1. Introduction
Seawalls are commonly established atop foundations of deep soft soils whose physical and mechanical features are distinctive, e.g., high compressibility, high water content, and diminished strength, as well as specific rheological behavior [
1,
2]. These characteristics lead to significant settlement during both the construction phase and post-construction phase. The total subsidence may reach several meters and the consolidation settlement period lasts more than 10 years [
3,
4,
5]. The large vertical settlement on soft soil foundations threatens the stability of seawalls, which greatly increases the risk of structural damage and safety incidents. Therefore, predicting seawall settlement is essential to engineering security operations and risk management.
Time series monitoring data record the historical behavior of seawalls, including its structural characteristics and operational patterns [
6,
7] among which settlement is one of the most crucial parameters. Predicting the settlement based on time series monitoring data using mathematical algorithms forms a reliable approach for assessing the safety status of the seawall [
8,
9]. At present, prediction methods commonly used in seawall settlement prediction based on monitoring data can be categorized into two groups: statistical methods and machine learning methods. Statistical methods such as the exponential curve method [
10], Asaoka method [
11], and Poisson curve method [
12] are established based on the idea of data fitting using mathematical curves. Statistical models can not only quantify the influence of each factor on data-varying tendencies, but also effectively describe the characteristics of the data sequence including the distribution and correlation of data. These models are usually established on the basis of certain assumptions such as normality, independence, etc., which means that the accuracy and reliability of the model cannot be guaranteed in the case where the assumptions are not met [
13,
14]. Machine learning methods, such as wavelet theory [
15], chaos theory [
16], and neural networks [
17], are able to process massive and multidimensional datasets to solve nonlinear and complicated problems. However, both statistical methods and machine learning methods are highly reliant on the quantity and quality of data sequences, meaning that either poor data quality or insufficient data quantity can lead to unsatisfactory prediction performance [
15,
18].
Insufficient data volume is a common issue in seawall settlement monitoring. In many cases, the volume of monitoring data is fairly limited, and this is not an isolated occurrence [
19,
20]. The reasons are multifaceted; the number of monitoring devices installed on the seawall may be insufficient to cover all critical areas, resulting in limited data availability. Even with adequate monitoring devices, the current technology may not support high-density and high-precision monitoring, thereby restricting the monitoring frequency and causing a shortage in data volume [
21]. Further, due to the intricate environmental conditions in coastal areas, environmental factors during critical periods such as storm surges and floods can further impede the acquisition of monitoring data. The insufficient amount of data in seawall monitoring is a significant issue as it may limit our comprehensive evaluation of a seawall’s health condition and potential risks [
22,
23]. This issue can be addressed in two aspects to ensure the accurate prediction of a seawall’s settlement based on monitoring data. We can either increase the number of monitoring points or strengthen the ability of data processing and analysis under the situation of limited data volume.
Most previous studies developed predictive models using monitoring data at a single monitoring point. Using multi-point monitoring data prediction offers several advantages over single-point data prediction, particularly in terms of robustness and ability to capture complex relationships [
24,
25]. First, multi-point monitoring data provides multiple observations of the same phenomenon, reducing the impact of errors or noise from any single point. Also, different data points can capture various aspects of the system, leading to a more comprehensive understanding and improved prediction accuracy. It allows the prediction model to be less sensitive to missing or erroneous data from individual sensors. Therefore, multi-point prediction provides a solution to ensure the efficiency and accuracy of seawall settlement displacement.
In addition, in engineering cases where a lack of monitoring data is already present, employing mathematical methods to analyze and predict the existing dataset emerges as the most practical, effective, and economical approach. Grey models, especially the GM(1,1) model, exhibit significant advantages in tackling issues related to insufficient data volume [
26,
27]. In the realm of grey theory, the grey system comprises known information (white) and unknown or uncertain information (grey or black). Grey models use limited and incomplete data to establish differential predictive models, thereby uncovering latent patterns within the dataset [
28,
29,
30,
31]. Their core competency lies in making predictions with relatively small amounts of data. Typically, only a few data points (four or more) are required to build a grey predictive model, effectively addressing the issues of scarce historical data, incomplete series, and low reliability. In addition, grey models do not require strict regularity in the distribution of sample data, further easing the data requirements.
While grey models possess these advantages, they also have limitations. For instance, they may not be optimal for systems with clearly defined internal mechanisms, and may fall into suboptimal solutions in predicting time series data with high volatility. Wu [
32] found that the GM(1,1) model exhibits considerable sensitivity to minor perturbations in data computation using matrix perturbation theory, resulting in significant interference with the identification of model parameters. To address this issue, he proposed a fractional-order grey model on the basis of the perturbation theory of least squares [
33]. The fractional-order grey model, as an extended grey prediction model, is exceptionally adept at handling data sequences that exhibit volatile variations. By introducing fractional-order calculus operators into a continuous grey model, it adeptly transforms original data sequences with fluctuations into ones with heightened regularity, thereby optimizing the traditional grey modeling mechanism and improving the modeling efficiency [
34].
Although the fractional-order grey model exhibits advantages in handling complex systems, its application to the prediction of seawall settlement with limited data volume can still be constrained by system and data characteristics. As the fractional-order grey model incorporates fractional-order derivatives and polynomial functions, the determination of its parameters becomes more complex, requiring the employment of specific optimization methods to solve the coefficients of polynomial functions. For example, the variable fractional order
r obtained by commonly used intelligent algorithms involves unavoidable randomness, which may increase the unitability of prediction results [
35]. For example, the swarm optimization algorithm may obtain a local optimal solution instead of a global optimal solution due to its high convergence speed [
36]. The artificial fish swarm algorithm is susceptible to premature convergence, that is, the algorithm may converge to a suboptimal solution without adequately exploring the searching space [
37]. Further, the fractional-order grey model cannot fit the time series data dynamically. Due to the high sensitivity and compressibility characteristics of the soft soil foundation of the seawall, and influenced by external factors such as tidal scouring, storm surges, and construction disturbances, the settlement of the seawall exhibits dynamic variations at small temporal scales [
38]. Seawall settlement represents a real-time evolving process, but the fractional-order grey model is limited to making predictions with a fixed step size based on existing data [
8,
39]; therefore, the dynamic prediction of seawall settlement still needs to be improved.
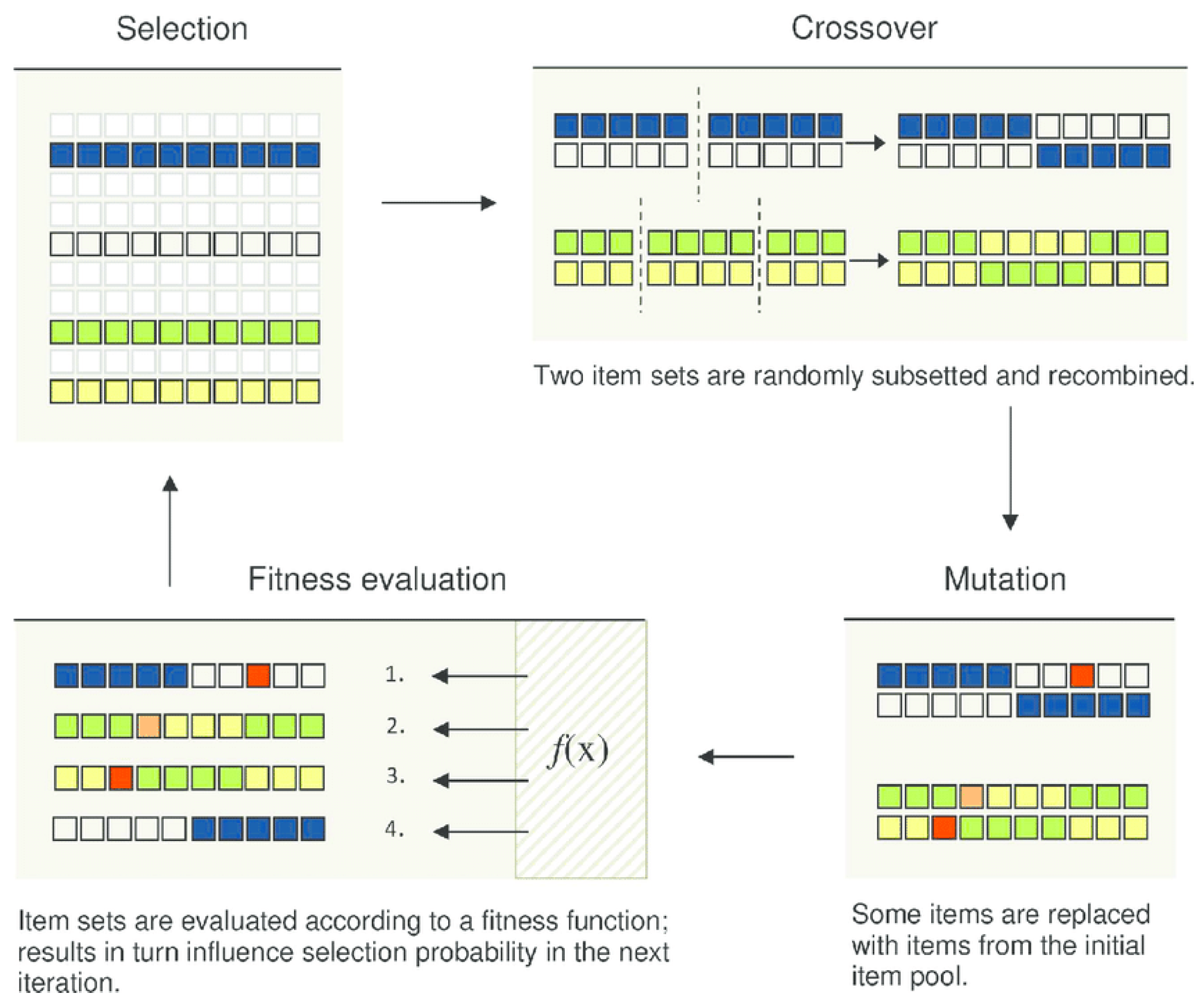
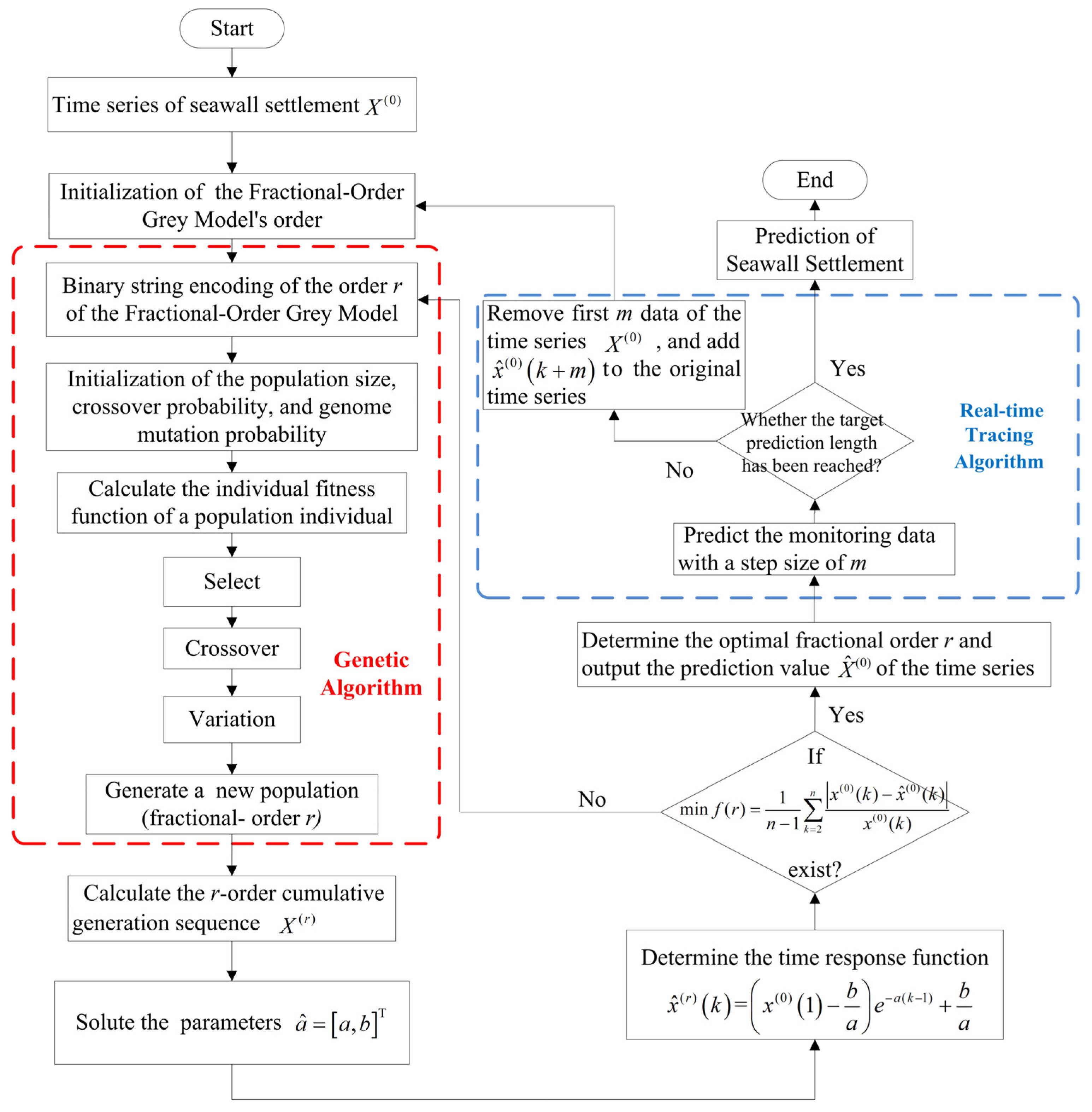
To solve the above two issues associated with the application of the fractional-order grey model in seawall settlement prediction in the case of limited data volume, this study aims to improve the fractional-order grey model by integrating other models. With this objective in mind, a genetic algorithm [
40] with enhanced search capabilities was used to solve and optimize the fractional order
r of the fractional-order grey model. Then, a real-time tracing algorithm [
41] was used to achieve the dynamic prediction. The monitoring of the data of a seawall at the northern bank of the Qiantang River, China, was used to validate the model. The performance of the proposed model was evaluated by comparison with the fractional-order GM(1,1), integer-order GM(1,1), and fractal theory model, respectively.
This paper is organized as follows:
Section 2 presents how the proposed model is developed.
Section 3 exhibits the information of the case study.
Section 4 shows the prediction results. Comparisons of the proposed model with other relative models are also illustrated in this section.
Section 5 presents the concluding remarks.
3. Case Study
To validate the proposed model, the Haiyan seawall, which is located on the north bank of the Qiantang River in Zhejiang province, China, was used as a case study. The total length of the seawall is around 11 km.
Figure 4a,b show the geographic location and the air-view of the Haiyan seawall, respectively.
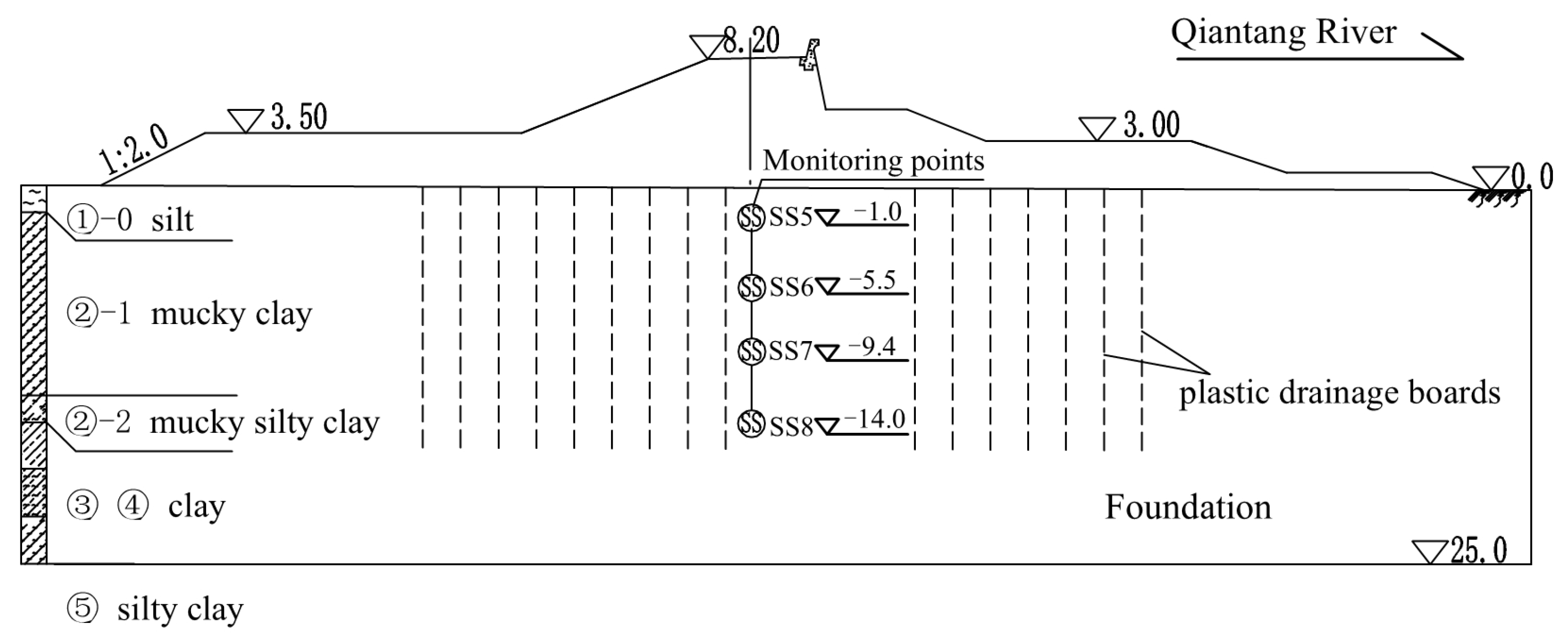
The Haiyan seawall is a vertical dike with a soil–rock mixed structure with revetments on both sides. The study area is mainly intertidal with flat terrain. The studied seawall is built on silty soft soil with an average thickness of 25.0 m, and it is reinforced by plastic drainage boards.
Figure 5 exhibits the distribution of the soil layers and monitoring points. The foundation boarding is arranged in a plum blossom pattern, with a horizontal range of 36.0 m, a depth of 15.0 m, and an interval of plastic drainage boards of 1.2 m. It can be seen from the figure that the foundation includes five layers: silt layer, mucky clay layer, mucky silty clay layer, clay layer, and silty clay layer. The settlement monitoring data used in this study was collected at the maximum settlement section Z7+000, which includes four monitoring points SS5, SS6, SS7, and SS8. As the four monitoring points are selected, the prediction involves using various data points collected from multiple sources or sensors over time to predict future values. Multipoint data can capture complex interactions and dependencies between different variables, leading to more accurate and insightful predictions. These monitoring points are located at 1 m, 5.5 m, 9.4 m, and 14 m under the foundation, respectively. We used the JG86 type electromagnetic induction instrument to monitor the settlement of the seawall, which consists of a settlement measuring tube and magnetic rings. A settlement magnetic ring is placed every 3 to 4 m along the settlement measuring tube. During the construction loading period, monitoring was conducted once every 3 days.
Figure 6 shows the time variation in settlement at the selected four monitoring points at section Z7+000. Overall, the monitoring data of each of these four selected points exhibit a nonlinear upward dynamic increasing trend. Furthermore, since seawall settlement primarily stems from the consolidation of the foundation soil, the settlement curve displays rapid growth at its initial stages followed by a slower progression. As the depth of the monitoring points increases, the change in settlement gradually increases. The settlement of monitoring point SS8 ranged within 40 mm; however, the settlement of monitoring point SS5 reached up to 200 mm. This is because the soil properties change with the increase in depth, for example, the transition from looser surface soil to denser subsurface soil. This change may increase the compressibility of the deeper soil layers, resulting in greater settlement under the same external force. Additionally, the deeper soil layers are subjected to a greater weight from the overlying soil layers (i.e., vertical stress). The increased stress can cause the voids between soil particles to be compressed, thereby making the settlement more serious. Furthermore, settlement is a process that develops over time. In some cases, the settlement of deeper soil layers may gradually increase due to time-dependent effects such as soil consolidation and creep.
4. Results and Discussions
This section presents the prediction results and intermediate calculation of the proposed model. In addition, the prediction performance of the proposed model is compared to other related methods including the fractional-order GM(1,1) model, the integer-order GM(1,1) model, and fractal theory. The proposed model does not require high computer specifications. A basic configuration, such as Intel Core i5 CPU, 8 GB RAM, and 256 GB SSD, is sufficient.
4.1. Intermediate Calculation and Prediction Results
Since the modelling processes for data at each monitoring point are the same, settlement at monitoring point SS5 was selected as an example to exhibit the intermediate calculation of the proposed model. It was a data sequence containing 20 numbers, wherein 15 of them were selected as fitting data, while the remaining 5 served as testing data.
The initial order was set to 1, to make the fractional-order GM(1,1) model equivalent to the integer-order GM(1,1) model. The initial order 1 was encoded as a binary string to generate the initial population. The genetic algorithm was employed with the control parameters including a population size M of 21, crossover probability Pc of 0.75, and mutation probability Pm of 0.01, and then the evolution was carried out for 50 generations.
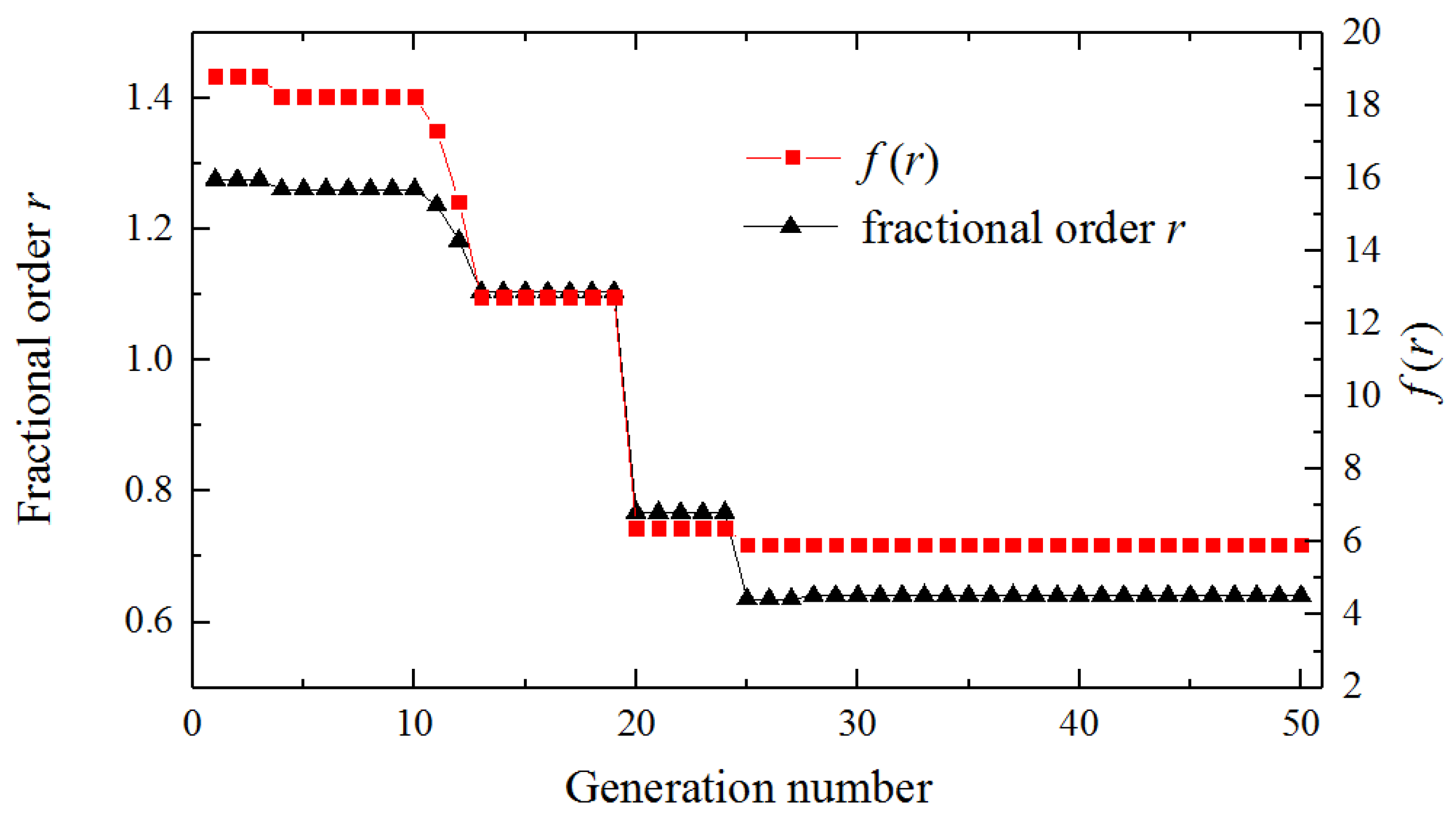
The evolution curve with respect to the genetic generations is depicted in
Figure 7. The results show that the average relative error reached its minimum (i.e., 5.934) at the 38th generation, corresponding to the optimal fractional order of 0.641.
Calculated by the fractional-order grey model, the time response function can be obtained:
The optimal fractional orders were incorporated into the fractional-order grey model using the real-time tracing algorithm, and then the settlement of the seawall can be predicted. The monitored and predicted settlement at monitoring point SS5 as well as their residual are shown in
Table 1. In general, the relative residual between the monitored data and predicted data is fairly small.
Figure 8 illustrates the time evolution of the predicted and monitored settlement at each monitoring point. The red points denote the predicted data, and the black points denote the monitored data. This comparison provides valuable insights into the accuracy and reliability of the prediction model. In detail, the data sequence at each monitoring point comprises 20 data points. Among these, the first 15 data points were chosen for fitting the model, meaning they were used to calibrate the model’s parameters and ensure it accurately reflects the monitored settlement. The remaining 5 data points, set aside as testing data, served to validate the model’s predictive capabilities on unseen data. It can be seen from the figure that the monitored data aligns remarkably well with the predicted data, not only for the fitting dataset but also for the testing dataset. This strong correlation indicates that the prediction model possesses a high degree of accuracy and is capable of generalizing well to unknown data. By comparing the predicted values with the actual monitored values, we can evaluate the accuracy of our prediction model and understand the relation between different monitoring points. The monitored settlement at monitoring points SS5 and SS6 over time shows a smooth curve. The monitored settlement at monitoring points SS7 and SS8 displays different characteristics compared to SS5 and SS6, where the fluctuations during day 5 to day 20 are more obvious. The specific reasons are analyzed as follows: The primary reason for the settlement of the seawall situated on soft soil foundations is the step-by-step loading during the construction of the embankment. The loading causes the gradual expulsion of water and air from between the soil particles, reducing the voids in the soft soil. As a result, the entire foundation undergoes systematic deformation. The surface layer of the seawall foundation consists of about 50 cm of silt. Unlike the underlying soft soil, the silt has a very high water content and low structural strength. During the initial half-month period of the project, the silt would have been squeezed out to the sides along with the construction loading process, resulting in significant instantaneous settlement. Due to construction constraints, the monitoring instruments took samples with an interval of 3 days. This resulted in poor trend consistency in the collected settlement data, making it difficult for current models to accurately fit the data from day 5 to day 20.
Figure 9 illustrates the time evolution of the relative residual of the predicted and monitored settlement at each monitoring point. The relative residual is below 0.1 for all four monitoring points, which suggests that the model is capable of capturing the general trends and behaviors of the settlement process, regardless of specific local conditions. This global accuracy is crucial for providing a comprehensive understanding of the settlement phenomenon and for making informed decisions regarding potential risks and mitigation measures. In addition, the relative residual exhibits some fluctuations at the initial stage. The fluctuations in the relative residual during the initial stage likely indicates that the model is still adjusting to the initial conditions and data. This could be due to the inherent uncertainty in the initial measurements or the model’s parameters being set to approximate values. Over time, as more data is collected and the model is able to learn from these observations, the fluctuations tend to decrease, indicating the model’s ability to adapt and improve its predictions. Even though the evolution curve of the relative residual of these four monitoring points are similar globally, the fluctuations of monitoring points SS5 and SS6 are more obvious than those of monitoring points SS7 and SS8. The relative residual globally reflects the prediction accuracy. Prediction accuracy for seawall settlement can vary at different monitoring points due to several factors related to both the characteristics of the site and the limitations of the prediction model. Different monitoring points are located on varying soil types, each with unique properties such as compressibility and permeability. These properties significantly influence settlement behavior. In addition, the distribution of loads on the seawall, including static and dynamic loads from waves, tides, and human activity, may differ across monitoring points, affecting settlement rates. Thus, the historical data used for training the model vary in quality and quantity across different monitoring points, affecting the model’s ability to learn accurate patterns. For the model’s prediction ability itself, as the interactions between different influencing factors (e.g., soil properties, environmental conditions) are complex and non-linear, the present model may not capture these interactions accurately.
4.2. The Evaluation Criteria of Prediction Performance
The prediction performance of the prediction model is evaluated by calculating the coefficient of determination (
R2), the mean relative error (MRE), the mean squared error (MSE), and the root mean squared error (RMSE) of the predicted results. These indexes express the extent of prediction error by measuring the deviation between the predicted data
and the monitored data
. The expression of MRE is shown in equation 15, and the expressions of
R2, MSE, and RMSE are as follows:
Table 2 exhibits the evaluation criteria including the
R2, MRE, MSE, and RMSE of the proposed model at each monitoring point. The
R2, which is a measure of how much the data points are spread out from their mean, is greater than 0.8 for both the testing dataset and the fitting dataset, which implies the model is robust and can be validated. The high
R2 suggests that the model explains a large portion of the variation in the dependent variable, indicating a good fit. The low values of MRE, MSE, and RMSE further confirm the model’s accuracy in predicting the target variable. These evaluation criteria collectively demonstrate the model’s reliability and effectiveness.
4.3. Comparison of the Proposed Model with Other Relevant Models
To better evaluate the performance of the proposed model, we compared its prediction accuracy with the fractional-order GM(1,1), integer-order GM(1,1), and fractal theory model. The integer-order GM(1,1) is a widely used grey model which relies on the principle of differential equations and exponential smoothing to generate predictions. The fractal theory model provides a framework for modeling complex processes that exhibit self-similarity across different scales, so as to capture the inherent hierarchical patterns in the data sequence. The fractional-order GM(1,1) is a generalization of the traditional integer-order grey model, which introduces the concept of fractional-order calculus to improve the flexibility and accuracy of the model. By allowing the order of differentiation and integration to be non-integer, the fractional-order model can better capture complex and non-linear dynamics in data.
Figure 10 shows the time evolution of fitting and predicting results of seawall settlement at the selected monitoring points using these four different models. Firstly, it is noteworthy that all these four models demonstrate a certain level of accuracy in fitting the historical data and predicting future seawall settlement trends, the curve trend of the predicted value aligns precisely with the actual curve. This indicates that the predicted curve generated through each model is rational and logical, and each model has captured essential elements of the system dynamics.
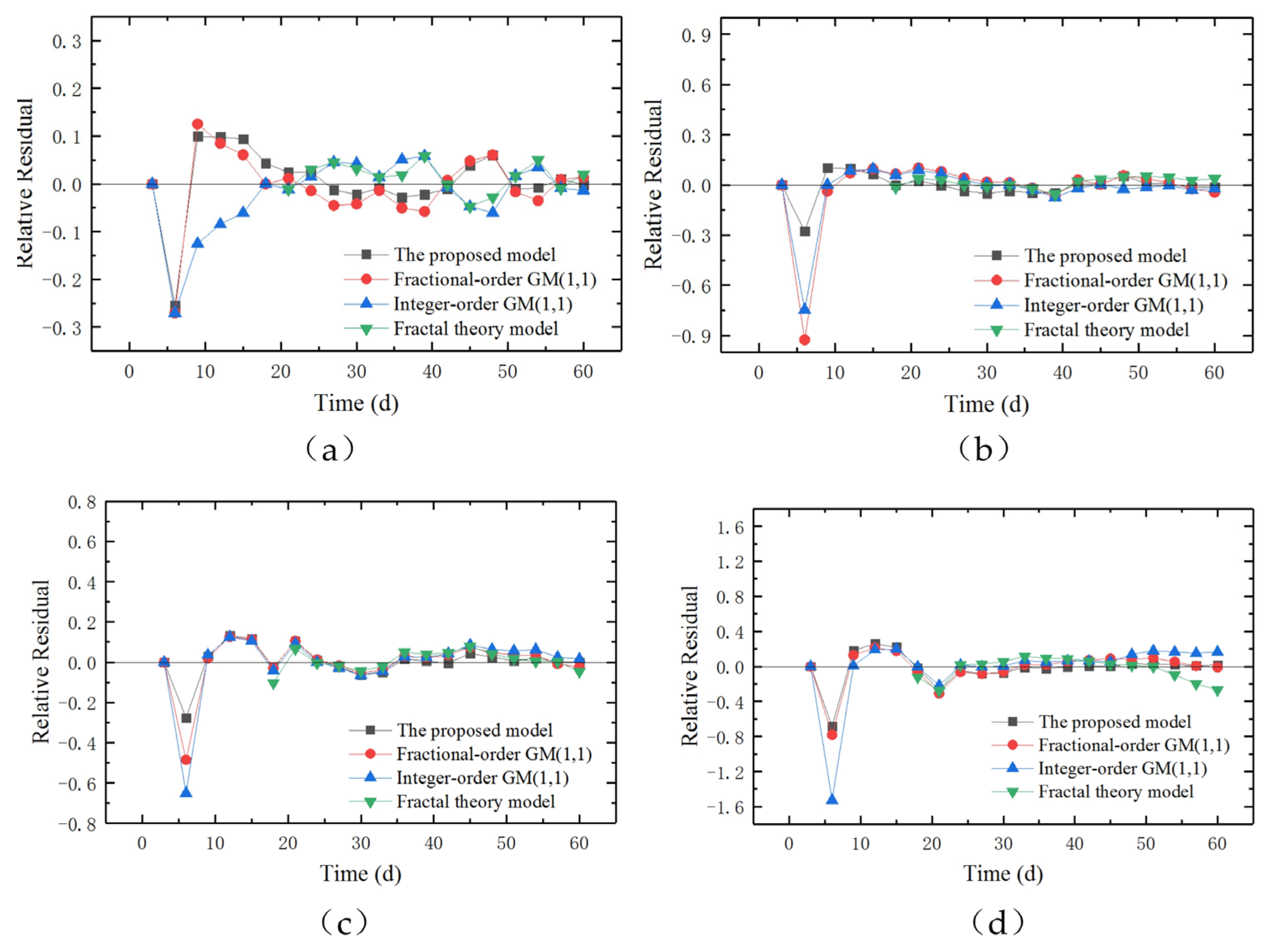
Figure 11 shows the time evolution of the relative residual of the four models for each monitoring point. The relative residuals of all four models are very small. Most are located within the range of −0.1 to 0.1. It can be seen that the proposed model shows a tighter fit to the monitoring data compared with the other three models, indicating a higher degree of accuracy. This can be evidenced by a narrower confidence interval or a high coefficient of determination between the predicted and monitored data. In addition, for all four prediction models, the relative residual exhibits some fluctuations at the initial stage. The relative residual refers to the difference between the predicted value and the actual value, normalized or scaled in a way that makes it easier to compare across different data points or time periods. These fluctuations in the relative residual at the initial stage may result from several reasons: First, the initial period does not have enough data points to accurately capture the trends, which may lead to higher errors and fluctuations in the relative residuals. Second, the models need initialization before they can start making accurate predictions. During this initial phase, the models might not be fully calibrated. Third, there might be external factors, such as measurement errors, which introduce noise and uncertainty into the predictions.
When discussing the performance of prediction models, it is important to consider not only how the models behave at different stages but also the overall accuracy.
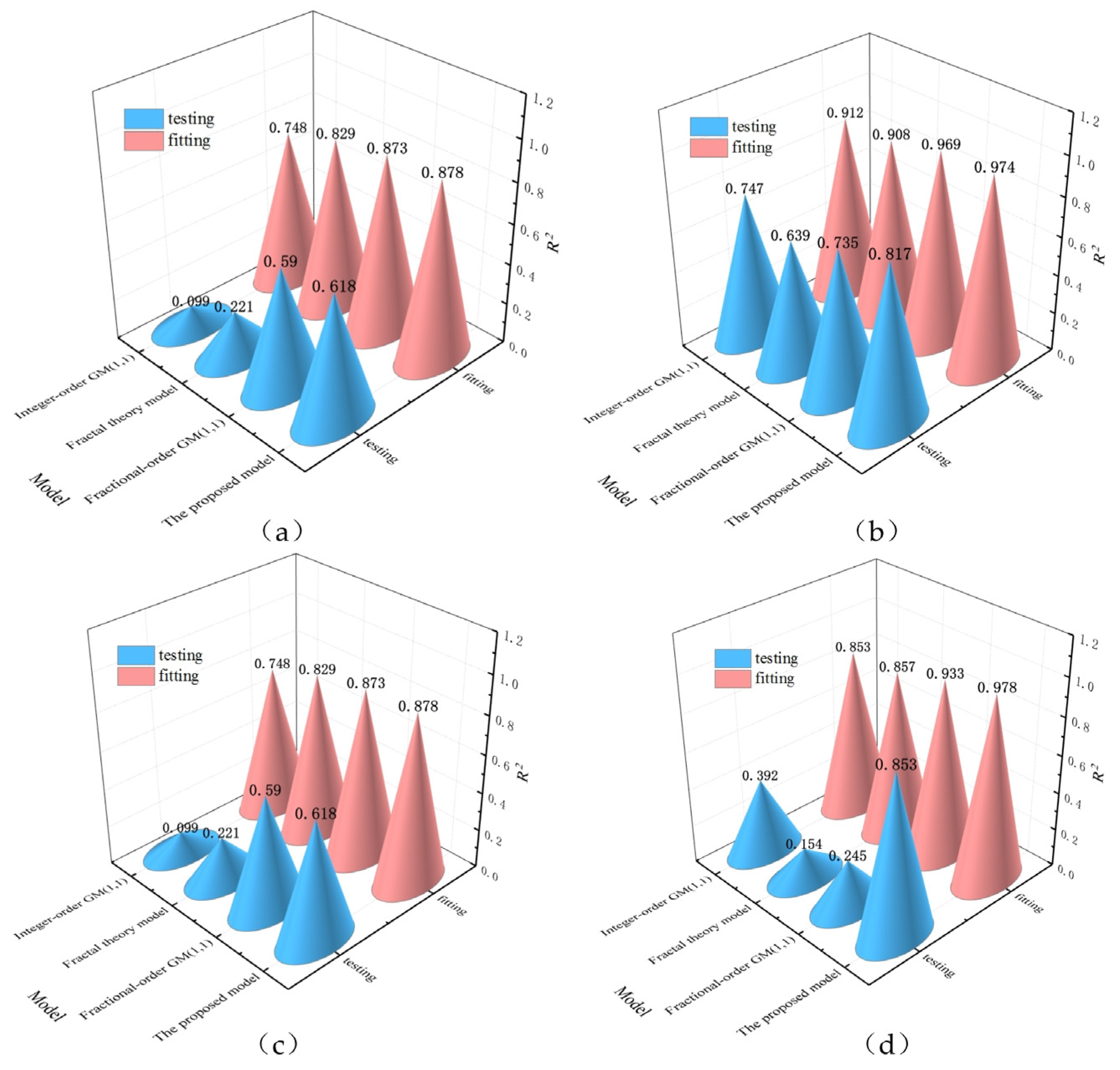
Figure 12 compares the coefficients of determination
R2 of the fitting and testing data for these four models, which represent an overall evaluation of the prediction performance. Using the datasets of all the monitoring points, the proposed model outperforms the other three models. The comparisons demonstrate that the proposed model exhibits superior predictive power, especially in capturing the nonlinearities and complexities of seawall settlement over time under the situation of limited data volume. Seawall settlement is affected by many factors including soil properties and hydrological conditions. A model that can accurately predict such complex processes is valuable for risk management. In addition, the
R2 calculated using fitting data is higher than that calculated using testing data for all these four models. It is a common observation that when the model is evaluated on testing data, which is independent of the training data, its performance tends to be lower. This is because the testing data contains additional uncertainty and variability that the model has not encountered during training.
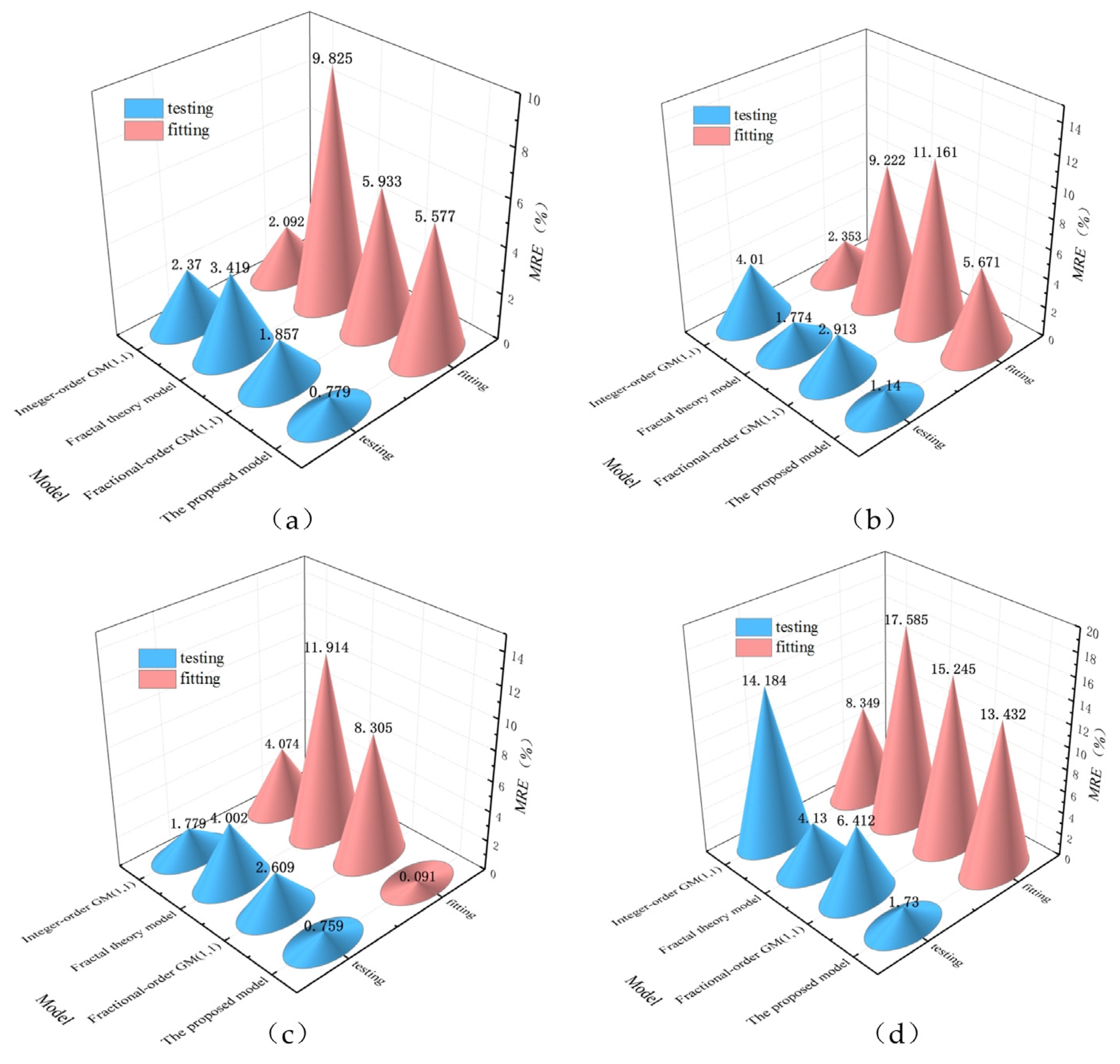
Figure 13 compares the MRE of the proposed model with the fractional-order GM(1,1), integer-order GM(1,1), and fractal theory model. A lower MRE indicates higher accuracy and better performance of the model. The proposed model exhibits a lower MRE than the other models for all monitoring points. This suggests that it is able to more accurately capture the underlying dynamics in the data sequence, leading to more reliable and accurate predictions.
5. Conclusions
As the performance of the fractional-order grey model is easily affected by the inappropriate setting of the fractional order, and considering the limited data volume and the nonlinear characteristics of seawall settlement monitoring data, this paper proposed an improved fractional-order grey model for seawall settlement prediction by integrating a genetic algorithm and the real-time tracing algorithm. First, the genetic algorithm with enhanced search capabilities was employed to solve the premature convergence problem. Then, to solve the problem of the fractional-order grey model associated with fixed step sizes, the real-time tracing algorithm was introduced to conduct equal-dimensionally recursive calculation. The proposed model was validated using monitoring data of the Haiyan seawall in Zhejiang province, China. The prediction performance of the proposed model was compared with those of the fractional-order GM(1,1), integer-order GM(1,1), and fractal theory model, demonstrating its superior performance compared to other methods such as the fractional-order GM(1,1) model, the integer-order GM(1,1) model, and fractal theory model.
The proposed model effectively predicts seawall settlement trends and can be extended to address prediction challenges in other fields with limited data volume. The significance of this finding lies in its practical implications. A reliable settlement prediction model is crucial in various engineering applications, such as construction projects, where precise forecasting of ground movements is essential for safety and stability. The high degree of fit between the predicted and monitored data suggests that the model can be trusted to provide accurate settlement predictions, thereby enhancing the safety and efficiency of related projects.
While the current model shows promising results, there are still opportunities for improvement. For example, its relatively high time complexity poses some disadvantages in terms of computation time (computational complexity of the proposed model with other models are shown in
Table 3). Additionally, the model could be further refined by incorporating additional influencing factors, such as soil properties, groundwater conditions, or changes in loading conditions. Also, this paper took multi-point monitoring data into account in the prediction model, which helps to provide a comprehensive understanding of the trends of seawall settlement comparing to single-point prediction. However, one disadvantage of the current study is that the correlation among different monitoring points is not entered. Considering the correlation among each monitoring point would be interesting for further studies.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}