

Edge vs. Cloud: Empirical Insights into Data-Driven Condition Monitoring



Abstract
1. Introduction
2. Background
2.1. Condition Monitoring of Industrial Motors
2.2. Edge Computing
2.3. Cloud Computing
2.4. Comparative Analysis and Research Gap
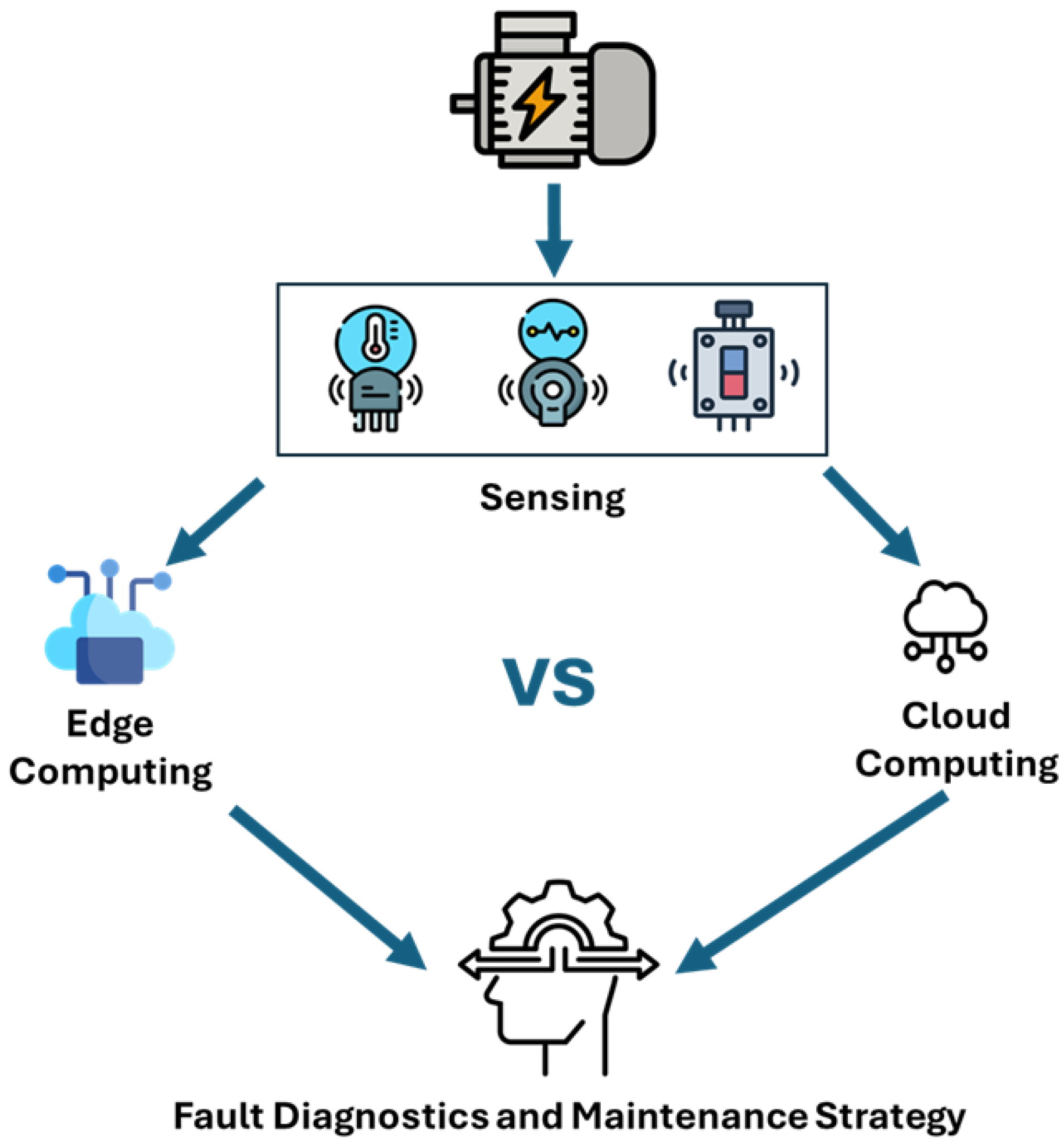
3. Methodology
3.1. Experimental Setup
3.1.1. Hardware Configuration
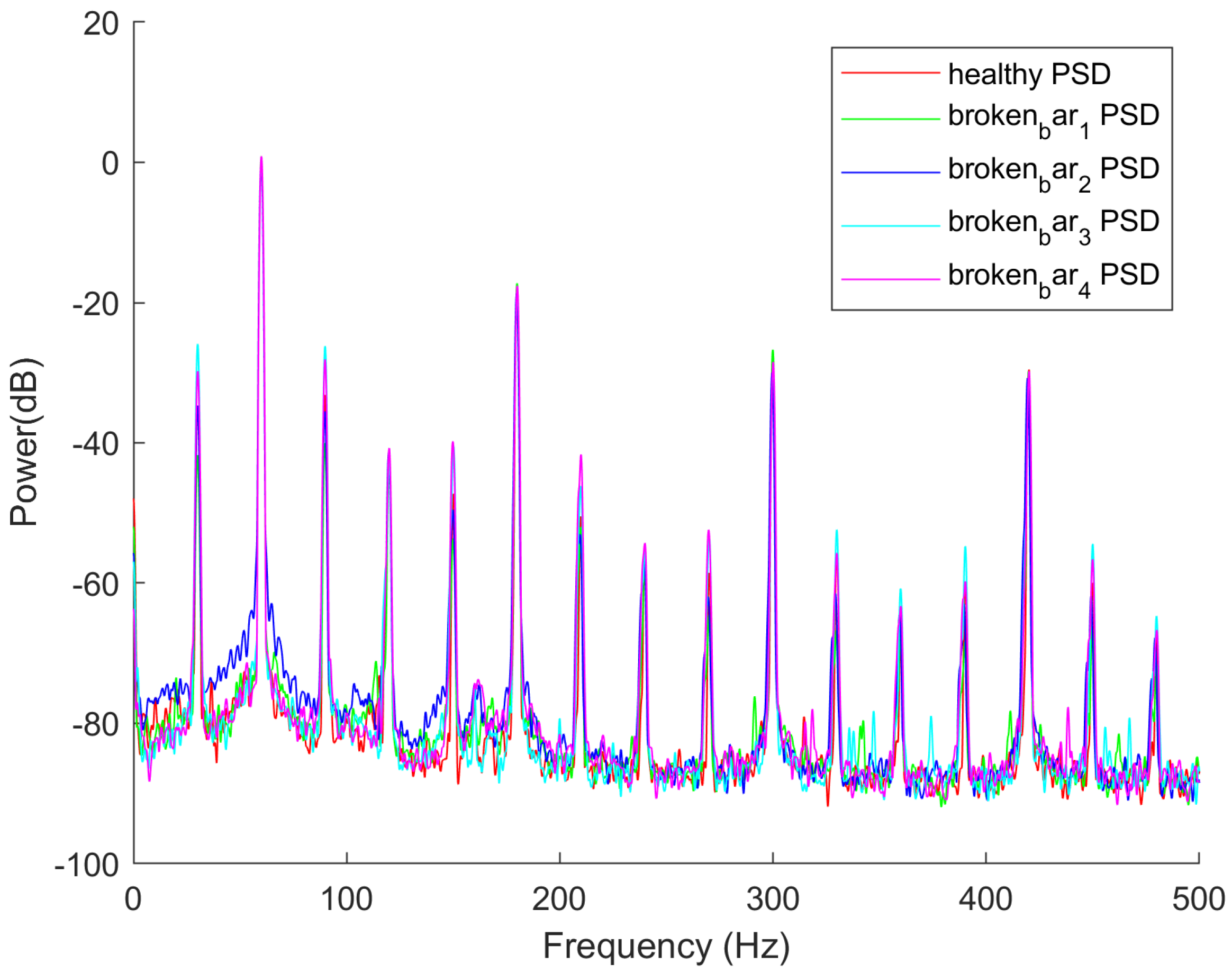
3.1.2. Dataset
3.1.3. Software Environment
3.2. Modelling
3.2.1. Machine Learning Models for Condition Monitoring
- SVM is suited to handling high-dimensional feature spaces, and it is effective in characterising non-linear relationships using kernel functions. This algorithm is selected here as it has been demonstrated to effectively separate condition monitoring features extracted through Power Spectral Density (PSD) analysis, enabling accurate classification of rotor bar faults [18].
- KNN classifies data instances based on their proximity in the feature space. Its non-parametric nature allows it to adapt well to varying fault patterns, making it suitable for condition monitoring with minimal computational overhead [42,43]. Bayesian optimisation was applied to tune the optimal value of K, improving the classification performance.
- The DT algorithm is a popular choice owing to its interpretability and low computational cost. Its hierarchical structure allows for efficient classification of rotor conditions by following decision paths based on feature thresholds [44].
3.2.2. Data Preprocessing and Feature Engineering
- 1.
- PCA was used to reduce the feature space from 8 to 2 dimensions, yielding a variance retention of 99.99%, which ensures minimal loss of information. The primary motivation for using PCA was to evaluate the impact of dimensionality reduction on both training efficiency and data transmission, particularly in edge computing environments. PCA has been widely recognised for reducing data transmission in IoT and Industry 4.0 applications, enhancing security by avoiding raw data transmission, and improving energy efficiency [46,47]. These benefits align with the needs of real-time, resource-constrained condition monitoring systems. Although PCA effectively reduces the complexity of the input data and improves training efficiency, the results indicate increased CPU and memory usage during inference. This is due to the computational cost of applying the transformation matrix to incoming data before classification, a known challenge in embedded machine learning implementations [46,48]. While previous studies suggested PCA could improve performance for DDCM applications [49,50], these results highlight a trade-off where PCA reduces training time and data transmission load, but this may come at the cost of latency in inference.
- 2.
- The evaluation metrics used in this study were the F1-score, training and inference times, resource utilisation (CPU and memory), and costs. With regards to resource utilisation, CPU usage is normalised across platforms to afford comparison between CPUs with different number of cores. Data burden and scalability were also evaluated by varying the size of the test data. The metrics were also evaluated with and without dimensionality reduction to estimate the impacts between platforms.
- 3.
- Experimental tests were conducted by firstly dividing the dataset, where 60% of the set was used for model development and testing, and 40% of the set was set aside for scalability testing. An 80:20 split was used for training and testing of the models. Scalability tests used data at different increments—i.e., 10%, 25%, 50%, and 100%. Models were developed using SVM, DT, and KNN, tuned using Bayesian optimisation, and tested on both edge and cloud platforms.
4. Results and Analysis
4.1. Tables of Results
4.2. Discussion of Results
4.2.1. F1-Score
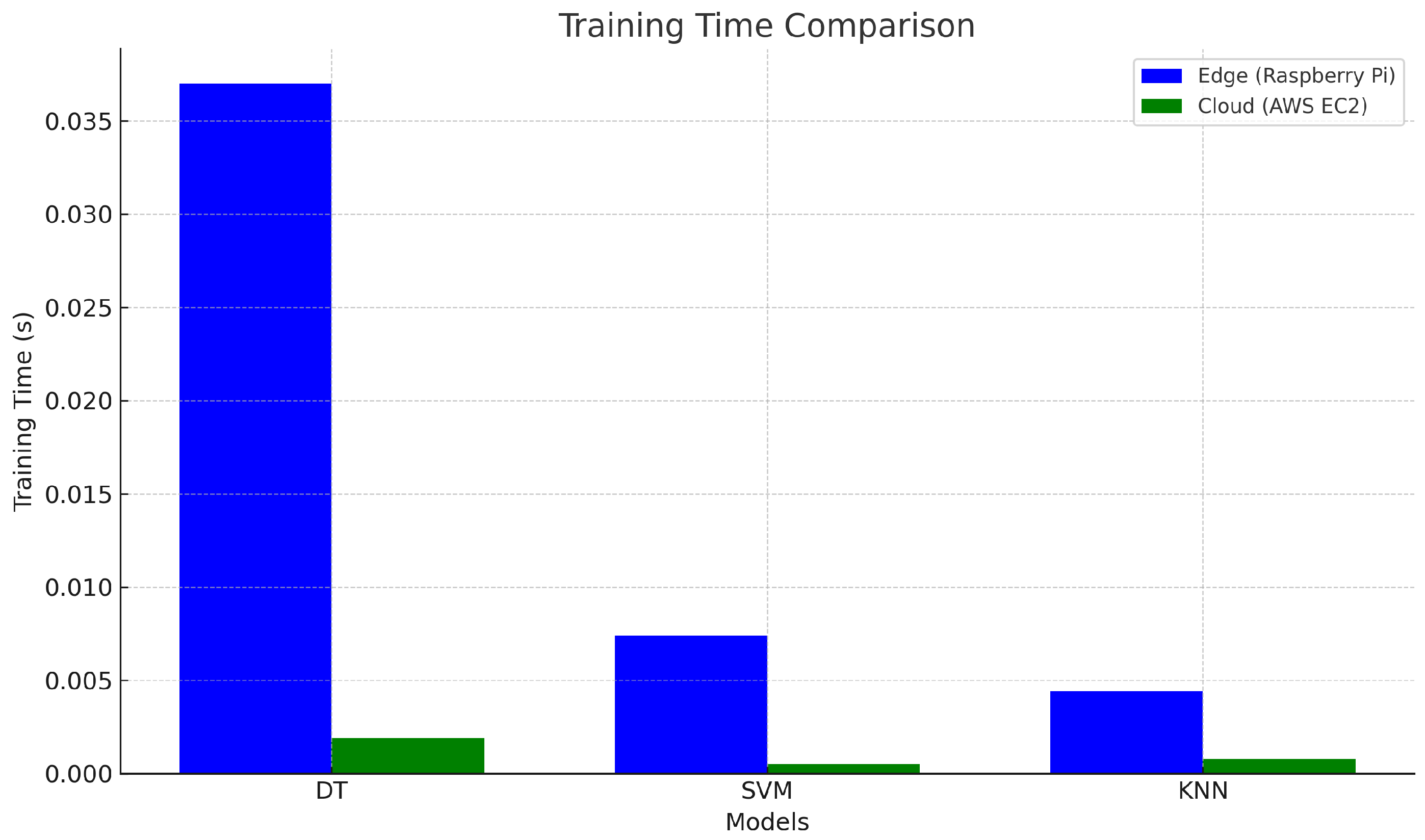
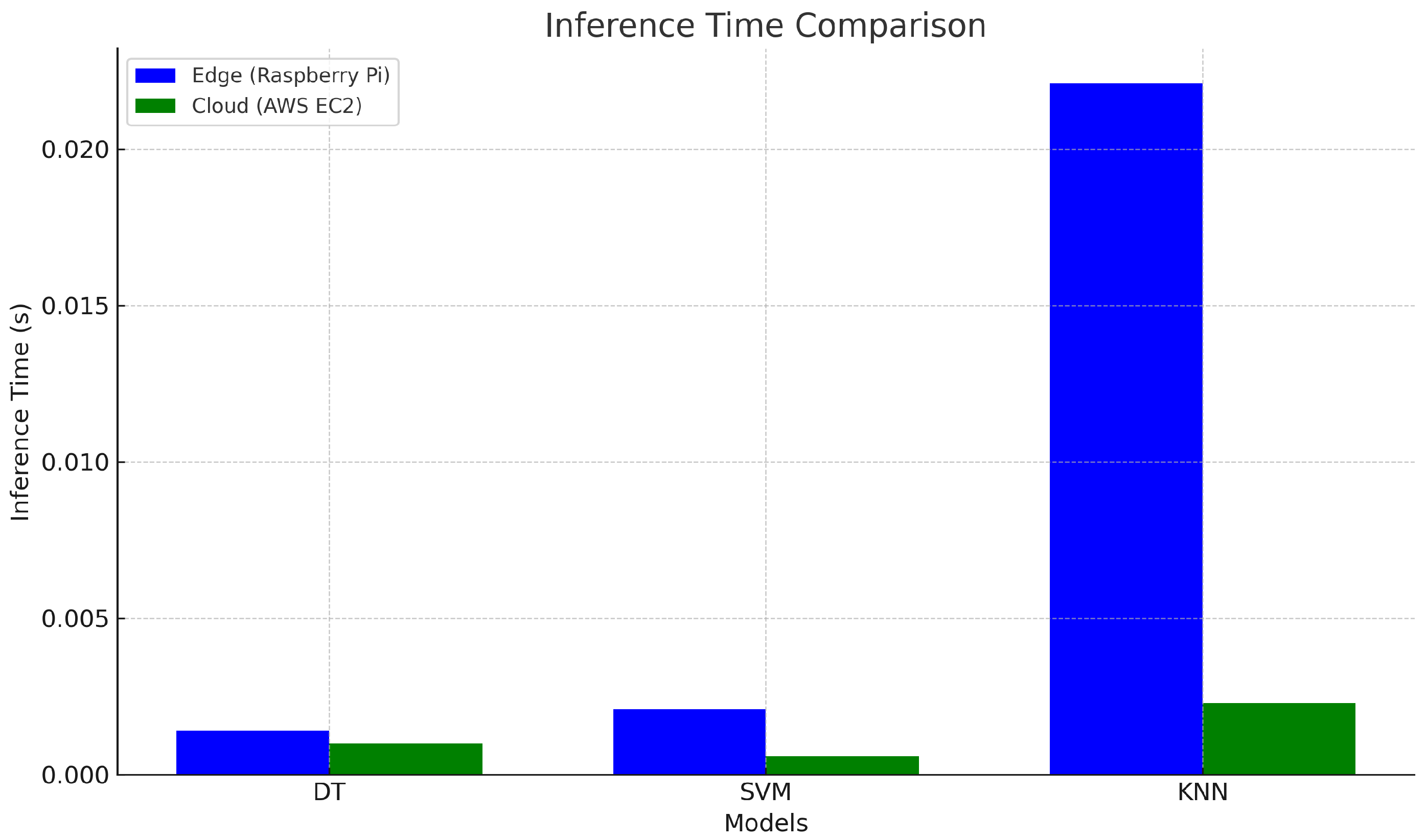
4.2.2. Training and Inference Times
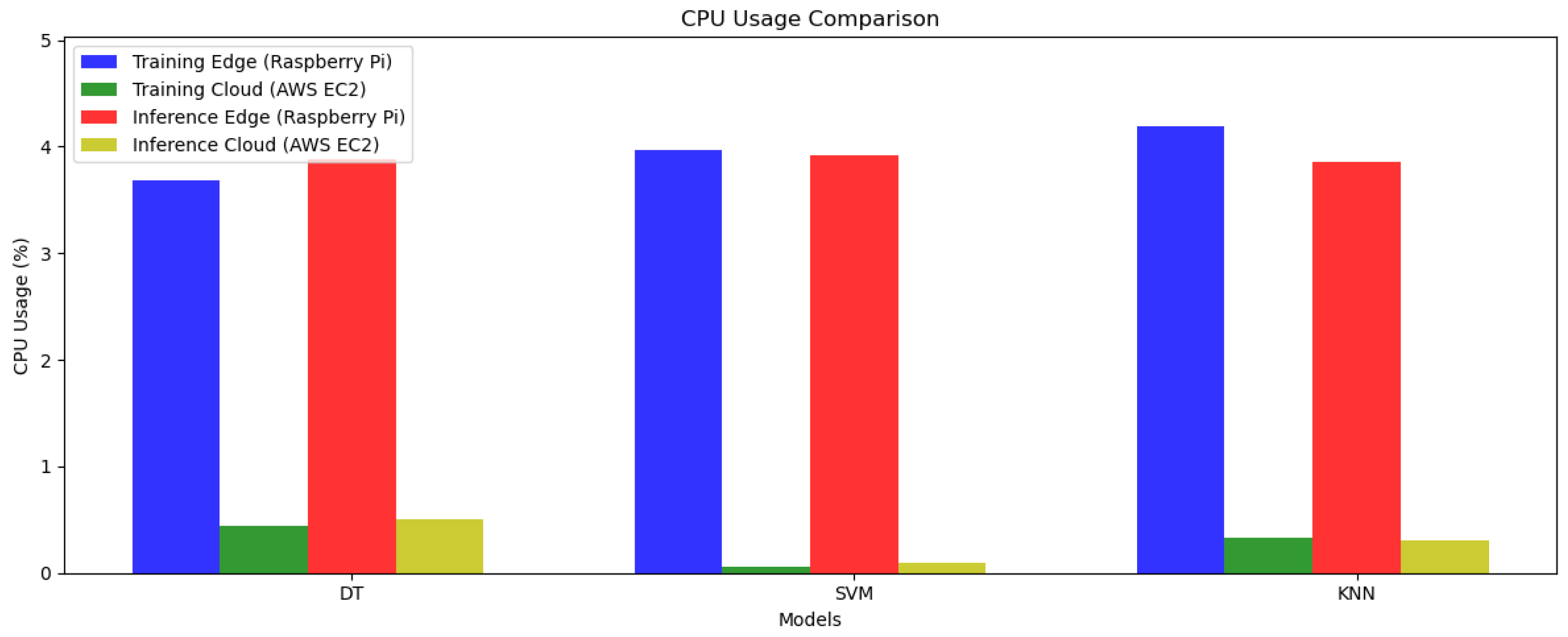
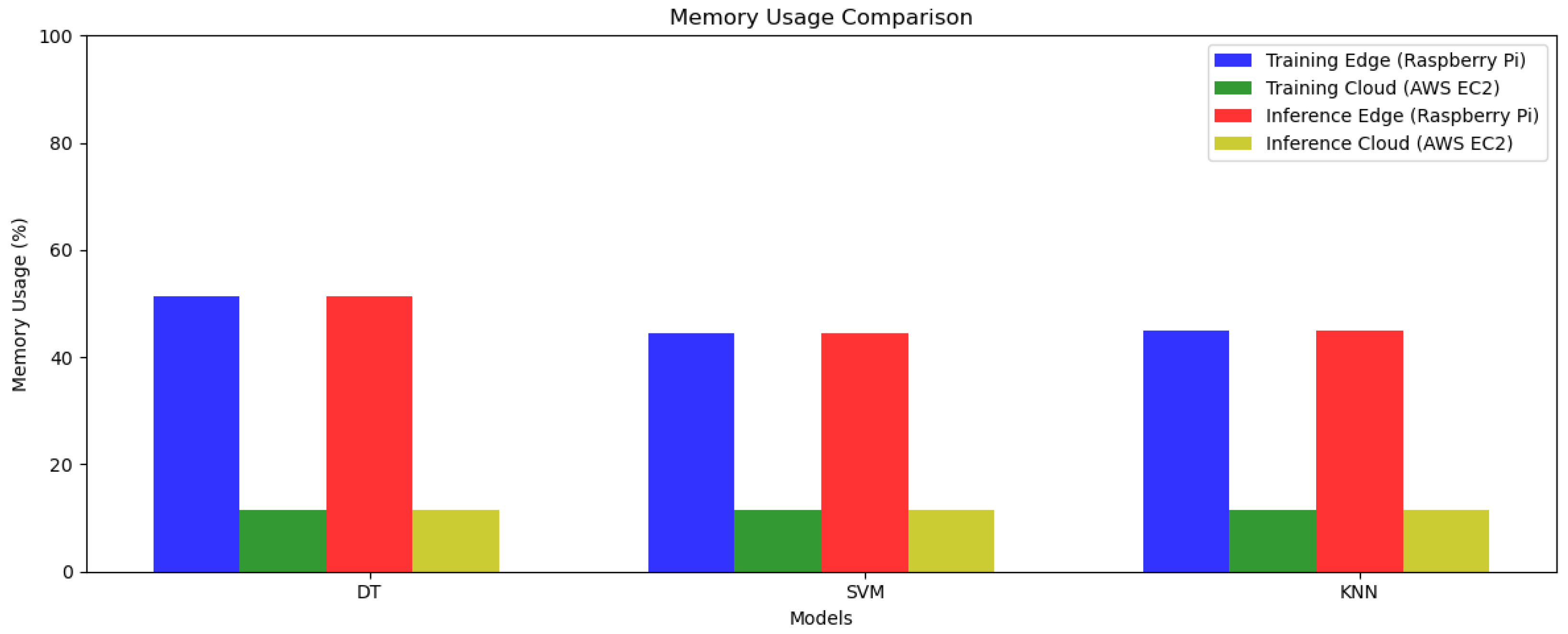
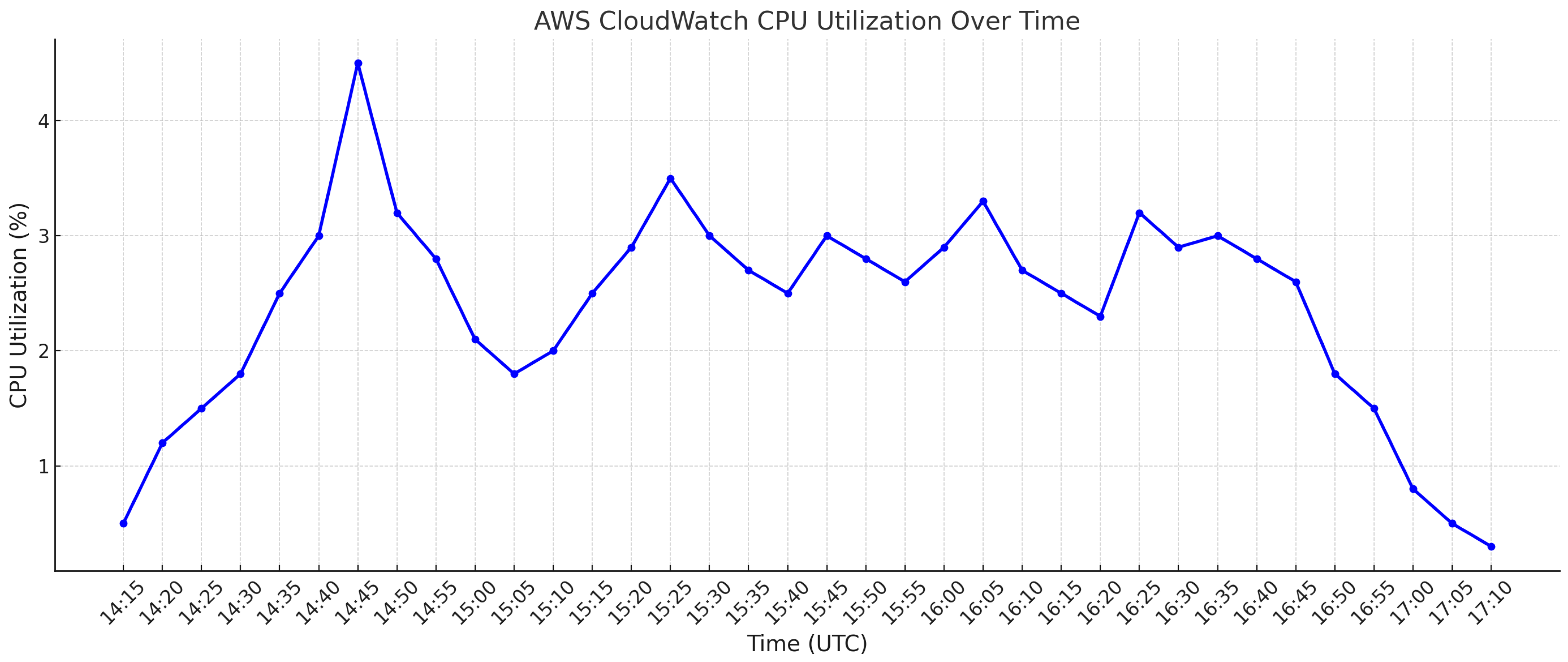
4.2.3. CPU and Memory Usage
4.2.4. Scalability Analysis
4.2.5. Data Burden
4.2.6. Cost Analysis
- Frequency of model retraining, which increases cloud usage costs.
- Power consumption of edge devices over extended periods.
- Data transmission costs, particularly when large amounts of sensor data are sent to the cloud.
- Maintenance and hardware replacement for edge devices.
4.3. Impact of PCA
4.4. Qualitative Considerations: Ease of Deployment, User Experience, and Network Variability
4.5. Practical Implications and Recommendations
4.5.1. Is Real-Time Fault Detection and Low Latency Critical?
4.5.2. How Large and Complex Are the Data That Are Being Processed?
4.5.3. What Are the Cost Constraints of Deployment and Operation?
4.5.4. How Frequently Does the Model Need to Be Retrained and Updated?
4.5.5. Is Network Reliability and Bandwidth Availability a Concern?
4.5.6. Large-Scale Industrial Condition Monitoring
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tavner, P.; Ran, L.; Penman, J.; Sedding, H. Condition Monitoring of rOtating Electrical Machines; The Institution of Engineering and Technology: London, UK, 2008. [Google Scholar]
- Ahmad, R.; Kamaruddin, S. A review of condition-based maintenance decision-making. Eur. J. Ind. Eng. 2012, 6, 519–541. [Google Scholar] [CrossRef]
- Ali, A.; Abdelhadi, A. Condition-based monitoring and maintenance: State of the art review. Appl. Sci. 2022, 12, 688. [Google Scholar] [CrossRef]
- Haq, S.U.; Trivedi, A.; Rochon, S.; Moorthy, M.T. Alternative Methods of Machine Online Condition Monitoring: Recommendations for Rotating Machines in the Petroleum and Chemical Industry. IEEE Ind. Appl. Mag. 2024, 30, 19–31. [Google Scholar] [CrossRef]
- Das, O.; Das, D.B.; Birant, D. Machine learning for fault analysis in rotating machinery: A comprehensive review. Eng. Appl. Artif. Intell. 2023, 9, e17584. [Google Scholar] [CrossRef]
- Latil, D.; Ngouna, R.H.; Medjaher, K.; Lhuisset, S. Enhancing Data-driven Vibration-based Machinery Fault Diagnosis Generalization Under Varied Conditions by Removing Domain-Specific Information Utilizing Sparse Representation. In Proceedings of the PHM Society European Conference, Prague, Czech Republic, 3–5 July 2024; Volume 8. [Google Scholar]
- Zhao, C.; Chen, J.; Jing, H. Condition-driven data analytics and monitoring for wide-range nonstationary and transient continuous processes. IEEE Trans. Autom. Sci. Eng. 2020, 18, 1563–1574. [Google Scholar] [CrossRef]
- Paul, A.K. Edge or Cloud: What to Choose? In Cloud Network Management; Chapman and Hall/CRC: New York, NJ, USA, 2020; pp. 15–25. [Google Scholar]
- Ferrari, P.; Rinaldi, S.; Sisinni, E.; Colombo, F.; Ghelfi, F.; Maffei, D.; Malara, M. Performance evaluation of full-cloud and edge-cloud architectures for Industrial IoT anomaly detection based on deep learning. In Proceedings of the 2019 II Workshop on Metrology for Industry 4.0 and IoT (MetroInd4.0 & IoT), Naples, Italy, 4–6 June 2019; IEEE: New York, NJ, USA, 2019; pp. 420–425. [Google Scholar]
- Verma, A.; Goyal, A.; Kumara, S.; Kurfess, T. Edge-cloud computing performance benchmarking for IoT based machinery vibration monitoring. Manuf. Lett. 2021, 27, 39–41. [Google Scholar] [CrossRef]
- Edomwandekhoe, K.I. Modeling and Fault Diagnosis of Broken Rotor Bar Faults in Induction Motors. Ph.D. Thesis, Memorial University of Newfoundland, St. John’s, NL, Canada, 2018. [Google Scholar]
- Lee, S.B.; Stone, G.C.; Antonino-Daviu, J.; Gyftakis, K.N.; Strangas, E.G.; Maussion, P.; Platero, C.A. Condition monitoring of industrial electric machines: State of the art and future challenges. IEEE Ind. Electron. Mag. 2020, 14, 158–167. [Google Scholar] [CrossRef]
- El Hachemi Benbouzid, M. A review of induction motors signature analysis as a medium for faults detection. IEEE Trans. Ind. Electron. 2000, 47, 984–993. [Google Scholar] [CrossRef]
- Raman, R.; Naikade, K. Smart Industrial Motor Monitoring with IoT-Enabled Photovoltaic System. In Proceedings of the 2023 7th International Conference on IoT in Social, Mobile, Analytics and Cloud (I-SMAC), Kirtipur, Nepal, 11–13 October 2023; IEEE: New York, NJ, USA, 2023; pp. 53–57. [Google Scholar]
- Thorsen, O.; Dalva, M. Condition monitoring methods, failure identification and analysis for high voltage motors in petrochemical industry. In Proceedings of the 8th International Conference on Electrical Machines and Drives, Cambridge, UK, 1–3 September 1997; IET: Stevenage, UK, 1997. [Google Scholar]
- Oñate, W.; Perez, R.; Caiza, G. Diagnosis of incipient faults in induction motors using mcsa and thermal analysis. In Advances in Emerging Trends and Technologies: Volume 2; Springer: Cham, Switzerland, 2020; pp. 74–84. [Google Scholar]
- Manikandan, S.; Duraivelu, K. Fault diagnosis of various rotating equipment using machine learning approaches–A review. Proc. Inst. Mech. Eng. Part E J. Process Mech. Eng. 2021, 235, 629–642. [Google Scholar] [CrossRef]
- Bensaoucha, S.; Moreau, S.; Bessedik, S.A.; Ameur, A. Broken Rotor Bars Fault Detection in Induction Machine Using Machine Learning Algorithms. In Proceedings of the 2022 19th International Multi-Conference on Systems, Signals & Devices (SSD), Sétif, Algeria, 6–10 May 2022; IEEE: New York, NJ, USA, 2022; pp. 851–856. [Google Scholar]
- Ali, M.Z.; Shabbir, M.N.S.K.; Liang, X.; Zhang, Y.; Hu, T. Machine learning-based fault diagnosis for single-and multi-faults in induction motors using measured stator currents and vibration signals. IEEE Trans. Ind. Appl. 2019, 55, 2378–2391. [Google Scholar] [CrossRef]
- Khalil, A.F.; Rostam, S. Machine Learning-based Predictive Maintenance for Fault Detection in Rotating Machinery: A Case Study. Eng. Technol. Appl. Sci. Res. 2024, 14, 13181–13189. [Google Scholar] [CrossRef]
- Ferraz Júnior, F.; Romero, R.A.F.; Hsieh, S.J. Machine Learning for the Detection and Diagnosis of Anomalies in Applications Driven by Electric Motors. Sensors 2023, 23, 9725. [Google Scholar] [CrossRef]
- Zhong, X.; Ban, H. Crack fault diagnosis of rotating machine in nuclear power plant based on ensemble learning. Ann. Nucl. Energy 2022, 168, 108909. [Google Scholar] [CrossRef]
- Qiu, T.; Chi, J.; Zhou, X.; Ning, Z.; Atiquzzaman, M.; Wu, D.O. Edge computing in industrial internet of things: Architecture, advances and challenges. IEEE Commun. Surv. Tutor. 2020, 22, 2462–2488. [Google Scholar] [CrossRef]
- Holmes, T.; McLarty, C.; Shi, Y.; Bobbie, P.; Suo, K. Energy Efficiency on Edge Computing: Challenges and Vision. In Proceedings of the 2022 IEEE International Performance, Computing, and Communications Conference (IPCCC), Austin, TX, USA, 11–13 November 2022; IEEE: New York, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- de Las Morenas, J.; Moya-Fernández, F.; López-Gómez, J.A. The edge application of machine learning techniques for fault diagnosis in electrical machines. Sensors 2023, 23, 2649. [Google Scholar] [CrossRef] [PubMed]
- Mostafavi, A.; Sadighi, A. A novel online machine learning approach for real-time condition monitoring of rotating machines. In Proceedings of the 2021 9th RSI International Conference on Robotics and Mechatronics (ICRoM), Tehran, Iran, 17–19 November 2021; IEEE: New York, NJ, USA, 2021; pp. 267–273. [Google Scholar]
- Shubita, R.R.; Alsadeh, A.S.; Khater, I.M. Fault detection in rotating machinery based on sound signal using edge machine learning. IEEE Access 2023, 11, 6665–6672. [Google Scholar] [CrossRef]
- Mirani, A.A.; Velasco-Hernandez, G.; Awasthi, A.; Walsh, J. Key challenges and emerging technologies in industrial IoT architectures: A review. Sensors 2022, 22, 5836. [Google Scholar] [CrossRef]
- Joshi, R.; Somesula, R.S.; Katkoori, S. Empowering Resource-Constrained IoT Edge Devices: A Hybrid Approach for Edge Data Analysis. In Proceedings of the IFIP International Internet of Things Conference, Denton, TX, USA, 2–3 November 2023; Springer: Cham, Switzerland, 2023; pp. 168–181. [Google Scholar]
- Filho, C.P.; Marques, E., Jr.; Chang, V.; Dos Santos, L.; Bernardini, F.; Pires, P.F.; Ochi, L.; Delicato, F.C. A systematic literature review on distributed machine learning in edge computing. Sensors 2022, 22, 2665. [Google Scholar] [CrossRef]
- Phan, T.L.J.; Gehrhardt, I.; Heik, D.; Bahrpeyma, F.; Reichelt, D. A systematic mapping study on machine learning techniques applied for condition monitoring and predictive maintenance in the manufacturing sector. Logistics 2022, 6, 35. [Google Scholar] [CrossRef]
- Jagati, A.; Subbulakshmi, T. Building ML workflow for walware images classification using machine learning services in leading cloud platforms. In Proceedings of the 2023 International Conference on Computational Intelligence and Sustainable Engineering Solutions (CISES), Greater Noida, India, 28–30 April 2023; IEEE: New York, NJ, USA, 2023; pp. 233–239. [Google Scholar]
- Gautam, A.; Jindal, S.; Baitha, P.; Arora, A.; Gautam, A. The role of cloud computing in machine learning approaches. Int. J. Eng. Appl. Sci. Technol. 2023, 8, 73–79. [Google Scholar] [CrossRef]
- Pourmajidi, W.; Steinbacher, J.; Erwin, T.; Miranskyy, A. On challenges of cloud monitoring. arXiv 2018, arXiv:1806.05914. [Google Scholar]
- Bajic, B.; Cosic, I.; Katalinic, B.; Moraca, S.; Lazarevic, M.; Rikalovic, A. Edge vs cloud computing: Challenges and opportunities in Industry 4.0. Ann. DAAAM Proc. 2019, 30, 864–871. [Google Scholar]
- Amazon Web Services. Amazon EC2 Instance Types. Available online: https://aws.amazon.com/ec2/instance-types (accessed on 20 January 2025).
- Treml, A.E.; Flauzino, R.A.; Suetake, M.; Maciejewski, N.R.; Afonso, N. Experimental database for detecting and diagnosing rotor broken bar in a three-phase induction motor. IEEE DataPort 2020. [Google Scholar] [CrossRef]
- Valles-Novo, R.; de Jesus Rangel-Magdaleno, J.; Ramirez-Cortes, J.M.; Peregrina-Barreto, H.; Morales-Caporal, R. Empirical mode decomposition analysis for broken-bar detection on squirrel cage induction motors. IEEE Trans. Instrum. Meas. 2014, 64, 1118–1128. [Google Scholar] [CrossRef]
- Qiao, W.; Qu, L. Prognostic condition monitoring for wind turbine drivetrains via generator current analysis. Chin. J. Electr. Eng. 2018, 4, 80–89. [Google Scholar]
- Li, Z.; Fei, F.; Zhang, G. Edge-to-cloud IIoT for condition monitoring in manufacturing systems with ubiquitous smart sensors. Sensors 2022, 22, 5901. [Google Scholar] [CrossRef]
- Ameen, S.; Siriwardana, K.; Theodoridis, T. Optimizing Deep Learning Models For Raspberry Pi. arXiv 2023, arXiv:2304.13039. [Google Scholar]
- Zhang, Z. Introduction to machine learning: K-nearest neighbors. Ann. Transl. Med. 2016, 4, 11. [Google Scholar] [CrossRef]
- Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A brief review of nearest neighbor algorithm for learning and classification. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; IEEE: New York, NJ, USA, 2019; pp. 1255–1260. [Google Scholar]
- Khan, M.A.; Bilal, A.; Vaimann, T.; Kallaste, A. An Advanced Diagnostic Approach for Broken Rotor Bar Detection and Classification in DTC Controlled Induction Motors by Leveraging Dynamic SHAP Interaction Feature Selection (DSHAP-IFS) GBDT Methodology. Machines 2024, 12, 495. [Google Scholar] [CrossRef]
- Edomwandekhoe, K.; Liang, X. Current spectral analysis of broken rotor bar faults for induction motors. In Proceedings of the 2018 IEEE Canadian Conference on Electrical & Computer Engineering (CCECE), Quebec, QC, Canada, 13–16 May 2018; IEEE: New York, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Marino, R.; Lanza-Gutierrez, J.M.; Riesgo, T.M. Embedding principal component analysis inference in expert sensors for big data applications. In Big Data Recommender Systems—Volume 2: Application Paradigms; IET: Stevenage, UK, 2019; Chapter 6; pp. 83–105. [Google Scholar] [CrossRef]
- Rooshenas, P.; Rabiee, H.R.; Movaghar, A.; Naderi, M.Y. Reducing the data transmission in Wireless Sensor Networks using the Principal Component Analysis. In Proceedings of the IEEE Sixth International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Brisbane, Australia, 7–10 December 2010; pp. 133–138. [Google Scholar]
- Burrello, A.; Marchioni, A.; Brunelli, D.; Benatti, S.; Mangia, M.; Benini, L. Embedded Streaming Principal Components Analysis for Network Load Reduction in Structural Health Monitoring. IEEE Internet Things J. 2021, 8, 4433–4447. [Google Scholar] [CrossRef]
- Chippalakatti, S.; Renumadhavi, C.; Pallavi, A. Comparison of unsupervised machine learning Algorithm for dimensionality reduction. In Proceedings of the 2022 International Conference on Knowledge Engineering and Communication Systems (ICKES), Chickballapur, India, 28–29 December 2022; IEEE: New York, NJ, USA, 2022; pp. 1–7. [Google Scholar]
- Reddy, G.T.; Reddy, M.P.K.; Lakshmanna, K.; Kaluri, R.; Rajput, D.S.; Srivastava, G.; Baker, T. Analysis of dimensionality reduction techniques on big data. IEEE Access 2020, 8, 54776–54788. [Google Scholar] [CrossRef]
- Ross, P.; Luckow, A. EdgeInsight: Characterizing and Modeling the Performance of Machine Learning Inference on the Edge and Cloud. In Proceedings of the IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 1897–1906. [Google Scholar]
- Raileanu, S.; Borangiu, T.; Morariu, O.; Iacob, I. Edge Computing in Industrial IoT Framework for Cloud-based Manufacturing Control. In Proceedings of the IEEE 22nd International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 10–12 October 2018; pp. 261–266. [Google Scholar]
- Sebbio, S.; Morabito, G.; Catalfamo, A.; Carnevale, L.; Fazio, M. Federated Learning on Raspberry Pi 4: A Comprehensive Power Consumption Analysis. In Proceedings of the IEEE/ACM 16th International Conference on Utility and Cloud Computing, Taormina, Italy, 4–7 December 2023; pp. 1–6. [Google Scholar]
- Anand, A.; Goel, S.; Panesar, G.S. Energy-Efficient Edge Computing Architectures for AI Workloads: A Comparative Analysis in Cloud-Driven Environments. In Proceedings of the 2024 International Conference on Emerging Innovations and Advanced Computing (INNOCOMP), Sonipat, India, 25–26 May 2024; pp. 614–620. [Google Scholar]
- Abdoulabbas, T.E.; Mahmoud, S.M. Power consumption and energy management for edge computing: State of the art. Telkomnika Telecommun. Comput. Electron. Control 2023, 21, 836–845. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Focus/Aim | Strengths | Limitations |
|---|---|---|---|
| Ferrari et al., 2019 [9] | Comparison of cloud vs. edge for time-series forecasting using lightweight ML models | Demonstrated lower latency with edge; useful for time-critical systems | Limited analysis on scalability; resource constraints not explored in depth |
| Paul et al., 2020 [8] | Edge-based deep learning for image-based fault detection | Effective in reducing data transmission; high accuracy in edge models | Focused on vision-based data; limited analysis on scalability and cost |
| Verma et al., 2021 [10] | Hybrid framework for anomaly detection in IoT environments | Achieved good trade-off between latency and computational load | Generalised IoT environment; lacks evaluation for condition monitoring-specific context |
| Jagati et al., 2023 [32] | Cloud-centric monitoring using AWS tools | Enabled scalable and complex model training | High cost and network reliance; lacking real-time response capability |
| Presented study (2025) | Empirical comparison using ML models on AWS EC2 vs. Raspberry Pi for fault diagnosis | Evaluation across performance, cost, data burden, and scalability in DDCM context | Limited to lightweight ML models; energy consumption not evaluated |
| Health | Instance | 60 Hz | 120 Hz | 180 Hz |
|---|---|---|---|---|
| healthy | 7 | 1.483471 | 0.010803 | 0.011020 |
| healthy | 10 | 2.703580 | 0.019458 | 0.005308 |
| healthy | 11 | 2.724468 | 0.019831 | 0.005443 |
| broken_bar_1 | 7 | 1.585917 | 0.011808 | 0.012588 |
| broken_bar_1 | 10 | 2.838809 | 0.020390 | 0.008129 |
| broken_bar_1 | 11 | 2.819858 | 0.020250 | 0.008034 |
| broken_bar_2 | 7 | 1.431021 | 0.010651 | 0.011763 |
| broken_bar_2 | 10 | 2.712764 | 0.019249 | 0.010197 |
| broken_bar_2 | 11 | 2.692282 | 0.019351 | 0.011599 |
| broken_bar_3 | 7 | 1.438370 | 0.010723 | 0.013016 |
| broken_bar_3 | 10 | 2.865887 | 0.020938 | 0.015434 |
| broken_bar_3 | 11 | 2.850097 | 0.020939 | 0.014791 |
| broken_bar_4 | 7 | 1.629478 | 0.012014 | 0.016912 |
| broken_bar_4 | 10 | 2.961412 | 0.021510 | 0.019296 |
| broken_bar_4 | 11 | 2.942672 | 0.021436 | 0.017215 |
| Metric | Edge (Raspberry Pi) | Cloud (AWS EC2) |
|---|---|---|
| DT | ||
| F1-Score | 1.00 | 1.00 |
| Training Time (s) | 0.0347 | 0.0015 |
| Inference Time (s) | 0.0014 | 0.0008 |
| Train CPU Usage (%) | 3.73 | 0.52 |
| Train Memory (MB) | 43.20 | 11.50 |
| SVM | ||
| F1-Score | 0.38 | 0.38 |
| Training Time (s) | 0.0124 | 0.0040 |
| Inference Time (s) | 0.0023 | 0.0004 |
| Train CPU Usage (%) | 3.79 | 0.93 |
| Train Memory (MB) | 43.96 | 11.62 |
| KNN | ||
| F1-Score | 0.75 | 0.75 |
| Training Time (s) | 0.0069 | 0.0009 |
| Inference Time (s) | 0.0196 | 0.0011 |
| Train CPU Usage (%) | 4.30 | 0.10 |
| Train Memory (MB) | 42.67 | 11.60 |
| Metric | Edge (Raspberry Pi) | Cloud (AWS EC2) |
|---|---|---|
| DT | ||
| F1-Score | 0.96 | 0.96 |
| Training Time (s) | 0.0067 | 0.0012 |
| Inference Time (s) | 0.0013 | 0.0006 |
| Train CPU Usage (%) | 8.07 | 0.41 |
| Train Memory (MB) | 71.61 | 13.30 |
| SVM | ||
| F1-Score | 0.93 | 0.93 |
| Training Time (s) | 0.0094 | 0.0004 |
| Inference Time (s) | 0.0031 | 0.0011 |
| Train CPU Usage (%) | 8.96 | 0.17 |
| Train Memory (MB) | 75.70 | 13.30 |
| KNN | ||
| F1-Score | 0.95 | 0.95 |
| Training Time (s) | 0.0043 | 0.0011 |
| Inference Time (s) | 0.0207 | 0.0023 |
| Train CPU Usage (%) | 7.22 | 0.28 |
| Train Memory (MB) | 76.60 | 13.40 |
| Model | Sample Size (%) | Edge Inference Time (s) | Edge Accuracy (%) | Cloud Inference Time (s) | Cloud Accuracy (%) |
|---|---|---|---|---|---|
| 10% | 0.0020 | 100.00 | 0.0000 | 100.00 | |
| 25% | 0.0010 | 88.89 | 0.0000 | 88.89 | |
| DT | 50% | 0.0010 | 94.44 | 0.0000 | 94.44 |
| 75% | 0.0011 | 96.30 | 0.0000 | 96.30 | |
| 100% | 0.0012 | 97.26 | 0.0000 | 97.26 | |
| 10% | 0.0023 | 100.00 | 0.0000 | 100.00 | |
| 25% | 0.0020 | 100.00 | 0.0000 | 100.00 | |
| SVM | 50% | 0.0028 | 100.00 | 0.0000 | 100.00 |
| 75% | 0.0037 | 100.00 | 0.0000 | 100.00 | |
| 100% | 0.0043 | 98.63 | 0.0000 | 98.63 | |
| 10% | 0.0265 | 100.00 | 0.0000 | 100.00 | |
| 25% | 0.0125 | 100.00 | 0.0081 | 100.00 | |
| KNN | 50% | 0.0214 | 97.22 | 0.0000 | 97.22 |
| 75% | 0.0243 | 98.15 | 0.0086 | 98.15 | |
| 100% | 0.0315 | 97.26 | 0.0000 | 97.26 |
| Data Type | Samples (18 s) | Samples (24 h) | Size per Sample/Segment | Total Size (24 h) | Impact on Network Bandwidth |
|---|---|---|---|---|---|
| Original Data | 1,001,000 | 4,318,320,000 | 8 Bytes | 34.55 GB | Extremely high, impractical for real-time cloud upload. |
| Feature Engineered Data | 245 | 52,920 | 15,680 Bytes/segment | 830.78 MB | Very low, feasible for real-time transmission. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walani, C.C.; Doorsamy, W. Edge vs. Cloud: Empirical Insights into Data-Driven Condition Monitoring. Big Data Cogn. Comput. 2025, 9, 121. https://doi.org/10.3390/bdcc9050121
Walani CC, Doorsamy W. Edge vs. Cloud: Empirical Insights into Data-Driven Condition Monitoring. Big Data and Cognitive Computing. 2025; 9(5):121. https://doi.org/10.3390/bdcc9050121
Chicago/Turabian StyleWalani, Chikumbutso Christopher, and Wesley Doorsamy. 2025. "Edge vs. Cloud: Empirical Insights into Data-Driven Condition Monitoring" Big Data and Cognitive Computing 9, no. 5: 121. https://doi.org/10.3390/bdcc9050121
APA StyleWalani, C. C., & Doorsamy, W. (2025). Edge vs. Cloud: Empirical Insights into Data-Driven Condition Monitoring. Big Data and Cognitive Computing, 9(5), 121. https://doi.org/10.3390/bdcc9050121