4.3. Evaluation Metrics
To analyze the experimental results, this study used mean Average Precision (mAP), number of parameters (Parameters), floating-point operations per gigaflop (FLOPs/G), and frames per second (FPSs) to evaluate model performance. In addition, Precision and Recall were used to measure false positive and false negative rates. The formulas for calculating Precision and Recall were as follows:
where TP denotes true positives (products with defects and correctly detected), FP denotes false positives (products without defects but detected as defective), and FN denotes false negatives (products with defects but not detected). Average Precision (AP) is the area under the Precision–Recall (PR) curve and mAP is the average of AP values across all categories. A higher mAP indicated better model detection accuracy. The calculation of AP and mAP is shown in Formulas (8) and (9), where N represents the number of categories in the dataset:
Intersection over Union (IoU) measured the overlap of predicted bounding boxes, with a threshold to distinguish between positive and negative samples. This study evaluated model performance using mAP@0.5 and mAP@0.5–0.95. The parameter count (Params) represented the sum of all trainable parameters within a model, serving as a metric for the spatial complexity of the model. The floating-point operations per second (FLOPs) quantified the computational load during a single forward propagation through the model and were typically utilized to evaluate the temporal complexity. The frames per second (FPSs) metric assessed the model’s processing velocity on hardware, reflecting the rate at which the model could handle images per second.
4.4. Experimental Results and Analysis
To verify that the improved modules did not conflict with the model and positively impacted its performance, we conducted ablation experiments on the model with the selected modules. The experimental results are shown in
Table 3. The results show that the improved model achieved peak performance, with mAP@0.5 and mAP@0.5–0.95 increasing to 68.3% and 34.0%, respectively, with only a slight increase in computational complexity. Overall, the detection performance was significantly improved with minimal additional computational burden.
To verify the advantages of the RFCAConv module in detecting long-range spatial dependencies and low-contrast defects, we conducted comprehensive comparison experiments based on the baseline model. As shown in
Table 4 and
Table 5, for the two typical long-range spatial dependency defects (Crease and Waist folding), RFCAConv improved mAP@0.5 by 27.8% and 2.3% and mAP@50–95 by 8.4% and 0.7%. For the two typical low-contrast defects (Silkspot and Water spot), it enhanced mAP@0.5 by 8% and 4.4% and mAP@0.5–95 by 2.9% and 2.1%.
To achieve the best balance between receptive field expansion, edge information retention, and global feature capture, we explored various dilation rate combinations. The pixel utilization distribution for each combination is shown in
Figure 8a–e. The r = [1,1,1] combination had slow receptive field expansion and focused on local information. The r = [1,2,3] combination’s receptive field grew with increasing dilation rates but payed less attention to edge details. The r = [2,1,2] combination balanced receptive field expansion and edge retention but had limited global feature capture. The r = [2,2,2] combination, with a common factor greater than 1, caused detail loss. Finally, the r = [1,3,5] combination rapidly expanded the receptive field and achieved the best balance between global features and edge information. We then verified the impact of dilated convolutions with different dilation rates on network predictions, with the results shown in
Table 6. The r = [1,3,5] combination showed the best performance in mAP@0.5, mAP@0.5–0.95, Precision, and Recall.
To validate the effectiveness of the Aux Head module for small-target defect detection, we performed multiple comparative experiments based on the baseline model, with detailed results presented in
Table 7. The experimental results demonstrated that for two representative small-target defect categories—Punching and Waist folding—the Aux Head module achieved optimal performance, showing improvements of 1.1% and 2.4% in mAP@0.5, along with enhancements of 2.0% and 0.8% in mAP@0.5–0.95 compared to the baseline, respectively.
To further validate the outstanding detection performance of FAD-Net, we conducted a comparative experiment on the GC10-DET dataset with mainstream detection algorithms: Faster-RCNN, DINO, Retinanet, RTMDET, RT-DETR, Swin-Transformer, and other YOLO series models. The experimental results are shown in
Table 8. FAD-Net achieved the best performance in terms of detection accuracy. Specifically, FAD-Net improved mAP@0.5 by 9% over RetinaNet and outperformed the high-precision two-stage detectors Faster-RCNN and DINO by 3.4% and 1.8%, respectively. When compared with other YOLO series algorithms, FAD-Net also achieved the highest detection accuracy. Notably, FAD-Net demonstrated superior computational efficiency while maintaining exceptional detection accuracy. Comparative analysis of floating-point operations (FLOPs) and parameter counts (Params) confirmed FAD-Net’s effective complexity control—a critical advantage for real-time structural health monitoring in urban infrastructure applications.
Figure 9 presents the model comparison results. YOLO-series algorithms, with their compact architectures and lower FLOPs/G, are more suitable for real-time inspection requirements of urban infrastructure steel structures, achieving superior balance between computational efficiency and detection speed. Comparative experiments revealed FAD-Net’s 5% mAP improvement over baseline models, demonstrating its distinct advantages.
To verify the generalization ability of the proposed framework for different types of defects in both structural components and road scenarios, cross-dataset evaluations were performed using the NEU dataset from Northeastern University and the RDD2022 road defect dataset, respectively. The NEU dataset comprises six common characteristic defect categories in structural components: rolled scale, patches, cracks, scratches, pitted surfaces, and inclusions, with 300 samples per class (1800 samples in total). The RDD2022 road defect dataset contains four common types of road surface defects: longitudinal cracks, transverse cracks, alligator cracks, and potholes, with a total of 173,767 samples. Both were split into training and validation sets at a ratio of 4:1. Generalization experiment results are shown in
Table 9. All models were trained and tested using the same hyperparameters as in
Table 2.
Figure 10 presents a comparison of key metrics between the baseline model and our proposed FAD-Net model over 300 training epochs on the validation set.
Figure 10a shows that FAD-Net significantly outperformed the baseline model in terms of mAP@0.5.
Figure 10b further illustrates that under the mAP@0.5–0.95 evaluation standard, FAD-Net continued to perform excellently, with improvements observed at multiple IoU thresholds.
Figure 10c,d show comparisons of Precision and Recall, where FAD-Net also significantly outperformed the baseline model, indicating its advantage in detection accuracy and recall rate. In conclusion, the FAD-Net model demonstrates higher accuracy and reliability in object detection tasks, validating its effectiveness.
Figure 11 presents the model’s prediction results, demonstrating the improvements of FAD-Net over the baseline model in terms of missed detection, false detection, and confidence level. Specifically, lower missed and false detection rates showed that the model’s feature extraction was more accurate and its ability to suppress background interference was stronger, highlighting the model’s robustness and generalization ability in complex scenarios. Higher confidence in detection boxes indicated a higher probability of the target being present, reflecting the model’s ability to capture more target details. The first set of images shows that FAD-Net detected defects missed by the baseline model, reducing the missed detection rate. The second set shows false detections from the baseline model, which FAD-Net successfully avoided. The third set further demonstrates that FAD-Net improved the detection accuracy of the baseline model.





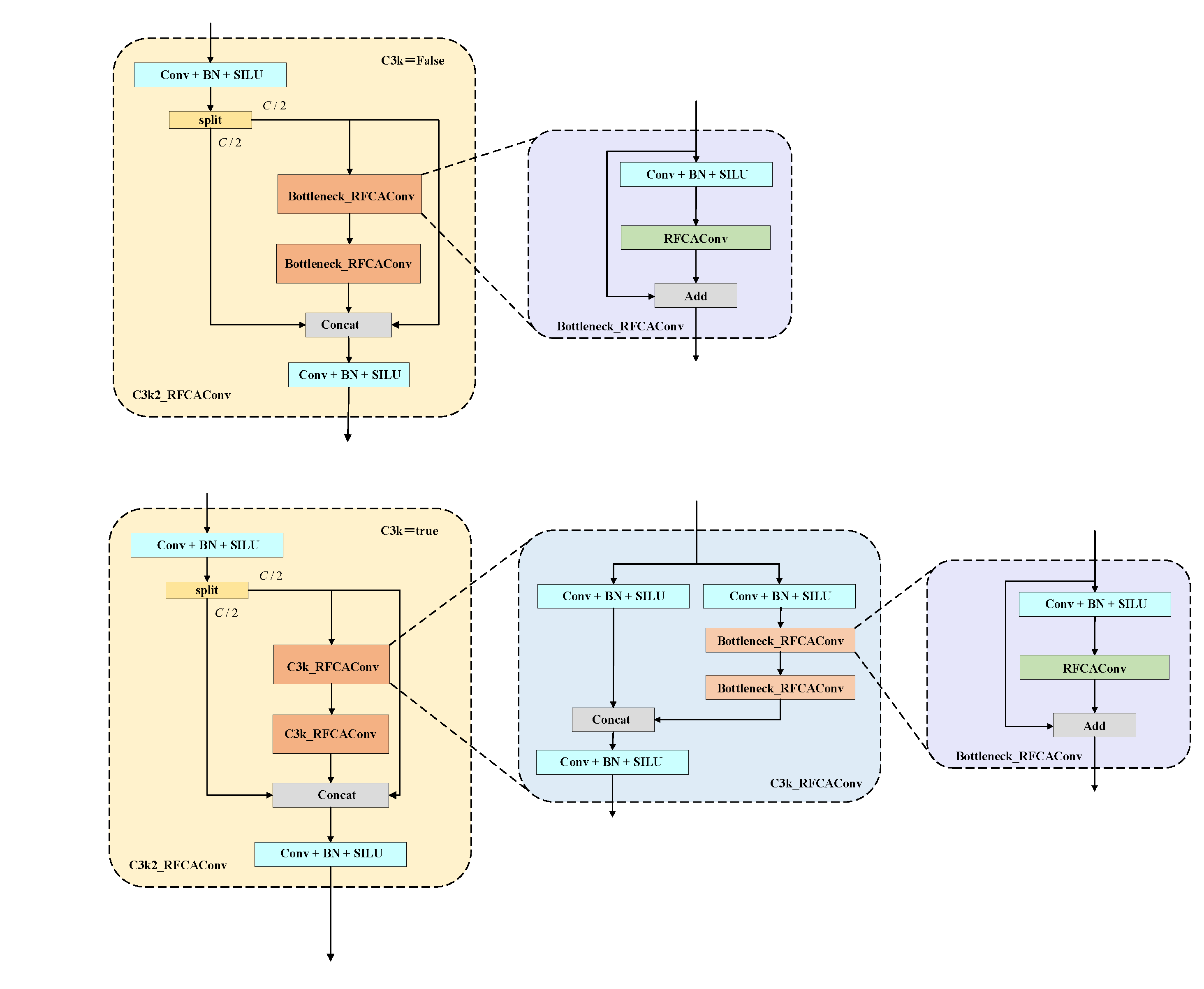







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}