
Segmentation of Concrete Cracks by Using Fractal Dimension and UHK-Net




Abstract
:1. Introduction
2. Proposed Method
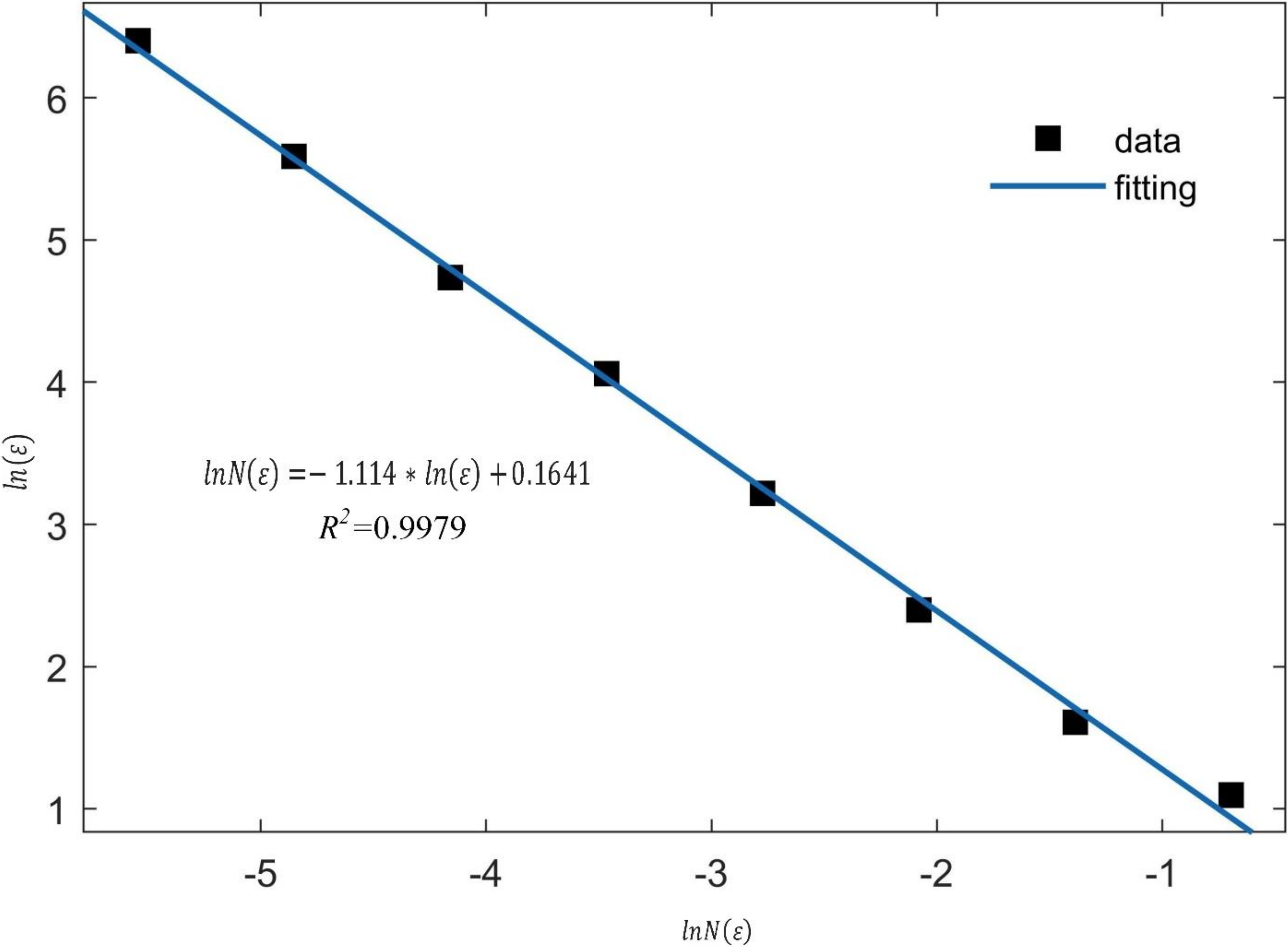
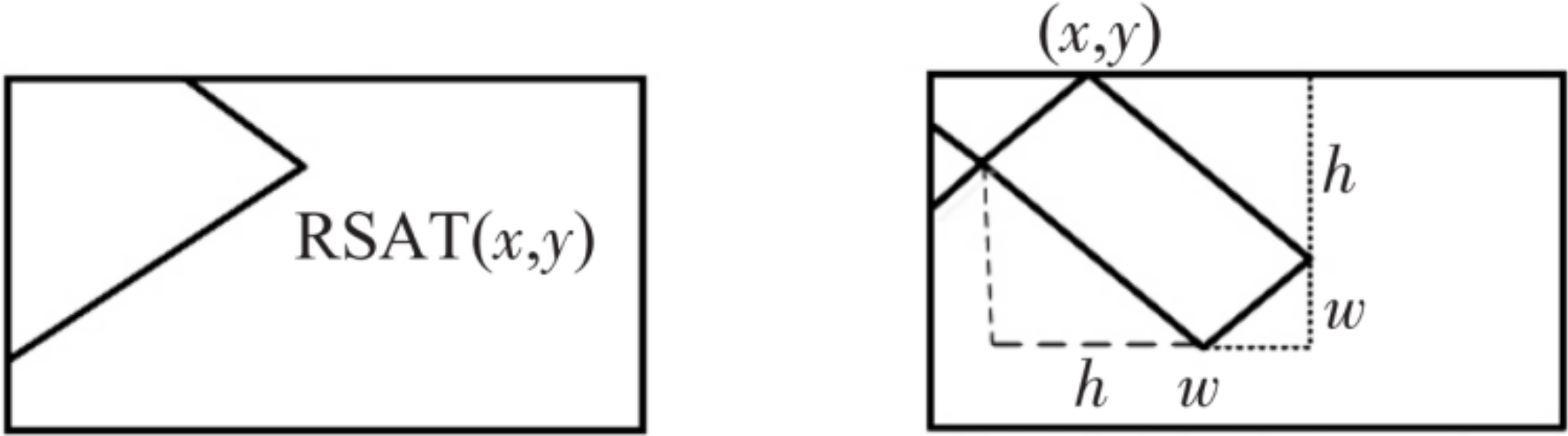
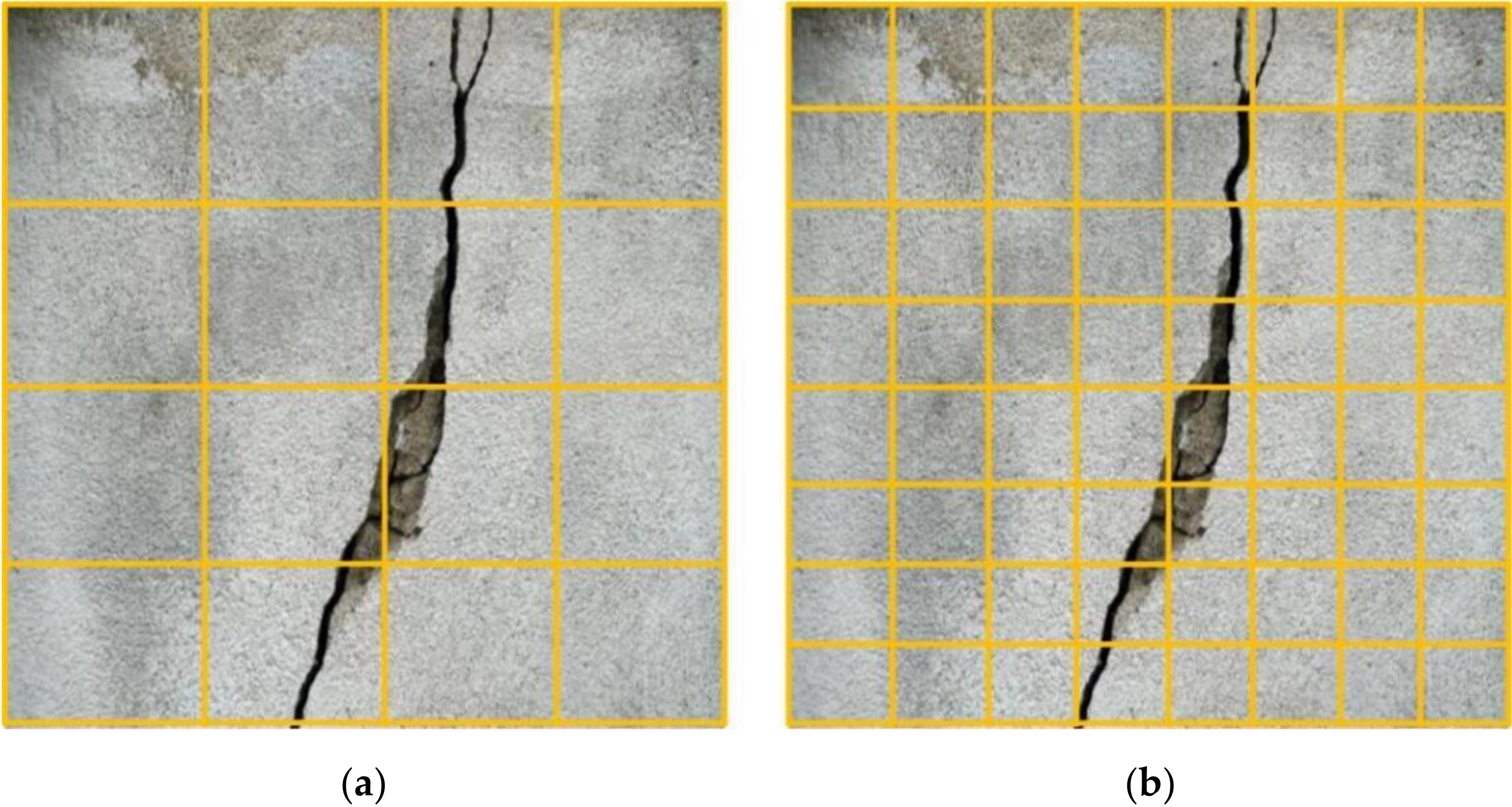
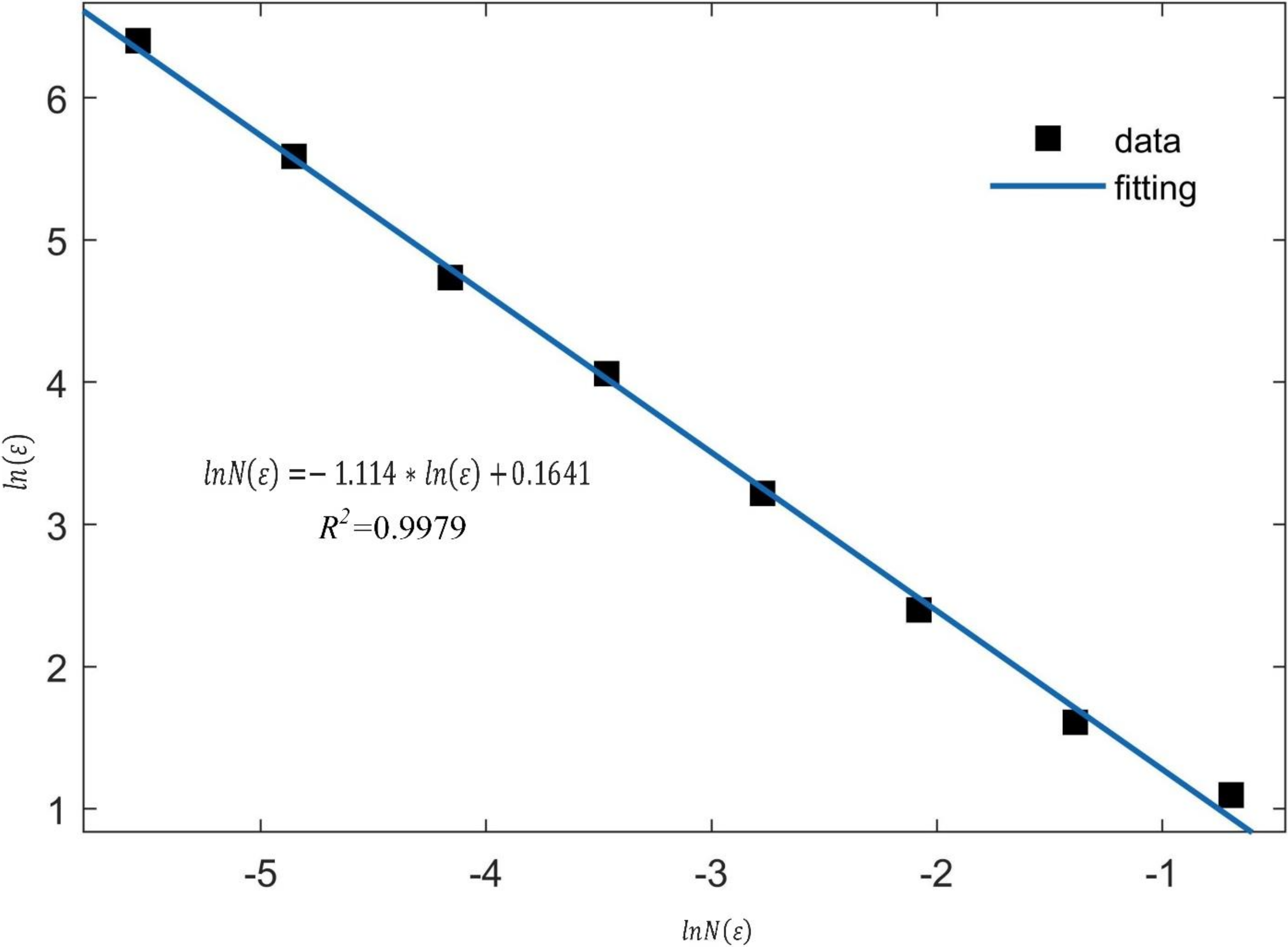
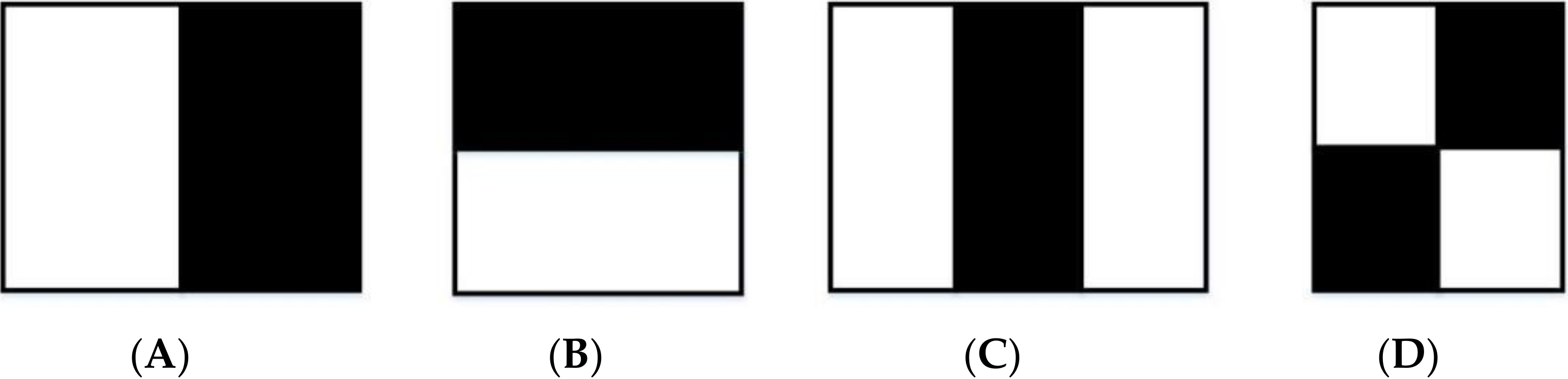
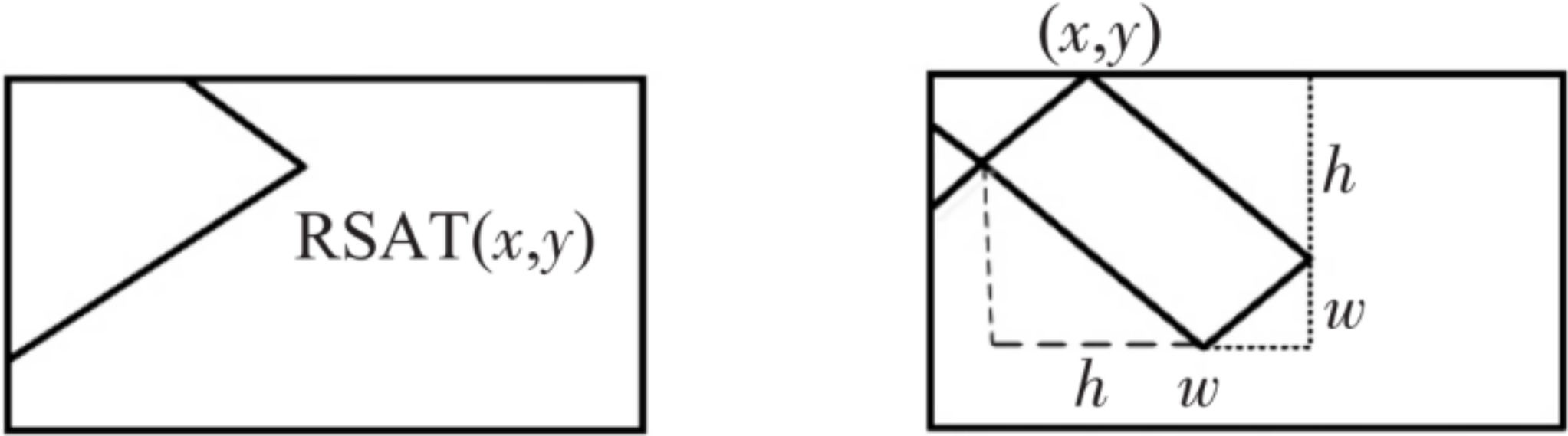
2.1. Fractal Dimension of Concrete Crack Image
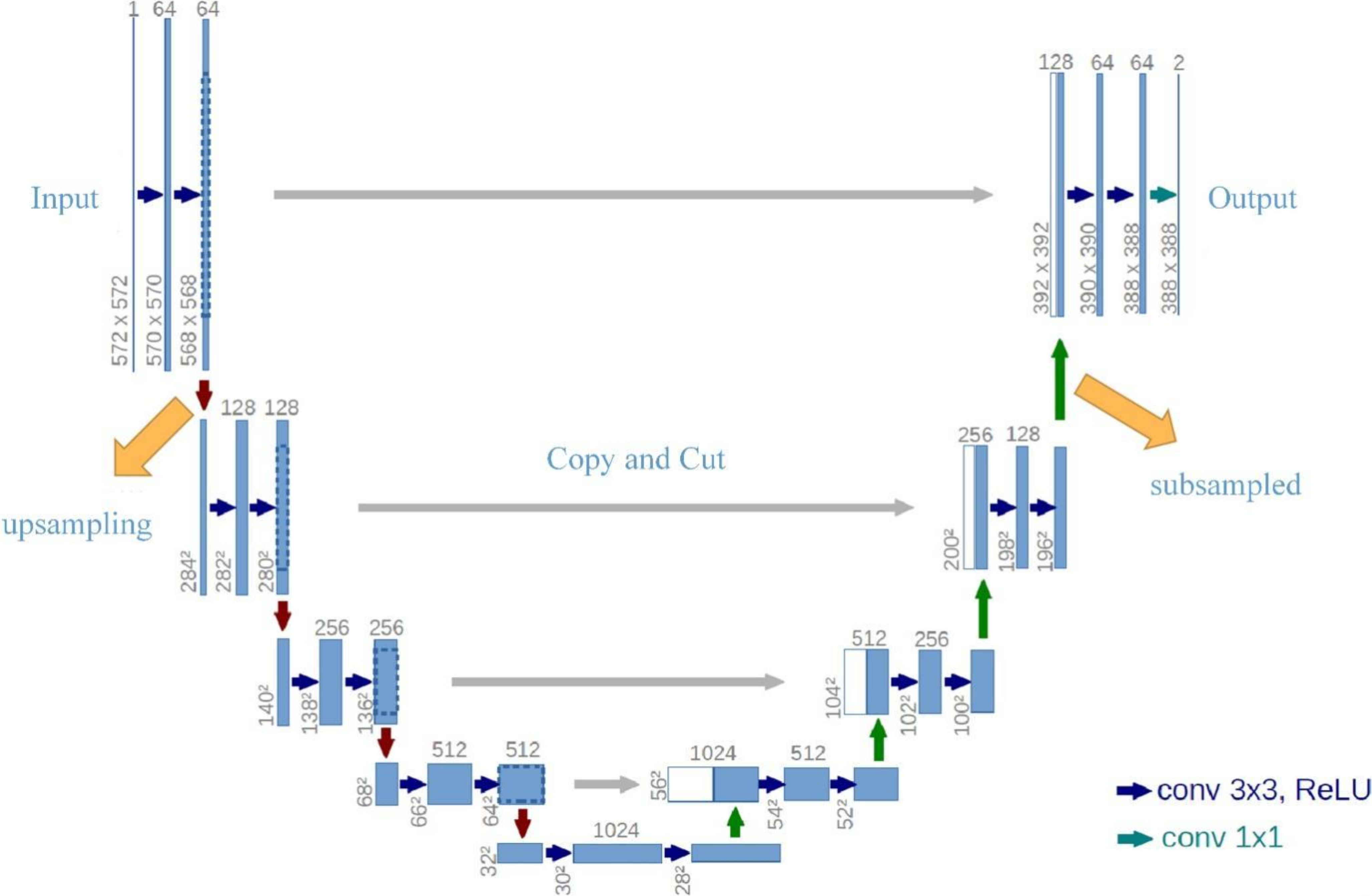
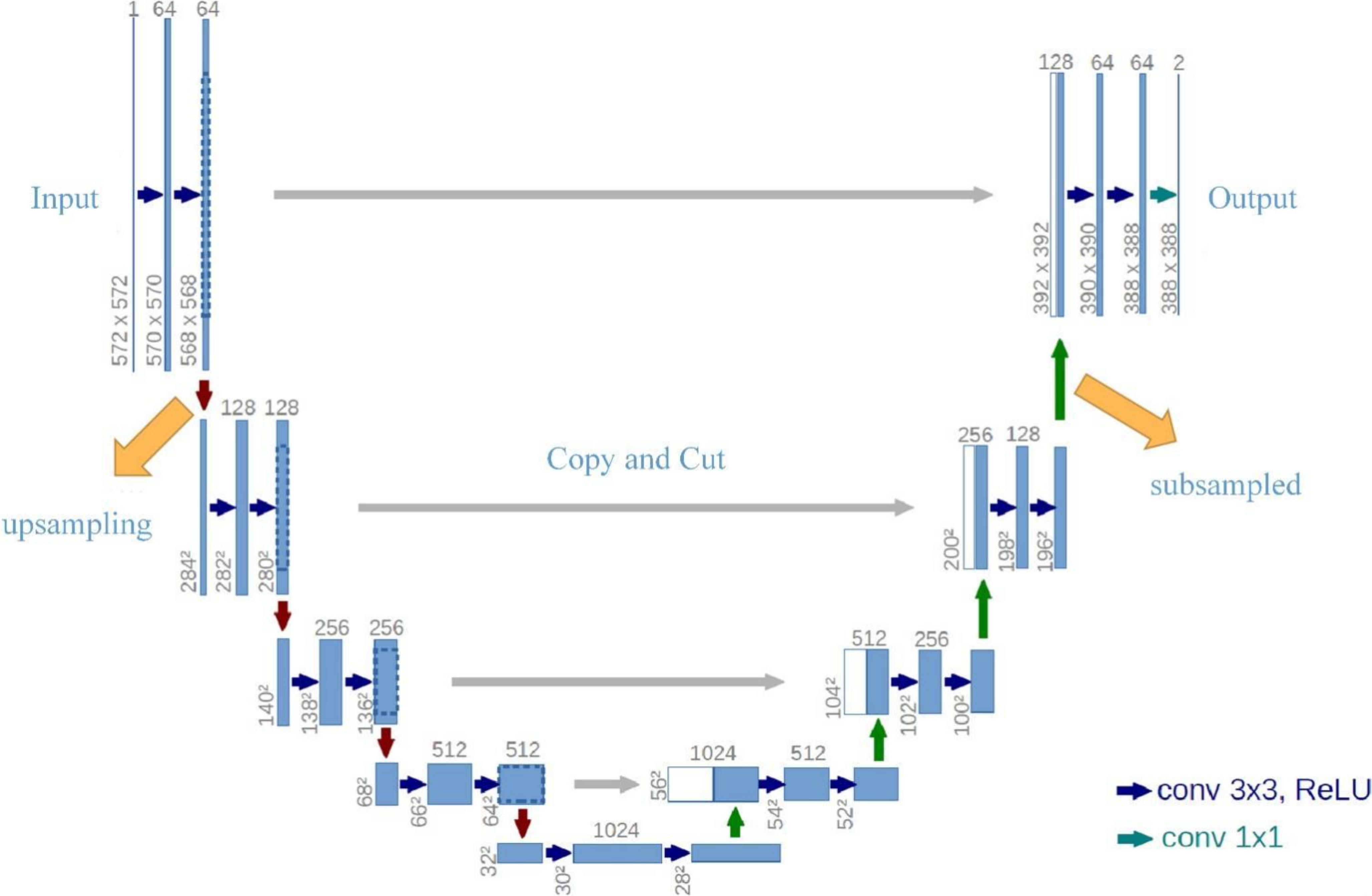
2.2. U-Net Network Model
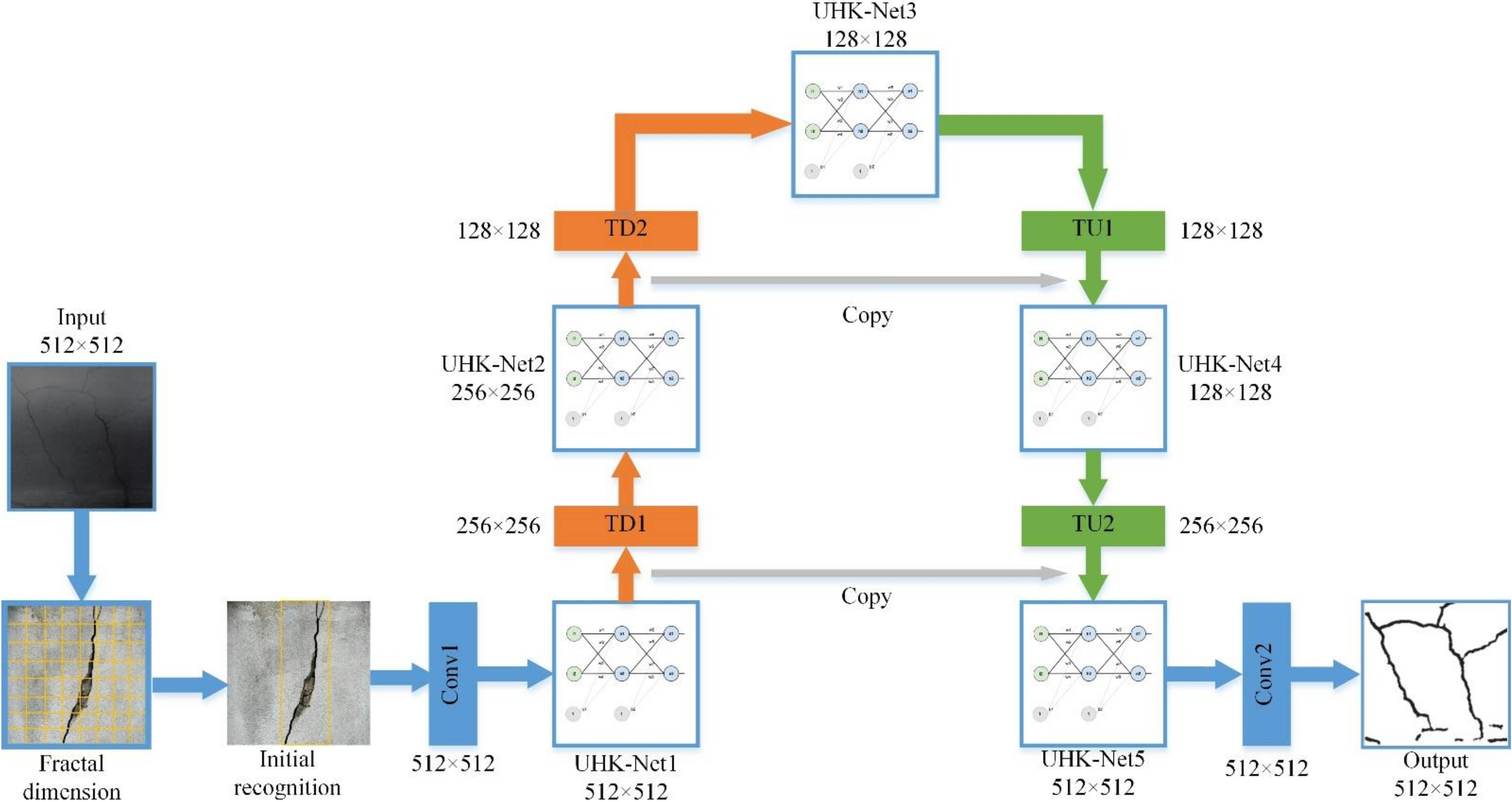
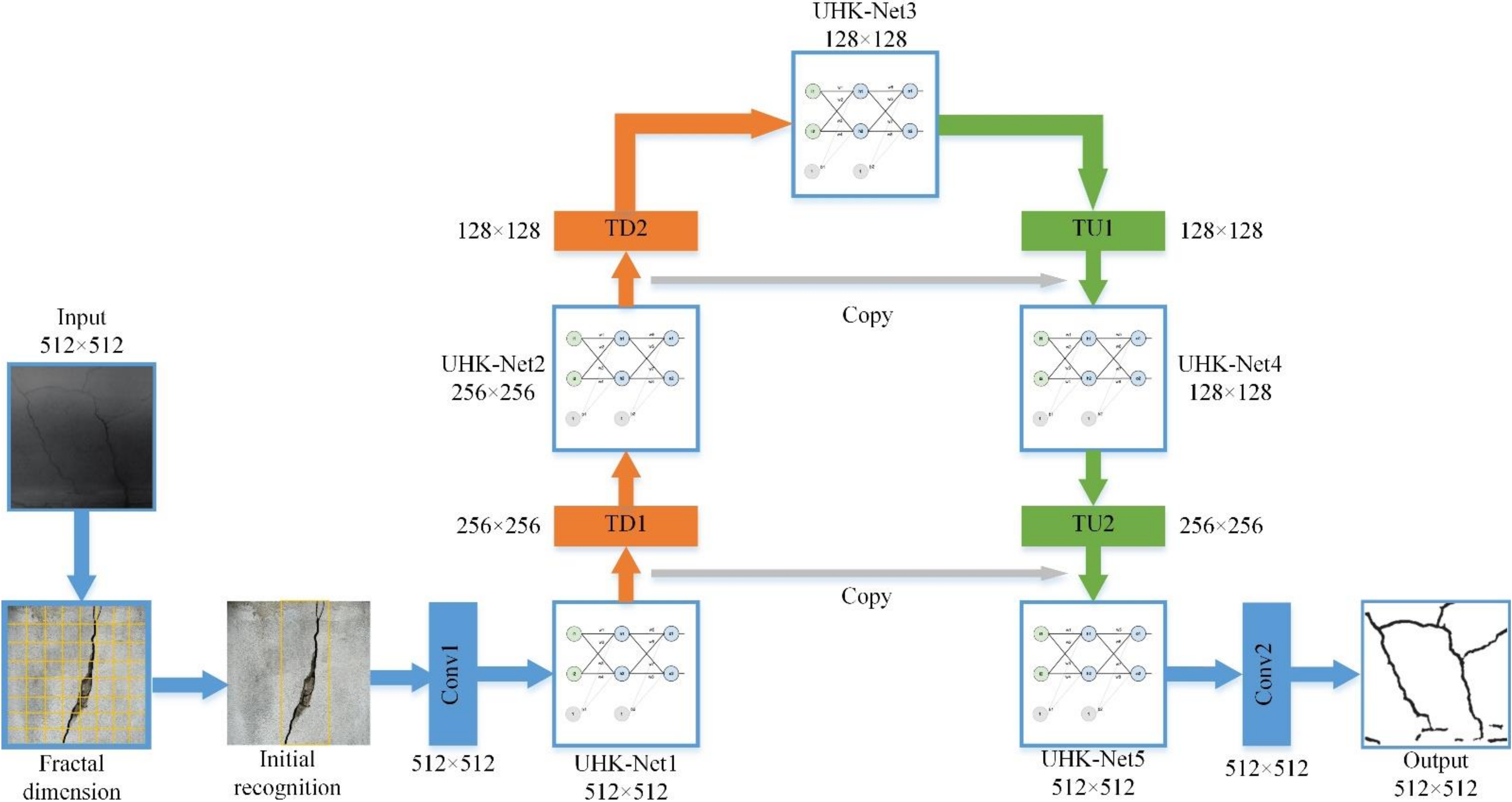
2.3. UHK-Net Network Model
3. Performance Evaluation Results
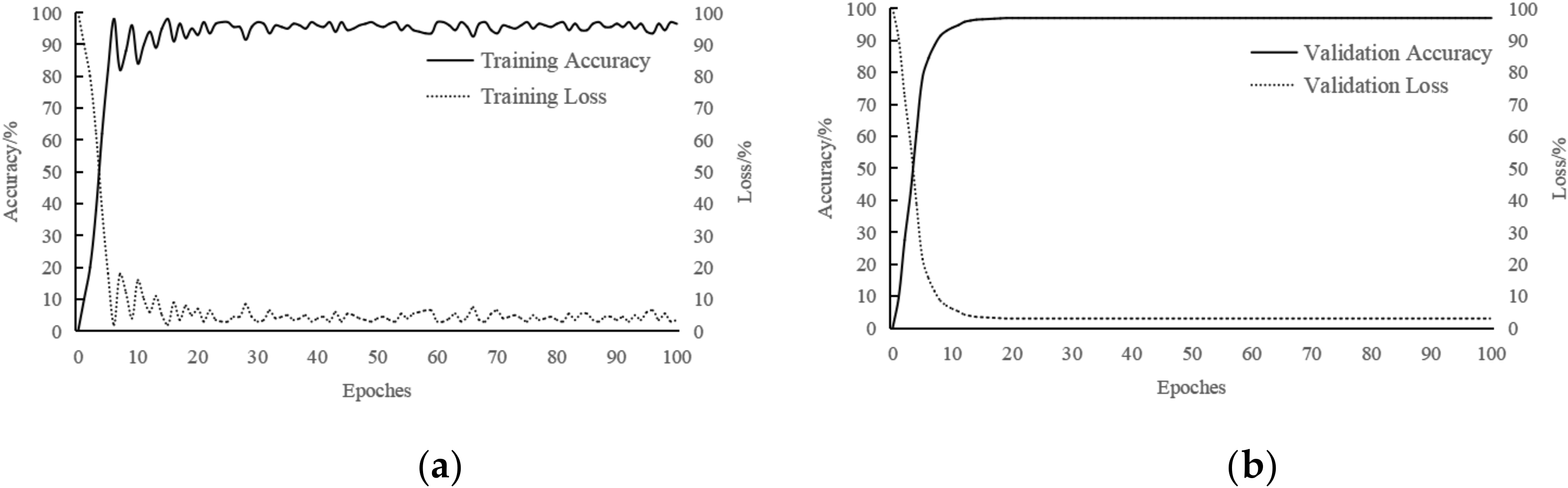
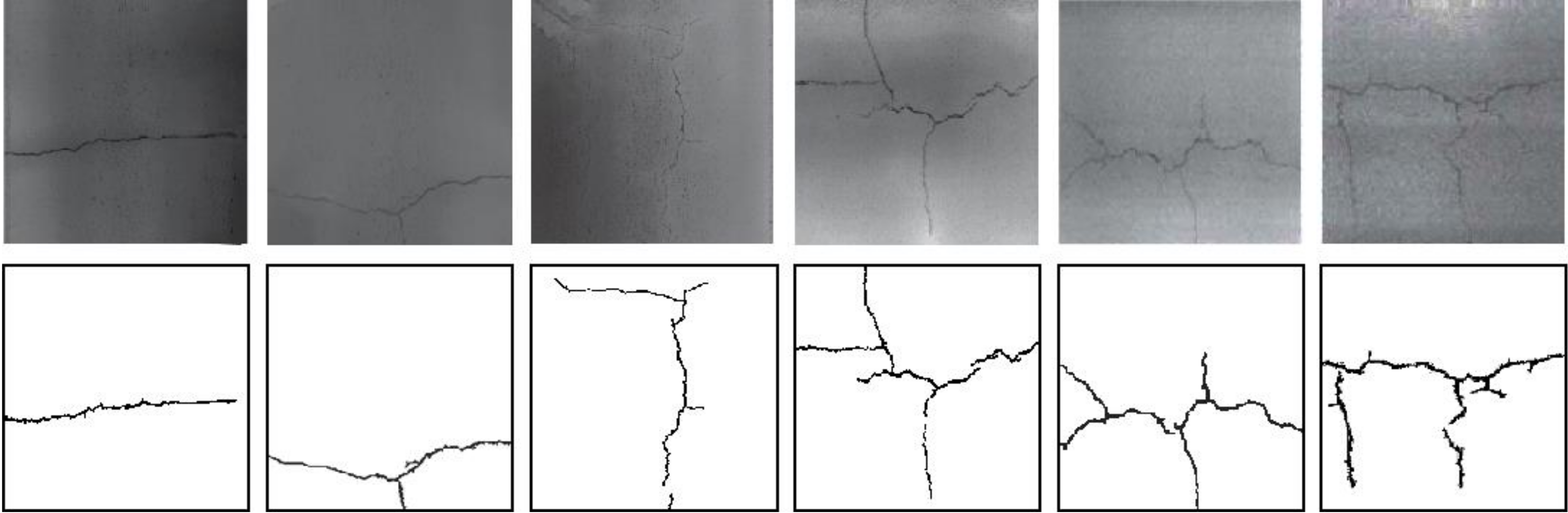
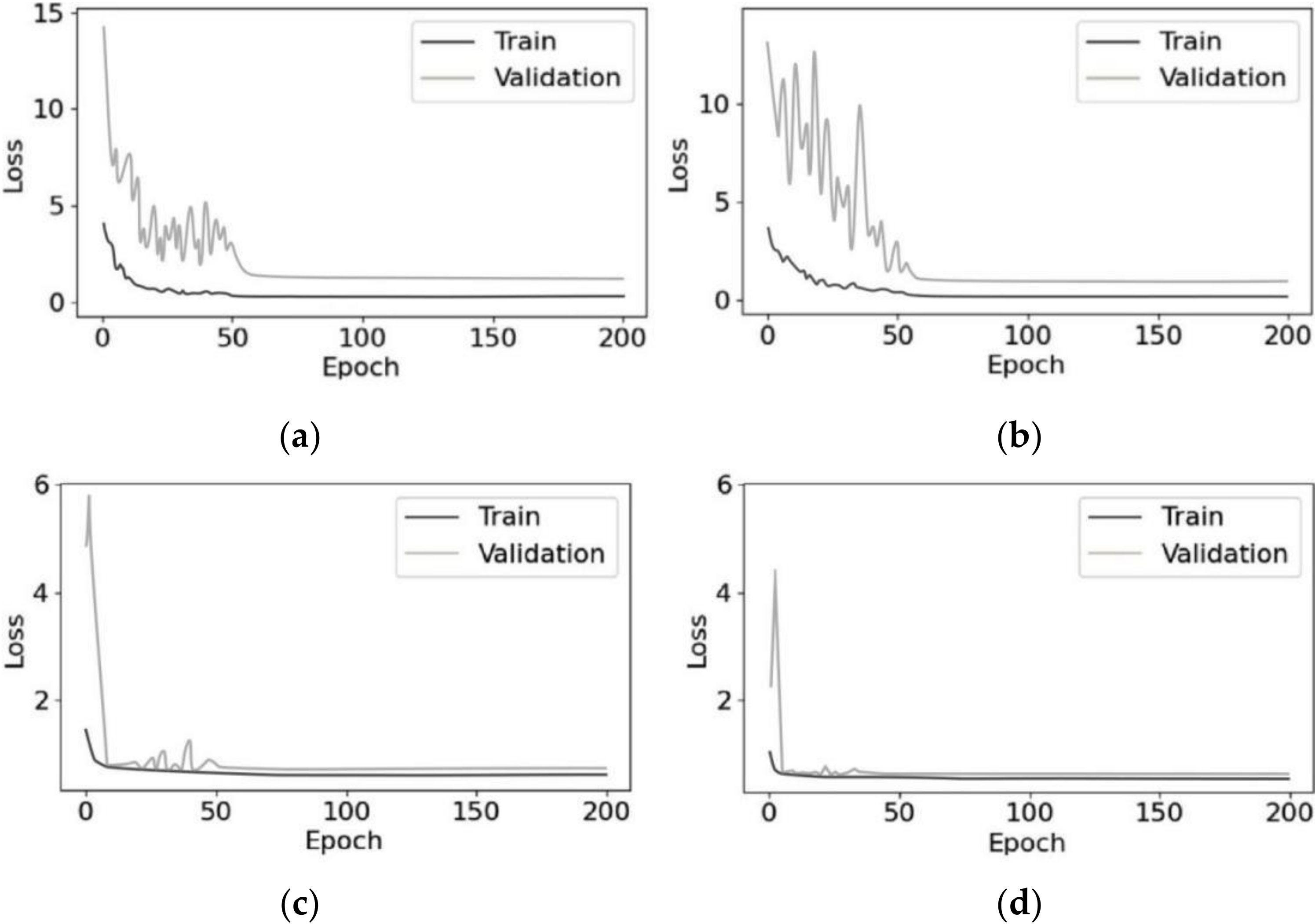
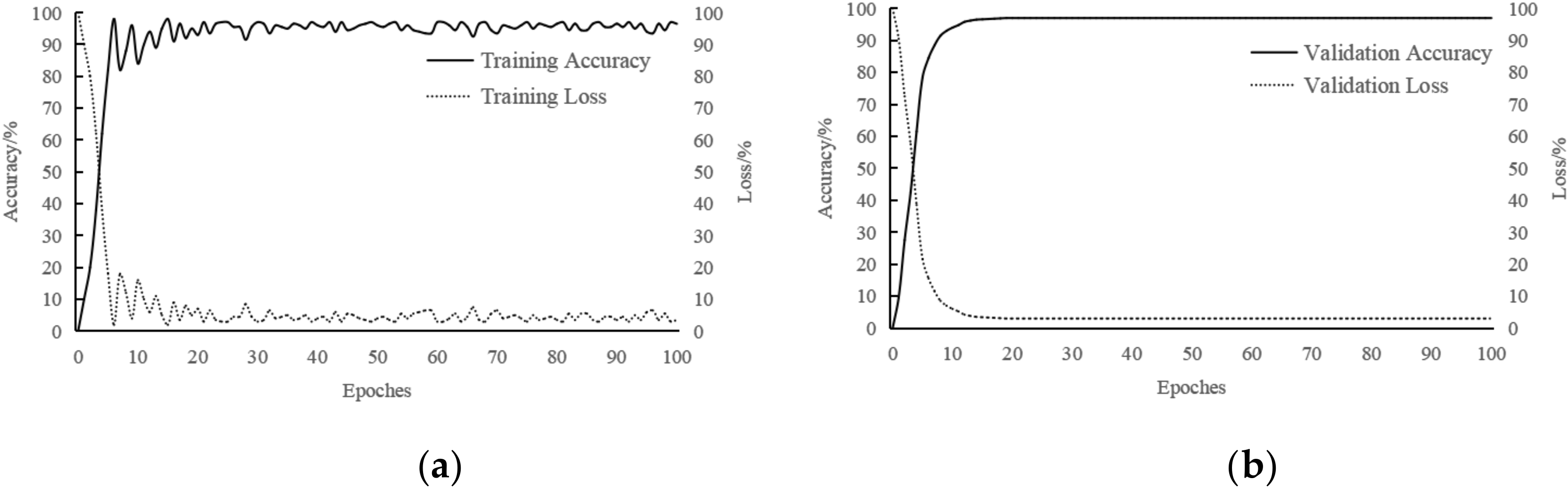
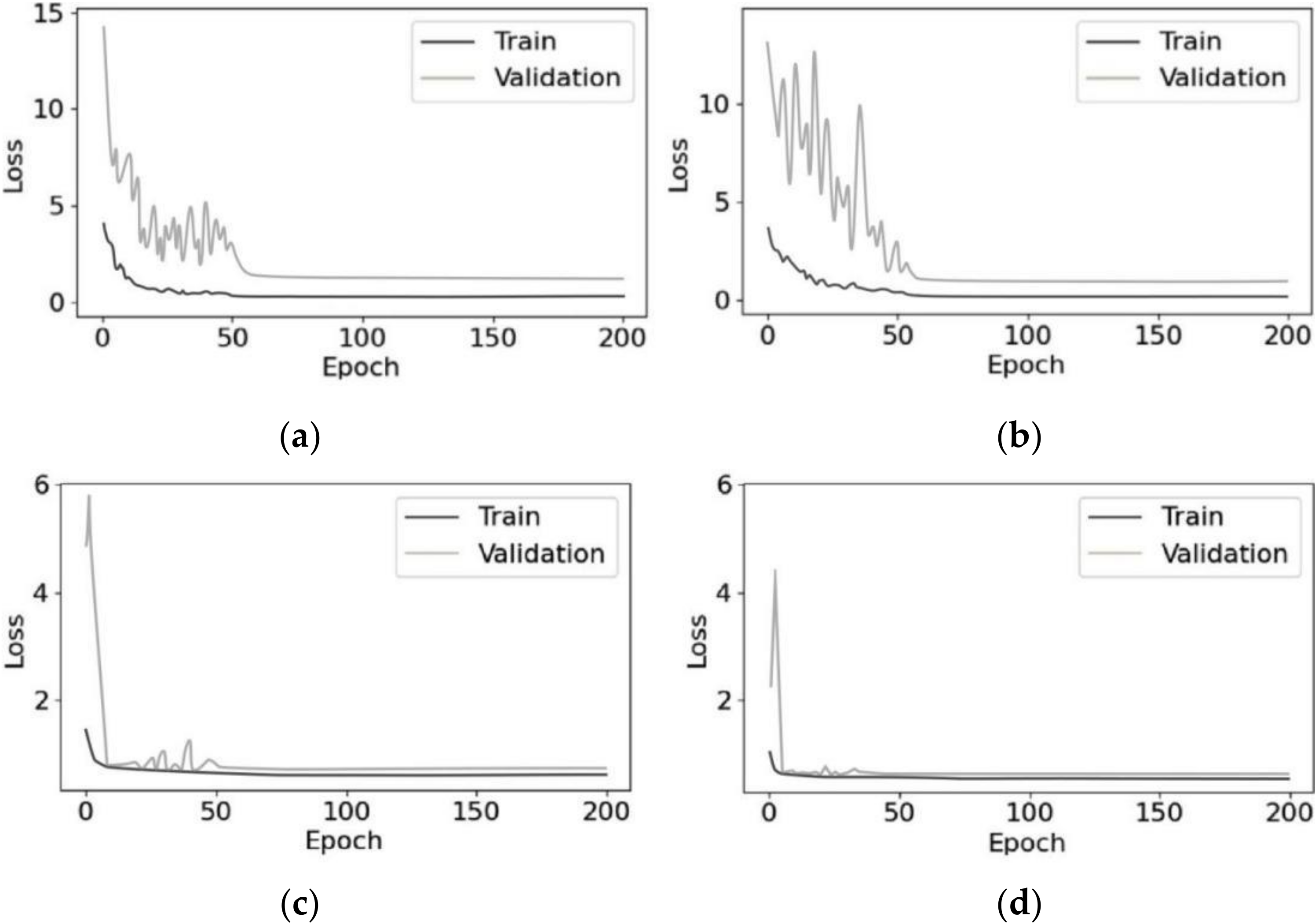
3.1. Model Preparation
3.2. Evaluation of Computational Complexity of Different Methods
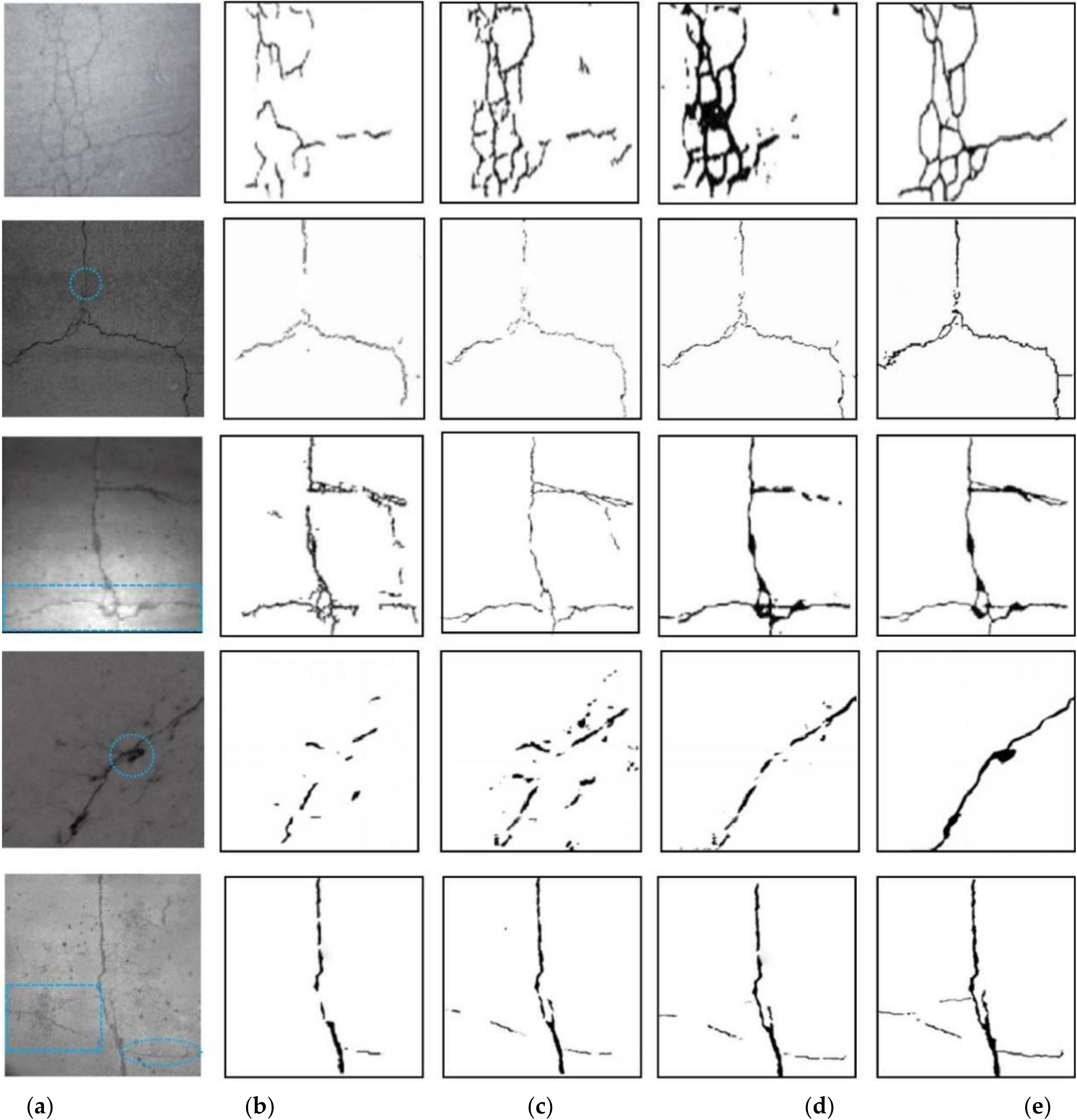
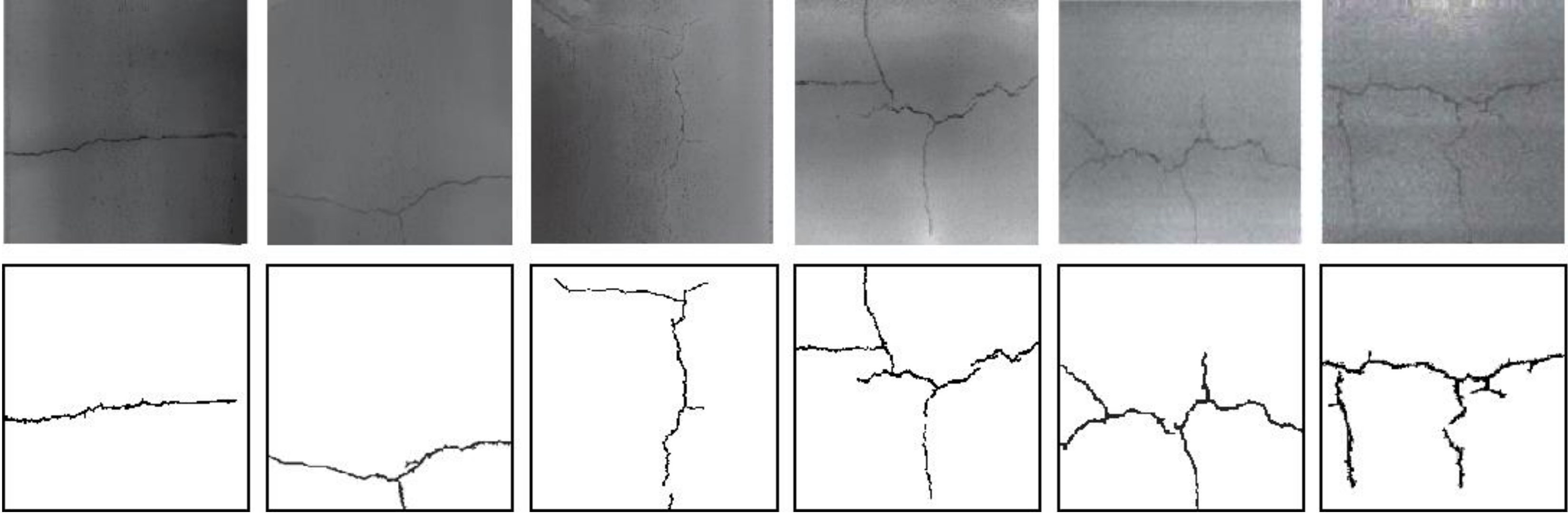
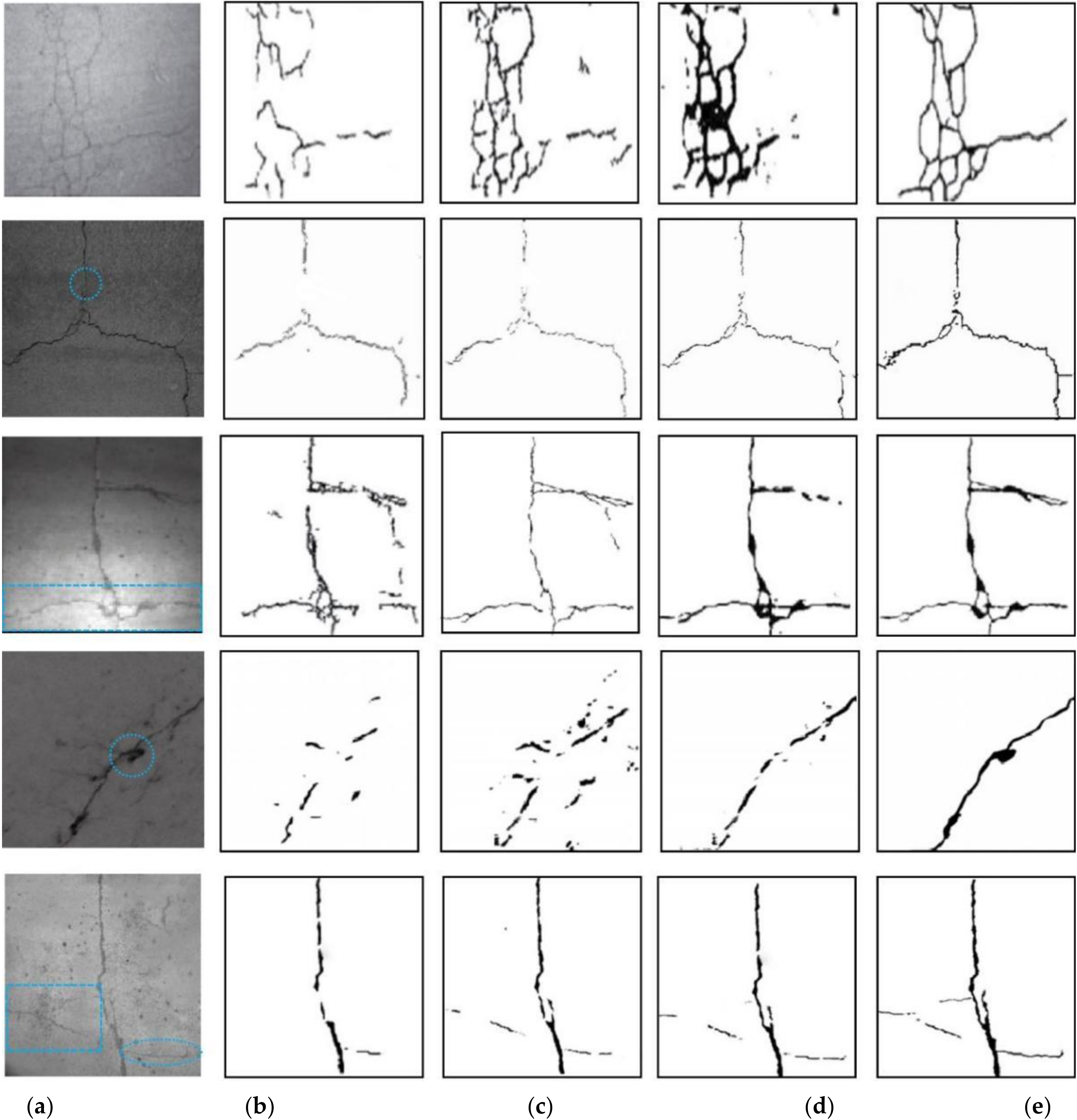
3.3. Comparison Analysis Based on the Visualization
3.4. Quantitative Evaluation of Different Methods
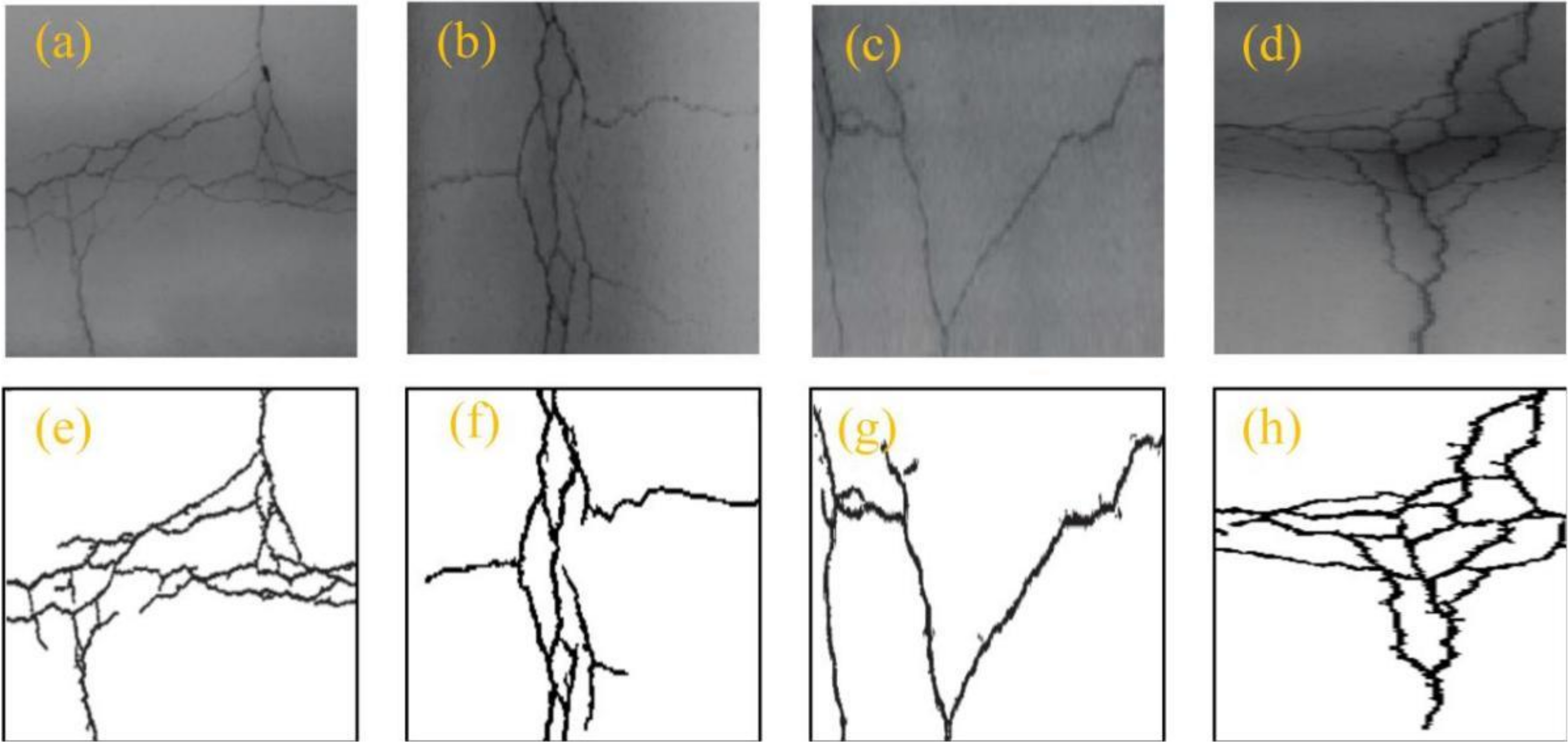
4. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, J.; Li, W.; Huang, D.; Wang, L.; Chen, E.; Wu, C.; Wang, B.; Deng, H.; Tang, S.; Shi, Y.; et al. Fractal Analysis on Pore Structure and Hydration of Magnesium Oxysulfate Cements by First Principle, Thermodynamic and Microstructure-Based Methods. Fractal Fract. 2021, 5, 164. [Google Scholar] [CrossRef]
- Wang, L.; Lu, X.; Liu, L.; Xiao, J.; Zhang, G.; Guo, F.; Li, L. Influence of MgO on the Hydration and Shrinkage Behavior of Low Heat Portland Cement-Based Materials via Pore Structural and Fractal Analysis. Fractal Fract. 2022, 6, 40. [Google Scholar] [CrossRef]
- Wang, L.; Luo, R.Y.; Zhang, W.; Jin, M.M.; Tang, S.W. Effects of Fineness and Content of Phosphorus Slag on Cement Hydration, Permeability, Pore Structure and Fractal Dimension of Concrete. Fractals 2021, 29, 2140004. [Google Scholar] [CrossRef]
- Zhu, H.C.; Tong, Y.J.; Ji, T.; Peng, W.W.; Chen, M.; Xiao, T.Q. Elimination technology of noise introduced by top-up injection in synchrotron radiation infrared beamline. J. Infrared Millim. Waves 2018, 37, 251–257. [Google Scholar]
- Su, T.-C.; Yang, M.-D.; Wu, T.-C.; Lin, J.-Y. Morphological segmentation based on edge detection for sewer pipe defects on CCTV images. Expert Syst. Appl. 2011, 38, 13094–13114. [Google Scholar] [CrossRef]
- Yang, S.; Shao, L.T.; Guo, X.X.; Liu, X.; Zhao, B.Y. A Crack Segmentation Approach Using the Combination of Gray Thresholds and Fractal Feature. Adv. Mater. Res. 2012, 487, 622–626. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, X.; Han, Y.; Wang, H.; Li, Y. Automatic multi-region segmentation of intracoronary optical coherence tomography images based on neutrosophic theory. Sheng Wu Yi Xue Gong Cheng Xue Za Zhi = J. Biomed. Eng. = Shengwu Yixue Gongchengxue Zazhi 2019, 36, 59–67. [Google Scholar]
- Lin, L.K.; Wang, S.Y.; Tang, Z.X. Point target detection in infrared over-sampling scanning images using deep convolutional neural networks. J. Infrared Millim. Waves 2018, 7, 219–226. [Google Scholar]
- Wu, Q.P.; Wu, C.M. A fast and robust clustering segmentation algorithm for kernel space graphics. CAAI Trans. Intell. Syst. 2019, 14, 804–811. [Google Scholar]
- Adhikari, R.S.; Moselhi, O.; Bagchi, A. Image-based retrieval of concrete crack properties for bridge inspection. Autom. Constr. 2014, 39, 180–194. [Google Scholar] [CrossRef]
- Nhat-Duc, H.; Nguyen, Q.-L.; Tran, V.-D. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Autom. Constr. 2018, 94, 203–213. [Google Scholar] [CrossRef]
- Arena, A.; Piane, C.D.; Sarout, J. A new computational approach to cracks quantification from 2D image analysis: Application to micro-cracks description in rocks. Comput. Geosci. 2014, 66, 106–120. [Google Scholar] [CrossRef]
- Li, L.; Wang, Q.; Zhang, G.K.; Shi, L.; Dong, J.; Jia, P. A method of detecting the cracks of concrete undergo high-temperature. Constr. Build. Mater. 2018, 162, 345–358. [Google Scholar] [CrossRef]
- Chen, X.; Li, J.; Huang, S.; Cui, H.; Liu, P.; Sun, Q. An Automatic Concrete Crack-Detection Method Fusing Point Clouds and Images Based on Improved Otsu’s Algorithm. Sensors 2021, 21, 1581. [Google Scholar] [CrossRef]
- Safaei, N.; Smadi, O.; Safaei, B.; Masoud, A. Efficient Road Crack Detection Based on an Adaptive Pixel-Level Segmentation Algorithm. Transp. Res. Rec. J. Transp. Res. Board 2021, 2675, 370–381. [Google Scholar] [CrossRef]
- Krawczuk, M.; Ostachowicz, W.M. Spectral Finite Element and Genetic Algorithm for Crack Detection in Cantilever Rod. Key Eng. Mater. 2001, 204, 241–250. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated pixel-level pavement crack detectionon 3D asphalt surfaces using a deep-learning network. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Song, L.; Wang, X. Faster region convolutional neural net-work for automated pavement distress detection. Road Mater. Pavement Des. 2019, 21, 1–19. [Google Scholar]
- Mandal, V.; Uong, L.; Adu-Gymfi, Y. Automated road crack detection using deep convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5212–5215. [Google Scholar]
- Cha, Y.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. arXiv 2019, arXiv:1901.06340. [Google Scholar] [CrossRef] [Green Version]
- Elkashef, M.; Williams, R.C.; Cochran, E. Investigation of fatigue and thermal cracking behavior of rejuvenated reclaimed asphalt pavement binders and mixtures. Int. J. Fatigue 2018, 108, 90–95. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning Hierarchical Features for Scene Labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1915–1929. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civil Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2018, 99, 52–58. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Han, C.J.; Tao, M.; Huyan, J.; Huang, X.; Zhang, Y. CrackW-Net: A novel pavement crack image segmentation convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2021, 12, 1–10. [Google Scholar] [CrossRef]
- Zhang, C.; Chang, C.-C. Surface damage detection for concrete bridges using single-stage convolutional neural networks. In Health Monitoring of Structural and Biological Systems XII; SPIE: Orlando, FL, USA, 2019; Volume 10972, pp. 527–534. [Google Scholar] [CrossRef]
- Wang, L.; Guo, F.X.; Yang, H.M.; Wang, Y.; Tang, S.W. Comparison of FLY ASH, PVA Fiber, MgO and Shrinkage-reducing Admixture on the Frost Resistance of Face Slab Concrete via Pore Structural and Fractal Analysis. Fractals 2021, 29, 2140002. [Google Scholar] [CrossRef]
- Wang, L.; Jin, M.M.; Guo, F.X.; Wang, Y.; Tang, S.W. Pore Structural and Fractal Analysis of the Influence of FLY ASH and Silica Fume on the Mechanical Property and Abrasion Resistance of Concrete. Fractals 2021, 29, 2140003. [Google Scholar] [CrossRef]
- Wang, L.; Zeng, X.; Yang, H.; Lv, X.; Guo, F.; Shi, Y.; Hanif, A. Investigation and Application of Fractal Theory in Cement-Based Materials: A Review. Fractal Fract. 2021, 5, 247. [Google Scholar] [CrossRef]
- Macek, W. Correlation between Fractal Dimension and Areal Surface Parameters for Fracture Analysis after Bending-Torsion Fatigue. Metals 2021, 11, 1790. [Google Scholar] [CrossRef]
- Mandelbrot, B.B.; Passoja, D.E.; Paullay, A.J. Fractal character of fracture surfaces of metals. Nature 1984, 308, 721–722. [Google Scholar] [CrossRef]
- Xiao, J.; Xu, Z.; Murong, Y.; Lei, B.; Chu, L.; Jiang, H.; Qu, W. Effect of chemical composition of fine aggregate on the frictional behavior of concrete–soil interface under sulfuric acid environment. Fractal Fract. 2022, 6, 22. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3 | 5 | 11 | 25 | 58 | 114 | 267 | 602 |
| Layer | Output Size | Operation Type | Operation Size | Depth |
|---|---|---|---|---|
| Input | 512 × 512 × 3 | non | non | non |
| Convl | 512 × 512 × 36 | conv | 3 × 3 | 3 |
| UHK-Netl | 512 × 512 × 36 | conv | 3 × 3 | 36 |
| TD1 | 256 × 256 × 36 | conv | 3 × 3 | 36 |
| 256 × 256 × 36 | pool | 4 × 4 | non | |
| UHK-Net2 | 256 × 256 × 36 | conv | 3 × 3 | 36 |
| TD2 | 128 × 128 × 36 | conv | 3 × 3 | 36 |
| 128 × 128 × 36 | pool | 4 × 4 | non | |
| UHK-Net3 | 128 × 128 × 36 | conv | 5 × 5 | 36 |
| TUI | 256 × 256 × 36 | deconv | 3 × 3 | 36 |
| UHK-Net4 | 256 × 256 × 36 | conv | 3 × 3 | 36 |
| TU2 | 512 × 512 × 36 | deconv | 3 × 3 | 36 |
| UHK-Net5 | 512 × 512 × 36 | conv | 3 × 3 | 36 |
| Conv2 | 512 × 512 × 36 | conv | 3 × 3 | 36 |
| Output | 512 × 512 × 3 | non | non | non |
| Different Methods | U-Net | FCN | YOLO v5 | UHK-Net |
|---|---|---|---|---|
| Training time (h) | 12.7 | 10.5 | 7.1 | 7 |
| Segmentation time (s) | 1.4 | 1.1 | 0.8 | 0.9 |
| Different Methods | PA | MPA | MIoU |
|---|---|---|---|
| FCN | 0.9366 | 0.8971 | 0.8406 |
| U-Net | 0.9542 | 0.9037 | 0.8594 |
| YOLO v5 | 0.9608 | 0.9143 | 0.8831 |
| Proposed method | 0.9723 | 0.9298 | 0.9012 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, Q.; Chen, X.; Wang, H.; Yang, H.; Yang, Y.; Huang, W.; Wang, L. Segmentation of Concrete Cracks by Using Fractal Dimension and UHK-Net. Fractal Fract. 2022, 6, 95. https://doi.org/10.3390/fractalfract6020095
An Q, Chen X, Wang H, Yang H, Yang Y, Huang W, Wang L. Segmentation of Concrete Cracks by Using Fractal Dimension and UHK-Net. Fractal and Fractional. 2022; 6(2):95. https://doi.org/10.3390/fractalfract6020095
Chicago/Turabian StyleAn, Qing, Xijiang Chen, Haojun Wang, Huamei Yang, Yuanjun Yang, Wei Huang, and Lei Wang. 2022. "Segmentation of Concrete Cracks by Using Fractal Dimension and UHK-Net" Fractal and Fractional 6, no. 2: 95. https://doi.org/10.3390/fractalfract6020095
APA StyleAn, Q., Chen, X., Wang, H., Yang, H., Yang, Y., Huang, W., & Wang, L. (2022). Segmentation of Concrete Cracks by Using Fractal Dimension and UHK-Net. Fractal and Fractional, 6(2), 95. https://doi.org/10.3390/fractalfract6020095