1. Introduction
Since the seminal work of McCulloch and Pitts on the neural model [
1] and Rosenblatt on perceptrons [
2], activation functions have been a topic of interest in the context of artificial neural networks. In particular, given the singularity of the Heaviside function, derivable functions such as Sigmoid or tanh were introduced as activation functions [
3]. Later, for deep learning, more activation functions were proposed to solve new challenges such as the gradient vanishing problem [
4,
5], where ReLU [
6] plays an important role to the point of being considered the state of the art. Given the success of ReLU, more variants have been proposed, including Leaky ReLU [
7], ELU [
8], GeLU [
9], Swish [
10], and Mish [
11], among others.
Two relevant concepts that have been considered to improve the results of neural networks are (i) activation functions with adaptive parameters and (ii) activation functions with fractional derivative, or even a combination of these, as in this paper. Certainly, this work is not a pioneer in introducing these concepts, and the papers [
12,
13,
14,
15,
16,
17] are evidence of this. In addition to the previous cited works, as justification and motivation to continue with this research of applying fractional derivatives to activation functions, the research of [
18,
19] was carried out, where fractional gradients were applied successfully to the backpropagation algorithm to improve the performance of the gradient descent algorithms available in Tensorflow and PyTorch. In such a case, the formula for updating the synaptic weights requires the derivative of the activation function and it involves the factor
, which reduces to 1 in the case of
, i.e., the first derivative of
x with respect to
x is 1, and makes it possible for it to be extended from integer to fractional orders. Furthermore, the experiments support the idea that fractional optimizers improve their integer-order versions.
Regarding activation functions with adaptive parameters, they can be trained through the learning process and are therefore called trainable or learnable, since the adaptation is obtained from the training data. Indeed, to improve the accuracy of neural networks, adaptive activation functions such as SPLASH or APTx have been studied. On the one hand, SPLASH is a class of learnable piecewise linear activation functions with parameterization to approximate non-linear functions [
20]. On the other hand, APTx is similar to Mish but is intended to be more efficient to compute [
21]. Other related works study ReLU variants, such as FELU [
22], SELU, MPELU, and DELU [
23], with parameters that consider non-zero values for the negative plane to solve the “Dying ReLU” phenomenon that stops learning [
24]. Specifically, DELU considers three parameters,
, to be determined, and special cases are ELU (
) and ReLU (
). The Shape Autotuning Activation Function (SAAF) was proposed to simultaneously overcome three weaknesses of ReLU related to non-zero mean, negative missing (zero values), and unbounded output [
25]. SAAF is a smooth function like Sigmoid and tanh, and piecewise like ReLU, but avoids some of their deficiencies by adjusting a pair of independent trainable parameters,
and
, to capture negative information and provide a near-zero mean output, which leads to better generalization and learning speed, as well as a bounded output. In [
26], three variants of tanh, tanhSoft1, tanhSoft2, and tanhSoft3, are presented as trainable variants depending of
, and
parameters that are used to control the slope of the curve on both positive and negative axes. Also, TanhLU is proposed in [
26] as a combination of the tanh and a linear unit. All these works are examples of the effort to build and generalize some activation functions that, in addition to inheriting good properties from the original, provide flexibility with parameters to acquire useful properties for machine learning, such as control of overfitting or stop learning.
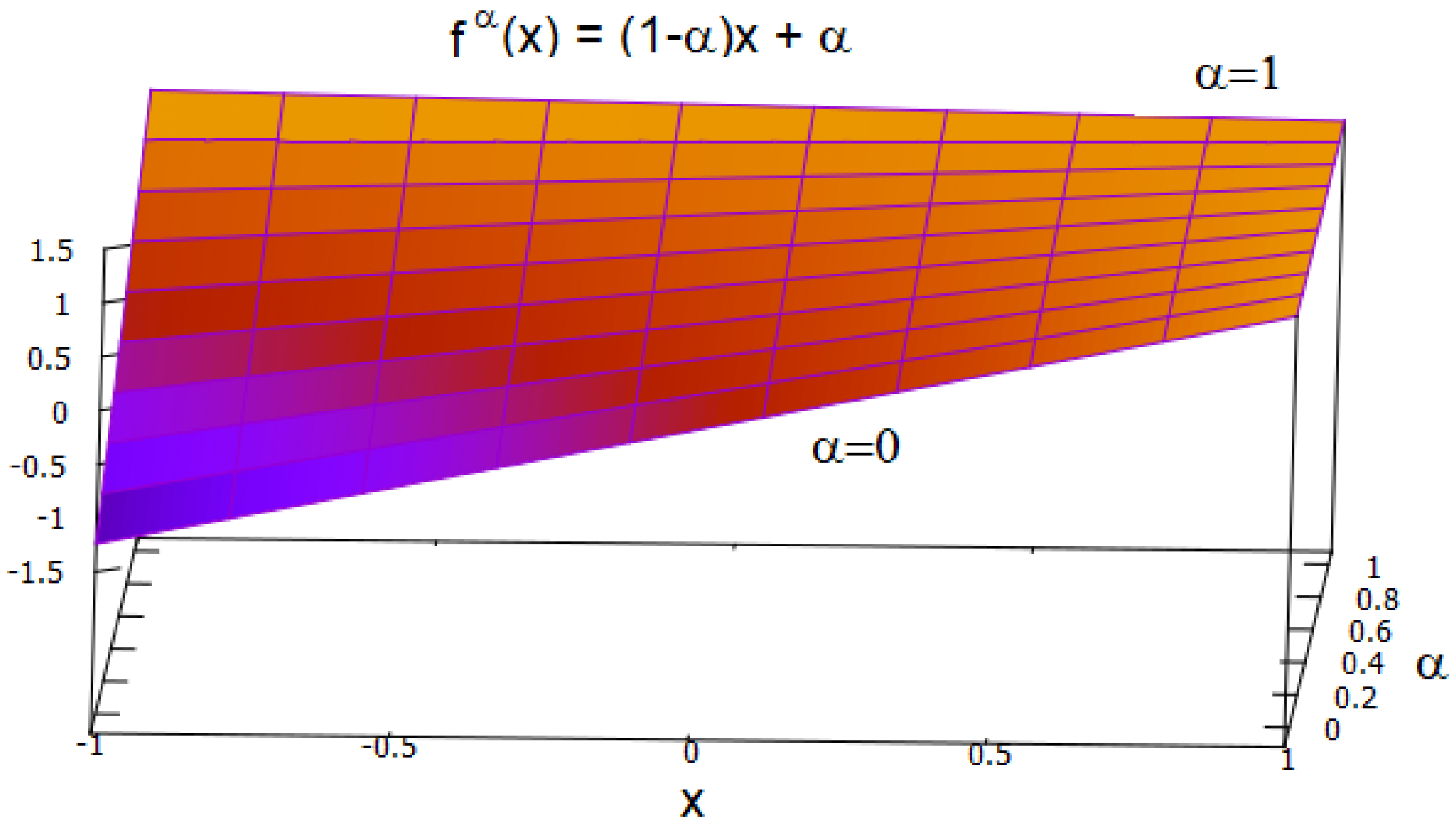
The other relevant topic considered in activation functions is the fractional derivative. The theoretical basis to extend the activation function derivative from integer to fractional order is the fractional calculus theory [
27,
28] that generalizes the integer operators: integration and differentiation. These two operators are combined in a single concept of fractional derivative once the integration is conceived as an antiderivative; thus, the orders are positive for derivatives and negative for antiderivatives so that, when added, the result is a real number, positive, negative, or zero. Historically, instead of “real”, it is referred to as “fractional”, maybe because, in a letter, L’Hopital asked Leibniz about the order
[
29]. An intuitive approach comes from the interpolation between two functions. Let
and its first derivative
; then, it is possible to build a “fractional” version with both of them. For
, we obtain
. Now, if
, there is no derivative, and
is equal to
x. However, if
, then
is equal to 1, meaning the first derivative of
x. For “fractional” values, i.e.,
, it corresponds to a line with gradient (slope)
. So, it offers a mechanism to control the gradient, which could be useful in backpropagation algorithms [
18,
19] by considering that
could represent a more sophisticated activation function. It is illustrated in
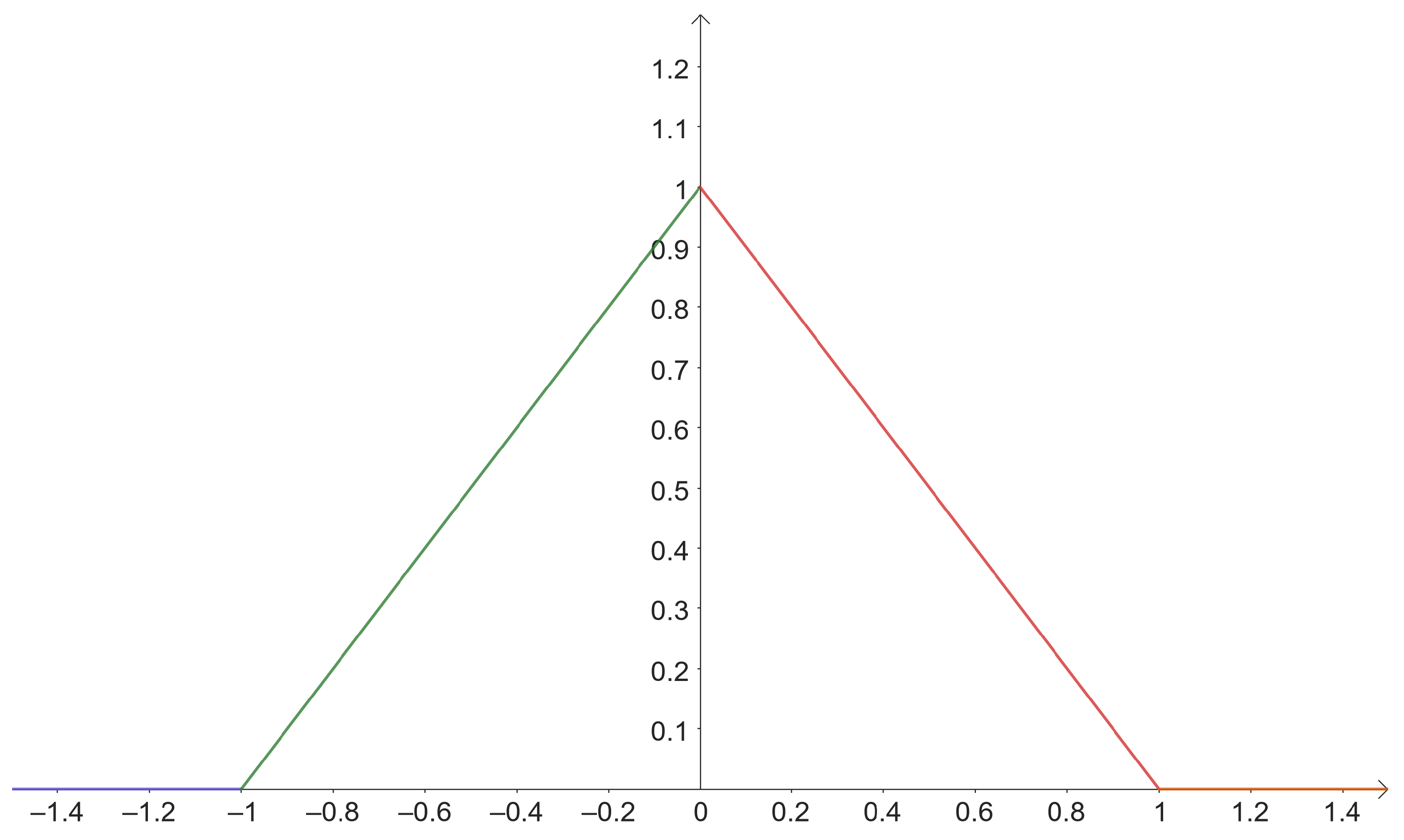
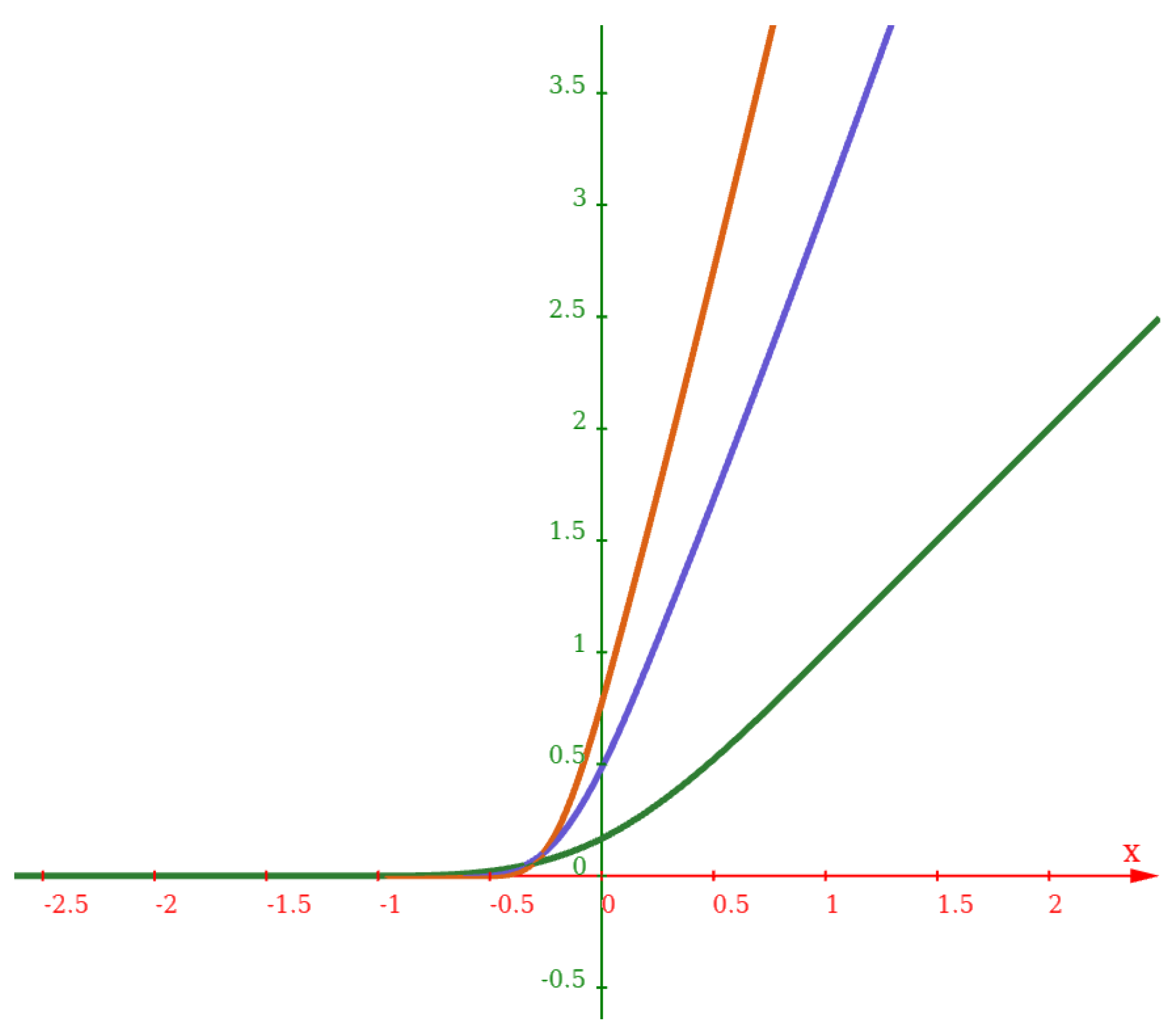
Figure 1, where there is a line with unitary slope for
and a horizontal line for
. This
graph represents all lines with slopes in the interval
.
Effectively, fractional gradient optimizers [
18,
19] and fractional activation functions have been proposed based on fractional calculus concepts, as a generalization to the classic integer-order operators. For example, ref. [
13] combines fractional derivatives on the activation functions and a fractional gradient descent backpropagation algorithm for perceptrons where, instead of choosing the first derivative, the fractional derivative of the activation function is applied. The experiments support the idea that the models that involve fractional derivatives are more accurate than the integer-order models. The fractional approach allows us to obtain the memory and hereditary properties of the processes described by the data, since it is a property of the fractional calculus operators [
27,
28,
30]. This is possible because the derivative focuses on a point, but the integral operator covers (observes) a neighborhood (integration interval) around a point of interest. A more extensive study of the interpretation of the fractional derivative can be reviewed in [
31], where one can find an analogy that was previously described from a physical point of view, specifically concerning the concept of divergence, which measures how much the vector field behaves like a source (positive divergence) or a sink (negative divergence).
In [
17], fractional sigmoid activation functions and Fractional Rectified Linear Units (FReLUs) are proposed, and the order of the derivative of linear fractional activation functions is optimized in [
15] to give a place to Fractional Adaptive Linear Units (FALUs).
Another possibility to apply fractional derivatives beyond the activation functions is to modify the standard loss functions, such as the Mean Squared Error (MSE), which involves a power of two, which can be modified to a fractional FMSE if it is multiplied by
[
12]. When the fractional order
, FSME is equivalent to MSE, but when
a is not an integer, FMSE identifies more complex relationships between the input and the output. A similar approach can be used with the Cross-Entropy Loss function, to obtain a Fractional Cross-Entropy Loss function. However, the authors of [
12] report that the fractional order
a must be adjusted by trial and error.
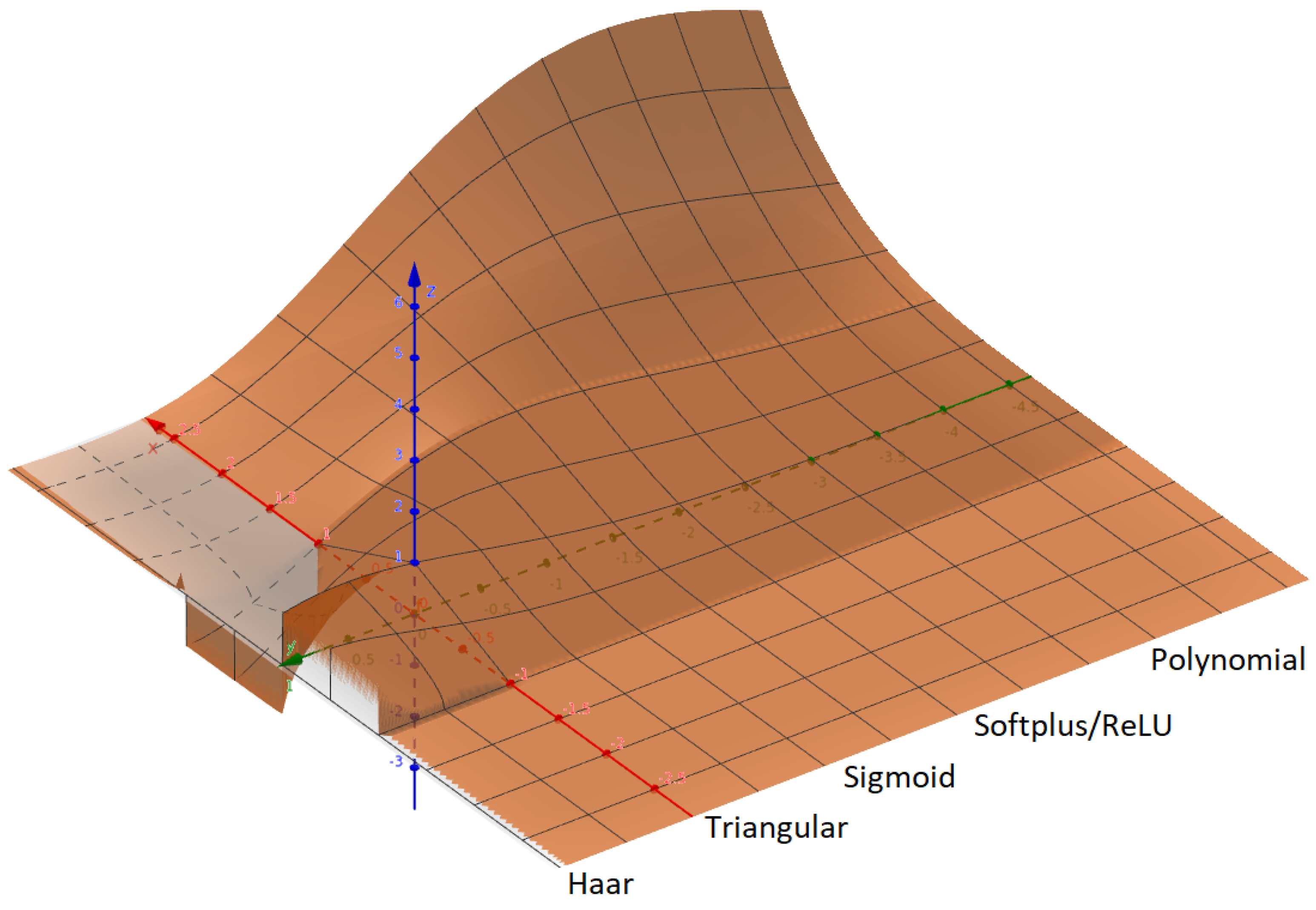
Wavelets are also on the list of activation functions [
32] and, due to their oscillatory property, they allow us to define sophisticated classification regions [
33]. In this paper, a morphing activation function is presented based on fractional calculus. Morphing refers to the idea of changing the shape gradually to mimic different activation functions. Morphing is possible by applying the Caputo derivative [
34] and varying the fractional
-order to obtain shapes very similar to other activation functions, including Heaviside, Sigmoid, ReLU, Softplus, GeLU, Swish, and Haar. Related works present relationships between a few similar activation functions, for example, ReLU and Leaky ReLU, or ReLU and Heaviside, or Sigmoid and Softplus, or hyperbolic tangent and square hyperbolic secant [
14]. All the revised papers on adaptive activation function groups focus on families of too-similar activation functions. Adaptive or fixed ReLU variants such as SAAF, SELU, MPELU, DELU, Leaky ReLU, ELU, GELU, Swish, and Mish focus on solving the drawbacks of the fundamental ReLU, but they follow a similar shape pattern. In contrast, SPLASH aims to approximate any function, included activation functions, but requires a significant amount of piecewise linear components to reach a smoothness similar to Sigmoid, tanh, Swish, or Mish, and leaks derivability at the hinges. However, at the time of writing this paper, the morphing function is unprecedented in the sense of linking several seemingly unrelated activation functions, essentially by means of the fractional-order derivative. The kind of shapes that the proposed morphing function can emulate is broad, since it evolves from wavelet to triangular, ReLU-variants, sigmoid, and polynomial by depending only on the fractional-order derivative. So, given a single parameter, it is able to reproduce an infinite set of activation functions, with different behavior, and when necessary, the shapes can be smooth. Indeed, the morphing activation function considers the fractional
-order as a parameter, and it is possible to obtain the optimal value from the data in the training process, so it is trainable. Additionally, it facilitates obtaining mathematical expressions of piecewise activation functions with a polynomial approach, which could lead to improved computational efficiency. It is worth noting that these points are relevant because, compared to other adaptive activation functions, the morphing function has the fewest number of parameters and explores different shapes. Thus, rather than focusing on a family or subset of adaptive or fixed activation functions, the morphing function aims to encompass as many activation functions as possible. Therefore, this research has a twofold purpose; the first aims to obtain a single equation that mimics a large list of activation functions, and the second is to obtain the optimal activation function shape by calculating the appropriate parameters from the training data using gradient descent algorithms, and this approach is different to other related works.
The approach that SAAF and MPELU follow shares some goals with this research, by attemping to combine the advantages of several activation functions. In the case of SAAF, it has parameters to mimic Mish or Swish in the negative plane, whereas MPELU is limited to ReLU and ELU variants. But Morph goes further and manages to unify more activation functions by introducing fractional derivatives and wavelet concepts.
Experimental results show a competitive performance of the morphing activation function, which learns the best shape from the data and adaptively mimics other existing and successful activation functions. How is this possible? The fractional-order derivative is declared as a hyperparameter in PyTorch, as part of the learning process. Given an initial value, it changes towards the optimal value guided by the gradient descent algorithm used to optimize the rest of the parameters. But why does the Morph activation function work so well? Because it is able to mimic other successful activation functions.
Finally, this paper aims to progress towards the construction of a more general formula to unify as many activation functions as possible.
3. Results
This section describes several experiments that support the conclusions. They include:
Experiments 1 to 7. Accuracy comparison between existing activation functions and polynomial versions obtained from the proposed morphing activation function.
Experiments 8 to 11. Adaptation of hyperparameters of activation functions (including Morph) during the training by using gradient descent algorithms with MNIST dataset.
Experiment 12. Adaptation of hyperparameters for Morph by using gradient descent algorithms with CIFAR10 dataset.
The experiments were developed in PyTorch running on a GPU NVIDIA GeForce RTX 3070. The optimizer was SGD with learning rate . The number of epochs is 30, and the metric for comparison purposes is the test accuracy.
For Experiments 1 to 11, the dataset was MNIST, with images, split into a training set of 50,000 and a test set of 10,000. The neural network architecture is:
Conv2d(1, 32, 3, 1)
Activation Function1(x, hyperparams)
Conv2d(32, 64, 3, 1)
Activation Function2(x, hyperparams)
max_pool2d(x, 2)
Dropout(0.25)
flatten(x, 1)
Linear(9216, 128)
Activation Function3(x, hyperparams)
Dropout(0.5)
Linear(128, 10)
output = log_softmax()
For Experiment 12, the dataset was CIFAR10. The neural network architecture is minimal:
nn.Linear(input_size, hidden_size)
nn.Linear(hidden_size, num_classes)
activation_function Morph()
Although the accuracy is not good, it aims to show how the parameters change during the training for different initializations.
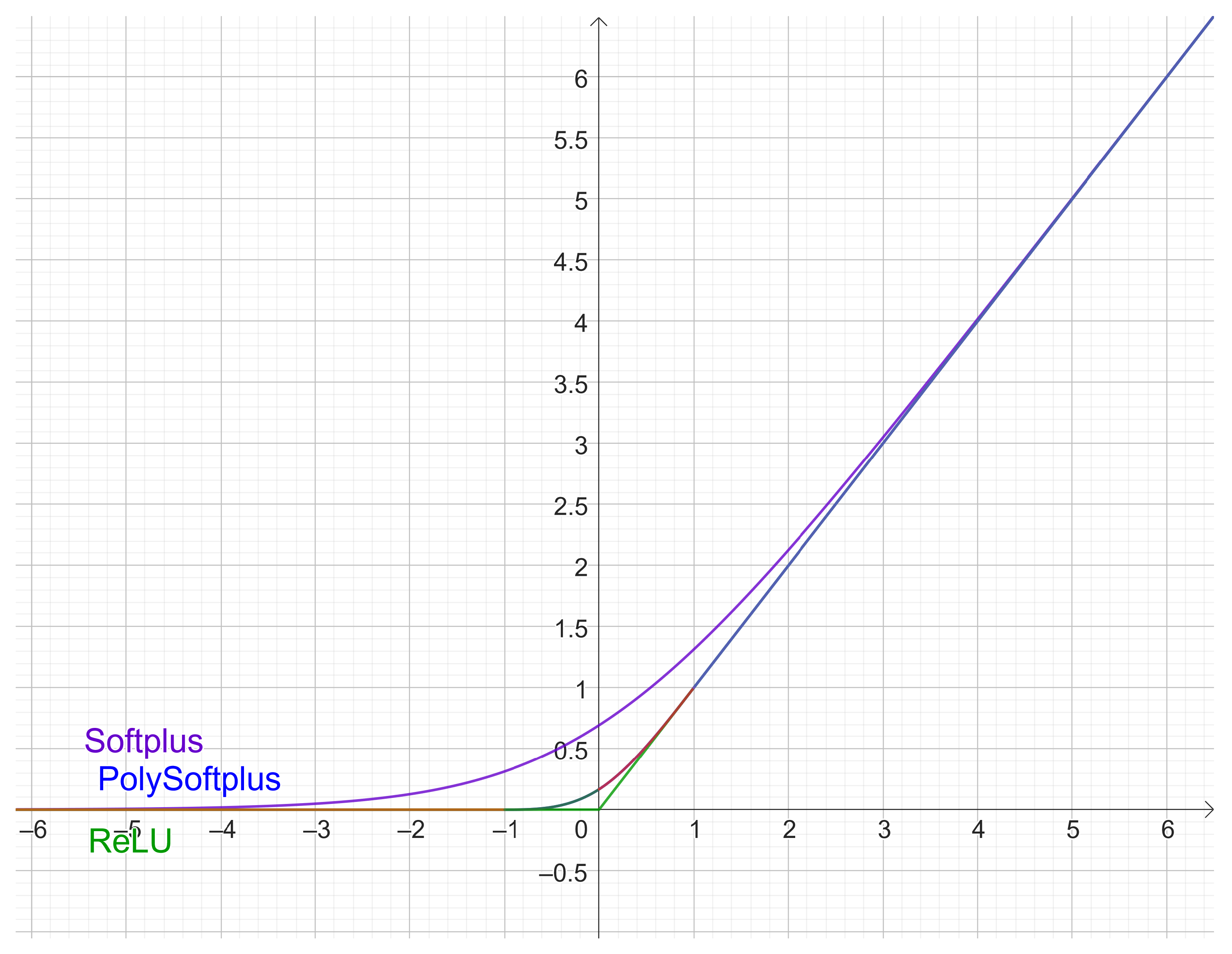
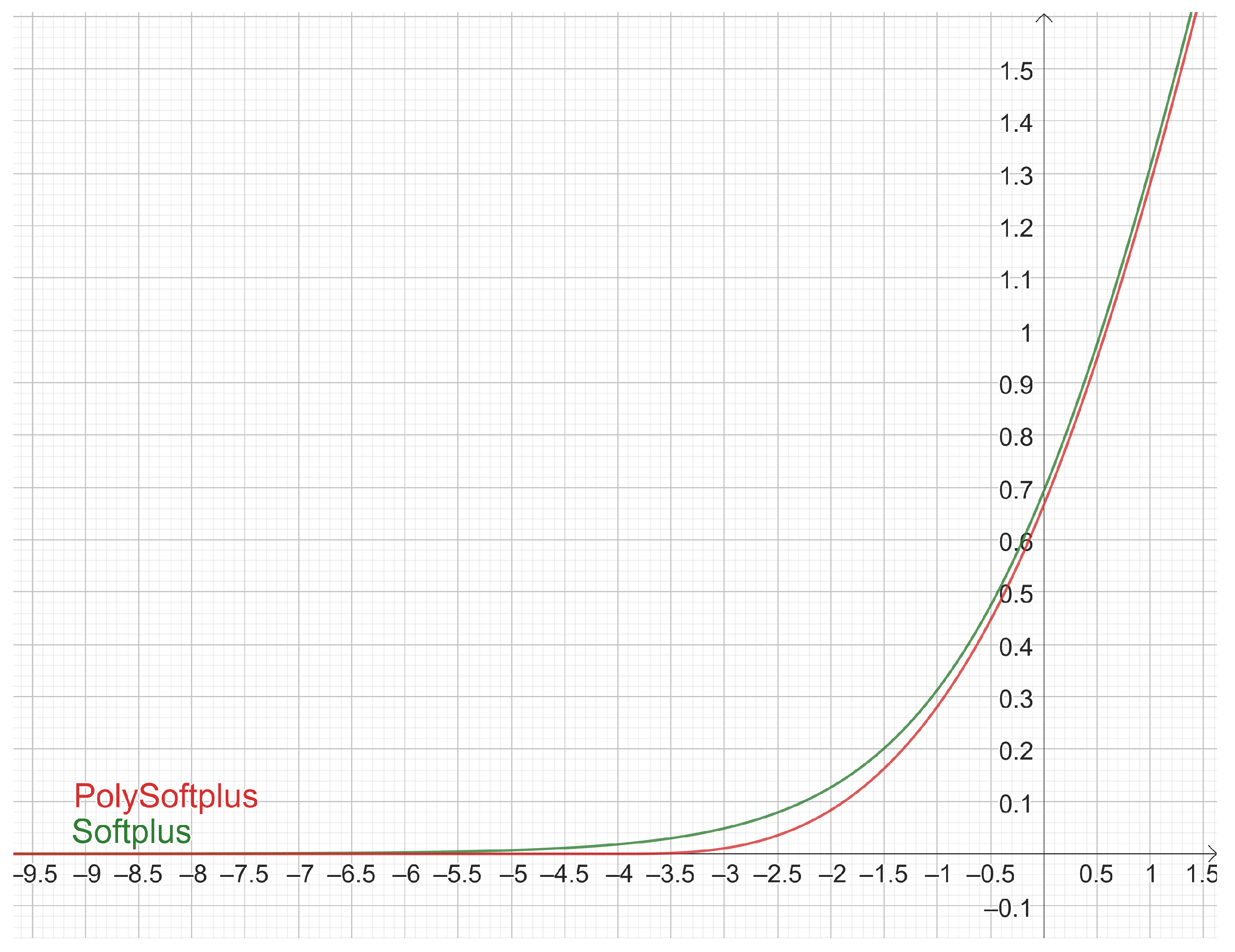
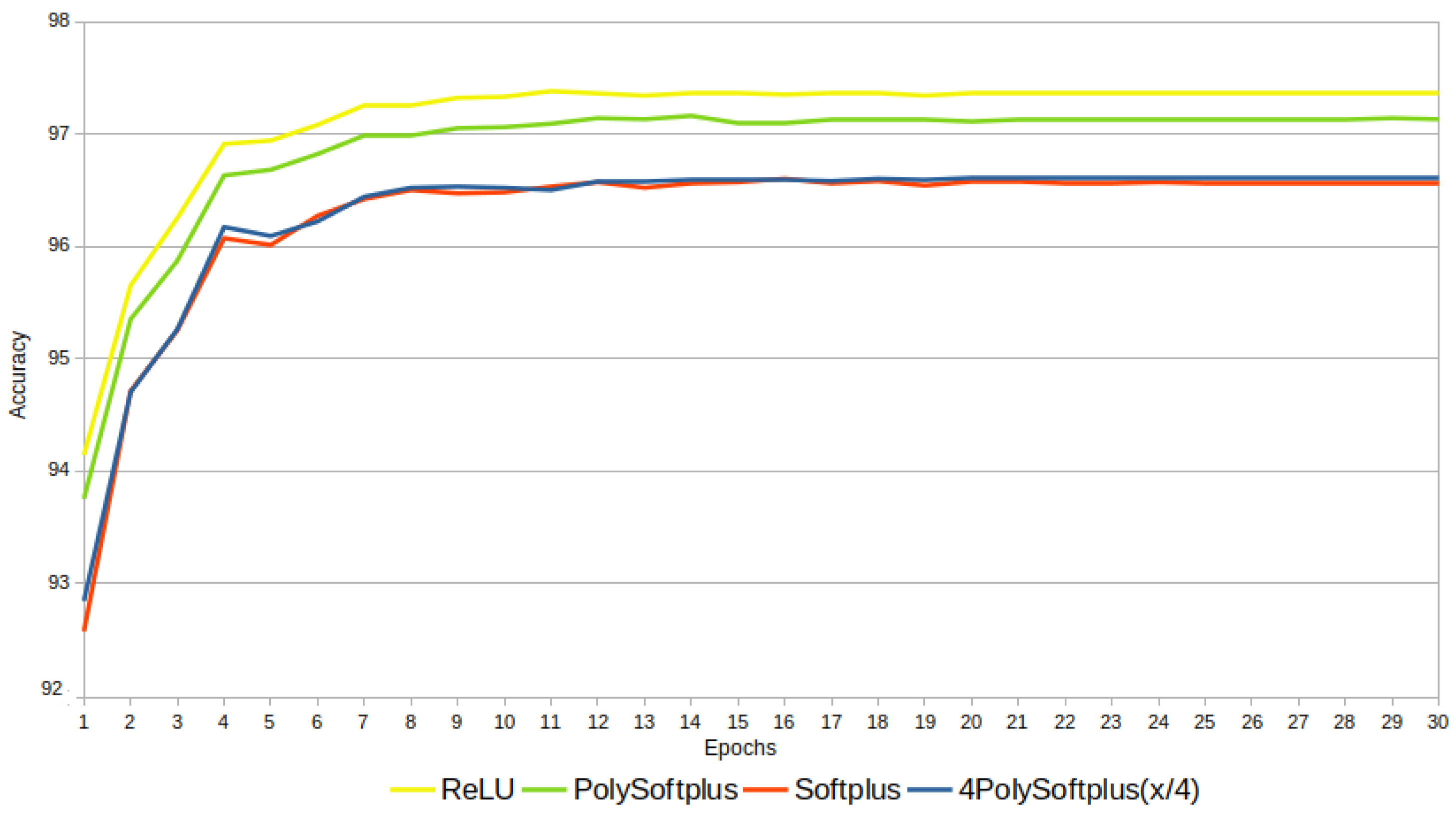
3.1. Experiment 1: PolySoftplus, Softplus, and Relu
A first experiment compares
,
, Softplus, and ReLU. The results are shown in the plots of
Figure 13. Note that:
ReLU is superior to all the other activation functions.
PolySoftplus outperforms Softplus. It is a bit intuitive after reading
Section 2.10, since PolySoftplus looks more similar to ReLU than to Softplus (see
Figure 10).
The version with is a good approximation of Softplus; therefore, it is not surprising that they produce essentially the same results.
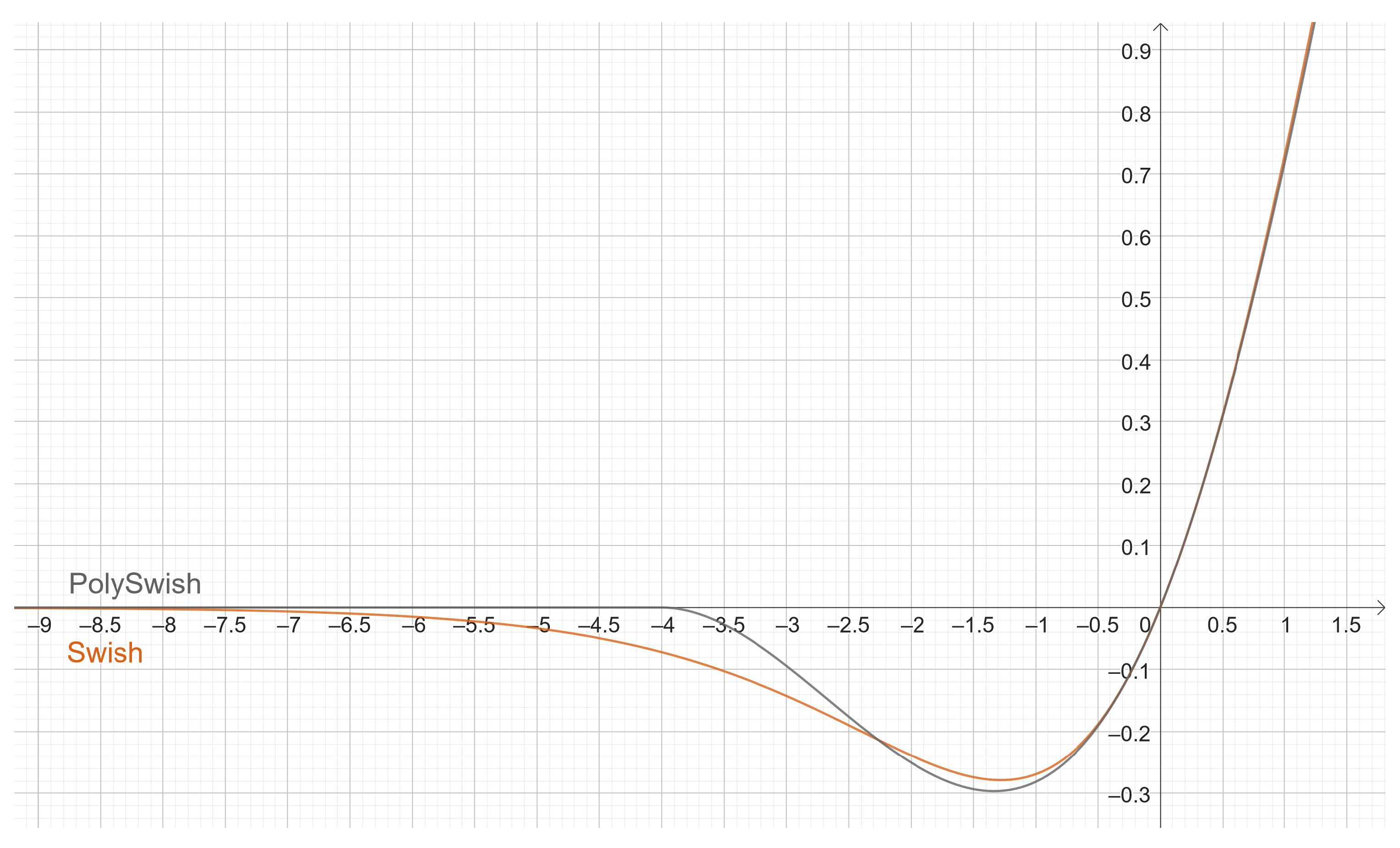
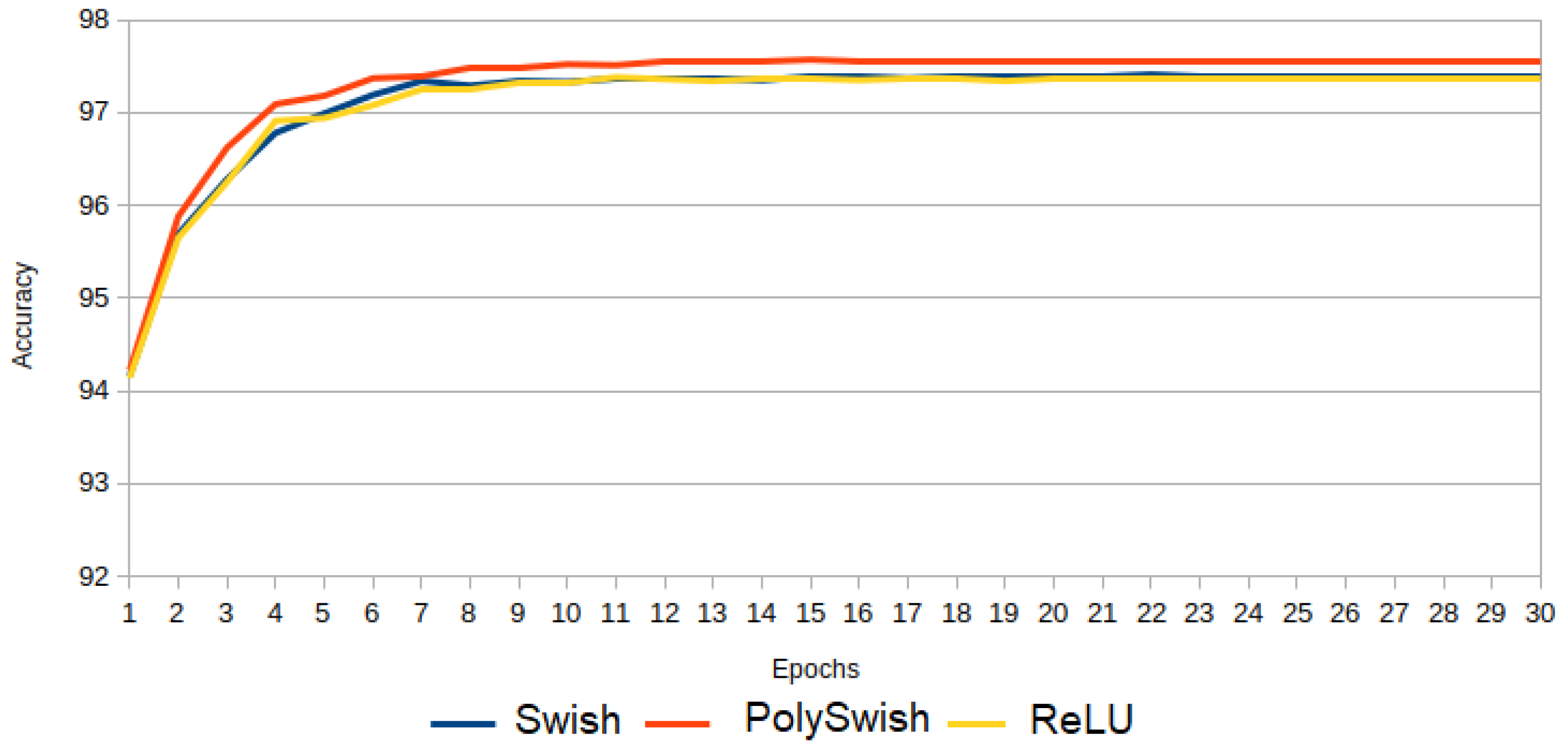
3.2. Experiment 2: PolySwish, Swish, and ReLU
In Experiment 2, PolySwish is compared with Swish and ReLU.
Figure 14 shows that PolySwish is superior to Swish and ReLU. Swish is slightly better than ReLU.
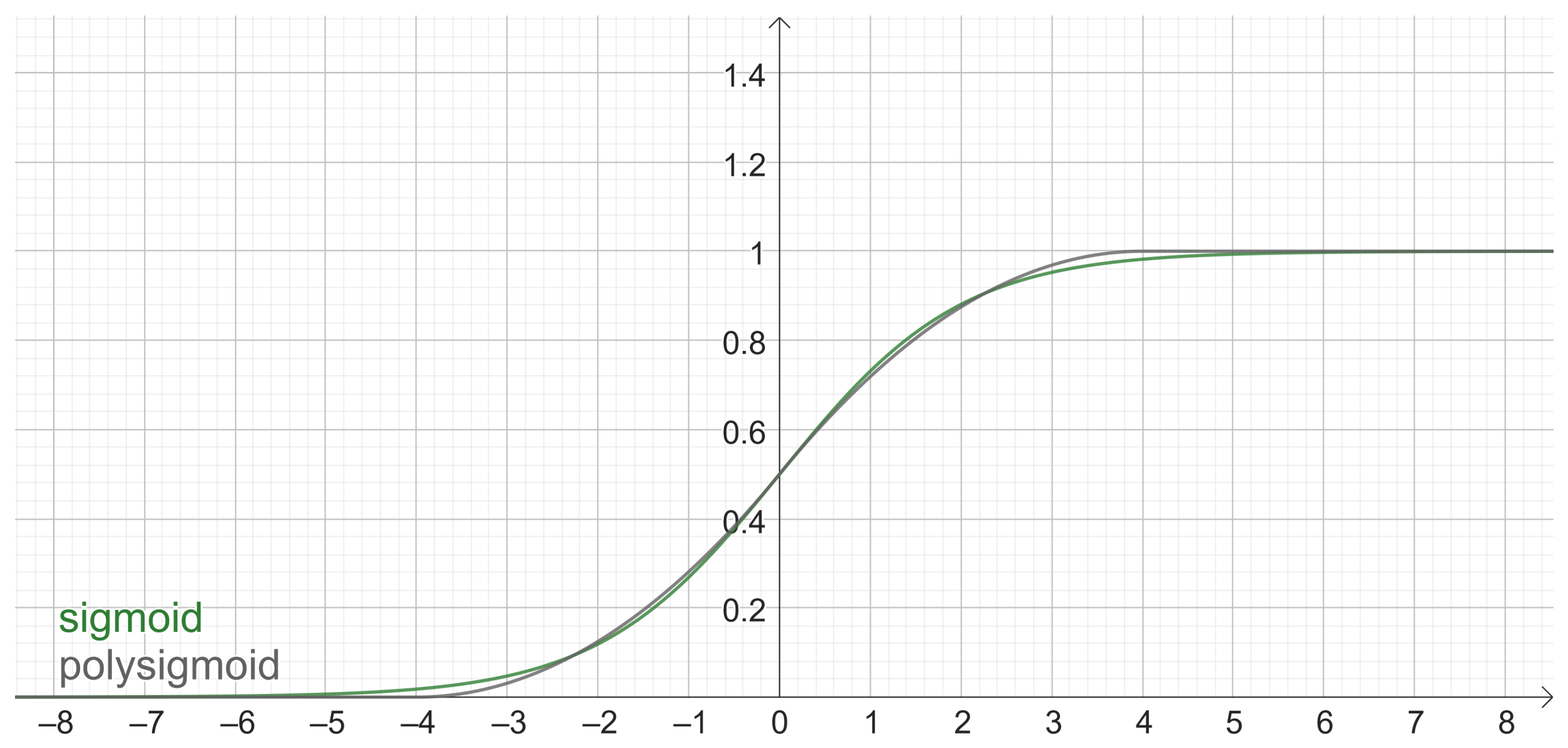
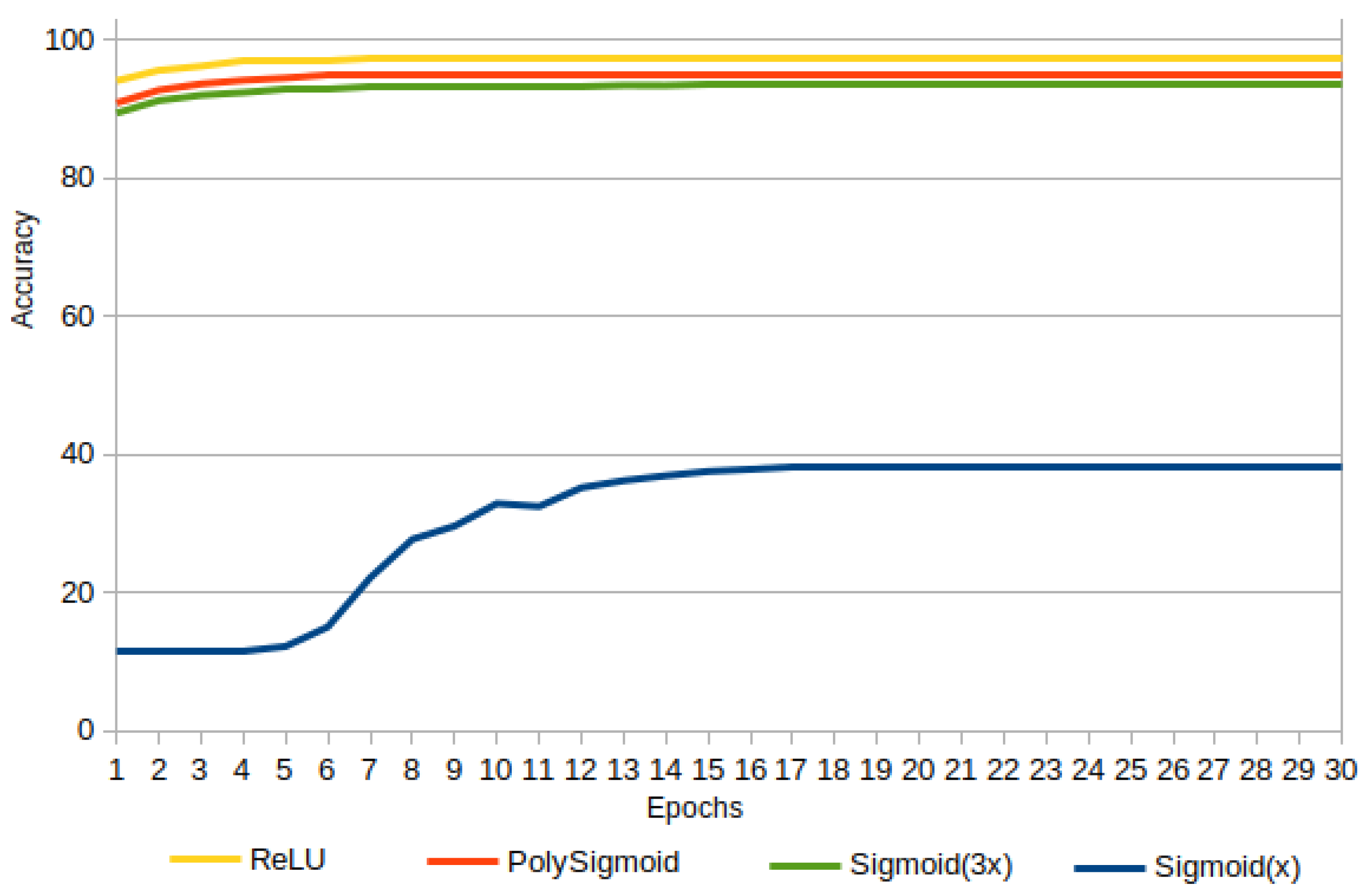
3.3. Experiment 3: PolySigmoid, Sigmoid, and ReLU
In Experiment 3, the Sigmoid performance was too low, starting with an accuracy of and reaching a maximum of . For this reason, instead of the original sigmoid , was considered, and the performance was improved from up to a maximum of .
Figure 15 shows the accuracies for PolySigmoid, Sigmoid
, Sigmoid
and ReLU. It is possible to appreciate that PolySigmoid is superior to
, and
. However, ReLU is better than PolySigmoid and therefore better than all activation functions in this experiment.
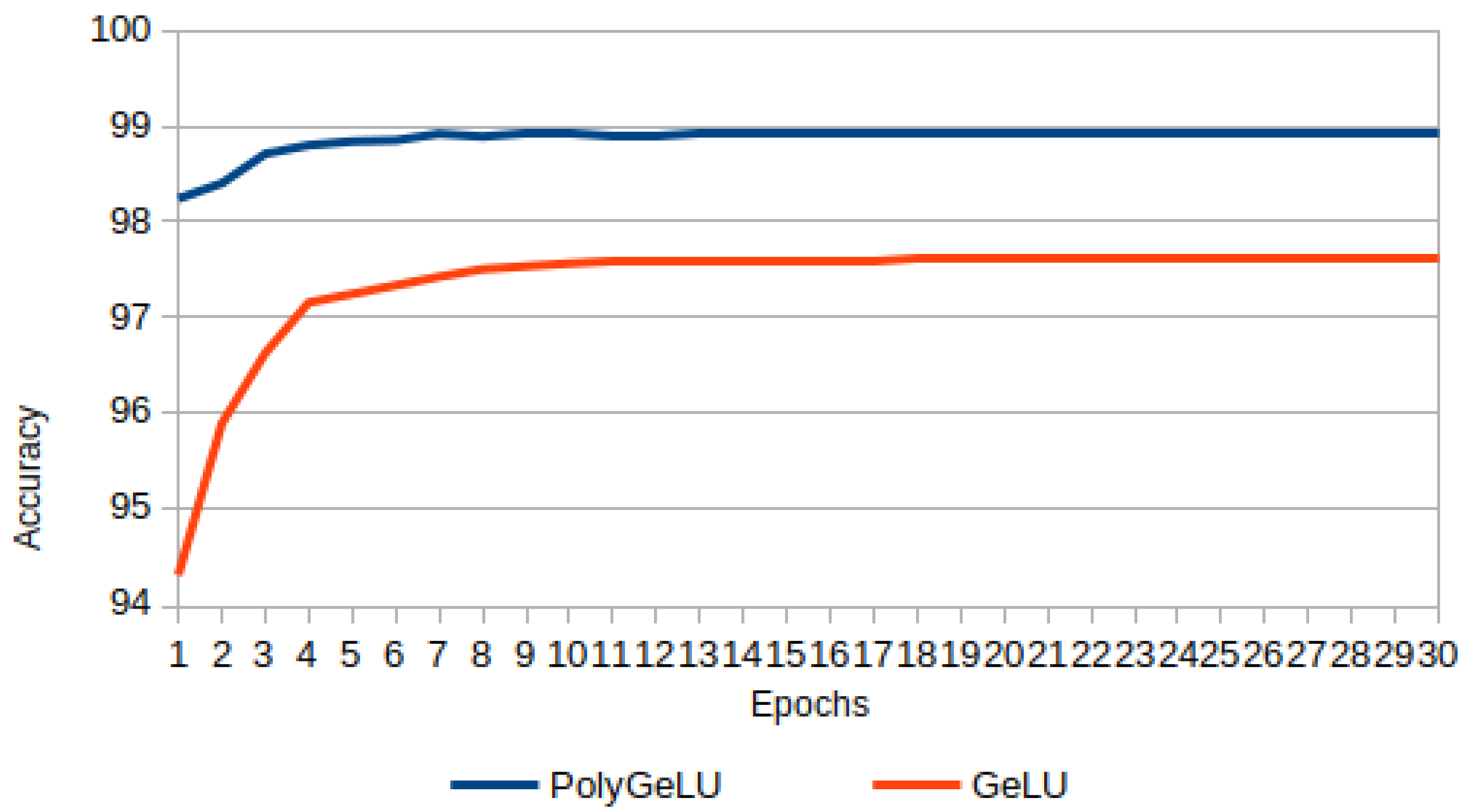
3.4. Experiment 4: PolyGeLU and GeLU
In this experiment, both activation functions, PolyGeLU (Equation (
44)) and GeLU (Equation (
14)), are compared.
Figure 16 shows the results, where it is evident that PolyGeLU outperforms GeLU.
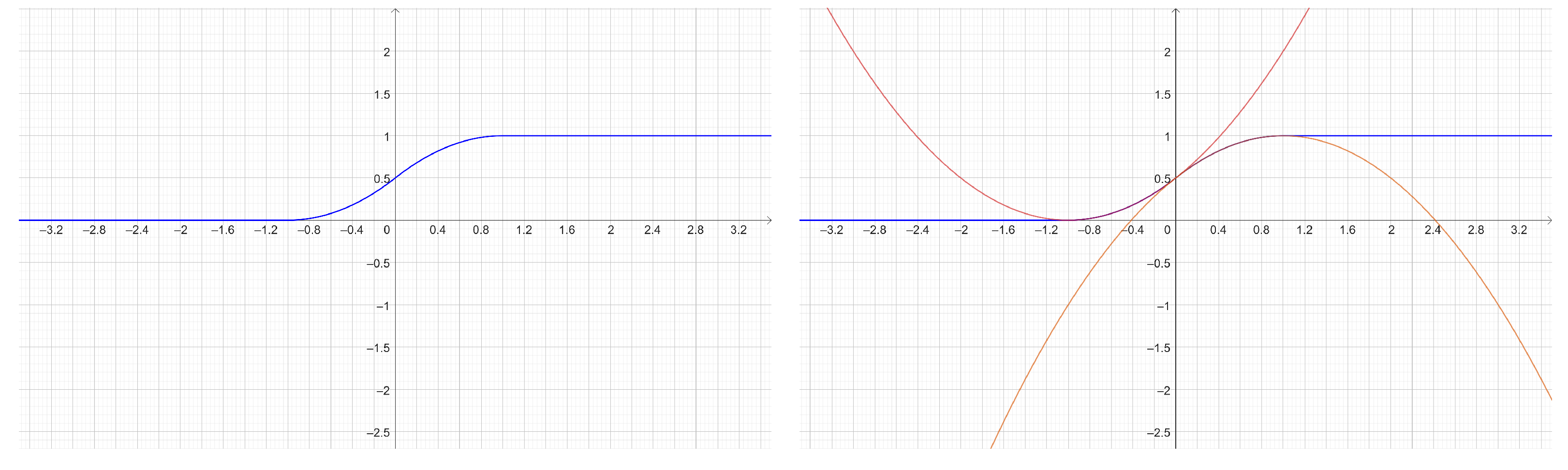
3.5. Experiment 5: ELU Approximation from PolySigmoid
In order to obtain a piecewise polynomial version of the ELU function, the following approximation is made. Given Equation (
42), which approximates Sigmoid via Polysigmoid, and focusing on the interval
, it follows that:
Thus,
, and solving for
:
With this approximation, it is possible to write a polynomial version for ELU named PolyELU, so:
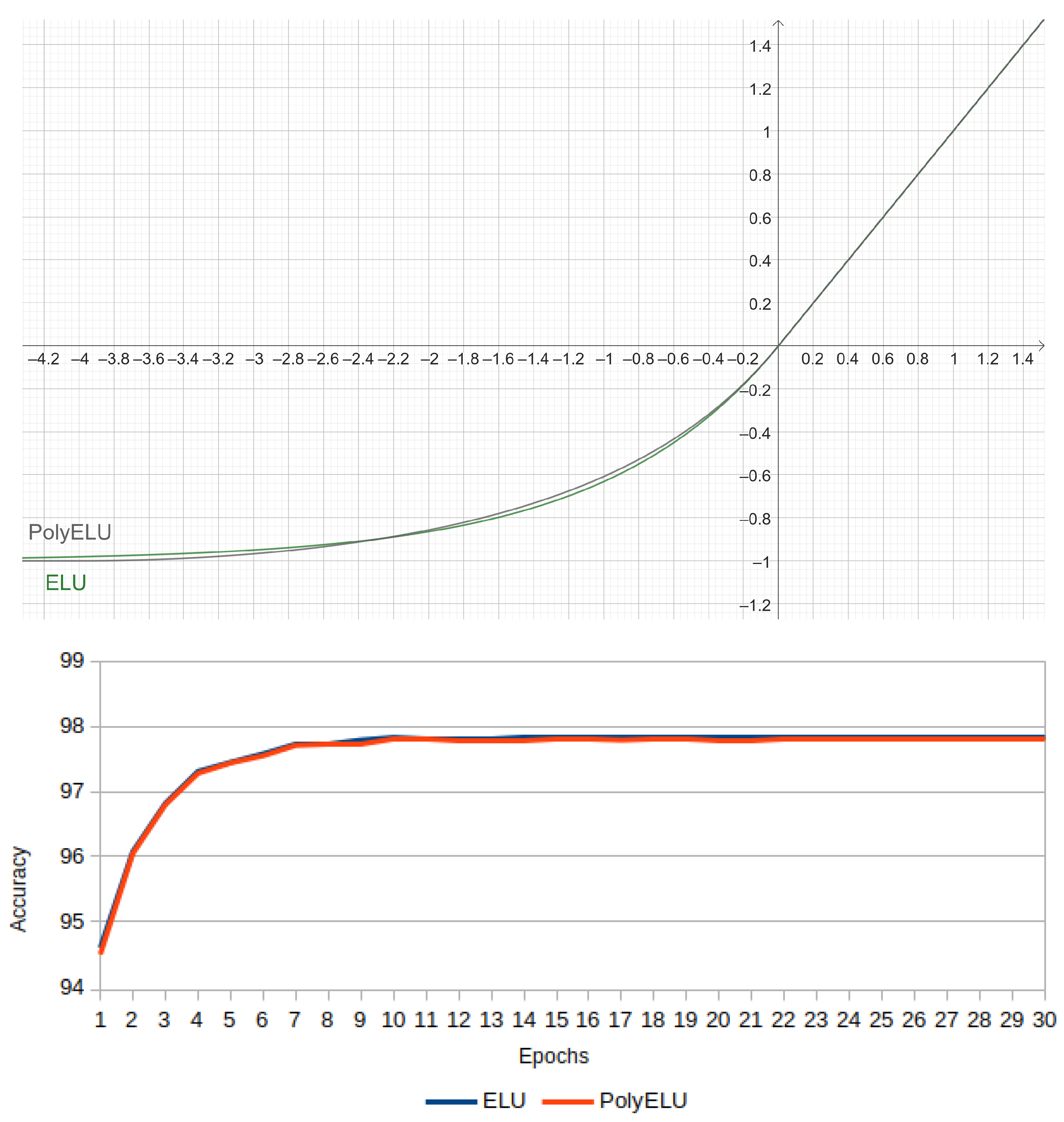
Figure 17 has the plots for
of PolyELU and ELU on the left side, whereas the corresponding accuracies are shown on the right side. Basically, they are overlapped and have a correlation of
. This confirms that there is a good approximation between these two activation functions.
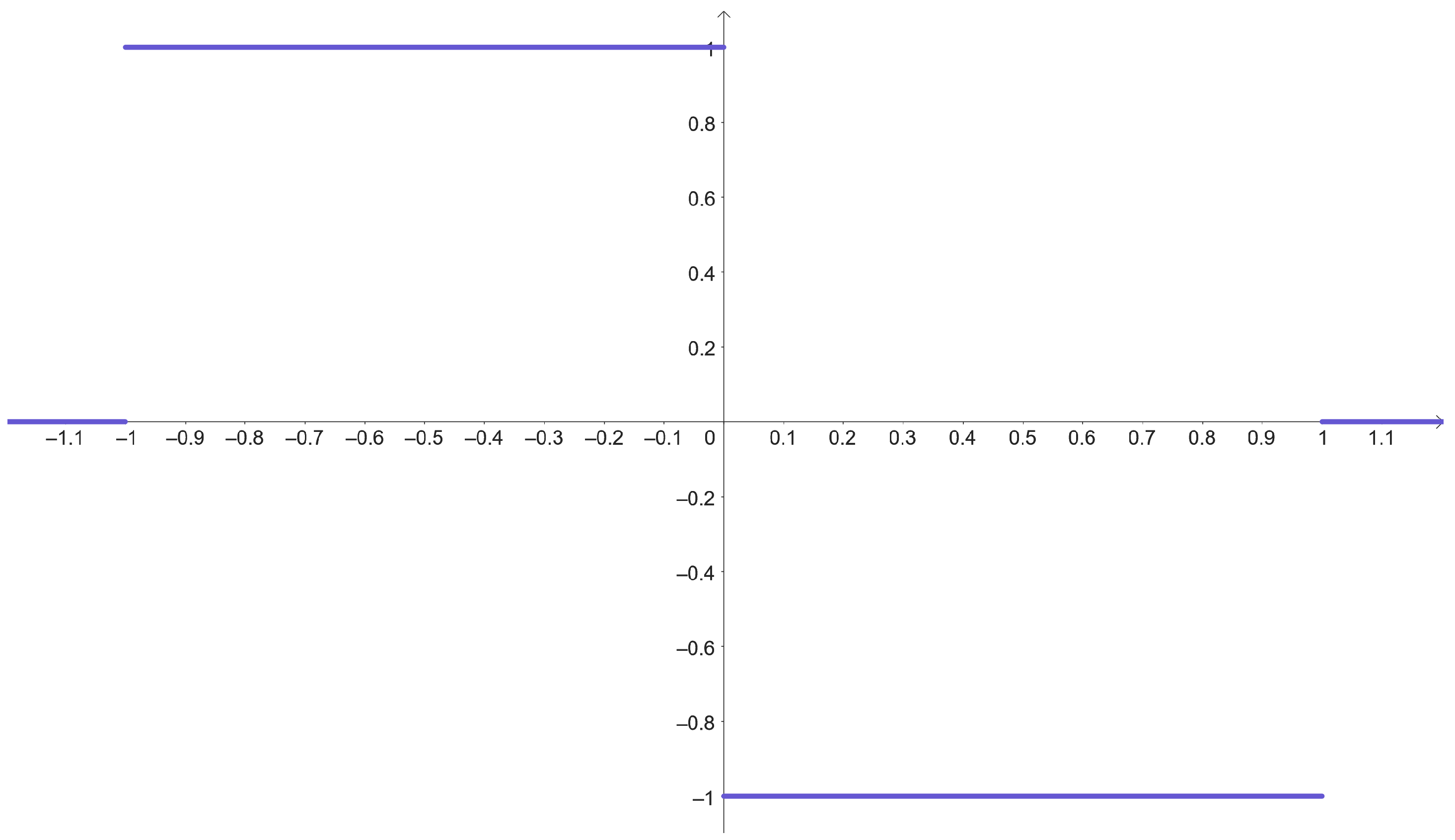
3.6. Experiment 6: Haar Wavelet, Triangular, Heaviside, and ReLU
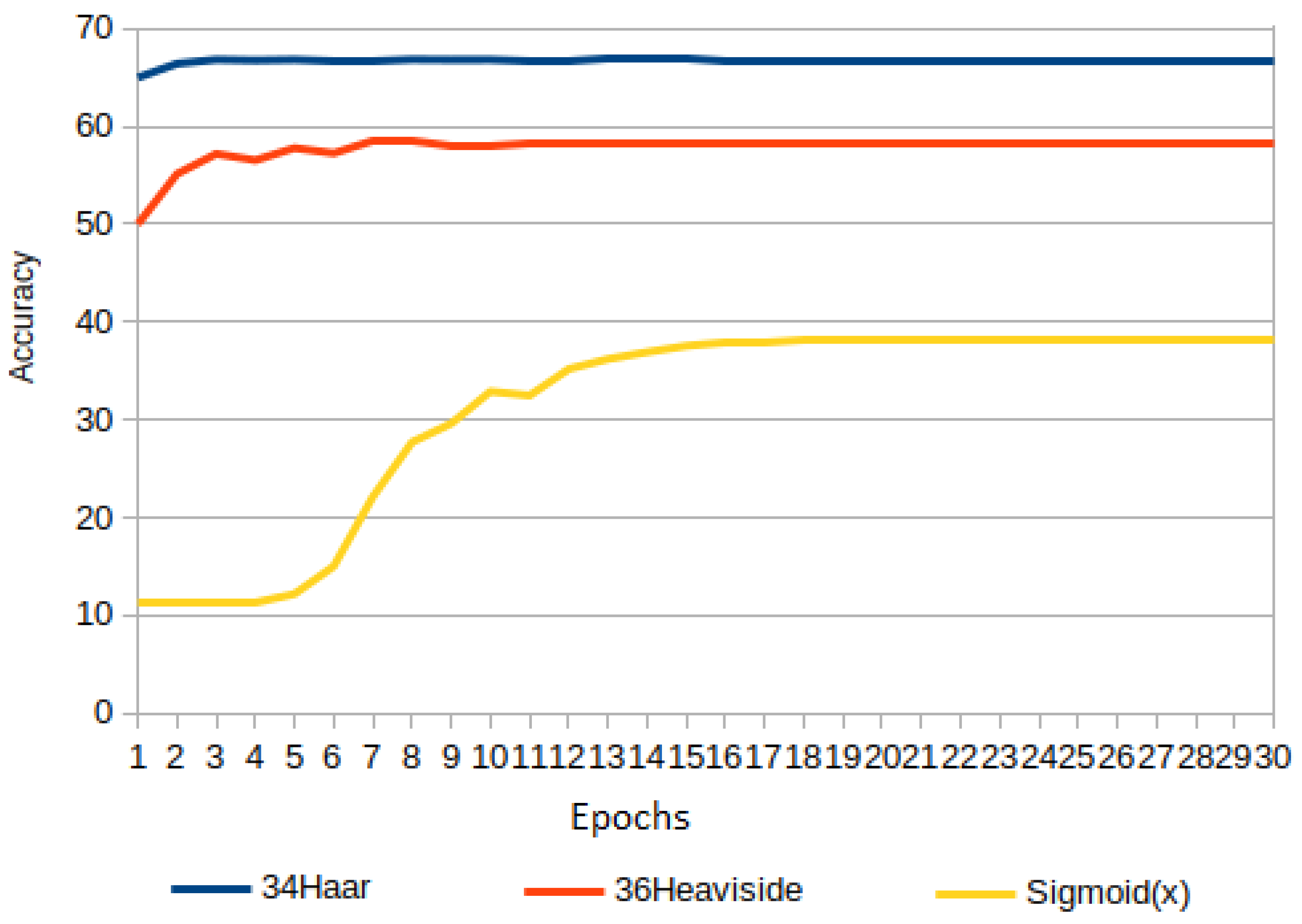
Experiment 6 gathers some activation functions that achieve a low accuracy: Haar, Heaviside, and Sigmoid, and it is shown in
Figure 18.
Haar’s accuracy is low, but higher than Heaviside and Sigmoid. Heaviside varies from up to , whereas Sigmoid is below . It is striking how a Sigmoid function that approaches Heaviside as tends to infinity can increase its accuracy. It has been experimentally calculated that as increases up to , the accuracy improves. In fact, the accuracy of Sigmoid with high -value outperformed that of Heaviside.
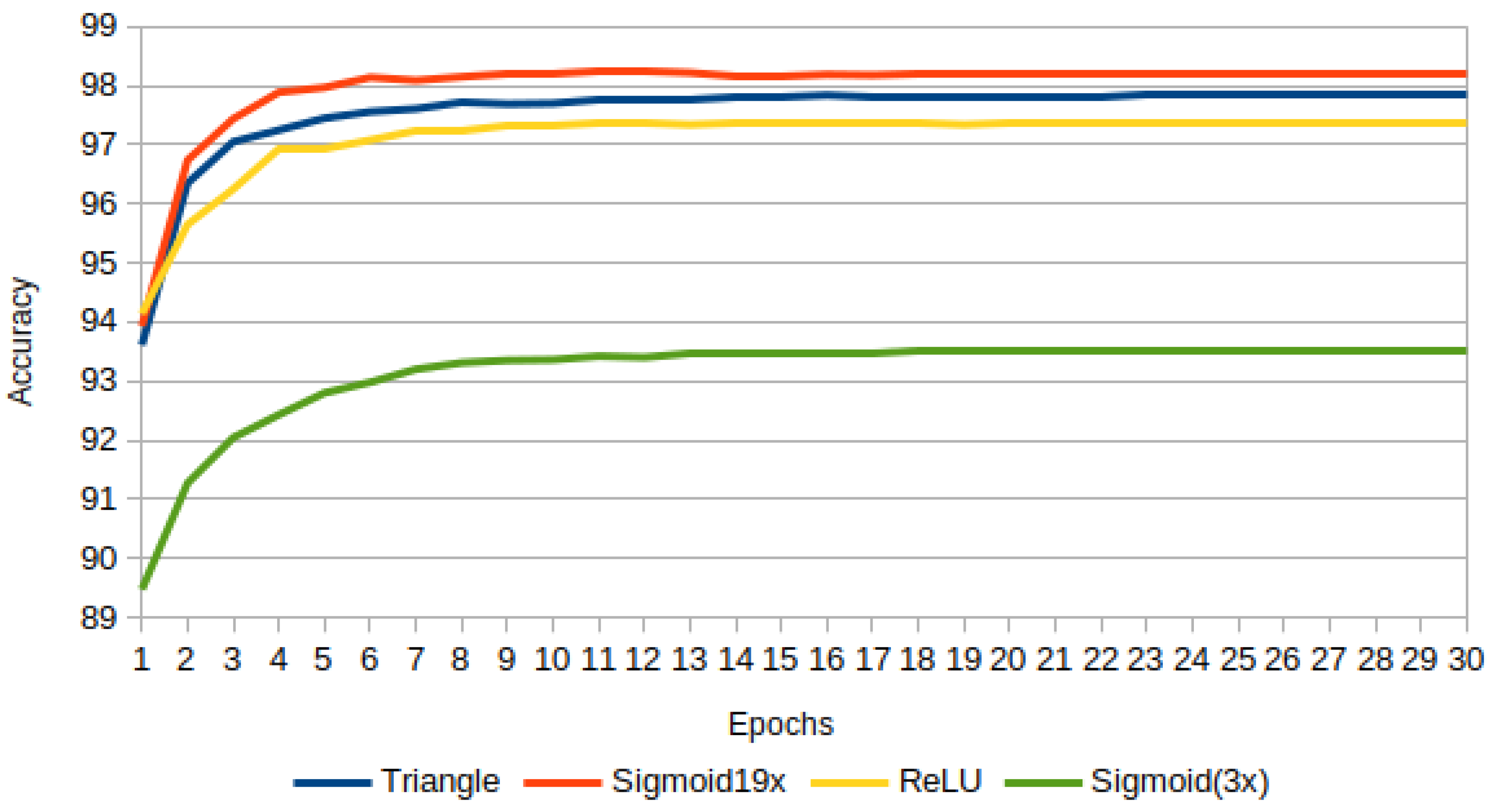
Obtaining the maximum accuracy for Sigmoid(
), it was compared with Triangular and ReLU. The results are in
Figure 19, where Sigmoid(
) outperforms Triangular followed by ReLU. Sigmoid(
) was also plotted just as a reference.
This experiment leads us to consider the importance of the non-zero gradient problem, challenging for Haar and Heaviside, which is extensive to Sigmoid for high scaling factors.
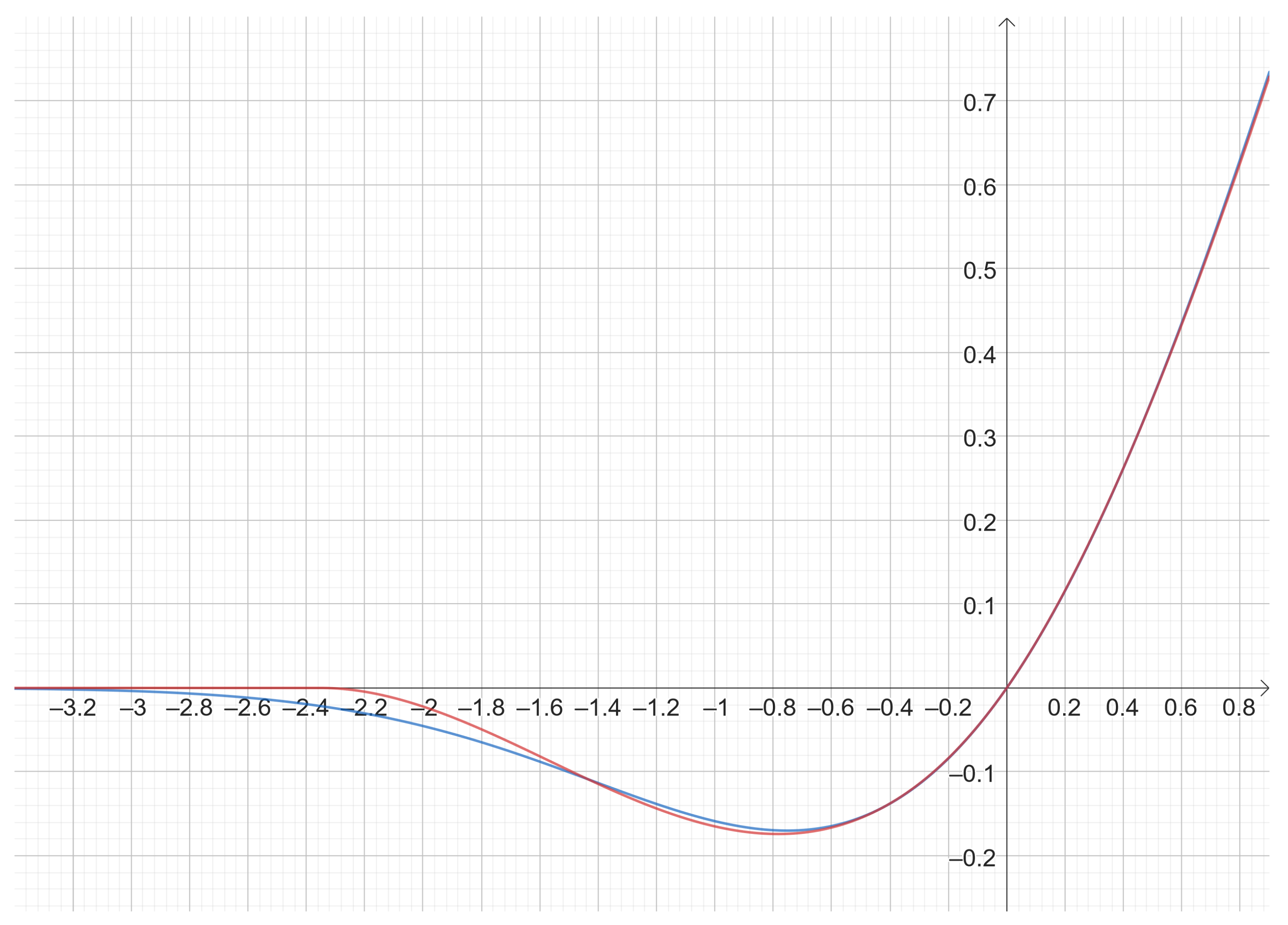
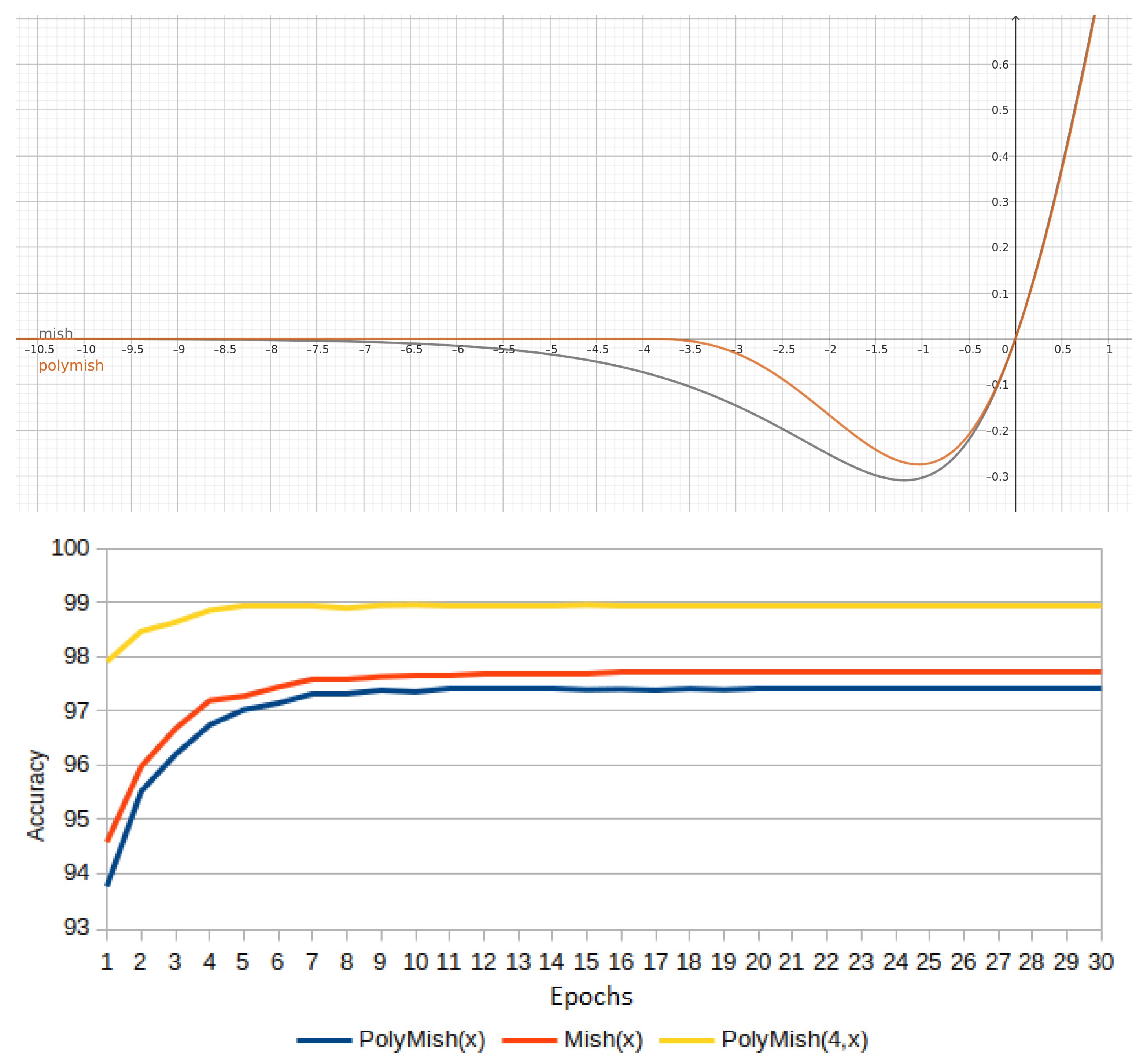
3.7. Experiment 7: Mish and PolyMish
Given the definition of PolySoftplus(x) in Equation (
45), and some advantages over Softplus described in
Section 3.1, is natural to propose a first Mish approximation named PolyMish, as follows:
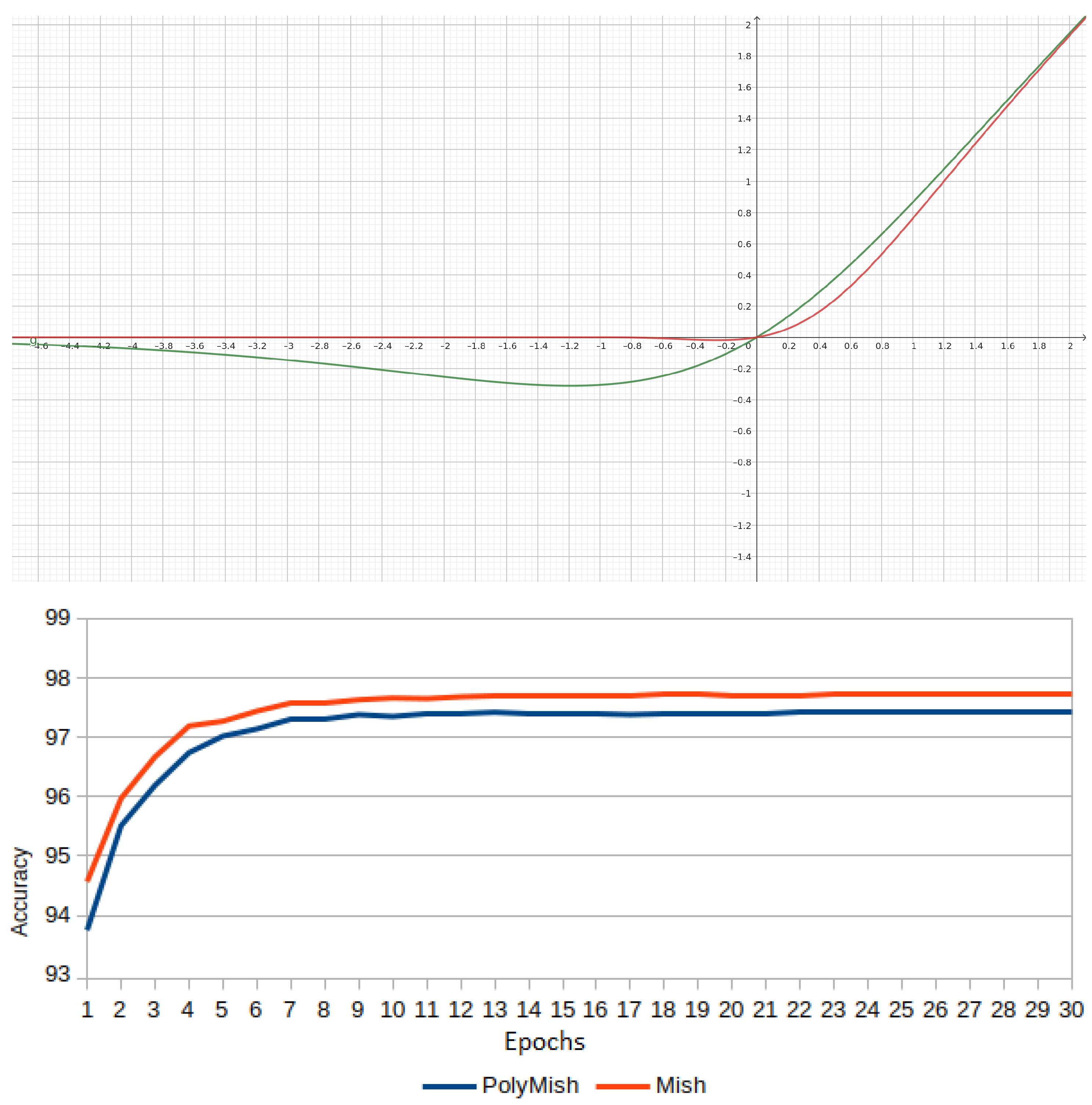
Figure 20 shows the plots of Mish vs. PolyMish. Mish(x) follows a smooth curve for
and asymptotical behavior to zero for
, whereas PolyMish vanishes faster than Mish and is exactly zero for
(see
Section 3.7). In other words, this first version is not a good approximation. Moreover, the bottom side of
Figure 20 illustrates how Mish outperforms PolyMish.
The approximation to Mish can be improved by considering an
factor, as in
Section 3.1, so that:
The top side of
Figure 21 shows the approximation of Mish using
. The accuracy results are shown on the bottom side of
Figure 21, where it is noticeable that this second version of
outperforms Mish.
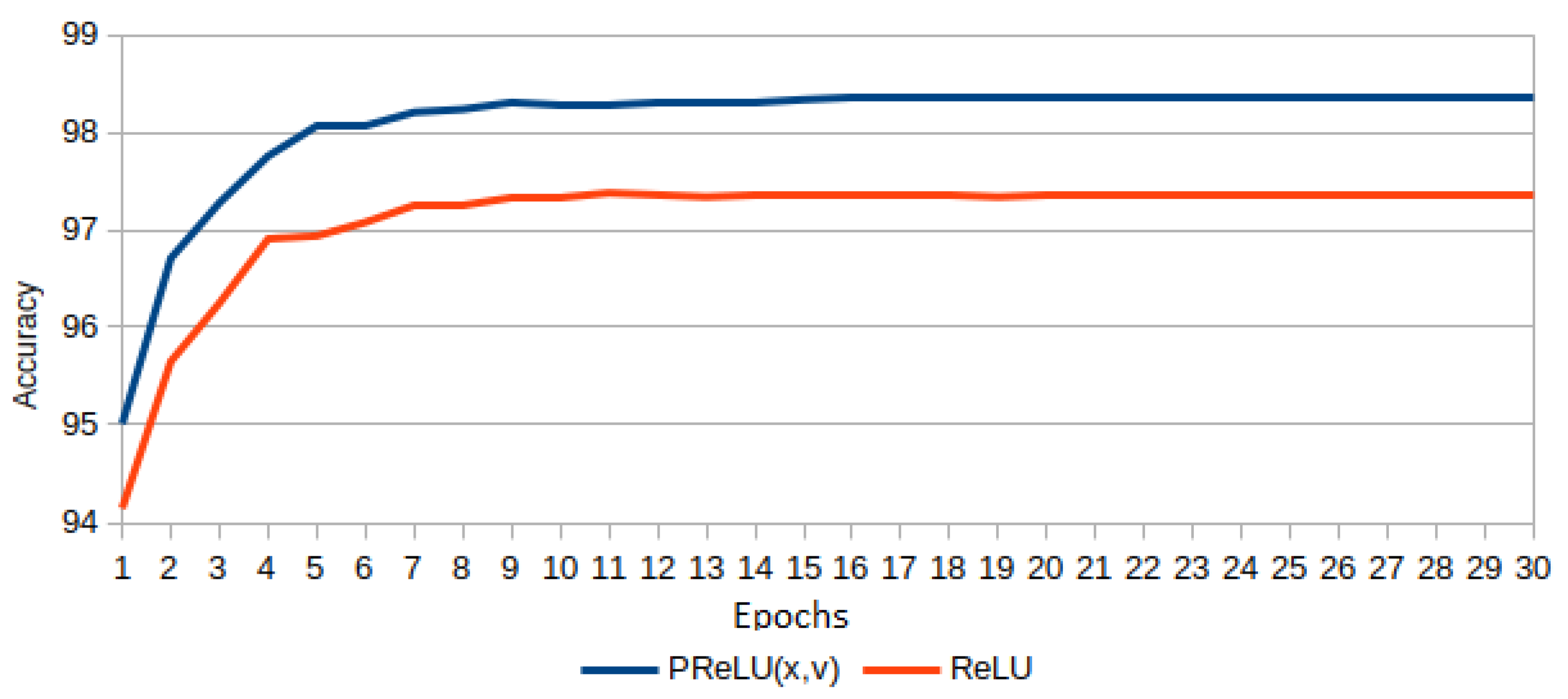
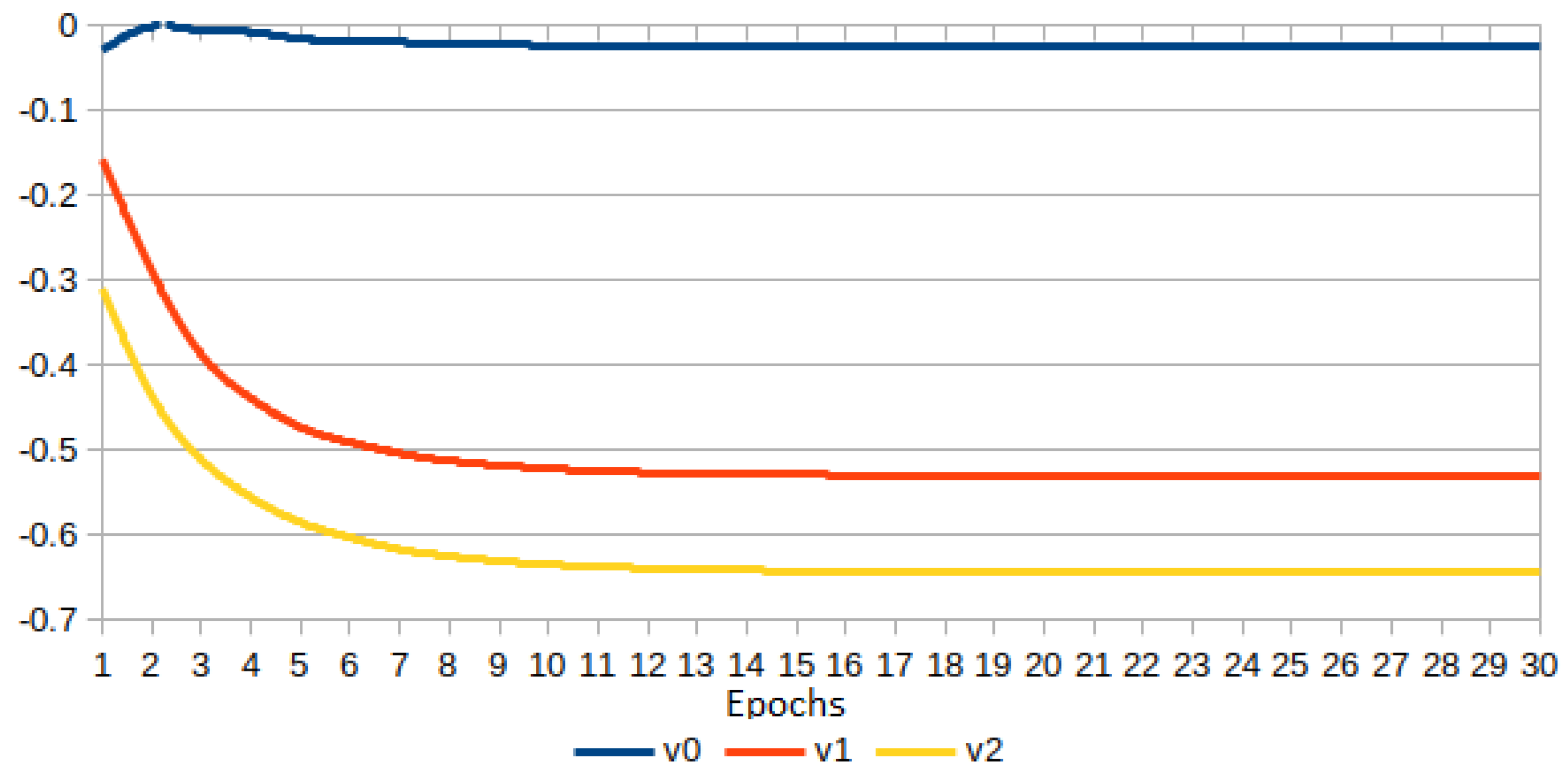
3.8. Experiment 8: Adaptive Fractional Derivative Order for vs.
In this experiment, given
, the parameter
is adapted during the learning (see Equation (
33)). The initial value for
is zero. The network architecture involves three
functions, and each
-parameter is adjusted with SGD as a hyperparameter in Pytorch. The results are shown in
Figure 22. From the top side, it is evident that the PReLU version outperforms the network built only with ReLUs. The adaptive
-values for the three PReLUs are shown at the bottom of
Figure 22, where the fractional derivatives have negative values, i.e., the power of
x is greater than
.
3.9. Experiment 9: Fractional Derivative of as Activation Function
The importance of having a non-zero gradient for
is a motivation to use a fractional derivative of
based on Equations (
33) and (
34), as follows:
Beyond this, different fractional-order derivatives can be used,
for
and
for
. Thus, for
:
If
, then Equation (
56) produces a zero division if
, but to avoid this situation, it is possible to add an
[
18]. In this experiment,
.
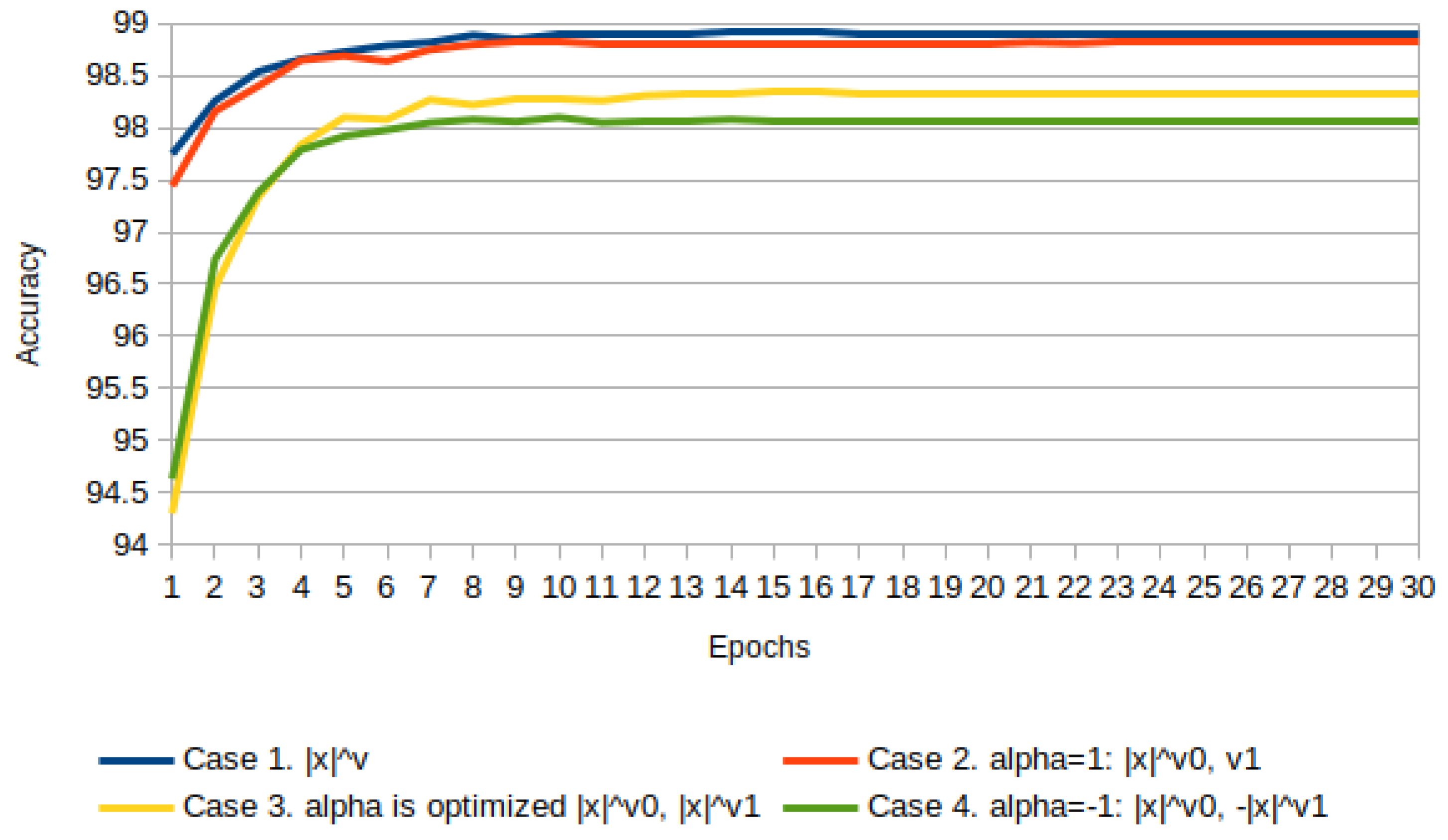
Results of four cases are reported in
Figure 23, sorted from best to worst:
Case 1.
, Equation (
55).
Case 2.
, Equation (
56)
.
Case 3.
, Equation (
56), where
is optimized with SGD as hyperparameter.
Case 4.
, Equation (
56)
.
All -parameters as well as are initialized to zero. For Case 3, is optimized in three activation functions AF1, AF2, and AF3.
3.10. Experiment 10: Trainable Activation Functions with Fractional Order: and vs. SPLASH
In this experiment, the adaptive -order of fractional functions is optimized with SGD in PyTorch. Three activation functions are compared: SPLASH, , and .
From Equation (
30), only seven terms are considered for SPLASH, then it is written as:
where
,
is initialized to one, and the rest to zero (see [
20]). These initial conditions mean initializing with ReLU shape. SPLASH does not involve fractional derivatives, but it is used in this experiment as a reference for comparison purposes.
The neural network architecture has three activation functions, and for SPLASH, each unit needs seven a-parameters. So, the total number of hyperparameters is 21 (it certainly consumes enough GPU memory).
For the fractional derivative
of Equation (
55), the total number of hyperparameters is 3, and the initialization was
, which means initializing with a piecewise linear shape.
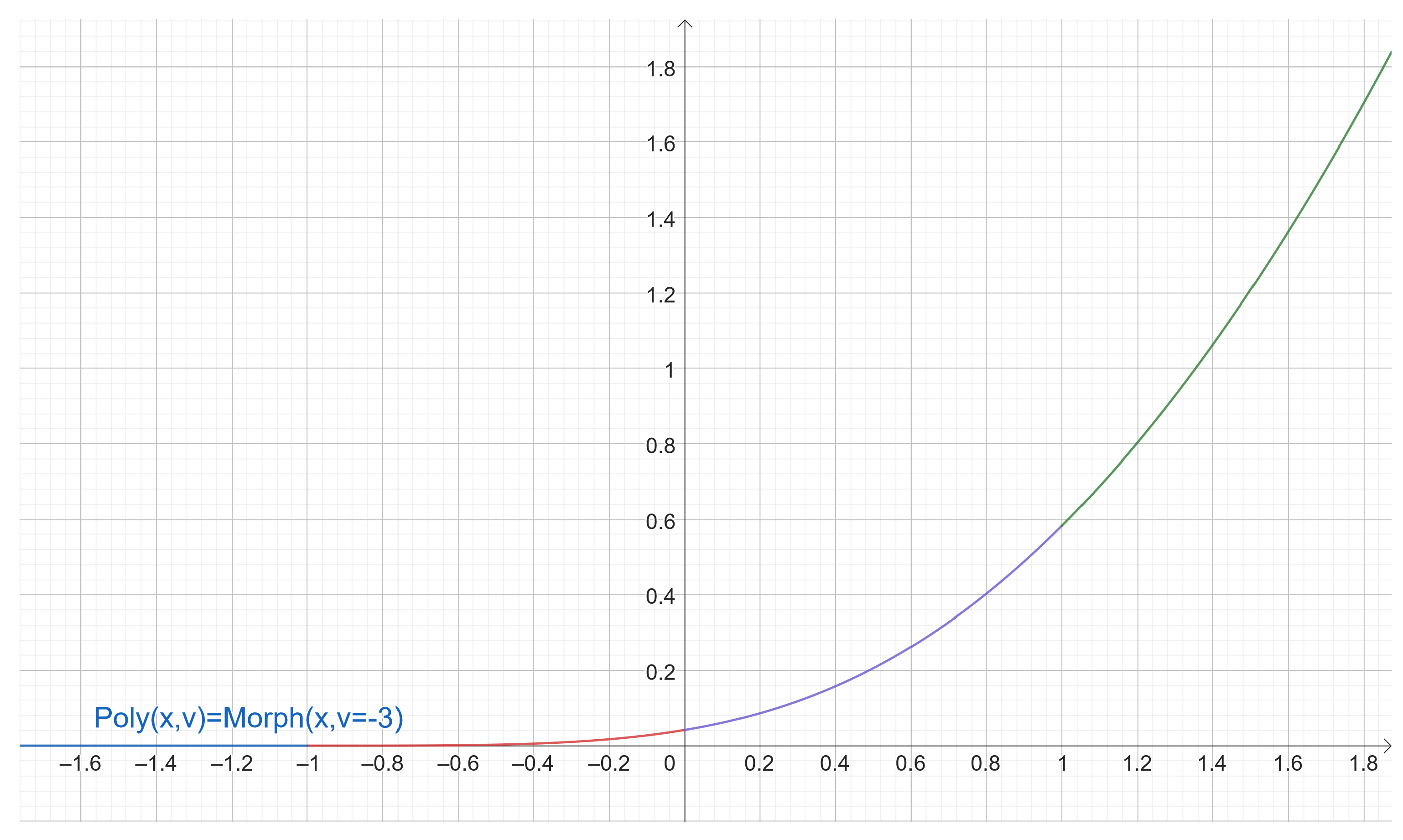
In the case of Morph, dilation
a and translation
b are used, so
and the initialization was
,
, and
. It corresponds to PolySoftplus of Equation (
45) illustrated in
Figure 10 (a shape similar to ReLU or Softplus, in
Section 2.10). In this case,
needs to adapt
hyperparameters.
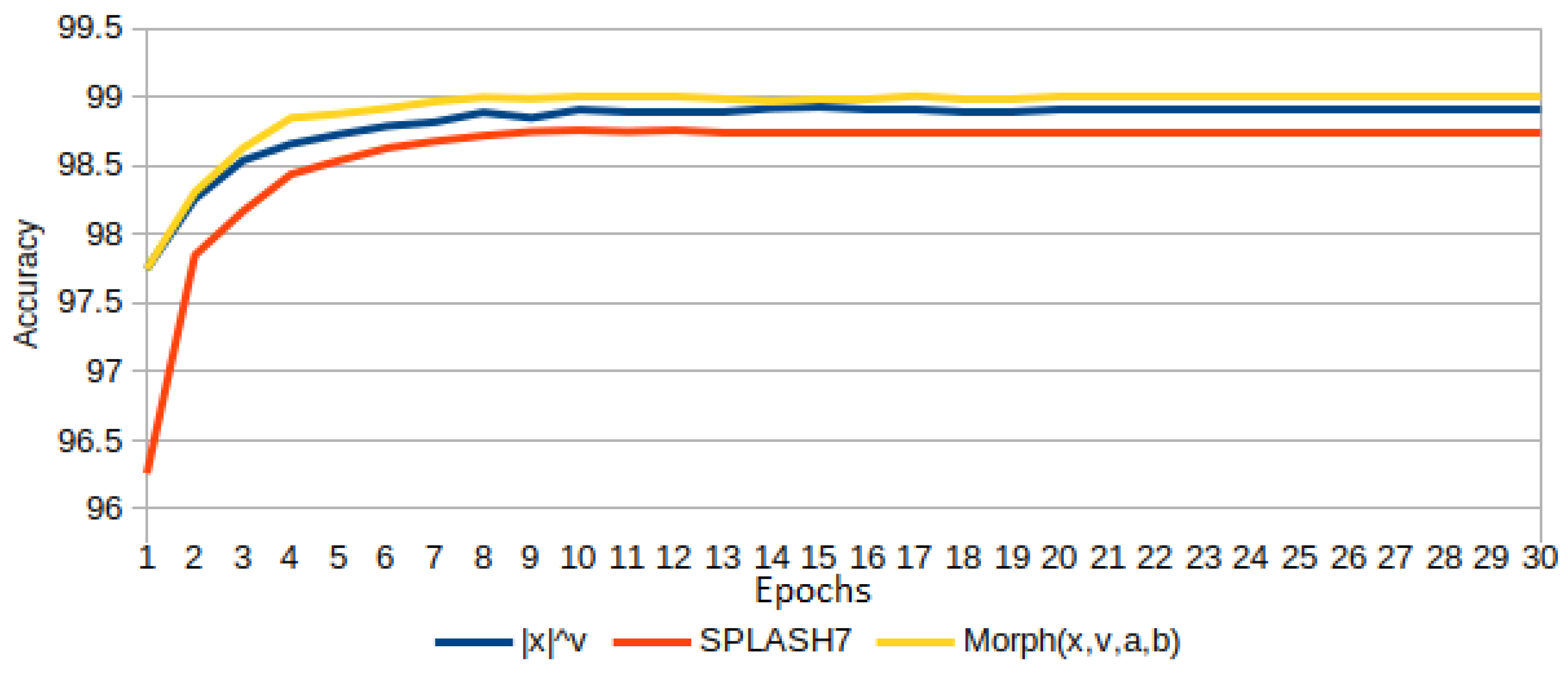
The accuracy results are show in
Figure 24. SPLASH adjust all of the
parameters, but its performance is lower than the corresponding of
, which, by the way, only uses three parameters.
Special attention is given to , which achieves the best accuracy compared to and .
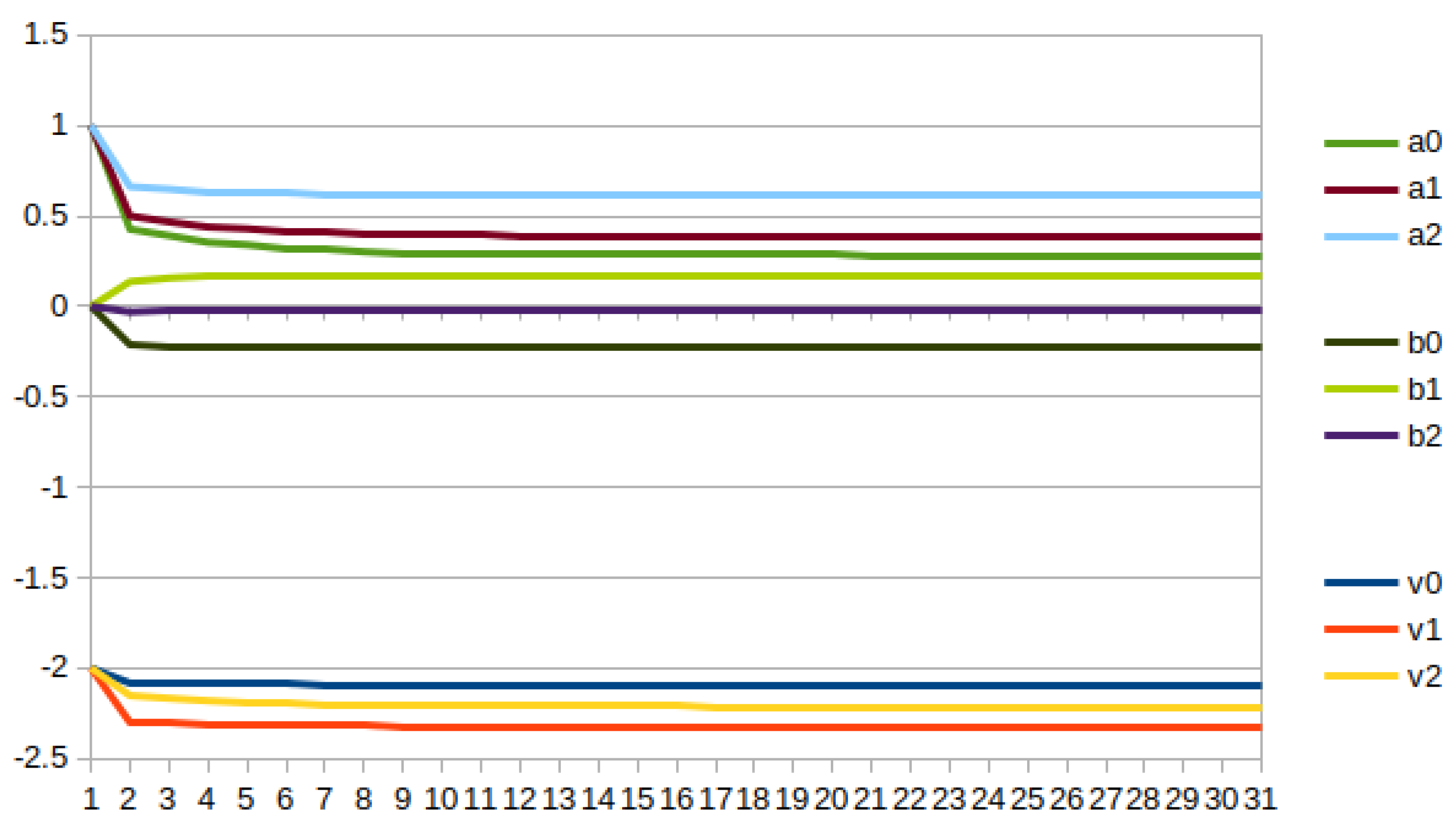
Figure 25 shows the change of the fractional orders of three
activation functions used in the network architecture:
,
, and
initialized to zero. Also, the parameters
a and
b of these three
functions are optimized, and they are plotted in the same figure.
Figure 26 shows the shape of
when the parameters
are updated to
, and then to
at epochs 0, 2, and 30, respectively. These parameters are optimized with the gradient descent algorithm SGD in PyTorch. Only the values of one of the three Morph functions are presented for reasons of space, and since they are similar to those of the other two units.
3.11. Experiment 11: Comparison of Morph() with Other 20 Activation Functions
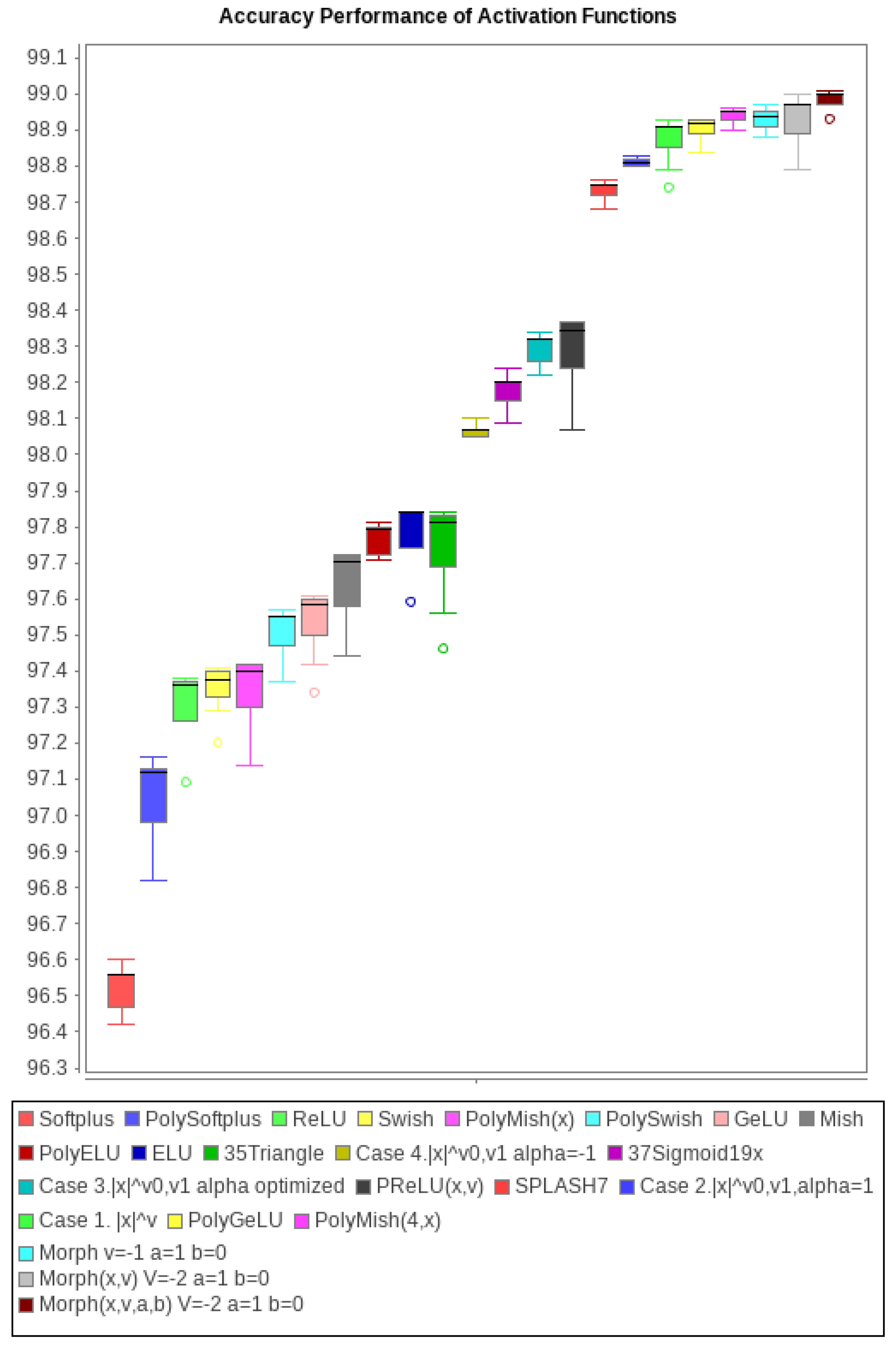
Experiment 11 compares several activation functions: piecewise polynomial obtained as special cases of
and other existing and well-known activation functions. Based on the accuracy results, they are shown in
Figure 27 sorted from left to right, worst to best, and enumerated in
Table 1. Highlighted in bold are cases where a polynomial version is better than its counterpart, for example, PolySoftplus is better than Softplus. Note that the highest accuracies are achieved by
with optimized parameters:
Case 21. , initializes and is optimized during the training.
Case 22. , initializes and is optimized during the training.
Case 23. , initializes and are optimized during the training.
3.12. Experiment 12: Adapting Morph with SGD and Adam
Finally, in the last experiment, a minimal neural network is used to illustrate how the fractional derivative
for
is updated using Adam and a fractional SGD (FSGD) [
19] with the fractional gradient set to
, which was determined experimentally for MNIST [
18,
19]. Note that the fractional gradient uses the fractional derivative of the activation function to update the learning parameters, but the approach is different (and complementary) to adjust the shape of the fractional derivative for
as activation function.
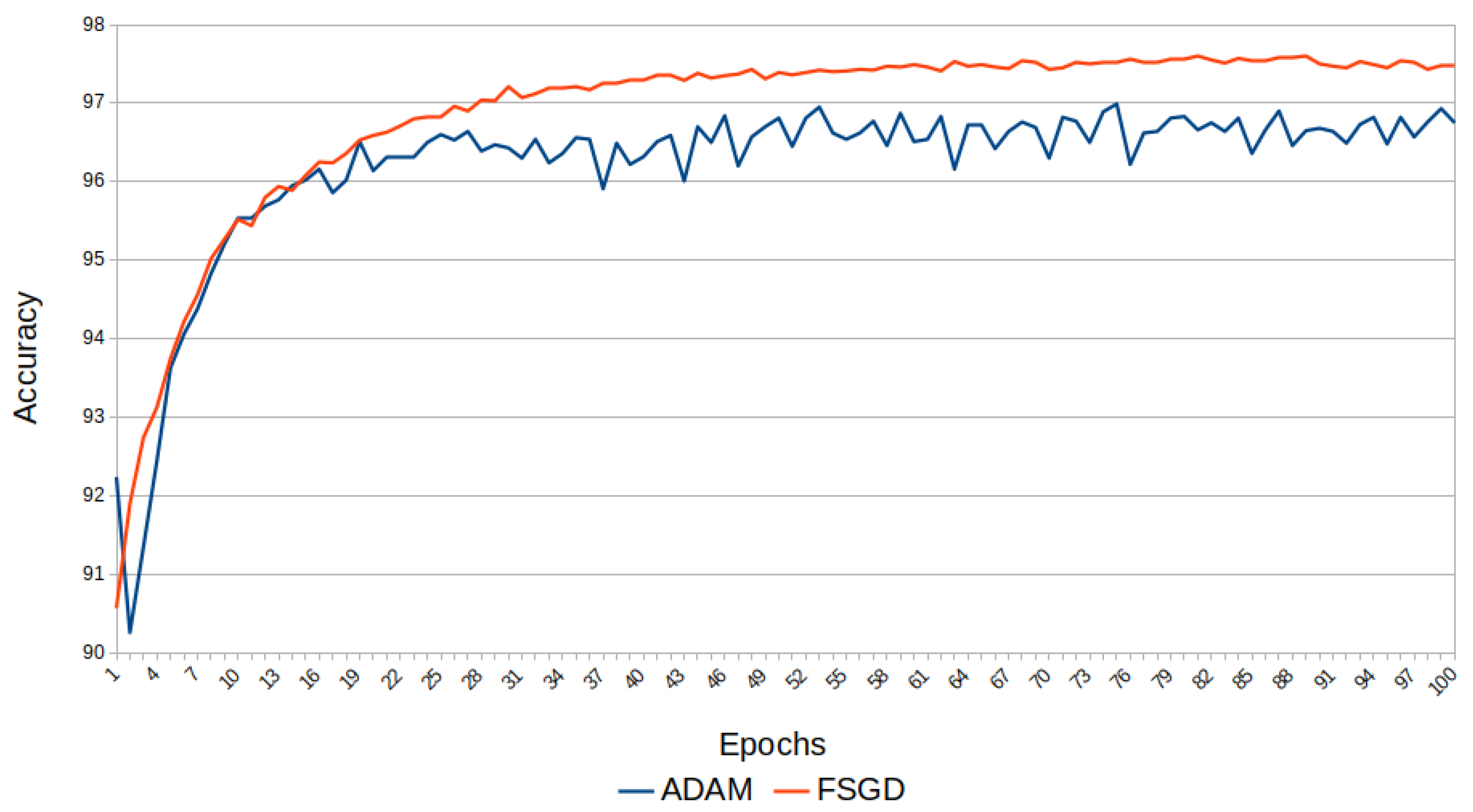
The number of epochs was 100, and the accuracy results are shown in
Figure 28. The parameter initialization is
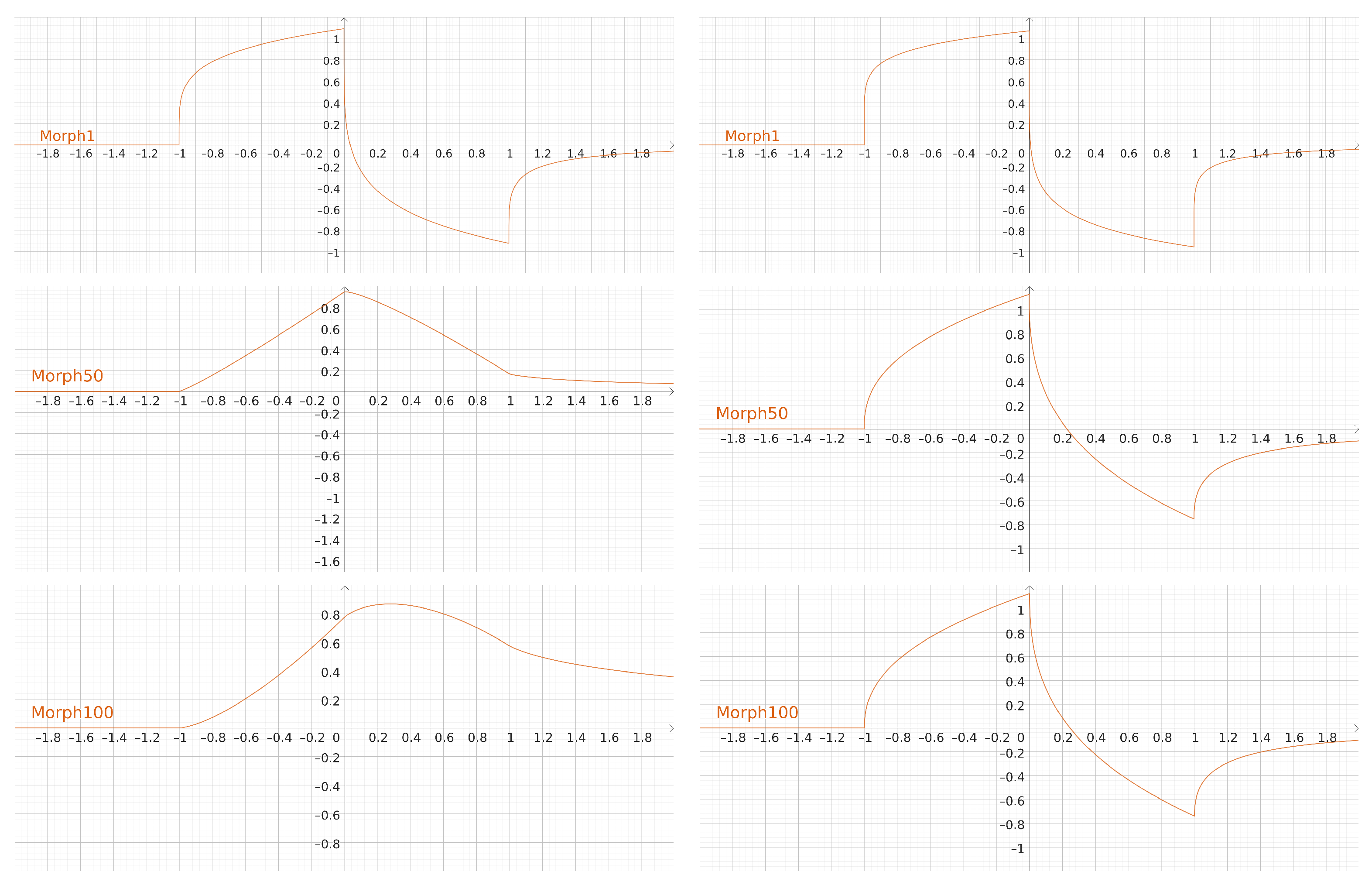
. In
Figure 29, the shapes for epochs
, and 100 are plotted for both Adam and FSGD. It is a demonstration that a fractional optimizer like SGD can be sufficiently competitive with other more sophisticated optimizers like Adam. In fact, FSGD outperforms Adam in this experiment.
The source code of all the experiments is available at
http://ia.azc.uam.mx accessed on 11 July 2024.
4. Discussion
One of the branches of artificial intelligence research is the architecture of neural networks, focused on the number of layers, types of modules, and their connections. However, another branch that has gained traction is proposing new activation functions that provide the non-linearity required by neural networks to efficiently map inputs to outputs of complex data.
Fractional calculus emerges as a mathematical tool to generalize to non-integer derivative orders, useful for building activation functions and, in this paper, a novel adaptive activation function was proposed based on fractional derivatives.
The search for the best activation function has led to the proposal of adaptive functions that learn from data. The adjustment of hyperparameters allows us to control stability, overfitting, and to enhance the performance of neural networks, among other challenges in machine learning.
Although we are certainly not working on function approximation with , but rather using it as an activation function, it is important to emphasize the approximation property of , and consequently to remark on how it provides the nonlinearity needed in a neural network to efficiently map inputs to outputs with good generalization capacity.
The proposed
function approximates the Sigmoid function sufficiently to satisfy the conditions of the Universal Approximation Theorem [
37]. Thus, there is a theoretical justification for
to approximate functions in compact subspaces.
Also,
is able to mimic shapes such as the Haar wavelet, which in turn are basis functions of vector spaces, and it gives an idea of the approximation capacity of this proposed function [
43]. In fact, the inspiring idea for
relies on the Haar decomposition as a linear combination of translated Heaviside functions.
Indeed, two fundamental operations on functions are translation and dilation [
43]. In this way, for
and
, the translated and dilated version of
is:
A successful application of this was the approximation of Sigmoid via PolySigmoid, Swish via PolySwish in
Section 2.7, and GeLU via PolyGeLU in
Section 2.9.
Given that several activation functions include
x as a factor, an adaptation to
is
, which can be defined as:
where
,
,
and
.
Considering this, other activation functions such as tanh can be written using
. For example, starting with the parameters for Sigmoid
, and
, it is possible to write
, and consequently:
Table 2 summarizes important cases of
that allow us to obtain shapes that sufficiently approximate existing activation functions.
not only allows us to obtain good approximations, but also provides formulas of piecewise polynomial versions of activation functions which could improve computational efficiency.
Future work includes proposing variants of that maintain flexibility without increasing the number of parameters. The aim is to progress towards the construction of a more general formula that unifies as many adaptive activation functions as possible, with properties useful in machine learning.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}