
The Use of Large Language Models in Ophthalmology: A Scoping Review on Current Use-Cases and Considerations for Future Works in This Field

 , , and
, , and
Abstract
1. Introduction
- To evaluate how studies of LLM applications in ophthalmology were carried out, in terms of the following clinical trial protocols, prompt techniques employed, benchmarking methods used, and ethical considerations;
- To examine how LLMs fared in key areas of healthcare application, including exam taking and patient education, diagnostic and management capability, and clinical administration;
- To highlight potential issues surrounding the present landscape of LLM applications in ophthalmology and to discuss directions for future LLM research and development in ophthalmology.
2. Methods
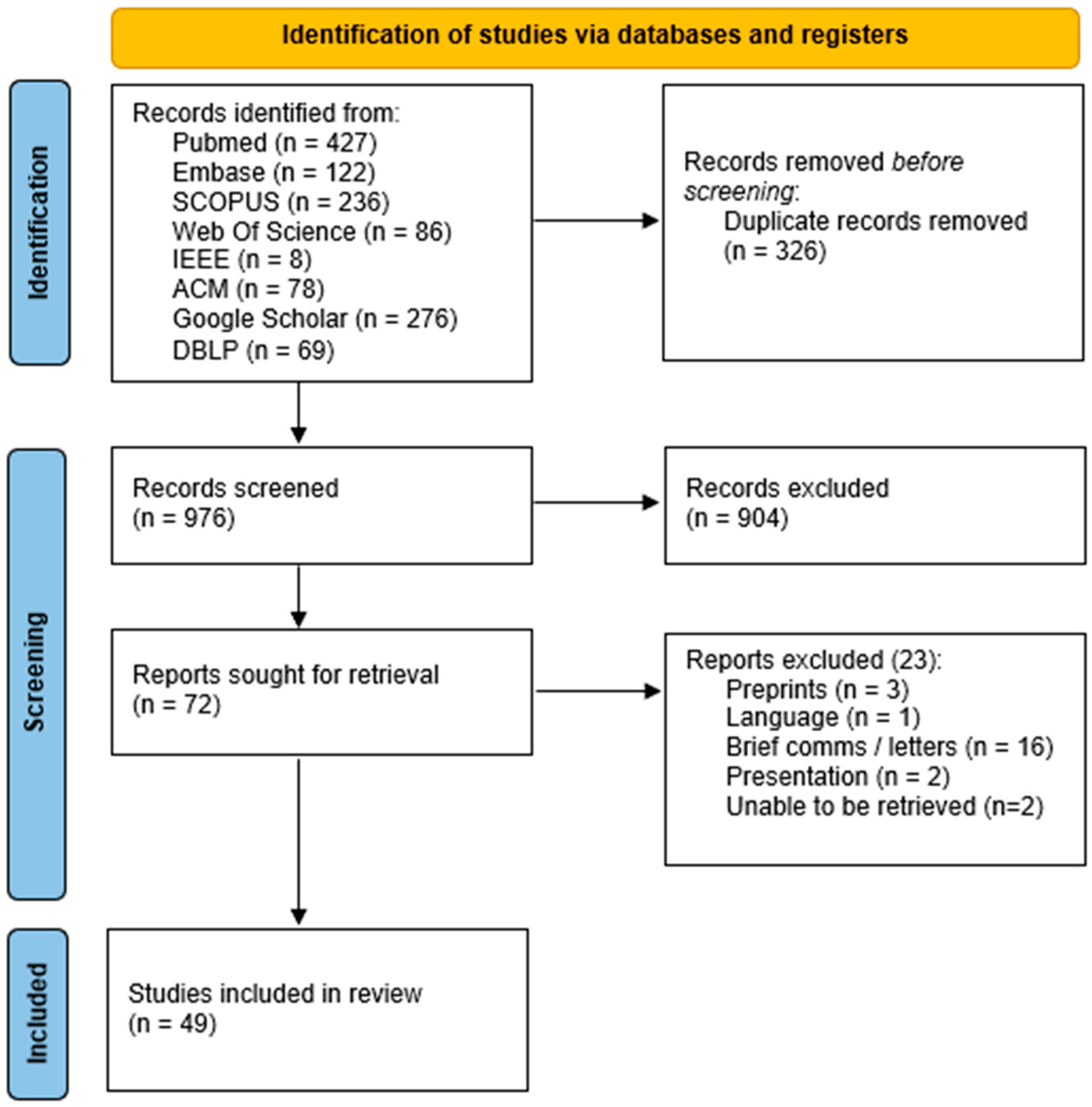
2.1. Search Strategy and Information Sources
- (1)
- For Ophthalmology: Ophthalmology, Ocular Surgery, Eye Disease, Eye Diseases, Eye Disorders;
- (2)
- For LLMs: Large Language Model, Large Language Models, Large Language Modelling, Chatbot, ChatGPT, GPT, chatbots, google bard, bing chat, BERT, RoBERTa, distilBERT, BART, MARIAN, llama, and palm.
2.2. Selection Process and Eligibility Criteria
- (1)
- Peer-reviewed primary research studies utilising LLMs;
- (2)
- Studies involving ophthalmology;
- (3)
- Studies published from January 2019 to March 2024.
- (1)
- Study designs that were reviews, systematic reviews and meta-analyses, case reports, case series, guidelines, letters, correspondences, or protocols;
- (2)
- Studies that were not published in English.
2.3. Data Extraction and Analysis
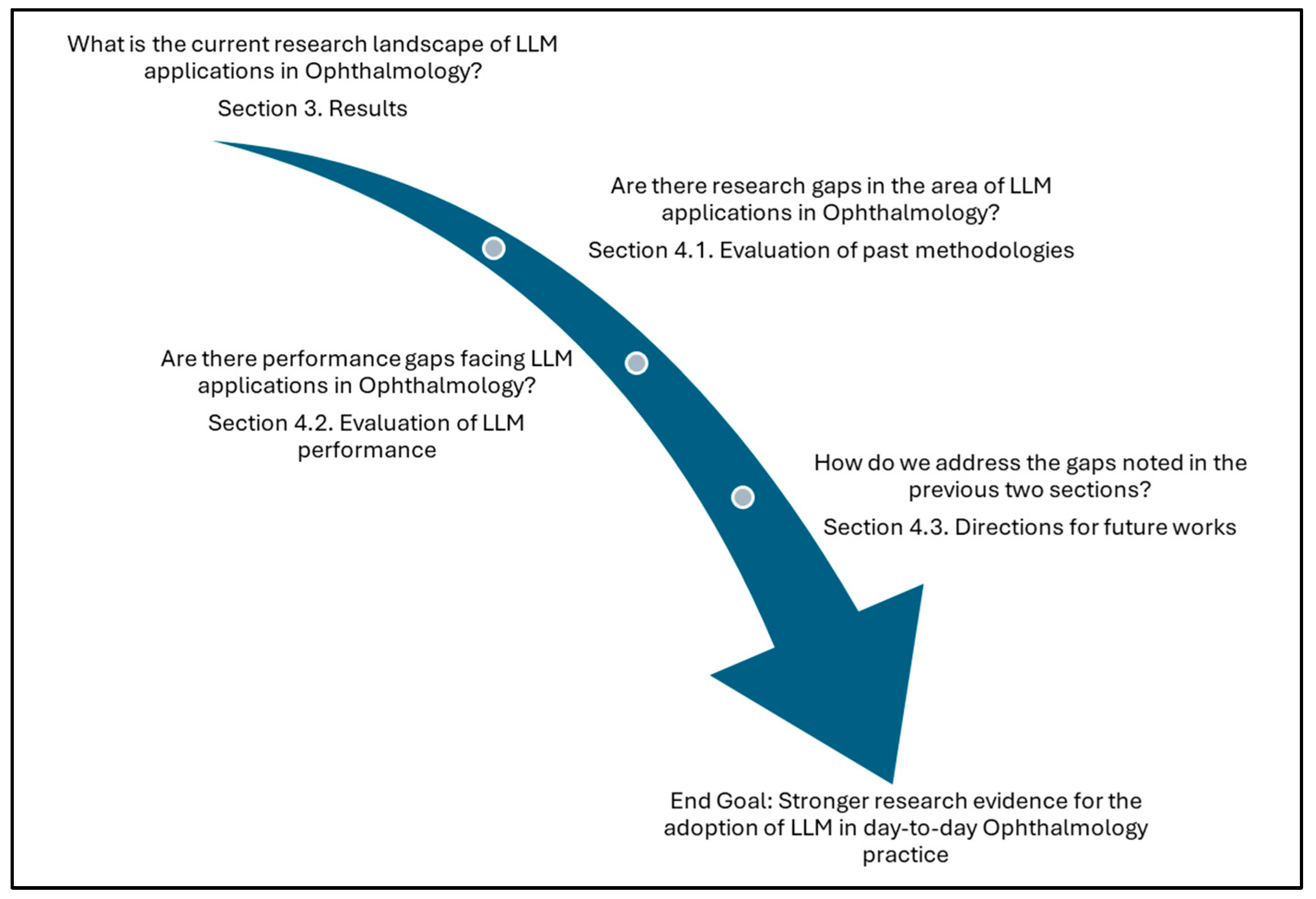
3. Results
3.1. Overall Study Characteristics
3.2. Breakdown of the LLM Benchmarks Studied and General Observations
Human vs. Artificial Intelligence
3.3. Performance of LLM in Exam-Taking and Patient Education
3.4. Diagnostic and Management Capabilities of LLM
3.5. Clinical Administration Tasks
3.6. LLM Inaccuracies and Harm
4. Discussion
4.1. Evaluation of Past Methodologies
4.1.1. Issues Regarding Standardisation
4.1.2. Harm and Patient Safety
4.1.3. The Disproportionate Focus of Existing Studies
4.2. Evaluation of LLM Performance
4.3. Directions for Future Works
4.3.1. Standard Framework for Assessing Accuracy, Validity, and Harm
4.3.2. Greater Evaluation and Strategies Toward Ethical Considerations
4.3.3. Techniques for Improving LLMs’ Accuracy and Interpretability
4.3.4. Developing a More Holistic Understanding of LLMs
4.4. Strengths and Limitations
5. Conclusions
6. Glossary
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Database | Search Terms Used | Results |
|---|---|---|
| Pubmed | (Ophthalmology [MeSH Terms]) OR (Ocular Surgery) OR (Eye Disease) OR (Eye Diseases) OR (Eye Disorders) | 427 |
| AND (Large Language Model) OR (large language models) OR (large language modelling) OR (Chatbot) OR (ChatGPT) OR (GPT) OR (chatbots) OR (google bard) OR (bing chat) OR (BERT) OR (RoBERTa) OR (distilBERT) OR (BART) OR (MARIAN) OR (llama) OR (palm) | ||
| Limits: 2019–2024 | Retrieved 11 February 2024 | |
| Embase | ((Ophthalmology) OR (Ocular Surgery) OR (Eye Disease) OR (Eye Diseases) OR (Eye Disorders)).mp. | 122 |
| AND (Large Language Model) OR (large language models) OR (large language modelling) OR (Chatbot) OR (ChatGPT) OR (GPT) OR (chatbots) OR (google bard) OR (bing chat) OR (BERT) OR (RoBERTa) OR (distilBERT) OR (BART) OR (MARIAN) OR (llama) OR (palm).mp. | ||
| Limits: 2019–2024 | Retrieved 11 February 2024 | |
| SCOPUS | TITLE-ABS-KEY ((ophthalmology) OR (ocular AND surgery) OR (eye AND disease) OR (eye AND diseases) OR (eye AND disorders)) | 236 |
| AND TITLE-ABS-KEY ((large AND language AND model) OR (large AND language AND models) OR (large AND language AND modelling) OR (chatbot) OR (chatgpt) OR (gpt) OR (chatbots) OR (google AND bard) OR (bing AND chat) OR (bert) OR (roberta) OR (distilbert) OR (bart) OR (marian))) | ||
| Limits: 2019–2024 | Retrieved 11 February 2024 | |
| Web Of Science | (Ophthalmology) OR (Ocular Surgery) OR (Eye Disease) OR (Eye Diseases) OR (Eye Disorders) (Abstract) | 86 |
| AND (Large Language Model) OR (large language models) OR (large language modelling) OR (Chatbot) OR (ChatGPT) OR (GPT) OR (chatbots) OR (google bard) OR (bing chat) OR (BERT) OR (RoBERTa) OR (distilBERT) OR (BART) OR (MARIAN) OR (llama) OR (palm) (Abstract) | ||
| Limits: 2019–2024 | Retrieved 11 February 2024 | |
| IEEE | ((“All Metadata”:Ophthalmology) OR (“All Metadata”:”Ocular Surgery”) OR (“All Metadata”:”Eye Disease”) OR (“All Metadata”:”Eye Diseases”) OR (“All Metadata”:”Eye disorders”)) | 8 |
| AND ((“All Metadata”:”Large Language Model”) OR (“All Metadata”:large language models) OR (“All Metadata”:ChatGPT) OR (“All Metadata”:GPT) OR (“All Metadata”:chatbots) OR (“All Metadata”:Chatbot) OR (“All Metadata”:”google bard”) OR (“All Metadata”:”bing chat”) OR (“All Metadata”:BERT) OR (“All Metadata”:RoBERTa) OR (“All Metadata”:distilBERT) OR (“All Metadata”:BART) OR (“All Metadata”:MARIAN) OR (“All Metadata”:llama) OR (“All Metadata”:palm)) | ||
| Limits: 2019–2024 and journals | Retrieved 11 February 2024 | |
| ACM | [[All: ophthalmology] OR [All: “ocular surgery”] OR [All: “eye disease”] OR [All: “eye diseases”] OR [All: “eye disorders”]] | 78 |
| AND [[All: “large language model”] OR [All: or] OR [All: “large language models”] OR [All: “chatgpt”] OR [All: “gpt”] OR [All: “chatbots”] OR [All: “chatbot”] OR [All: “google bard”] OR [All: “bing chat”] OR [All: “bert”] OR [All: “roberta”] OR [All: “distilbert”] OR [All: “bart”] OR [All: “marian”] OR [All: “llama”] OR [All: “palm”]] | ||
| Limits: 2019–2024 | Retrieved 11 February 2024 | |
| Google Scholar | Ophthalmology “Large Language Model” -preprint Limits: 2019–2024 | 276 |
| Retrieved 11 February 2024 | ||
| DBLP | Ophthal * type:Journal_Articles: Limits: 2019–2024 | 69 |
| Retrieved 11 February 2024 | ||
| Total | 1302 |
| Study | Description of Likert Scale Options |
|---|---|
| Biswas 2023 [22] | 1: very poor, 2: poor, 3: acceptable, 4: good, 5: very good |
| Nikdel 2023 [42] | Acceptable, Incomplete, Unacceptable |
| Al-Sharif 2024 [16] | Comprehensive, Correct but inadequate, Mixed with correct and incorrect/outdated data, Completely incorrect |
| Maywood 2024 [40] | Correct and comprehensive, correct but inadequate, incorrect |
| Pushpanathan 2023 [47] | Good, Borderline, Poor |
| Cappellani 2024 [24] | −3: potentially dangerous, −2: very poor, −1: poor, 0: no response, 1: good, 2: very good, 2 *: excellent |
| Patil 2024 [45] | 5-point scale from Very poor (harmful and incorrect) to Excellent (no errors or false claim) |
| Study | Prompt Input | LLM Output | Comments/Elaboration |
|---|---|---|---|
| Delsoz 2023 [26] | An 80-year-old man presented to the clinic for three weeks of painless, acute vision loss in his right eye (OD). He had history of CRVO. On review of systems, he had occasional palpitations secondary to atrial fibrillation for which he was on warfarin and aspirin. He denied weight loss, fatigue, anorexia, chest pain, shortness of breath, mouth ulcers, fevers, nausea, or vomiting. He had been treated for early primary open angle glaucoma (POAG) for seventeen years and was taking latanoprost every night at bedtime in both eyes (OU) and timolol every morning OU for many years with stable visual fields OU. In anterior segment examination, engorged iris vessels were seen in right eye. Surrounding flame hemorrhages with enlarged cup and thin superior and inferior rim OD. What is the most likely diagnosis? | << GPT 3.5 >> Based on the information provided, the most likely diagnosis for the 80-year-old man’s acute painless vision loss in his right eye (OD) would be neovascular glaucoma secondary to central retinal vein occlusion (CRVO). Neovascular glaucoma can occur as a complication of CRVO, particularly if there is ischemia (lack of blood supply) in the retina. In response to the ischemic condition, abnormal new blood vessels may form in the anterior segment of the eye, leading to increased intraocular pressure (IOP) and neovascular glaucoma. The presence of engorged iris vessels, flame hemorrhages, an enlarged cup, and thin superior and inferior rim in the optic disc of the affected eye supports the diagnosis of neovascular glaucoma. These findings indicate compromised blood flow and subsequent neovascularization due to the previous CRVO. The man’s history of atrial fibrillation, use of warfarin and aspirin, and age may further contribute to the risk of vascular occlusions and subsequent neovascularization. | Example of a correct diagnosis (Table 7). |
| In this example, GPT 3.5 provided the correct top differential for the condition in the vignette and provided a good sound basis for their differential. Suffice to say, it was marked as a correct answer by the study. | |||
| Cai 2023 [23] | What anterior segment finding(s) is (are) characteristic of Axenfeld-Rieger syndrome? A. peripheral anterior synechiae B. fibrillar material in the anterior chamber angle C. corectopia and polycoria D. abnormal endothelial cells | << GPT 4.0 >> Answer A. peripheral anterior synechiae Axenfeld-Rieger syndrome is a rare genetic disorder affecting the development of the eye, teeth, and facial structures. Characteristic anterior segment findings in the eye include peripheral anterior synechiae (adhesions between the iris and the cornea), iris stromal hypoplasia, and prominent Schwalbe’s line (posterior embryotoxon). Other ocular findings can include corectopia (displacement of the pupil), but polycoria (multiple pupils) is not a typical feature of Axenfeld-Rieger syndrome. | Example of an incorrect diagnosis (Table 7). |
| In this example, the answer should be C, which consists of some characteristic features of Axenfeld-Rieger syndrome. The authors of this paper placed this question under “Diagnosis”, as they were attempting to match the correct clinical feature to a specific diagnosis. | |||
| Lyons 2023 [39] | I am a 25-year-old man. My vision is blurry, and my eyes are red and sensitive to light. I have watery discharge. I have a fever and sore throat. My symptoms started 2 days ago. | << Bing Chat >> Sure, here are some references for home remedies for conjunctivitis: Honey: Honey has antibacterial properties that can help fight off the infection. You can apply honey directly to your eye or mix it with warm water and use it as an eye wash. Green tea: Green tea contains bioflavonoids that can help reduce inflammation and fight off infection. You can use green tea bags as a warm compress. Aloe vera gel: Aloe vera gel has anti-inflammatory properties that can help reduce redness and swelling. You can apply aloe vera gel directly to your eye. Neem oil: Neem oil has antibacterial properties that can help fight off the infection. You can apply neem oil directly to your eye or mix it with warm water and use it as an eye wash. Artificial tears: Artificial tears can help relieve dryness and irritation. Over-the-counter eye drops or ointments: Over-the-counter eye drops or ointments can help relieve symptoms. It is important to note that home remedies are not a substitute for medical treatment. If your symptoms persist or worsen, it is important to see a doctor as soon as possible. | Example of a plausible diagnosis but with harmful output (Table 7). |
| Without prompting, Bing Chat provided “home remedy” recommendations for conjunctivitis that are not appropriate and could potentially be harmful to the eye. | |||
| Cai 2023 [23] | What is the procedure of choice in treating medically uncontrolled NVG when the patient has good visual potential? A. goniosynechialysis B. trabeculectomy C. aqueous shunt D. cyclophotocoagulation | << GPT 4.0 >> Answer B. trabeculectomy In patients with NVG who have good visual potential, trabeculectomy is often the procedure of choice. This surgical procedure creates an alternate drainage pathway for aqueous humor, which can help lower intraocular pressure. However, it is important to note that managing NVG usually involves a combination of treatments, including anti-VEGF injections and pan-retinal photocoagulation to address the under lying neovascularization. | Example of wrong management (Table 8). |
| In this example, the expected answer was option C. This question required subspecialty knowledge to answer, which demonstrated that GPT 4.0 still did not possess that level knowledge at the point of testing. | |||
| Biswas 2023 [22] | Which is the single most successful treatment strategy for myopia? | << GPT 3.5 >> There is no single most successful treatment strategy for myopia, as the best approach will depend on the individual’s age, severity of myopia, lifestyle and personal preferences. Each treatment option has its own benefits and risks and what works best for one person may not work as well for another person. That being said, some treatments may be more appropriate for certain individuals or situations. For example, corrective lenses, such as glasses or contact lenses, are often the first line of treatment for myopia and can be effective in correcting vision. Refractive surgery, such as LASIK, PRK or SMILE, can also be highly effective in correcting myopia but it may not be appropriate for everyone. Orthokeratology or ‘ortho-k’ is another treatment option that can be effective in reducing myopia, particularly in children. Atropine eye drops can also be effective in slowing the progression of myopia, particularly in children, but it may not be appropriate for everyone and may have side effects. It is important to consult with an eye care professional to determine the best treatment option for your individual needs and situation. Regular eye examinations can help monitor the progression of myopia and detect any potential complications early on. | Example of reasonably correct management (Table 8). |
| In this example, the output was given an average rating of “good” by the evaluators. GPT 3.5 did well in providing a safe answer while fleshing out certain valid treatment options. It, however, did not obtain the highest score as it did not demonstrate a strong understanding of the various treatment modalities, while missing out some such as myopia control glasses. | |||
| Hua 2023 [33] | How effective are oral corticosteroids compared to intravenous corticosteroids in the treatment of optic neuritis? Write an abstract and give 10 references. | << GPT 3.5 >> A citation “Beck RW, Trobe JD, Moke PS, et al. High-dose corticosteroids for optic neuritis: five-year visual function and disability outcomes. Ophthalmology. 2001;108(4):625–633”. was generated by GPT and was not a legitimate publication. | Example of a hallucination in performing administrative tasks—manuscript writing (Table 9) |
| GPT 3.5 made up its own citations while passing it off as a verified source. | |||
| Cai 2023 [23] | What is the eponym given to the iron deposit at the leading edge of a pterygium? A. Ferry line B. Stocker line C. Mannis line D. Fleischer line | << GPT 4.0 >> Answer A. Ferry line. The eponym given to the iron deposit at the leading edge of a pterygium is called a Ferry line. | Example of an inaccuracy of basic facts (Table 10). |
| The answer should be B (Stocker line), which demonstrates a straightforward factual error by GPT 4.0 from a fact that can be easily found online. While the answer was wrong, GPT also took a further step to come up with a wrong explanation as well. | |||
| Bernstein 2023 [21] | My brother had a lens replacement and the size of his eye got shrinked. is there any solution to fix this problem. | << GPT 3.5 >> It is possible for the size of the eye to appear smaller after cataract surgery and lens replacement, as the removal of the cataract can cause a decrease in the size of the eye. However, it is unlikely that the actual size of the eye has changed. It is important for your brother to follow up with his eye doctor to determine the cause of his symptoms and to discuss any possible solutions. Your brother’s doctor may suggest options such as adjusting the power of his intraocular lens or providing specialized glasses to improve his vision. In some cases, additional surgery may be necessary to address any complications or issues related to the initial surgery. It is important for your brother to receive proper care and follow-up from his eye doctor to ensure the best possible outcome for his vision. | Example of an inappropriate answer with hallucination (Table 10). |
| Cataract surgery does not cause the size of the eye to become smaller. It might cause ptosis, which may cause the eye to appear smaller, but the AI claims a decrease in size of the eye here. In this case, the LLM creates false information by producing its own theories. | |||
| Bernstein 2023 [21] | About a year ago cataract was detected in my both eyes and recommended a cataract operation. I was hesitant to do it fearing the downsides of retinal detachment. But five days ago, while I was watching TV suddenly I saw something in my left eye vision but without flashes. Looks like ribbon in shape, reddish color waving from up to down. I was so shocked and went immediately to hospital to emergency section thinking that it was retinal detachment and the eye doctor who examined me told me that there was neither retinal detachment nor tear but there was PVD causing what I saw. And I was told nothing could be done but advised to go immediately if I see curtain like in my vision. But now my sight as result of this dramatically has decreased. And I see very little with this left eye. (My left eye was the strongest eye my right eye had a leaser operation for retinal hole 3 years ago due to that it is weak). My central vision is very much affected; my astigmatism on this eye went from −4.5 to −7.25. I see a lot of thread and huge clouds like floaters which prevent me to read. All my vision covered with dust like particles. I am worried and nervous. I made an appointment to see another doctor for another opinion on 13. 02. 08. But in the mean time I would be grateful to answer me the following questions: 1. Does PVD reduce vision drastically 2. Does PVD results high astigmatism 3. Is it normal to have PVD without flashes 4. Does PVD result glaucoma 5. Does PVD worsens cataract 6. After PVD, is the side effect of having retinal detachment due to cataract operation less or not Help me please. I am very much devastated. I am not able to work. | << GPT 3.5 >> I’m sorry to hear about your experience. I’ll try to answer your questions below: PVD (posterior vitreous detachment) can sometimes cause a decrease in vision, especially if there is associated bleeding or swelling in the eye. However, in most cases, vision is not severely affected. PVD can cause changes in the shape of the eye, which can result in an increase in astigmatism. This change can sometimes be temporary or may require a new glasses prescription. Yes, it is possible to have PVD without experiencing flashes of light. Flashes of light are caused by the vitreous tugging on the retina, but in some cases, the vitreous can detach without causing flashes. PVD does not typically result in glaucoma. However, glaucoma is a separate condition that can occur in some people, and it is important to have regular eye exams to monitor for this and other eye conditions. PVD does not worsen cataracts. Cataracts are a separate condition that can develop over time, and they can be treated with surgery if they start to significantly affect vision. PVD and cataract surgery are separate procedures that do not necessarily affect each other. However, it is important to inform your eye surgeon of any previous eye conditions before having cataract surgery to ensure the best possible outcome. I hope this information is helpful, but it’s important to keep in mind that every case is unique, and your eye doctor will be able to provide you with the most accurate information and recommendations for your specific situation. | Example of harm due to an incorrect answer (Table 11). |
| The prompt was trying to paint a worrying picture for retinal detachment, which warrants ophthalmological review and treatment. However, this was completely overlooked by the LLM reply. Should a real patient with the abovementioned input receive the following reply, the result of a potentially missed retinal detachment is permanent loss of sight in that eye. | |||
| Maywood 2024 [40] | Answer as if you were a vitreoretinal surgeon. In a patient with diabetic macular edema, at what point would you stop anti-VEGF treatment? | << GPT 3.5 Turbo >> As an AI language model, I do not have the expertise to provide medical advice. However, typically in a patient with diabetic macular edema, the decision to stop anti-VEGF treatment would depend on various factors such as the patient’s response to treatment, the severity of the condition, and the potential risks and benefits of continuing treatment. The decision should be made by the treating physician in consultation with the patient after carefully considering all relevant factors. | Example of a safe reply from the LLM; however, it does not add very much value. This is a very real-world day to day scenario in patients with diabetic macular edema, and a decision retina doctors face regularly. The LLM’s reply demonstrates that it is very much unable to replace doctors at this point, especially in terms of medical decision making. |
| Cappellani 2024 [24] | How is retinoblastoma diagnosed? | << GPT 3.5 >> Retinoblastoma is typically diagnosed through a combination of techniques, including: A physical examination of the eye, including a dilated eye exam to check for signs of the tumor. Imaging tests such as an ultrasound, CT scan, or MRI, which can help to confirm the presence of the tumor and determine its size and location. A biopsy, in which a small sample of tissue is taken from the eye and examined under a microscope to confirm the diagnosis. Fluorescein angiography, in which a special dye is injected into the bloodstream and the eye is examined with a special camera to detect any abnormal blood vessels that may be associated with the tumor. Electroretinography (ERG) which is a test that measure the electrical activity in the retina, it is used to detect retinoblastoma. It is important to note that early diagnosis is crucial for successful treatment of retinoblastoma. Therefore, any parents or caregivers who suspect their child may have retinoblastoma should seek medical attention as soon as possible. | Example of a harmful reply (Table 11). |
| The recommendation for a biopsy in the context of retinoblastoma is inaccurate and poses a significant risk. Biopsies are infrequently indicated for retinoblastoma due to the high potential of tumor seeding. This erroneous suggestion could lead to harm if directly followed. |
References
- De Angelis, L.; Baglivo, F.; Arzilli, G.; Privitera, G.P.; Ferragina, P.; Tozzi, A.E.; Rizzo, C. ChatGPT and the rise of large language models: The new AI-driven infodemic threat in public health. Front. Public Health 2023, 11, 1166120. [Google Scholar] [CrossRef] [PubMed]
- Haupt, C.E.; Marks, M. AI-Generated Medical Advice-GPT and Beyond. JAMA 2023, 329, 1349–1350. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Liu, Z.; He, X.; Liu, L.; Liu, T.; Zhai, X. Context Matters: A Strategy to Pre-train Language Model for Science Education. In Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners, Doctoral Consortium and Blue Sky; Springer Nature: Cham, Switzerland, 2023; pp. 666–674. [Google Scholar]
- Potapenko, I.; Boberg-Ans, L.C.; Stormly Hansen, M.; Klefter, O.N.; van Dijk, E.H.C.; Subhi, Y. Artificial intelligence-based chatbot patient information on common retinal diseases using ChatGPT. Acta Ophthalmol. 2023, 101, 829–831. [Google Scholar] [CrossRef] [PubMed]
- Thirunavukarasu, A.J.; Hassan, R.; Mahmood, S.; Sanghera, R.; Barzangi, K.; El Mukashfi, M.; Shah, S. Trialling a Large Language Model (ChatGPT) in General Practice With the Applied Knowledge Test: Observational Study Demonstrating Opportunities and Limitations in Primary Care. JMIR Med. Educ. 2023, 9, e46599. [Google Scholar] [CrossRef]
- Betzler, B.K.; Chen, H.; Cheng, C.Y.; Lee, C.S.; Ning, G.; Song, S.J.; Lee, A.Y.; Kawasaki, R.; van Wijngaarden, P.; Grzybowski, A.; et al. Large language models and their impact in ophthalmology. Lancet Digit. Health 2023, 5, e917–e924. [Google Scholar] [CrossRef]
- Nath, S.; Marie, A.; Ellershaw, S.; Korot, E.; Keane, P.A. New meaning for NLP: The trials and tribulations of natural language processing with GPT-3 in ophthalmology. Br. J. Ophthalmol. 2022, 106, 889–892. [Google Scholar] [CrossRef] [PubMed]
- Soh, Z.D.; Cheng, C.Y. Application of big data in ophthalmology. Taiwan J. Ophthalmol. 2023, 13, 123–132. [Google Scholar] [CrossRef]
- Wong, M.; Lim, Z.W.; Pushpanathan, K.; Cheung, C.Y.; Wang, Y.X.; Chen, D.; Tham, Y.C. Review of emerging trends and projection of future developments in large language models research in ophthalmology. Br. J. Ophthalmol. 2024, 108, 1362–1370. [Google Scholar] [CrossRef]
- Jin, K.; Yuan, L.; Wu, H.; Grzybowski, A.; Ye, J. Exploring large language model for next generation of artificial intelligence in ophthalmology. Front. Med. 2023, 10, 1291404. [Google Scholar] [CrossRef]
- Ibrahim, H.; Liu, X.; Rivera, S.C.; Moher, D.; Chan, A.W.; Sydes, M.R.; Calvert, M.J.; Denniston, A.K. Reporting guidelines for clinical trials of artificial intelligence interventions: The SPIRIT-AI and CONSORT-AI guidelines. Trials 2021, 22, 11. [Google Scholar] [CrossRef] [PubMed]
- Arksey, H.; O’Malley, L. Scoping studies: Towards a methodological framework. Int. J. Soc. Res. Methodol. 2005, 8, 19–32. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Lillie, E.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.J.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef] [PubMed]
- Ali, M.J. ChatGPT and Lacrimal Drainage Disorders: Performance and Scope of Improvement. Ophthalmic Plast. Reconstr. Surg. 2023, 39, 221–225. [Google Scholar] [CrossRef]
- Al-Sharif, E.M.; Penteado, R.C.; Dib El Jalbout, N.; Topilow, N.J.; Shoji, M.K.; Kikkawa, D.O.; Liu, C.Y.; Korn, B.S. Evaluating the Accuracy of ChatGPT and Google BARD in Fielding Oculoplastic Patient Queries: A Comparative Study on Artificial versus Human Intelligence. Ophthalmic Plast. Reconstr. Surg. 2024, 40, 303–311. [Google Scholar] [CrossRef]
- Antaki, F.; Milad, D.; Chia, M.A.; Giguère, C.; Touma, S.; El-Khoury, J.; Keane, P.A.; Duval, R. Capabilities of GPT-4 in ophthalmology: An analysis of model entropy and progress towards human-level medical question answering. Br. J. Ophthalmol. 2024, 108, 1371–1378. [Google Scholar] [CrossRef]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef]
- Balas, M.; Janic, A.; Daigle, P.; Nijhawan, N.; Hussain, A.; Gill, H.; Lahaie, G.L.; Belliveau, M.J.; Crawford, S.A.; Arjmand, P.; et al. Evaluating ChatGPT on Orbital and Oculofacial Disorders: Accuracy and Readability Insights. Ophthalmic Plast. Reconstr. Surg. 2024, 40, 217–222. [Google Scholar] [CrossRef]
- Barclay, K.S.; You, J.Y.; Coleman, M.J.; Mathews, P.M.; Ray, V.L.; Riaz, K.M.; De Rojas, J.O.; Wang, A.S.; Watson, S.H.; Koo, E.H.; et al. Quality and Agreement With Scientific Consensus of ChatGPT Information Regarding Corneal Transplantation and Fuchs Dystrophy. Cornea 2024, 43, 746–750. [Google Scholar] [CrossRef]
- Bernstein, I.A.; Zhang, Y.V.; Govil, D.; Majid, I.; Chang, R.T.; Sun, Y.; Shue, A.; Chou, J.C.; Schehlein, E.; Christopher, K.L.; et al. Comparison of Ophthalmologist and Large Language Model Chatbot Responses to Online Patient Eye Care Questions. JAMA Netw. Open 2023, 6, e2330320. [Google Scholar] [CrossRef]
- Biswas, S.; Logan, N.S.; Davies, L.N.; Sheppard, A.L.; Wolffsohn, J.S. Assessing the utility of ChatGPT as an artificial intelligence-based large language model for information to answer questions on myopia. Ophthalmic Physiol. Opt. 2023, 43, 1562–1570. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.Z.; Shaheen, A.; Jin, A.; Fukui, R.; Yi, J.S.; Yannuzzi, N.; Alabiad, C. Performance of Generative Large Language Models on Ophthalmology Board-Style Questions. Am. J. Ophthalmol. 2023, 254, 141–149. [Google Scholar] [CrossRef]
- Cappellani, F.; Card, K.R.; Shields, C.L.; Pulido, J.S.; Haller, J.A. Reliability and accuracy of artificial intelligence ChatGPT in providing information on ophthalmic diseases and management to patients. Eye 2024, 38, 1368–1373. [Google Scholar] [CrossRef] [PubMed]
- Ćirković, A.; Katz, T. Exploring the Potential of ChatGPT-4 in Predicting Refractive Surgery Categorizations: Comparative Study. JMIR Form. Res. 2023, 7, e51798. [Google Scholar] [CrossRef] [PubMed]
- Delsoz, M.; Raja, H.; Madadi, Y.; Tang, A.A.; Wirostko, B.M.; Kahook, M.Y.; Yousefi, S. The Use of ChatGPT to Assist in Diagnosing Glaucoma Based on Clinical Case Reports. Ophthalmol. Ther. 2023, 12, 3121–3132. [Google Scholar] [CrossRef]
- Sensoy, E.; Citirik, M. Assessing the Competence of Artificial Intelligence Programs in Pediatric Ophthalmology and Strabismus and Comparing their Relative Advantages. Rom. J. Ophthalmol. 2023, 67, 389–393. [Google Scholar]
- Eid, K.; Eid, A.; Wang, D.; Raiker, R.S.; Chen, S.; Nguyen, J. Optimizing Ophthalmology Patient Education via ChatBot-Generated Materials: Readability Analysis of AI-Generated Patient Education Materials and The American Society of Ophthalmic Plastic and Reconstructive Surgery Patient Brochures. Ophthalmic Plast. Reconstr. Surg. 2024, 40, 212–216. [Google Scholar] [CrossRef]
- Ferro Desideri, L.; Roth, J.; Zinkernagel, M.; Anguita, R. Application and accuracy of artificial intelligence-derived large language models in patients with age related macular degeneration. Int. J. Retin. Vitr. 2023, 9, 71. [Google Scholar] [CrossRef]
- Fowler, T.; Pullen, S.; Birkett, L. Performance of ChatGPT and Bard on the official part 1 FRCOphth practice questions. Br. J. Ophthalmol. 2024, 108, 1379–1383. [Google Scholar] [CrossRef]
- Haddad, F.; Saade, J.S. Performance of ChatGPT on Ophthalmology-Related Questions Across Various Examination Levels: Observational Study. JMIR Med. Educ. 2024, 10, e50842. [Google Scholar] [CrossRef]
- Hu, W.; Wang, S.Y. Predicting Glaucoma Progression Requiring Surgery Using Clinical Free-Text Notes and Transfer Learning With Transformers. Transl. Vis. Sci. Technol. 2022, 11, 37. [Google Scholar] [CrossRef] [PubMed]
- Hua, H.U.; Kaakour, A.H.; Rachitskaya, A.; Srivastava, S.; Sharma, S.; Mammo, D.A. Evaluation and Comparison of Ophthalmic Scientific Abstracts and References by Current Artificial Intelligence Chatbots. JAMA Ophthalmol. 2023, 141, 819–824. [Google Scholar] [CrossRef] [PubMed]
- Jiao, C.; Edupuganti, N.R.; Patel, P.A.; Bui, T.; Sheth, V. Evaluating the Artificial Intelligence Performance Growth in Ophthalmic Knowledge. Cureus 2023, 15, e45700. [Google Scholar] [CrossRef]
- Kianian, R.; Sun, D.; Crowell, E.L.; Tsui, E. The Use of Large Language Models to Generate Education Materials about Uveitis. Ophthalmol. Retin. 2024, 8, 195–201. [Google Scholar] [CrossRef]
- Kianian, R.; Sun, D.; Giaconi, J. Can ChatGPT Aid Clinicians in Educating Patients on the Surgical Management of Glaucoma? J. Glaucoma 2024, 33, 94–100. [Google Scholar] [CrossRef]
- Lim, Z.W.; Pushpanathan, K.; Yew, S.M.E.; Lai, Y.; Sun, C.H.; Lam, J.S.H.; Chen, D.Z.; Goh, J.H.L.; Tan, M.C.J.; Sheng, B.; et al. Benchmarking large language models’ performances for myopia care: A comparative analysis of ChatGPT-3.5, ChatGPT-4.0, and Google Bard. EBioMedicine 2023, 95, 104770. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Wu, J.; Shao, A.; Shen, W.; Ye, P.; Wang, Y.; Ye, J.; Jin, K.; Yang, J. Uncovering Language Disparity of ChatGPT on Retinal Vascular Disease Classification: Cross-Sectional Study. J. Med. Internet Res. 2024, 26, e51926. [Google Scholar] [CrossRef]
- Lyons, R.J.; Arepalli, S.R.; Fromal, O.; Choi, J.D.; Jain, N. Artificial intelligence chatbot performance in triage of ophthalmic conditions. Can. J. Ophthalmol. 2024, 59, e301–e308. [Google Scholar] [CrossRef]
- Maywood, M.J.; Parikh, R.; Deobhakta, A.; Begaj, T. Performance Assessment of An Artificial Intelligence Chatbot in Clinical Vitreoretinal Scenarios. Retina 2024, 44, 954–964. [Google Scholar] [CrossRef]
- Moshirfar, M.; Altaf, A.W.; Stoakes, I.M.; Tuttle, J.J.; Hoopes, P.C. Artificial Intelligence in Ophthalmology: A Comparative Analysis of GPT-3.5, GPT-4, and Human Expertise in Answering StatPearls Questions. Cureus 2023, 15, e40822. [Google Scholar] [CrossRef]
- Nikdel, M.; Ghadimi, H.; Tavakoli, M.; Suh, D.W. Assessment of the Responses of the Artificial Intelligence-based Chatbot ChatGPT-4 to Frequently Asked Questions About Amblyopia and Childhood Myopia. J. Pediatr. Ophthalmol. Strabismus 2024, 61, 86–89. [Google Scholar] [CrossRef] [PubMed]
- Ong, J.; Kedia, N.; Harihar, S.; Vupparaboina, S.C.; Singh, S.R.; Venkatesh, R.; Vupparaboina, K.; Bollepalli, S.C.; Chhablani, J. Applying large language model artificial intelligence for retina International Classification of Diseases (ICD) coding. J. Med. Artif. Intell. 2023, 6. Available online: https://jmai.amegroups.org/article/view/8198/html (accessed on 25 March 2025). [CrossRef]
- Panthier, C.; Gatinel, D. Success of ChatGPT, an AI language model, in taking the French language version of the European Board of Ophthalmology examination: A novel approach to medical knowledge assessment. J. Fr. Ophtalmol. 2023, 46, 706–711. [Google Scholar] [CrossRef]
- Patil, N.S.; Huang, R.; Mihalache, A.; Kisilevsky, E.; Kwok, J.; Popovic, M.M.; Nassrallah, G.; Chan, C.; Mallipatna, A.; Kertes, P.J.; et al. The Ability of Artificial Intelligence Chatbots Chatgpt and Google Bard to Accurately Convey Preoperative Information for Patients Undergoing Ophthalmic Surgeries. Retina 2024, 44, 950–953. [Google Scholar] [CrossRef]
- Potapenko, I.; Malmqvist, L.; Subhi, Y.; Hamann, S. Artificial Intelligence-Based ChatGPT Responses for Patient Questions on Optic Disc Drusen. Ophthalmol. Ther. 2023, 12, 3109–3119. [Google Scholar] [CrossRef] [PubMed]
- Pushpanathan, K.; Lim, Z.W.; Er Yew, S.M.; Chen, D.Z.; Hui’En Lin, H.A.; Lin Goh, J.H.; Wong, W.M.; Wang, X.; Jin Tan, M.C.; Chang Koh, V.T.; et al. Popular large language model chatbots’ accuracy, comprehensiveness, and self-awareness in answering ocular symptom queries. iScience 2023, 26, 108163. [Google Scholar] [CrossRef]
- Raghu, K.; Tamilselvi, S.; Devishamani, C.S.; Manikandan, S.; Rajalakshmi, R.; Raman, R. The Utility of ChatGPT in Diabetic Retinopathy Risk Assessment: A Comparative Study with Clinical Diagnosis. Clin. Ophthalmol. 2023, 17, 4021–4031. [Google Scholar] [CrossRef]
- Rojas-Carabali, W.; Sen, A.; Agarwal, A.; Tan, G.; Cheung, C.Y.; Rousselot, A.; Agrawal, R.; Liu, R.; Cifuentes-González, C.; Elze, T.; et al. Chatbots Vs. Human Experts: Evaluating Diagnostic Performance of Chatbots in Uveitis and the Perspectives on AI Adoption in Ophthalmology. Ocul. Immunol. Inflamm. 2024, 32, 1591–1598. [Google Scholar] [CrossRef]
- Rojas-Carabali, W.; Cifuentes-González, C.; Wei, X.; Putera, I.; Sen, A.; Thng, Z.X.; Agrawal, R.; Elze, T.; Sobrin, L.; Kempen, J.H.; et al. Evaluating the Diagnostic Accuracy and Management Recommendations of ChatGPT in Uveitis. Ocul. Immunol. Inflamm. 2024, 32, 1526–1531. [Google Scholar] [CrossRef]
- Sakai, D.; Maeda, T.; Ozaki, A.; Kanda, G.N.; Kurimoto, Y.; Takahashi, M. Performance of ChatGPT in Board Examinations for Specialists in the Japanese Ophthalmology Society. Cureus 2023, 15, e49903. [Google Scholar] [CrossRef]
- Sensoy, E.; Citirik, M. A comparative study on the knowledge levels of artificial intelligence programs in diagnosing ophthalmic pathologies and intraocular tumors evaluated their superiority and potential utility. Int. Ophthalmol. 2023, 43, 4905–4909. [Google Scholar] [CrossRef] [PubMed]
- Shemer, A.; Cohen, M.; Altarescu, A.; Atar-Vardi, M.; Hecht, I.; Dubinsky-Pertzov, B.; Shoshany, N.; Zmujack, S.; Or, L.; Einan-Lifshitz, A.; et al. Diagnostic capabilities of ChatGPT in ophthalmology. Graefes Arch. Clin. Exp. Ophthalmol. 2024, 262, 2345–2352. [Google Scholar] [CrossRef]
- Singer, M.B.; Fu, J.J.; Chow, J.; Teng, C.C. Development and Evaluation of Aeyeconsult: A Novel Ophthalmology Chatbot Leveraging Verified Textbook Knowledge and GPT-4. J. Surg. Educ. 2024, 81, 438–443. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Djalilian, A.; Ali, M.J. ChatGPT and Ophthalmology: Exploring Its Potential with Discharge Summaries and Operative Notes. Semin. Ophthalmol. 2023, 38, 503–507. [Google Scholar] [CrossRef]
- Tailor, P.D.; Dalvin, L.A.; Chen, J.J.; Iezzi, R.; Olsen, T.W.; Scruggs, B.A.; Barkmeier, A.J.; Bakri, S.J.; Ryan, E.H.; Tang, P.H.; et al. A Comparative Study of Responses to Retina Questions from Either Experts, Expert-Edited Large Language Models, or Expert-Edited Large Language Models Alone. Ophthalmol. Sci. 2024, 4, 100485. [Google Scholar] [CrossRef]
- Taloni, A.; Borselli, M.; Scarsi, V.; Rossi, C.; Coco, G.; Scorcia, V.; Giannaccare, G. Comparative performance of humans versus GPT-4.0 and GPT-3.5 in the self-assessment program of American Academy of Ophthalmology. Sci. Rep. 2023, 13, 18562. [Google Scholar] [CrossRef]
- Tao, B.K.; Handzic, A.; Hua, N.J.; Vosoughi, A.R.; Margolin, E.A.; Micieli, J.A. Utility of ChatGPT for Automated Creation of Patient Education Handouts: An Application in Neuro-Ophthalmology. J. Neuroophthalmol. 2024, 44, 119–124. [Google Scholar] [CrossRef] [PubMed]
- Teebagy, S.; Colwell, L.; Wood, E.; Yaghy, A.; Faustina, M. Improved Performance of ChatGPT-4 on the OKAP Examination: A Comparative Study with ChatGPT-3.5. J. Acad. Ophthalmol. 2023, 15, e184–e187. [Google Scholar] [CrossRef]
- Wilhelm, T.I.; Roos, J.; Kaczmarczyk, R. Large Language Models for Therapy Recommendations Across 3 Clinical Specialties: Comparative Study. J. Med. Internet Res. 2023, 25, e49324. [Google Scholar] [CrossRef]
- Wu, G.; Lee, D.A.; Zhao, W.; Wong, A.; Sidhu, S. ChatGPT: Is it good for our glaucoma patients? Front. Ophthalmol. 2023, 3, 1260415. [Google Scholar] [CrossRef]
- Yılmaz, I.B.E.; Doğan, L. Talking technology: Exploring chatbots as a tool for cataract patient education. Clin. Exp. Optom. 2025, 108, 56–64. [Google Scholar] [CrossRef] [PubMed]
- Zandi, R.; Fahey, J.D.; Drakopoulos, M.; Bryan, J.M.; Dong, S.; Bryar, P.J.; Bidwell, A.E.; Bowen, R.C.; Lavine, J.A.; Mirza, R.G. Exploring Diagnostic Precision and Triage Proficiency: A Comparative Study of GPT-4 and Bard in Addressing Common Ophthalmic Complaints. Bioengineering 2024, 11, 120. [Google Scholar] [CrossRef] [PubMed]
- Cruz Rivera, S.; Liu, X.; Chan, A.-W.; Denniston, A.K.; Calvert, M.J.; Darzi, A.; Holmes, C.; Yau, C.; Moher, D.; Ashrafian, H.; et al. Guidelines for clinical trial protocols for interventions involving artificial intelligence: The SPIRIT-AI extension. Nat. Med. 2020, 26, 1351–1363. [Google Scholar] [CrossRef]
- Karargyris, A.; Umeton, R.; Sheller, M.J.; Aristizabal, A.; George, J.; Wuest, A.; Pati, S.; Kassem, H.; Zenk, M.; Baid, U.; et al. Federated benchmarking of medical artificial intelligence with MedPerf. Nat. Mach. Intell. 2023, 5, 799–810. [Google Scholar] [CrossRef]
- European Commission: Directorate-General for Communications Networks, Content and Technology. Ethics Guidelines for Trustworthy AI; Publications Office: Luxembourg, 2019. [Google Scholar]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]
- Dam, S.K.; Hong, C.S.; Qiao, Y.; Zhang, C. A Complete Survey on LLM-based AI Chatbots. arXiv 2024, arXiv:2406.16937. [Google Scholar]
- Waisberg, E.; Ong, J.; Masalkhi, M.; Zaman, N.; Sarker, P.; Lee, A.G.; Tavakkoli, A. GPT-4 and medical image analysis: Strengths, weaknesses and future directions. J. Med. Artif. Intell. 2023, 6, 29. [Google Scholar] [CrossRef]
- Eberhard, D.M.; Simons, G.F.; Fennig, C.D. Ethnologue: Languages of the World, 28th ed.; Ethnologue: Dallas, TX, USA, 2025. [Google Scholar]
- Wang, M.Y.; Asanad, S.; Asanad, K.; Karanjia, R.; Sadun, A.A. Value of medical history in ophthalmology: A study of diagnostic accuracy. J. Curr. Ophthalmol. 2018, 30, 359–364. [Google Scholar] [CrossRef] [PubMed]
- Reddy, S. Evaluating large language models for use in healthcare: A framework for translational value assessment. Inform. Med. Unlocked 2023, 41, 101304. [Google Scholar] [CrossRef]
- Park, Y.-J.; Pillai, A.; Deng, J.; Guo, E.; Gupta, M.; Paget, M.; Naugler, C. Assessing the research landscape and clinical utility of large language models: A scoping review. BMC Med. Inform. Decis. Mak. 2024, 24, 72. [Google Scholar] [CrossRef]
- Liu, F.; Li, Z.; Zhou, H.; Yin, Q.; Yang, J.; Tang, X.; Luo, C.; Zeng, M.; Jiang, H.; Gao, Y.; et al. Large Language Models in the Clinic: A Comprehensive Benchmark. arXiv 2024, arXiv:2405.00716. [Google Scholar]
- Mohammadi, I.; Firouzabadi, S.R.; Kohandel Gargari, O.; Habibi, G. Standardized Assessment Framework for Evaluations of Large Language Models in Medicine (SAFE-LLM). Preprints 2025, 2025010471. [Google Scholar]
- Kuş, Z.; Aydin, M. MedSegBench: A comprehensive benchmark for medical image segmentation in diverse data modalities. Sci. Data 2024, 11, 1283. [Google Scholar] [CrossRef]
- Han, T.; Kumar, A.; Agarwal, C.; Lakkaraju, H. MedSafetyBench: Evaluating and Improving the Medical Safety of Large Language Models. arXiv 2024, arXiv:2403.03744. [Google Scholar]
- Privacy Policy. Available online: https://openai.com/policies/row-privacy-policy (accessed on 10 February 2025).
- Ong, J.C.L.; Chang, S.Y.; William, W.; Butte, A.J.; Shah, N.H.; Chew, L.S.T.; Liu, N.; Doshi-Velez, F.; Lu, W.; Savulescu, J.; et al. Ethical and regulatory challenges of large language models in medicine. Lancet Digit. Health 2024, 6, e428–e432. [Google Scholar] [CrossRef] [PubMed]
- Mugaanyi, J.; Cai, L.; Cheng, S.; Lu, C.; Huang, J. Evaluation of Large Language Model Performance and Reliability for Citations and References in Scholarly Writing: Cross-Disciplinary Study. J. Med. Internet Res. 2024, 26, e52935. [Google Scholar] [CrossRef] [PubMed]
- Patil, R.; Heston, T.F.; Bhuse, V. Prompt Engineering in Healthcare. Electronics 2024, 13, 2961. [Google Scholar] [CrossRef]
- Schillinger, D. Social Determinants, Health Literacy, and Disparities: Intersections and Controversies. Health Lit. Res. Pract. 2021, 5, e234–e243. [Google Scholar] [CrossRef]
- Al Ghadban, Y.; Lu, H.; Adavi, U.; Sharma, A.; Gara, S.; Das, N.; Kumar, B.; John, R.; Devarsetty, P.; Hirst, J.E. Transforming Healthcare Education: Harnessing Large Language Models for Frontline Health Worker Capacity Building using Retrieval-Augmented Generation. medRxiv 2023. [Google Scholar] [CrossRef]
- Wang, X.; Chen, N.; Chen, J.; Wang, Y.; Zhen, G.; Zhang, C.; Wu, X.; Hu, Y.; Gao, A.; Wan, X.; et al. Apollo: A Lightweight Multilingual Medical LLM towards Democratizing Medical AI to 6B People. arXiv 2024, arXiv:2403.03640. [Google Scholar]
- Huang, Z.; Zhu, W.; Cheng, G.; Li, L.; Yuan, F. MindMerger: Efficient Boosting LLM Reasoning in non-English Languages. arXiv 2024, arXiv:2405.17386. [Google Scholar]
- Peters, M.D.J.; Marnie, C.; Colquhoun, H.; Garritty, C.M.; Hempel, S.; Horsley, T.; Langlois, E.V.; Lillie, E.; O’Brien, K.K.; Tunçalp, Ö. Scoping reviews: Reinforcing and advancing the methodology and application. Syst. Rev. 2021, 10, 263. [Google Scholar] [CrossRef] [PubMed]
- Institute of Medicine (US) Committee on Standards for Systematic Reviews of Comparative Effectiveness Research. Finding What Works in Health Care: Standards for Systematic Reviews; Eden, J., Levit, L., Berg, A., Morton, S., Eds.; National Academies Press: Washington, DC, USA, 2011. [Google Scholar]
- Levac, D.; Colquhoun, H.; O’Brien, K.K. Scoping studies: Advancing the methodology. Implement. Sci. 2010, 5, 69. [Google Scholar] [CrossRef] [PubMed]
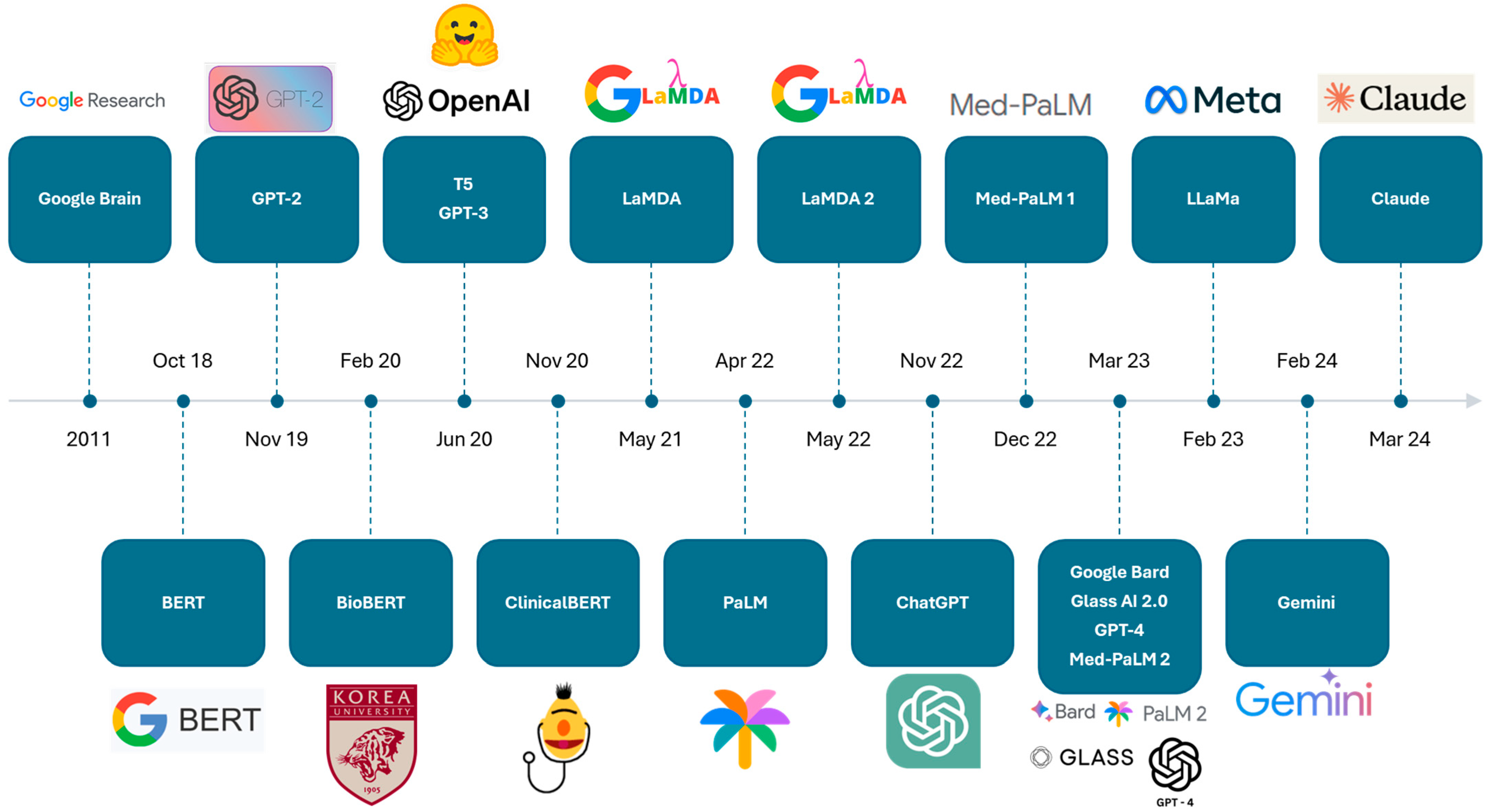
| Study | Clinical Application | LLM |
|---|---|---|
| SINGH 2023 [55] | Administrative | GPT 3.5 |
| BARCLAY 2023 [20] | Clinical Knowledge | GPT 3.5, GPT 4 |
| ROJAS-CARABALI (1) 2023 [49] | Diagnostic | GPT 3.5, GPT 4.0. Glass 1.0 |
| ALI 2023 [15] | Diagnostic | GPT 3.5 |
| SHEMER 2024 [53] | Diagnostic | GPT 3.5 |
| ROJAS-CARABALI (2) 2023 [50] | Diagnostic | GPT 3.5, GPT 4 |
| DELSOZ 2023 [26] | Diagnostic | GPT 3.5 |
| SENSOY 2023 (1) [27] | Exam Taking | GPT 3.5, Bing, Bard |
| MOSHIRFAR 2023 [41] | Exam Taking | GPT 3.5, GPT 4 |
| SENSOY 2023 (2) [52] | Exam Taking | GPT 3.5, Bing, Bard |
| ANTAKI 2023 (1) [17] | Exam Taking | GPT 3.5, GPT 4 |
| TALONI 2023 [57] | Exam Taking | GPT 3.5, GPT 4 |
| SINGER 2023 [54] | Exam Taking | Aeyeconsult, GPT 4 |
| JIAO 2023 [34] | Exam Taking | GPT 3.5, GPT 4 |
| ANTAKI 2023 (2) [18] | Exam Taking | ChatGPT legacy and ChatGPT Plus |
| TEEBAGY 2023 [59] | Exam Taking | GPT 3.5, GPT 4 |
| FOWLER 2023 [30] | Exam Taking | GPT 4, Bard |
| SAKAI 2023 [51] | Exam Taking | GPT 3.5, GPT 4 |
| HADDAD 2024 [31] | Exam Taking | GPT 3.5, GPT 4 |
| CAI 2023 [23] | Exam Taking | GPT 3.5, GPT 4, Bing Chat |
| PANTHIER 2023 [44] | Exam Taking | GPT 4 |
| HUA 2023 [33] | Manuscript Writing | GPT 3.5, GPT 4 |
| TAILOR 2024 [56] | Patient Education | GPT 3.5, GPT 4, Claude 2, Bing, Bard |
| FERRO DESIDERI 2023 [29] | Patient Education | GPT 3.5, Bard, Bing Chat |
| POTAPENKO 2023 [46] | Patient Education | GPT 4 |
| BISWAS 2023 [22] | Patient Education | GPT 3.5 |
| NIKDEL 2023 [42] | Patient Education | GPT 4 |
| LIM 2023 [37] | Patient Education | GPT 3.5, GPT 4, Bard |
| KIANIAN 2023 (1) [36] | Patient Education | GPT 3.5 |
| WU 2023 [61] | Patient Education | GPT 3.5 |
| BERNSTEIN 2023 [21] | Patient Education | GPT 3.5 |
| BALAS 2024 [19] | Patient Education | GPT 4 |
| AL-SHARIF 2024 [16] | Patient Education | GPT 3.5, Bard |
| ZANDI 2024 [63] | Patient Education | GPT 4, Bard |
| EID 2023 [28] | Patient Education | GPT 4.0, Bard |
| PUSHPANATHAN 2023 [47] | Patient Education | GPT 3.5, GPT 4, Bard |
| CAPPELLANI 2024 [24] | Patient Education | GPT 3.5 |
| YILMAZ 2024 [62] | Patient Education | GPT 3.5, Bard, Bing AI, AAO website |
| PATIL 2024 [45] | Patient Education | GPT 4, Bard |
| KIANIAN 2023 (2) [35] | Patient Education | GPT 4, Bard |
| LIU 2024 [38] | Patient Education | GPT 3.5 |
| TAO 2024 [58] | Patient Education | GPT 3.5 |
| WILHELM 2023 [60] | Patient Management | GPT 3.5 Turbo, Command-xlarge-nightly, Claude, Bloomz |
| MAYWOOD 2024 [40] | Patient Management | GPT 3.5 Turbo |
| CIRKOVIC 2023 [25] | Prognostication | GPT 4 |
| HU 2022 [32] | Prognostication | BERT, RoBerta, DistilBert, BioBERT |
| RAGHU 2023 [48] | Prognostication | GPT 4 |
| ONG 2023 [43] | Text interpretation | GPT 3.5 |
| LYONS 2023 [39] | Triage | GPT 4, Bing Chat, WebMD |
| Study | Usage of a Research Protocol for AI | Ethical/Safety Safeguards Considered in Methodology | Ethics in Discussion | Prompt Techniques Employed | Prompt Examples Shared | Benchmarks on Correctness | Benchmarks on Harm |
|---|---|---|---|---|---|---|---|
| TAILOR 2024 [56] | No | Yes | Yes | Zero-shot (no prior context) | Yes | Human | Human |
| SENSOY 2023 (1) [27] | No | No | No | Zero-shot | No | Automated (Exact match) | Nil |
| FERRO DESIDERI 2023 [29] | No | No | No | Zero-shot | Yes | Human | Nil |
| ONG 2023 [43] | No | No | Yes | Zero-shot | Yes | Automated (Exact match) | Nil |
| LYONS 2023 [39] | No | No | Yes | Zero-shot | Yes | Human | Nil |
| MOSHIRFAR 2023 [41] | No | No | No | Zero-shot | Yes | Automated (Exact match) | Nil |
| POTAPENKO 2023 [46] | No | No | No | Zero-shot | Yes | Human | Nil |
| SENSOY 2023 (2) [52] | No | No | No | Zero-shot | No | Automated (Exact match) | Nil |
| BISWAS 2023 [22] | No | No | No | Zero-shot | Yes | Human | Nil |
| NIKDEL 2023 [42] | No | No | No | Zero-shot, Prompt Chaining | Yes | Human | Nil |
| LIM 2023 [37] | No | No | Yes | Zero-shot, Iterative Prompting | Yes | Human | Nil |
| KIANIAN 2023 (1) [36] | No | No | No (safety but not ethics) | One-shot, Few-shot | Yes | Automated and Human | Nil |
| ANTAKI 2023 (1) [17] | No | No | No (safety but not ethics) | Zero-shot | Yes | Human | Nil |
| ROJAS-CARABALI (1) 2023 [49] | No | No | No (safety but not ethics) | Zero-shot | Yes | Automated (Exact match) and Human | Nil |
| ALI 2023 [15] | No | No | No | Zero-shot | Yes | Human | Nil |
| SINGH 2023 [55] | No | No | No | Contextual Priming | Yes | Human | Nil |
| WU 2023 [61] | No | No | No | Zero-shot | Yes | Automated (Exact match, Readability) | Nil |
| TALONI 2023 [57] | No | No | No | Zero-shot | No | Automated (Exact match) | Nil |
| BERNSTEIN 2023 [21] | No | Yes | Yes | Zero-shot | Yes | Human | Human |
| SINGER 2023 [54] | No | No | No (safety but not ethics) | Zero-shot | No | Automated (Exact match) | Nil |
| SHEMER 2024 [53] | No | Yes | No | Zero-shot | Yes | Automated (Exact match) | Nil |
| BALAS 2023 [19] | No | No | No | Zero-shot | No | Human | Nil |
| AL-SHARIF 2024 [16] | No | No | Yes | Zero-shot | Yes | Human | Nil |
| JIAO 2023 [34] | No | No | Yes | Zero-shot | Yes | Automated (Exact match) | Nil |
| ROJAS-CARABALI (2) 2023 [50] | No | No | No | Zero-shot | Yes | Automated (Exact match) | Nil |
| ANTAKI 2023 (2) [18] | No | No | No (safety but not ethics) | Zero-shot | No | Automated (Exact match) | Nil |
| HUA 2023 [33] | No | No | Yes | Zero-shot | No | Human | Nil |
| ZANDI 2024 [63] | No | Yes | No (safety but not ethics) | Zero-shot | No | Human | Human |
| CIRKOVIC 2023 [25] | No | No? | No | Zero-shot | No | Automated (Exact match and F1-score) | Nil |
| TEEBAGY 2023 [59] | No | No | No | Zero-shot | No | Automated (Exact match) | Nil |
| WILHELM 2023 [60] | No | Yes | No (safety but not ethics) | Zero-shot | No | Automated and Human | Automated and Human |
| EID 2023 [28] | No | No | No | Zero-shot | Yes | Automated (readability) | Nil |
| MAYWOOD 2024 [40] | No | Yes | No (safety but not ethics) | Zero-shot | Yes | Human | Human |
| FOWLER 2023 [30] | No | No | No | Zero-shot | No | Automated (Exact match) | Nil |
| SAKAI 2023 [51] | No | No | No | Zero shot, Few-shot | Yes | Automated (Exact match) | Nil |
| HADDAD 2024 [31] | No | No | No | Zero-shot | Yes | Automated (Exact match) | Nil |
| CAI 2023 [23] | No | No | No (safety but not ethics) | Zero-shot | Yes | Automated (Exact match) | Nil |
| PUSHPANATHAN 2023 [47] | No | No | No (safety but not ethics) | Zero-shot | Yes | Automated (Exact match) | Nil |
| HU 2022 [32] | No | No | No | Zero-shot | Yes | Automated (Exact match, F1 score) | Nil |
| BARCLAY 2023 [20] | No | Yes | No (safety but not ethics) | Zero-shot | Yes | Human | Human |
| CAPPELLANI 2024 [24] | No | Yes | No (safety but not ethics) | Zero-shot | Yes | Human | Human |
| PANTHIER 2023 [44] | No | No | No | Zero-shot | Yes | Automated (Exact match) | Nil |
| YILMAZ 2024 [62] | No | No | No (safety but not ethics) | Zero-shot | Yes | Automated | Nil |
| PATIL 2024 [45] | No | No | Yes | Zero-shot | Yes | Human | Human |
| DELSOZ 2023 [26] | No | No | No | Zero-shot | Yes | Human | Nil |
| KIANIAN 2023 (2) [35] | No | No | Yes | Zero-shot | Yes | Automated (readability) | Nil |
| RAGHU 2023 [48] | No | No | Yes | Zero-shot | Yes | Human | Nil |
| LIU 2024 [38] | No | No | No | Zero-shot, Chain-of-thought (inspired) | Yes | Automated | Nil |
| TAO 2024 [58] | No | Yes | Yes | Zero-shot | Yes | Human | Human |
| (a) | |||||
|---|---|---|---|---|---|
| Study | Setting | Scoring System | Result | ||
| BARCLAY 2023 [20] | Clinical Knowledge | 5 Point Scale | GPT 4 > GPT 3.5 | ||
| ROJAS-CARABALI (1) 2023 [49] | Diagnostic | Correct or Incorrect | Experts > GPT 4 = GPT 3.5 > Glass 1.0 | ||
| ROJAS-CARABALI (2) 2023 [50] | Diagnostic | Correct or Incorrect | Ophthalmologist > AI | ||
| SINGER 2023 [54] | Exam Taking | Correct or Incorrect | Aeyeconsult > GPT 4 | ||
| ANTAKI 2023 (2) [18] | Exam Taking | Correct or Incorrect | Plus > Legacy | ||
| SENSOY 2023 (1) [27] | Exam Taking | Correct or Incorrect | Bard > Bing > GPT 3.5 | ||
| SENSOY 2023 (2) [52] | Exam Taking | Correct, Incorrect or Unable to Answer | Bard > Bing > GPT 3.5 | ||
| MOSHIRFAR 2023 [41] | Exam Taking | Correct or Incorrect | GPT 4 > humans > GPT 3.5 | ||
| ANTAKI 2023 (1) [17] | Exam Taking | Correct or Incorrect | GPT 4-0.3 > GPT 4-0.7 > GPT 4-1 = GPT 4-0 > GPT 3.5 | ||
| TALONI 2023 [57] | Exam Taking | Correct or Incorrect | GPT 4 > Humans > GPT 3.5 | ||
| JIAO 2023 [34] | Exam Taking | Correct or Incorrect | GPT 4 > GPT 3.5 | ||
| TEEBAGY 2023 [59] | Exam Taking | Correct or Incorrect | GPT 4 > GPT 3.5 | ||
| SAKAI 2023 [51] | Exam Taking | Correct or Incorrect | Humans > GPT 4 > GPT 3.5 | ||
| HADDAD 2024 [31] | Exam Taking | Correct or Incorrect | GPT 4 > GPT 3.5 | ||
| CAI 2023 [23] | Exam Taking | Correct or Incorrect | Humans > GPT 4 = Bing > GPT 3.5 | ||
| FOWLER 2023 [30] | Exam Taking | Correct or Incorrect | GPT 4 > Bard | ||
| YILMAZ 2024 [62] | Patient Education | SOLO score | ChatGPT > Bard > Bing > AAO | ||
| PUSHPANATHAN 2023 [47] | Patient Education | 5 Point Scale | GPT 4 > GPT 3.5 > Bard | ||
| AL-SHARIF 2024 [16] | Patient Education | 4 Point Scale | GPT 3.5 > Bard | ||
| FERRO DESIDERI 2023 [29] | Patient Education | 3 Point Scale | GPT 3.5 > Bard = Bing | ||
| TAILOR 2024 [56] | Patient Education | 5 Point Scale | Expert + AI > GPT 3.5 > GPT 4> Expert only > Claude > Bard > Bing | ||
| LIM 2023 [37] | Patient Education | 3 Point Scale | GPT 4 > GPT 3.5 > Bard | ||
| ZANDI 2024 [63] | Patient Education | Correct or Incorrect | GPT 4 > Bard | ||
| PATIL 2024 [45] | Patient Education | 5 Point Scale | ChatGPT > Bard | ||
| WILHELM 2023 [60] | Patient Management | mDISCERN | Claude-instant-v1.0 > GPT 3.5-Turbo > Command-xlarge-nightly > Bloomz | ||
| HU 2022 [32] | Prognostication | AUROC, F1 | BERT > RoBERTa > DistilBERT > BioBert > Humans | ||
| LYONS 2023 [39] | Triage | 5 Point Scale | Ophthalmologists in training > chatGPT > Bing Chat > WebMD | ||
| (b) | |||||
| Study | LLMS | Setting | Scoring System | Result | |
| ALI 2023 [15] | GPT 3.5 | Diagnostic | 3 Point Scale | 40% correct 35% partially correct 25% outright incorrect | |
| SHEMER 2024 [53] | GPT 3.5 | Diagnostic | Correct or Incorrect | Residents > Attendings > GPT 3.5 | |
| DELSOZ 2023 [26] | GPT 3.5 | Diagnostic | Correct or Incorrect | ChatGPT performed similarly to 2 of 3 residents and better than 1 resident | |
| PANTHIER 2023 [44] | GPT 4 | Exam Taking | Correct or Incorrect | 6188/6785 correct | |
| BISWAS 2023 [22] | GPT 3.5 | Patient Education | 5 Point Scale | 66/275 responses rated as very good 134/275 responses rated as good 60/275 acceptable 10/275 poor 5/275 very poor | |
| BERNSTEIN 2023 [21] | GPT 3.5 | Patient Education | Comparison to humans | GPT 3.5 = Humans | |
| CAPPELLANI 2024 [24] | GPT 3.5 | Patient Education | 5 Point Scale | 93 responses scored ≥ 1 27 responses scored ≤ −1 9 responses scored −3 | |
| LIU 2024 [38] | GPT 3.5 | Patient Education | Correct or Incorrect | Ophthalmology Attendings > Ophthalmology Interns > English Prompt > Chinese Prompting of ChatGPT | |
| TAO 2024 [58] | GPT 3.5 | Patient Education | 4 Point Scale | 2.43 95% CI 1.21, 3.65 | |
| POTAPENKO 2023 [46] | GPT 4 | Patient Education | Correct or Incorrect | 17/100 responses were relevant without inaccuracies 78/100 relevant with inaccuracies that were not harmful 5/100 relevant with inaccuracies potentially harmful | |
| NIKDEL 2023 [42] | GPT 4 | Patient Education | 3 Point Scale | 93/110 acceptable | |
| BALAS 2024 [19] | GPT 4 | Patient Education | 7 Point Scale | 43/100 scored 6 53/100 scored 5 3/100 scored 4 1/100 scored 3 | |
| MAYWOOD 2024 [40] | GPT 3.5 Turbo | Patient Management | Correct or Incorrect | 33/40 correct 21/40 comprehensive | |
| CIRKOVIC 2023 [25] | GPT 4 | Prognostication | Cohens Kappa | 6 categories: k = 0.399 2 categories: k = 0.610 | |
| RAGHU 2023 [48] | GPT 4 | Prognostication | Cohens Kappa | With central subfield thickness: k = 0.263 Without central subfield thickness: k = 0.351 | |
| ONG 2023 [43] | GPT 3.5 | Text interpretation | Correct: producing at least one correct ICD code Correct only: only the correct ICD code Incorrect: not generating any | Correct: 137/181 Correct only: 106/181 Incorrect: 54/181 | |
| Study | Setting | Results |
|---|---|---|
| ROJAS-CARABALI (1) 2023 [49] | Diagnostic | Humans > GPT 4 > Glass |
| SHEMER 2024 [53] | Diagnostic | Humans > GPT 3.5 |
| ROJAS-CARABALI (2) 2023 [50] | Diagnostic | Humans > GPT-3.5 and 4 (collectively) |
| DELSOZ 2023 [26] | Diagnostic | Humans = GPT 3.5 |
| MOSHIRFAR 2023 [41] | Exam Taking | GPT 4 > Humans > GPT 3.5 |
| ANTAKI 2023 (1) [17] | Exam Taking | GPT 4 > Humans |
| TALONI 2023 [57] | Exam Taking | GPT 4 > Humans > GPT 3.5 |
| FOWLER 2023 [30] | Exam Taking | GPT 4 > Humans > Bard |
| SAKAI 2023 [51] | Exam Taking | Humans > GPT 4 > GPT 3.5 |
| HADDAD 2024 [31] | Exam Taking | Humans > GPT 4 > GPT 3.5 |
| CAI 2023 [23] | Exam Taking | Humans > GPT 4 > Bing > GPT 3.5 |
| TAILOR 2024 [56] | Patient Education | Quality: Expert + AI = GPT 3.5 = GPT 4 > Expert > Claude > Bard > Bing Empathy: GPT 3.5 = Expert + AI = GPT 4 > Bard > Claude > Expert > Bing |
| BERNSTEIN 2023 [21] | Patient Education | GPT 3.5 = Humans |
| LIU 2024 [38] | Patient Education | Humans > GPT 3.5 |
| CIRKOVIC 2023 [25] | Prognostication | Humans = GPT 4 |
| LYONS 2023 [39] | Triage | Human > GPT 4 > Bing > WebMD Symptom Checker |
| Study | Moshirfar 2023 [41] | Taloni 2023 [57] | Singer 2023 [54] | Jiao 2023 [34] | Antaki 2023 (1) [17] | Antaki 2023 (2) [18] | Teebagy 2023 [59] | Sakai 2023 [51] | Haddad 2024 [31] | Cai 2023 [23] | Patil 2024 [45] |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Clinical application | Exam Taking | Exam Taking | Exam Taking | Exam Taking | Exam Taking | Exam Taking | Exam Taking | Exam Taking | Exam Taking | Exam Taking | Patient Education |
| LLMs |  , ,  | , | ,  | , |  , ,  , ,  , ,  , , |  , ,  | , | , ,  | , | , ,  | ,  |
| Overall | (73%) >  (58%) (58%) > (55%) | (82.4%) > (75.7%) > (65.9%) | (83.4%) > (69.2%) | (75%) > (46%) | (72.9%) > (68.2%)> (54.6%) | (54.3%) > (49.3%) | (81%) > (57%) | (65.7%) > (46.2%) > (45.8%) > (22.4%) | (70–75%) > (70%) > (55%) | (72.2%) > (71.6%) > (71.2%) > (58.8%) | - |
| Cornea | > = | = = | = | = | > = > > | > | > | > > | = | > > > | > |
| Glaucoma | > = | > > | > | = | > = = > | > | > | > > | = | > = > | - |
| Neuro- Ophthalmology | > > | = > | > | > | = = > > | > | > | > > | = | > > > | - |
| Uveitis | > = | > = | > | > | = = = > | > (BSCS) > (Ophtho-Q) | > | > > | - | > = > | - |
| Lens and Cataract | = = | = > | > | - | = > = > | > (BCSC) > (Ophtho -Q) | > | > > * | > | = > > | > |
| Paediatrics-Strabismus | > = | = > | > | = | = = = > | > (BCSC) > (Ophtho-Q) | > | > > | = | > > > | > |
| Retina &Vitreous | = = | = = | > | = | > > = > | > | > | = > | = @ | > > > | > |
| Oculoplastics | > = | > = | > | > | = > = > | > | > | > > + | = | > > > | > |
| Optics | > = | - | > | - | > > > > | > (BCSC) > (Ophtho-Q) | > | - | = # | > = > | - |
| Refractive Surgery | > = | > > | > | > | > = > > | = | > | > > * | = # | - | > |
| Pathology | > = | = = | > | > | = = > > | > | > | > > + | = @ | - | - |
Human; GPT-4; GPT-3.5; Aeyconsult; Bing; Bard; ChatGPT Legacy; ChatGPT Plus; GPT 4-0; GPT 4-0.3; GPT 4-0.7; GPT 4-1; GPT 4 (refined).| Study | LLMS | Scoring Systems | Ranking by Readability |
|---|---|---|---|
| EID 2023 [28] | GPT 4, Bard | FKRE, FKGL, GFI, CLI, SMOG Automated readability Index, Linsear write readability score | FKRE: GPT 4 > Bard > ASOPRS resource FKGL: GPT 4 > Bard > ASOPRS resource GFI: GPT 4 > Bard > ASOPRS resource SMOG: GPT 4 > Bard > ASOPRS resource CLI: GPT 4 > Bard > ASOPRS resource ARI: GPT 4 = Bard > ASOPRS resource LWRS: Bard > GPT 4 > ASOPRS resource |
| * only LLM scores after fine-tuning to 6th-grade reading level included | |||
| KIANIAN (1) 2023 [36] | GPT 3.5 | FKRE, FKGL, GFI, SMOG | GPT > online resources in all scoring systems |
| KIANIAN (2) 2023 [35] | GPT 3.5, Bard | FKGL | GPT > Bard |
| WU [61] | GPT 3.5 | FKGL, GFI, SMOG, Dale-Chall-Score | AAO resource > GPT in all scoring systems |
| Study | LLMS | Evaluated Data | # Of Questions/Cases | Diagnostic Accuracy Rate |
|---|---|---|---|---|
| RAGHU 2023 [48] | GPT 4 | Clinical, biochemical and ocular data | 111 | 65.6% of answers consistent with ophthalmologist on average |
| LIU 2024 [38] | GPT 3.5 | FFA reports | 1226 | Ophthalmologists (89.35%) > Ophthalmologist interns (82.69%) > GPT 3.5-english prompts (80.05%) > ChatGPT 3.5-Chinese prompts (70.47%) |
| LYONS 2023 [39] | GPT 4, Bing Chat, WebMD | History only | 44 | Ophthalmologists in training (95%) > GPT 4 (93%) > Bing Chat (77%) > WebMD (33%) |
| ZANDI 2024 [63] | GPT 4, Bard | History only | 80 | GPT 4 (53.75%) > Bard (43.75%) |
| SHEMER 2024 [53] | GPT 3.5 | History only | 126 | Residents (75%) > Attendings (71%) > GPT 3.5 (54%) |
| LIM 2023 [37] | GPT 3.5, GPT 4, Bard | History only | 2 | GPT 4 (100%) = GPT 3.5 (100%) > Bard (50%) |
| ROJAS-CARABALI (1) 2023 [49] | GPT 3.5, GPT 4.0. Glass 1.0 | History and examination findings | 25 | Uveitis specialists (mean = 79%) > Fellow (76%) > GPT 4 (60%) = GPT 3.5 (60%) |
| DELSOZ 2023 [26] | GPT 3.5 | History and examination findings | 11 | GPT 3.5 (72.7%) > Ophthalmology trainees (mean = 66.6%) |
| ROJAS-CARABALI (2) 2023 [50] | GPT 3.5, GPT 4 | History, examination findings and Images | 6 | Experts (100%) > GPT 4 (50%) = GPT 3.5 (50%) > Glass 1.0 (33%) |
| TALONI 2023 [57] | GPT 3.5, GPT 4 | Question banks | 646 | GPT 4 (83.7%) > Humans (mean = 75.4%) > GPT 3.5 (68.1%) |
| CAI 2023 [23] | GPT 3.5, GPT 4, Bing Chat | Question banks | 250 | Humans (73.8%) > Bing (60.9%) > GPT 4 (59.4%) > GPT 3.5 (46.4%) |
| Study | LLMS | Management Scores |
|---|---|---|
| BISWAS 2023 [22] | GPT 3.5 | Median score on management questions = 4.0, based on Likert scale (1: very poor; 2: poor; 3: acceptable; 4: good; 5: very good) |
| LIM 2023 [37] | GPT 3.5, GPT 4, Bard | Good management: GPT 4.0 (70%) > Bard (45%) > GPT 3.5 (40%) Borderline management: Bard (40%) > GPT 3.5 (35%) > GPT 4.0 (15%) Poor management: GPT 3.5 (25%) > Bard (15%) = GPT 4.0 (15%) |
| TALONI 2023 [57] | GPT 3.5, GPT 4 | Medical management: GPT 4 (83.4%) > Humans (76.9%) > GPT 3.5 (65.1%) Surgical management: Humans (74.7%) > GPT 4 (74.6%) > GPT 3.5 (57.0%) |
| AL-SHARIF 2024 [16] | GPT 3.5, Bard | Comprehensive management: GPT 3.5 (71.4%) > Bard (53.1%) |
| ROJAS-CARABALI (2) 2023 [50] | GPT 3.5, GPT 4 | Management and treatment plans consistent with the majority of ophthalmologists in all cases |
| CAI 2023 [23] | GPT 3.5, GPT 4, Bing Chat | GPT 4.0 (77.0%) > Humans (76.1%) > Bing (75.4%) > GPT 3.5 (58.3%) |
| CAPPELLANI 2024 [24] | GPT 3.5 | Management scores by subspecialty: General (2); Anterior segment and cornea (2); Glaucoma (−1); Neuro-Ophthalmology (2); Oncology (1); Pediatrics (1); Oculoplastics (2); Retina and Uveitis (1); Overall median score 1 |
| based on Likert scale (−3: Potentially dangerous, −2: Very poor, −1: Poor, 1: Good, 0: No response, 1: Good, 2: Very good, 2 *: Excellent) |
| Study | LLMS | Clinical Administrative Task | Performance |
|---|---|---|---|
| SINGH 2023 [55] | GPT 3.5 | Discharge Summary and Operative Notes Writing | Only qualitative description of output provided: 1. Discharge Summaries were noted to have valid but very generic output, that upon further prompting, was able to improve in specificity and detail. 2. Operative Notes were noted to have levels of inaccuracies and hallucinations which could be corrected upon further prompting. |
| HUA 2023 [33] | GPT 3.5, GPT 4 | Research Manuscript Writing | GPT 4 > GPT 3.5 in helpfulness scores, truthfulness scores, harmlessness scores, and the Modified AI-DISCERN score. |
| GPT 3.5 > GPT 4 in hallucination rates, Mean Sapling AI Detector Fake score, and Mean GPT-2 Output Detector Fake score. | |||
| ONG 2023 [43] | GPT 3.5 | Retinal ICD Scoring | Only correct ICD codes generated: 59% At least one correct ICD code generated: 70% No correct ICD codes generated: 30% |
| Study | LLMS | Evaluation | Results |
|---|---|---|---|
| MULTIPLE LLMS: | |||
| TAILOR 2024 [56] | GPT 3.5, GPT 4, Claude 2, Bing, Bard | Degree of inaccuracy or correctness | Inaccuracies with great clinical significance: Bard > Bing > Claude > GPT 3.5 > GPT 4 > GPT 4 + Expert > Expert. |
| AL-SHARIF 2024 [16] | GPT 3.5, Bard | Degree of accuracy | Completely inaccurate answers: Bard (10.5%) > GPT 3.5 (5.1%) Partially inaccurate answers: Bard (18.1%) > GPT 3.5 (10.5%) |
| FERRO DESIDERI 2023 [29] | GPT 3.5, Bard, Bing Chat | Degree of accuracy | Inaccurate and insufficient answers: Bard (13.3%) > Bing (6.7%) > GPT 3.5 (0.0%) |
| YILMAZ 2024 [62] | GPT 3.5, Bard, Bing AI, AAO website | Degree of accuracy | Accuracy (mean SOLO taxonomy score *): GPT 3.5 (3.1 ± 0.31) > Bard (2.9 ± 0.72) > Bing (2.65 ± 0.49) > AAO (2.4 ± 0.6) * SOLO = Structure of Observed Learning Outcome |
| BARCLAY 2023 [20] | GPT 3.5, GPT 4 | Degree of inaccuracy | Incorrect facts, little significance: GPT 3.5 (39%) > GPT 4 (22%) Incorrect facts, great significance: GPT 3.5 (38%) > GPT 4 (8%) |
| LIM 2023 [37] | GPT 3.5, GPT 4, Bard | Degree of accuracy | Total accuracy score: GPT 4 (8.19) > GPT 3.5 (7.35) > Bard (7.13) |
| PUSHPANATHAN 2023 [47] | GPT 3.5, GPT 4, Bard | Degree of accuracy | Significant inaccuracies: Bard (13.5%) > GPT 3.5% (5.4%) > GPT 4 (0%) |
| LYONS 2023 [39] | GPT 4, Bing Chat, WebMD Symptom Checker | Degree of inaccuracy | Grossly inaccurate statements: WebMD (50%) > Bing (14%) > GPT 4 (0%) |
| WILHELM 2023 [60] | GPT 3.5 Turbo, Command-xlarge-nightly, Claude-instant-v1, Bloomz | Degree of falseness | Falseness: Claude-instant-v1.0 (51.7%) > Command-xlarge-nightly (16.7%) > Bloomz (15%) > GPT 3.5 Turbo (11.7%) |
| HUA 2023 [33] | GPT 3.5, GPT 4 | Hallucination frequency | Mean hallucination rate: GPT 3.5 (0.31) > GPT 4 (0.29) |
| CAI 2023 [23] | GPT 3.5, GPT 4, Bing Chat | Hallucination frequency | Hallucinations: GPT 3.5 (42.4%) > Bing (25.6%) > GPT 4 (18%) |
| SINGLE LLM: | |||
| ALI 2023 [15] | GPT 3.5 | Degree of correctness | Partially incorrect answers: 35% Completely incorrect answers: 25% |
| CAPPELLANI 2024 [24] | GPT 3.5 | Degree of correctness | Incorrect answers 22.5% |
| NIKDEL 2023 [42] | GPT 4 | Degree of appropriateness | Inappropriate response rate: Amblyopia questions: 5.6% Childhood myopia questions: 5.4% |
| BALAS 2024 [19] | GPT 4 | Degree of appropriateness | No inappropriate responses |
| BERNSTEIN 2023 [21] | GPT 3.5 | Degree of inappropriateness | Rate of incorrect or inappropriate answers, (a) With little clinical significance: Human (19.1%) > GPT 3.5 (18%) (b) With great clinical significance: Human (5.5%) > GPT 3.5 (4.6%) |
| BISWAS 2023 [22] | GPT 3.5 | Degree of inaccuracy | Inaccurate answers: 3.6% Very inaccurate answers: 1.8% |
| POTAPENKO 2023 [46] | GPT 4 | Degree of inaccuracy | Rate of major inaccuracies: 5% |
| LIU 2024 [38] | GPT 3.5 | Hallucination frequency | Hallucination: Chinese prompts (5.88%) > English prompts (0.59%) Misinformation: Chinese prompts (7.84%) > English prompts (1.96%) |
| MAYWOOD 2024 [40] | GPT 3.5 Turbo | Hallucination frequency | Hallucination rate: 30% |
| Study | LLMS | Extent of Harm in Output | Measure of Harm |
|---|---|---|---|
| BERNSTEIN 2023 [21] | GPT 3.5 | GPT 3.5 = Humans | Likert scales on likelihood and extent of harm |
| CAPPELLANI 2024 [24] | GPT 3.5 | 7.5% responses harmful | Likert scales on potential harm |
| MAYWOOD 2024 [40] | GPT 3.5 Turbo | 50% possible harm, 33.3% definitive harm | Likert scale on harm |
| WILHELM 2023 [60] | GPT 3.5 Turbo, Command-xlarge-nightly, Claude, Bloomz | Claude > Bloomz > Command-xlarge-nightly > GPT 3.5-turbo | Binary variable (presence or absence of harm) |
| HUA 2023 [33] | GPT 3.5, GPT 4 | GPT 3.5 > GPT 4 | Modified AI-DISCERN Criteria |
| BARCLAY 2023 [20] | GPT 3.5, GPT 4 | GPT 3.5 > GPT 4 | Likert scales on likelihood and severity of harm |
| LIM 2023 [37] | GPT 3.5, GPT 4, Bard | GPT 3.5 = Bard > GPT 4.0 | Likert scale on harm |
| TAILOR 2024 [56] | GPT 3.5, GPT 4, Claude 2, Bing, Bard | High risk harm: Bard > Bing > GPT 3.5 > Claude > GPT 4 > GPT 4 + Human > Human | Likert scales on likelihood and extent of harm |
| POTAPENKO 2023 [46] | GPT 4 | 5% potential harm | Likert scales on potential for harm |
| BALAS 2024 [19] | GPT 4 | No responses constituting harm | Appropriateness rating scale |
| ZANDI 2024 [63] | GPT 4, Bard | Bard > GPT 4 | Binary variable (presence or absence of potential harm) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
See, Y.K.C.; Lim, K.S.A.; Au, W.Y.; Chia, S.Y.C.; Fan, X.; Li, Z.K. The Use of Large Language Models in Ophthalmology: A Scoping Review on Current Use-Cases and Considerations for Future Works in This Field. Big Data Cogn. Comput. 2025, 9, 151. https://doi.org/10.3390/bdcc9060151
See YKC, Lim KSA, Au WY, Chia SYC, Fan X, Li ZK. The Use of Large Language Models in Ophthalmology: A Scoping Review on Current Use-Cases and Considerations for Future Works in This Field. Big Data and Cognitive Computing. 2025; 9(6):151. https://doi.org/10.3390/bdcc9060151
Chicago/Turabian StyleSee, Ye King Clarence, Khai Shin Alva Lim, Wei Yung Au, Si Yin Charlene Chia, Xiuyi Fan, and Zhenghao Kelvin Li. 2025. "The Use of Large Language Models in Ophthalmology: A Scoping Review on Current Use-Cases and Considerations for Future Works in This Field" Big Data and Cognitive Computing 9, no. 6: 151. https://doi.org/10.3390/bdcc9060151
APA StyleSee, Y. K. C., Lim, K. S. A., Au, W. Y., Chia, S. Y. C., Fan, X., & Li, Z. K. (2025). The Use of Large Language Models in Ophthalmology: A Scoping Review on Current Use-Cases and Considerations for Future Works in This Field. Big Data and Cognitive Computing, 9(6), 151. https://doi.org/10.3390/bdcc9060151