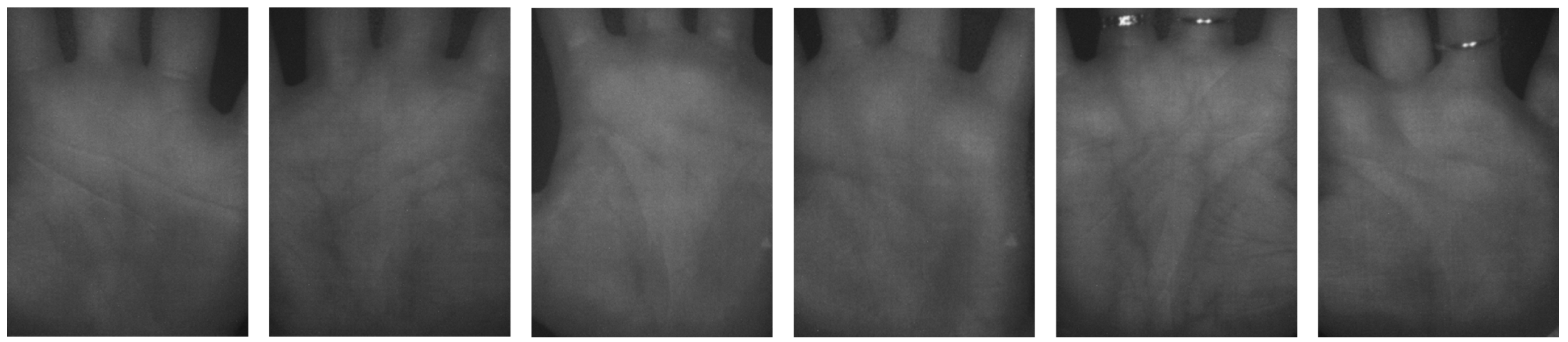
3.3. Generation of Fake Palm-Vein Image for Spoof Attack
3.4. Post-Processing of Fake Palm-Vein Images
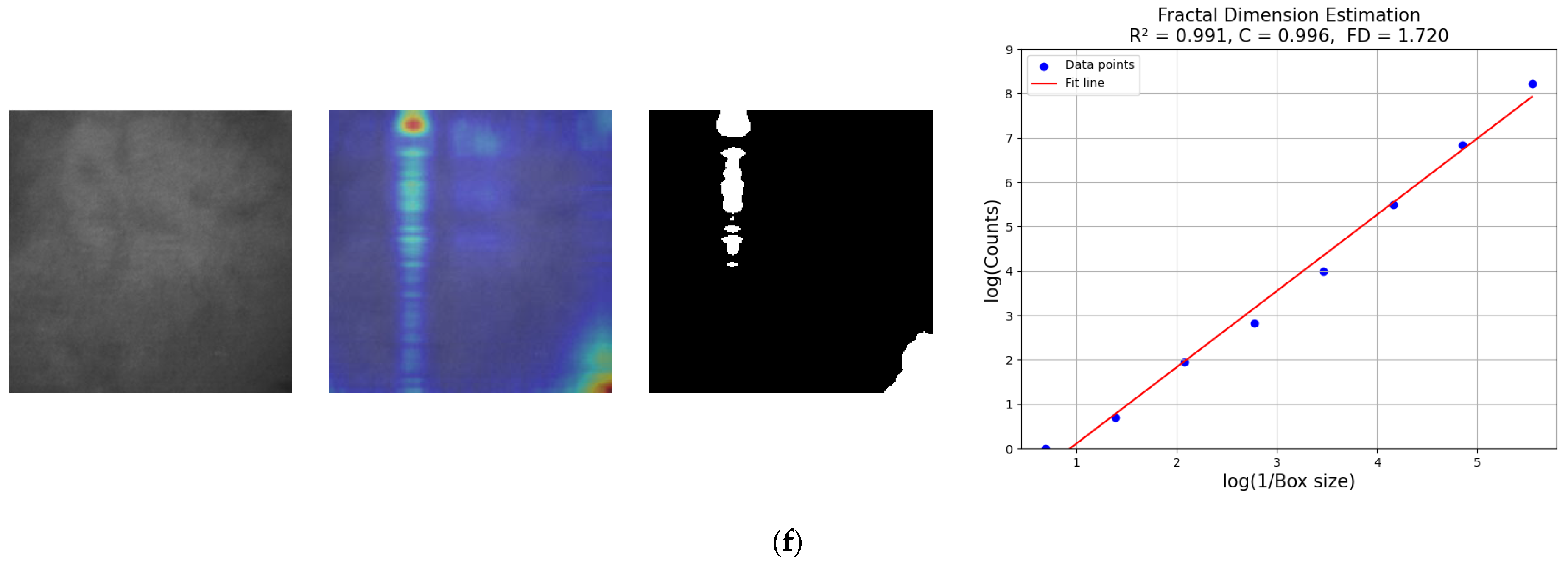
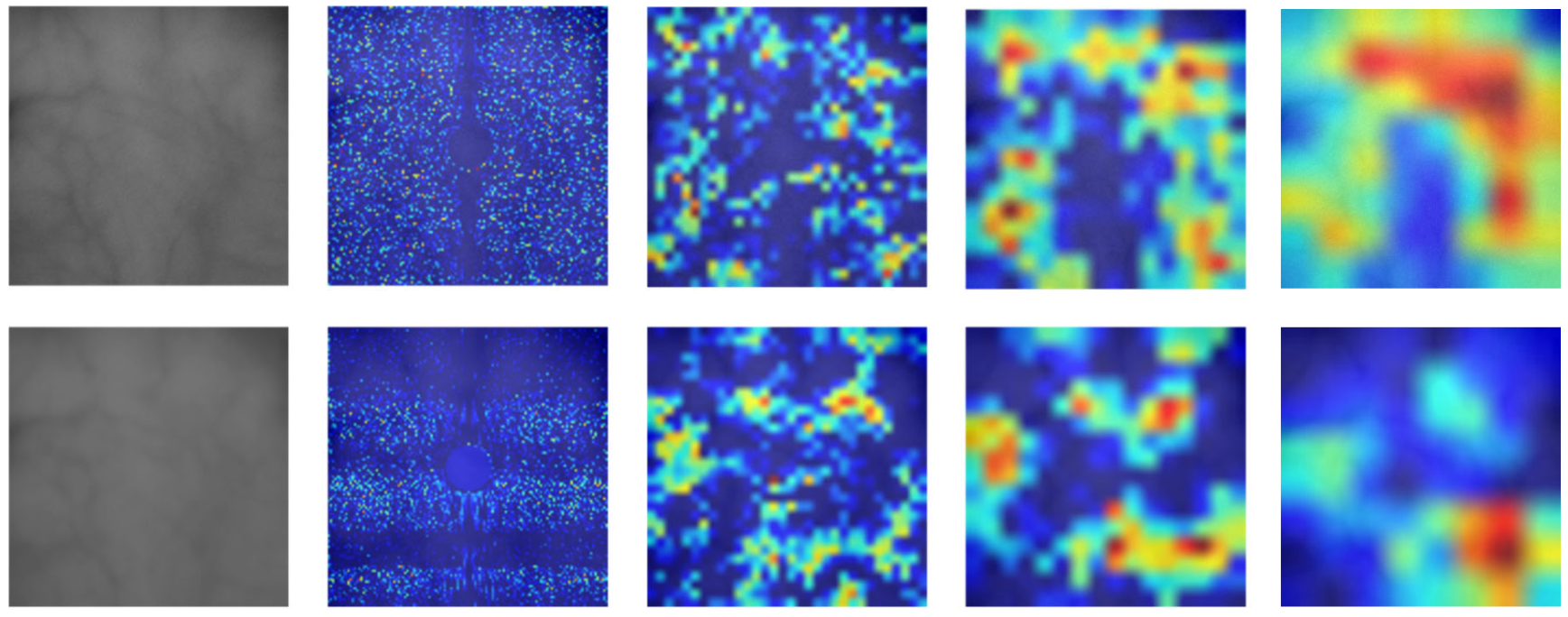
3.5. Fractal Dimension Estimation
| Algorithm 1 Pseudocode for FDE |
| Input: Binary_CAM: Binary class activation map extracted from CycleGAN’s encoder or FGFNet Output: FD: Fractal dimension 1: Determine the maximum dimension of the box and round it to the nearest power of 2 Max_dimension = max(size(Binary_CAM)) = 2[log2(Max_dimension)] 2: If the image size is smaller than , apply padding to align it with the dimensions of if size(Binary_CAM) < size() Padding_width = ((0, − Binary_CAM.shape [0]), (0, − Binary_CAM.shape [1])) Padding_Binary_CAM = pad(Binary_CAM, Padding_width, mode = ‘constant’, constant_values = 0) else Padding_Binary_CAM = Binary_CAM 3: Initialize an array to record the box counts for each dimension scale. n = zeros(1, + 1) 4: Determine , the number of boxes at scale that intersect with the positive region n[ + 1] = sum(Binary_CAM [:]) 5: While > 1: a. Reduce the size of by a factor of 2. b. Update with the latest result. 6: Compute log-values of box counts and scales for each . 7: Perform least squares fitting on [(, ]. 8: FD is defined as the slope of the fitted log-log line. Return FD |
3.6. Spoof Detection by FGFNet
3.6.1. MF-GF Block
3.6.2. FA-GCL Block
4. Experimental Results
4.1. Experimental Datasets and Environments
4.2. Training of Proposed Framework
4.2.1. Training of CycleGAN for the Generation of Fake Palm-Vein Images
4.2.2. Training of FGFNet for Spoof Detection
4.3. Evaluation Metrics
4.3.1. Evaluation of the Quality of Fake Palm-Vein Images
4.3.2. Evaluation of Spoof Detection Accuracy
4.4. Testing of Spoof Attack Method
4.4.1. Quality Assessment of Generated Fake Palm-Vein Images by FID and LPIPS
4.4.2. Quality Assessment of Generated Fake Palm-Vein Images by FDE
4.4.3. Comparisons of Spoof Detection Accuracies on the Fake Generated Images by CycleGAN and SOTA Methods
4.5. Testing of Spoof Detection Method
4.5.1. Ablation Studies of FGFNet
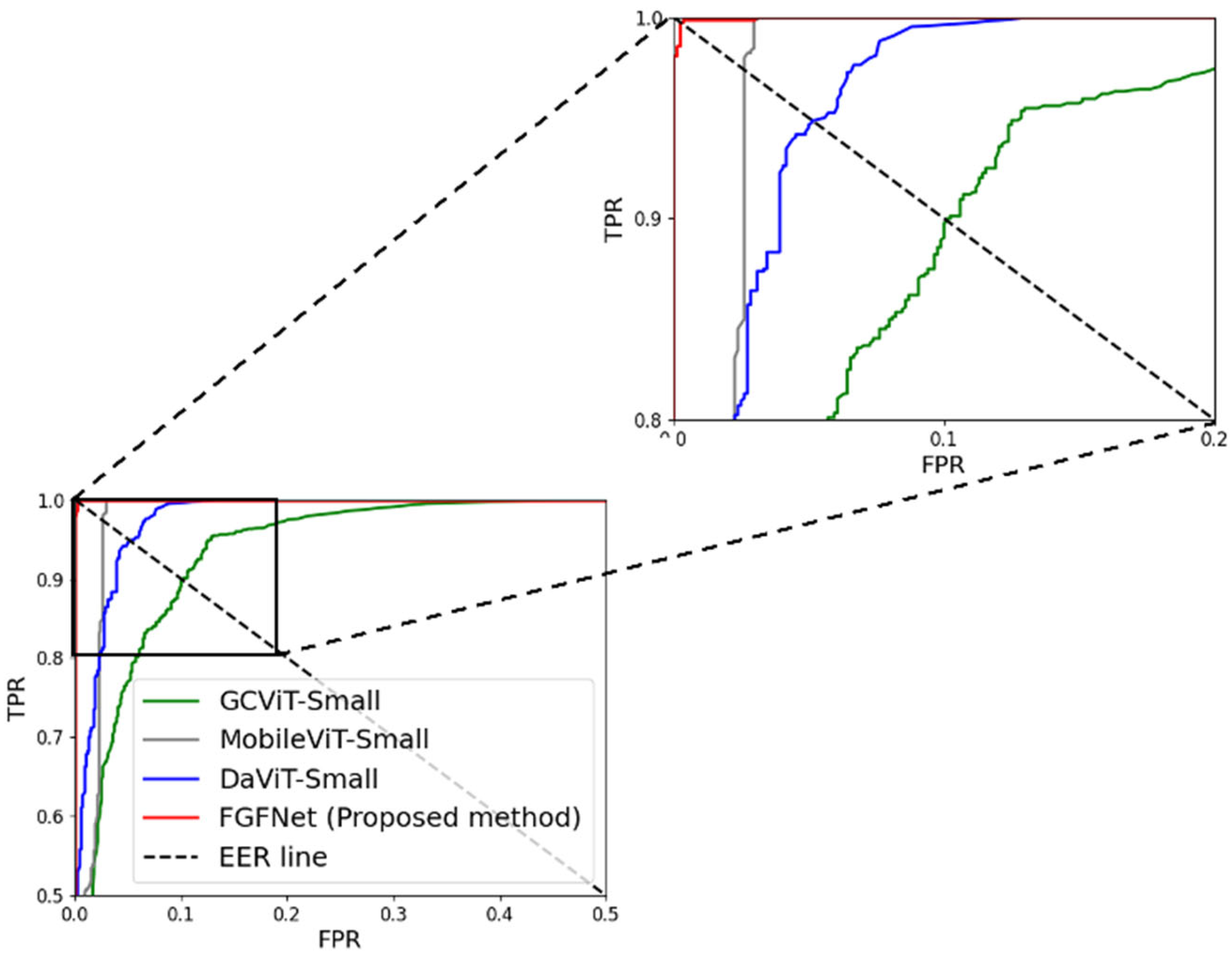
4.5.2. Comparisons with SOTA Approaches
4.5.3. Cross-Generator and Cross-Detector Evaluations
4.6. Comparisons of Processing Time and Algorithm Complexity
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nguyen, D.T.; Park, Y.H.; Shin, K.Y.; Kwon, S.Y.; Lee, H.C.; Park, K.R. Spoof detection for finger-vein recognition system using NIR camera. Sensors 2017, 17, 2261. [Google Scholar] [CrossRef]
- Choi, J.; Hong, J.S.; Kim, S.G.; Park, C.; Nam, S.H.; Park, K.R. RMOBF-Net: Network for the restoration of motion and optical blurred finger-vein images for improving recognition accuracy. Mathematics 2022, 10, 3948. [Google Scholar] [CrossRef]
- Hong, J.S.; Choi, J.; Kim, S.G.; Owais, M.; Park, K.R. INF-GAN: Generative adversarial network for illumination normalization of finger-vein images. Mathematics 2021, 9, 2613. [Google Scholar] [CrossRef]
- Kim, S.G.; Choi, J.; Hong, J.S.; Park, K.R. Spoof detection based on score fusion using ensemble networks robust against adversarial attacks of fake finger-vein images. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 9343–9362. [Google Scholar] [CrossRef]
- Kim, S.G.; Hong, J.S.; Kim, J.S.; Park, K.R. Estimation of Fractal Dimension and Detection of Fake Finger-Vein Images for Finger-Vein Recognition. Fractal Fract. 2024, 8, 646. [Google Scholar] [CrossRef]
- Yang, J.; Wong, W.K.; Fei, L.; Zhao, S.; Wen, J.; Teng, S. Decoupling visual and identity features for adversarial palm-vein image attack. Neural Netw. 2024, 180, 106693–106706. [Google Scholar] [CrossRef] [PubMed]
- FGFNet. Available online: https://github.com/SeungguKim98/Palm-Vein-Spoof-Detection/ (accessed on 2 March 2025).
- Nguyen, D.T.; Park, Y.H.; Shin, K.Y.; Kwon, S.Y.; Lee, H.C.; Park, K.R. Fake finger-vein image detection based on Fourier and wavelet transforms. Digit. Signal Process. 2013, 23, 1401–1413. [Google Scholar] [CrossRef]
- Tirunagari, S.; Poh, N.; Bober, M.; Windridge, D. Windowed DMD as a microtexture descriptor for finger vein counter-spoofing in biometrics. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Rome, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Kocher, D.; Schwarz, S.; Uhl, A. Empirical evaluation of LBP-extension features for finger vein spoofing detection. In Proceedings of the International Conference of the Biometrics Special Interest Group, Darmstadt, Germany, 21–23 September 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Bok, J.Y.; Suh, K.H.; Lee, E.C. Detecting fake finger-vein data using remote photoplethysmography. Electronics 2019, 8, 1016. [Google Scholar] [CrossRef]
- Patil, I.; Bhilare, S.; Kanhangad, V. Assessing vulnerability of dorsal hand-vein verification system to spoofing attacks using smartphone camera. In Proceedings of the IEEE International Conference on Identity, Security and Behavior Analysis, Sendai, Japan, 29 February–2 March 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Vedaldi, A.; Fulkerson, B. VLFeat: An open and portable library of computer vision algorithms. In Proceedings of the ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1469–1472. [Google Scholar] [CrossRef]
- Bhilare, S.; Kanhangad, V.; Chaudhari, N. Histogram of oriented gradients based presentation attack detection in dorsal hand-vein biometric system. In Proceedings of the IAPR International Conference on Machine Vision Applications, Nagoya, Japan, 8–12 May 2017; pp. 39–42. [Google Scholar] [CrossRef]
- Tome, J.P.; Marcel, S. On the vulnerability of palm vein recognition to spoofing attacks. In Proceedings of the International Conference on Biometrics, Phuket, Thailand, 19–22 May 2015; pp. 319–325. [Google Scholar] [CrossRef]
- Zhang, W.; Shan, S.; Gao, W.; Chen, X.; Zhang, H. Local Gabor binary pattern histogram sequence (LGBPHS): A novel non-statistical model for face representation and recognition. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 1, pp. 786–791. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 84–90. [Google Scholar] [CrossRef]
- Shaheed, K.; Mao, A.; Qureshi, I.; Abbas, Q.; Kumar, M.; Zhang, X. Finger-vein presentation attack detection using depthwise separable convolution neural network. Expert Syst. Appl. 2022, 198, 116786. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Singh, A.; Jaswal, G.; Nigam, A. FDSNet: Finger dorsal image spoof detection network using light field camera. In Proceedings of the IEEE International Conference on Identity, Security, and Behavior Analysis, Hyderabad, India, 22–24 January 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sajjad, M.; Khan, S.; Hussain, T.; Muhammad, K.; Sangaiah, A.K.; Castiglione, A.; Esposito, C.; Baik, S.W. CNN-based anti-spoofing two-tier multi-factor authentication system. Pattern Recognit. Lett. 2019, 126, 123–131. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar] [CrossRef]
- Guo, M.-H.; Lu, C.-Z.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Vorderleitner, A.; Hämmerle-Uhl, J.; Uhl, A. Hand vein spoof GANs: Pitfalls in the assessment of synthetic presentation attack artefacts. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Chicago, IL, USA, 28–30 June 2023; pp. 133–138. [Google Scholar] [CrossRef]
- Benaim, S.; Wolf, L. One-sided unsupervised domain mapping. In Proceedings of the International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 752–762. [Google Scholar]
- Li, Y.; Ruan, S.; Qin, H.; Deng, S.; El-Yacoubi, M.A. Transformer based defense GAN against palm-vein adversarial attacks. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1509–1523. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar] [CrossRef]
- Wong, E.; Rice, L.; Kolter, J.Z. Fast is better than free: Revisiting adversarial training. arXiv 2020. [Google Scholar] [CrossRef]
- Madry, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar] [CrossRef]
- Kauba, C.; Prommegger, B.; Uhl, A. Combined fully contactless finger and hand vein capturing device with a corresponding dataset. Sensors 2019, 19, 5014. [Google Scholar] [CrossRef] [PubMed]
- Yu, N.; Davis, L.S.; Fritz, M. Attributing fake images to GANs: Learning and analyzing GAN fingerprints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7556–7566. [Google Scholar] [CrossRef]
- Neves, J.C.; Tolosana, R.; Vera-Rodriguez, R.; Lopes, V.; Proença, H.; Fierrez, J. GANprintR: Improved fakes and evaluation of the state of the art in face manipulation detection. IEEE J. Sel. Top. Signal Process. 2020, 14, 1038–1048. [Google Scholar] [CrossRef]
- Brouty, X.; Garcin, M. Fractal properties; information theory, and market efficiency. Chaos Solitons Fractals 2024, 180, 114543. [Google Scholar] [CrossRef]
- Yin, J. Dynamical fractal: Theory and case study. Chaos Solitons Fractals 2023, 176, 114190. [Google Scholar] [CrossRef]
- Crownover, R.M. Introduction to Fractals and Chaos, 1st ed.; Jones & Bartlett Publisher: Burlington, MA, USA, 1995. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar] [CrossRef]
- Wang, S.-Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated images are surprisingly easy to spot... for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- NVIDIA GeForce RTX 3060. Available online: https://www.nvidia.com/en-us/geforce/graphics-cards/30-series/rtx-3060-3060ti/ (accessed on 25 June 2024).
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local Nash equilibrium. In Proceedings of the International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6629–6640. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- ISO/IEC JTC1 SC37 Biometrics. ISO/IEC WD 30107–3: Information Technology—Presentation Attack Detection-Part 3: Testing and Reporting and Classification of Attacks; International Organization for Standardization: Geneva, Switzerland, 2014. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.-Y. Contrastive learning for unpaired image-to-image translation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 319–345. [Google Scholar]
- Han, J.; Shoeiby, M.; Petersson, L.; Armin, M.A. Dual contrastive learning for unsupervised image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 746–755. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 6840–6851. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar] [CrossRef]
- Muhammad, M.B.; Yeasin, M. Eigen-cam: Class activation map using principal components. In Proceedings of the International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Ding, M.; Xiao, B.; Codella, N.; Luo, P.; Wang, J.; Yuan, L. Davit: Dual attention vision transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 74–92. [Google Scholar] [CrossRef]
- Hatamizadeh, A.; Yin, H.; Heinrich, G.; Kautz, J.; Molchanov, P. Global context vision transformers. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 12633–12646. [Google Scholar]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. Inceptionnext: When inception meets convnext. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 5672–5683. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxvit: Multi-axis vision transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 459–479. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 12009–12019. [Google Scholar]
- Face Anti-Spoofing Challenge. Available online: https://sites.google.com/view/face-anti-spoofing-challenge/ (accessed on 26 February 2024).
- Jetson TX2 Module. Available online: https://developer.nvidia.com/embedded/jetson-tx2 (accessed on 23 July 2024).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Student’s T-Test. Available online: https://en.wikipedia.org/wiki/Student%27s_t-test (accessed on 27 February 2024).
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 155–159. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the Advanced in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 2017–2025. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Number of Transformers | Number of Filters | Filter Size | Stride | Feature Map Size | ||||
|---|---|---|---|---|---|---|---|---|---|
| MF-GF block | Input | - | - | - | - | 256 × 256 × 3 | |||
| - | FFT | - | - | - | - | 256 × 256 × 3 | |||
| - | FFT Norm | - | - | - | - | 256 × 256 × 3 | |||
| - | Abs | - | - | - | - | 256 × 256 × 3 | |||
| - | Mask | - | - | - | - | 256 × 256 × 3 | |||
| Conv | Conv | - | 16 | 3 × 3 | 2 | 128 × 128 × 16 | |||
| Gated fusion | Dense | - | 16 | - | - | 128 × 128 × 16 | |||
| Dense | - | 16 | - | - | 128 × 128 × 16 | ||||
| 1st MobileNet V2 block (Add) | Conv | - | 64 | 1 × 1 | 1 | 128 × 128 × 64 | |||
| Depth-wise Conv | - | 64 | 3 × 3 | 1 | 128 × 128 × 64 | ||||
| Conv | - | 32 | 1 × 1 | 1 | 128 × 128 × 32 | ||||
| 2nd MobileNet V2 block (Down) | - | 64 | * | 2 | 64 × 64 × 64 | ||||
| 3rd MobileNet V2 block (Add) | - | 64 | * | 1 | 64 × 64 × 64 | ||||
| 4th MobileNet V2 block (Add) | - | 64 | * | 1 | 64 × 64 × 64 | ||||
| 5th MobileNet V2 block (Down) | - | 96 | * | 2 | 32 × 32 × 96 | ||||
| FA-GCL block | 1st MobileViT block | Conv | 1st MobileViT FFC block | FFC | - | 96 | 3 × 3 | 1 | 32 × 32 × 96 |
| Conv | FFC | - | 114 | 1 × 1 | 1 | 32 × 32 × 96 | |||
| Transformer | Transformer | 2 | - | - | - | - | |||
| Conv | FFC | - | 96 | 1 × 1 | 1 | 32 × 32 × 96 | |||
| Concat | Concat | - | - | - | - | 32 × 32 × 192 | |||
| Conv | FFC | - | 96 | 3 × 3 | 1 | 32 × 32 × 96 | |||
| Add | - | - | - | - | 32 × 32 × 96 | ||||
| 6th MobileNet V2 block (Down) | - | 128 | * | 2 | 16 × 16 × 128 | ||||
| 2nd MobileViT block | 2nd MobileViT FFC block | 4 | 128 | ** | 1 | 16 × 16 × 128 | |||
| Add | - | - | - | - | 16 × 16 × 128 | ||||
| 7th MobileNet V2 block (Down) | - | 160 | * | 2 | 8 × 8 × 160 | ||||
| 3rd MobileViT block | 3rd MobileViT FFC block | 3 | 160 | ** | 1 | 8 × 8 × 160 | |||
| Add | - | -- | - | - | 8 × 8 × 160 | ||||
| Conv | - | 640 | 3 × 3 | 1 | 8 × 8 × 640 | ||||
| Global Average Pooling | - | - | - | - | 640 | ||||
| Dense (output) | - | 2 | - | - | 2 | ||||
| Dataset | # Lights | # Session | # People | # Hands | # Trials | # Images |
|---|---|---|---|---|---|---|
| VERA | 1 | 2 | 50 | 2 | 5 | 1000 |
| PLUS | 2 | 1 | 42 | 2 | 5 | 840 |
| Parameters | Value |
|---|---|
| Batch size | 1 |
| Epochs | 200 |
| Learning rate | 0.0002 |
| Optimizer | Adam |
| Beta 1 | 0.6 |
| Scheduler | Linear decay |
| Epoch decay | 100 |
| Loss | LSGAN |
| Parameters | Value |
|---|---|
| Batch size | 4 |
| Epochs | 30 |
| Learning rate | 0.00001 |
| Optimizer | Adam |
| Loss1 | Cross entropy |
| Loss2 | Global contrastive |
| Dataset | Method | FID | LPIPS | ||||
|---|---|---|---|---|---|---|---|
| 1-Fold | 2-Fold | Avg. | 1-Fold | 2-Fold | Avg. | ||
| VERA | Pix2Pix [47] | 43.52 | 37.11 | 40.32 | 46.41 | 45.22 | 45.82 |
| Pix2PixHD [48] | 32.54 | 32.89 | 32.72 | 45.71 | 44.76 | 45.24 | |
| CycleGAN [25] | 13.04 | 17.97 | 15.51 | 39.21 | 42.64 | 40.93 | |
| CUT [50] | 22.26 | 13.00 | 17.63 | 48.62 | 51.97 | 50.3 | |
| DCL-GAN [50] | 16.59 | 23.32 | 19.96 | 56.65 | 56.32 | 56.49 | |
| DCS-GAN [5] | 13.43 | 28.29 | 20.86 | 48.75 | 50.93 | 49.84 | |
| DDPM [51] | 33.52 | 47.42 | 40.47 | 53.85 | 58.15 | 56 | |
| DDIM [52] | 28.62 | 40.48 | 34.55 | 51.44 | 50.64 | 51.04 | |
| PLUS | Pix2Pix [47] | 31.06 | 33.62 | 32.34 | 52.52 | 52.51 | 52.52 |
| Pix2PixHD [48] | 19.15 | 12.85 | 16 | 50.87 | 50.58 | 50.73 | |
| CycleGAN [25] | 10.79 | 8.36 | 9.58 | 47.99 | 50.05 | 49.02 | |
| CUT [50] | 20.78 | 17.34 | 19.06 | 65.22 | 64.91 | 65.07 | |
| DCL-GAN [50] | 30.77 | 32.37 | 31.57 | 66.43 | 67.59 | 67.01 | |
| DCS-GAN [5] | 26.33 | 24.74 | 25.54 | 74.97 | 76.38 | 75.68 | |
| DDPM [51] | 71.84 | 44.42 | 58.13 | 58.44 | 59.29 | 58.87 | |
| DDIM [52] | 30.71 | 60.55 | 45.63 | 52.43 | 57.31 | 54.87 | |
| Results | Case 1 | Case 2 | Case 3 | |||
|---|---|---|---|---|---|---|
| Real Figure 12a | Fake Figure 12b | Real Figure 12c | Fake Figure 12d | Real Figure 12e | Fake Figure 12f | |
| R2 | 0.965 | 0.969 | 0.97 | 0.962 | 0.984 | 0.991 |
| C | 0.982 | 0.985 | 0.985 | 0.981 | 0.992 | 0.996 |
| FD | 1.589 | 1.64 | 1.531 | 1.562 | 1.764 | 1.72 |
| Model | Post- Processing | APCER/BPCER/ACER | ||
|---|---|---|---|---|
| 1-Fold | 2-Fold | Avg. | ||
| Pix2Pix [47] | without | 0/0/0 | 0/0/0 | 0/0/0 |
| 3 × 3 Gaussian | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 Gaussian | 0/0/0 | 0/0/0 | 0/0/0 | |
| 3 × 3 median | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 median | 0/0/0 | 0/0/0 | 0/0/0 | |
| 3 × 3 average | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 average | 0/0/0 | 0/0/0 | 0/0/0 | |
| Pix2PixHD [48] | without | 0.2/1.8/1 | 7/1/4 | 3.6/1.4/2.5 |
| 3 × 3 Gaussian | 0.8/1.8/1.3 | 5.8/1/3.4 | 3.3/1.4/2.4 | |
| 5 × 5 Gaussian | 7.6/1.8/4.7 | 16/1/8.5 | 11.8/1.4/6.6 | |
| 3 × 3 median | 2/1.8/1.9 | 6.2/1/3.6 | 4.1/1.4/2.8 | |
| 5 × 5 median | 74/1.8/37.9 | 74.4/1/37.7 | 74.2/1.4/37.8 | |
| 3 × 3 average | 2.8/1.8/2.3 | 8.6/1/4.8 | 5.7/1.4/3.6 | |
| 5 × 5 average | 81/1.8/41.4 | 88/1/44.5 | 84.5/1.4/43 | |
| CycleGAN [25] | without | 41/21.2/31.1 | 83.8/4.4/44.1 | 62.4/12.8/37.6 |
| 3 × 3 Gaussian | 100/21.2/60.6 | 100/4.4/52.2 | 100/12.8/56.4 | |
| 5 × 5 Gaussian | 100/21.2/60.6 | 100/4.4/52.2 | 100/12.8/56.4 | |
| 3 × 3 median | 100/21.2/60.6 | 100/4.4/52.2 | 100/12.8/56.4 | |
| 5 × 5 median | 100/21.2/60.6 | 100/4.4/52.2 | 100/12.8/56.4 | |
| 3 × 3 average | 100/21.2/60.6 | 100/4.4/52.2 | 100/12.8/56.4 | |
| 5 × 5 average | 100/21.2/60.6 | 100/4.4/52.2 | 100/12.8/56.4 | |
| CUT [49] | without | 0/0/0 | 0/0/0 | 0/0/0 |
| 3 × 3 Gaussian | 9/0/4.5 | 1/0/0.5 | 5/0/2.5 | |
| 5 × 5 Gaussian | 76/0/38 | 2.4/0/1.2 | 39.2/0/19.6 | |
| 3 × 3 median | 11.4/0/5.7 | 1/0/0.5 | 6.2/0/3.1 | |
| 5 × 5 median | 100/0/50 | 45.8/0/22.9 | 72.9/0/36.5 | |
| 3 × 3 average | 32.8/0/16.4 | 1.6/0/0.8 | 17.2/0/8.6 | |
| 5 × 5 average | 100/0/50 | 74.6/0/37.3 | 87.3/0/43.7 | |
| DCL-GAN [50] | without | 0/0/0 | 0/0/0 | 0/0/0 |
| 3 × 3 Gaussian | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 Gaussian | 1.6/0/0.8 | 0.4/0/0.2 | 1/0/0.5 | |
| 3 × 3 median | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 median | 70.4/0/35.2 | 42.4/0/21.2 | 56.4/0/28.2 | |
| 3 × 3 average | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 average | 87/0/43.5 | 78.4/0/39.2 | 82.7/0/21.4 | |
| DCS-GAN [5] | without | 2.6/0.2/1.4 | 0.8/0/0.4 | 1.7/0.1/0.9 |
| 3 × 3 Gaussian | 0.8/0.2/0.5 | 4.4/0/2.2 | 2.6/0.1/1.4 | |
| 5 × 5 Gaussian | 0.2/0.2/0.2 | 30.2/0/15.1 | 15.2/0.1/7.7 | |
| 3 × 3 median | 2.4/0.2/1.3 | 7/0/3.5 | 4.7/0.1/2.4 | |
| 5 × 5 median | 3/0.2/1.6 | 77.2/0/38.6 | 40.1/0.1/20.1 | |
| 3 × 3 average | 0.4/0.2/0.3 | 10/0/5 | 5.2/0.1/2.7 | |
| 5 × 5 average | 0.2/0.2/0.2 | 63.4/0/31.7 | 31.8/0.1/16 | |
| DDPM [51] | without | 5.8/6.2/6 | 3.2/0.4/1.8 | 4.5/3.3/3.9 |
| 3 × 3 Gaussian | 0/5.6/2.8 | 0/0.2/0.1 | 0/2.9/1.5 | |
| 5 × 5 Gaussian | 0/5.6/2.8 | 0/0.2/0.1 | 0/2.9/1.5 | |
| 3 × 3 median | 0/5.6/2.8 | 0/0.2/0.1 | 0/2.9/1.5 | |
| 5 × 5 median | 0/5.6/2.8 | 0/0.2/0.1 | 0/2.9/1.5 | |
| 3 × 3 average | 0/5.6/2.8 | 0/0.2/0.1 | 0/2.9/1.5 | |
| 5 × 5 average | 0/5.6/2.8 | 0/0.2/0.1 | 0/2.9/1.5 | |
| DDIM [52] | without | 7.6/3.4/5.5 | 2.2/1.4/1.8 | 4.9/2.4/3.7 |
| 3 × 3 Gaussian | 0.8/3.6/2.2 | 1.6/1.4/1.5 | 1.2/2.5/1.9 | |
| 5 × 5 Gaussian | 0.8/3.6/2.2 | 4.6/1.4/3 | 2.7/2.5/2.6 | |
| 3 × 3 median | 0.8/3.6/2.2 | 2/1.4/1.7 | 1.4/2.5/2 | |
| 5 × 5 median | 1.4/3.6/2.5 | 17.2/1.4/9.3 | 9.3/2.5/5.9 | |
| 3 × 3 average | 0.8/3.6/2.2 | 2.6/1.4/2 | 1.7/2.5/2.1 | |
| 5 × 5 average | 0.4/3.6/2 | 49.2/1.4/25.3 | 24.8/2.5/13.7 | |
| Model | Post- Processing | APCER/BPCER/ACER | ||
|---|---|---|---|---|
| 1-Fold | 2-Fold | Avg. | ||
| Pix2Pix [47] | without | 0.71/0/0.36 | 0.71/0/0.36 | 0.71/0/0.36 |
| 3 × 3 Gaussian | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 Gaussian | 0.48/0/0.24 | 30.71/0/15.36 | 15.6/0/7.8 | |
| 3 × 3 median | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 median | 12.86/0/6.43 | 9.29/0/4.64 | 11.08/0/5.54 | |
| 3 × 3 average | 0/0/0 | 0/0/0 | 0/0/0 | |
| 5 × 5 average | 60.71/0/30.36 | 30.71/0/15.36 | 45.71/0/22.86 | |
| Pix2PixHD [48] | without | 1.19/0/0.6 | 0/0/0 | 0.6/0/0.3 |
| 3 × 3 Gaussian | 1.43/0/0.71 | 0/0/0 | 0.72/0/0.36 | |
| 5 × 5 Gaussian | 1.43/0/0.71 | 0.24/0/0.12 | 0.84/0/0.42 | |
| 3 × 3 median | 1.9/0/0.95 | 0/0/0 | 0.95/0/0.48 | |
| 5 × 5 median | 72.62/0/36.31 | 9.04/0/4.52 | 40.83/0/20.42 | |
| 3 × 3 average | 2.14/0/1.07 | 0.71/0/0.36 | 1.43/0/0.72 | |
| 5 × 5 average | 99.52/0/49.76 | 29.05/0/14.52 | 64.29/0/32.14 | |
| CycleGAN [25] | without | 11.43/1.9/6.67 | 15/0.71/7.86 | 13.22/1.31/7.27 |
| 3 × 3 Gaussian | 100/1.9/50.95 | 100/0.71/50.36 | 100/1.31/50.66 | |
| 5 × 5 Gaussian | 100/1.9/50.95 | 100/0.71/50.36 | 100/1.31/50.66 | |
| 3 × 3 median | 100/1.9/50.95 | 100/0.71/50.36 | 100/1.31/50.66 | |
| 5 × 5 median | 100/1.9/50.95 | 100/0.71/50.36 | 100/1.31/50.66 | |
| 3 × 3 average | 100/1.9/50.95 | 100/0.71/50.36 | 100/1.31/50.66 | |
| 5 × 5 average | 100/1.9/50.95 | 100/0.71/50.36 | 100/1.31/50.66 | |
| CUT [49] | without | 0/0/0 | 0/0/0 | 0/0/0 |
| 3 × 3 Gaussian | 0.48/0/0.24 | 0/0/0 | 0.24/0/0.12 | |
| 5 × 5 Gaussian | 0.48/0/0.24 | 0/0/0 | 0.24/0/0.12 | |
| 3 × 3 median | 0.71/0/0.36 | 0/0/0 | 0.36/0/0.18 | |
| 5 × 5 median | 95.95/0/47.98 | 4.05/0/2.03 | 50/0/25.01 | |
| 3 × 3 average | 3.57/0/1.79 | 0/0/0 | 1.79/0/0.9 | |
| 5 × 5 average | 99.76/0/49.88 | 54.29/0/27.14 | 77.03/0/38.51 | |
| DCL-GAN [50] | without | 0/0/0 | 0/0/0 | 0/0/0 |
| 3 × 3 Gaussian | 0.24/0/0.12 | 0/0/0 | 0.12/0/0.06 | |
| 5 × 5 Gaussian | 0.24/0/0.12 | 0/0/0 | 0.12/0/0.06 | |
| 3 × 3 median | 0.24/0/0.12 | 0/0/0 | 0.12/0/0.06 | |
| 5 × 5 median | 11.19/0/5.60 | 16.43/0/8.21 | 13.81/0/6.91 | |
| 3 × 3 average | 0.48/0/0.24 | 0.24/0/0.12 | 0.36/0/0.18 | |
| 5 × 5 average | 85.24/0/42.62 | 98.10/0/49.05 | 91.67/0/45.84 | |
| DCS-GAN [5] | without | 0/0/0 | 0/0/0 | 0/0/0 |
| 3 × 3 Gaussian | 0.24/0/0.12 | 1.19/0/0.6 | 0.72/0/0.36 | |
| 5 × 5 Gaussian | 0.24/0/0.12 | 1.19/0/0.6 | 0.72/0/0.36 | |
| 3 × 3 median | 0.24/0/0.12 | 1.19/0/0.6 | 0.72/0/0.36 | |
| 5 × 5 median | 0.71/0/0.36 | 31.67/0/15.83 | 16.19/0/8.1 | |
| 3 × 3 average | 0.24/0/0.12 | 1.19/0/0.6 | 0.72/0/0.36 | |
| 5 × 5 average | 2.14/0/1.07 | 31.67/0/15.83 | 16.91/0/8.45 | |
| DDPM [51] | without | 0.48/0/0.24 | 4.76/3.10/3.93 | 2.62/1.55/2.09 |
| 3 × 3 Gaussian | 0/0/0 | 0.24/3.10/1.67 | 0.12/1.55/0.84 | |
| 5 × 5 Gaussian | 0.24/0/0.12 | 0.24/3.10/1.67 | 0.24/1.55/0.9 | |
| 3 × 3 median | 0.24/0/0.12 | 0.24/3.10/1.67 | 0.24/1.55/0.9 | |
| 5 × 5 median | 0.24/0/0.12 | 0.48/3.10/1.79 | 0.36/1.55/0.96 | |
| 3 × 3 average | 0.24/0/0.12 | 0.24/3.10/1.67 | 0.24/1.55/0.9 | |
| 5 × 5 average | 0.24/0/0.12 | 0.24/3.10/1.67 | 0.24/1.55/0.9 | |
| DDIM [52] | without | 50.48/6.9/28.69 | 57.38/5.95/31.67 | 53.93/6.43/30.18 |
| 3 × 3 Gaussian | 1.9/6.9/4.4 | 34.76/5.95/20.36 | 18.33/6.43/12.38 | |
| 5 × 5 Gaussian | 1.67/6.9/4.29 | 32.62/5.95/19.29 | 17.15/6.43/11.79 | |
| 3 × 3 median | 5.0/6.9/5.95 | 36.19/5.95/21.07 | 20.6/6.43/13.51 | |
| 5 × 5 median | 2.86/6.9/4.88 | 37.38/5.95/21.67 | 20.12/6.43/13.28 | |
| 3 × 3 average | 3.81/6.9/5.36 | 34.76/5.95/20.36 | 19.29/6.43/12.86 | |
| 5 × 5 average | 2.14/6.9/4.52 | 35/5.95/20.48 | 18.57/6.43/12.5 | |
| Pretrained Weights | FFC in Backbone | FA-GCL | MF-GF | APCER/BPCER/ACER | |||
|---|---|---|---|---|---|---|---|
| FA | GCL | 1-Fold | 2-Fold | Avg. | |||
| 4/1.4/2.7 | 10.6/0.2/5.4 | 7.3/0.8/4.1 | |||||
| √ | 3/0.4/1.7 | 0.8/5/2.9 | 1.9/2.7/2.3 | ||||
| √ | 4.4/0.4/2.4 | 4.8/0.4/2.6 | 4.6/0.4/2.5 | ||||
| √ | 2.8/0.2/1.5 | 4.6/0.4/2.5 | 3.7/0.3/2 | ||||
| √ | √ | 1.8/0/0.9 | 4.8/0.6/2.7 | 3.3/0.3/1.8 | |||
| √ | √ | √ | 0.4/0.4/0.4 | 0/0.4/0.2 | 0.2/0.4/0.3 | ||
| Pretrained Weights | FFC in Backbone | FA-GCL | MF-GF | APCER/BPCER/ACER | |||
|---|---|---|---|---|---|---|---|
| FA | GCL | 1-Fold | 2-Fold | Avg. | |||
| 3.33/2.38/2.86 | 3.81/2.86/3.33 | 3.57/2.62/3.1 | |||||
| √ | 0/2.38/1.19 | 0/4.76/2.38 | 0/3.57/1.79 | ||||
| √ | 1.43/0.24/0.83 | 4.05/0.95/2.5 | 2.74/0.6/1.67 | ||||
| √ | 1.43/0/0.71 | 1.9/0/0.95 | 1.67/0/0.83 | ||||
| √ | √ | 0.24/0.24/0.24 | 1.19/0.24/0.71 | 0.72/0.24/0.48 | |||
| √ | √ | √ | 0/0.24/0.12 | 0.48/0.48/0.48 | 0.24/0.36/0.3 | ||
| Model | APCER/BPCER/ACER | ||
|---|---|---|---|
| 1-Fold | 2-Fold | Avg. | |
| ConvNeXt-Small [27] | 100/20.8/60.4 | 100/4.4/52.2 | 100/12.6/56.3 |
| DaViT-Small [54] | 71.8/2.6/37.2 | 63.2/0.2/31.7 | 67.5/1.4/34.5 |
| GCViT-Small [55] | 10.2/3.2/6.7 | 23.8/1.2/12.5 | 17/2.2/9.6 |
| InceptionNeXt-Small [56] | 100/5/52.5 | 99.6/1.8/50.7 | 99.8/3.4/51.6 |
| MaxViT-Small [57] | 96.8/0/48.4 | 100/0.2/50.1 | 98.4/0.1/49.3 |
| MobileViT-Small [6,38] | 3/0.4/1.7 | 0.8/5/2.9 | 1.9/2.7/2.3 |
| SwinTrasnformerV2-Small [58] | 0.8/3.8/2.3 | 2.6/3.2/2.9 | 1.7/3.5/2.6 |
| VGG + PCA + SVM [1] | 47.8/4.4/26.1 | 69.2/0.4/34.8 | 58.5/2.4/30.5 |
| Enhanced ConvNeXt-Small [5] | 100/0.8/50.4 | 6.8/0/3.4 | 53.4/0.4/26.9 |
| Xception + SVM [19] | 100/9.8/54.9 | 89.8/11.4/50.6 | 94.9/10.6/52.8 |
| Ensemble DenseNet + SVM [4] | 100/3.8/51.9 | 100/0.8/50.4 | 100/2.3/51.2 |
| FGFNet (proposed method) | 0.4/0.4/0.4 | 0/0.4/0.2 | 0.2/0.4/0.3 |
| Model | APCER/BPCER/ACER | ||
|---|---|---|---|
| 1-Fold | 2-Fold | Avg. | |
| ConvNeXt-Small [27] | 100/1.9/50.95 | 100/0.71/50.36 | 100/1.31/50.66 |
| DaViT-Small [54] | 35.71/1.19/18.45 | 8.81/2.86/5.83 | 22.26/2.03/12.14 |
| GCViT-Small [55] | 21.19/6.9/14.05 | 6.67/10.48/8.57 | 13.93/8.69/11.31 |
| InceptionNeXt-Small [56] | 100/6.43/53.21 | 70.48/1.19/35.83 | 85.24/3.81/44.52 |
| MaxViT-Small [57] | 92.38/1.43/46.9 | 99.76/0.24/50 | 96.07/0.84/48.45 |
| MobileViT-Small [6,38] | 0/2.38/1.19 | 0/4.76/2.38 | 0/3.57/1.79 |
| SwinTrasnformerV2-Small [58] | 38.57/0/19.29 | 44.05/0/22.02 | 41.31/0/20.66 |
| VGG + PCA + SVM [1] | 26.9/17.15/22.02 | 36.9/3.1/20 | 31.9/10.13/21.01 |
| Enhanced ConvNeXt-Small [5] | 75.48/0.71/38.1 | 1.43/10.95/6.19 | 38.46/5.83/22.15 |
| Xception + SVM [19] | 100/7.14/53.57 | 100/15.24/57.62 | 100/11.19/55.6 |
| Ensemble DenseNet + SVM [4] | 26.19/0.71/13.45 | 78.1/0/39.05 | 52.15/0.36/26.25 |
| FGFNet (proposed method) | 0/0.24/0.12 | 0.48/0.48/0.48 | 0.24/0.36/0.3 |
| Image Generation Model | Spoof Detection Model | APCER/BPCER/ACER | ||
|---|---|---|---|---|
| 1-Fold | 2-Fold | Avg. | ||
| Pix2PixHD [48] | SwinTrasnformerV2-Small [58] | 0/2.2/1.1 | 1.4/1.4/1.4 | 0.7/1.8/1.3 |
| MobileViT-Small [6,38] | 1.2/0/0.6 | 0/3.8/1.9 | 0.6/1.9/1.3 | |
| FGFNet (Proposed method) | 1.6/0/0.8 | 1.6/0.2/0.9 | 1.6/0.1/0.9 | |
| CUT [49] | SwinTrasnformerV2-Small [58] | 0/0/0 | 0.2/0.4/0.3 | 0.1/0.2/0.2 |
| MobileViT-Small [6,38] | 0/0.2/0.1 | 0.4/0/0.2 | 0.2/0.1/0.2 | |
| FGFNet (Proposed method) | 0/0/0 | 0/0.4/0.2 | 0/0.2/0.1 | |
| CycleGAN [25] | SwinTrasnformerV2-Small [58] | 0.8/3.8/2.3 | 2.6/3.2/2.9 | 1.7/3.5/2.6 |
| MobileViT-Small [6,38] | 3/0.4/1.7 | 0.8/5/2.9 | 1.9/2.7/2.3 | |
| FGFNet (Proposed method) | 0.4/0.4/0.4 | 0/0.4/0.2 | 0.2/0.4/0.3 | |
| Model | Processing Time (Unit: ms (fps)) | GPU Memory Usage (Unit: MB) | Number of Param. (Unit: M) | FLOPs (Unit: GB) |
|---|---|---|---|---|
| ConvNeXt-Small [27] | 75.29 (13.28) | 201.87 | 49.46 | 17.49 |
| DaViT-Small [54] | 126.17 (7.93) | 214.46 | 48.98 | 17.68 |
| GCViT-Small [55] | 163.16 (6.13) | 220.1 | 50.32 | 17.29 |
| InceptionNeXt-Small [56] | 90.1 (11.1) | 180.77 | 47.1 | 16.8 |
| MaxViT-Small [57] | 218.06 (4.59) | 314.98 | 68.23 | 22.32 |
| MobileViT-Small [6,38] | 45.7 (21.88) | 20 | 4.95 | 4.08 |
| SwinTrasnformerV2-Small [58] | 148.29 (6.74) | 210.12 | 48.96 | 23.3 |
| VGG + PCA + SVM [1] | 61.7 (16.2) | 538.85 | 14.71 | 30.95 |
| Enhanced ConvNeXt-Small [5] | 97.22 (10.29) | 219.16 | 51.29 | 17.17 |
| Xception + SVM [19] | 27.87 (35.88) | 96.58 | 1.4 | 3.03 |
| Ensemble DenseNet + SVM [4] | 113.30 (8.83) | 190.66 | 39.34 | 22.27 |
| FGFNet (Proposed method) | 43.32 (23.08) | 22.79 | 3.79 | 3.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.G.; Kim, J.S.; Park, K.R. FGFNet: Fourier Gated Feature-Fusion Network with Fractal Dimension Estimation for Robust Palm-Vein Spoof Detection. Fractal Fract. 2025, 9, 478. https://doi.org/10.3390/fractalfract9080478
Kim SG, Kim JS, Park KR. FGFNet: Fourier Gated Feature-Fusion Network with Fractal Dimension Estimation for Robust Palm-Vein Spoof Detection. Fractal and Fractional. 2025; 9(8):478. https://doi.org/10.3390/fractalfract9080478
Chicago/Turabian StyleKim, Seung Gu, Jung Soo Kim, and Kang Ryoung Park. 2025. "FGFNet: Fourier Gated Feature-Fusion Network with Fractal Dimension Estimation for Robust Palm-Vein Spoof Detection" Fractal and Fractional 9, no. 8: 478. https://doi.org/10.3390/fractalfract9080478
APA StyleKim, S. G., Kim, J. S., & Park, K. R. (2025). FGFNet: Fourier Gated Feature-Fusion Network with Fractal Dimension Estimation for Robust Palm-Vein Spoof Detection. Fractal and Fractional, 9(8), 478. https://doi.org/10.3390/fractalfract9080478