

Fractional Gradient Optimizers for PyTorch: Enhancing GAN and BERT


Abstract
:1. Introduction
2. Materials
2.1. Caputo Fractional Derivative
2.2. Backpropagation Update Formula for MLP
- X is the input layer (input data),
- H hidden layers,
- O is the output layer,
- L layers, because of the hidden layers and the output layer,
- is a matrix of synaptic weights, , that connects neuron k of layer with neuron j of layer l,
- are synaptic weights () that connect the first hidden layer with X,
- is the desired output of neuron k at output layer when the i-th input data is presented,
- is the activation function in the L layers,
- is the output of neuron k at output layer O, when the i-th input data is presented and at layer O,
- is the potential activation of neuron k at layer l, , with inputs . For , considering the j-th component of X,
- is the output of neuron k at a hidden layer l, .
- When synaptic weights take zero values that yields to the indetermination of for ,
- When is rational, let and s is even (for example and ) hence if , then complex values will be generated.
2.3. Fractional Gradient Optimizers for PyTorch
- opt=optim .SGD(model . parameters () , learning_rate=0.001 ,momentum=0.9)
- whereas the Adam optimizer can be used as follows:
- opt=optim .Adam(model . parameters () , learning_rate =0.001).
- __all__ = [ ’SGD’ , ’sgd’ ]
- __all__ = [ ’FSGD’ , ’fsgd’ ].

{kind=link}
{kind=link}
{kind=link}
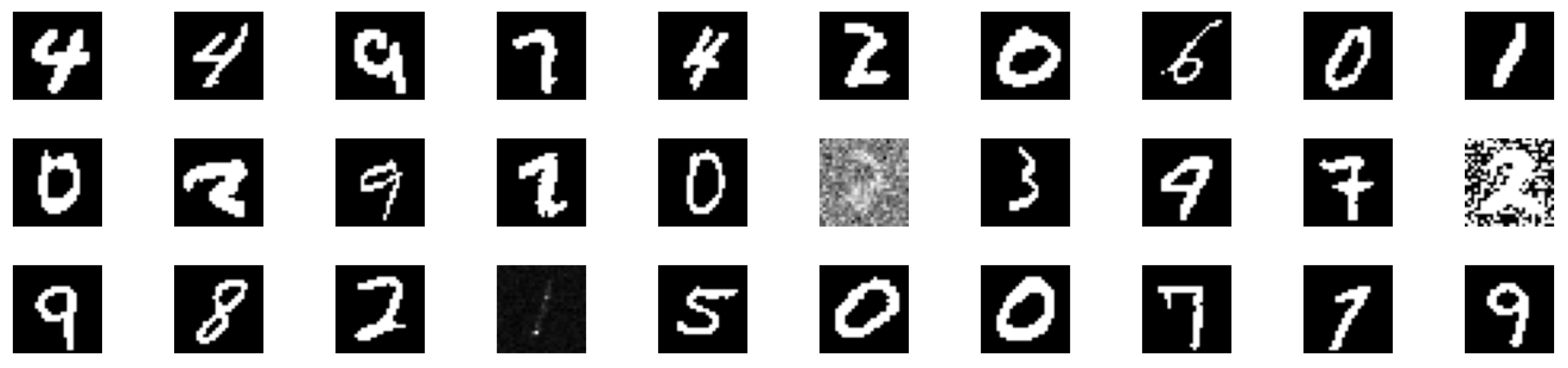{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # Parameters: Set v= Cnnu.nnu, 0 < v < 2.0 |
| Cnnu.nnu = 1.75 |
| eps = 0.000001 |
| class FSGD(Optimizer): |
| … |
| def _single_tensor_sgd (…): |
| … |
| for i, param in enumerate (params): |
| d_p = d_p_list [ i ] if not maximize else -d_p_list [ i ] |
| v = Cnnu.nnu |
| t1 = torch . pow( abs(d_p)+eps, 1-v ) |
| t2 = torch . exp(torch . lgamma(torch . tensor(2.0-v))) |
| d_p = d_p * t1/ t2 |
| #Parameters: Set v= Cnnu.nnu, 0 < v < 2.0 |
| Cnnu.nnu = 1.75 |
| eps = 0.000001 |
| class FAdam(Optimizer): |
| … |
| def _single_tensor_adam (…): |
| … |
| for i , param in enumerate (params): |
| grad = grads [ i ] if not maximize else -grads [ i ] |
| v = Cnnu . nnu |
| t1=torch . pow( abs(grad)+eps , 1-v ) |
| t2=torch . exp ( torch.lgamma(torch . tensor(2.0-v))) |
| grad = grad * t1/t2 |
2.4. Fractional GAN
| Algorithm 1 Fractional GAN minibatch stochastic gradient-descent training algorithm. |
|
2.5. Fractional BERT
- optim = optim.Adam(model.parameters(), learning_rate=0.001)
- a fractional optimizer from the package torch.Foptim can be used. In case of the fractional Adam (FAdam) the code is as follows:
- optim = Foptim.FAdam(model.parameters(), learning_rate=0.001).
3. Results
3.1. Experiment 1: FGAN
3.2. Experiment 2: FBERT
- hCLS: token classification,
- SEP: sentence separation,
- END: end of sentence,
- PAD: equal length and sentence truncation,
- MASK: mask creation and word replacement.
- optim = optim.Adam(model.parameters(), learning_rate=0.001)
- to the corresponding fractional. For example, for the fractional Foptim.FAdam, the following line of code can be used:
- optim = Foptim.FAdam(model.parameters(), learning_rate=0.001)
- and similarly for the other fractional optimizers.
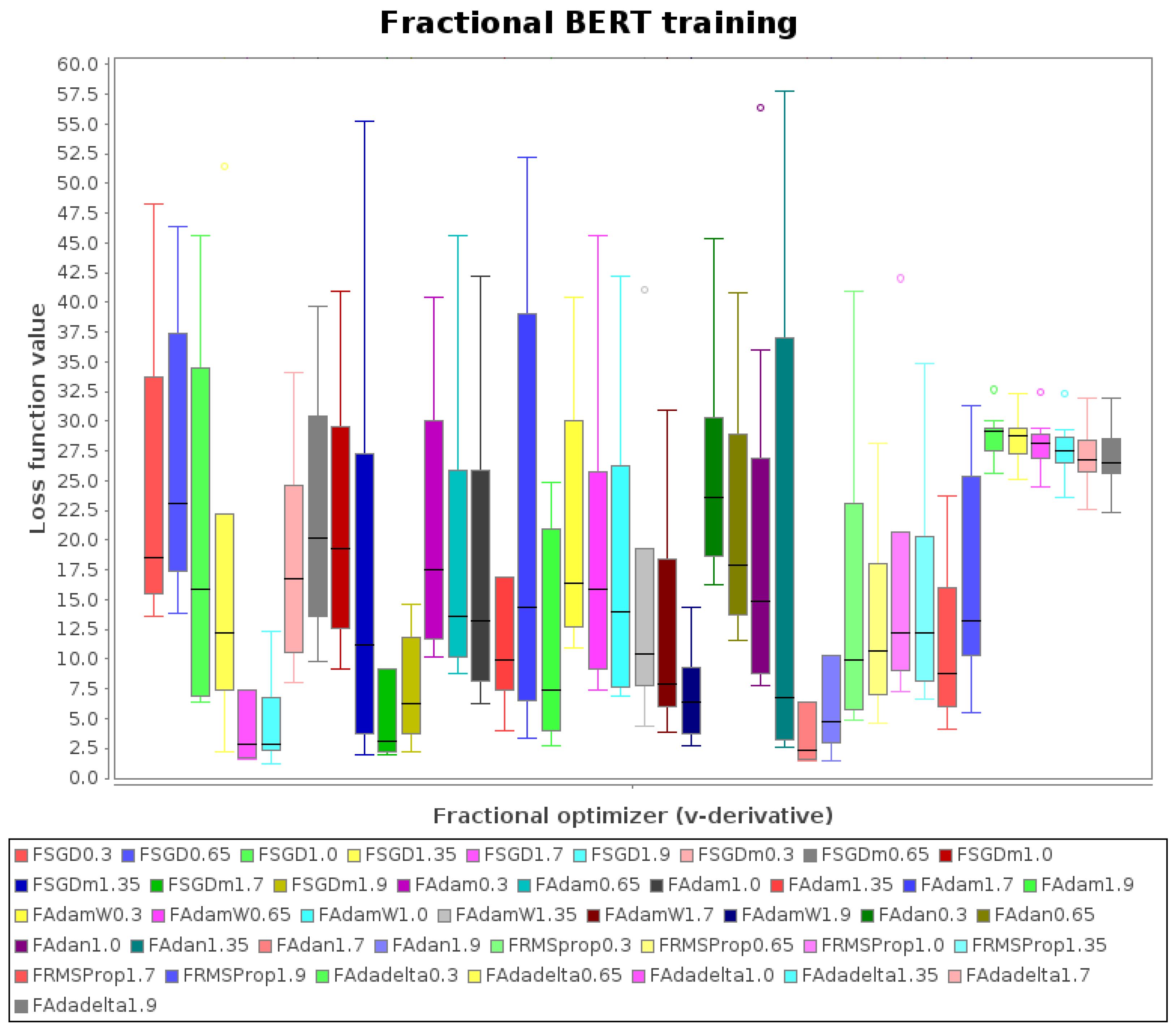
- Focused on FAdam, and considering the original experiment with Adam (i.e., FAdam with ), it is suboptimal and is outperformed by others with fractional derivatives
- Focused on FSGD and FSGDm, the best results are for and
- Focused on FAdan, the best results are for and
- FRMSProp and FAdadelta do not show a competitive performance
- From all the 42 bars in the boxplot, the best results are for FSGD, FSGDm, and FAdam, and the minimum is for FSGD with .
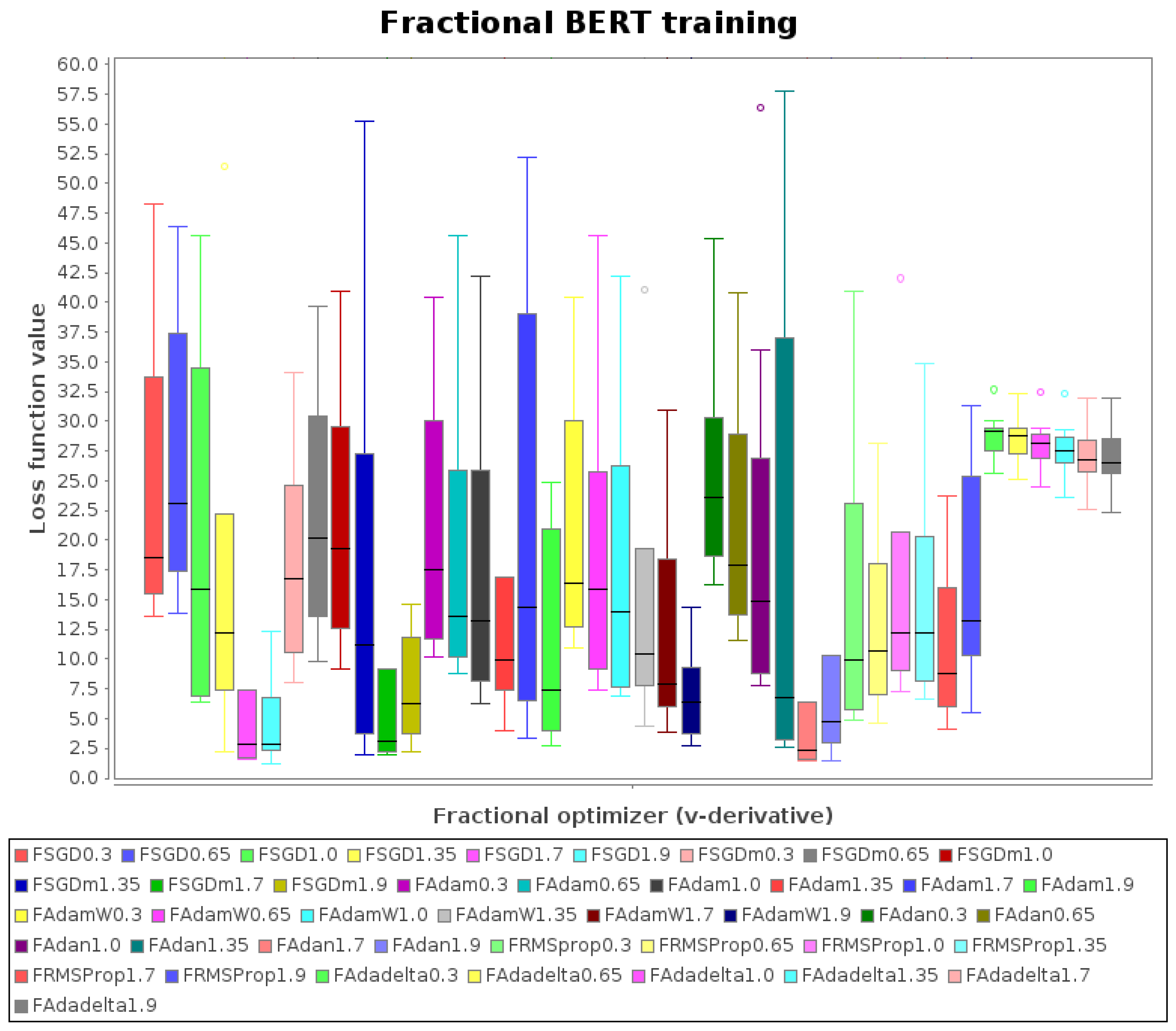
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Haykin, S.S. Neural Networks and Learning Machines, 3rd. ed.; Pearson Education: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Schmidt, R.M.; Schneider, F.; Hennig, P. Descending through a Crowded Valley—Benchmarking Deep Learning Optimizers. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual Event. 18–24 July 2021; Meila, M., Zhang, T., Eds.; 2021; Volume 139, pp. 9367–9376. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 400–407. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Abdulkadirov, R.; Lyakhov, P.; Nagornov, N. Survey of Optimization Algorithms in Modern Neural Networks. Mathematics 2023, 11, 2466. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, Y.; Zhang, H. Recent Advances in Stochastic Gradient Descent in Deep Learning. Mathematics 2023, 11, 682. [Google Scholar] [CrossRef]
- Herrera-Alcántara, O. Fractional Derivative Gradient-Based Optimizers for Neural Networks and Human Activity Recognition. Appl. Sci. 2022, 12, 9264. [Google Scholar] [CrossRef]
- PyTorch-Contributors. TOPTIM: Implementing Various Optimization Algorithms. 2023. Available online: https://pytorch.org/docs/stable/optim.html (accessed on 1 May 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Oldham, K.B.; Spanier, J. The Fractional Calculus; Academic Press [A Subsidiary of Harcourt Brace Jovanovich, Publishers]: New York, NY, USA; London, UK, 1974; Volume 111, p. xiii+234. [Google Scholar]
- Miller, K.; Ross, B. An Introduction to the Fractional Calculus and Fractional Differential Equations; Wiley: Hoboken, NJ, USA, 1993. [Google Scholar]
- Mainardi, F. Fractional Calculus and Waves in Linear Viscoelasticity, 2nd ed.; Number 2; World Scientific: Singapore, 2022; p. 628. [Google Scholar]
- Yousefi, F.; Rivaz, A.; Chen, W. The construction of operational matrix of fractional integration for solving fractional differential and integro-differential equations. Neural Comput. Applic 2019, 31, 1867–1878. [Google Scholar] [CrossRef]
- Gonzalez, E.A.; Petráš, I. Advances in fractional calculus: Control and signal processing applications. In Proceedings of the 2015 16th International Carpathian Control Conference (ICCC), Szilvasvarad, Hungary, 27–30 May 2015; pp. 147–152. [Google Scholar] [CrossRef]
- Henriques, M.; Valério, D.; Gordo, P.; Melicio, R. Fractional-Order Colour Image Processing. Mathematics 2021, 9, 457. [Google Scholar] [CrossRef]
- Pang, G.; Lu, L.; Karniadakis, G.E. fPINNs: Fractional Physics-Informed Neural Networks. SIAM J. Sci. Comput. 2019, 41, A2603–A2626. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wen, Y.; Gou, Y.; Ye, Z.; Chen, H. Fractional-order gradient descent learning of BP neural networks with Caputo derivative. Neural Netw. 2017, 89, 19–30. [Google Scholar] [CrossRef] [PubMed]
- Bao, C.; Pu, Y.; Zhang, Y. Fractional-Order Deep Backpropagation Neural Network. Comput. Intell. Neurosci. 2018, 2018, 7361628. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Yu, Y.; Wen, G. Stability analysis of fractional-order Hopfield neural networks with time delays. Neural Netw. 2014, 55, 98–109. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F.; Zhu, Q.; Rahman, F.; Lee, T.; Marmiesse, G.; Zabluda, O.; Qian, C.; Jin, H.; Watson, M.; Chao, R.; et al. Keras. 2015. Available online: https://keras.io/ (accessed on 1 May 2023).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://tensorflow.org (accessed on 1 May 2023).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics, Minneapolis, MN, USA; 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Garrappa, R.; Kaslik, E.; Popolizio, M. Evaluation of Fractional Integrals and Derivatives of Elementary Functions: Overview and Tutorial. Mathematics 2019, 7, 407. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zhuang, Z.; Liu, M.; Cutkosky, A.; Orabona, F. Understanding adamw through proximal methods and scale-freeness. arXiv 2022, arXiv:2202.00089. [Google Scholar]
- Tieleman, T.; Hinton, G. Neural Networks for Machine Learning; Technical Report; COURSERA: Napa County, CA, USA, 2012. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Seo, J.D. Only Numpy: Implementing GAN (General Adversarial Networks) and Adam Optimizer Using Numpy with Interactive Code. 2023. Available online: https://towardsdatascience.com/only-numpy-implementing-gan-general-adversarial-networks-and-adam-optimizer-using-numpy-with-2a7e4e032021 (accessed on 1 May 2023).
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Barla, N. How to code BERT using PyTorch. Available online: https://neptune.ai/blog/how-to-code-bert-using-pytorch-tutorial (accessed on 1 May 2023).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herrera-Alcántara, O.; Castelán-Aguilar, J.R. Fractional Gradient Optimizers for PyTorch: Enhancing GAN and BERT. Fractal Fract. 2023, 7, 500. https://doi.org/10.3390/fractalfract7070500
Herrera-Alcántara O, Castelán-Aguilar JR. Fractional Gradient Optimizers for PyTorch: Enhancing GAN and BERT. Fractal and Fractional. 2023; 7(7):500. https://doi.org/10.3390/fractalfract7070500
Chicago/Turabian StyleHerrera-Alcántara, Oscar, and Josué R. Castelán-Aguilar. 2023. "Fractional Gradient Optimizers for PyTorch: Enhancing GAN and BERT" Fractal and Fractional 7, no. 7: 500. https://doi.org/10.3390/fractalfract7070500
APA StyleHerrera-Alcántara, O., & Castelán-Aguilar, J. R. (2023). Fractional Gradient Optimizers for PyTorch: Enhancing GAN and BERT. Fractal and Fractional, 7(7), 500. https://doi.org/10.3390/fractalfract7070500